
接口自动化测试思路和实战(5):【推荐】混合测试自动化框架(关键字+数据驱动)
混合测试自动化框架(关键字+数据驱动)
关键字驱动或表驱动的测试框架
这个框架需要开发数据表和关键字。这些数据表和关键字独立于执行它们的测试自动化工具,并可以用来“驱动"待测应用程序和数据的测试脚本代码,关键字驱动测试看上去与手工测试用例很类似。在一个关键字驱动测试中,把待测应用程序的功能和每个测试的执行步骤一起写到一个表中。
这个测试框架可以通过很少的代码来产生大量的测试用例。同样的代码在用数据表来产生各个测试用例的同时被复用。
混合测试自动化框架
最普遍的执行框架是上面介绍的所有技术的一个结合,取其长处,弥补其不足。这个混合测试框架是由大部分框架随着时间并经过若干项目演化而来的。
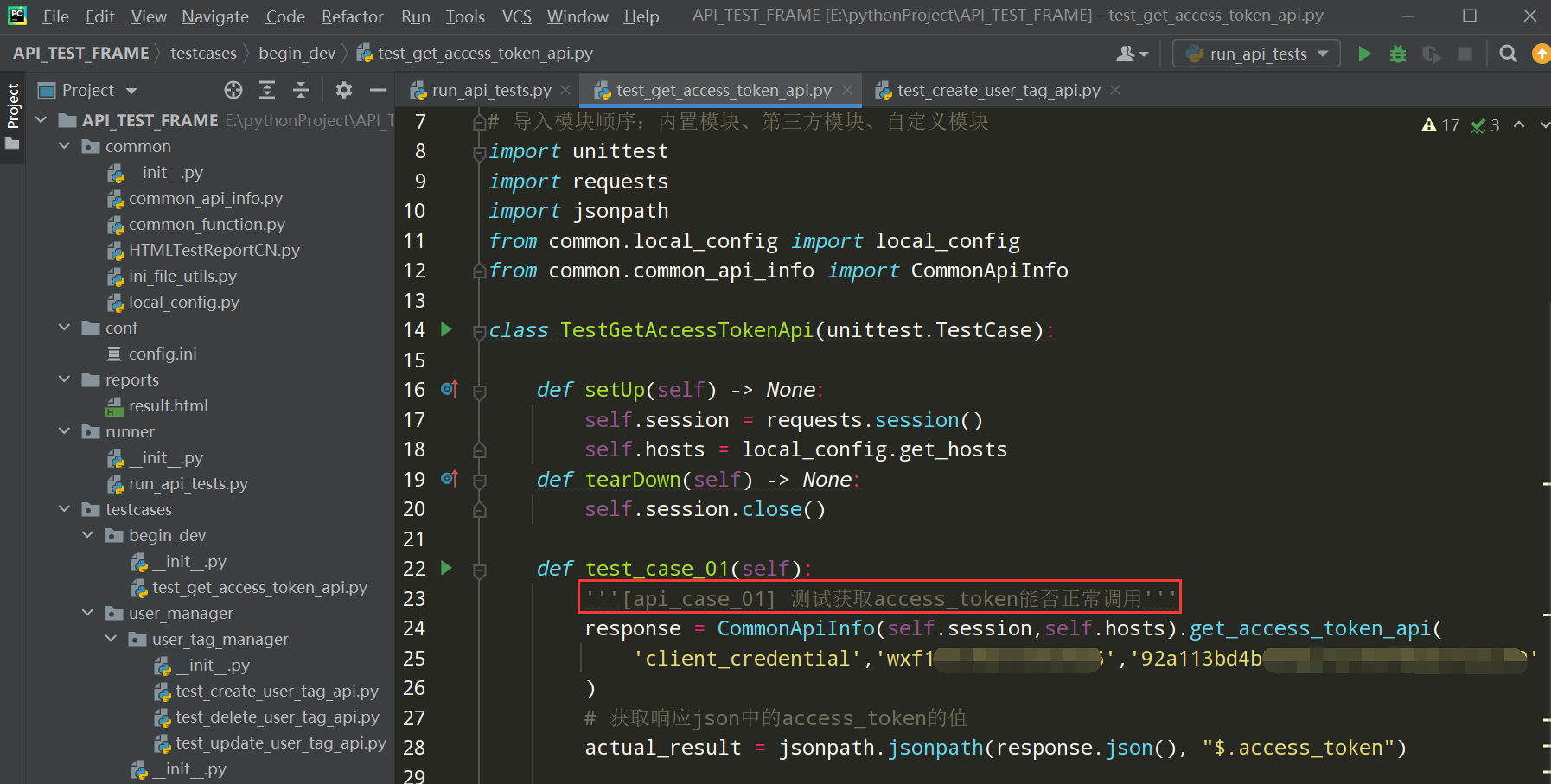
unittest关于测试报告展示用例名称的细节:
在unittest有两个内置属性,可以自定义用例名称
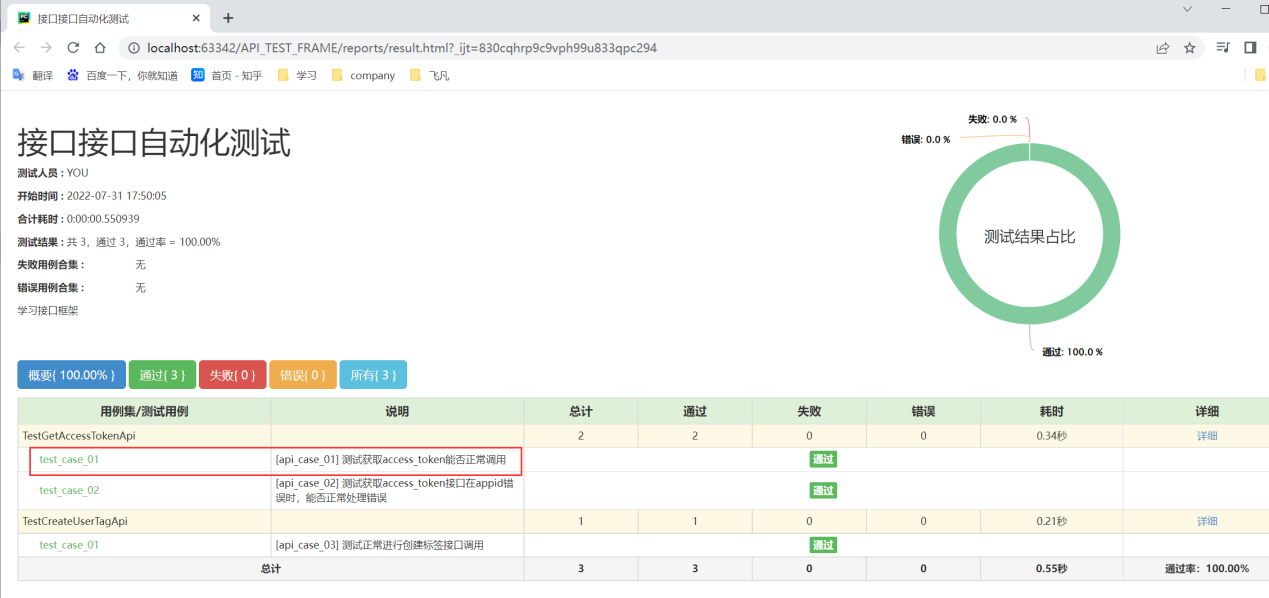
之前的效果:
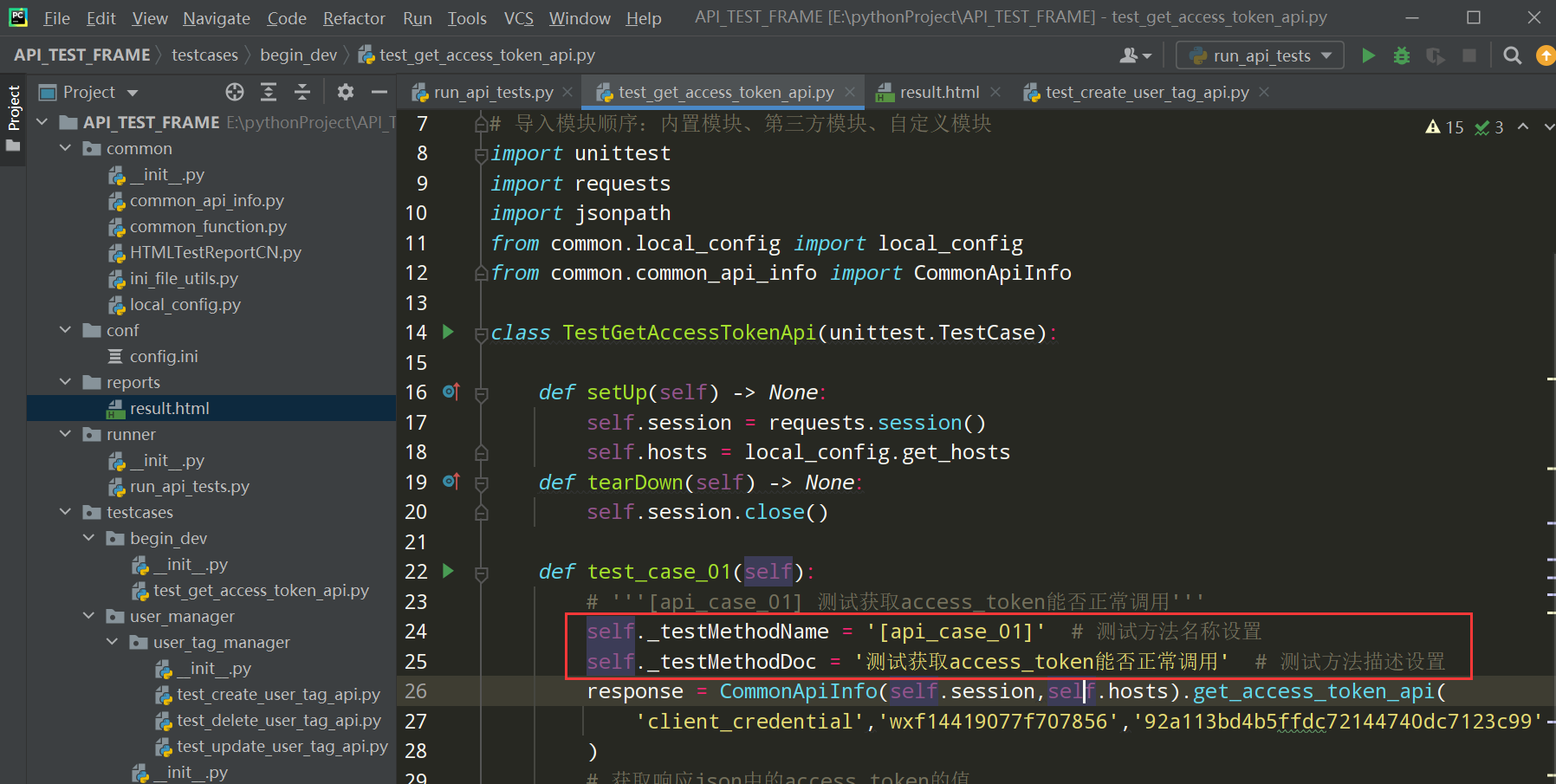
使用内置属性效果:
框架设计目标
设计出来的框架是直接给测试人员,而且其他的测试人员只需要简单的向里面不断的补充测试用例即可;所以我们的框架设计必须三简化即操作简单,维护简单,扩展简单。
设计框架的同时一定要结合业务流程,而不仅仅靠技术实现,其实技术实现不难,难点对业务流程的理解和把握。
设计框架时要将基础的封装成公用的,如:get请求、post请求和断言封装成同基础通用类。
测试用例要与代码分开,这样便于用例管理,采用数据驱动框架实现。
如下图所示:
通过在excel录入测试用例,框架运行后自动进行用例执行,产生html网页版本的测试报告。

报告结果:
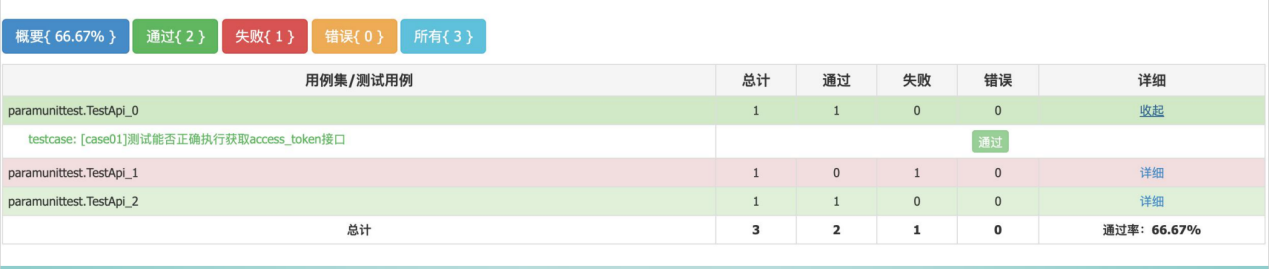
框架用到的技术点
1、语言:python
2、测试框架:unittest(assertEqual)或pytest
3、接口调用:requests(API非常简洁)
4、数据驱动:paramunittest (组装一定的格式数据就可以参数化)
5、数据管理:xlrd(读取excel文件数据)、configparser(读取配置文件)
6、数据格式的转换:ast,json
7、日志处理:logging ---清晰的执行过程,快速定位问题
8、测试报表:HTMLTestReportCN(由网友制作设计,显示清晰美观)
9、测试邮件发送测试报告:smtplib(邮件内容格式设置)、email(收发邮件)
10、持续集成:Jenkins(按策略执行接口测试脚本)
(推荐)混合测试自动化框架(关键字+数据驱动)
数据源实现:
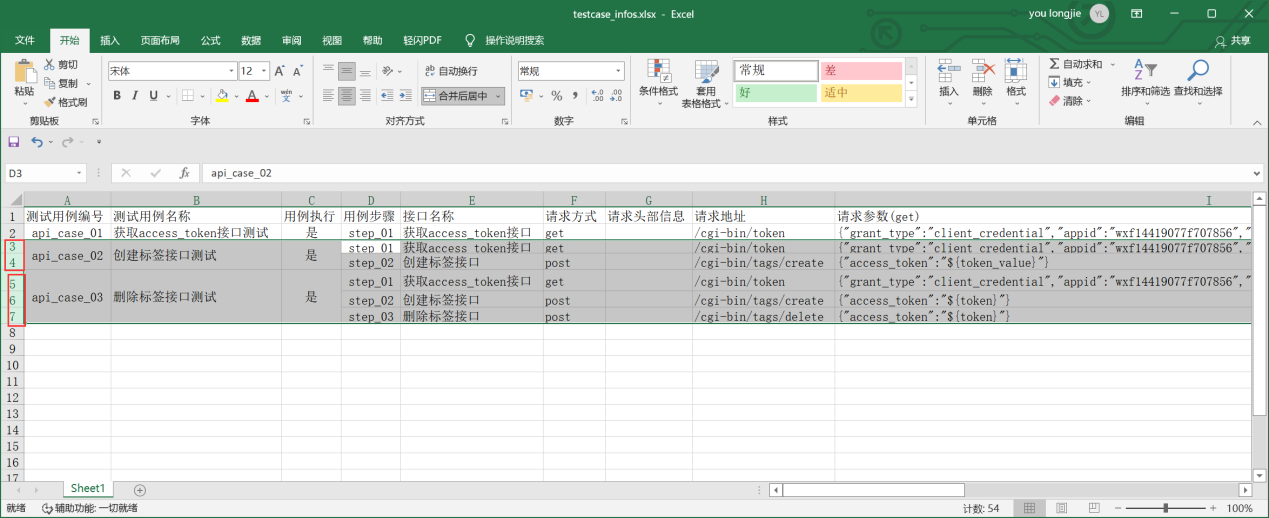
数据源目前使用excel,数据如下:
链接:https://pan.baidu.com/s/1VvvGYRvGbElSlP6ngg0ktw
提取码:ppua
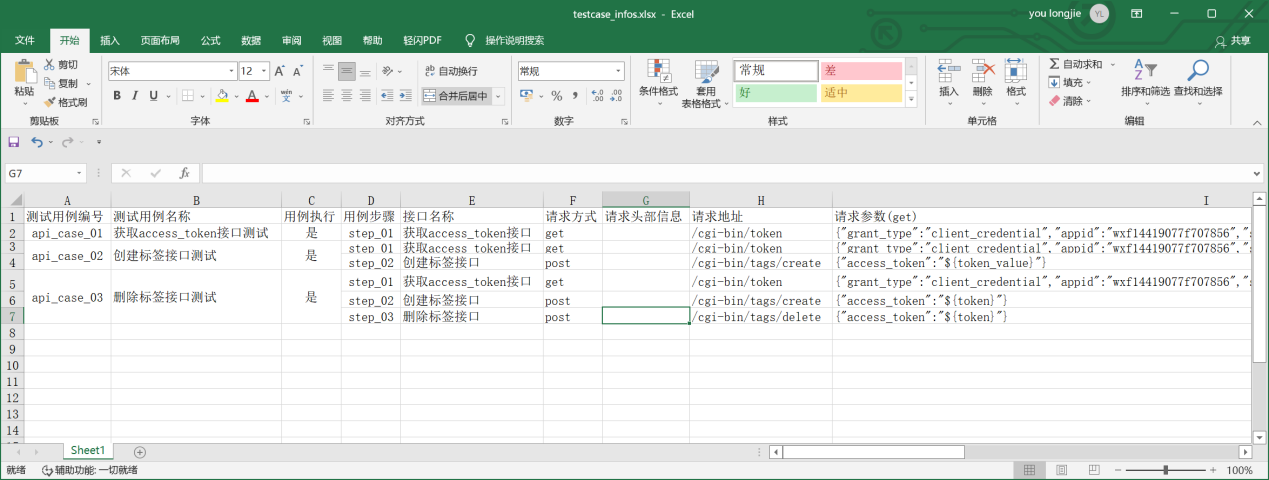
思路:使用python读取excel数据;使用xlrd3
框架01:新建项目API_KEY_WORD_TEST_FRAME;
步骤1、在项目根目录下新建common的py文件夹和conf的普通文件夹;samples文件夹是用来写测试代码的demo;
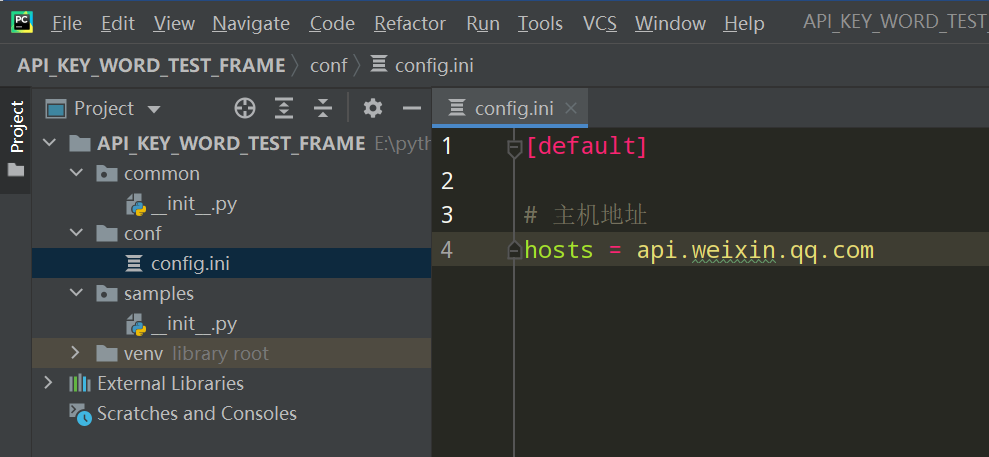
步骤2、在conf下新建config.ini文件
编写代码:
[default] # 主机地址 hosts = api.weixin.qq.com
步骤3、在common下新建ini_file_utils.py文件和config_utils.py文件
ini_file_utils.py文件如下:
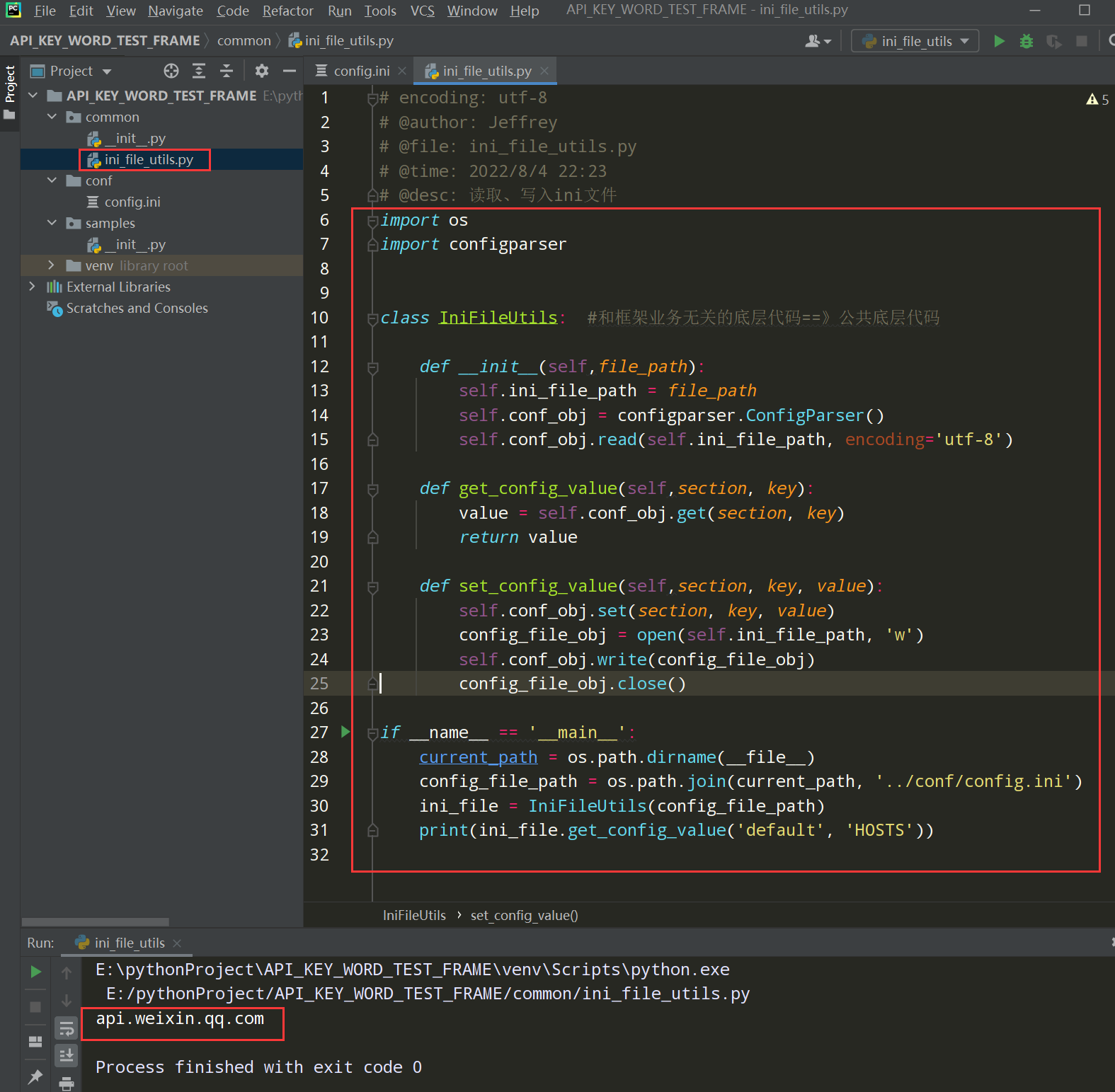
编写代码:
# encoding: utf-8 # @author: Jeffrey # @file: ini_file_utils.py # @time: 2022/8/4 22:23 # @desc: 读取、写入ini文件 import os import configparser class IniFileUtils: #和框架业务无关的底层代码==》公共底层代码 def __init__(self,file_path): self.ini_file_path = file_path self.conf_obj = configparser.ConfigParser() self.conf_obj.read(self.ini_file_path, encoding='utf-8') def get_config_value(self,section, key): value = self.conf_obj.get(section, key) return value def set_config_value(self,section, key, value): '''设置config.ini文件中的值''' self.conf_obj.set(section, key, value) config_file_obj = open(self.ini_file_path, 'w') self.conf_obj.write(config_file_obj) config_file_obj.close() if __name__ == '__main__': current_path = os.path.dirname(__file__) config_file_path = os.path.join(current_path, '../conf/config.ini') ini_file = IniFileUtils(config_file_path) print(ini_file.get_config_value('default', 'HOSTS'))
config_utils.py文件如下:
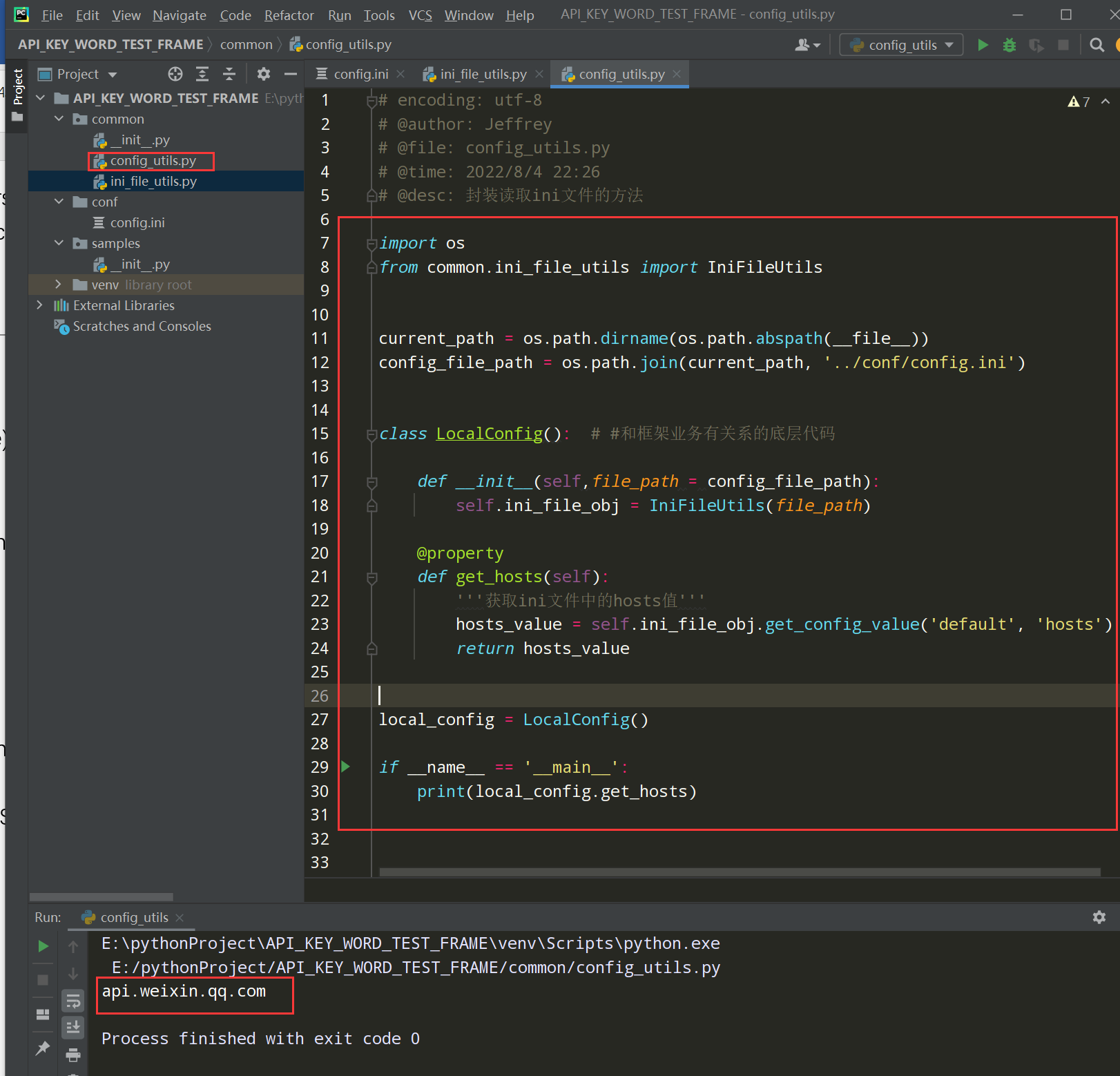
编写代码:
# encoding: utf-8 # @author: Jeffrey # @file: config_utils.py # @time: 2022/8/4 22:26 # @desc: 封装读取ini文件的方法 import os from common.ini_file_utils import IniFileUtils current_path = os.path.dirname(os.path.abspath(__file__)) config_file_path = os.path.join(current_path, '../conf/config.ini') class LocalConfig(): # #和框架业务有关系的底层代码 def __init__(self,file_path = config_file_path): self.ini_file_obj = IniFileUtils(file_path) @property def get_hosts(self): '''获取ini文件中的hosts值''' hosts_value = self.ini_file_obj.get_config_value('default', 'hosts') return hosts_value local_config = LocalConfig() if __name__ == '__main__': print(local_config.get_hosts)
步骤4、在samples文件下编写线性脚本,读取excel中的合并单元格
Excel表格如下:
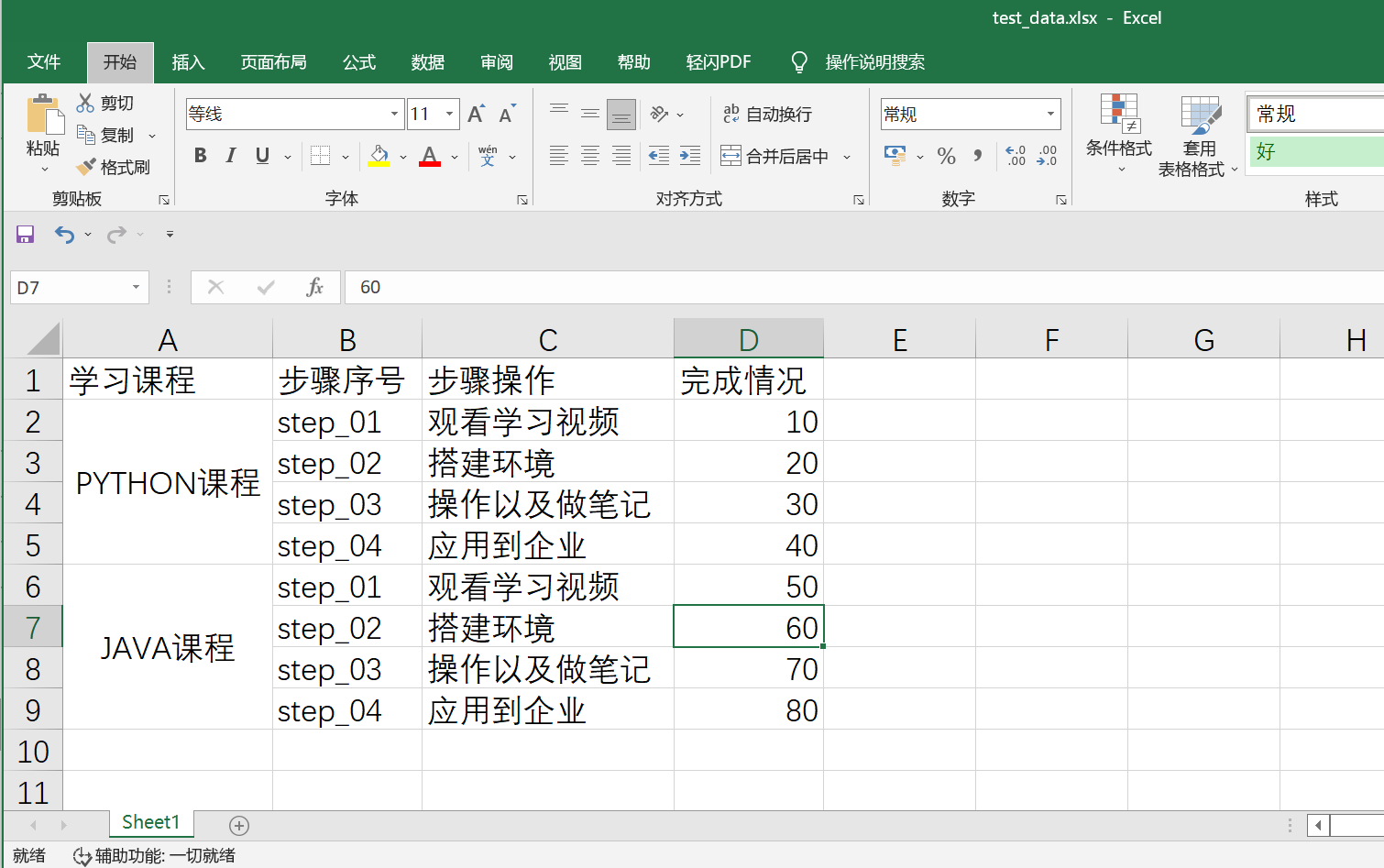
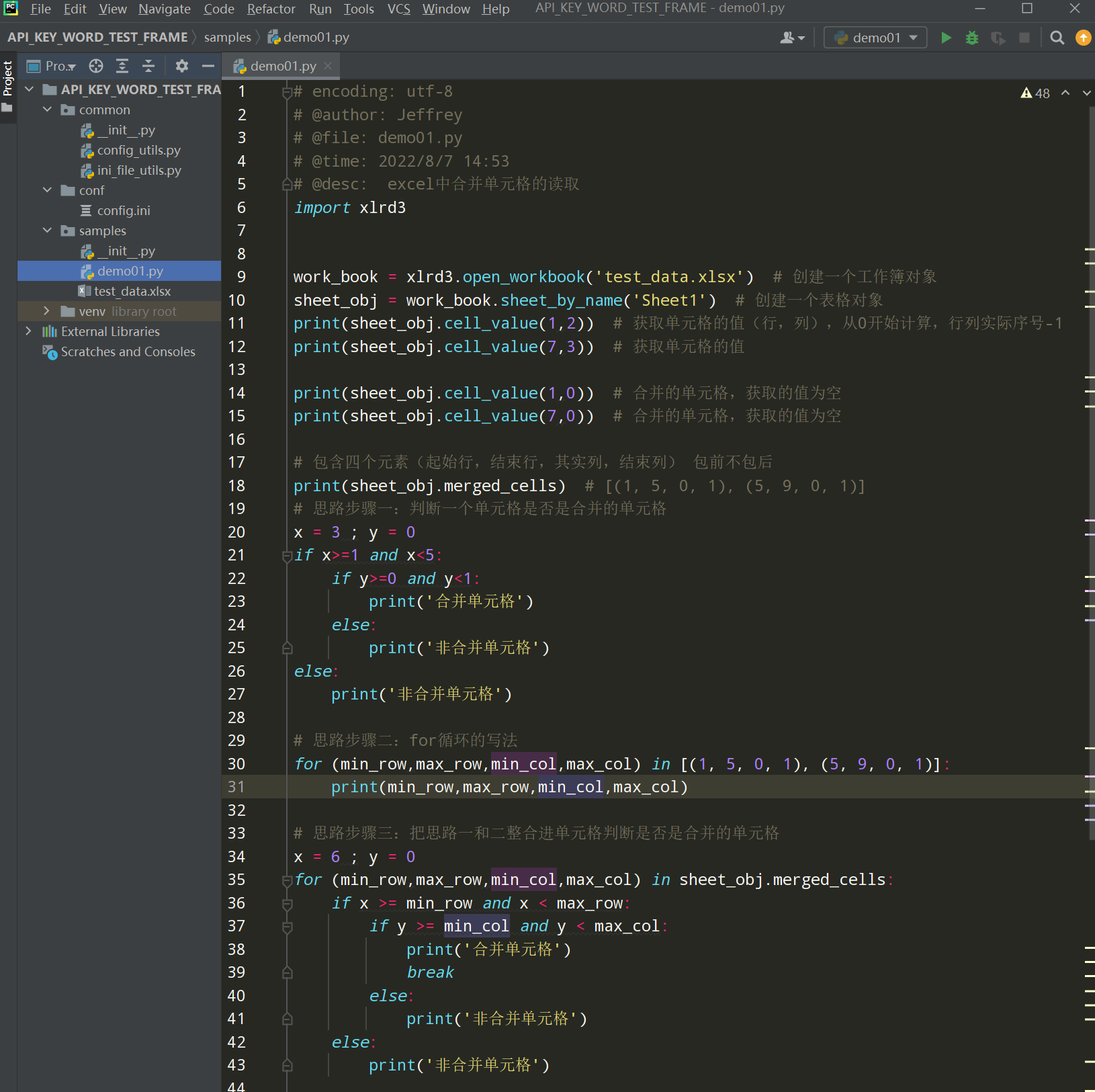
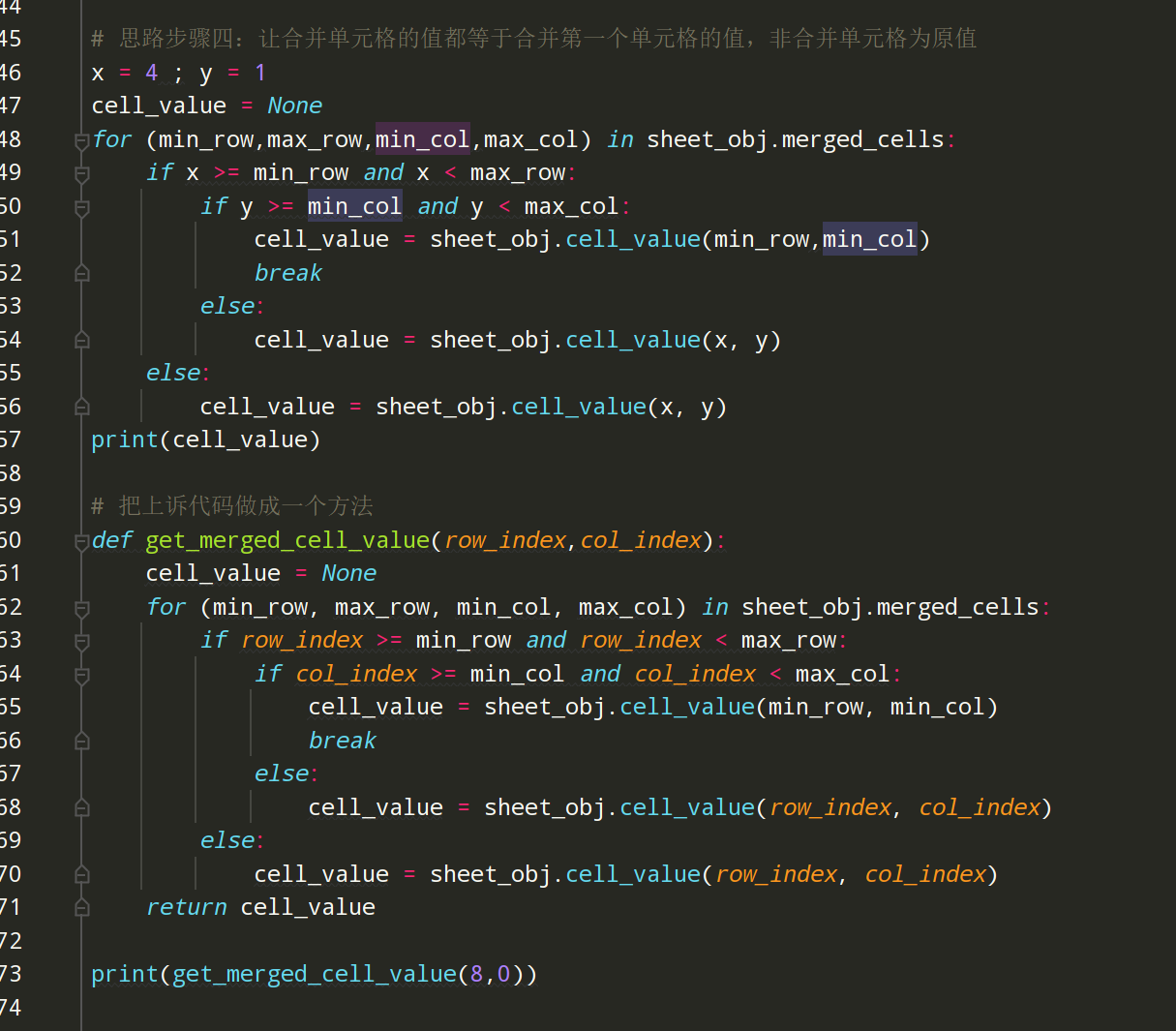
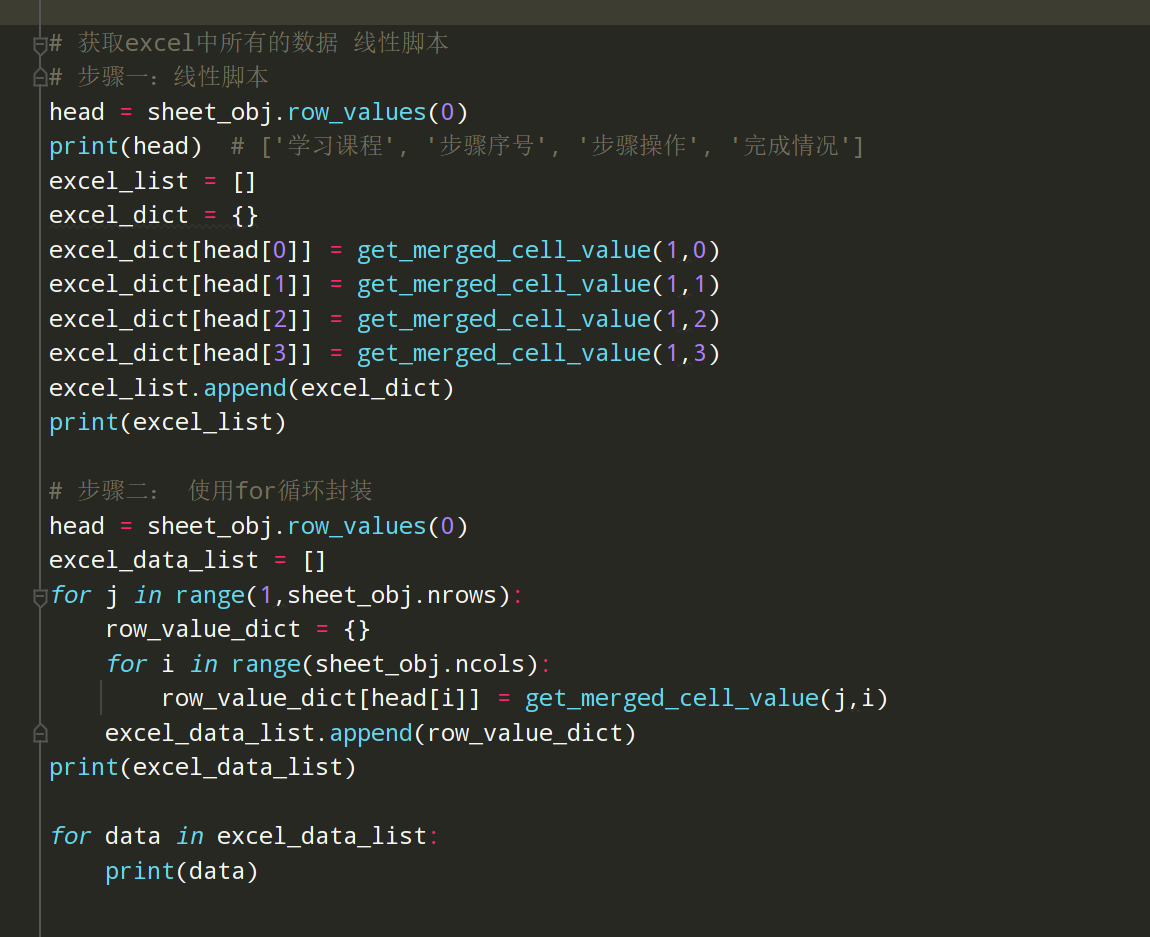
编写代码:
# encoding: utf-8 # @author: Jeffrey # @file: demo01.py # @time: 2022/8/7 14:53 # @desc: excel中合并单元格的读取 import xlrd3 work_book = xlrd3.open_workbook('test_data.xlsx') # 创建一个工作簿对象 sheet_obj = work_book.sheet_by_name('Sheet1') # 创建一个表格对象 print(sheet_obj.cell_value(1,2)) # 获取单元格的值(行,列),从0开始计算,行列实际序号-1 print(sheet_obj.cell_value(7,3)) # 获取单元格的值 print(sheet_obj.cell_value(1,0)) # 合并的单元格,获取的值为空 print(sheet_obj.cell_value(7,0)) # 合并的单元格,获取的值为空 # 包含四个元素(起始行,结束行,其实列,结束列) 包前不包后 print(sheet_obj.merged_cells) # [(1, 5, 0, 1), (5, 9, 0, 1)] # 思路步骤一:判断一个单元格是否是合并的单元格 x = 3 ; y = 0 if x>=1 and x<5: if y>=0 and y<1: print('合并单元格') else: print('非合并单元格') else: print('非合并单元格') # 思路步骤二:for循环的写法 for (min_row,max_row,min_col,max_col) in [(1, 5, 0, 1), (5, 9, 0, 1)]: print(min_row,max_row,min_col,max_col) # 思路步骤三:把思路一和二整合进单元格判断是否是合并的单元格 x = 6 ; y = 0 for (min_row,max_row,min_col,max_col) in sheet_obj.merged_cells: if x >= min_row and x < max_row: if y >= min_col and y < max_col: print('合并单元格') break else: print('非合并单元格') else: print('非合并单元格') # 思路步骤四:让合并单元格的值都等于合并第一个单元格的值,非合并单元格为原值 x = 4 ; y = 1 cell_value = None for (min_row,max_row,min_col,max_col) in sheet_obj.merged_cells: if x >= min_row and x < max_row: if y >= min_col and y < max_col: cell_value = sheet_obj.cell_value(min_row,min_col) break else: cell_value = sheet_obj.cell_value(x, y) else: cell_value = sheet_obj.cell_value(x, y) print(cell_value) # 把上诉代码做成一个方法 def get_merged_cell_value(row_index,col_index): cell_value = None for (min_row, max_row, min_col, max_col) in sheet_obj.merged_cells: if row_index >= min_row and row_index < max_row: if col_index >= min_col and col_index < max_col: cell_value = sheet_obj.cell_value(min_row, min_col) break else: cell_value = sheet_obj.cell_value(row_index, col_index) else: cell_value = sheet_obj.cell_value(row_index, col_index) return cell_value print(get_merged_cell_value(8,0)) # 获取excel中所有的数据 线性脚本 # 步骤一:线性脚本 head = sheet_obj.row_values(0) print(head) # ['学习课程', '步骤序号', '步骤操作', '完成情况'] excel_list = [] excel_dict = {} excel_dict[head[0]] = get_merged_cell_value(1,0) excel_dict[head[1]] = get_merged_cell_value(1,1) excel_dict[head[2]] = get_merged_cell_value(1,2) excel_dict[head[3]] = get_merged_cell_value(1,3) excel_list.append(excel_dict) print(excel_list) # 步骤二: 使用for循环封装 head = sheet_obj.row_values(0) excel_data_list = [] for j in range(1,sheet_obj.nrows): row_value_dict = {} for i in range(sheet_obj.ncols): row_value_dict[head[i]] = get_merged_cell_value(j,i) excel_data_list.append(row_value_dict) print(excel_data_list) for data in excel_data_list: print(data)
步骤5、在common下新建excel_file_utils.py文件
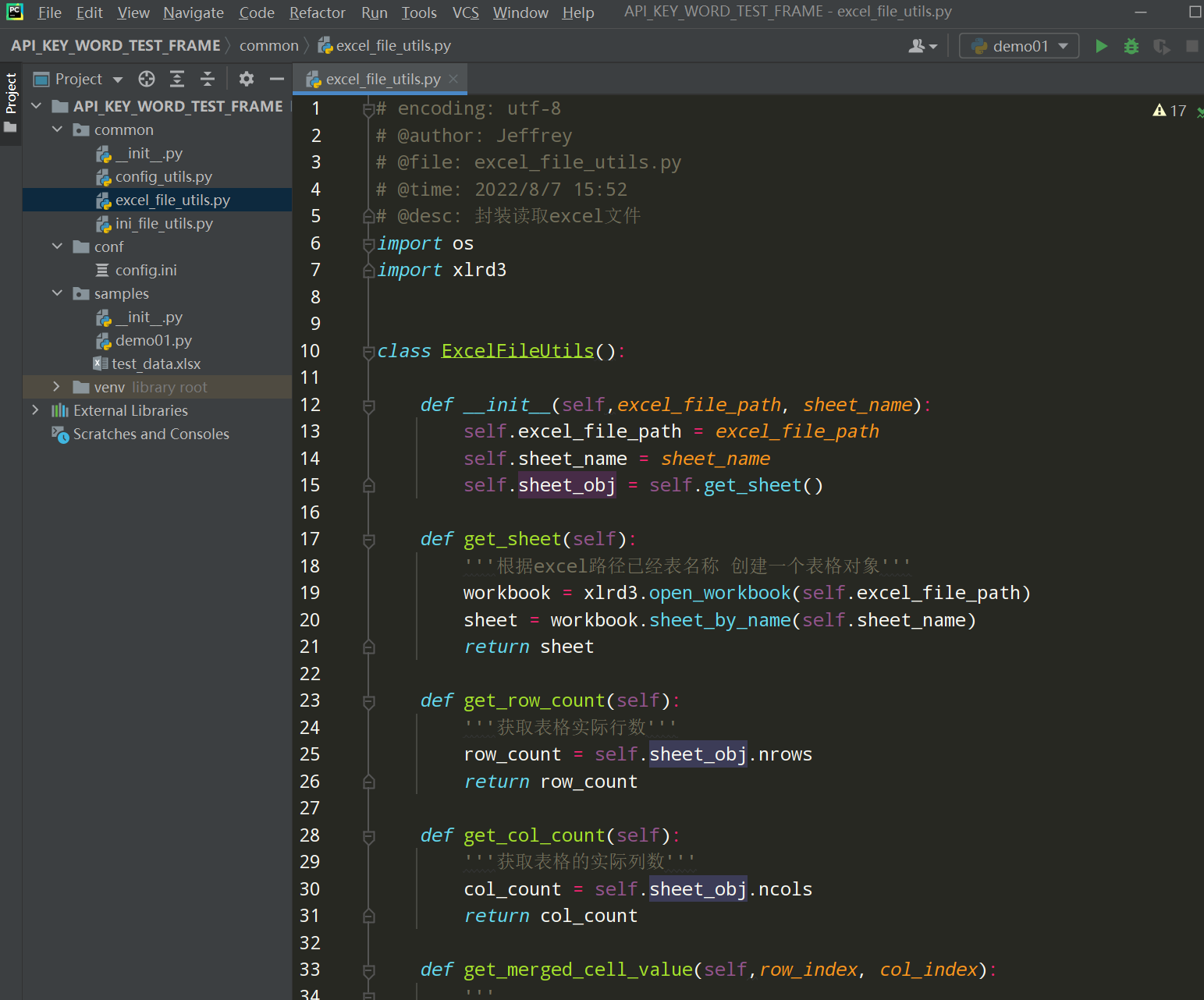
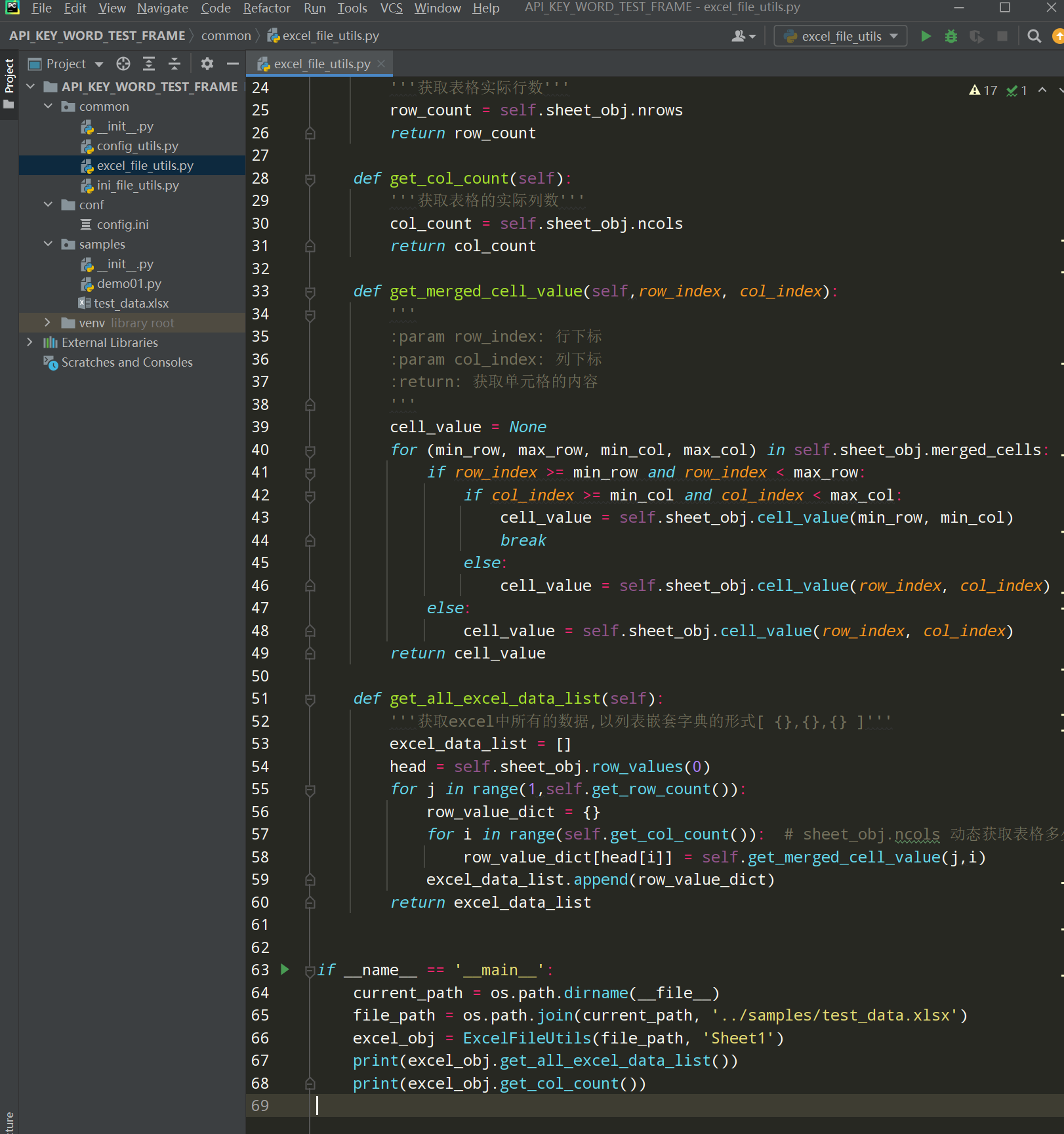
编写代码:
# encoding: utf-8 # @author: Jeffrey # @file: excel_file_utils.py # @time: 2022/8/7 15:52 # @desc: 封装读取excel文件 import os import xlrd3 class ExcelFileUtils(): def __init__(self,excel_file_path, sheet_name): self.excel_file_path = excel_file_path self.sheet_name = sheet_name self.sheet_obj = self.get_sheet() def get_sheet(self): '''根据excel路径已经表名称 创建一个表格对象''' workbook = xlrd3.open_workbook(self.excel_file_path) sheet = workbook.sheet_by_name(self.sheet_name) return sheet def get_row_count(self): '''获取表格实际行数''' row_count = self.sheet_obj.nrows return row_count def get_col_count(self): '''获取表格的实际列数''' col_count = self.sheet_obj.ncols return col_count def get_merged_cell_value(self,row_index, col_index): ''' :param row_index: 行下标 :param col_index: 列下标 :return: 获取单元格的内容 ''' cell_value = None for (min_row, max_row, min_col, max_col) in self.sheet_obj.merged_cells: if row_index >= min_row and row_index < max_row: if col_index >= min_col and col_index < max_col: cell_value = self.sheet_obj.cell_value(min_row, min_col) break else: cell_value = self.sheet_obj.cell_value(row_index, col_index) else: cell_value = self.sheet_obj.cell_value(row_index, col_index) return cell_value def get_all_excel_data_list(self): '''获取excel中所有的数据,以列表嵌套字典的形式''' excel_data_list = [] head = self.sheet_obj.row_values(0) for j in range(1,self.get_row_count()): row_value_dict = {} for i in range(self.get_col_count()): # sheet_obj.ncols 动态获取表格多少列 row_value_dict[head[i]] = self.get_merged_cell_value(j,i) excel_data_list.append(row_value_dict) return excel_data_list if __name__ == '__main__': current_path = os.path.dirname(__file__) file_path = os.path.join(current_path, '../samples/test_data.xlsx') excel_obj = ExcelFileUtils(file_path, 'Sheet1') print(excel_obj.get_all_excel_data_list()) print(excel_obj.get_col_count())
测试执行结果:
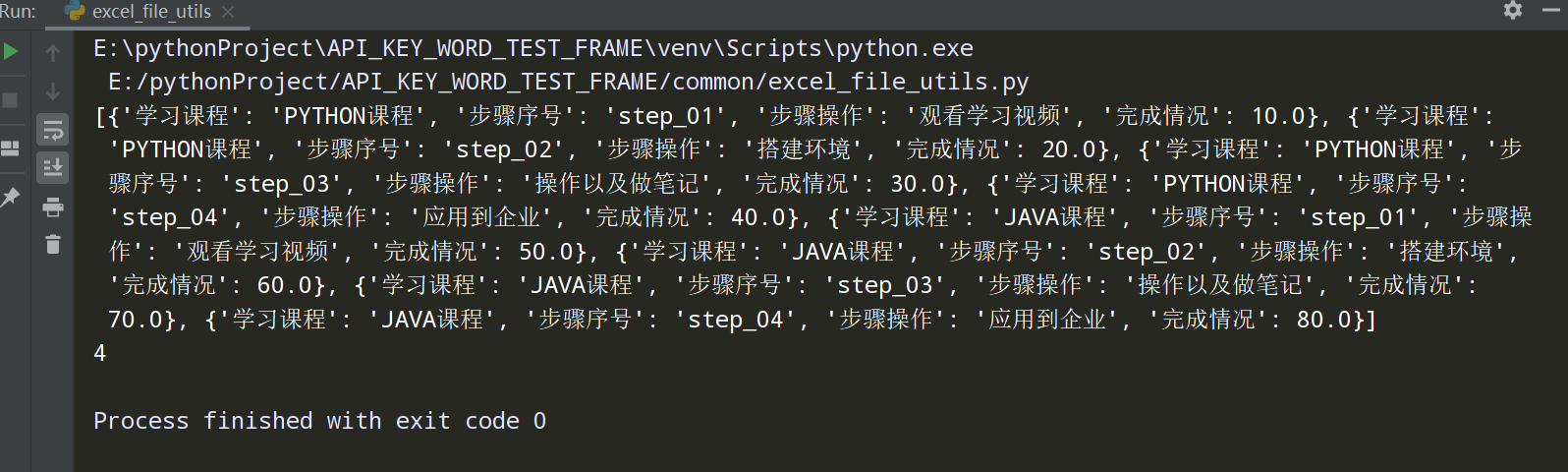
步骤6、在项目根目录下新建test_data普通文件夹,把测试用例文件放里面
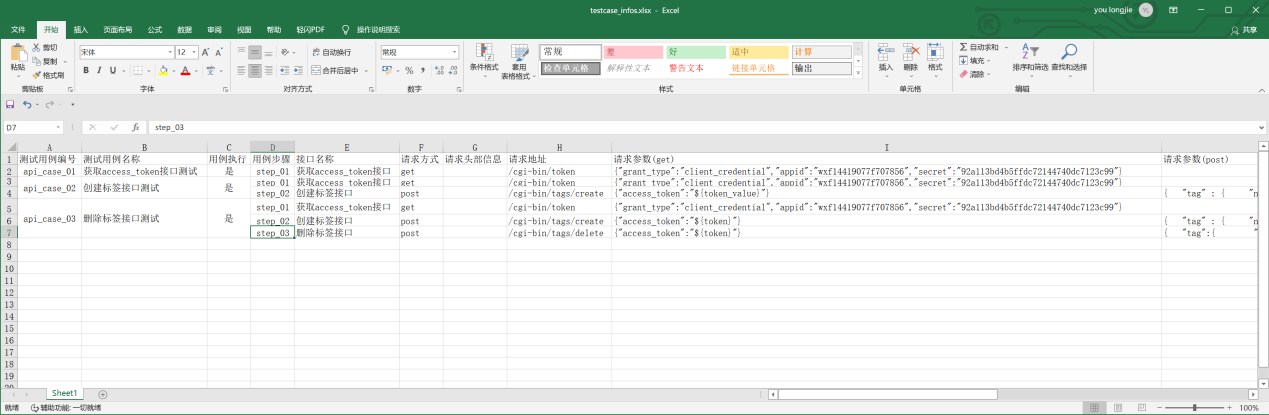
步骤7、在common下新建testcase_data_utils.py文件把测试用例的数据转换成框架需要用到的格式
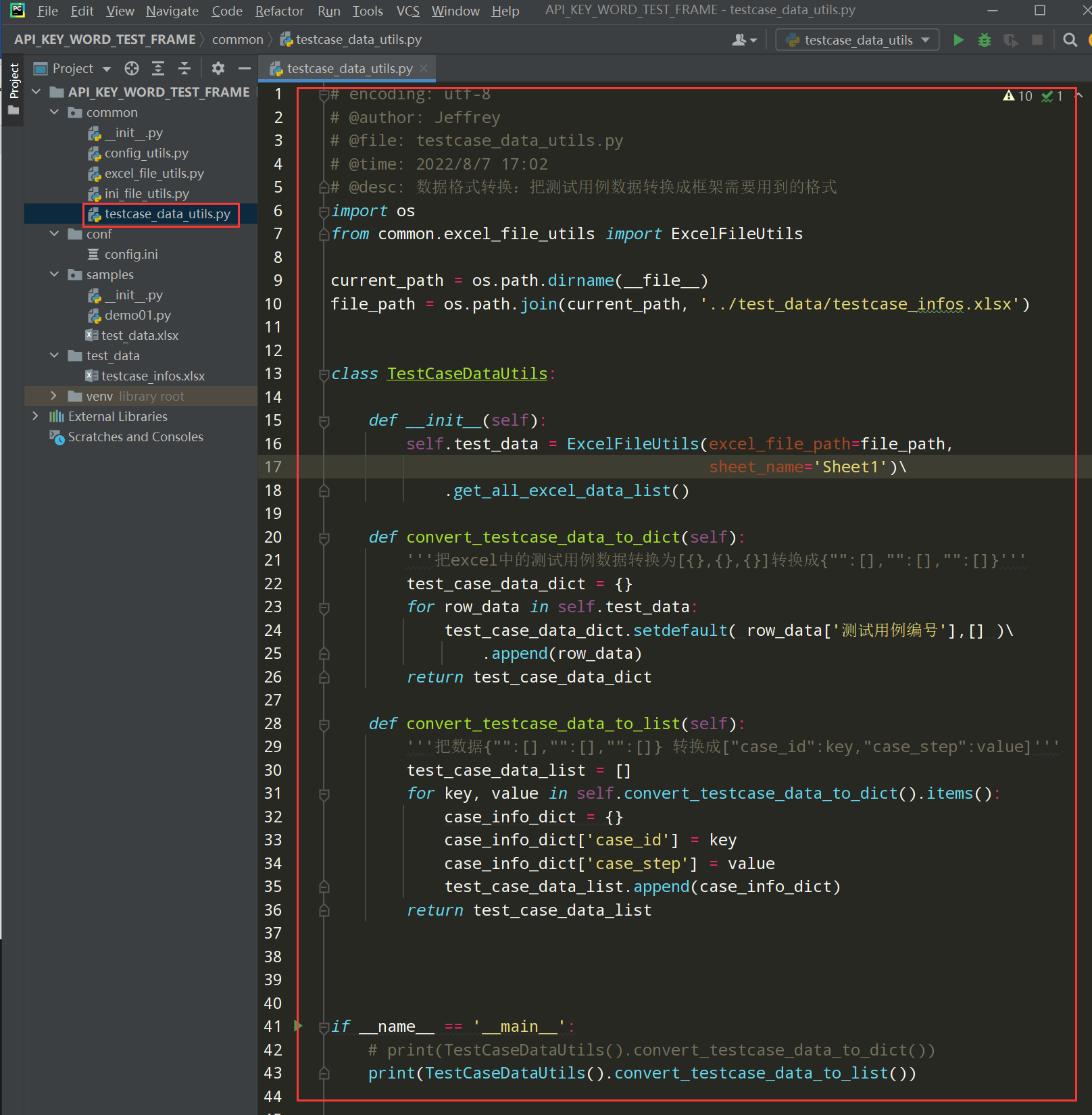
编写代码:
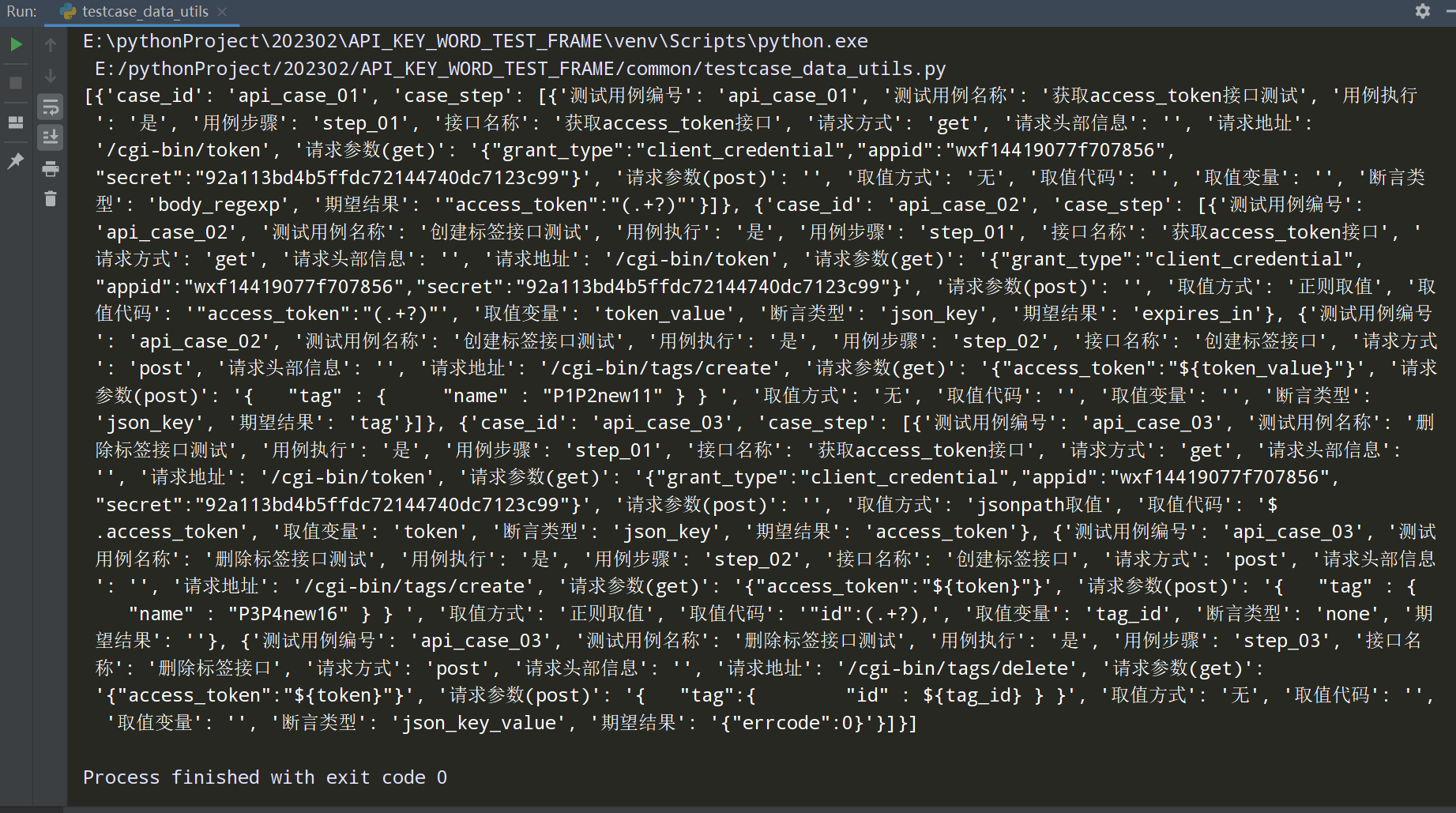
# encoding: utf-8 # @author: Jeffrey # @file: testcase_data_utils.py # @time: 2022/8/7 17:02 # @desc: 数据格式转换:把测试用例数据转换成框架需要用到的格式 import os from common.excel_file_utils import ExcelFileUtils current_path = os.path.dirname(__file__) file_path = os.path.join(current_path, '../test_data/testcase_infos.xlsx') class TestCaseDataUtils: def __init__(self): self.test_data = ExcelFileUtils(excel_file_path=file_path, sheet_name='Sheet1')\ .get_all_excel_data_list() def convert_testcase_data_to_dict(self): '''把excel中的测试用例数据转换为[{},{},{}]转换成{"":[],"":[],"":[]}''' test_case_data_dict = {} for row_data in self.test_data: test_case_data_dict.setdefault( row_data['测试用例编号'],[] )\ .append(row_data) return test_case_data_dict def convert_testcase_data_to_list(self): '''把数据{"":[],"":[],"":[]} 转换成["case_id":key,"case_step":value]''' test_case_data_list = [] for key, value in self.convert_testcase_data_to_dict().items(): case_info_dict = {} case_info_dict['case_id'] = key case_info_dict['case_step'] = value test_case_data_list.append(case_info_dict) return test_case_data_list if __name__ == '__main__': # print(TestCaseDataUtils().convert_testcase_data_to_dict()) print(TestCaseDataUtils().convert_testcase_data_to_list())
convert_testcase_data_to_dict()方法的目的是把用例数据以用例编号和用例数据分开
'''把excel中的测试用例数据转换为[{},{},{}]转换成{"":[],"":[],"":[]}'''
查看执行结果:
convert_testcase_data_to_list()方法的目的是以用例编号和用例步骤分开
'''把数据{"":[],"":[],"":[]} 转换成["case_id":key,"case_step":value]'''
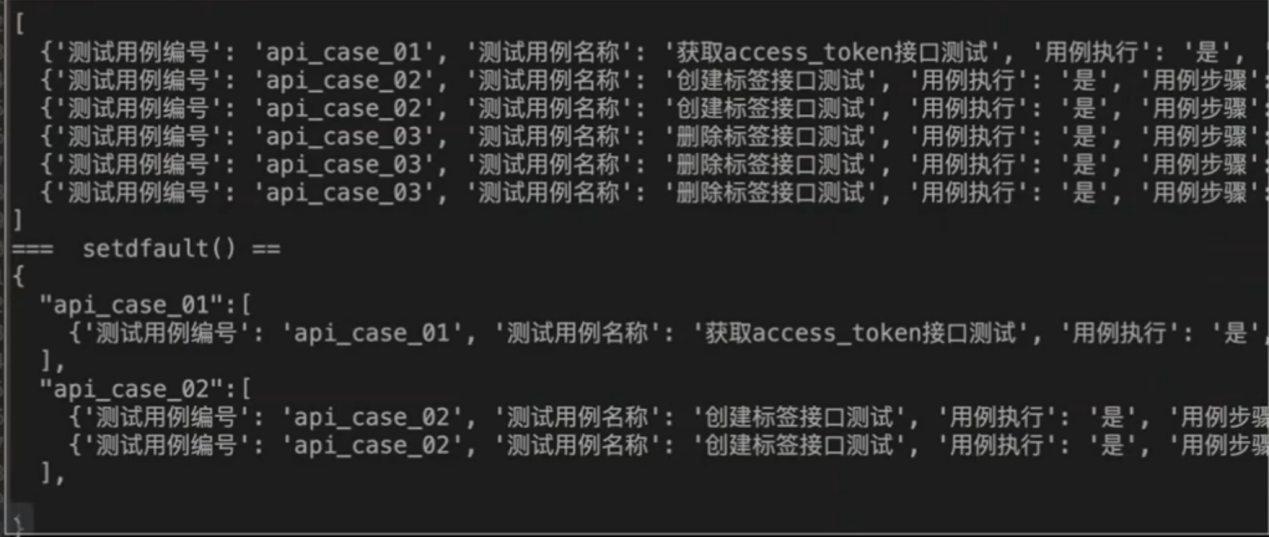
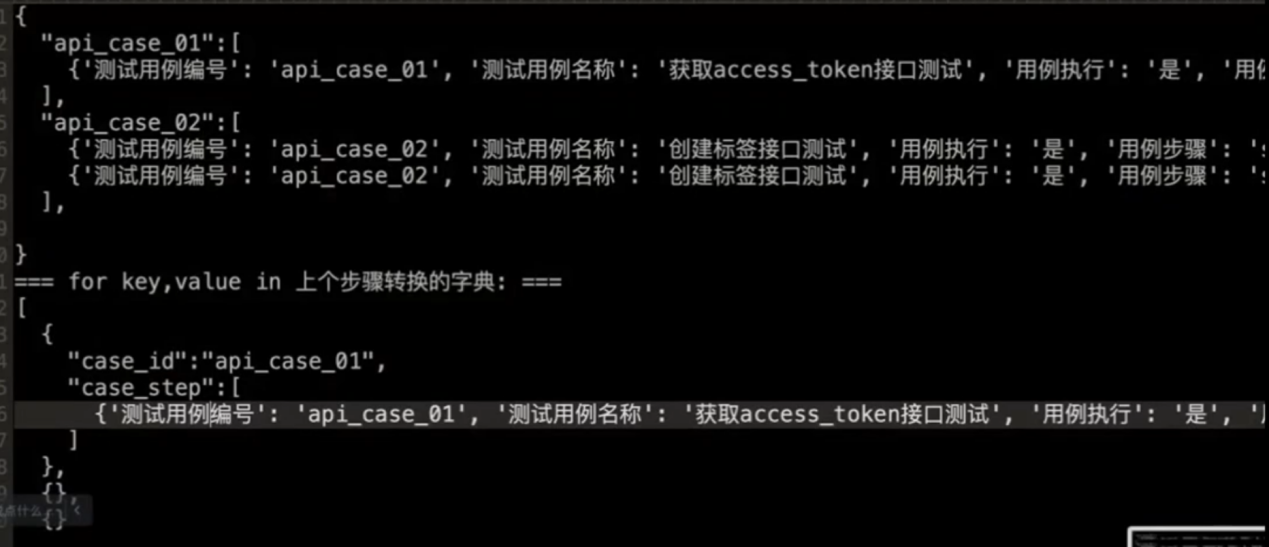
转换后数据
框架02,封装requests请求,在common下新建一个requests_utils.py文件
步骤1,封装get请求
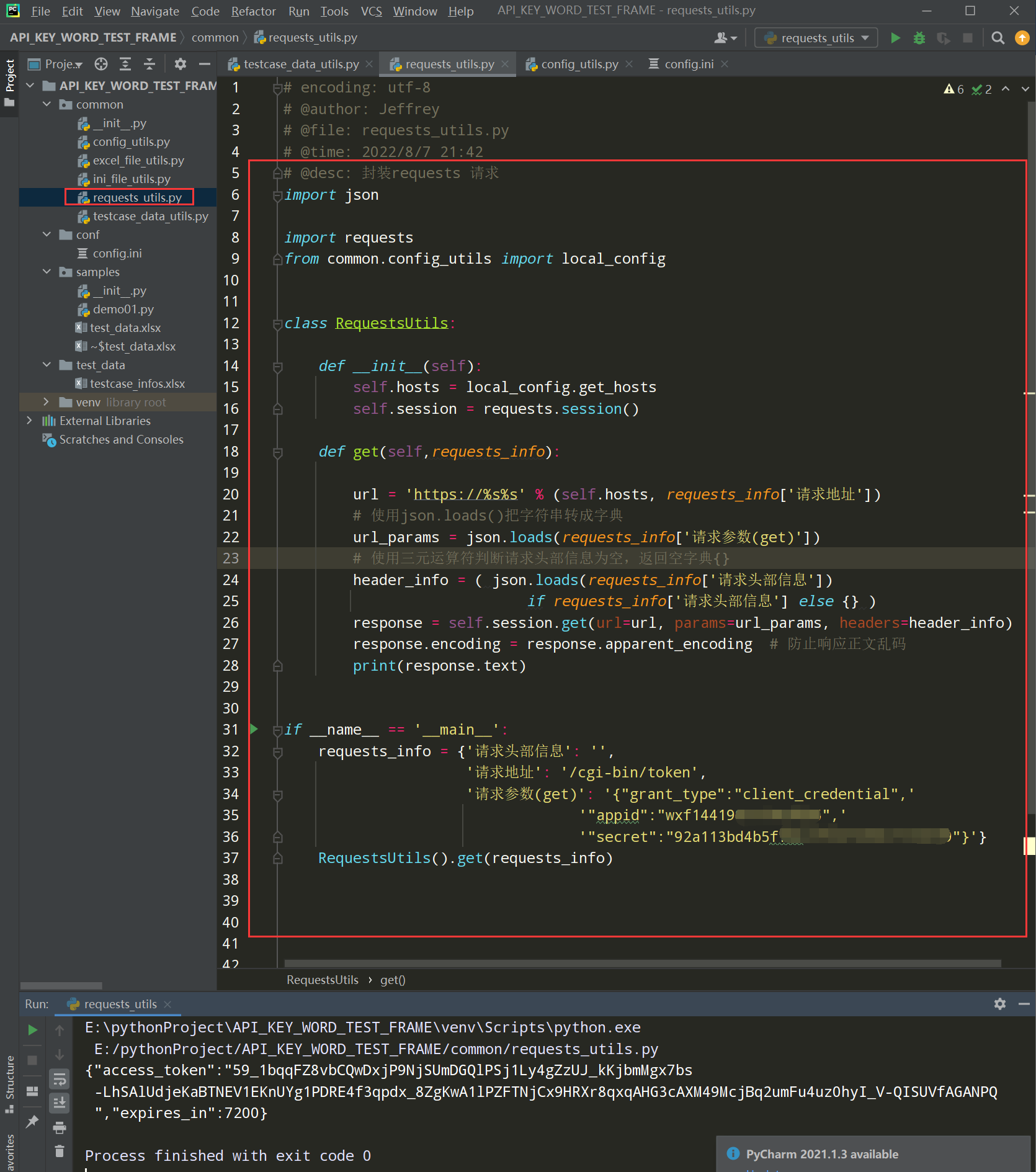
编写代码:
# encoding: utf-8 # @author: Jeffrey # @file: requests_utils.py # @time: 2022/8/7 21:42 # @desc: 封装requests 请求 import json import requests from common.config_utils import local_config class RequestsUtils: def __init__(self): self.hosts = local_config.get_hosts self.session = requests.session() def get(self,requests_info): url = 'https://%s%s' % (self.hosts, requests_info['请求地址']) # 使用json.loads()把字符串转成字典 url_params = json.loads(requests_info['请求参数(get)']) # 使用三元运算符判断请求头部信息为空,返回空字典{} header_info = ( json.loads(requests_info['请求头部信息']) if requests_info['请求头部信息'] else {} ) response = self.session.get(url=url, params=url_params, headers=header_info) response.encoding = response.apparent_encoding # 防止响应正文乱码 print(response.text) if __name__ == '__main__': requests_info = {'请求头部信息': '', '请求地址': '/cgi-bin/token', '请求参数(get)': '{"grant_type":"client_credential",' '"appid":"wxf1856",' '"secret":"92a113bd423c99"}'} result = RequestsUtils().get(requests_info) print(result)
步骤2、把返回的所有响应信息,作为一个字典,且多一个code字段
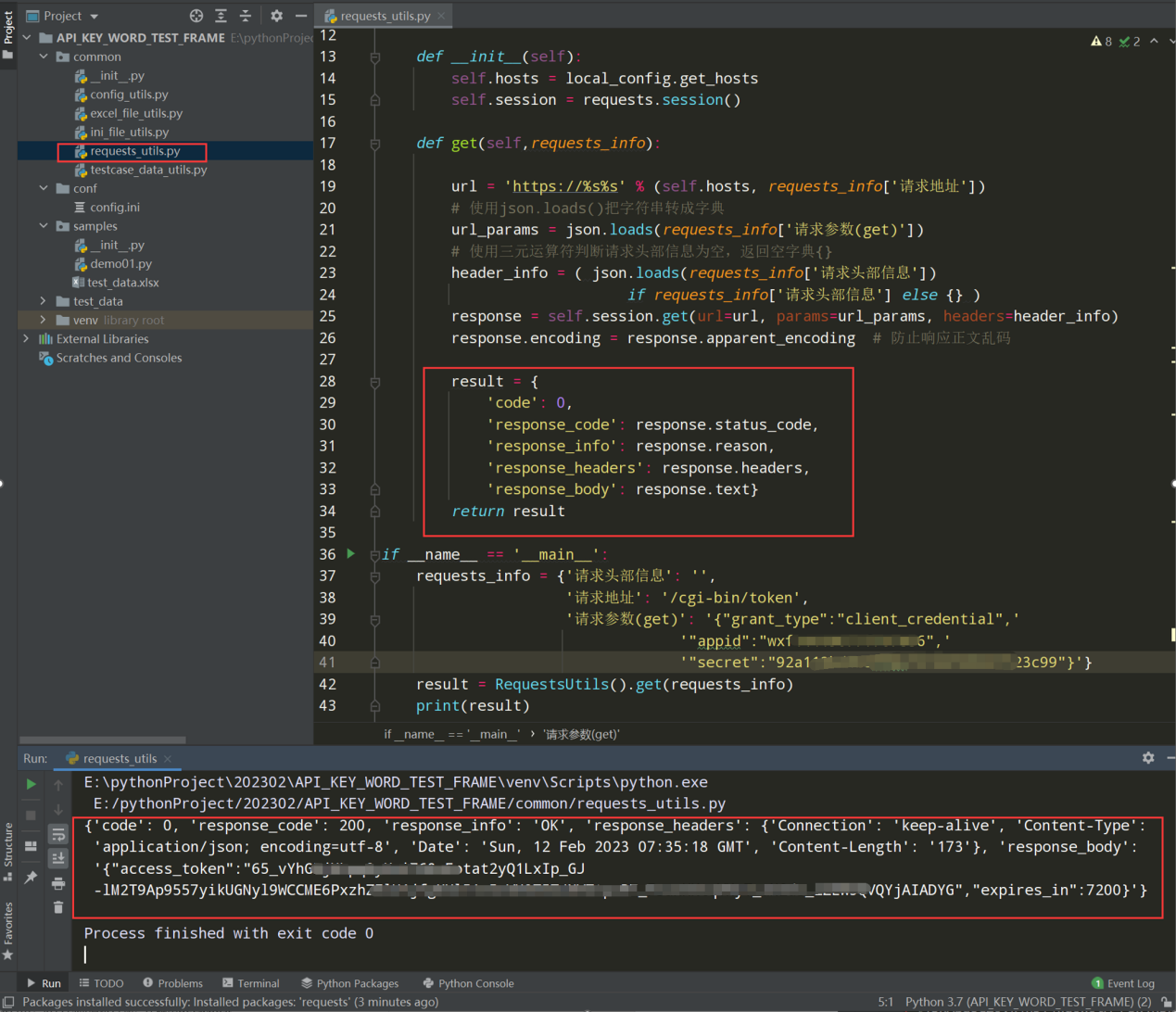
编写代码:
result = { 'code':0, 'response_code':response.status_code, 'response_info':response.reason, 'response_headers':response.headers, 'response_body':response.text }
步骤3、封装post请求
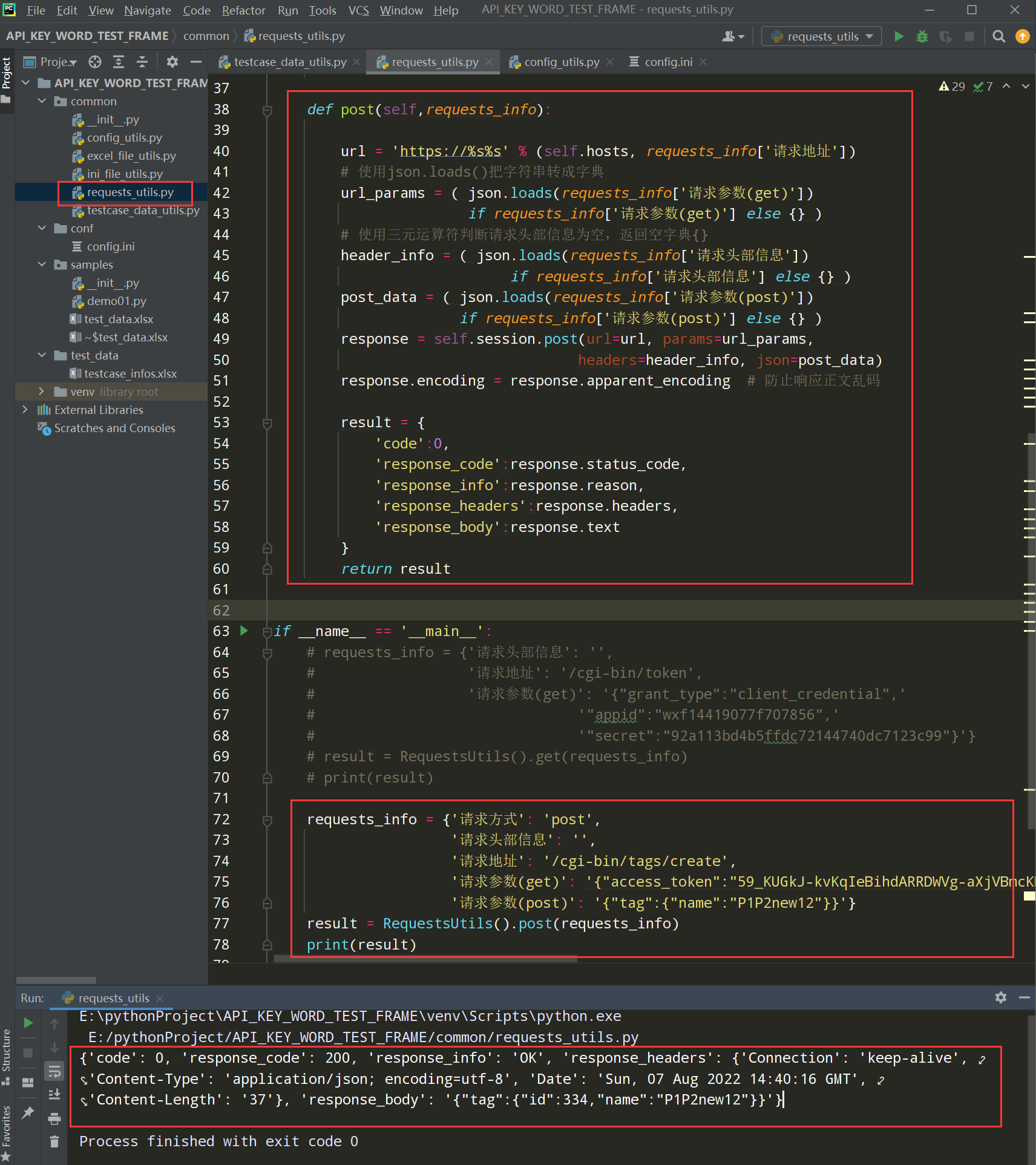
编写代码:
def post(self,requests_info): url = 'https://%s%s' % (self.hosts, requests_info['请求地址']) # 使用json.loads()把字符串转成字典 url_params = ( json.loads(requests_info['请求参数(get)']) if requests_info['请求参数(get)'] else {} ) # 使用三元运算符判断请求头部信息为空,返回空字典{} header_info = ( json.loads(requests_info['请求头部信息']) if requests_info['请求头部信息'] else {} ) post_data = ( json.loads(requests_info['请求参数(post)']) if requests_info['请求参数(post)'] else {} ) response = self.session.post(url=url, params=url_params, headers=header_info, json=post_data) response.encoding = response.apparent_encoding # 防止响应正文乱码 result = { 'code':0, 'response_code':response.status_code, 'response_info':response.reason, 'response_headers':response.headers, 'response_body':response.text } return result 测试代码: if __name__ == '__main__': requests_info = {'请求方式': 'post', '请求头部信息': '', '请求地址': '/cgi-bin/tags/create', '请求参数(get)': '{"access_token":"59_KUGkJ-kcp6IgP5BpK4t4cCO4DRNilMYH836oD8H9MEqnIXAGgAEANQW"}', '请求参数(post)': '{"tag":{"name":"P1P2new12"}}'} result = RequestsUtils().post(requests_info) print(result)
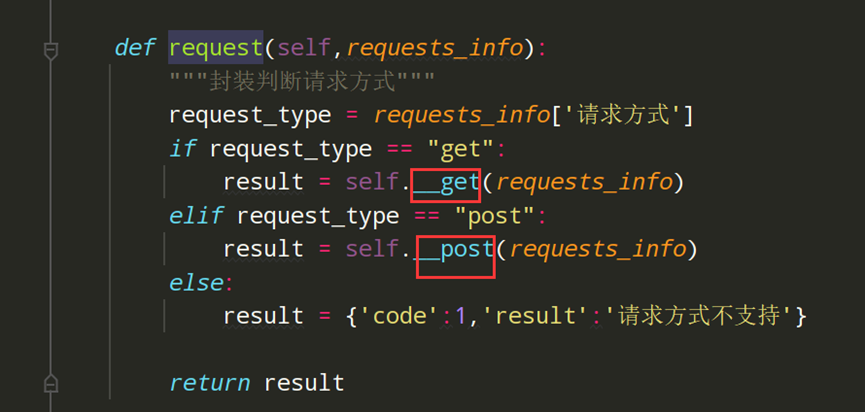
步骤4、封装request方法,进行判断请求方式,在调用get或post
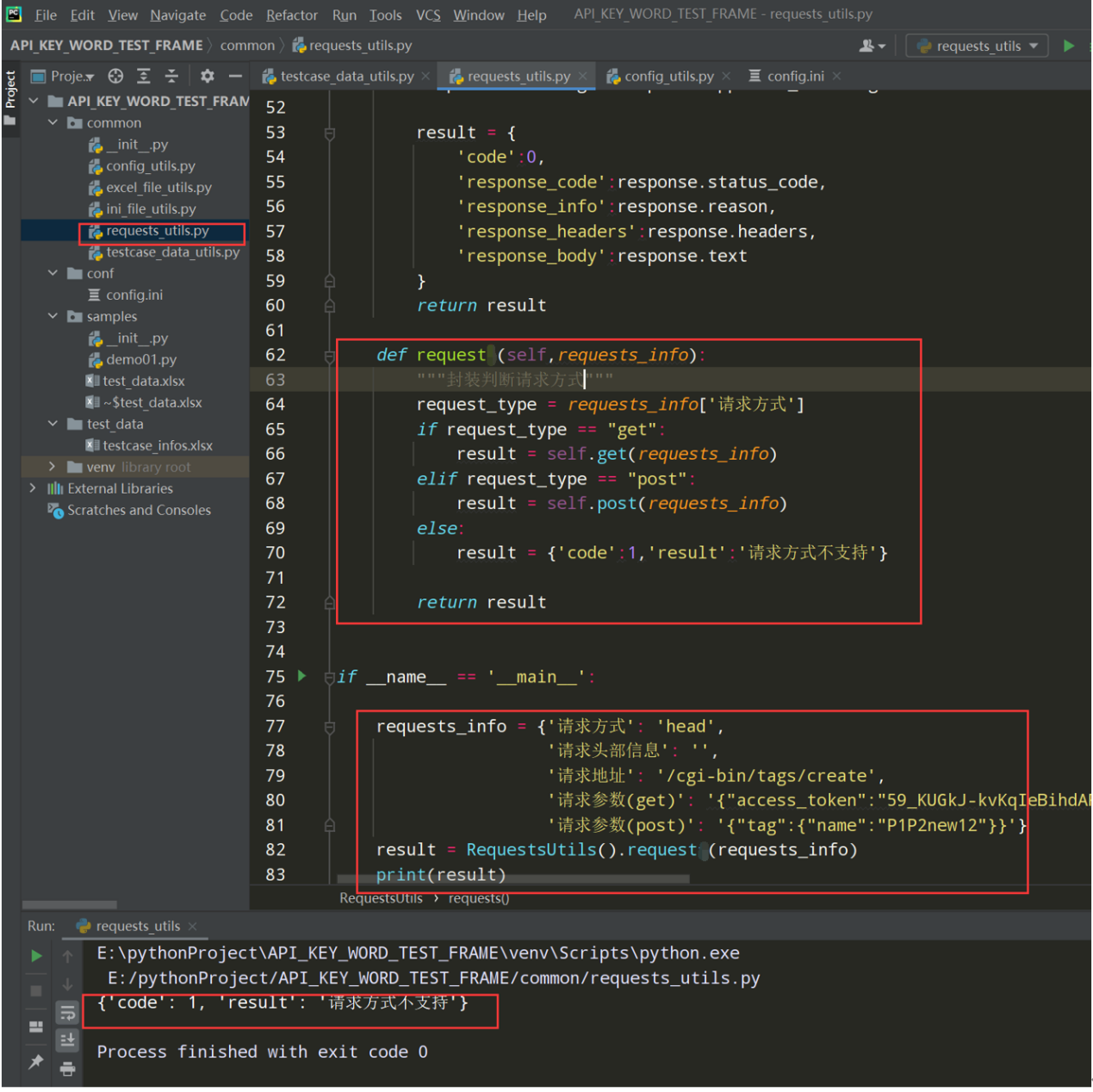
编写代码:
def request(self,requests_info): """封装判断请求方式""" request_type = requests_info['请求方式'] if request_type == "get": result = self.get(requests_info) elif request_type == "post": result = self.post(requests_info) else: result = {'code':1,'result':'请求方式不支持'} return result
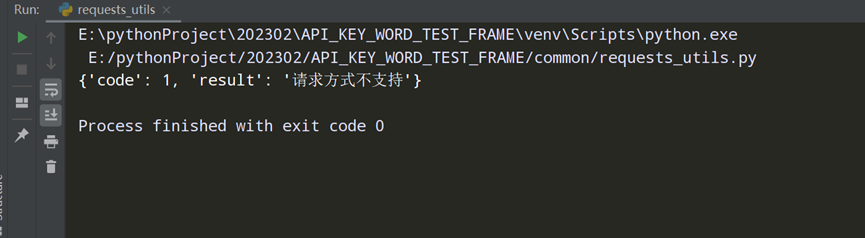
if __name__ == '__main__': requests_info = {'请求方式': 'head', '请求头部信息': '', '请求地址': '/cgi-bin/tags/create', '请求参数(get)': '{"access_token":"59_KUGkJ-kvKqIrOUD6RyZR9dJWHK_UFph2TTs6nPYRfMYH836oD8H9MEqnIXAGgAEANQW"}', '请求参数(post)': '{"tag":{"name":"P1P2new12"}}'} result = RequestsUtils().request(requests_info) print(result)
查看执行结果:
步骤5、小优化,由于对外的requests,只需要出现requests方法,所以get/post可以在类中做成私有的
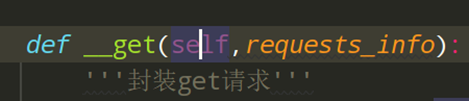

框架03,多接口顺序运行
由于站在测试用例的角度,一条测试用例可能由多个接口调用组成,所以我们需要把一条测试用例的多个接口一次执行完
多接口运行相当于excel测试用例的用例步骤,当一个用例需要依次调用A、B、C三个接口执行,此时A正确执行、B执行错误,此时由于B的错误整个测试用例也执行失败了,可以不必调用执行接口C。这个逻辑可以在多接口运行方法中实现。
思路是用for循环调用单接口运行方法时,把单接口的返回字典数据结果作为判断 依据,当出现code不为0时,表示失败,此时可以用break终止循环。
步骤1、在requests_utils.py文件中封装request_by_step()方法
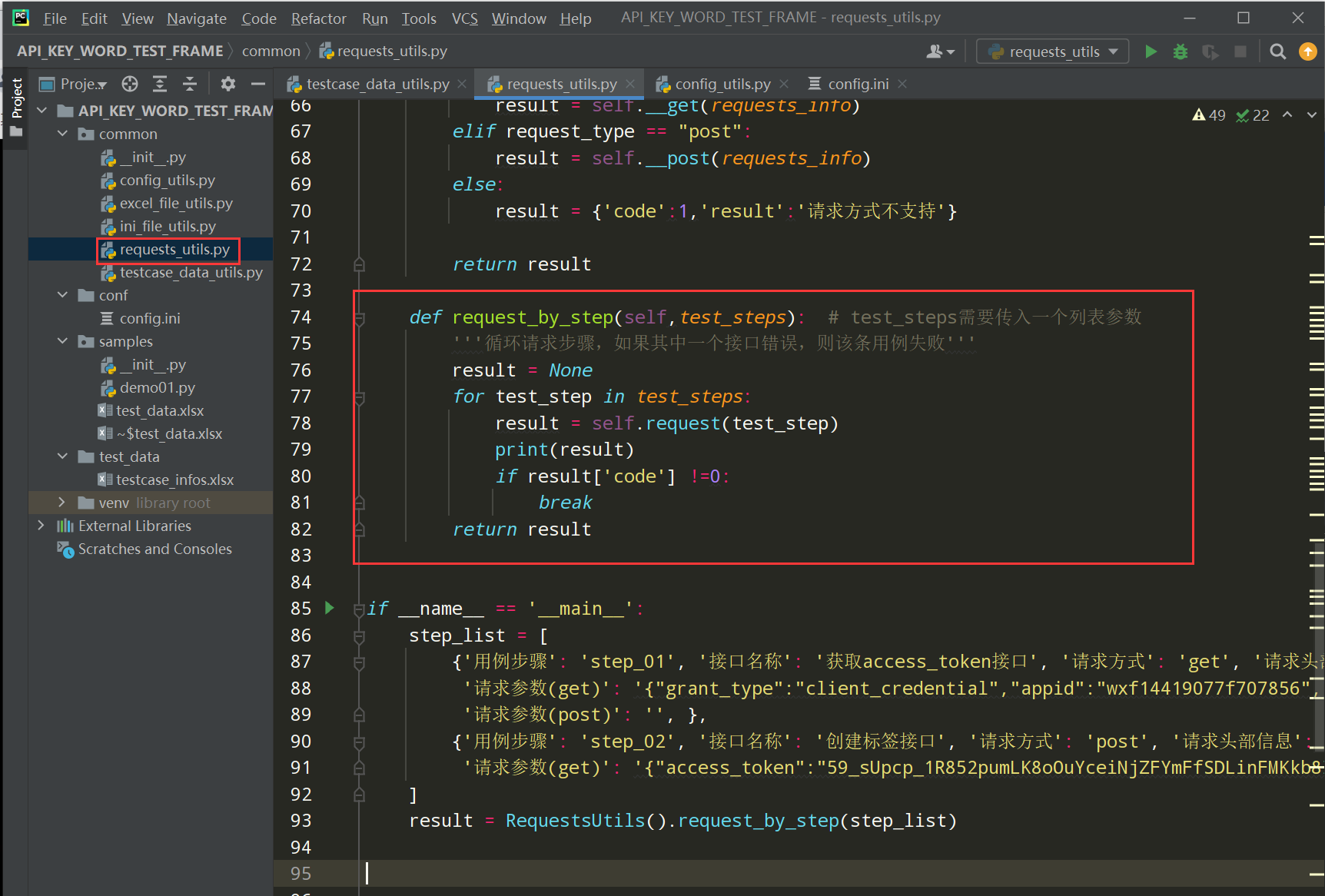
编写代码:
def request_by_step(self,test_steps): # test_steps需要传入一个列表参数 '''循环请求步骤,如果其中一个接口错误,则该条用例失败''' result = None for test_step in test_steps: result = self.request(test_step) print(result) if result['code'] !=0: break return result if __name__ == '__main__': step_list = [ {'用例步骤': 'step_01', '接口名称': '获取access_token接口', '请求方式': 'get', '请求头部信息': '', '请求地址': '/cgi-bin/token', '请求参数(get)': '{"grant_type":"client_credential","appid":"wxf1447856","secret":"92a113dc7123c99"}', '请求参数(post)': '', }, {'用例步骤': 'step_02', '接口名称': '创建标签接口', '请求方式': 'post', '请求头部信息': '', '请求地址': '/cgi-bin/tags/create', '请求参数(get)': '{"access_token":"59_sUpcp_1R8mFfSDLinFMKkb9D-Ux1CB5_1Kxu0KpO585QSUiACALNP"}', '请求参数(post)': '{ "tag" : { "name" : "P1P2new11" } } '} ] result = RequestsUtils().request_by_step(step_list)
测试执行一下:
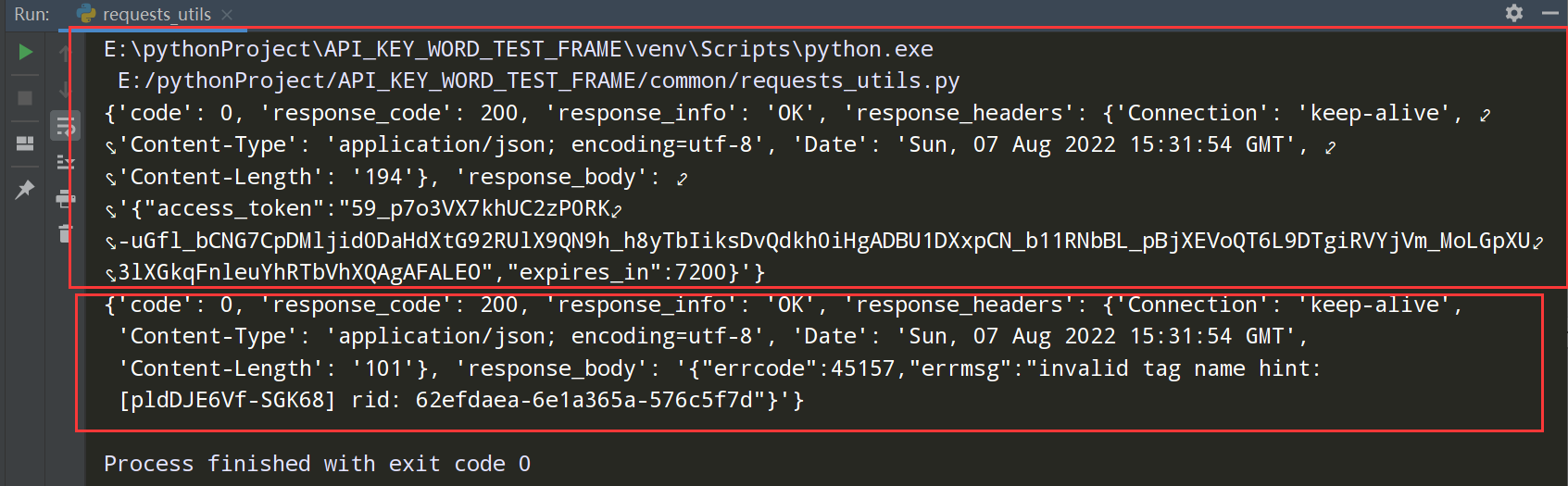
框架04 接口关联实现
关联:把上一个接口返回的值作为下一个接口的参数的过程。由于设计的框架支持单独用例执行,所以会出现很多需要关联的场景,处理设计思路如下:
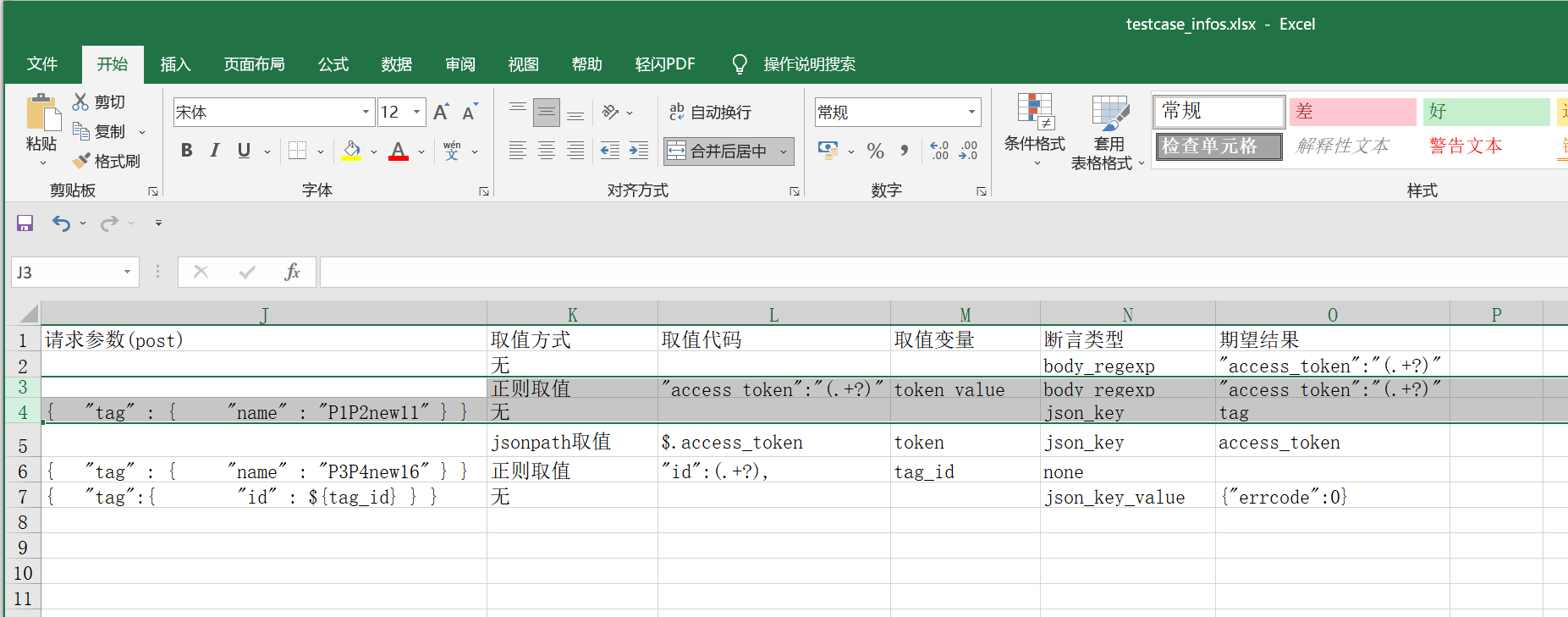
1、设计excel用例信息时,多设计取值方式、传值变量、取值代码三个字段
2、取值方式支持json、正则两种常用的方式和取值代码配合分别用python的jsonpath和re模块实现上一个接口返回值的截取操作
3、传值变量字段内的值作为字典的key,而通过上一步骤所取的值作为key对应的value,由于用例的独立性,每个用例执行之前,需要清空上一个用例临时的字典,可以使用在接口封装的类中增加一个属性来实现
4、下一个接口取值的思路是优化单接口运行方法,在单接口运行方法中使用re模块的findall方法找到要替换的key,然后把字典的key对应的value替换进来,实际可能牵涉到多个关联参数要替换的情况,用循环实现;
提前准备:excel 变量名字段 取值方式 取值代码;
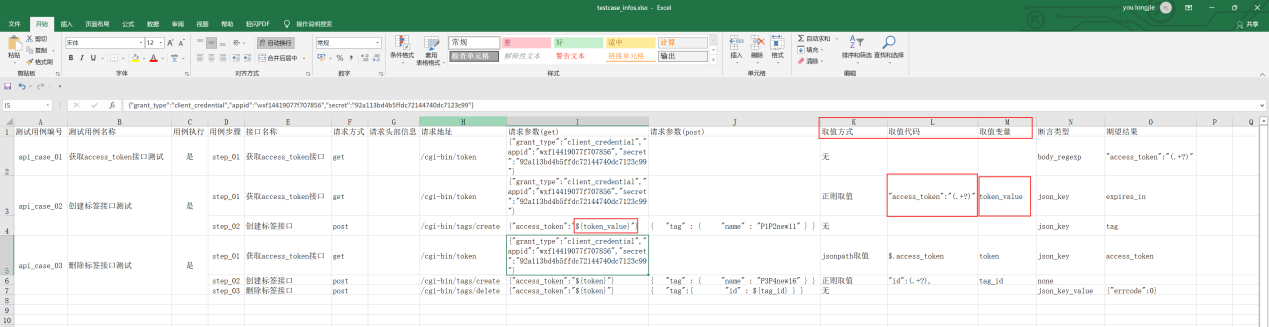
取值方式包含jsonpath取值,正则表达式取值
Python处理jsonpath模块
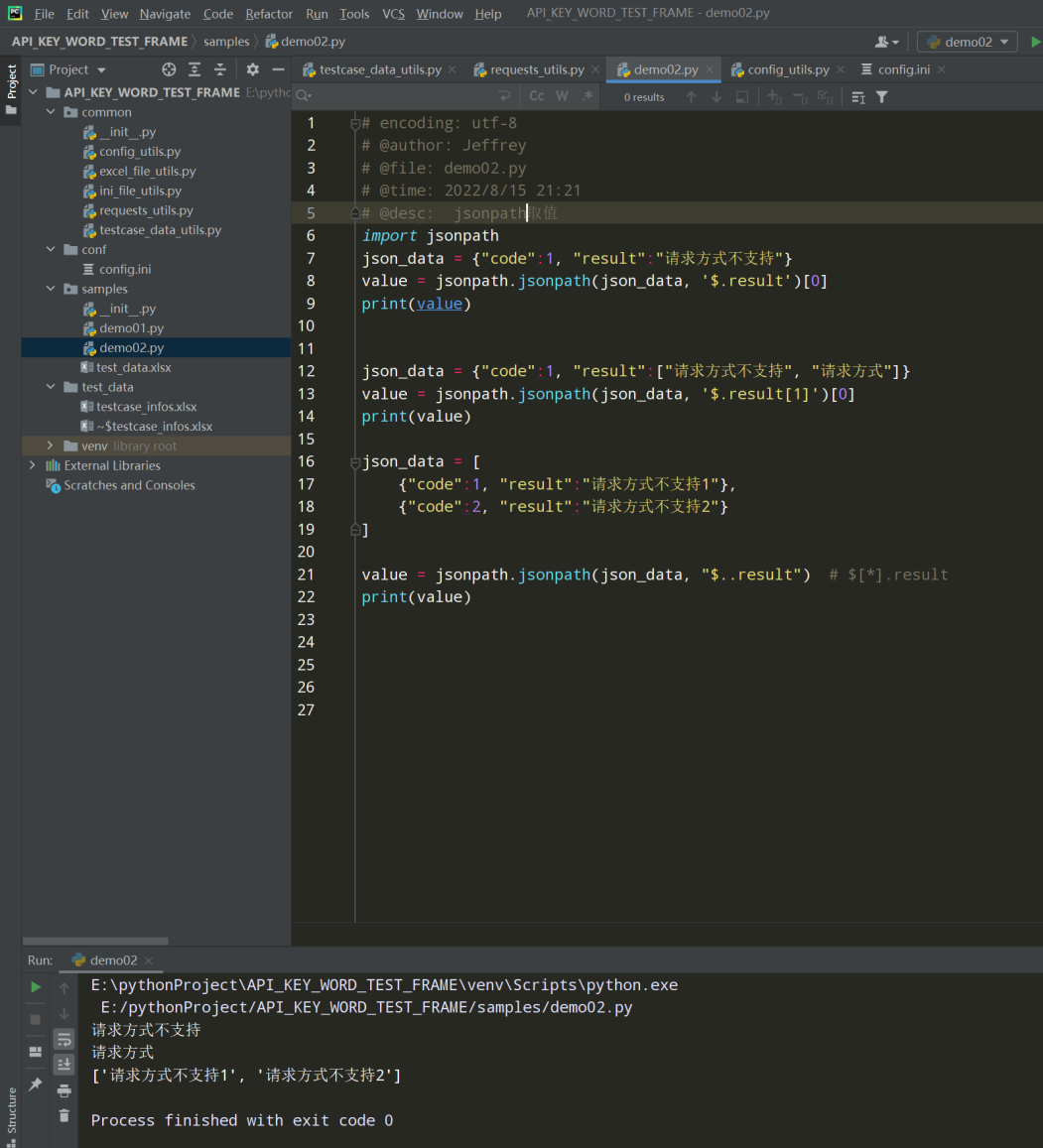
Python处理正则表达式 re模块
关联代码实现上分为两个步骤
步骤1、截取出接口的返回值,存放到定义的变量中
定义临时存放 变量的字典
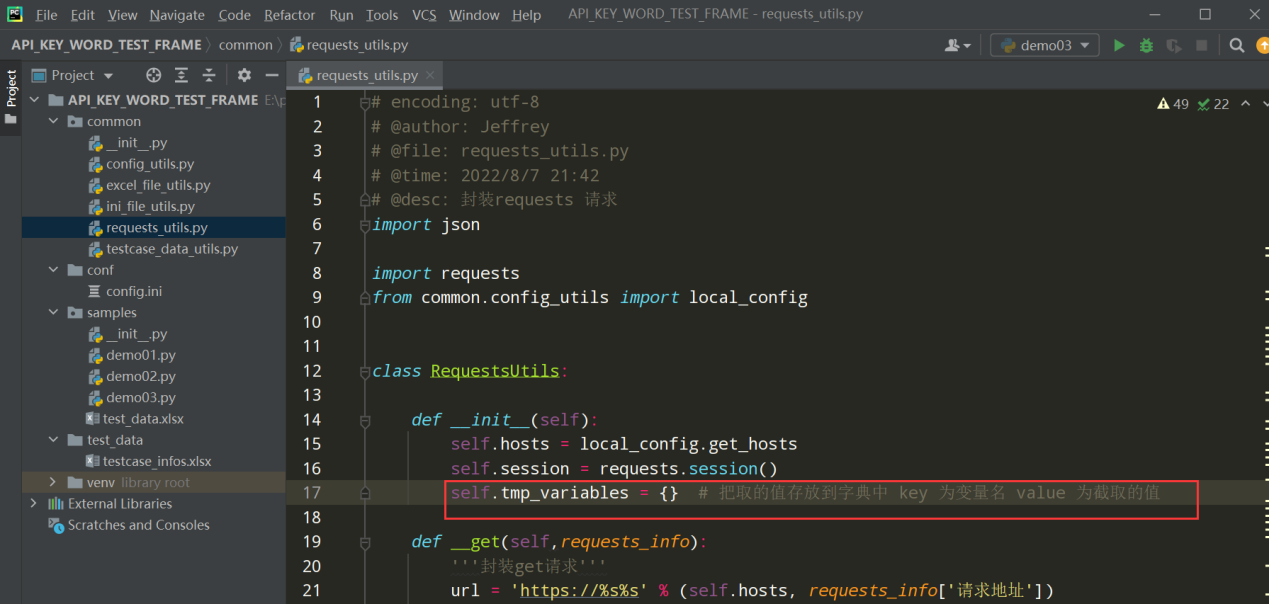
编写代码:
self.tmp_variables = {} # 把取的值存放到字典中 key为变量没弄过 value 为截取的值
步骤2、在封装好的get和post方法中都放入如下代码,用来截取接口返回值存放到临时变量字典中
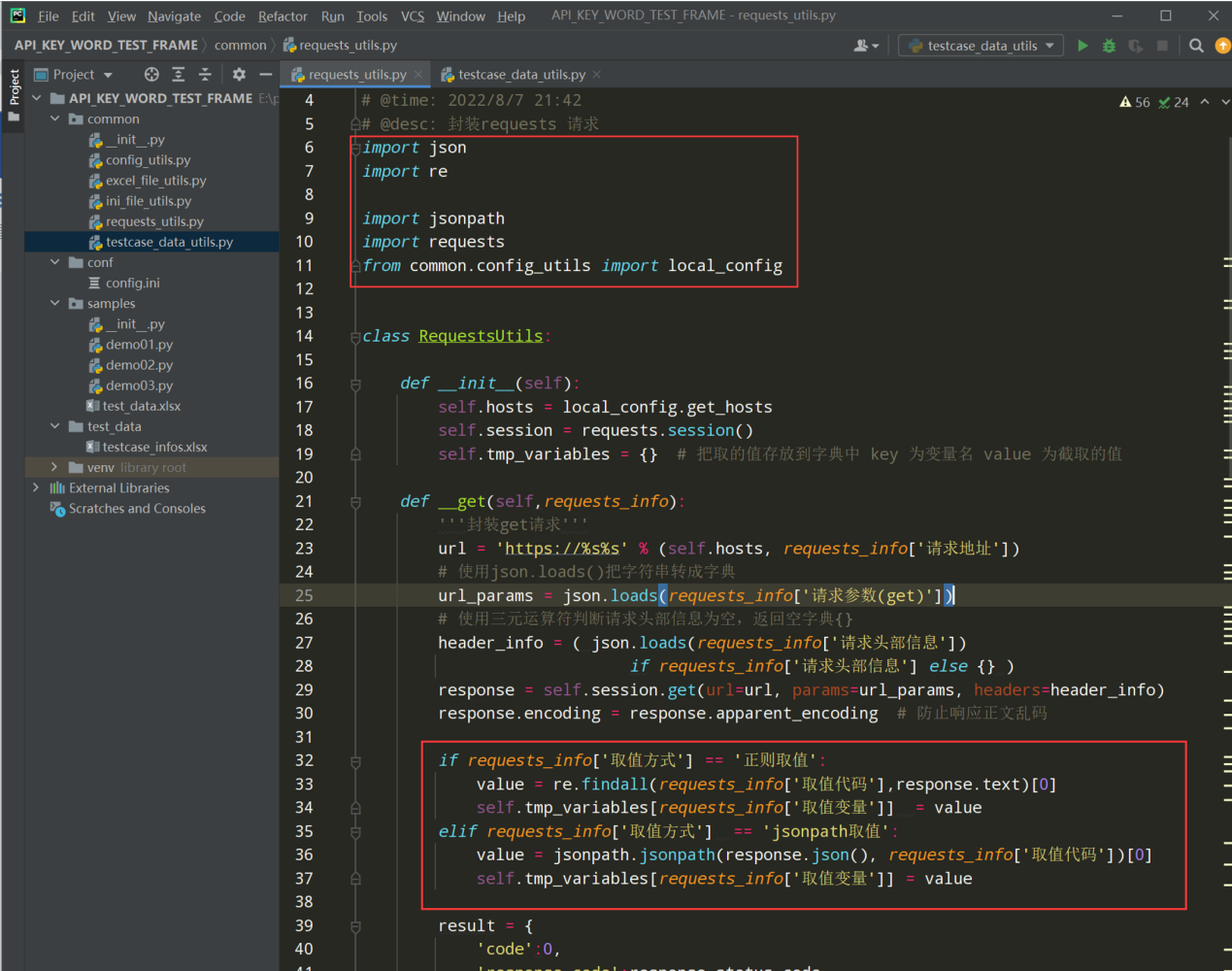
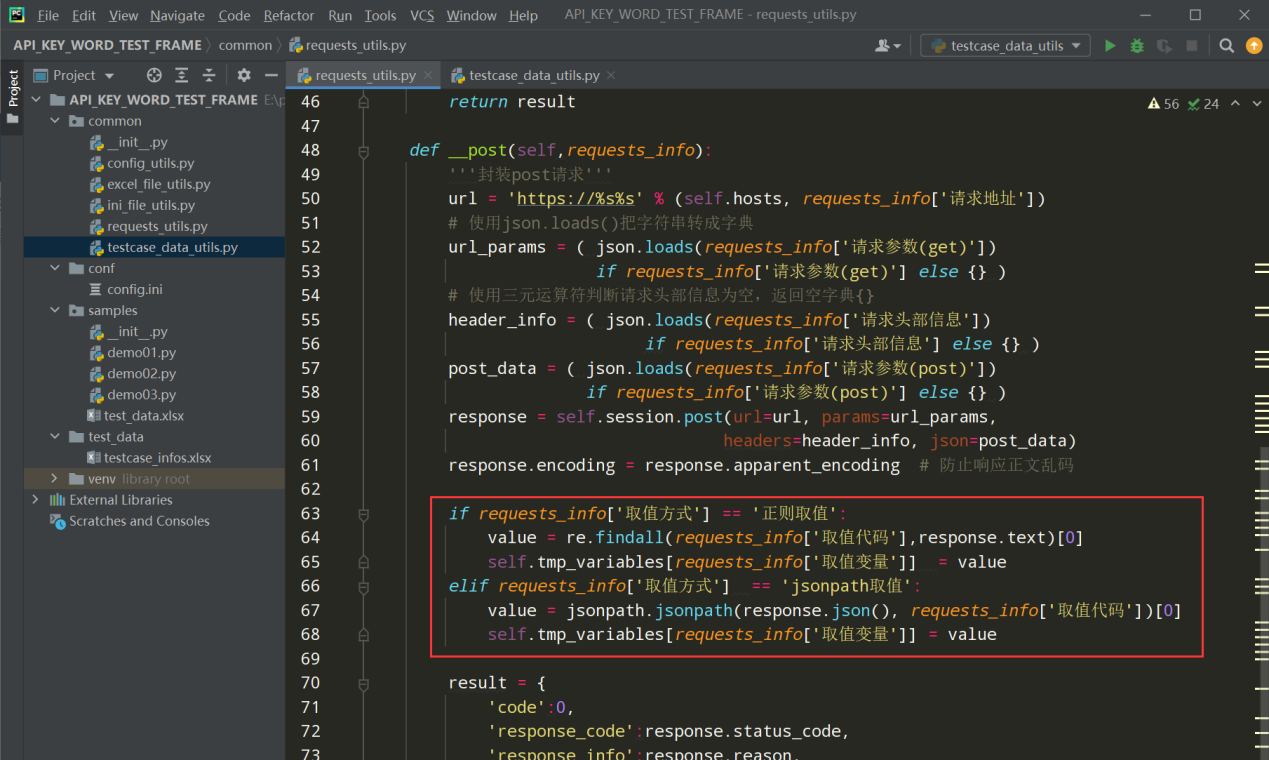
编写代码:
# 先导入import re 和import jsonpath if requests_info['取值方式'] == '正则取值': value = re.findall(requests_info['取值代码'],response.text)[0] self.tmp_variables[requests_info['取值变量']] = value elif requests_info['取值方式'] == 'jsonpath取值': value = jsonpath.jsonpath(response.json(), requests_info['取值代码'])[0] self.tmp_variables[requests_info['取值变量']] = value 测试代码: if __name__ == '__main__': step_list = [ { '用例步骤': 'step_01', '接口名称': '获取access_token接口', '请求方式': 'get', '请求头部信息': '', '请求地址': '/cgi-bin/token', '请求参数(get)': '{"grant_type":"client_credential","appid":"wxf17856","secret":"92a140dc7123c99"}', '请求参数(post)': '', '取值方式': '无', '取值代码': '"access_token":"(.+?)"', '取值变量': 'token_value', '断言类型': 'json_key', '期望结果': 'expires_in'} ] result = RequestsUtils().request_by_step(step_list) print(result)
步骤3、把存储在临时字典中的变量替换到指定的请求信息中(可以是url参数或post请求消息体)
举例:
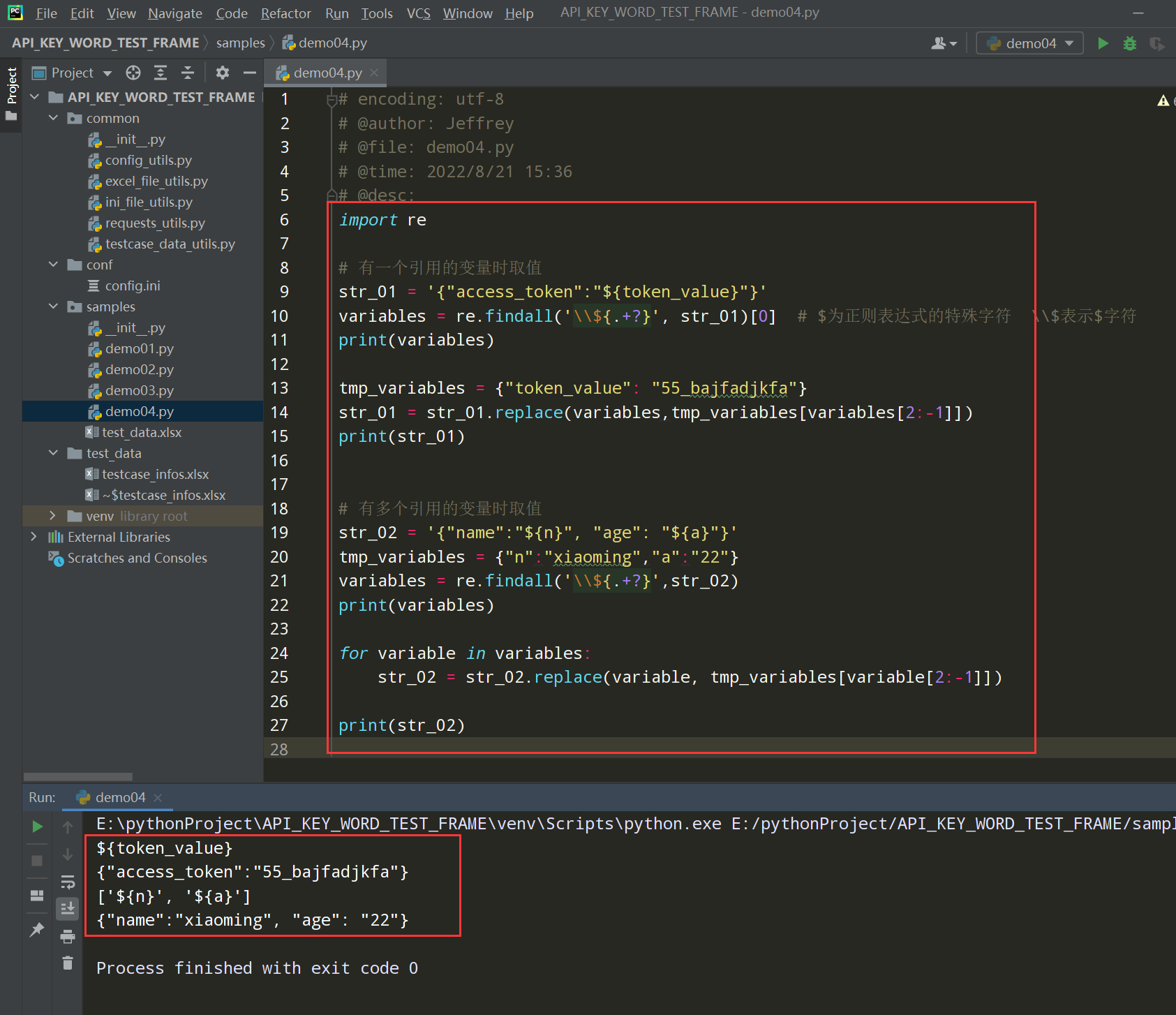
由于 接口要替换的值是请求的数据,把请求数据替换好之后,发送给服务器,所以调整get/post封装的时候,调整在请求发出之前
Get请求如下图调整:
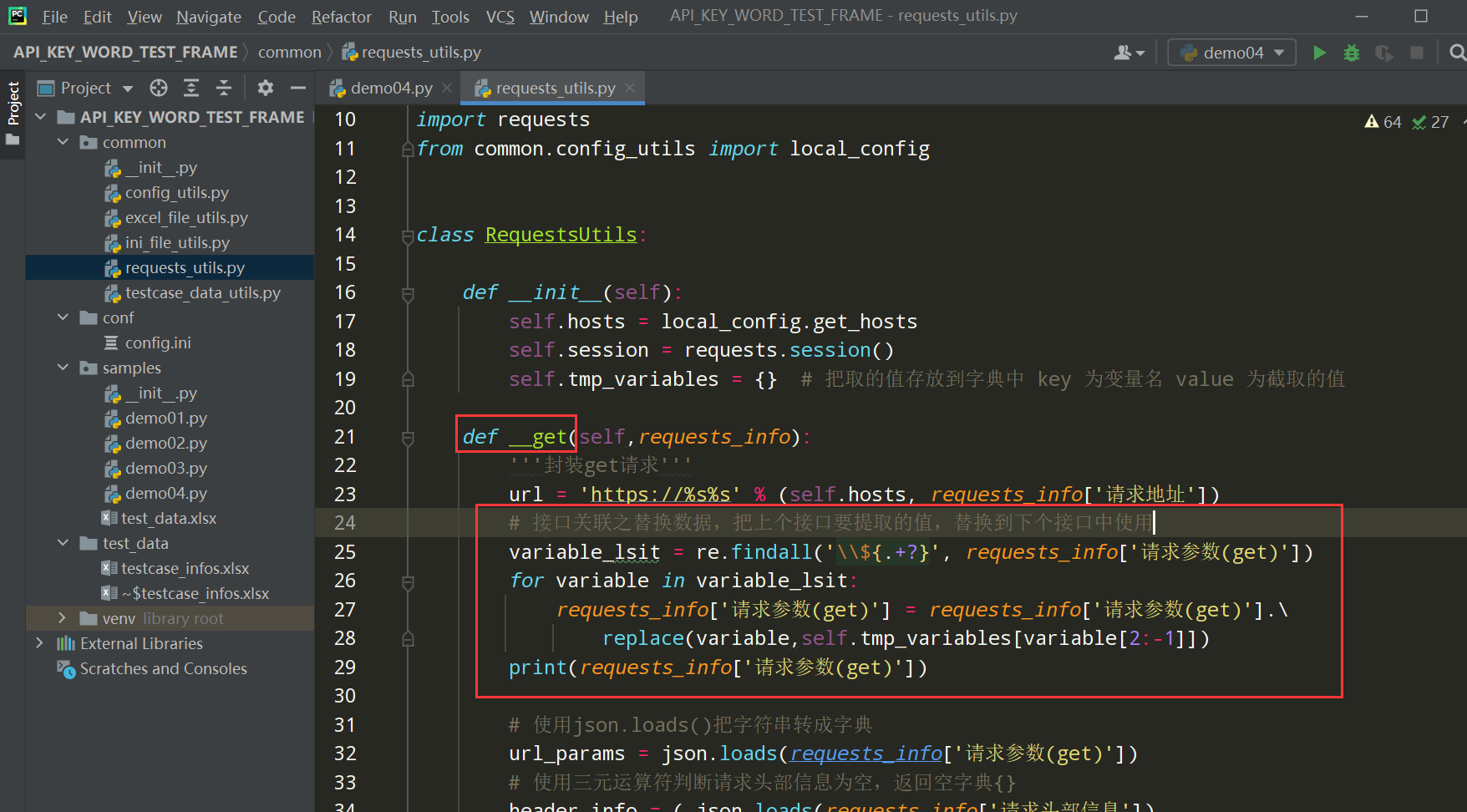
编写代码:
# 接口关联之替换数据,把上个接口要提取的值,替换到下个接口中的请求参数中使用 variable_lsit = re.findall('\\${.+?}', requests_info['请求参数(get)']) for variable in variable_lsit: requests_info['请求参数(get)'] = requests_info['请求参数(get)'].\ replace(variable,self.tmp_variables[variable[2:-1]]) print(requests_info['请求参数(get)'])
Post请求由于请求参数有body消息体,所以需要替换两处
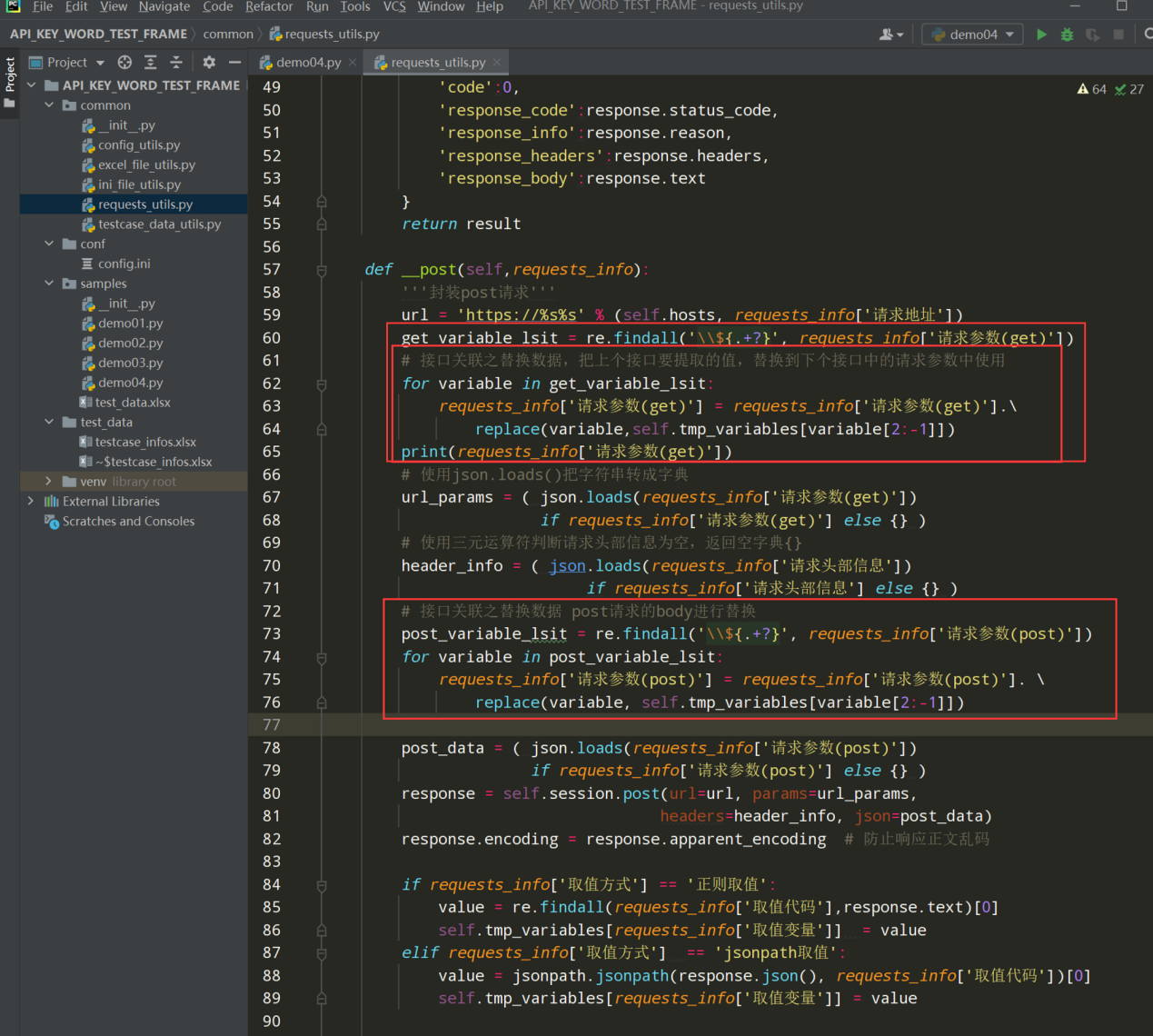
编写代码:
# 接口关联之替换数据,把上个接口要提取的值,替换到下个接口中的请求参数中使用 get_variable_lsit = re.findall('\\${.+?}', requests_info['请求参数(get)']) for variable in get_variable_lsit: requests_info['请求参数(get)'] = requests_info['请求参数(get)'].\ replace(variable,self.tmp_variables[variable[2:-1]]) print(requests_info['请求参数(get)']) # 接口关联之替换数据 post请求的body进行替换 post_variable_lsit = re.findall('\\${.+?}', requests_info['请求参数(post)']) for variable in post_variable_lsit: requests_info['请求参数(post)'] = requests_info['请求参数(post)']. \ replace(variable, self.tmp_variables[variable[2:-1]]) main主入口下的测试代码: if __name__ == '__main__': step_list = [ { '用例步骤': 'step_01', '接口名称': '获取access_token接口', '请求方式': 'get', '请求头部信息': '', '请求地址': '/cgi-bin/token', '请求参数(get)': '{"grant_type":"client_credential","appid":"wxf56","secret":"92a1123c99"}', '请求参数(post)': '', '取值方式': '正则取值', '取值代码': '"access_token":"(.+?)"', '取值变量': 'token_value', '断言类型': 'json_key', '期望结果': 'expires_in'}, {'用例步骤': 'step_02', '接口名称': '创建标签接口', '请求方式': 'post', '请求头部信息': '', '请求地址': '/cgi-bin/tags/create', '请求参数(get)': '{"access_token":"${token_value}"}', '请求参数(post)': '{ "tag" : { "name" : "newday0821" } } ', '取值方式': '无', '取值代码': '', '取值变量': '', '断言类型': 'json_key', '期望结果': 'tag'} ] result = RequestsUtils().request_by_step(step_list) print(result)
完整代码如下:
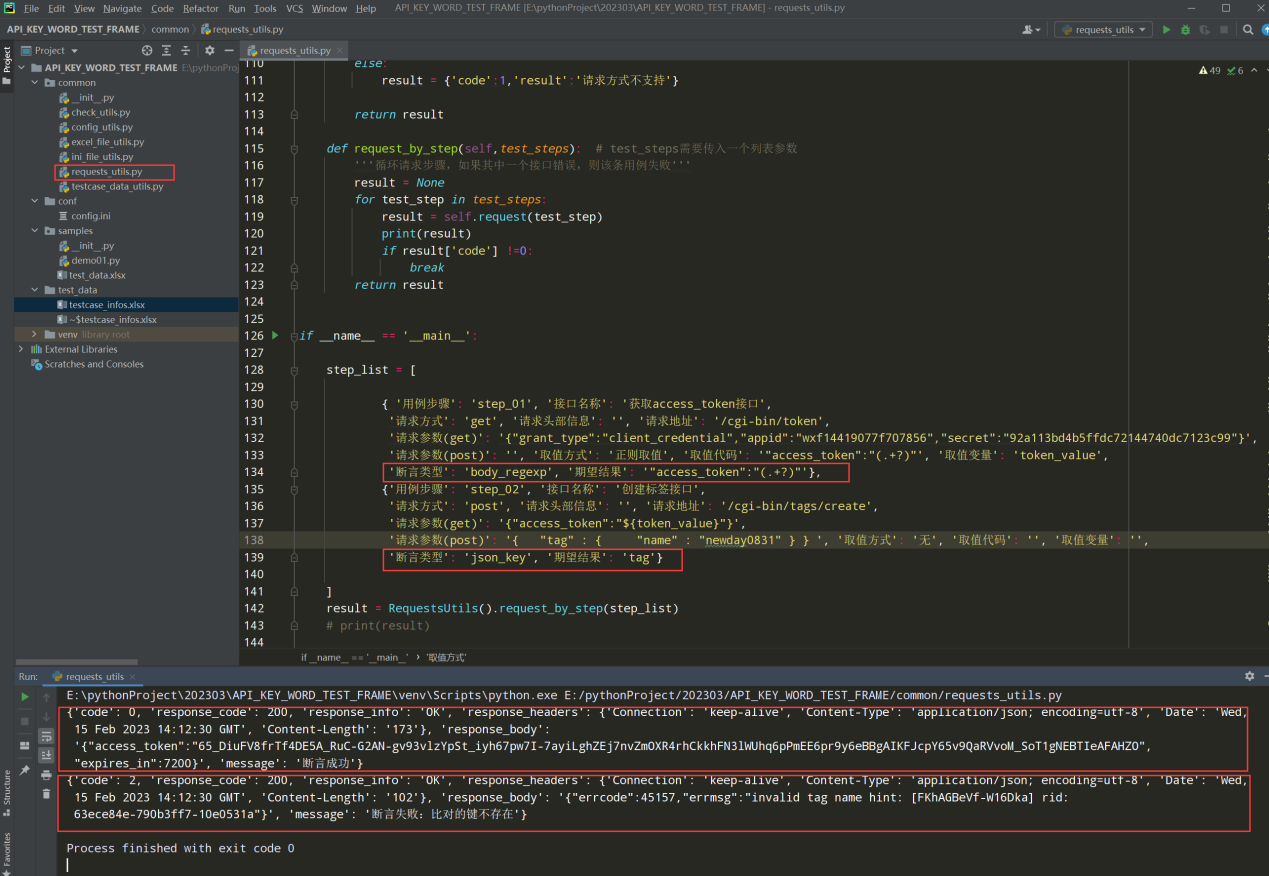
# encoding: utf-8 # @author: Jeffrey # @file: requests_utils.py # @time: 2022/8/7 21:42 # @desc: 封装requests 请求 import json import re import jsonpath import requests from common.config_utils import local_config class RequestsUtils: def __init__(self): self.hosts = local_config.get_hosts self.session = requests.session() self.tmp_variables = {} # 把取的值存放到字典中 key 为变量名 value 为截取的值 def __get(self,requests_info): '''封装get请求''' url = 'https://%s%s' % (self.hosts, requests_info['请求地址']) # 接口关联之替换数据,把上个接口要提取的值,替换到下个接口中的请求参数中使用 variable_lsit = re.findall('\\${.+?}', requests_info['请求参数(get)']) for variable in variable_lsit: requests_info['请求参数(get)'] = requests_info['请求参数(get)'].\ replace(variable,self.tmp_variables[variable[2:-1]]) print(requests_info['请求参数(get)']) # 使用json.loads()把字符串转成字典 url_params = json.loads(requests_info['请求参数(get)']) # 使用三元运算符判断请求头部信息为空,返回空字典{} header_info = ( json.loads(requests_info['请求头部信息']) if requests_info['请求头部信息'] else {} ) response = self.session.get(url=url, params=url_params, headers=header_info) response.encoding = response.apparent_encoding # 防止响应正文乱码 if requests_info['取值方式'] == '正则取值': value = re.findall(requests_info['取值代码'],response.text)[0] self.tmp_variables[requests_info['取值变量']] = value elif requests_info['取值方式'] == 'jsonpath取值': value = jsonpath.jsonpath(response.json(), requests_info['取值代码'])[0] self.tmp_variables[requests_info['取值变量']] = value result = { 'code':0, 'response_code':response.status_code, 'response_info':response.reason, 'response_headers':response.headers, 'response_body':response.text } return result def __post(self,requests_info): '''封装post请求''' url = 'https://%s%s' % (self.hosts, requests_info['请求地址']) get_variable_lsit = re.findall('\\${.+?}', requests_info['请求参数(get)']) # 接口关联之替换数据,把上个接口要提取的值,替换到下个接口中的请求参数中使用 for variable in get_variable_lsit: requests_info['请求参数(get)'] = requests_info['请求参数(get)'].\ replace(variable,self.tmp_variables[variable[2:-1]]) print(requests_info['请求参数(get)']) # 使用json.loads()把字符串转成字典 url_params = ( json.loads(requests_info['请求参数(get)']) if requests_info['请求参数(get)'] else {} ) # 使用三元运算符判断请求头部信息为空,返回空字典{} header_info = ( json.loads(requests_info['请求头部信息']) if requests_info['请求头部信息'] else {} ) # 接口关联之替换数据 post请求的body进行替换 post_variable_lsit = re.findall('\\${.+?}', requests_info['请求参数(post)']) for variable in post_variable_lsit: requests_info['请求参数(post)'] = requests_info['请求参数(post)']. \ replace(variable, self.tmp_variables[variable[2:-1]]) post_data = ( json.loads(requests_info['请求参数(post)']) if requests_info['请求参数(post)'] else {} ) response = self.session.post(url=url, params=url_params, headers=header_info, json=post_data) response.encoding = response.apparent_encoding # 防止响应正文乱码 if requests_info['取值方式'] == '正则取值': value = re.findall(requests_info['取值代码'],response.text)[0] self.tmp_variables[requests_info['取值变量']] = value elif requests_info['取值方式'] == 'jsonpath取值': value = jsonpath.jsonpath(response.json(), requests_info['取值代码'])[0] self.tmp_variables[requests_info['取值变量']] = value result = { 'code':0, 'response_code':response.status_code, 'response_info':response.reason, 'response_headers':response.headers, 'response_body':response.text } return result def request(self,requests_info): """封装判断请求方式""" request_type = requests_info['请求方式'] if request_type == "get": result = self.__get(requests_info) elif request_type == "post": result = self.__post(requests_info) else: result = {'code':1,'result':'请求方式不支持'} return result def request_by_step(self,test_steps): # test_steps需要传入一个列表参数 '''循环请求步骤,如果其中一个接口错误,则该条用例失败''' result = None for test_step in test_steps: result = self.request(test_step) # print(result) if result['code'] !=0: break return result if __name__ == '__main__': step_list = [ { '用例步骤': 'step_01', '接口名称': '获取access_token接口', '请求方式': 'get', '请求头部信息': '', '请求地址': '/cgi-bin/token', '请求参数(get)': '{"grant_type":"client_credential","appid":"wxf14856","secret":"92ac99"}', '请求参数(post)': '', '取值方式': '正则取值', '取值代码': '"access_token":"(.+?)"', '取值变量': 'token_value', '断言类型': 'json_key', '期望结果': 'expires_in'}, {'用例步骤': 'step_02', '接口名称': '创建标签接口', '请求方式': 'post', '请求头部信息': '', '请求地址': '/cgi-bin/tags/create', '请求参数(get)': '{"access_token":"${token_value}"}', '请求参数(post)': '{ "tag" : { "name" : "newday0821" } } ', '取值方式': '无', '取值代码': '', '取值变量': '', '断言类型': 'json_key', '期望结果': 'tag'} ] result = RequestsUtils().request_by_step(step_list) print(result)
步骤4、测试执行:
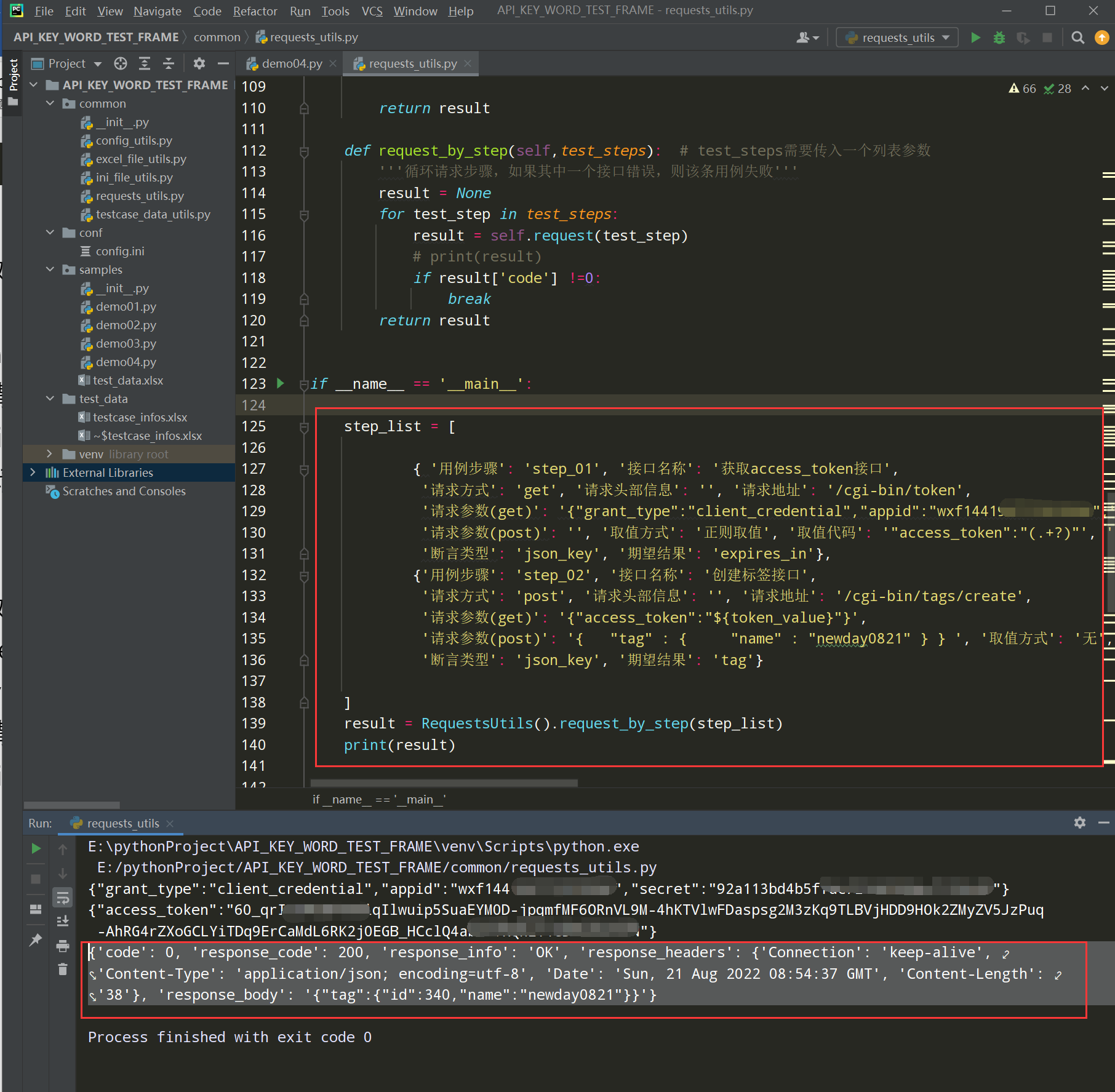
框架05 接口断言的设计
在自动化测试框架中,断言这一部分是必不可少的,使用unittest自带的断言功能不太适合框架,且断言支持不强大(比如json断言、正则断言都不支持),所以在框架中把断言重新设计封装成check类。
具体设计思想:
1、设计excel用例信息时,添加 期望结果类型(无、json键是否存在、正则匹配、json键值对)、期望结果两个字段
2、通过check类的方法实现断言后返回一个json数据,里面包含断言结果以及相应返回值
3、check类返回的结果放入封装的get和post方法中,然后在多接口运行方法中把结果作为是否继续执行下一个接口的依据
4、返回最后的结果在unitest中获取到后,只需要统一使用assertTrue来进行断言即可
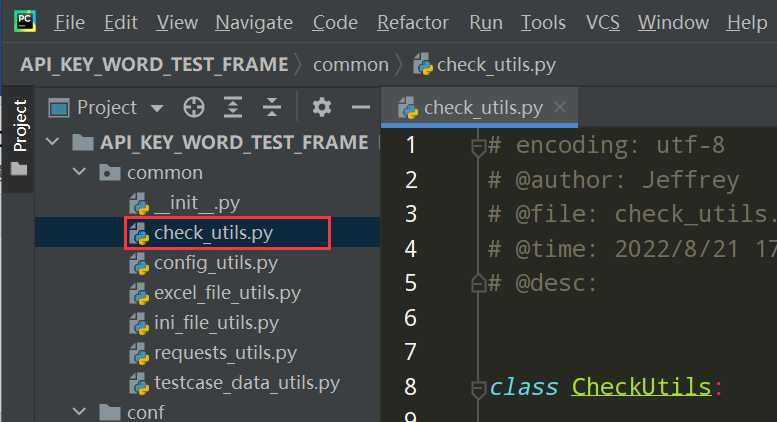
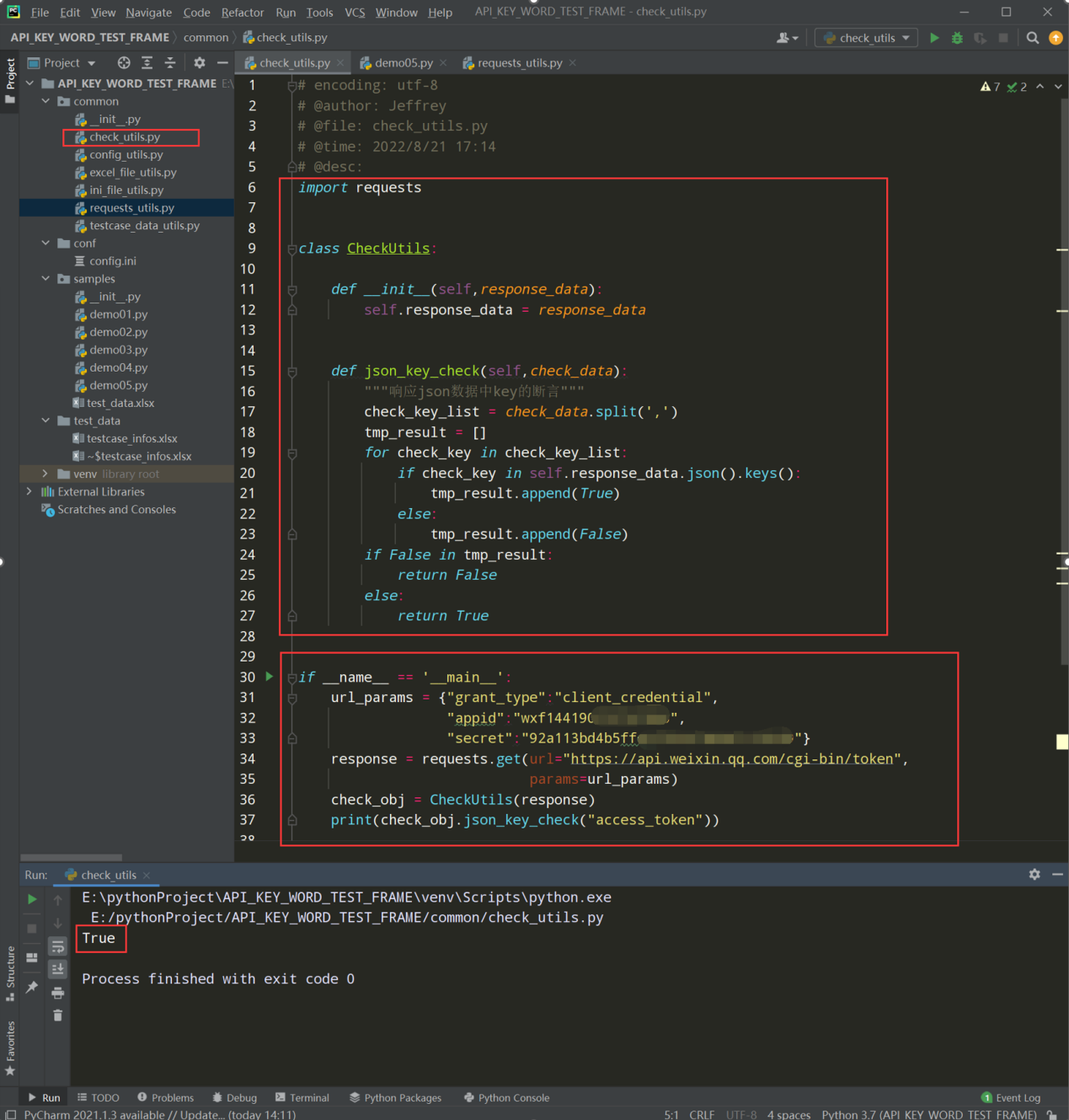
步骤1、在common下新建check_utils.py文件,创建CheckUtils类;断言库;
步骤2、编写代码:响应json数据中key的断言
举例:在samples文件下新建一个demo文件编写线性代码
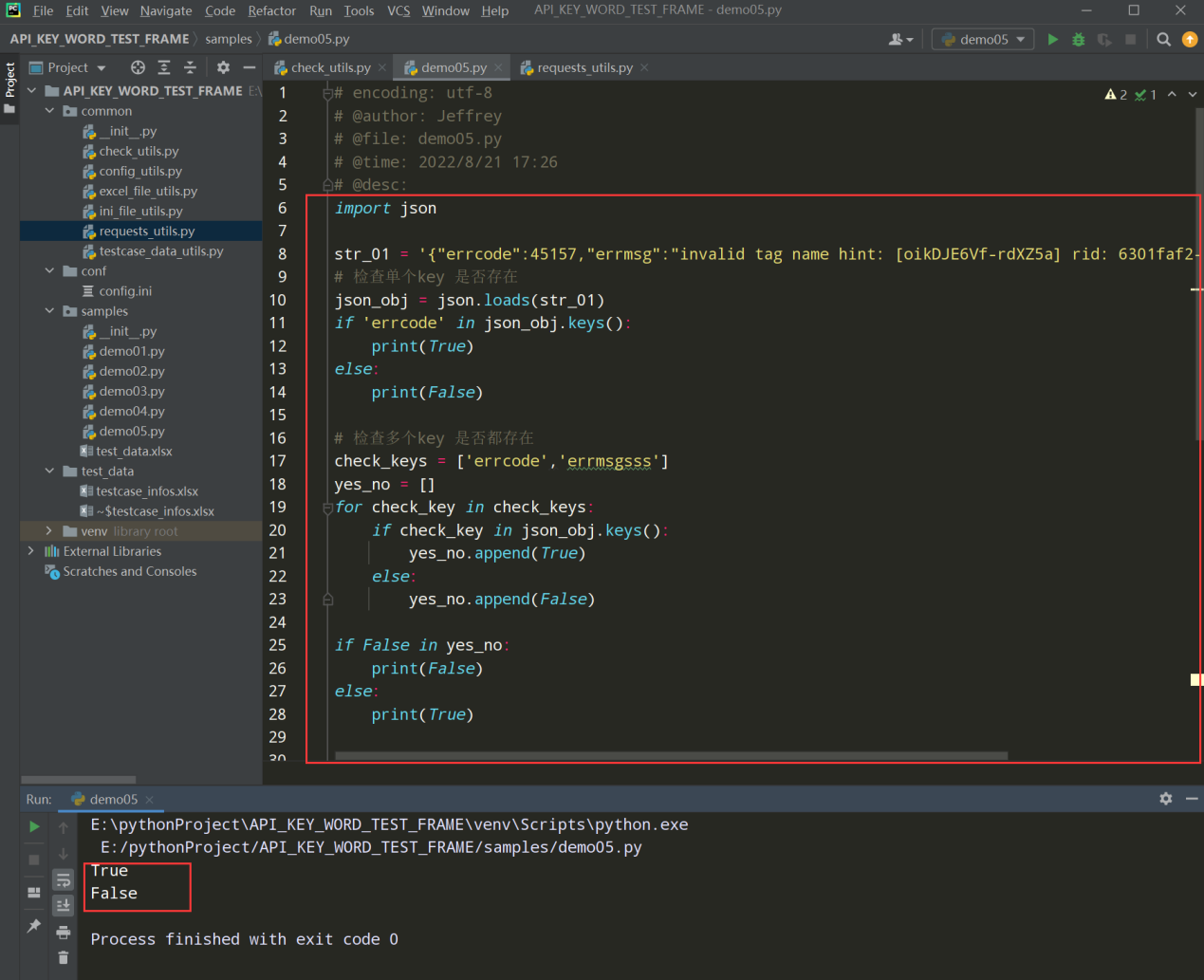
把代码接入框架中,如下图:
编写代码:
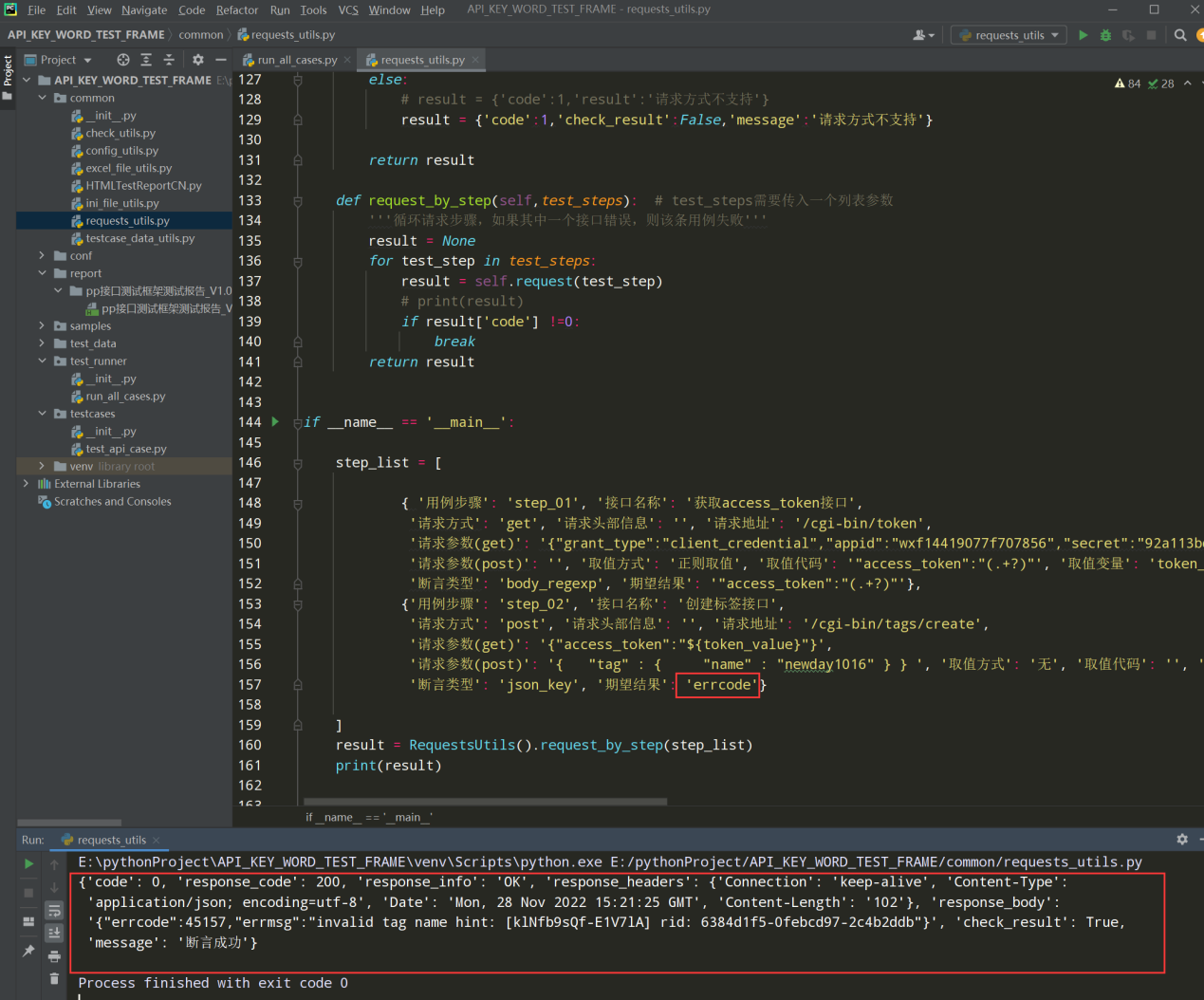
# encoding: utf-8 # @author: Jeffrey # @file: check_utils.py # @time: 2022/8/21 17:14 # @desc: import requests import json class CheckUtils: def __init__(self,response_data): self.response_data = response_data def json_key_check(self,check_data): """响应json数据中key的断言""" check_key_list = check_data.split(',') tmp_result = [] for check_key in check_key_list: if check_key in self.response_data.json().keys(): tmp_result.append(True) else: tmp_result.append(False) if False in tmp_result: return False else: return True if __name__ == '__main__': url_params = {"grant_type":"client_credential", "appid":"wxf144190756", "secret":"92a113bd4b523c99"} response = requests.get(url="https://api.weixin.qq.com/cgi-bin/token", params=url_params) check_obj = CheckUtils(response) print(check_obj.json_key_check("access_token"))
查看执行结果:
步骤3、编写响应json数据中key和value的断言
举例:在samples文件下新建一个demo文件编写线性代码;线性代码写入框架中;如下图
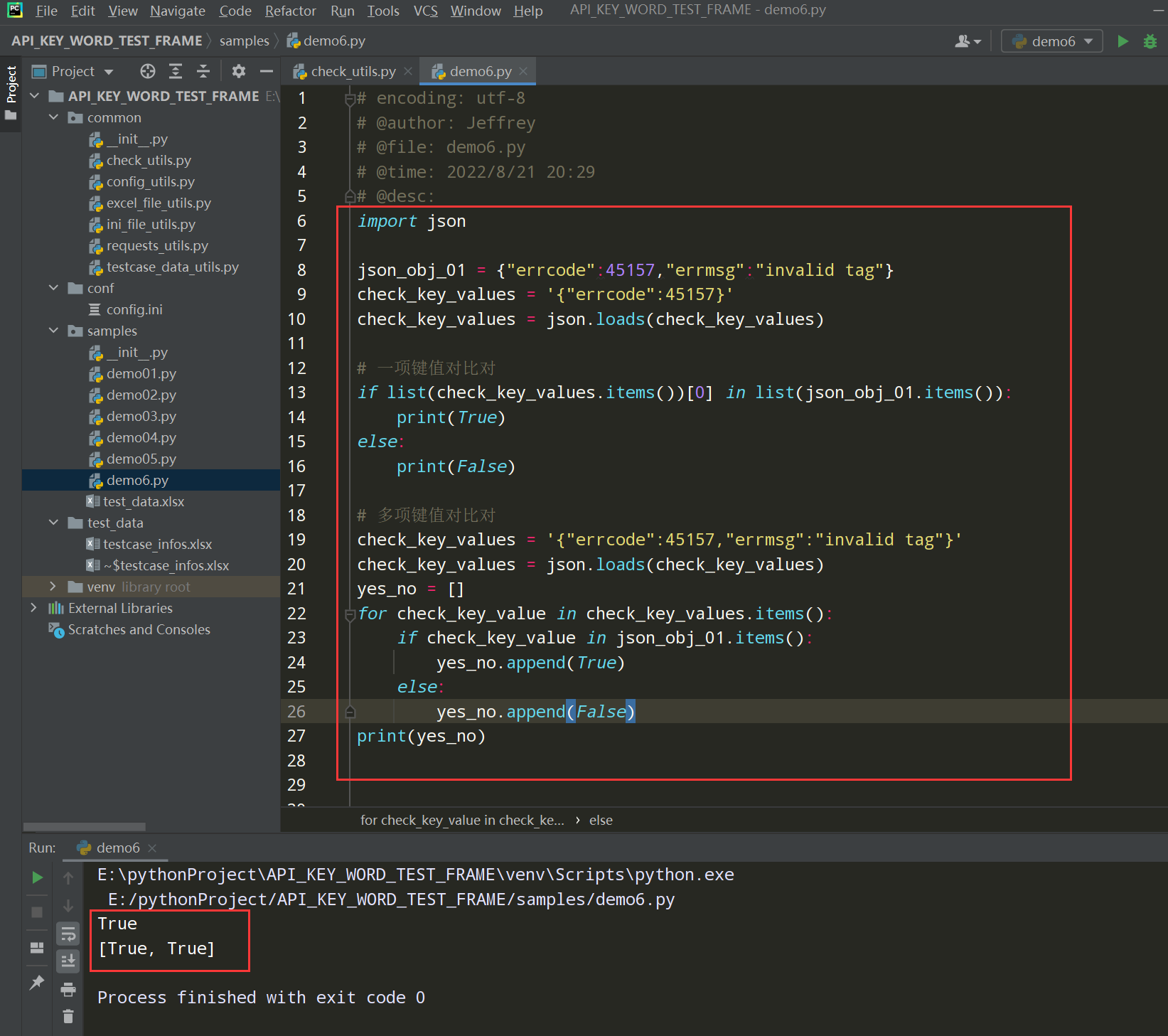
编写响应json数据中key和value的断言,调整到框架中;如下图
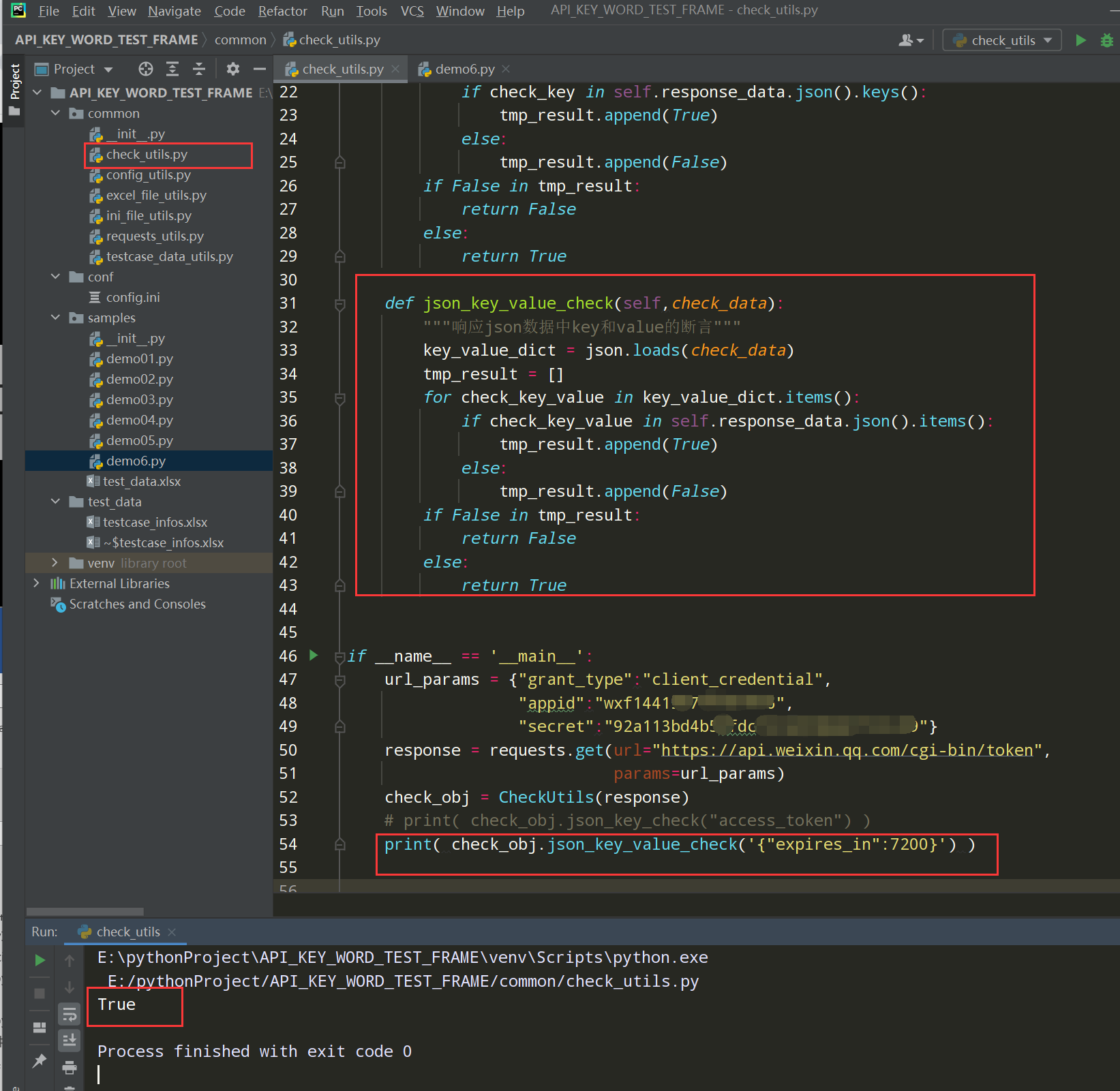
编写代码:
def json_key_value_check(self,check_data): """响应json数据中key和value的断言""" key_value_dict = json.loads(check_data) tmp_result = [] for check_key_value in key_value_dict.items(): if check_key_value in self.response_data.json().items(): tmp_result.append(True) else: tmp_result.append(False) if False in tmp_result: return False else: return True main主入口的测试代码: print(check_obj.json_key_value_check( '{"expires_in":7200}') )
查看执行结果:

步骤4、编写响应状态码的断言

编写代码:
def response_code_check(self,check_data): """响应状态码的断言""" if self.response_data.status_code == check_data: return True else: return False main主入口的测试代码: print(check_obj.response_code_check(200))
查看执行结果:
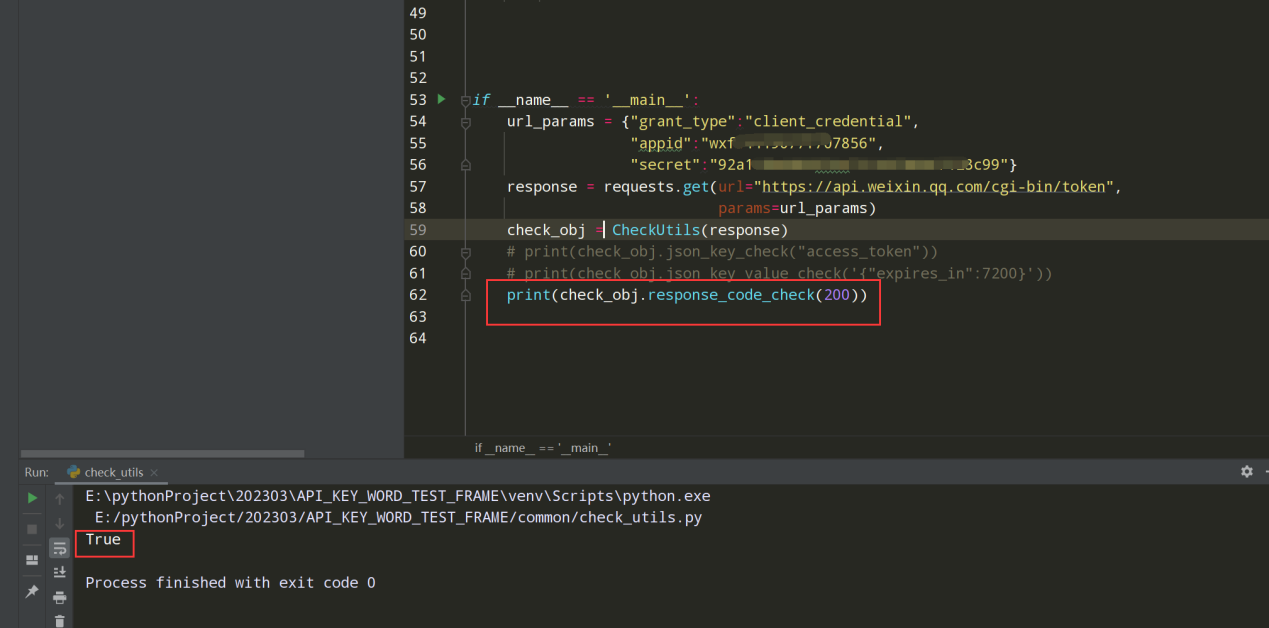
步骤5、封装断言结果,调整上方三个断言方法
1、在构造方法中添加断言成功和断言失败的json字典数据;如下图
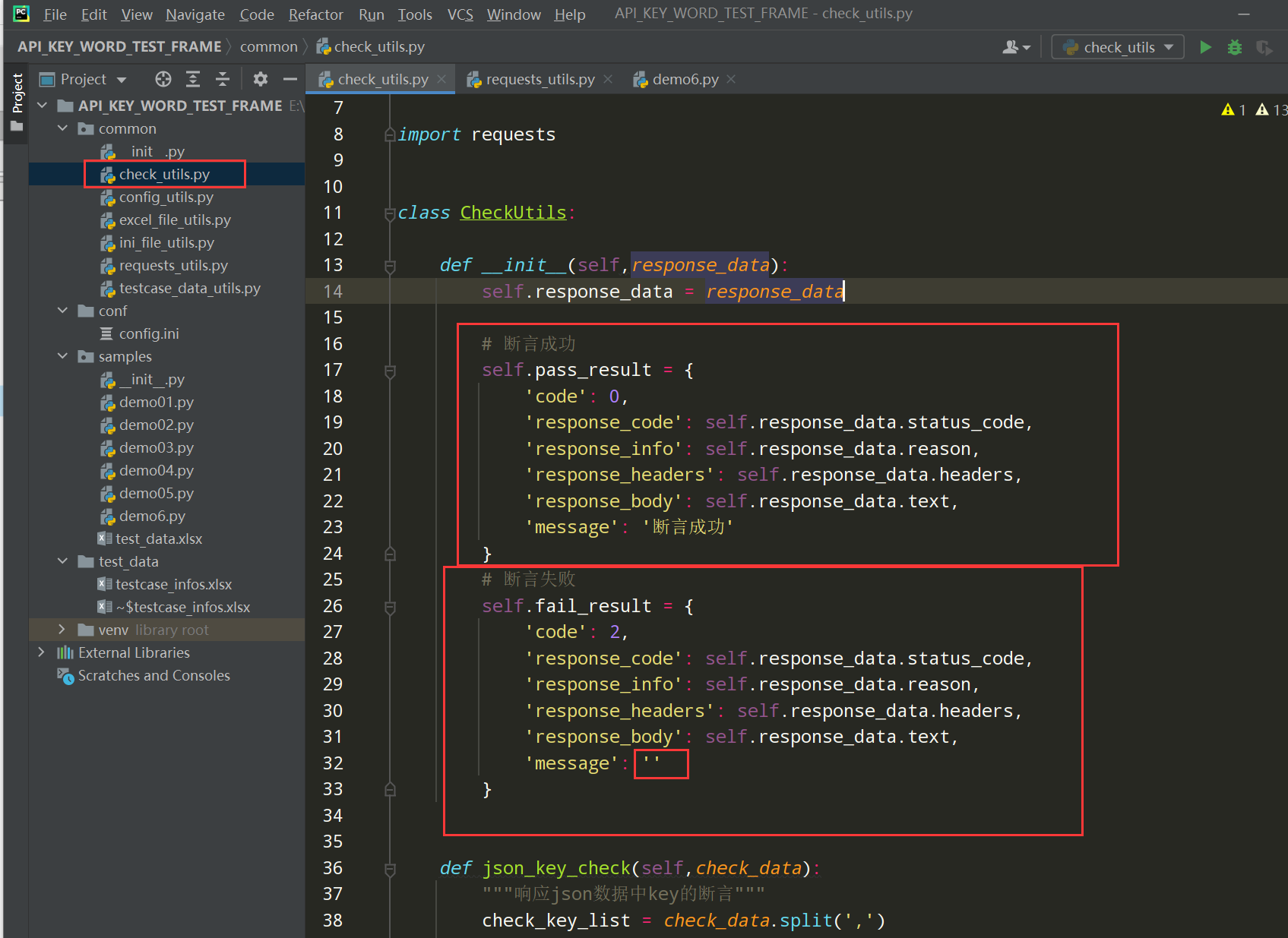
编写代码:
# 断言成功 self.pass_result = { 'code': 0, 'response_code': self.response_data.status_code, 'response_info': self.response_data.reason, 'response_headers': self.response_data.headers, 'response_body': self.response_data.text, 'message': '断言成功' } # 断言失败 self.fail_result = { 'code': 2, 'response_code': self.response_data.status_code, 'response_info': self.response_data.reason, 'response_headers': self.response_data.headers, 'response_body': self.response_data.text, 'message': '' }
2、调整封装的方法;优化断言之后的返回值,由true和false改为一个json数据;如下图:
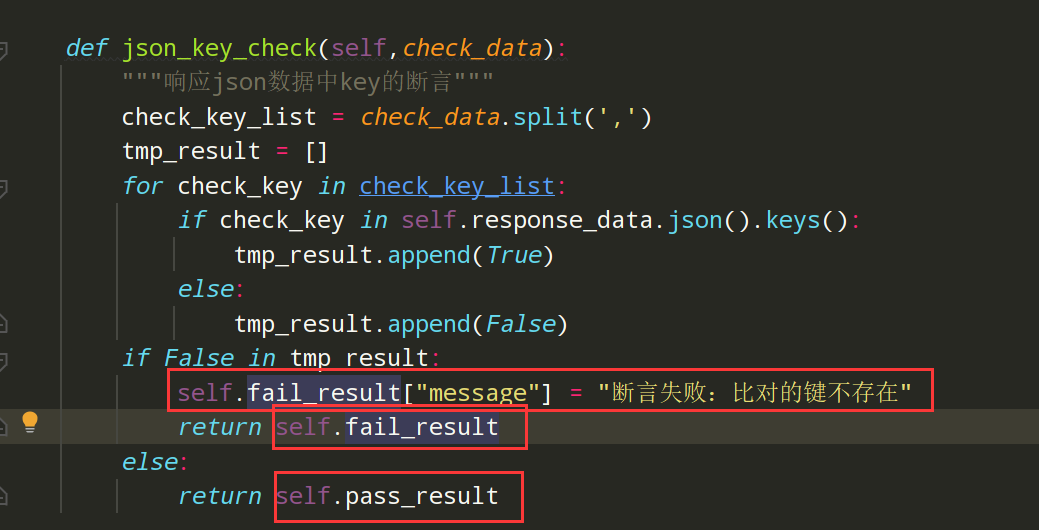
编写代码:
def json_key_check(self,check_data): """响应json数据中key的断言""" check_key_list = check_data.split(',') tmp_result = [] for check_key in check_key_list: if check_key in self.response_data.json().keys(): tmp_result.append(True) else: tmp_result.append(False) if False in tmp_result: self.fail_result["message"] = "断言失败:比对的键不存在" return self.fail_result else: return self.pass_result
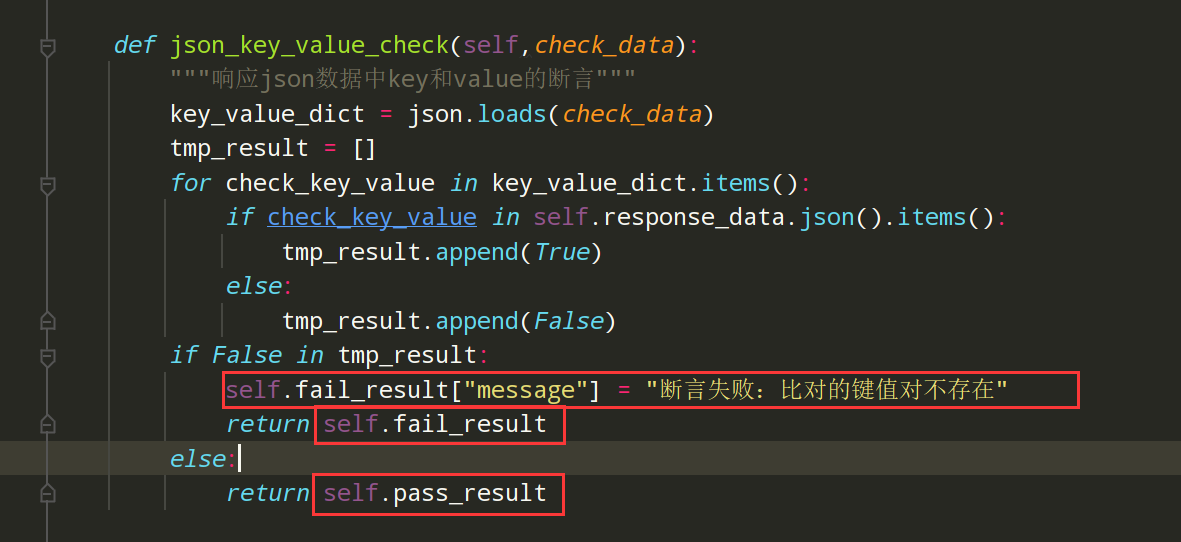
编写代码:
def json_key_value_check(self,check_data): """响应json数据中key和value的断言""" key_value_dict = json.loads(check_data) tmp_result = [] for check_key_value in key_value_dict.items(): if check_key_value in self.response_data.json().items(): tmp_result.append(True) else: tmp_result.append(False) if False in tmp_result: self.fail_result["message"] = "断言失败:比对的键值对不存在" return self.fail_result else: return self.pass_result
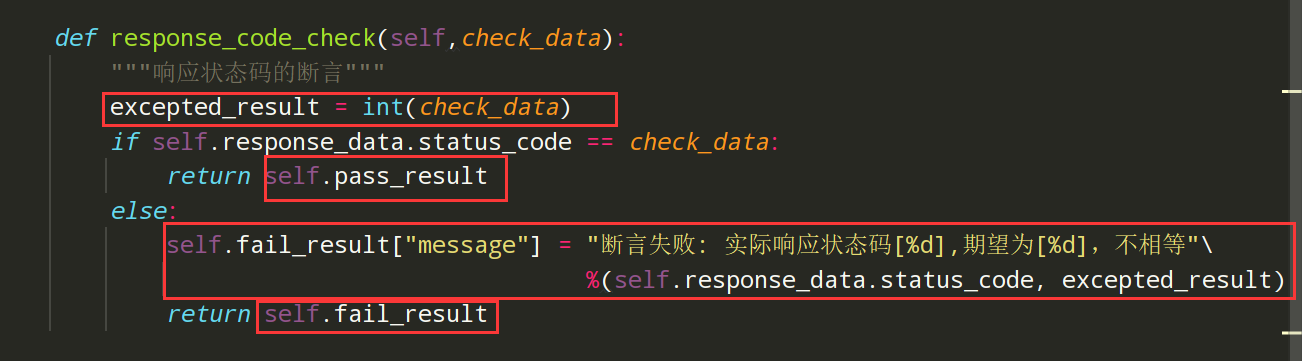
编写代码:
def response_code_check(self,check_data): """响应状态码的断言""" excepted_result = int(check_data) if self.response_data.status_code == check_data: return self.pass_result else: self.fail_result["message"] = "断言失败: 实际响应状态码[%d],期望为[%d],不相等"\ %(self.response_data.status_code, excepted_result) return self.fail_result
完整代码如下:
# encoding: utf-8 # @author: Jeffrey # @file: check_utils.py.py # @time: 2023/2/12 16:18 # @desc: import requests import json class CheckUtils: def __init__(self,response_data): self.response_data = response_data # 断言成功 self.pass_result = { 'code': 0, 'response_code': self.response_data.status_code, 'response_info': self.response_data.reason, 'response_headers': self.response_data.headers, 'response_body': self.response_data.text, 'message': '断言成功' } # 断言失败 self.fail_result = { 'code': 2, 'response_code': self.response_data.status_code, 'response_info': self.response_data.reason, 'response_headers': self.response_data.headers, 'response_body': self.response_data.text, 'message': '' } def json_key_check(self, check_data): """响应json数据中key的断言""" check_key_list = check_data.split(',') tmp_result = [] for check_key in check_key_list: if check_key in self.response_data.json().keys(): tmp_result.append(True) else: tmp_result.append(False) if False in tmp_result: self.fail_result["message"] = "断言失败:比对的键不存在" return self.fail_result else: return self.pass_result def json_key_value_check(self, check_data): """响应json数据中key和value的断言""" key_value_dict = json.loads(check_data) tmp_result = [] for check_key_value in key_value_dict.items(): if check_key_value in self.response_data.json().items(): tmp_result.append(True) else: tmp_result.append(False) if False in tmp_result: self.fail_result["message"] = "断言失败:比对的键值对不存在" return self.fail_result else: return self.pass_result def response_code_check(self, check_data): """响应状态码的断言""" excepted_result = int(check_data) if self.response_data.status_code == check_data: return self.pass_result else: self.fail_result["message"] = "断言失败: 实际响应状态码[%d],期望为[%d],不相等" \ % (self.response_data.status_code, excepted_result) return self.fail_result if __name__ == '__main__': url_params = {"grant_type":"client_credential", "appid":"wxf14419077f707856", "secret":"92a113bd4b5ffdc72144740dc7123c99"} response = requests.get(url="https://api.weixin.qq.com/cgi-bin/token", params=url_params) check_obj = CheckUtils(response) # print(check_obj.json_key_check("access_token")) # print(check_obj.json_key_value_check( '{"expires_in":7200}') ) print(check_obj.response_code_check(200))
测试执行:
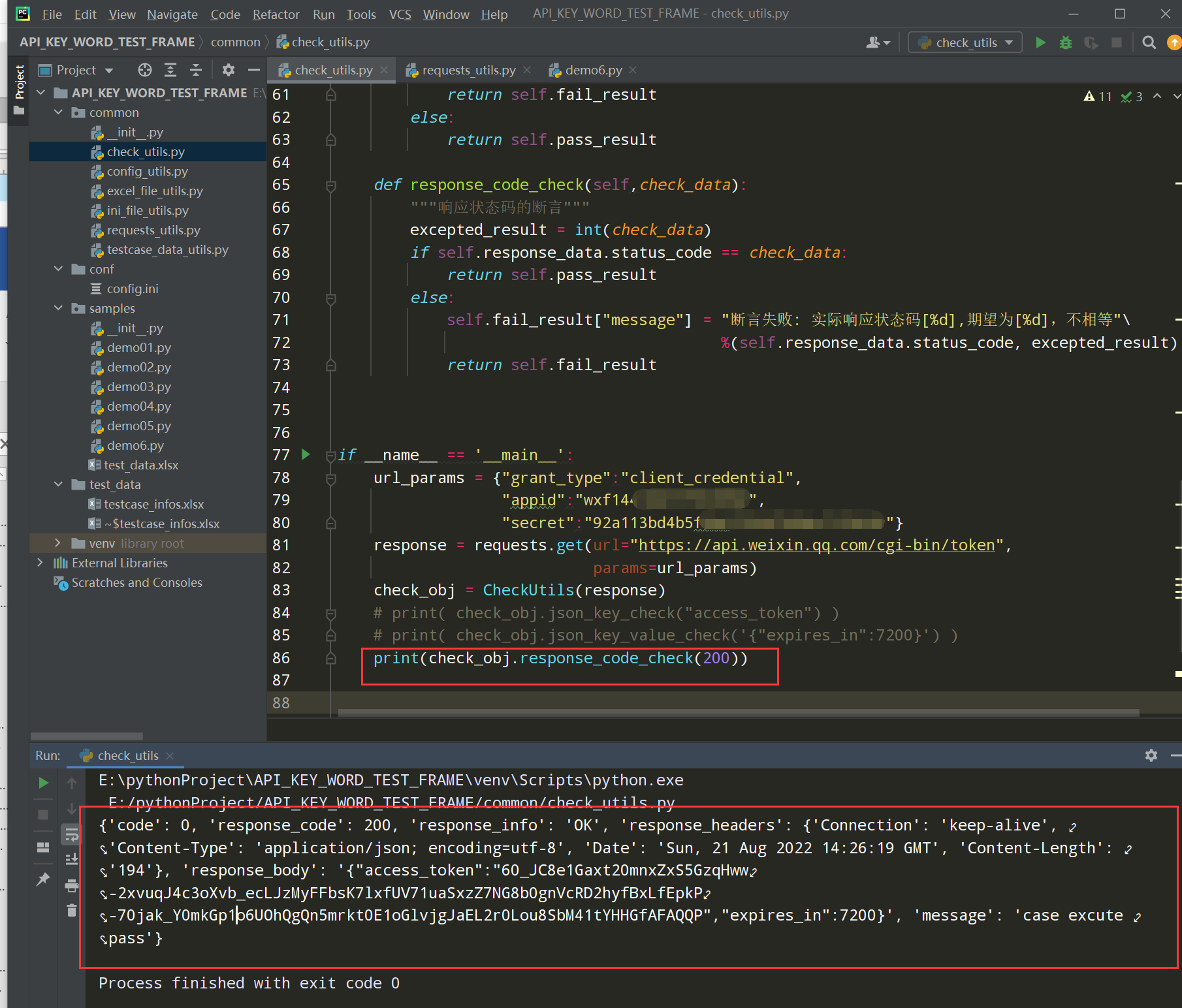
步骤6、优化断言的运行方式,由统一的run_check()方法进行判断
1、在构造方法中添加断言规则
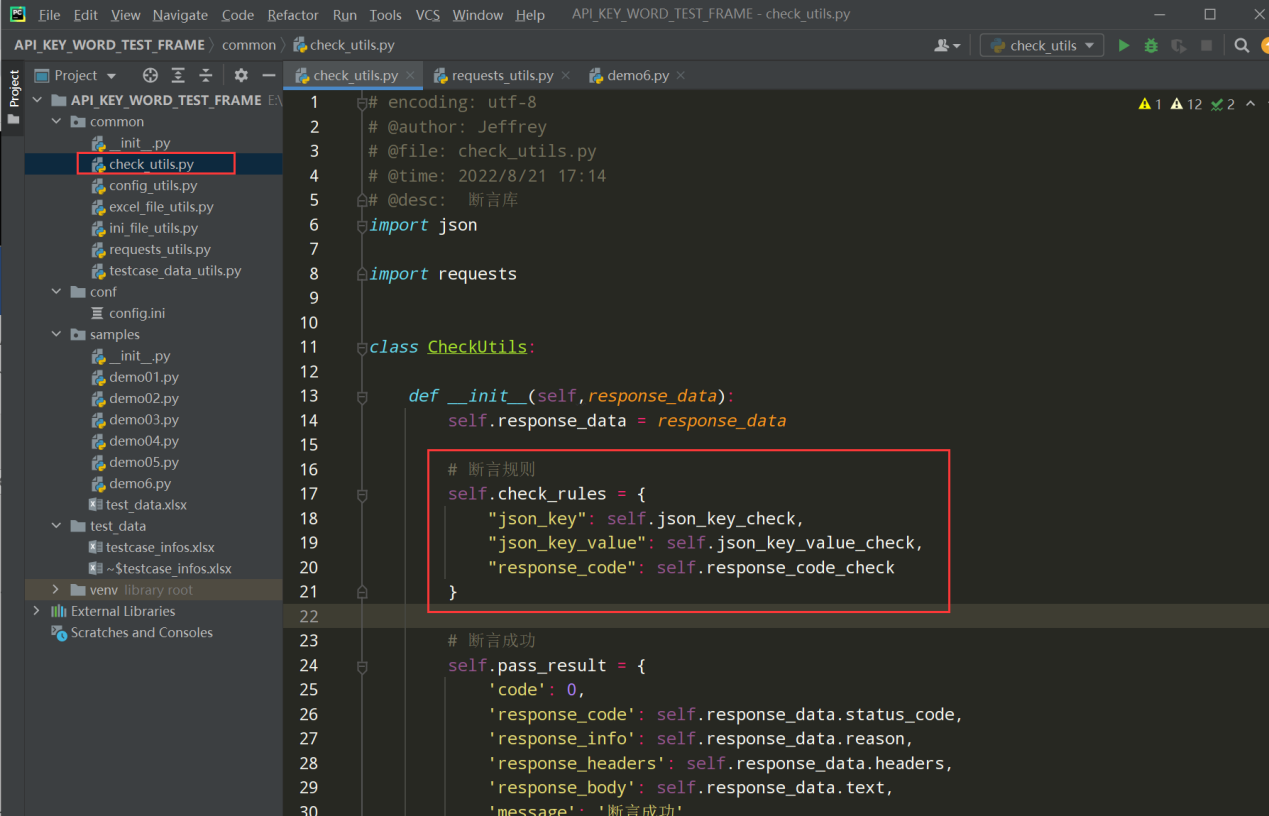
编写代码:
# 断言规则 self.check_rules = { "json_key": self.json_key_check, "json_key_value": self.json_key_value_check, "response_code": self.response_code_check }
2、新建run_check()方法,由该方法统一执行断言;如下图:
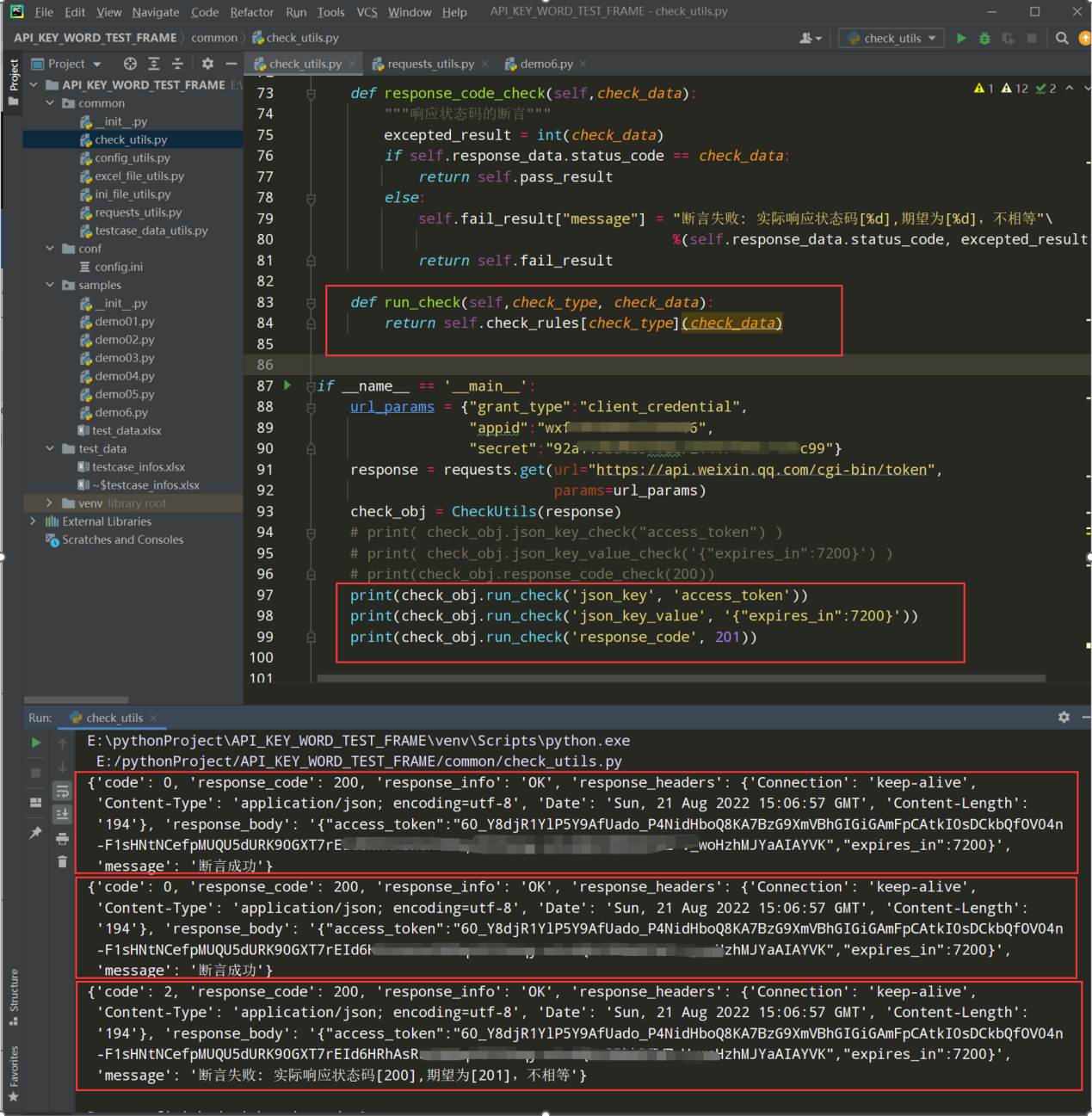
编写代码:
def run_check(self,check_type,check_data): return self.check_rules[check_type](check_data)
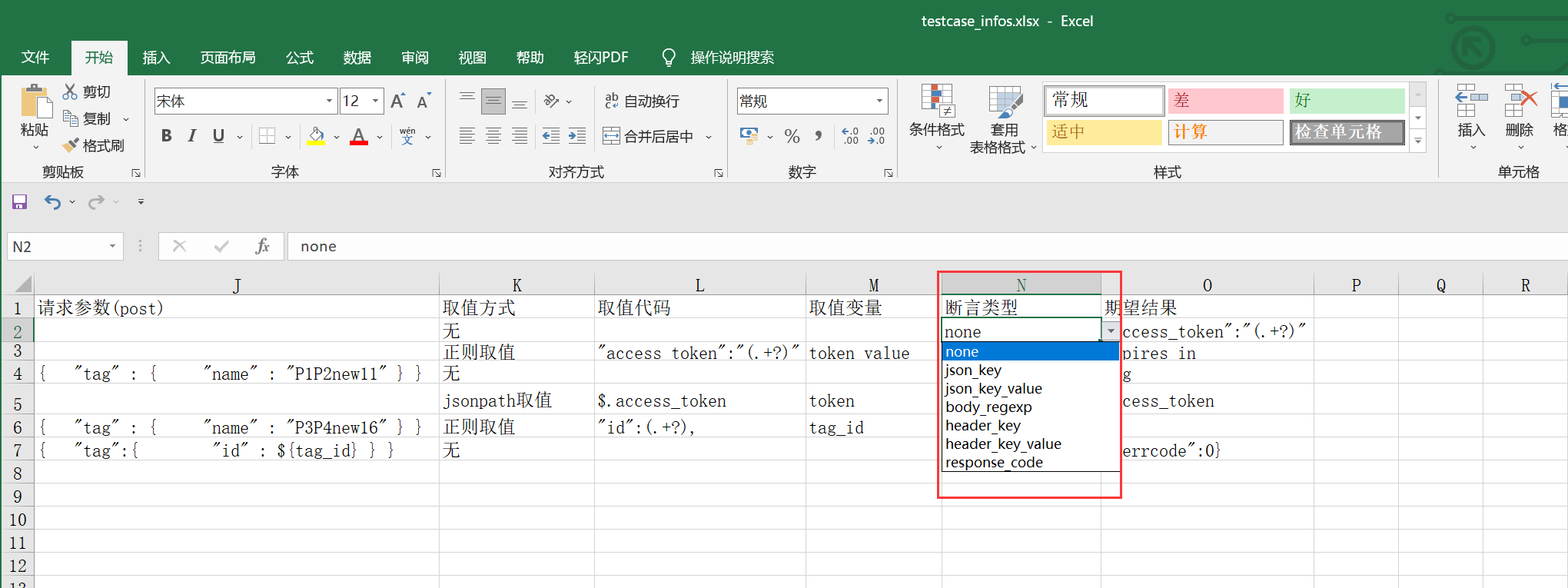
3、根据excel表格中的断言类型完善代码中的断言规则
根据excel中的断言类型补充代码;如下图
补充断言类型为none的代码
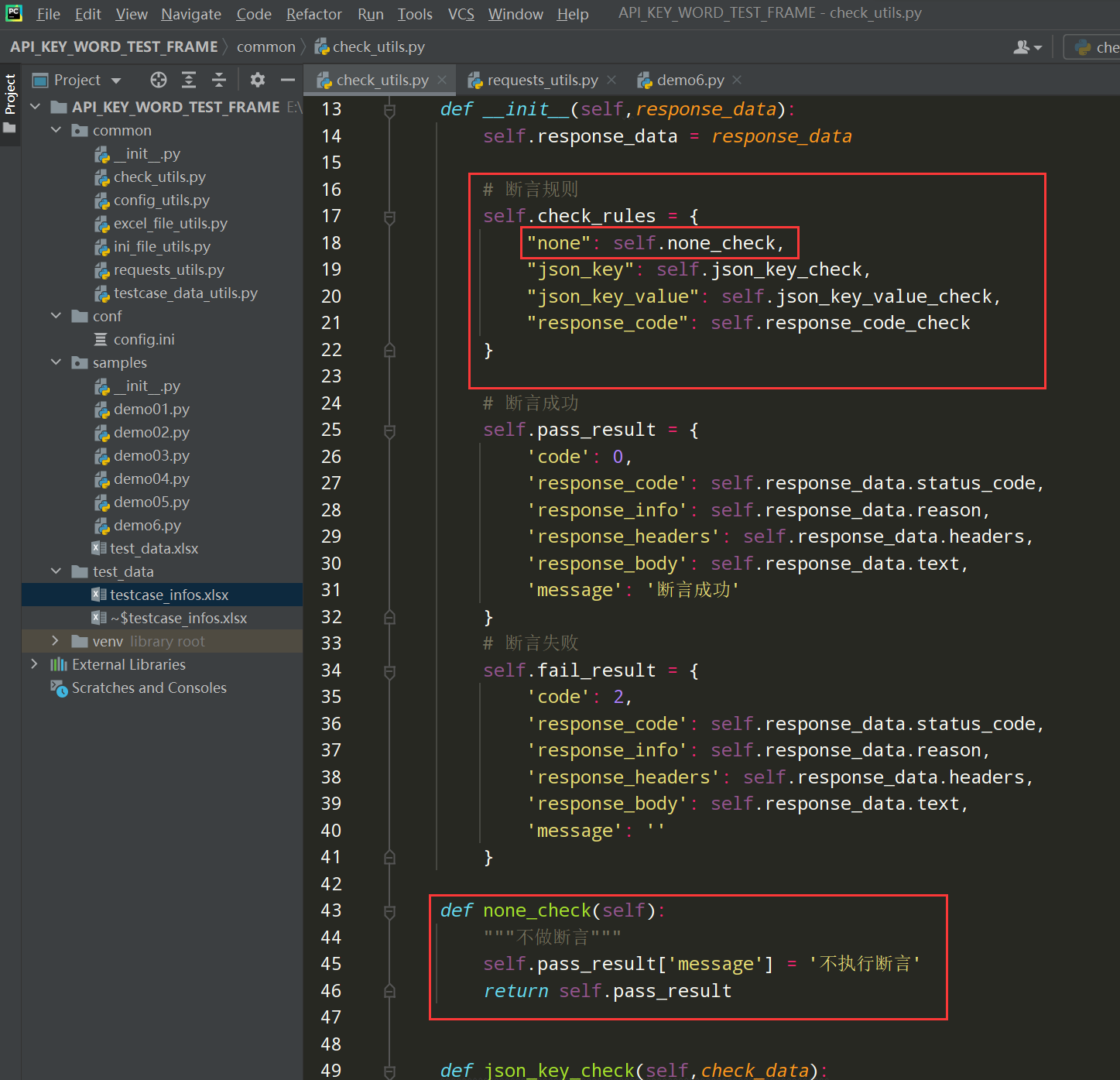
编写代码:
def none_check(self): """不做断言""" self.pass_result['message'] = '不执行断言' return self.pass_result # 断言规则中添加 "none":self.none_check,
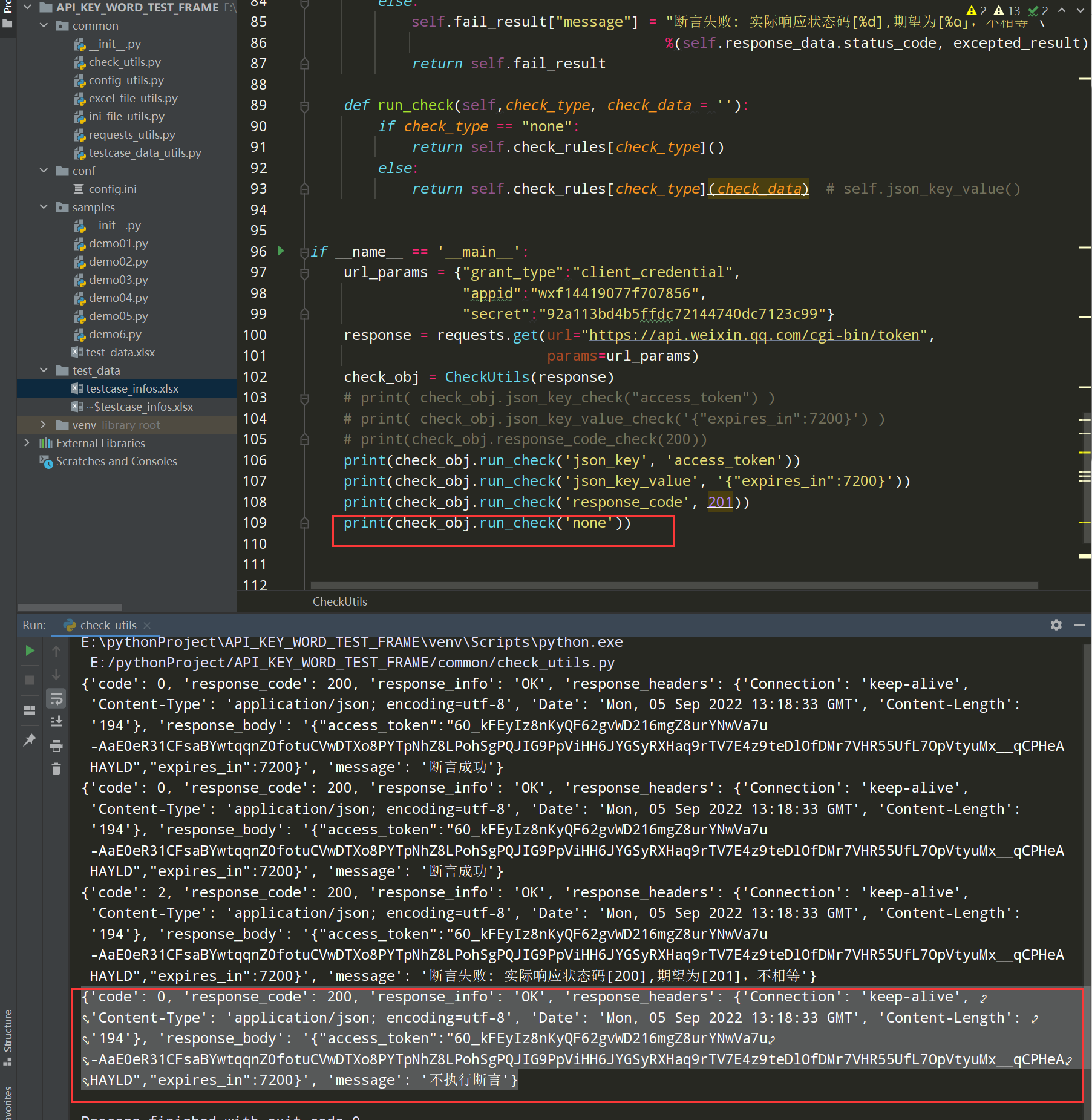
因为断言类型为none的话,会报错,所有对none类型单独做个判断;如下图

编写代码:
def run_check(self,check_type, check_data = ''): if check_type == "none": return self.check_rules[check_type]() else: return self.check_rules[check_type](check_data) # self.json_key_value()
查看执行:
4、响应正文正则断言编写
正则表达式的代码演练在demo07中;如下图
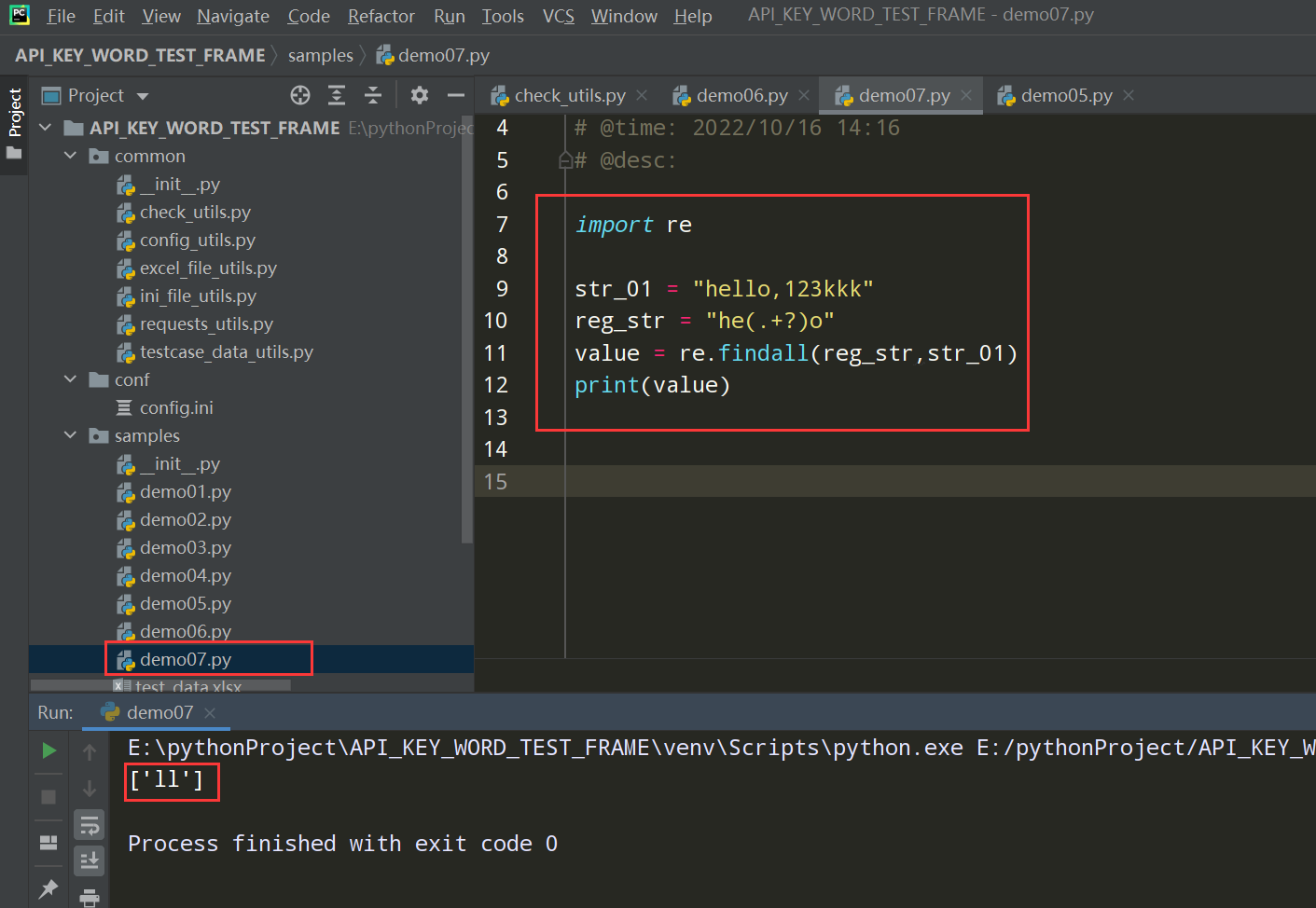
1、在check_utils.py文件中补充断言类型为正则表达式的断言代码;如下图:
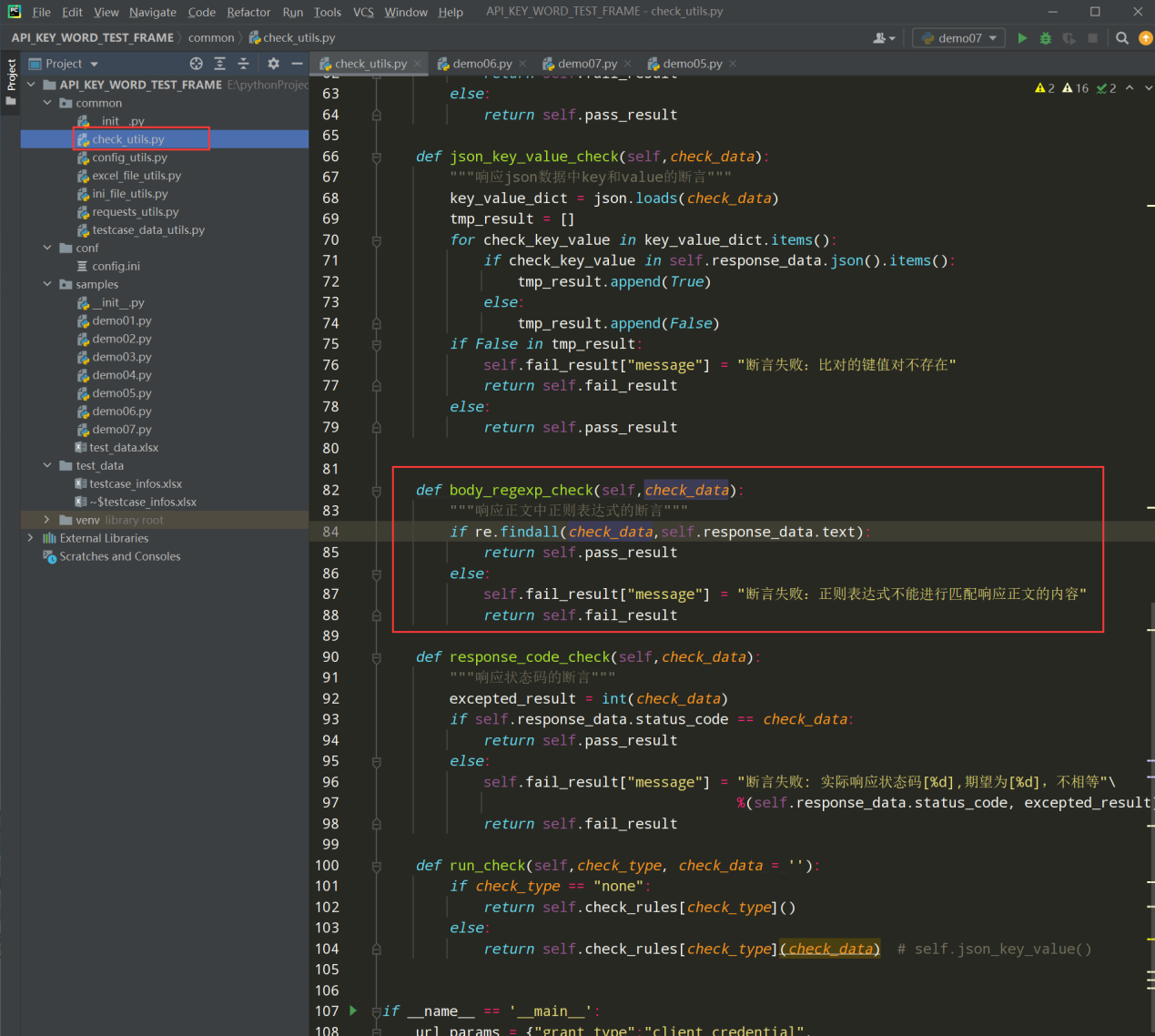
编写代码:
import re def body_regexp_check(self,check_data): """响应正文中正则表达式的断言""" if re.findall(check_data,self.response_data.text): return self.pass_result else: self.fail_result["message"] = "断言失败:正则表达式不能进行匹配响应正文的内容" return self.fail_result
2、在断言规则中再添加新编写的响应正文正则的方法;如下图:

编写代码:"body_regexp": self.body_regexp_check,
查看执行结果:
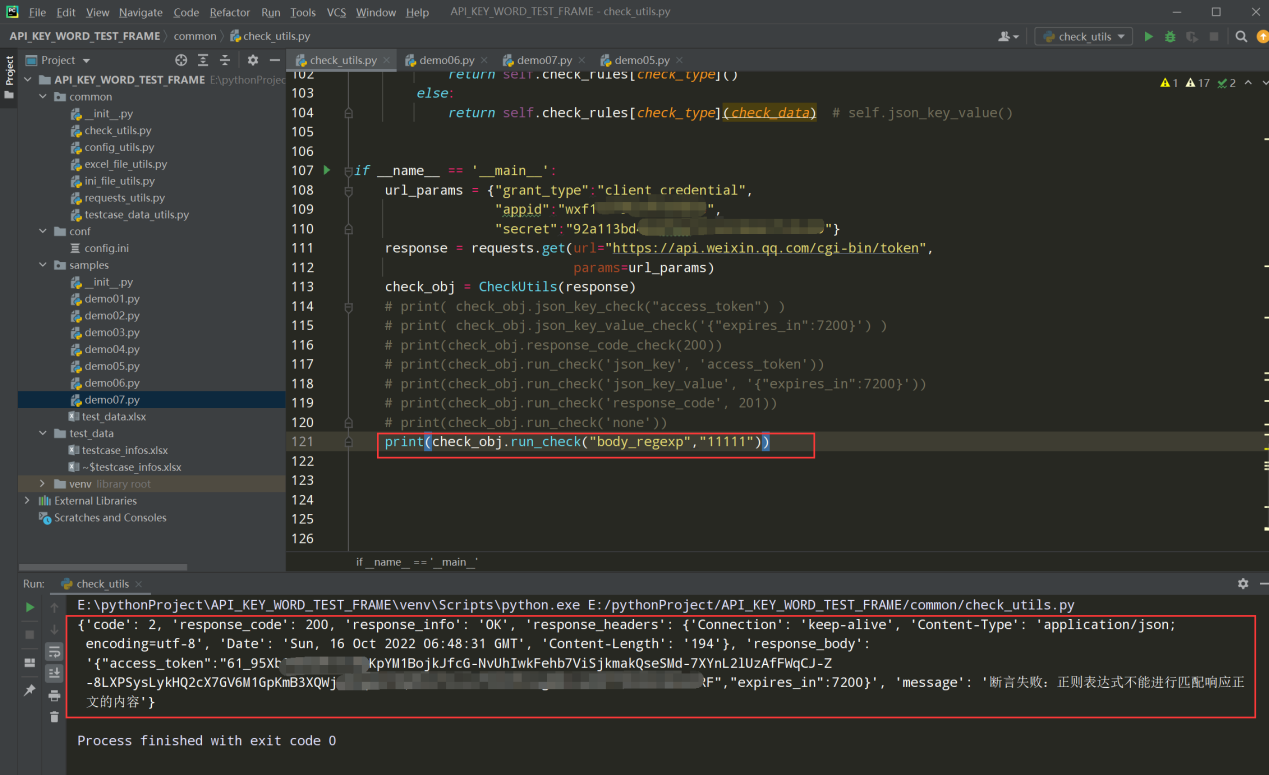
测试代码: print(check_obj.run_check('body_regexp','11111'))
5、响应头部key键的断言编写
1、在check_utils.py文件中编写断言类型为响应头部的断言代码;如下图:
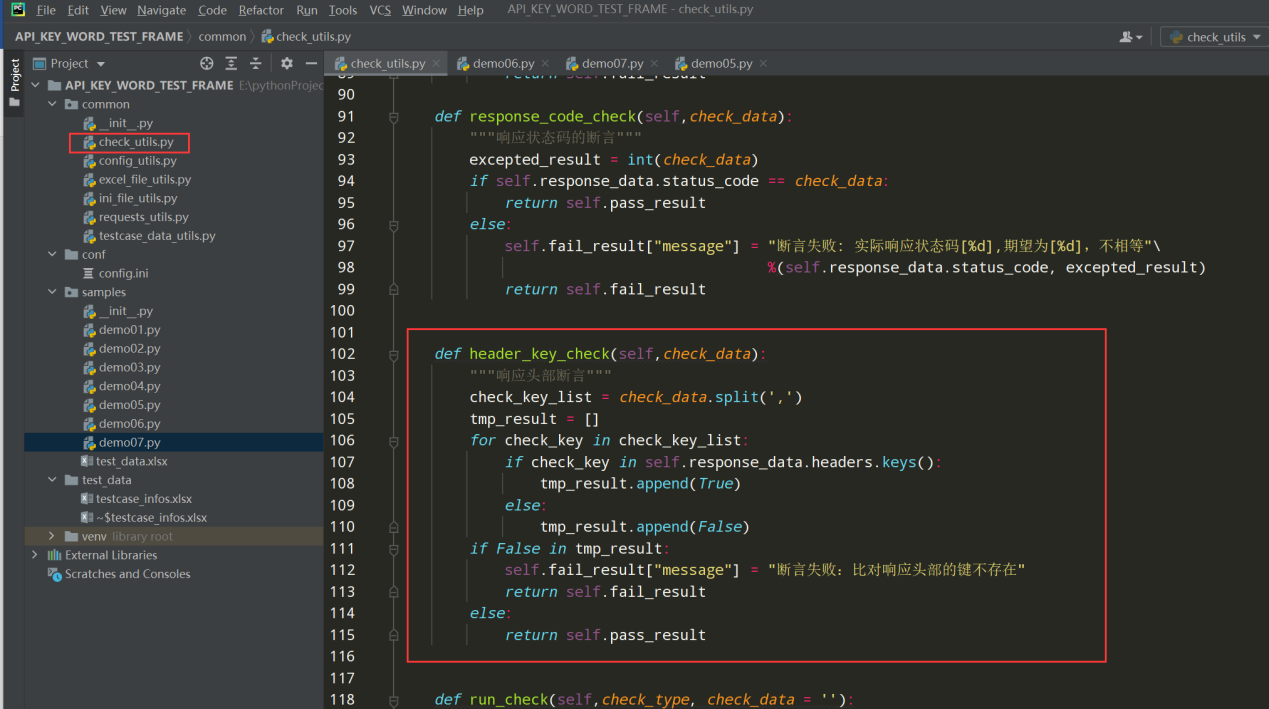
编写代码:
def header_key_check(self,check_data): """响应头部key键的断言""" check_key_list = check_data.split(',') tmp_result = [] for check_key in check_key_list: if check_key in self.response_data.headers.keys(): tmp_result.append(True) else: tmp_result.append(False) if False in tmp_result: self.fail_result["message"] = "断言失败:比对响应头部的键不存在" return self.fail_result else: return self.pass_result
2、在断言规则中再添加新编写的响应头部的方法;如下图:
编写代码:"header_key": self.header_key_check,
查看执行结果:
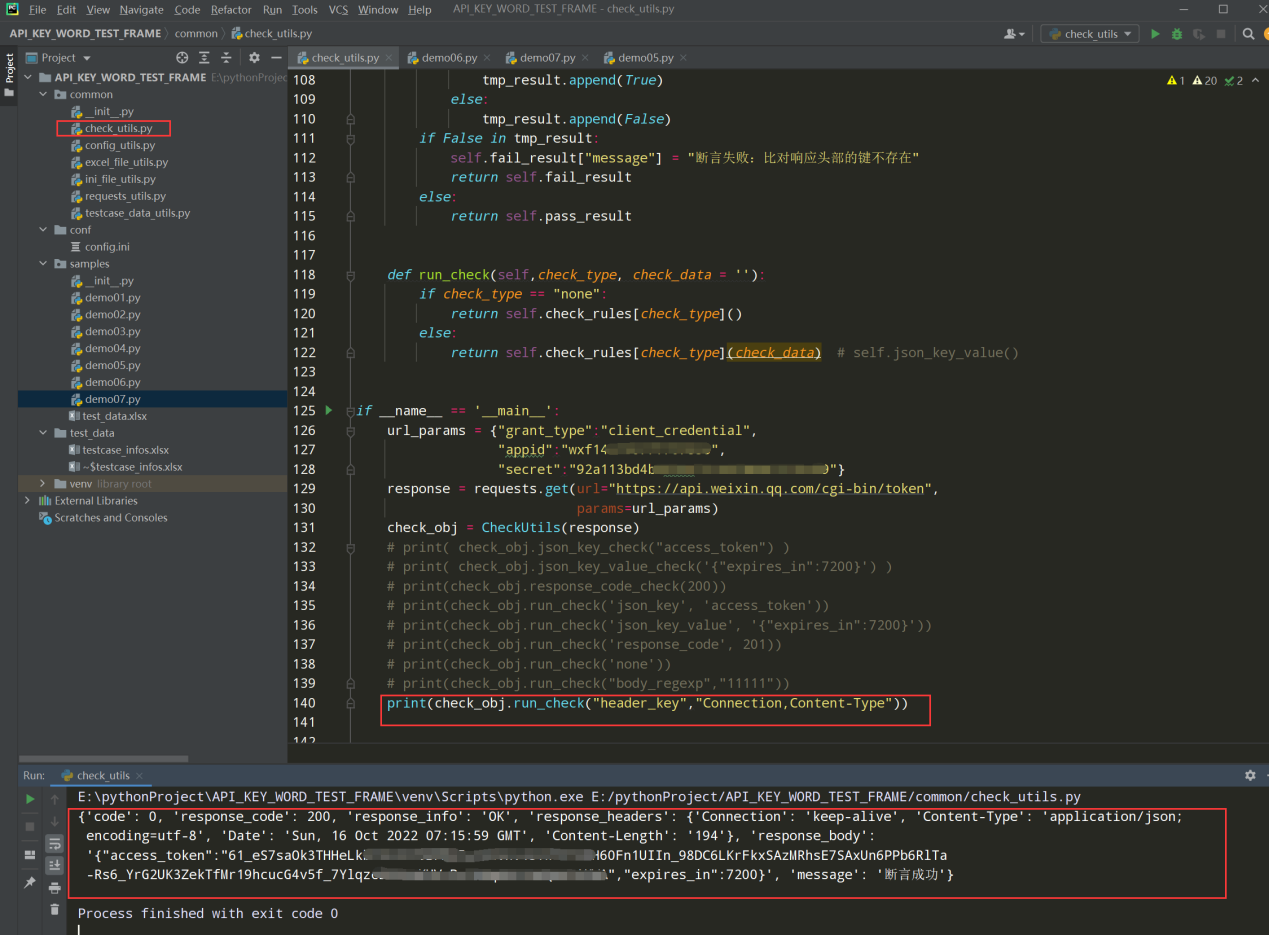
测试代码: print(check_obj.run_check("header_key","Connection,Content-Type"))
6、响应头部value值的断言编写
1、在check_utils.py文件中编写断言类型为响应头部值的断言代码;如下图:
编写代码:
def header_key_value_check(self,check_data): """响应头部value的断言""" key_value_dict = json.loads(check_data) tmp_result = [] for check_key_value in key_value_dict.items(): if check_key_value in self.response_data.headers.items(): tmp_result.append(True) else: tmp_result.append(False) if False in tmp_result: self.fail_result["message"] = "断言失败:比对的响应头及对应的值不正确" return self.fail_result else: return self.pass_result
2、在断言规则中再添加新编写的响应头部的方法;如下图:
编写代码:"header_key_value": self.header_key_value_check,
查看执行结果:
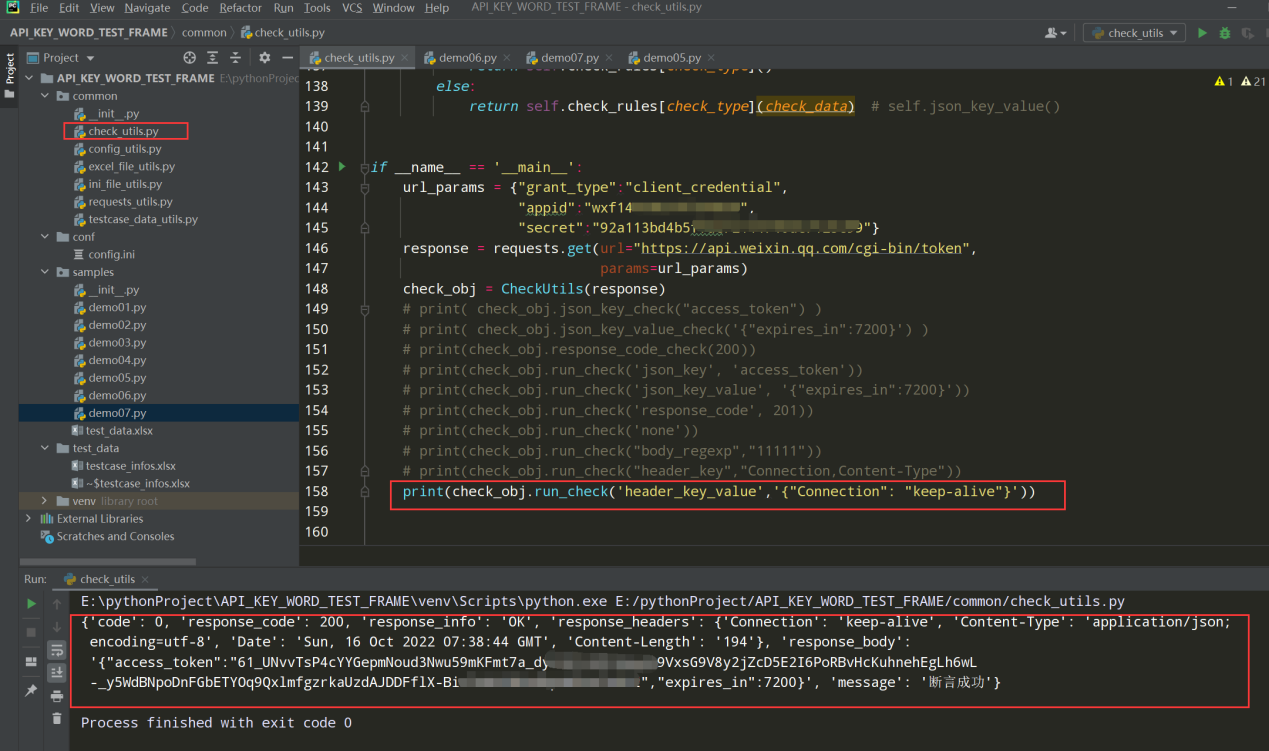
测试代码: print(check_obj.run_check("header_key_value", '{"Connection":"keep-alive"}'))
步骤7、断言类引入到request_utils.py文件中的get/post请求中
check类返回的结果放入封装的get和post方法中,然后在多接口运行方法中把结果作为是否继续执行下一个接口的依据
1、 打开request_utils.py文件,导入封装好的断言类;如下图:
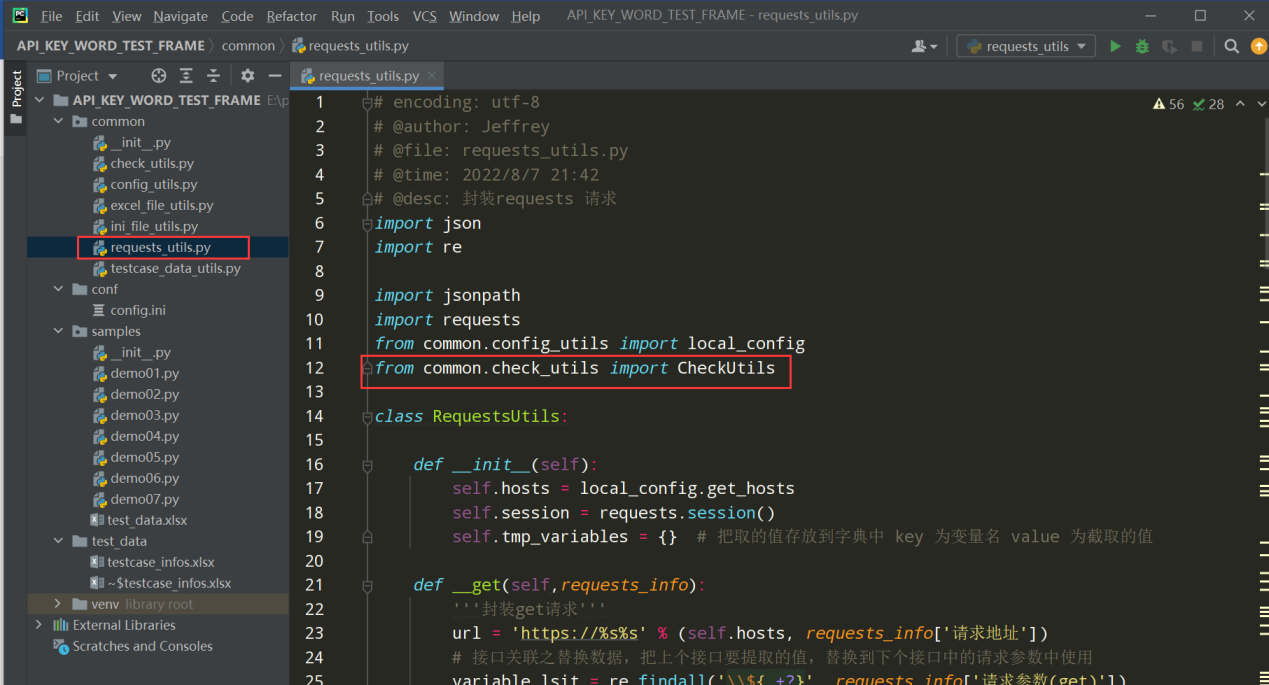
导包:from common.check_utils import CheckUtils
2、 把断言的执行方法引入到get/post请求中;如下图:
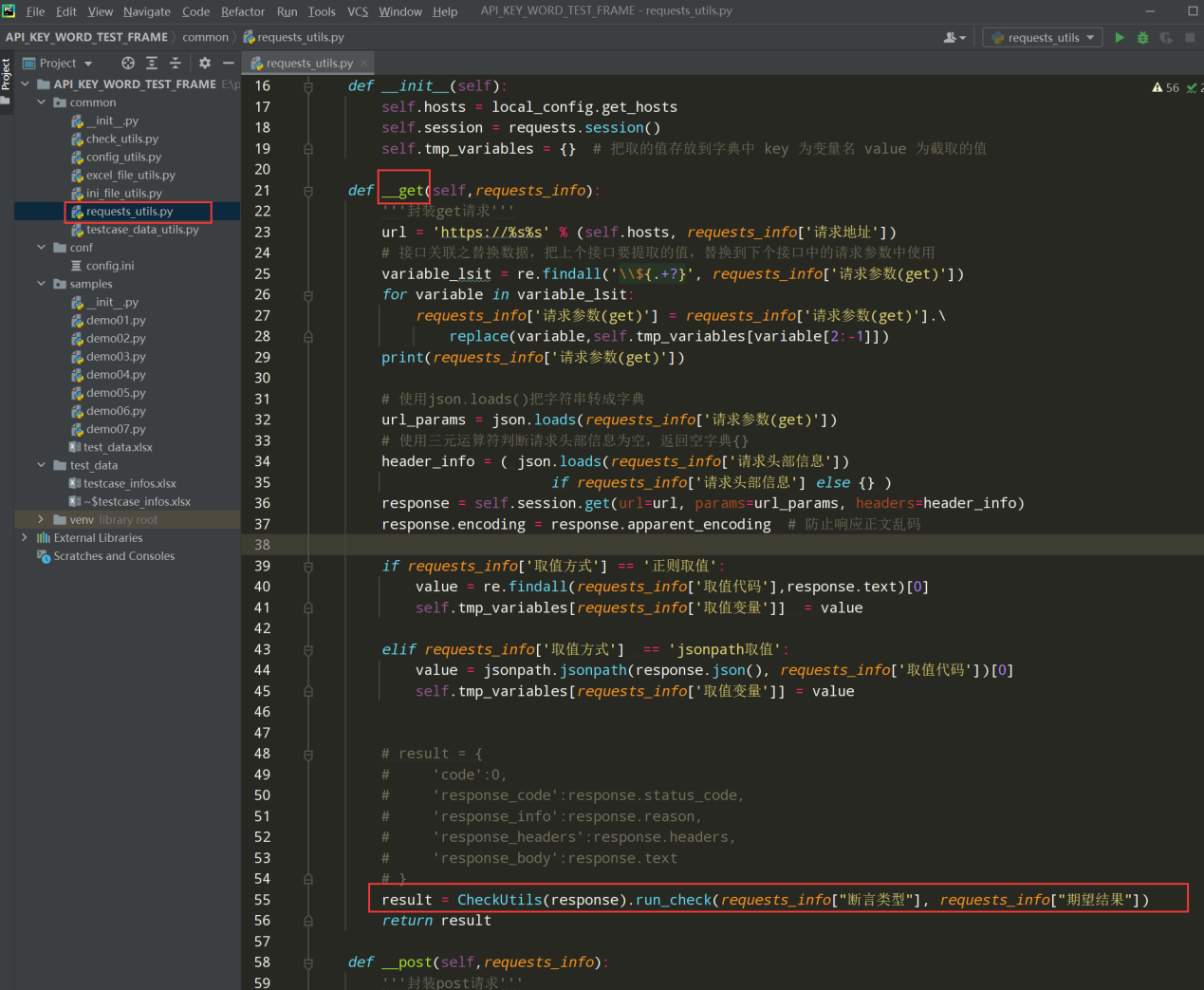
编写代码:
result = CheckUtils(response).run_check(requests_info["断言类型"], requests_info["期望结果"])
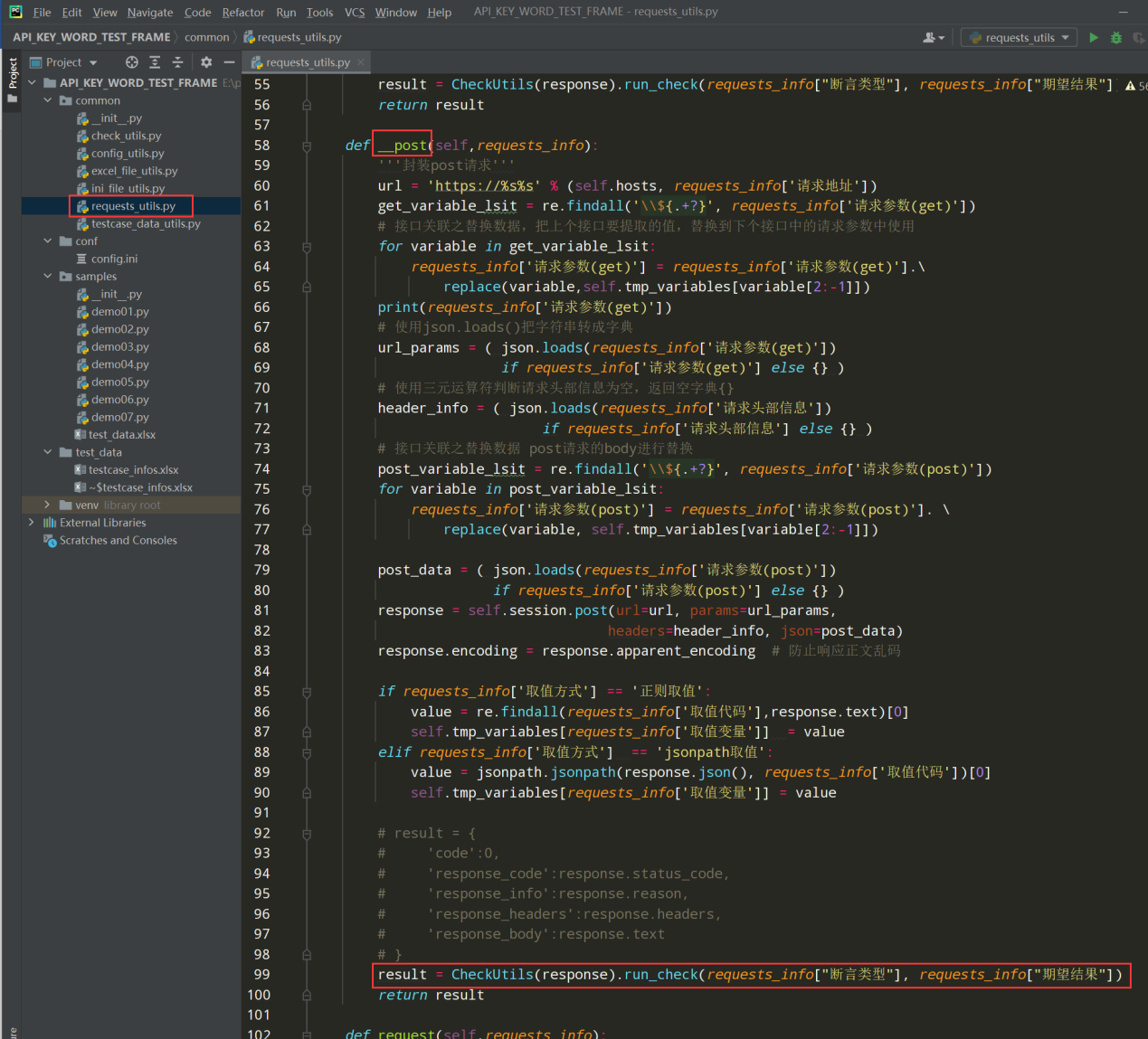
编写代码:
result = CheckUtils(response).run_check(requests_info["断言类型"], requests_info["期望结果"])
3、查看执行结果:
框架06 paramunitest参数化基础及应用
一、paramunitest参数化基础及应用

paramunitest参数可传入元组,列表,字典,数据对象,函数;
paramunittest模块安装:pip install paramunittest
示例如下:
代码示例:
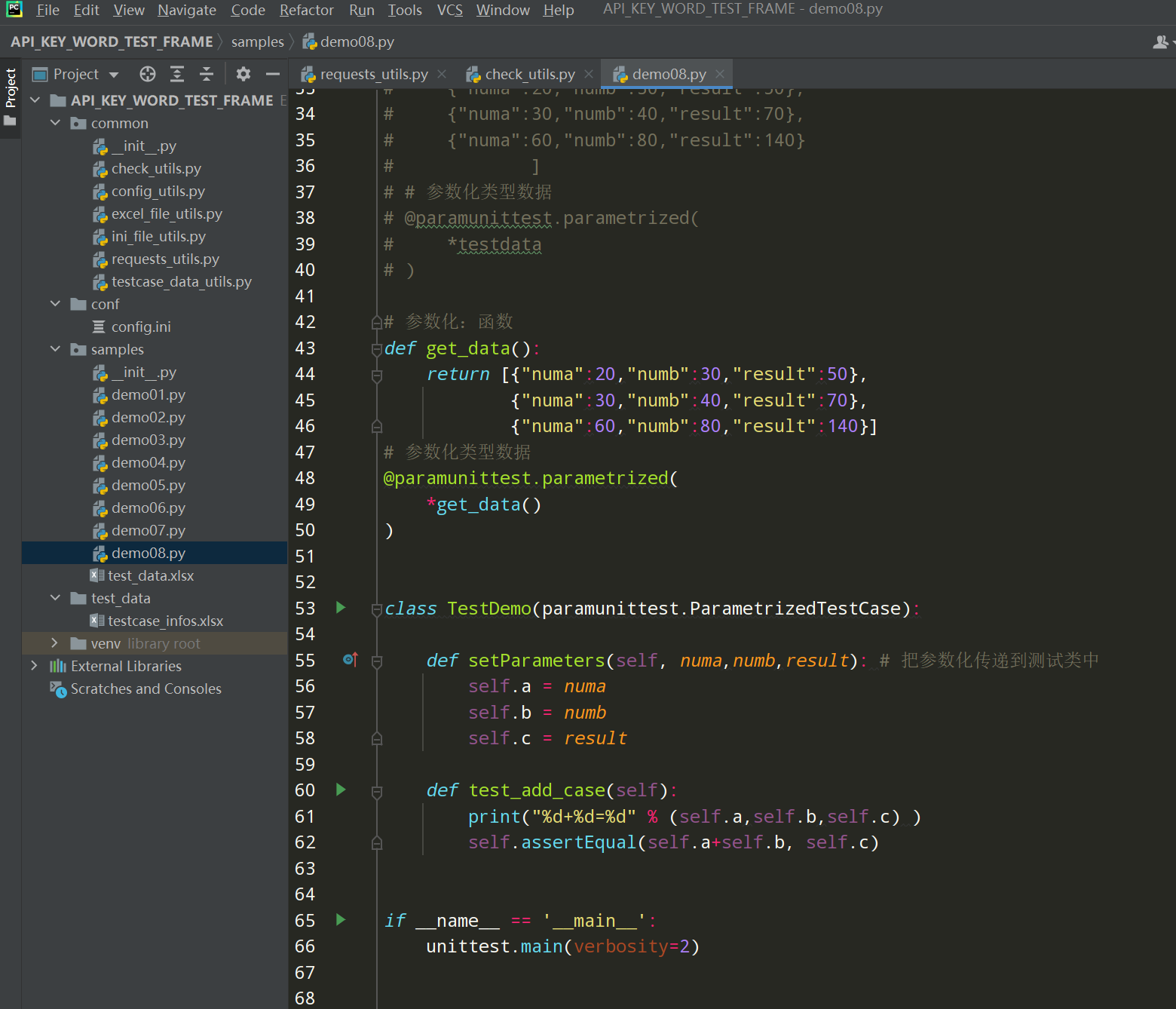
import unittest import paramunittest #p ip install paramunittest # # 参数化元组类型数据 # @paramunittest.parametrized( # (20,30,50), # (30,40,70), # (60,80,140) # ) # 参数化列表类型数据 # @paramunittest.parametrized( # [20,30,50], # [30,40,70], # [60,80,140] # ) # # # 参数化字典类型数据(字典中的key要和setParameters方法中的形参一致) # @paramunittest.parametrized( # {"numa":20,"numb":30,"result":50}, # {"numa":30,"numb":40,"result":70}, # {"numa":60,"numb":80,"result":140} # ) # # 参数化:数据对象 # testdata = [ # {"numa":20,"numb":30,"result":50}, # {"numa":30,"numb":40,"result":70}, # {"numa":60,"numb":80,"result":140} # ] # # 参数化类型数据 # @paramunittest.parametrized( # *testdata # ) # 参数化:函数 def get_data(): return [{"numa":20,"numb":30,"result":50}, {"numa":30,"numb":40,"result":70}, {"numa":60,"numb":80,"result":140}] # 参数化类型数据 @paramunittest.parametrized( *get_data() ) class TestDemo(paramunittest.ParametrizedTestCase): def setParameters(self, numa,numb,result): # 把参数化传递到测试类中 self.a = numa self.b = numb self.c = result def test_add_case(self): print("%d+%d=%d" % (self.a,self.b,self.c) ) self.assertEqual(self.a+self.b, self.c) if __name__ == '__main__': unittest.main(verbosity=2)
二、把excel文件和paramunitest进行参数化整合
1、在项目的根目录下新建一个testcases的py文件夹,在该文件夹下新建test_api_case.py文件;如下图:
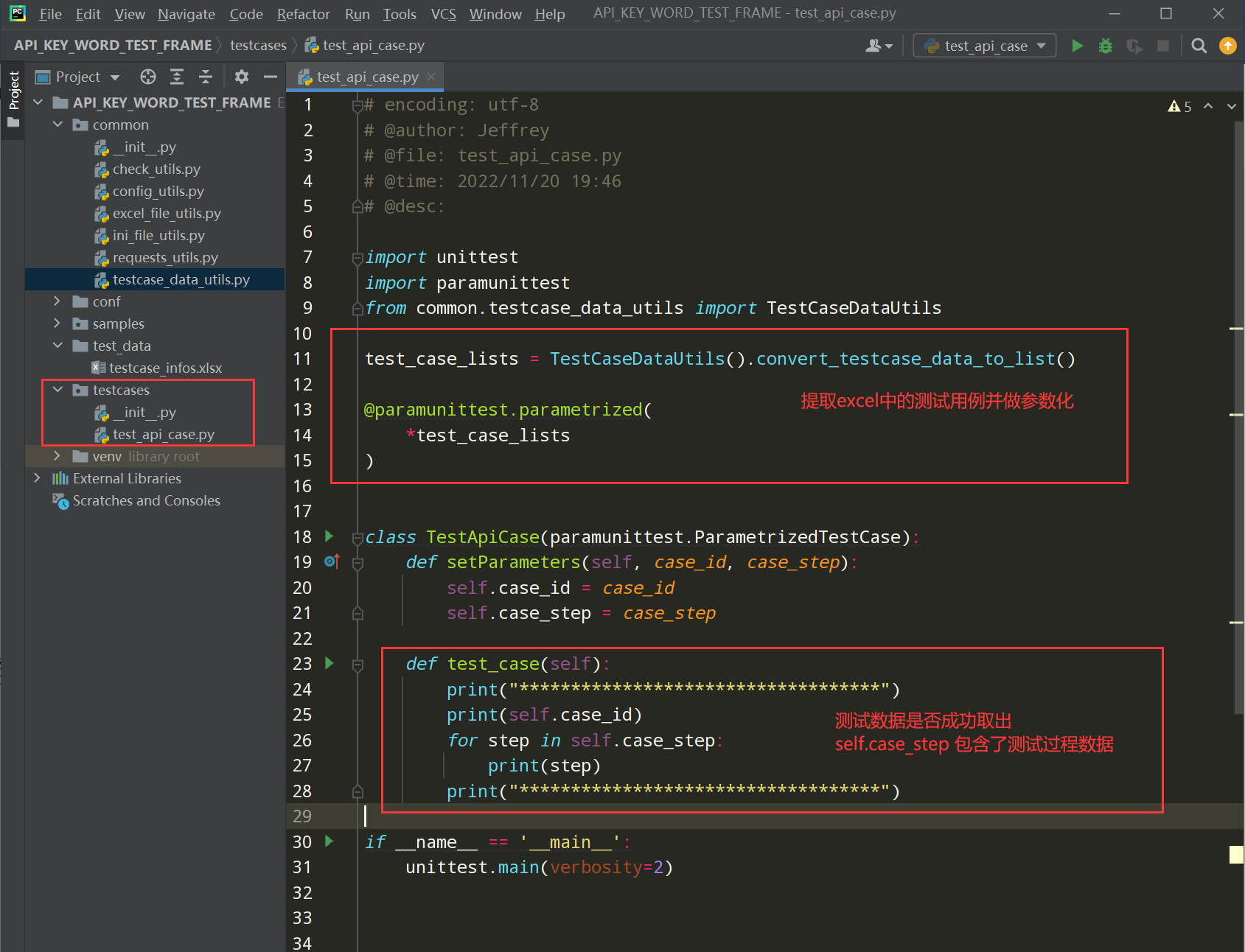
编写代码:
# encoding: utf-8 # @author: Jeffrey # @file: test_api_case.py # @time: 2022/11/20 19:46 # @desc: import unittest import paramunittest from common.testcase_data_utils import TestCaseDataUtils test_case_lists = TestCaseDataUtils().convert_testcase_data_to_list() @paramunittest.parametrized( *test_case_lists ) class TestApiCase(paramunittest.ParametrizedTestCase): def setParameters(self, case_id, case_step): self.case_id = case_id self.case_step = case_step def test_case(self): print("***********************************") print(self.case_id) for step in self.case_step: print(step) print("***********************************") self.assertTrue(True) if __name__ == '__main__': unittest.main(verbosity=2)
备注:如果python版本是3.10版本则执行会报错;因为在3.10版本中已经把Mapping这个数据取消了;如下图
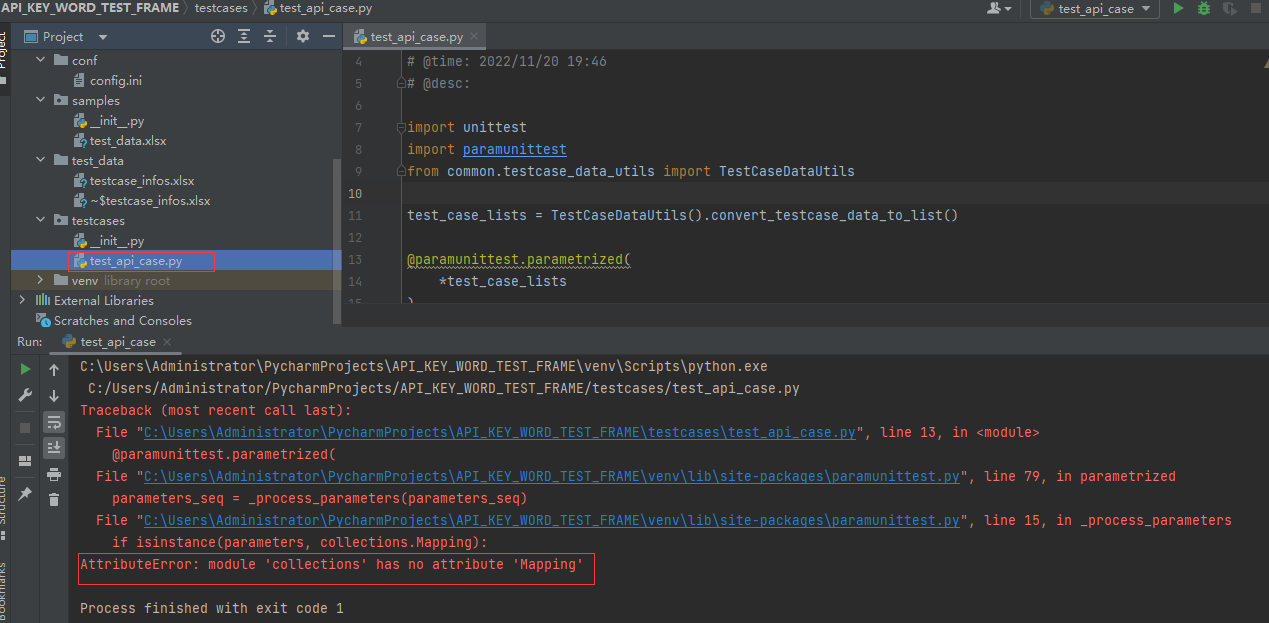
解决方法:把python降到3.10版本一下即可
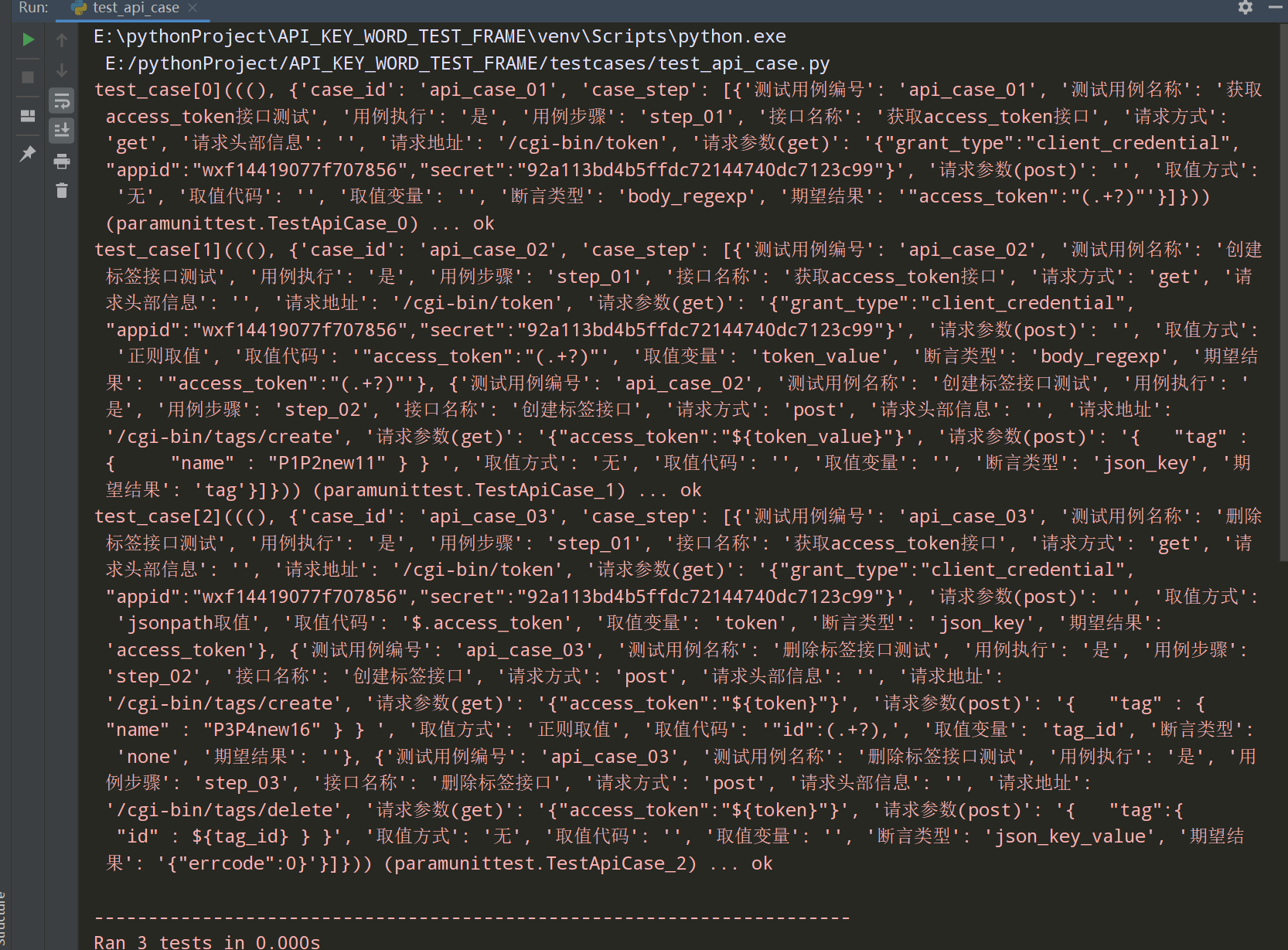
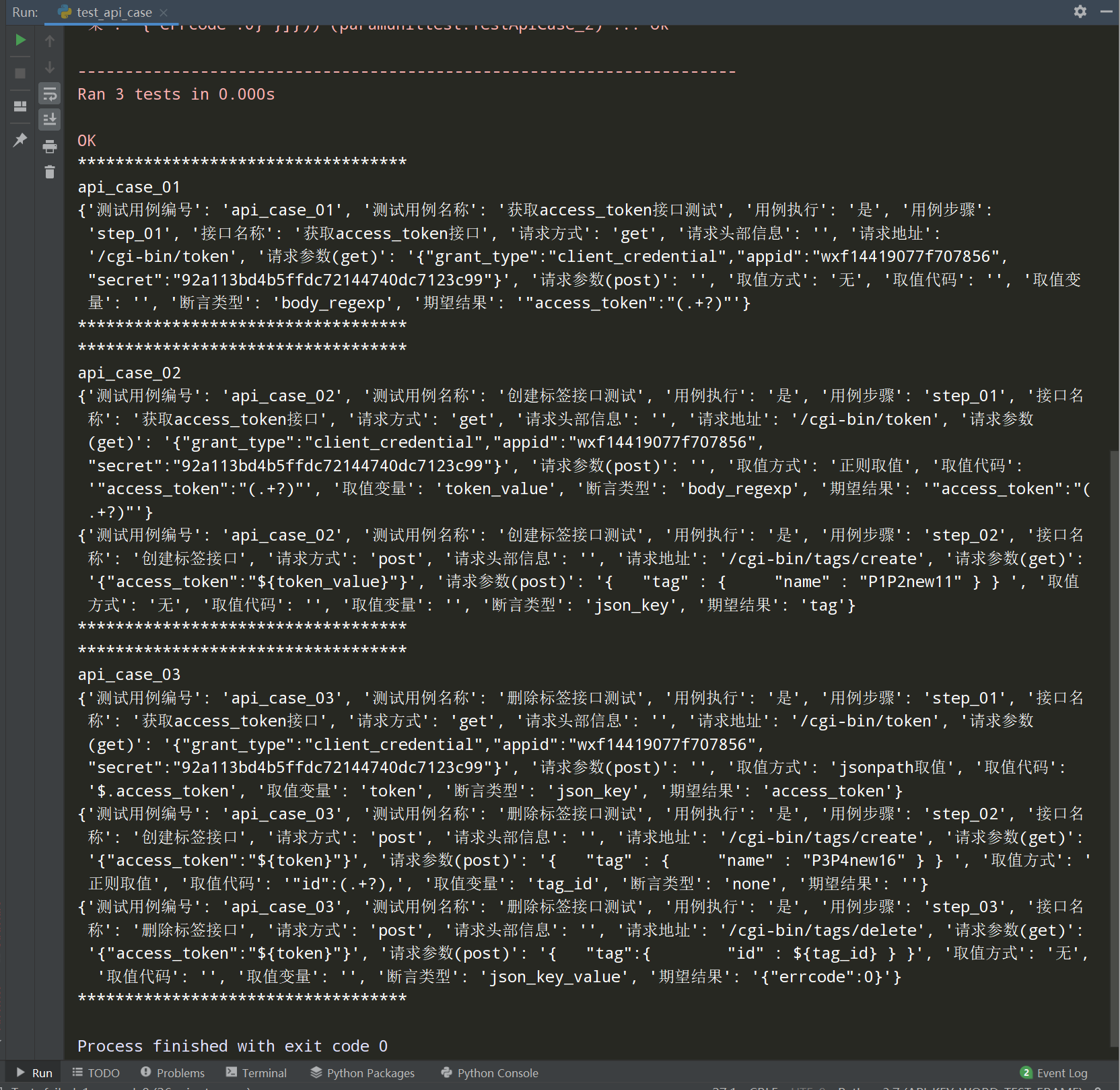
查看执行结果:
三、把参数化测试用例融入到框架中(requests_utils文件的请求及断言融合)
1、修改test_api_case.py文件中的test_case方法;如下:
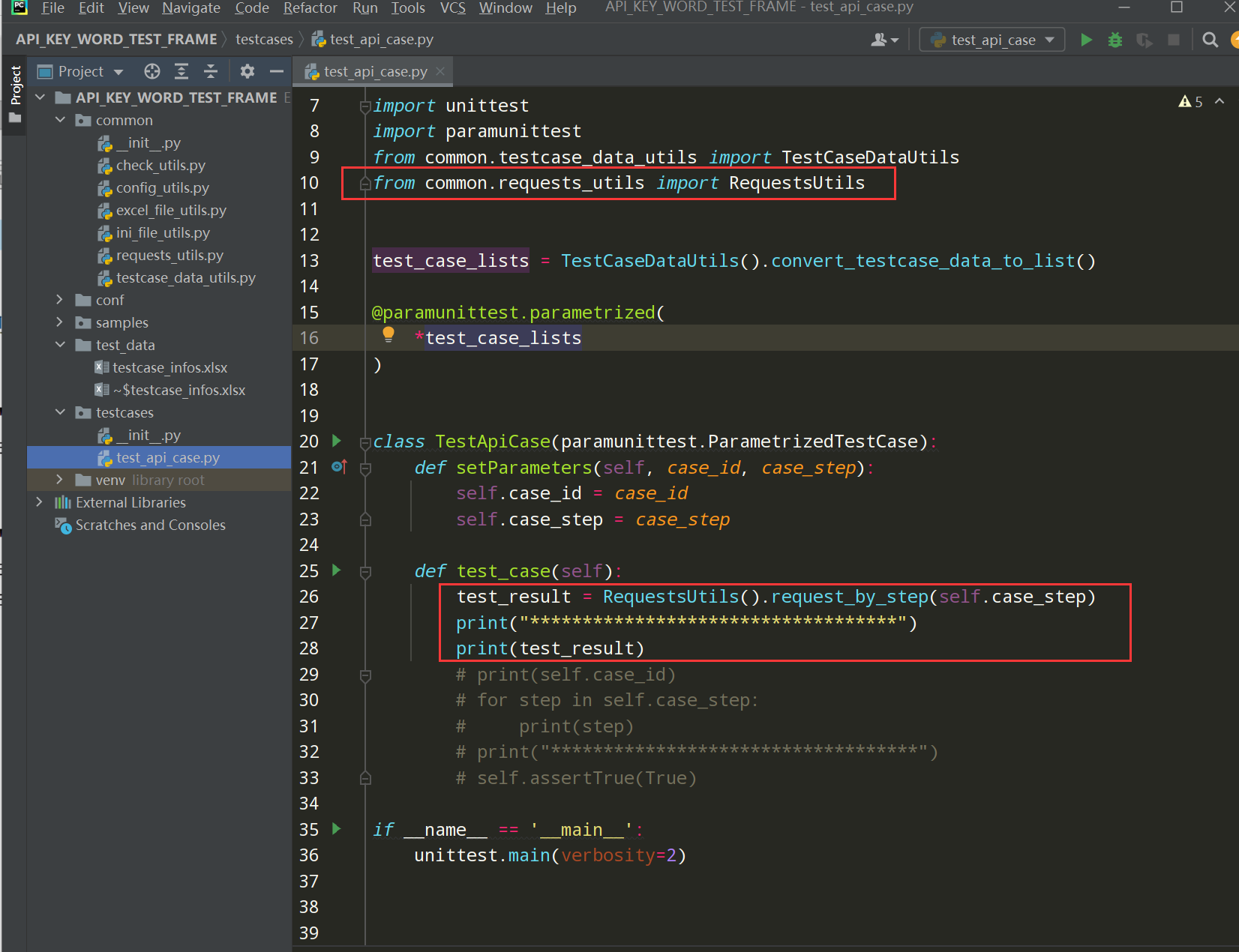
前置条件:先导入from common.requests_utils import RequestsUtils
编写代码:
def test_case(self): test_result = RequestsUtils().request_by_step(self.case_step) print("***********************************") print(test_result)
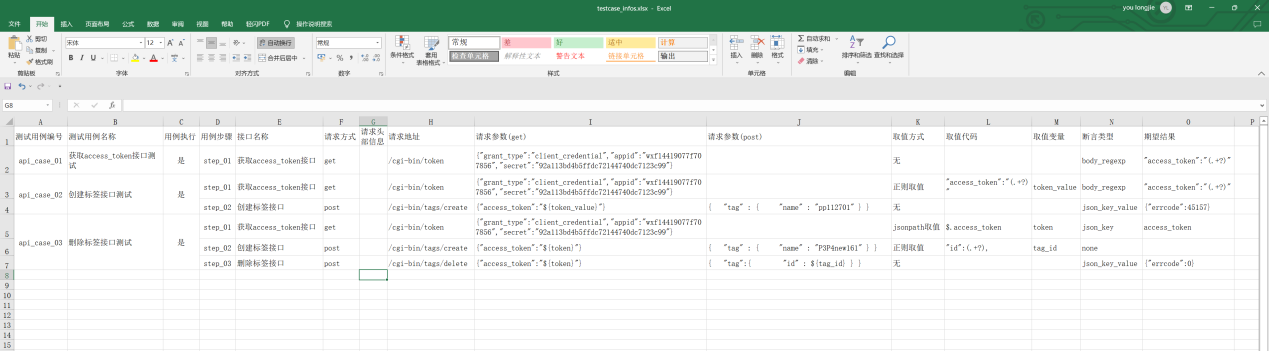
excel文件中的用例展示如下:
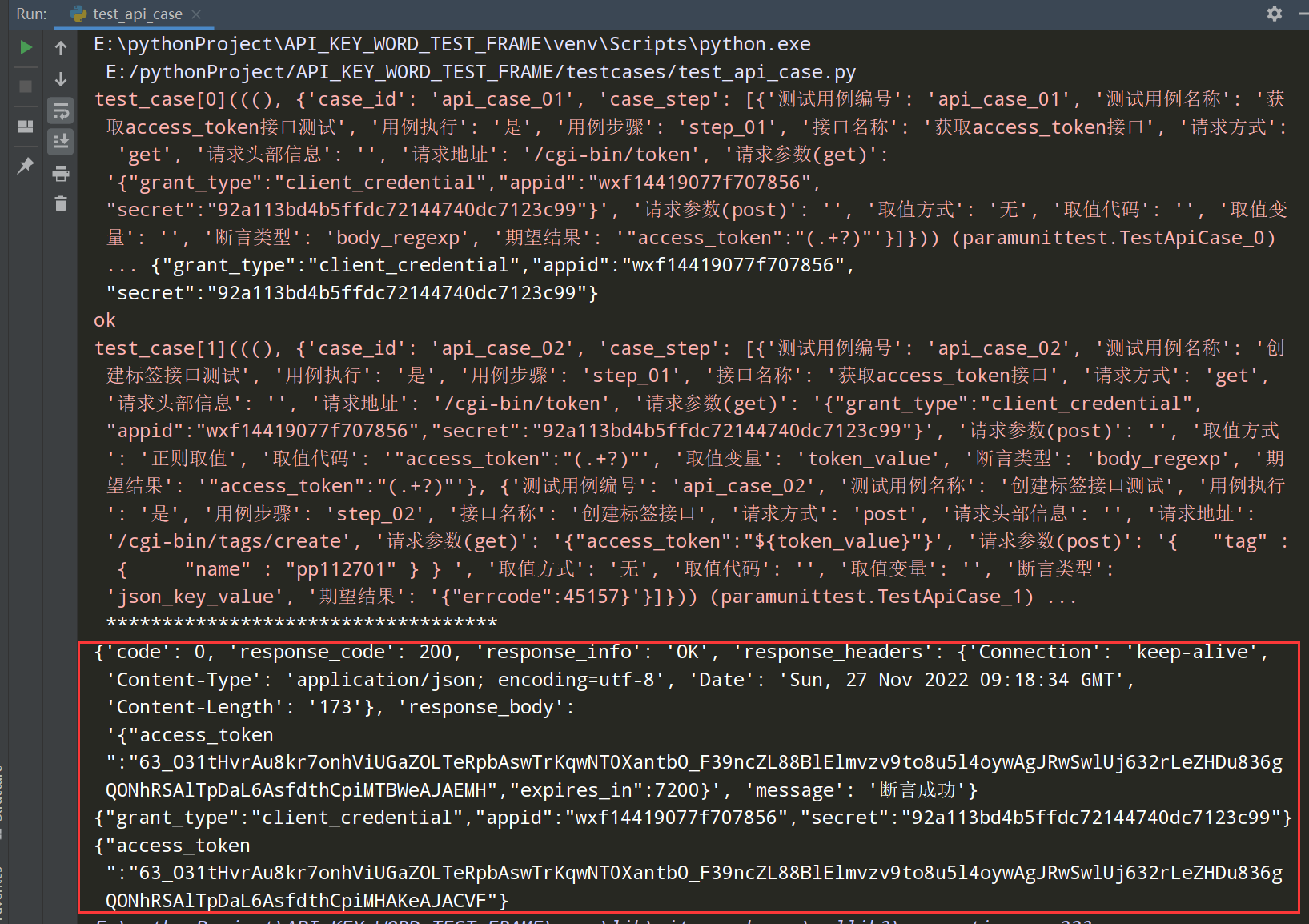
执行test_api_case.py文件结果如下;

2、在check_utils.py中增加check_result断言结果;
在check_utils.py中json结果中增加check_result,成功用True,失败用False;主要是用来做断言的,其他也可以用code=0/2做断言;如下:
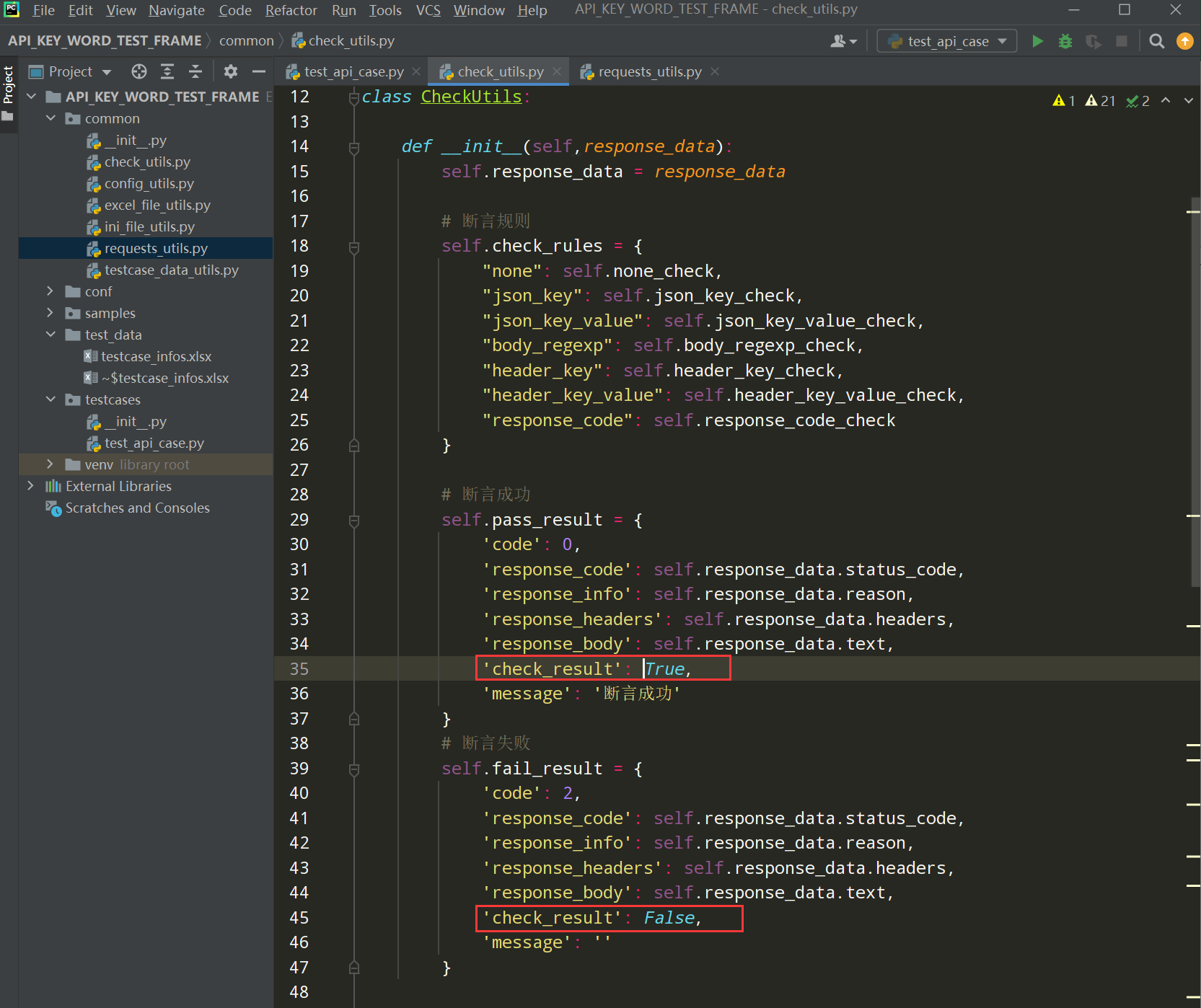
编写代码:'check_result':True, 'check_result': False,
在requests_utils.py文件中调整如下:
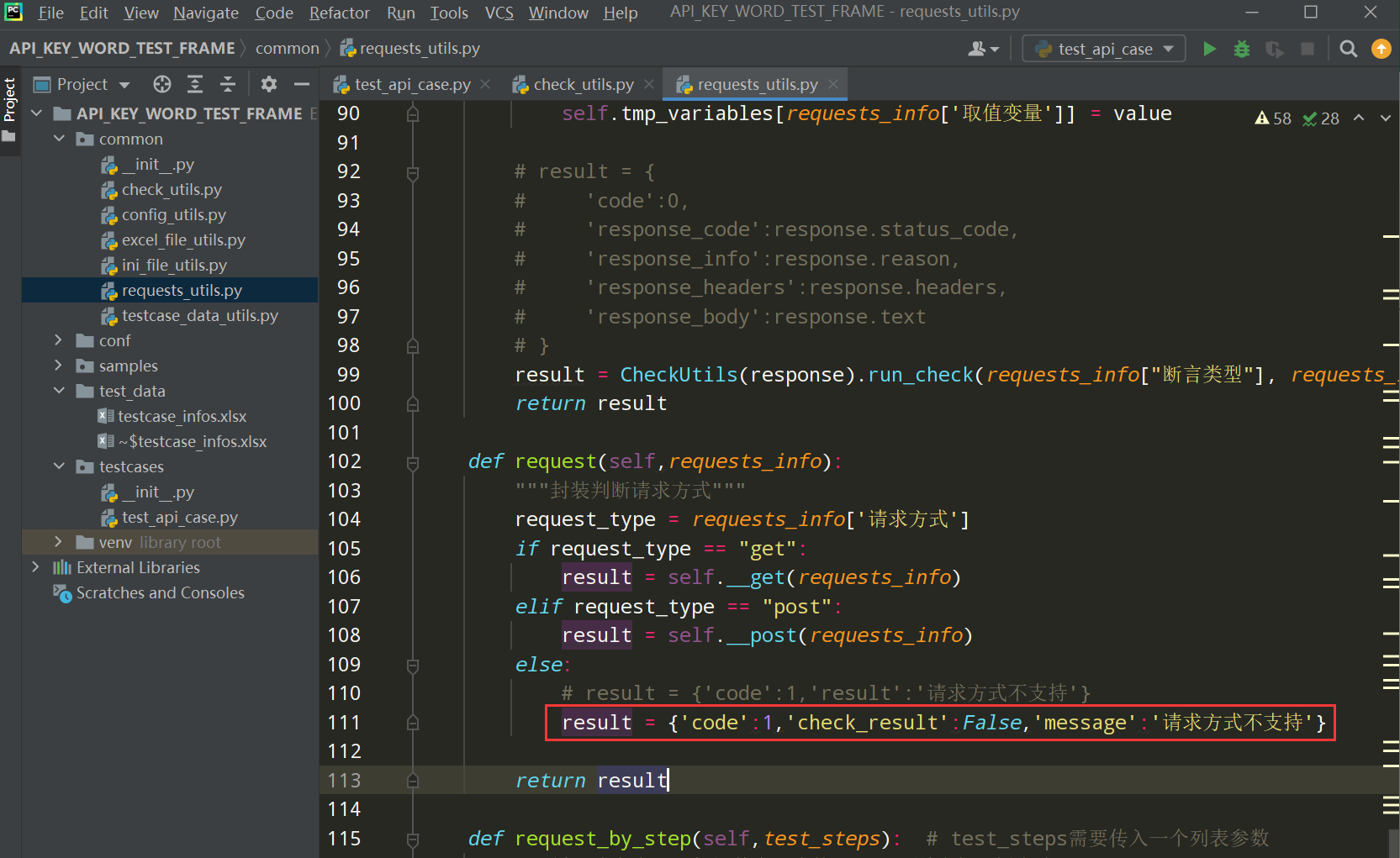
编写代码: result = {'code': 1, 'check_result':False,'message':'请求方式不支持'}
3、在test_api_case.py文件中添加断言;
在test_api_case.py文件中的test_case方法添加断言;如下图:

编写代码: self.assertTrue(test_result['check_result'])
执行test_api_case.py结果:
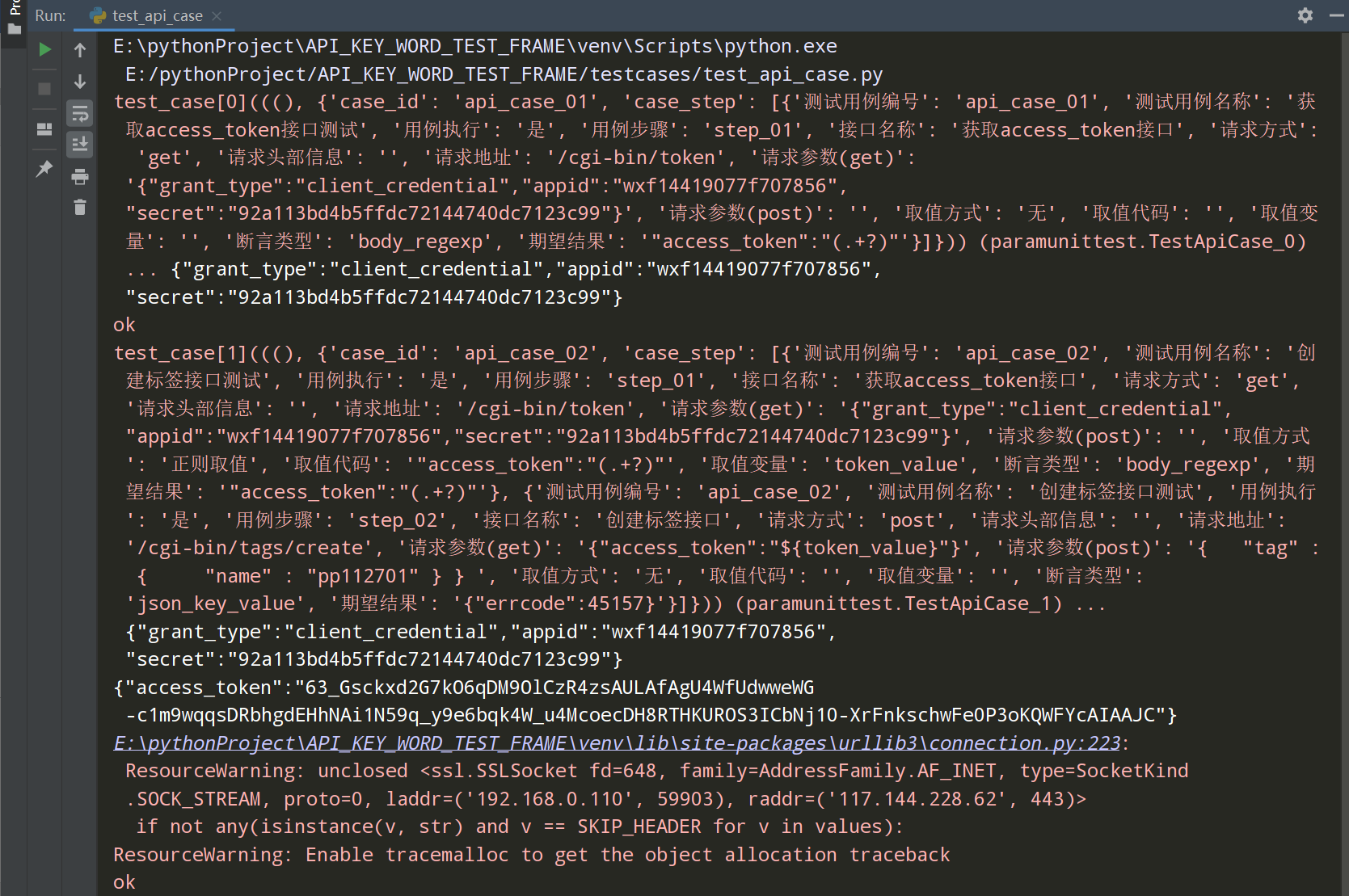
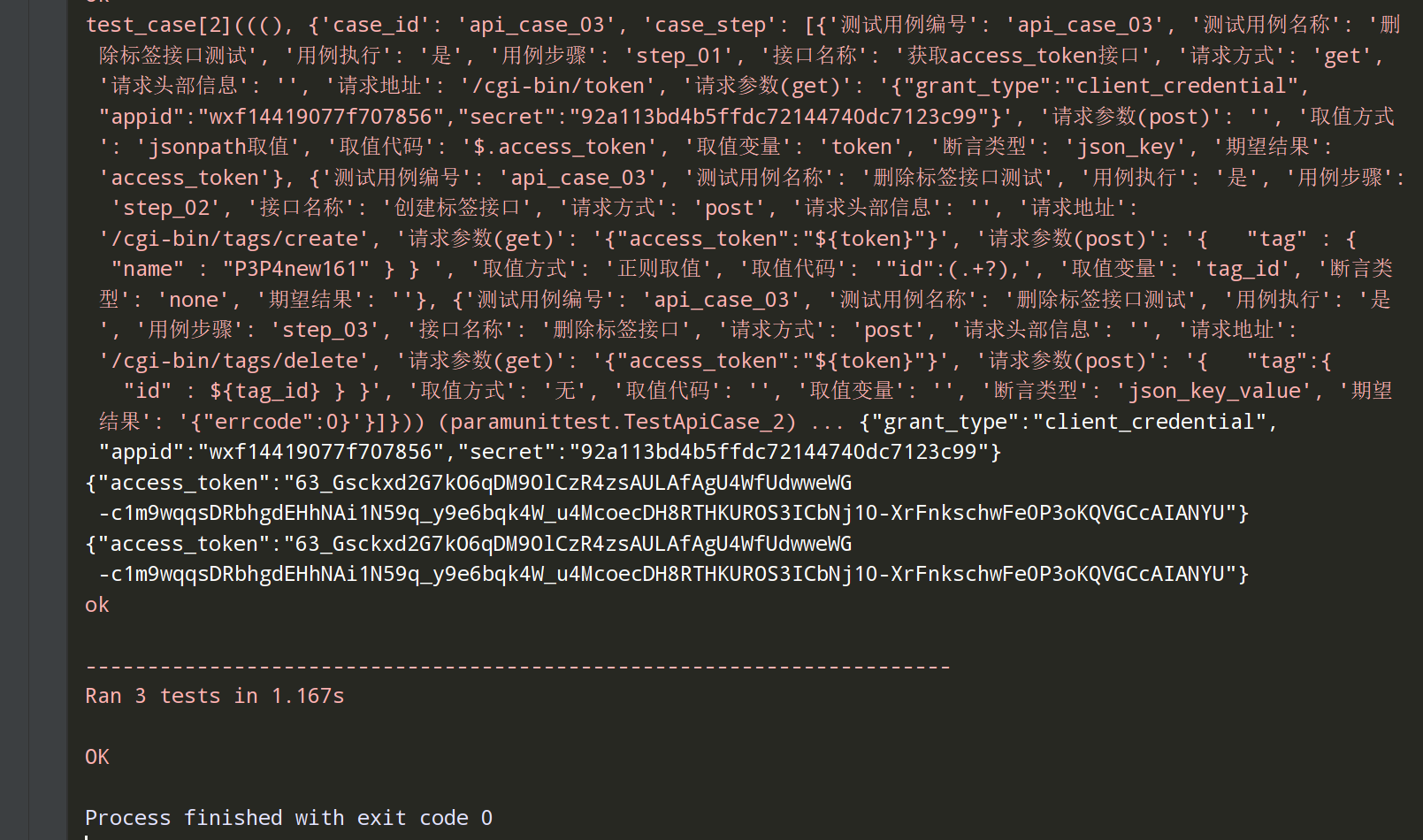
备注:如果不想把执行结果中的输出值展示,可以在requests_utils.py文件中把get和post请求中的print注释掉。
框架07 测试执行及生成网页版测试报告
前置条件
在common中放入一个第三方测试报告插件模块HTMLTestReportCN.py
通过网盘分享的文件:HTMLTestReportCN.py
链接: https://pan.baidu.com/s/1sXRfebHok94QtYeY4pAS8A 提取码: v7a3
一、新增执行主入口和报告路径
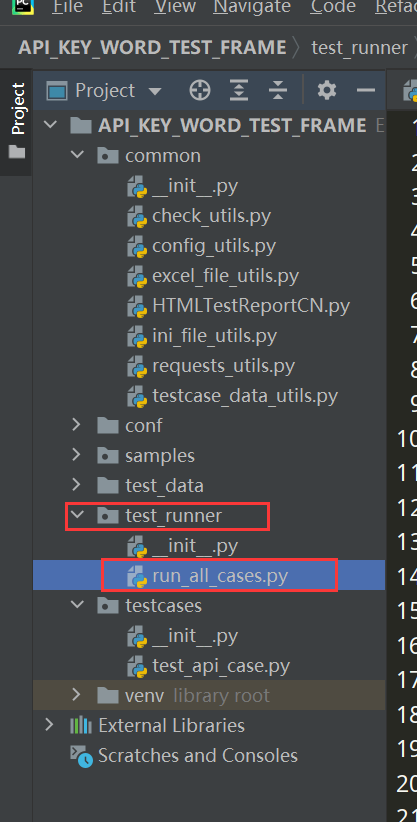
1、 在项目根目录下新建test_runner的py文件夹然后再该下面新增run_all_cases.py文件
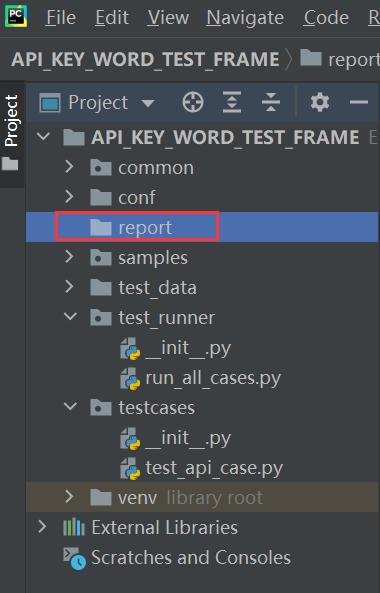
2、在项目根目录下新建report普通文件夹
二、编写代码生成测试报告
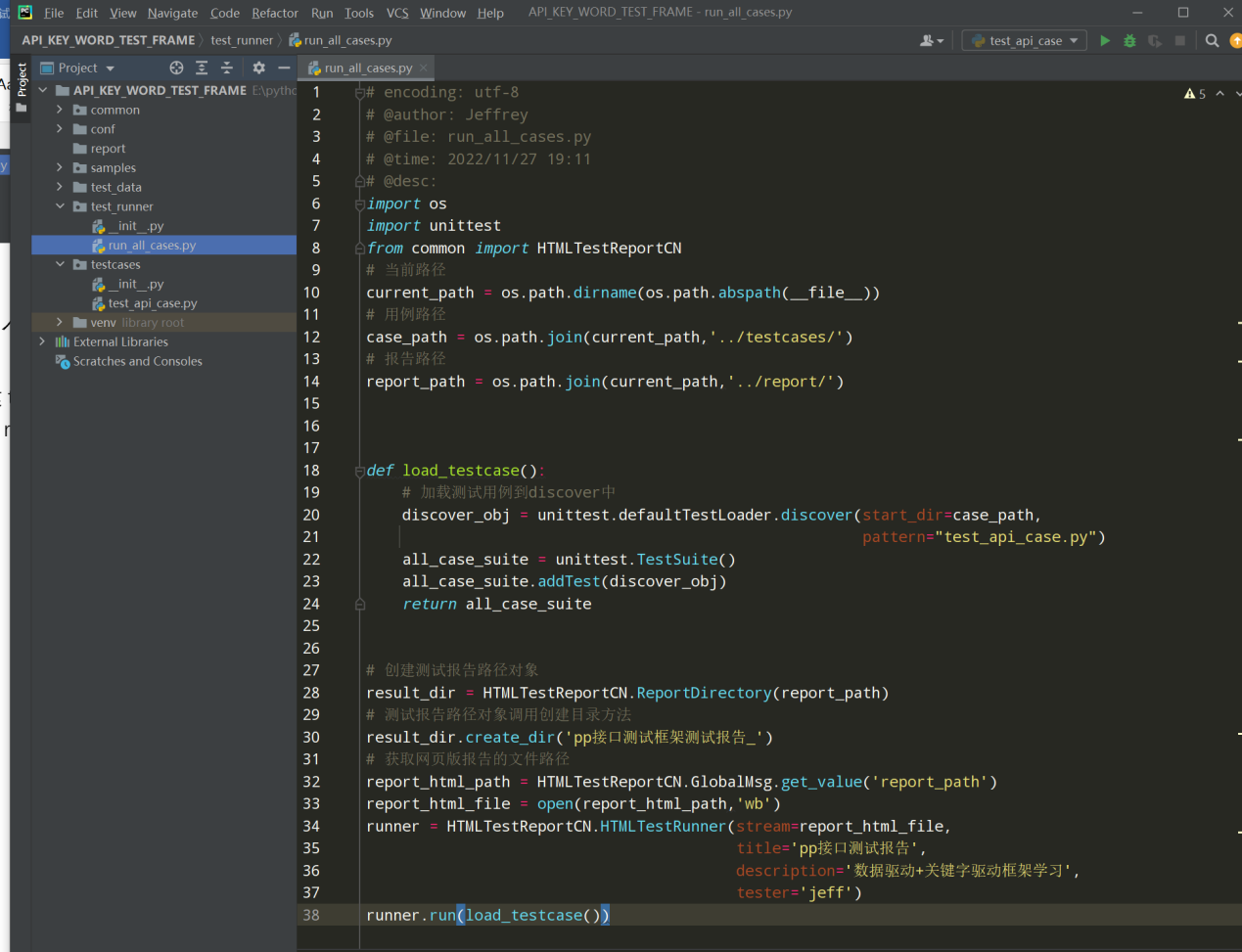
在run_all_cases.py文件中编写生成网页版测试报告代码;如下
编写代码:
import os import unittest from common import HTMLTestReportCN # 当前路径 current_path = os.path.dirname(os.path.abspath(__file__)) # 用例路径 case_path = os.path.join(current_path,'../testcases/') # 报告路径 report_path = os.path.join(current_path,'../report/') def load_testcase(): # 加载测试用例到discover中 discover_obj = unittest.defaultTestLoader.discover(start_dir=case_path, pattern="test_api_case.py") all_case_suite = unittest.TestSuite() all_case_suite.addTest(discover_obj) return all_case_suite # 创建测试报告路径对象 result_dir = HTMLTestReportCN.ReportDirectory(report_path) # 测试报告路径对象调用创建目录方法 result_dir.create_dir('pp接口测试框架测试报告_') # 获取网页版报告的文件路径 report_html_path = HTMLTestReportCN.GlobalMsg.get_value('report_path') report_html_file = open(report_html_path,'wb') runner = HTMLTestReportCN.HTMLTestRunner(stream=report_html_file, title='pp接口测试报告', description='数据驱动+关键字驱动框架学习', tester='jeff') runner.run(load_testcase())
查看执行结果:
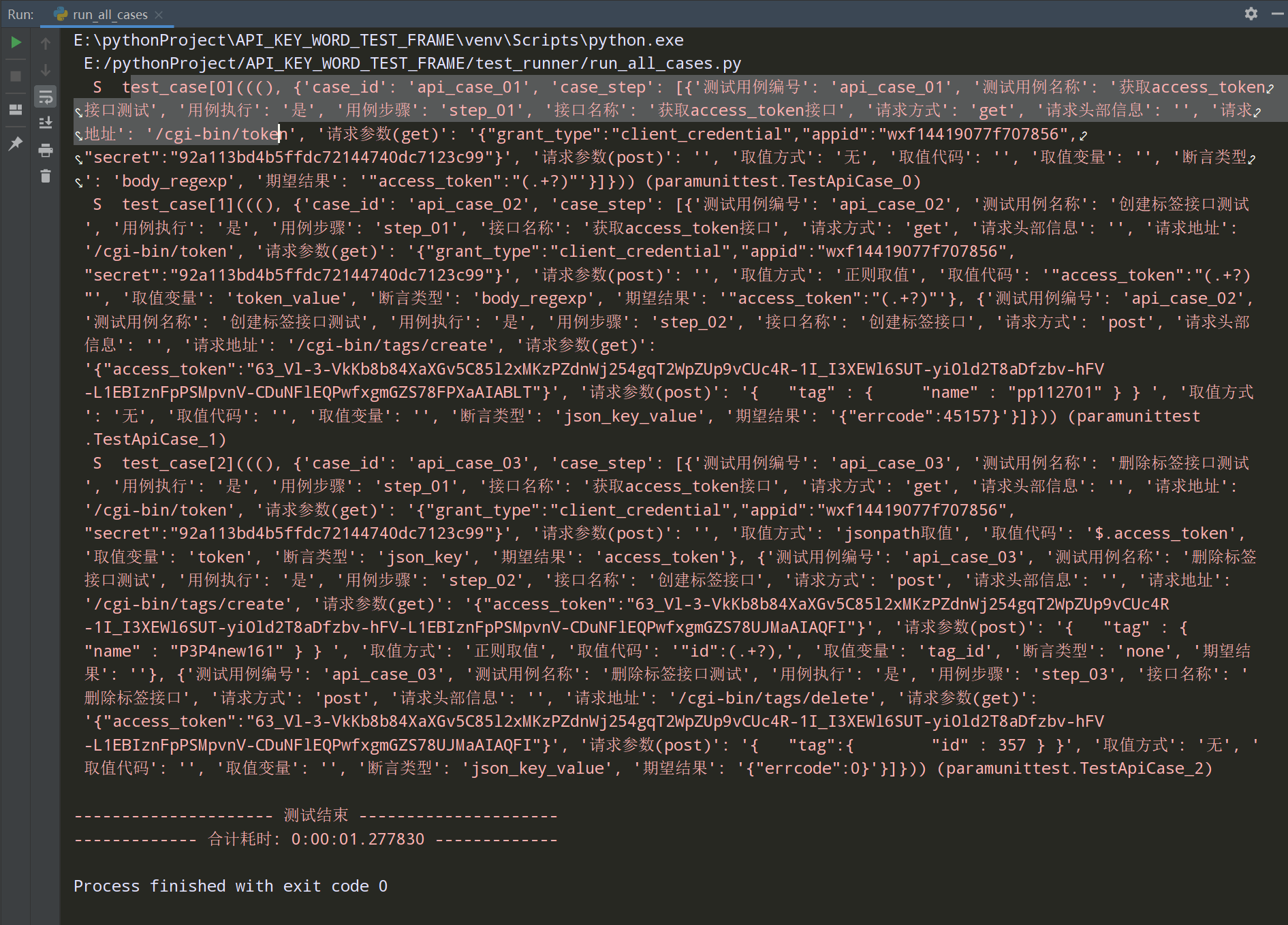
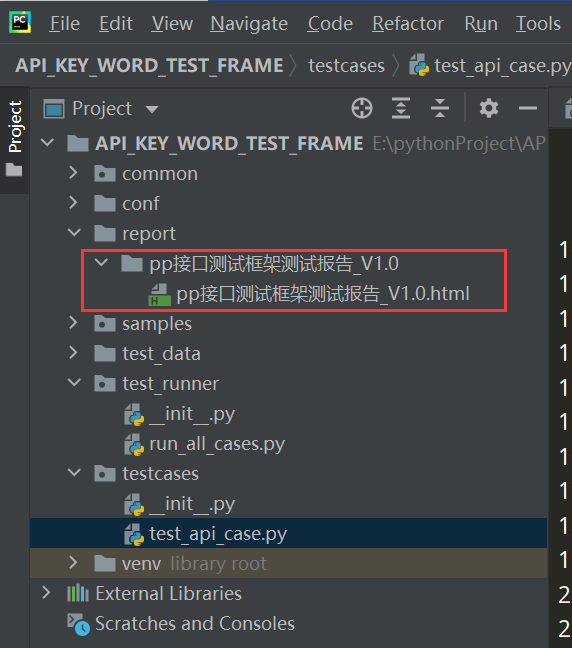
测试报告展示
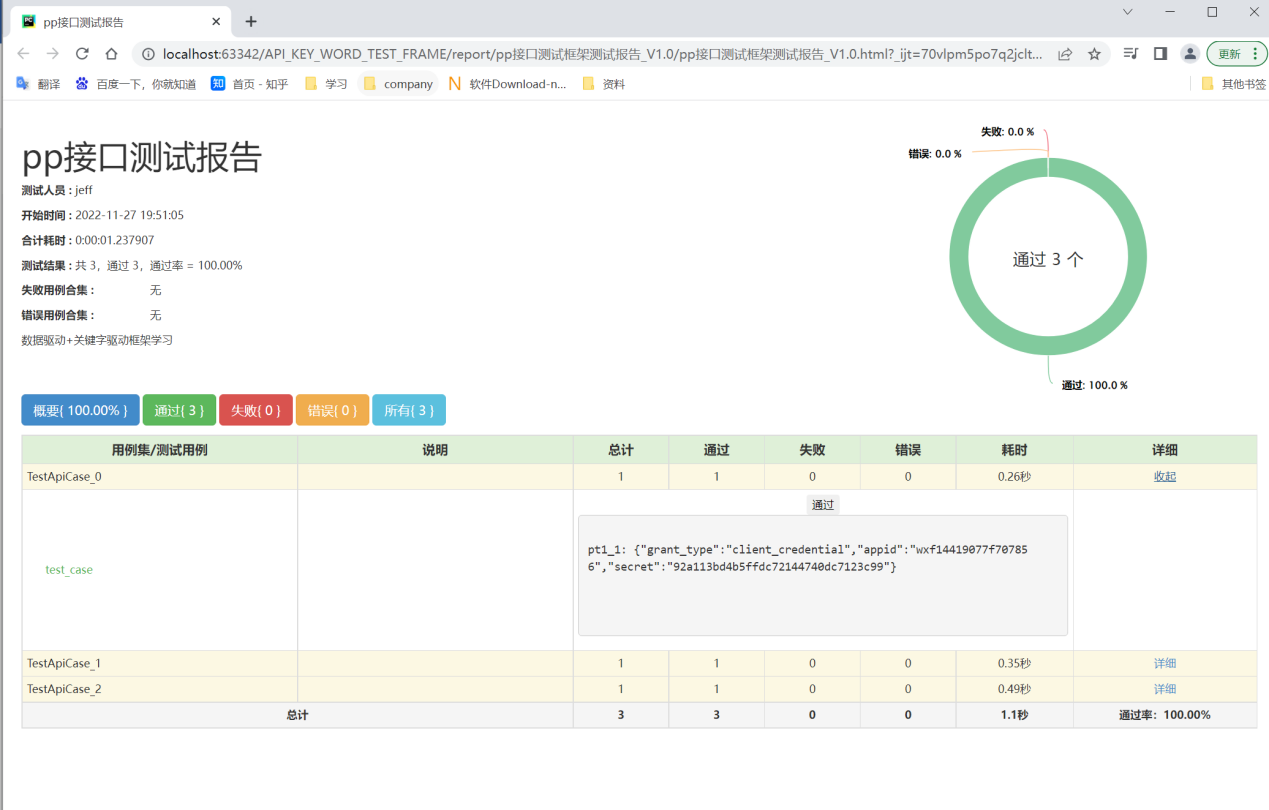
三、优化测试报告的显示
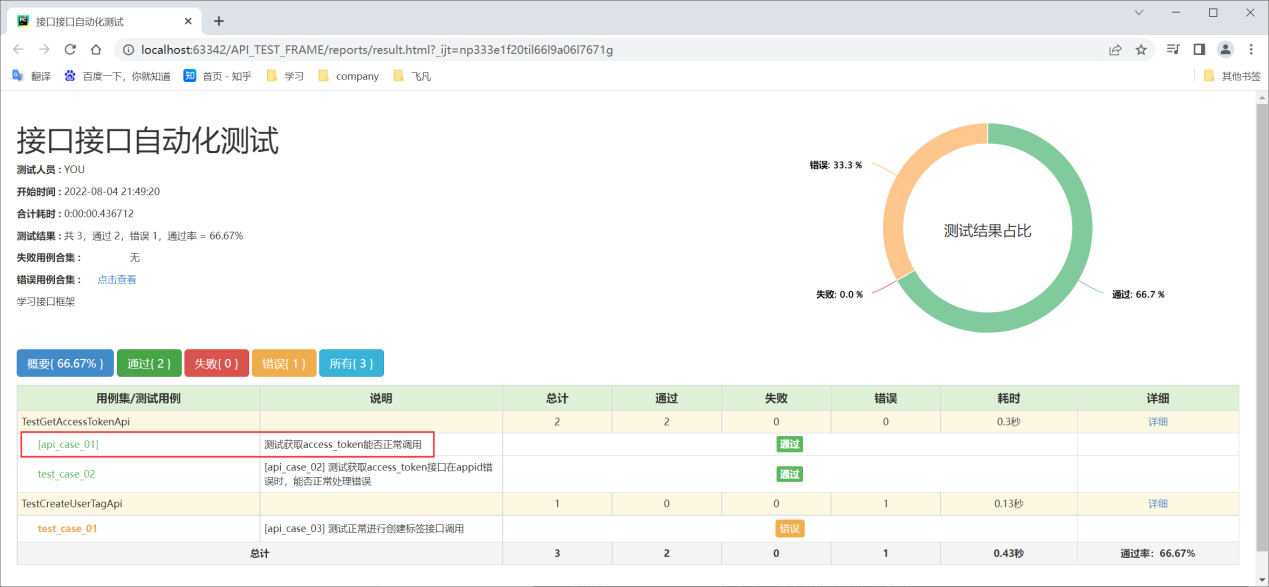
由于上述的报告每条测试用例的用例名称都是test_case,导致分不清,所以进行如下调整;
在test_api_case.py文件中进行调整:
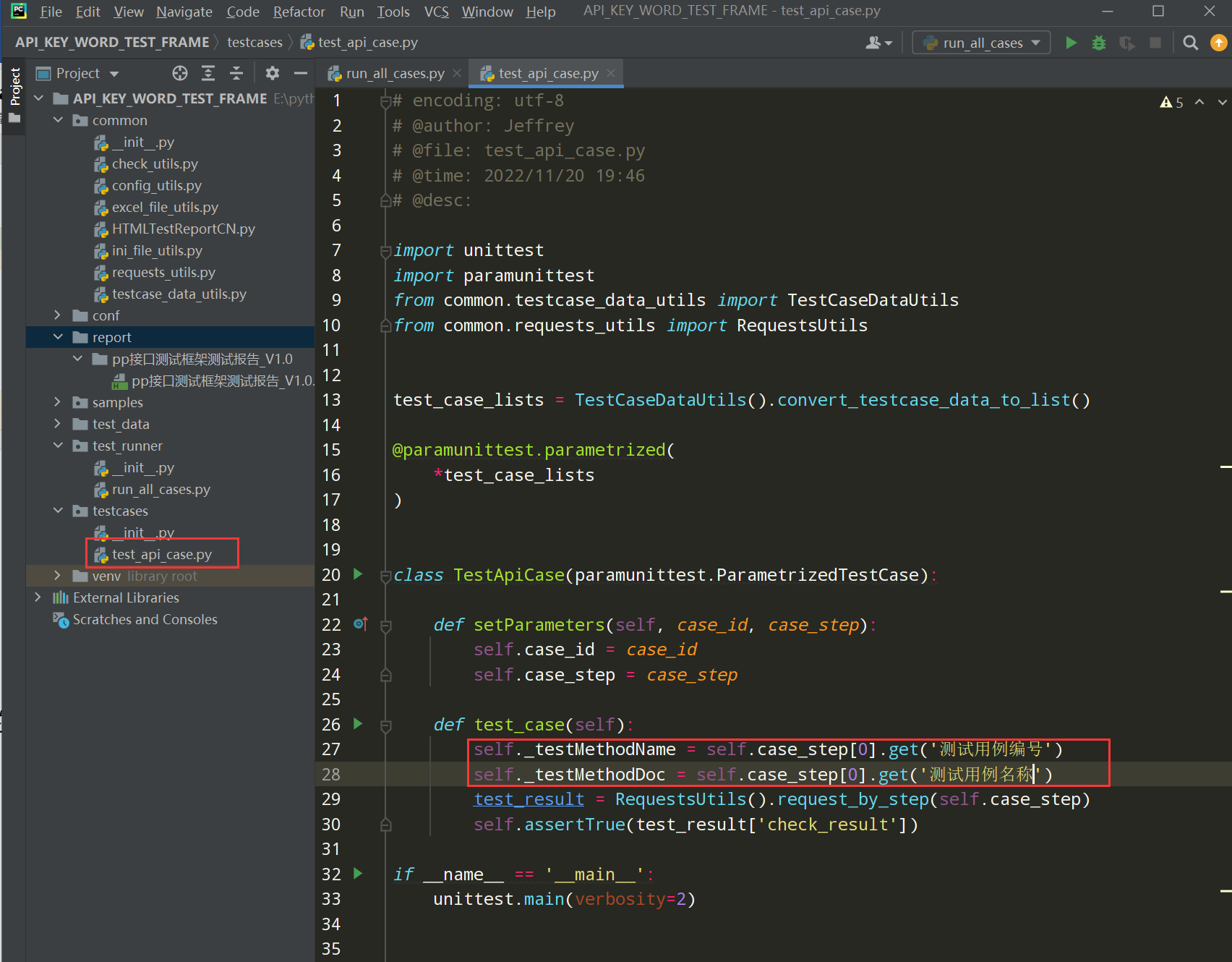
编写代码:
self._testMethodName = self.case_step[0].get('测试用例编号')
self._testMethodDoc = self.case_step[0].get('测试用例名称')
执行run_all_cases.py查看测试报告
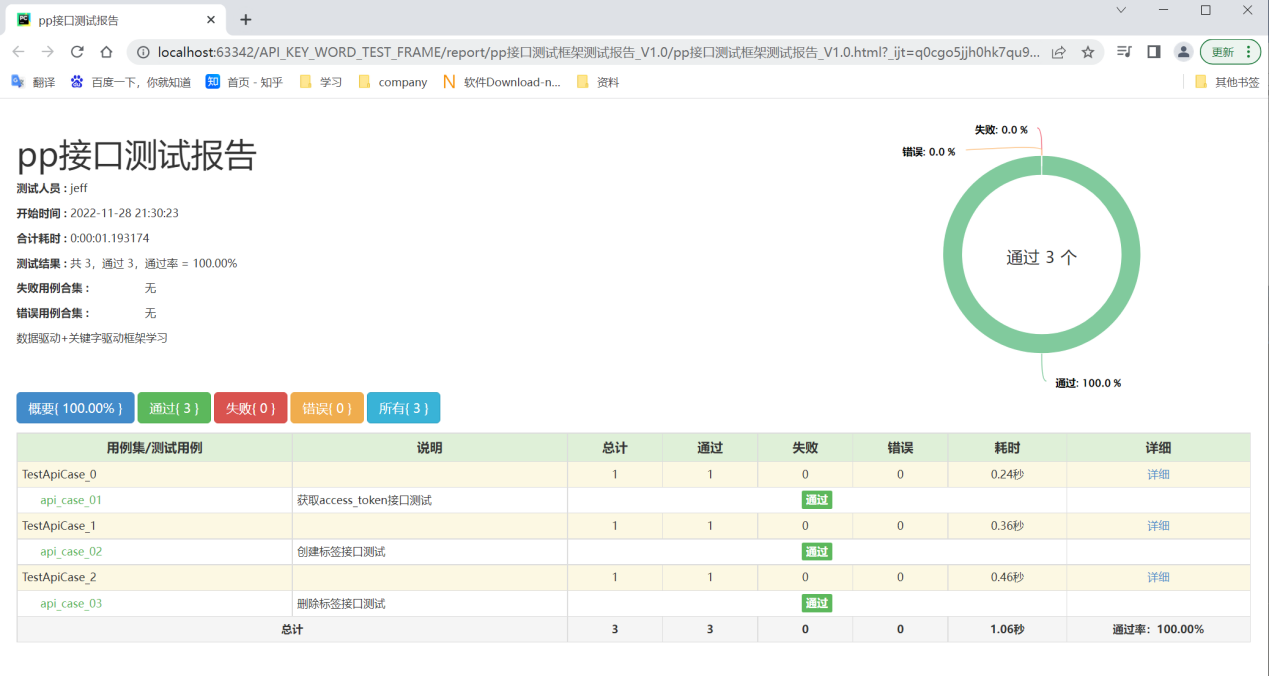
四、控制测试用例是否执行
思路:excel中包含了一个用例是否执行的字段,那么excel_file_utils.py是读取excel数据的封装,所有不需要处理它,可以从数据源把 ‘用例是否执行’为 否的进行过滤,过滤不能再excel_file_utils.py进行,所以只能通过testcase_data_utils.py进行过滤。
Excel测试用例是否执行如下:
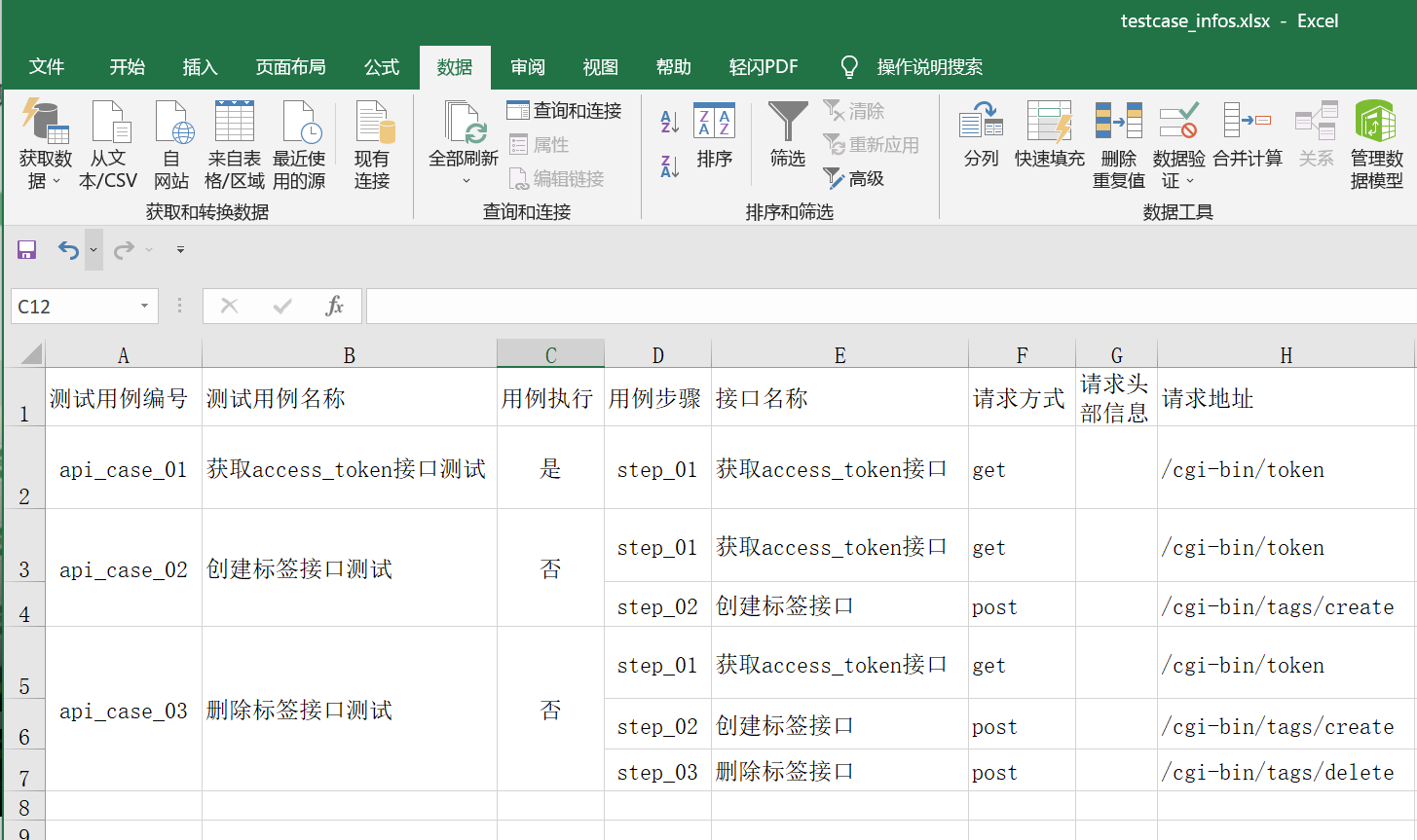
在testcase_data_utils.py补充代码如下:
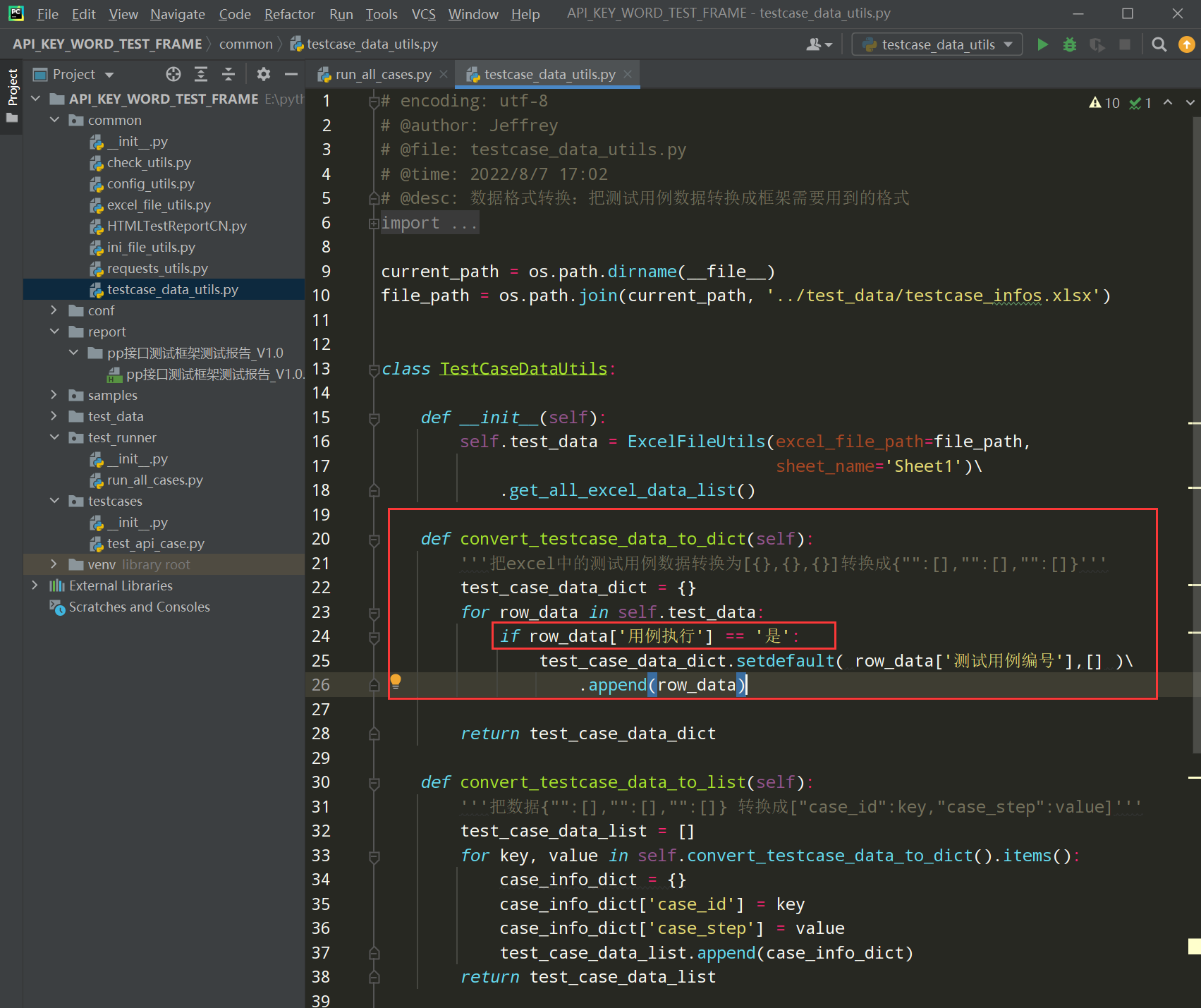
编写代码: if row_data['用例执行'] == '是':
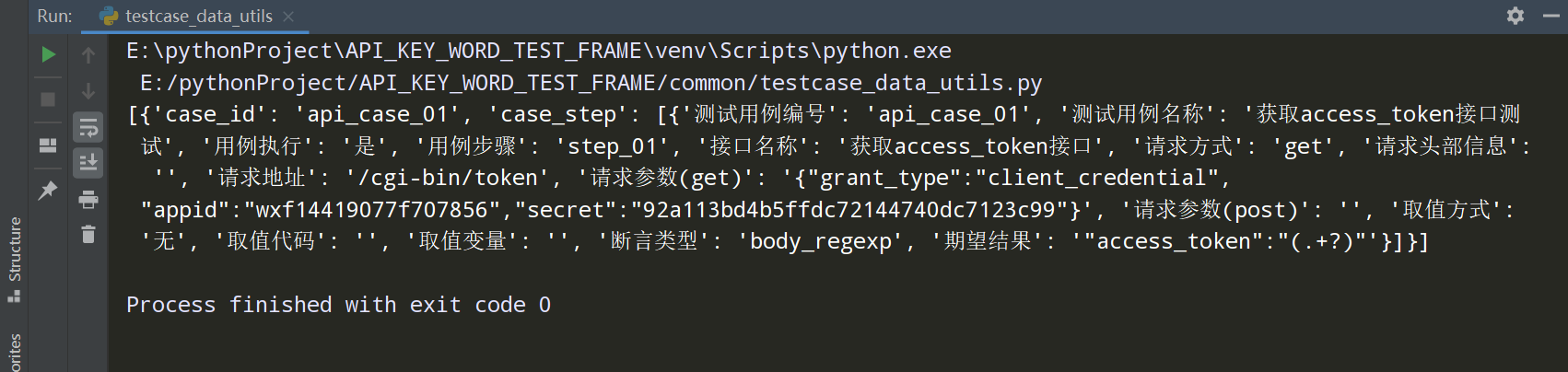
执行该文件的代码后,只展示 ‘用例执行为是’ 的测试用例;如下图:
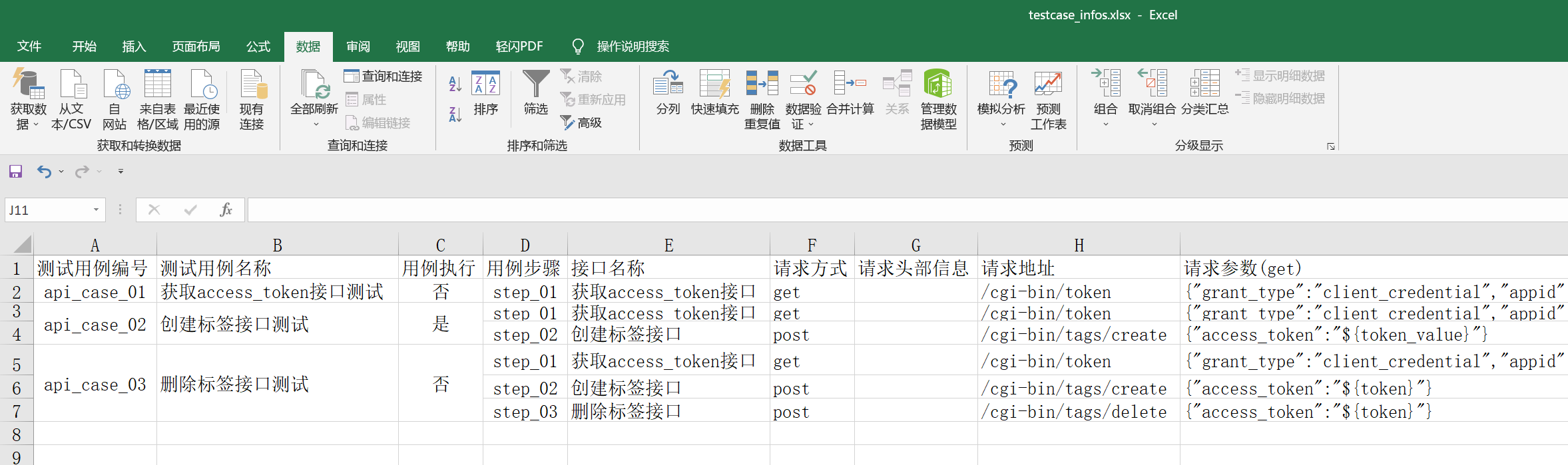
执行run_all_cases.py主入口文件,查看执行结果:
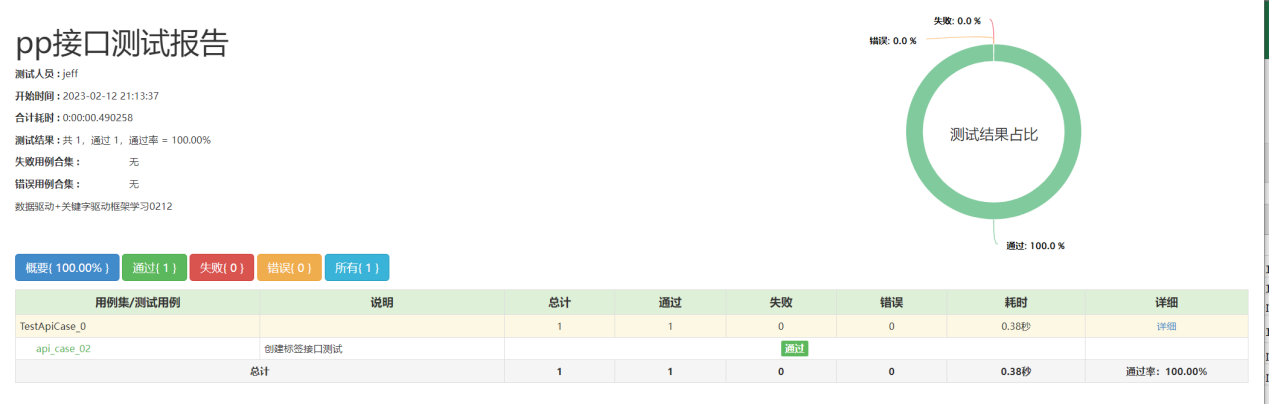
框架08 异常处理
作为一个成熟的框架,需要有一定的异常处理
一、针对requests请求做异常处理
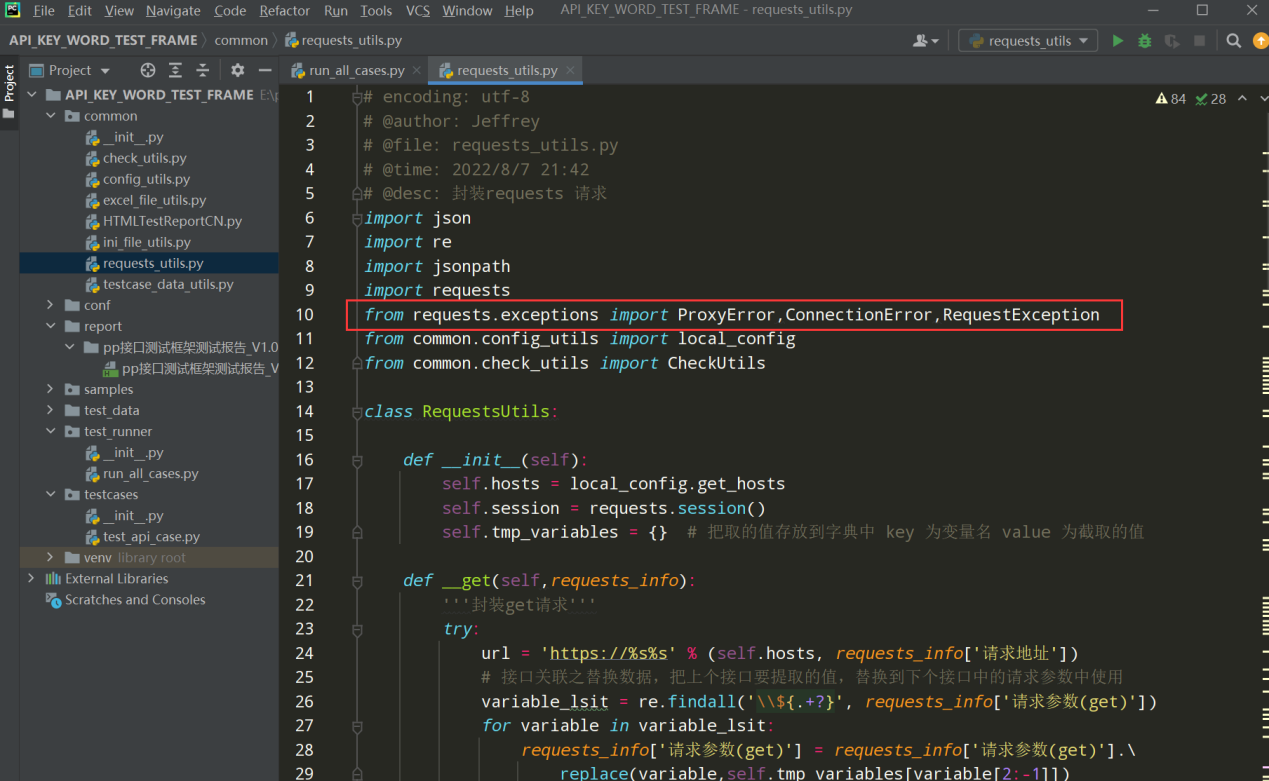
1、在requests_utils.py文件中先导入requests的异常方法;如下图:
from requests.exceptions import ProxyError,ConnectionError,RequestException
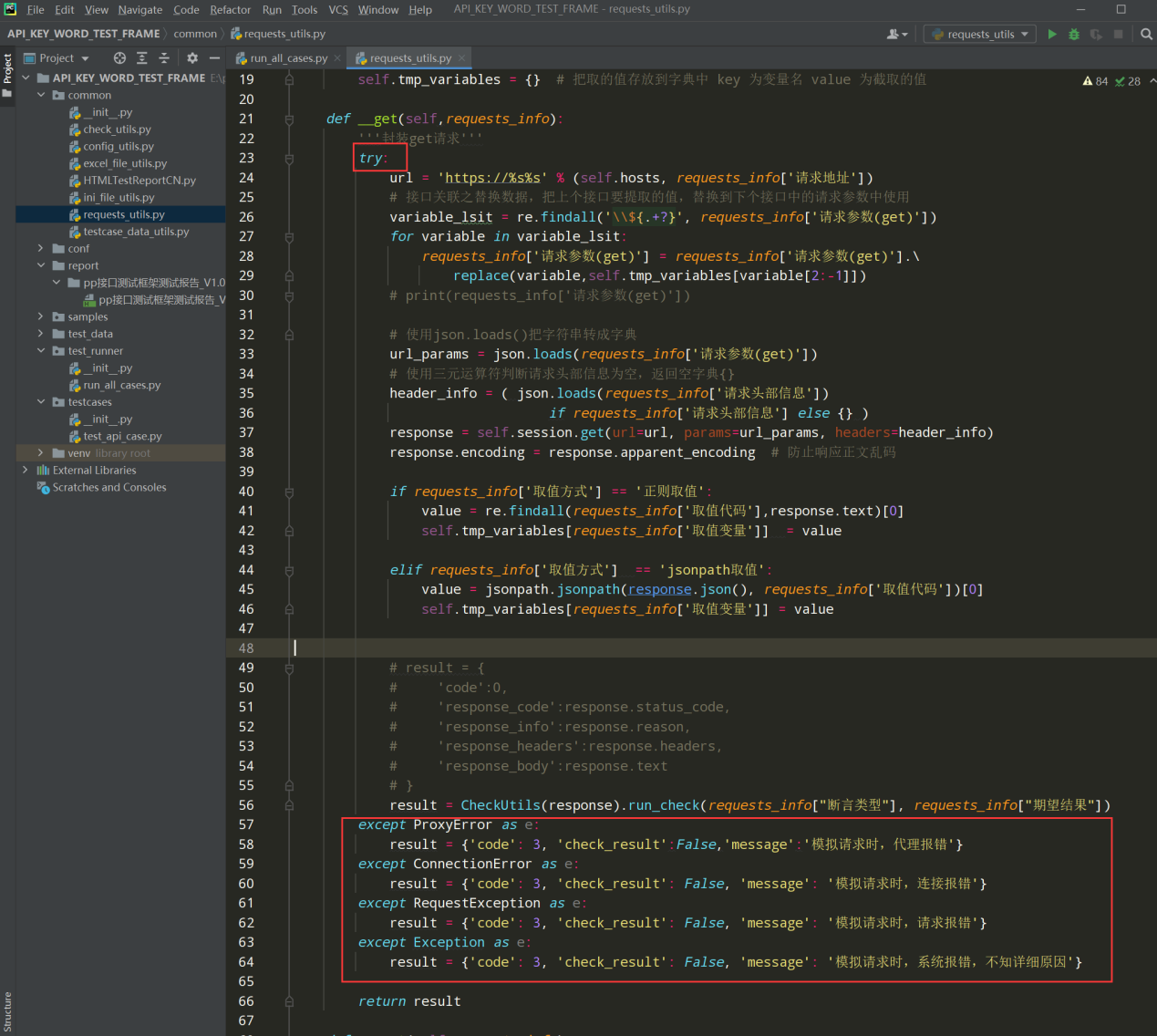
2、 在get和post请求方法中加入异常处理try….except;如下图:
get方法:
编写代码:
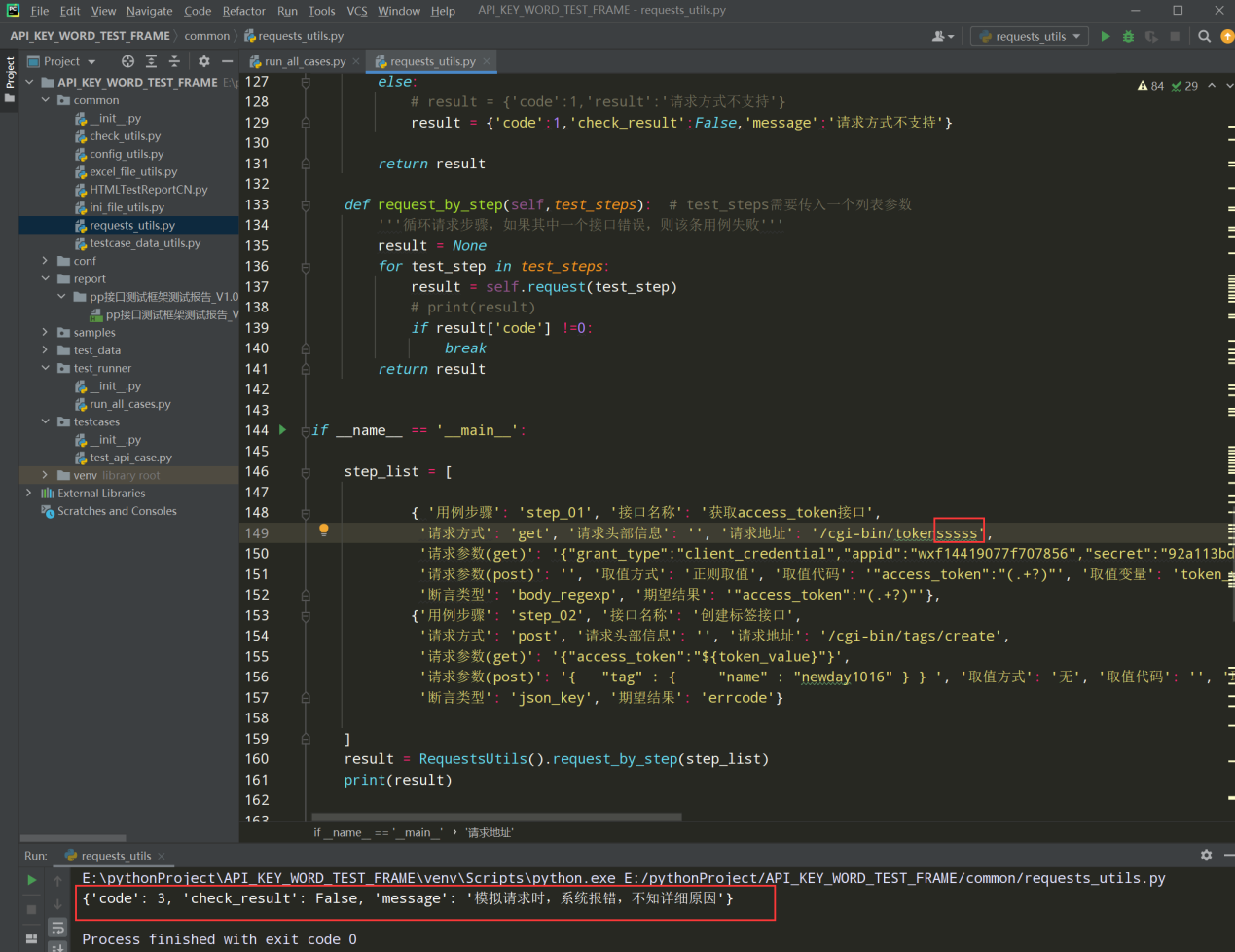
try: except ProxyError as e: result = {'code': 3, 'check_result':False,'message':'模拟请求时,代理报错'} except ConnectionError as e: result = {'code': 3, 'check_result': False, 'message': '模拟请求时,连接报错'} except RequestException as e: result = {'code': 3, 'check_result': False, 'message': '模拟请求时,请求报错'} except Exception as e: result = {'code': 3, 'check_result': False, 'message': '模拟请求时,系统报错,不知详细原因'}
post方法:
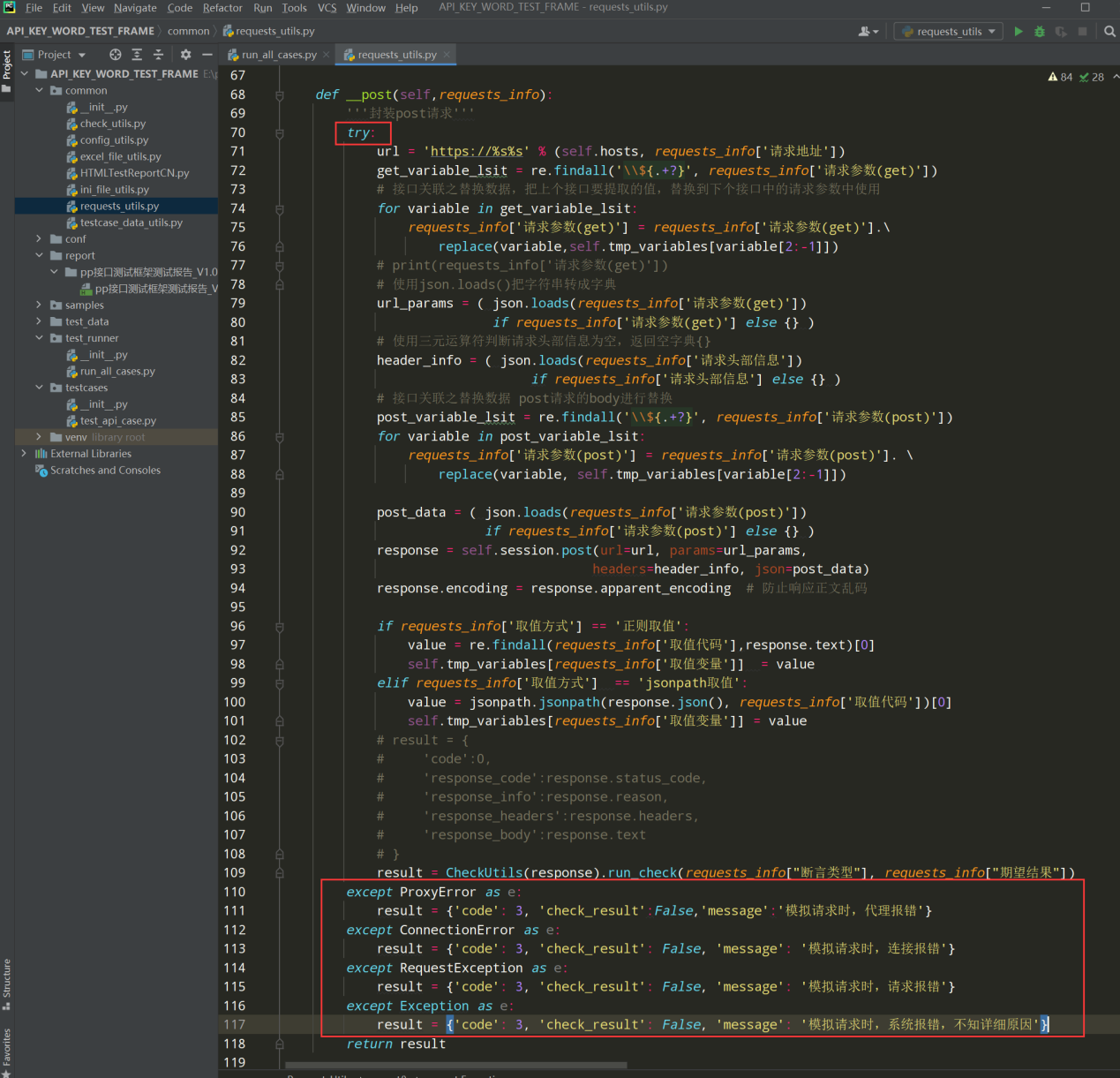
编写代码:
try: except ProxyError as e: result = {'code': 3, 'check_result':False,'message':'模拟请求时,代理报错'} except ConnectionError as e: result = {'code': 3, 'check_result': False, 'message': '模拟请求时,连接报错'} except RequestException as e: result = {'code': 3, 'check_result': False, 'message': '模拟请求时,请求报错'} except Exception as e: result = {'code': 3, 'check_result': False, 'message': '模拟请求时,系统报错,不知详细原因'}
3、执行requests_utils.py文件;如下图
如果测试用例有错误的情况,则直接抛出异常信息;如下:
框架09 添加日志整合到框架
日志模块整合到框架:
在自动化测试框架中,日志模块的主要用途是记录执行过程中的相关信息,方便框架执行过程中的问题定位;

方式一、利用python自带的logger模块进行日志的封装
编写线性代码 控制台输出日志:
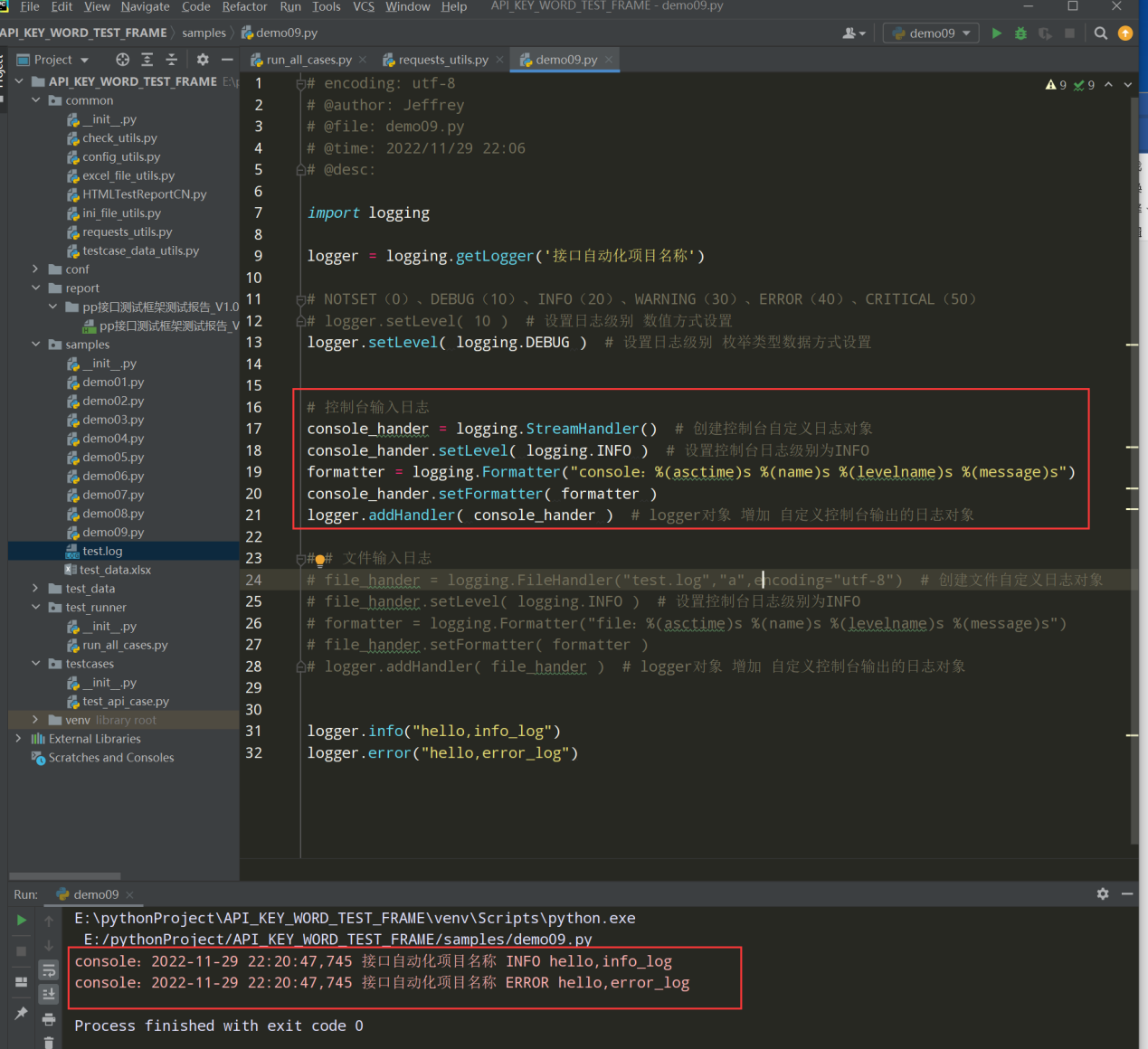
编写线性代码 文件输出日志:
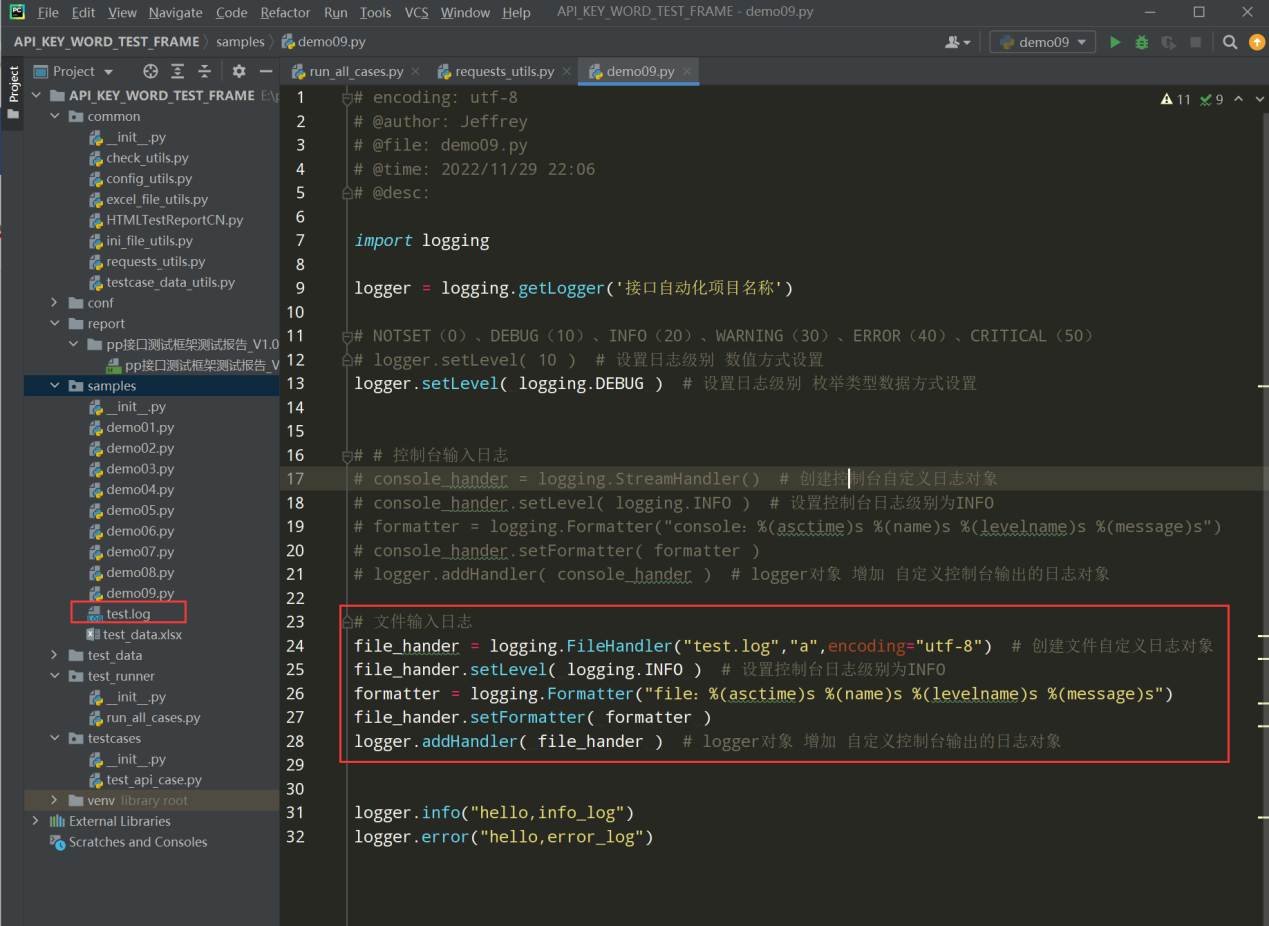
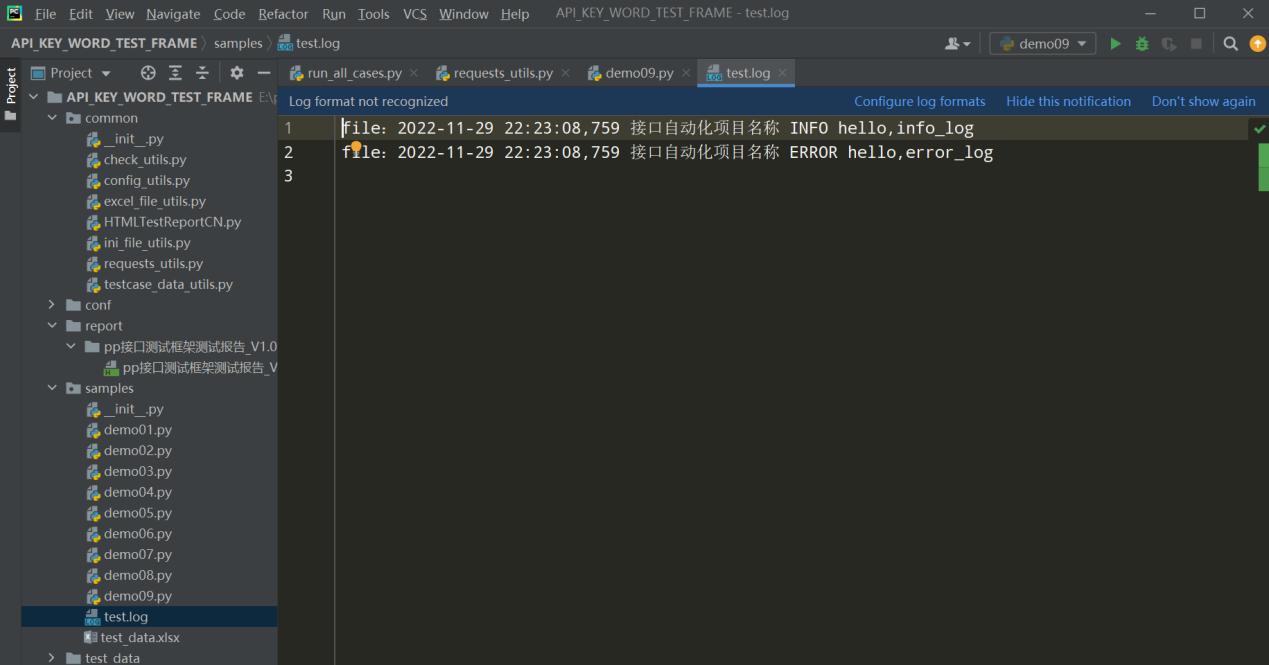
备注:一个logger对象,可以同时增加多个hander
日志模块的封装
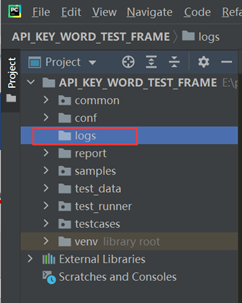
1、新建存放日志文件的文件夹
在项目根目录下新建logs普通文件夹
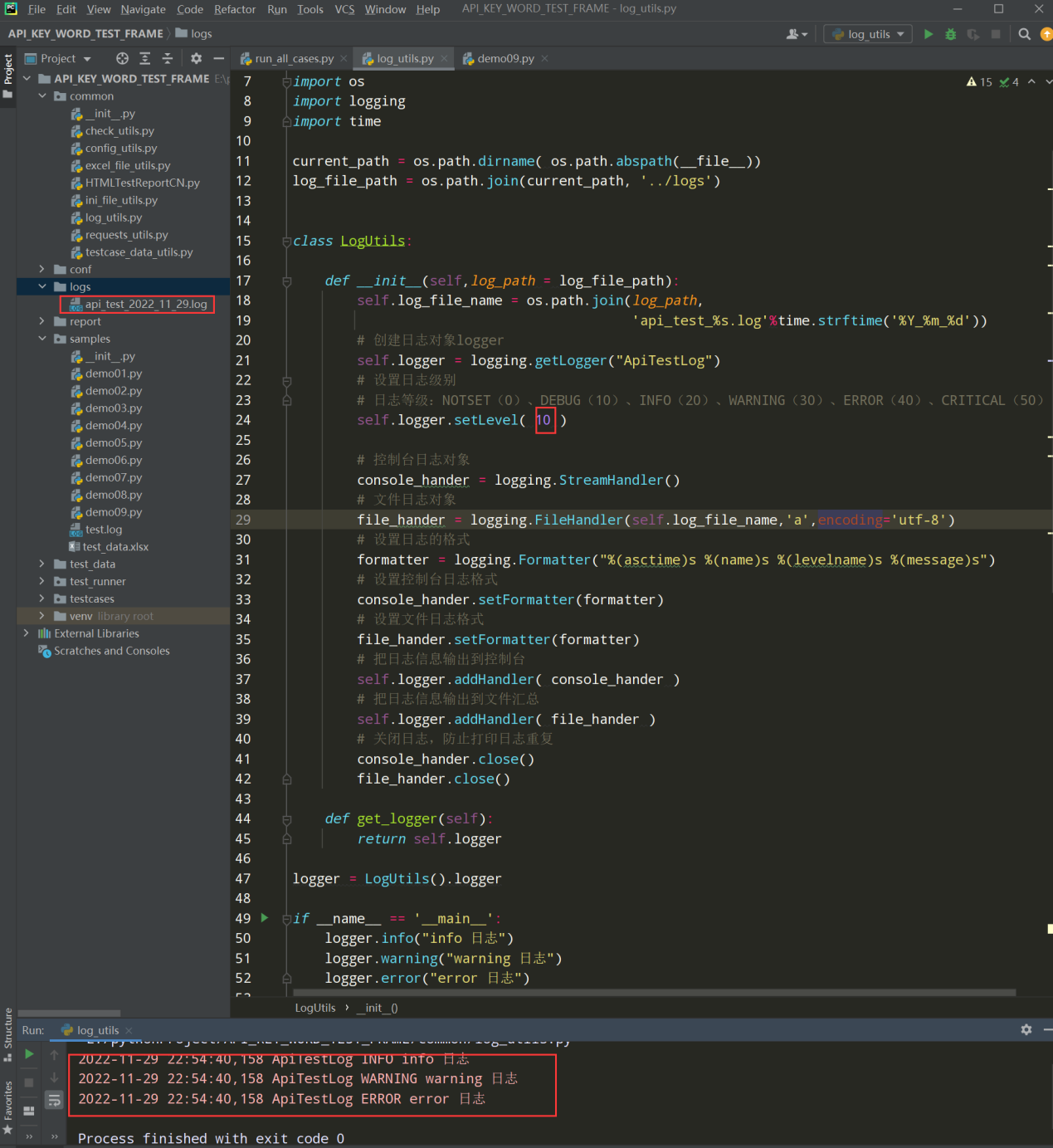
2、对日志模块进行封装
在common下新建log_utils.py文件进行日志模块的封装
编写代码:
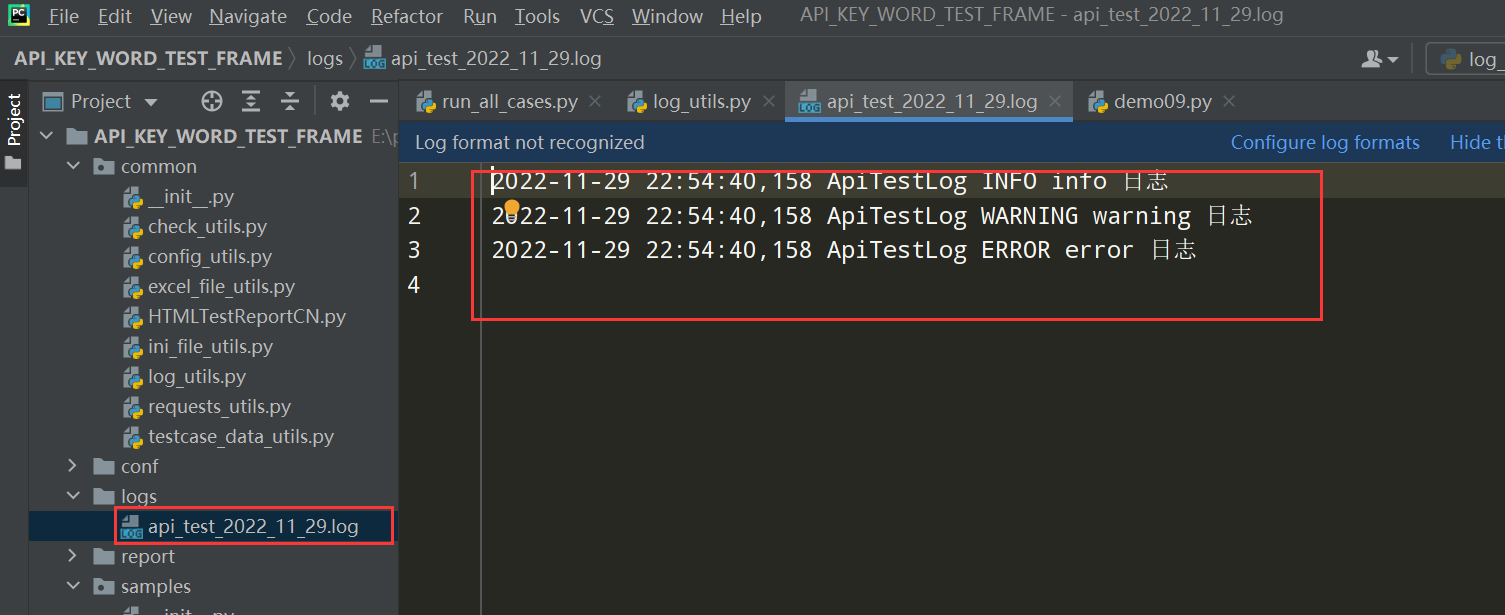
# encoding: utf-8 # @author: Jeffrey # @file: log_utils.py # @time: 2022/11/29 22:29 # @desc: import os import logging import time current_path = os.path.dirname( os.path.abspath(__file__)) log_file_path = os.path.join(current_path, '../logs') class LogUtils: def __init__(self,log_path = log_file_path): self.log_file_name = os.path.join(log_path, 'api_test_%s.log'%time.strftime('%Y_%m_%d')) # 创建日志对象logger self.logger = logging.getLogger("ApiTestLog") # 设置日志级别 # 日志等级:NOTSET(0)、DEBUG(10)、INFO(20)、WARNING(30)、ERROR(40)、CRITICAL(50) self.logger.setLevel( 10 ) # 控制台日志对象 console_hander = logging.StreamHandler() # 文件日志对象 file_hander = logging.FileHandler(self.log_file_name,'a',encoding='utf-8') # 设置日志的格式 formatter = logging.Formatter("%(asctime)s %(name)s %(levelname)s %(message)s") # 设置控制台日志格式 console_hander.setFormatter(formatter) # 设置文件日志格式 file_hander.setFormatter(formatter) # 把日志信息输出到控制台 self.logger.addHandler( console_hander ) # 把日志信息输出到文件汇总 self.logger.addHandler( file_hander ) # 关闭日志,防止打印日志重复 console_hander.close() file_hander.close() def get_logger(self): return self.logger logger = LogUtils().logger if __name__ == '__main__': logger.info("info 日志") logger.warning("warning 日志") logger.error("error 日志")
查看执行结果:
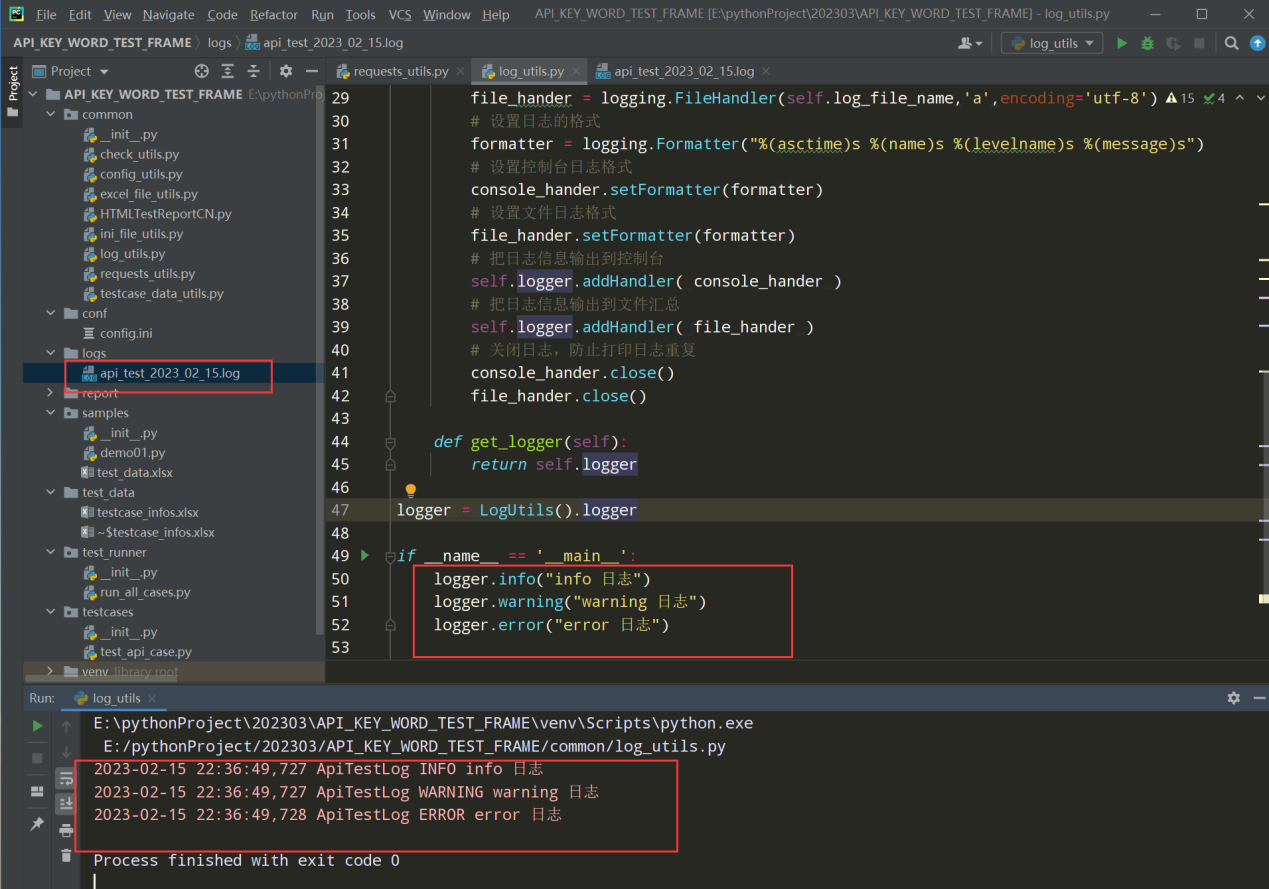
3、优化-把日志级别做成公共的配置文件
在config.ini文件中添加日志级别
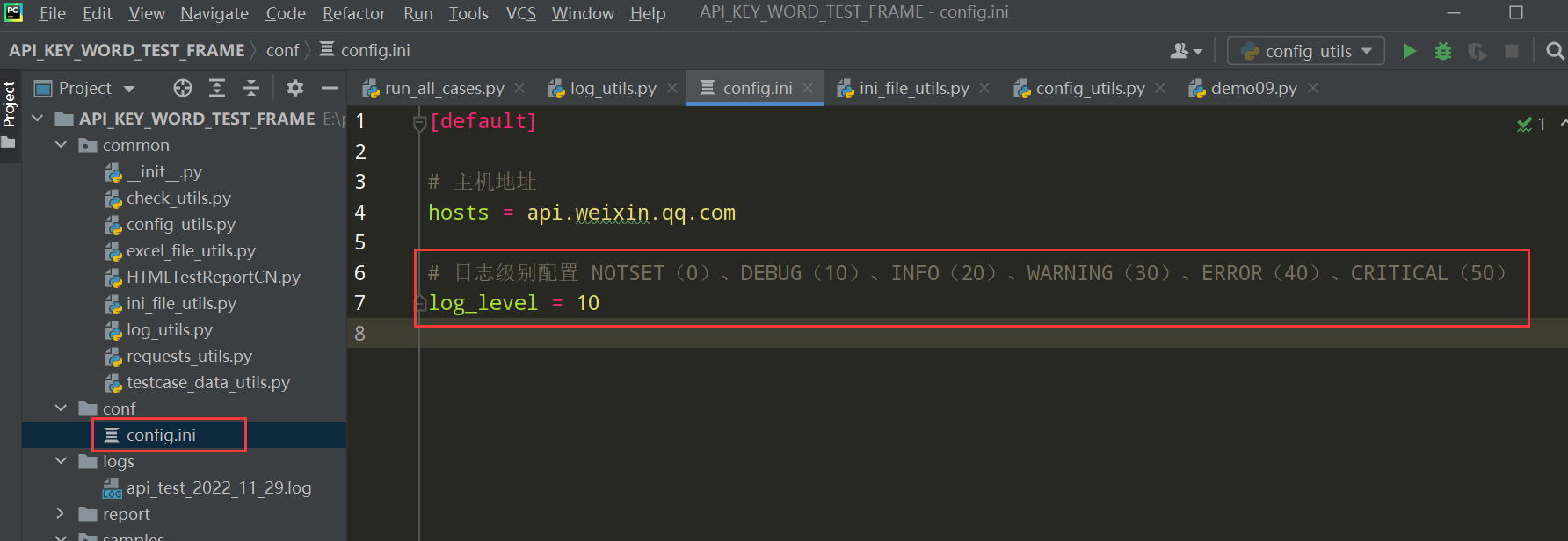
# 日志级别配置 NOTSET(0)、DEBUG(10)、INFO(20)、WARNING(30)、ERROR(40)、CRITICAL(50)
log_level = 10
在config_utils.py文件中添加获取日志级别的方法
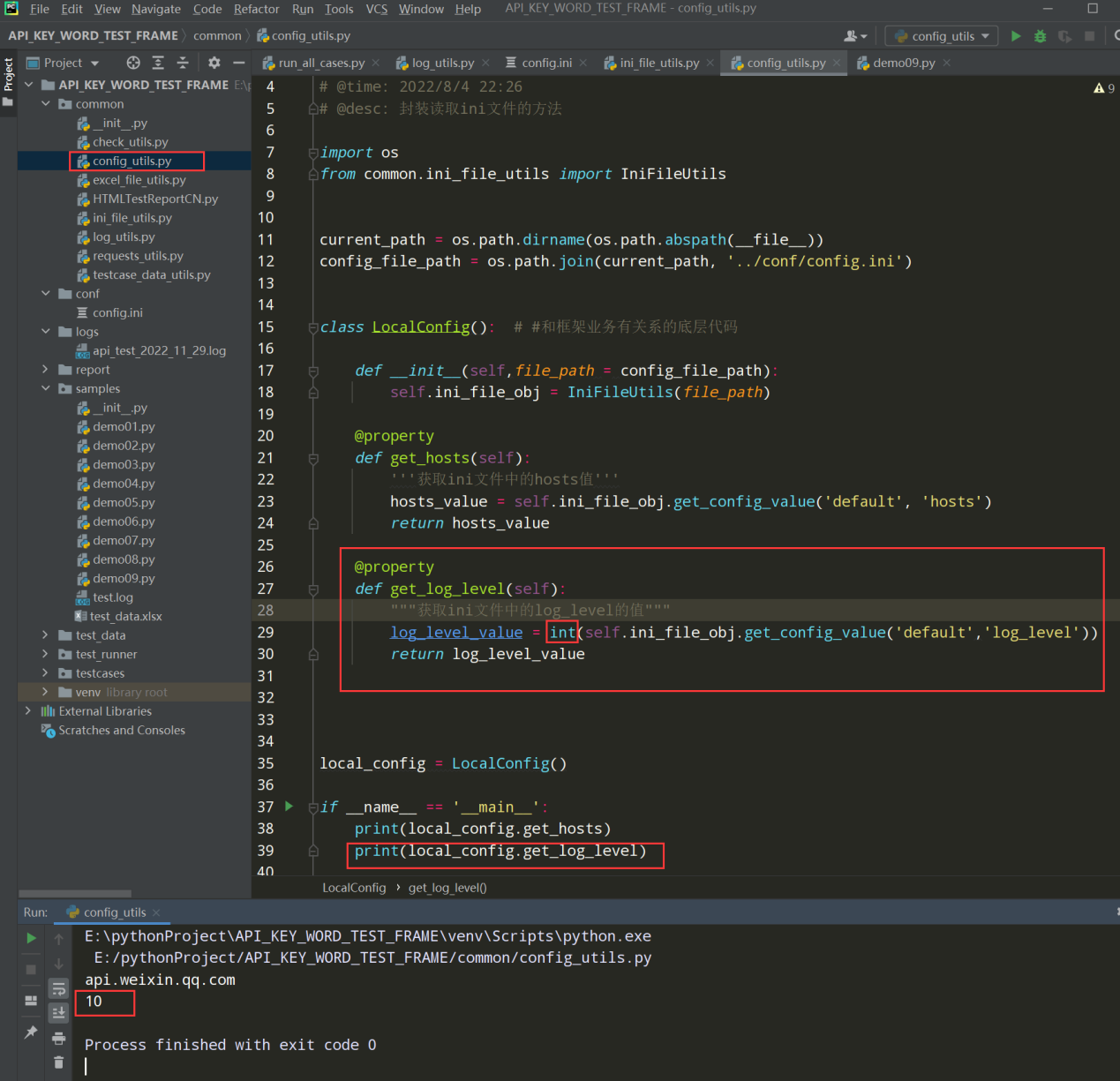
编写代码:
@property def get_log_level(self): """获取ini文件中的log_level的值""" log_level_value = int(self.ini_file_obj.get_config_value('default','log_level')) return log_level_value 测试代码: print(local_config.get_log_level)
在把配置文件导入到log_utils.py文件中;如下
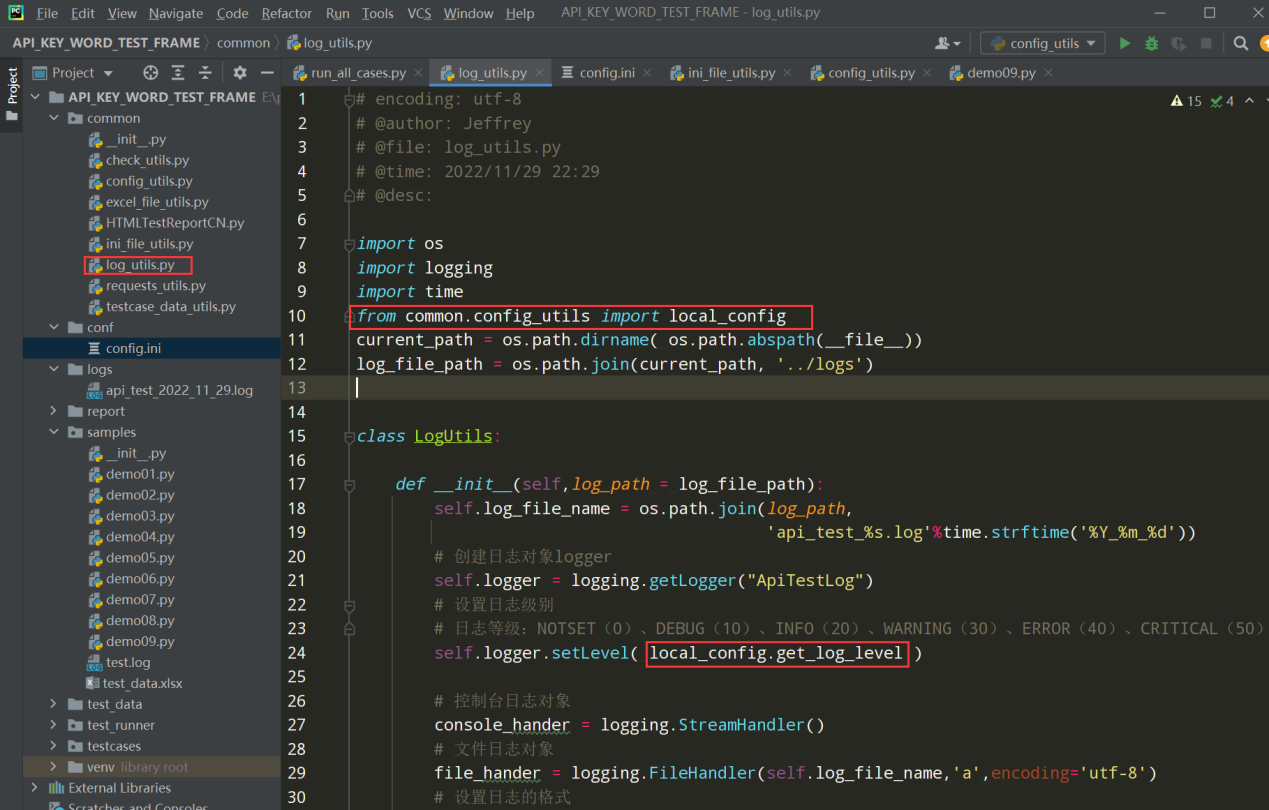
4、把日志模块引入到run_all_cases.py文件中并使用
前置条件:先导入from common.log_utils import logger
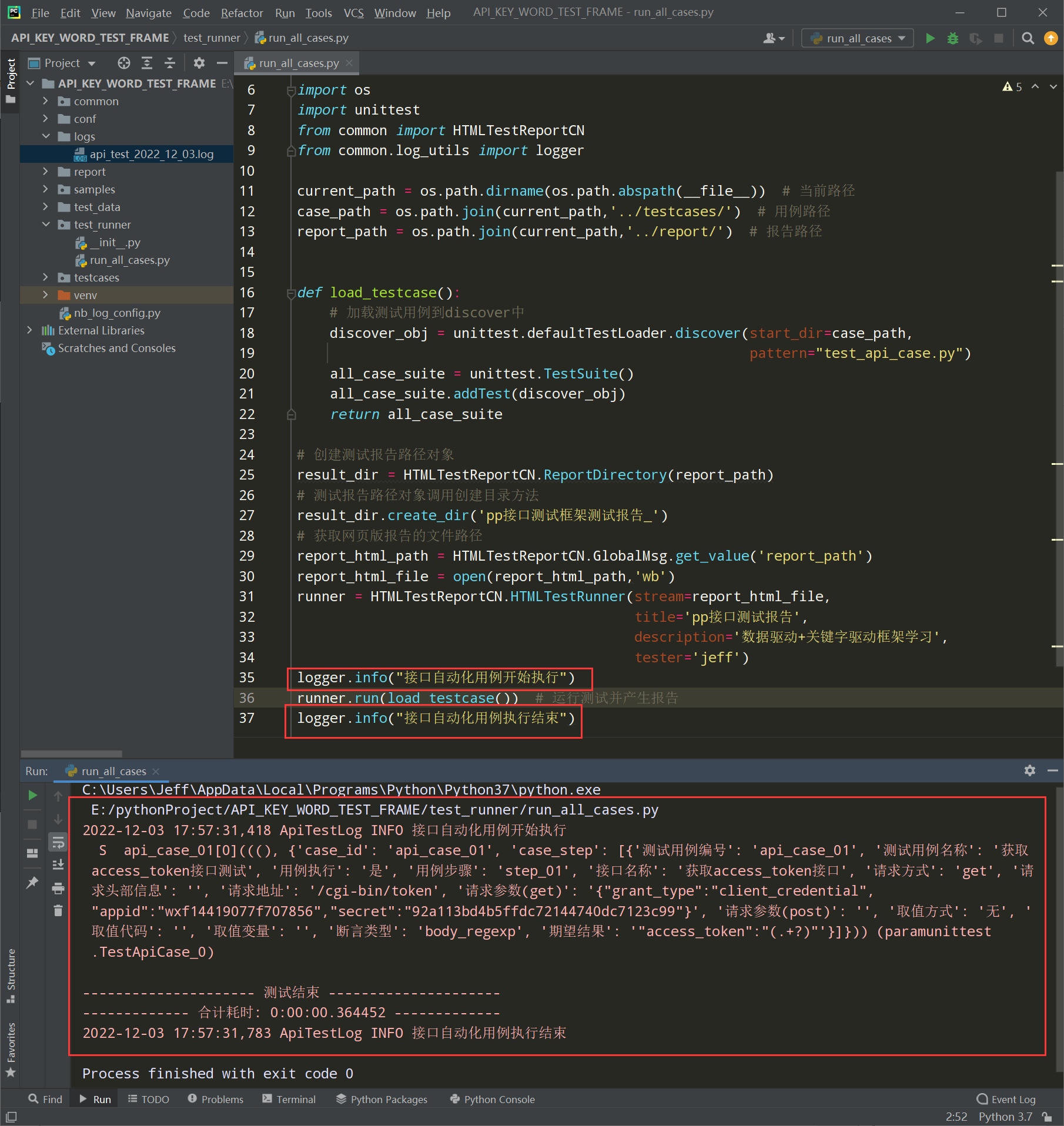
备注:可以把日志添加到想要输出日志的地方
方式二、利用第三方日志模块 nb_log.py进行日志的打印
学习及下载地址:https://pypi.org/project/nb-log/
一、nb_log 的写法
当第一次执行nb_log产生日志后,会在项目的根路径下生成一个nb_log_config,py文件,这个文件就是nb_log配置文件;
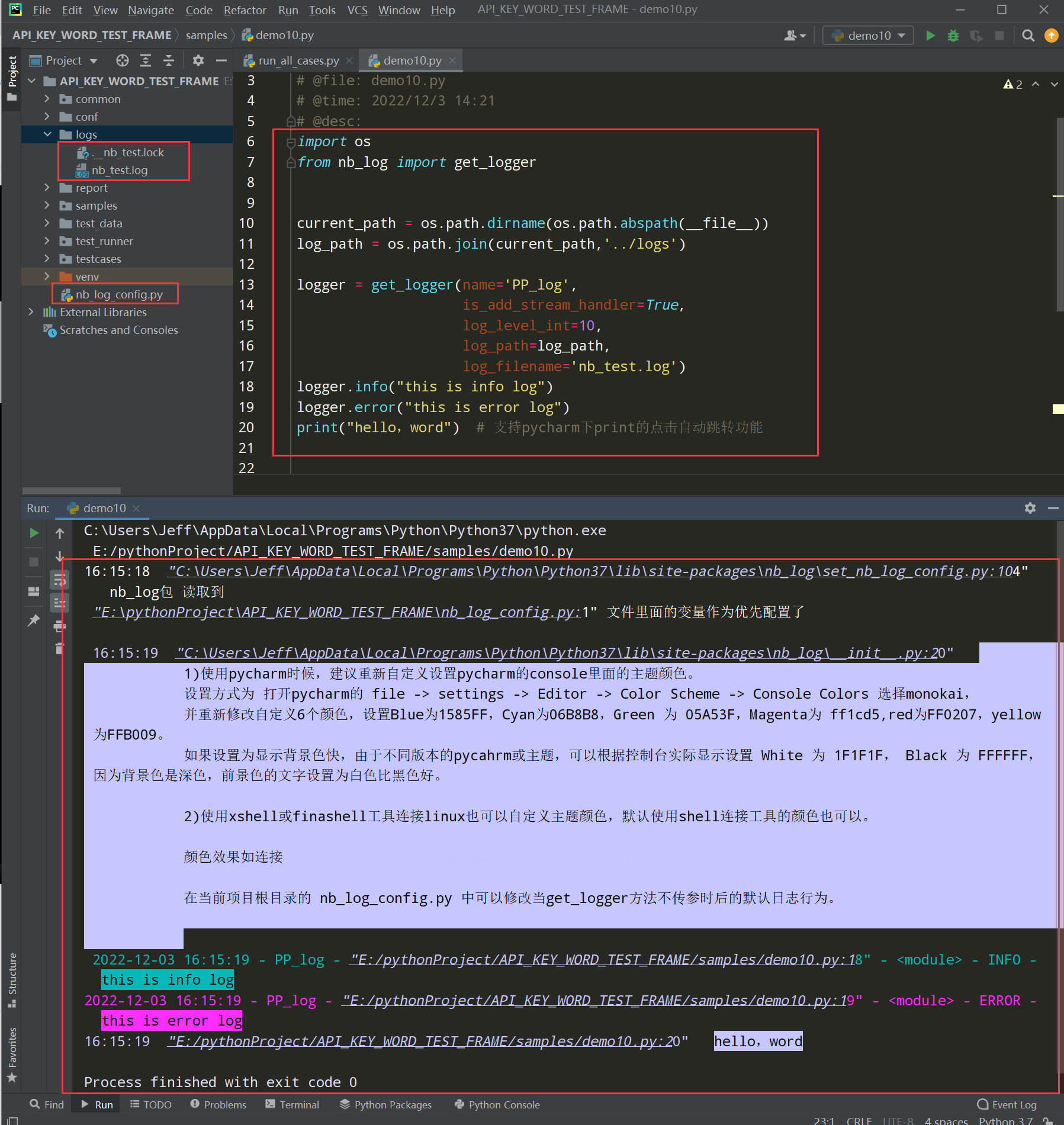
编写代码:
import os from nb_log import get_logger current_path = os.path.dirname(os.path.abspath(__file__)) log_path = os.path.join(current_path,'../logs') logger = get_logger(name='PP_log', is_add_stream_handler=True, log_level_int=10, log_path=log_path, log_filename='nb_test.log') logger.info("this is info log") logger.error("this is error log") print("hello,word") # 支持pycharm下print的点击自动跳转功能
如果想把控制台中把提示怎么优化pycahrm控制台颜色的提示文案取消可以在nb_log_config.py文件中把WARNING_PYCHARM_COLOR_SETINGS = False进行配置;
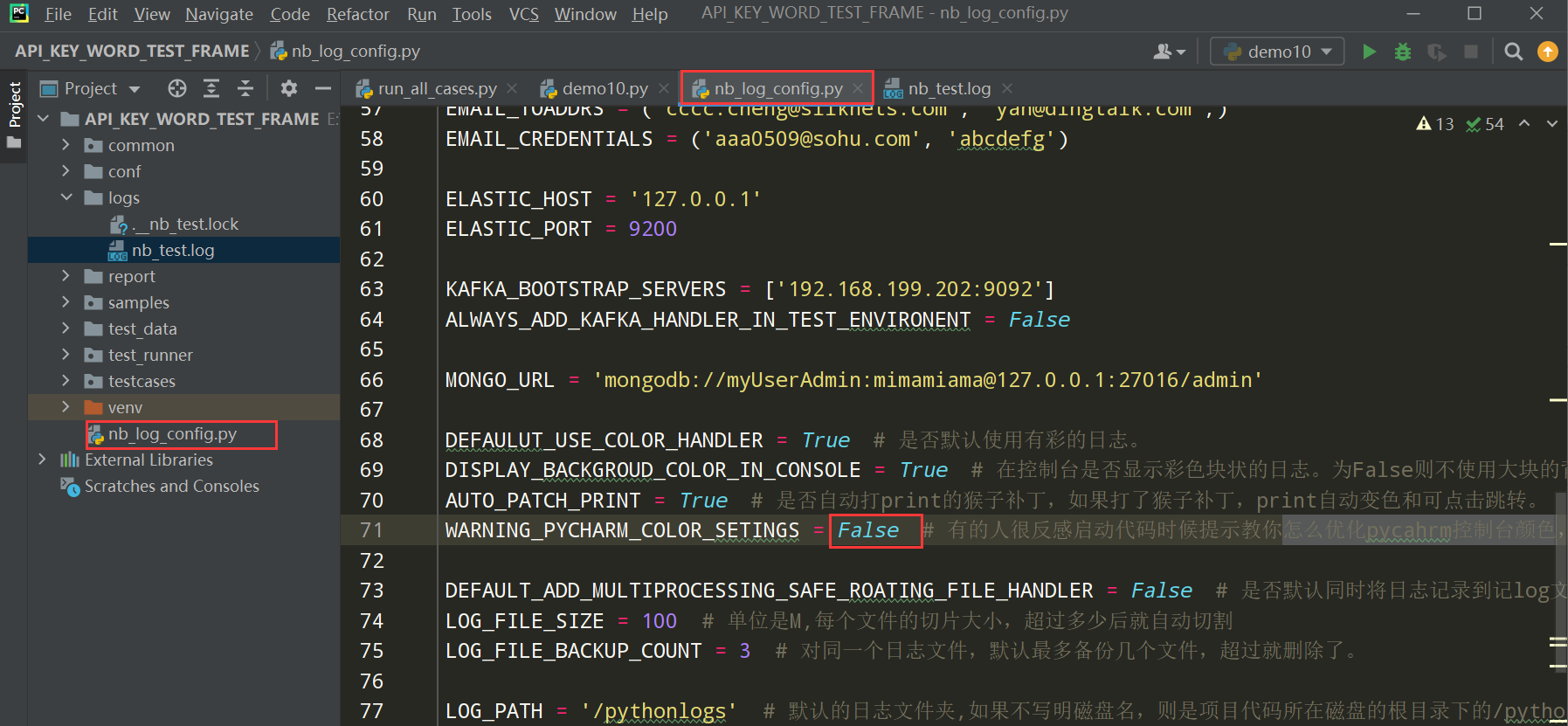
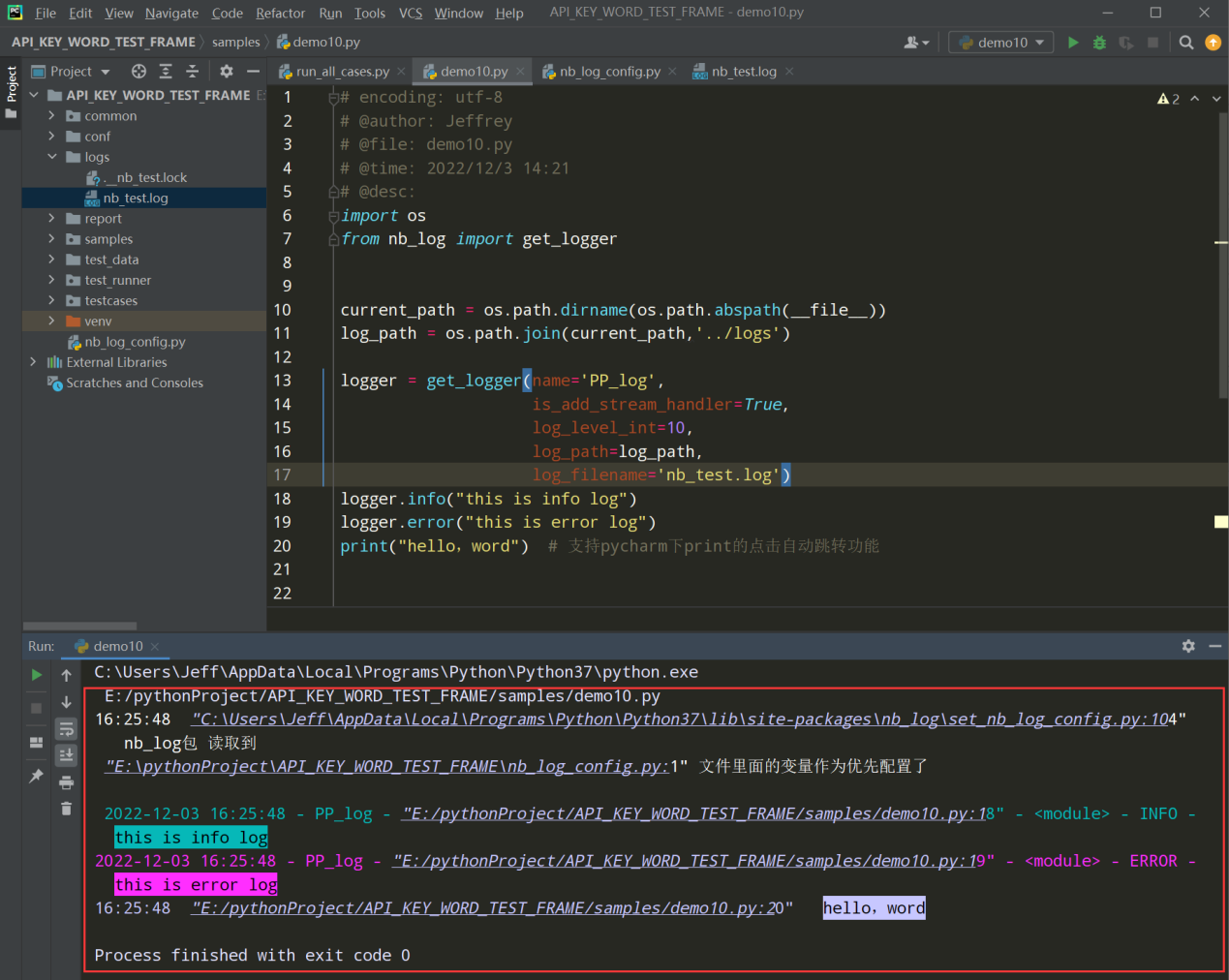
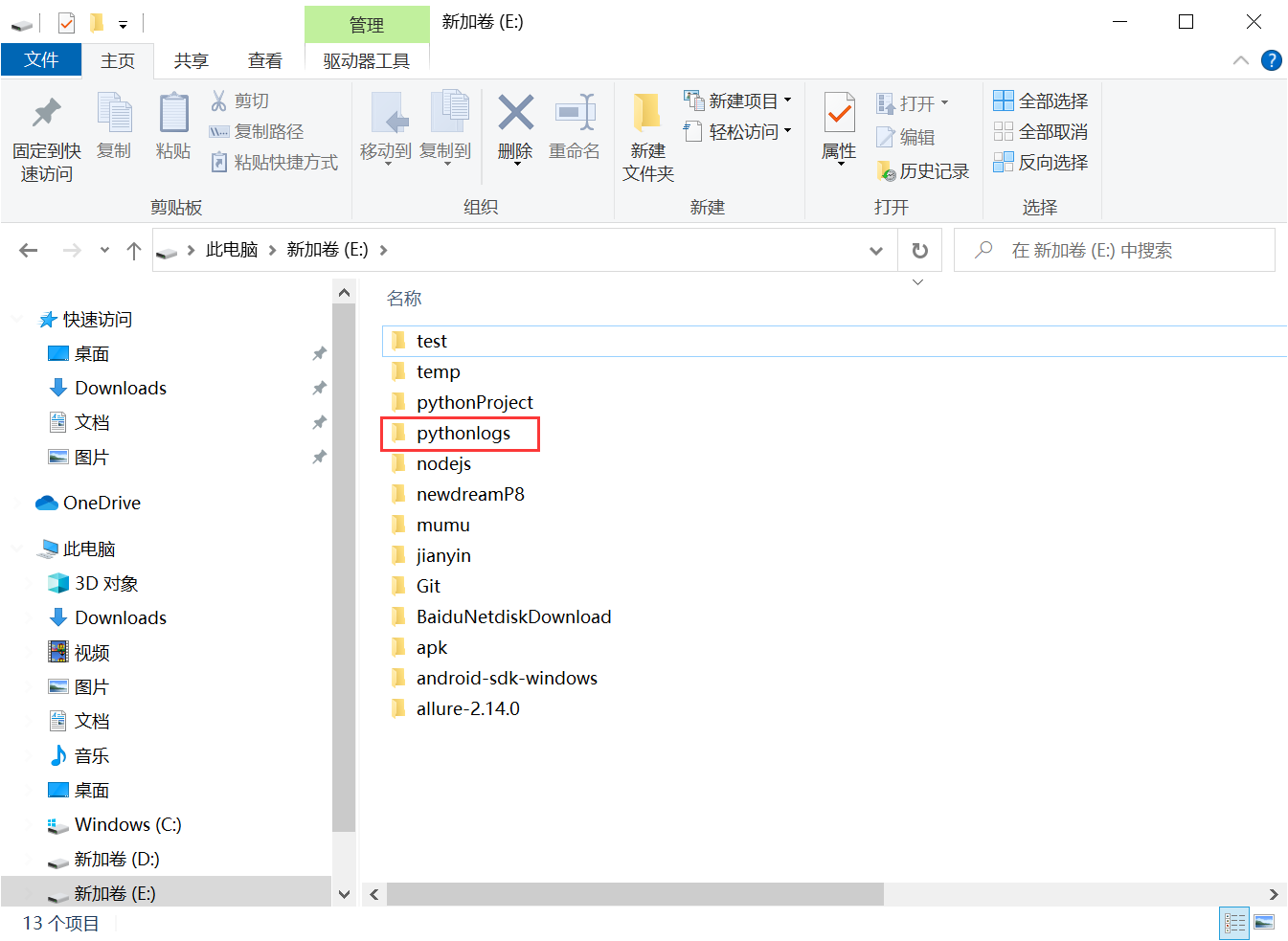
如何把pythonlogs文件添加到项目根路径下,如果不配置就会在项目代码所在的磁盘下生成pythonlogs文件夹;
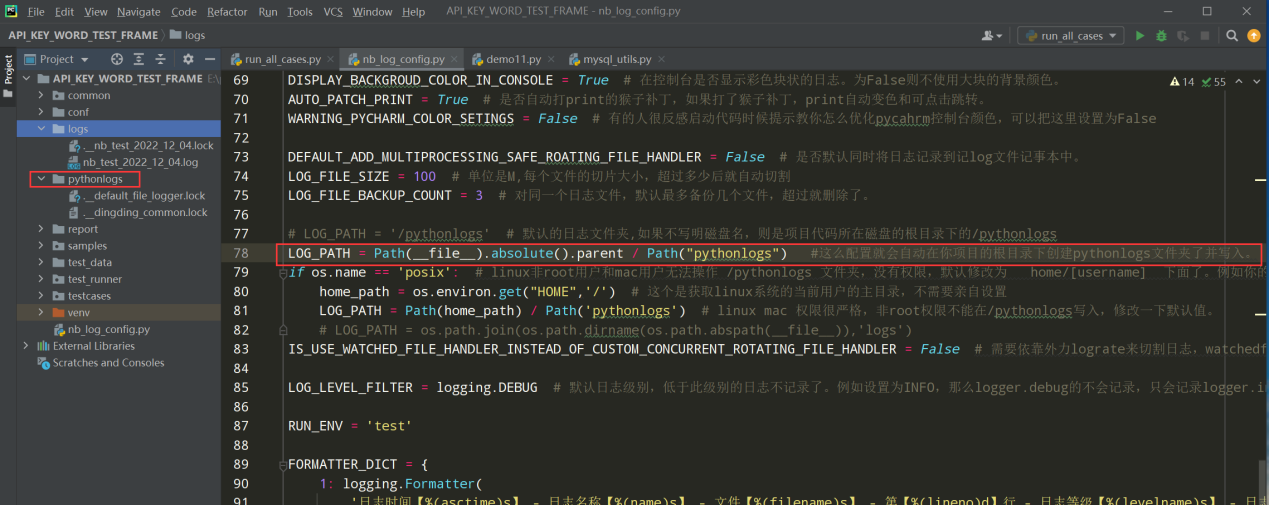
修改nb_log_config.py文件中的配置如下:
二、nb_log 的封装
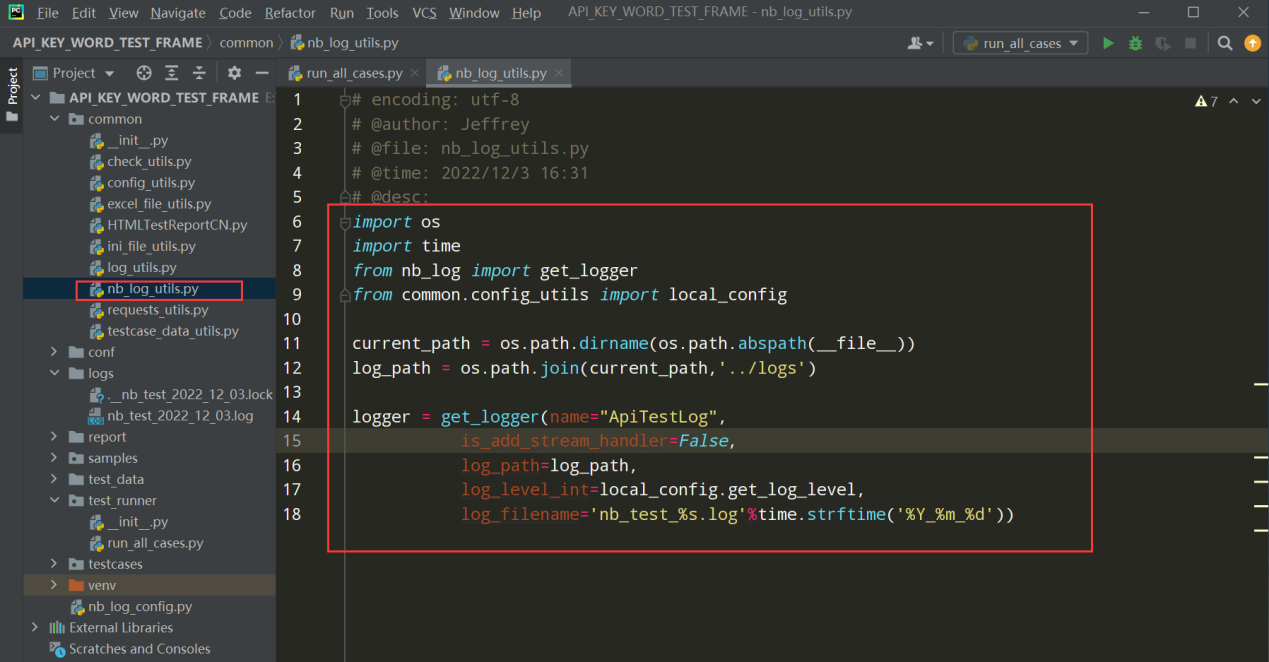
在common中新建nb_log_utils.py文件,封装nb_log;
编写代码:
import os import time from nb_log import get_logger from common.config_utils import local_config current_path = os.path.dirname(os.path.abspath(__file__)) log_path = os.path.join(current_path,'../logs') logger = get_logger(name="ApiTestLog", is_add_stream_handler=False, log_path=log_path, log_level_int=local_config.get_log_level, log_filename='nb_test_%s.log'%time.strftime('%Y_%m_%d'))
最后修改run_all_cases.py文件的日志导入路径,然后执行查看结果:
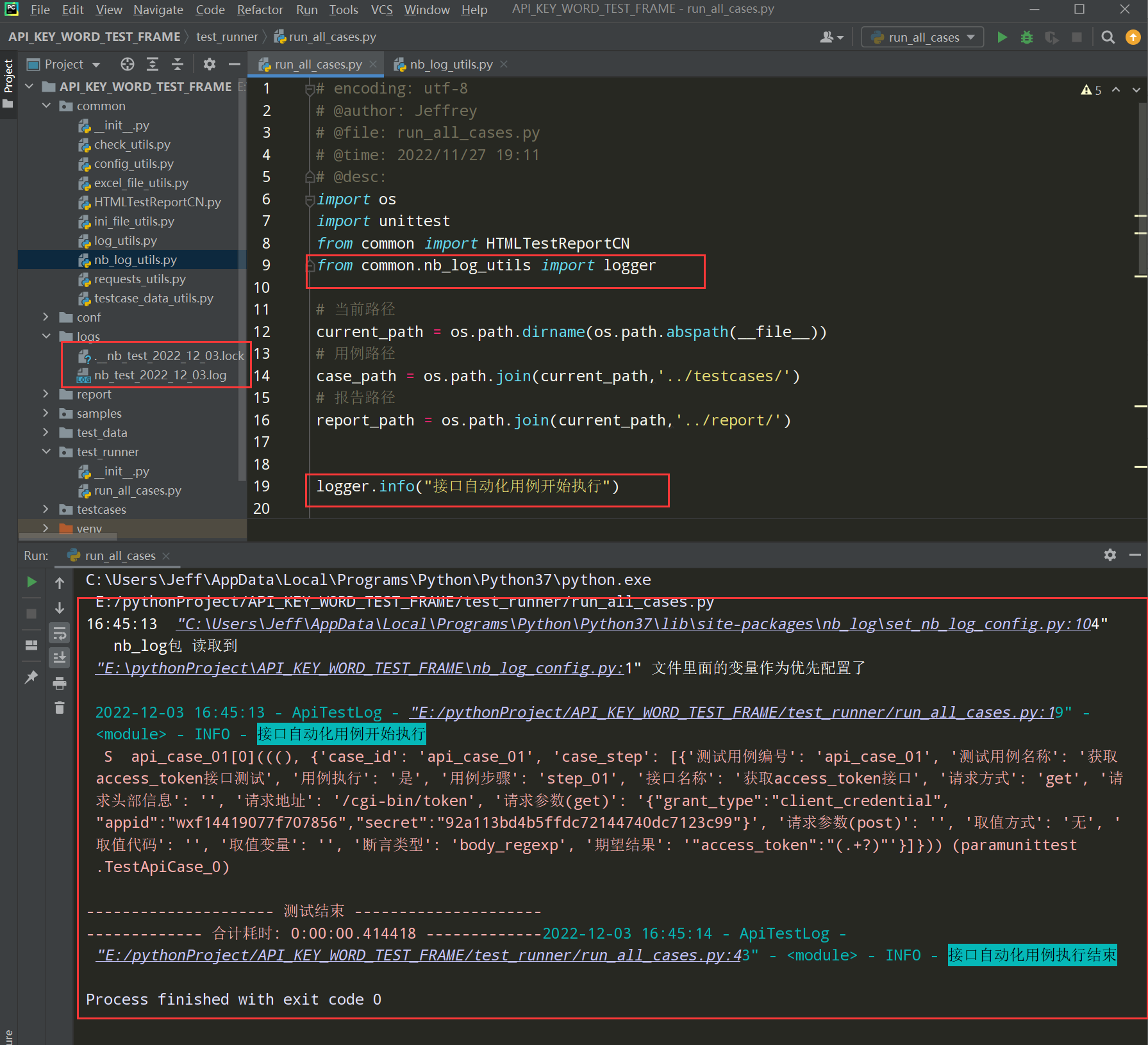
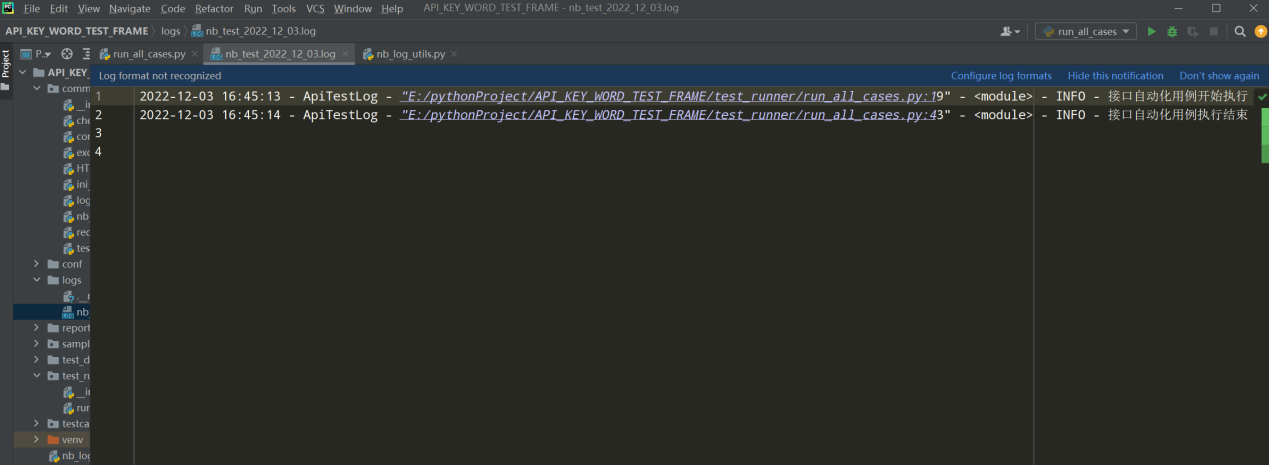
日志整合到框架中
如何在框架中增加相关日志信息
从起点开始加日志
1、在run_all_cases.py文件中添加日志
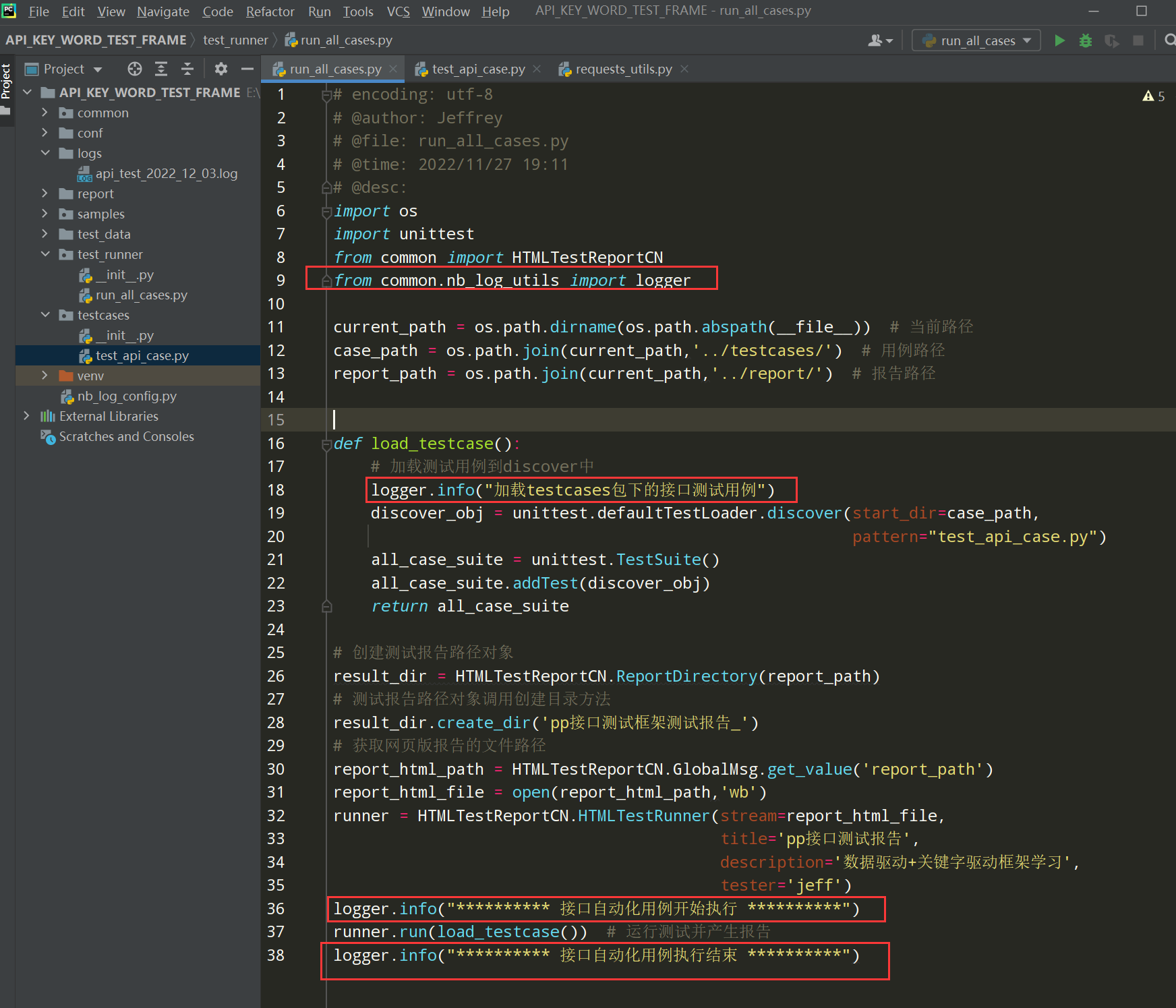
前置条件:先导入日志模块的包
编写代码:
logger.info("加载testcases包下的接口测试用例")
logger.info(" ********** 接口自动化用例开始执行 ********** ")
logger.info(" ********** 接口自动化用例执行结束 ********** ")
2、在获取接口测试用例中添加日志
在testcases下的test_api_case.py文件中添加日志
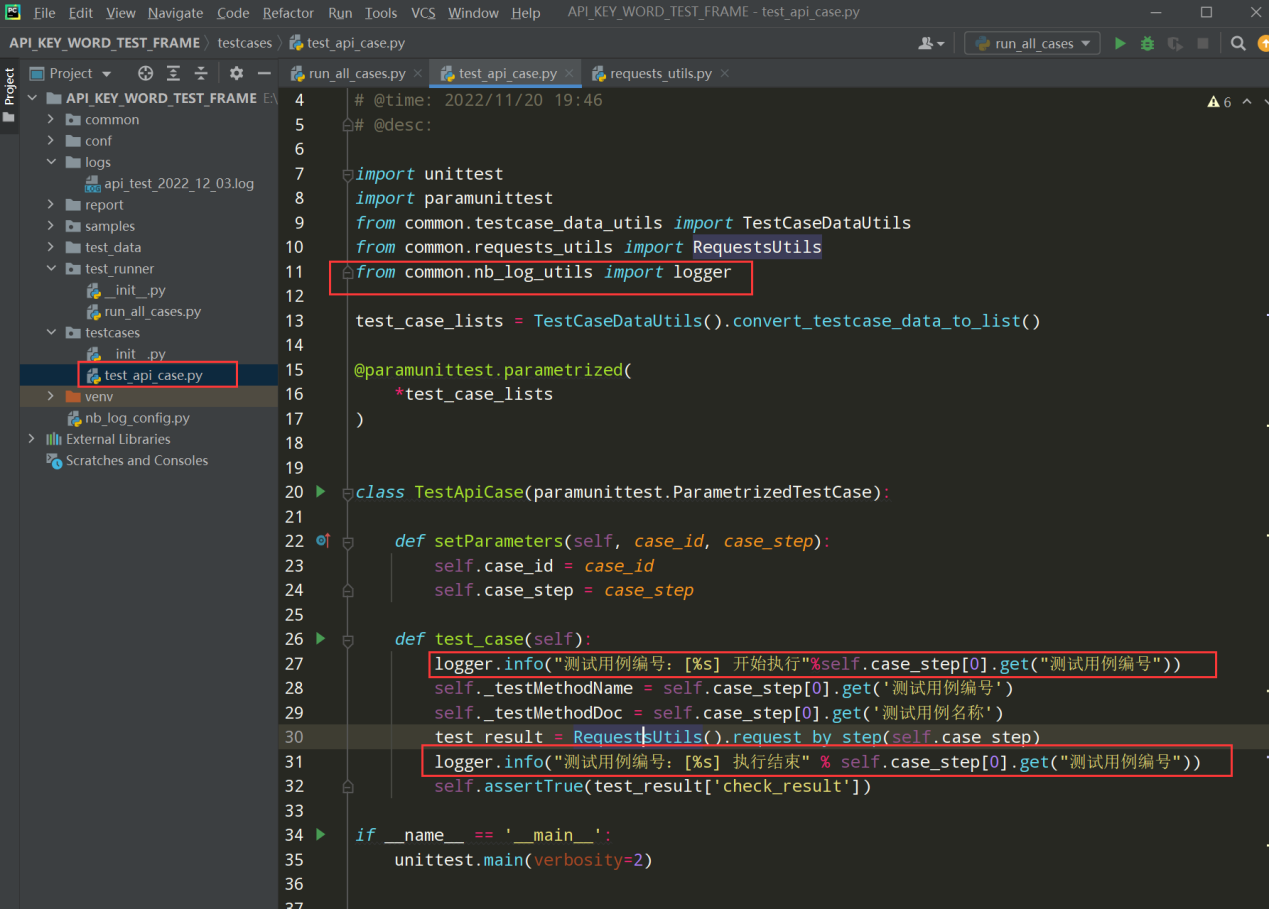
前置条件:先导入日志模块包
编写代码:
logger.info("测试用例编号:[%s] 开始执行"%self.case_step[0].get("测试用例编号"))
logger.info("测试用例编号:[%s] 执行结束" % self.case_step[0].get("测试用例编号"))
3、在requests底层脚本中添加日志
在requests_utils.py文件中添加日志;增加日志时,异常处理中的日志使用error级别日志,普通操作流程日志,使用info级别日志;
3.1 先导入日志模块
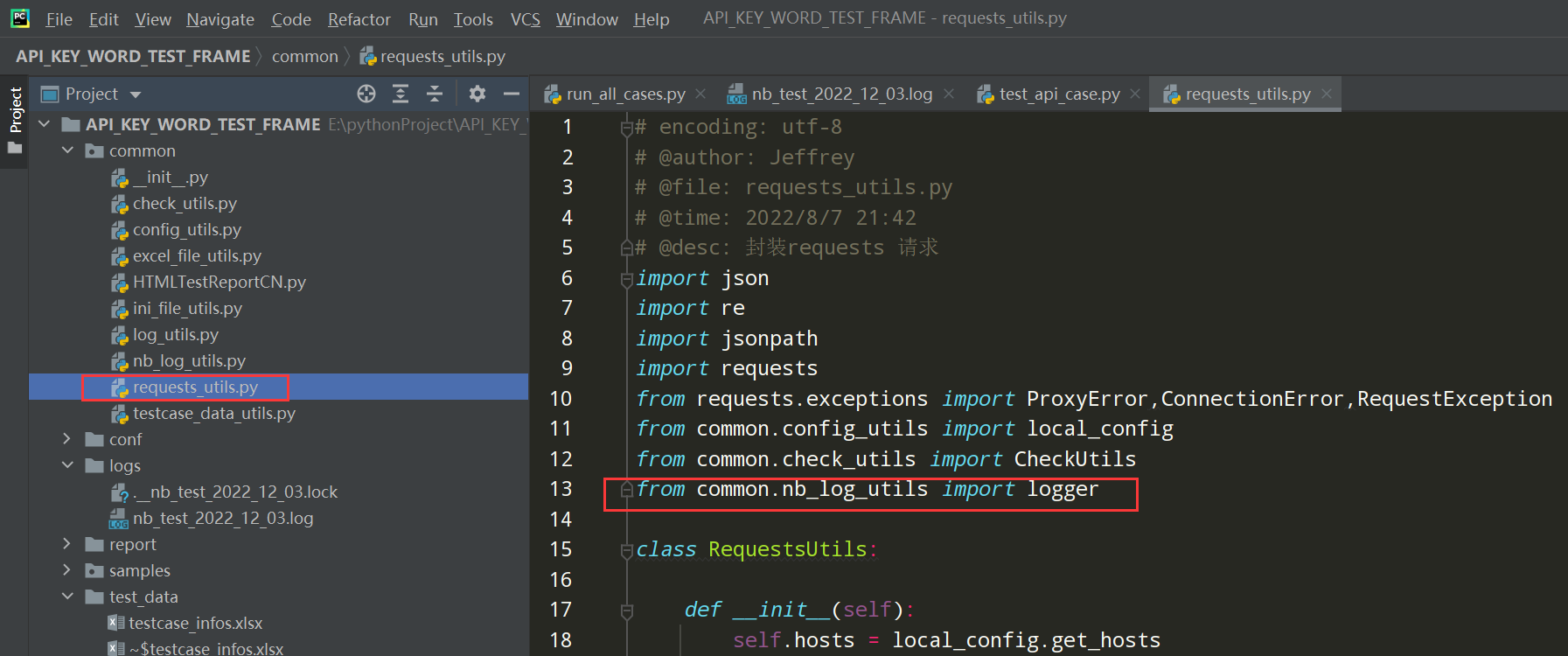
3.2 在get和post请求方法中把异常的error日志加上
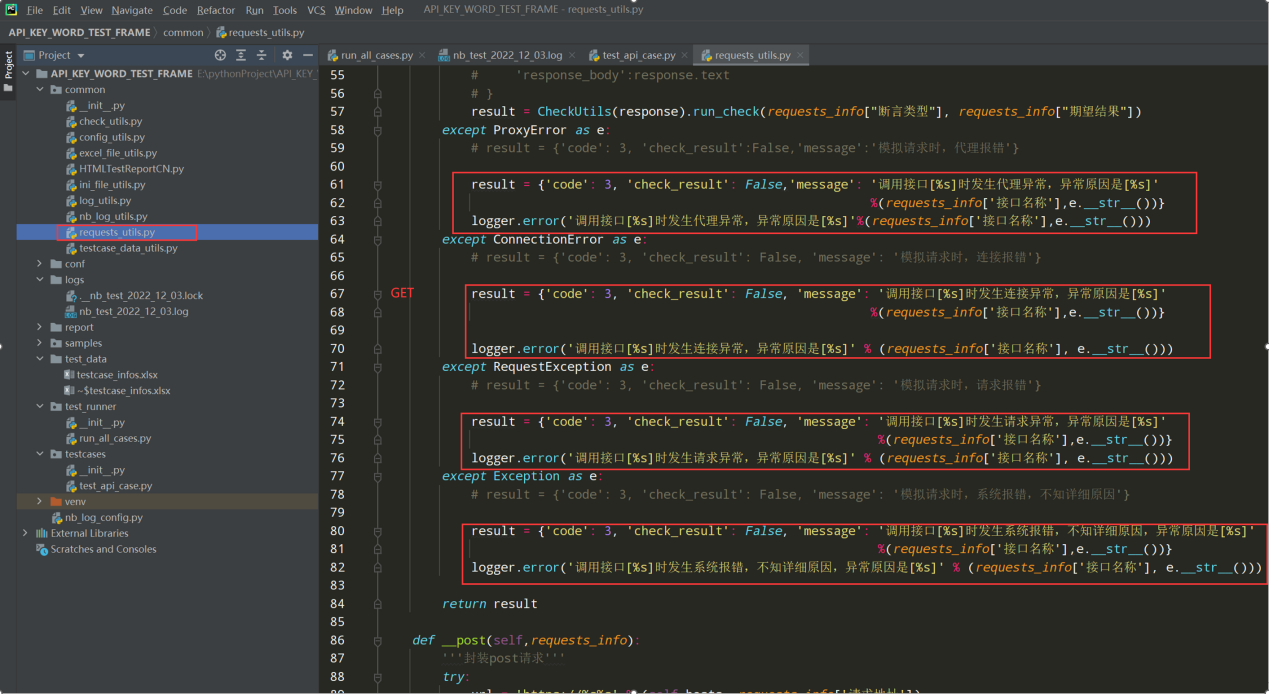
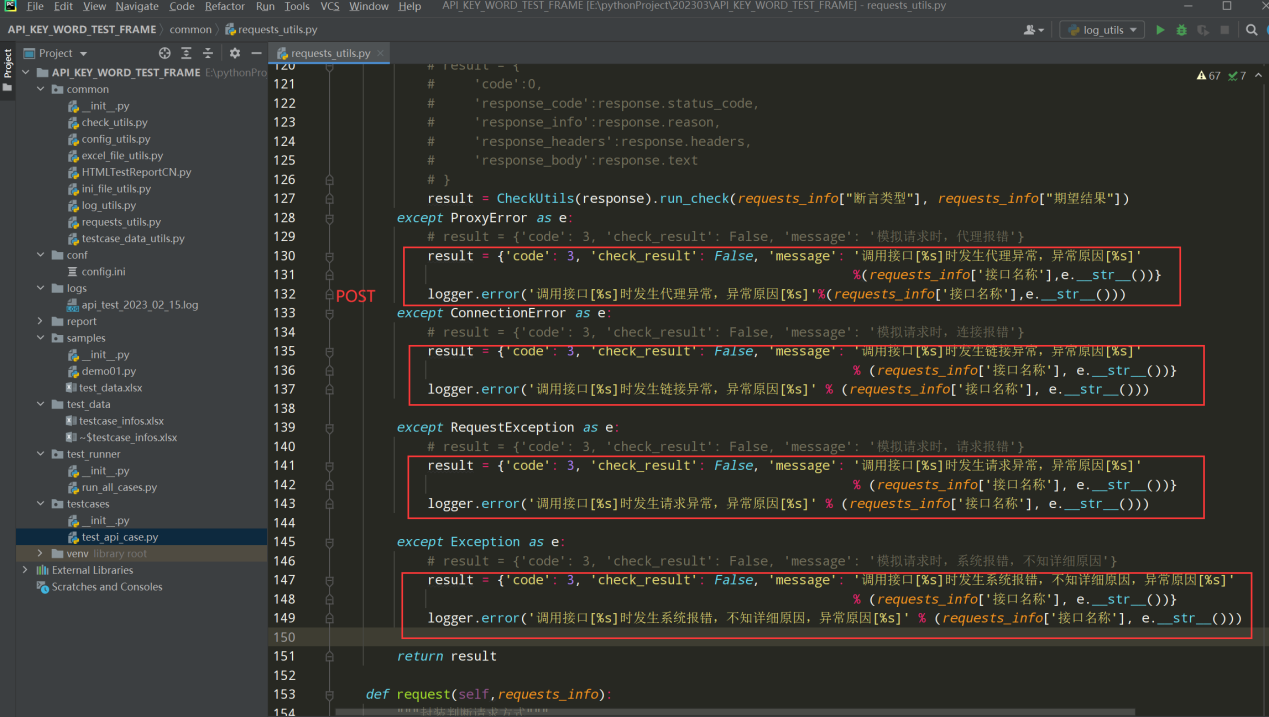
编写代码:
except ProxyError as e: # result = {'code': 3, 'check_result': False, 'message': '模拟请求时,代理报错'} result = {'code': 3, 'check_result': False, 'message': '调用接口[%s]时发生代理异常,异常原因[%s]' %(requests_info['接口名称'],e.__str__())} logger.error('调用接口[%s]时发生代理异常,异常原因[%s]'%(requests_info['接口名称'],e.__str__())) except ConnectionError as e: # result = {'code': 3, 'check_result': False, 'message': '模拟请求时,连接报错'} result = {'code': 3, 'check_result': False, 'message': '调用接口[%s]时发生链接异常,异常原因[%s]' % (requests_info['接口名称'], e.__str__())} logger.error('调用接口[%s]时发生链接异常,异常原因[%s]' % (requests_info['接口名称'], e.__str__())) except RequestException as e: # result = {'code': 3, 'check_result': False, 'message': '模拟请求时,请求报错'} result = {'code': 3, 'check_result': False, 'message': '调用接口[%s]时发生请求异常,异常原因[%s]' % (requests_info['接口名称'], e.__str__())} logger.error('调用接口[%s]时发生请求异常,异常原因[%s]' % (requests_info['接口名称'], e.__str__())) except Exception as e: # result = {'code': 3, 'check_result': False, 'message': '模拟请求时,系统报错,不知详细原因'} result = {'code': 3, 'check_result': False, 'message': '调用接口[%s]时发生系统报错,不知详细原因,异常原因[%s]' % (requests_info['接口名称'], e.__str__())} logger.error('调用接口[%s]时发生系统报错,不知详细原因,异常原因[%s]' % (requests_info['接口名称'], e.__str__()))
3.3、 在调用接口请求和获取测试步骤的两个方法中添加info日志
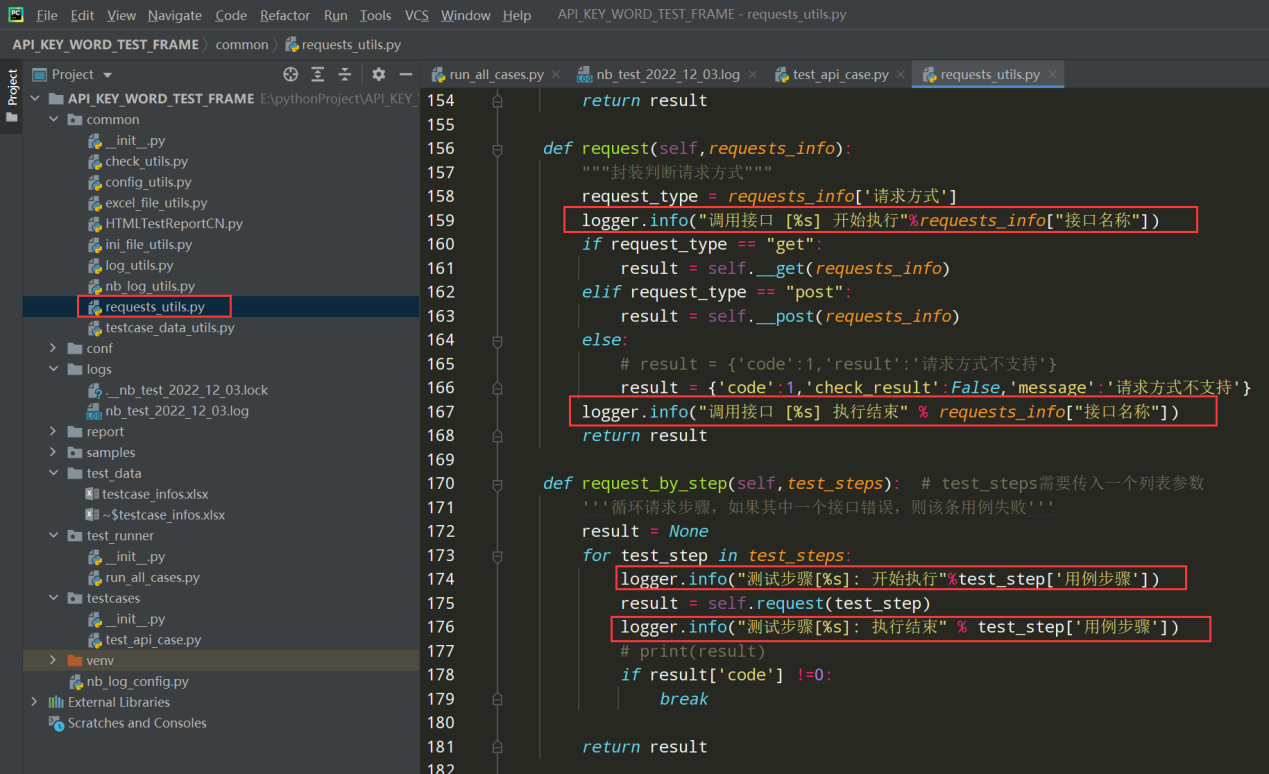
编写代码:
logger.info("调用接口 [%s] 开始执行"%requests_info["接口名称"])
logger.info("调用接口 [%s] 执行结束" % requests_info["接口名称"])
logger.info("测试步骤 [%s] 开始执行" % test_step["用例步骤"])
logger.info("测试步骤 [%s] 执行结束" % test_step["用例步骤"])
4、执行run_all_cases.py文件查看日志文件
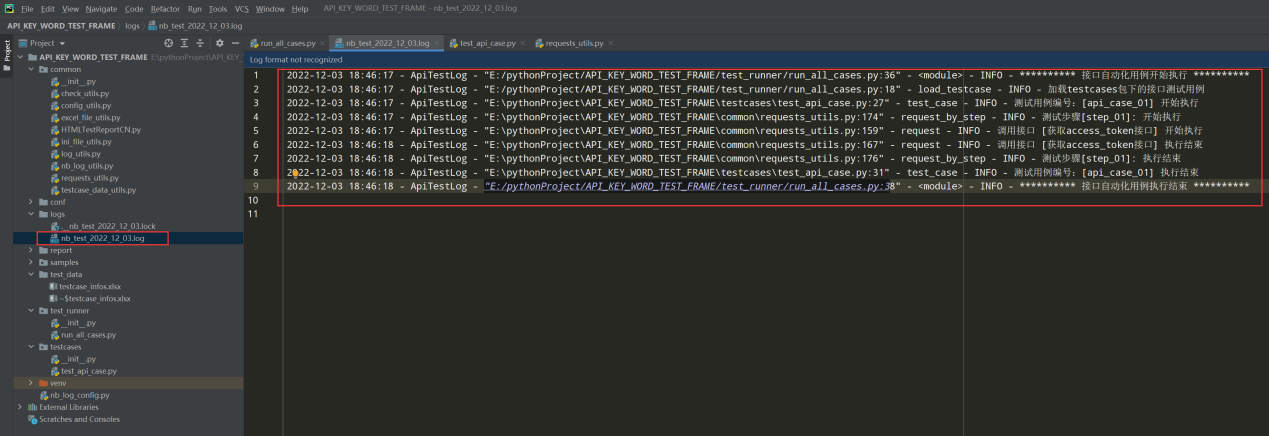
框架10 拓展-数据源mysql
整体框架功能已经实现
目前使用的是excel数据源,切换成 用户信息数据存放mysql中去
第一步:先在mysql中创建数据库,插入用例信息数据
接口请求信息表(requests_info)

测试步骤表(case_step_info)

测试用例信息表(case_info)
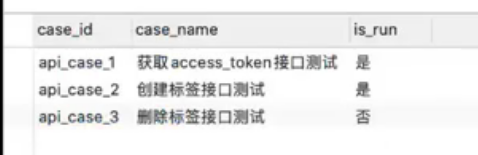
整理数据后通过一个sql语句,让其查询结果和excel返回的所有数据格式是一致的;
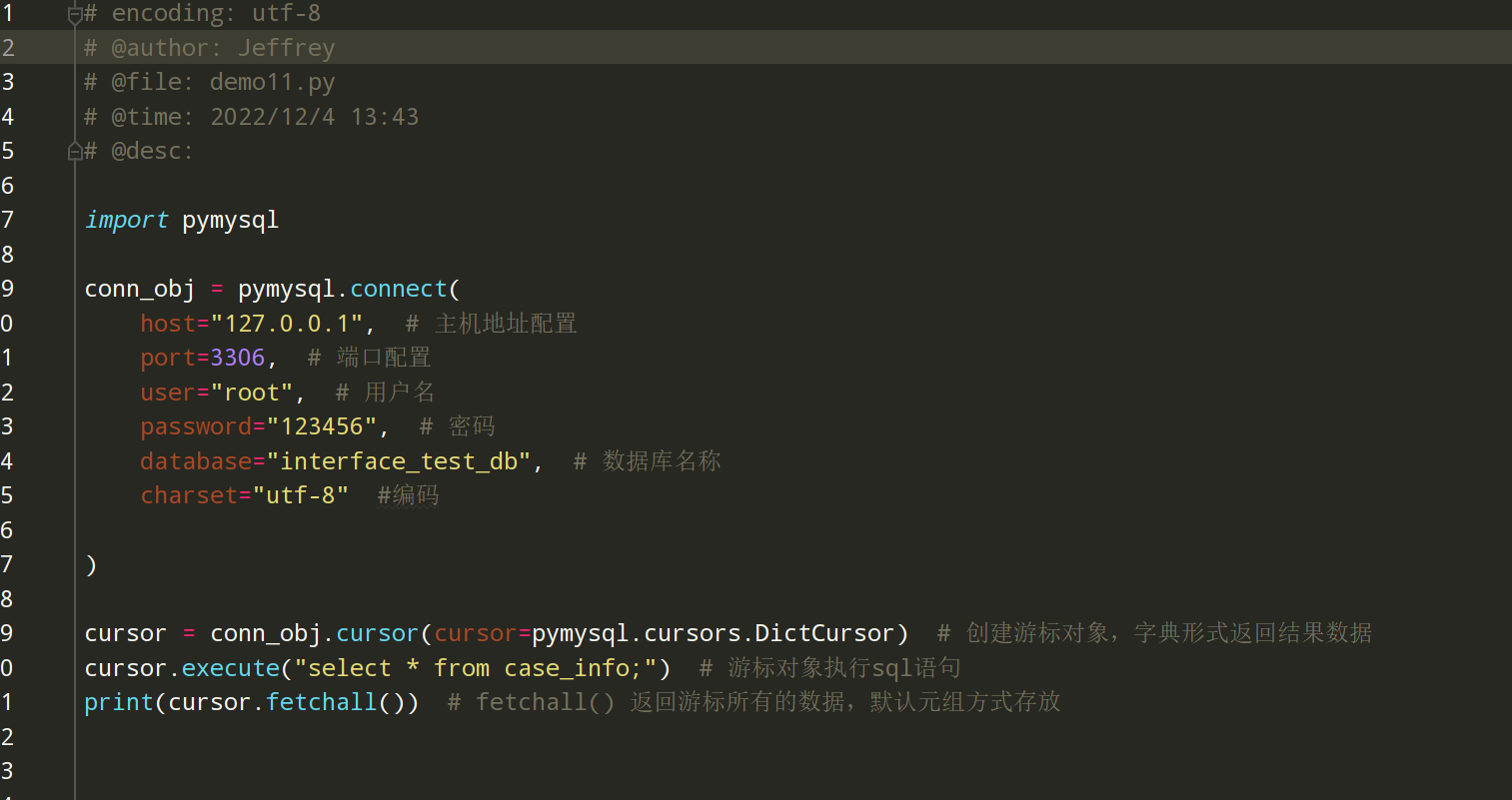
第二步:python读取mysql数据 pip install pymysql
第三步:编写的大型sql执行后发现和excel返回的数据内容一致,格式也一致
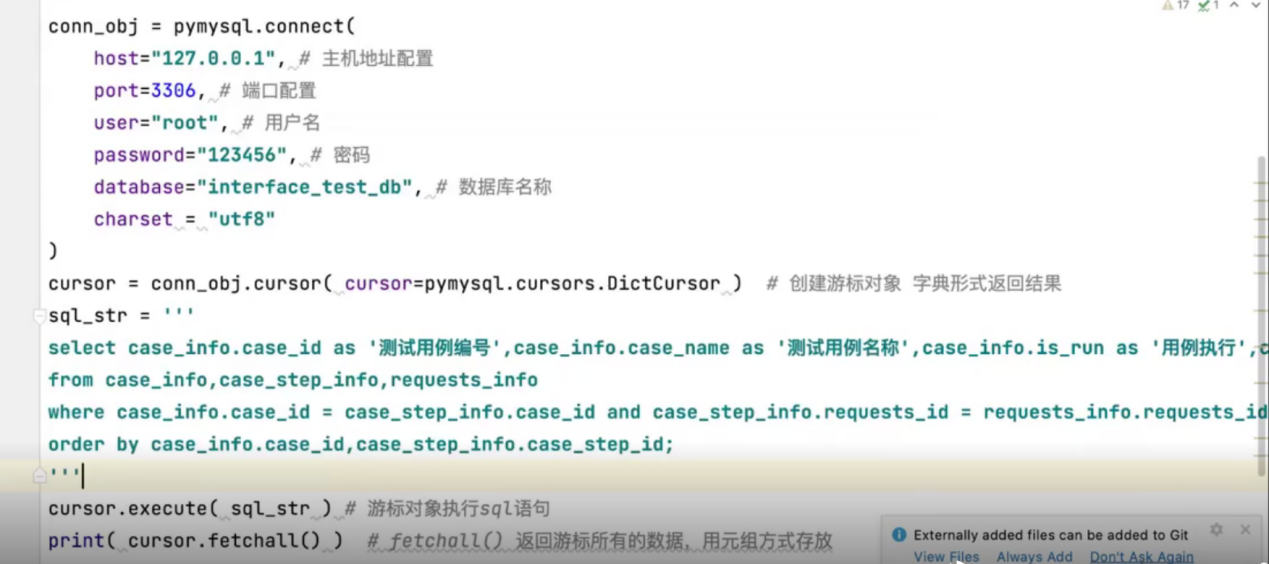
第四步:进行mysql的封装
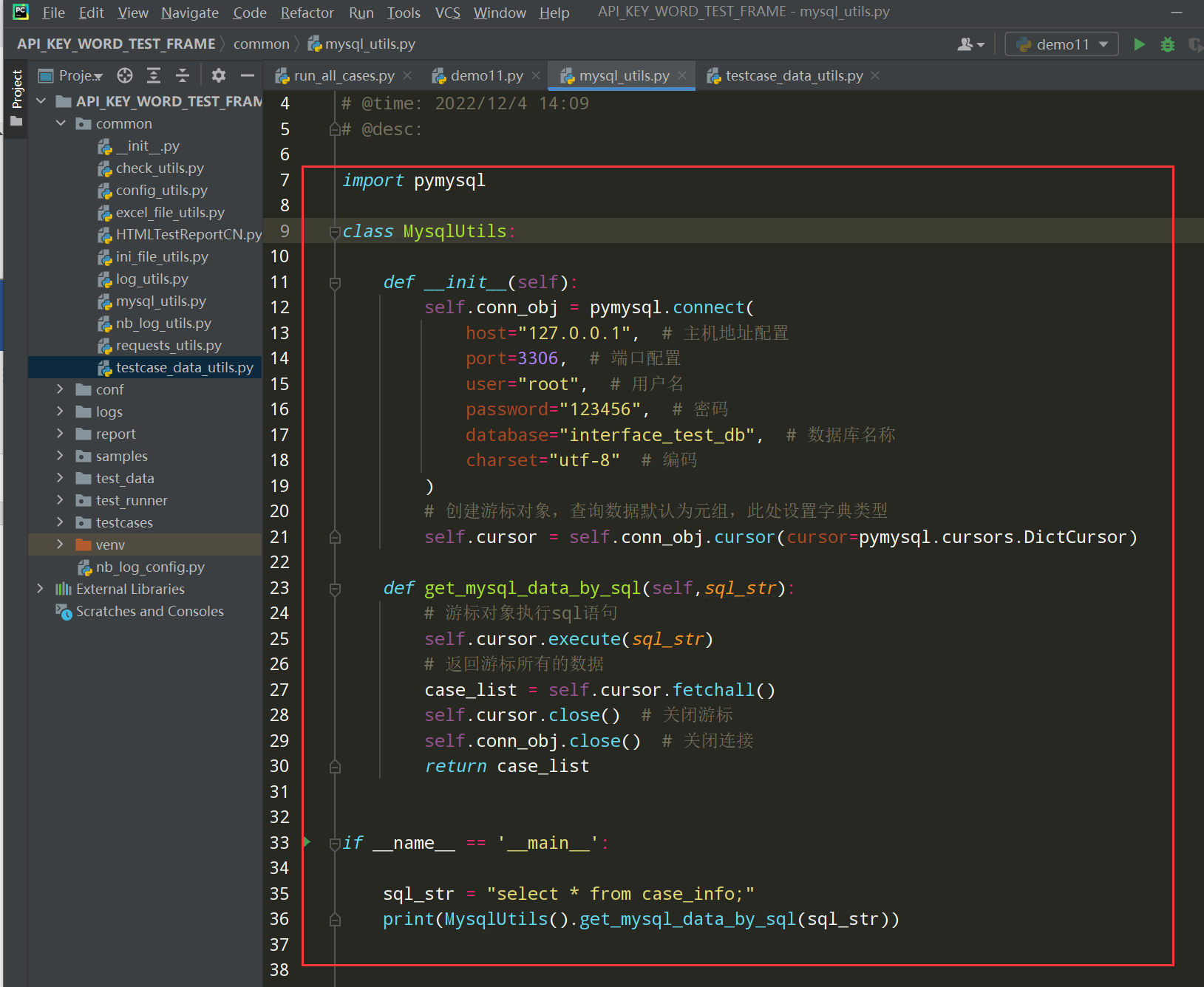
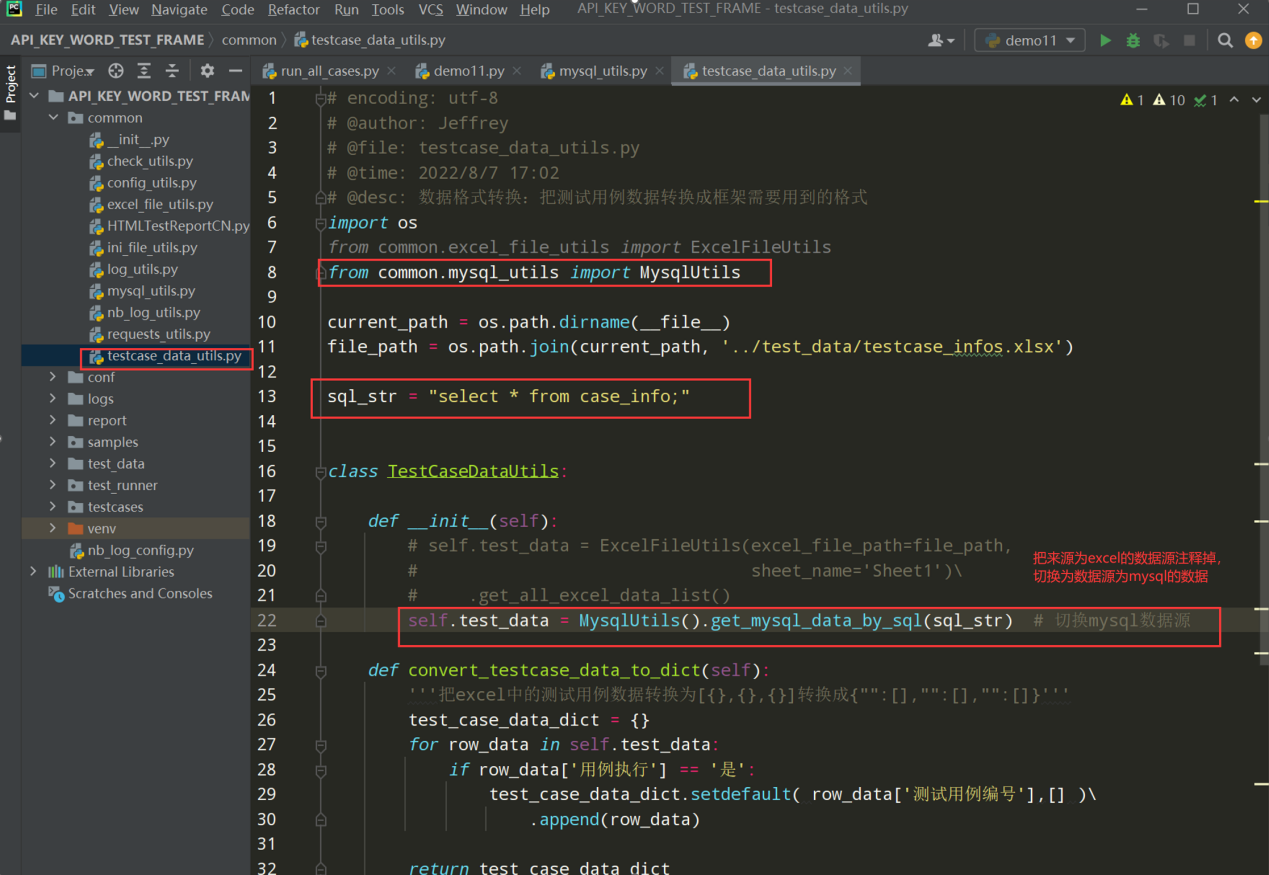
第五步:切换数据源
数据源如果为其他格式比如yaml或xml最终切换数据源都如下所示:
框架11 Jenkins使用实战
jenkins简介:
Jenkins是基于Java开发的一款开源的持续集成工具,用于监控持续重复的工作,功能包括:
1、持续的软件版本发布/测试项目;
2、监控外部调用执行的工作。
Windows安装Jenkins

持续集成基础概念
CI/CD 概念:

CICD 是一种通过在应用开发阶段引入自动化来频繁向客户交付应用的方法。CI/CD 的核心概念是持续集成、持续交付和持续部署。作为一个面向开发和运营团队的解决方案,CI/CD 主要针对在集成新代码时所引发的问题。
“CI’指持续集成,它属于开发人员的自动化流程。成功的CI 意味着应用代码的新更改会定期构建、测试并合并到共享存储库中。该解决方案可以解决在一次开发中有太多应用分支,从而导致相互冲突的问题。
(企业中的 CI·是指·开发编写好代码并提交到版本控制工具 (git/svn),后续的源码编译、打包、发布到测试环境、自动化测试、出具结果、合并分支等全部是自动化完成)
一般公司的持续集成·由管理流程·和·持续集成工具配置·两部分完成
持续集成工具有很多,jenkins
测试团队应用的比较广深,·是一款开源的持续集成工具
自动化测试: 只要用工具或代码·降低了·大量的重复测试工作,都可以称之为自动化
“CD”指的是持续交付和/或持续部署,,持续交付通常是指开发人员对应用的更改会自动进行错误测试并上传到存储库 (如 GitHu 或容器注册表),然后由运维团队将其部署到实时生产环境中。这旨在解决开发和运维团队之间可见性及沟通较差的问题。持续部署:(另一种.“CD”).指的是自动将开发人员的更改从存储库发布到生产环境,以供客户使用。它主要为了解决因手动流程降低应用交付速度,从而使运维团队超负荷的问题。持续部署以持续交付的优势为根基,实现了管道后续阶段的自动化。
持续集成价值:
持续集成本质上是一种软件开发实践,即团队开发成员经常集成它们的工作通过每个成员每天至少集成一次,:也就意味着每天可能会发生多次集成。每次集成都通过自动化的构建~(包括编译,发布,自动化测试)”来验证,从而尽早地发现集成错误。
好处:
1、 减少风险
一天中进行多次的集成,并做了相应的测试,这样有利于检查缺陷,了解软件的健康状况减少假定。
2、减少重复过程
减少重复的过程可以节省时间、费用和工作量。说起来简单,做起来难。这些浪费时间的重复劳动可能在我们的项目活动的任何一个环节发生,包括代码编译、数据库集成、测试、审查、部署及反馈。通过自动化的持续集成可以将这些重复的动作都变成自动化的,无需太多人工干预,让人们的时间更多的投入到动脑筋的、更高价值的事情上。
3、任何时间、任何地点生成可部署的软件
持续集成可以让您在任何时间发布可以部署的软件。从外界来看,这是持续集成最明显的好处,我们可以对改进软件品质和减少风险说起来滔滔不绝,但对于客户来说,可以部署的软件产品是最实际的资产工利用持续集成,您可以经常对源代码进行一些小改动,并将这些改动和其他的代码进行集成。如果出现问题项目成员马上就会被通知到,问题会第一时间被修复:不采用持续集成的情况下这些问题有可能到交付前的集成测试的时候才发现,有可能会导致延迟发布产品而在急于修复这些缺陷的时候又有可能引入新的缺陷,最终可能导致项目失败。
4、增强项目的可见性
持续集成让我们能够注意到趋势并进行有效的决策。如果没有真实或最新的数据提供支持,项目就会遇到麻烦,每个人都会提出他最好的猜测。通常,项目成员通过手工收集这些信息,增加了负担,也很耗时。持续集成可以带来两点积极效果。
(1)有效决策:持续集成系统为项目构建状态和品质指标提供了及时的信息,有些持续集成系统可以报告功能完成度和缺陷率。
(2)注意到趋势: 由于经常集成,我们可以看到一些趋势,如构建成功或失败总体品质以及其它的项目信息。
5、建立团队对开发产品的信心
持续集成可以建立开发团队对开发产品的信心,因为他们清楚的知道每一次构建的结果,他们知道他们对软件的改动造成了哪些影响,结果怎么样。
6、增强项目的稳定性
持续继承的要素:
1.统一的代码库
2.自动构建
3.自动测试
4.每少人每天都要向代码库主干提交代码
5.每次代码递交后都会在持续集成服务器上触发一次构建
6.保证快速构建
7.模拟生产环境的自动测试
8.每个人都可以很容易的获取最新可执行的应用程序
9.每个人都清楚正在发生的状况
10.自动化的部署
持续集成的原则:
1.所有的开发人员需要在本地机器上做本地构建,然后再提交的版本控制库中从而确保他们的变更不会导致持续集成失败。:
2.开发人员每天至少向版本控制库中提交一次代码
3.开发人员每天至少需要从版本控制库中更新一次代码到本地机器
4.需要有专门的集成服务器来执行集成构建,每天要执行多次构建
5.每次构建都要100%通过
6.每次构建都可以生成可发布的产品。
7.修复失败的构建是优先级最高的事情。
8.测试是未来,未来是测试
Jenkins实战操作:
实战一:
利用jenkins执行 批处理命令(windows)/ shell脚本(mac/linux)
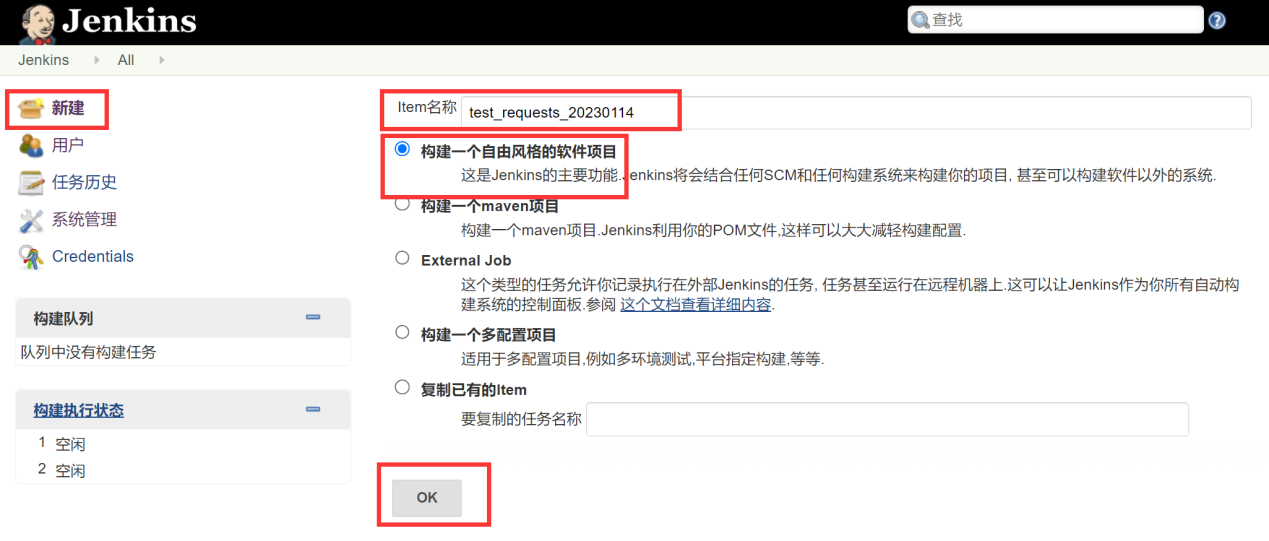
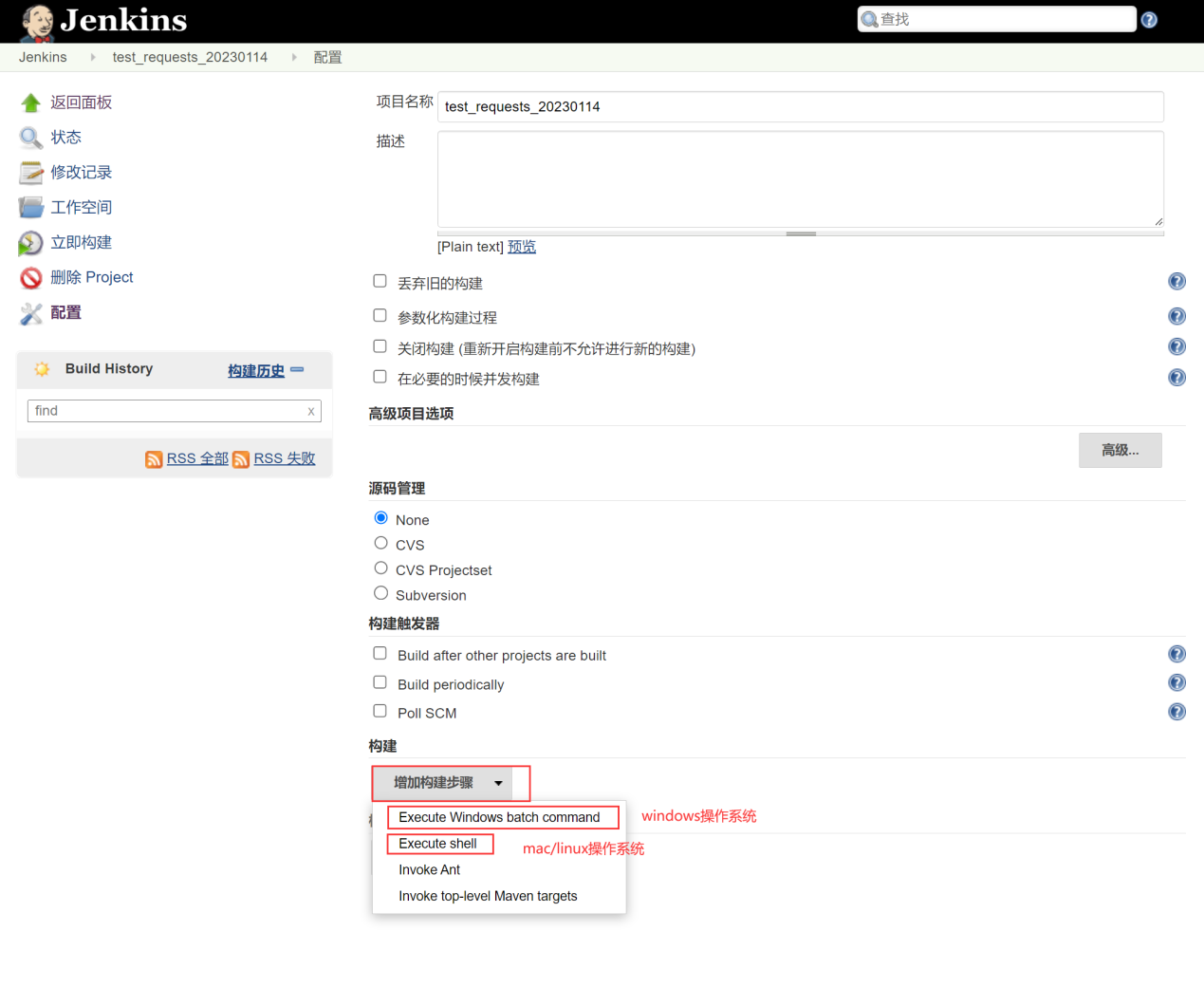
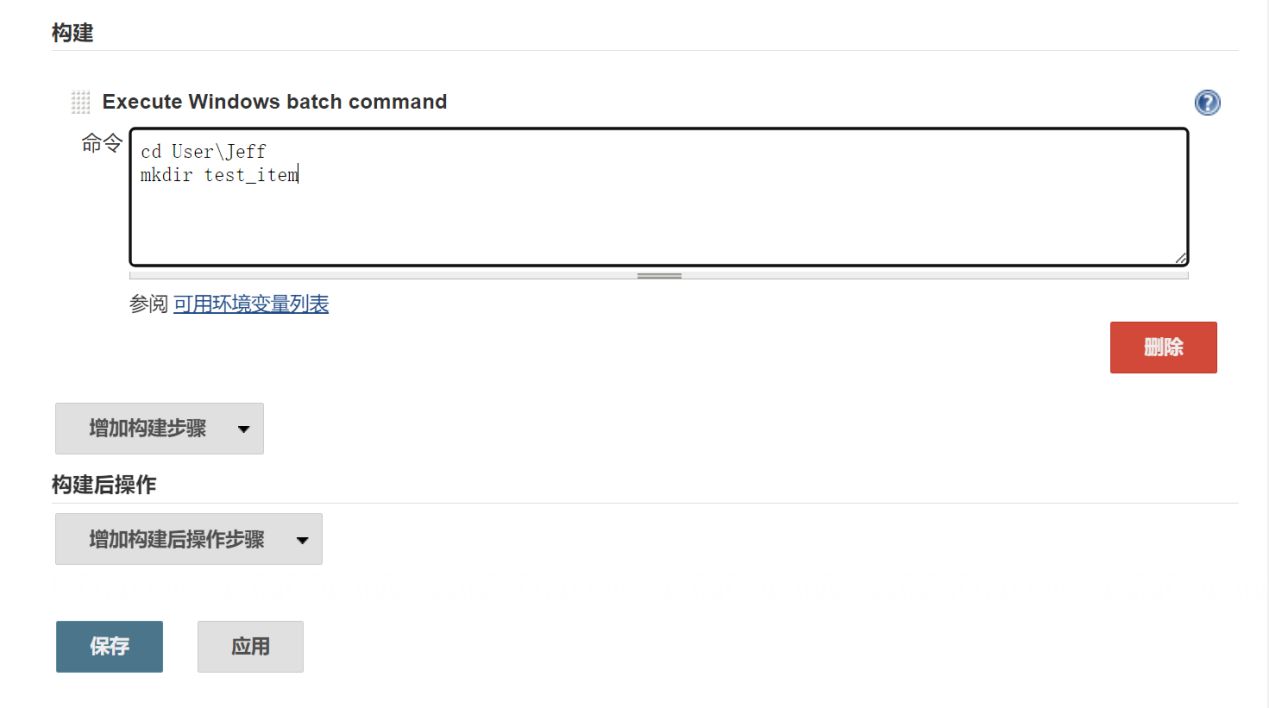
完成上述操作之后,点击保存
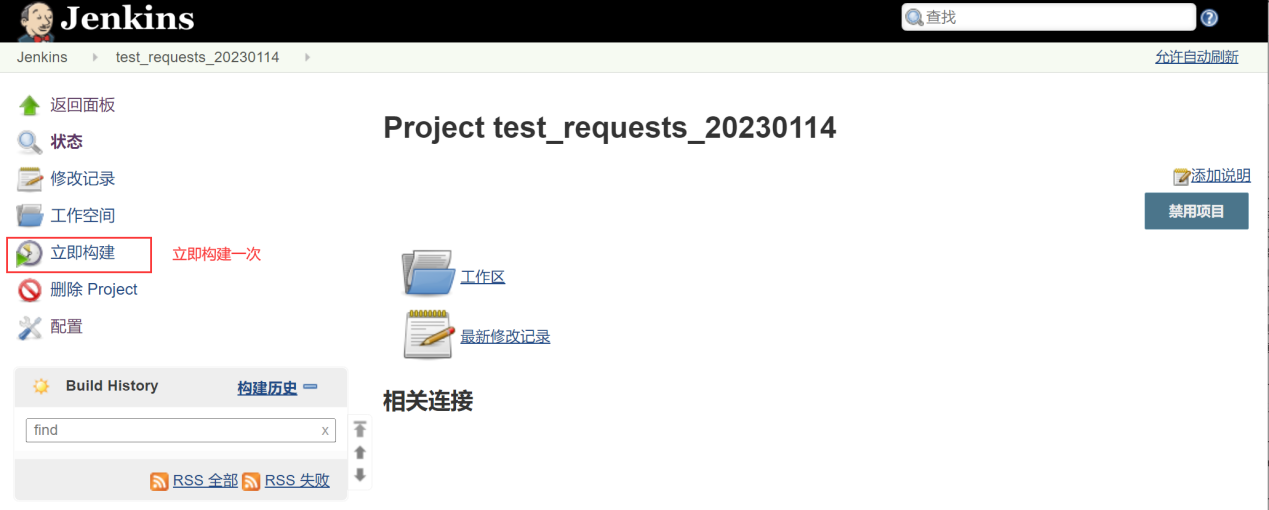
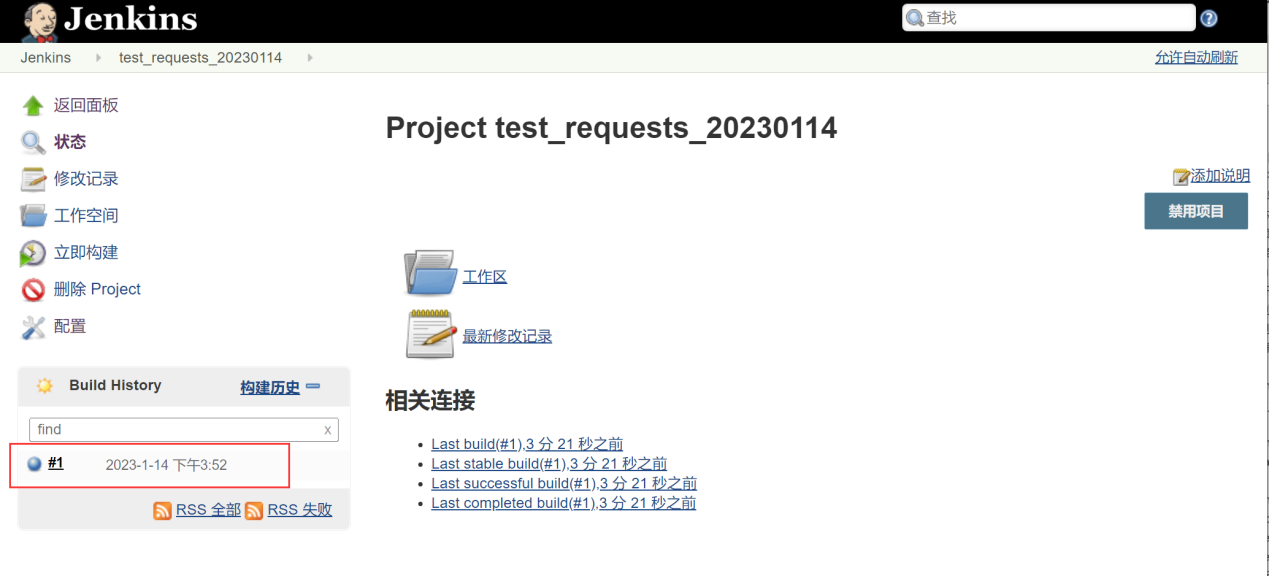
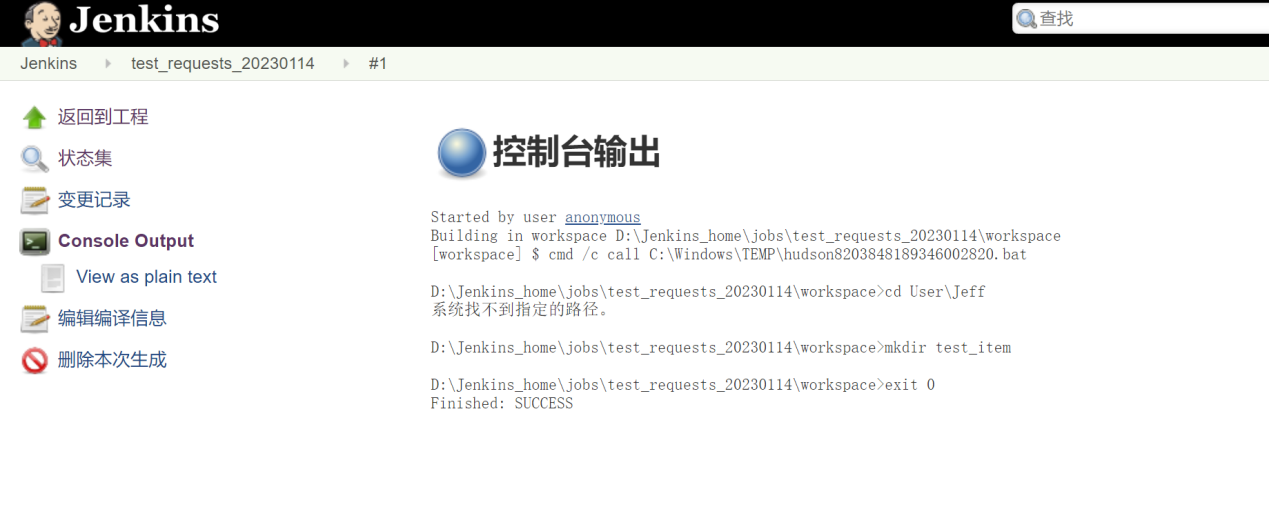
通过上述操作,可以发现jenkins能执行 命令行的命令
实战二:
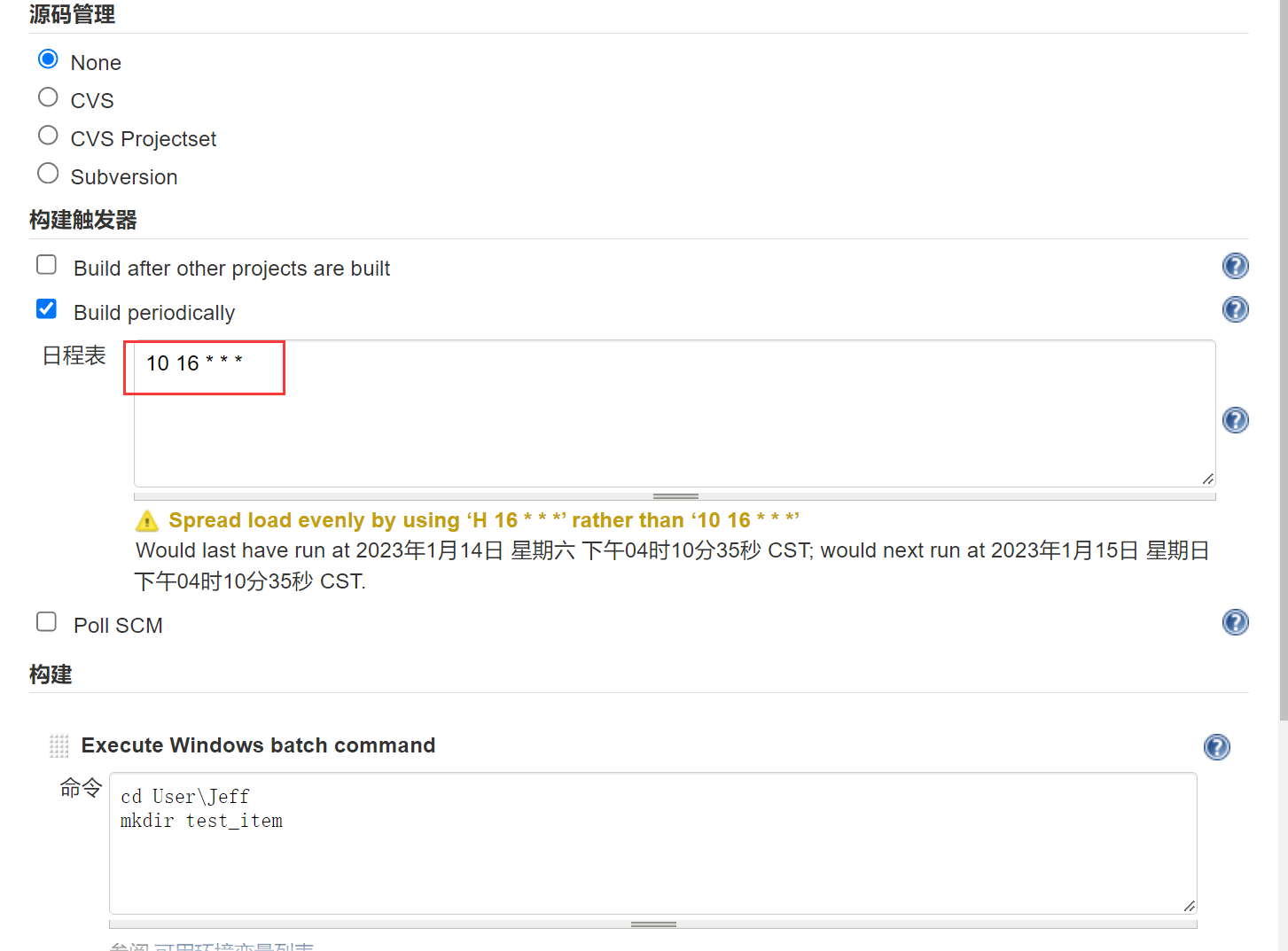
Jenkins定时执行命令

* * * * * : 分时日月周
55 * * * * :每个小时的第55分钟执行一次
55 20 * * * :每天的20:55分钟执行一次
55 20 15 * * :每个月15号的20:55分钟执行一次
55 20 15 3 * :每年的3月15号的20:55分钟执行一次
55 20 * * 4 :每周四的20:55分钟执行一次(0和7表示周日)

设置为每天的16:10分执行一次构建;如下图
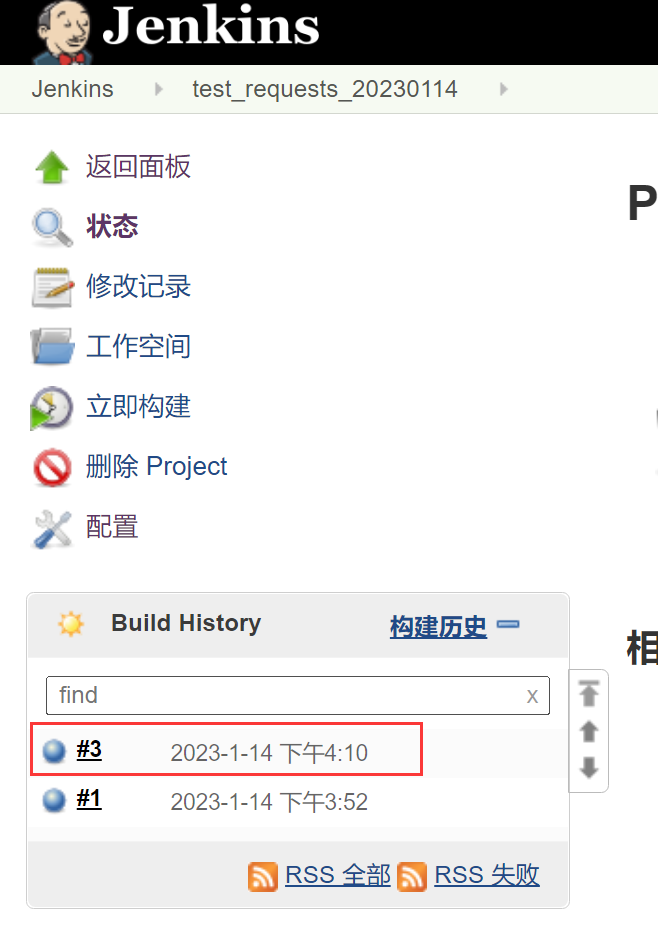
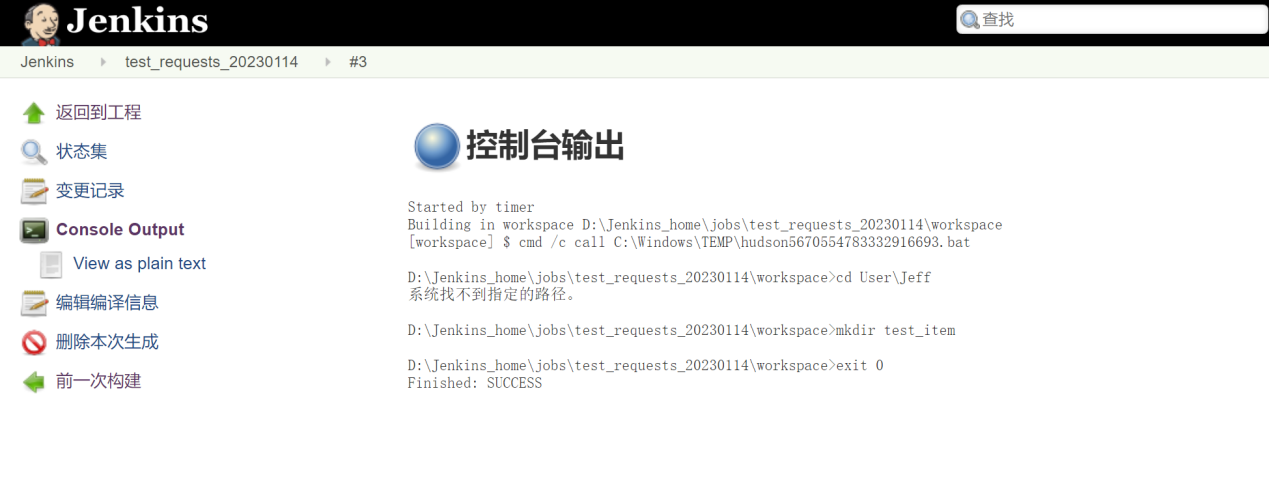
接口测试框架配置到jenkins进行定时执行
第一步:确保接口测试框架代码能通过 命令行运行
cd \pythonProject\API_KEY_WORD_TEST_FRAME
mac/linux系统设置临时环境变量如下export
export PYTHONPATH=\pythonProject\API_KEY_WORD_TEST_FRAME
python3 ./test_runner/run_all_case.py
系统设置临时环境变量如下:
mac/linux:export PYTHONPATH=接口框架的根目录
windows:set PYTHONPATH=接口框架的根目录
第二步:把命令行的脚本配置到jenkins中
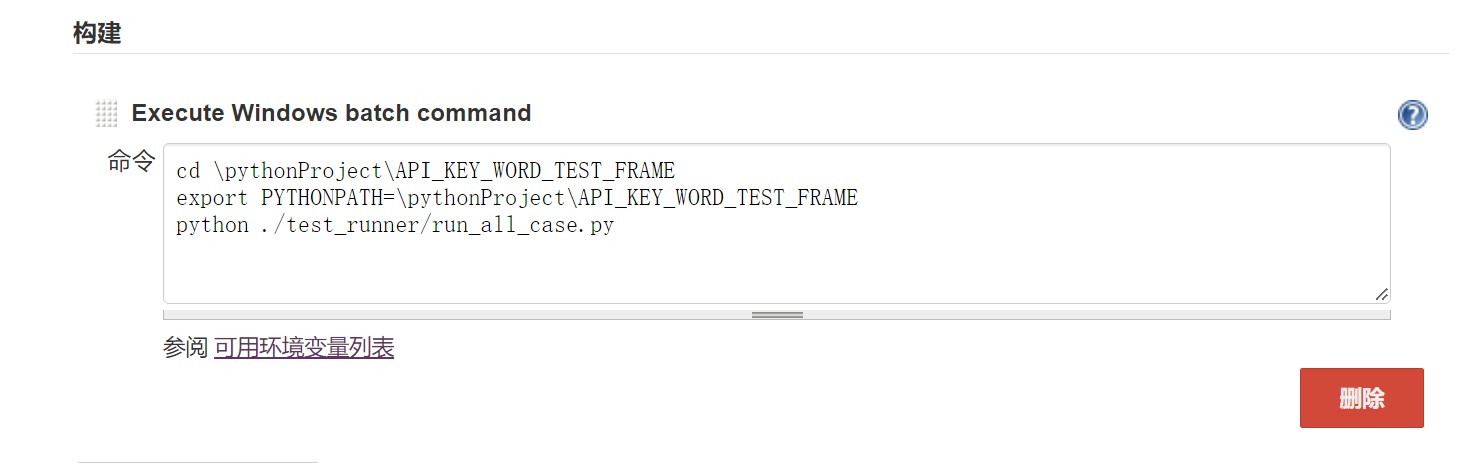
第三步:jenkins配置邮件发送功能
步骤1、测试jenkins能否和指定邮箱配合发送邮件
依次进入jenkins主页——Manage Jenkins——Configure System
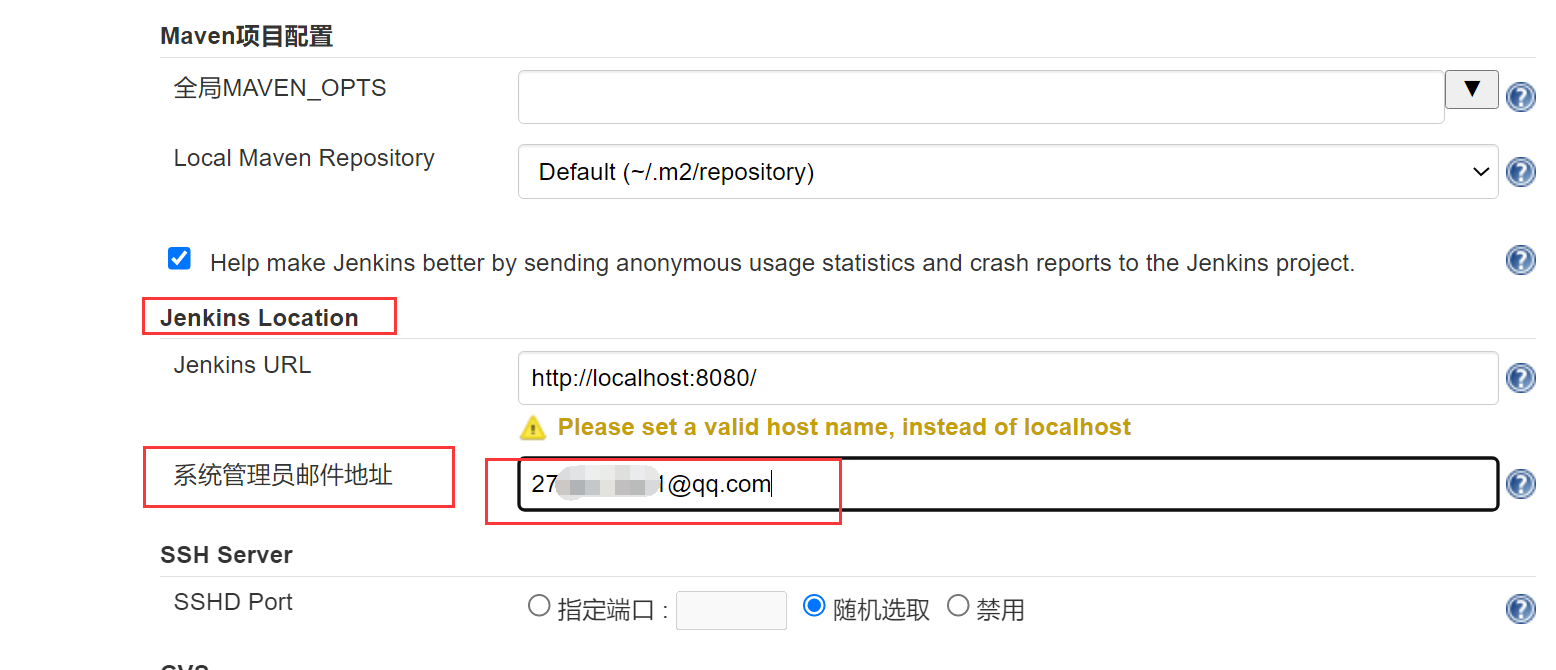
拖动到页面的最下面
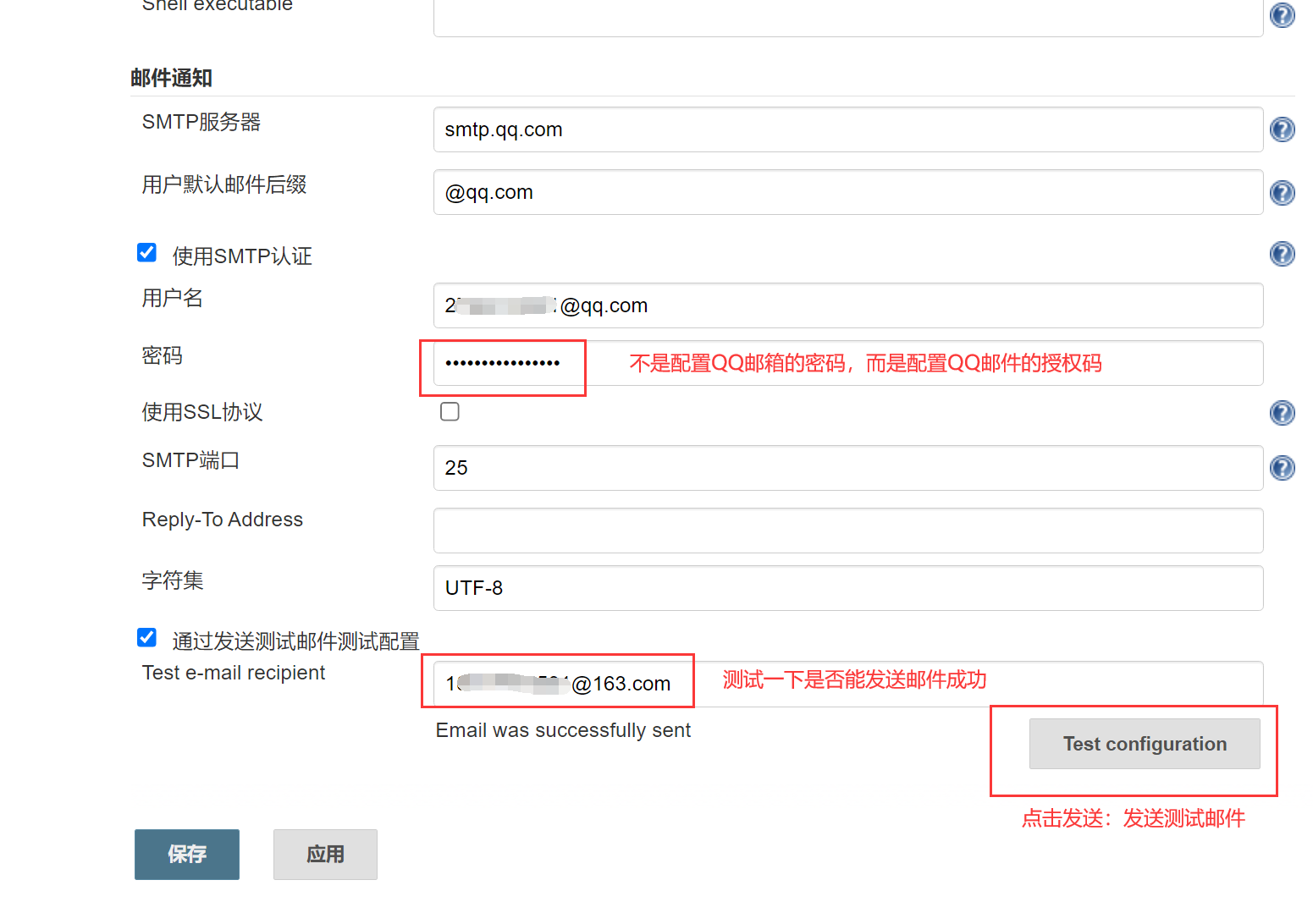
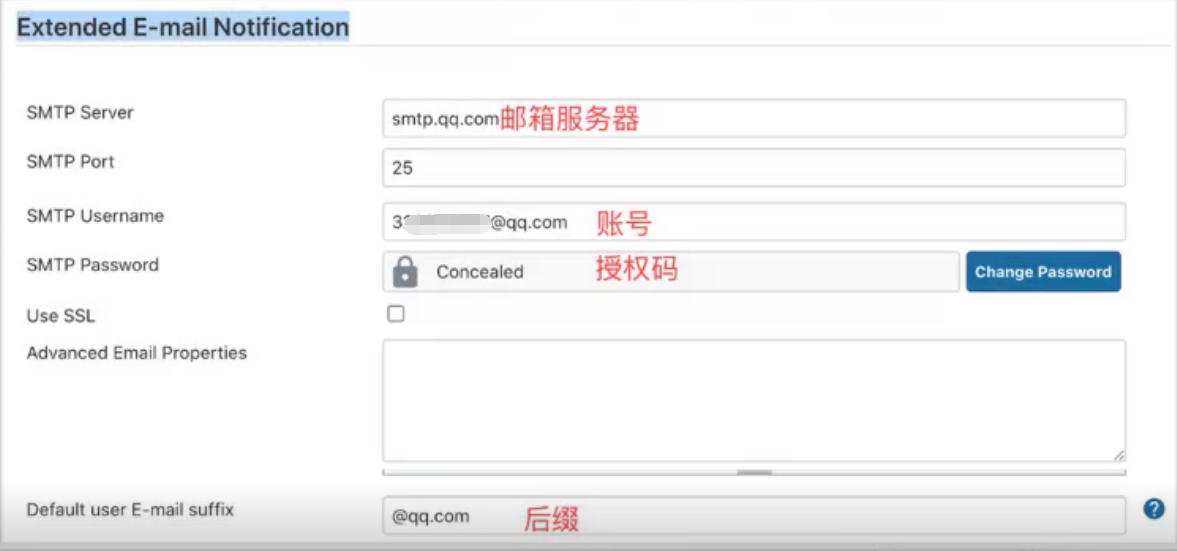
邮箱授权码如何获取:打开QQ邮箱——设置——账户设置——开通smtp——发条短信——授权码
步骤2、真实的配置邮件发送功能
2.1、在jenkins主页——Manage Jenkins ——Configure System 找到Extended E-mail Notification;
2.2、

往下拉


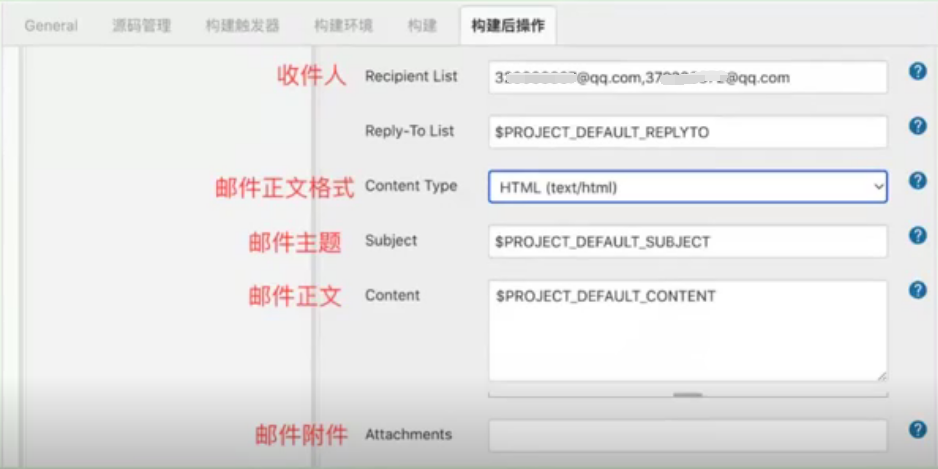
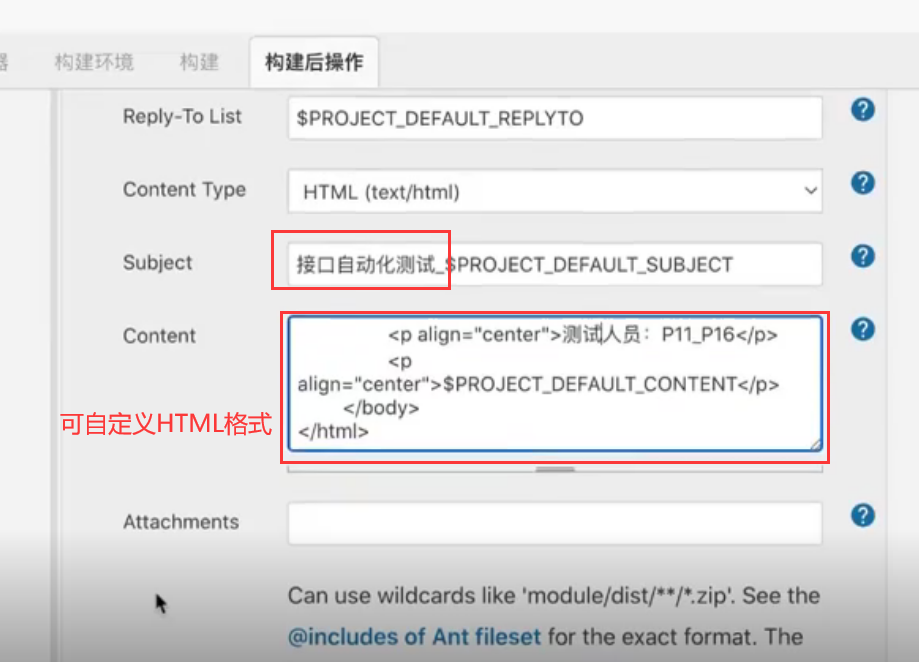

邮件附件配置:
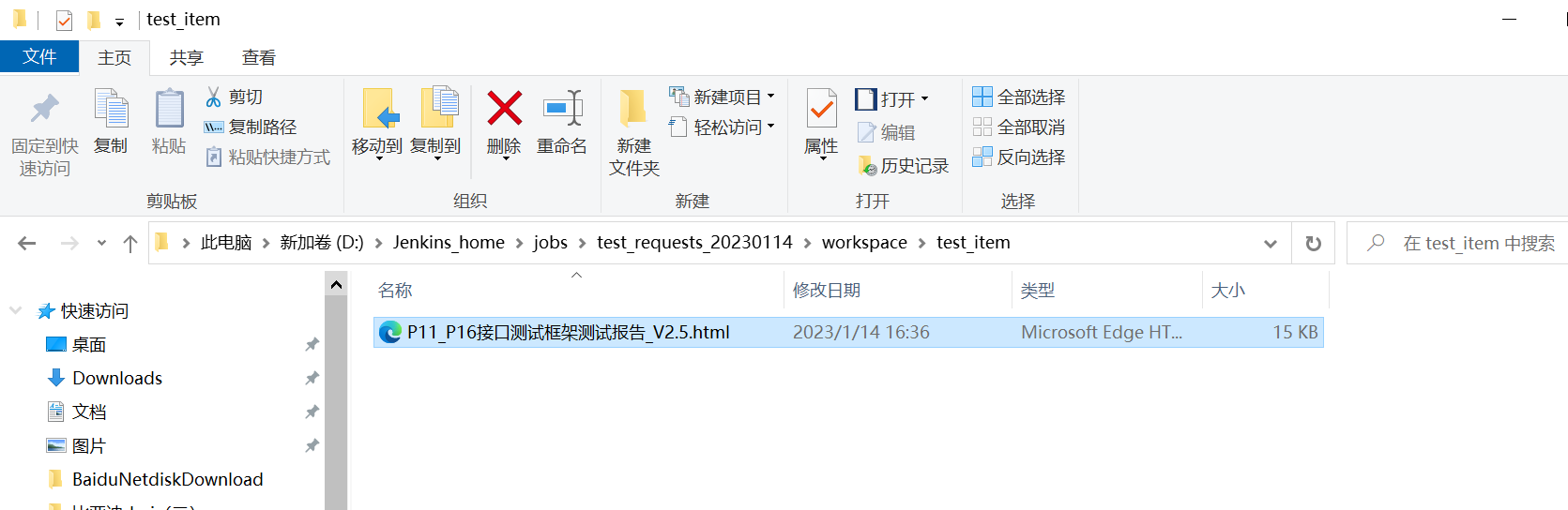
邮件附件必须放置在item的workspace工作空间中,然后此处填写附件名称即可
Jenkins安装目录/workspace/test_item ==》workspace工作空间
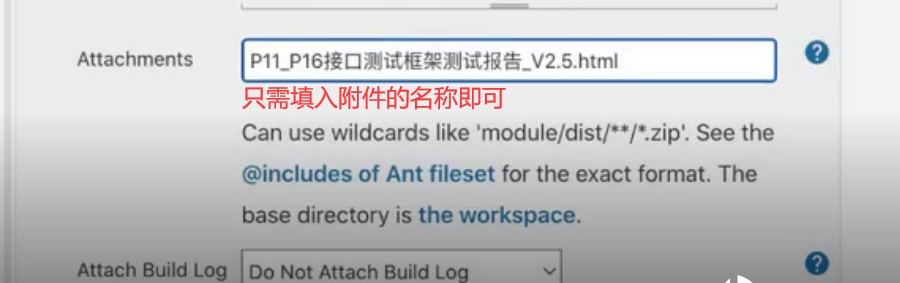
此时邮件配置成功,点击保存
解决 ,每次邮件发送最新的测试报告

把jenkins的附件改为下方的名字
框架12 Pytest 替换unittest 做接口自动化测试框架
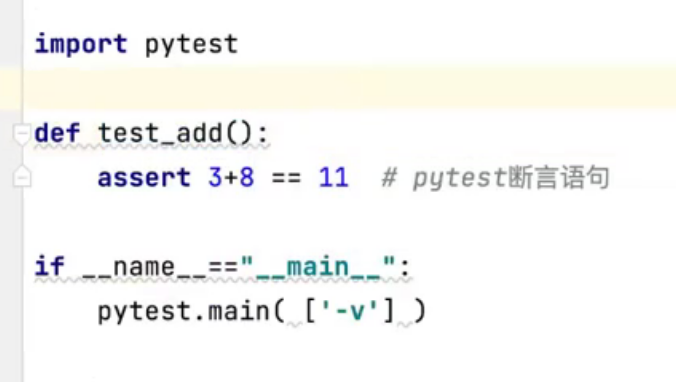
Pytest代码简单实例:
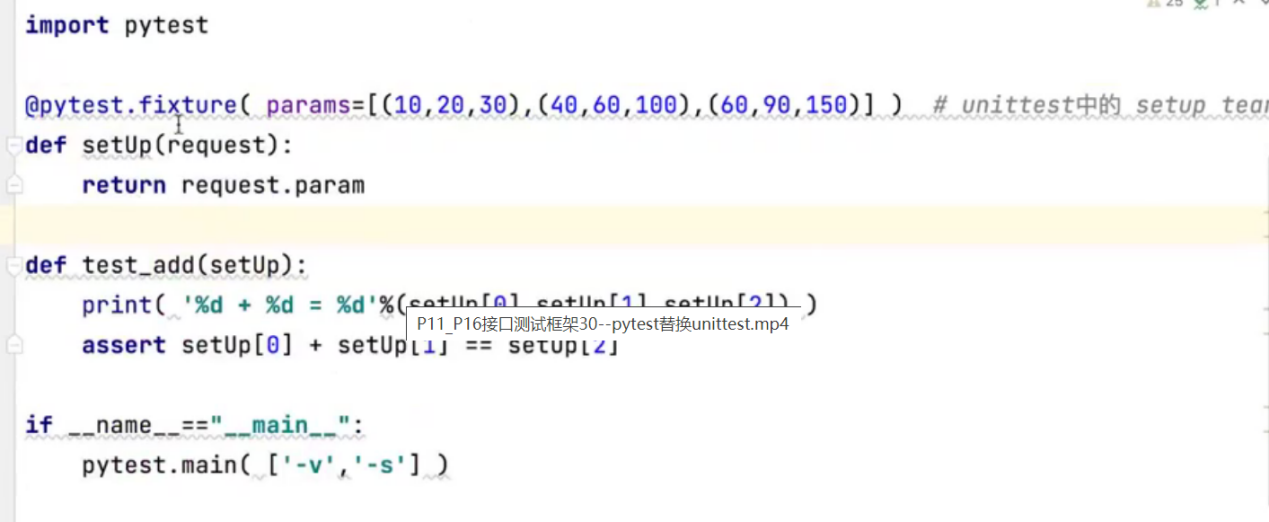
Pytest参数化第一种方式:
Pytest参数化第二种方式:
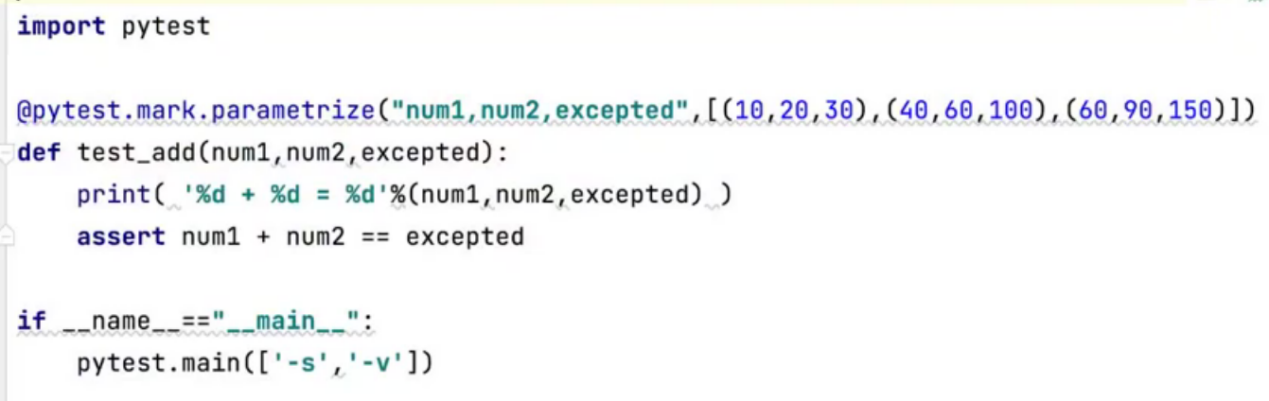
Unittest参数化切换成pytest参数化的代码
步骤1
在testcases文件夹下新建test_api_case_by_pytest.py文件,编写代码
备注:(可以把之前unittest的test_api_case.py修改为unittest_test_api_case.py,防止执行主入口的时候调用test_api_case.py的文件代码)
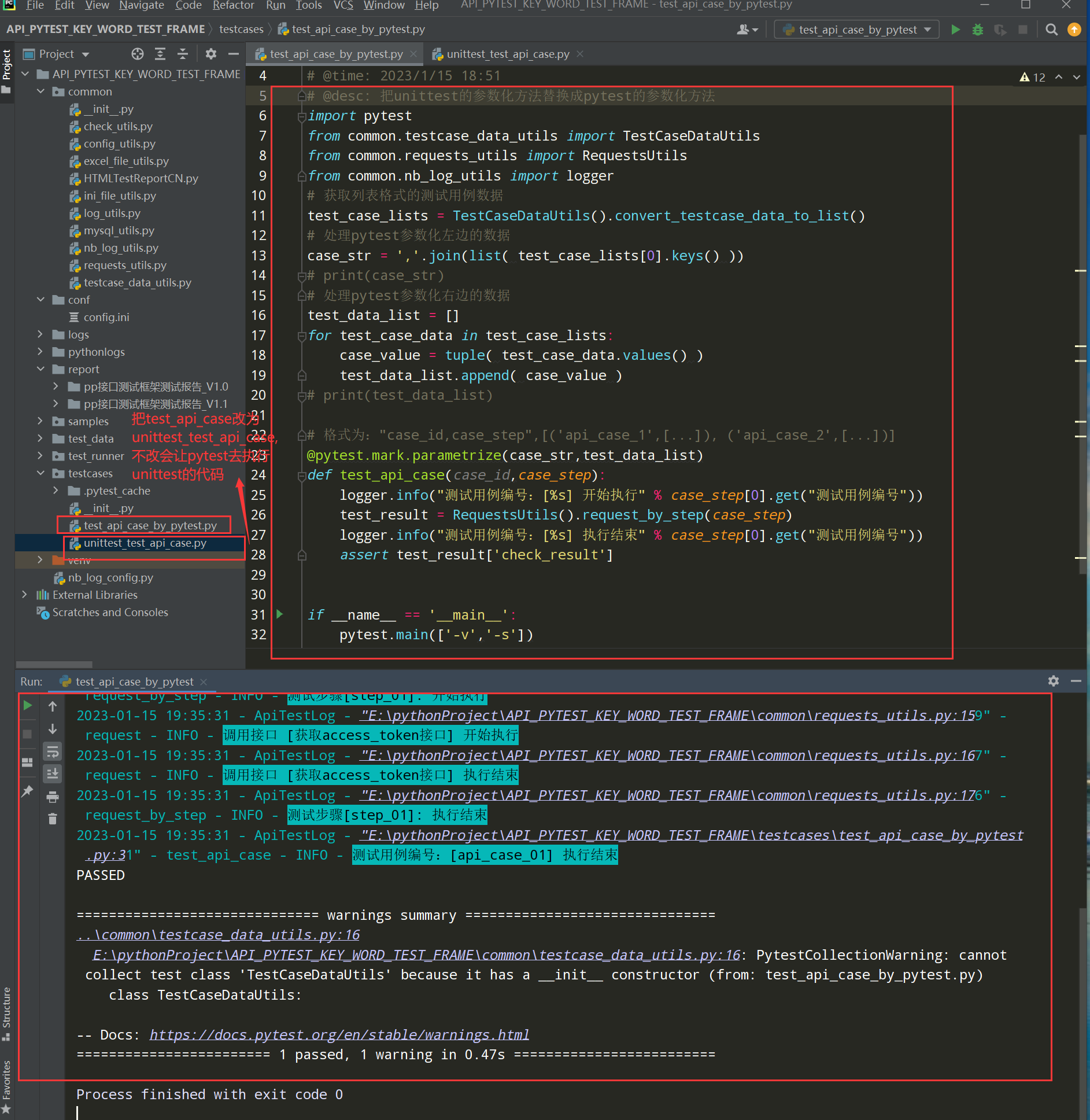
编写代码:
# encoding: utf-8 # @author: Jeffrey # @file: test_api_case_by_pytest.py # @time: 2023/1/15 18:51 # @desc: 把unittest的参数化方法替换成pytest的参数化方法 import pytest from common.testcase_data_utils import TestCaseDataUtils from common.requests_utils import RequestsUtils from common.nb_log_utils import logger # 获取列表格式的测试用例数据 test_case_lists = TestCaseDataUtils().convert_testcase_data_to_list() # 处理pytest参数化左边的数据 case_str = ','.join(list( test_case_lists[0].keys() )) # print(case_str) # 处理pytest参数化右边的数据 test_data_list = [] for test_case_data in test_case_lists: case_value = tuple( test_case_data.values() ) test_data_list.append( case_value ) # print(test_data_list) # 格式为:"case_id,case_step",[('api_case_1',[...]), ('api_case_2',[...])] @pytest.mark.parametrize(case_str,test_data_list) def test_api_case(case_id,case_step): logger.info("测试用例编号:[%s] 开始执行" % case_step[0].get("测试用例编号")) test_result = RequestsUtils().request_by_step(case_step) logger.info("测试用例编号:[%s] 执行结束" % case_step[0].get("测试用例编号")) assert test_result['check_result'] if __name__ == '__main__': pytest.main(['-v','-s'])
思路:
把unittest的数据,转换成pytest需要的数据
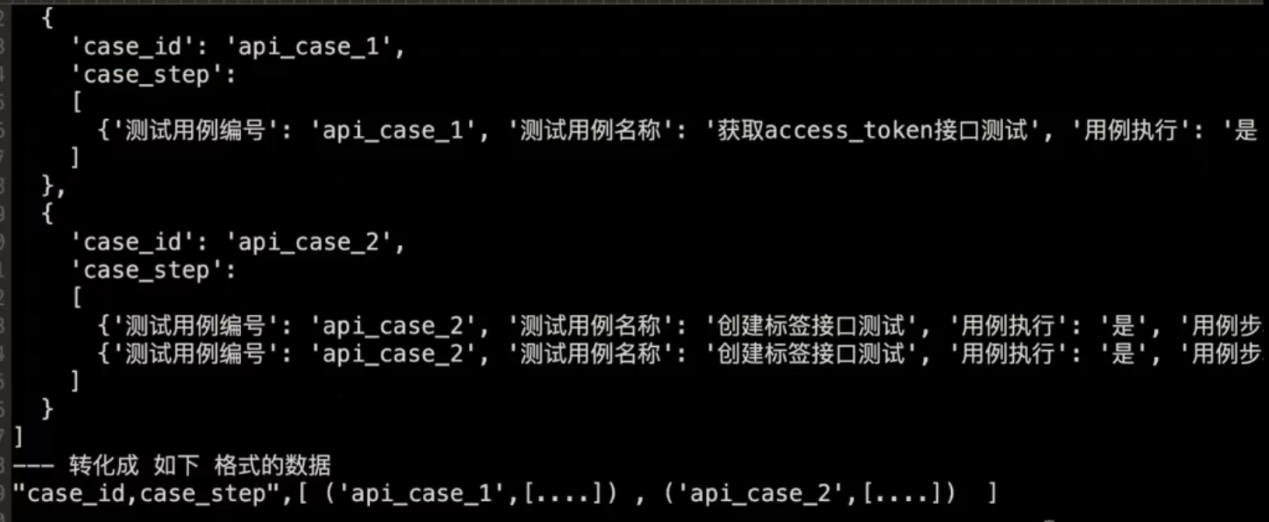
把列表转换为字符串的语法

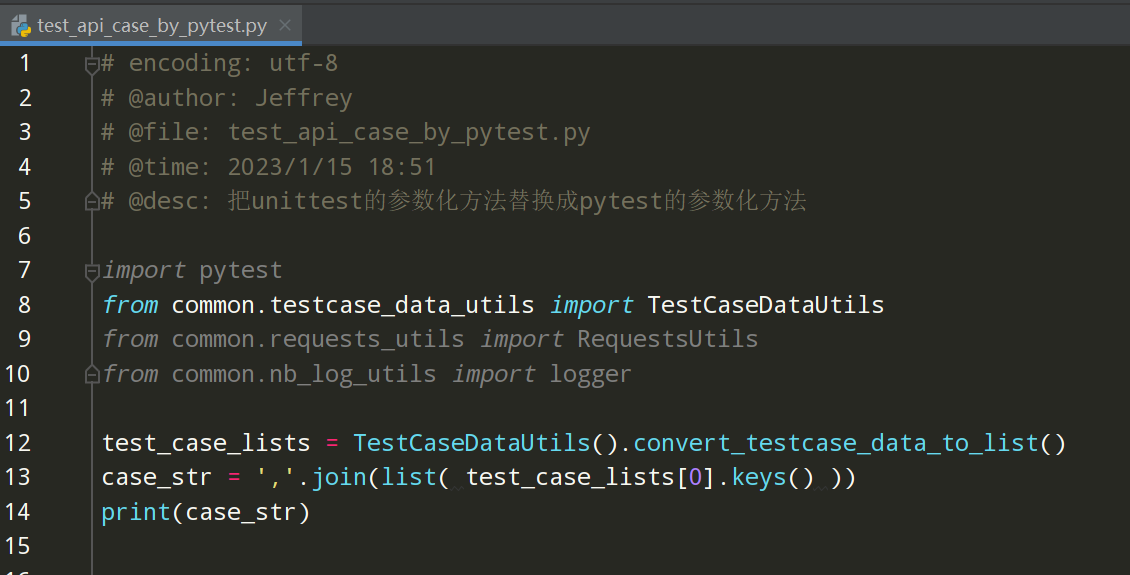
Pytest参数化左边的数据处理完成,如下

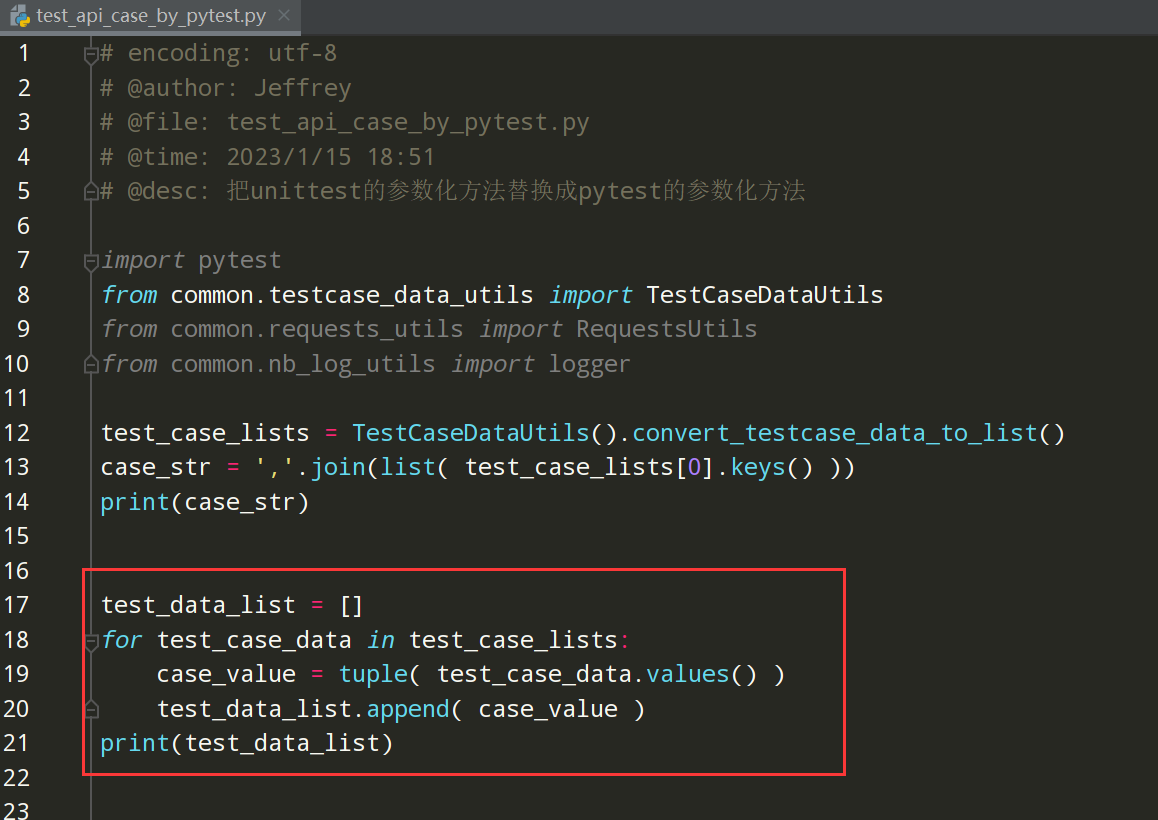
Pytest参数化右边的数据处理完成;如下
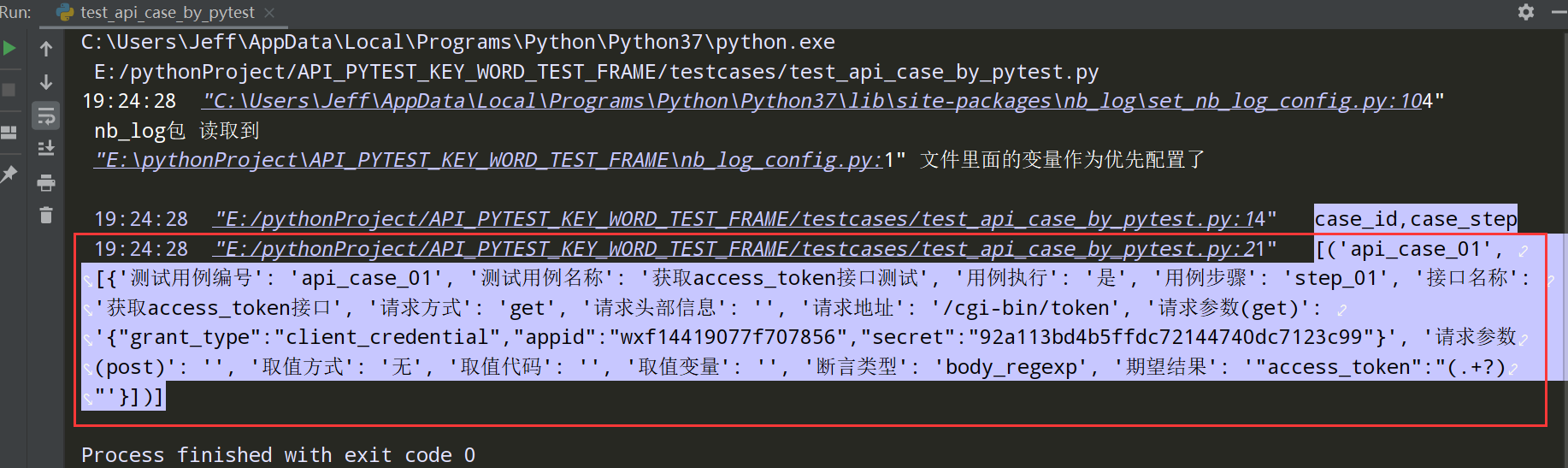
步骤2:
在test_runner下新建pytest的总执行入口(run_all_cases_by_pytest.py)
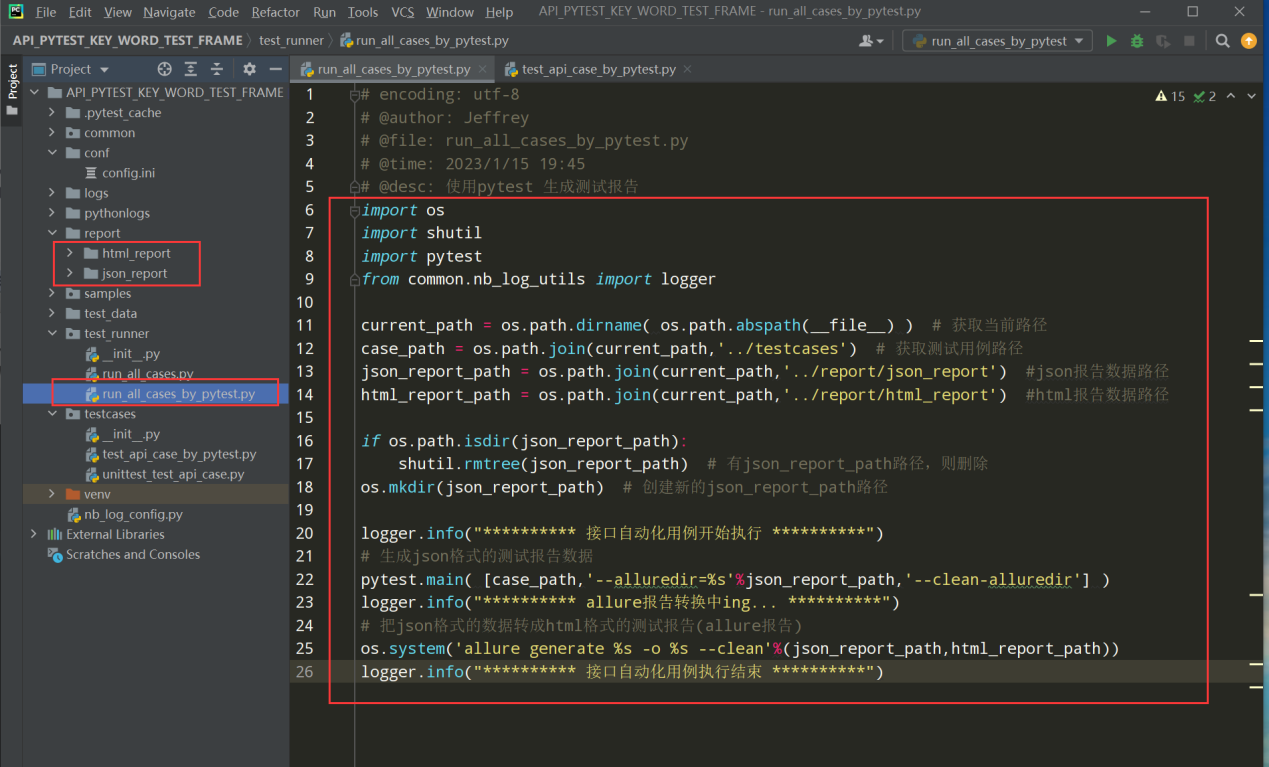
先下载并导入import pytest
编写代码:
# encoding: utf-8 # @author: Jeffrey # @file: run_all_cases_by_pytest.py # @time: 2023/1/15 19:45 # @desc: 使用pytest 生成测试报告 import os import shutil import pytest from common.nb_log_utils import logger current_path = os.path.dirname( os.path.abspath(__file__) ) # 获取当前路径 case_path = os.path.join(current_path,'../testcases') # 获取测试用例路径 json_report_path = os.path.join(current_path,'../report/json_report') #json报告数据路径 html_report_path = os.path.join(current_path,'../report/html_report') #html报告数据路径 if os.path.isdir(json_report_path): shutil.rmtree(json_report_path) # 有json_report_path路径,则删除 os.mkdir(json_report_path) # 创建新的json_report_path路径 logger.info("********** 接口自动化用例开始执行 **********") # 生成json格式的测试报告数据 pytest.main( [case_path,'--alluredir=%s'%json_report_path,'--clean-alluredir'] ) logger.info("********** allure报告转换中ing... **********") # 把json格式的数据转成html格式的测试报告(allure报告) os.system('allure generate %s -o %s --clean'%(json_report_path,html_report_path)) logger.info("********** 接口自动化用例执行结束 **********")
执行查看结果:
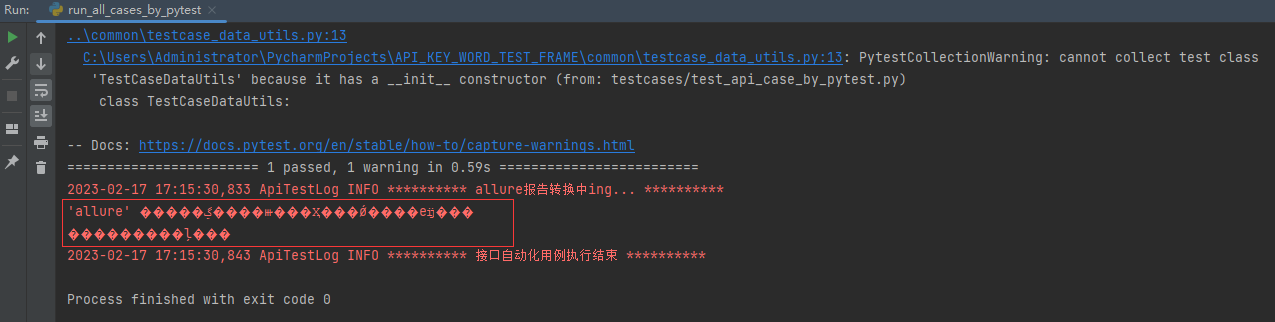
如果出现上方是情况就是allure没有配置环境变量
前置条件:先在本地查看是否配置allure的环境变量;如下图
配置了环境变量:
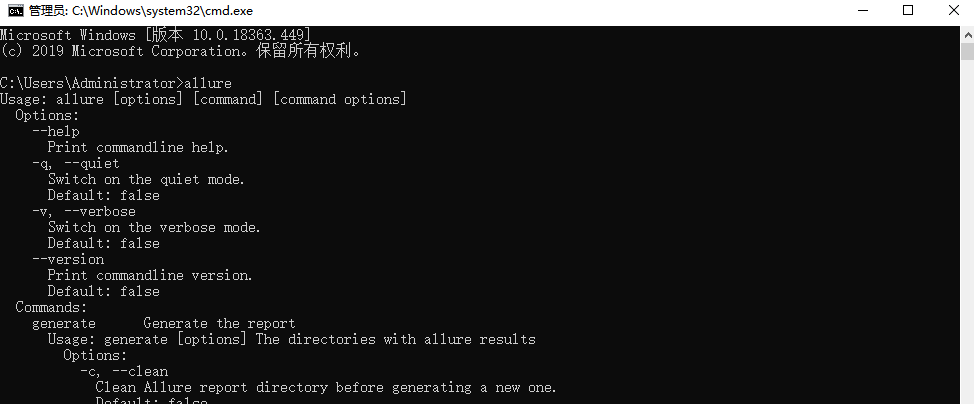
未配置环境变量:
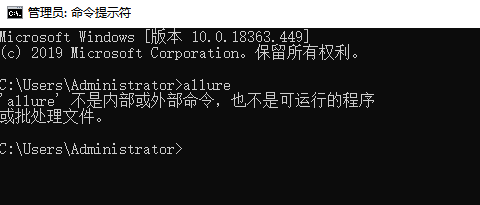
如果本地没有配置allure环境变量会导致allure命令无法执行;在执行run_all_cases_by_pytest.py文件的时候会提示‘allure‘不是内部或外部命令,也不是可运行的程序 或批处理文件;
具体就是下面的代码无法执行:
os.system('allure generate %s -o %s --clean'%(json_report_path,html_report_path))
配置环境变量的操作:
参考地址:https://www.cnblogs.com/YouJeffrey/p/15487401.html
再次执行查看结果:因为没有下载allure-pytest插件导致--alluredir命令无法使用;如下图
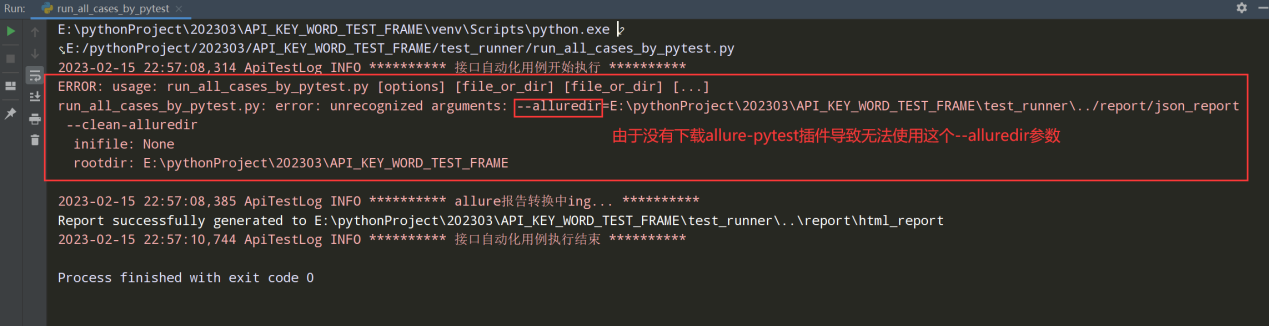
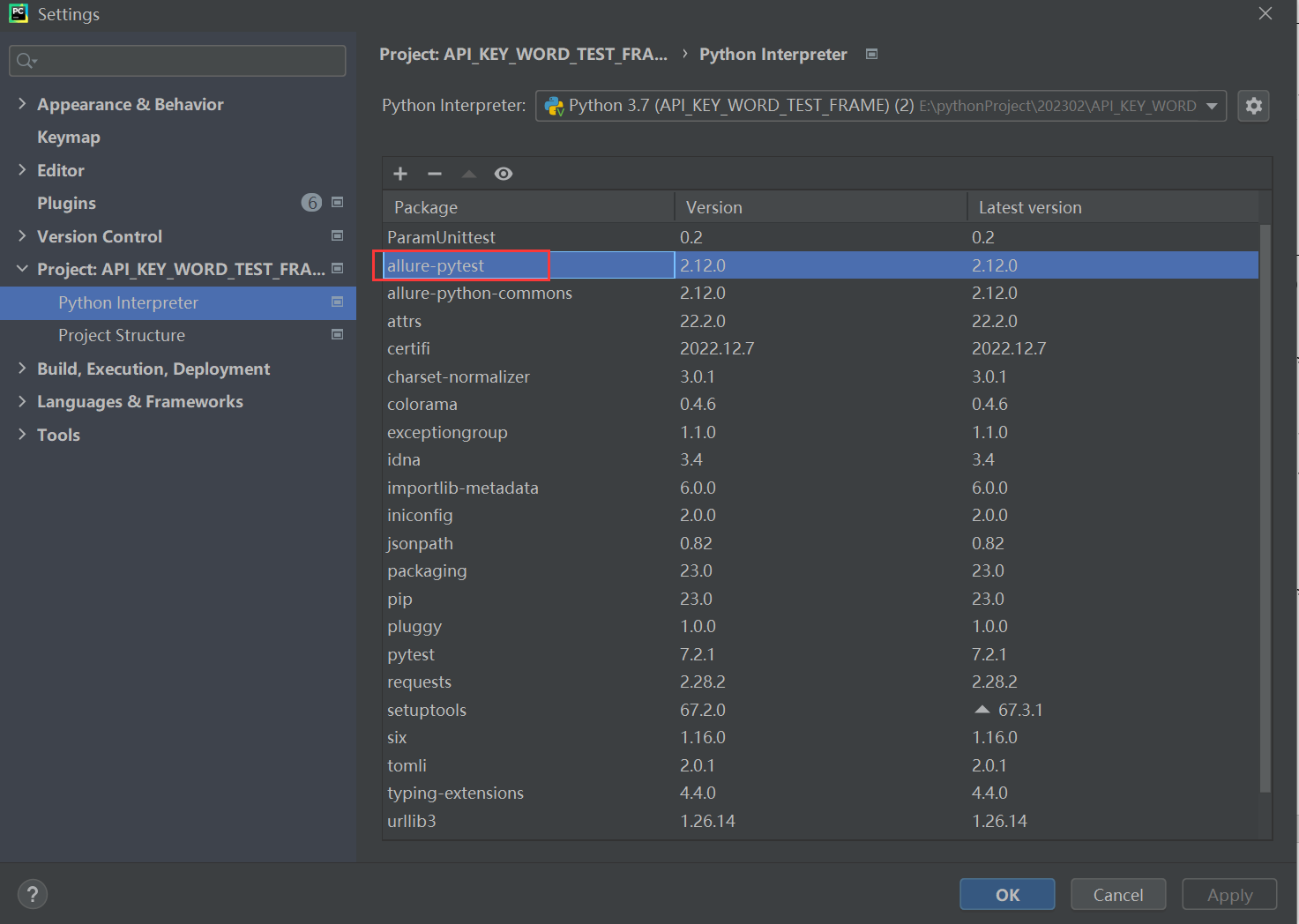
解决办法:
下载allure-pytest,才能使用
pytest.main( [case_path,'--alluredir=%s'%json_report_path,'--clean-alluredir'] )中的--alluredir参数;
步骤3:
执行查看生成的allure测试报告
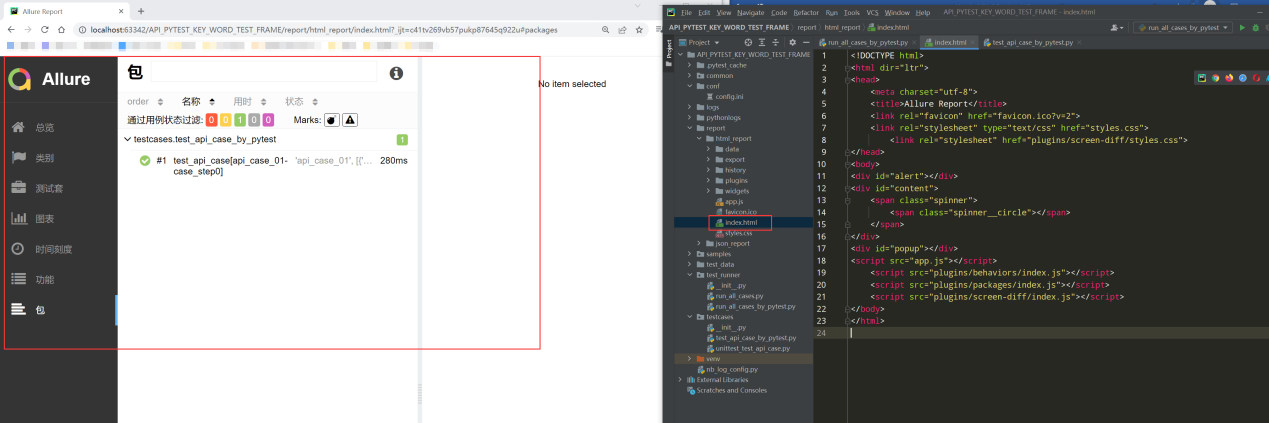
优化allure测试报告

在allure测试报告中展示测试用例名称;在test_api_case_by_pytest.py中进行调整;
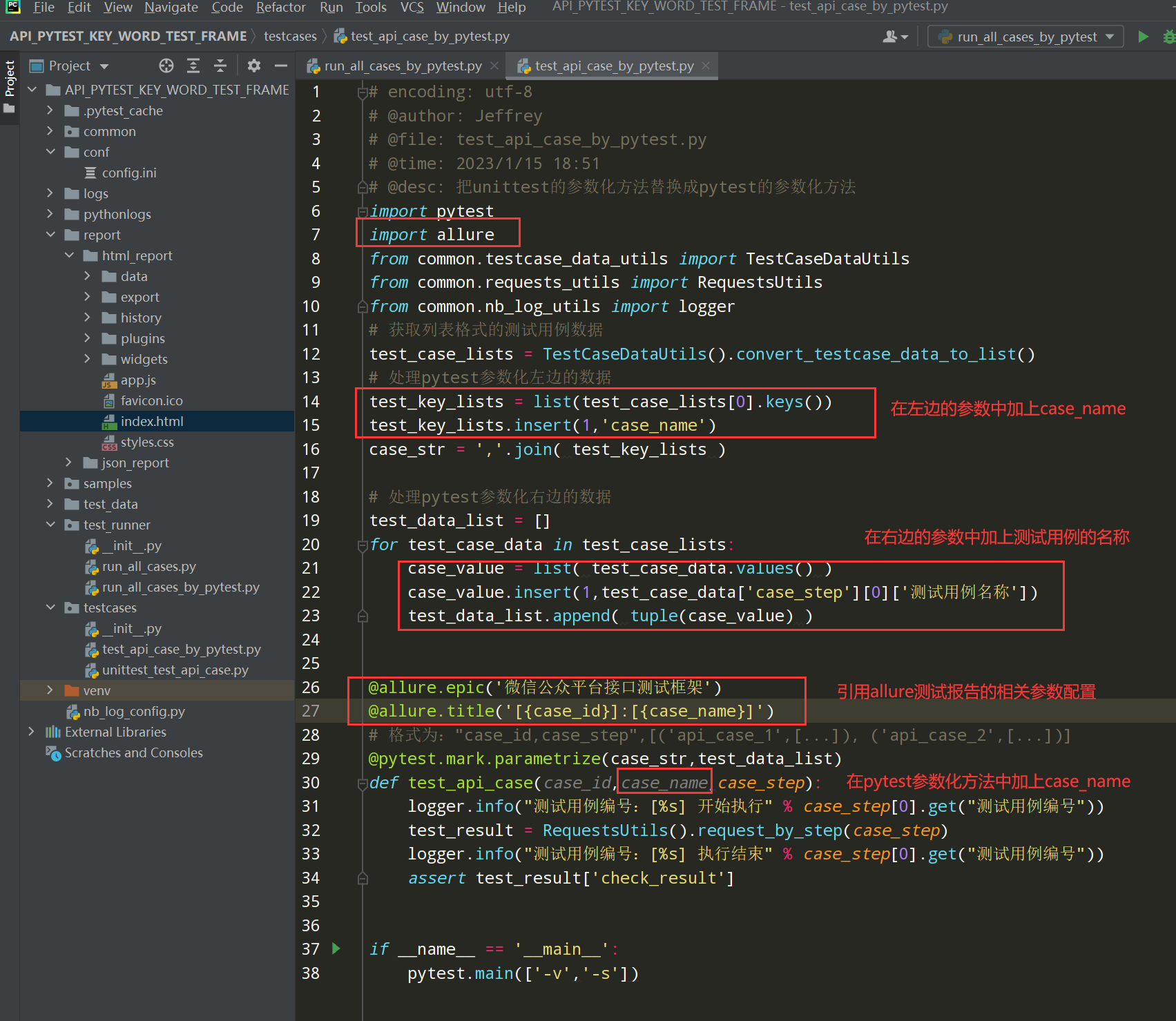
编写代码:
# encoding: utf-8 # @author: Jeffrey # @file: test_api_case_by_pytest.py # @time: 2023/1/15 18:51 # @desc: 把unittest的参数化方法替换成pytest的参数化方法 import pytest import allure from common.testcase_data_utils import TestCaseDataUtils from common.requests_utils import RequestsUtils from common.nb_log_utils import logger # 获取列表格式的测试用例数据 test_case_lists = TestCaseDataUtils().convert_testcase_data_to_list() # 处理pytest参数化左边的数据 test_key_lists = list(test_case_lists[0].keys()) test_key_lists.insert(1,'case_name') case_str = ','.join( test_key_lists ) # 处理pytest参数化右边的数据 test_data_list = [] for test_case_data in test_case_lists: case_value = list( test_case_data.values() ) case_value.insert(1,test_case_data['case_step'][0]['测试用例名称']) test_data_list.append( tuple(case_value) ) @allure.epic('微信公众平台接口测试框架') @allure.title('[{case_id}]:[{case_name}]') # 格式为:"case_id,case_step",[('api_case_1',[...]), ('api_case_2',[...])] @pytest.mark.parametrize(case_str,test_data_list) def test_api_case(case_id,case_name,case_step): logger.info("测试用例编号:[%s] 开始执行" % case_step[0].get("测试用例编号")) test_result = RequestsUtils().request_by_step(case_step) logger.info("测试用例编号:[%s] 执行结束" % case_step[0].get("测试用例编号")) assert test_result['check_result'] if __name__ == '__main__': pytest.main(['-v','-s'])
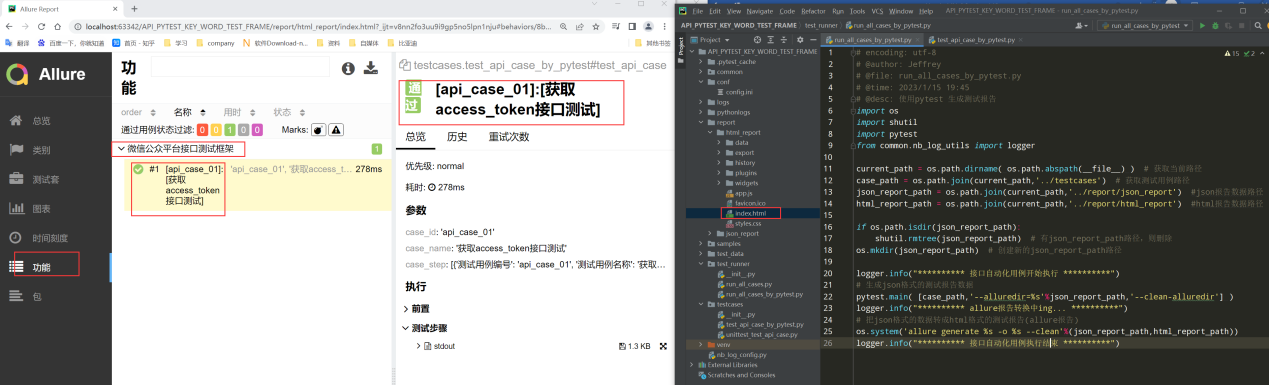
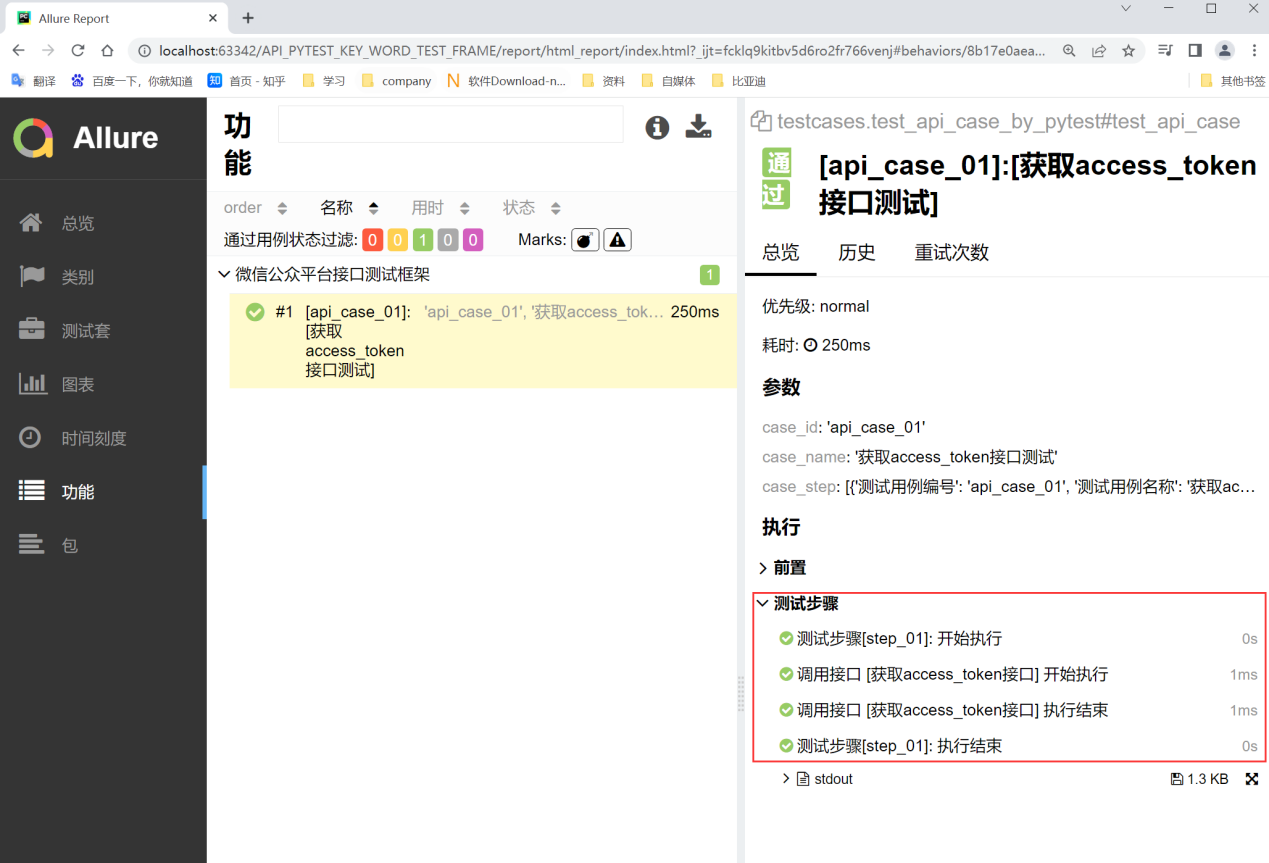
最后执行pytest的主入口run_all_cases_by_pytest.py,查看生成的测试报告
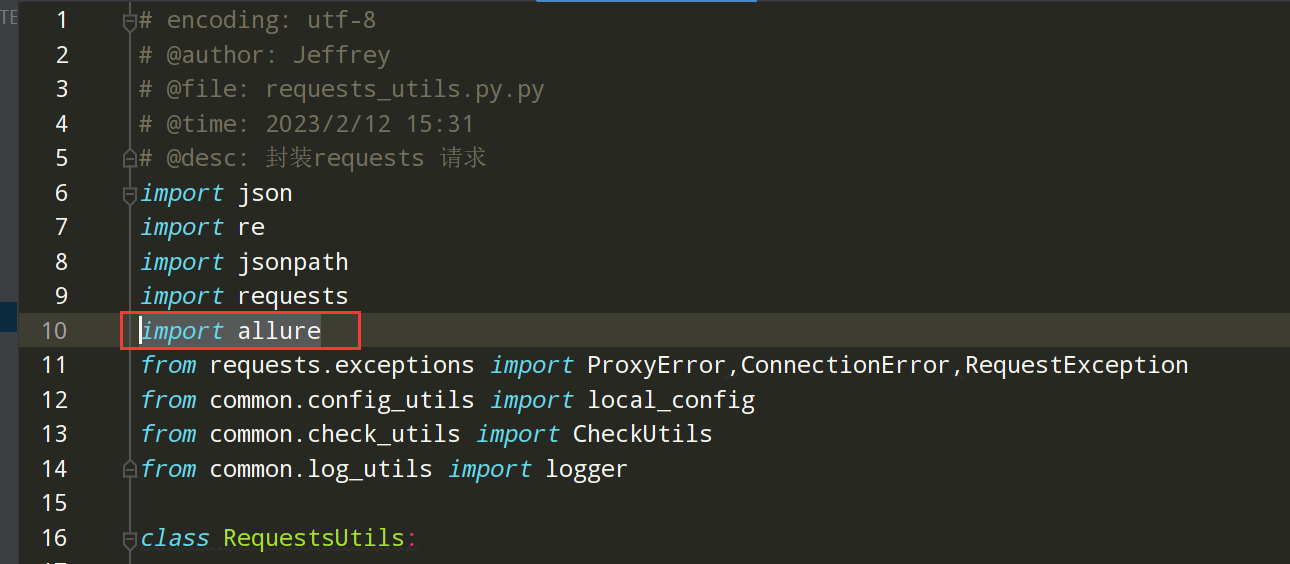
优化allure报告中的测试步骤,可以在requests_utils.py文件中进行如下调整:
前置条件:先导入import allure;
调整如下:
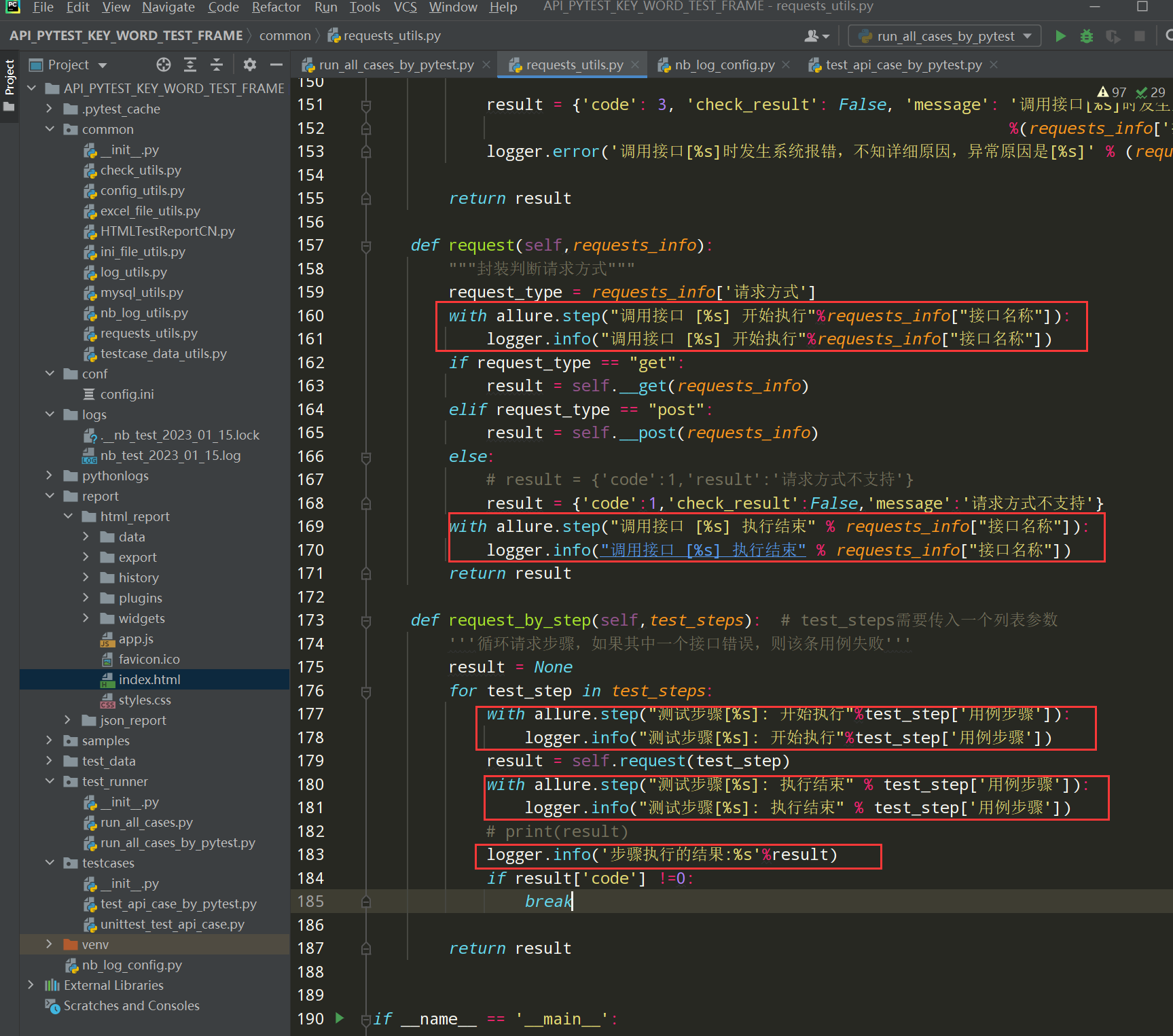
编写代码:
with allure.step("调用接口 [%s] 开始执行"%requests_info["接口名称"]): logger.info("调用接口 [%s] 开始执行"%requests_info["接口名称"]) with allure.step("调用接口 [%s] 执行结束" % requests_info["接口名称"]): logger.info("调用接口 [%s] 执行结束" % requests_info["接口名称"]) with allure.step("测试步骤 [%s] 开始执行" % test_step["用例步骤"]): logger.info("测试步骤 [%s] 开始执行" % test_step["用例步骤"]) with allure.step("测试步骤 [%s] 执行结束" % test_step["用例步骤"]): logger.info("测试步骤 [%s] 执行结束" % test_step["用例步骤"]) logger.info('步骤执行的结果:%s' % result)
再次执行pytest的主入口run_all_cases_by_pytest.py,查看生成的测试报告
至此结束

