web自动化测试思路及实战(2):web自动化测试思路及实战
web自动化测试思路及实战
全部代码-Gitee:
Web_Auto_Test_FrameWork: WEB自动化测试实战练习 (gitee.com)
前期准备工作:
1、 python 列表、字典、循环、面向对象 (python语言基础)
2、 python第三方模块的使用:
os time 、文件操作、日期查找、配置文件ini、log日志、excel (框架底层的工具)
3、selenium入门:驱动、浏览器、元素识别、元素操作(页面元素识别、元素操作)
4、unittest框架:(优化成4章)框架的流程、断言、忽略测试、构建套件、测试报告生成(测试用例层、执行层)
5. selenium+unittest实战:编写线性脚本框架,
6. 正式开始编写PO模式的UI自动化框架
pageobjects 设计模式
Page Objects概念:
Page Objects是指UI界面上用于与用户进行交互的对象
pageobjects 设计模式概念:
pageobjects 模式是Selenium中的一种测试设计模式,主要是将每一个页面设计为一个Class,其中包含页面中需要测试的元素(按钮,输入框,标题 等),这样在Selenium测试页面中可以通过调用页面类来获取页面元素,这样巧妙的避免了当页面元素id或者位置变化时,需要改测试页面代码的情况。 当页面元素id变化时,只需要更改测试页Class中页面的属性即可。
简单来讲,就是将代码以页面为单位进行组织,针对这个页面上的所有信息,相关操作都放到一个类中;从而使具体的测试用例变成了简单的调用和验证操作
pageobjects 设计模式:把页面设计成类,把页面上的控件作为属性,把控件的操作设计成方法
类=属性+方法
以下是以关键字数据驱动框架做的实战项目
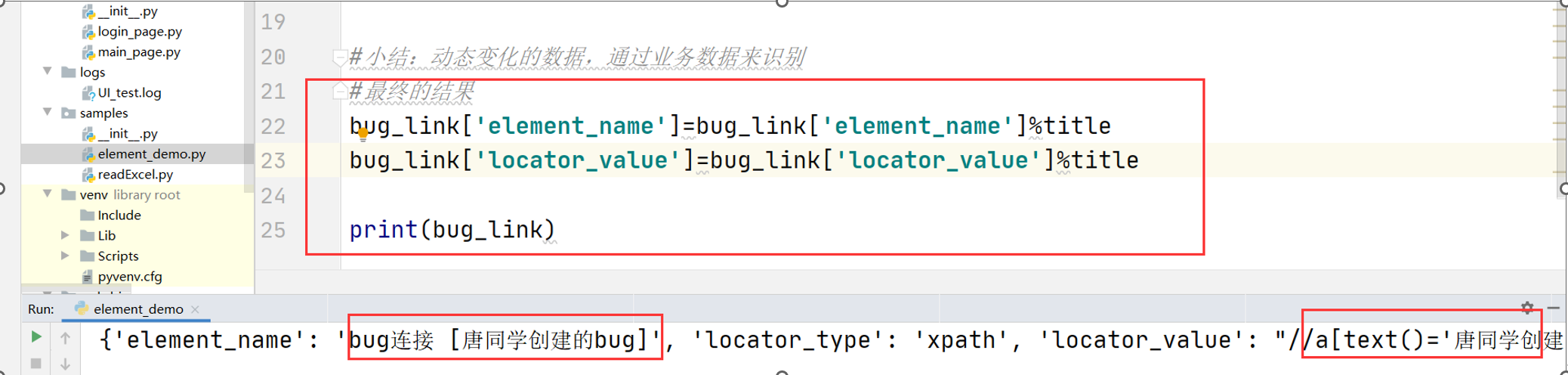
被测系统:禅道系统
框架01-pageobjects模型基础及应用

思路:
1. 新建一个元素信息包element_info,存放我们的页面
2. 新建webdriver驱动文件夹,导入浏览器的驱动文件
3. 新建login_page.py,添加属性、方法
4. 新建一个main_page.py
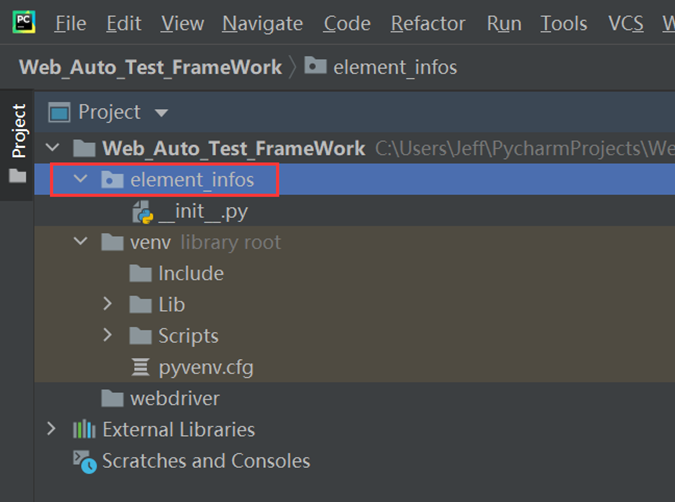
1. 在项目名下新建一个python的文件夹element_infos
新建Web_Auto_Test_Framework项目,在该项目的下面新建element_infos的py文件夹
2. 新建webdriver驱动文件夹,导入浏览器驱动文件

3. 在element_infos下新建login_page.py,添加属性、方法
前置条件下载selenium库:
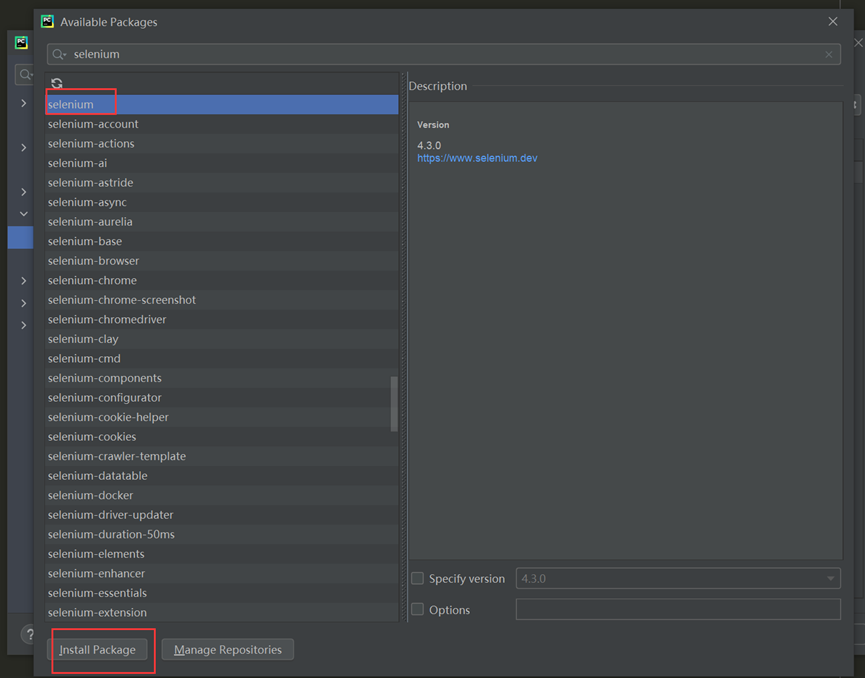
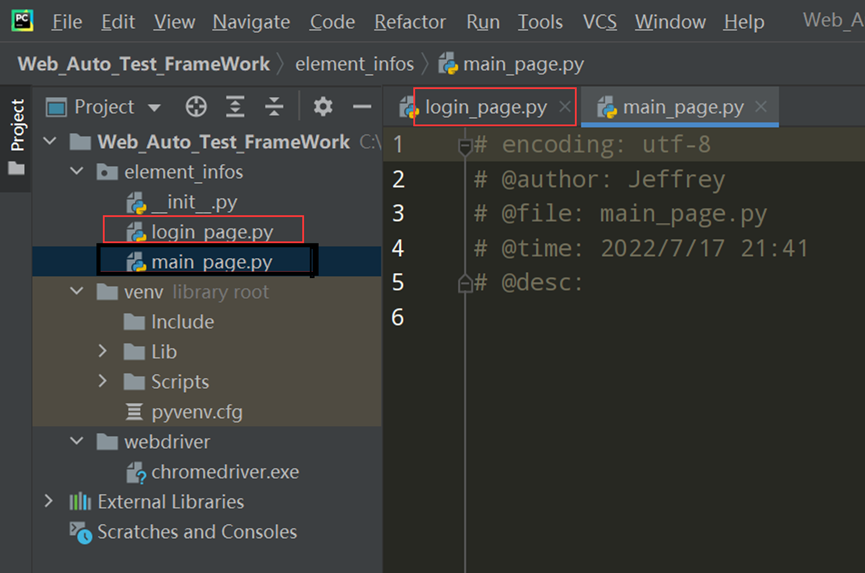
代码示例:
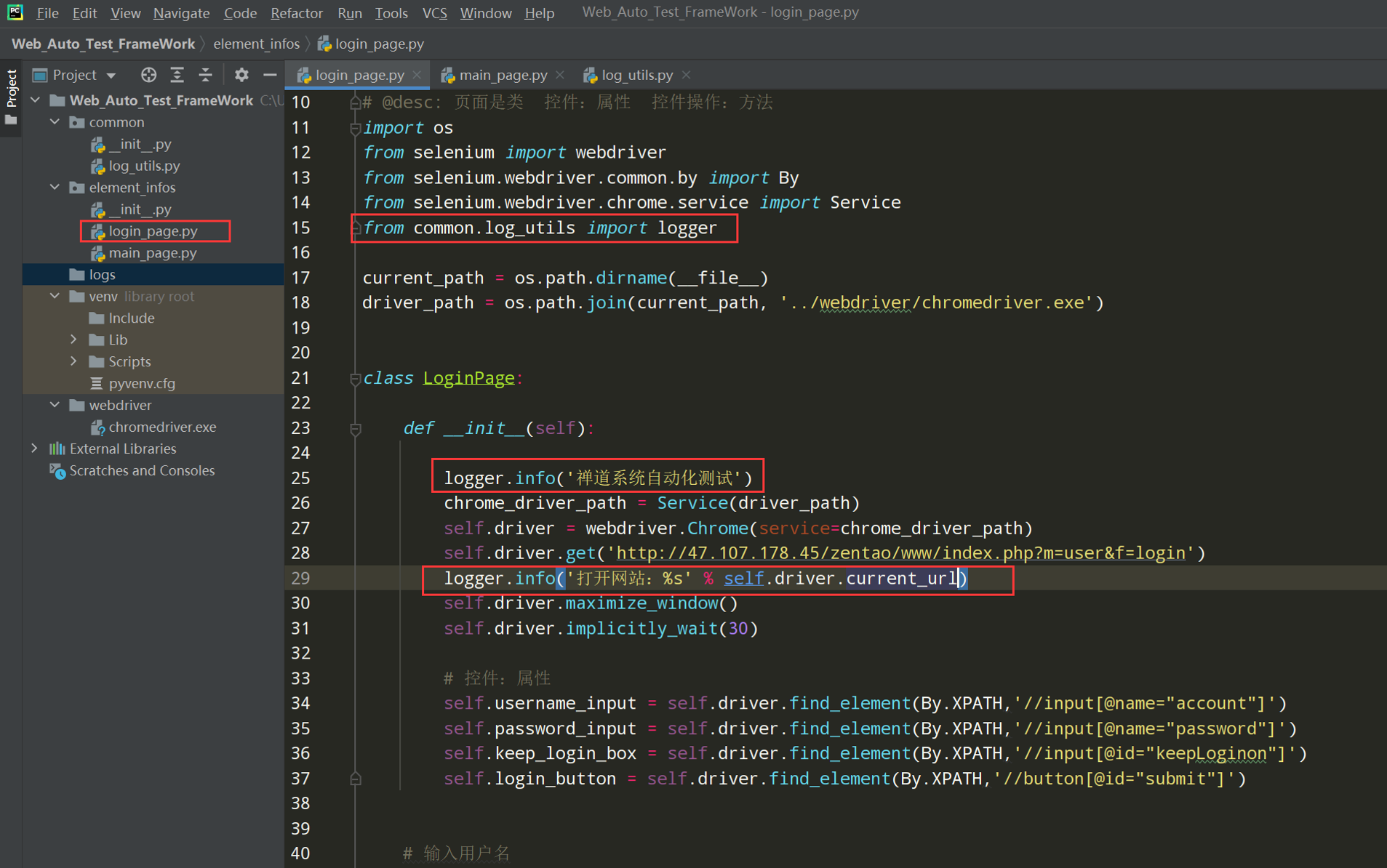
# encoding: utf-8 # @author: Jeffrey # @file: login_page.py # @time: 2022/7/17 21:39 # @desc: 页面是类 控件:属性 控件操作:方法 import os from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service current_path = os.path.dirname(__file__) driver_path = os.path.join(current_path, '../webdriver/chromedriver.exe') class LoginPage: def __init__(self): chrome_driver_path = Service(driver_path) self.driver = webdriver.Chrome(service=chrome_driver_path) self.driver.get('http://47.107.178.45/zentao/www/index.php?m=user&f=login') self.driver.maximize_window() self.driver.implicitly_wait(30) # 控件:属性 self.username_input = self.driver.find_element(By.XPATH,'//input[@name="account"]') self.password_input = self.driver.find_element(By.XPATH,'//input[@name="password"]') self.keep_login_box = self.driver.find_element(By.XPATH,'//input[@id="keepLoginon"]') self.login_button = self.driver.find_element(By.XPATH,'//button[@id="submit"]') # 输入用户名 def input_username(self,username): self.username_input.send_keys(username) # 输入密码 def input_password(self,password): self.password_input.send_keys(password) # 点击保持登录 def keep_login(self): self.keep_login_box.click() # 点击登录按钮 def click_login(self): self.login_button.click() if __name__ == '__main__': loginpage = LoginPage() loginpage.input_username('test01') loginpage.input_password('newdream123') loginpage.click_login() # 小结:页面=属性+方法 # 属性的命名:名称_元素类型 # 操作的命名:动作_元素名称
4. 新建一个main_page.py
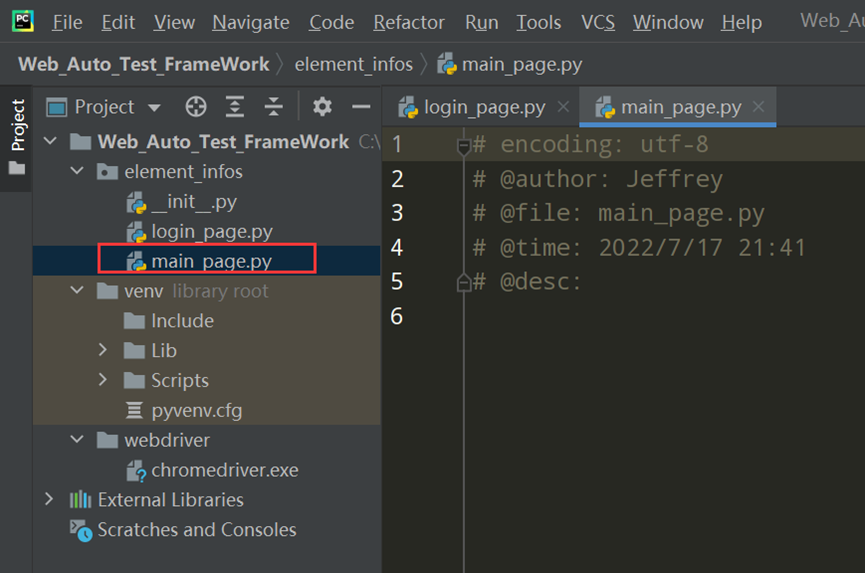
思路:
1. 添加元素--属性
2. 添加动作--方法
3. 处理好driver,把login的driver 转给主页面
代码示例:
#第二个页面 # encoding: utf-8 # @author: Jeffrey # @file: main_page.py # @time: 2022/7/2 13:04 # @desc: import os import time from selenium import webdriver from selenium.webdriver.common.by import By from element_infos.login_page import LoginPage class MainPage: def __init__(self): login_page = LoginPage() login_page.input_username('test01') login_page.input_password('newdream123') login_page.click_login() # 把登录页面的driver转移到main_page self.driver = login_page.driver self.companyname_showbox = self.driver.find_element(By.XPATH, '//h1[@id="companyname"]') self.myzone_menu = self.driver.find_element(By.XPATH, '//li[@data-id="my"]') self.product_menu = self.driver.find_element(By.XPATH, '//li[@data-id="product"]') self.username_showbox = self.driver.find_element(By.XPATH, '//span[@class="user-name"]') # 获取公司名称 def get_companyname(self): value = self.companyname_showbox.get_attribute('title') return value # 选择我的地盘 def goto_myzone(self): self.myzone_menu.click() # 选择我的产品 def goto_product(self): self.product_menu.click() # 获取登录的用户名 def get_username(self): value = self.username_showbox.text return value if __name__ == '__main__': main_page = MainPage() print(main_page.get_username()) # pageobject模式是实例化页面之后,需要识别所有的元素,然后再去操作,导致有些元素不能识别的问题;如下三个方法会报错,可参考框架02 # print(main_page.get_companyname()) # main_page.goto_myzone() # # main_page.goto_product()
5、新建common的py文件夹再添加日志封装log_utils.py
前置条件:在项目根目录下新建一个logs的文件夹
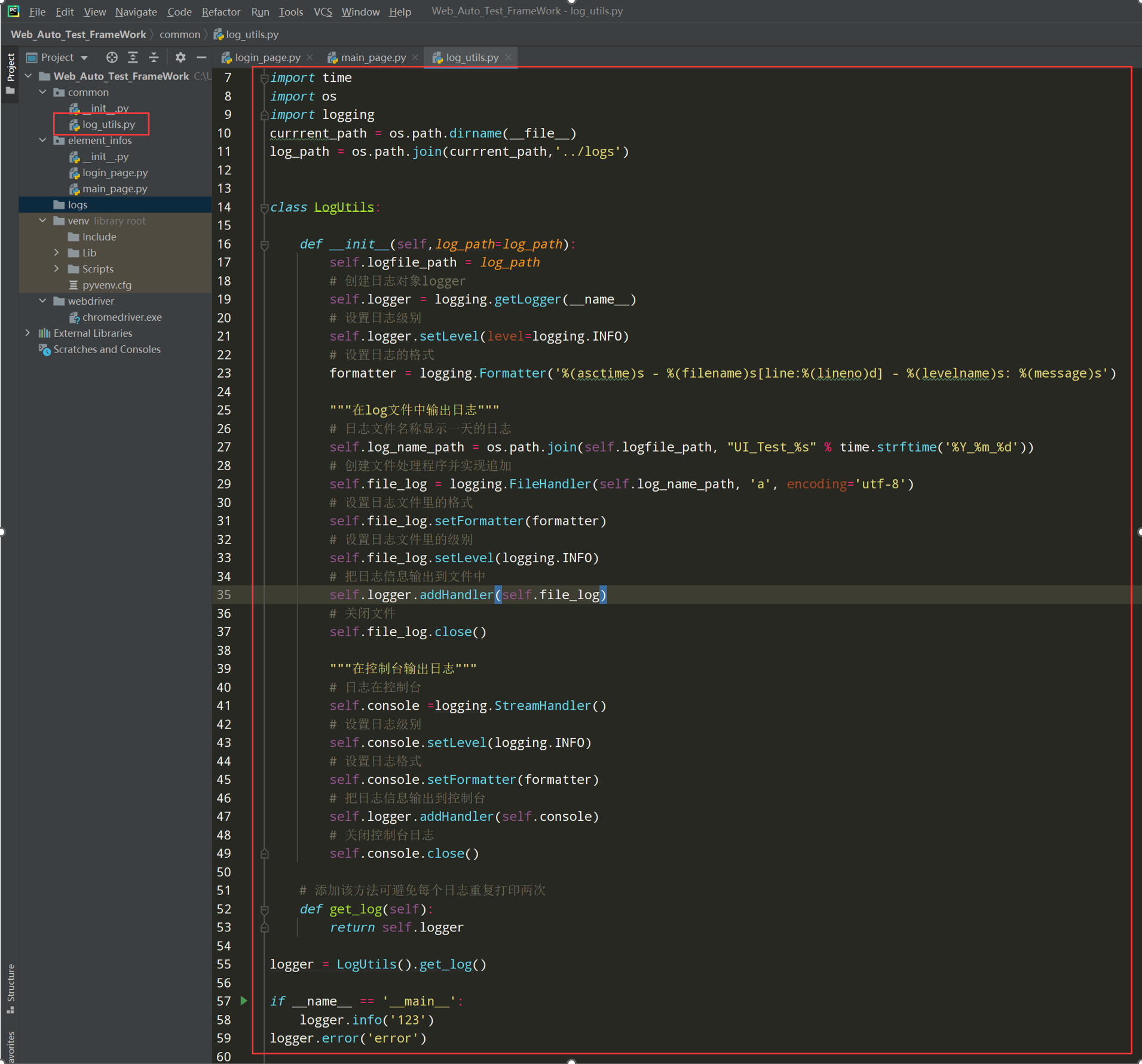
代码示例:
import time import os import logging currrent_path = os.path.dirname(__file__) log_path = os.path.join(currrent_path,'../logs') class LogUtils: def __init__(self,log_path=log_path): self.logfile_path = log_path # 创建日志对象logger self.logger = logging.getLogger(__name__) # 设置日志级别 self.logger.setLevel(level=logging.INFO) # 设置日志的格式 formatter = logging.Formatter('%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s') """在log文件中输出日志""" # 日志文件名称显示一天的日志 self.log_name_path = os.path.join(self.logfile_path, "UI_Test_%s" % time.strftime('%Y_%m_%d')) # 创建文件处理程序并实现追加 self.file_log = logging.FileHandler(self.log_name_path, 'a', encoding='utf-8') # 设置日志文件里的格式 self.file_log.setFormatter(formatter) # 设置日志文件里的级别 self.file_log.setLevel(logging.INFO) # 把日志信息输出到文件中 self.logger.addHandler(self.file_log) # 关闭文件 self.file_log.close() """在控制台输出日志""" # 日志在控制台 self.console =logging.StreamHandler() # 设置日志级别 self.console.setLevel(logging.INFO) # 设置日志格式 self.console.setFormatter(formatter) # 把日志信息输出到控制台 self.logger.addHandler(self.console) # 关闭控制台日志 self.console.close() # 添加该方法可避免每个日志重复打印两次 def get_log(self): return self.logger logger = LogUtils().get_log() if __name__ == '__main__': logger.info('123') logger.error('error') # 把封装的日志引入到login_page.py文件中
把日志添加到login_page.py文件中
小结:
1. 封装log_utils工具类
2. 避免一行日志出现多行的情况,在log_utils.py添加了一个logger对象
框架02--pageobject模型优化使用
界面层: 界面的元素
控件层: 单独验证每个控件的功能
功能层:单个或者多个功能组合操作形成的功能
业务层:单个或多个功能形成业务
PO模式分层和线性脚本的比较
线性脚本:按操作识别元素,识别一个元素操作一个,风险比较小
pageobject模式模型:先全部识别元素,然后再进行操作
注意:由于po模式是要先识别全部元素,才能进行操作所以会引出下面的问题
问题引出:
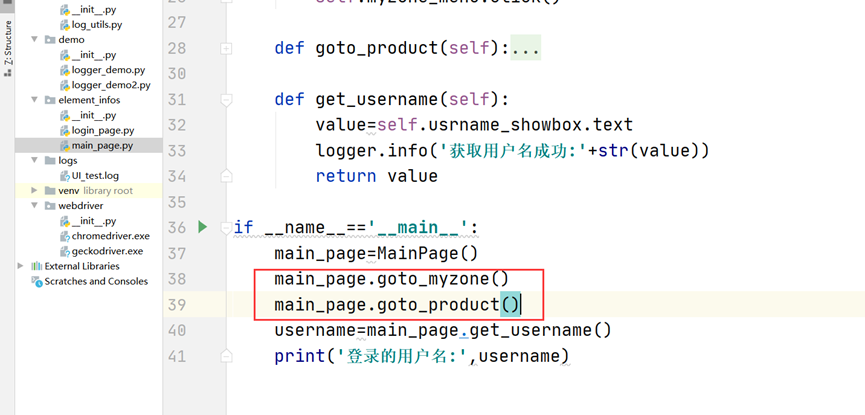
分析:加了这二句之后,出现问题,原因:pageobject模式是实例化页面之后,需要识别所有的元素,然后再去操作,导致有些元素不能识别的问题。
处理方法:识别数据分离,实例化对象的时候不识别元素,操作的时候再去识别。
思路:
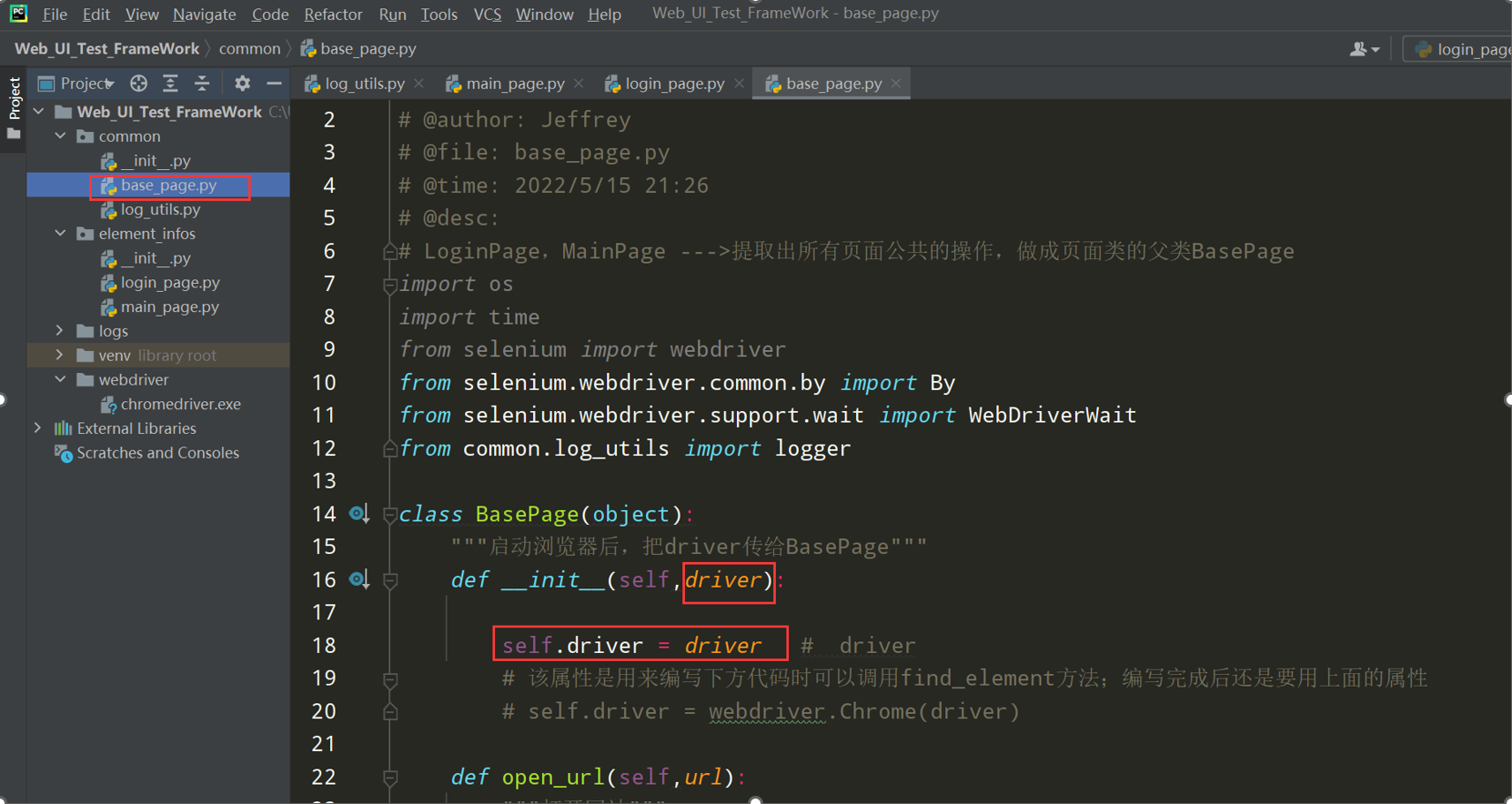
1. 在common中创建一个base_page.py-->BasePage类
2. 页面层元素识别方法,改为不用识别好元素,只需要识别到元素的信息
3. 在BasePage类中封装元素识别方法
4. 完善login_page.py中的LoginPage类继承BasePage类,并完善代码
1、在common中创建一个base_page.py-->BasePage类
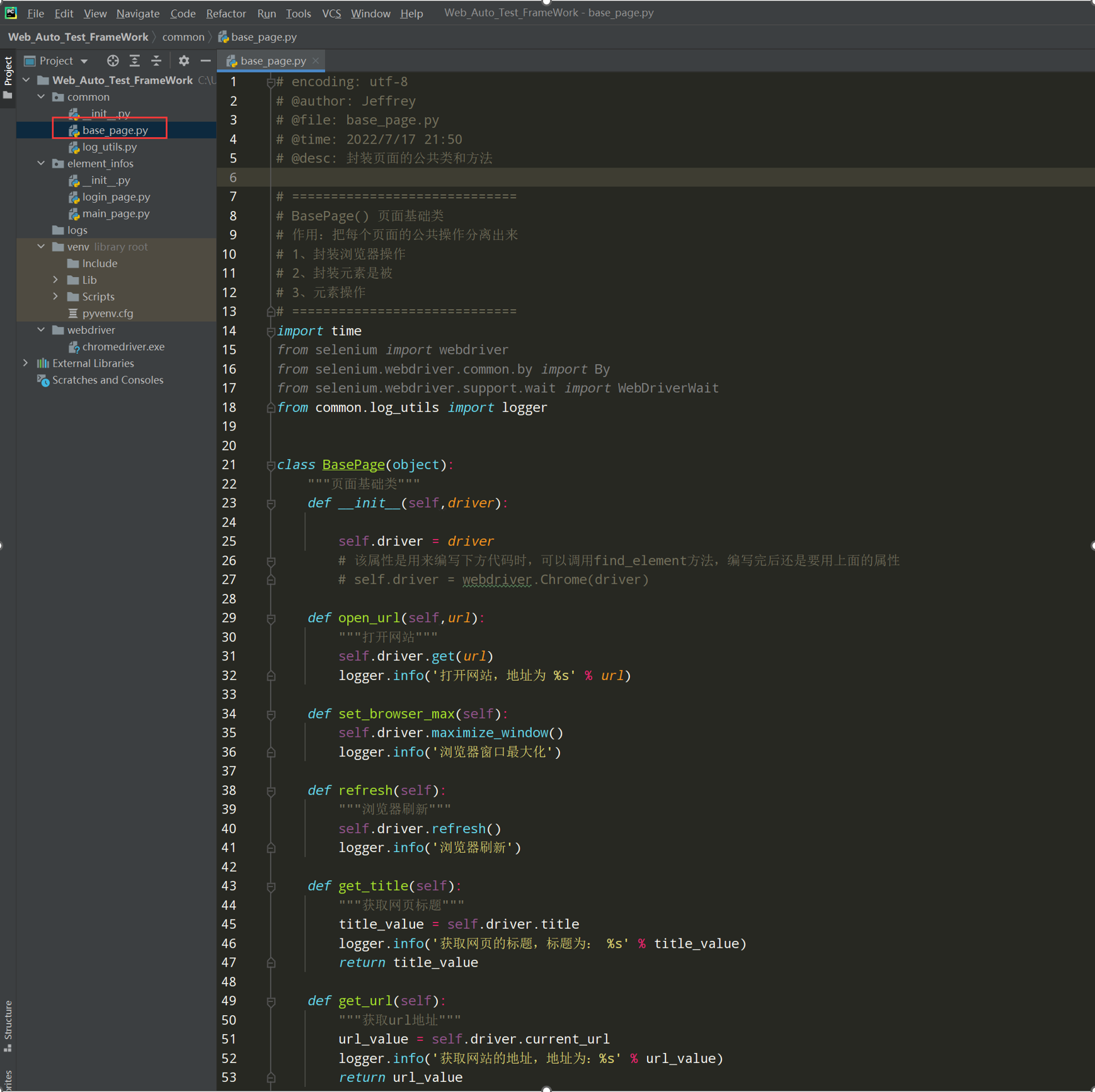
代码示例:
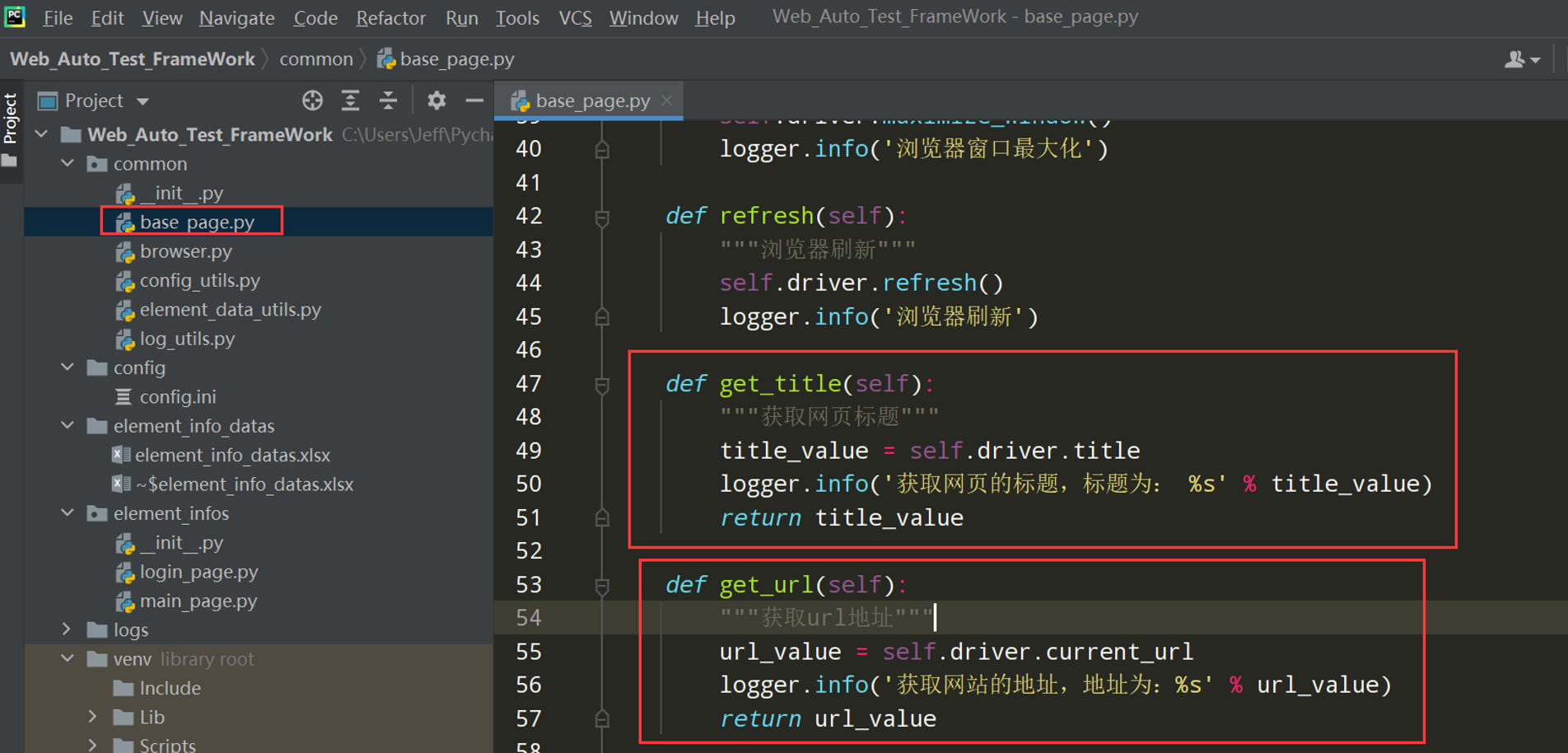
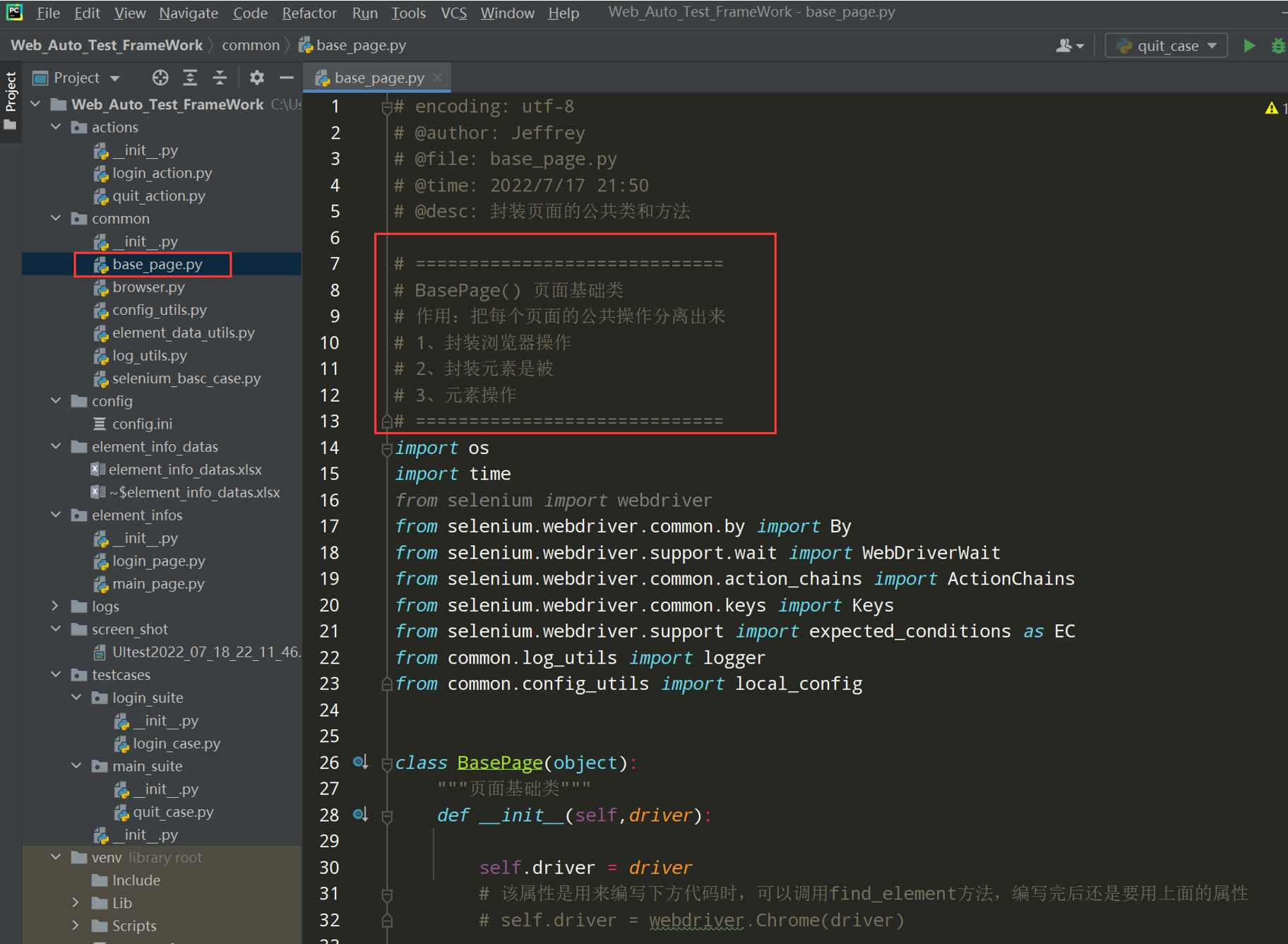
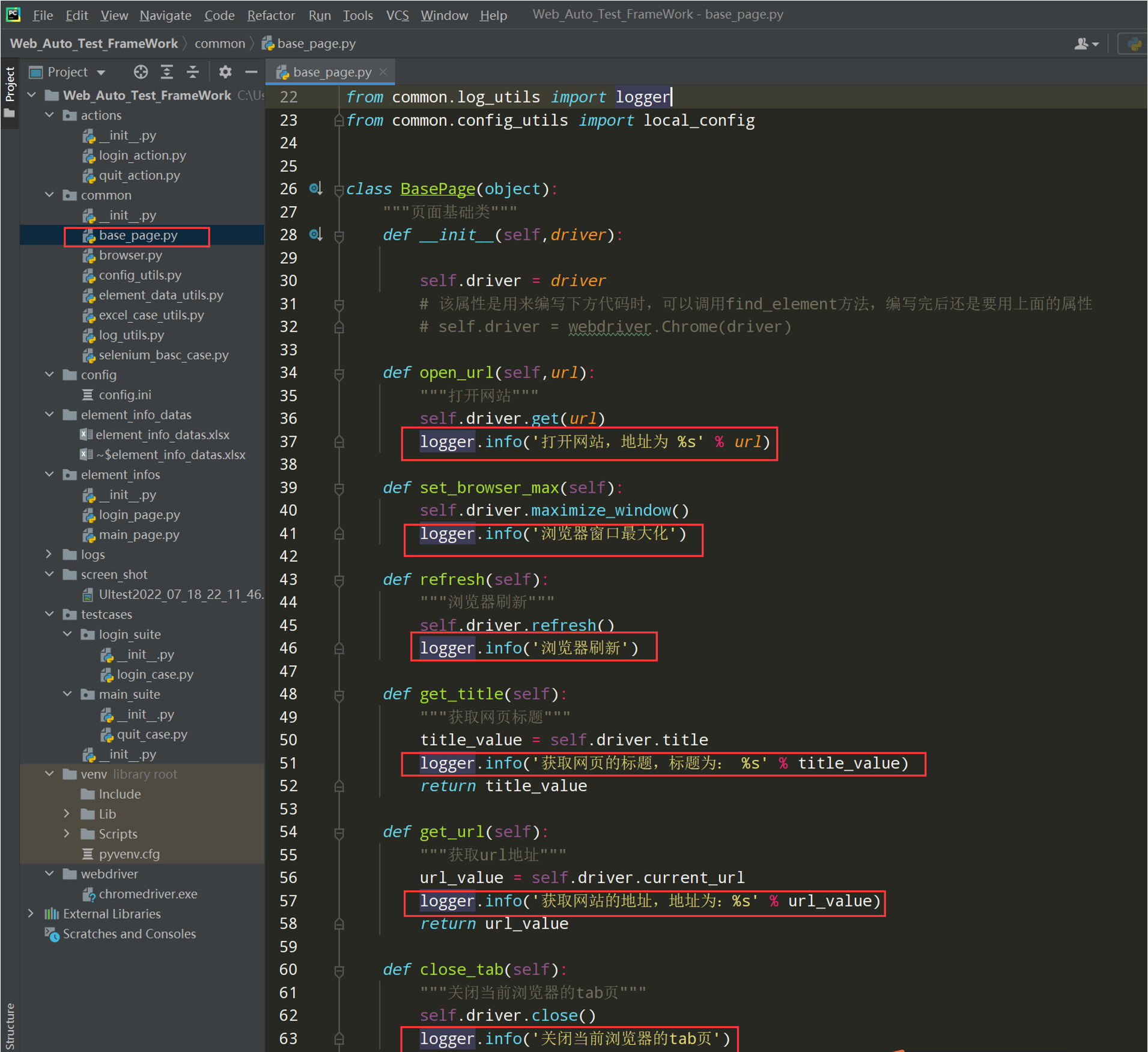
# encoding: utf-8 # @author: Jeffrey # @file: base_page.py # @time: 2022/7/2 17:18 # @desc: 封装页面的公共类和方法 # ============================= # BasePage() 页面基础类 # 作用:把每个页面的公共操作分离出来 # 1、封装浏览器操作 # 2、封装元素是被 # 3、元素操作 # ============================= import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from common.log_utils import logger class BasePage(object): """页面基础类""" def __init__(self,driver): self.driver = driver # 该属性是用来编写下方代码时,可以调用find_element方法,编写完后还是要用上面的属性 # self.driver = webdriver.Chrome(driver) def open_url(self,url): """打开网站""" self.driver.get(url) logger.info('打开网站,地址为 %s' % url) def set_browser_max(self): self.driver.maximize_window() logger.info('浏览器窗口最大化') def refresh(self): """浏览器刷新""" self.driver.refresh() logger.info('浏览器刷新') def get_title(self): """获取网页标题""" title_value = self.driver.title logger.info('获取网页的标题,标题为: %s' % title_value) return title_value def get_url(self): """获取url地址""" url_value = self.driver.current_url logger.info('获取网站的地址,地址为:%s' % url_value) return url_value def close_tab(self): """关闭当前浏览器的tab页""" self.driver.close() logger.info('关闭当前浏览器的tab页') def exit_driver(self): """退出浏览器""" self.driver.quit() logger.info('退出浏览器') """封装等待时间(显式,隐式,固定等待)""" def implicitly_wait(self, seconds): """封装隐式等待""" self.driver.implicitly_wait(seconds) logger.info('浏览器隐式等待:%s' % seconds) # 固定等待封装 def wait(self, seconds): time.sleep(seconds) logger.info('固定等待时间:%s 秒' % seconds)
2、 在login_page.py页面层元素识别方法,改为不用识别好元素,只需要识别到元素的信息
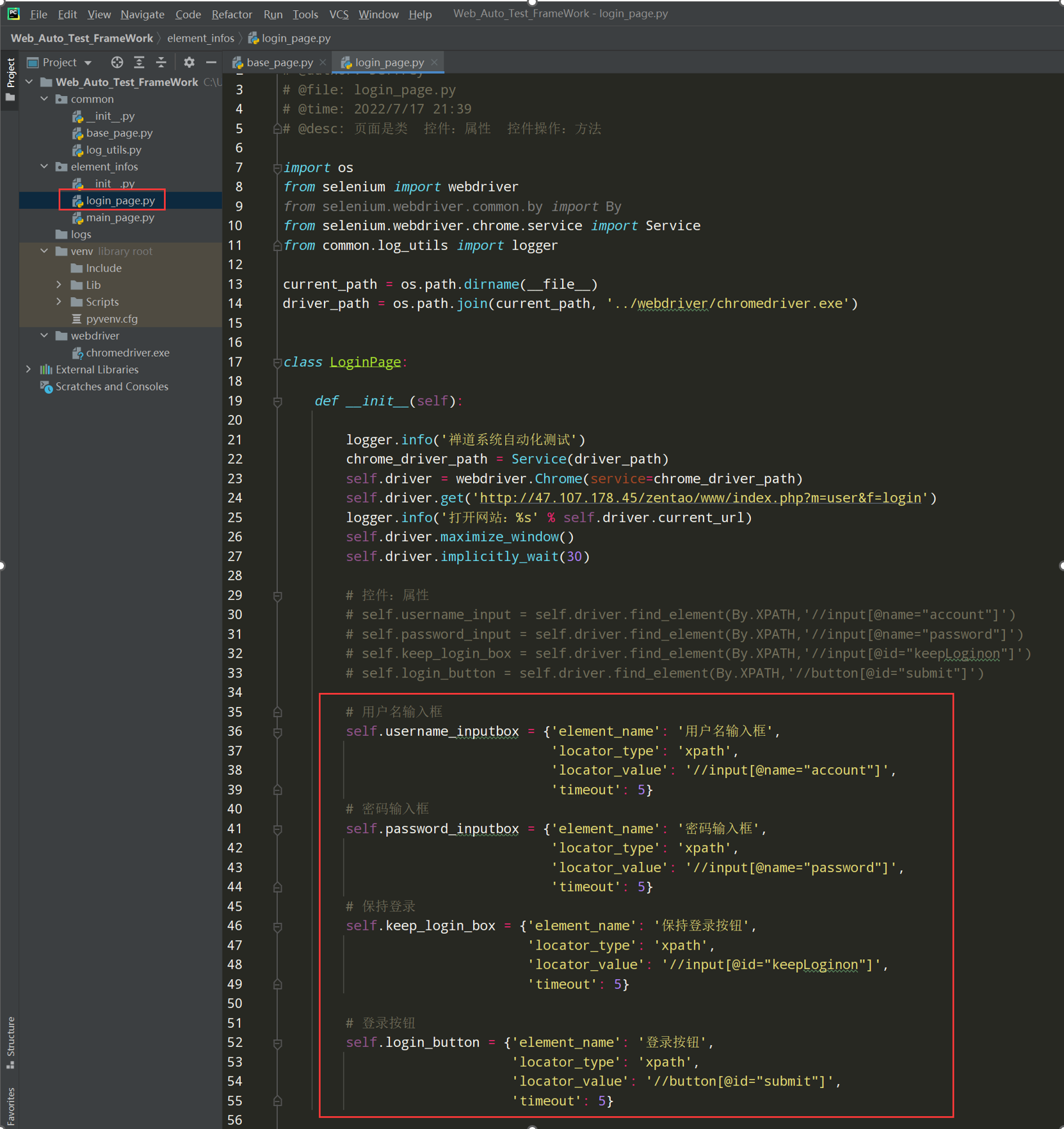
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: login_page.py # @time: 2022/7/17 21:39 # @desc: 页面是类 控件:属性 控件操作:方法 import os from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from common.log_utils import logger current_path = os.path.dirname(__file__) driver_path = os.path.join(current_path, '../webdriver/chromedriver.exe') class LoginPage: def __init__(self): logger.info('禅道系统自动化测试') chrome_driver_path = Service(driver_path) self.driver = webdriver.Chrome(service=chrome_driver_path) self.driver.get('http://47.107.178.45/zentao/www/index.php?m=user&f=login') logger.info('打开网站:%s' % self.driver.current_url) self.driver.maximize_window() self.driver.implicitly_wait(30) # 控件:属性 # self.username_input = self.driver.find_element(By.XPATH,'//input[@name="account"]') # self.password_input = self.driver.find_element(By.XPATH,'//input[@name="password"]') # self.keep_login_box = self.driver.find_element(By.XPATH,'//input[@id="keepLoginon"]') # self.login_button = self.driver.find_element(By.XPATH,'//button[@id="submit"]') # 用户名输入框 self.username_inputbox = {'element_name': '用户名输入框', 'locator_type': 'xpath', 'locator_value': '//input[@name="account"]', 'timeout': 5} # 密码输入框 self.password_inputbox = {'element_name': '密码输入框', 'locator_type': 'xpath', 'locator_value': '//input[@name="password"]', 'timeout': 5} # 保持登录 self.keep_login_box = {'element_name': '保持登录按钮', 'locator_type': 'xpath', 'locator_value': '//input[@id="keepLoginon"]', 'timeout': 5} # 登录按钮 self.login_button = {'element_name': '登录按钮', 'locator_type': 'xpath', 'locator_value': '//button[@id="submit"]', 'timeout': 5} # 输入用户名 def input_username(self,username): self.username_inputbox.send_keys(username) # 输入密码 def input_password(self,password): self.password_inputbox.send_keys(password) # 点击保持登录 def keep_login(self): self.keep_login_box.click() # 点击登录按钮 def click_login(self): self.login_button.click() if __name__ == '__main__': loginpage = LoginPage() loginpage.input_username('test01') loginpage.input_password('newdream123') loginpage.click_login() # 小结:页面=属性+方法 # 属性的命名:名称_元素类型 # 操作的命名:动作_元素名称
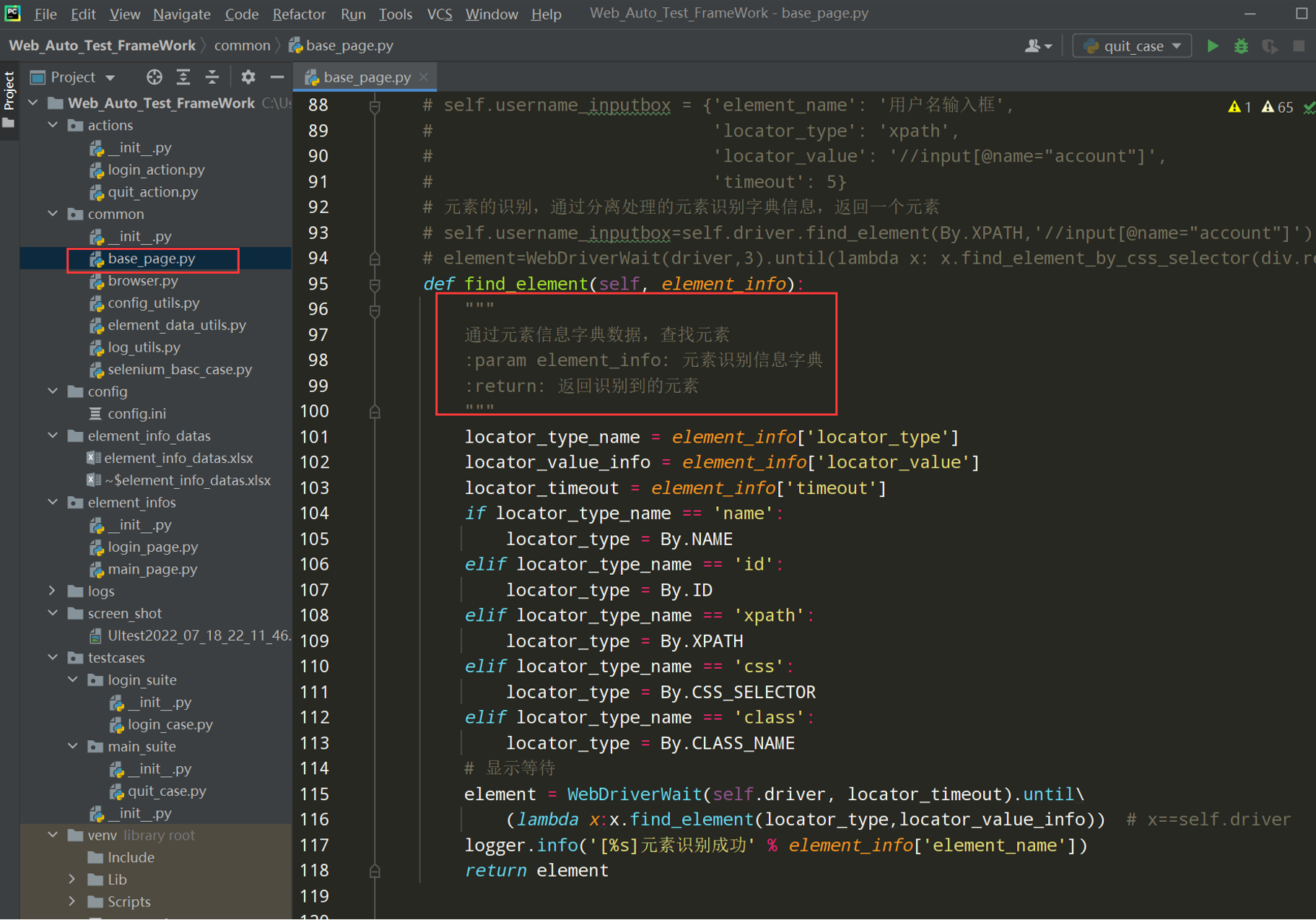
3、在BasePage类中封装元素识别方法
前置条件:导包
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from common.log_utils import logger
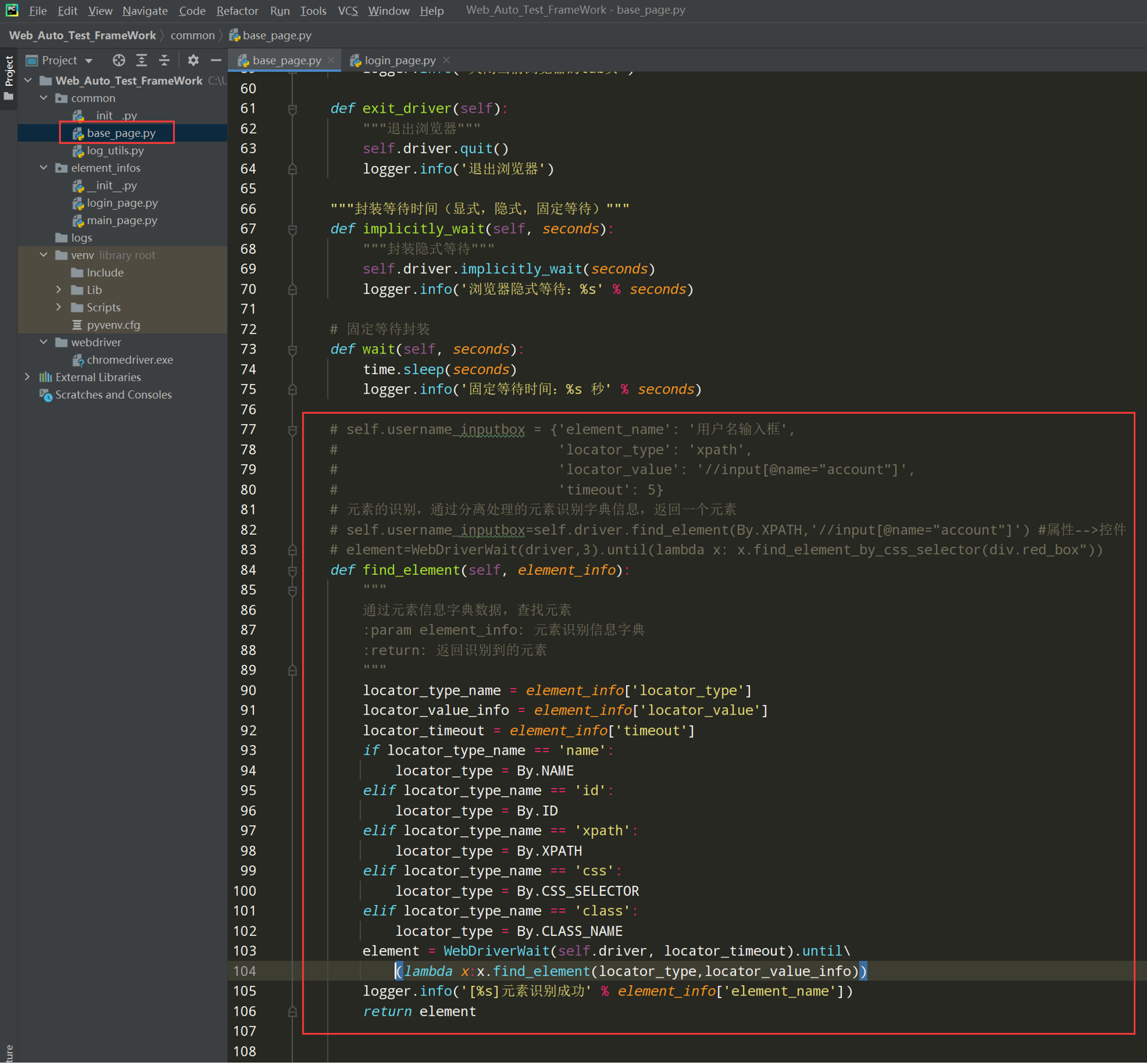
代码示例:
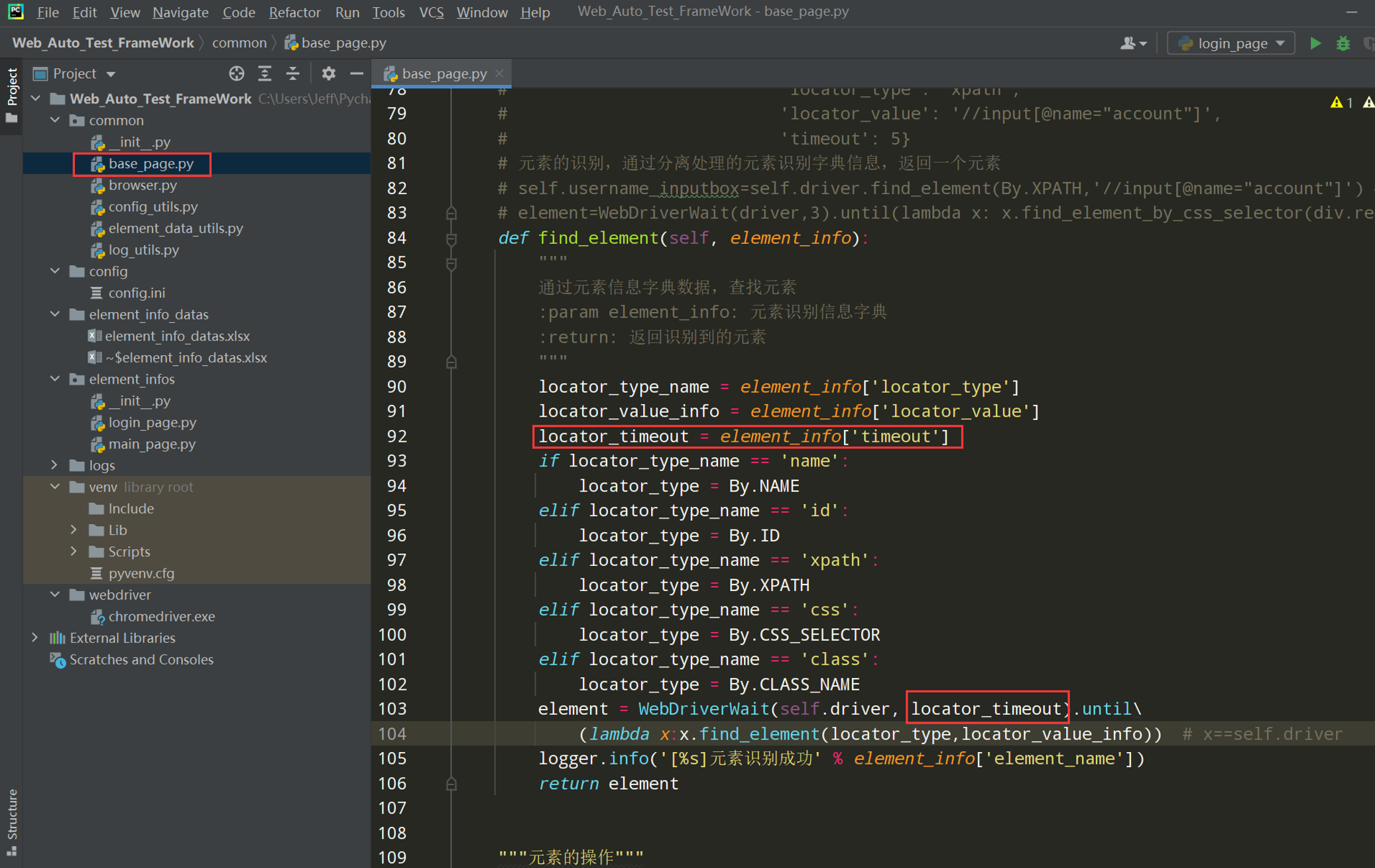
# self.username_inputbox = {'element_name': '用户名输入框', # 'locator_type': 'xpath', # 'locator_value': '//input[@name="account"]', # 'timeout': 5} # 元素的识别,通过分离处理的元素识别字典信息,返回一个元素 # self.username_inputbox=self.driver.find_element(By.XPATH,'//input[@name="account"]') #属性-->控件 # element=WebDriverWait(driver,3).until(lambda x: x.find_element_by_css_selector(div.red_box")) def find_element(self, element_info): """ 通过元素信息字典数据,查找元素 :param element_info: 元素识别信息字典 :return: 返回识别到的元素 """ locator_type_name = element_info['locator_type'] locator_value_info = element_info['locator_value'] locator_timeout = element_info['timeout'] if locator_type_name == 'name': locator_type = By.NAME elif locator_type_name == 'id': locator_type = By.ID elif locator_type_name == 'xpath': locator_type = By.XPATH elif locator_type_name == 'css': locator_type = By.CSS_SELECTOR elif locator_type_name == 'class': locator_type = By.CLASS_NAME element = WebDriverWait(self.driver, locator_timeout).until(lambda x:x.find_element(locator_type,locator_value_info)) logger.info('[%s]元素识别成功' % element_info['element_name']) return element

""" 元素的操作 """ def input(self,element_info,content): """元素输入操作""" element = self.find_element(element_info) element.send_keys(content) logger.info('[%s]元素输入数据:%s' % (element_info['element_name'], content)) def click(self,element_info): """元素点击操作""" element = self.find_element(element_info) element.click() logger.info('[%s] 元素进行点击操作' % element_info['element_name'])
BasePage类:浏览器操作、元素识别、元素操作(切框架、切句柄等等)
4、完善login_page.py中的LoginPage类继承BasePage类,并完善代码
完善login_page.py
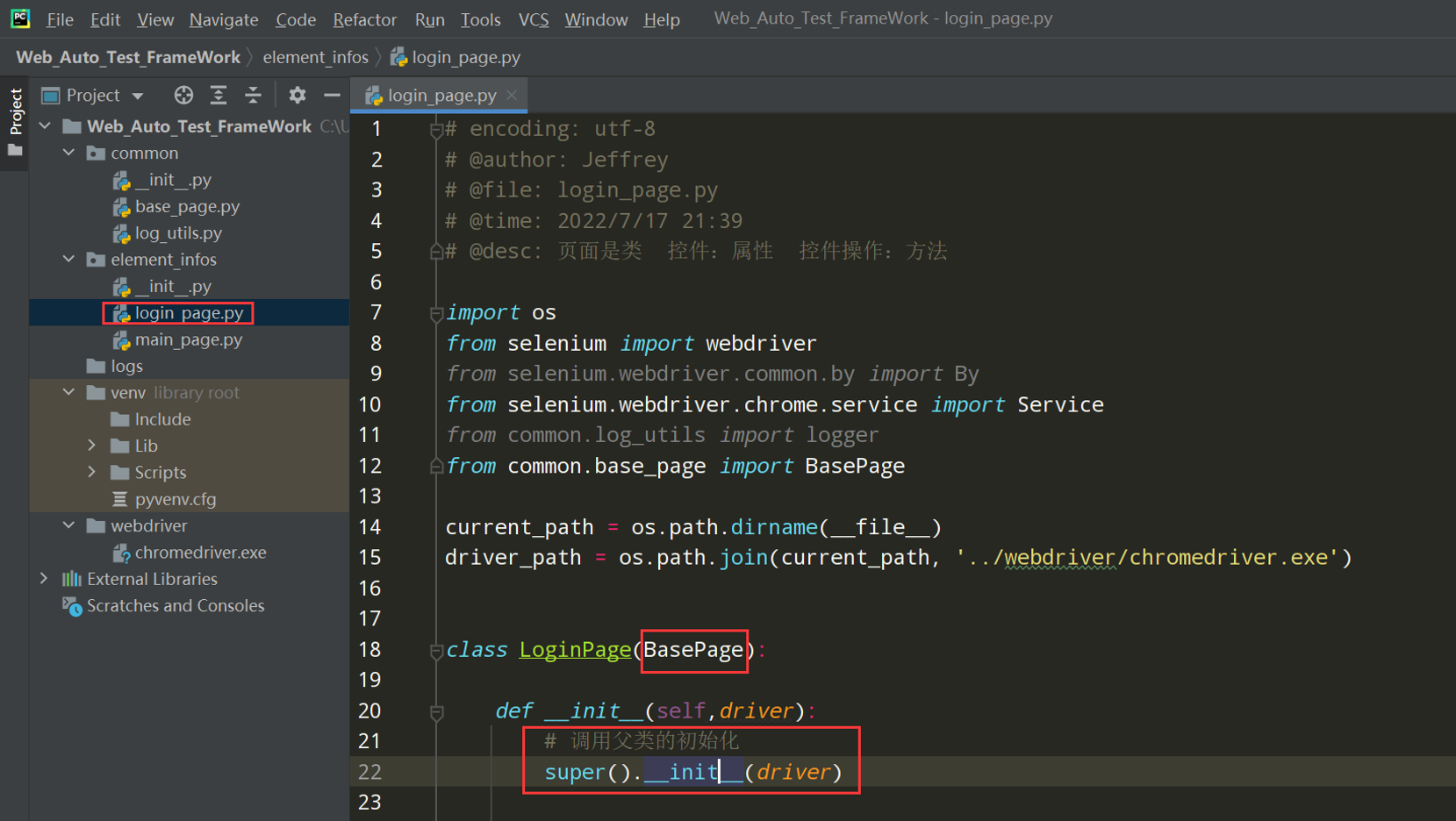
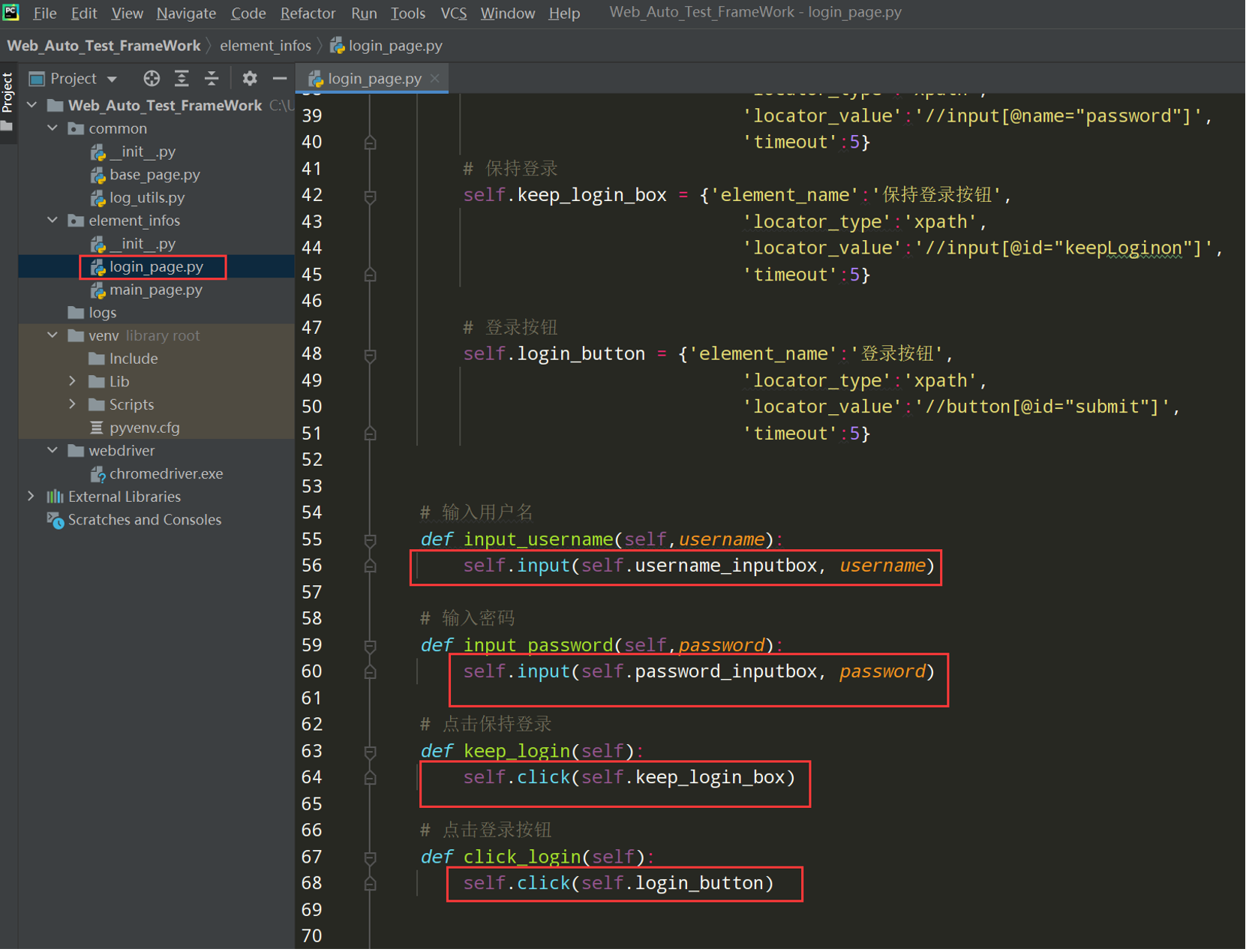
代码示例:
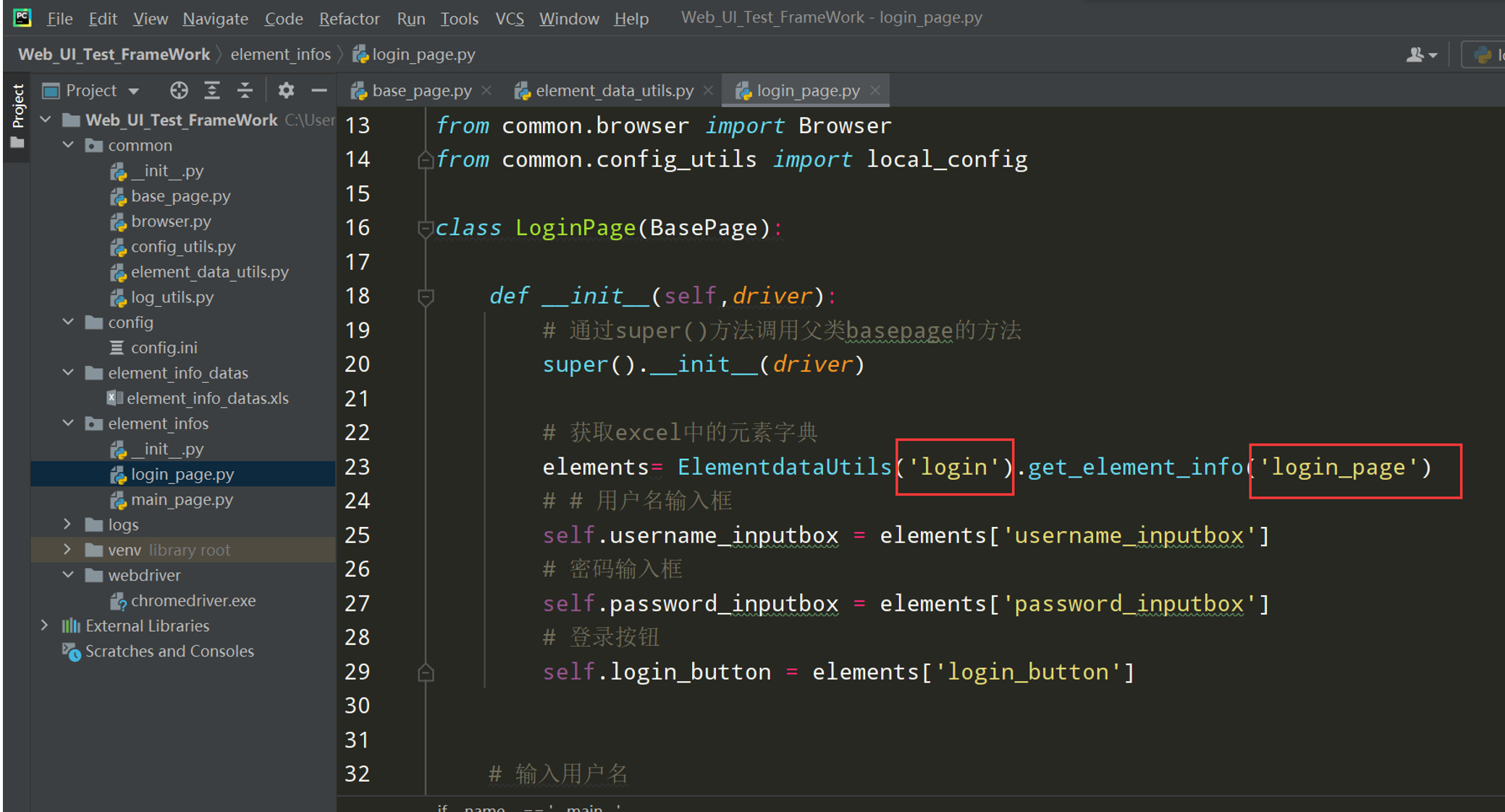
# encoding: utf-8 # @author: Jeffrey # @file: login_page.py # @time: 2022/7/2 12:39 # @desc: 页面是类 控件:属性 控件操作:方法 import os from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from common.base_page import BasePage from common.log_utils import logger from common.element_data_utils import ElementDataUtils current_path = os.path.dirname(__file__) driver_path = os.path.join(current_path, '../webdriver/chromedriver.exe') class LoginPage(BasePage): def __init__(self,driver): # 调用父类的初始化 super().__init__(driver) # 控件:属性 # self.username_inputbox = self.driver.find_element(By.XPATH,'//input[@name="account"]') # self.password_inputbox = self.driver.find_element(By.XPATH,'//input[@name="password"]') # self.keep_login_box = self.driver.find_element(By.XPATH,'//input[@id="keepLoginon"]') # self.login_button = self.driver.find_element(By.XPATH,'//button[@id="submit"]') # 用户名输入框 self.username_inputbox = {'element_name':'用户名输入框', 'locator_type':'xpath', 'locator_value':'//input[@name="account"]', 'timeout':5} # 密码输入框 self.password_inputbox = {'element_name':'密码输入框', 'locator_type':'xpath', 'locator_value':'//input[@name="password"]', 'timeout':5} # 保持登录 self.keep_login_box = {'element_name':'保持登录按钮', 'locator_type':'xpath', 'locator_value':'//input[@id="keepLoginon"]', 'timeout':5} # 登录按钮 self.login_button = {'element_name':'登录按钮', 'locator_type':'xpath', 'locator_value':'//button[@id="submit"]', 'timeout':5} # 输入用户名 def input_username(self,username): self.input(self.username_inputbox, username) # 输入密码 def input_password(self,password): self.input(self.password_inputbox, password) # 点击保持登录 def keep_login(self): self.click(self.keep_login_box) # 点击登录按钮 def click_login(self): self.click(self.login_button) if __name__ == '__main__': chrome_driver_path = Service(driver_path) driver = webdriver.Chrome(service=chrome_driver_path) loginpage = LoginPage(driver) loginpage.open_url('http://47.107.178.45/zentao/www/index.php?m=user&f=login') loginpage.set_browser_max() loginpage.implicitly_wait(30) loginpage.input_username('test01') loginpage.input_password('newdream123') loginpage.click_login()
小结:
在页面类拿到元素的识别信息字典-->通过BasePage的元素识别方法获取一个元素-->再操作元素--->再页面类再根据具体的业务封装操作
框架03--元素信息分离设计
思路:元素识别信息数据放代码中是否好维护?
数据的类型:1. 元素识别数据 2. 配置数据(url,路径,邮箱) 3. 测试用例数据
数据与代码的分离:
1. 数据放ini配件文件中
2. 放excel表中
3. 放 mysql
4. 放yaml文件中
数据放Excel表中思路
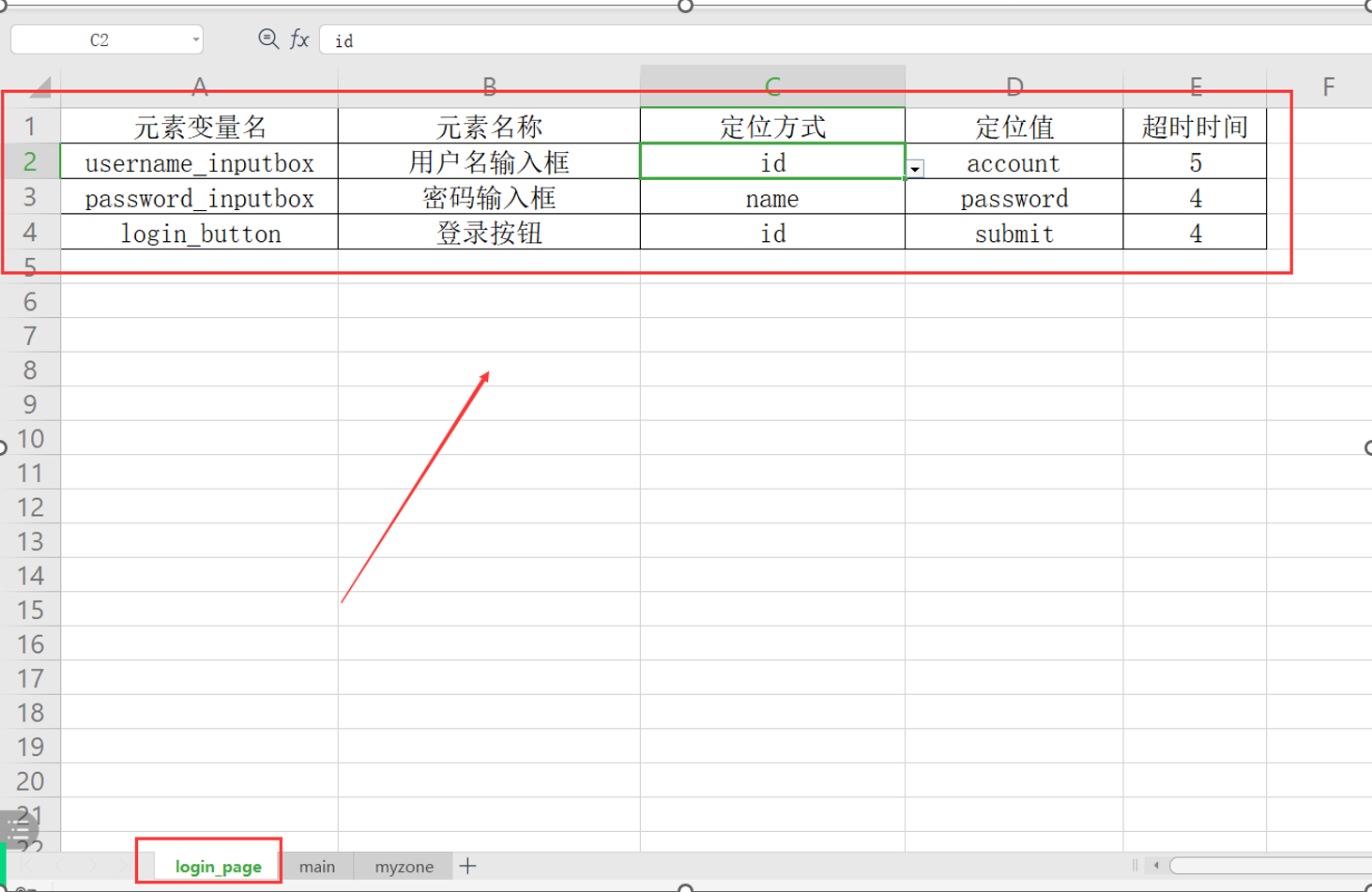
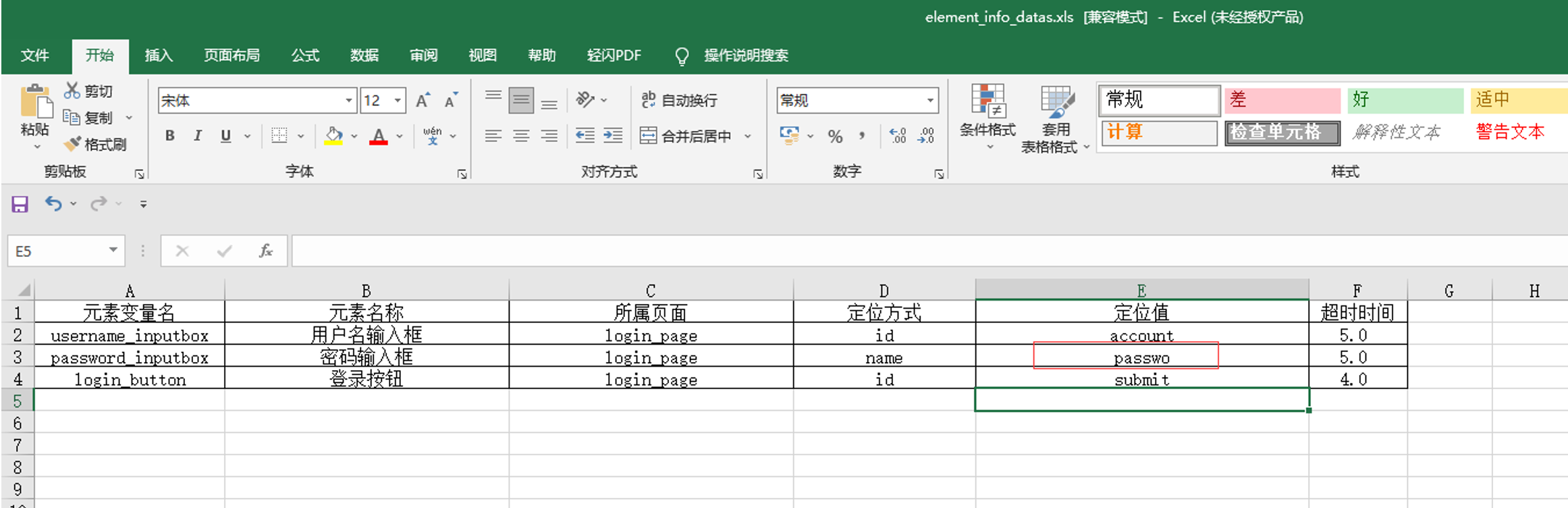
1. 新建一个element_info_datas文件夹,把元素识别的数据放Excel表中
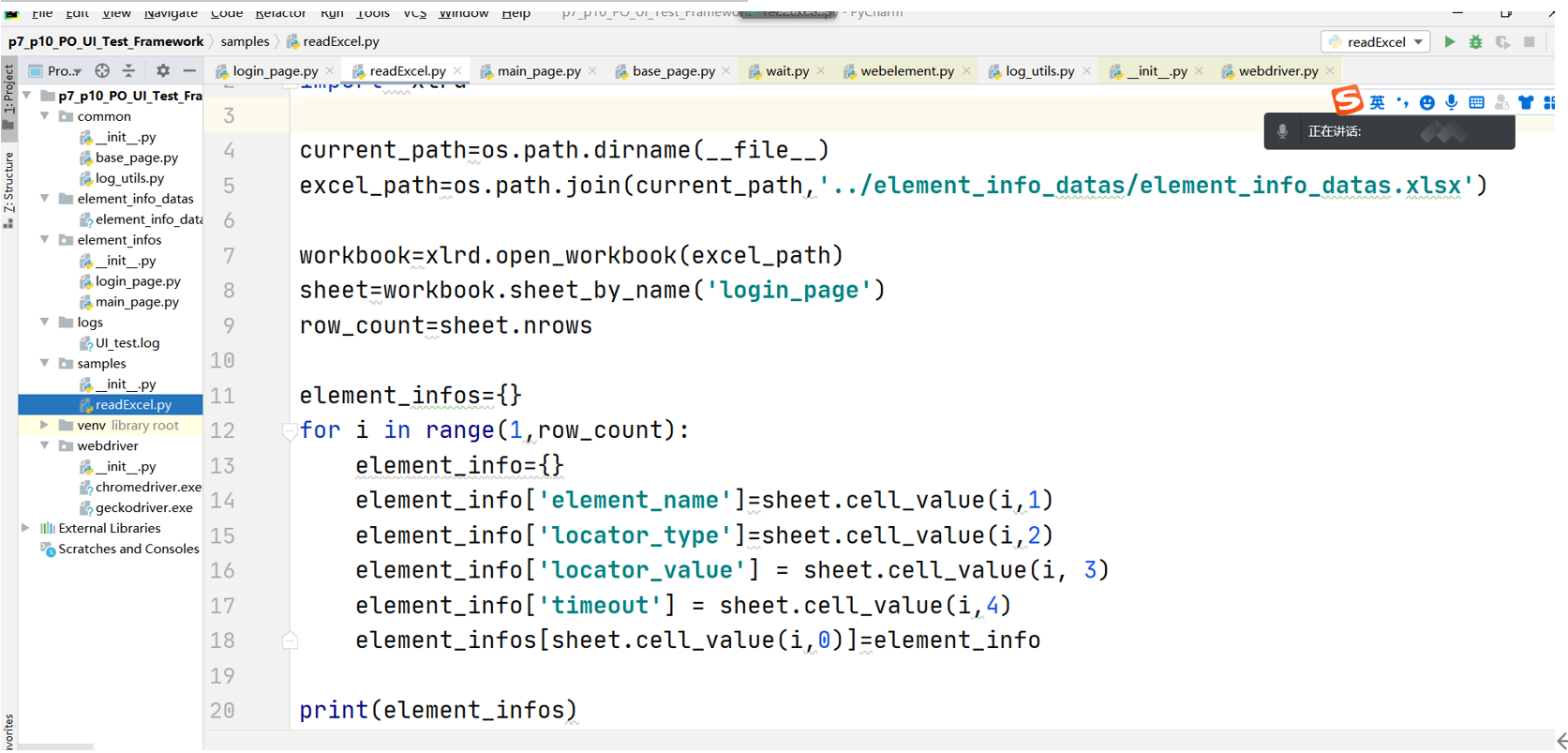
2. 步骤2:编写测试代码,读取excel表中数据元素识别数据
3. 把读取excel的代码封装element_data_utils.py文件中
4. 步骤4:改造LoginPage,从Excel中拿元素识别数据
1.新建一个element_info_datas文件夹,把元素识别的数据放Excel表中
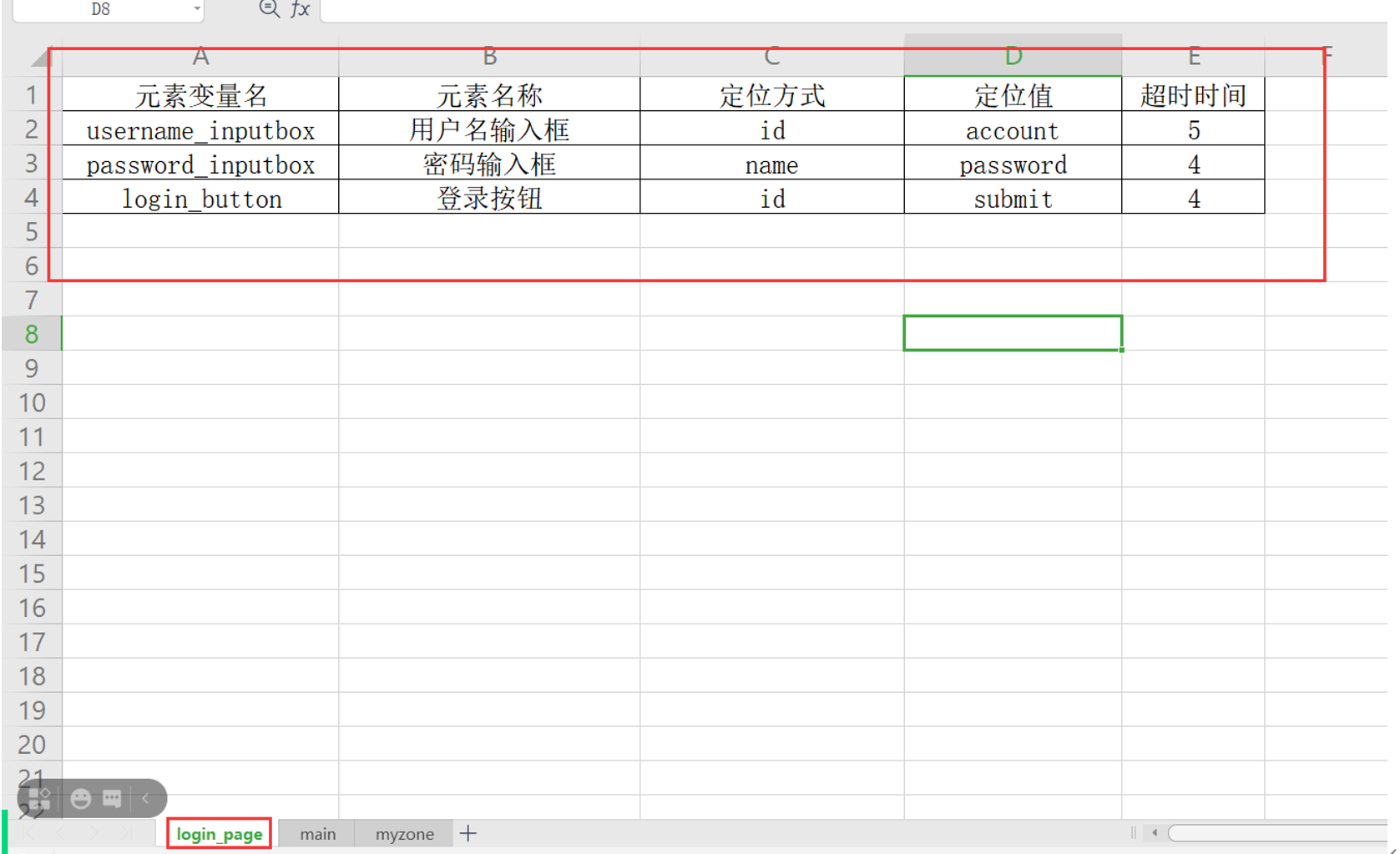
数据结构:一个字典套一层字典:{ {},{},{}}
{
‘username_inputbox’:{'element_name':'用户名输入框',
'locator_type':'xpath','
locator_value':'//input[@name="account"]',
'timeout':5}
}
2、编写测试代码,读取excel表中数据元素识别数据
安装一个1.2.0版本的xlrd pip install xlrd==1.2.0
在samples文件下在demo中编写线性代码
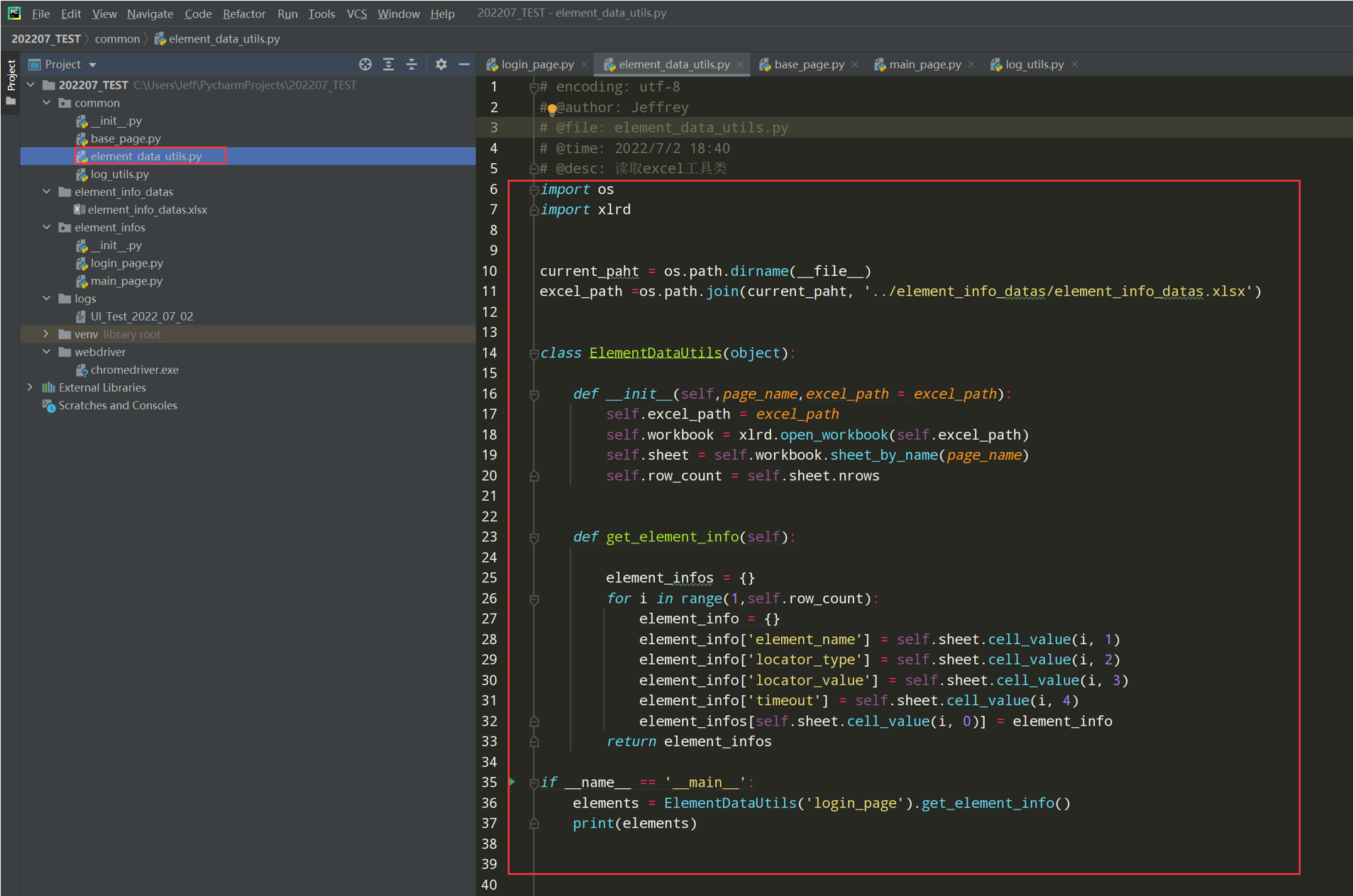
3、把读取excel的代码封装element_data_utils.py文件中
代码示例:
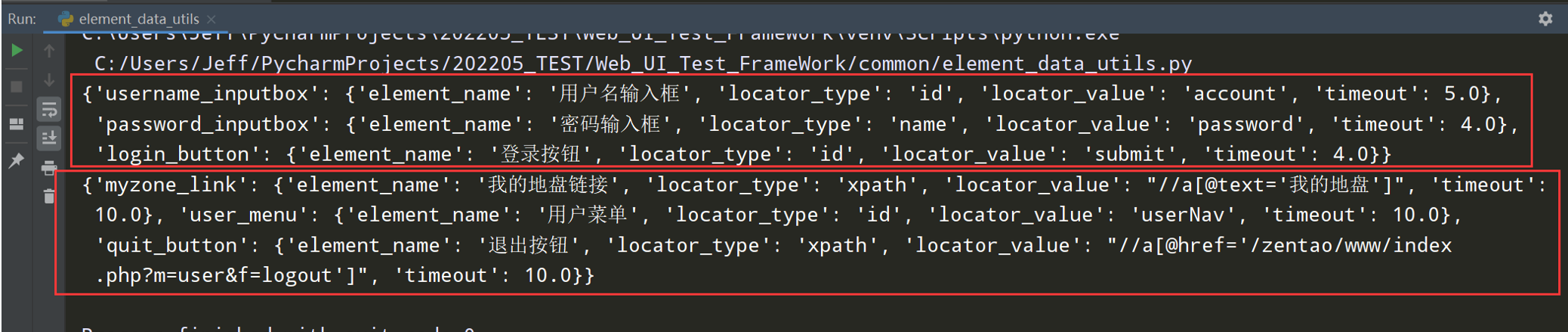
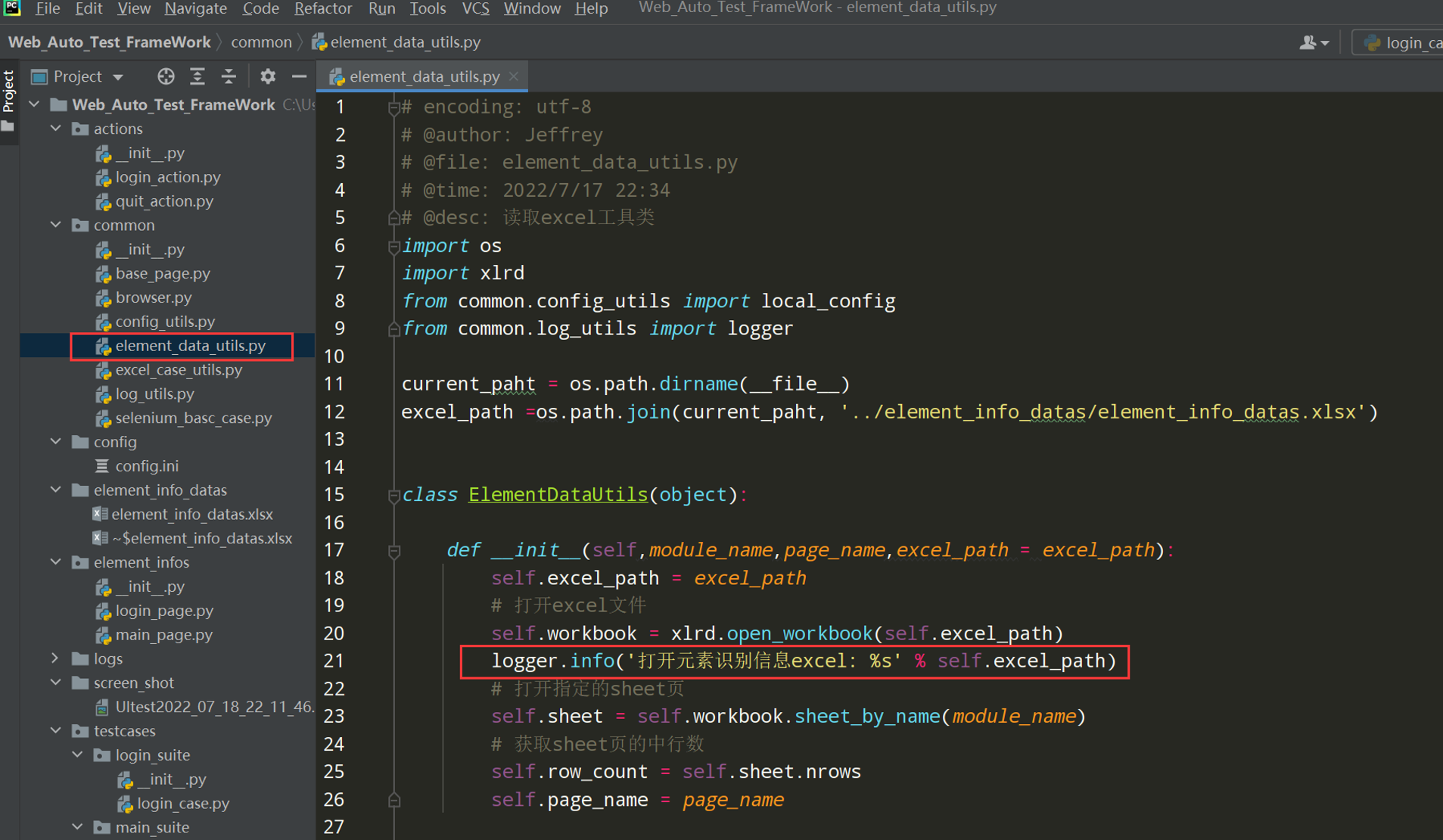
# encoding: utf-8 # @author: Jeffrey # @file: element_data_utils.py # @time: 2022/7/2 18:40 # @desc: 读取excel工具类 import os import xlrd current_paht = os.path.dirname(__file__) excel_path =os.path.join(current_paht, '../element_info_datas/element_info_datas.xlsx') class ElementDataUtils(object): def __init__(self,page_name,excel_path = excel_path): self.excel_path = excel_path self.workbook = xlrd.open_workbook(self.excel_path) self.sheet = self.workbook.sheet_by_name(page_name) self.row_count = self.sheet.nrows def get_element_info(self): element_infos = {} for i in range(1,self.row_count): element_info = {} element_info['element_name'] = self.sheet.cell_value(i, 1) element_info['locator_type'] = self.sheet.cell_value(i, 2) element_info['locator_value'] = self.sheet.cell_value(i, 3) element_info['timeout'] = self.sheet.cell_value(i, 4) element_infos[self.sheet.cell_value(i, 0)] = element_info return element_infos if __name__ == '__main__': elements = ElementDataUtils('login_page').get_element_info() print(elements)
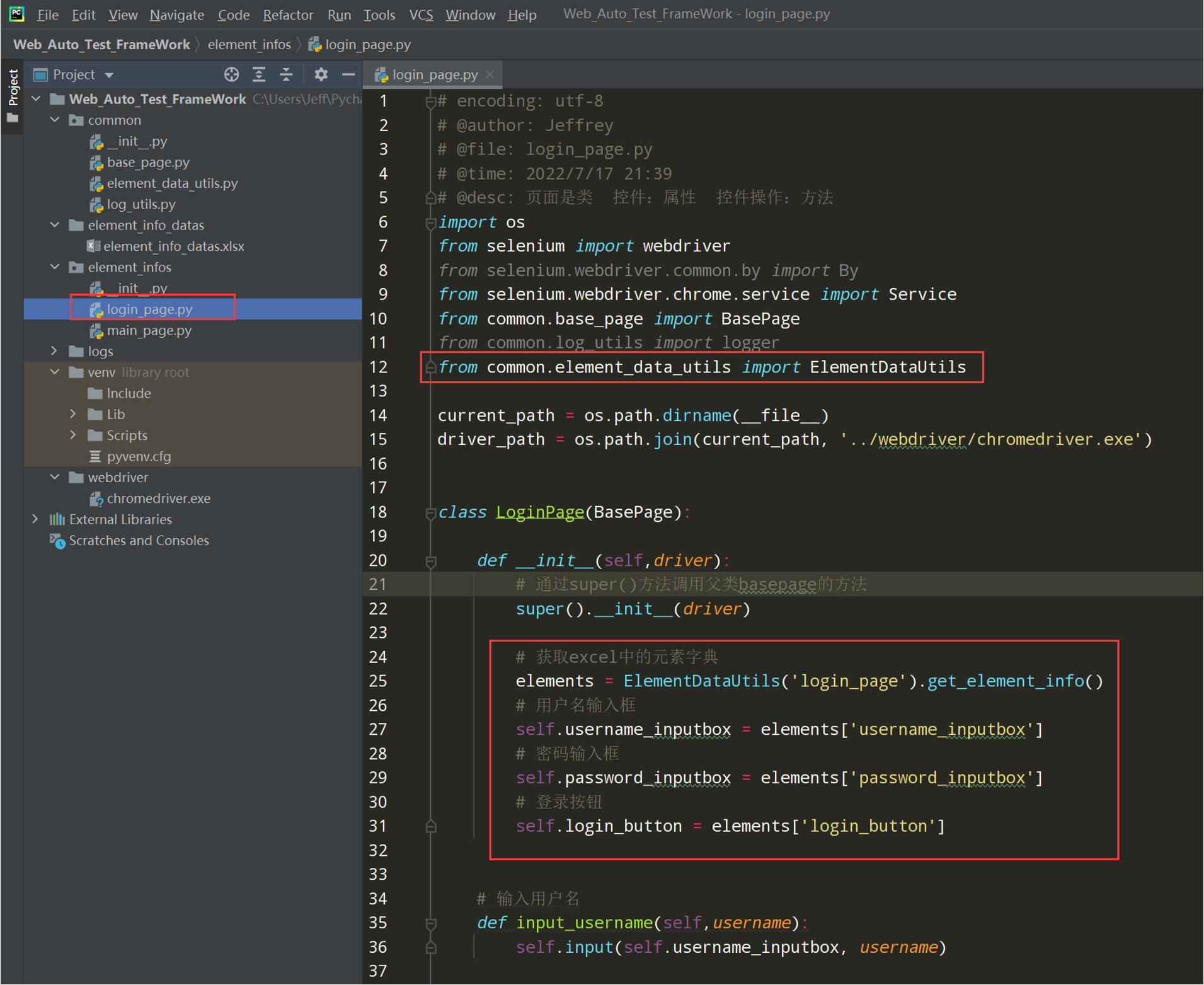
4、改造LoginPage,从Excel中拿元素识别数据
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: login_page.py # @time: 2022/7/2 12:39 # @desc: 页面是类 控件:属性 控件操作:方法 import os from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from common.base_page import BasePage from common.log_utils import logger from common.element_data_utils import ElementDataUtils current_path = os.path.dirname(__file__) driver_path = os.path.join(current_path, '../webdriver/chromedriver.exe') class LoginPage(BasePage): def __init__(self,driver): # 调用父类的初始化 super().__init__(driver) # 获取excel中的元素字典 elements = ElementDataUtils('login_page').get_element_info() # 用户名输入框 self.username_inputbox = elements['username_inputbox'] # 密码输入框 self.password_inputbox = elements['password_inputbox'] # 登录按钮 self.login_button = elements['login_button'] # 输入用户名 def input_username(self,username): self.input(self.username_inputbox, username) # 输入密码 def input_password(self,password): self.input(self.password_inputbox, password) # # 点击保持登录 # def keep_login(self): # self.click(self.keep_login_box) # 点击登录按钮 def click_login(self): self.click(self.login_button) if __name__ == '__main__': chrome_driver_path = Service(driver_path) driver = webdriver.Chrome(service=chrome_driver_path) loginpage = LoginPage(driver) loginpage.open_url('http://47.107.178.45/zentao/www/index.php?m=user&f=login') loginpage.set_browser_max() loginpage.implicitly_wait(30) loginpage.input_username('test01') loginpage.input_password('newdream123') loginpage.click_login()
5、把 Excel表格中的定位方法,做成下拉的方法
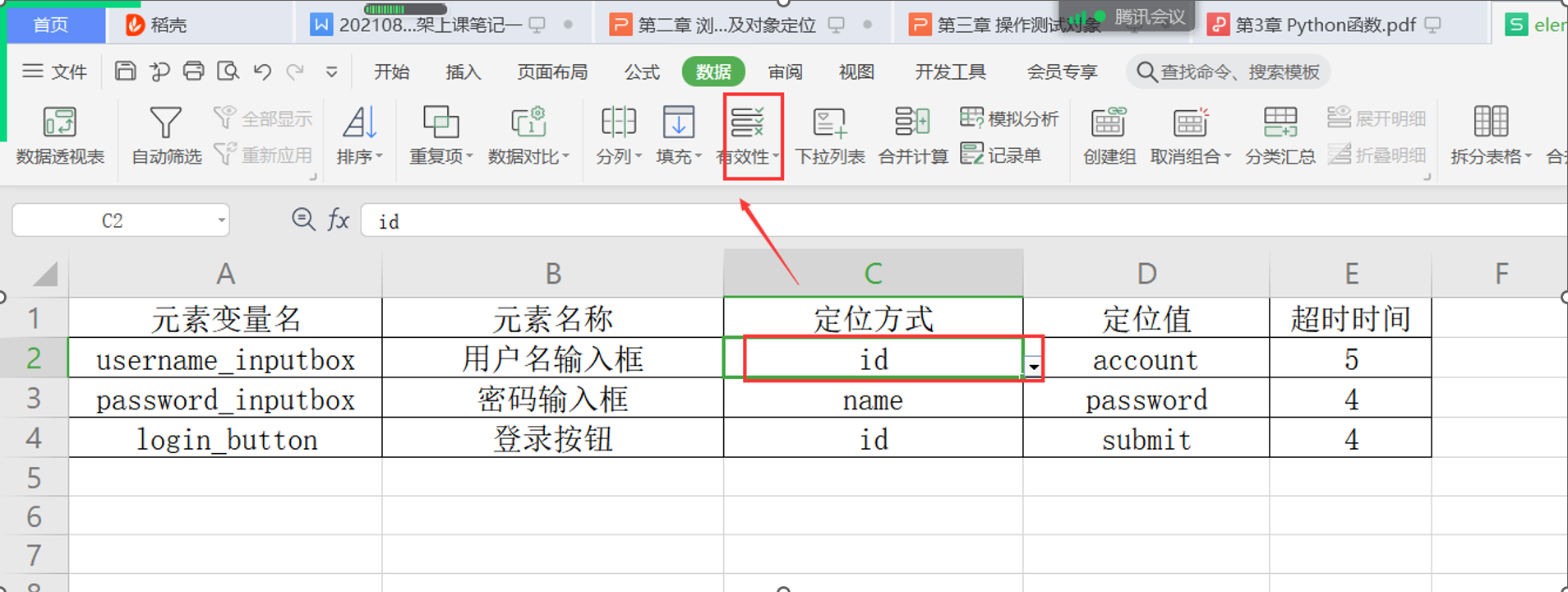
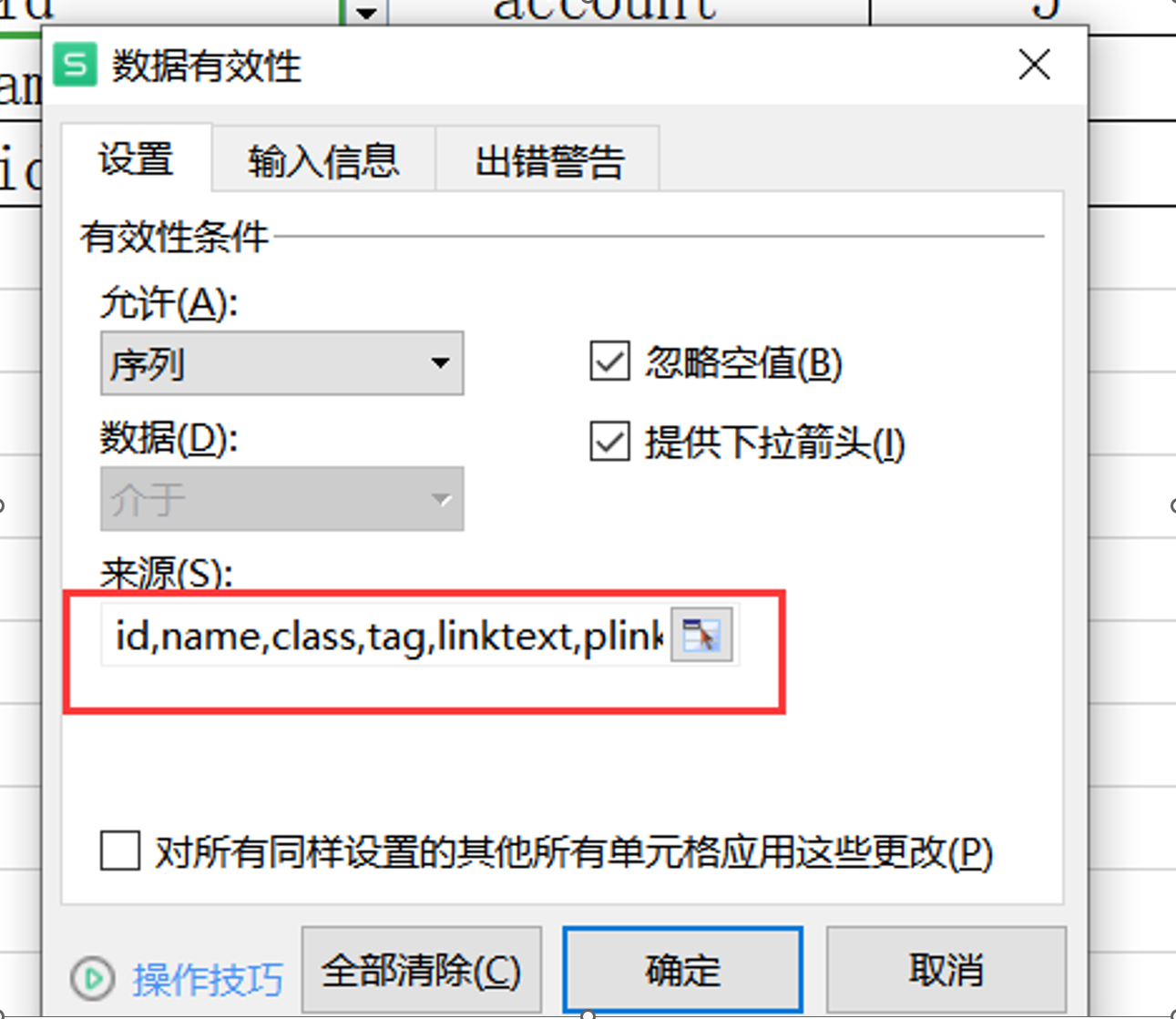
id,name,class,tag,linktext,plinktext,xpath,css
框架04--drive的二次封装及页面类的拆分

1、在项目根目录下新建一个config文件夹,然后再新建一个config.ini文件,然后放入配置的数据
2、在common下封装一个读取ini配置文件的 config_utils.py
代码示例:
# 读取配置文件 import os import configparser current_path=os.path.dirname(__file__) config_path=os.path.join(current_path,'../config/config.ini') class ConfigUtils(): def __init__(self,path=config_path): self.cfg=configparser.ConfigParser() self.cfg.read(path,encoding='utf-8') #@property装饰器负责把类中的方法转换成属性来调用 @property def get_url(self): value=self.cfg.get('default','url') return value @property def get_driver_path(self): value=self.cfg.get('default','driver_path') return value #封装一个读取配置文件的对象 local_config=ConfigUtils() if __name__=='__main__': print(local_config.get_url) print(local_config.get_driver_path)
3、在common下新建browser.py文件
编写浏览器Browser类;如下图
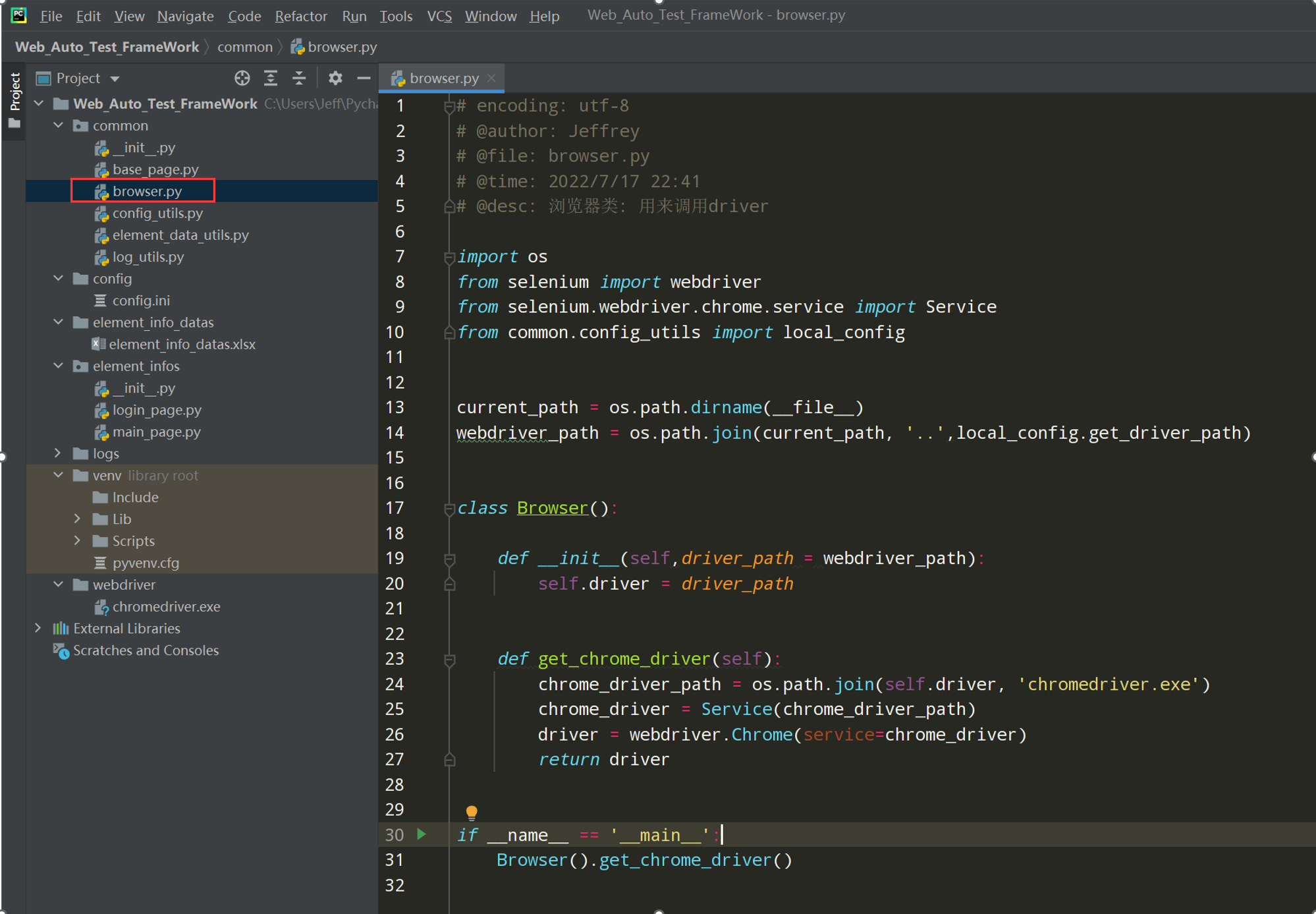
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: browser.py # @time: 2022/7/2 19:55 # @desc:浏览器类: 用来调用driver import os from selenium import webdriver from selenium.webdriver.chrome.service import Service from common.config_utils import local_config current_path = os.path.dirname(__file__) webdriver_path = os.path.join(current_path, '..',local_config.get_driver_path) class Browser(): def __init__(self,driver_path = webdriver_path): self.driver = driver_path def get_chrome_driver(self): chrome_driver_path = os.path.join(self.driver, 'chromedriver.exe') chrome_driver = Service(chrome_driver_path) driver = webdriver.Chrome(service=chrome_driver) return driver if __name__ == '__main__': Browser().get_chrome_driver()
4、替换LoginPage中的执行脚本
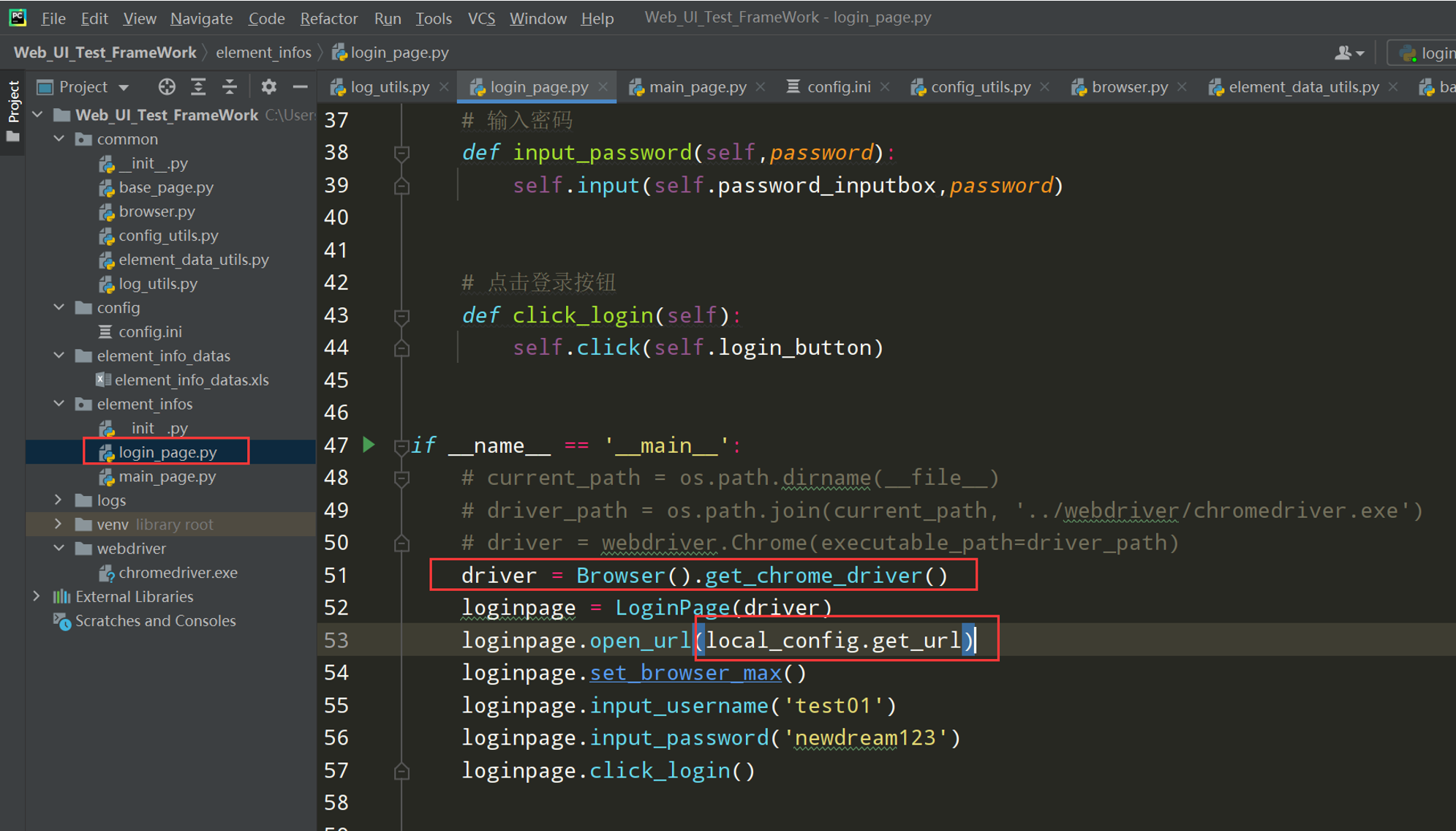
前置条件:导包
from common.browser import Browser
from common.config_utils import local_config
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: login_page.py # @time: 2022/7/2 12:39 # @desc: 页面是类 控件:属性 控件操作:方法 import os from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from common.base_page import BasePage from common.log_utils import logger from common.element_data_utils import ElementDataUtils from common.browser import Browser from common.config_utils import local_config class LoginPage(BasePage): def __init__(self,driver): # 调用父类的初始化 super().__init__(driver) # 获取excel中的元素字典 elements = ElementDataUtils('login_page').get_element_info() # 用户名输入框 self.username_inputbox = elements['username_inputbox'] # 密码输入框 self.password_inputbox = elements['password_inputbox'] # 登录按钮 self.login_button = elements['login_button'] # 输入用户名 def input_username(self,username): self.input(self.username_inputbox, username) # 输入密码 def input_password(self,password): self.input(self.password_inputbox, password) # # 点击保持登录 # def keep_login(self): # self.click(self.keep_login_box) # 点击登录按钮 def click_login(self): self.click(self.login_button) if __name__ == '__main__': driver = Browser().get_chrome_driver() loginpage = LoginPage(driver) loginpage.open_url(local_config.get_url) loginpage.set_browser_max() loginpage.implicitly_wait(30) loginpage.input_username('test01') loginpage.input_password('newdream123') loginpage.click_login()
5、处理google浏览器去掉 受控制提示框
把下方代码在browser.py文件中封装
注意:导入Service包是因为webdriver的executable_path即将弃用,会报警告
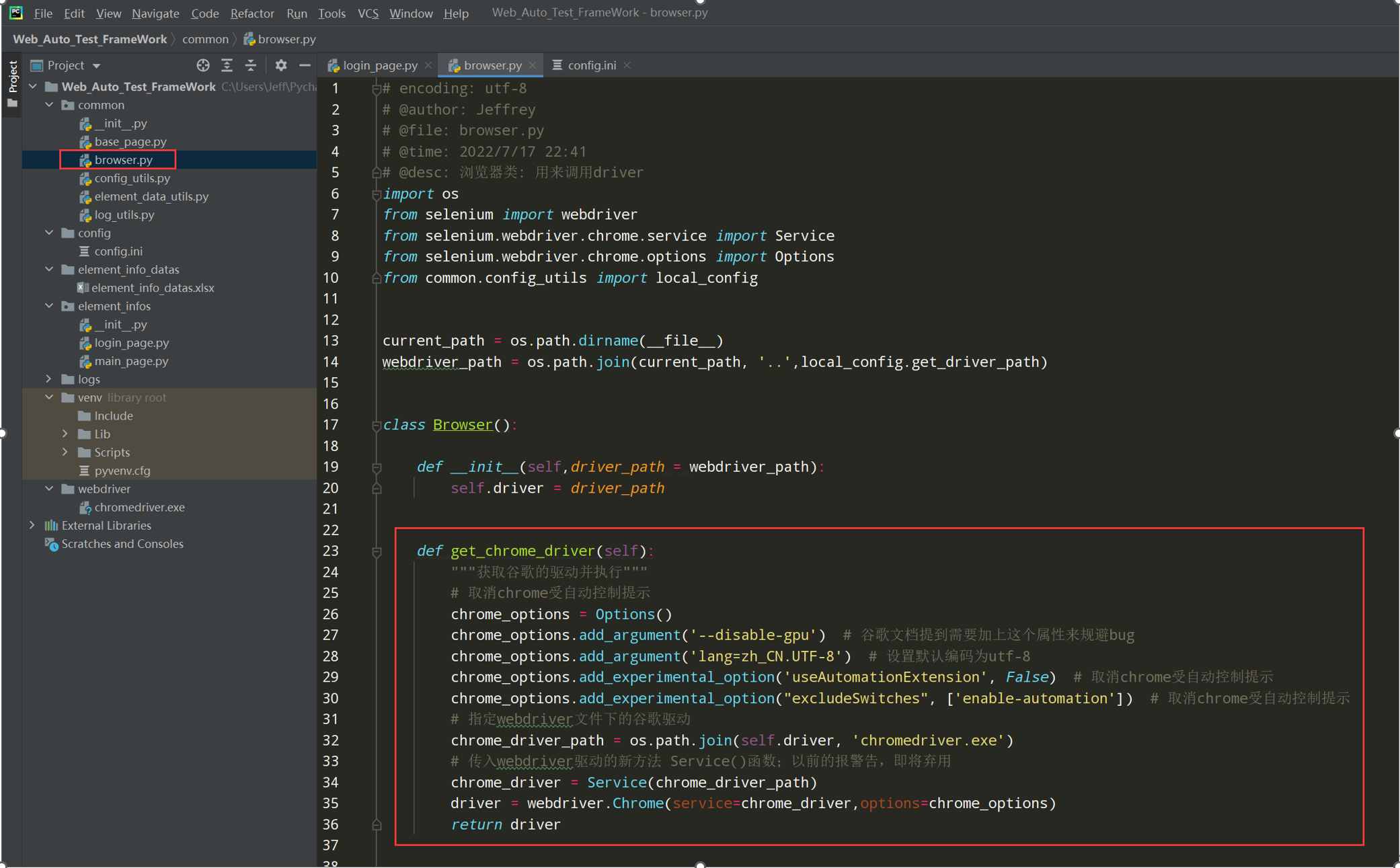
代码示例:
导包:
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
def get_chrome_driver(self): """获取谷歌的驱动并执行""" # 取消chrome受自动控制提示 chrome_options = Options() chrome_options.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避bug chrome_options.add_argument('lang=zh_CN.UTF-8') # 设置默认编码为utf-8 chrome_options.add_experimental_option('useAutomationExtension', False) # 取消chrome受自动控制提示 chrome_options.add_experimental_option("excludeSwitches", ['enable-automation']) # 取消chrome受自动控制提示 # 指定webdriver文件下的谷歌驱动 chrome_driver_path = os.path.join(self.driver, 'chromedriver.exe') # 传入webdriver驱动的新方法 Service()函数;以前的报警告,即将弃用 chrome_driver_path_obj = Service(chrome_driver_path) driver = webdriver.Chrome(service=chrome_driver_path_obj, options=chrome_options) return driver
5、 把火狐和edge驱动也封装进来
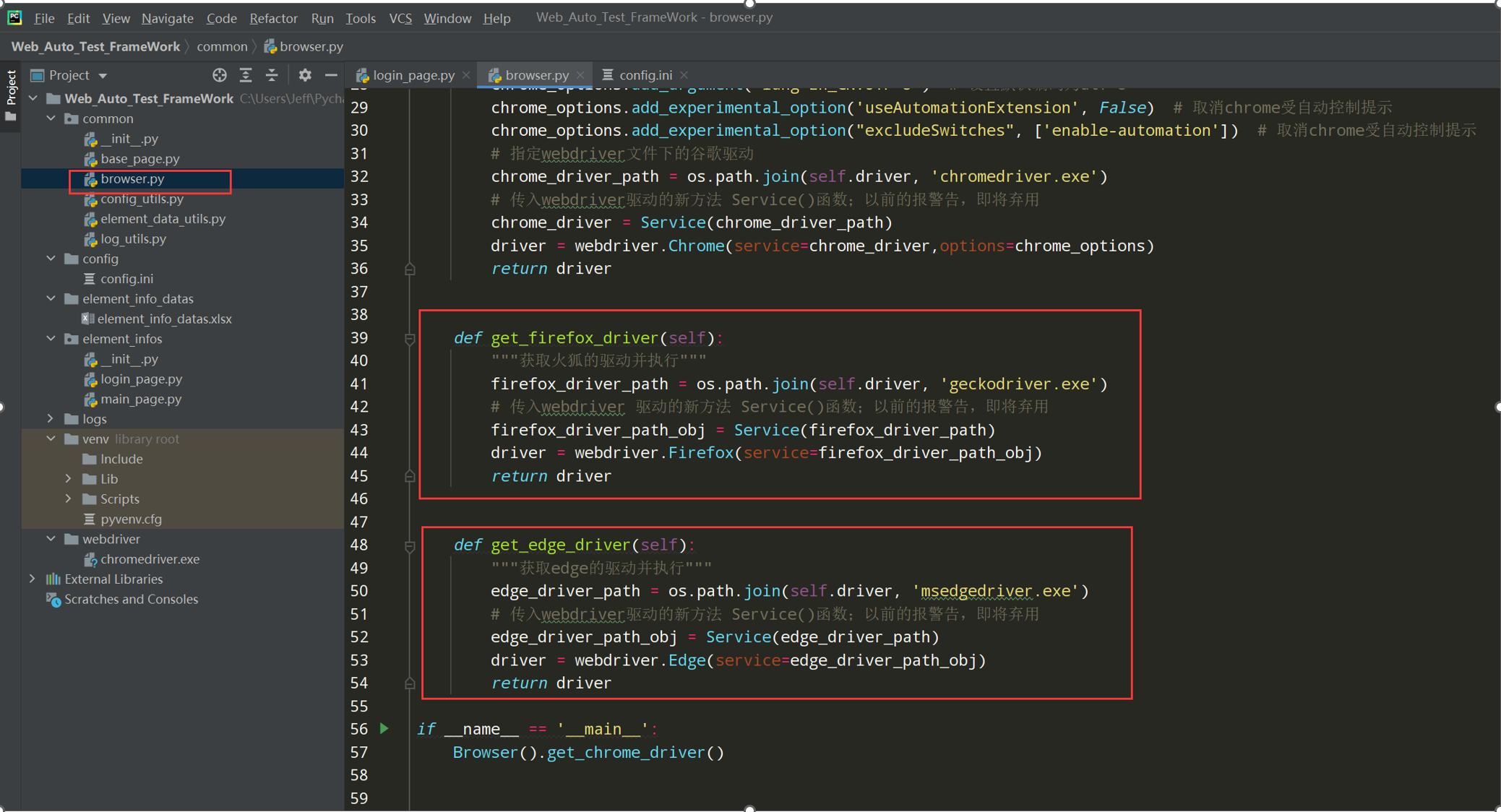
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: browser.py # @time: 2022/7/2 19:55 # @desc:浏览器类: 用来调用driver import os from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options from common.config_utils import local_config current_path = os.path.dirname(__file__) webdriver_path = os.path.join(current_path, '..',local_config.get_driver_path) class Browser(): def __init__(self,driver_path = webdriver_path): self.driver = driver_path def get_chrome_driver(self): """获取谷歌的驱动并执行""" # 取消chrome受自动控制提示 chrome_options = Options() chrome_options.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避bug chrome_options.add_argument('lang=zh_CN.UTF-8') # 设置默认编码为utf-8 chrome_options.add_experimental_option('useAutomationExtension', False) # 取消chrome受自动控制提示 chrome_options.add_experimental_option("excludeSwitches", ['enable-automation']) # 取消chrome受自动控制提示 # 指定webdriver文件下的谷歌驱动 chrome_driver_path = os.path.join(self.driver, 'chromedriver.exe') # 传入webdriver驱动的新方法 Service()函数;以前的报警告,即将弃用 chrome_driver = Service(chrome_driver_path) driver = webdriver.Chrome(service=chrome_driver,options=chrome_options) return driver def get_firefox_driver(self): """获取火狐的驱动并执行""" firefox_driver_path = os.path.join(self.driver, 'geckodriver.exe') # 传入webdriver 驱动的新方法 Service()函数;以前的报警告,即将弃用 firefox_driver_path_obj = Service(firefox_driver_path) driver = webdriver.Firefox(service=firefox_driver_path_obj) return driver def get_edge_driver(self): """获取edge的驱动并执行""" edge_driver_path = os.path.join(self.driver, 'msedgedriver.exe') # 传入webdriver驱动的新方法 Service()函数;以前的报警告,即将弃用 edge_driver_path_obj = Service(edge_driver_path) driver = webdriver.Edge(service=edge_driver_path_obj) return driver
7、设置默认驱动,封装一个总的获取driver后,把其他获驱动的方法封装成私有的
1、先在config.ini文件中配置驱动名字driver_name
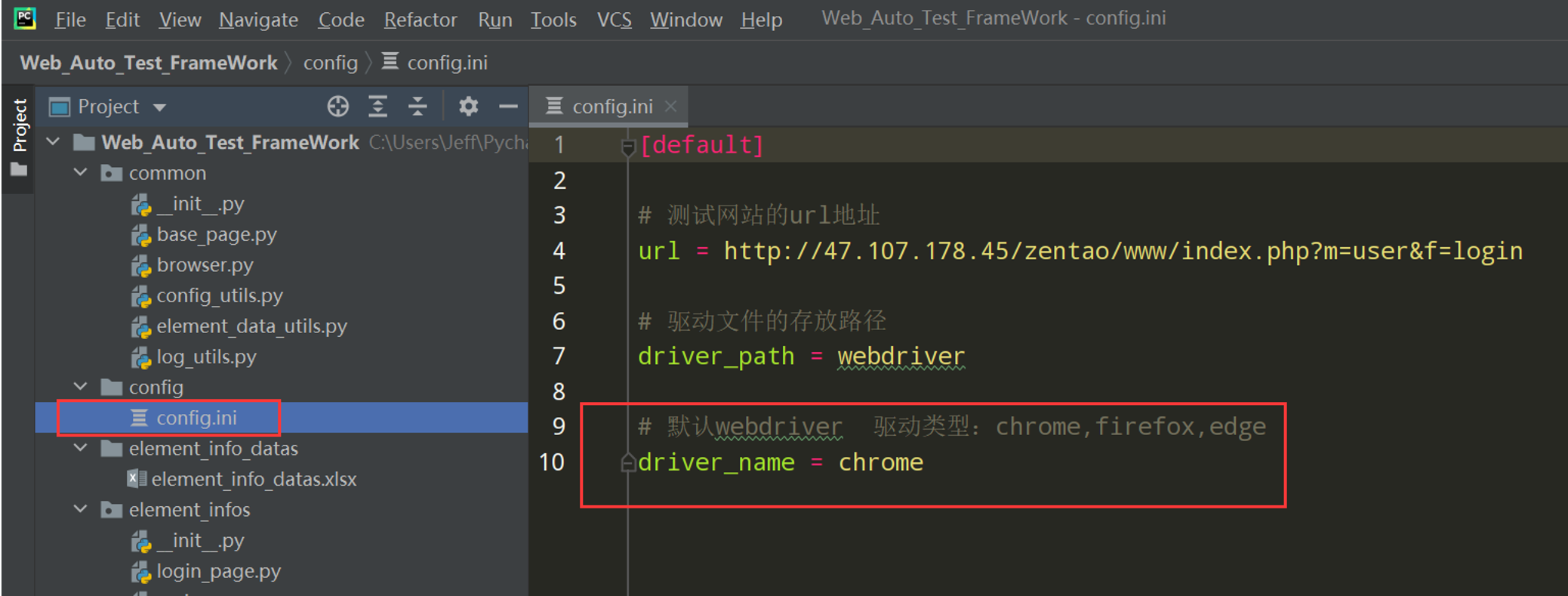
2、在config_utils.py文件中读取config.ini文件中的驱动名字;
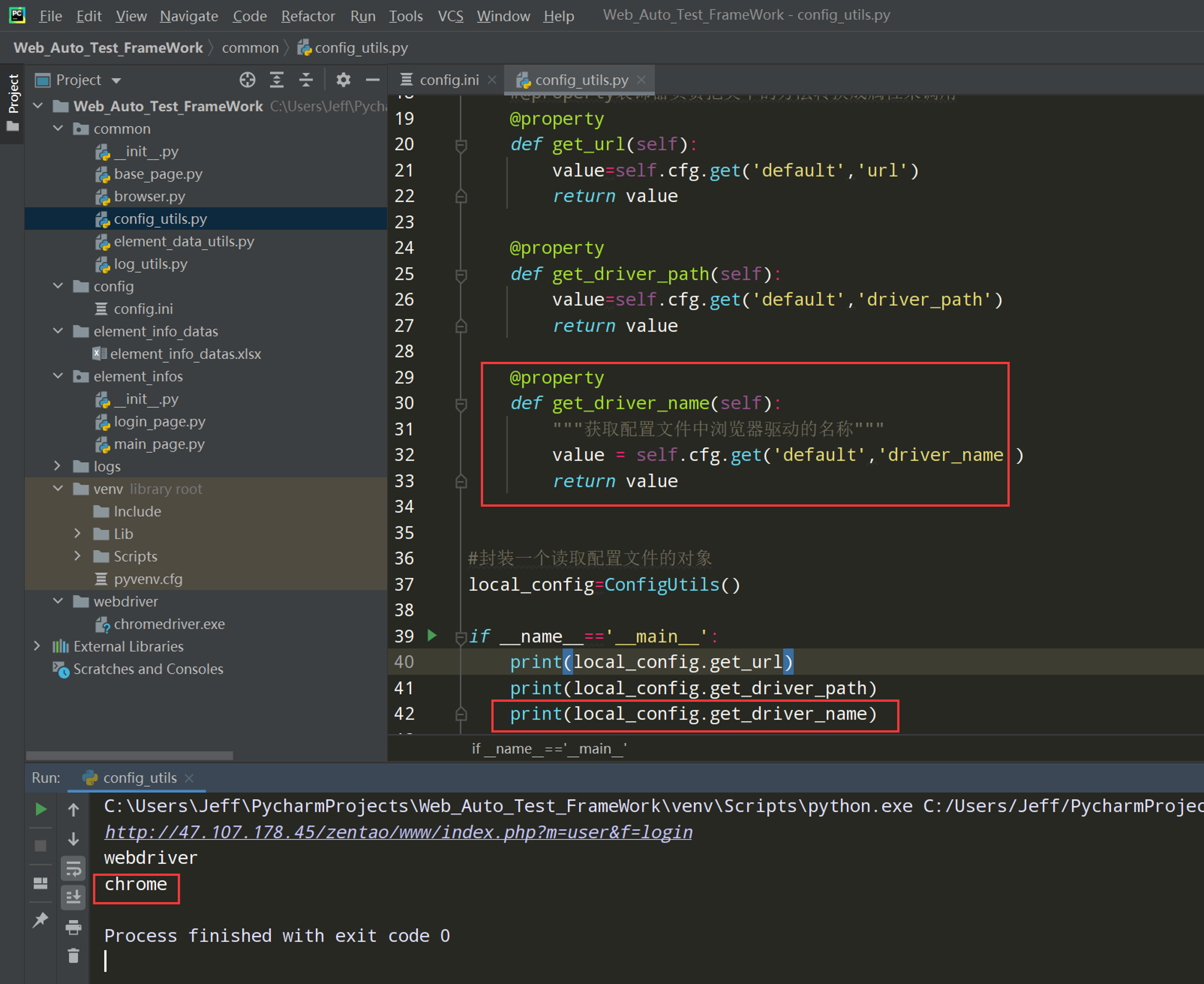
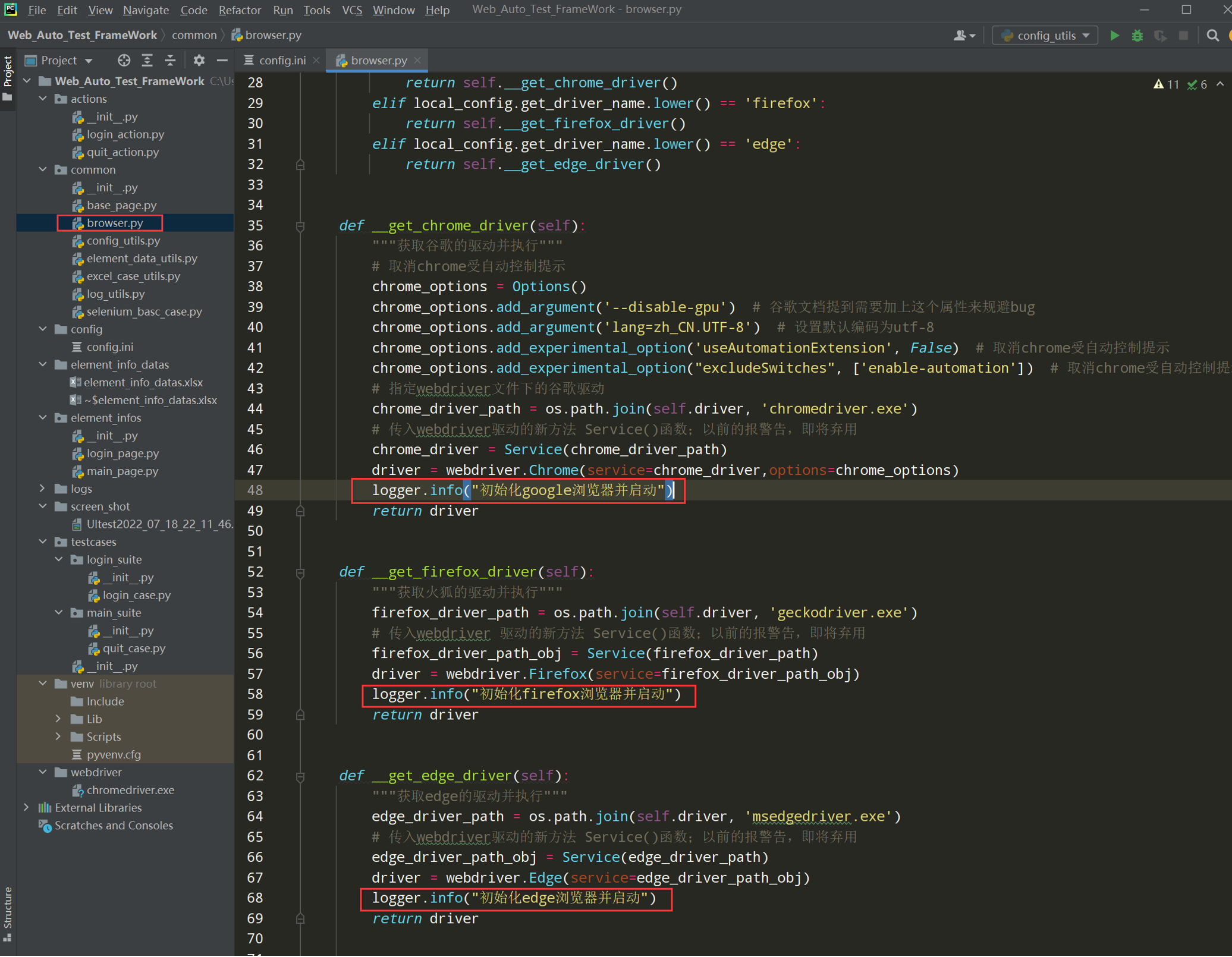
3、在browser.py中封装一个总的获取driver后,把其他获取驱动的方法封装成私有,并加上日志;然后在类的构造方法中获取到驱动名driver_name;然后封装总的获取driver
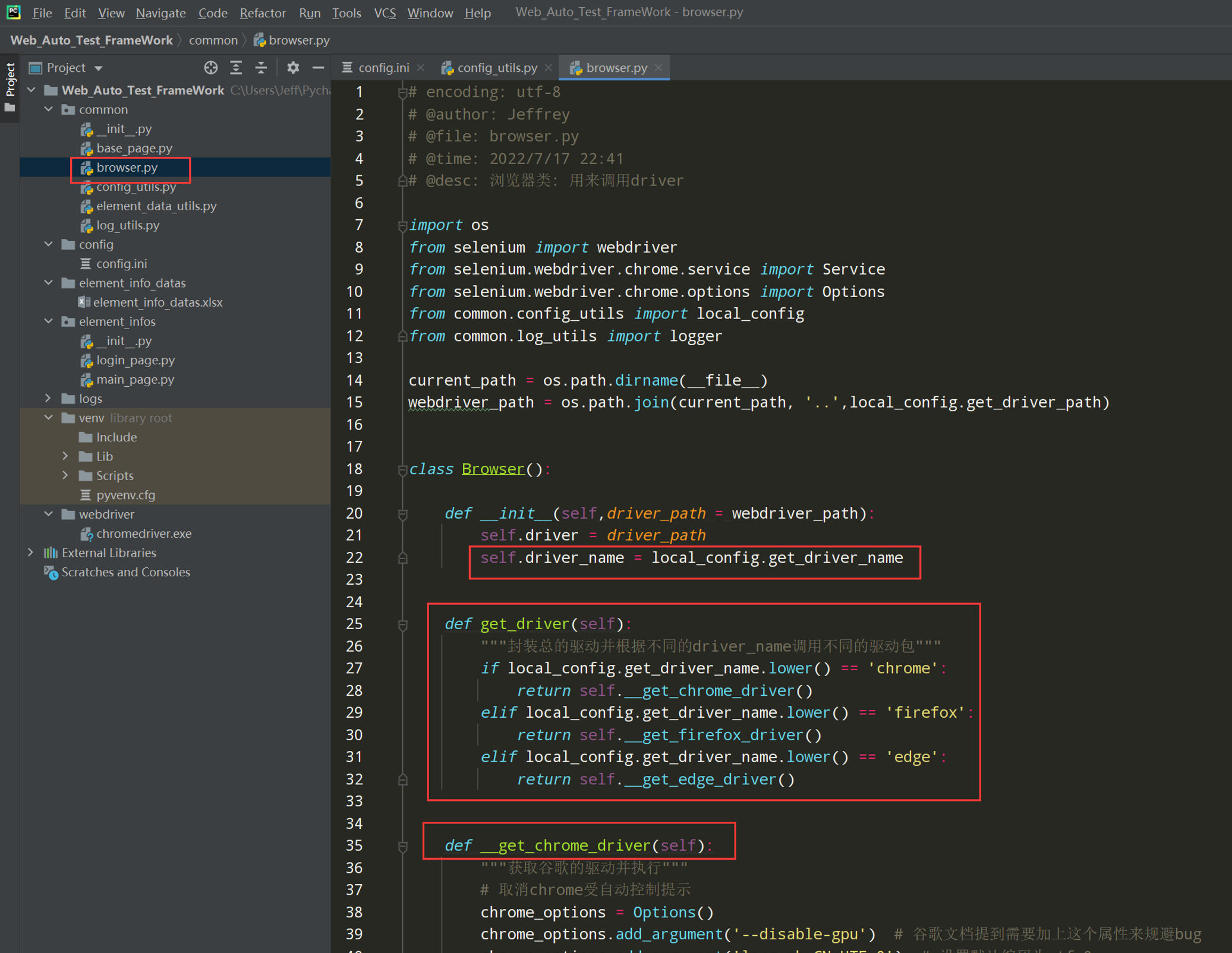
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: browser.py # @time: 2022/7/2 19:55 # @desc:浏览器类: 用来调用driver import os from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options from common.config_utils import local_config from common.log_utils import logger current_path = os.path.dirname(__file__) webdriver_path = os.path.join(current_path, '..',local_config.get_driver_path) class Browser(): def __init__(self,driver_path = webdriver_path): self.driver = driver_path self.driver_name = local_config.get_driver_name def get_driver(self): """封装总的驱动并根据不同的driver_name调用不同的驱动包""" if local_config.get_driver_name.lower() == 'chrome': return self.__get_chrome_driver() elif local_config.get_driver_name.lower() == 'firefox': return self.__get_firefox_driver() elif local_config.get_driver_name.lower() == 'edge': return self.__get_edge_driver() def __get_chrome_driver(self): """获取谷歌的驱动并执行""" # 取消chrome受自动控制提示 chrome_options = Options() chrome_options.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避bug chrome_options.add_argument('lang=zh_CN.UTF-8') # 设置默认编码为utf-8 chrome_options.add_experimental_option('useAutomationExtension', False) # 取消chrome受自动控制提示 chrome_options.add_experimental_option("excludeSwitches", ['enable-automation']) # 取消chrome受自动控制提示 # 指定webdriver文件下的谷歌驱动 chrome_driver_path = os.path.join(self.driver, 'chromedriver.exe') # 传入webdriver驱动的新方法 Service()函数;以前的报警告,即将弃用 chrome_driver = Service(chrome_driver_path) driver = webdriver.Chrome(service=chrome_driver,options=chrome_options) logger.info("初始化google浏览器并启动") return driver def __get_firefox_driver(self): """获取火狐的驱动并执行""" firefox_driver_path = os.path.join(self.driver, 'geckodriver.exe') # 传入webdriver 驱动的新方法 Service()函数;以前的报警告,即将弃用 firefox_driver_path_obj = Service(firefox_driver_path) driver = webdriver.Firefox(service=firefox_driver_path_obj) logger.info("初始化firefox浏览器并启动") return driver def __get_edge_driver(self): """获取edge的驱动并执行""" edge_driver_path = os.path.join(self.driver, 'msedgedriver.exe') # 传入webdriver驱动的新方法 Service()函数;以前的报警告,即将弃用 edge_driver_path_obj = Service(edge_driver_path) driver = webdriver.Edge(service=edge_driver_path_obj) logger.info("初始化edge浏览器并启动") return driver
在login_page.py中执行测试一下:正常三个浏览器都可以调用
小结:
8、页面类的拆分实战
页面拆分实战
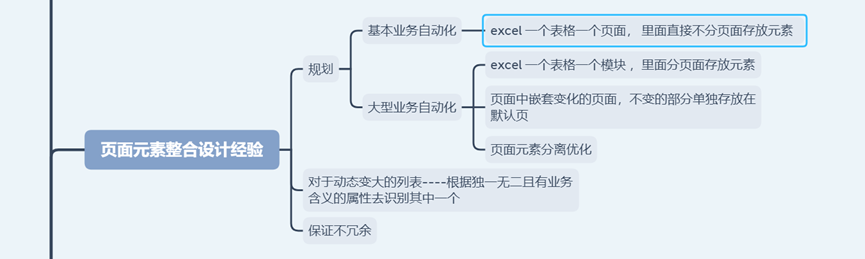
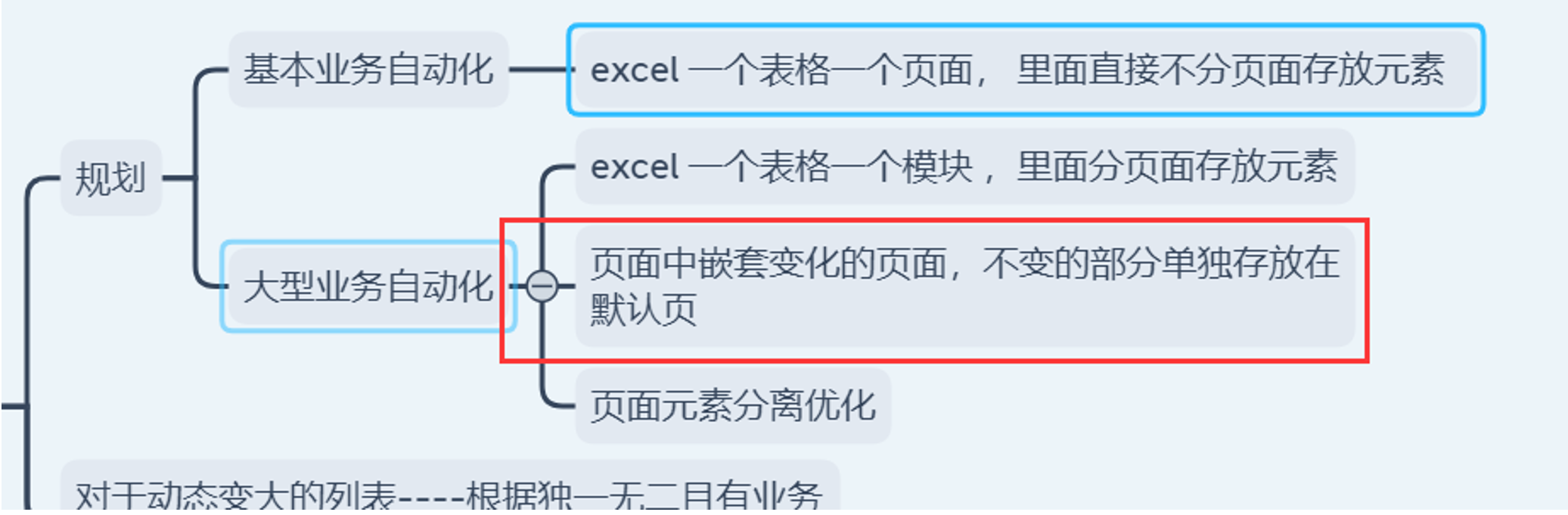
基本业务自动化:
目前是一个页面的元素信息放一个页签里面,如果100一个页面,就会有100个页签,怎么办
大型业务自动化

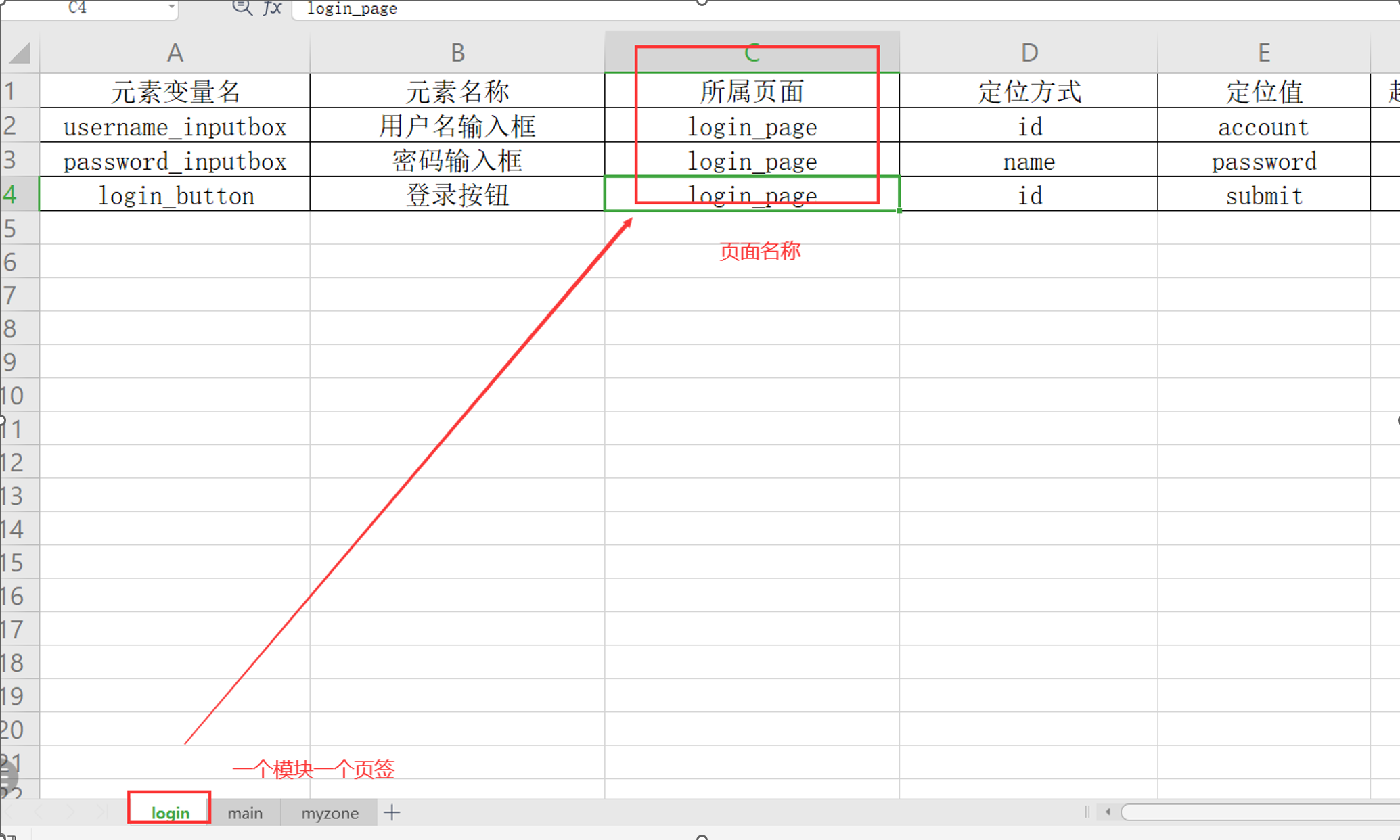
方式一:
1. 在element_data_utils.py文件中调整代码
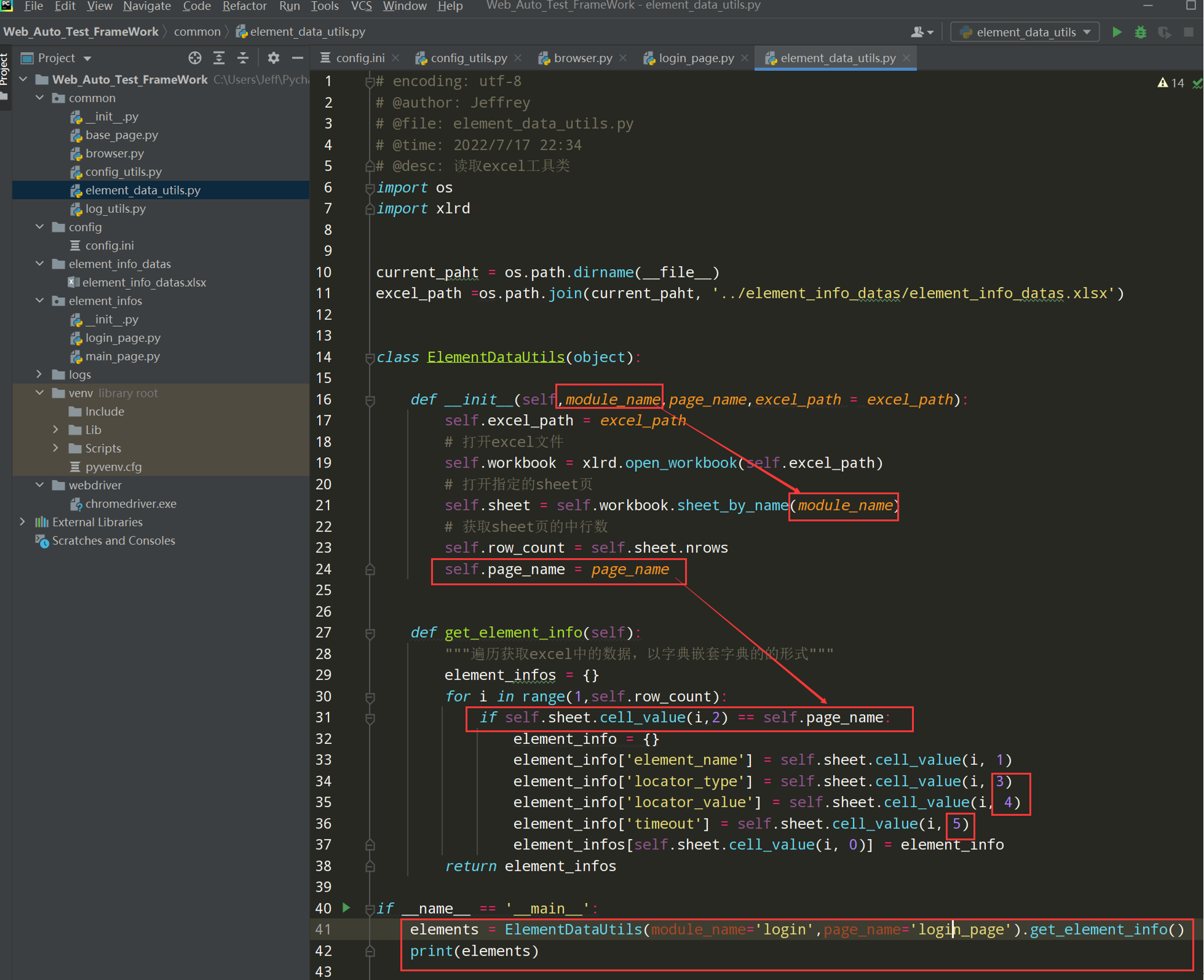
代码示例:
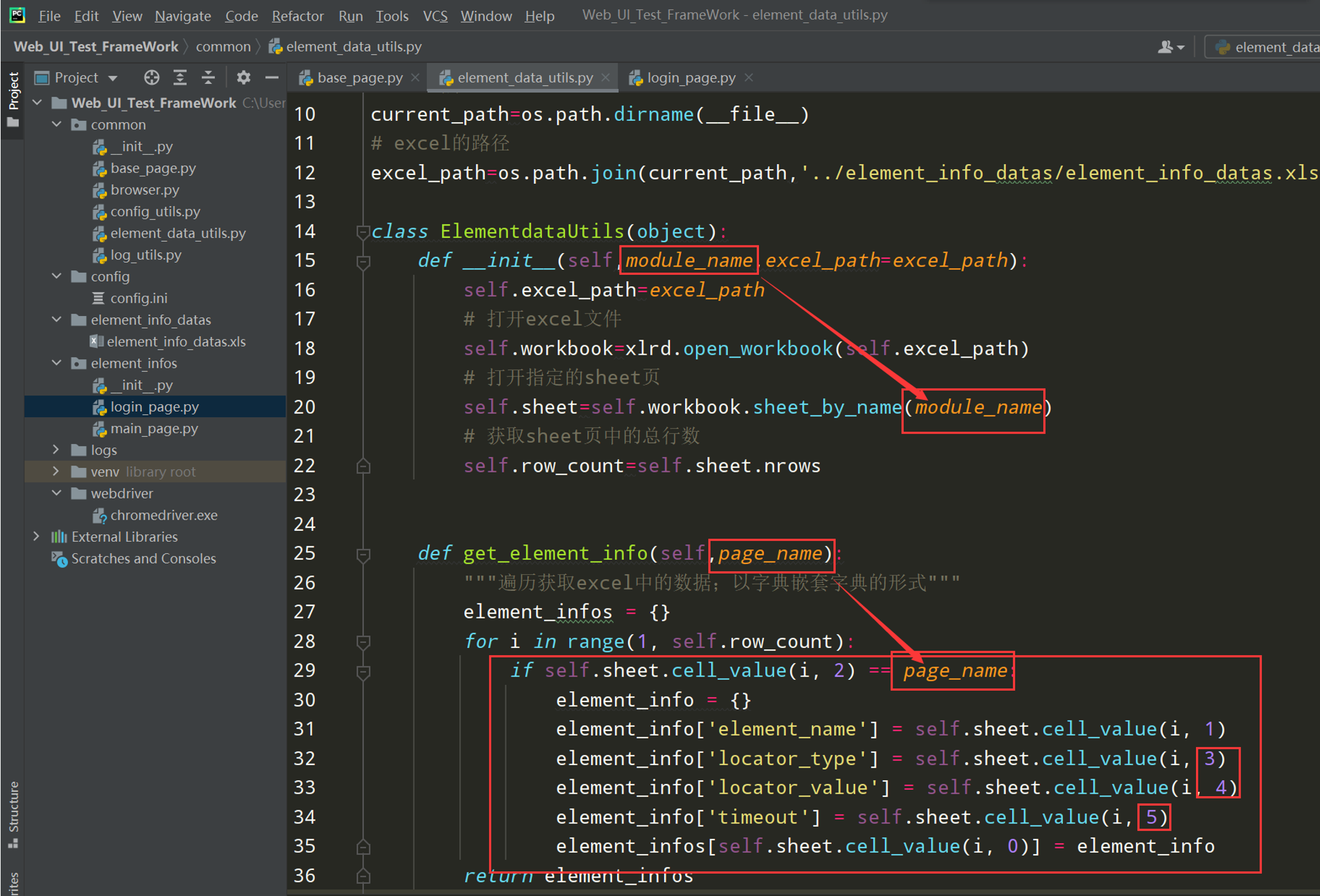
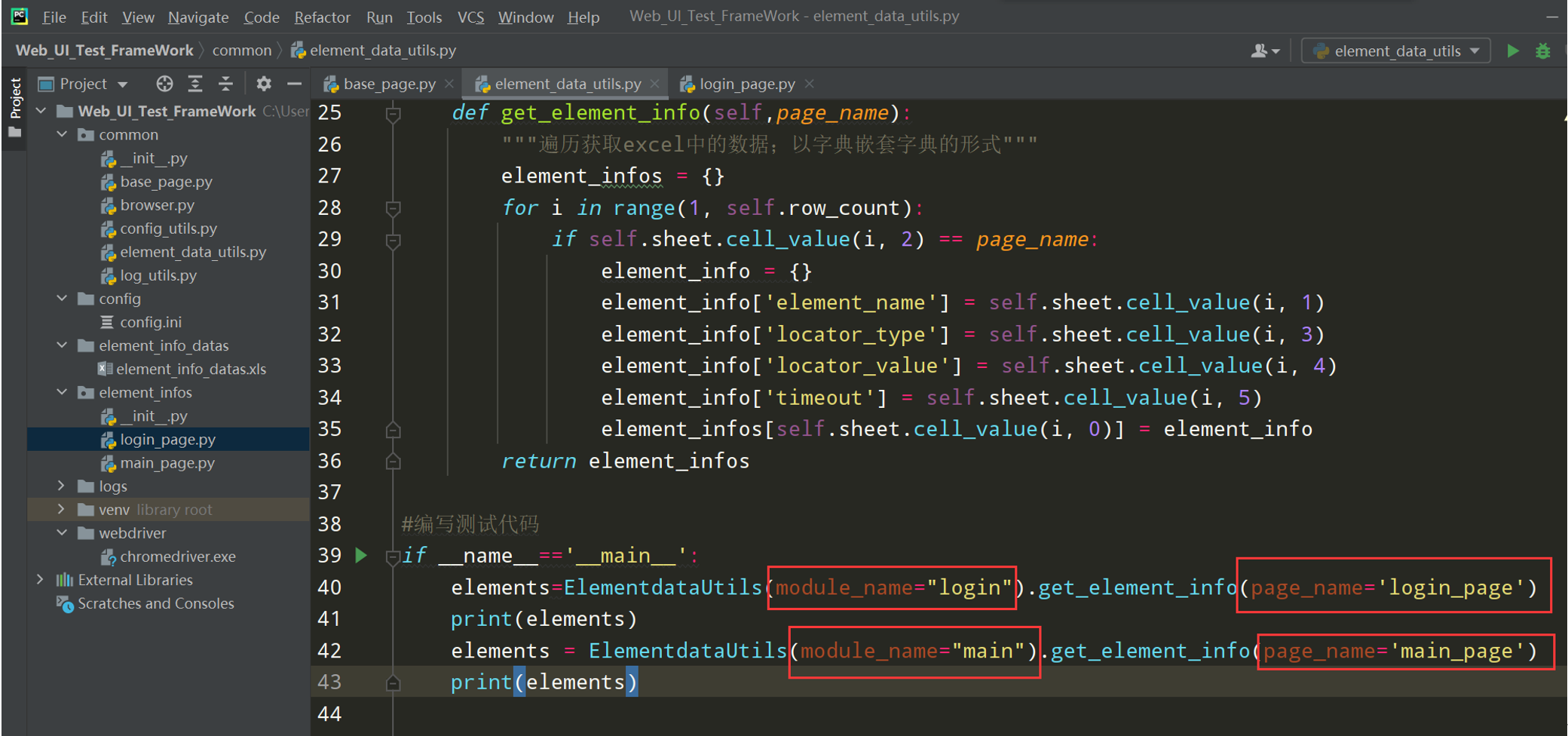
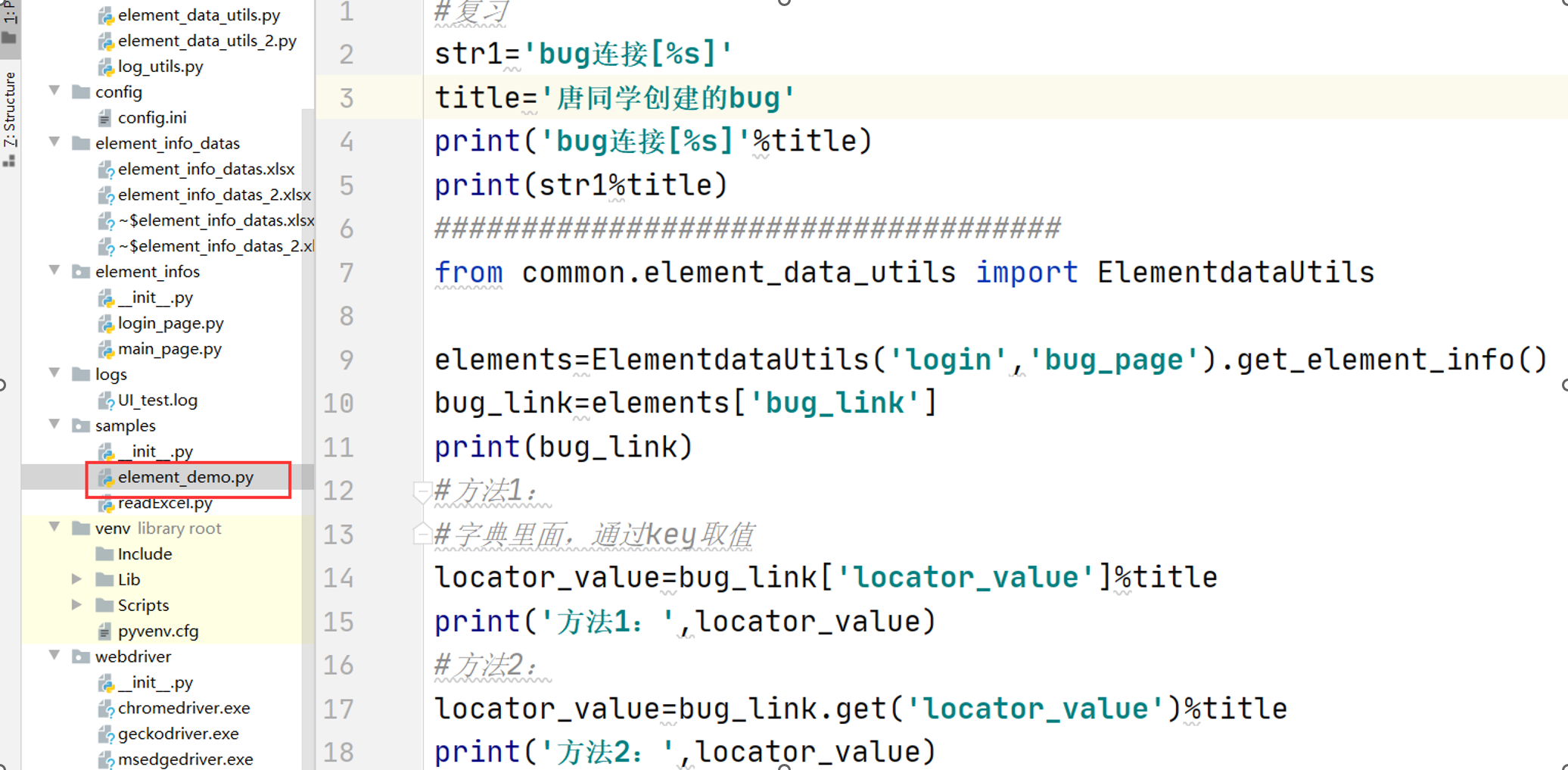
# encoding: utf-8 # @author: Jeffrey # @file: element_data_utils.py # @time: 2022/7/2 18:40 # @desc: 读取excel工具类 import os import xlrd current_paht = os.path.dirname(__file__) excel_path =os.path.join(current_paht, '../element_info_datas/element_info_datas.xlsx') class ElementDataUtils(object): def __init__(self,module_name,page_name,excel_path = excel_path): self.excel_path = excel_path # 打开excel文件 self.workbook = xlrd.open_workbook(self.excel_path) # 打开指定的sheet页 self.sheet = self.workbook.sheet_by_name(module_name) # 获取sheet页的中行数 self.row_count = self.sheet.nrows self.page_name = page_name def get_element_info(self): """遍历获取excel中的数据,以字典嵌套字典的的形式""" element_infos = {} for i in range(1,self.row_count): if self.sheet.cell_value(i,2) == self.page_name: element_info = {} element_info['element_name'] = self.sheet.cell_value(i, 1) element_info['locator_type'] = self.sheet.cell_value(i, 3) element_info['locator_value'] = self.sheet.cell_value(i, 4) element_info['timeout'] = self.sheet.cell_value(i, 5) element_infos[self.sheet.cell_value(i, 0)] = element_info return element_infos if __name__ == '__main__': elements = ElementDataUtils(module_name='login',page_name='login_page').get_element_info() print(elements)
2.查看执行效果:

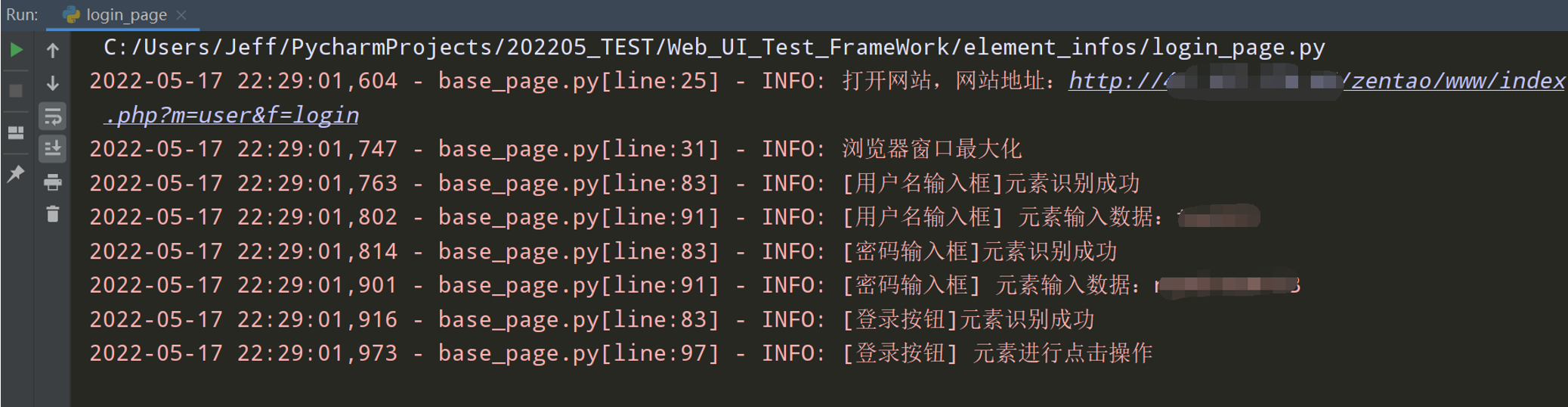
3、完善login_page.py文件
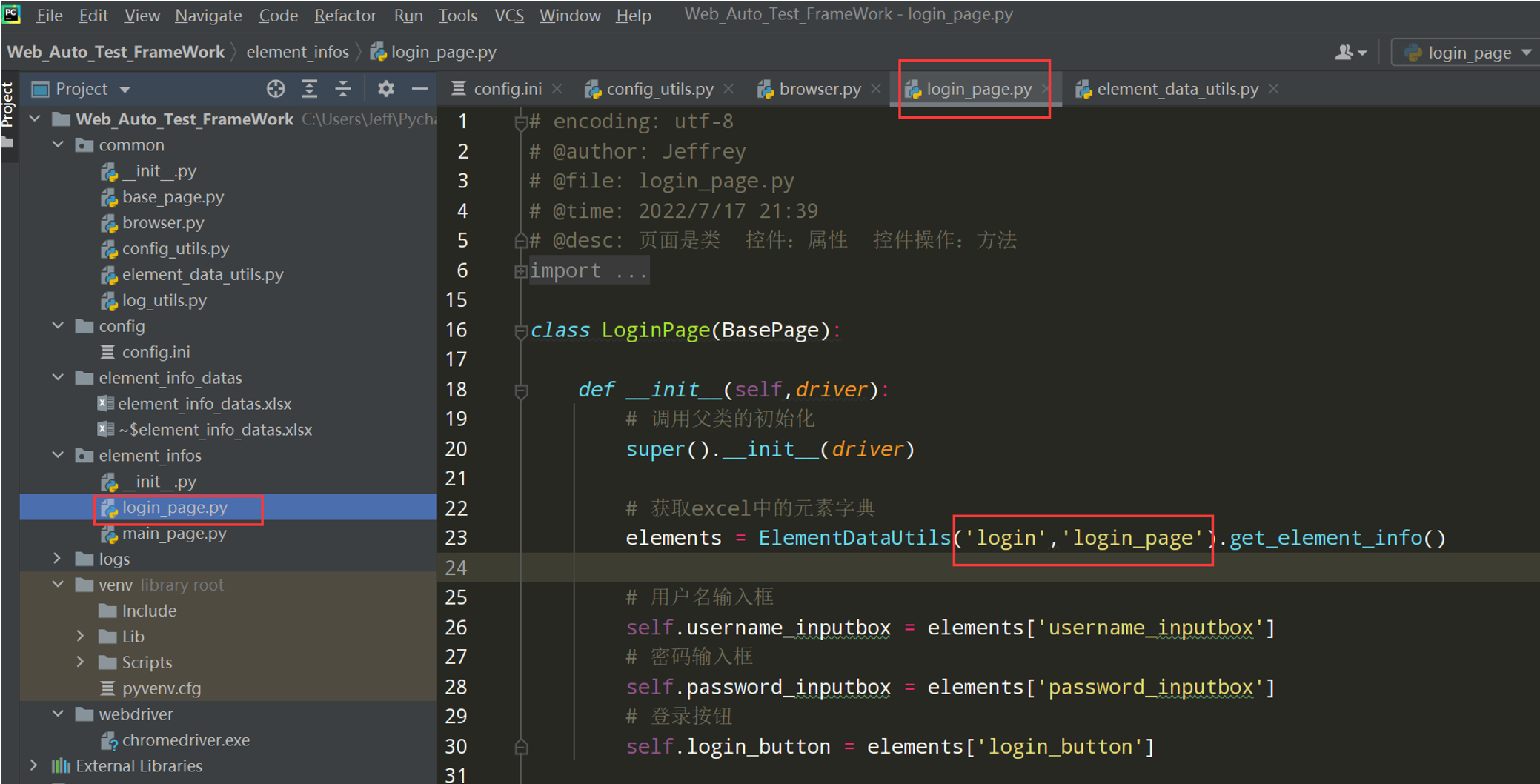
4、查看执行效果:
方式二:
1、element_data_utils.py文件调整代码;如下图
2.查看执行效果:
3.再完善login_page.py文件
4.查看执行效果:

每个模块下都有相同的子模块;怎么操作;如下图:
比如下图:一个模块下和别的模块有相同的子模块,那就把不变的部门单独放到一个模块的excel表格中;比如main模块的sheet页签中

动态变化的元素怎么定位:

举例:在login_page页加个别的页面;如下图:


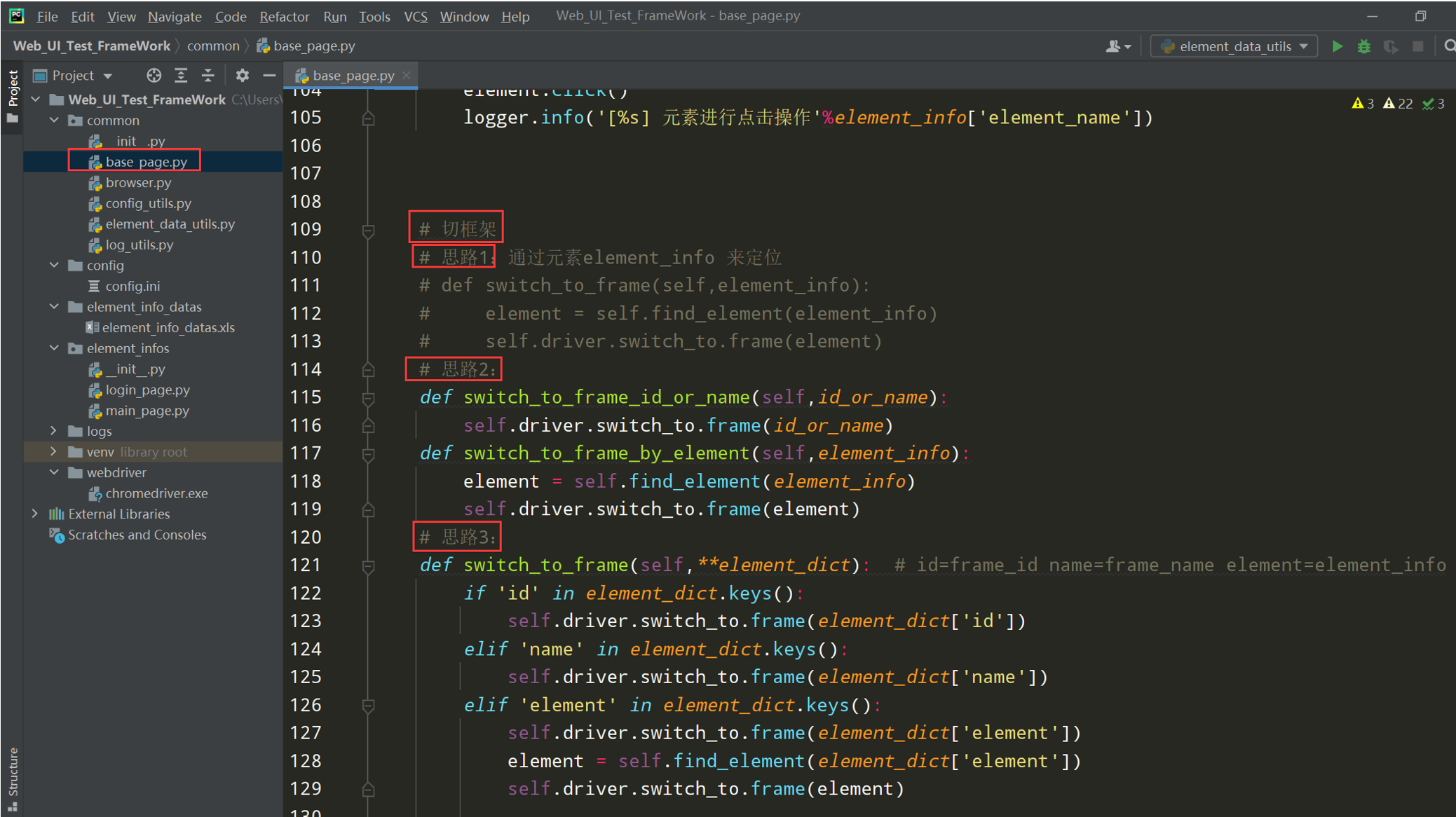
框架05---base_page封装实战
实战1:在base_page封装切框架
代码示例:
"""切框架""" # 思路1:通诺元素element_info 来定位 def switch_to_frame(self,element_info): element = self.find_element(element_info) self.driver.switch_to.frame(element) # 思路2: def switch_to_frame_id_or_name(self,id_or_name): self.driver.switch_to.frame(id_or_name) def switch_to_frame_by_element(self,element_info): element = self.find_element(element_info) self.driver.switch_to.frame(element) # 思路3: def switch_to_frame_element_dict(self,**element_dict): if 'id' in element_dict.keys(): self.driver.switch_to.frame(element_dict['id']) elif 'name' in element_dict.keys(): self.driver.switch_to.frame(element_dict['name']) elif 'element' in element_dict.keys(): self.driver.switch_to.frame(element_dict['element']) element = self.find_element(element_dict['element']) self.driver.switch_to.frame(element)
实战2:执行js的封装
前置条件:在demo中先执行一下是否执行成功

步骤1:


步骤2:继续封装selenium执行js的脚本

步骤3:封装成私有
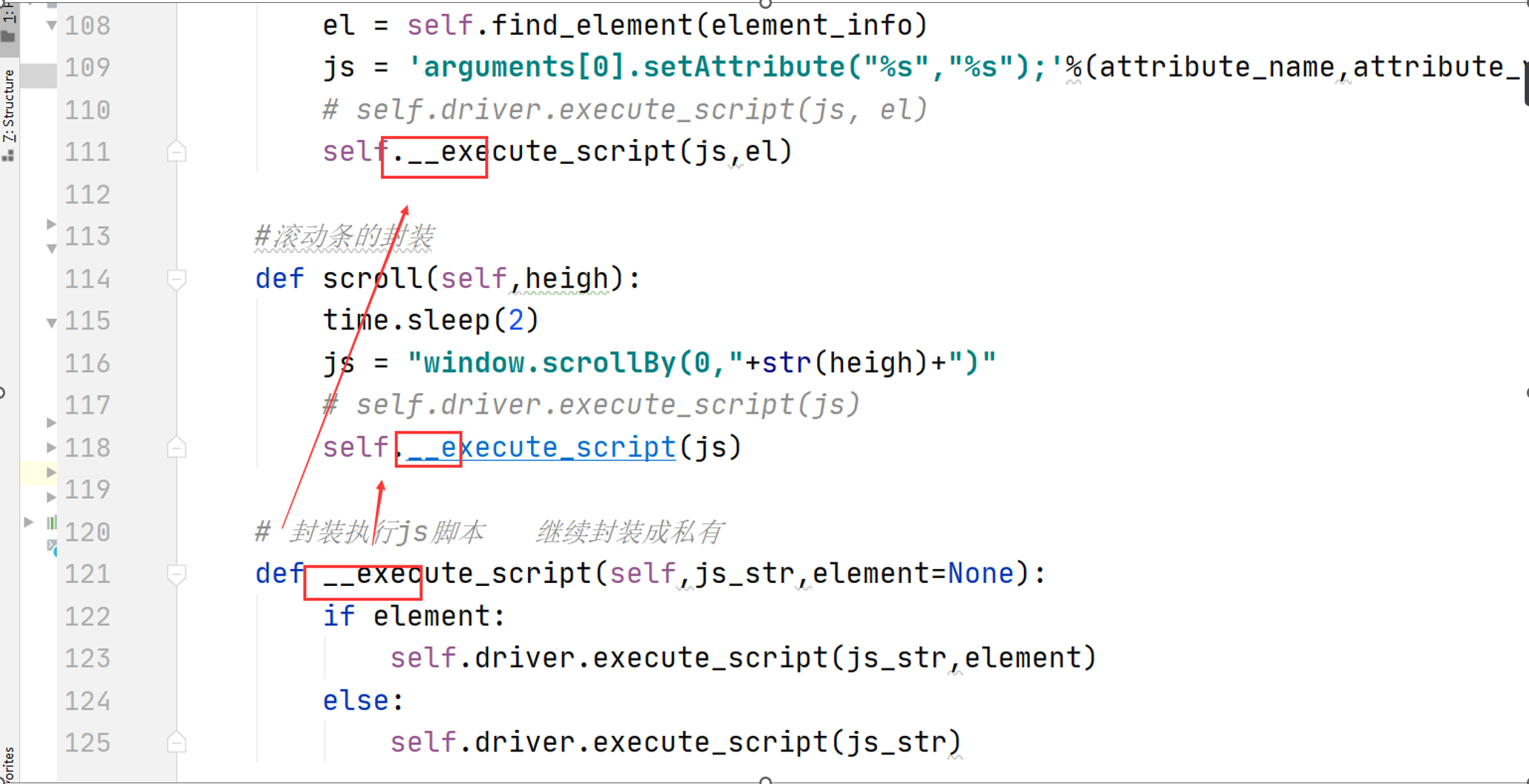
以上三个步骤的编写代码:
"""js执行的封装""" # 移除元素属性的封装 def delete_element_attribute(self,element_info,attibute_name): el = self.find_element(element_info) Js = 'arguments[0].removeAttribute("%s");'% attibute_name # 移除元素的value 属性 # self.driver.execute_script(Js, el) # 执行js 脚本 self.__execute_script(Js,el) logger.info('在[%s]元素上,移除属性[%s]' % (element_info['element_name'], attibute_name) ) # 修改元素属性 def update_element_attribute(self, element_info, attribute_name, attribute_value): el = self.find_element(element_info) js = 'arguments[0].setAttribute("%s","%s");'%(attribute_name,attribute_value) # self.driver.execute_script(js, el) self.__execute_script(js, el) logger.info('在[%s]元素上,修改属性;属性名:[%s],属性值:[%s]' % (element_info['element_name'], attribute_name,attribute_value)) # 滚动条的封装 def scroll(self,heigh): self.wait(2) js = "window.scrollBy(0,"+str(heigh)+")" # self.driver.execute_script(js) self.__execute_script(js) logger.info('滚动浏览器,滚动高度为 %d' % heigh) # 封装执行js脚本 def __execute_script(self,js_str, element=None): if element: self.driver.execute_script(js_str,element) else: self.driver.execute_script(js_str)
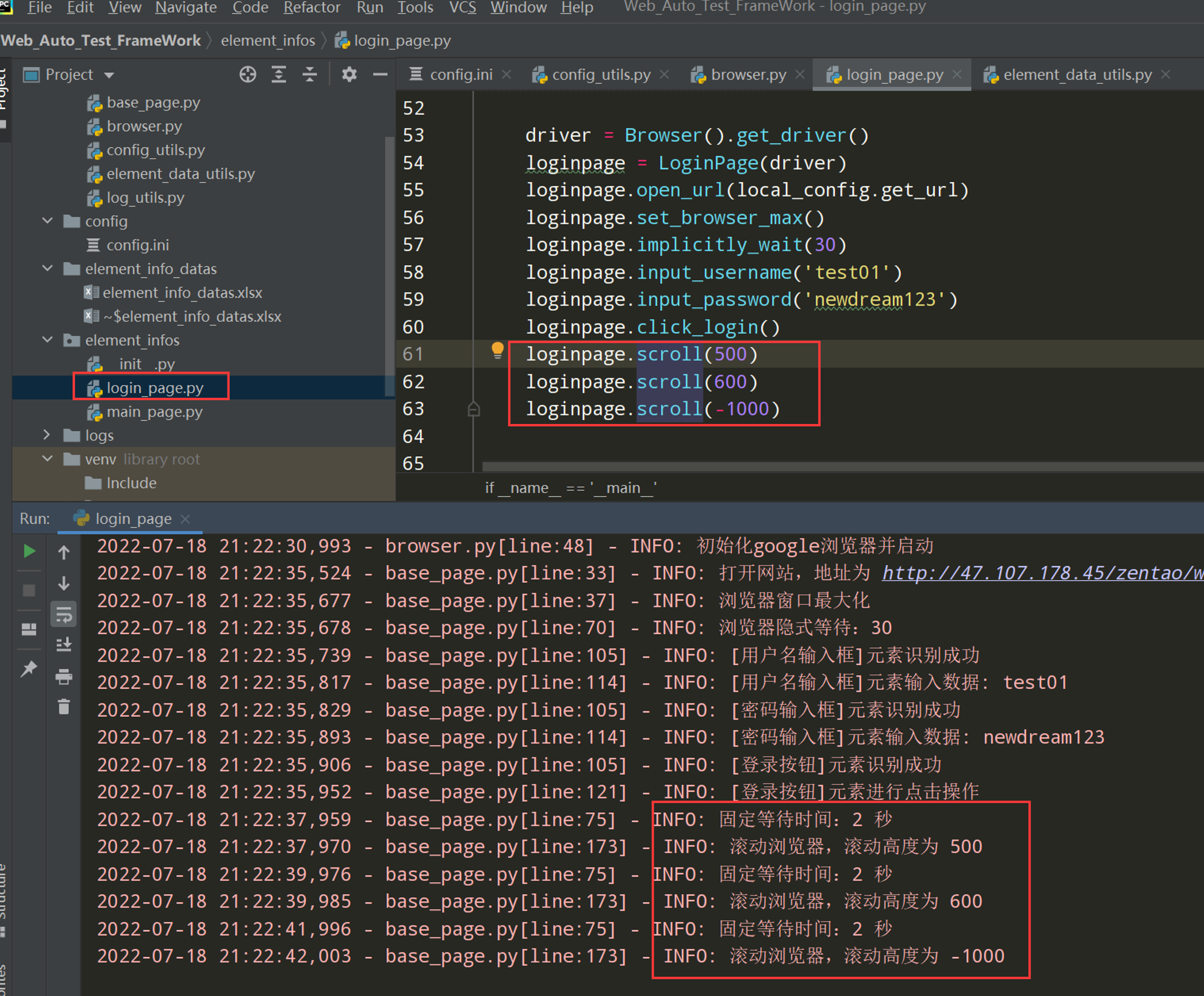
步骤4:编写测试代码,调试
步骤5:自己继续扩展
1. 加日志
2. 加异常处理
3. 封装获取属性
实战3:封装等待时间
显式,隐式,固定等待
步骤1:封装固定等待
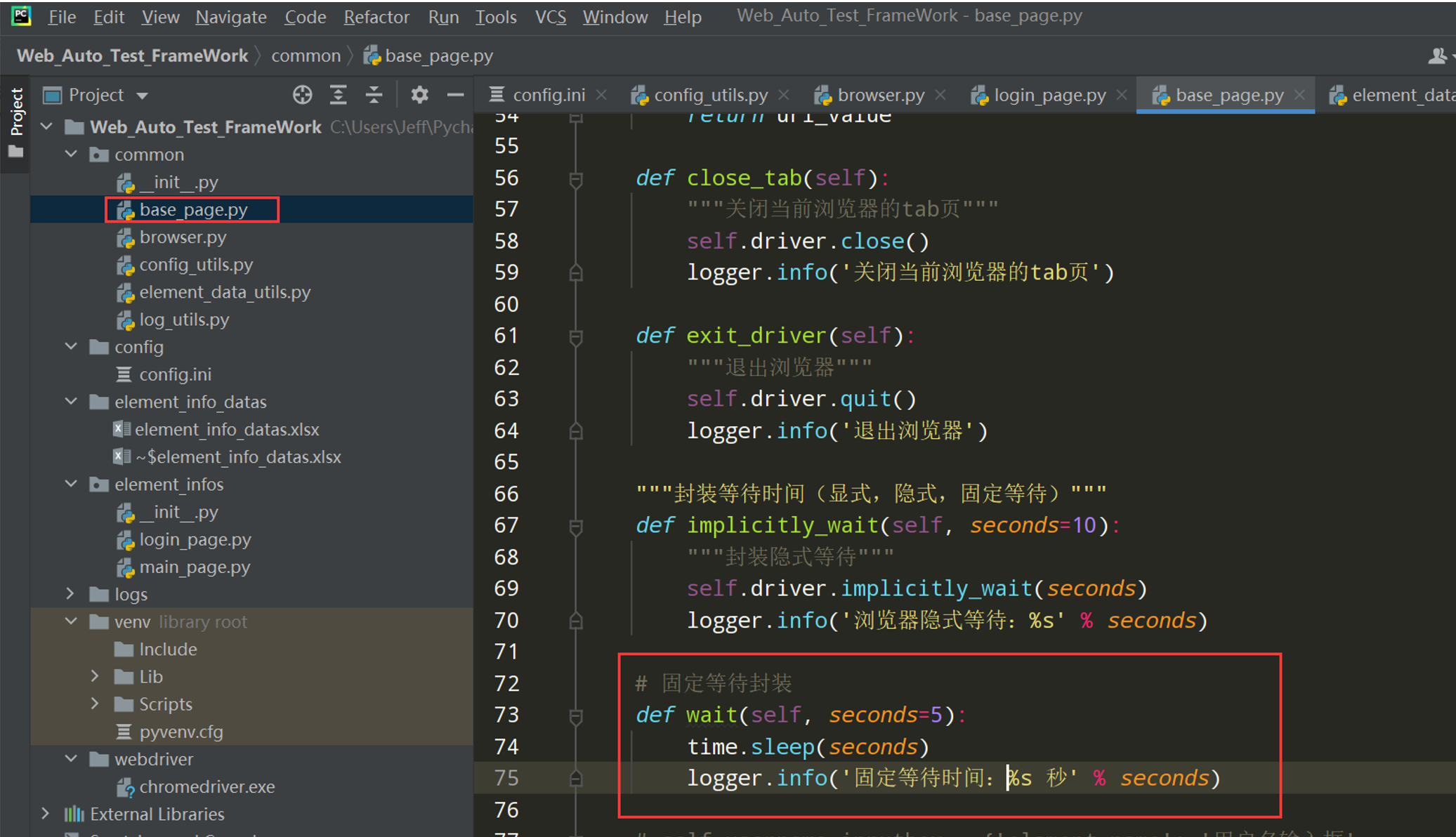
# 固定等待封装
def wait(self, seconds=5):
time.sleep(seconds)
logger.info('固定等待时间:%s 秒' % seconds)
步骤2:封装隐式等待
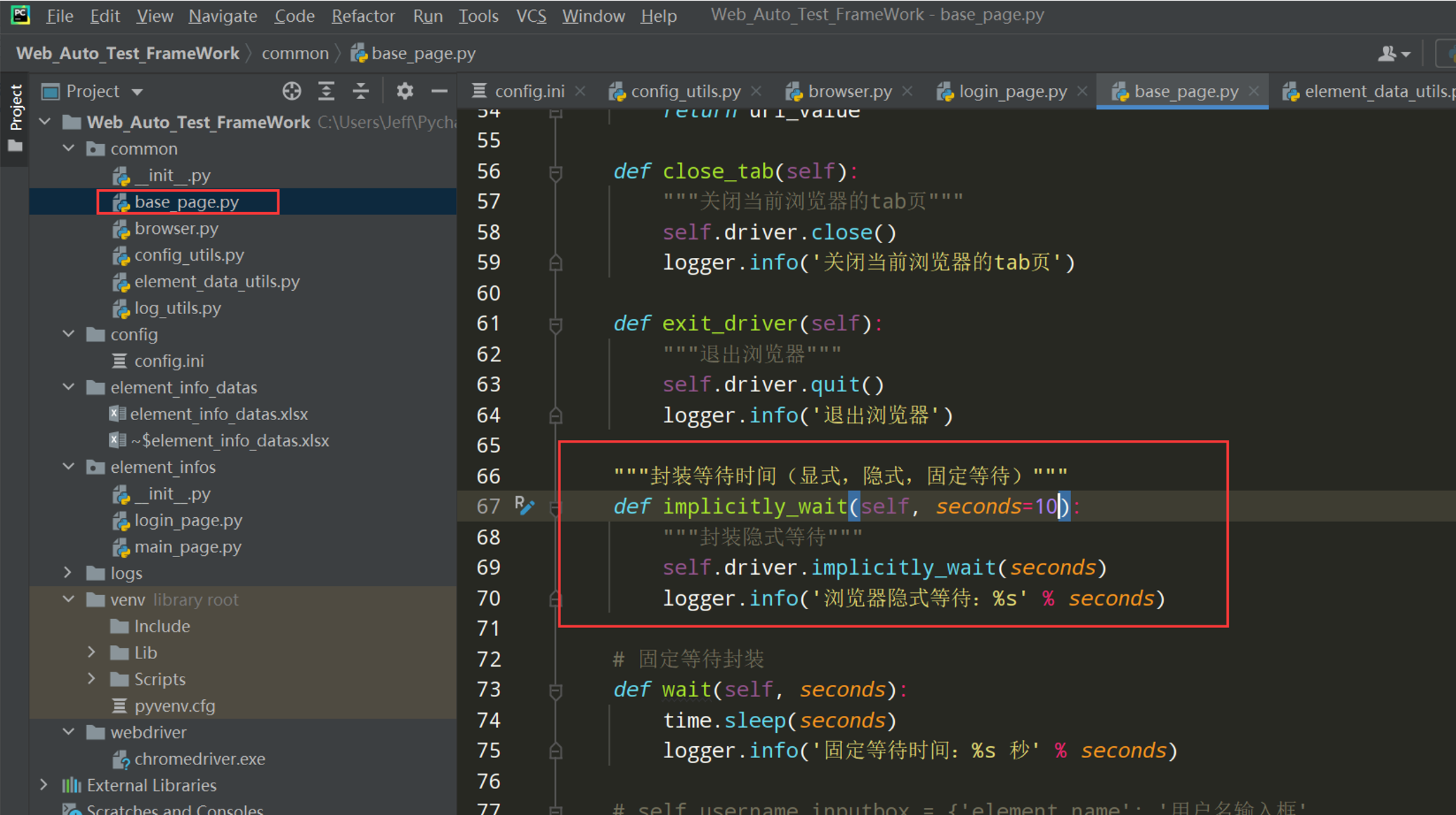
"""封装等待时间(显式,隐式,固定等待)"""
def implicitly_wait(self, seconds=10):
"""封装隐式等待"""
self.driver.implicitly_wait(seconds)
logger.info('浏览器隐式等待:%s' % seconds)
步骤3:显式等待的封装如下图(显示等待封装在find_element()函数中是为了等待每一个元素信息)
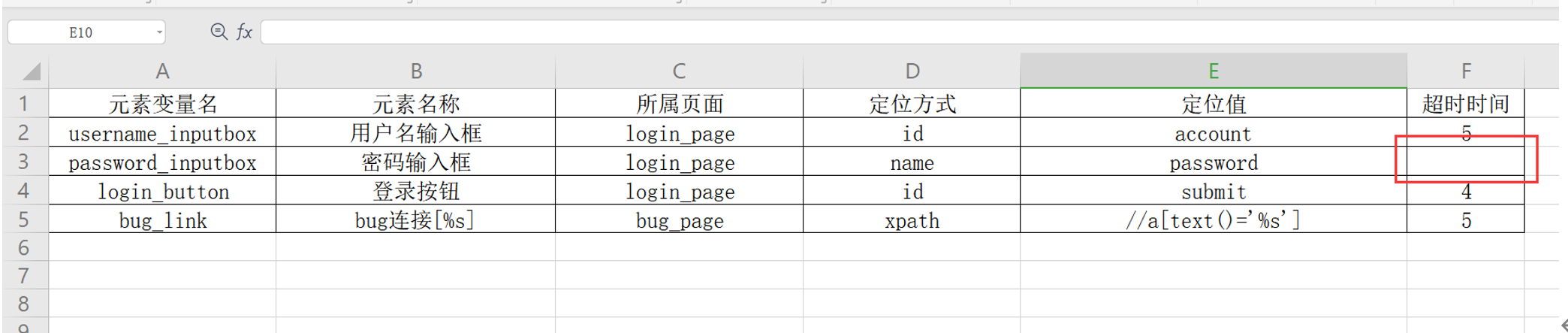
步骤4:如果excel元素表中没有设置超时时间,我们设置一个系统默认等待的时间;如下图中元素识别信息中的超时时间没有值;
可在系统中设置一个默认等待时间;如下图
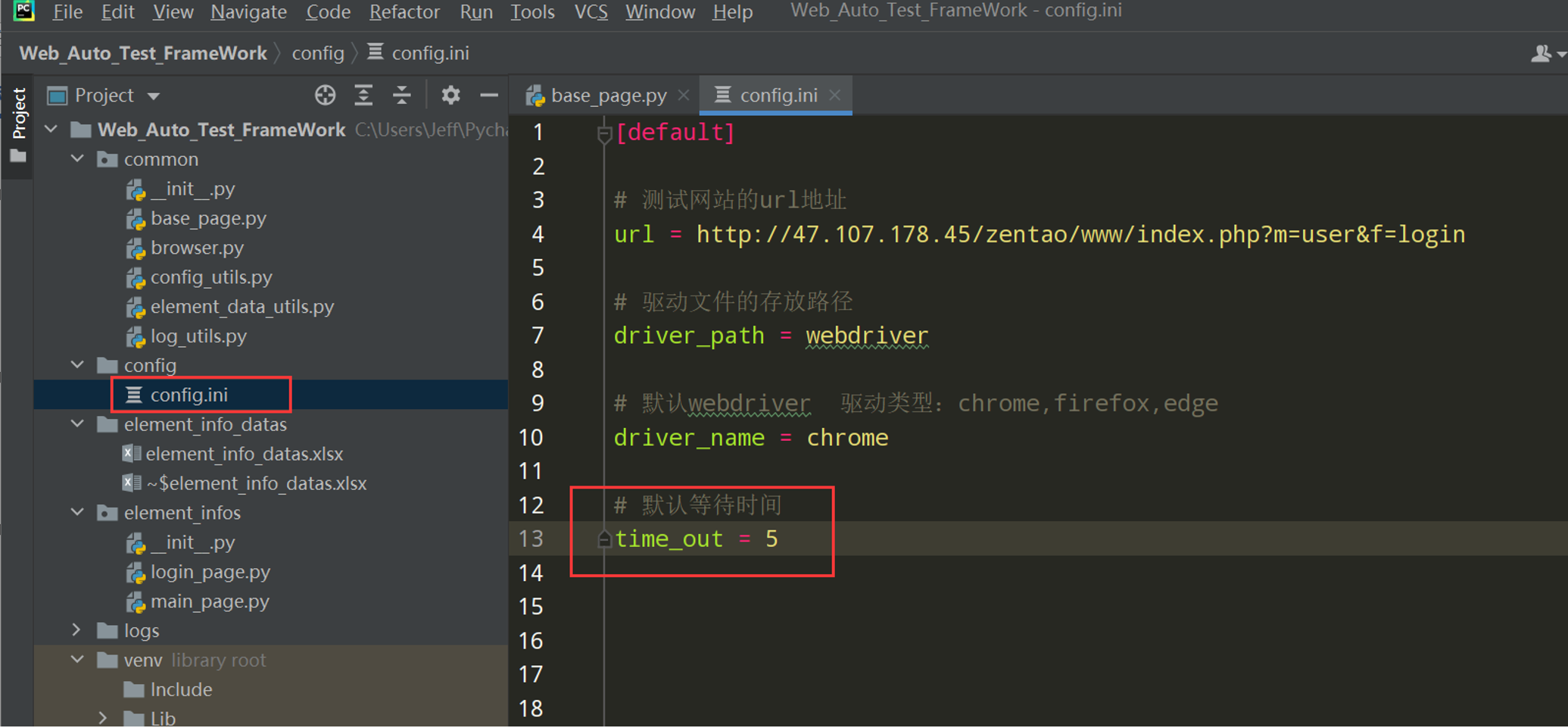
再通过config_utils.py获取默认等待时间的值;如下图:
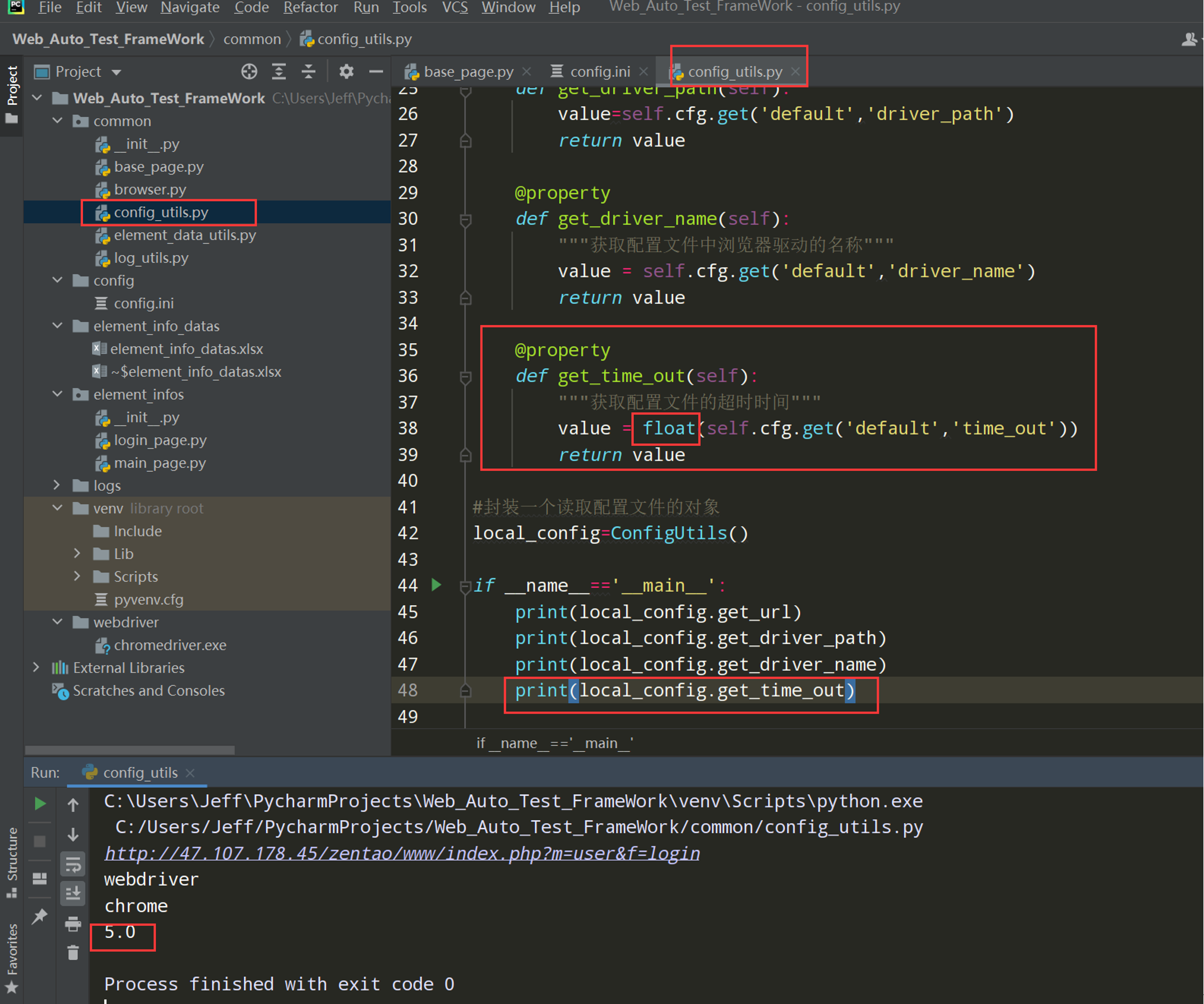
Config_utils.py中的代码如下:
# encoding: utf-8 # @author: Jeffrey # @file: config_utils.py # @time: 2022/7/2 19:45 # @desc: 读取配置文件 import os import configparser current_path = os.path.dirname(__file__) config_path = os.path.join(current_path, '../config/config.ini') class ConfigUtils: def __init__(self, path = config_path): self.cfg = configparser.ConfigParser() self.cfg.read(path, encoding='utf-8') # @property 装饰器负责吧类中的方法转换成类属性来调用 @property def get_url(self): """获取配置文件中的url地址""" value = self.cfg.get('default', 'url') return value @property def get_driver_path(self): """获取配置文件中的浏览器驱动路径""" value = self.cfg.get('default','driver_path') return value @property def get_driver_name(self): """获取配置文件中浏览器驱动的名称""" value = self.cfg.get('default','driver_name') return value @property def get_time_out(self): """获取配置文件的超时时间""" value = float(self.cfg.get('default','time_out')) return value # 封装一个读取配置文件的对象 local_config = ConfigUtils() if __name__ == '__main__': print(local_config.get_url) print(local_config.get_driver_path) print(local_config.get_driver_name) print(local_config.get_time_out)
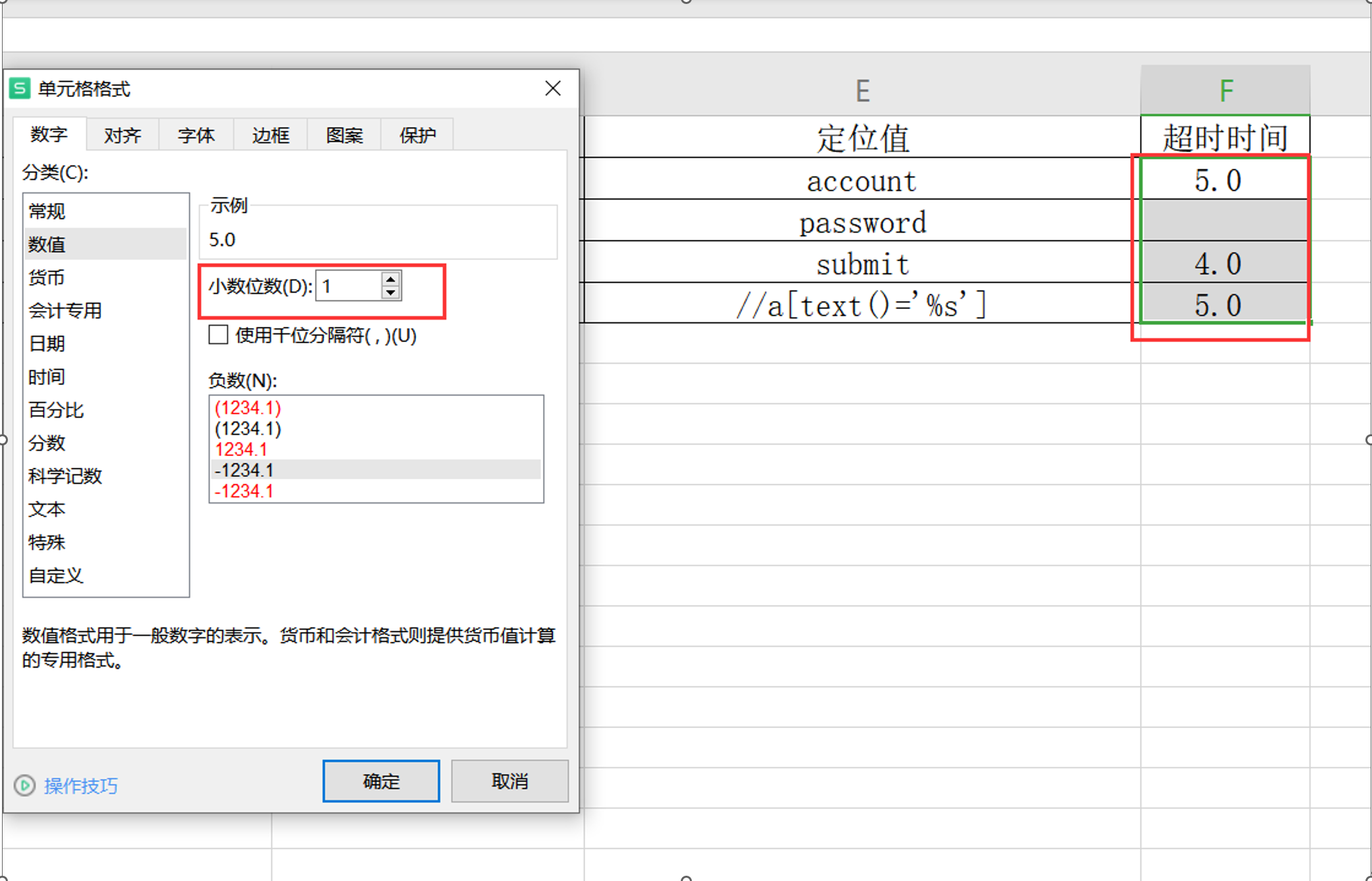
元素excel信息表可以把时间值设置为浮点数;
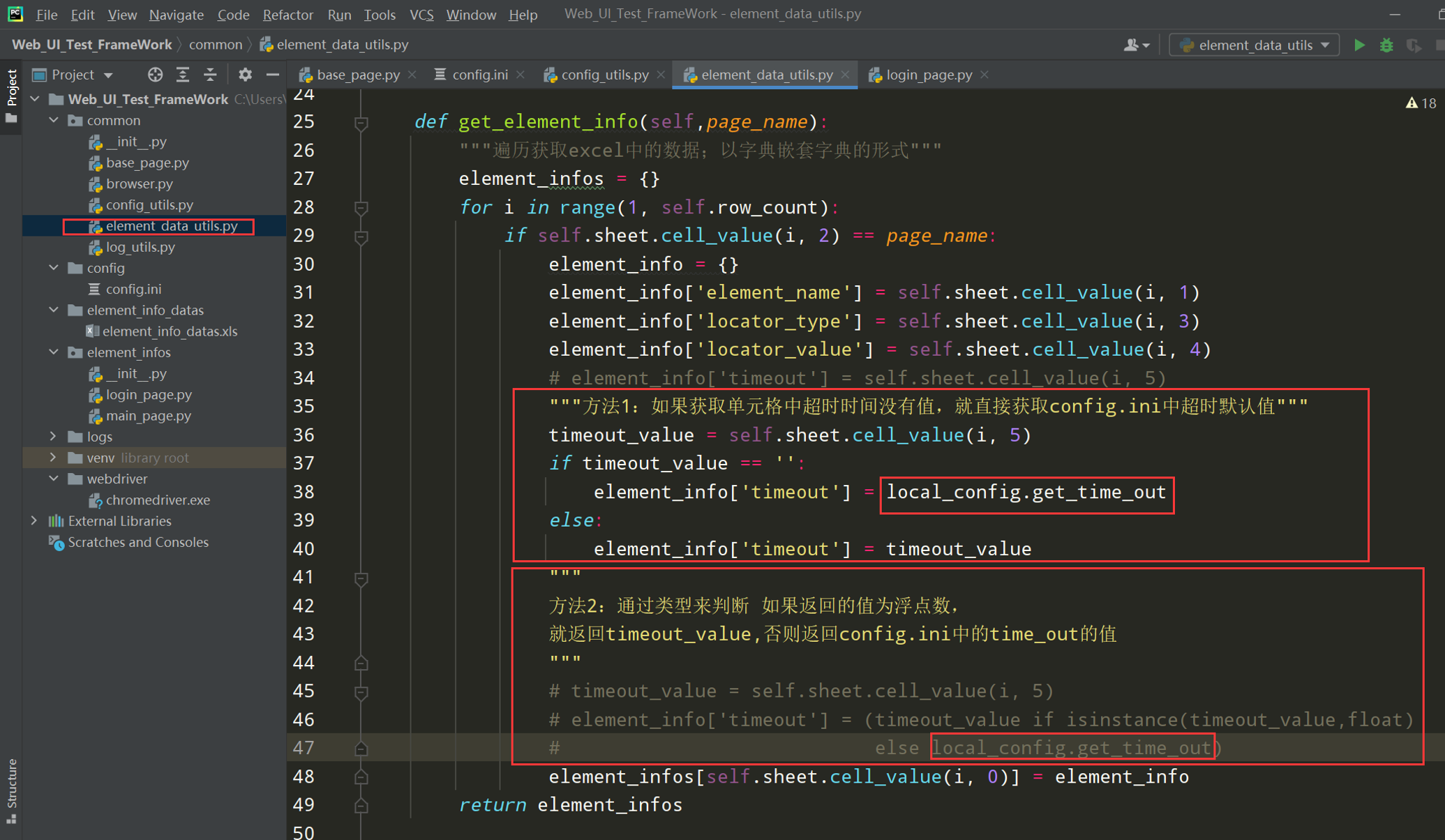
在element_data_utils.py文件中,把获取excel的函数加上如下代码;判断如果excel中的超时时间没有值的话默认取ini中的超时时间;如下图:
from common.config_utils import local_config
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: element_data_utils.py # @time: 2022/7/2 18:40 # @desc: 读取excel工具类 import os import xlrd from common.config_utils import local_config current_paht = os.path.dirname(__file__) excel_path =os.path.join(current_paht, '../element_info_datas/element_info_datas.xlsx') class ElementDataUtils(object): def __init__(self,module_name,page_name,excel_path = excel_path): self.excel_path = excel_path # 打开excel文件 self.workbook = xlrd.open_workbook(self.excel_path) # 打开指定的sheet页 self.sheet = self.workbook.sheet_by_name(module_name) # 获取sheet页的中行数 self.row_count = self.sheet.nrows self.page_name = page_name def get_element_info(self): """遍历获取excel中的数据,以字典嵌套字典的的形式""" element_infos = {} for i in range(1,self.row_count): if self.sheet.cell_value(i,2) == self.page_name: element_info = {} element_info['element_name'] = self.sheet.cell_value(i, 1) element_info['locator_type'] = self.sheet.cell_value(i, 3) element_info['locator_value'] = self.sheet.cell_value(i, 4) # element_info['timeout'] = self.sheet.cell_value(i, 5) """方法1:如果获取单元格中超时时间没有值,就直接获取config.ini中超时默认值""" timeout_value = self.sheet.cell_value(i, 5) if timeout_value == '': element_info['timeout'] = local_config.get_time_out else: element_info['timeout'] = timeout_value # """方法2:通过类型判断 如果返回的值为浮点数, # 就返回 timeout_value,否则返回config.ini中的time_out的值""" # timeout_value = self.sheet.cell_value(i, 5) # element_info['timeout'] = (timeout_value if isinstance(timeout_value,float) # else local_config.get_time_out) element_infos[self.sheet.cell_value(i, 0)] = element_info return element_infos if __name__ == '__main__': elements = ElementDataUtils(module_name='login',page_name='login_page').get_element_info() print(elements)
测试一下:
步骤5:在basepage.py中把刚才封装的几种等待的时间值设置为config.ini中默认的等待时间
导包:from common.config_utils import local_config
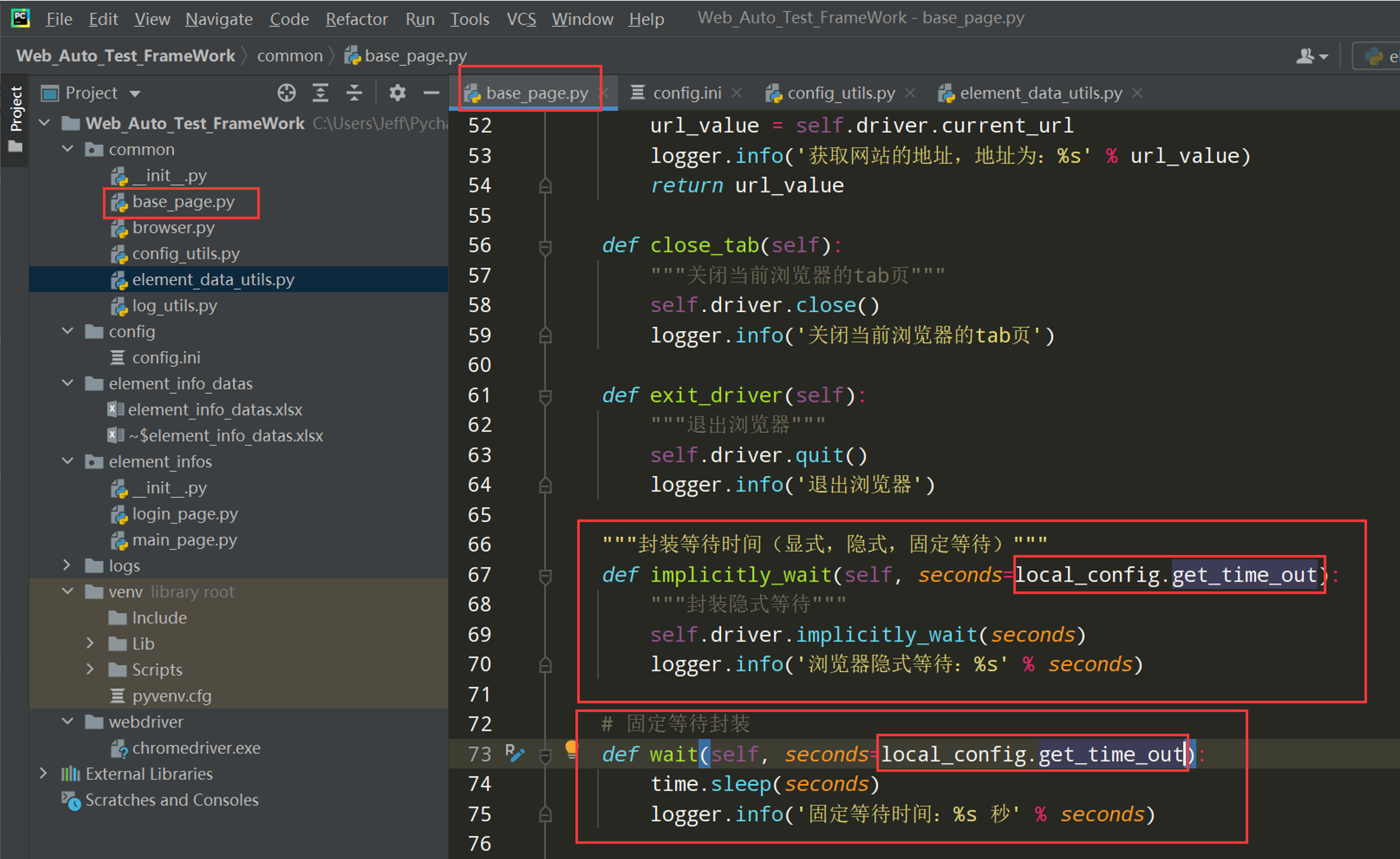
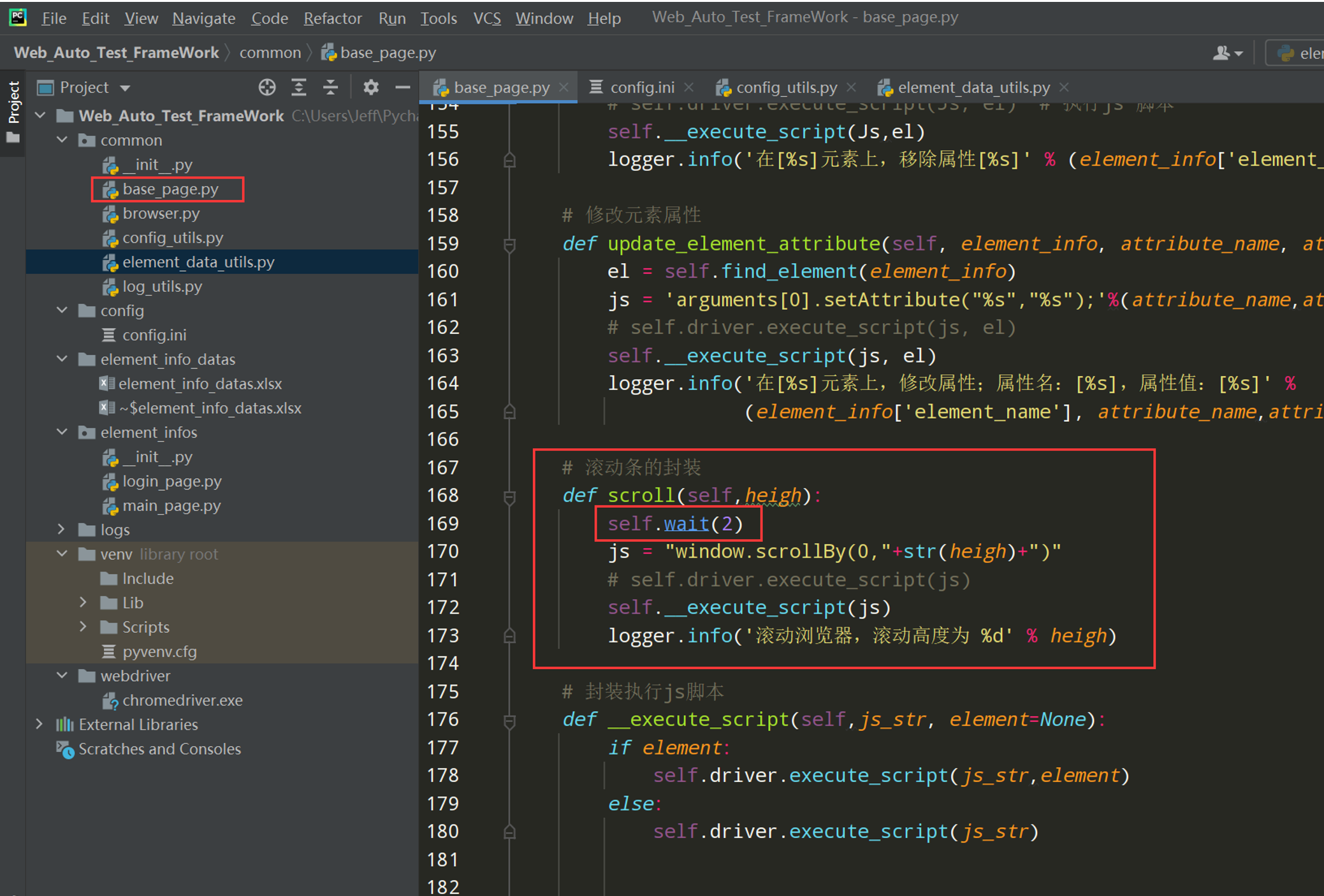
注:有个疑问,把固定等待和隐式等待都设置了ini配置文件中超时时间的默认值了,那为什么不设置显示等待的?
其实在上面的element_data_utils.py文件已经写好了获取excel中的超时时间,如果超时时间的值为空直接默认取ini文件中的超时时间,然后再下图中的find_element()函数中传入的元素信息其实已经匹配到超时时间的值(locator_timeout),故可以直接做判断;
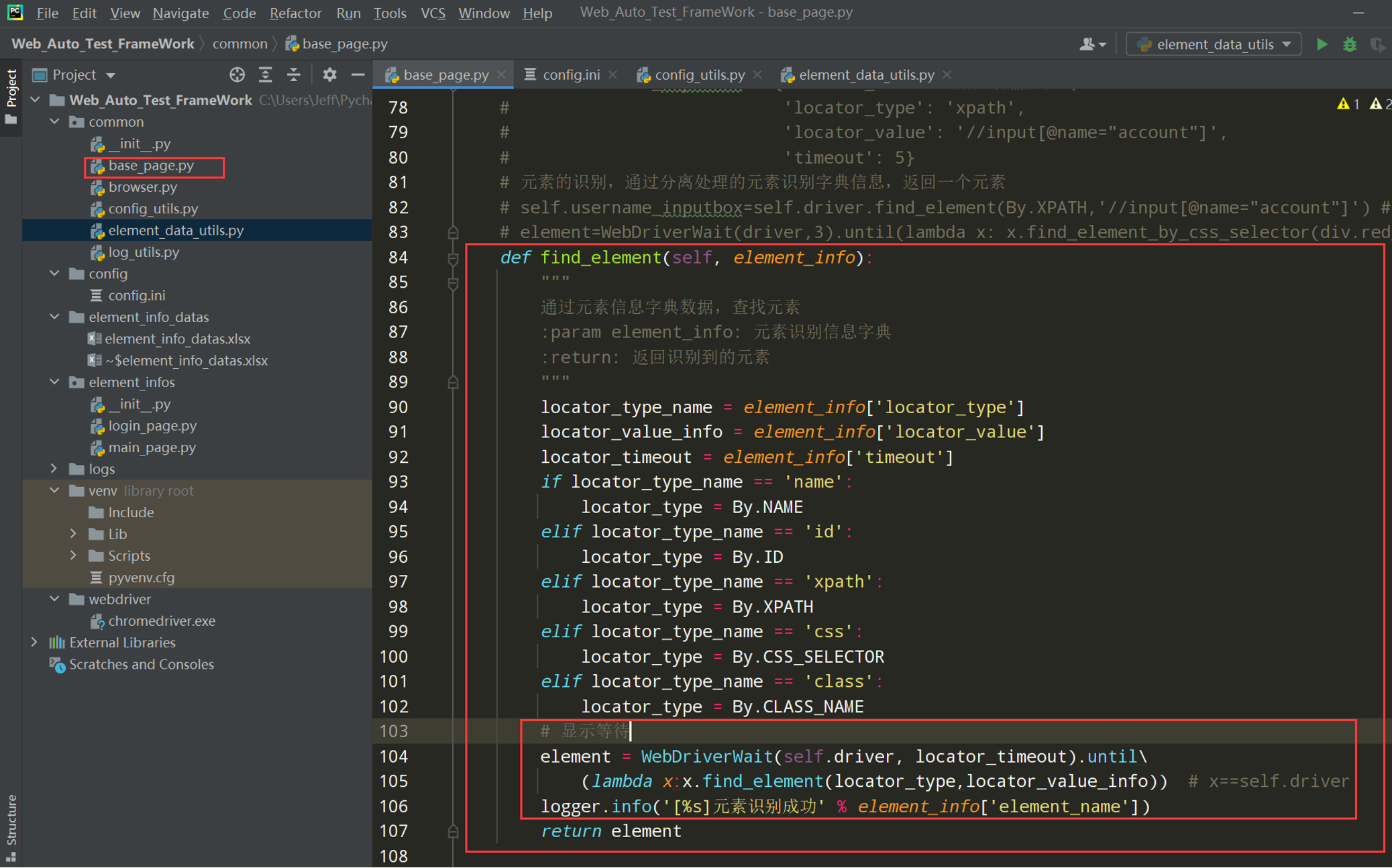
实战4:鼠标键盘事件的封装
在base_page.py文件中封装鼠标键盘方法
前置条件:导入包
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
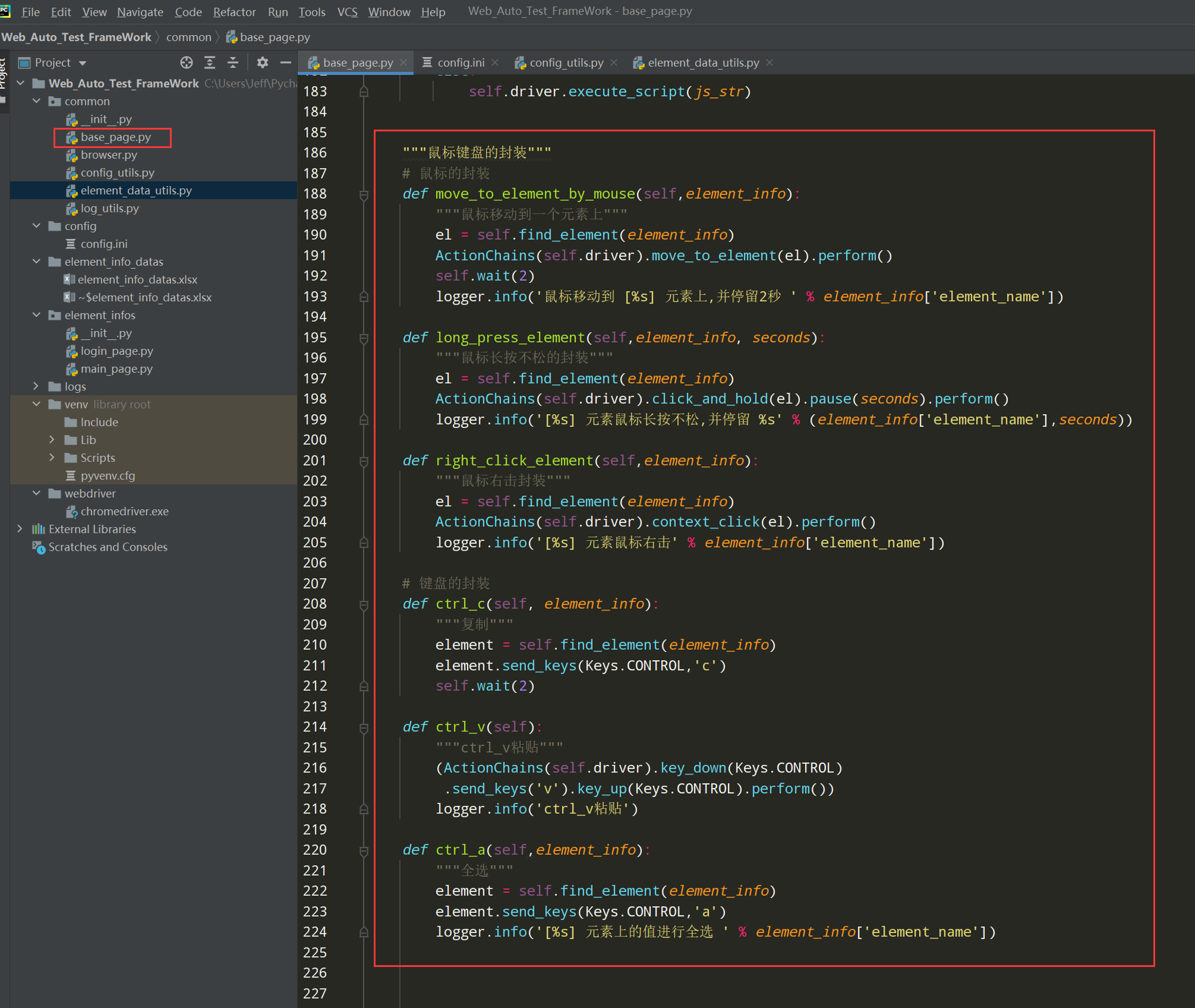
代码示例:
"""鼠标键盘的封装""" # 鼠标的封装 def move_to_element_by_mouse(self,element_info): """鼠标移动到一个元素上""" el = self.find_element(element_info) ActionChains(self.driver).move_to_element(el).perform() self.wait(2) logger.info('鼠标移动到 [%s] 元素上,并停留2秒 ' % element_info['element_name']) def long_press_element(self,element_info, seconds): """鼠标长按不松的封装""" el = self.find_element(element_info) ActionChains(self.driver).click_and_hold(el).pause(seconds).perform() logger.info('[%s] 元素鼠标长按不松,并停留 %s' % (element_info['element_name'],seconds)) def right_click_element(self,element_info): """鼠标右击封装""" el = self.find_element(element_info) ActionChains(self.driver).context_click(el).perform() logger.info('[%s] 元素鼠标右击' % element_info['element_name']) # 键盘的封装 def ctrl_c(self, element_info): """复制""" element = self.find_element(element_info) element.send_keys(Keys.CONTROL,'c') self.wait(2) def ctrl_v(self): """ctrl_v粘贴""" (ActionChains(self.driver).key_down(Keys.CONTROL) .send_keys('v').key_up(Keys.CONTROL).perform()) logger.info('ctrl_v粘贴') def ctrl_a(self,element_info): """全选""" element = self.find_element(element_info) element.send_keys(Keys.CONTROL,'a') logger.info('[%s] 元素上的值进行全选 ' % element_info['element_name'])
补充元素点击的操作
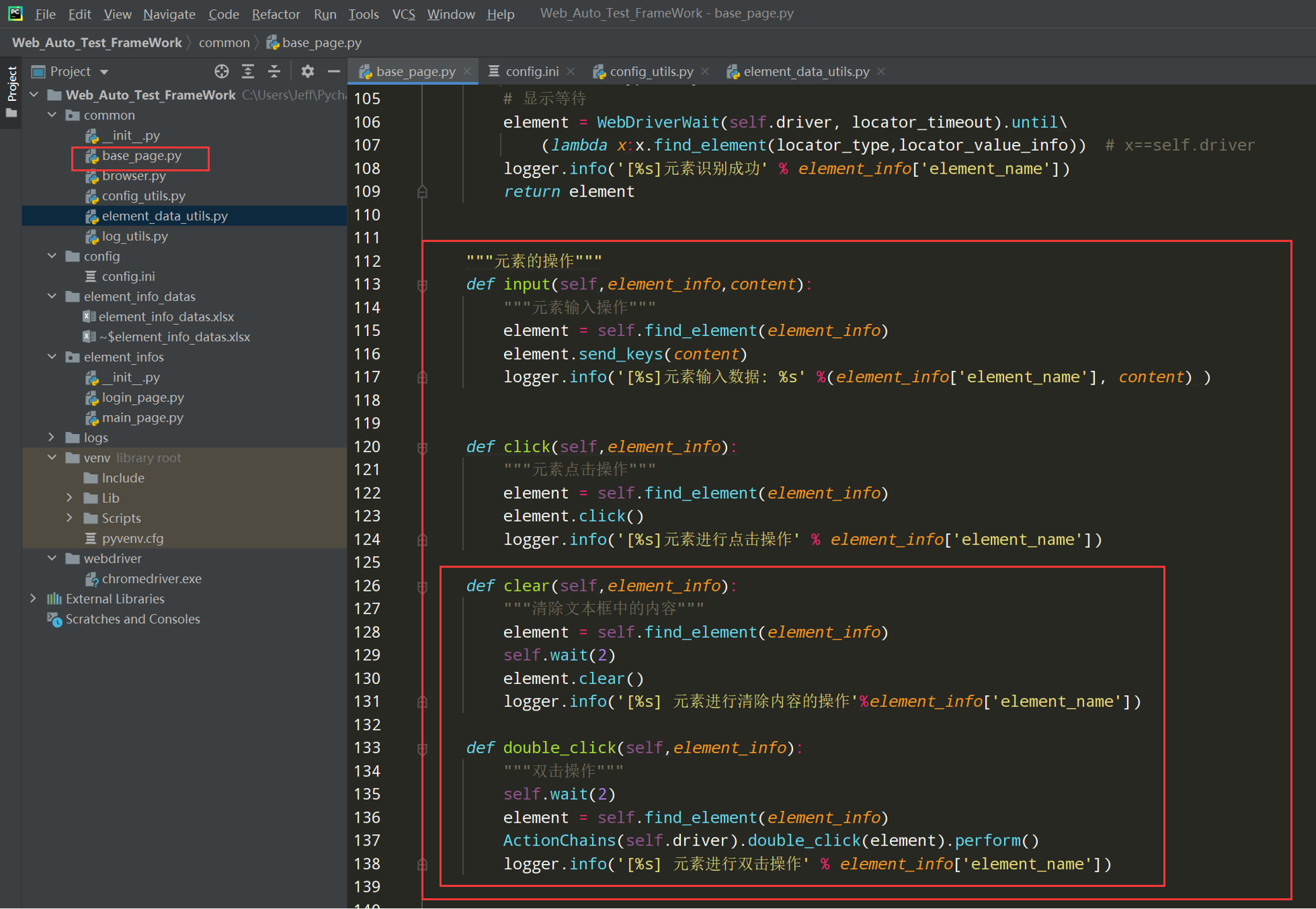
代码示例:
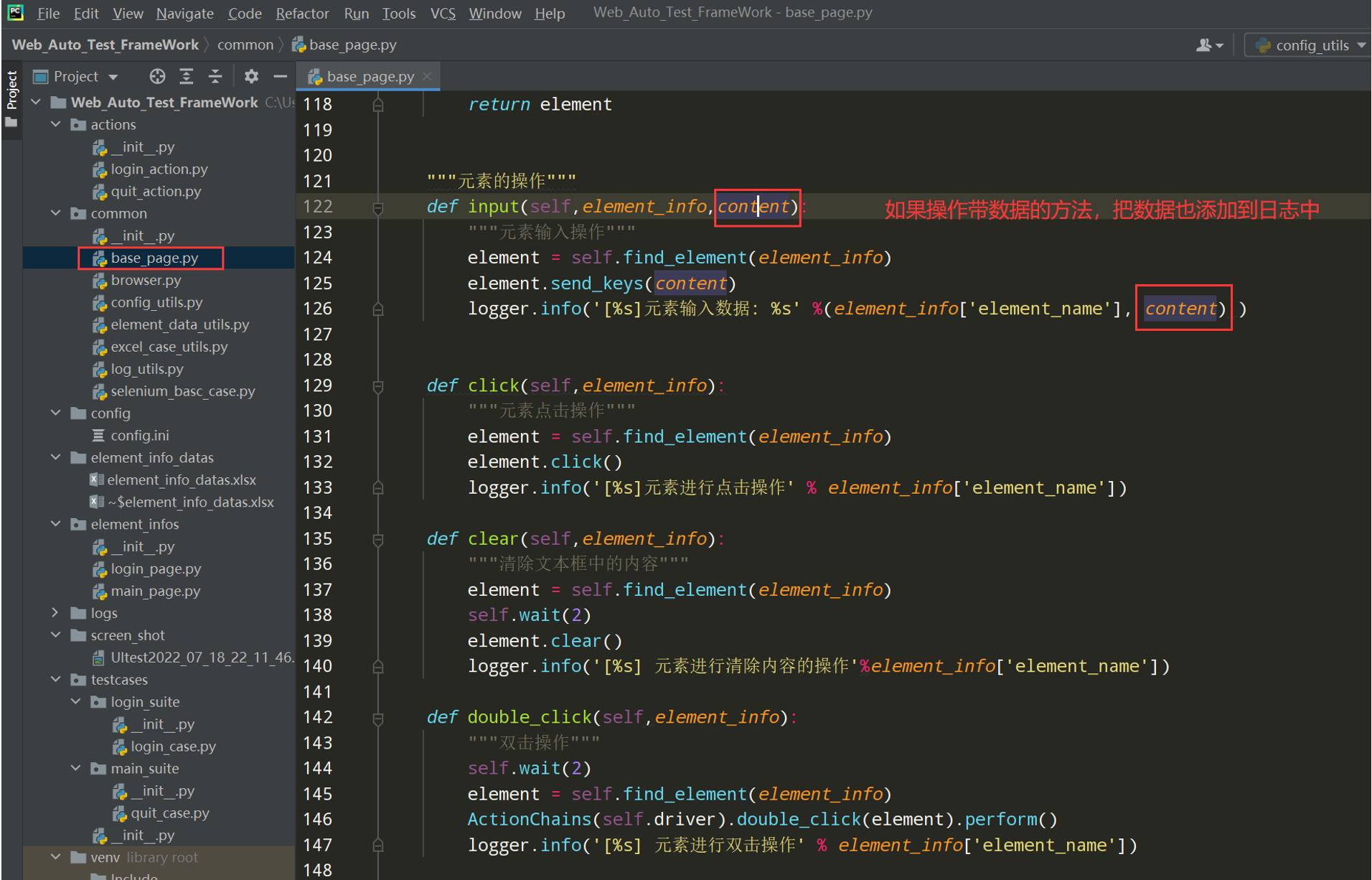
"""元素的操作""" def input(self,element_info,content): """元素输入操作""" element = self.find_element(element_info) element.send_keys(content) logger.info('[%s]元素输入数据: %s' %(element_info['element_name'], content) ) def click(self,element_info): """元素点击操作""" element = self.find_element(element_info) element.click() logger.info('[%s]元素进行点击操作' % element_info['element_name']) def clear(self,element_info): """清除文本框中的内容""" element = self.find_element(element_info) self.wait(2) element.clear() logger.info('[%s] 元素进行清除内容的操作'%element_info['element_name']) def double_click(self,element_info): """双击操作""" self.wait(2) element = self.find_element(element_info) ActionChains(self.driver).double_click(element).perform() logger.info('[%s] 元素进行双击操作' % element_info['element_name'])
实战5:弹出框的封装
思路1:
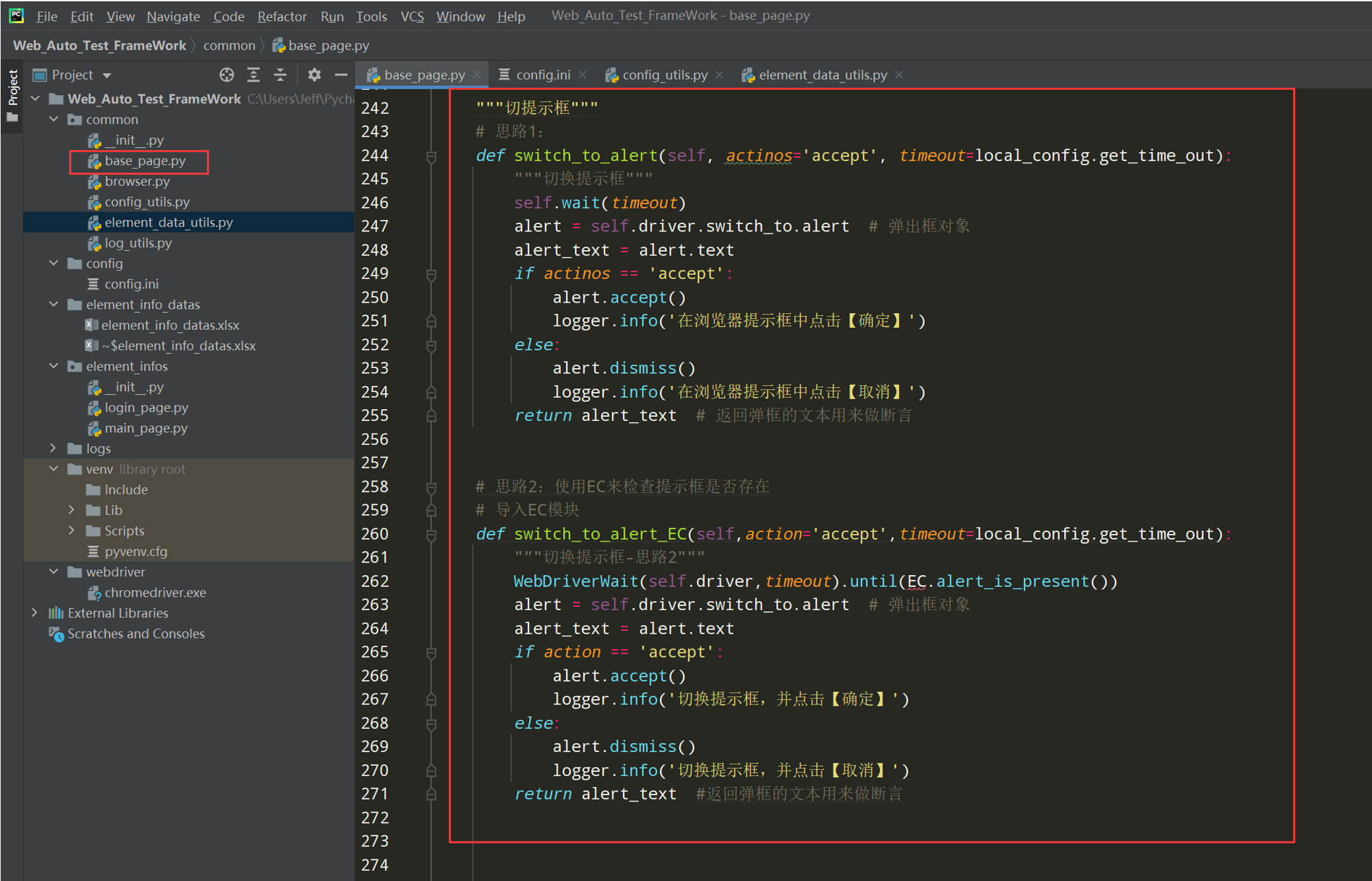
代码示例:
"""切提示框""" # 思路1: def switch_to_alert(self, actinos='accept', timeout=local_config.get_time_out): """切换提示框""" self.wait(timeout) alert = self.driver.switch_to.alert # 弹出框对象 alert_text = alert.text if actinos == 'accept': alert.accept() logger.info('在浏览器提示框中点击【确定】') else: alert.dismiss() logger.info('在浏览器提示框中点击【取消】') return alert_text # 返回弹框的文本用来做断言 # 思路2:使用EC来检查提示框是否存在 # 导入EC模块 def switch_to_alert_EC(self,action='accept',timeout=local_config.get_time_out): """切换提示框-思路2""" WebDriverWait(self.driver,timeout).until(EC.alert_is_present()) alert = self.driver.switch_to.alert # 弹出框对象 alert_text = alert.text if action == 'accept': alert.accept() logger.info('切换提示框,并点击【确定】') else: alert.dismiss() logger.info('切换提示框,并点击【取消】') return alert_text #返回弹框的文本用来做断言
测试一下
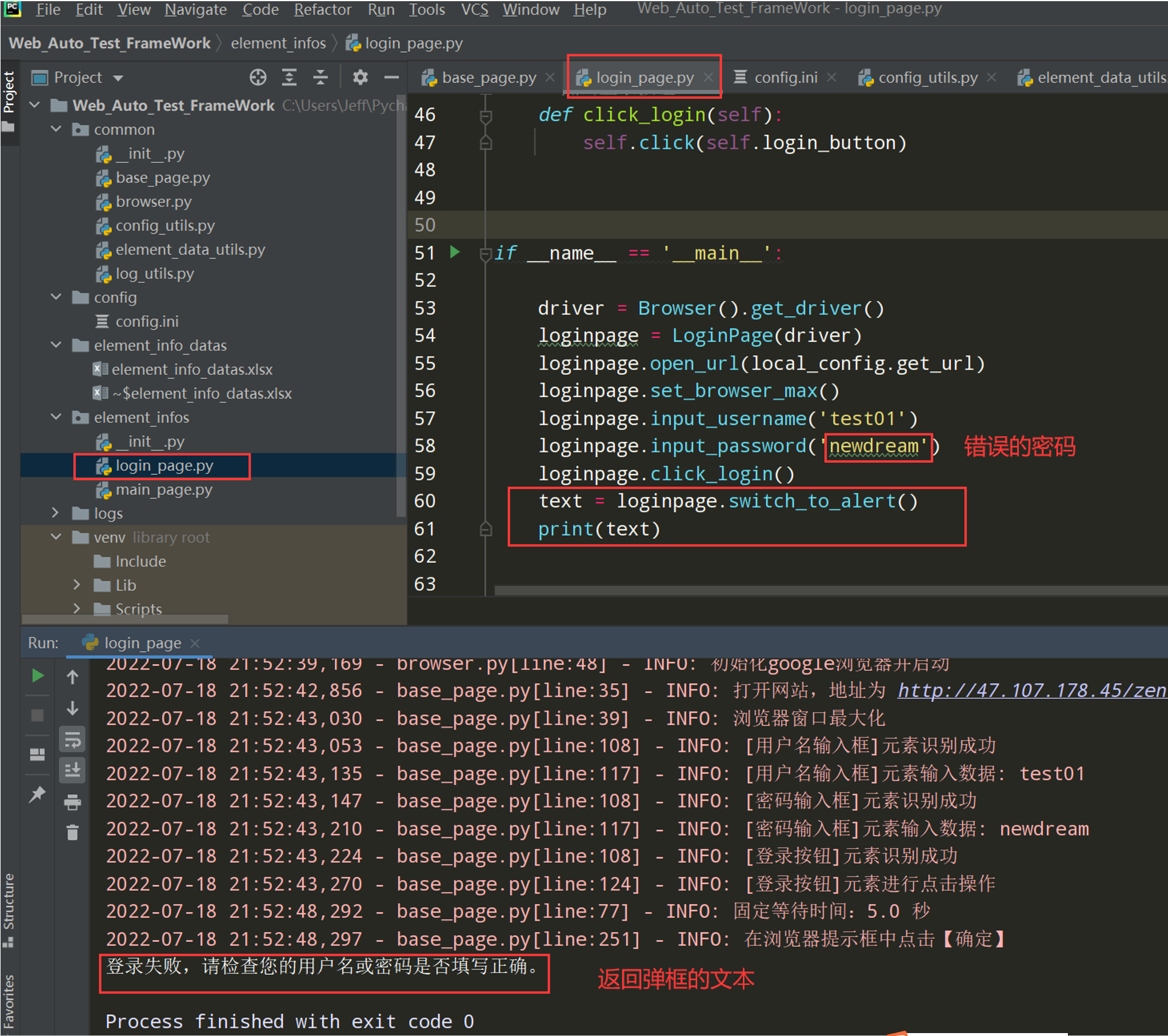
思路2
前置条件:导包
通过EC判断弹框是否存在;导入包
from selenium.webdriver.support import expected_conditions as EC
代码示例:
# 思路2:使用EC来检查提示框是否存在 # 导入EC模块 def switch_to_alert_EC(self,action='accept',timeout=local_config.get_time_out): """切换提示框-思路2""" WebDriverWait(self.driver,timeout).until(EC.alert_is_present()) alert = self.driver.switch_to.alert # 弹出框对象 alert_text = alert.text if action == 'accept': alert.accept() logger.info('切换提示框,并点击【确定】') else: alert.dismiss() logger.info('切换提示框,并点击【取消】') return alert_text #返回弹框的文本用来做断言
测试一下:
实战6:切句柄的封装
代码示例:
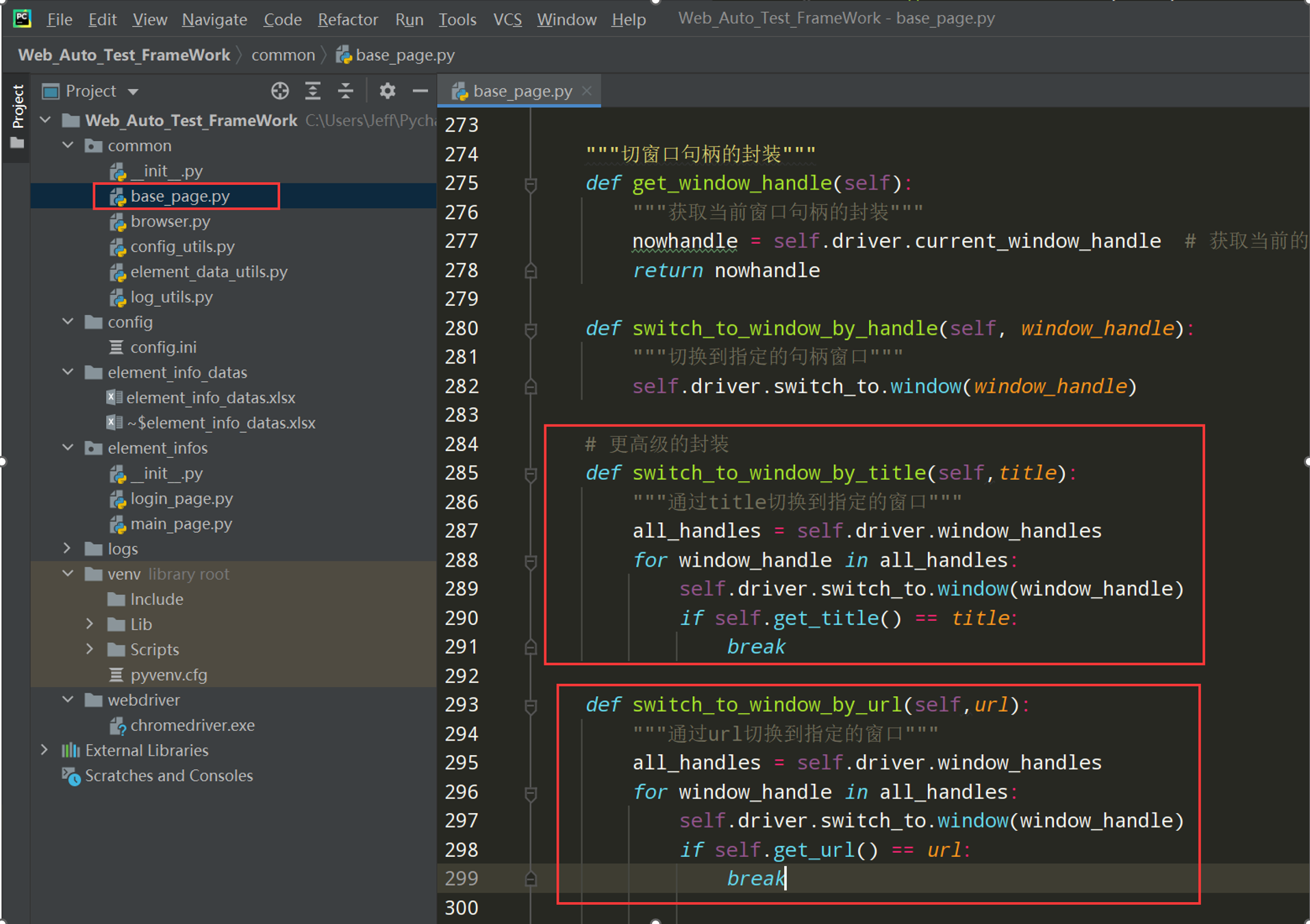
"""切窗口句柄的封装""" def get_window_handle(self): """获取当前窗口句柄的封装""" nowhandle = self.driver.current_window_handle # 获取当前的窗口句柄 return nowhandle def switch_to_window_by_handle(self, window_handle): """切换到指定的句柄窗口""" self.driver.switch_to.window(window_handle)
更高级的方法
前置条件:封装获取标题和url的方法;如下图
继续优化,加等待时间
代码示例:
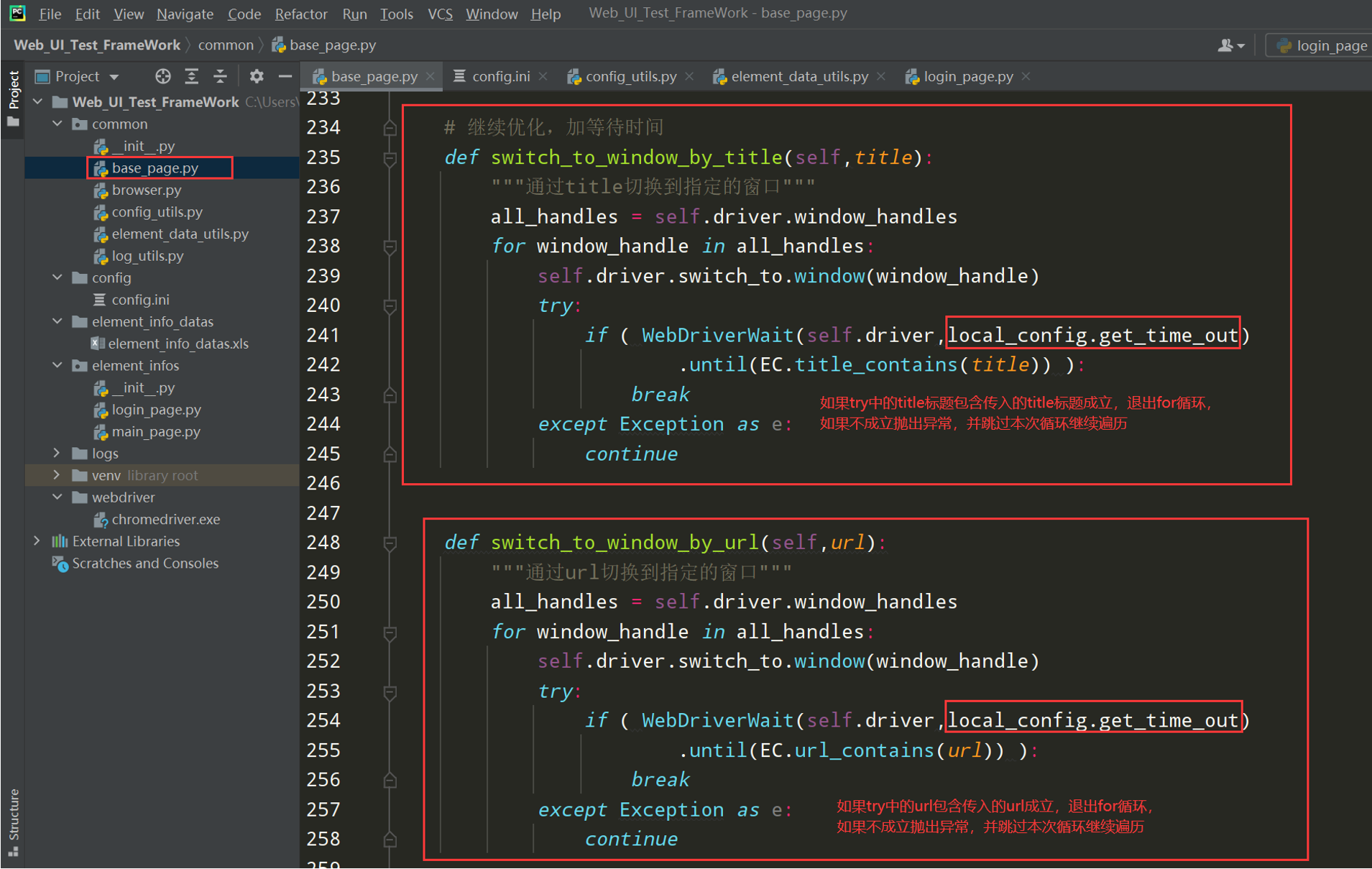
"""切窗口句柄的封装""" def get_window_handle(self): """获取当前窗口句柄的封装""" nowhandle = self.driver.current_window_handle # 获取当前的窗口句柄 return nowhandle def switch_to_window_by_handle(self, window_handle): """切换到指定的句柄窗口""" self.driver.switch_to.window(window_handle) # 更高级的封装 def switch_to_window_by_title(self,title): """通过title切换到指定的窗口""" all_handles = self.driver.window_handles for window_handle in all_handles: self.driver.switch_to.window(window_handle) if self.get_title() == title: break def switch_to_window_by_url(self,url): """通过url切换到指定的窗口""" all_handles = self.driver.window_handles for window_handle in all_handles: self.driver.switch_to.window(window_handle) if self.get_url() == url: break # 继续优化,加等待时间 def switch_to_window_by_title_time(self, title): """通过title切换到指定的窗口""" all_handles = self.driver.window_handles for window_handle in all_handles: self.driver.switch_to.window(window_handle) try: if ( WebDriverWait(self.driver,local_config.get_time_out) .until(EC.title_contains(title)) ): break except Exception as e: continue def switch_to_window_by_url_time(self,url): """通过url切换到指定的窗口""" all_handles = self.driver.window_handles for window_handle in all_handles: self.driver.switch_to.window(window_handle) try: if ( WebDriverWait(self.driver,local_config.get_time_out) .until(EC.url_contains(url)) ): break except Exception as e: continue
测试一下:在新的文件中编写代码,测试上面封装是否正确
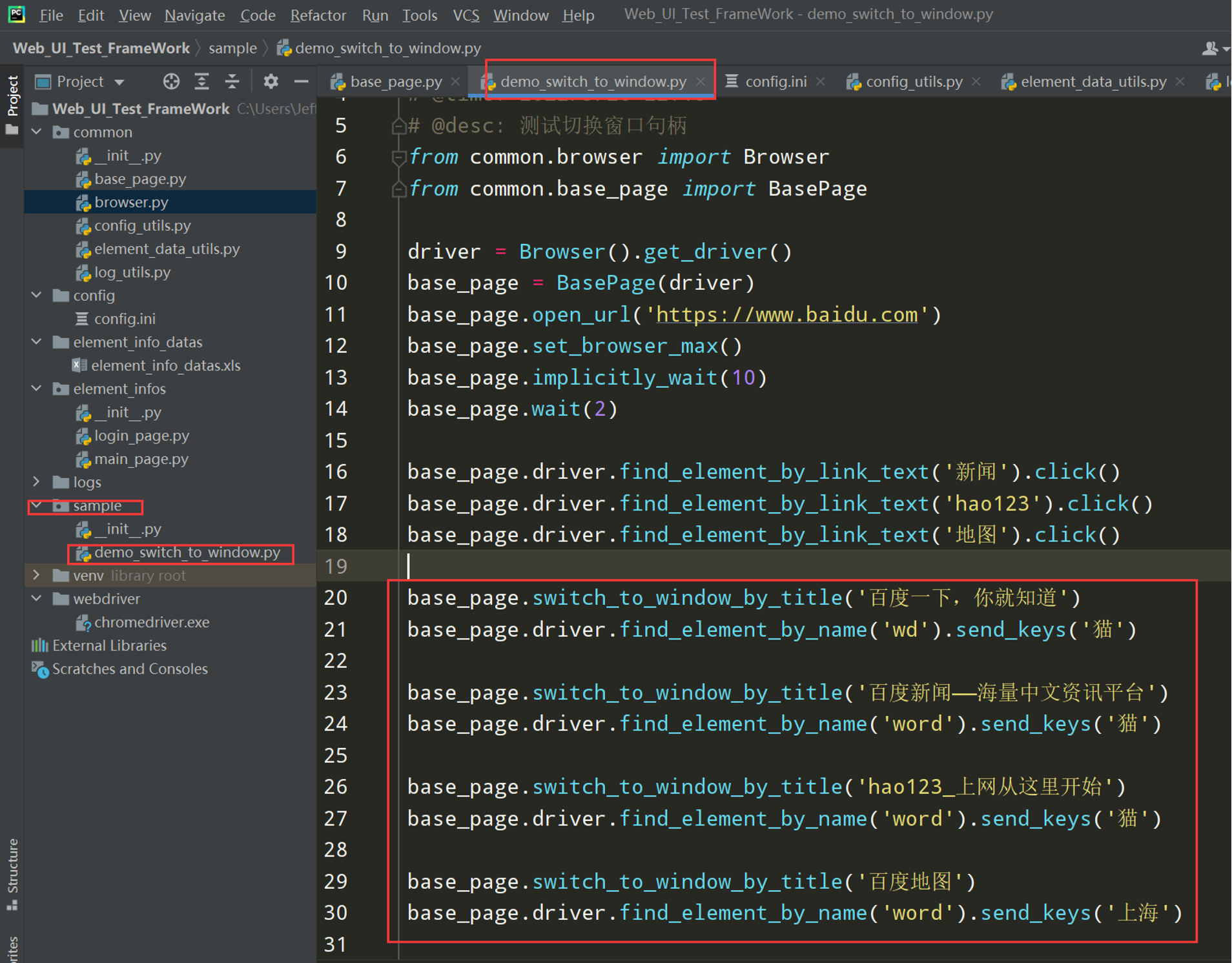
不能操作的,使用 autoIT 录制操作 请开发办法帮忙写 js 脚本
实战7:截图的封装
步骤1:
先在config.ini文件中配置错误截图的路径;并在项目根目录下新建一个screen_shot的文件夹;
步骤2:在config_utils.py文件中封装获取截图的路径
@property
def get_screen_shot_path(self):
"""获取配置文件中存放错误截图的路径"""
value = self.cfg.get('default','screen_shot_path')
return value
步骤3:在base_page.py中封装截图的方法
前置条件:import os
代码示例:
import os """截图""" def screenshot_as_file_old(self, *screenshot_path): # *:收集元组 """截图""" if len(screenshot_path) == 0: # 没有传入地址,存放到默认路径下 screenshot_path = local_config.get_screen_shot_path else: screenshot_path = screenshot_path[0] now= time.strftime("%Y_%m_%d_%H_%M_%S") # 如果每次文件名一样,就覆盖老的文件名 current_dir = os.path.dirname(__file__) filename = os.path.join(current_dir, '..',screenshot_path,'UItest%s.png' % now) self.driver.save_screenshot(filename) logger.info('截图保存成功,保存路径在:%s' % filename)
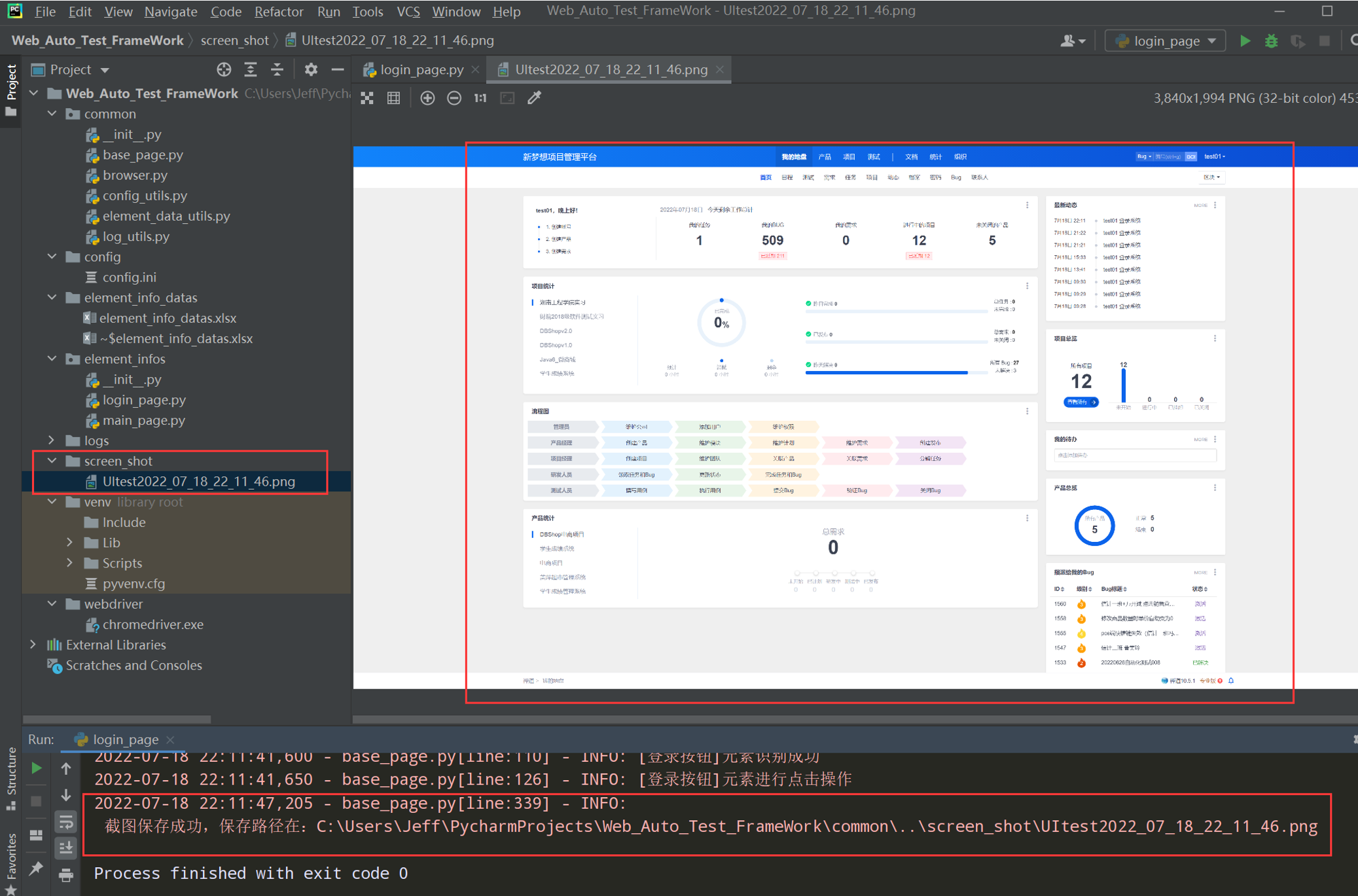
步骤4:测试一下,在login_page.py调用截图的方法
查看日志和screen_shot文件夹下是否有截图
实战8:分区域存放封装
把每个页面封装成一个py文件;如上图
框架 06--功能层的编写
功能层:把页面的单个元素的操作组合成一个功能,或者完成一个业务操作,例如:登录、 下单、发货、退出
步骤 1:在项目根目录下新建一个 actions 包-->login_action.py

代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: login_action.py # @time: 2022/7/19 22:00 # @desc: 登录的业务不同场景的操作 class LoginAction(): def __init__(self): pass def login_success(self): """登录成功""" pass def login_fail(self): """登录失败""" pass def default_login(self): """默认登录""" pass # cookie登录,拓展 def login_by_cookie(self): """cookie登录""" pass
封装一个登陆的公共操作
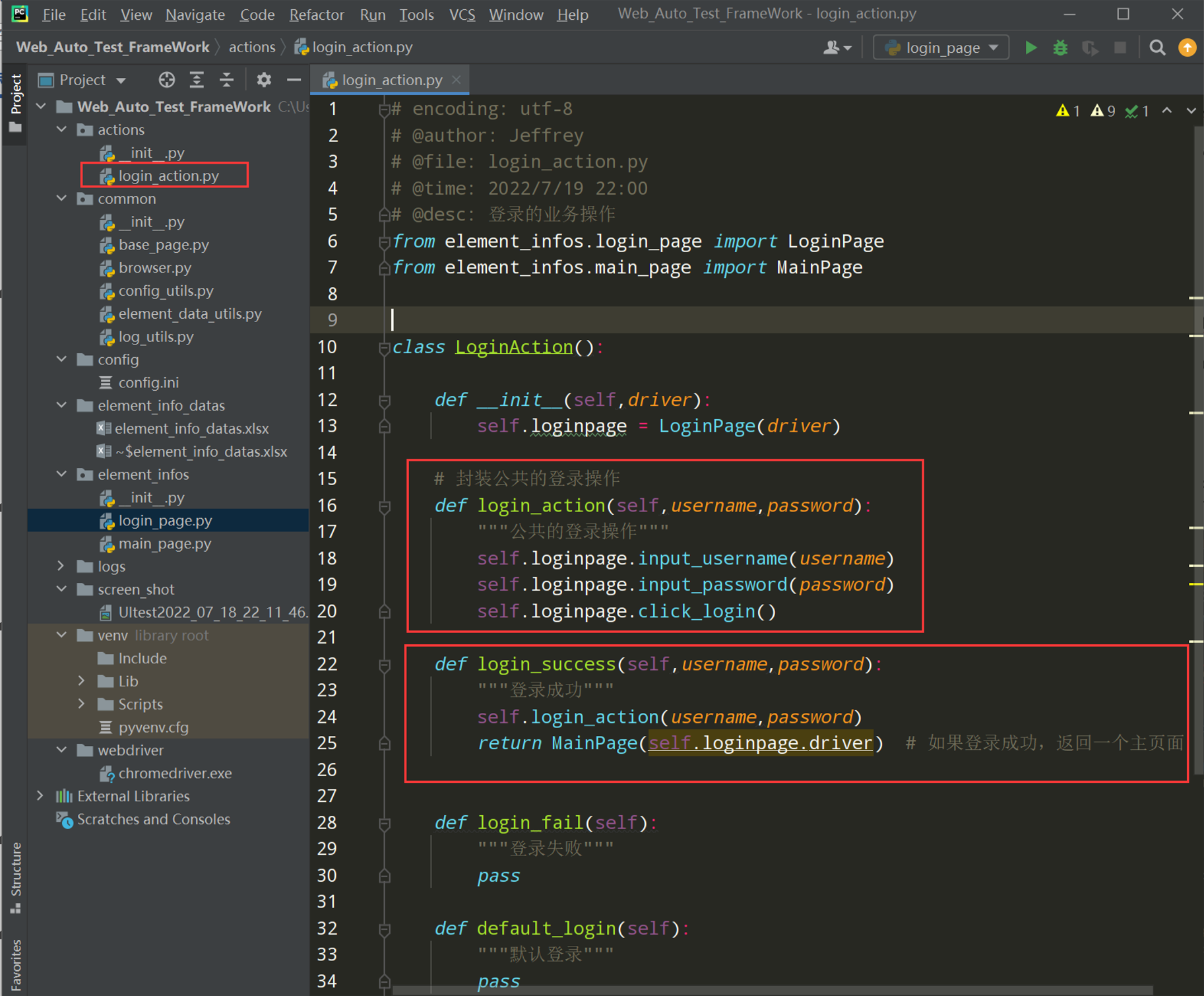
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: login_action.py # @time: 2022/7/19 22:00 # @desc: 登录的业务操作 from element_infos.login_page import LoginPage from element_infos.main_page import MainPage class LoginAction(): def __init__(self,driver): self.loginpage = LoginPage(driver) # 封装公共的登录操作 def login_action(self,username,password): """公共的登录操作""" self.loginpage.input_username(username) self.loginpage.input_password(password) self.loginpage.click_login() def login_success(self,username,password): """登录成功""" self.login_action(username,password) return MainPage(self.loginpage.driver) # 如果登录成功,返回一个主页面
注:上图中self.loginpage.driver标黄是因为mainpage.py需重写,见框架07中的步骤2;
步骤 2:在 LoginPage 类里面封装一个提示框中点击确认,并返回提示内容的方法,用在login_action.py的login_fail方法中
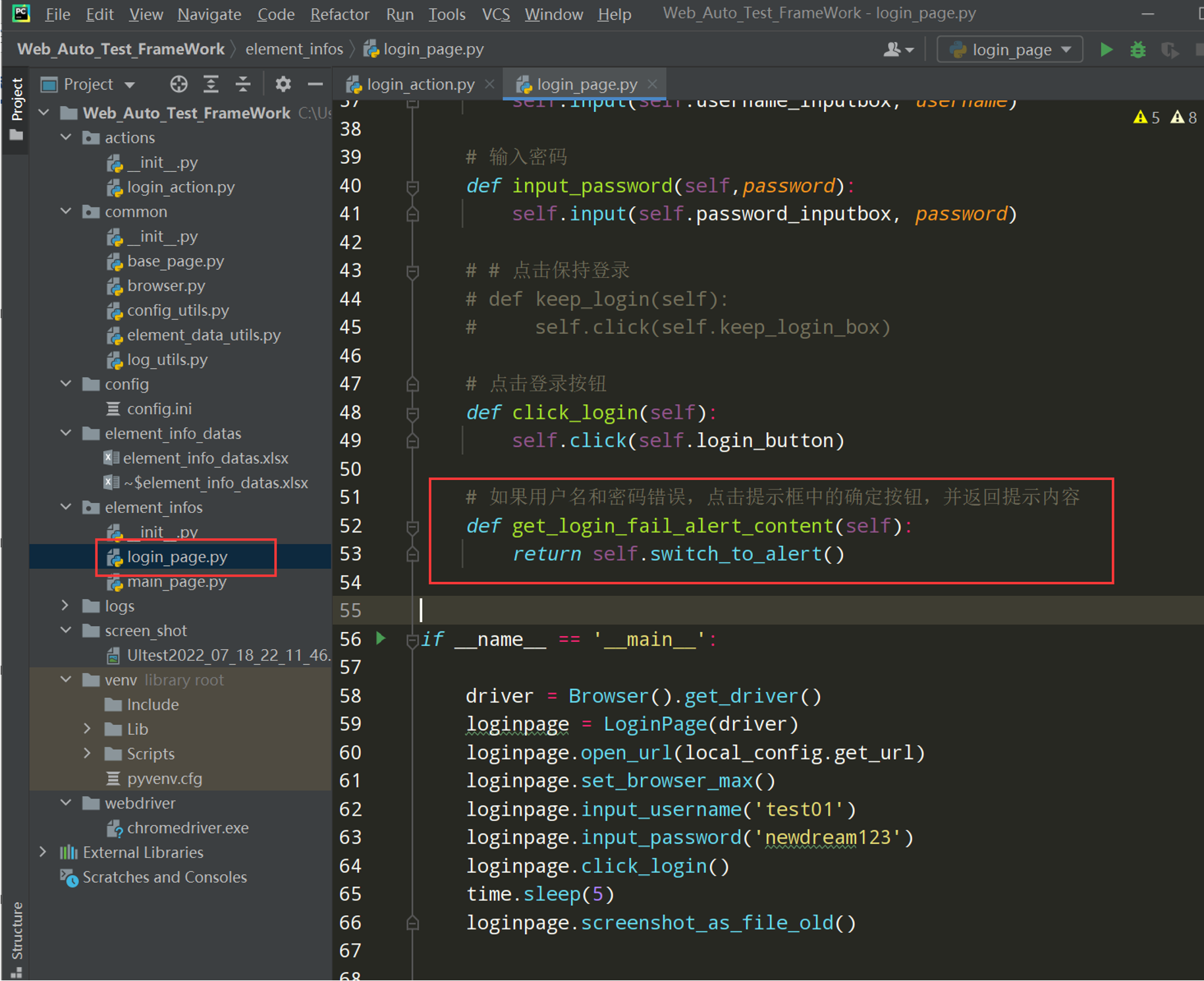
# 如果用户名和密码错误,点击提示框中的确定按钮,并返回提示内容
def get_login_fail_alert_content(self):
return self.switch_to_alert()
在login_action.py文件中封装登陆失败,返回提示框的文本内容
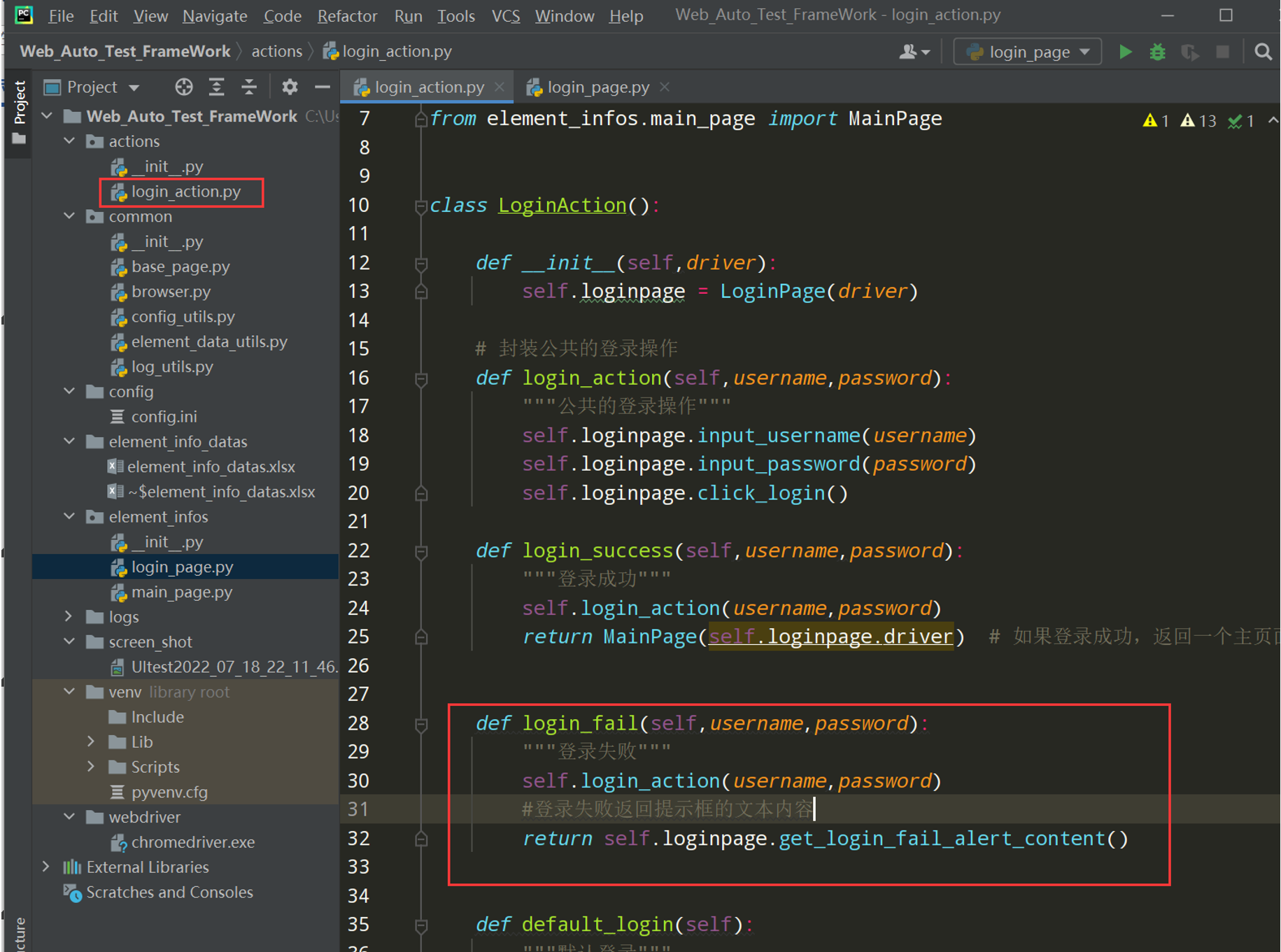
def login_fail(self,username,password):
"""登录失败"""
self.login_action(username,password)
#登录失败返回提示框的文本内容
return self.loginpage.get_login_fail_alert_content()
注:上图中self.loginpage.driver标黄是因为mainpage.py需重写,见框架07中的步骤2;
步骤3:在config.ini配置默认登录的账号和密码
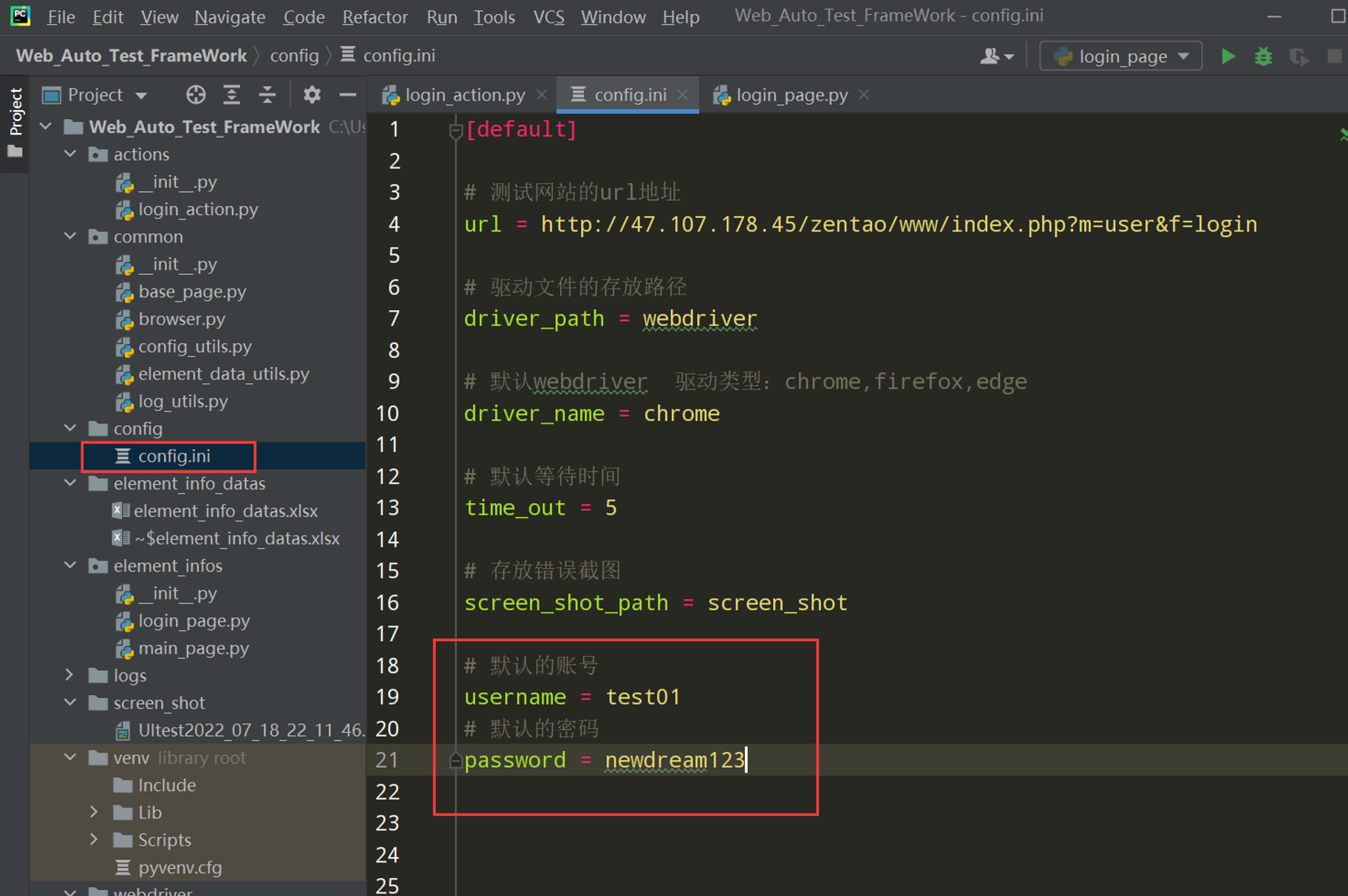
在config_utils.py文件中封装读取账号和密码的方法
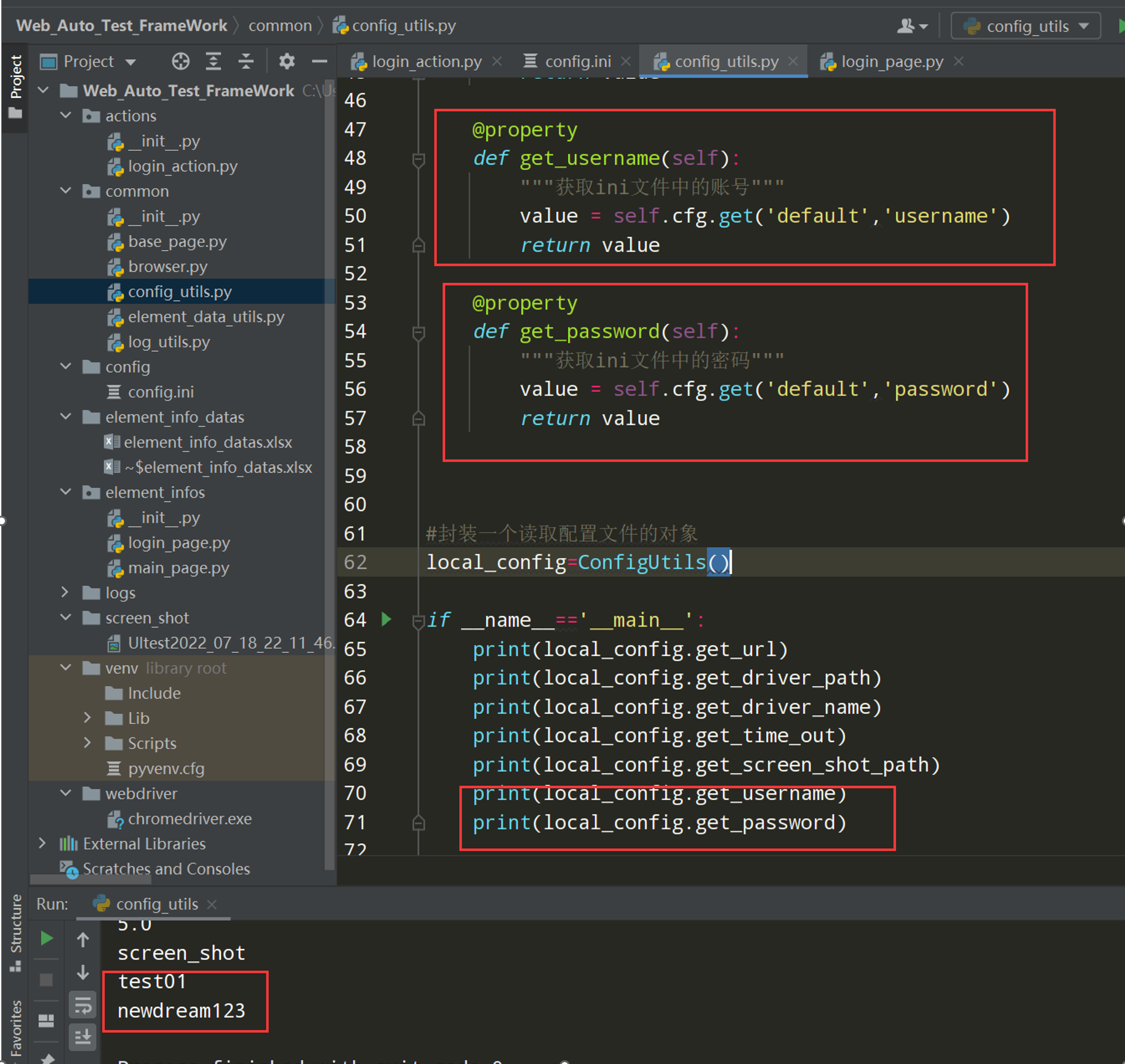
@property
def get_username(self):
"""获取ini文件中的账号"""
value = self.cfg.get('default','username')
return value
@property
def get_password(self):
"""获取ini文件中的密码"""
value = self.cfg.get('default','password')
return value
步骤4:完善login_action.py文件中默认登录的方法
导包:from common.config_utils import local_config
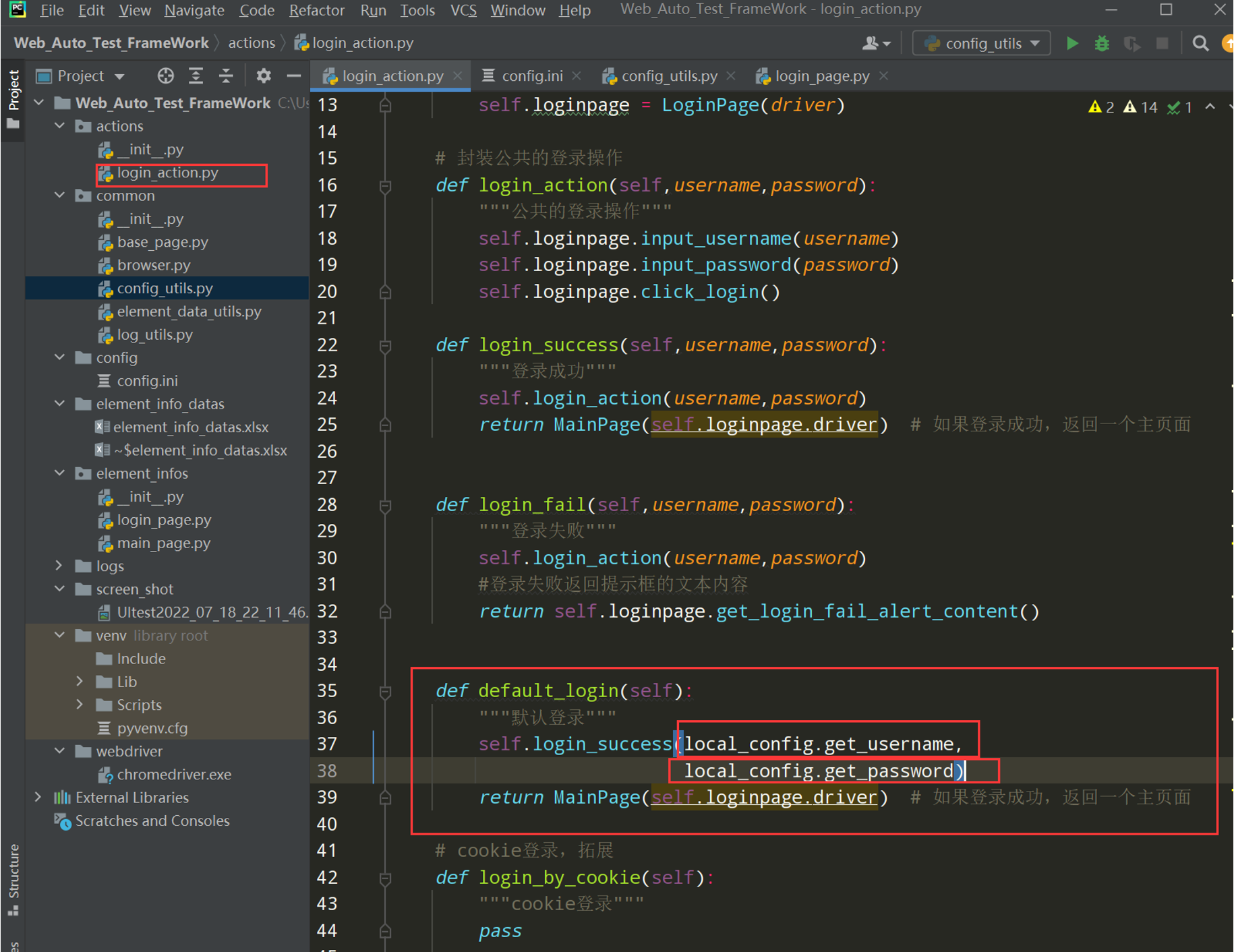
编写代码:
def default_login(self):
"""默认登录"""
self.login_success(local_config.get_username,
local_config.get_password)
return MainPage(self.loginpage.driver) # 如果登录成功,返回一个主页面
注:上面两个图片中self.loginpage.driver标黄是因为mainpage.py需要重写,见框架07中的步骤2;
小结:
动作封装思路 1:先封装成类,再在类里面封装动作方法
动作封装思路 2:把动作封装成函数(把所有动作封装成函数,在需要地方调用)
框架 07-用例层的编写
前置操作:在 BasePage 封装关闭浏览器
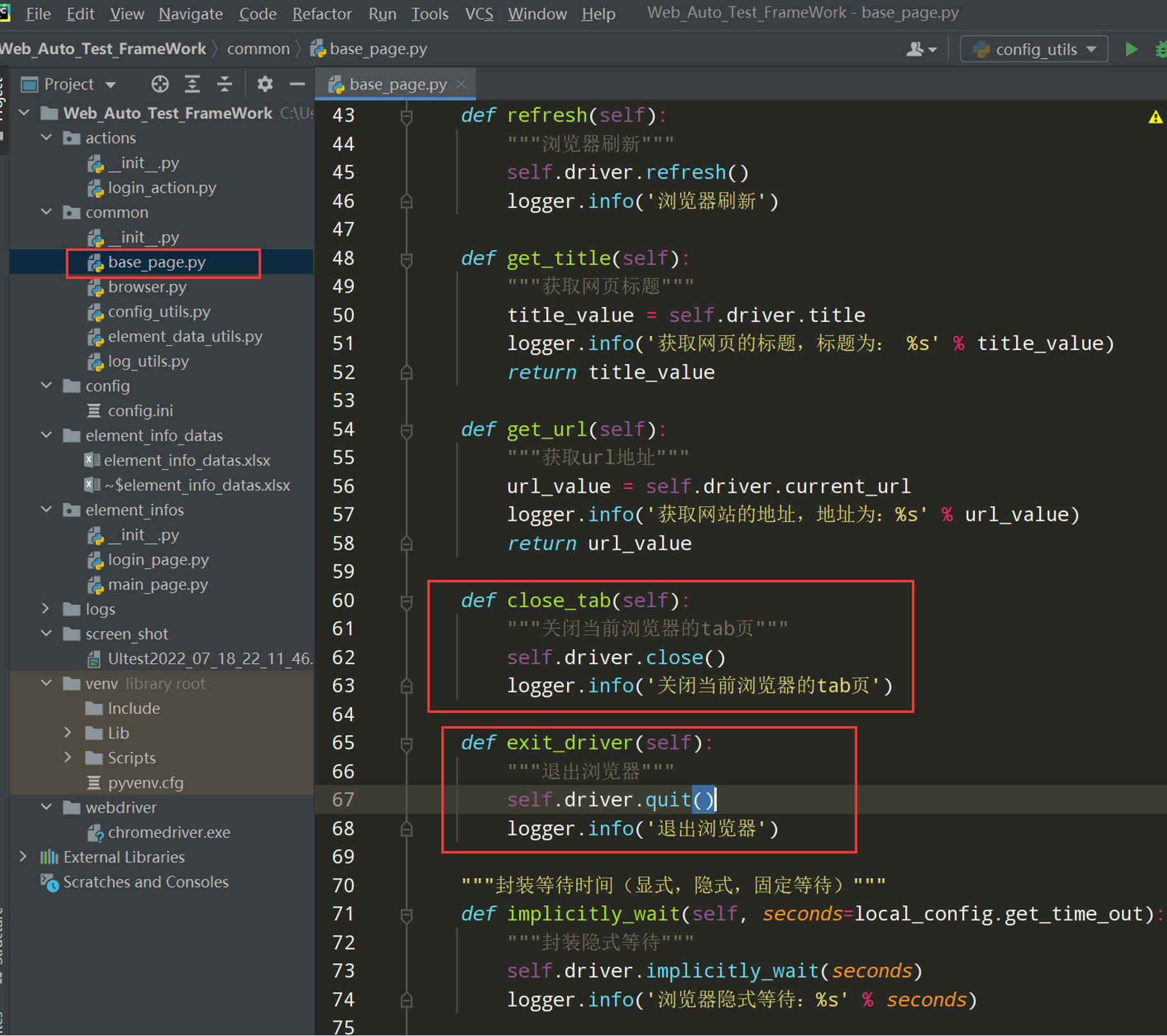
编写代码:
def close_tab(self):
"""关闭当前浏览器的tab页"""
self.driver.close()
logger.info('关闭当前浏览器的tab页')
def exit_driver(self):
"""退出浏览器"""
self.driver.quit()
logger.info('退出浏览器')
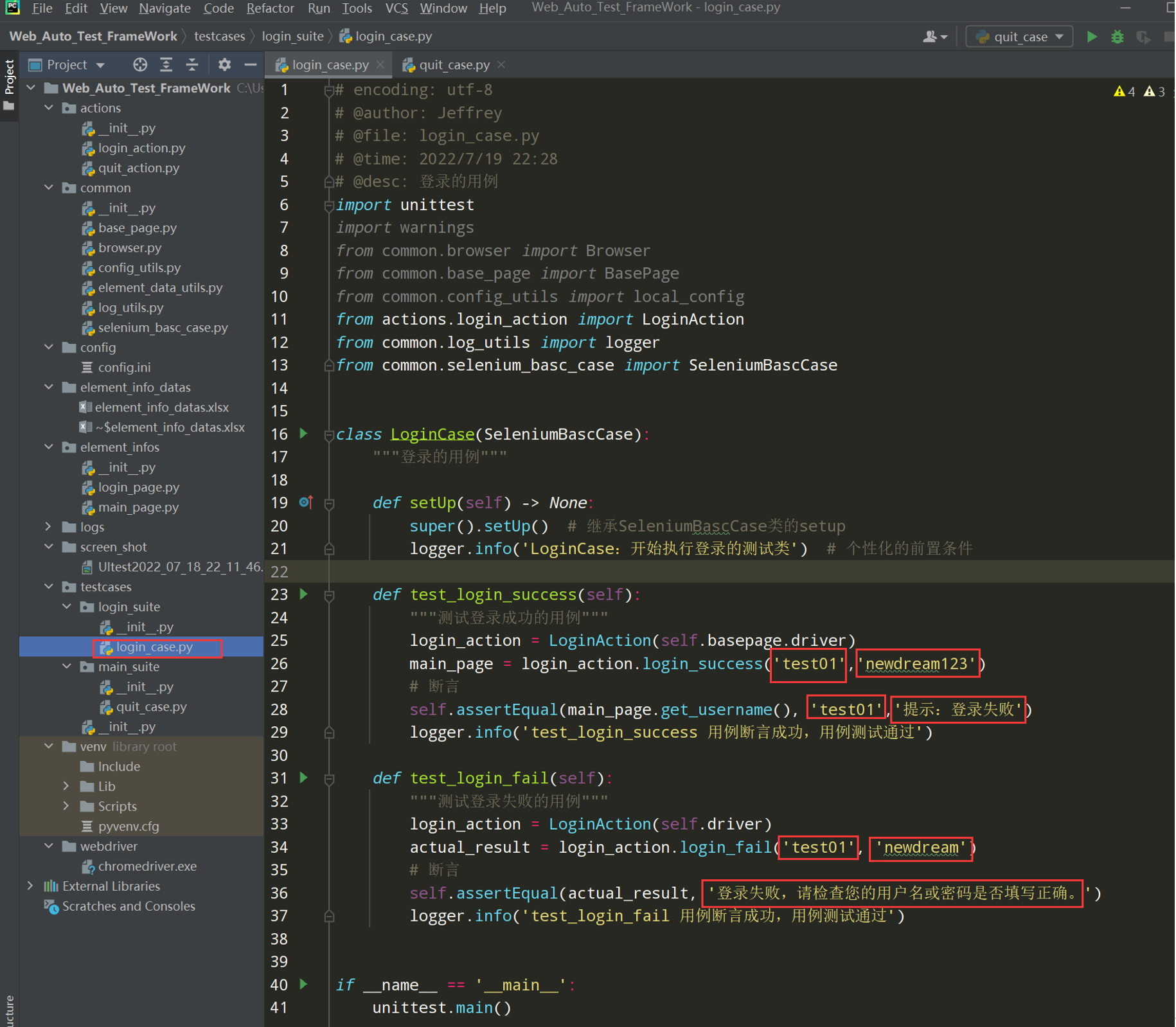
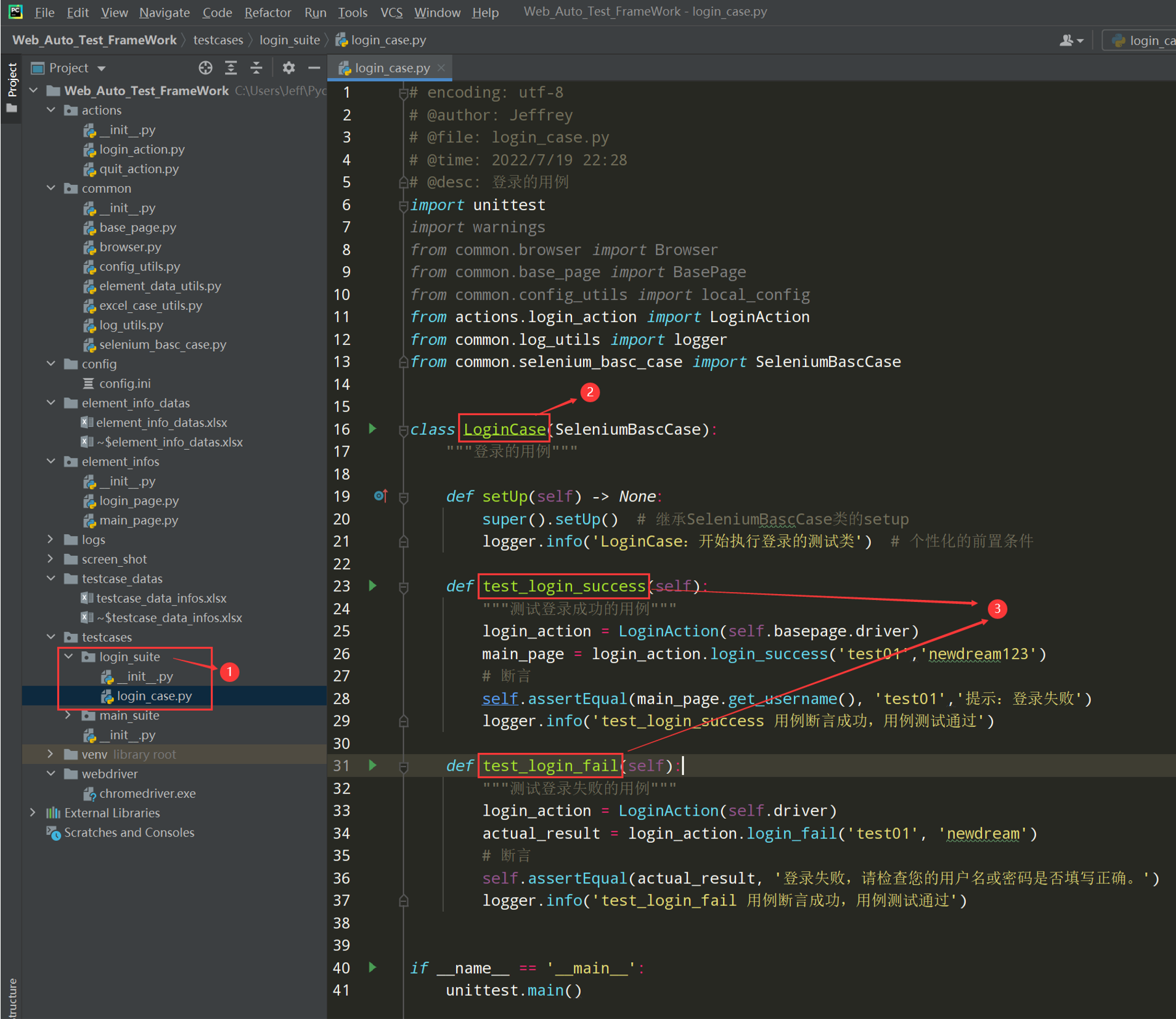
在项目根目录下新建用例层testcases—》login_suite-->login_case.py
步骤 1: 编写登录的测试用例
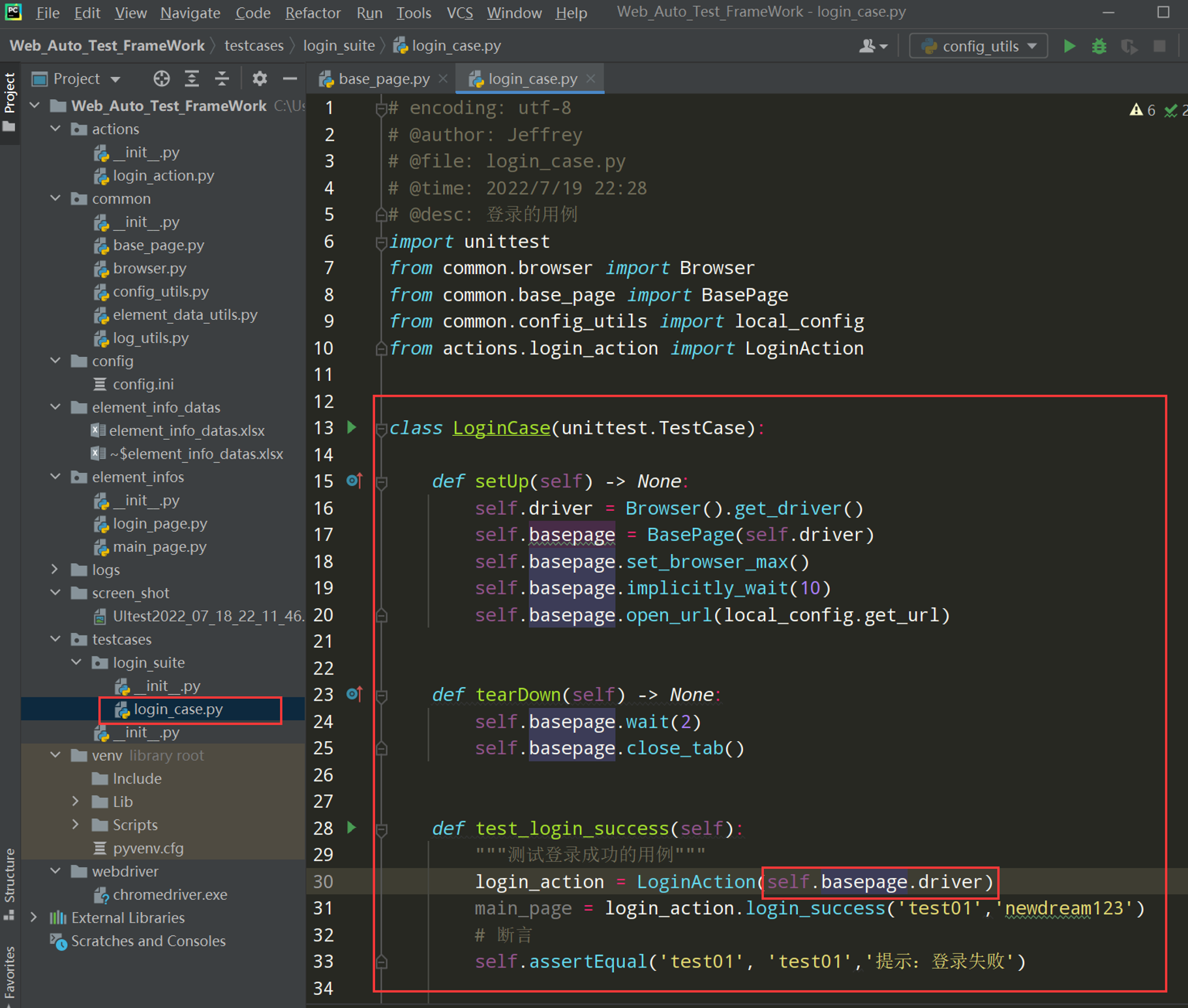
此时还跑不通,因为Mainpage.py需要重写
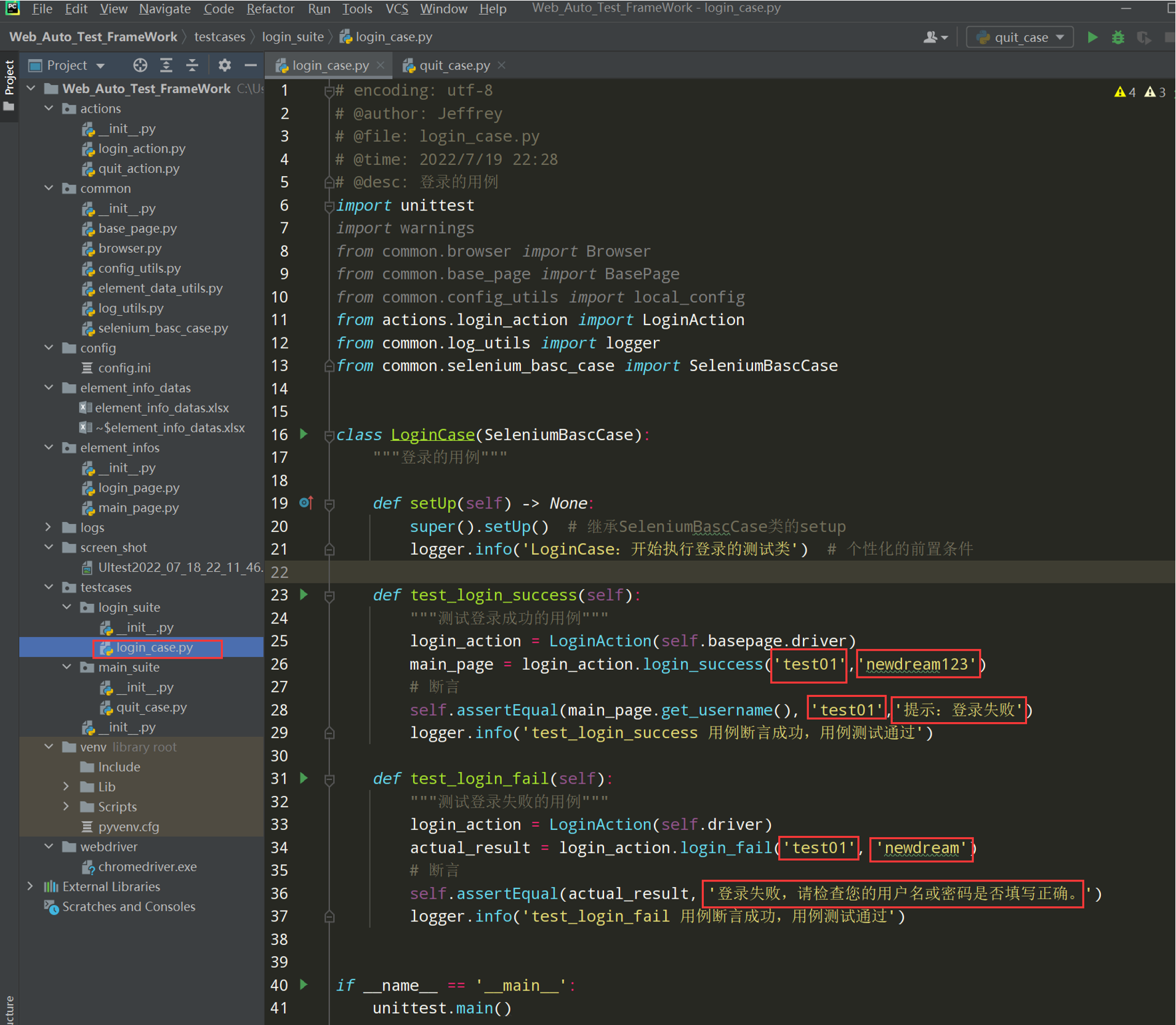
# encoding: utf-8 # @author: Jeffrey # @file: login_case.py # @time: 2022/7/4 1:01 # @desc: 登录的用例 import unittest from common.browser import Browser from common.base_page import BasePage from common.config_utils import local_config from actions.login_action import LoginAction class LoginCase(unittest.TestCase): def setUp(self) -> None: self.driver = Browser().get_driver() self.basepage = BasePage(self.driver) self.basepage.set_browser_max() self.basepage.implicitly_wait(10) self.basepage.open_url(local_config.get_url) def tearDown(self) -> None: self.basepage.wait(2) self.basepage.close_tab() def test_login_success(self): """测试登录成功的用例""" login_action = LoginAction(self.basepage.driver) main_page = login_action.login_success('test01','newdream123') # 断言 self.assertEqual('test01', 'test01','提示:登录失败')
步骤 2: 重写 MainPage
检查元素信息表中main页签的数据
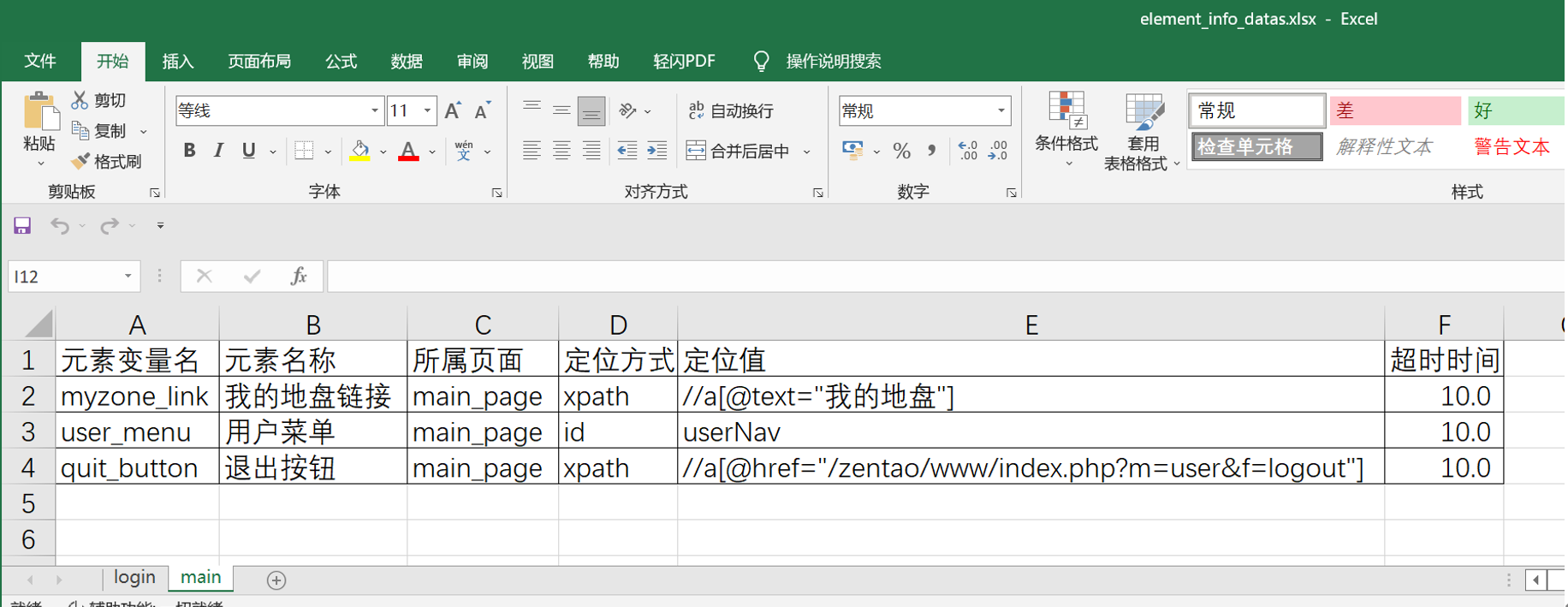
代码示例:
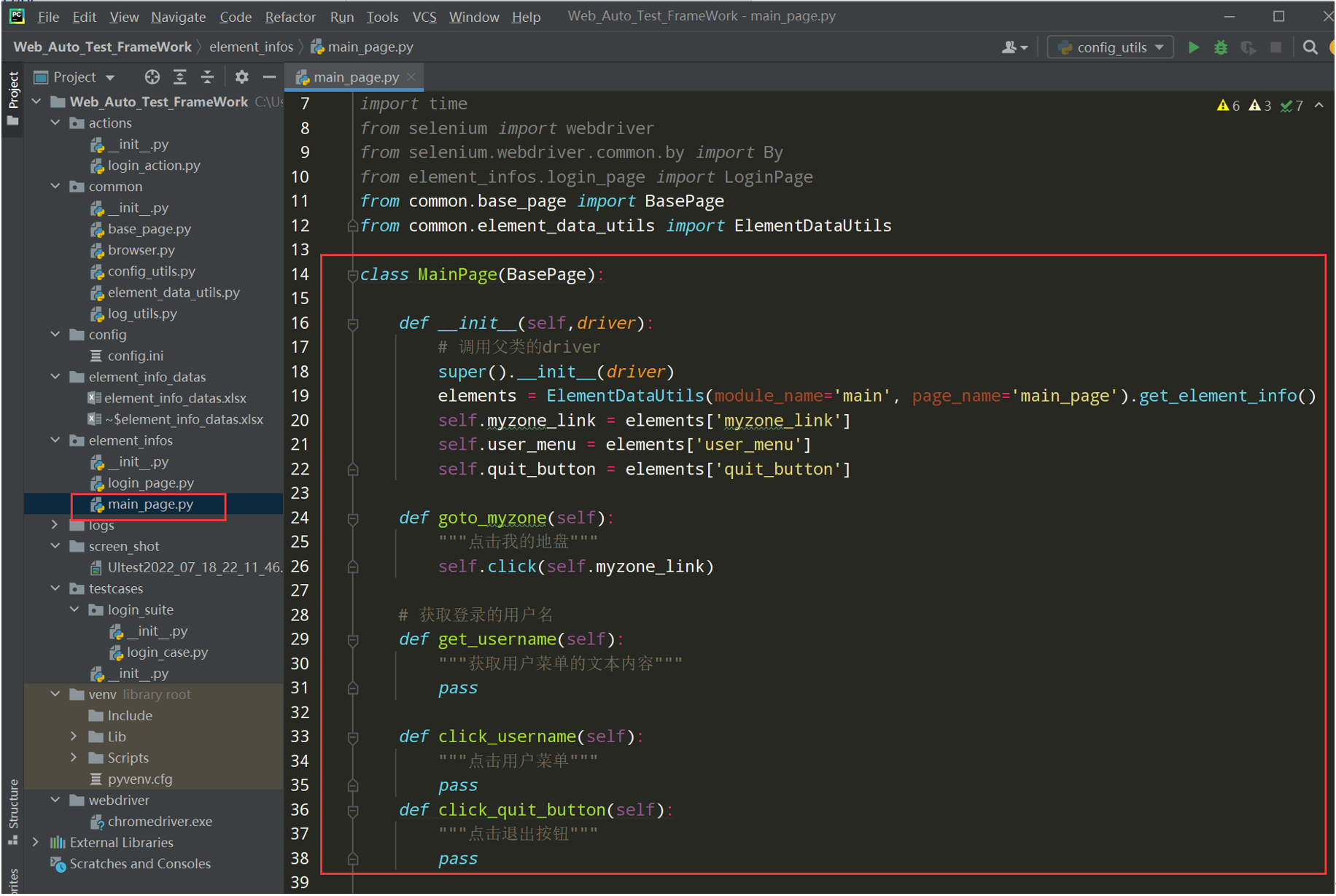
# encoding: utf-8 # @author: Jeffrey # @file: main_page.py # @time: 2022/7/2 13:04 # @desc: import os import time from selenium import webdriver from selenium.webdriver.common.by import By from element_infos.login_page import LoginPage from common.base_page import BasePage from common.element_data_utils import ElementDataUtils class MainPage(BasePage): def __init__(self,driver): # 调用父类的driver super().__init__(driver) elements = ElementDataUtils(module_name='main', page_name='main_page').get_element_info() self.myzone_link = elements['myzone_link'] self.user_menu = elements['user_menu'] self.quit_button = elements['quit_button'] def goto_myzone(self): """点击我的地盘""" self.click(self.myzone_link) # 获取登录的用户名 def get_username(self): """获取用户菜单的文本内容""" pass def click_username(self): """点击用户菜单""" pass def click_quit_button(self): """点击退出按钮""" pass
在base_page.py文件中封装获取元素的文本内容;如下图:
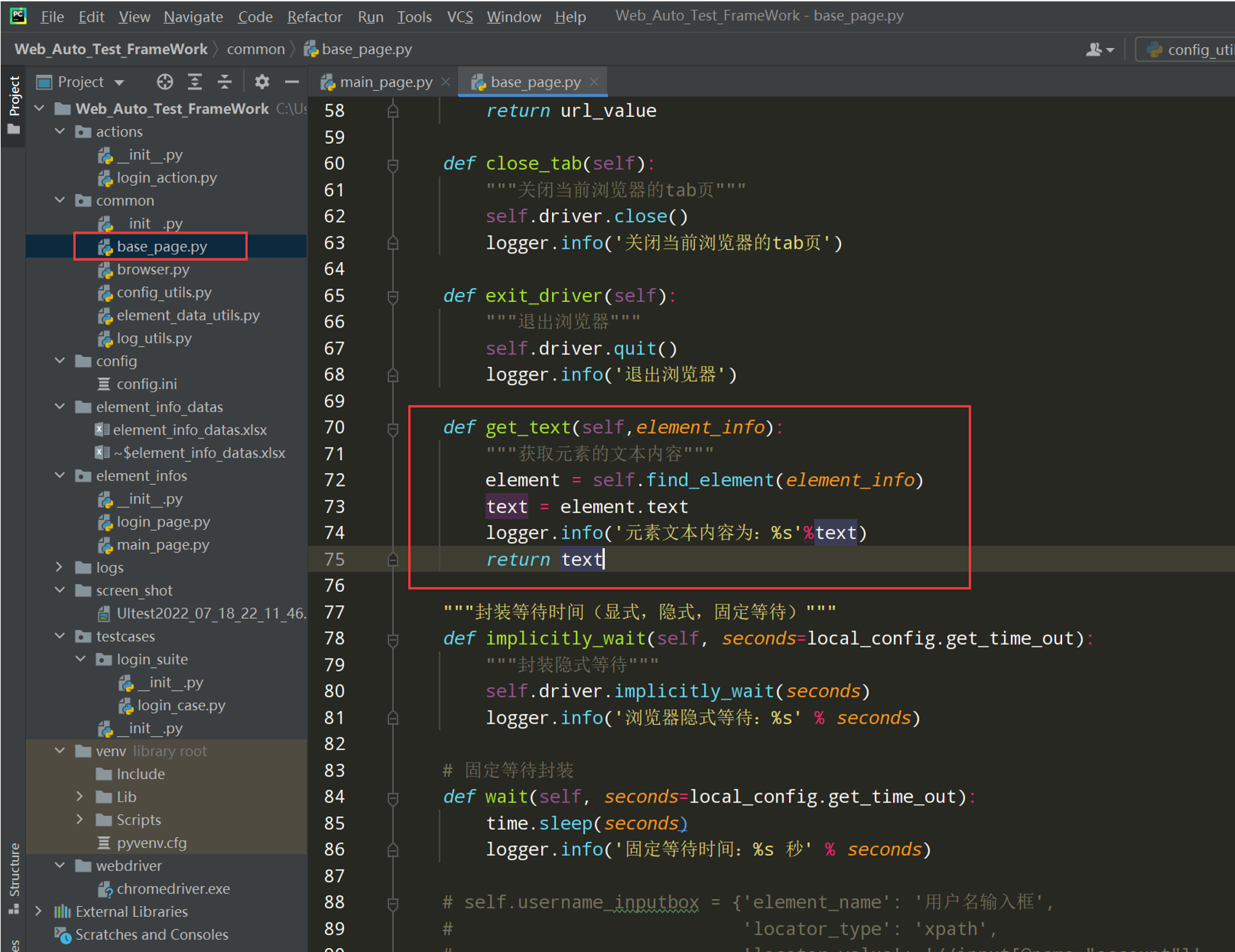
代码示例:
def get_text(self,element_info): """获取元素的文本内容""" element = self.find_element(element_info) text = element.text logger.info('元素文本内容为:%s'%text) return text
在main_page.py文件中调用上图中的方法;如下图所示;
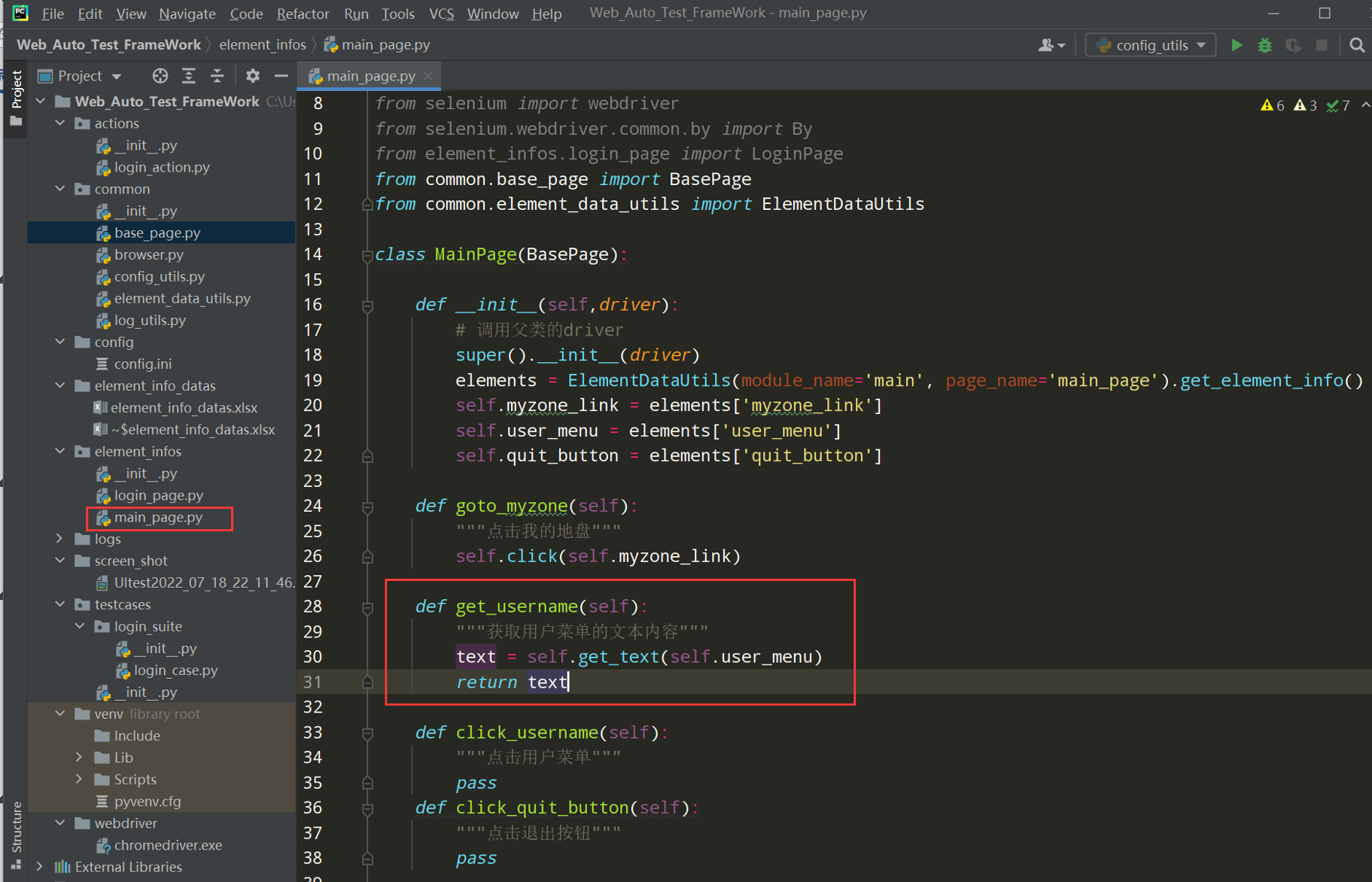
代码示例:
# 获取登录的用户名 def get_username(self): """获取用户菜单的文本内容""" text = self.get_text(self.user_menu) return text
测试一下:在sample下编写demo文件测试一下mainpage是否正确;
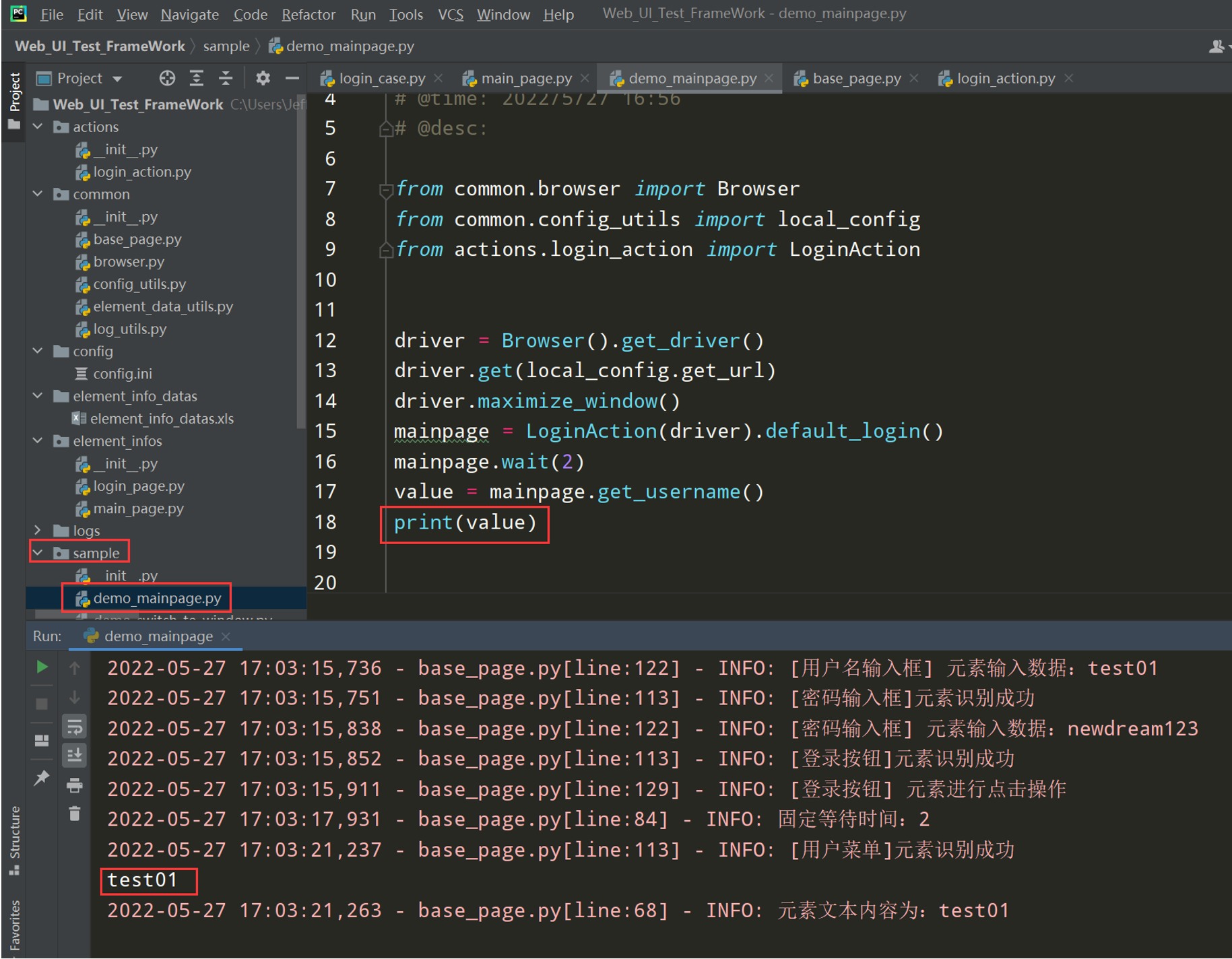

步骤 3: 完善登录的测试
在login_case.py文件中完善登录的代码
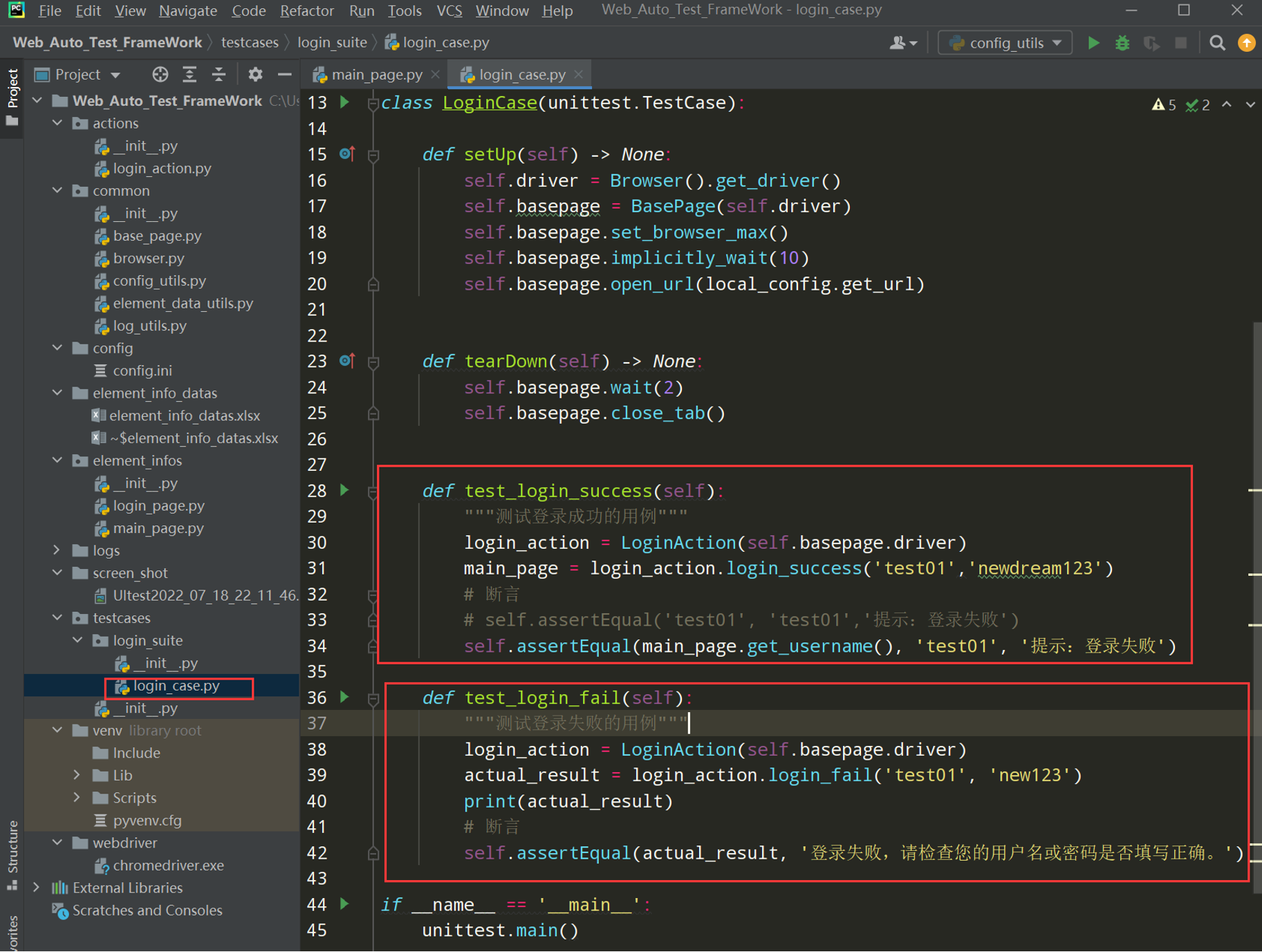
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: login_case.py # @time: 2022/7/19 22:28 # @desc: 登录的用例 import unittest from common.browser import Browser from common.base_page import BasePage from common.config_utils import local_config from actions.login_action import LoginAction class LoginCase(unittest.TestCase): def setUp(self) -> None: self.driver = Browser().get_driver() self.basepage = BasePage(self.driver) self.basepage.set_browser_max() self.basepage.implicitly_wait(10) self.basepage.open_url(local_config.get_url) def tearDown(self) -> None: self.basepage.wait(2) self.basepage.close_tab() def test_login_success(self): """测试登录成功的用例""" login_action = LoginAction(self.basepage.driver) main_page = login_action.login_success('test01','newdream123') # 断言 # self.assertEqual('test01', 'test01','提示:登录失败') self.assertEqual(main_page.get_username(), 'test01', '提示:登录失败') def test_login_fail(self): """测试登录失败的用例""" login_action = LoginAction(self.basepage.driver) actual_result = login_action.login_fail('test01', 'new123') print(actual_result) # 断言 self.assertEqual(actual_result, '登录失败,请检查您的用户名或密码是否填写正确。') if __name__ == '__main__': unittest.main()
执行 login_case.py 文件,使用 unittest 执行

提示告警:
C:\Users\Jeff\AppData\Local\Programs\Python\Python37\lib\unittest\suite.py:84: ResourceWarning: unclosed <socket.socket fd=400, family=AddressFamily.AF_INET6, type=SocketKind.SOCK_STREAM, proto=0, laddr=('::1', 63378, 0, 0), raddr=('::1', 63375, 0, 0)>
return self.run(*args, **kwds)
解决方法:可以通过warnings库来忽略掉相关告警。
import warnings
warnings.simplefilter("ignore", ResourceWarning)
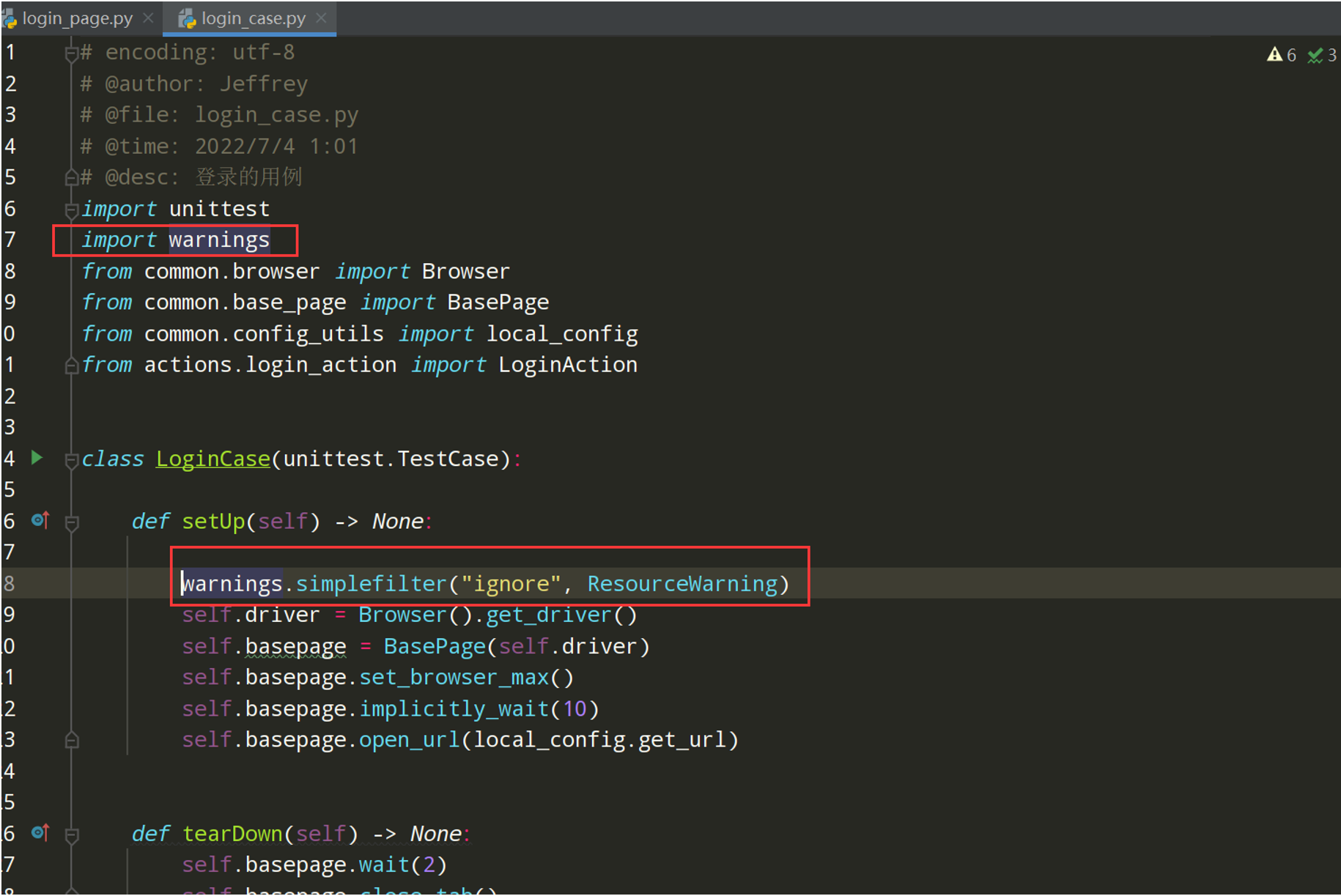
完成代码如下:
# encoding: utf-8 # @author: Jeffrey # @file: login_case.py # @time: 2022/7/4 1:01 # @desc: 登录的用例 import unittest import warnings from common.browser import Browser from common.base_page import BasePage from common.config_utils import local_config from actions.login_action import LoginAction class LoginCase(unittest.TestCase): def setUp(self) -> None: warnings.simplefilter("ignore", ResourceWarning) self.driver = Browser().get_driver() self.basepage = BasePage(self.driver) self.basepage.set_browser_max() self.basepage.implicitly_wait(10) self.basepage.open_url(local_config.get_url) def tearDown(self) -> None: self.basepage.wait(2) self.basepage.close_tab() def test_login_success(self): """测试登录成功的用例""" login_action = LoginAction(self.basepage.driver) main_page = login_action.login_success('test01','newdream123') # 断言 self.assertEqual(main_page.get_username(), 'test01','提示:登录失败') def test_login_fail(self): login_action = LoginAction(self.driver) actual_result = login_action.login_fail('test01', 'newdream') # 断言 self.assertEqual(actual_result, '登录失败,请检查您的用户名或密码是否填写正确。') if __name__ == '__main__': unittest.main()
步骤4:编写第二条测试用例,quit_test退出测试用例
思路:
1、 不熟悉的情况下,可以先编写线性脚本
2、 在数据层的元素识别excel添加元素识别信息

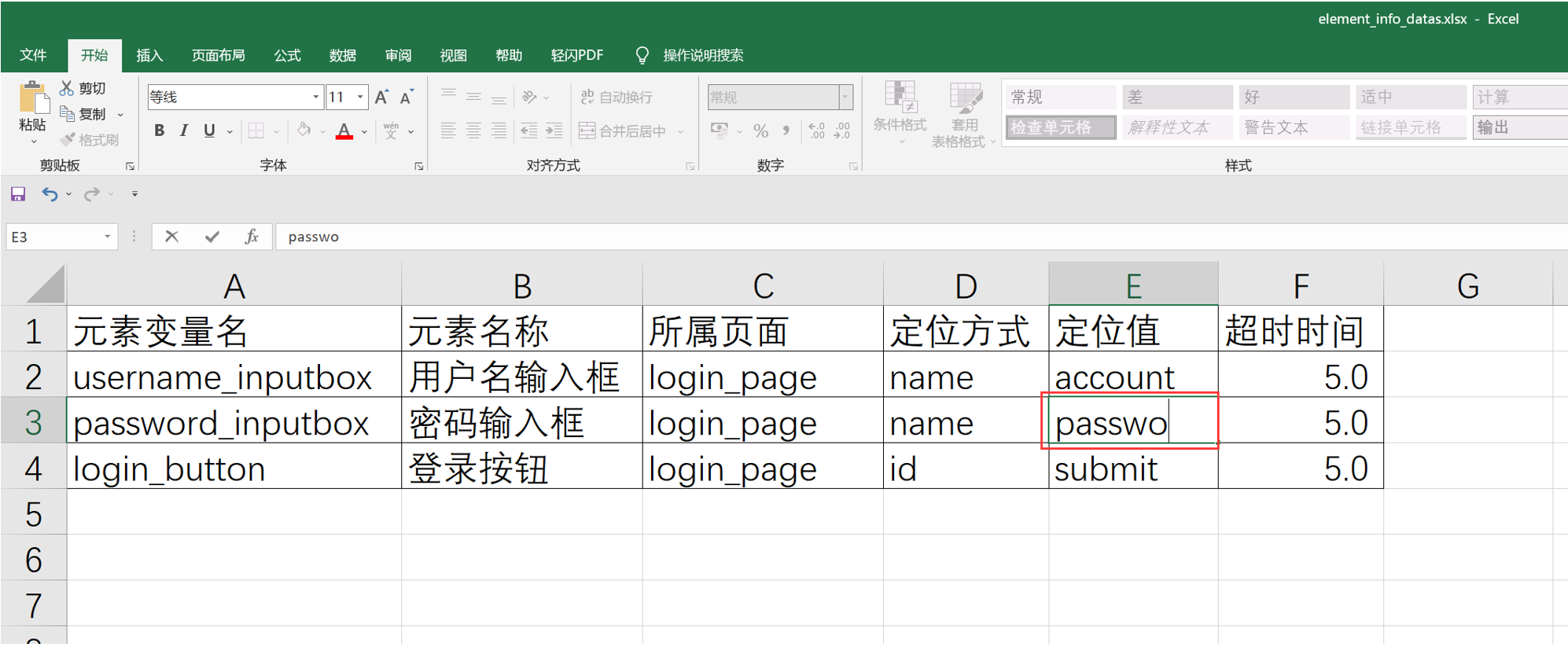
注意:定位值的引号要使用双引号,因为读取excel中的值时,用到单引号,故引号不可一致
步骤5:在页面层中main_page.py中添加元素和元素的操作

代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: main_page.py # @time: 2022/7/2 13:04 # @desc: import os import time from selenium import webdriver from selenium.webdriver.common.by import By from element_infos.login_page import LoginPage from common.base_page import BasePage from common.element_data_utils import ElementDataUtils class MainPage(BasePage): def __init__(self,driver): # 调用父类的driver super().__init__(driver) elements = ElementDataUtils(module_name='main', page_name='main_page').get_element_info() self.myzone_link = elements['myzone_link'] self.user_menu = elements['user_menu'] self.quit_button = elements['quit_button'] def goto_myzone(self): """点击我的地盘""" self.click(self.myzone_link) # 获取登录的用户名 def get_username(self): """获取用户菜单的文本内容""" text = self.get_text(self.user_menu) return text def click_username(self): """点击用户菜单""" self.click(self.user_menu) def click_quit_button(self): """点击退出按钮""" self.click(self.quit_button)
步骤6:编写动作类
在actions文件夹下新增quit_action.py文件

代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: quit_action.py # @time: 2022/7/4 12:33 # @desc: 退出的动作类 from element_infos.main_page import MainPage from element_infos.login_page import LoginPage class QuitAction(): def __init__(self,driver): self.main_page = MainPage(driver) def quit(self): """退出""" self.main_page.click_username() self.main_page.click_quit_button() return LoginPage(self.main_page.driver) # 退出操作后返回登录页面
步骤7:编写测试用例类
在test_cases文件夹下新建main_suite==》quit_case.py
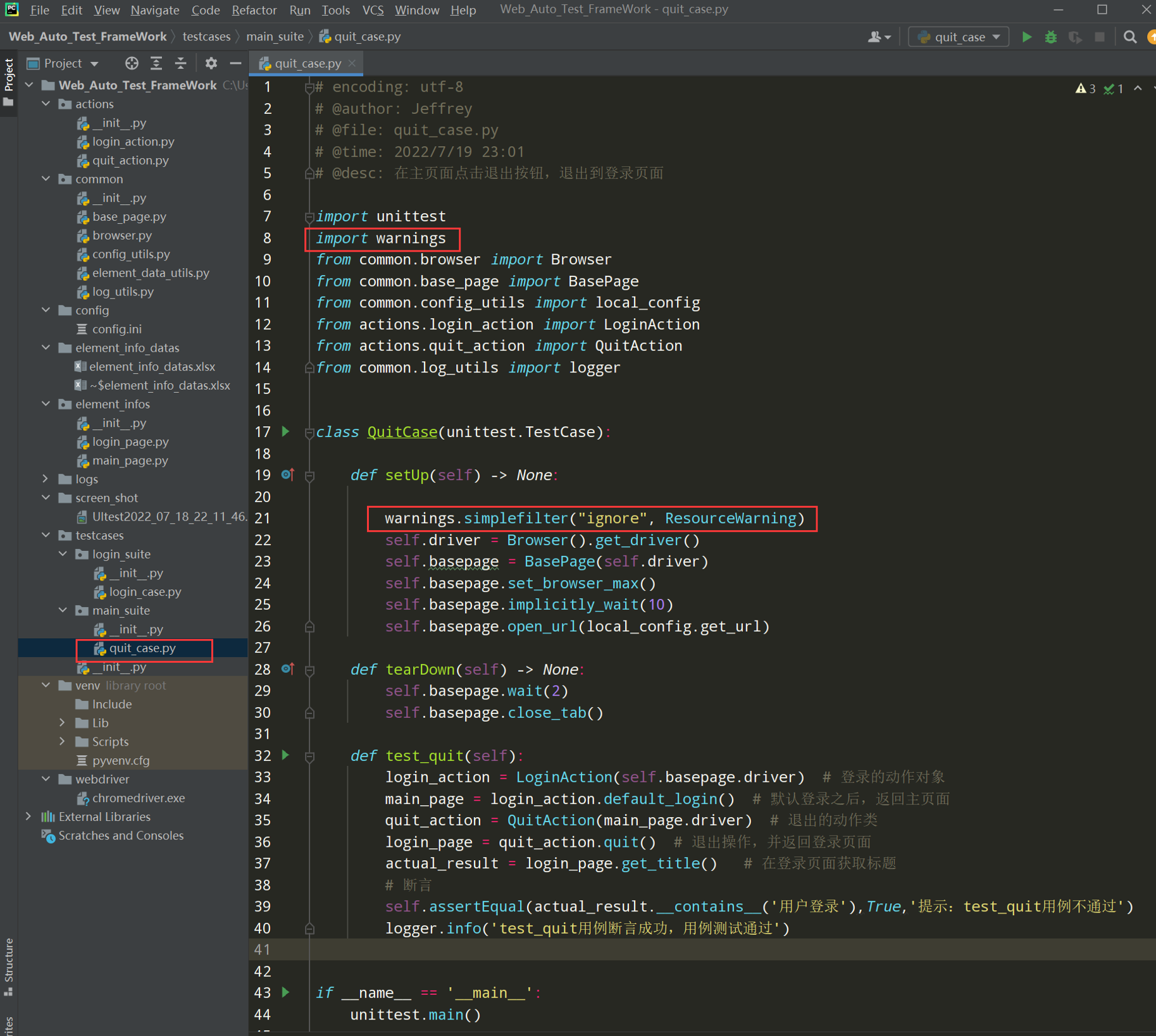
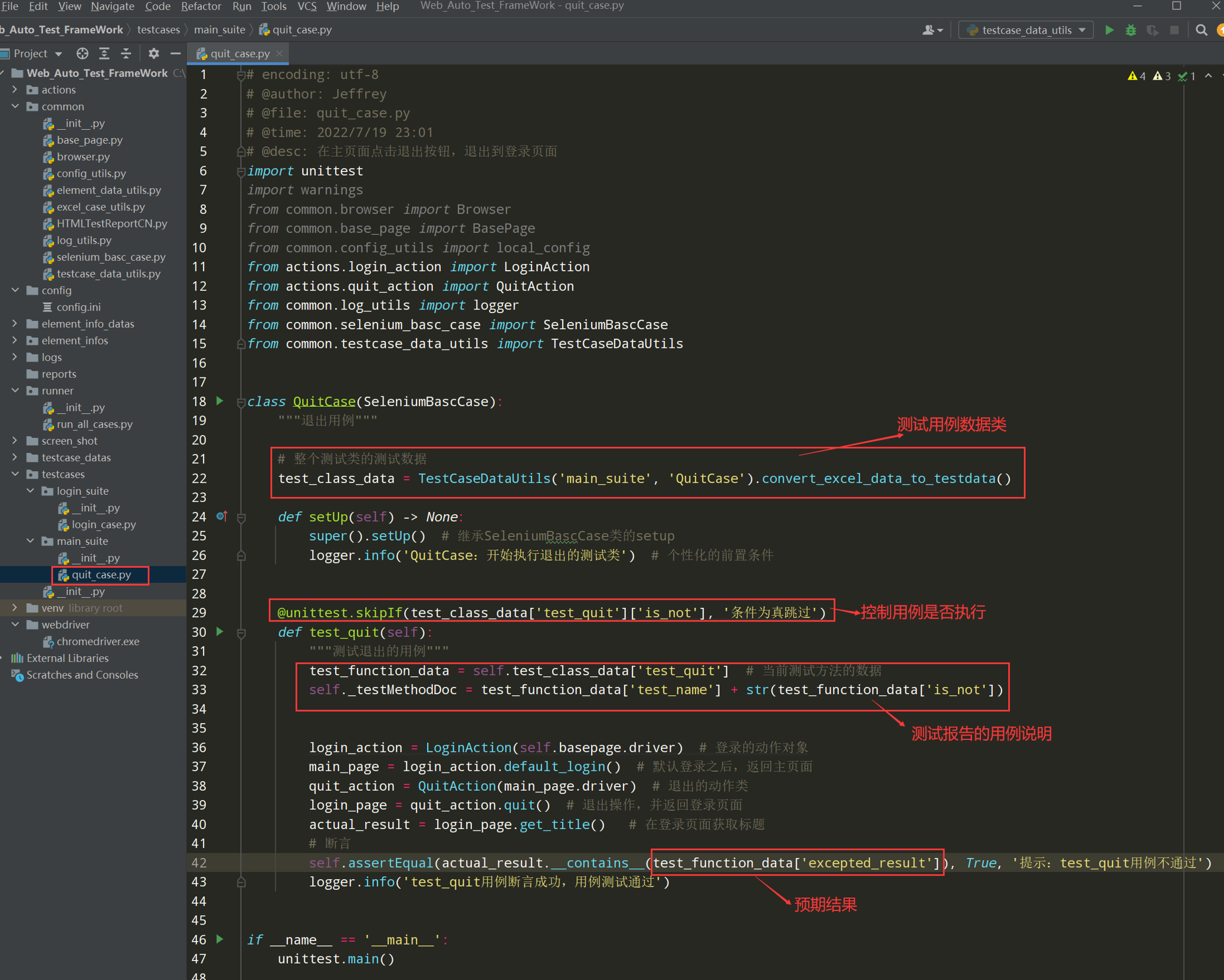
代码示例:
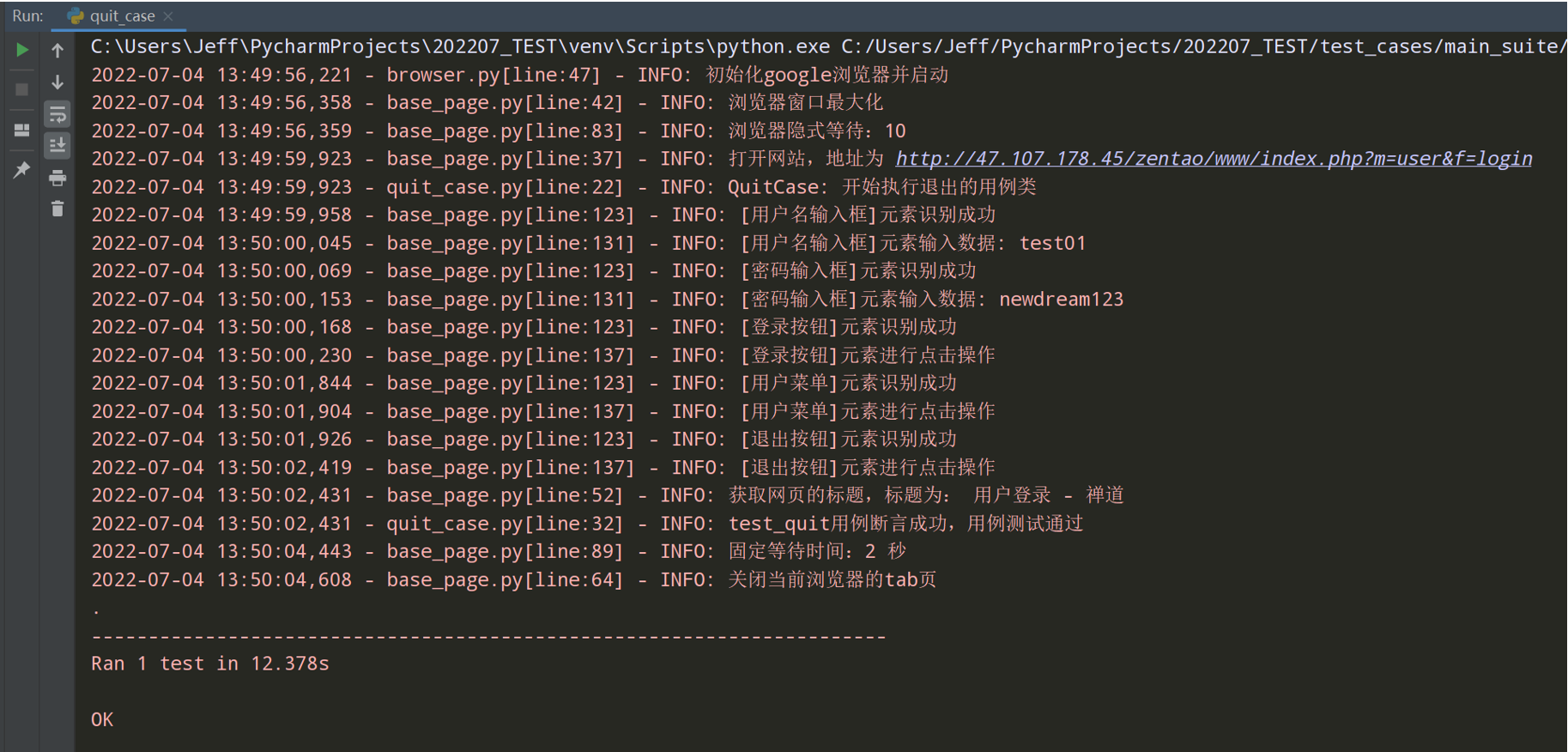
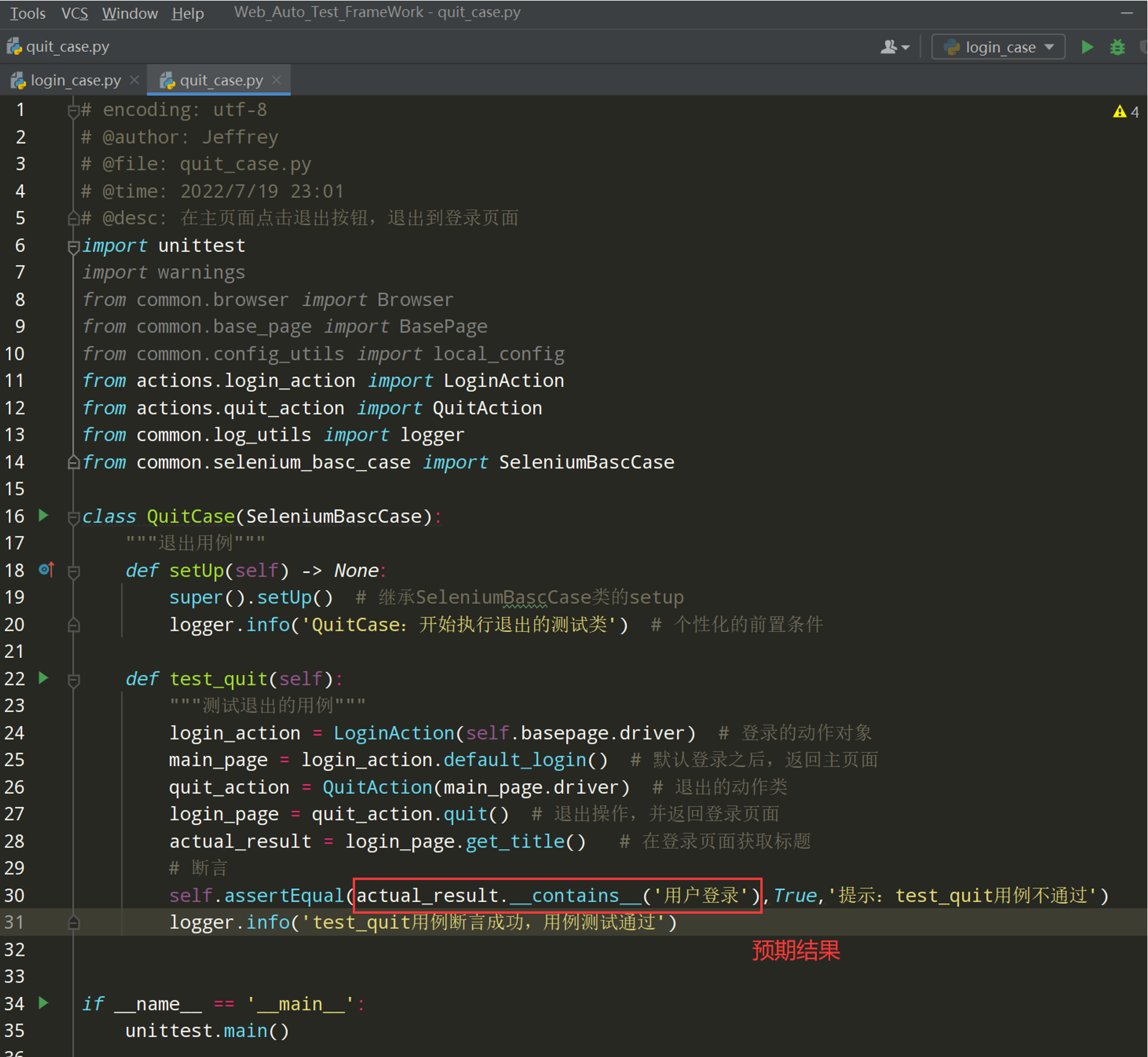
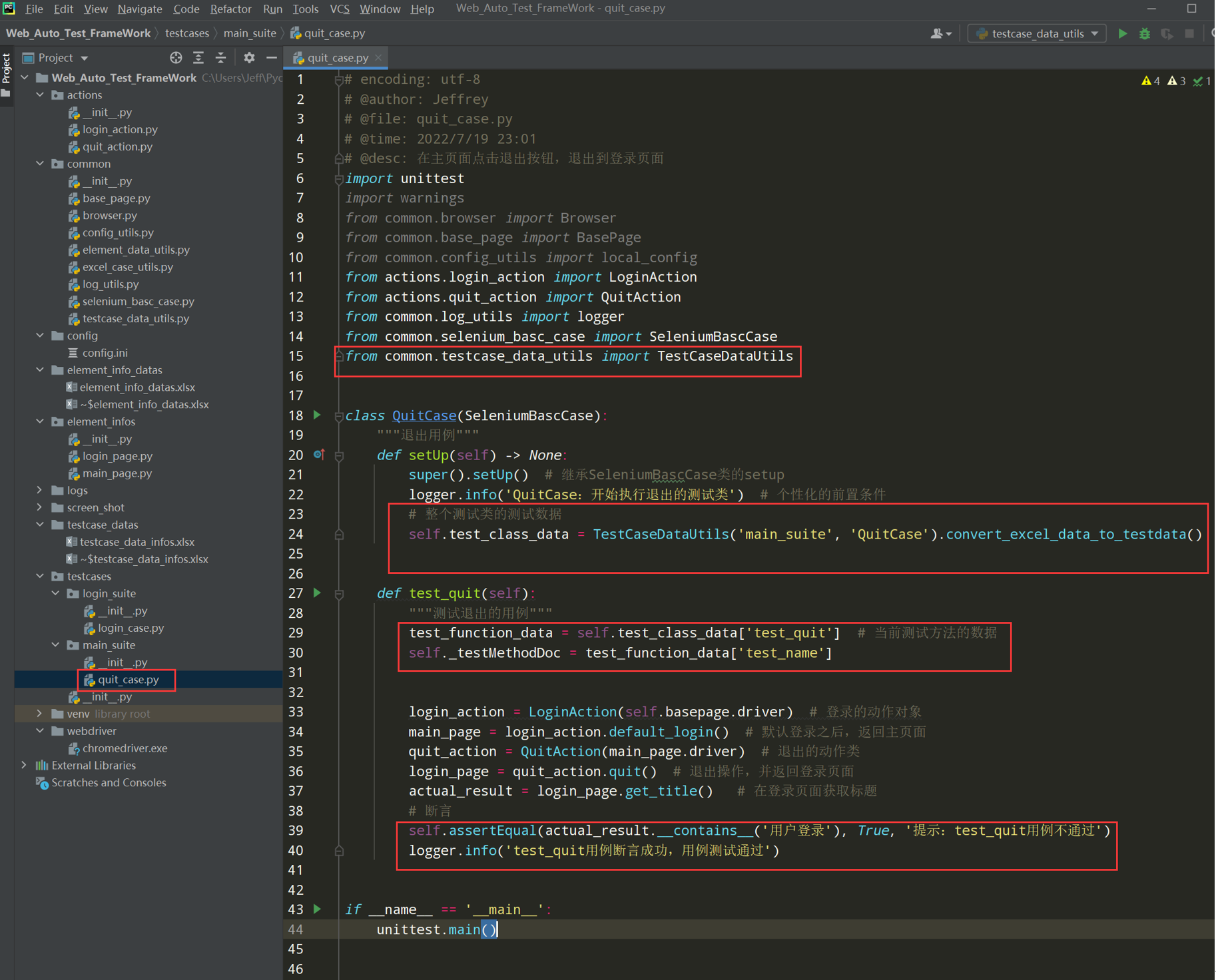
# encoding: utf-8 # @author: Jeffrey # @file: quit_case.py # @time: 2022/7/4 12:38 # @desc: 在主页面点击退出按钮,退出到登录页面 import unittest import warnings from common.browser import Browser from common.base_page import BasePage from common.config_utils import local_config from actions.login_action import LoginAction from actions.quit_action import QuitAction from common.log_utils import logger class QuitCase(unittest.TestCase): def setUp(self) -> None: warnings.simplefilter("ignore", ResourceWarning) self.driver = Browser().get_driver() self.basepage = BasePage(self.driver) self.basepage.set_browser_max() self.basepage.implicitly_wait(10) self.basepage.open_url(local_config.get_url) def tearDown(self) -> None: self.basepage.wait(2) self.basepage.close_tab() def test_quit(self): login_action = LoginAction(self.basepage.driver) # 登录的动作对象 main_page = login_action.default_login() # 默认登录之后,返回主页面 quit_action = QuitAction(main_page.driver) # 退出的动作类 login_page = quit_action.quit() # 退出操作,并返回登录页面 actual_result = login_page.get_title() # 在登录页面获取标题 # 断言 self.assertEqual(actual_result.__contains__('用户登录'),True,'提示:test_quit用例不通过') logger.info('test_quit用例断言成功,用例测试通过') if __name__ == '__main__': unittest.main()
注:提示告警:
C:\Users\Jeff\AppData\Local\Programs\Python\Python37\lib\unittest\suite.py:84: ResourceWarning: unclosed <socket.socket fd=400, family=AddressFamily.AF_INET6, type=SocketKind.SOCK_STREAM, proto=0, laddr=('::1', 63378, 0, 0), raddr=('::1', 63375, 0, 0)>
return self.run(*args, **kwds)
解决方法:可以通过warnings库来忽略掉相关告警。如上图红框内容
import warnings
warnings.simplefilter("ignore", ResourceWarning)
步骤8:执行当前测试用例,查看结果
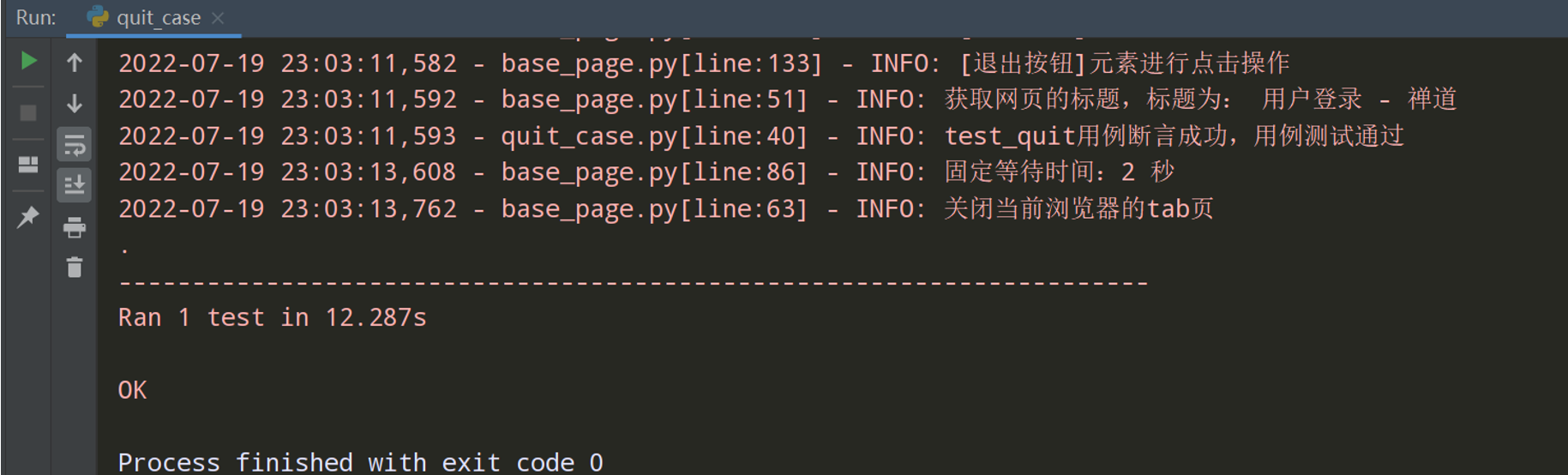
注:从上图用例层中login_case.py和quit_case.py文件中都写了setup函数和teardown函数进行前置后置的处理,但每次都要写一次,很麻烦,可以把它们再进行封装;方法见下面的框架08;
框架 08--unittest 进行二次封装

痛苦点:
1. 每个测试类都有前置和后置的操作,每次都要重复写;需把它们提取出来
如下图:login_case.py和quit_case.py
2.用例层中的前置后置机制分离出来;
步骤1: 了解一个知识点,setUpClass()、setUp() 前置方法的讲解
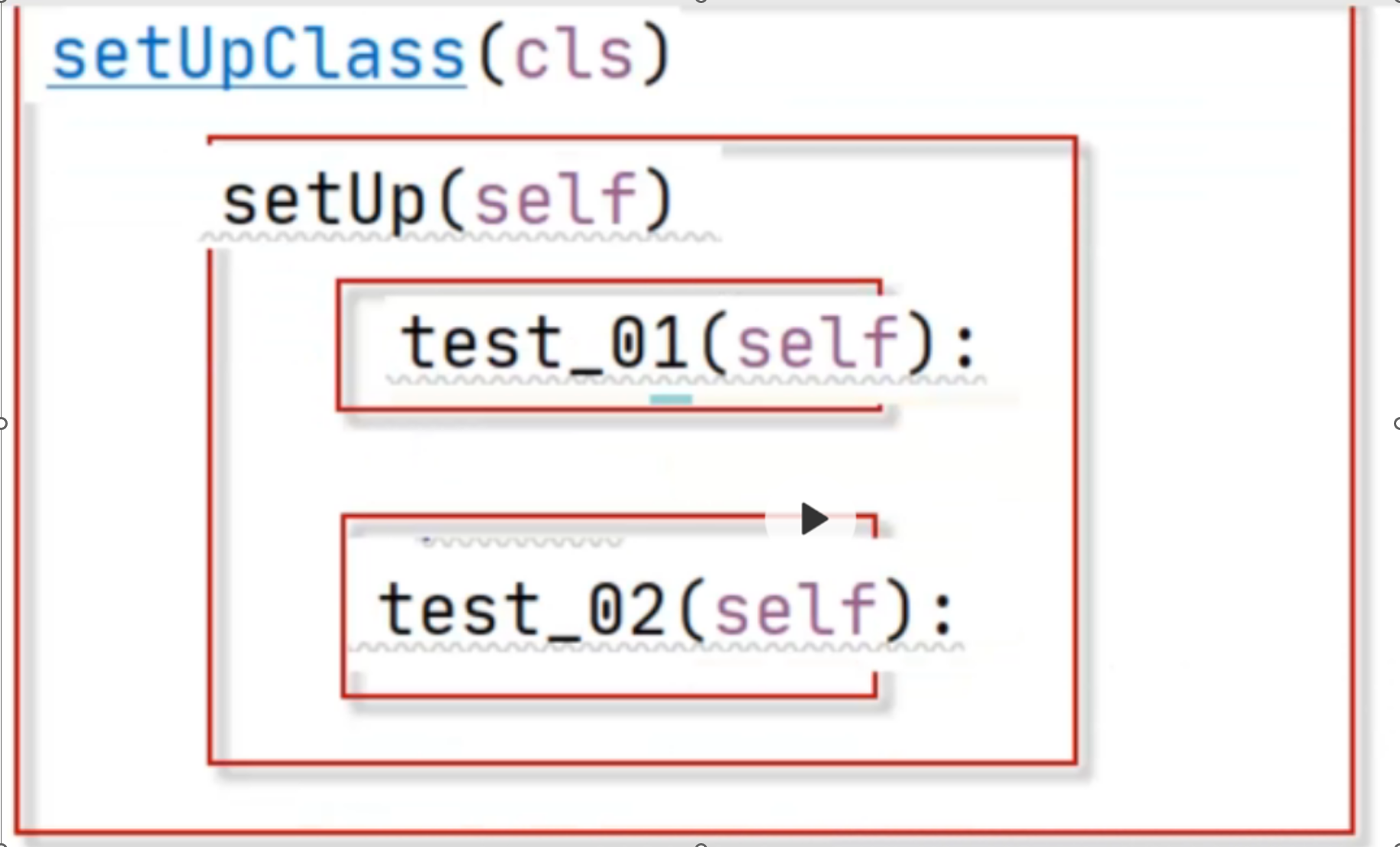
代码示例:
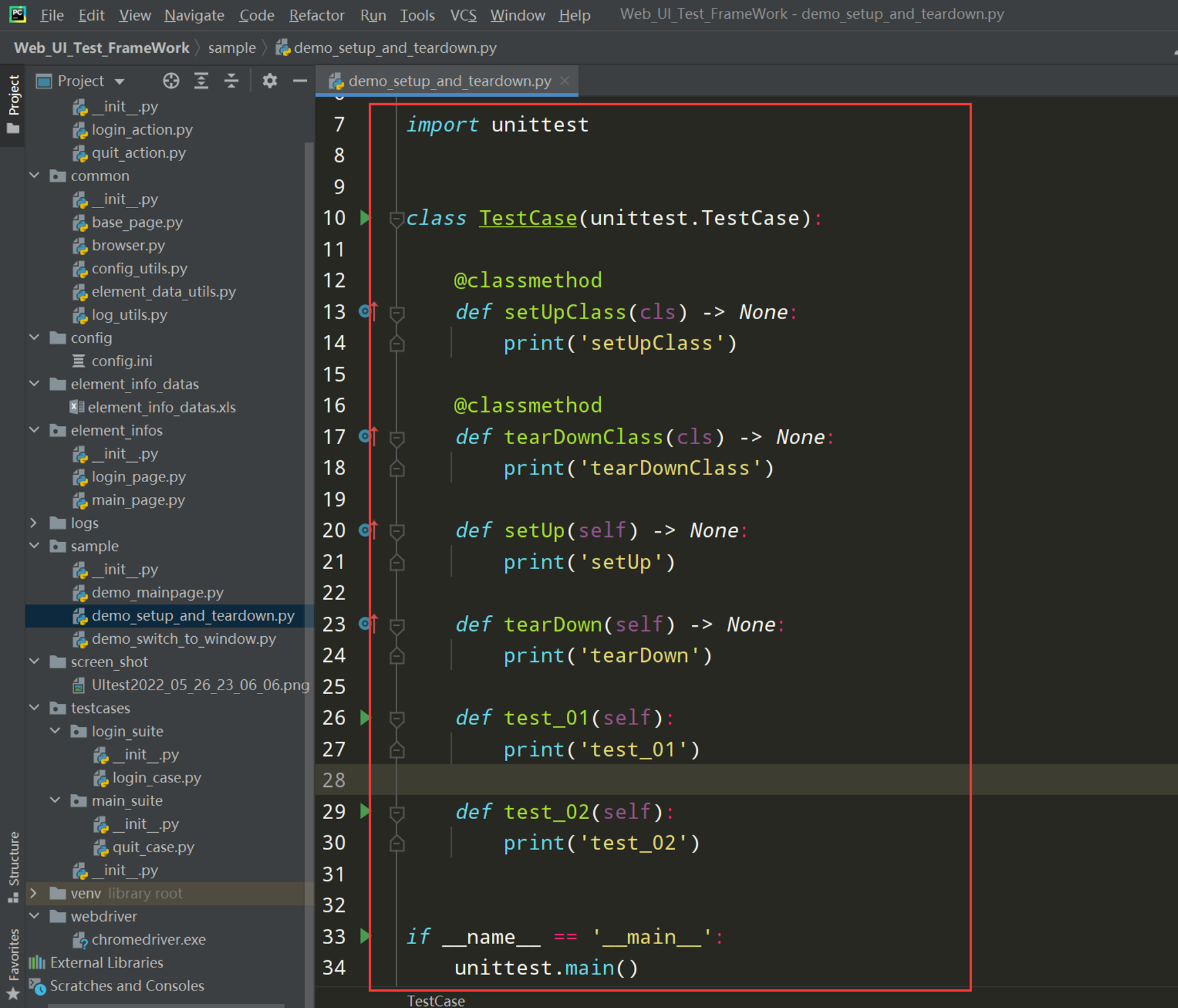
执行效果:
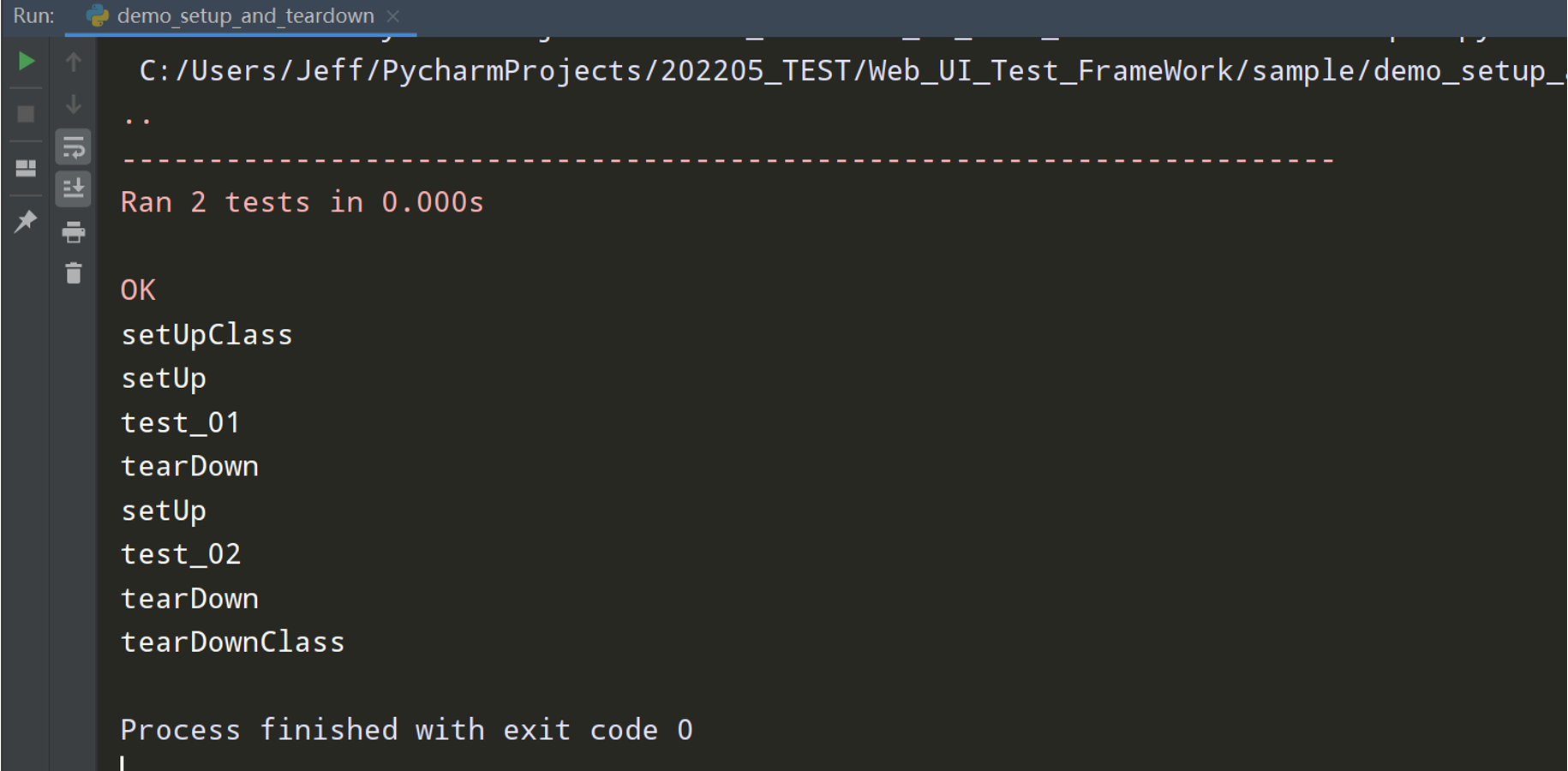
从上图中可以看到setUpClass和tearDownClass是把类中的函数都执行结束后才最后执行tearDownClass的处理;而是setUp和tearDown是把类中每一个函数执行结束后、才执行tearDown的处理;
总结:setUp和tearDown是针对每个函数进行前置后置的操作;setUpClass和tearDownClass是针对整个类进行前置后置的操作;
步骤2:测试类的基类封装
在common—》selenium_basc_case.py—》编写SeleniumBascCase()类,这个基础类继承于unittest.TestCase

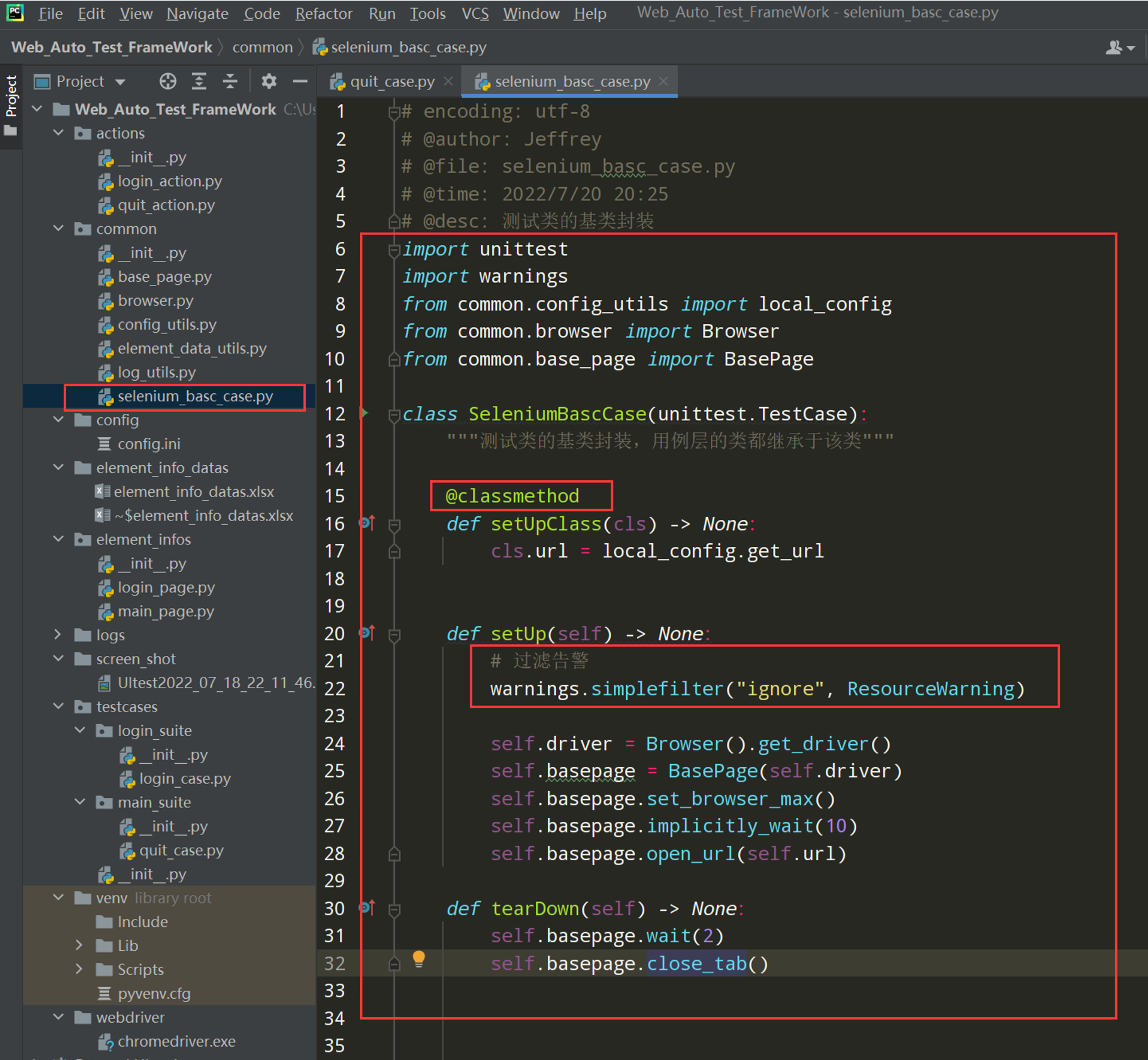
注:加上上图中的过滤告警代码,日志输出后不出出现告警信息;
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: selenium_basc_case.py # @time: 2022/7/4 13:29 # @desc: 测试类的基类封装 import unittest import warnings from common.config_utils import local_config from common.browser import Browser from common.base_page import BasePage class SeleniumBascCase(unittest.TestCase): """测试类的基类封装,用例层的类都继承于该类""" @classmethod def setUpClass(cls) -> None: cls.url = local_config.get_url def setUp(self) -> None: # 过滤告警 warnings.simplefilter("ignore", ResourceWarning) self.driver = Browser().get_driver() self.basepage = BasePage(self.driver) self.basepage.set_browser_max() self.basepage.implicitly_wait(10) self.basepage.open_url(self.url) def tearDown(self) -> None: self.basepage.wait(2) self.basepage.close_tab()
步骤3:改造之前编写的的用例,继承于SeleniumBascCase()类;删除原有的前置后置方法
改造login_case.py文件;
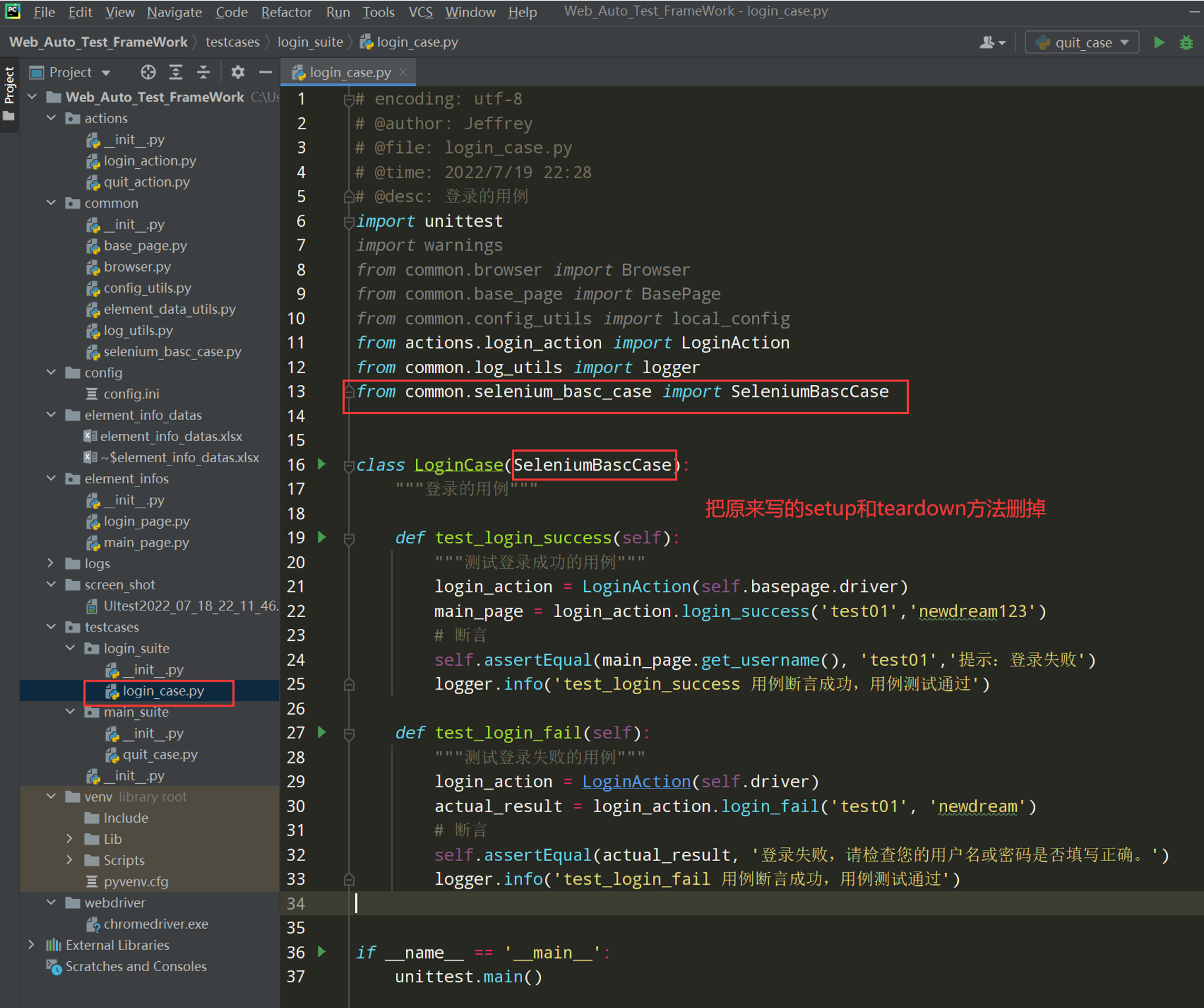
代码示例:
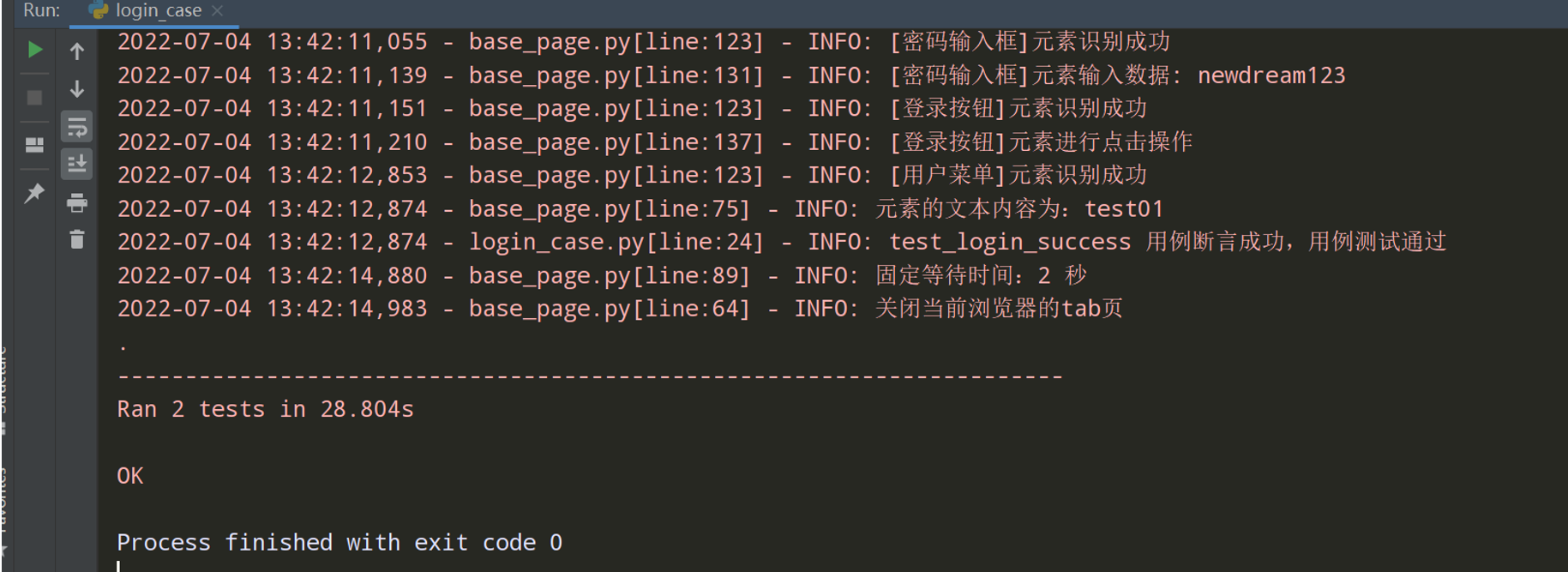
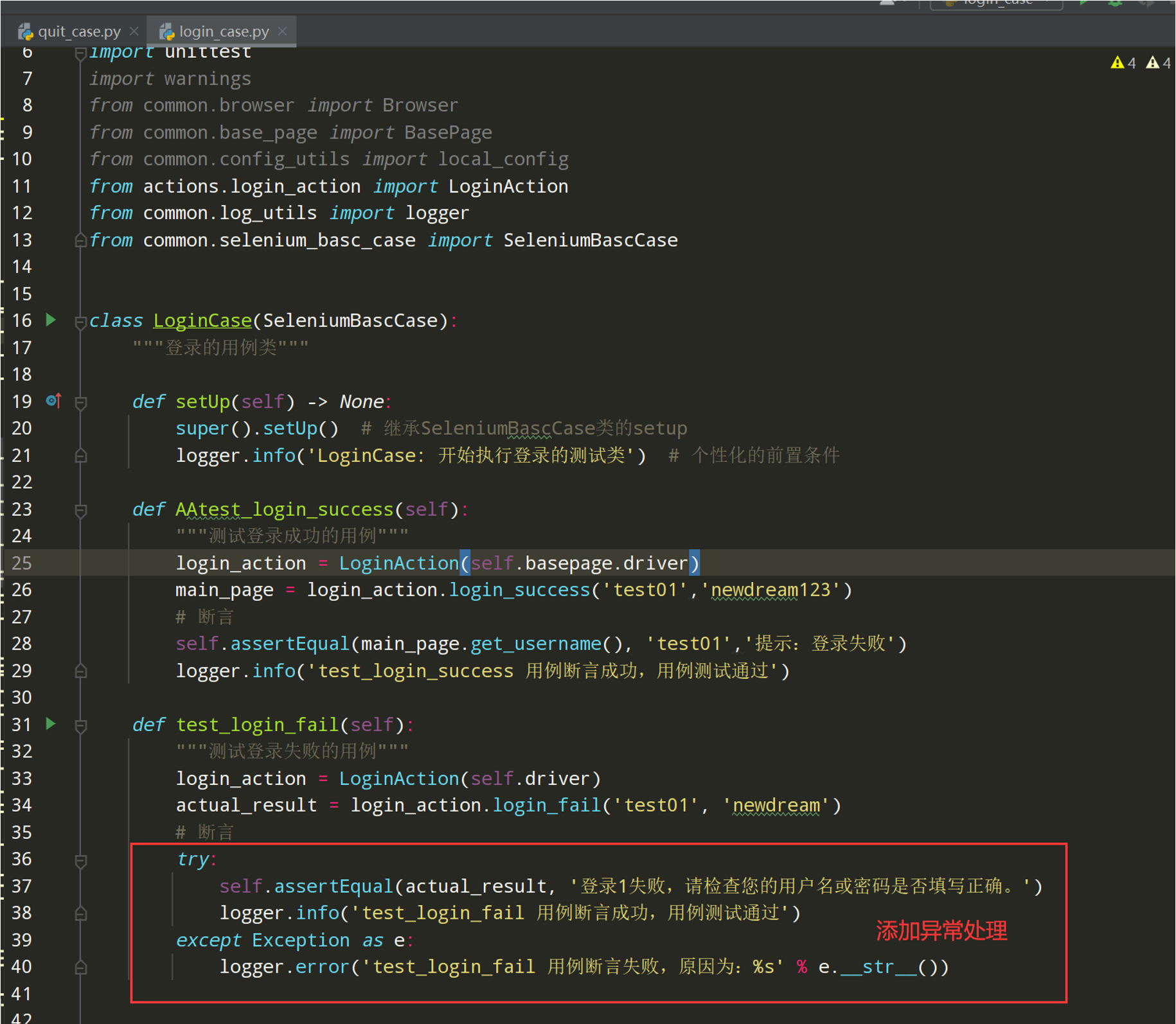
# encoding: utf-8 # @author: Jeffrey # @file: login_case.py # @time: 2022/7/4 1:01 # @desc: 登录的用例 import unittest import warnings from common.browser import Browser from common.base_page import BasePage from common.config_utils import local_config from actions.login_action import LoginAction from common.log_utils import logger from common.selenium_basc_case import SeleniumBascCase class LoginCase(SeleniumBascCase): def test_login_success(self): """测试登录成功的用例""" login_action = LoginAction(self.basepage.driver) main_page = login_action.login_success('test01','newdream123') # 断言 self.assertEqual(main_page.get_username(), 'test01','提示:登录失败') logger.info('test_login_success 用例断言成功,用例测试通过') def test_login_fail(self): """测试登录失败的用例""" login_action = LoginAction(self.driver) actual_result = login_action.login_fail('test01', 'newdream') # 断言 self.assertEqual(actual_result, '登录失败,请检查您的用户名或密码是否填写正确。') logger.info('test_login_fail 用例断言成功,用例测试通过') if __name__ == '__main__': unittest.main()
测试执行一下:
改造之前quit_case.py文件:
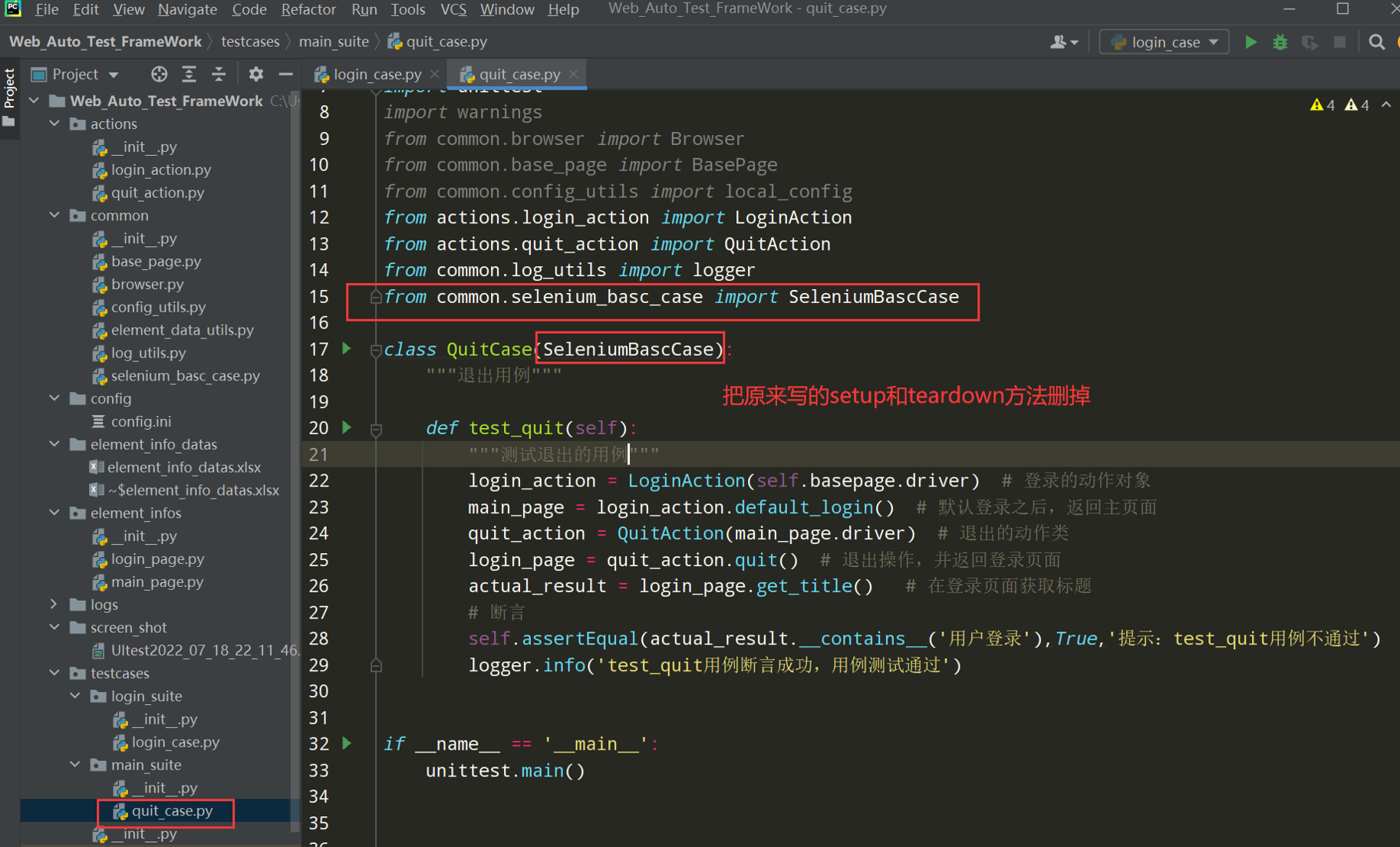
代码示例:
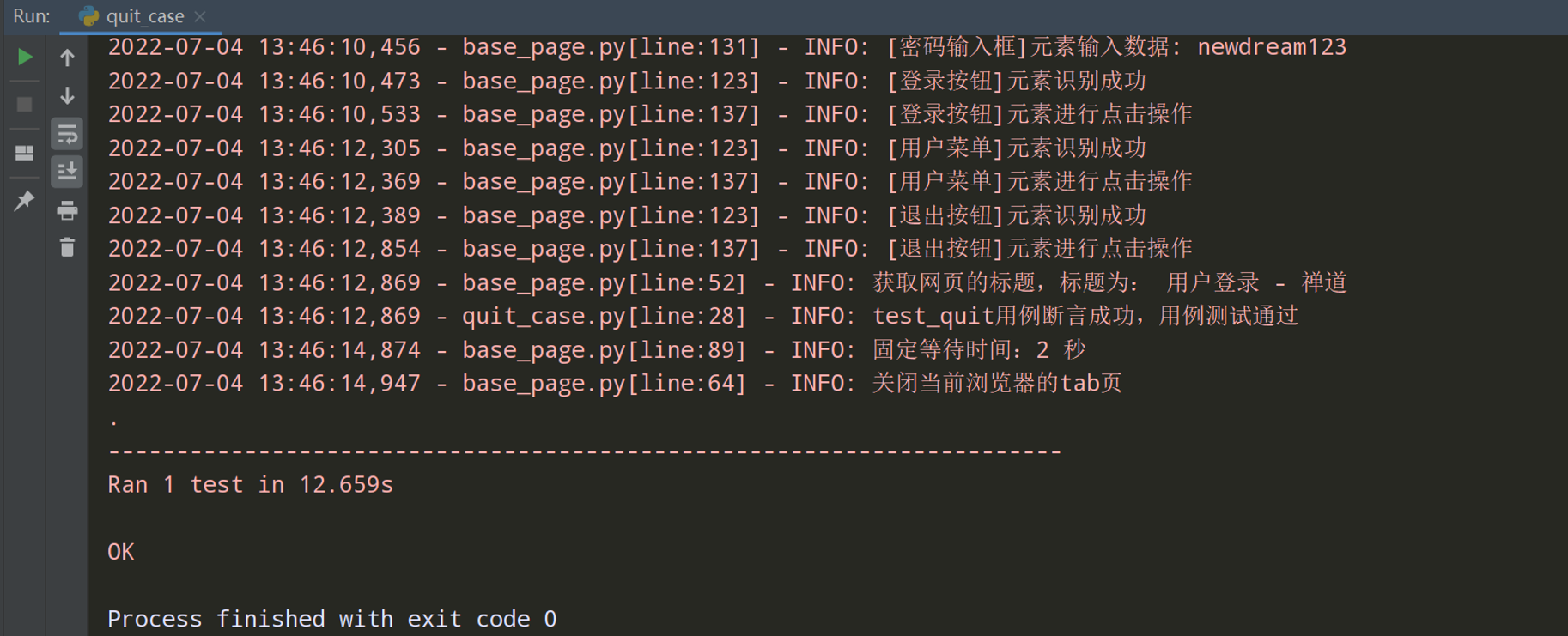
# encoding: utf-8 # @author: Jeffrey # @file: quit_case.py # @time: 2022/7/19 23:01 # @desc: 在主页面点击退出按钮,退出到登录页面 import unittest import warnings from common.browser import Browser from common.base_page import BasePage from common.config_utils import local_config from actions.login_action import LoginAction from actions.quit_action import QuitAction from common.log_utils import logger from common.selenium_basc_case import SeleniumBascCase class QuitCase(SeleniumBascCase): """退出用例""" def test_quit(self): """测试退出的用例""" login_action = LoginAction(self.basepage.driver) # 登录的动作对象 main_page = login_action.default_login() # 默认登录之后,返回主页面 quit_action = QuitAction(main_page.driver) # 退出的动作类 login_page = quit_action.quit() # 退出操作,并返回登录页面 actual_result = login_page.get_title() # 在登录页面获取标题 # 断言 self.assertEqual(actual_result.__contains__('用户登录'),True,'提示:test_quit用例不通过') logger.info('test_quit用例断言成功,用例测试通过') if __name__ == '__main__': unittest.main()
测试执行一下:
步骤4:个性化设置
可在测试类下在再设置前置操作,实现个性化设置;
调整login_case.py文件:
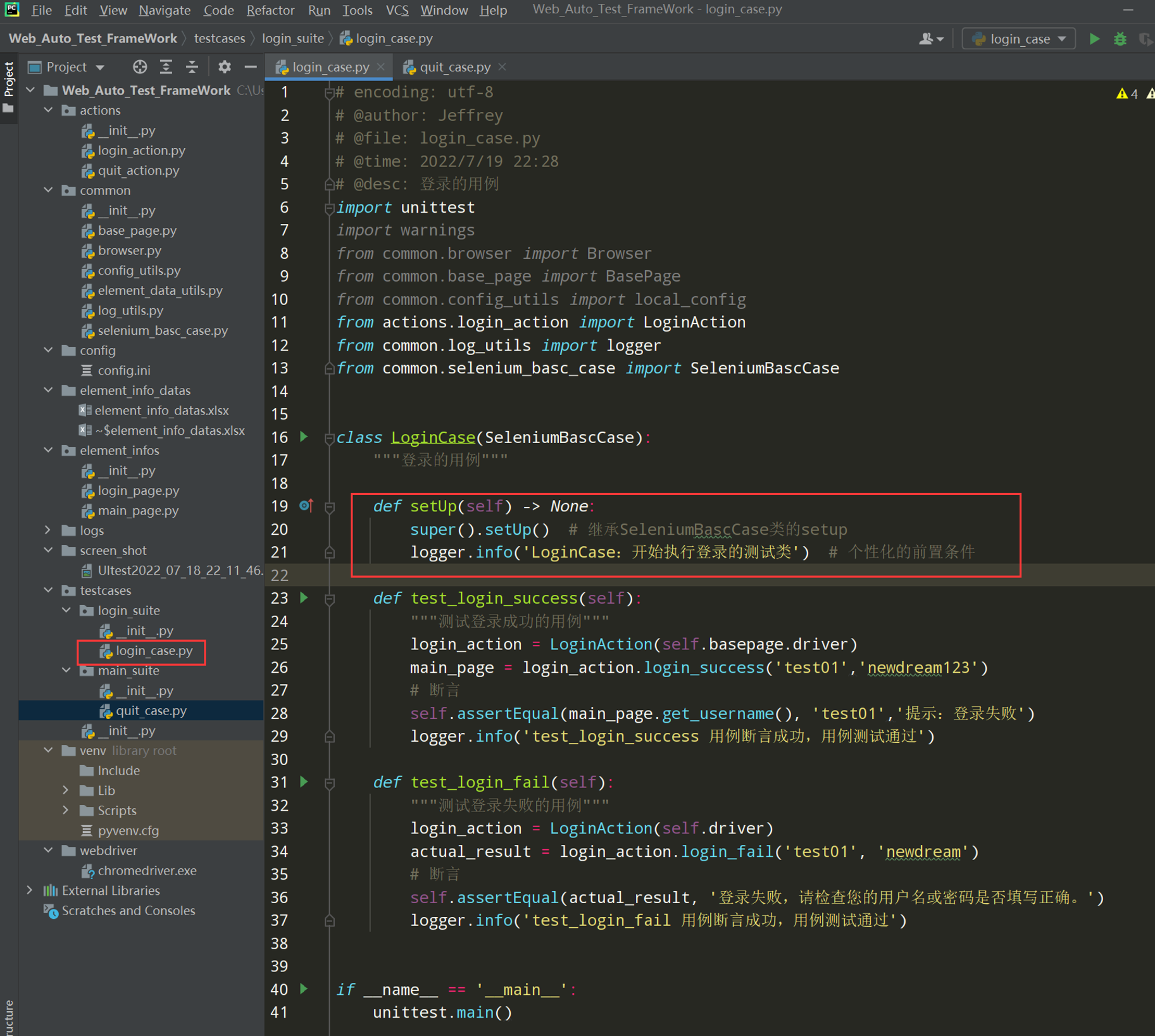
def setUp(self) -> None:
super().setUp() # 继承SeleniumBascCase类的setup
logger.info('LoginCase:开始执行登录的测试类') # 个性化的前置条件
执行结果:

调整quit_case.py文件:
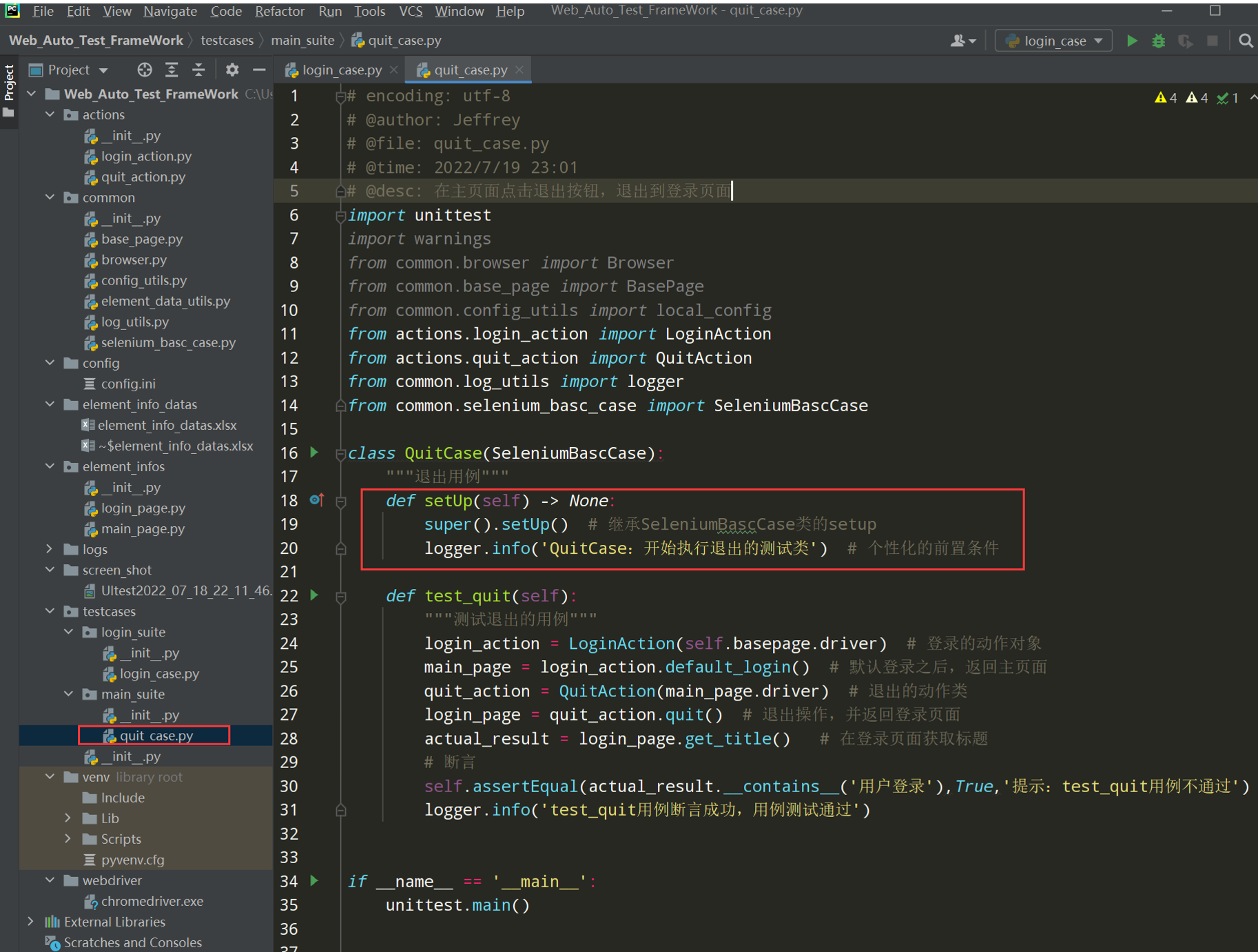
def setUp(self) -> None:
super().setUp() # 继承SeleniumBascCase类的setup
logger.info('QuitCase:开始执行退出的测试类') # 个性化的前置条件
执行结果:
步骤5:扩展,如果断言失败,加错误截图等内容;
注:如后面要用到HTMLTestReportCN.py报告的话,用例中的断言不可添加异常处理,否则HTMLTestReportCN.py中自带的截图功能无法嵌入到测试报告中;详情见框架13步骤8
框架09—底层封装,测试用例的数据分离
测试用例中的数据需要分离出来;如下图:
代码注释
作用:让代码更清晰,方便或者其他人员查看
块注释: 位置:.py文件开始或者方法开始的地方写
行注释:在代码关键的地方
自动注释:
Pycharm设置注释
1.打开pycharm,左上角点击File->settings->Editor->File and Code Templates->Python Script
# encoding: utf-8
# @author: Jeffrey
# @file: ${NAME}.py
# @time: ${DATE} ${TIME}
# @desc:
代码注释经验:
注释不是越多越好。对于一目了然的代码,不需要添加注释。对于复杂的操作,应该在操作开始前写上相应的注释。
对于不是一目了然的代码,应该在代码之后添加注释。
绝对不要描述代码。一般阅读代码的人都了解Python 的语法,只是不知道代码要干什么。
把base_page.py文件中的代码进行注释:
文件开头加上注释写明该文件的作用;
把每个函数下面添加注释;如下图
读取测试用例数据excel表的底层封装
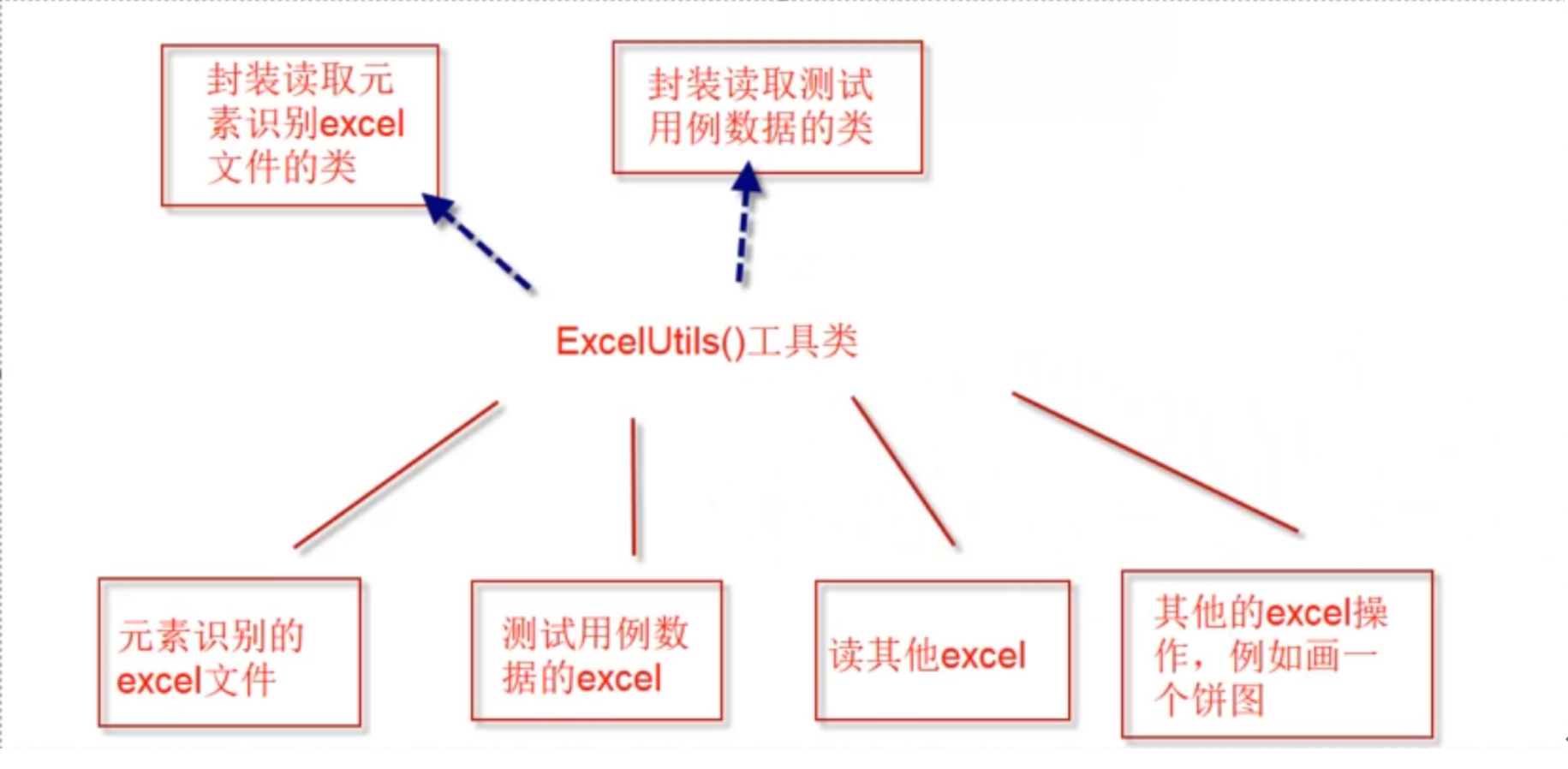
Xlrd模块—》excel_case_utils.py—》ExcelCaseUtils类
ExcelUtils类封装思路:返回嵌套列表[ [], [], [] ]
1、 在common包下新建excel_case_utils.py文件,并进行底层的封装;如下图
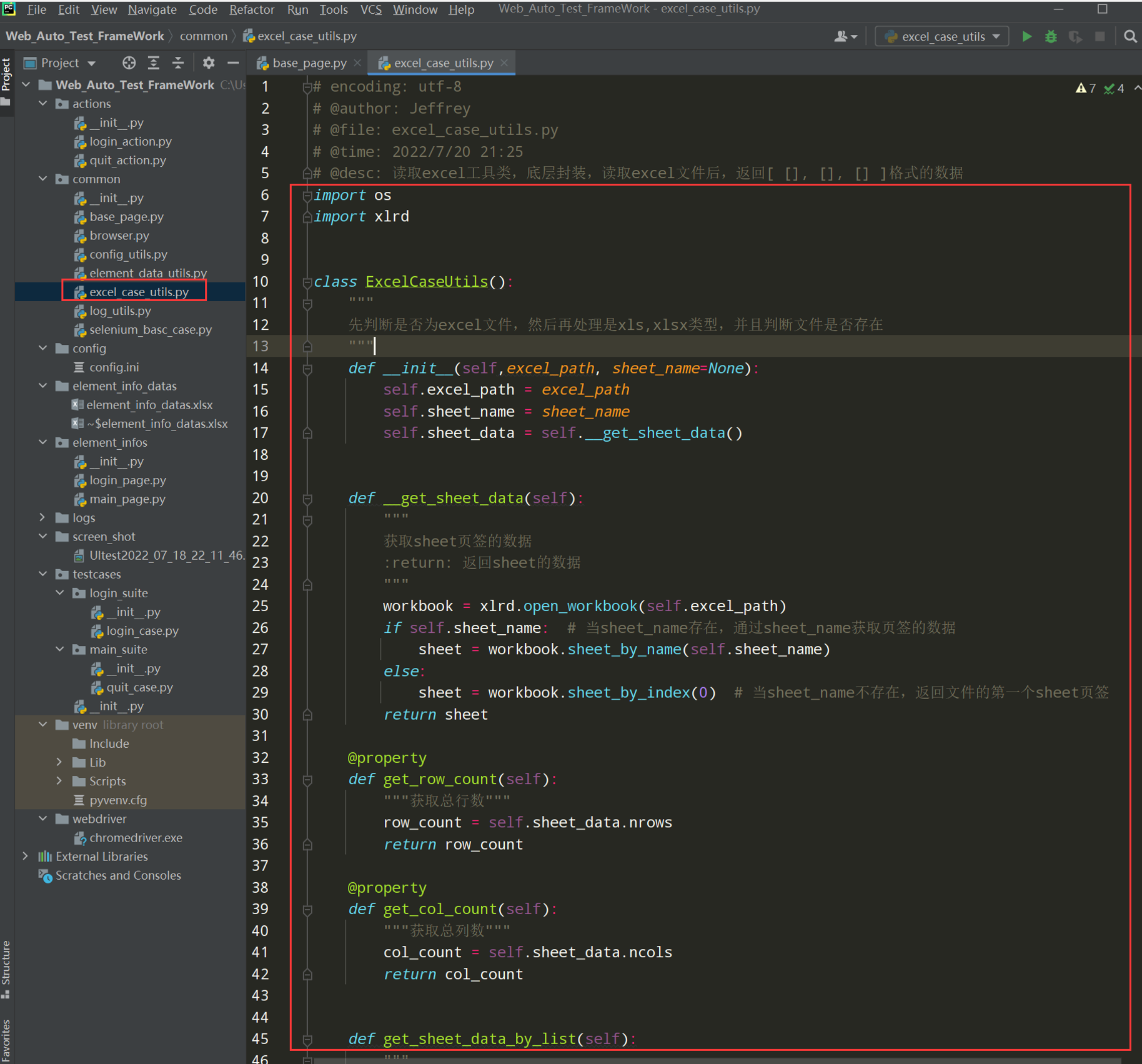
遍历获取sheet页中的所有数据,以嵌套列表的格式;如下图
代码示例:
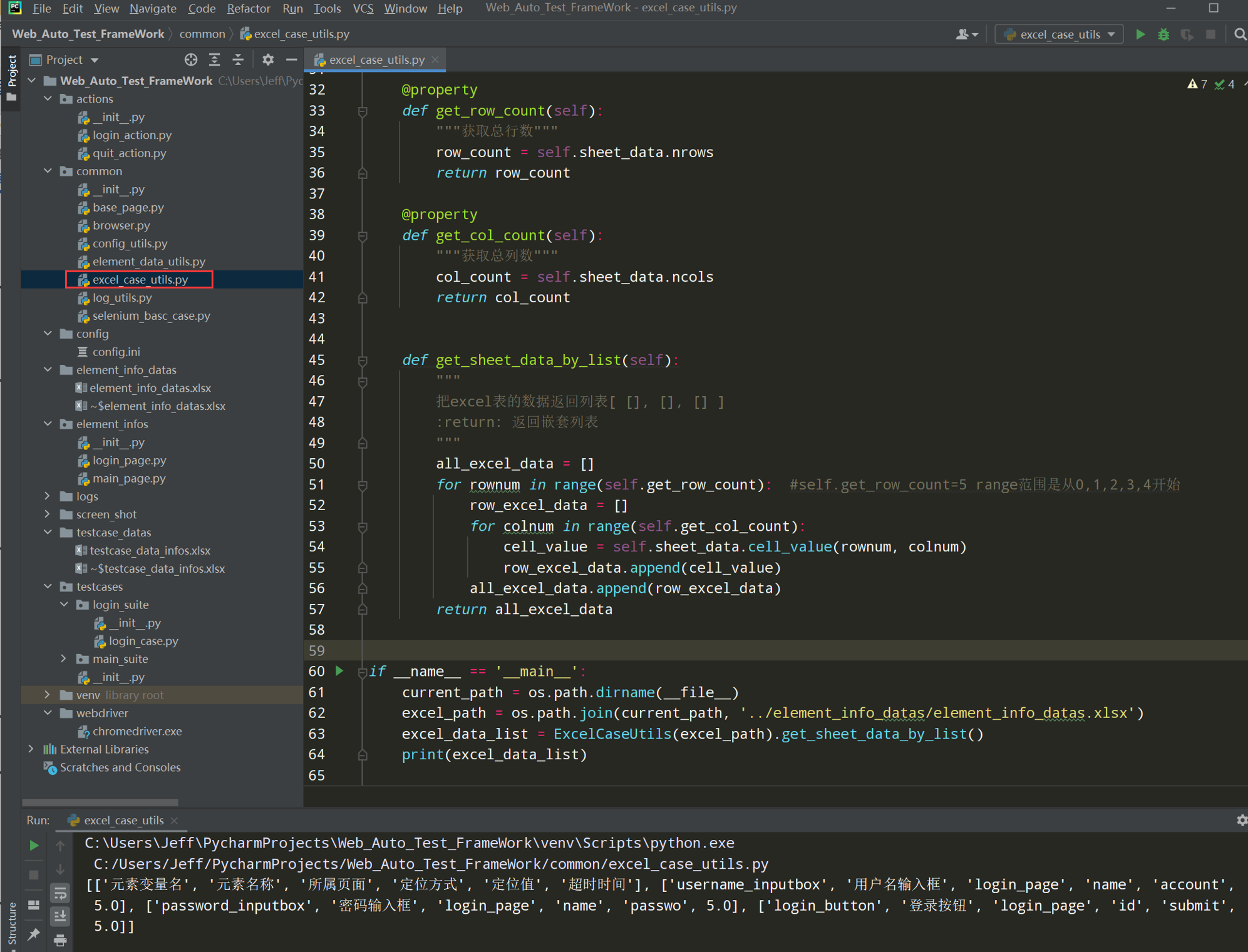
# encoding: utf-8 # @author: Jeffrey # @file: excel_case_utils.py # @time: 2022/7/4 17:35 # @desc: 读取excel工具类,底层封装,读取excel文件后,返回[ [], [], [] ]格式的数据 import os import xlrd class ExcelCaseUtils(): def __init__(self,excel_path, sheet_name=None): self.excel_path = excel_path self.sheet_name = sheet_name self.sheet_data = self.__get_sheet_data() def __get_sheet_data(self): """ 获取sheet页签的数据 :return: 返回sheet的数据 """ workbook = xlrd.open_workbook(self.excel_path) if self.sheet_name: # 当sheet_name存在,通过sheet_name获取页签的数据 sheet = workbook.sheet_by_name(self.sheet_name) else: sheet = workbook.sheet_by_index(0) # 当sheet_name不存在,返回文件的第一个sheet页签 return sheet @property def get_row_count(self): """获取总行数""" row_count = self.sheet_data.nrows return row_count @property def get_col_count(self): """获取总列数""" col_count = self.sheet_data.ncols return col_count def get_sheet_data_by_list(self): """ 把excel表的数据返回列表[ [], [], [] ] :return: 返回嵌套列表 """ all_excel_data = [] for rownum in range(self.get_row_count): #self.get_row_count=5 range范围是从0,1,2,3,4开始 row_excel_data = [] for colnum in range(self.get_col_count): cell_value = self.sheet_data.cell_value(rownum, colnum) row_excel_data.append(cell_value) all_excel_data.append(row_excel_data) return all_excel_data if __name__ == '__main__': current_path = os.path.dirname(__file__) excel_path = os.path.join(current_path, '../element_info_datas/element_info_datas.xlsx') excel_data_list = ExcelCaseUtils(excel_path).get_sheet_data_by_list() print(excel_data_list)
测试执行效果:

框架10—日志模块的 引用
复习:
1、 两种日志输入方式
方式1:输出到控制台
方式2:输出到日志文件
2、日志的级别
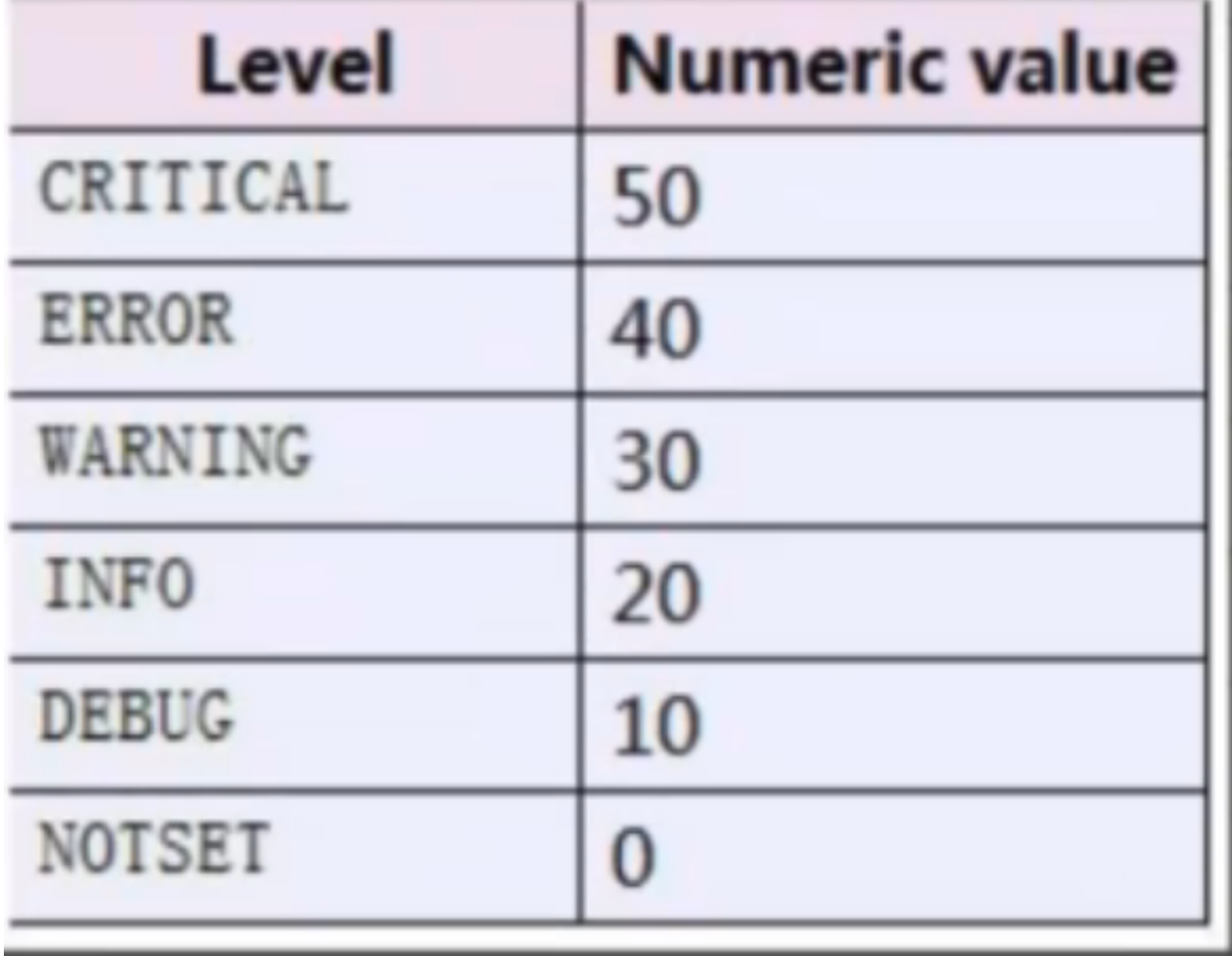
引入日志模块的思路
1. 在common封装一个log_utils.py文件,然后在里面新建一个日志对象
在框架01中已完成
2.在config.ini把日志文件添加进入;见下图3
3.为了控制日志的级别,把日志级别的配置也写入config.ini文件中;见下图
# log日志文件存放的位置
log_path = logs
# log日志级别 NOTSET=0,DEBUG=10,INFO=20,WARNING=30,ERROR=40,CRITICAL=50
log_level = 20
4、 在common-->config_utils.py添加获取的方法
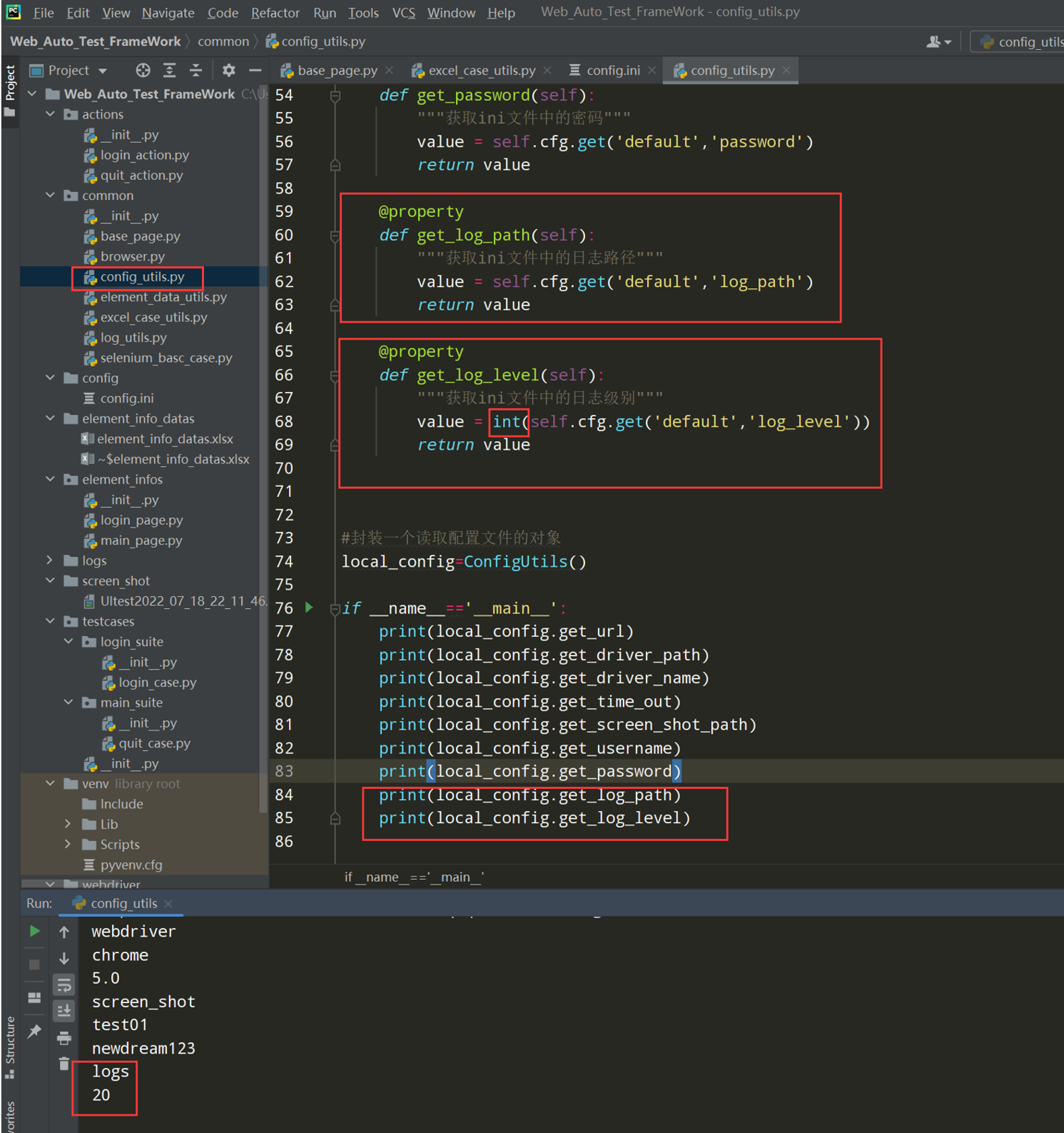
代码示例:
@property def get_log_path(self): """获取ini文件中的日志路径""" value = self.cfg.get('default','log_path') return value @property def get_log_level(self): """获取ini文件中的日志级别""" value = int(self.cfg.get('default','log_level')) return value # 封装一个读取配置文件的对象 local_config = ConfigUtils() if __name__ == '__main__': print(local_config.get_url) print(local_config.get_driver_path) print(local_config.get_driver_name) print(local_config.get_time_out) print(local_config.get_screen_shot_path) print(local_config.get_username) print(local_config.get_password) print(local_config.get_log_path) print(local_config.get_log_level)
完善log_utils.py文件;

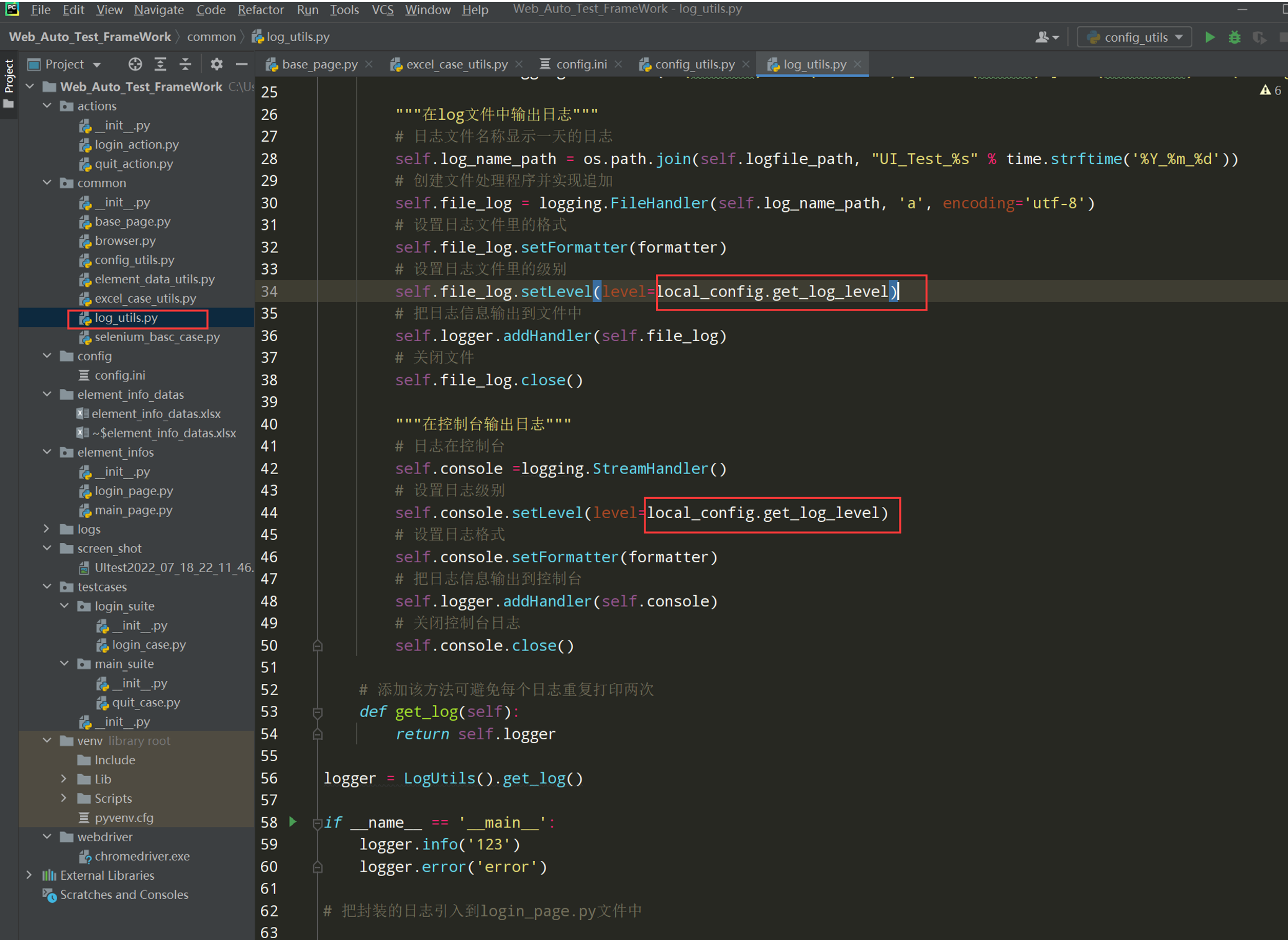
完整代码:
# encoding: utf-8 # @author: Jeffrey # @file: log_utils.py # @time: 2022/7/2 13:27 # @desc: 日志封装 import os import time import logging from common.config_utils import local_config cuttent_path = os.path.dirname(__file__) log_path = os.path.join(cuttent_path,'..', local_config.get_log_path) class LogUtils: def __init__(self,log_path = log_path): self.log_file_path = log_path # 创建日志对象logger self.logger = logging.getLogger(__name__) # 设置日志级别 self.logger.setLevel(level=local_config.get_log_level) # 设置日志的格式 formatter = logging.Formatter('%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s') """在日志文件中输出日志""" # 日志文件名显示一天的日志 self.log_name_path = os.path.join(self.log_file_path,'UI_Test_%s' % time.strftime('%Y_%m_%d')) # 创建文件处理程序并实现追加 self.file_log = logging.FileHandler(self.log_name_path,'a',encoding='utf-8') # 设置日志文件中的格式 self.file_log.setFormatter(formatter) # 设置文件中的日志级别 self.file_log.setLevel(level=local_config.get_log_level) # 把日志信息输出到文件中 self.logger.addHandler(self.file_log) # 关闭文件 self.file_log.close() """在控制台输出日志""" # 日志在控制台 self.console =logging.StreamHandler() # 设置日志级别 self.console.setLevel(level=local_config.get_log_level) # 设置日志格式 self.console.setFormatter(formatter) # 把日志信息输出到控制台 self.logger.addHandler(self.console) # 关闭控制台日志 self.console.close() # 添加该方法可避免每个日志重复打印两次 def get_log(self): return self.logger logger = LogUtils().get_log() if __name__ == '__main__': logger.info('this is a infos') logger.error('this is a error') logger.warning('this is a warning') logger.critical('this is a critical') logger.debug('this is a debug')
5、调整日志级别,控制日志的输出
6、在框架底层代码中添加日志
要求:
1、 从框架最开始的地方开始加日志
2、 尽量把日志添加在框架底层
在browser.py文件中添加日志
导包:from common.log_utils import logger
在base_page.py文件中添加日志;把封装的方法都加上日志
导包:from common.log_utils import logger
在selenium_basc_case.py添加日志
导包:from common.log_utils import logger

代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: selenium_basc_case.py # @time: 2022/7/20 20:25 # @desc: 测试类的基类封装 import unittest import warnings from common.config_utils import local_config from common.browser import Browser from common.base_page import BasePage from common.log_utils import logger class SeleniumBascCase(unittest.TestCase): """测试类的基类封装,用例层的类都继承于该类""" @classmethod def setUpClass(cls) -> None: cls.url = local_config.get_url def setUp(self) -> None: # 过滤告警 warnings.simplefilter("ignore", ResourceWarning) logger.info('') logger.info('----------开始执行测试方法----------') self.driver = Browser().get_driver() self.basepage = BasePage(self.driver) self.basepage.set_browser_max() self.basepage.implicitly_wait(10) self.basepage.open_url(self.url) def tearDown(self) -> None: self.basepage.wait(2) self.basepage.close_tab() logger.info('----------执行方法执行结束,关闭浏览器----------')
在element_data_utils.py中添加日志
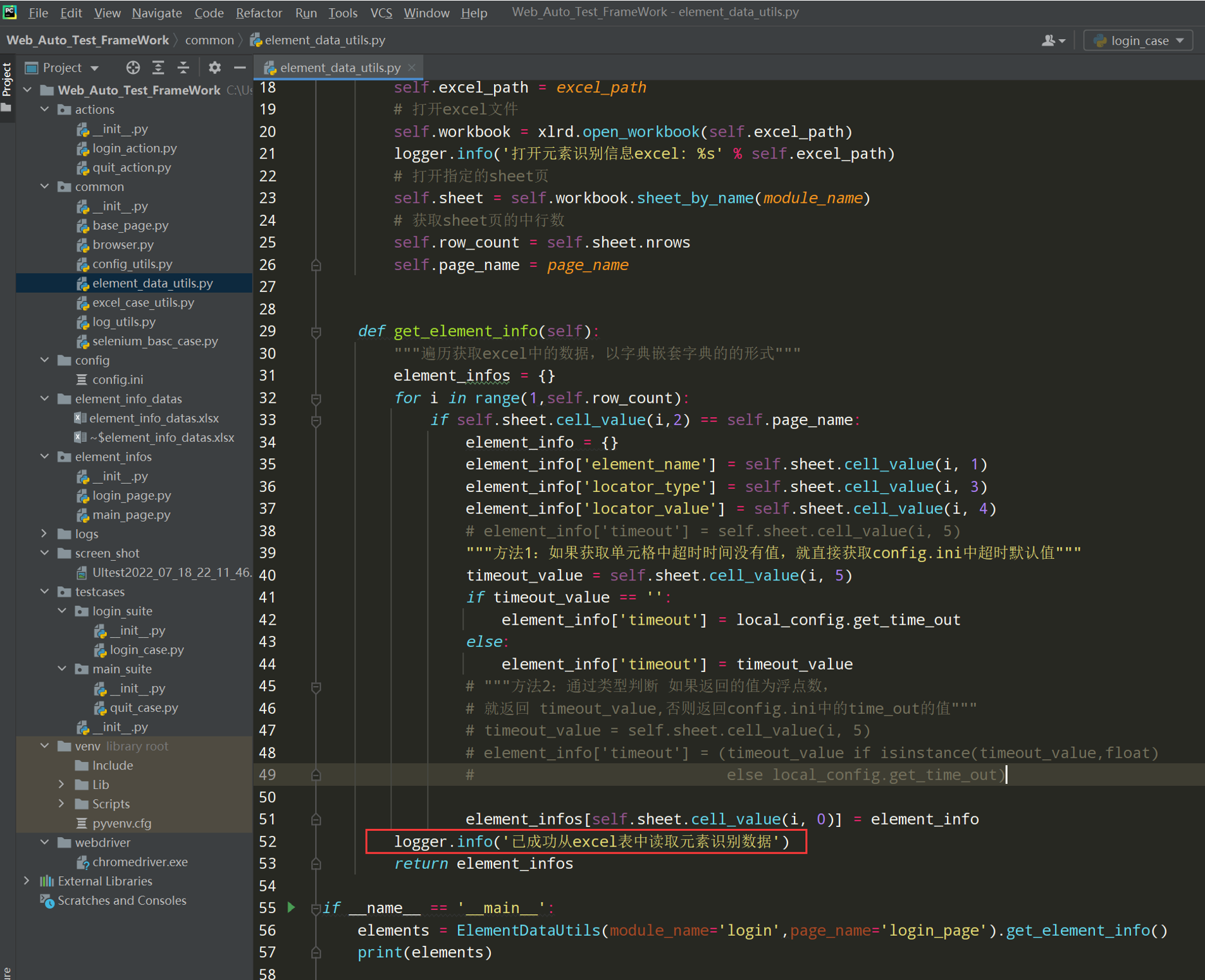
框架11--自动化运行异常的日志和截图
步骤1:登录页面元素excel表故意写错,演示错误断言
步骤2:在BasePage()类中元素识别添加异常处理
步骤3:先把元素识别错误去掉,改为正确的数据,在登录成功的方法前面加上AA,不执行,手工登录禅道,输入错误的面,让错误提示变一下;执行代码时会出错,这属于误报,需要手工确认一下是否为bug;
步骤4:在元素操作里面添加异常日志
步骤5:添加元素识别错误截图
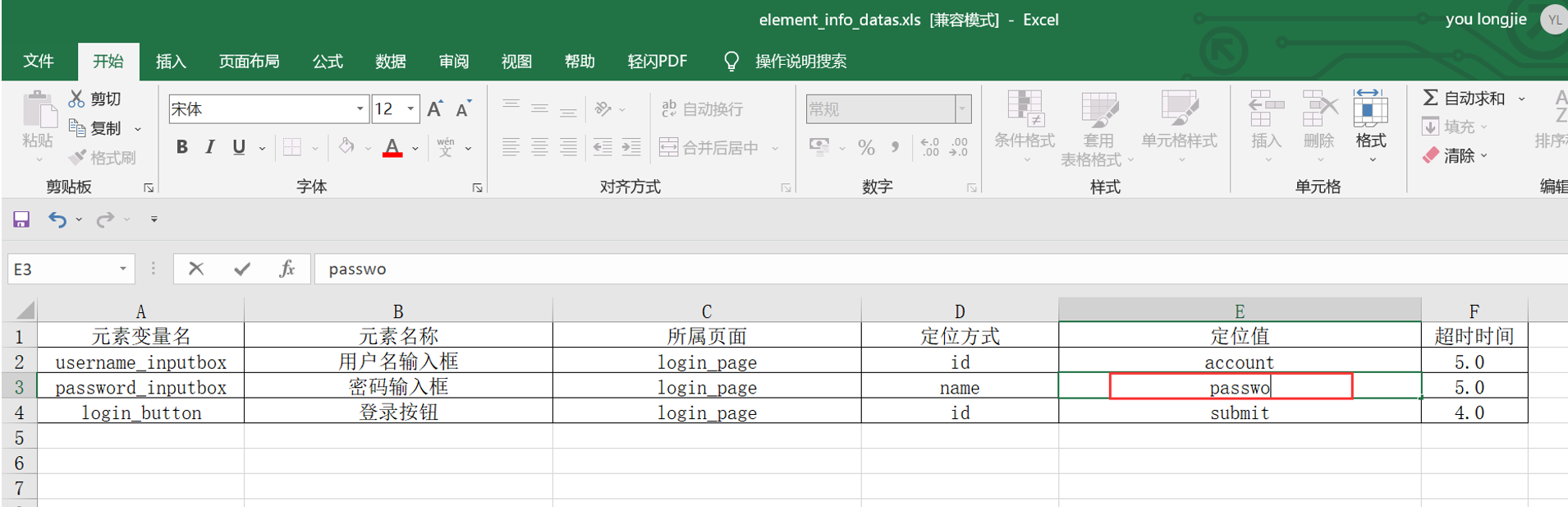
步骤1:登录页面元素excel表故意写错,演示错误断言
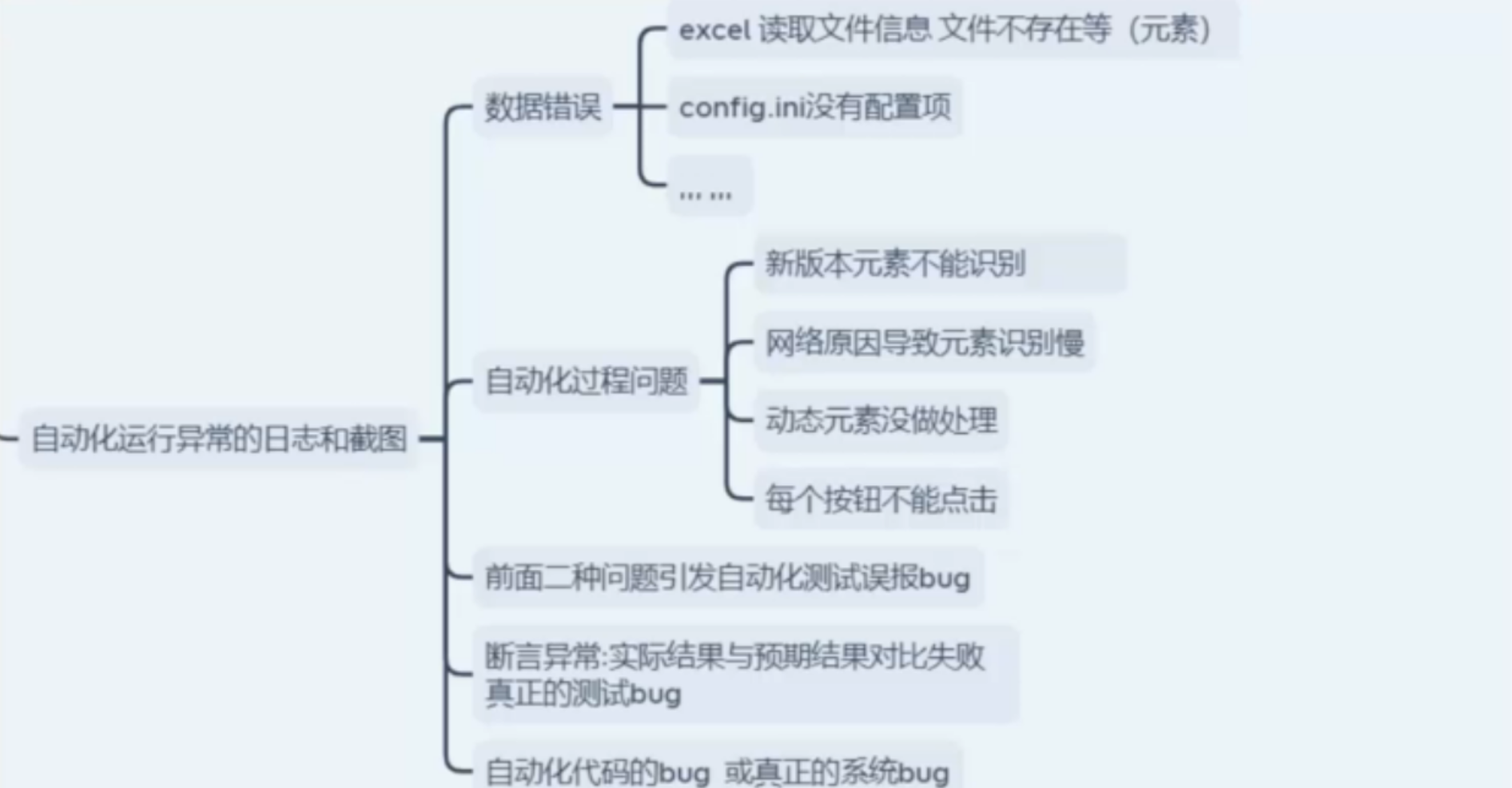
异常报错的类型分析:
断言异常,代码运行失败
1、 自动化代码问题
2、 软件BUG
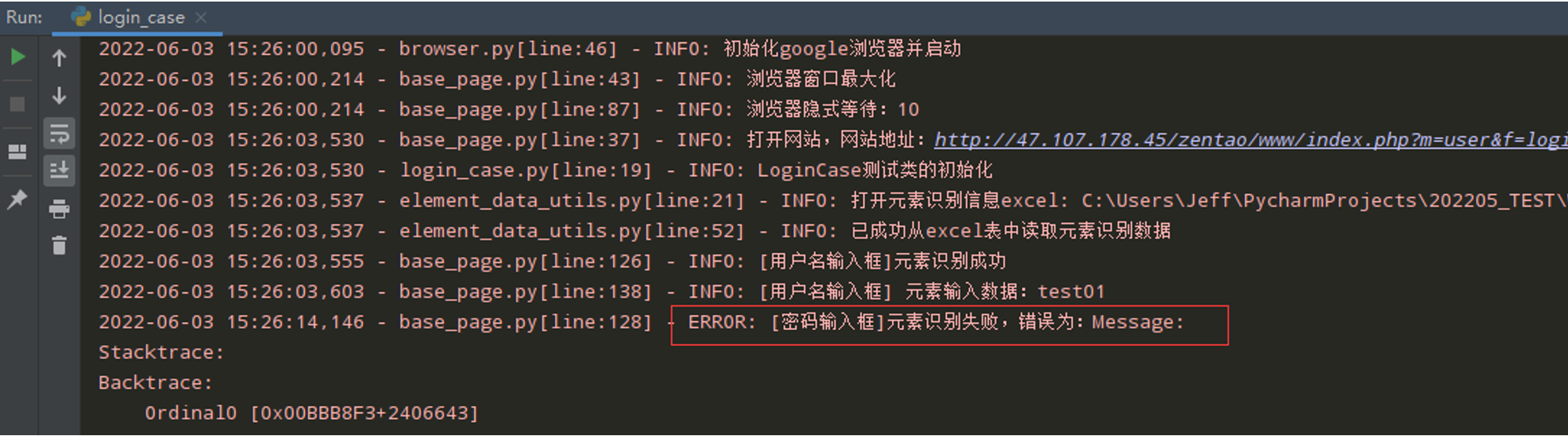
错误演示1:元素识别错误
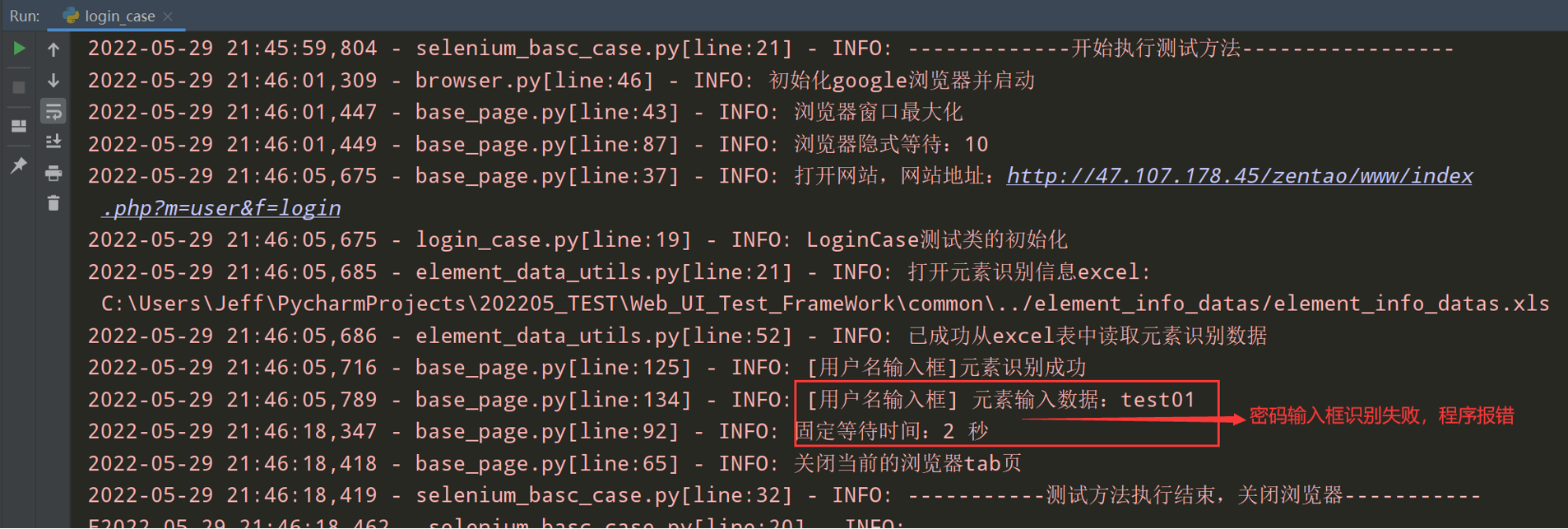
执行login_case.py文件,无法识别密码输入框元素,程序报错
错误演示2:断言错误,把test01改为test02;
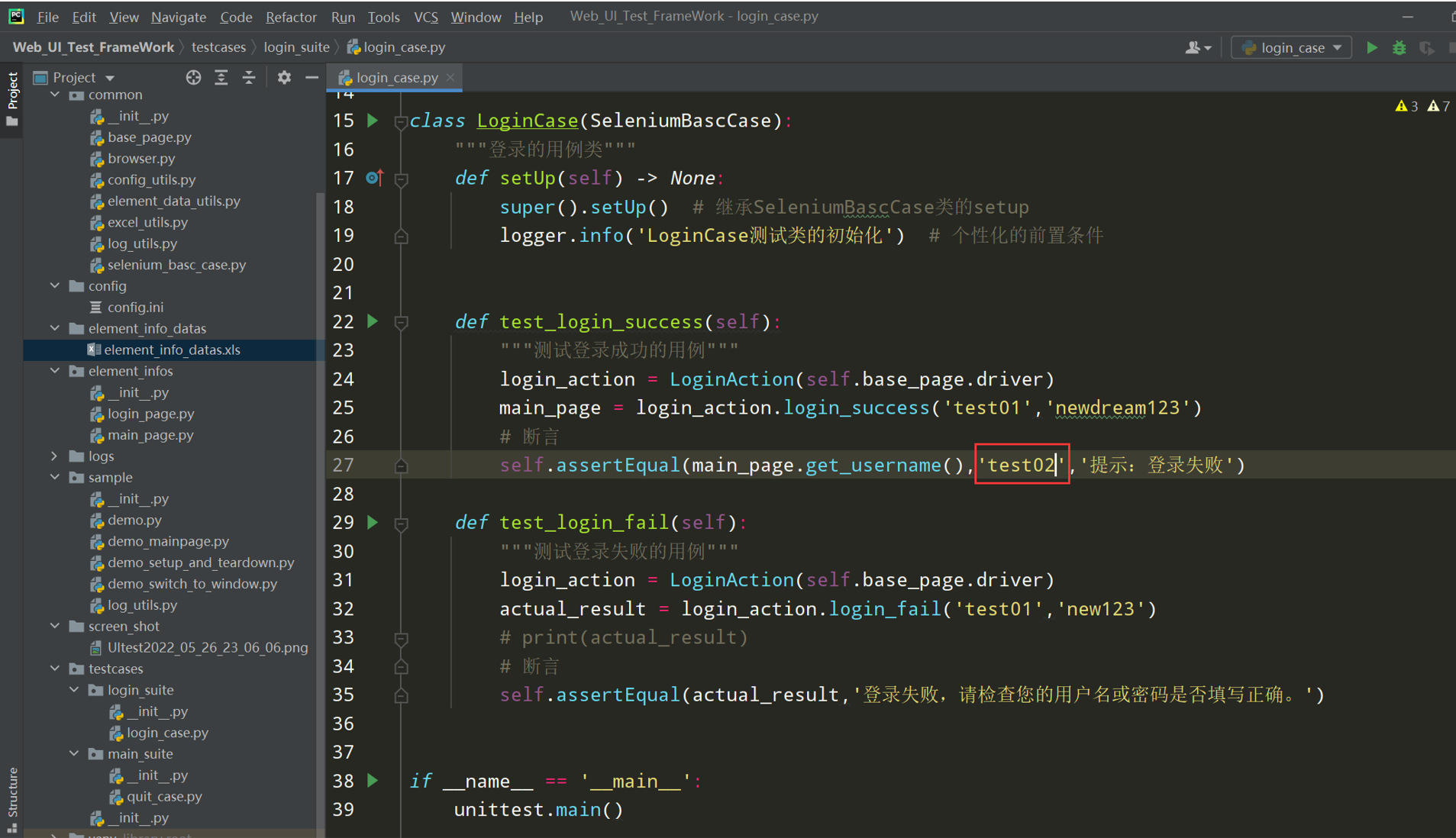
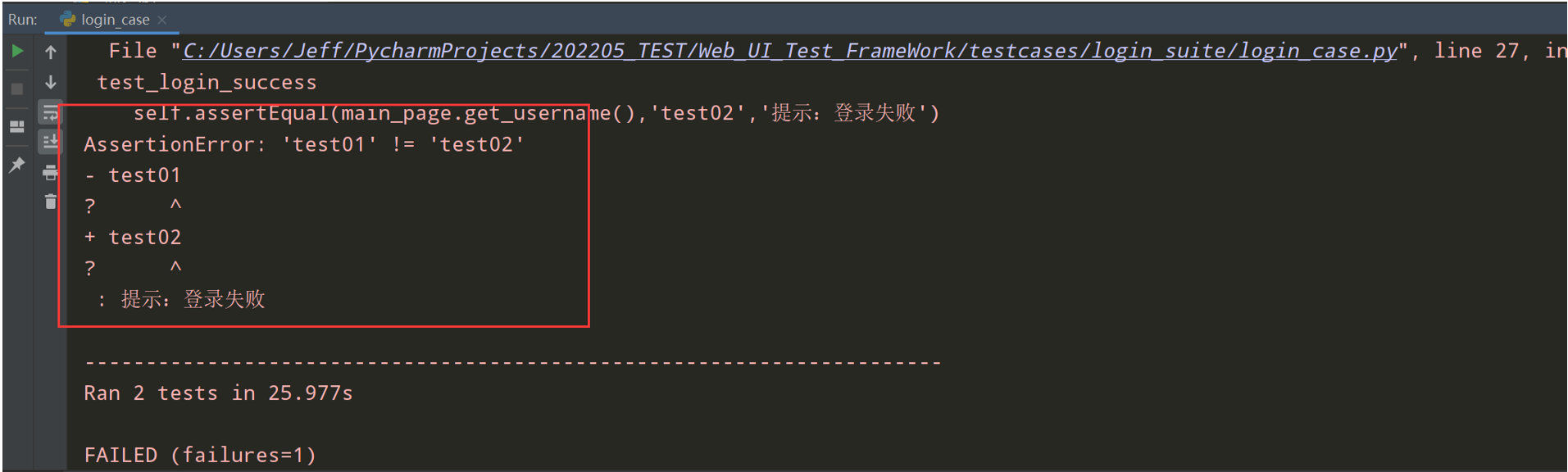
我们上报问题的话,只能上报错误问题2,因为问题1是我们测试框架的问题
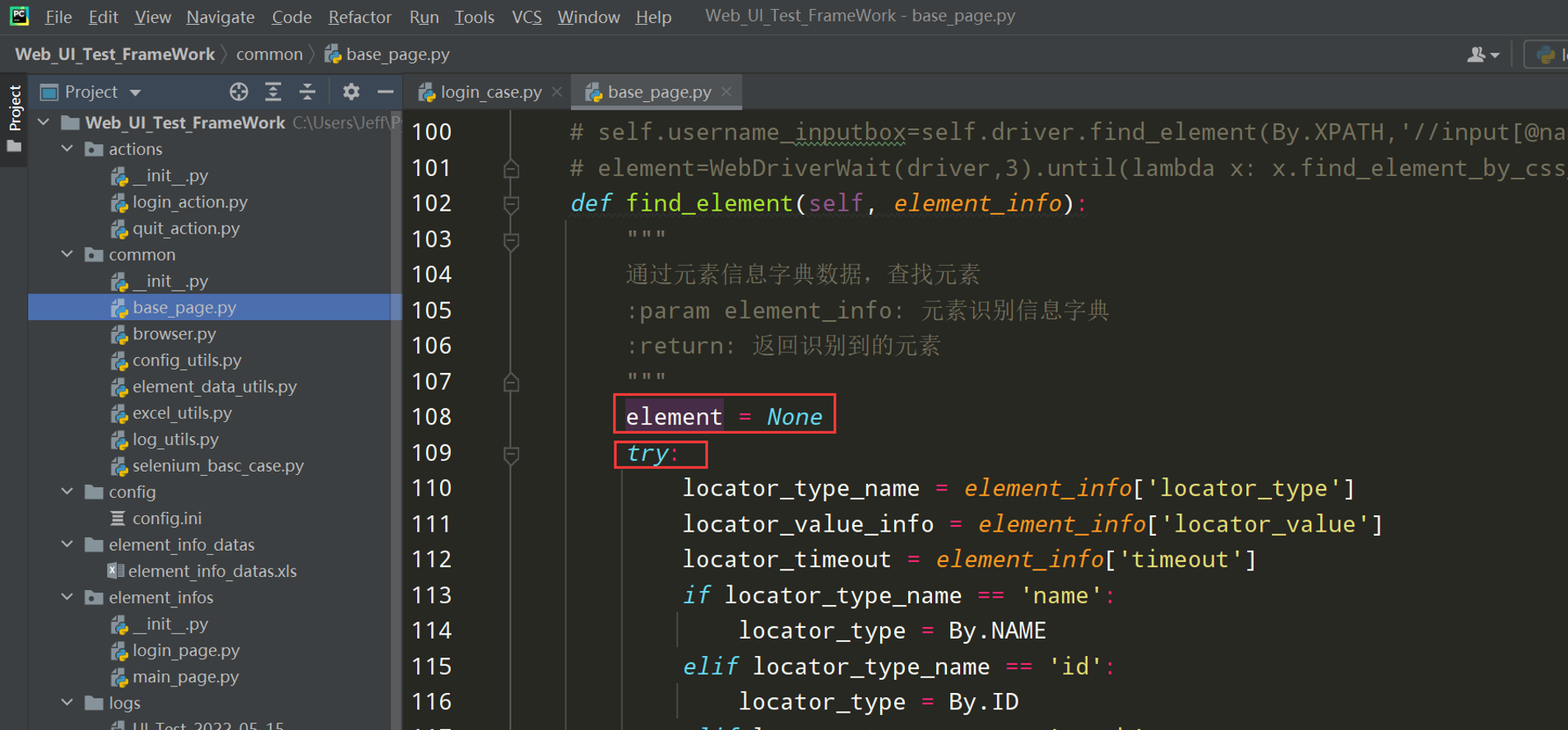
步骤2:在BasePage()类中元素识别添加异常处理
问题1中元素识别失败的处理;添加异常处理的日志
在base_page.py文件中添加异常处理的日志
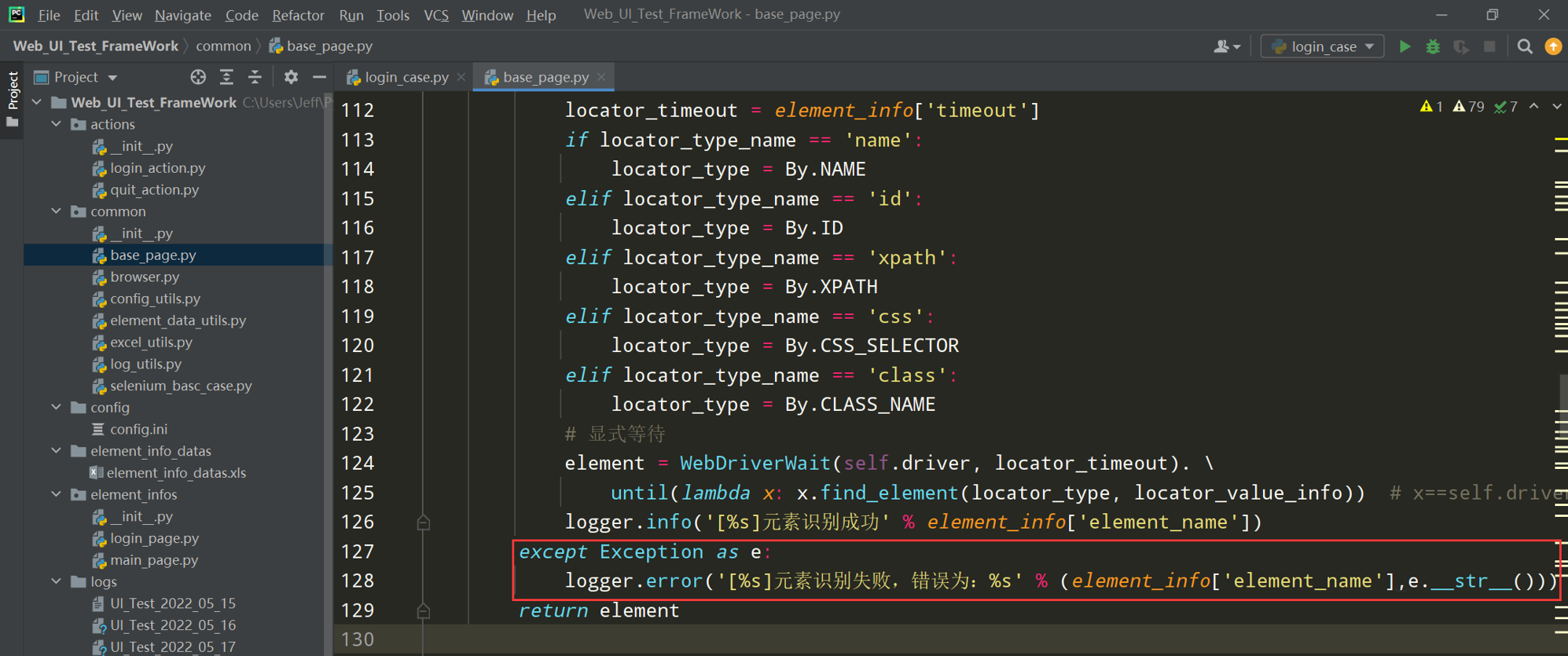
注:在except中异常日志要用logger.error(‘*****’)
执行结果如下:
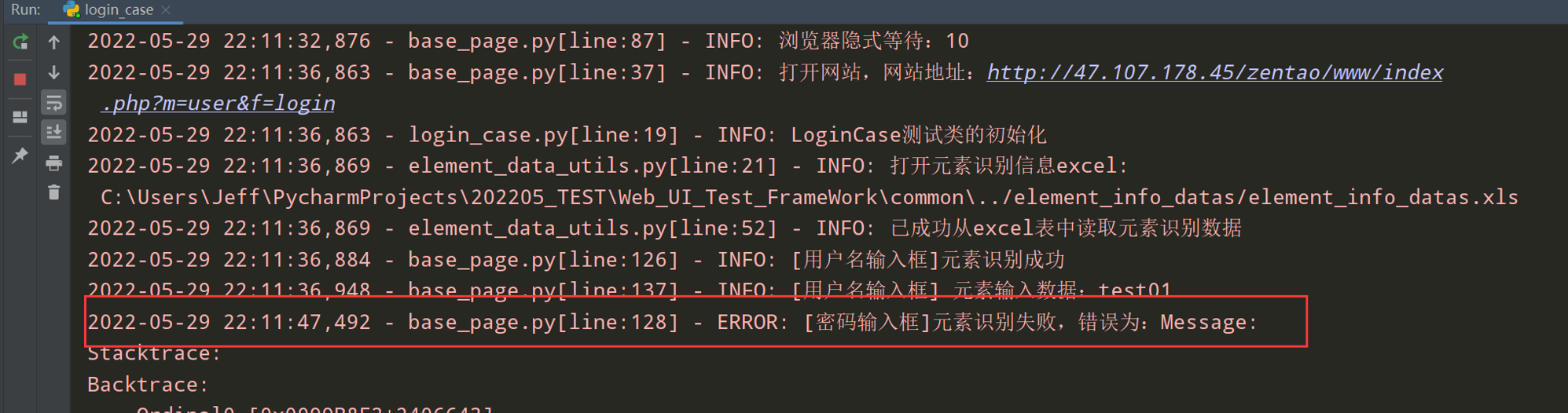
步骤3:登录失败的提示信息变更,需手动验证是否为问题
先把元素识别错误去掉,改为正确的数据,在登录成功的方法前面加上AA,不执行,手工登录禅道,输入错误的密码,让错误提示变一下;执行代码时会出错,这属于误报,需要手工确认一下是否为bug;
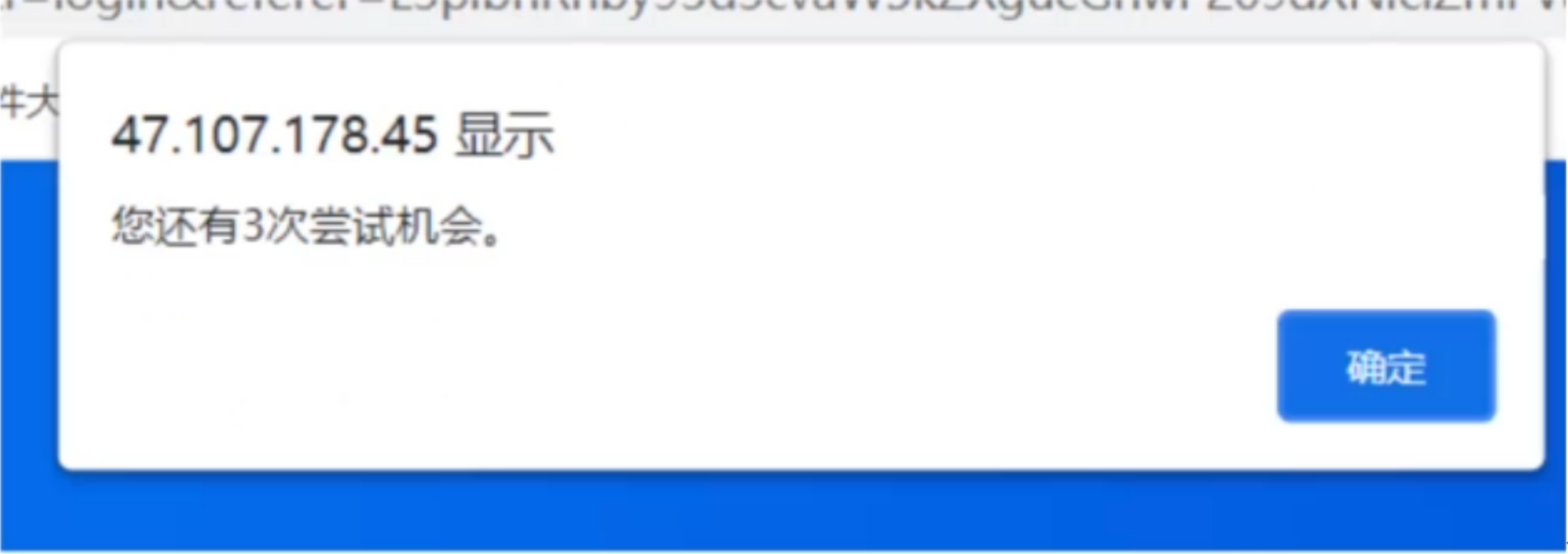
输入错误的密码,错误提示调整为如下图中所示

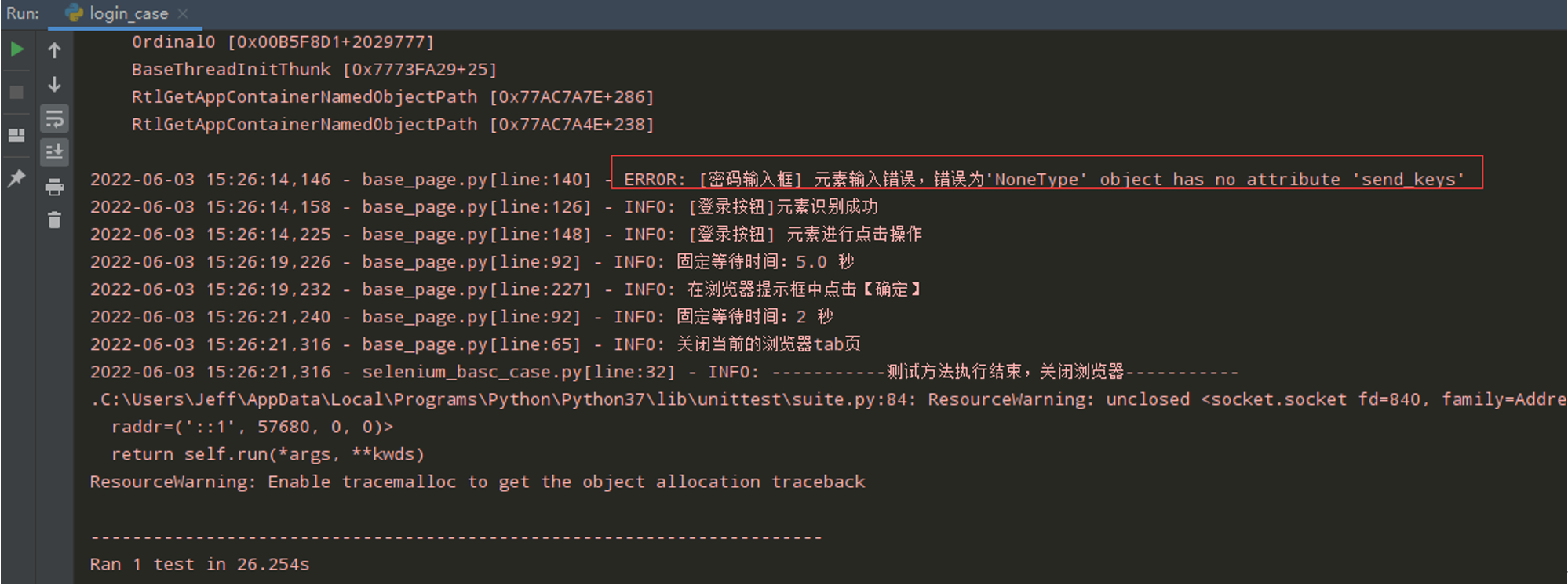
步骤4:在元素操作里面添加异常日志

代码示例:
"""元素的操作""" def input(self,element_info,content): """元素输入操作""" try: element = self.find_element(element_info) element.send_keys(content) logger.info('[%s]元素输入数据: %s' %(element_info['element_name'], content) ) except Exception as e: logger.error('[%s] 元素输入错误,错误为%s' % ( element_info['element_name'], e.__str__())) def click(self,element_info): """元素点击操作""" try: element = self.find_element(element_info) element.click() logger.info('[%s]元素进行点击操作' % element_info['element_name']) except Exception as e: logger.error('[%s] 元素点击操作失败,原因为%s' % ( element_info['element_name'], e.__str__()))
把元素信息excel表中的定位值去掉,测试执行一下login_case.py文件
步骤5:添加元素识别错误截图
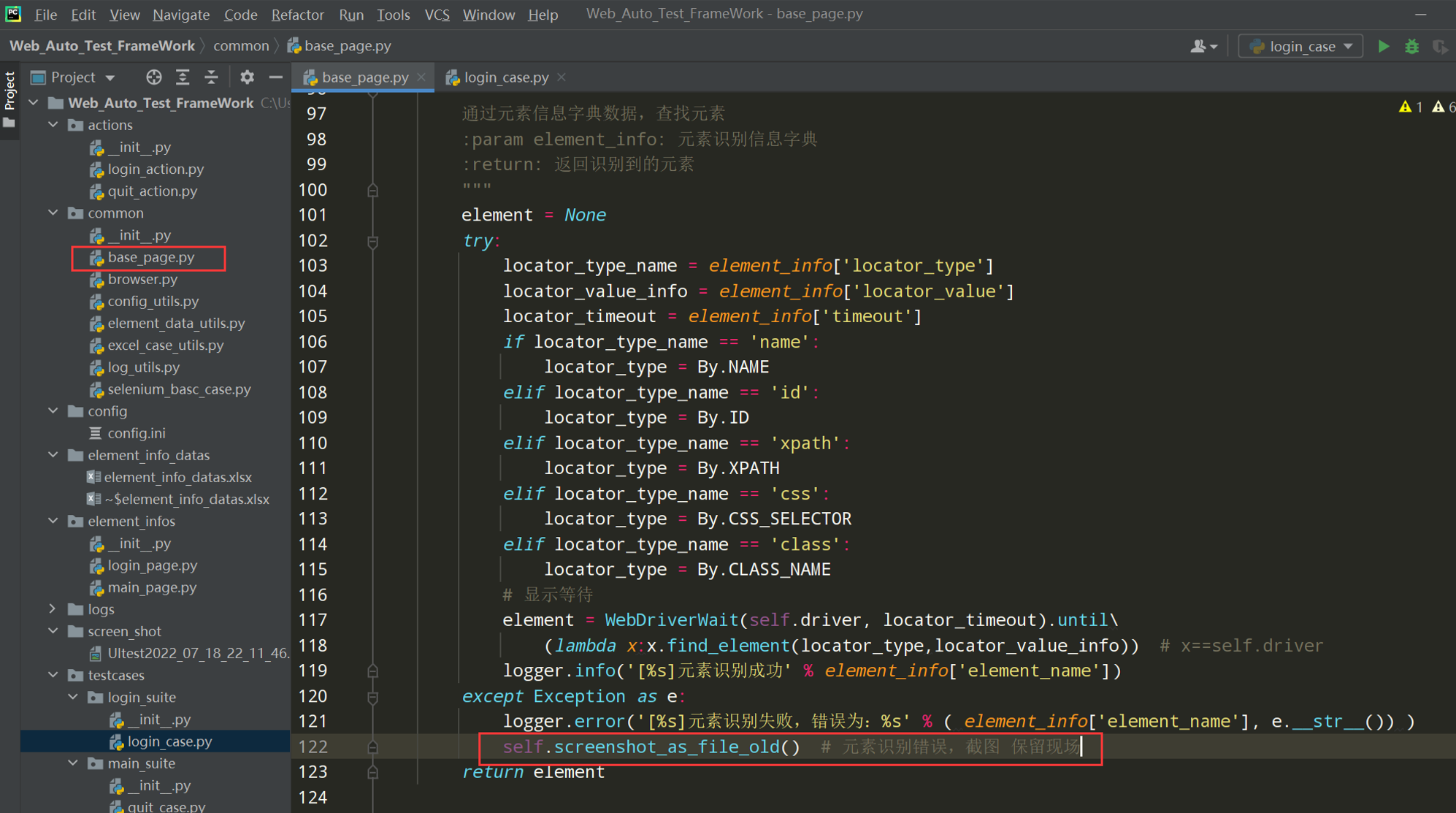
在base_page.py中添加错误截图
测试执行login_case.py文件
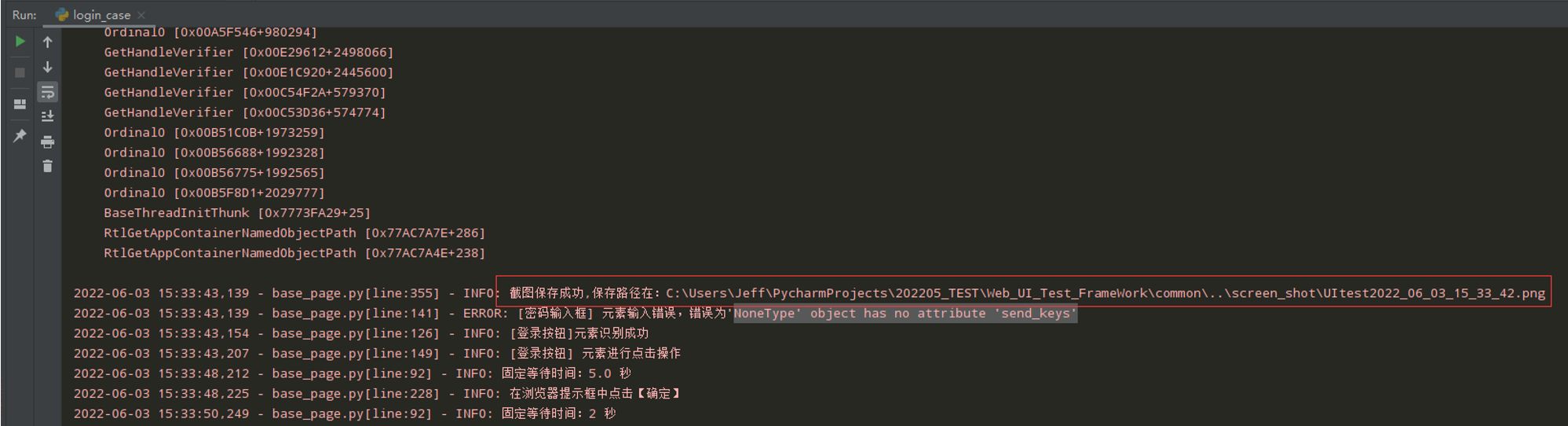
截图:
框架12—测试用例数据设计
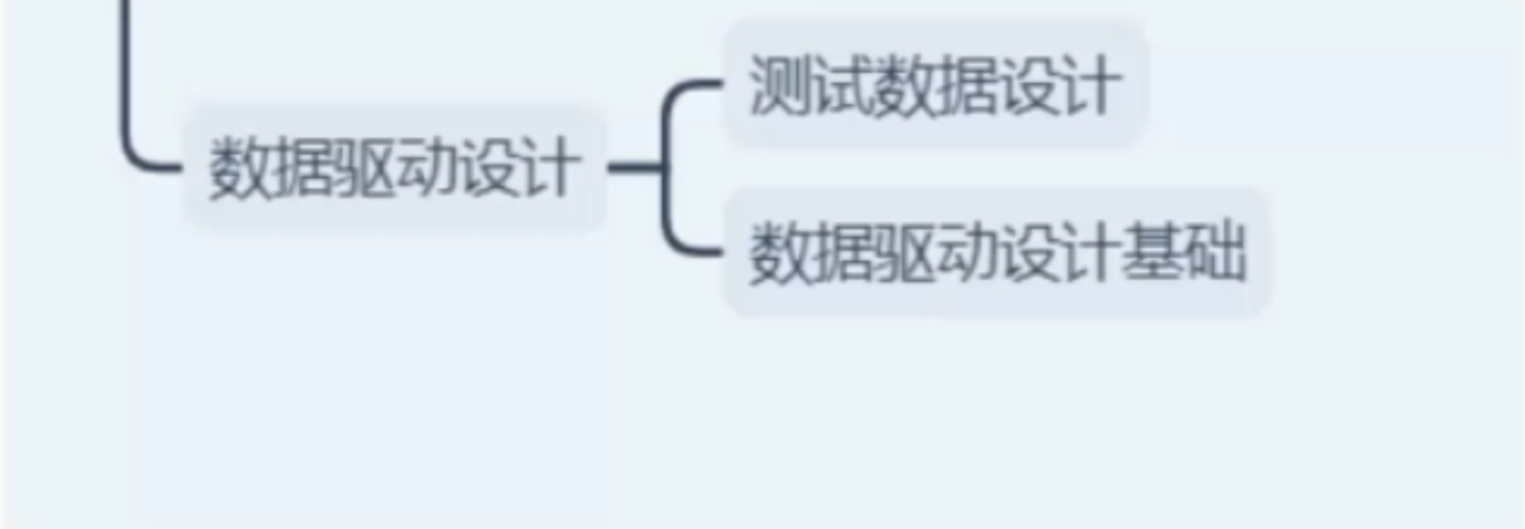
思路:
步骤1:测试用例分析
测试用例数据的关键信息:
前置条件、标题、步骤、是否执行、优先级、期望结果、输入数据、用例编写、所属模块、
测试用例的三大要素:测试用例名称、操作步骤、输入数据、预期结果;
哪些是测试数据需要分离的:
思考一个问题:每条测试用例输入的数据的参数个数是不一样的
步骤2:使用excel表设计测试用例
在项目的根目录下新建testcase_datas文件夹,并新建一个excel文件命名为testcase_data_infos.xlsx用来编写测试用例;
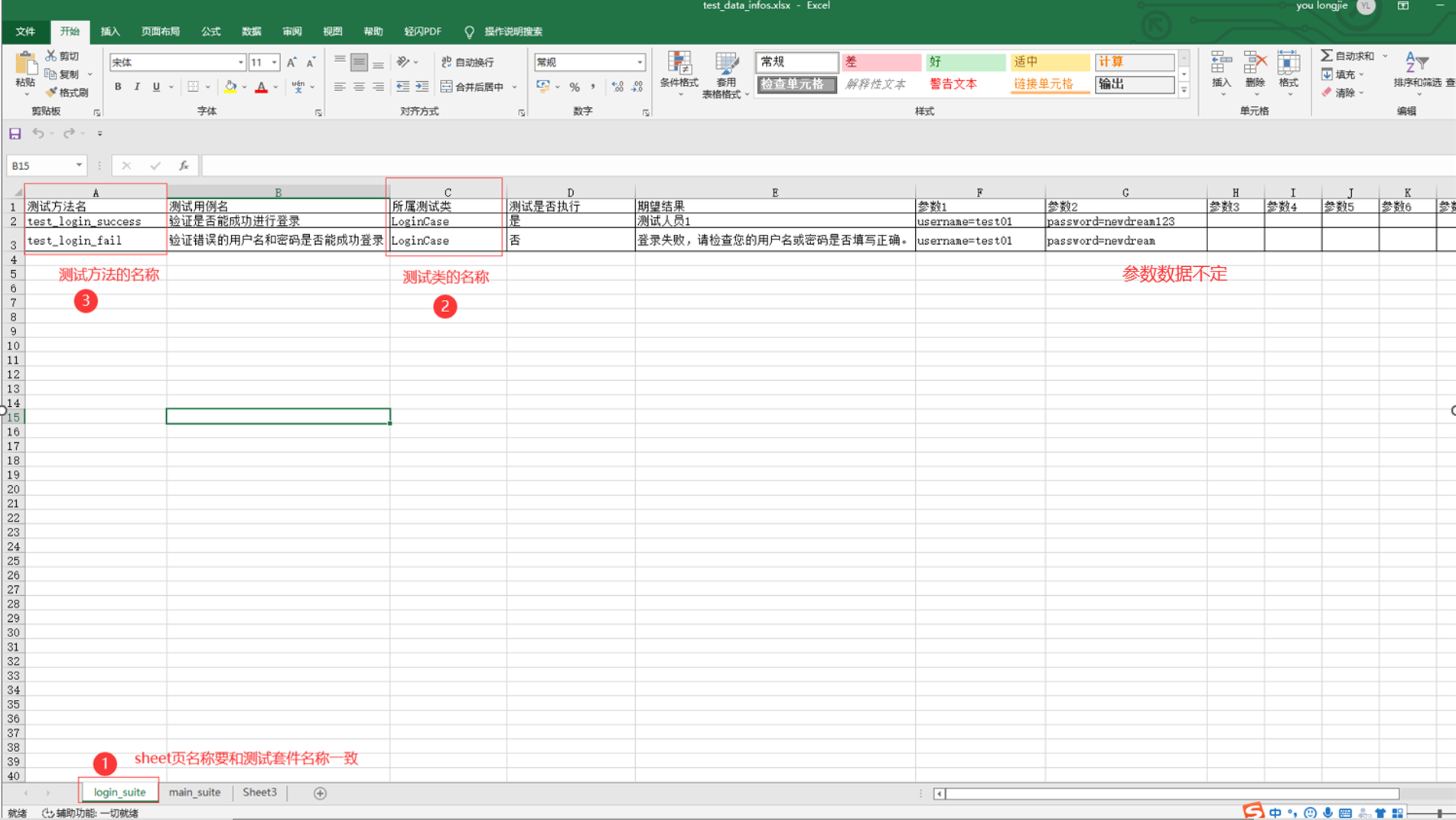
查看一下代码中的1、2、3是否一致
步骤3:把测试用例数据路径添加 配置文件中
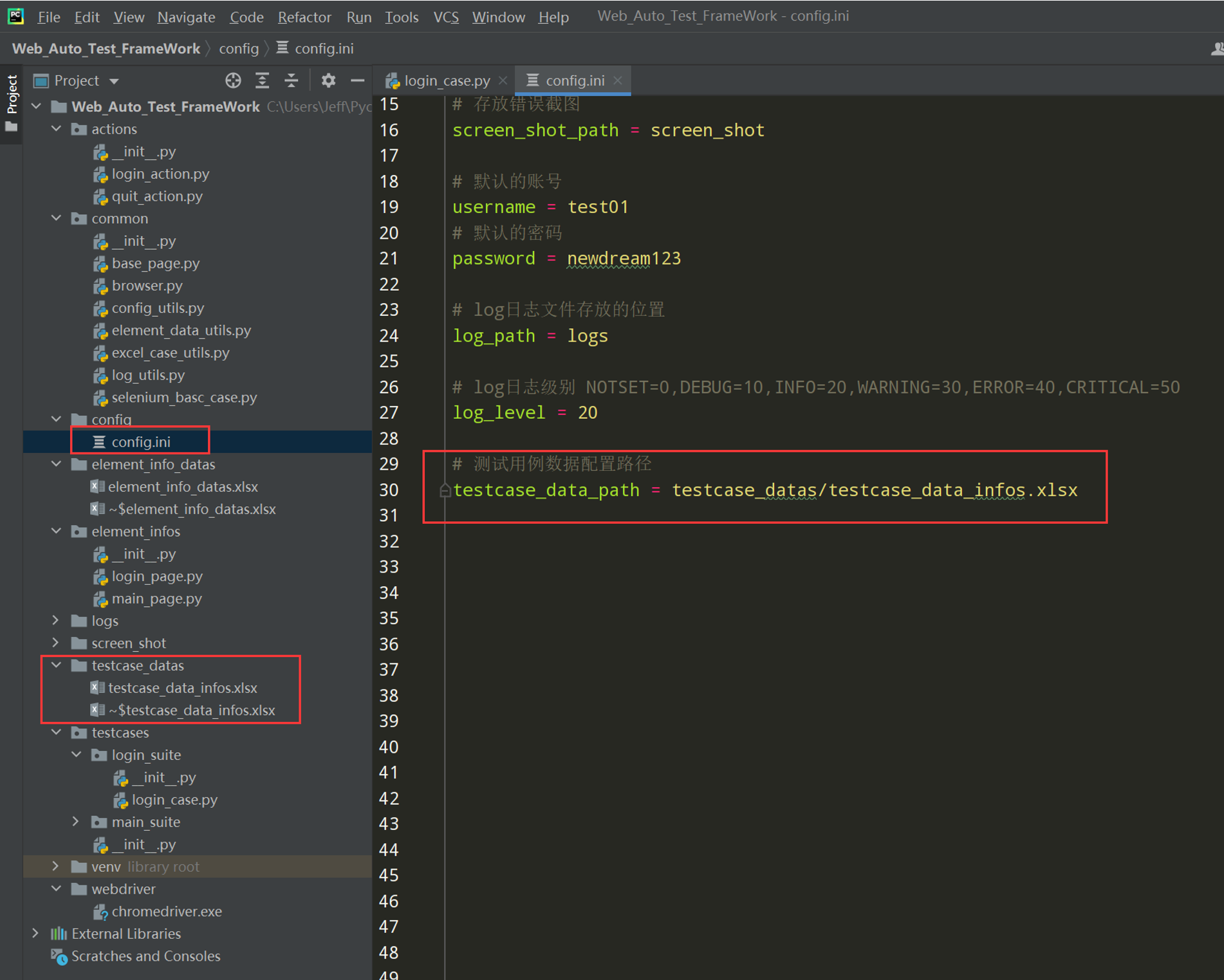
在config_utils.py文件中添加代码;如下图
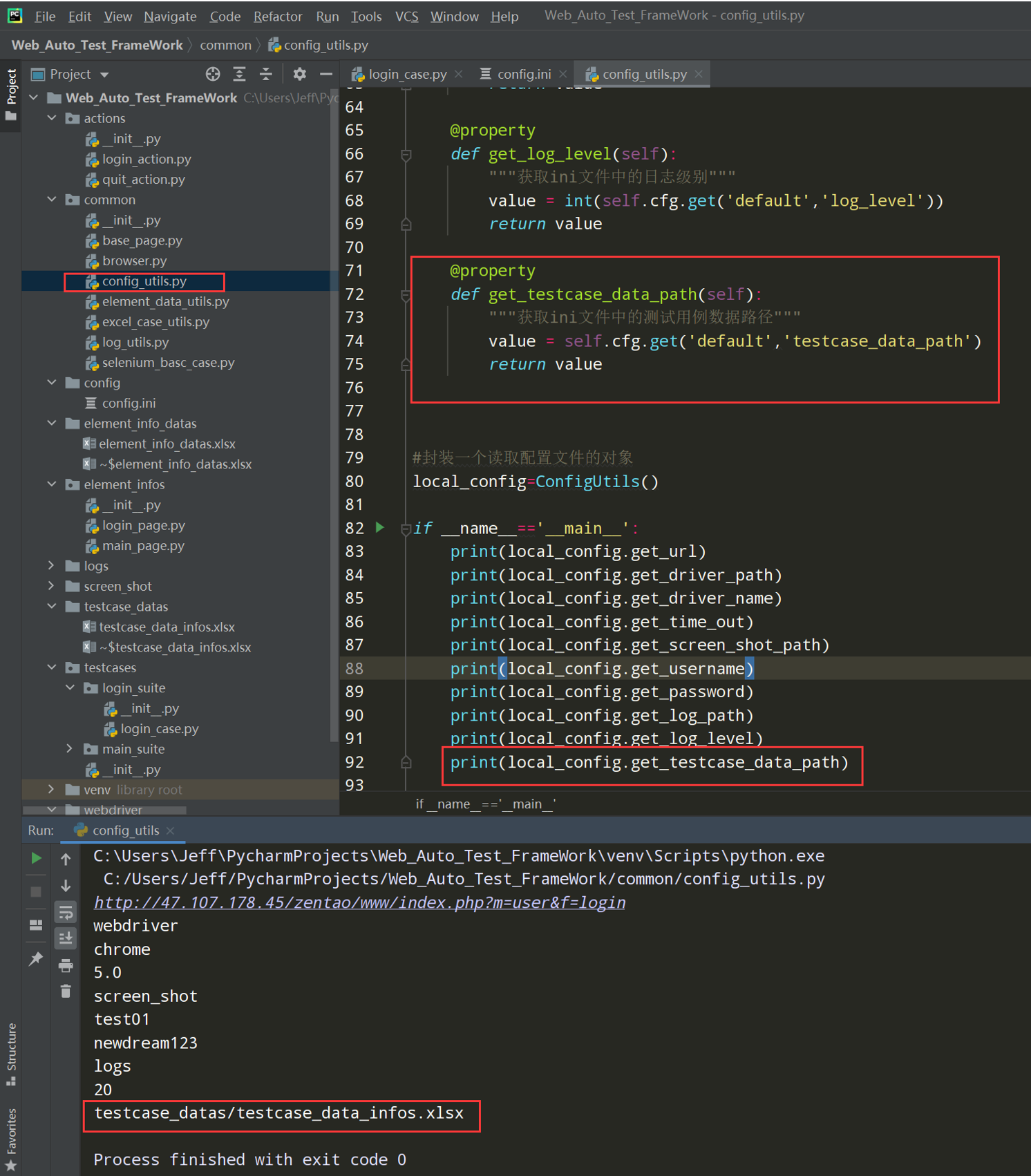
步骤4:先使用excel_case_utils.py文件测试一下读取数据(见框架09)
步骤5:创建testcase_data_utils.py-->TestCaseDataUtils类读取测试用例数据
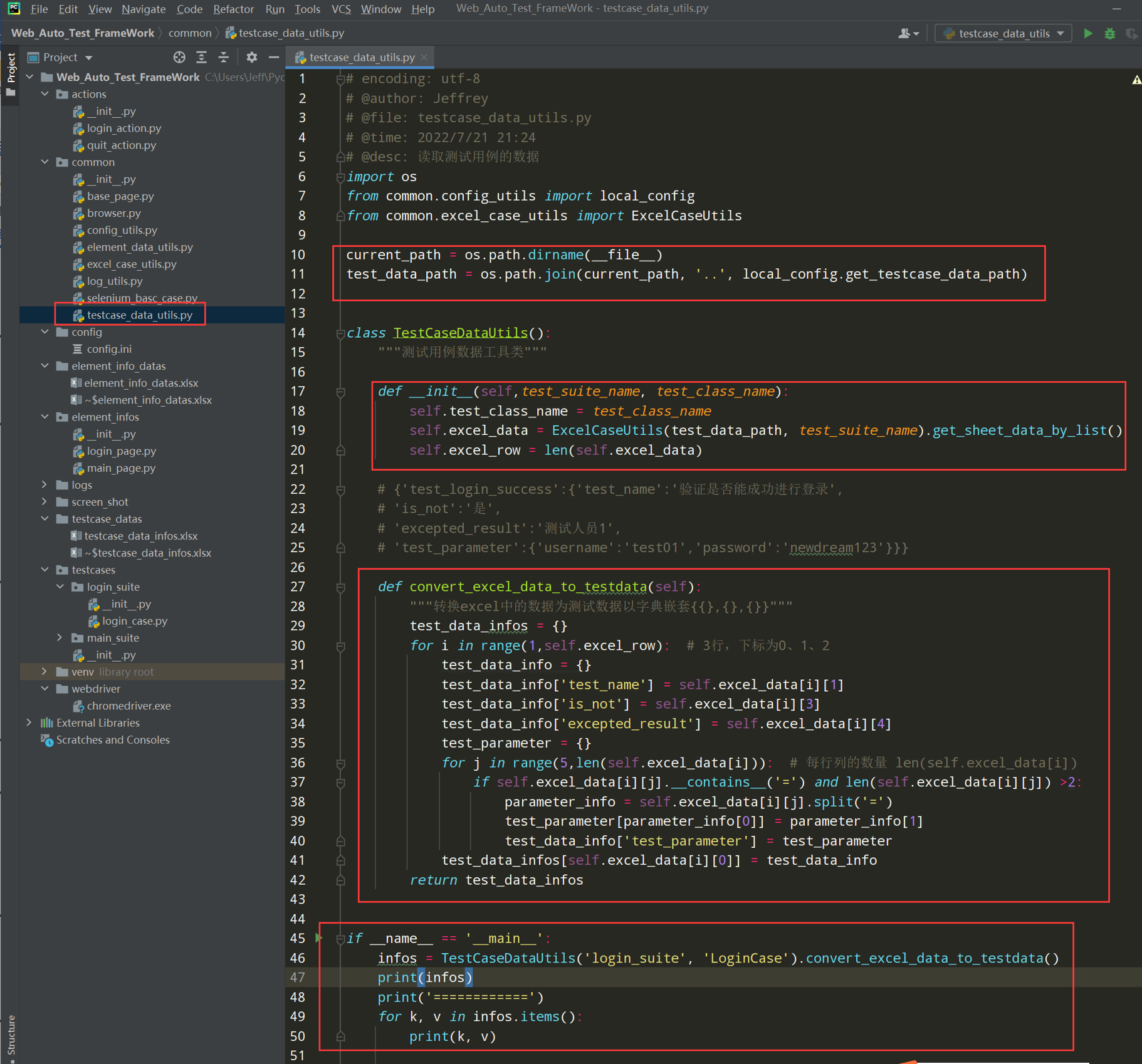
在common文件夹中创建testcase_data_utils.py文件,类名TestCaseDataUtils;
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: testcase_data_utils.py # @time: 2022/7/4 22:13 # @desc: 读取测试用例的数据 import os from common.config_utils import local_config from common.excel_case_utils import ExcelCaseUtils current_path = os.path.dirname(__file__) test_data_path = os.path.join(current_path, '..', local_config.get_testcase_data_path) class TestCaseDataUtils(): """测试用例数据工具类""" def __init__(self,test_suite_name, test_class_name): self.test_class_name = test_class_name self.excel_data = ExcelCaseUtils(test_data_path, test_suite_name).get_sheet_data_by_list() self.excel_row = len(self.excel_data) # {'test_login_success':{'test_name':'验证是否能成功进行登录', # 'is_not':'是', # 'excepted_result':'测试人员1', # 'test_parameter':{'username':'test01','password':'newdream123'}}} def convert_excel_data_to_testdata(self): """转换excel中的数据为测试数据以字典嵌套{{},{},{}}""" test_data_infos = {} for i in range(1,self.excel_row): # 3行,下标为0、1、2 test_data_info = {} test_data_info['test_name'] = self.excel_data[i][1] test_data_info['is_not'] = self.excel_data[i][3] test_data_info['excepted_result'] = self.excel_data[i][4] test_parameter = {} for j in range(5,len(self.excel_data[i])): # 每行列的数量 len(self.excel_data[i]) if self.excel_data[i][j].__contains__('=') and len(self.excel_data[i][j]) >2: parameter_info = self.excel_data[i][j].split('=') test_parameter[parameter_info[0]] = parameter_info[1] test_data_info['test_parameter'] = test_parameter test_data_infos[self.excel_data[i][0]] = test_data_info return test_data_infos if __name__ == '__main__': infos = TestCaseDataUtils('login_suite', 'LoginCase').convert_excel_data_to_testdata() print(infos) print('============') for k, v in infos.items(): print(k, v)
测试执行一下:

步骤6:对LoginCase测试类进行改造,从excel中导入测试数据
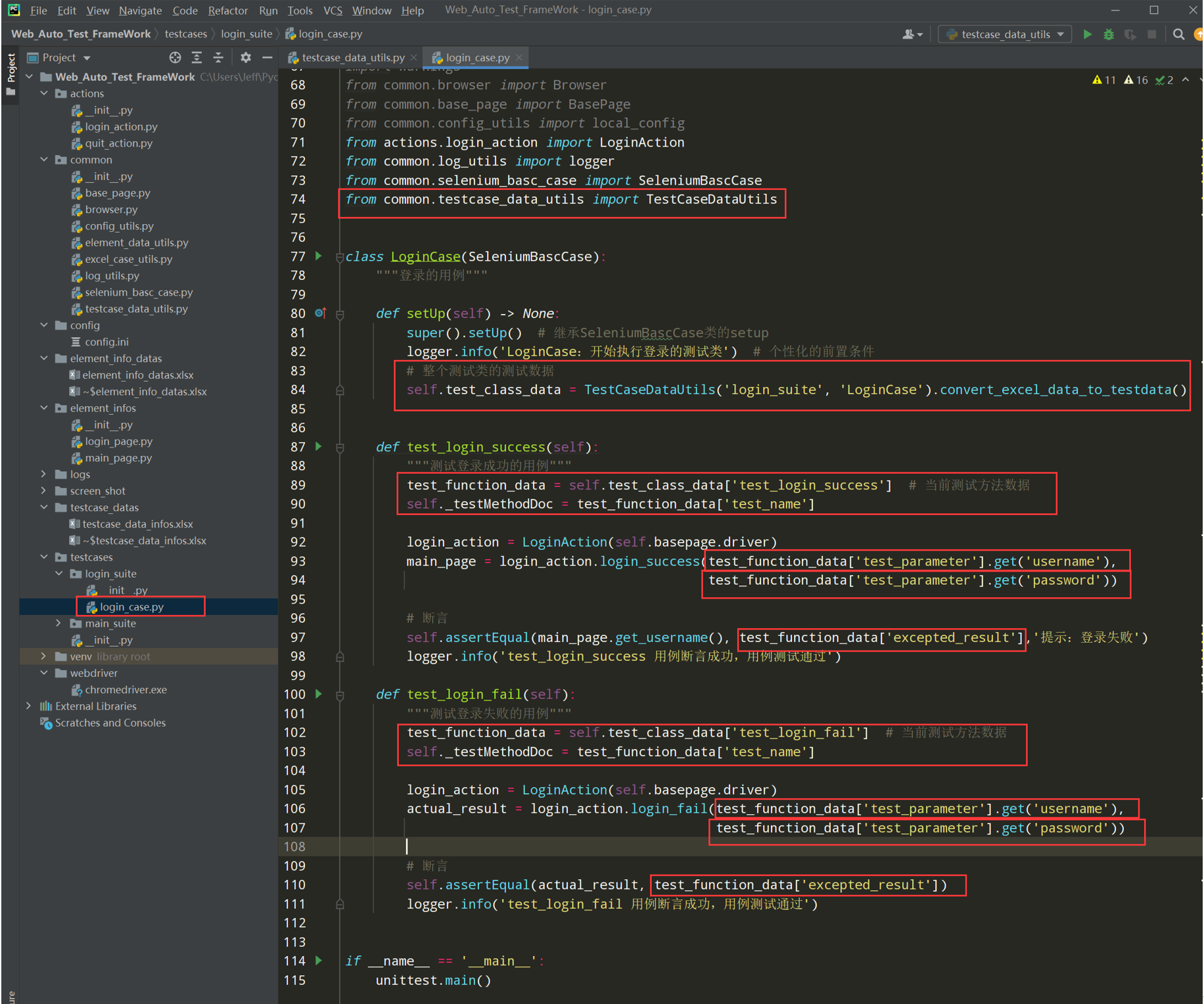
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: login_case.py # @time: 2022/7/19 22:28 # @desc: 登录的用例 import unittest import warnings from common.browser import Browser from common.base_page import BasePage from common.config_utils import local_config from actions.login_action import LoginAction from common.log_utils import logger from common.selenium_basc_case import SeleniumBascCase from common.testcase_data_utils import TestCaseDataUtils class LoginCase(SeleniumBascCase): """登录的用例""" def setUp(self) -> None: super().setUp() # 继承SeleniumBascCase类的setup logger.info('LoginCase:开始执行登录的测试类') # 个性化的前置条件 # 整个测试类的测试数据 self.test_class_data = TestCaseDataUtils('login_suite', 'LoginCase').convert_excel_data_to_testdata() def test_login_success(self): """测试登录成功的用例""" test_function_data = self.test_class_data['test_login_success'] # 当前测试方法数据 self._testMethodDoc = test_function_data['test_name'] login_action = LoginAction(self.basepage.driver) main_page = login_action.login_success(test_function_data['test_parameter'].get('username'), test_function_data['test_parameter'].get('password')) # 断言 self.assertEqual(main_page.get_username(), test_function_data['excepted_result'],'提示:登录失败') logger.info('test_login_success 用例断言成功,用例测试通过') def test_login_fail(self): """测试登录失败的用例""" test_function_data = self.test_class_data['test_login_fail'] # 当前测试方法数据 self._testMethodDoc = test_function_data['test_name'] login_action = LoginAction(self.basepage.driver) actual_result = login_action.login_fail(test_function_data['test_parameter'].get('username'), test_function_data['test_parameter'].get('password')) # 断言 self.assertEqual(actual_result, test_function_data['excepted_result']) logger.info('test_login_fail 用例断言成功,用例测试通过') if __name__ == '__main__': unittest.main()
对QuitCase测试类进行改造
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: quit_case.py # @time: 2022/7/19 23:01 # @desc: 在主页面点击退出按钮,退出到登录页面 import unittest import warnings from common.browser import Browser from common.base_page import BasePage from common.config_utils import local_config from actions.login_action import LoginAction from actions.quit_action import QuitAction from common.log_utils import logger from common.selenium_basc_case import SeleniumBascCase from common.testcase_data_utils import TestCaseDataUtils class QuitCase(SeleniumBascCase): """退出用例""" def setUp(self) -> None: super().setUp() # 继承SeleniumBascCase类的setup logger.info('QuitCase:开始执行退出的测试类') # 个性化的前置条件 # 整个测试类的测试数据 self.test_class_data = TestCaseDataUtils('main_suite', 'QuitCase').convert_excel_data_to_testdata() def test_quit(self): """测试退出的用例""" test_function_data = self.test_class_data['test_quit'] # 当前测试方法的数据 self._testMethodDoc = test_function_data['test_name'] login_action = LoginAction(self.basepage.driver) # 登录的动作对象 main_page = login_action.default_login() # 默认登录之后,返回主页面 quit_action = QuitAction(main_page.driver) # 退出的动作类 login_page = quit_action.quit() # 退出操作,并返回登录页面 actual_result = login_page.get_title() # 在登录页面获取标题 # 断言 self.assertEqual(actual_result.__contains__('用户登录'), True, '提示:test_quit用例不通过') logger.info('test_quit用例断言成功,用例测试通过') if __name__ == '__main__': unittest.main()
步骤7:执行代码,查看结果,验证是否成功
框架13—测试报告的设计和重新封装截图
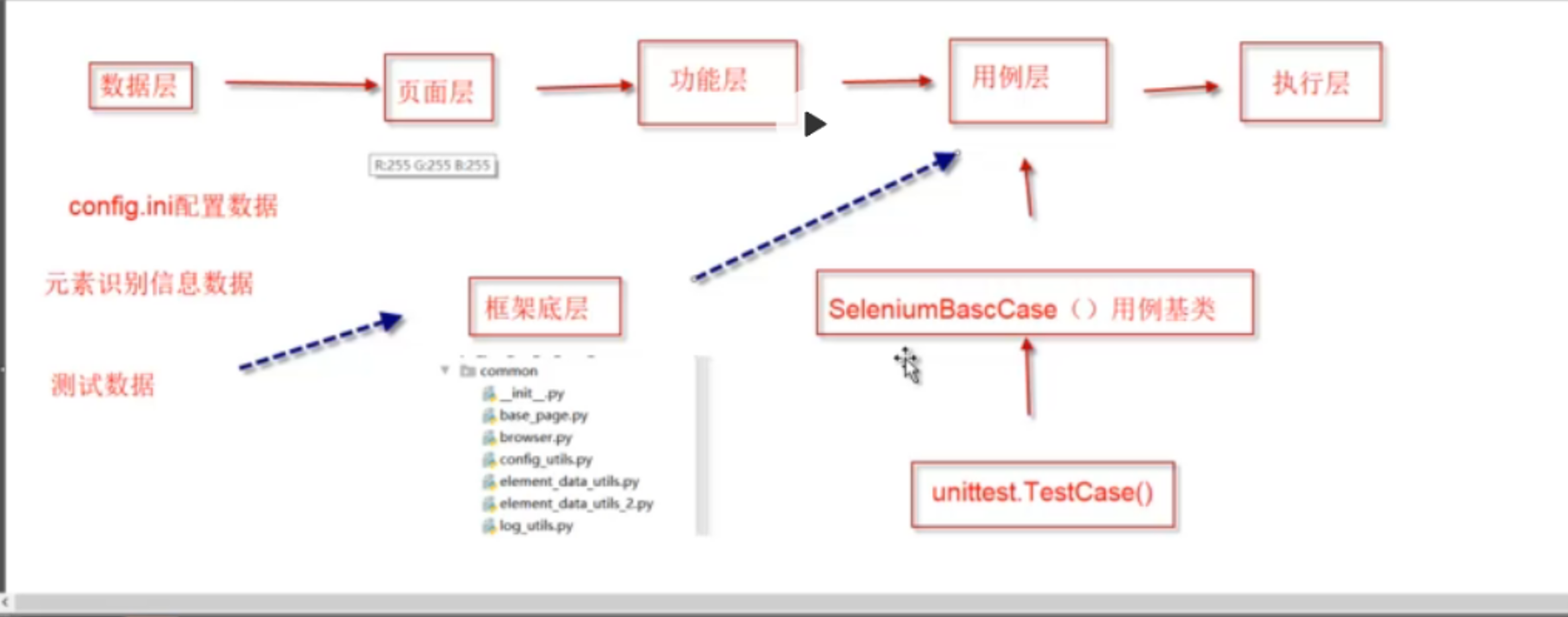
执行层代码编写
思路:
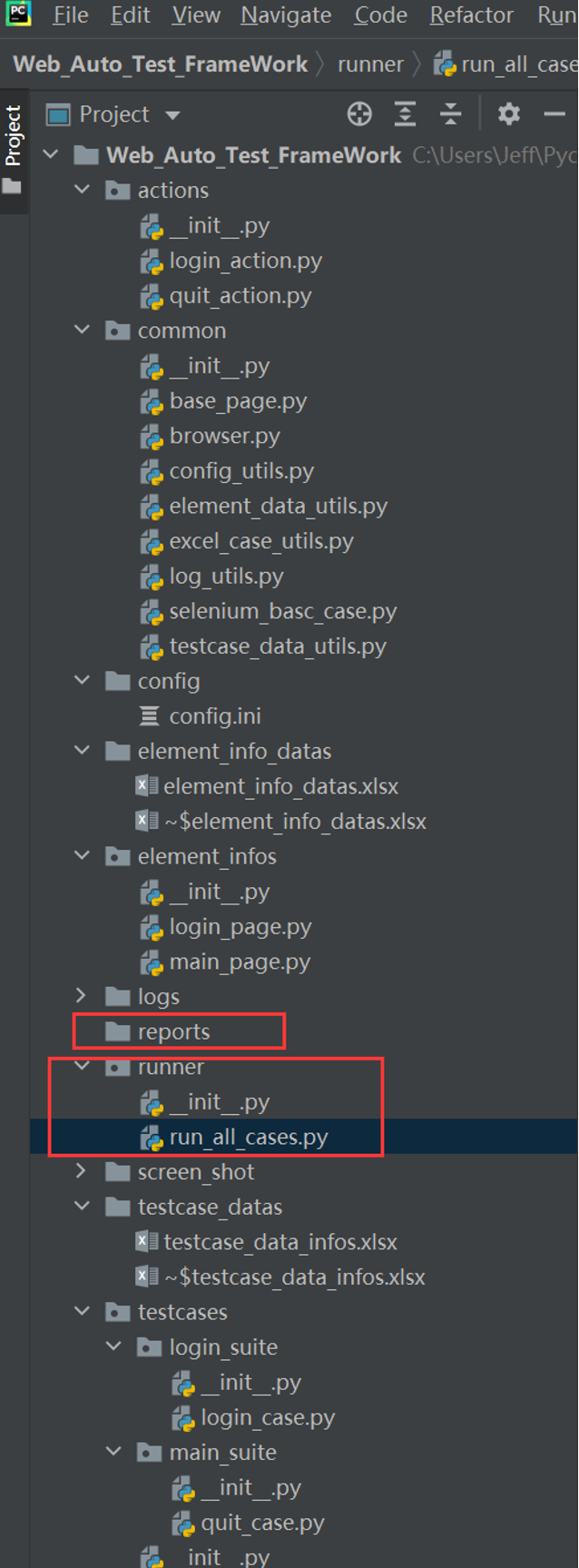
步骤1:在项目根目录下新建reports报告文件夹和runner执行层py文件夹
在runner执行层的py文件夹下新建run_all_cases.py文件
步骤2:在配置文件中添加信息
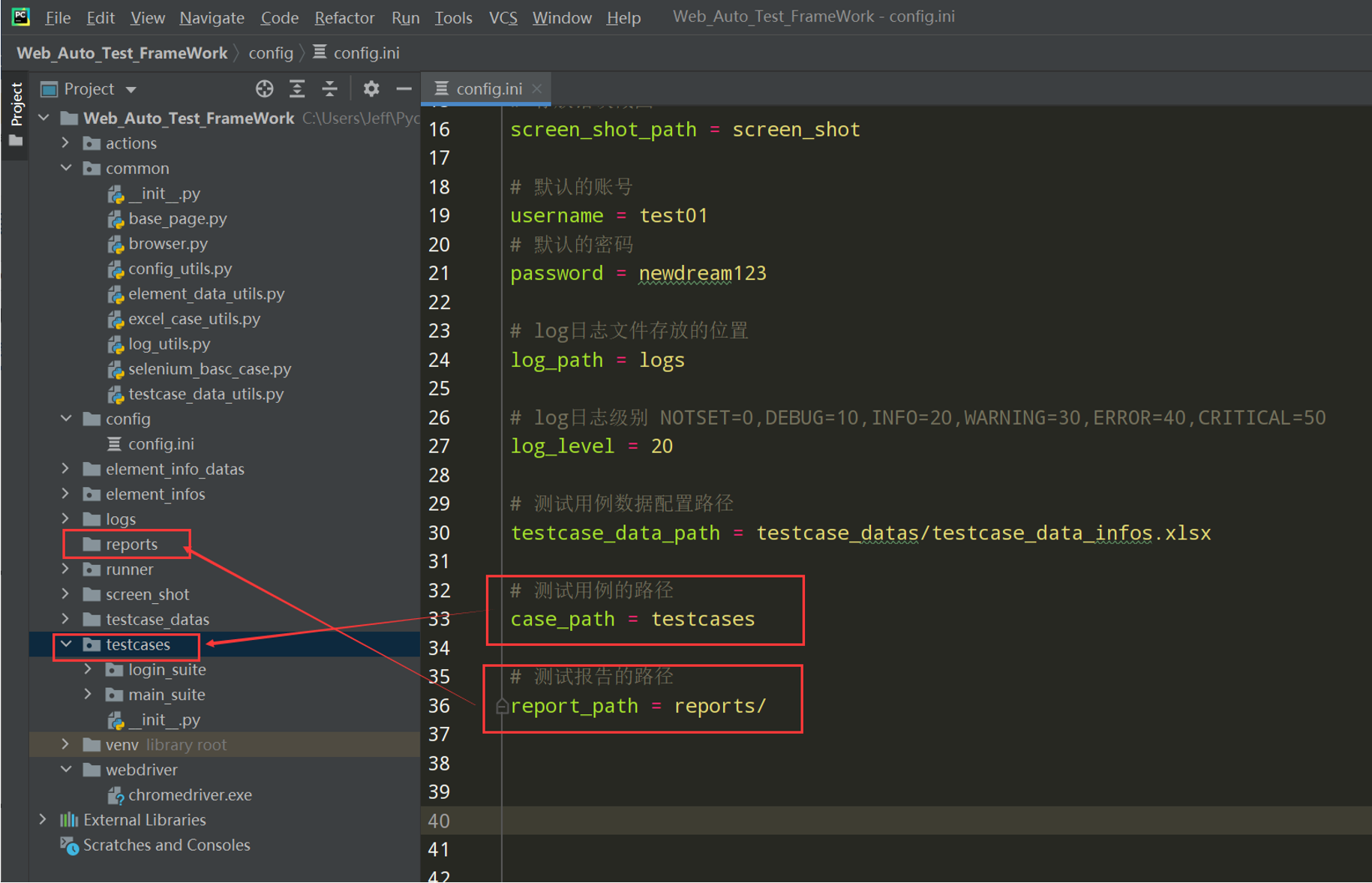
然后在config_utils.py中读取ini文件中的信息
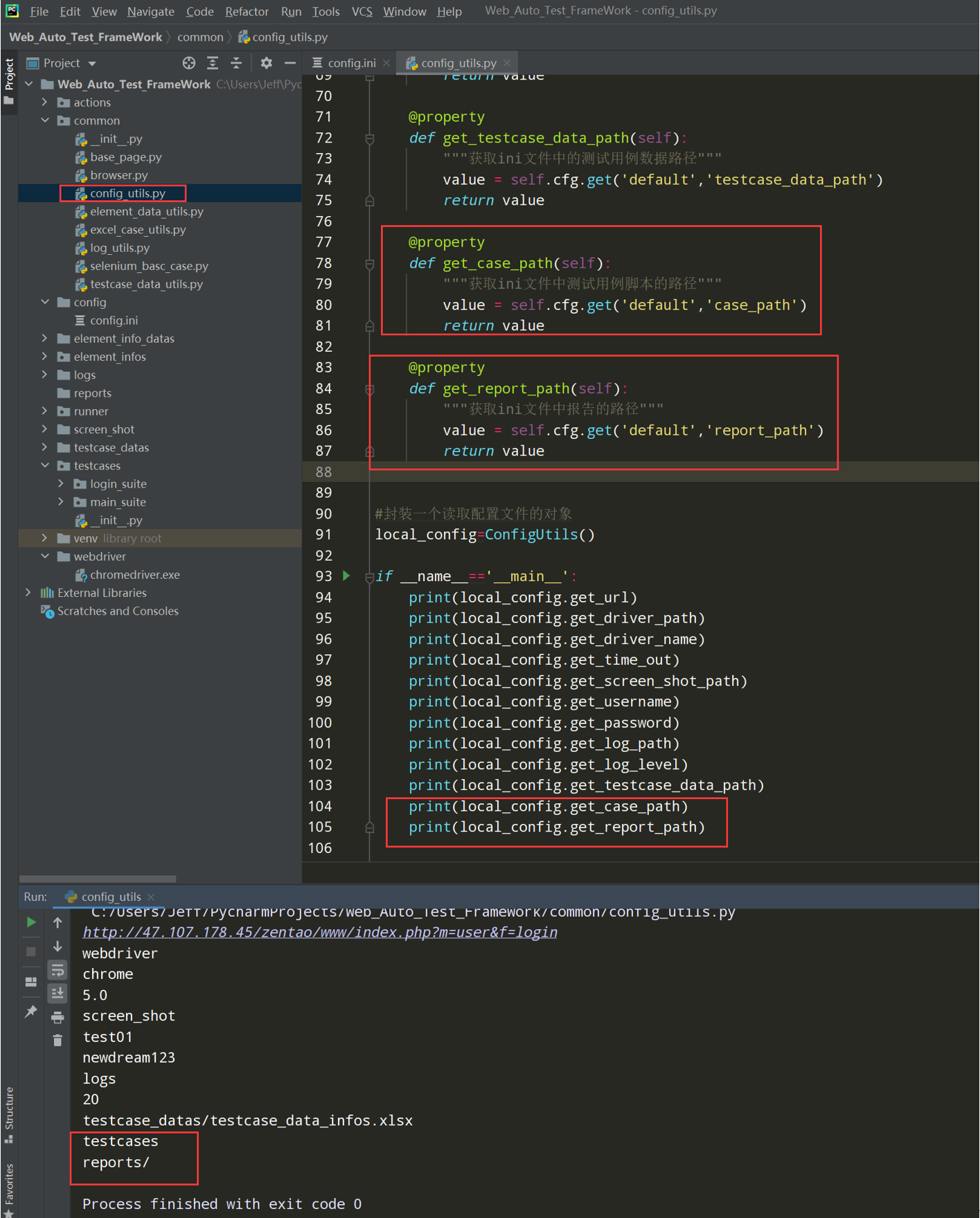
代码示例:
@property def get_case_path(self): """获取ini文件中测试用例脚本的路径""" value = self.cfg.get('default','case_path') return value @property def get_report_path(self): """获取ini文件中报告的路径""" value = self.cfg.get('default','report_path') return value
步骤3:在common中导入HTMLTestReportCN.py模块
HTMLTestReportCN.py模块分享地址
链接:https://pan.baidu.com/s/1PXqY_9L8OIMGRjELnRHBIw
提取码:0mmw
步骤4:编写执行层脚本run_all_cases.py
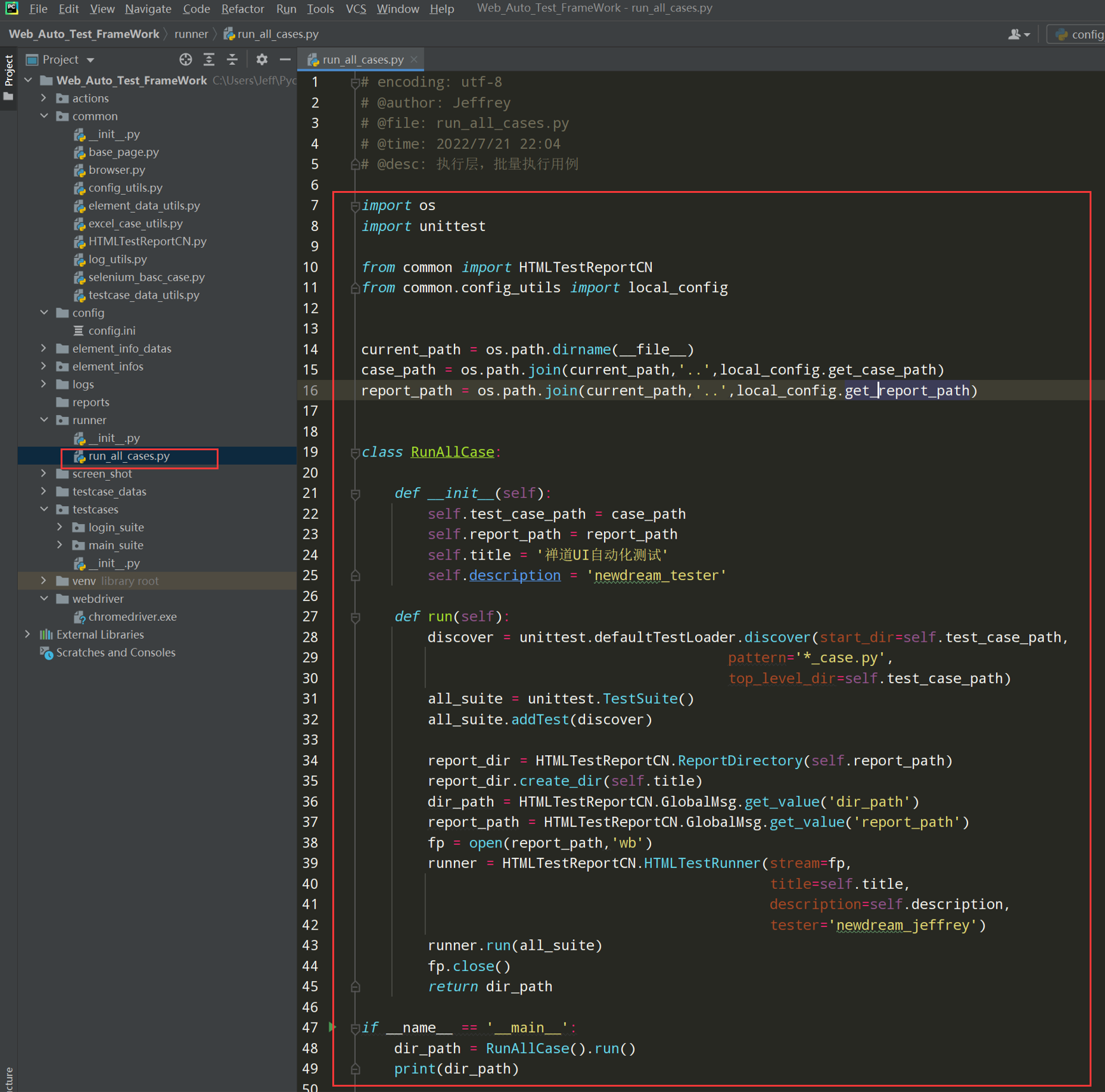
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: run_all_cases.py # @time: 2022/6/4 15:10 # @desc: 执行层,批量执行用例 import os import unittest from common import HTMLTestReportCN from common.config_utils import local_config current_path = os.path.dirname(__file__) case_path = os.path.join(current_path,'..',local_config.get_case_path) report_path = os.path.join(current_path,'..',local_config.get_report_path) class RunAllCase: def __init__(self): self.test_case_path = case_path self.report_path = report_path self.title = '禅道UI自动化测试' self.description = 'newdream_tester' def run(self): discover = unittest.defaultTestLoader.discover(start_dir=self.test_case_path, pattern='*_case.py', top_level_dir=self.test_case_path) all_suite = unittest.TestSuite() all_suite.addTest(discover) report_dir = HTMLTestReportCN.ReportDirectory(self.report_path) report_dir.create_dir(self.title) dir_path = HTMLTestReportCN.GlobalMsg.get_value('dir_path') report_path = HTMLTestReportCN.GlobalMsg.get_value('report_path') fp = open(report_path,'wb') runner = HTMLTestReportCN.HTMLTestRunner(stream=fp, title=self.title, description=self.description, tester='newdream_jeffrey') runner.run(all_suite) fp.close() return dir_path if __name__ == '__main__': dir_path = RunAllCase().run() print(dir_path)
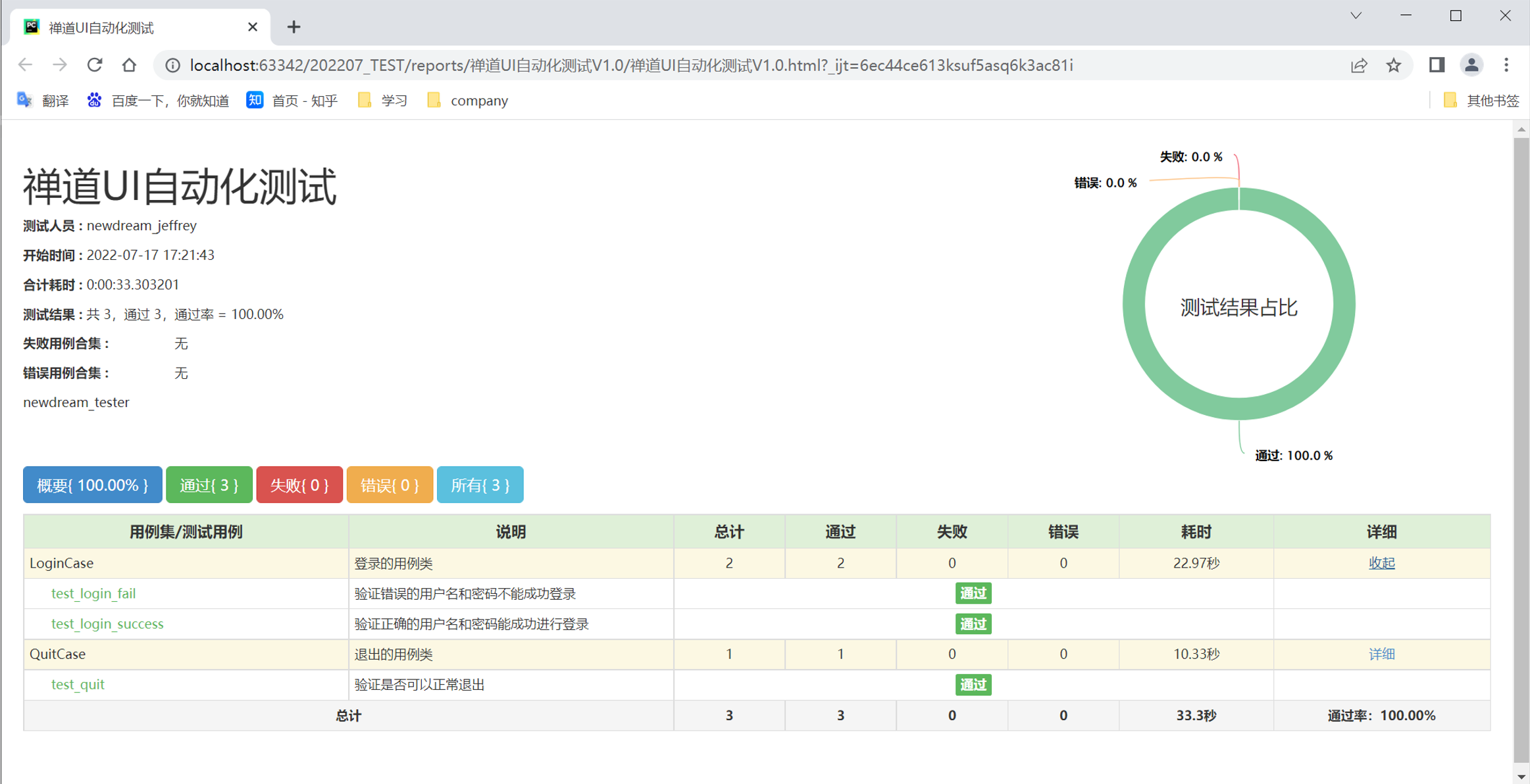
步骤5:执行run_all_cases.py查看结果
步骤6:在base_page.py文件中重新封装错误截图,在报告中添加截图
导包:from common import HTMLTestReportCN
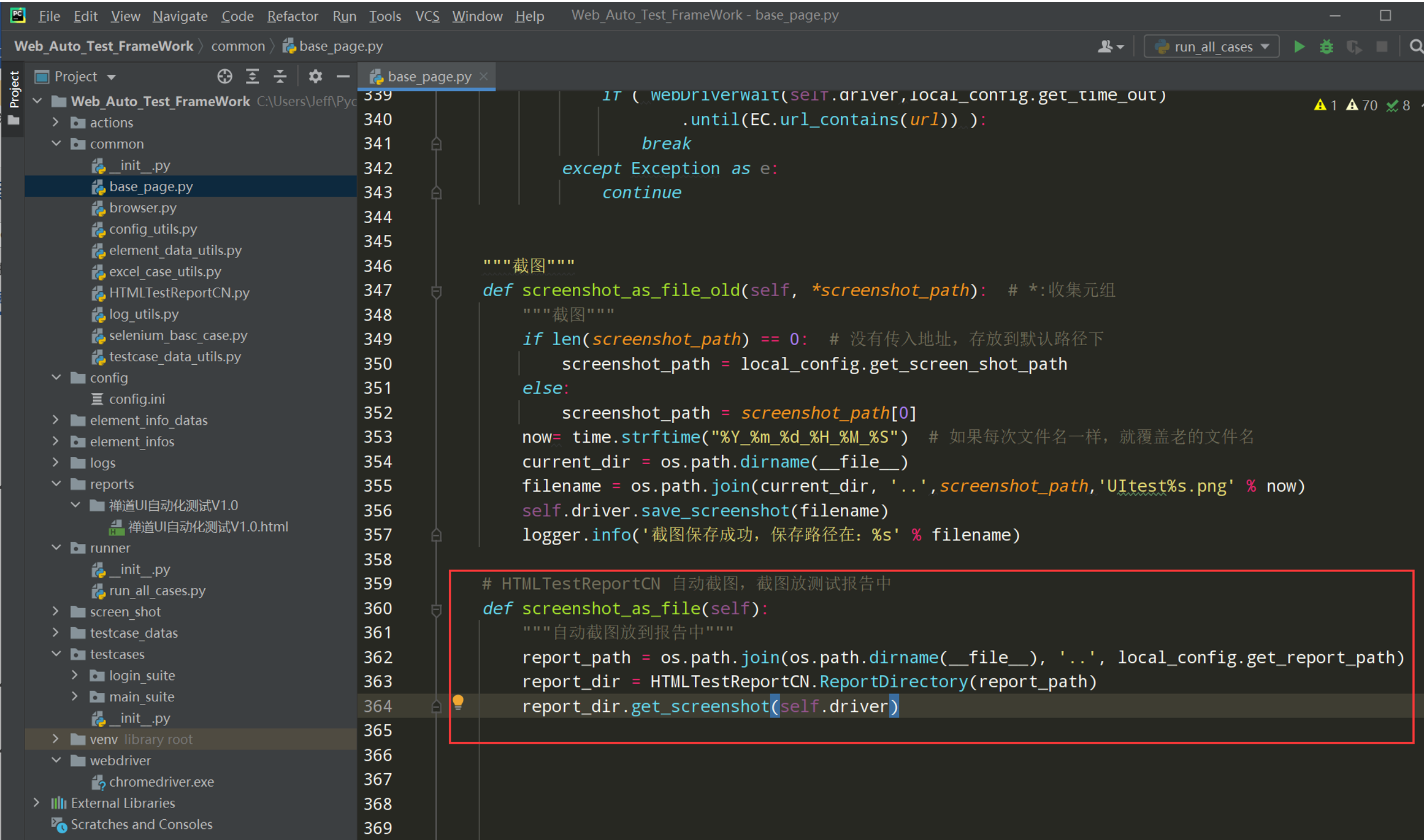
代码示例:
# HTMLTestReportCN 自动截图,截图放测试报告中 def screenshot_as_file(self): """自动截图放到报告中""" report_path = os.path.join(os.path.dirname(__file__), '..', local_config.get_report_path) report_dir = HTMLTestReportCN.ReportDirectory(report_path) report_dir.get_screenshot(self.driver)
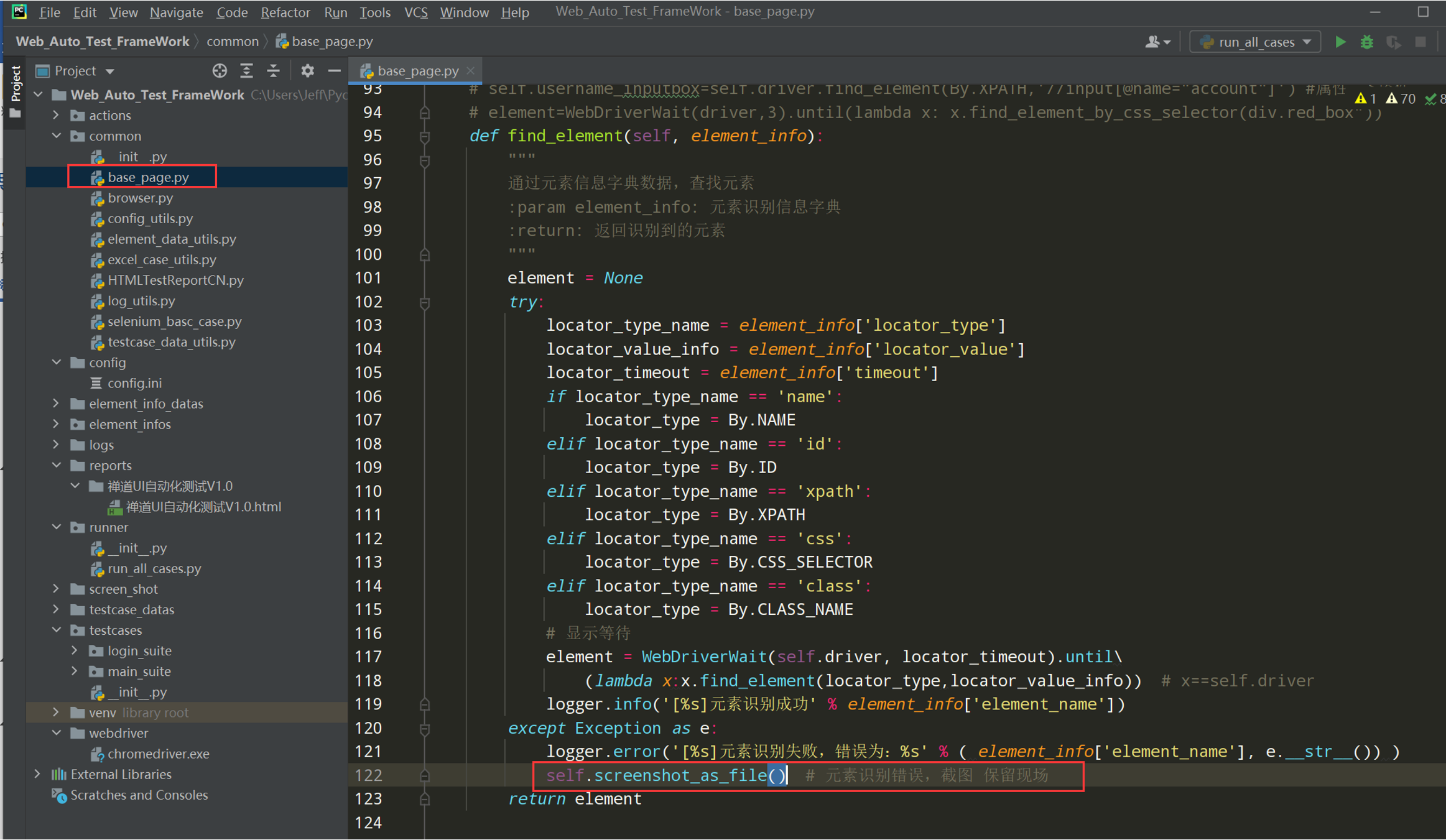
在find_element()方法中添加截图;
步骤7:元素识别错误,执行excel中元素识别信息,报错
备注:如果用例中的断言不加异常处理在后面的报告中可自动把错误的信息放到报告中
执行run_all_cases.py文件查看截图是否存放在测试报告中
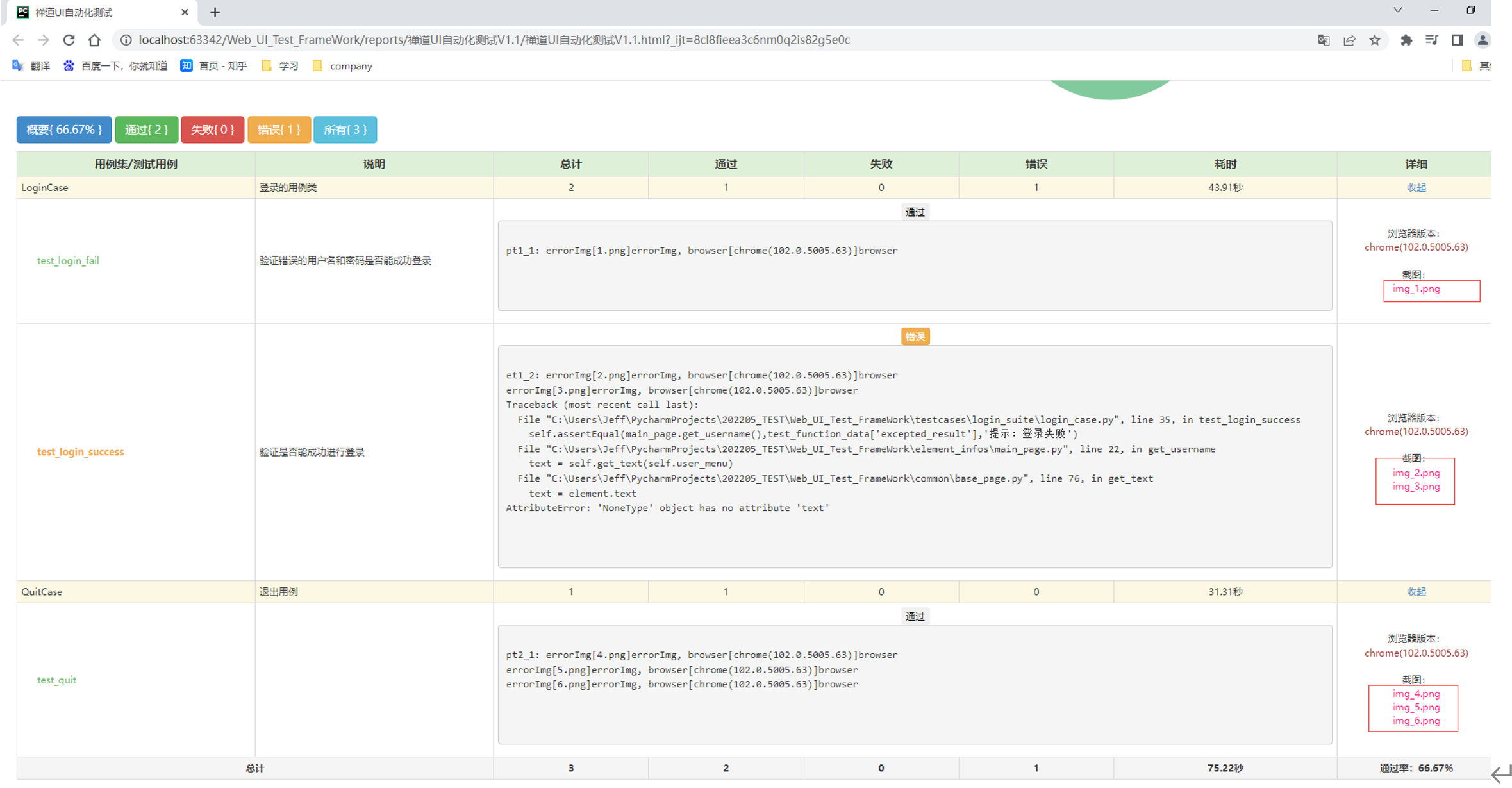
注:执行结束后把元素信息补充正常
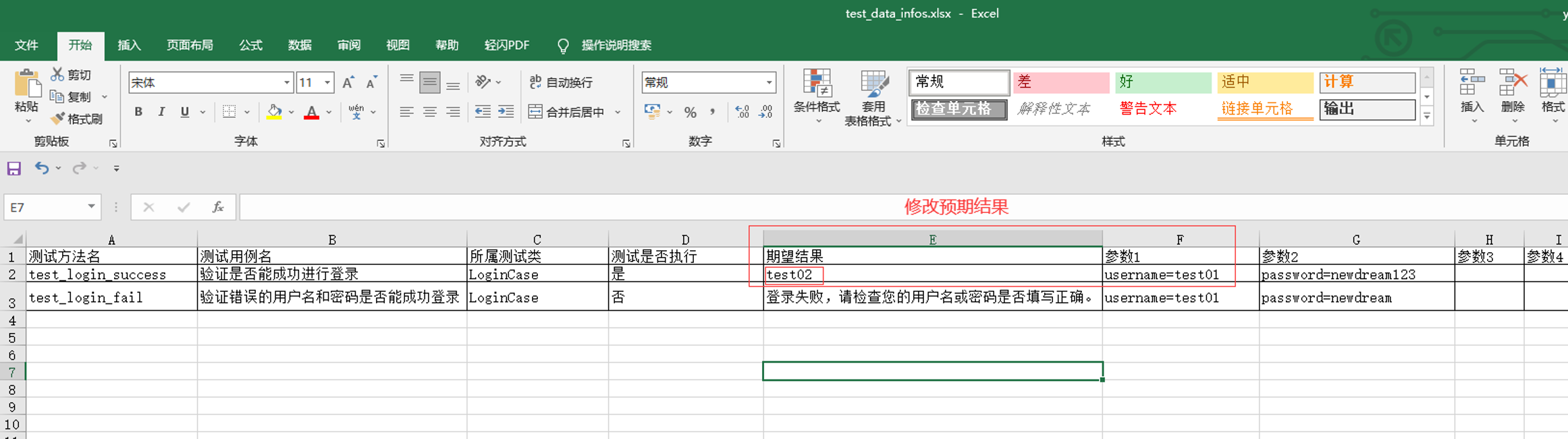
步骤8:修改测试用例预期结果数据,让断言报错,但没有截图,需要在SeleniumBascCase类在·中添加断言失败截图的方法;
备注:如果用例中的断言不加异常处理在后面的报告中可自动把错误的信息放到报告中
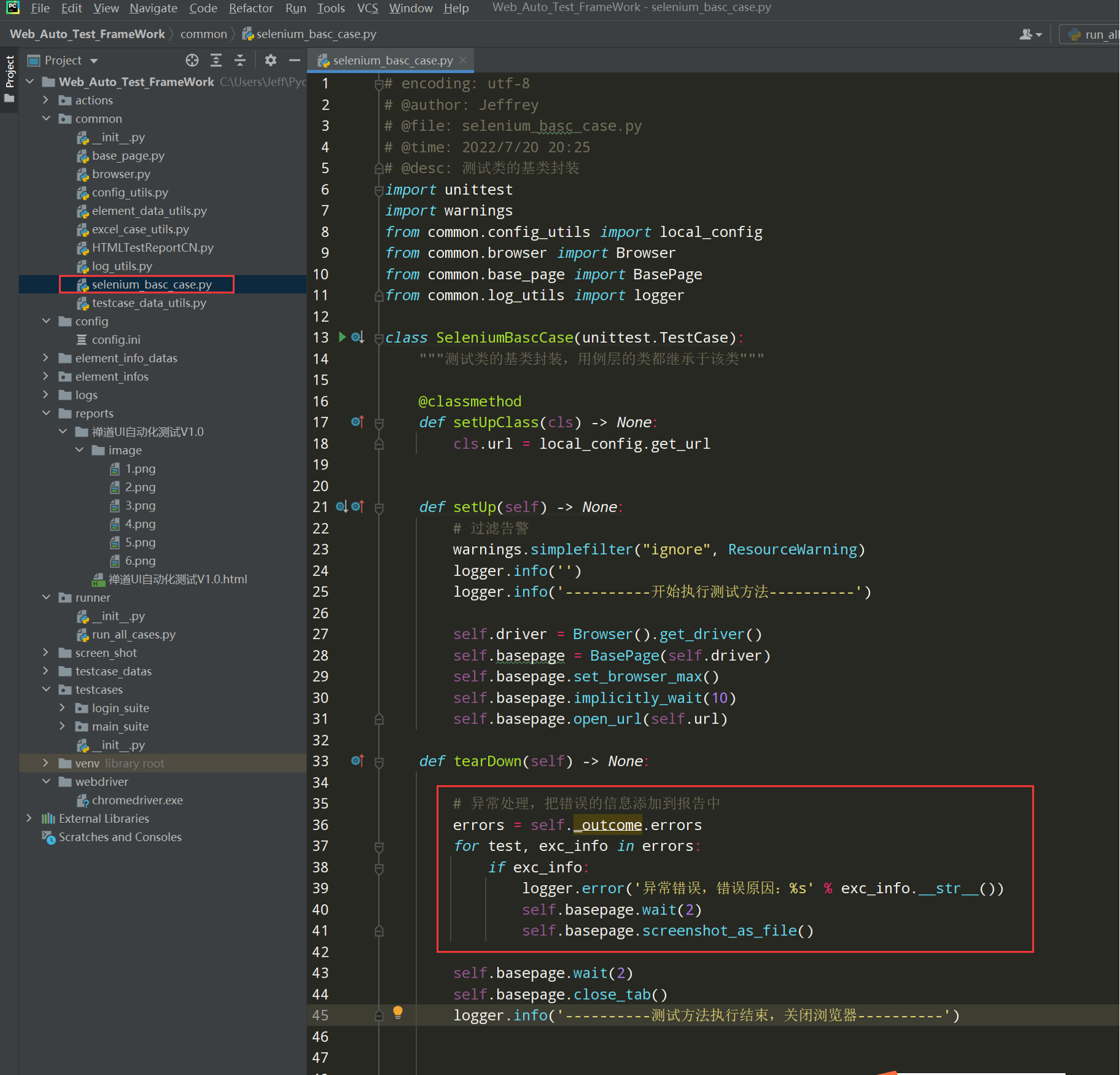
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: selenium_basc_case.py # @time: 2022/7/20 20:25 # @desc: 测试类的基类封装 import unittest import warnings from common.config_utils import local_config from common.browser import Browser from common.base_page import BasePage from common.log_utils import logger class SeleniumBascCase(unittest.TestCase): """测试类的基类封装,用例层的类都继承于该类""" @classmethod def setUpClass(cls) -> None: cls.url = local_config.get_url def setUp(self) -> None: # 过滤告警 warnings.simplefilter("ignore", ResourceWarning) logger.info('') logger.info('----------开始执行测试方法----------') self.driver = Browser().get_driver() self.basepage = BasePage(self.driver) self.basepage.set_browser_max() self.basepage.implicitly_wait(10) self.basepage.open_url(self.url) def tearDown(self) -> None: # 异常处理,把错误的信息添加到报告中 errors = self._outcome.errors for test, exc_info in errors: if exc_info: logger.error('异常错误,错误原因:%s' % exc_info.__str__()) self.basepage.wait(2) self.basepage.screenshot_as_file() self.basepage.wait(2) self.basepage.close_tab() logger.info('----------测试方法执行结束,关闭浏览器----------')
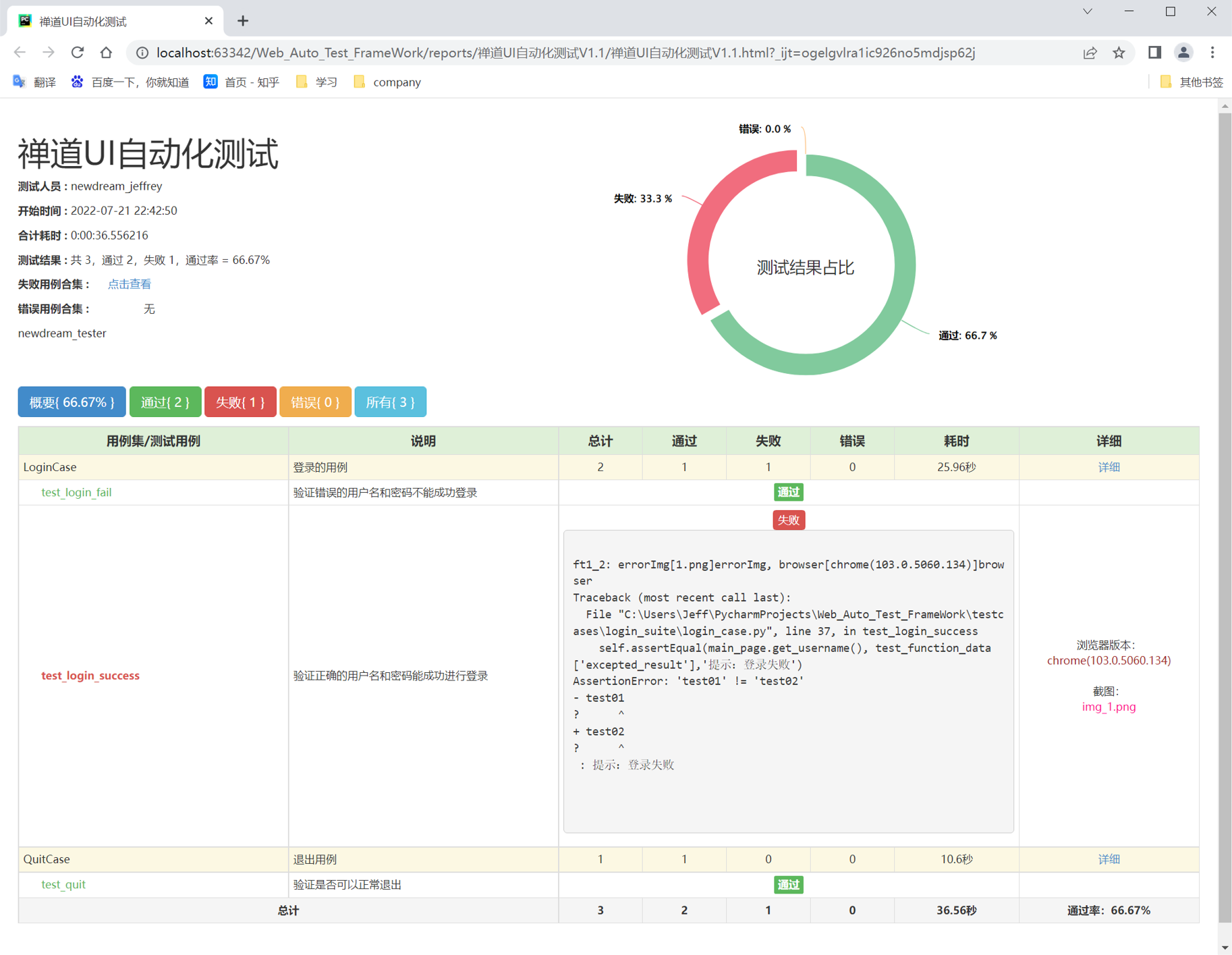
执行run_all_cases.py文件,查看执行结果:
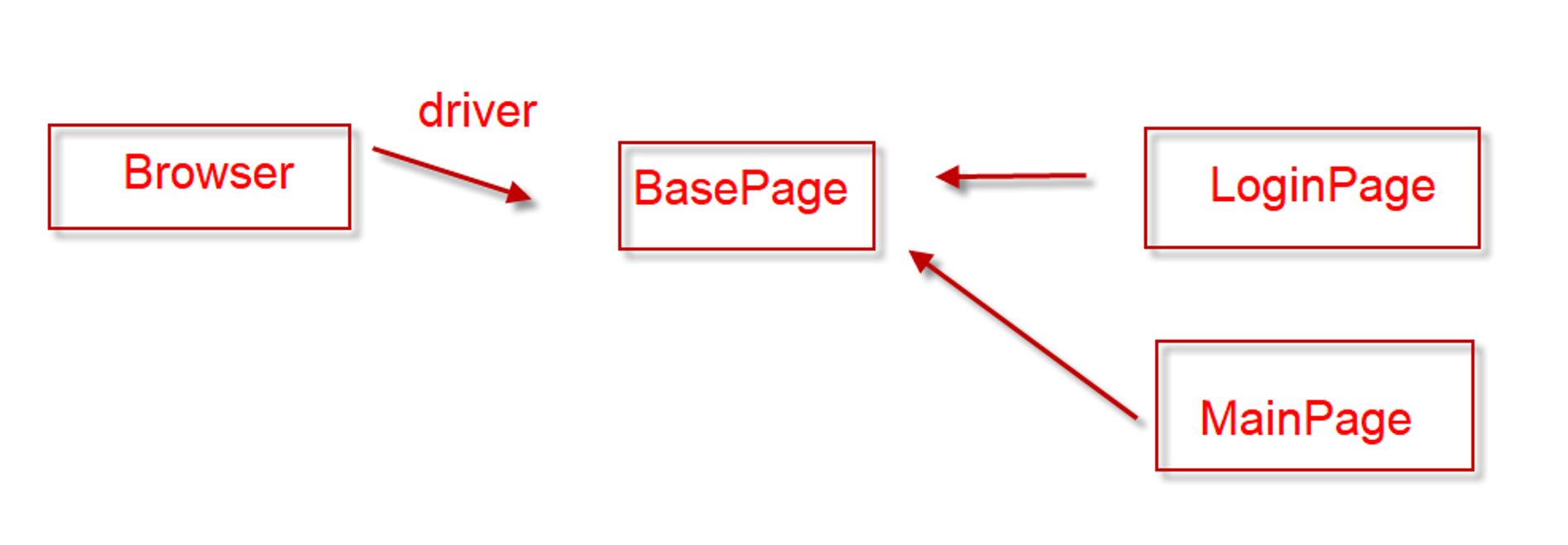
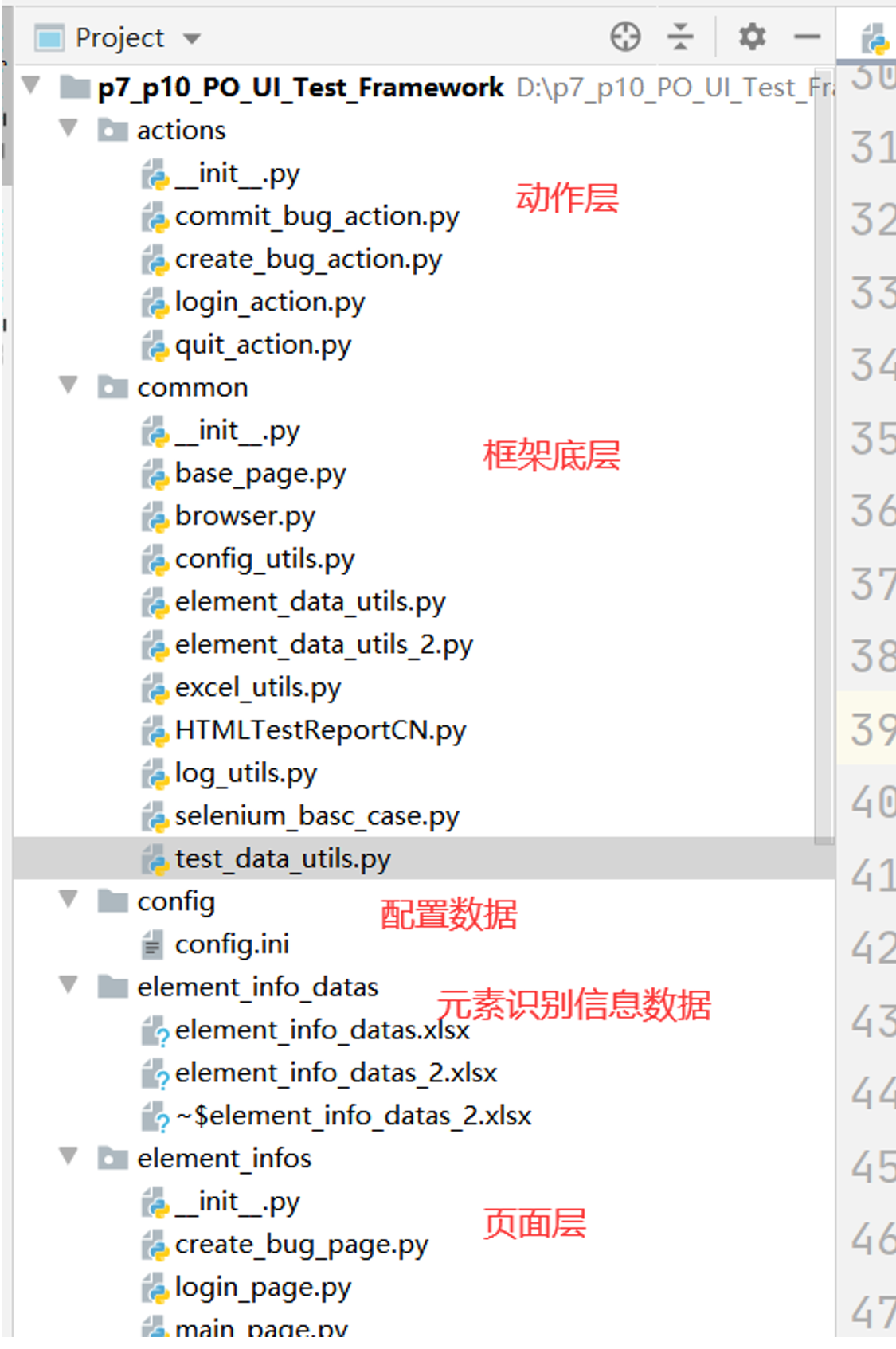
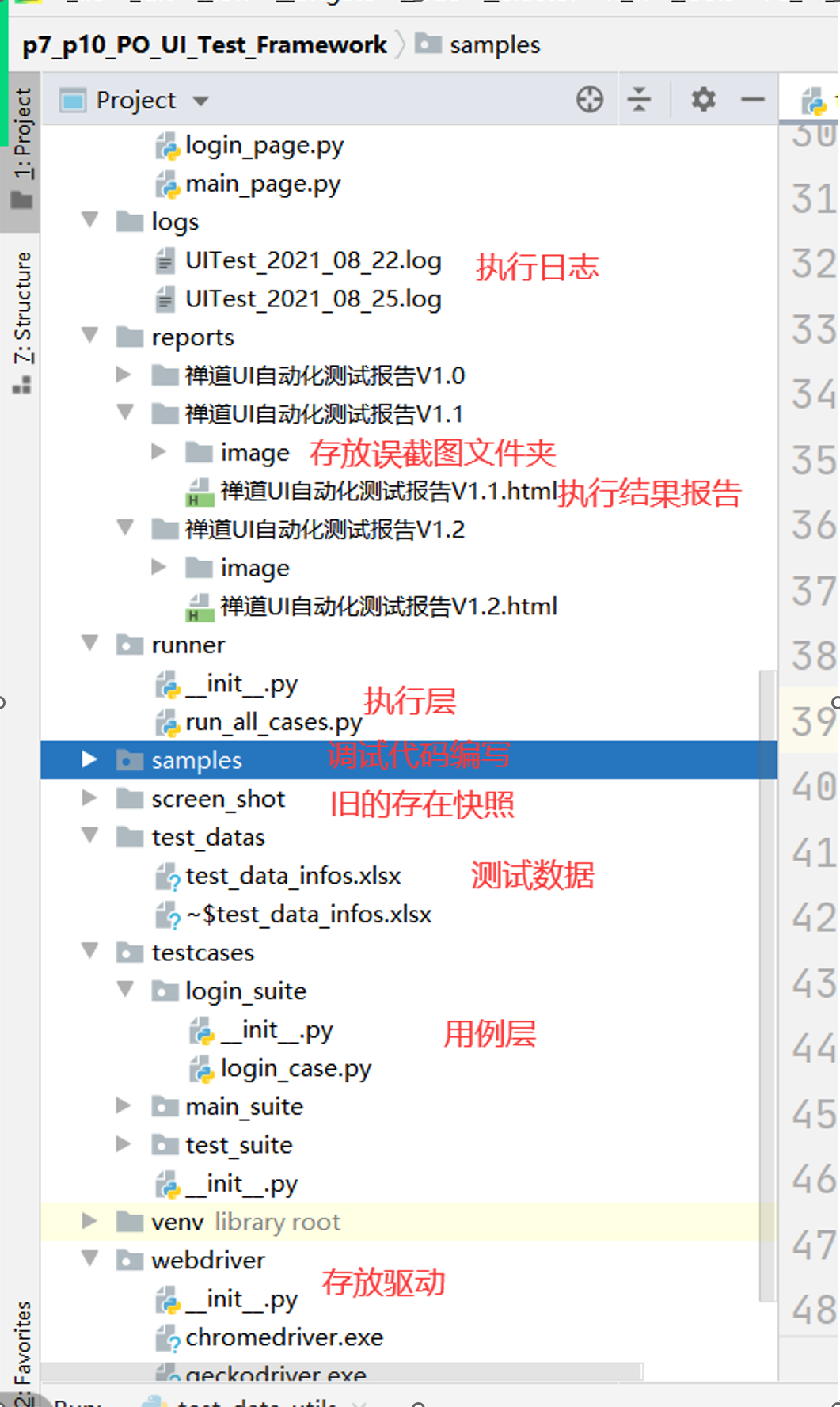
复习框架层级:
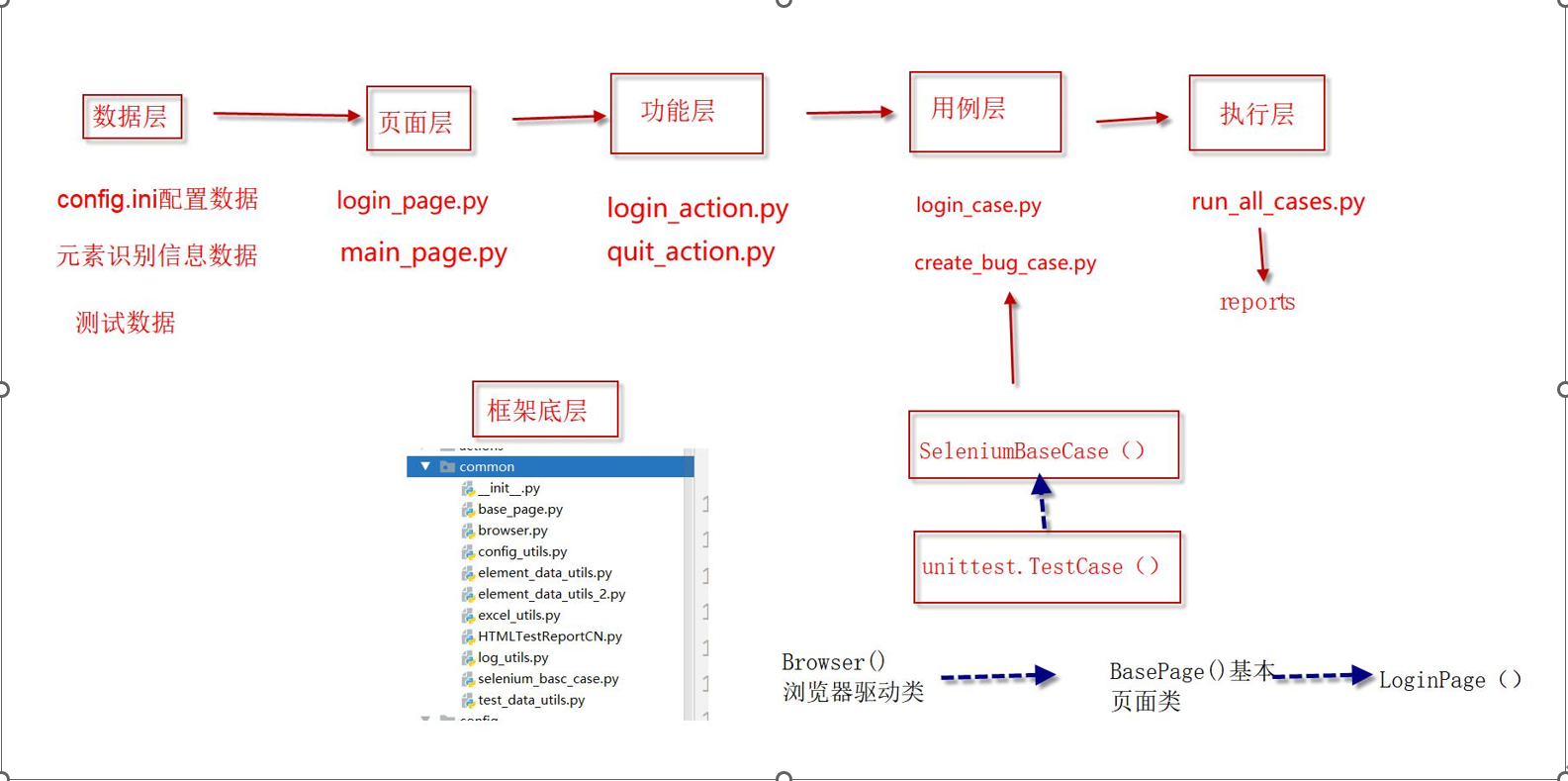
框架14—控制用例是否执行
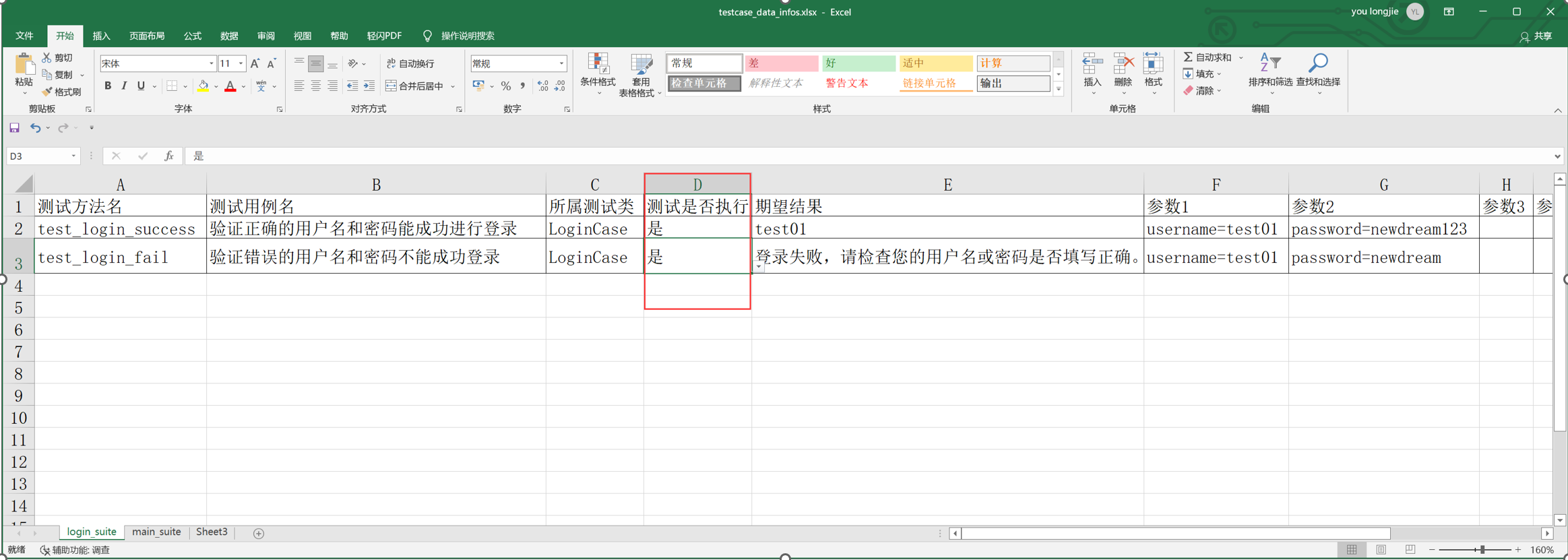
在测试数据中可以看到测试是否执行列,可在代码中做判断,如果为是,执行该用例,为否 则跳过该用例,不执行;
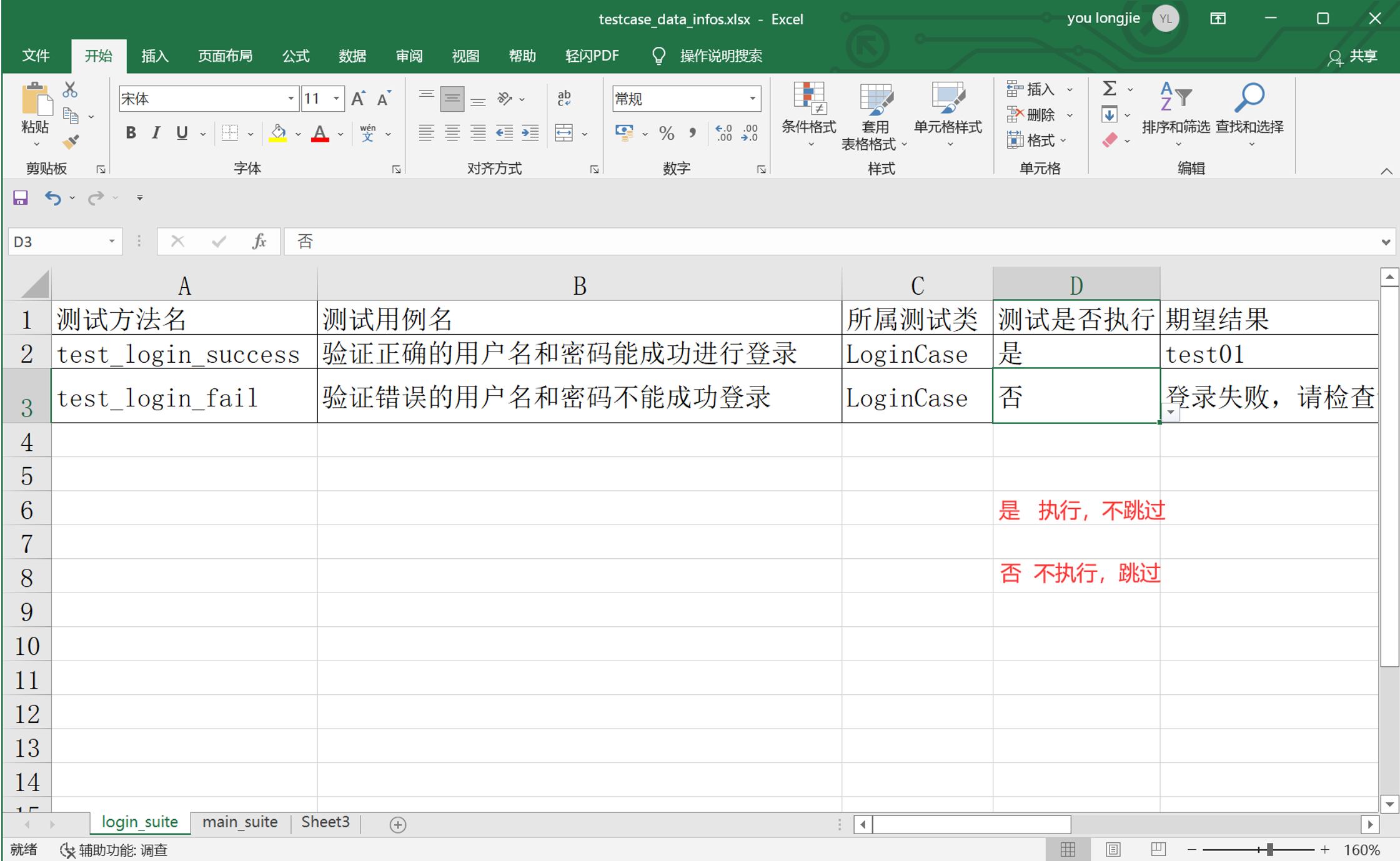
步骤1:跳过登录的测试
@unittest.skipIf(condition.reason):condition为True时跳过

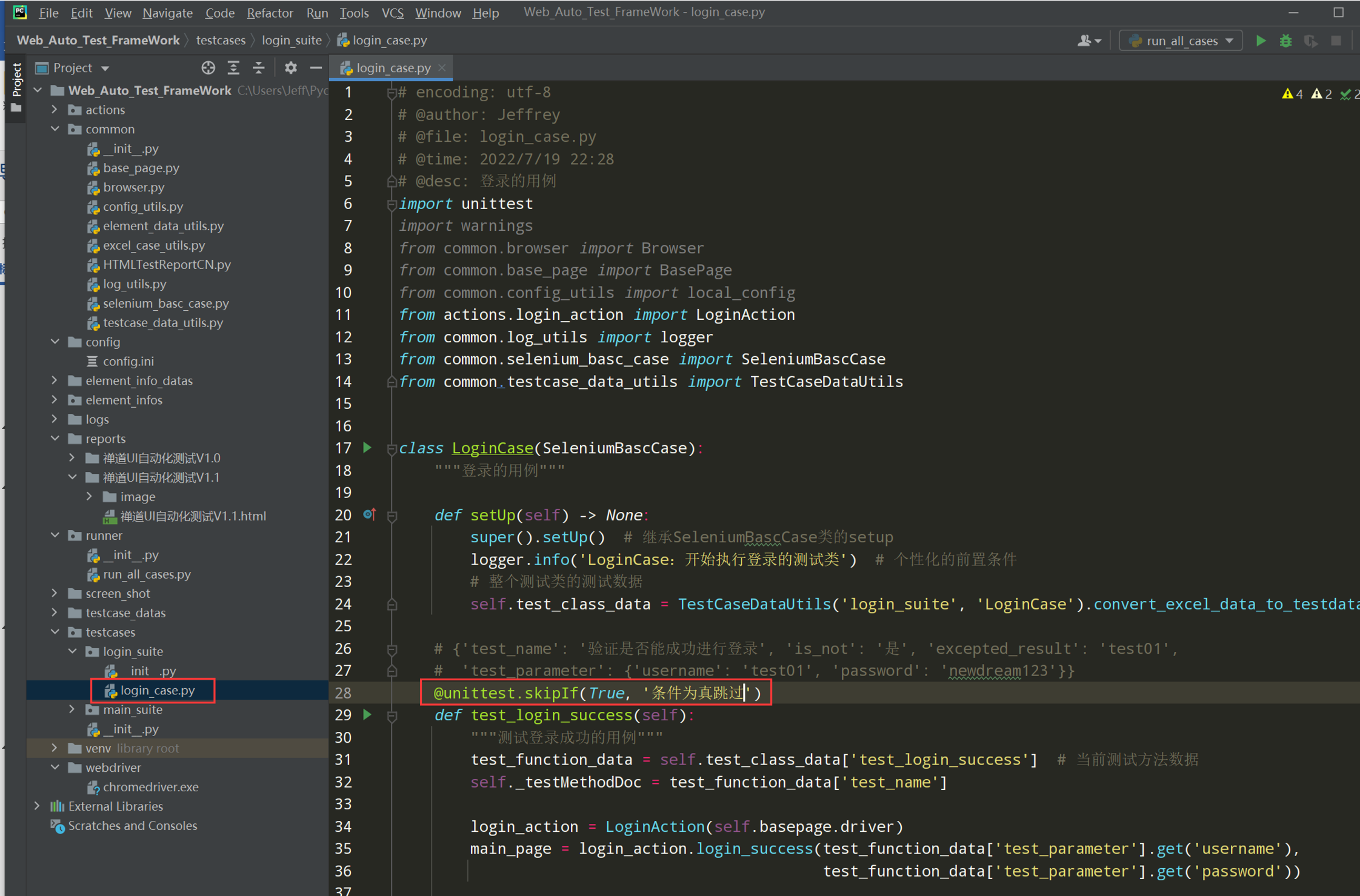
步骤2:如果为否,不执行 ,值返回True ;如果执行用例,不跳过 值返回false;
在testcase_data_utils.py文件中代码修改
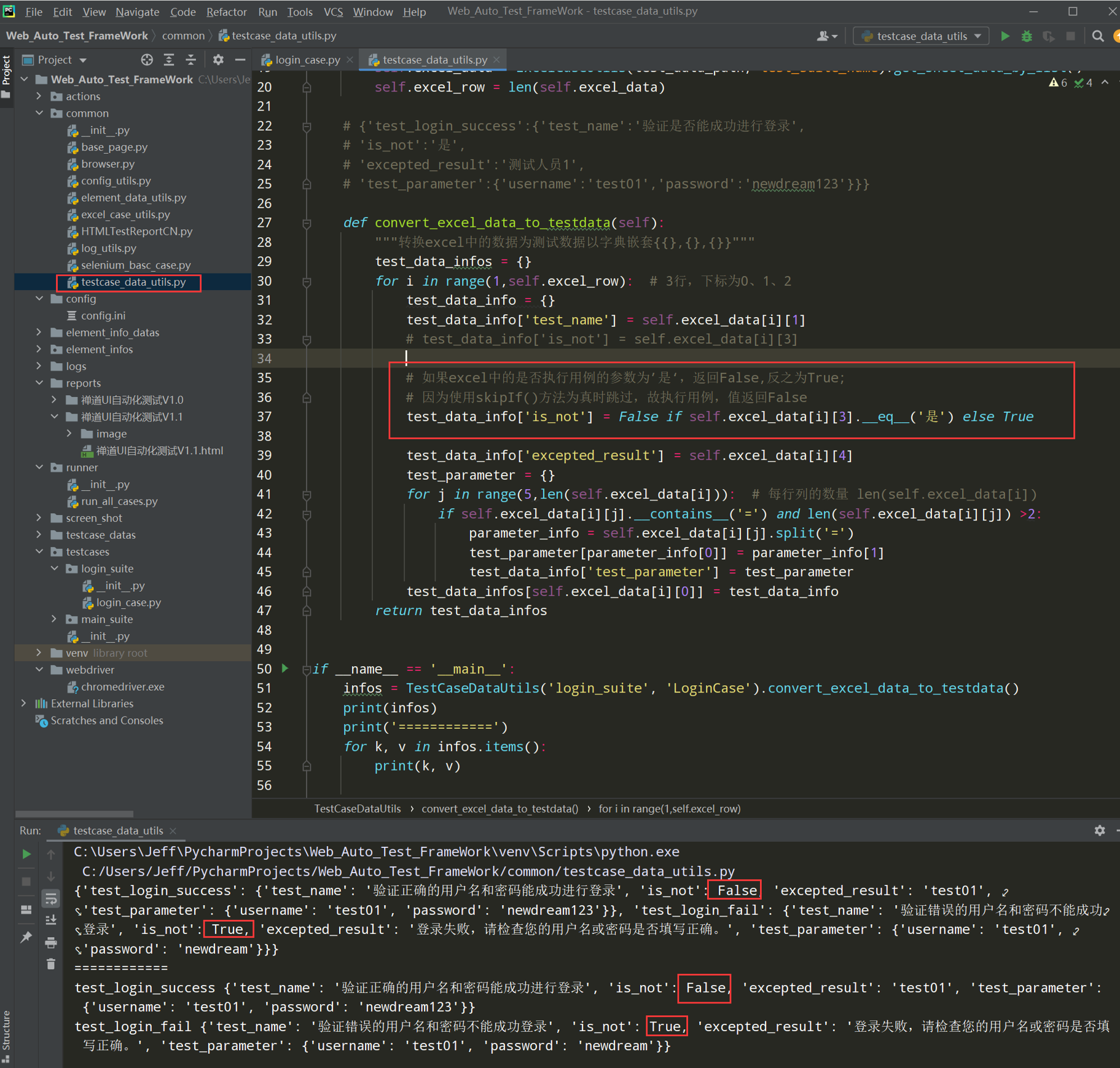
代码示例:
# 如果excel中的是否执行用例的参数为’是‘,返回False,反之为True; # 因为使用skipIf()方法为真时跳过,故执行用例,值返回False test_data_info['is_not'] = False if self.excel_data[i][3].__eq__('是') else True
步骤3:设置用例是否执行 第一条执行,第二条不执行
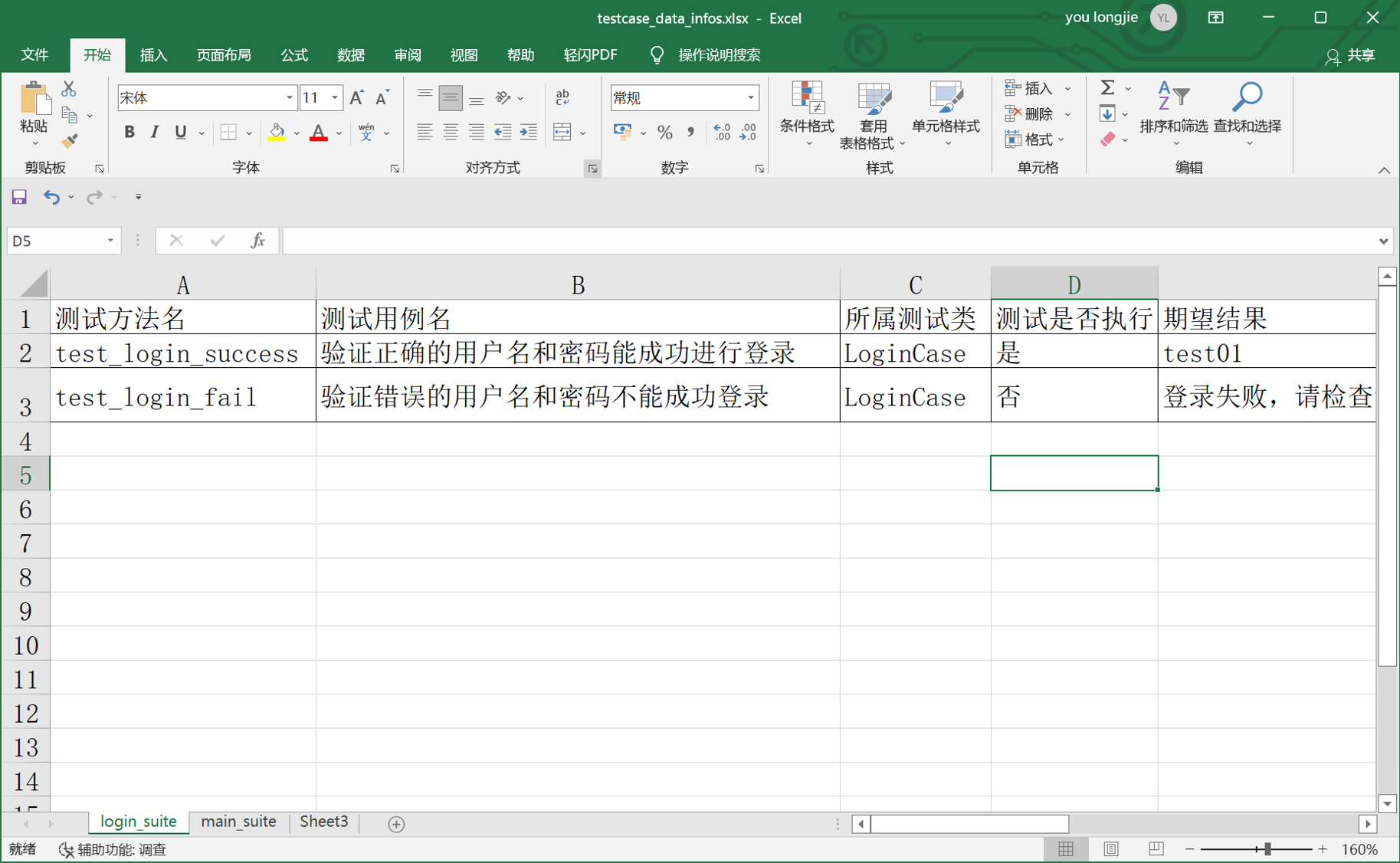
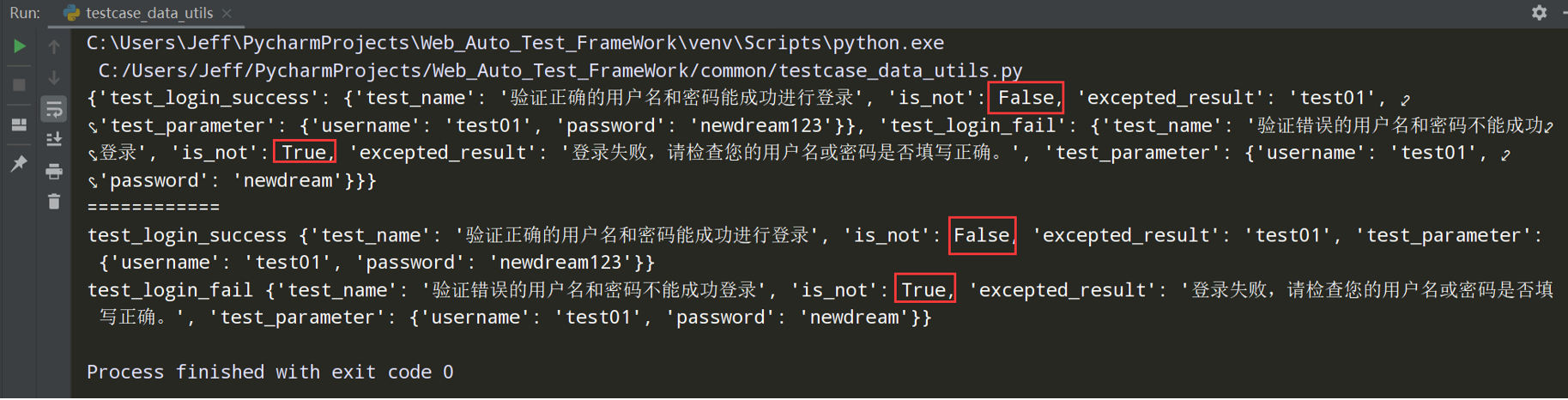
测试执行一下testcase_data_utils.py文件
步骤4:修改login_case.py文件
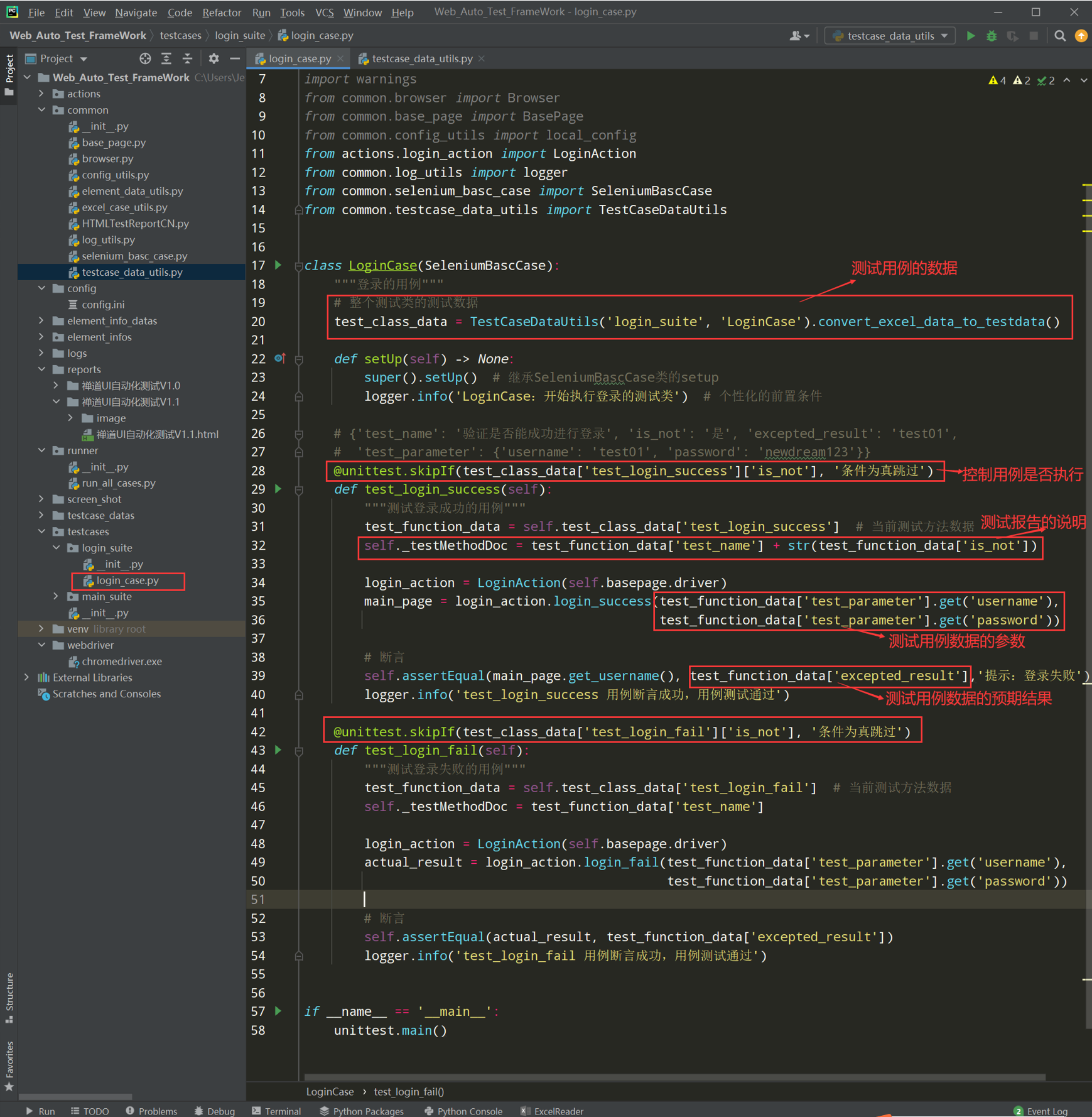
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: login_case.py # @time: 2022/7/19 22:28 # @desc: 登录的用例 import unittest import warnings from common.browser import Browser from common.base_page import BasePage from common.config_utils import local_config from actions.login_action import LoginAction from common.log_utils import logger from common.selenium_basc_case import SeleniumBascCase from common.testcase_data_utils import TestCaseDataUtils class LoginCase(SeleniumBascCase): """登录的用例""" # 整个测试类的测试数据 test_class_data = TestCaseDataUtils('login_suite', 'LoginCase').convert_excel_data_to_testdata() def setUp(self) -> None: super().setUp() # 继承SeleniumBascCase类的setup logger.info('LoginCase:开始执行登录的测试类') # 个性化的前置条件 # {'test_name': '验证是否能成功进行登录', 'is_not': '是', 'excepted_result': 'test01', # 'test_parameter': {'username': 'test01', 'password': 'newdream123'}} @unittest.skipIf(test_class_data['test_login_success']['is_not'], '条件为真跳过') def test_login_success(self): """测试登录成功的用例""" test_function_data = self.test_class_data['test_login_success'] # 当前测试方法数据 self._testMethodDoc = test_function_data['test_name'] + str(test_function_data['is_not']) login_action = LoginAction(self.basepage.driver) main_page = login_action.login_success(test_function_data['test_parameter'].get('username'), test_function_data['test_parameter'].get('password')) # 断言 self.assertEqual(main_page.get_username(), test_function_data['excepted_result'],'提示:登录失败') logger.info('test_login_success 用例断言成功,用例测试通过') @unittest.skipIf(test_class_data['test_login_fail']['is_not'], '条件为真跳过') def test_login_fail(self): """测试登录失败的用例""" test_function_data = self.test_class_data['test_login_fail'] # 当前测试方法数据 self._testMethodDoc = test_function_data['test_name'] login_action = LoginAction(self.basepage.driver) actual_result = login_action.login_fail(test_function_data['test_parameter'].get('username'), test_function_data['test_parameter'].get('password')) # 断言 self.assertEqual(actual_result, test_function_data['excepted_result']) logger.info('test_login_fail 用例断言成功,用例测试通过') if __name__ == '__main__': unittest.main()
执行run_all_cases.py查看报告
框架15--测试用例数据分离操作
步骤1:先编写测试类,数据先放测试脚本中
先编写excel_case_utils.py的ExcelCaseUtils类,再编写testcase_data_utils.py的TestCaseDataUtils类
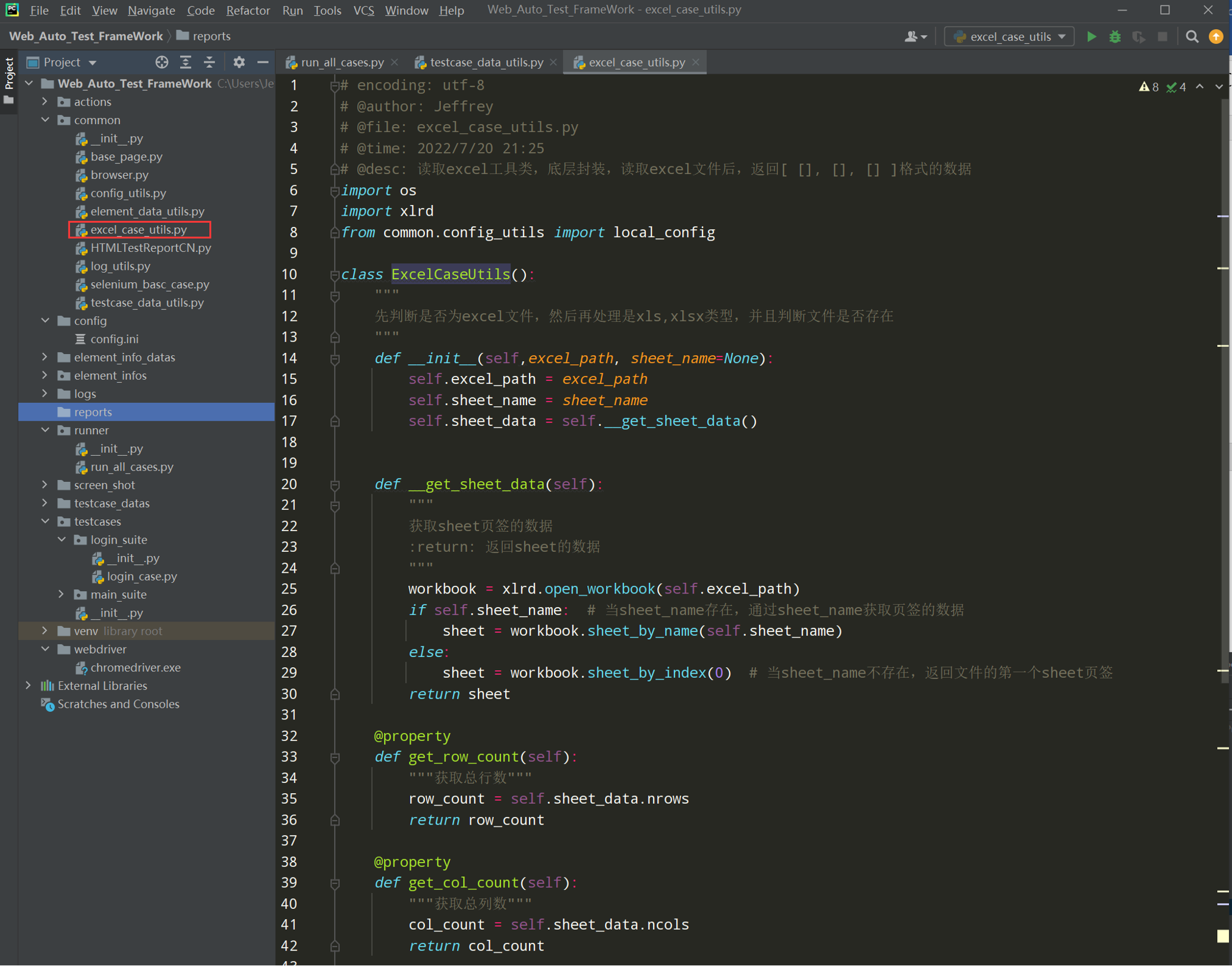
编写excel_case_utils.py
代码示例:
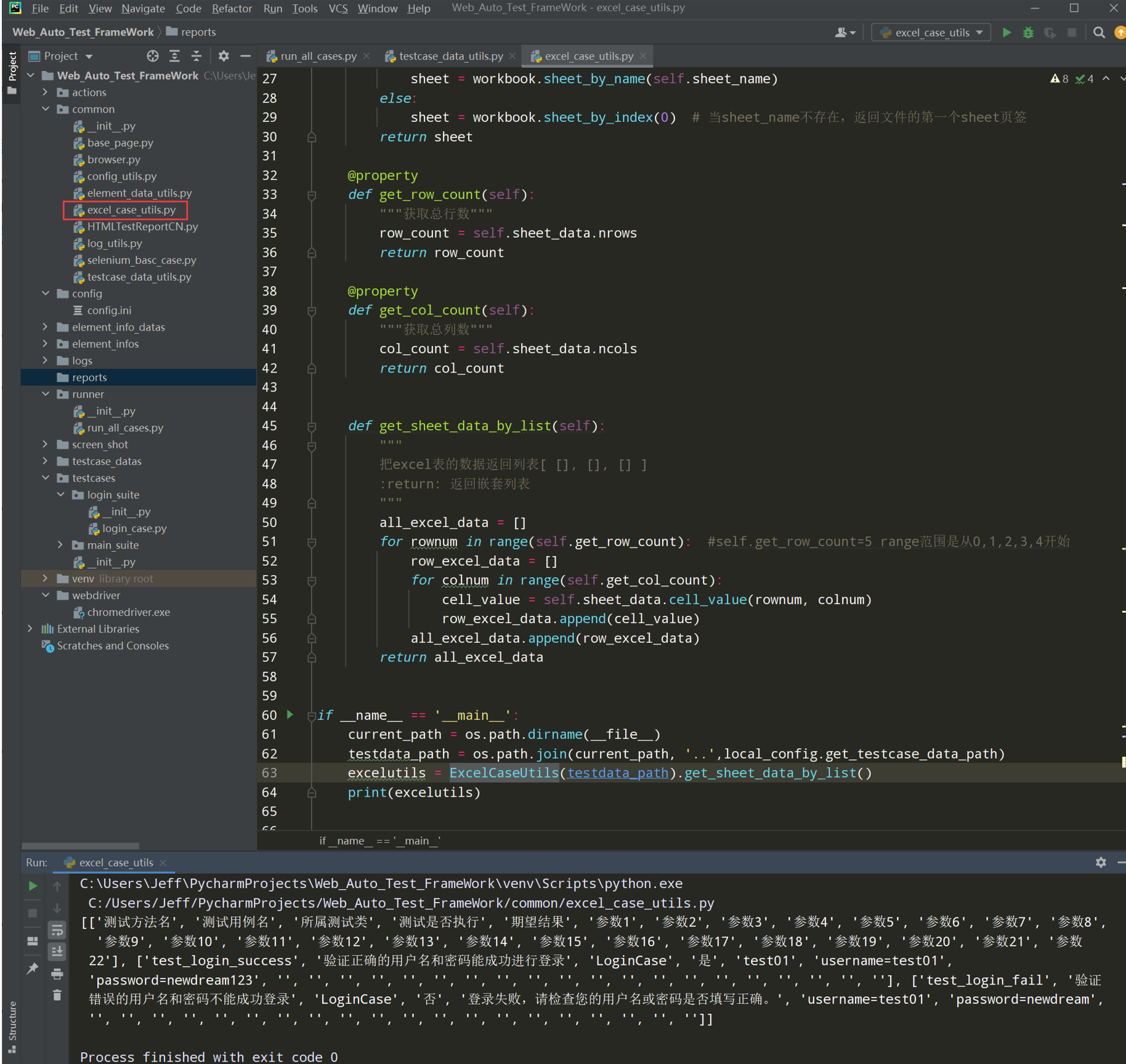
# encoding: utf-8 # @author: Jeffrey # @file: excel_case_utils.py # @time: 2022/7/20 21:25 # @desc: 读取excel工具类,底层封装,读取excel文件后,返回[ [], [], [] ]格式的数据 import os import xlrd from common.config_utils import local_config class ExcelCaseUtils(): """ 先判断是否为excel文件,然后再处理是xls,xlsx类型,并且判断文件是否存在 """ def __init__(self,excel_path, sheet_name=None): self.excel_path = excel_path self.sheet_name = sheet_name self.sheet_data = self.__get_sheet_data() def __get_sheet_data(self): """ 获取sheet页签的数据 :return: 返回sheet的数据 """ workbook = xlrd.open_workbook(self.excel_path) if self.sheet_name: # 当sheet_name存在,通过sheet_name获取页签的数据 sheet = workbook.sheet_by_name(self.sheet_name) else: sheet = workbook.sheet_by_index(0) # 当sheet_name不存在,返回文件的第一个sheet页签 return sheet @property def get_row_count(self): """获取总行数""" row_count = self.sheet_data.nrows return row_count @property def get_col_count(self): """获取总列数""" col_count = self.sheet_data.ncols return col_count def get_sheet_data_by_list(self): """ 把excel表的数据返回列表[ [], [], [] ] :return: 返回嵌套列表 """ all_excel_data = [] for rownum in range(self.get_row_count): #self.get_row_count=5 range范围是从0,1,2,3,4开始 row_excel_data = [] for colnum in range(self.get_col_count): cell_value = self.sheet_data.cell_value(rownum, colnum) row_excel_data.append(cell_value) all_excel_data.append(row_excel_data) return all_excel_data if __name__ == '__main__': current_path = os.path.dirname(__file__) testdata_path = os.path.join(current_path, '..',local_config.get_testcase_data_path) excelutils = ExcelCaseUtils(testdata_path).get_sheet_data_by_list() print(excelutils)
测试执行:

编写testcase_data_utils.py
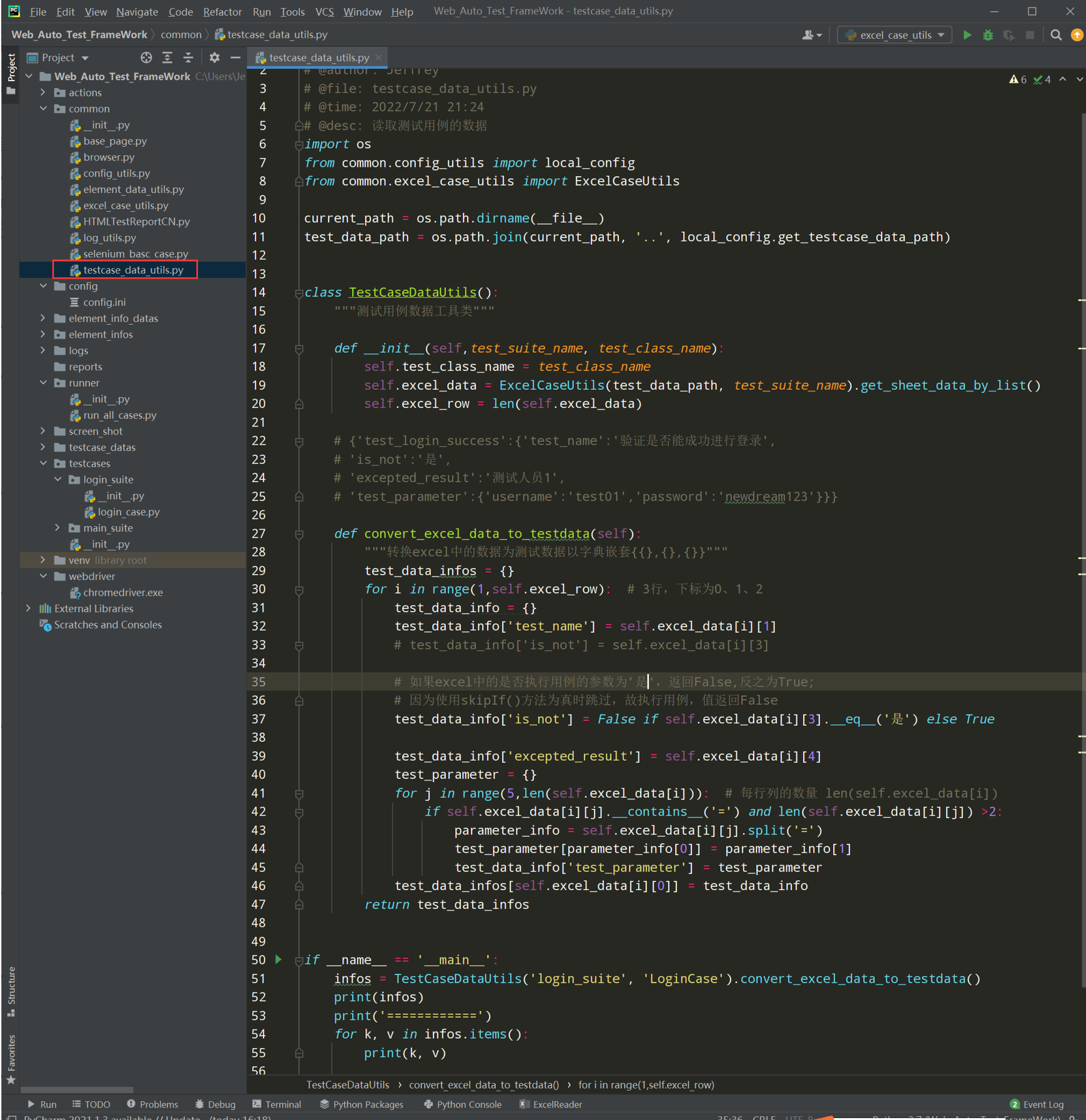
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: testcase_data_utils.py # @time: 2022/7/21 21:24 # @desc: 读取测试用例的数据 import os from common.config_utils import local_config from common.excel_case_utils import ExcelCaseUtils current_path = os.path.dirname(__file__) test_data_path = os.path.join(current_path, '..', local_config.get_testcase_data_path) class TestCaseDataUtils(): """测试用例数据工具类""" def __init__(self,test_suite_name, test_class_name): self.test_class_name = test_class_name self.excel_data = ExcelCaseUtils(test_data_path, test_suite_name).get_sheet_data_by_list() self.excel_row = len(self.excel_data) # {'test_login_success':{'test_name':'验证是否能成功进行登录', # 'is_not':'是', # 'excepted_result':'测试人员1', # 'test_parameter':{'username':'test01','password':'newdream123'}}} def convert_excel_data_to_testdata(self): """转换excel中的数据为测试数据以字典嵌套{{},{},{}}""" test_data_infos = {} for i in range(1,self.excel_row): # 3行,下标为0、1、2 test_data_info = {} test_data_info['test_name'] = self.excel_data[i][1] # test_data_info['is_not'] = self.excel_data[i][3] # 如果excel中的是否执行用例的参数为’是‘,返回False,反之为True; # 因为使用skipIf()方法为真时跳过,故执行用例,值返回False test_data_info['is_not'] = False if self.excel_data[i][3].__eq__('是') else True test_data_info['excepted_result'] = self.excel_data[i][4] test_parameter = {} for j in range(5,len(self.excel_data[i])): # 每行列的数量 len(self.excel_data[i]) if self.excel_data[i][j].__contains__('=') and len(self.excel_data[i][j]) >2: parameter_info = self.excel_data[i][j].split('=') test_parameter[parameter_info[0]] = parameter_info[1] test_data_info['test_parameter'] = test_parameter test_data_infos[self.excel_data[i][0]] = test_data_info return test_data_infos if __name__ == '__main__': infos = TestCaseDataUtils('login_suite', 'LoginCase').convert_excel_data_to_testdata() print(infos) print('============') for k, v in infos.items(): print(k, v)
测试执行一下:

步骤2:准备测试数据的excel 调整sheet页的名称
sheet 名称=测试子套件名字
修改测试类的名称,测试方法名称
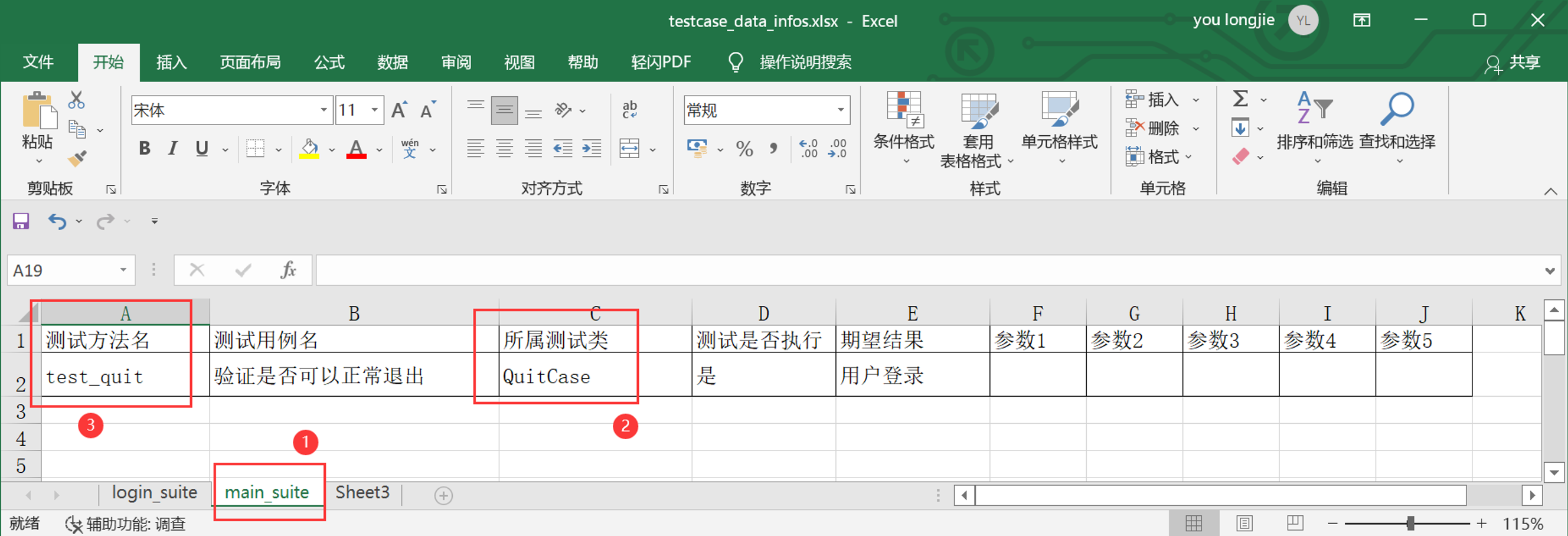
步骤3:再修改excel表汇总测试用例的名称,是否执行,预期结果,输入参数
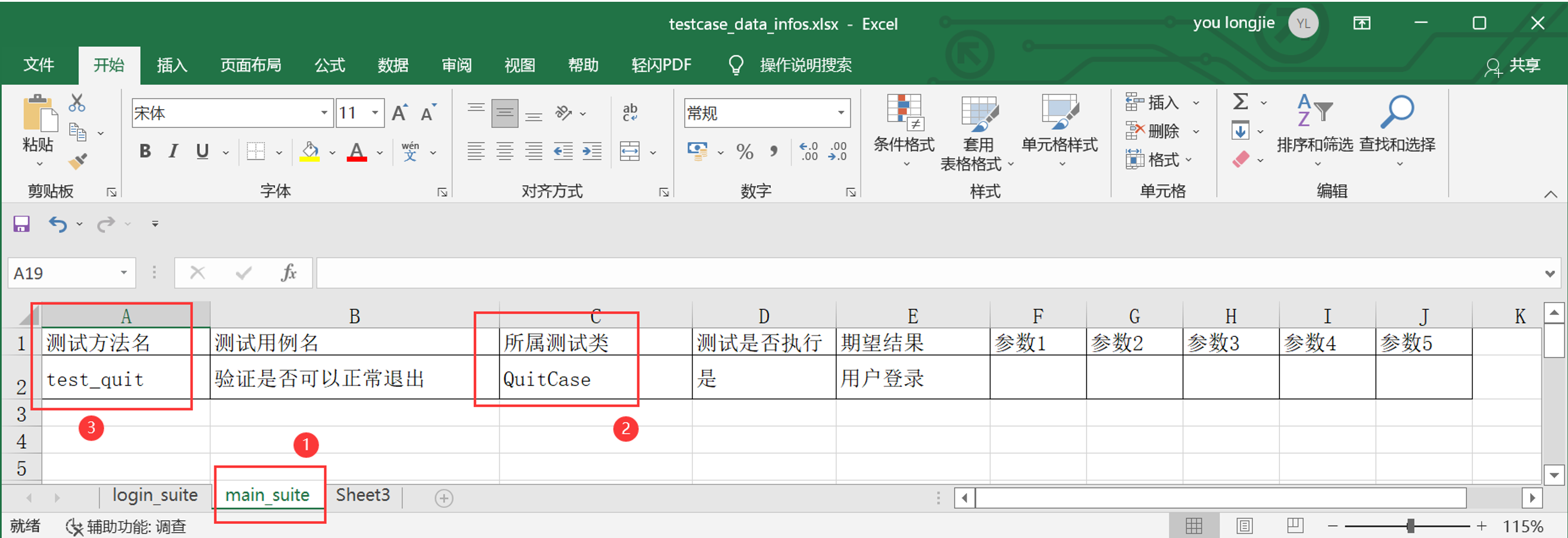
步骤4:完善quit_case.py测试类,从Excel表中读取数据,替换数据
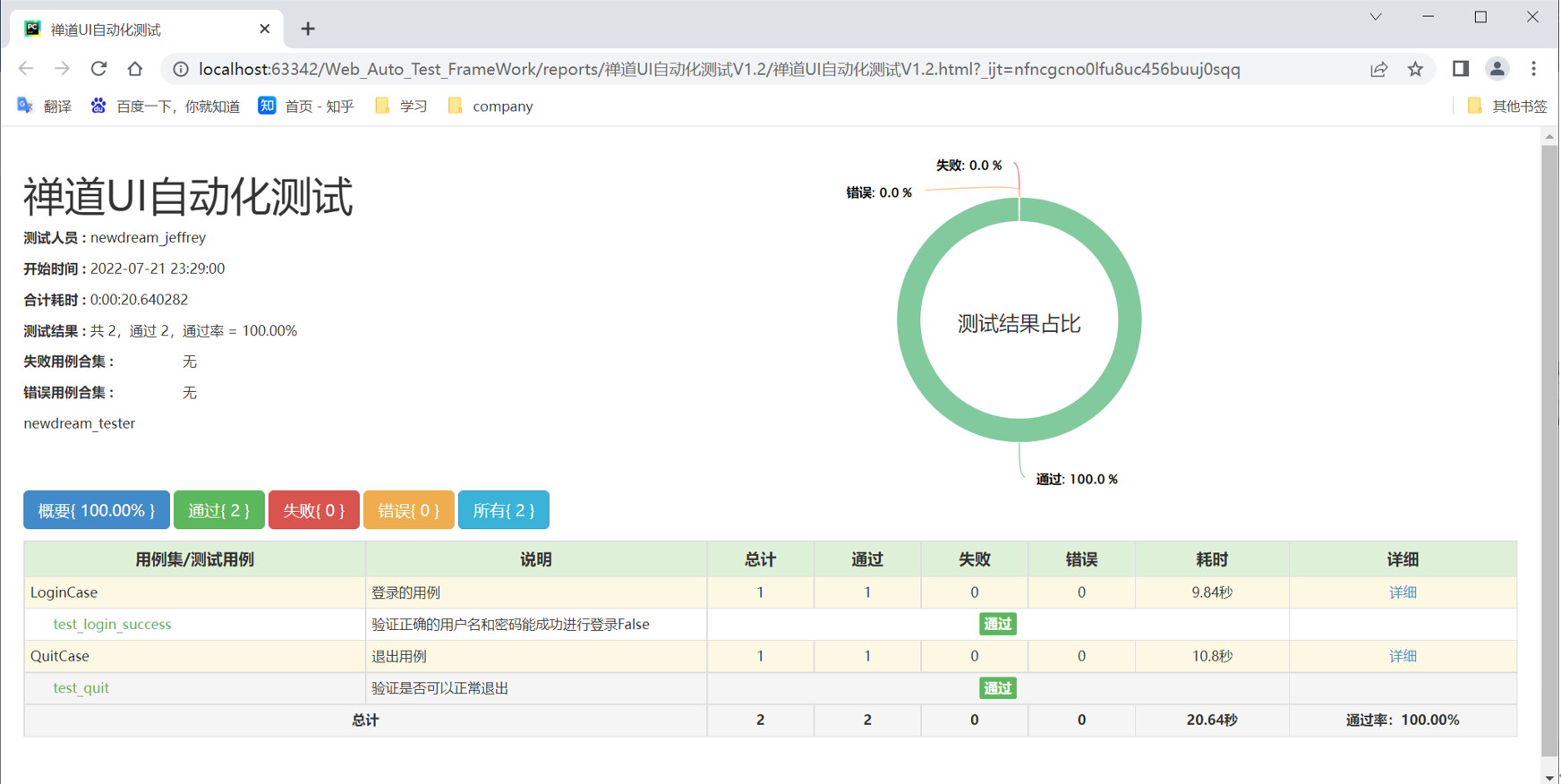
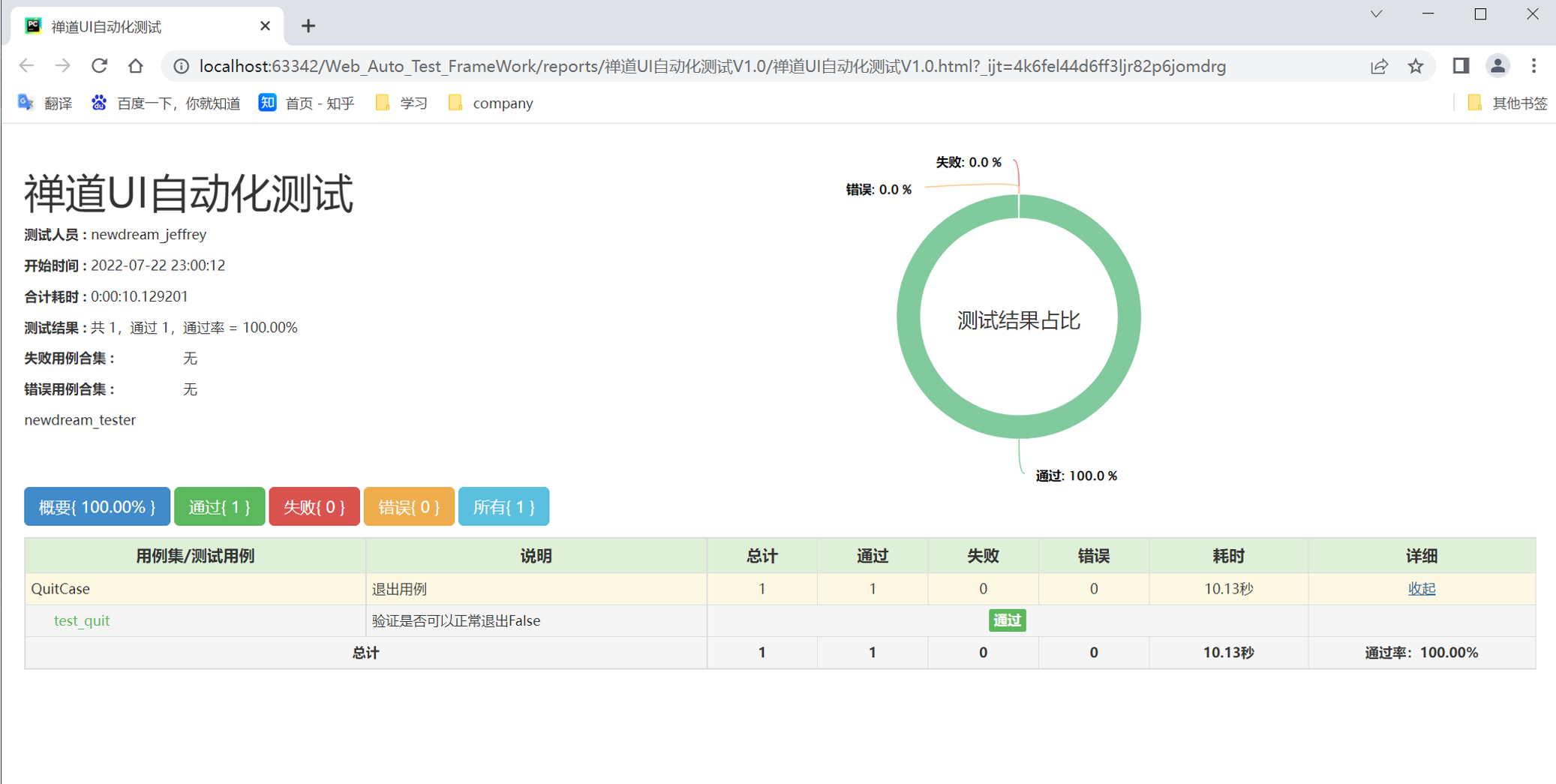
步骤5:执行run_all_cases.py
查看测试报告:
框架16--邮件发送测试报告
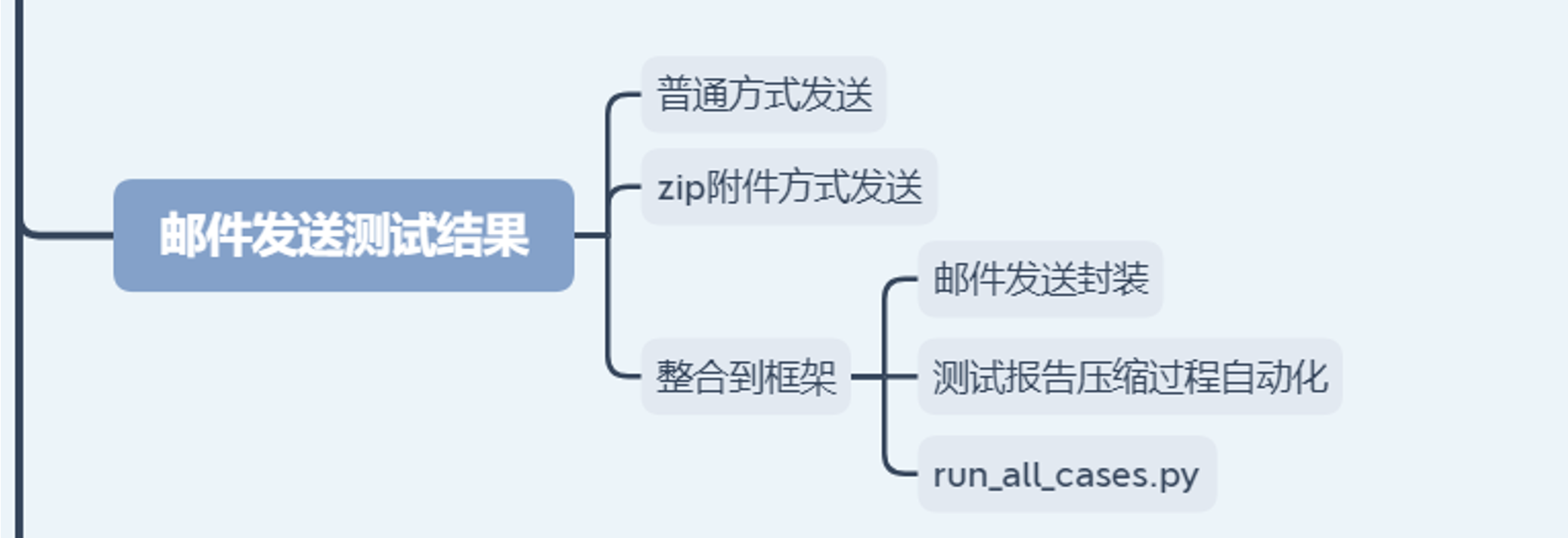
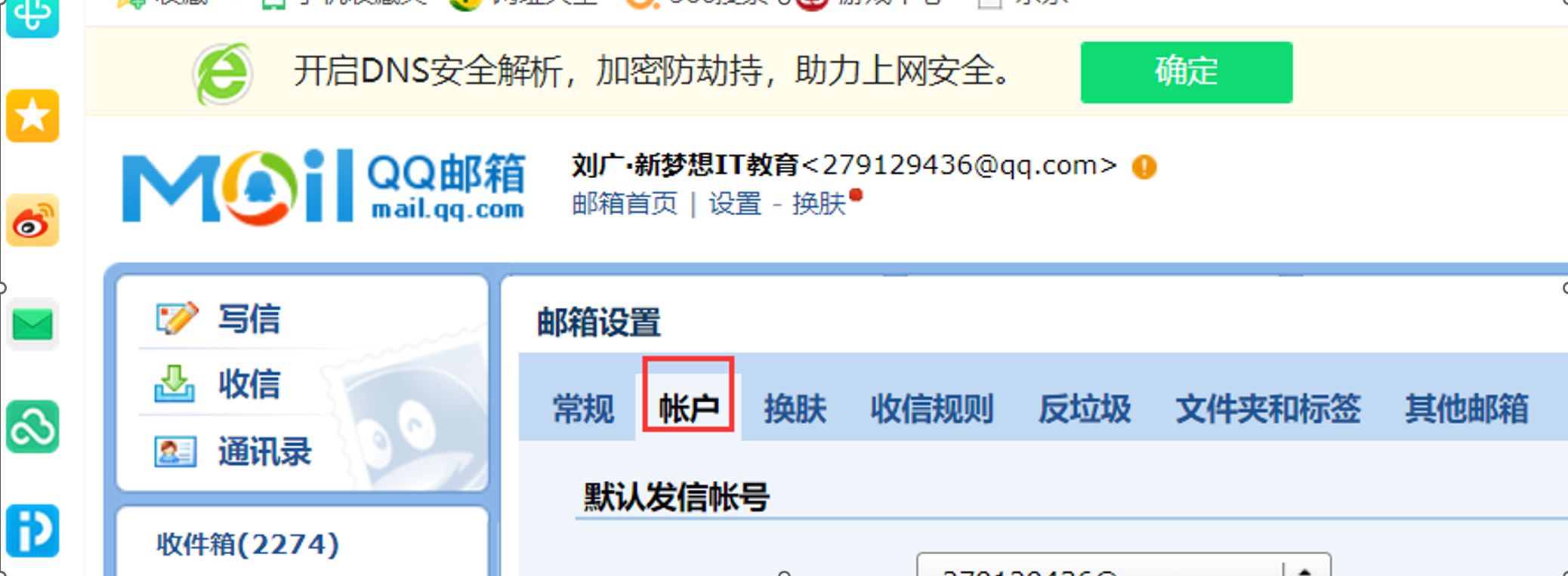
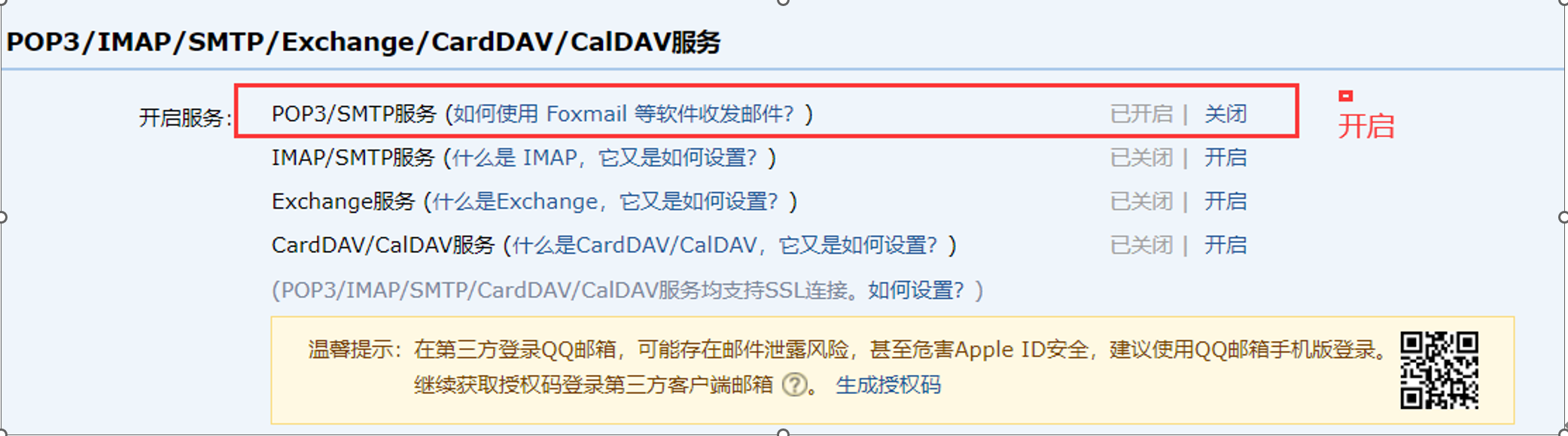
前置条件:开通QQ邮箱第三方登录,并拿到密码;
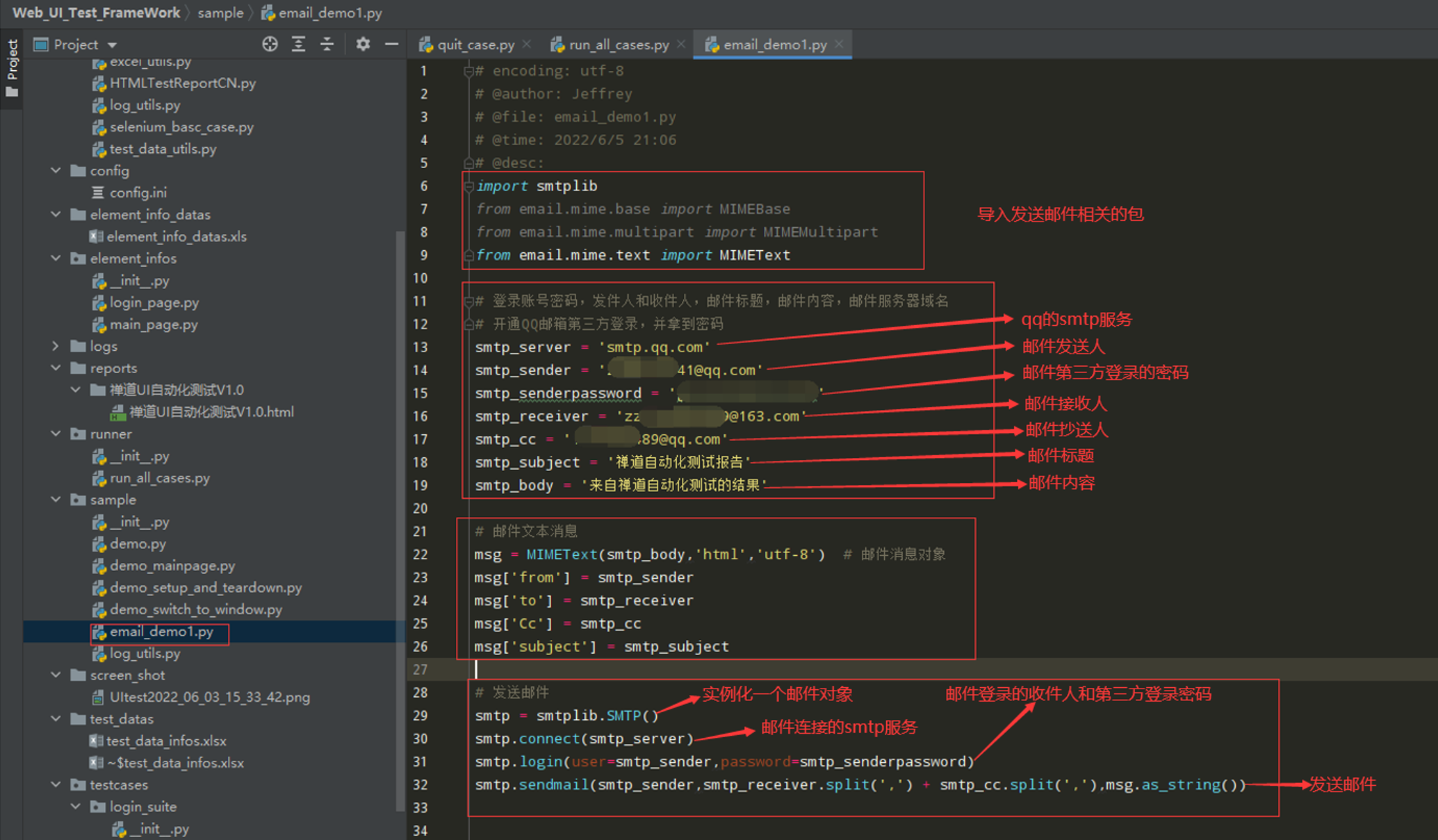
步骤1:编写测试代码,先发送一个文本的邮件
在sample文件中编写线性代码:
步骤2:编写一个带附件的邮件
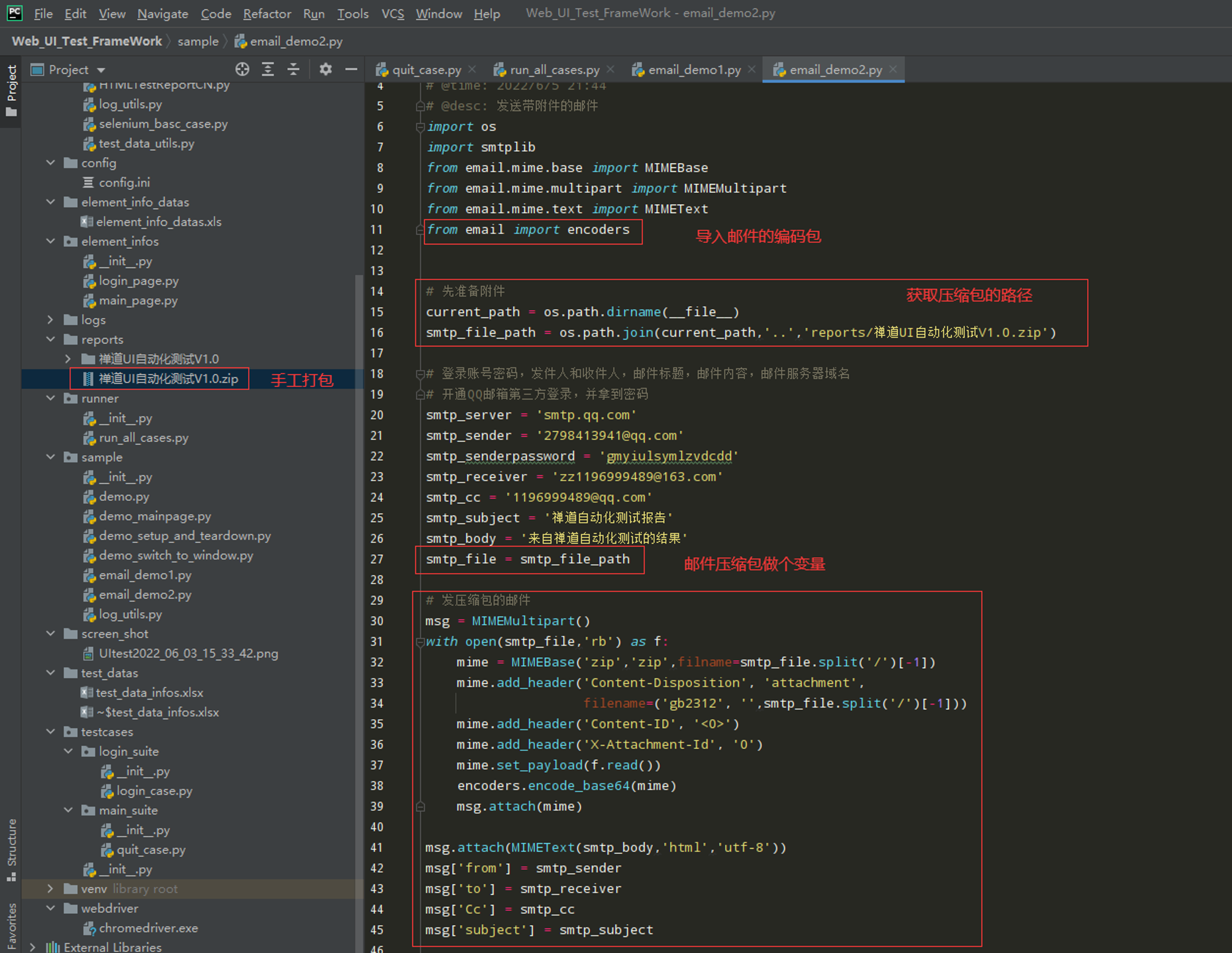
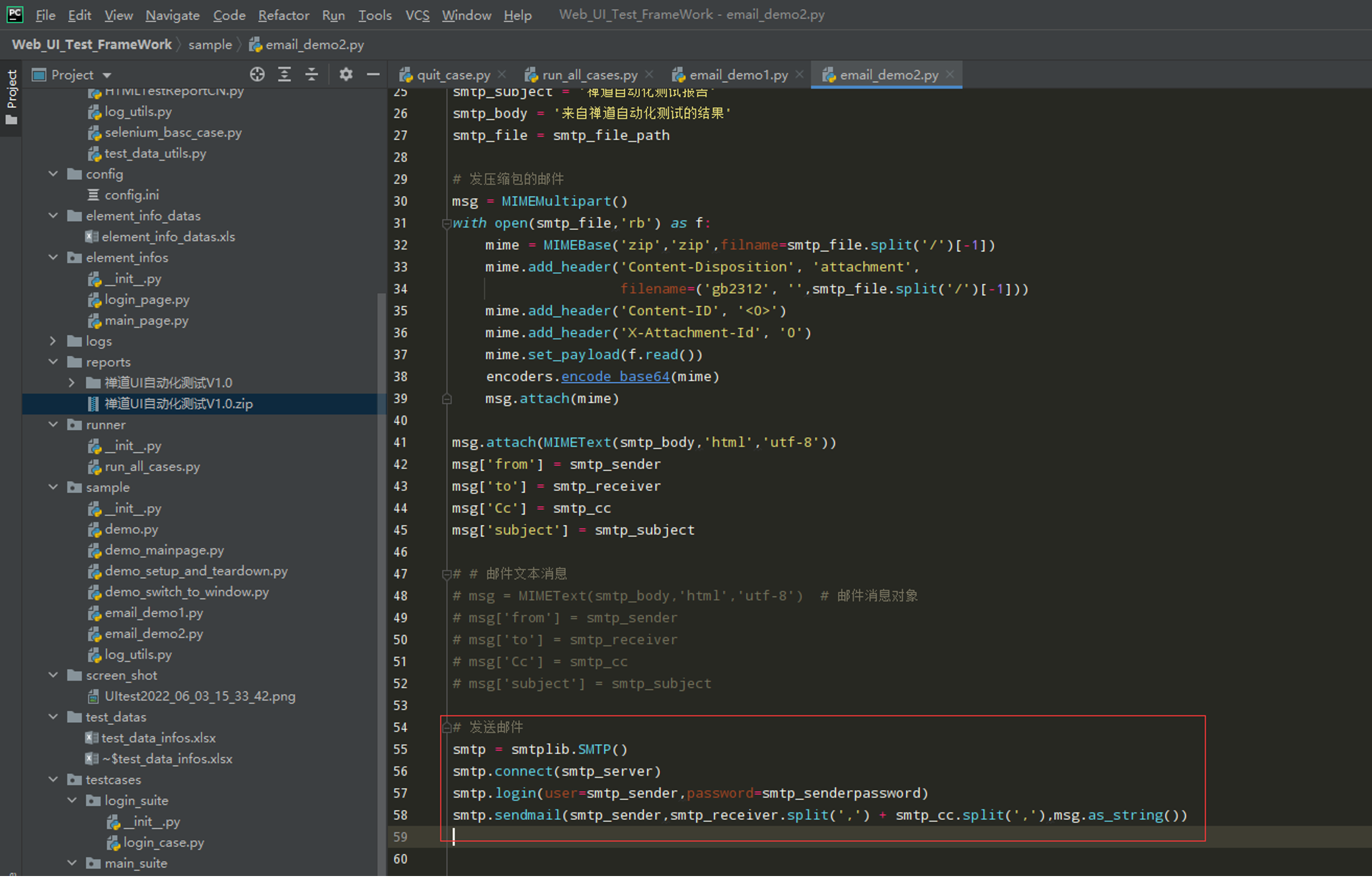
代码示例:
import os import smtplib from email.mime.base import MIMEBase from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText from email import encoders # 先准备附件 current_path = os.path.dirname(__file__) smtp_file_path = os.path.join(current_path,'..','reports/禅道UI自动化测试V1.0.zip') # 登录账号密码,发件人和收件人,邮件标题,邮件内容,邮件服务器域名 # 开通QQ邮箱第三方登录,并拿到密码 smtp_server = 'smtp.qq.com' smtp_sender = '2798413941@qq.com' smtp_senderpassword = 'gmyiulsymlzvdcdd' smtp_receiver = 'zz1196999489@163.com' smtp_cc = '1196999489@qq.com' smtp_subject = '禅道自动化测试报告' smtp_body = '来自禅道自动化测试的结果' smtp_file = smtp_file_path # 发压缩包的邮件 msg = MIMEMultipart() with open(smtp_file,'rb') as f: mime = MIMEBase('zip','zip',filname=smtp_file.split('/')[-1]) mime.add_header('Content-Disposition', 'attachment', filename=('gb2312', '',smtp_file.split('/')[-1])) mime.add_header('Content-ID', '<0>') mime.add_header('X-Attachment-Id', '0') mime.set_payload(f.read()) encoders.encode_base64(mime) msg.attach(mime) msg.attach(MIMEText(smtp_body,'html','utf-8')) msg['from'] = smtp_sender msg['to'] = smtp_receiver msg['Cc'] = smtp_cc msg['subject'] = smtp_subject # # 邮件文本消息 # msg = MIMEText(smtp_body,'html','utf-8') # 邮件消息对象 # msg['from'] = smtp_sender # msg['to'] = smtp_receiver # msg['Cc'] = smtp_cc # msg['subject'] = smtp_subject # 发送邮件 smtp = smtplib.SMTP() smtp.connect(smtp_server) smtp.login(user=smtp_sender,password=smtp_senderpassword) smtp.sendmail(smtp_sender,smtp_receiver.split(',') + smtp_cc.split(','),msg.as_string())
查看邮件:
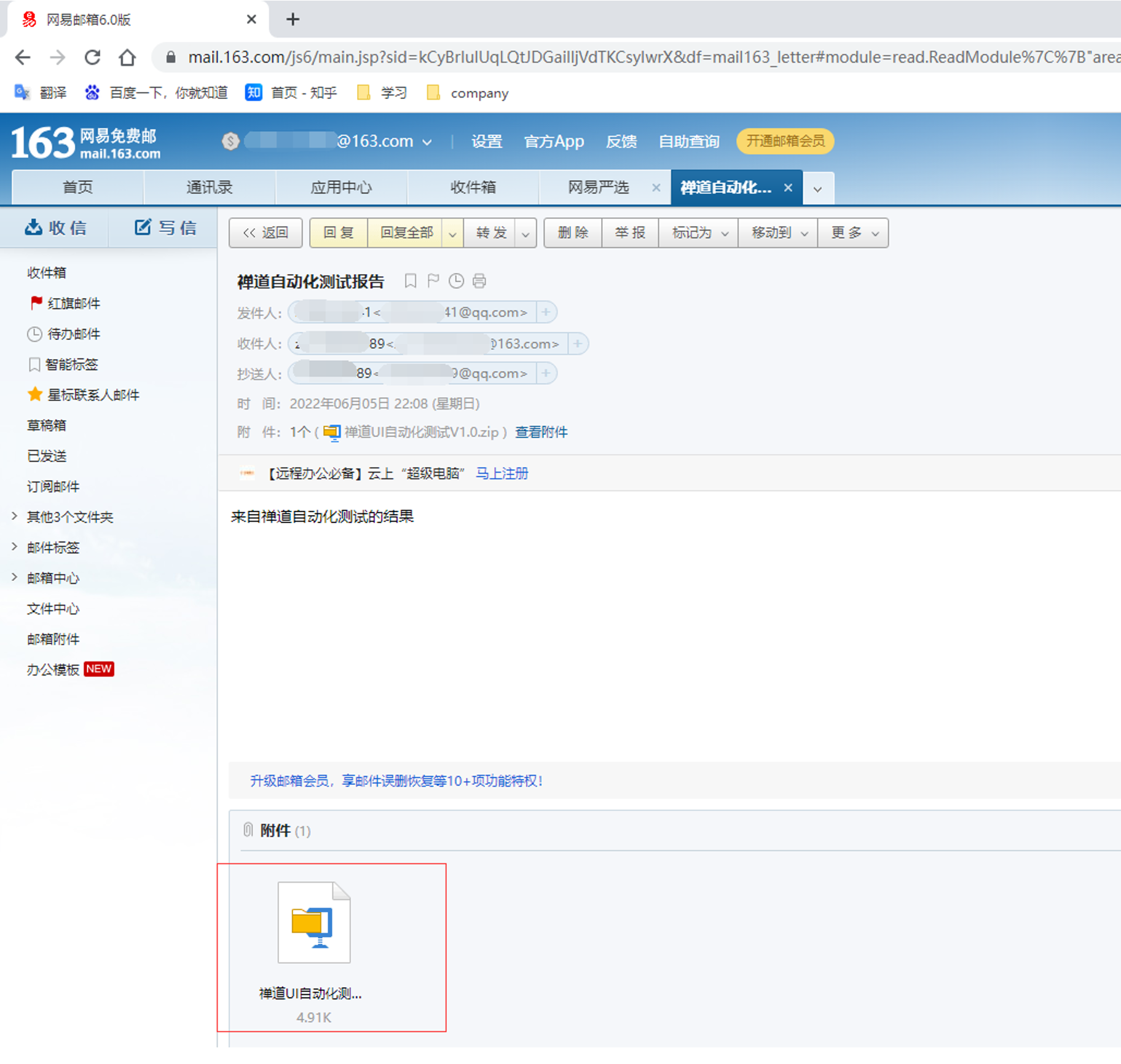
步骤3:封装压缩文件夹的代码
在common文件下新建zip_utils.py文件,编写压缩文件的代码
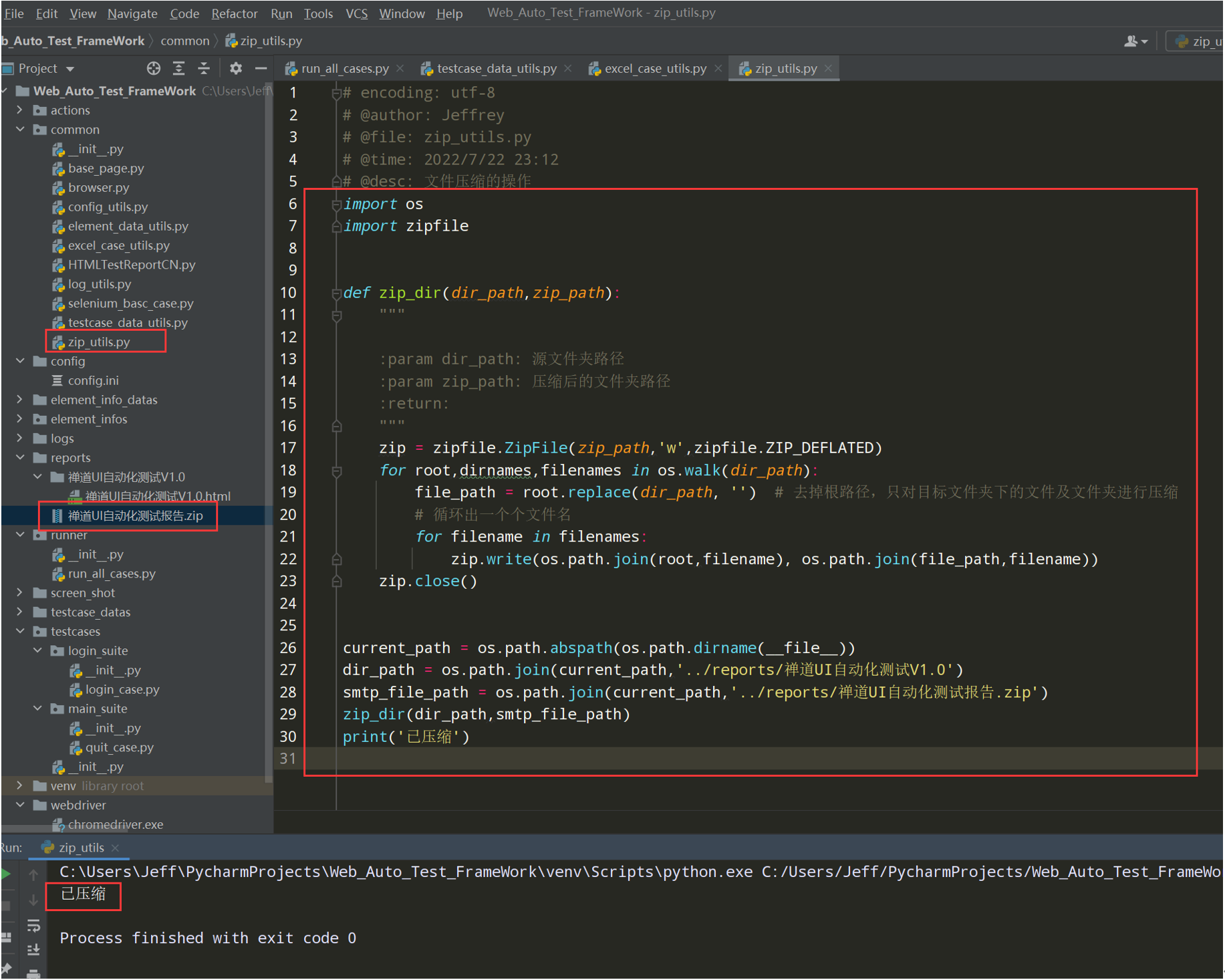
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: zip_utils.py # @time: 2022/7/22 23:12 # @desc: 文件压缩的操作 import os import zipfile def zip_dir(dir_path,zip_path): """ :param dir_path: 源文件夹路径 :param zip_path: 压缩后的文件夹路径 :return: """ zip = zipfile.ZipFile(zip_path,'w',zipfile.ZIP_DEFLATED) for root,dirnames,filenames in os.walk(dir_path): file_path = root.replace(dir_path, '') # 去掉根路径,只对目标文件夹下的文件及文件夹进行压缩 # 循环出一个个文件名 for filename in filenames: zip.write(os.path.join(root,filename), os.path.join(file_path,filename)) zip.close() current_path = os.path.abspath(os.path.dirname(__file__)) dir_path = os.path.join(current_path,'../reports/禅道UI自动化测试V1.0') smtp_file_path = os.path.join(current_path,'../reports/禅道UI自动化测试报告.zip') zip_dir(dir_path,smtp_file_path) print('已压缩')
步骤4:把邮件的用户名,密码等信息分离到配置文件中
先把邮件的信息放到config.ini文件中;
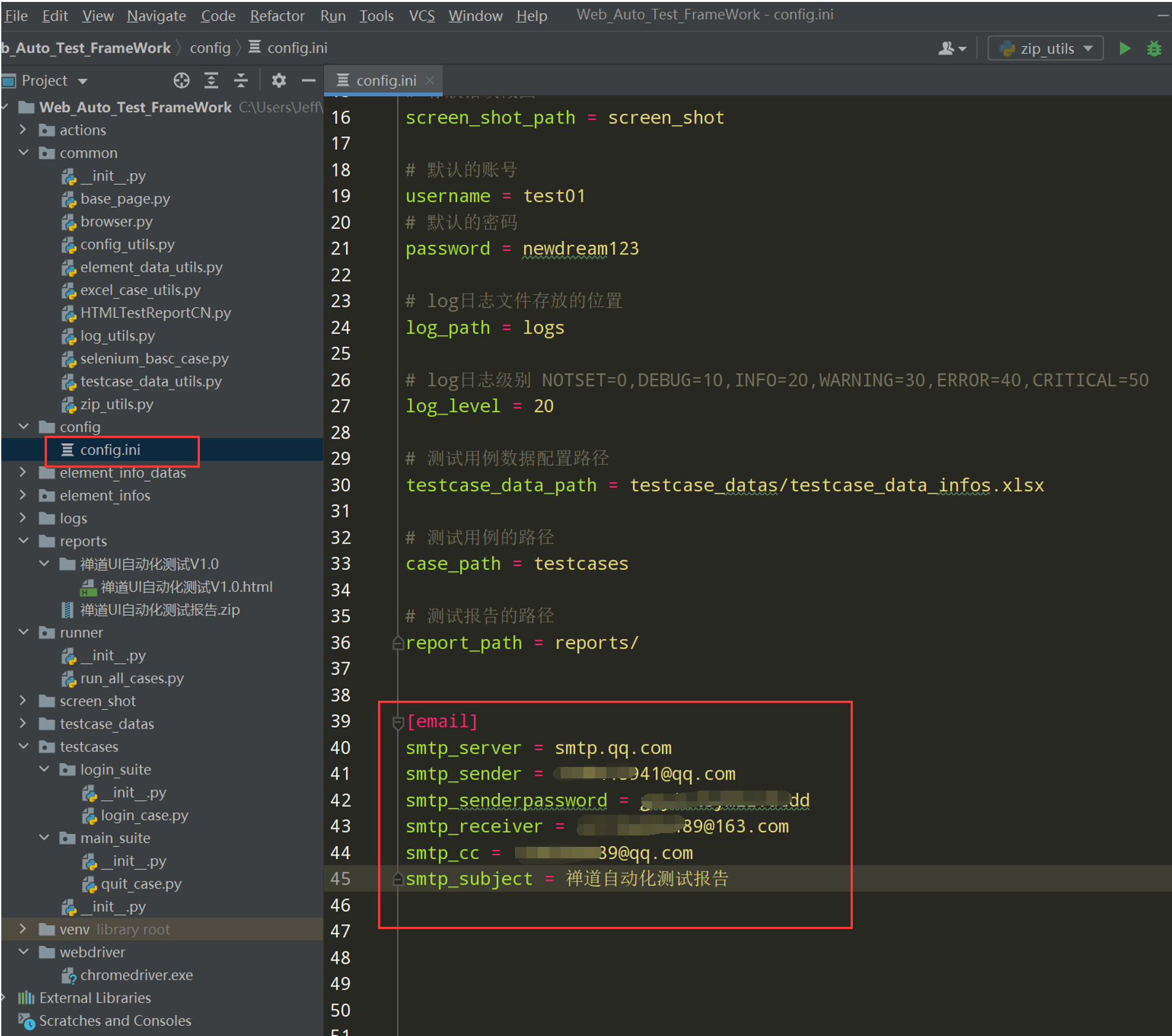
在config_utils文件中调用ini文件中的信息;
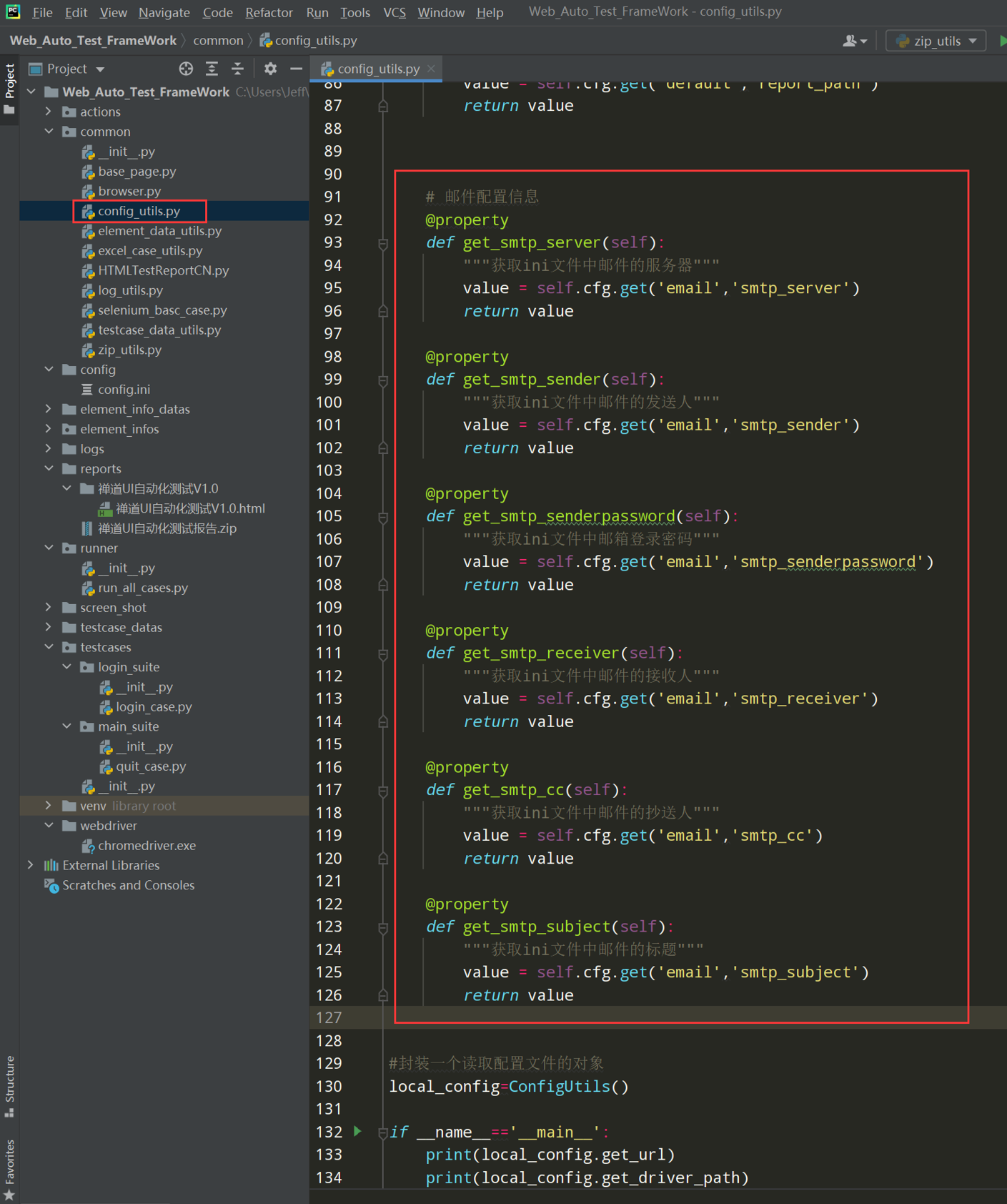
代码示例:
# 邮件配置信息 @property def get_smtp_server(self): """获取ini文件中邮件的服务器""" value = self.cfg.get('email','smtp_server') return value @property def get_smtp_sender(self): """获取ini文件中邮件的发送人""" value = self.cfg.get('email','smtp_sender') return value @property def get_smtp_senderpassword(self): """获取ini文件中邮箱登录密码""" value = self.cfg.get('email','smtp_senderpassword') return value @property def get_smtp_receiver(self): """获取ini文件中邮件的接收人""" value = self.cfg.get('email','smtp_receiver') return value @property def get_smtp_cc(self): """获取ini文件中邮件的抄送人""" value = self.cfg.get('email','smtp_cc') return value @property def get_smtp_subject(self): """获取ini文件中邮件的标题""" value = self.cfg.get('email','smtp_subject') return value
查看执行结果:
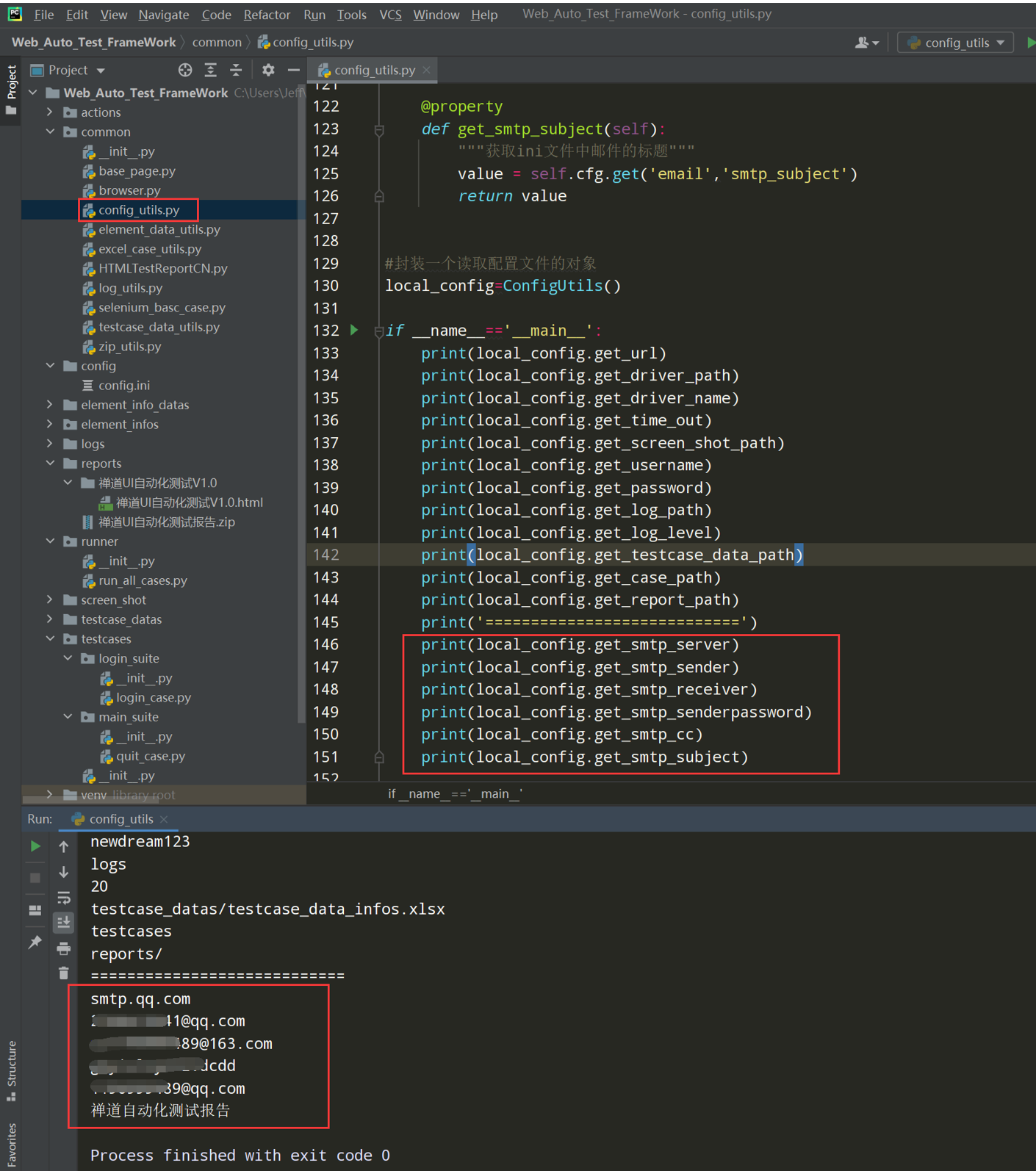
步骤5:封装发送邮件的代码
在common文件下新建email_utils.py;
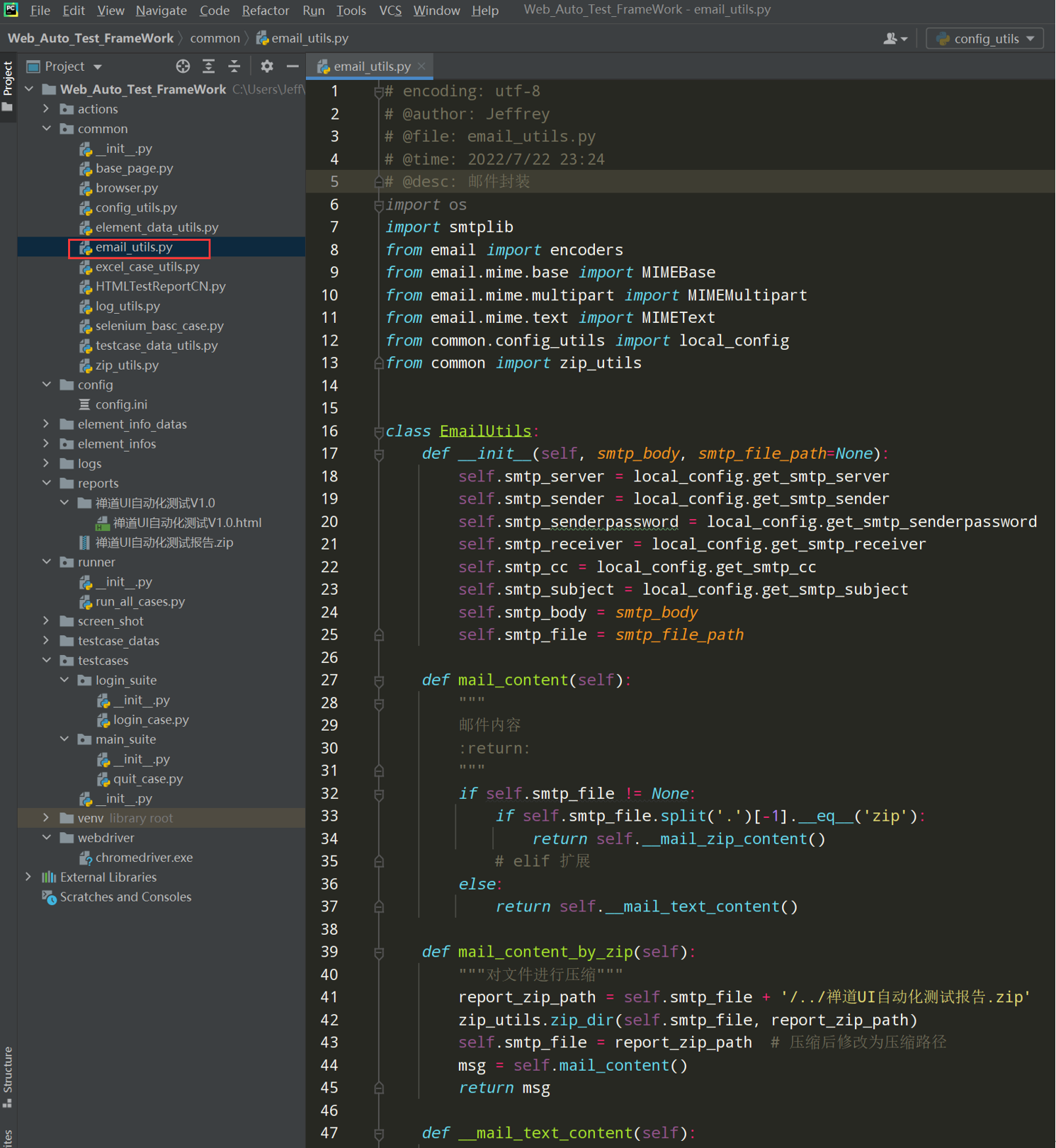
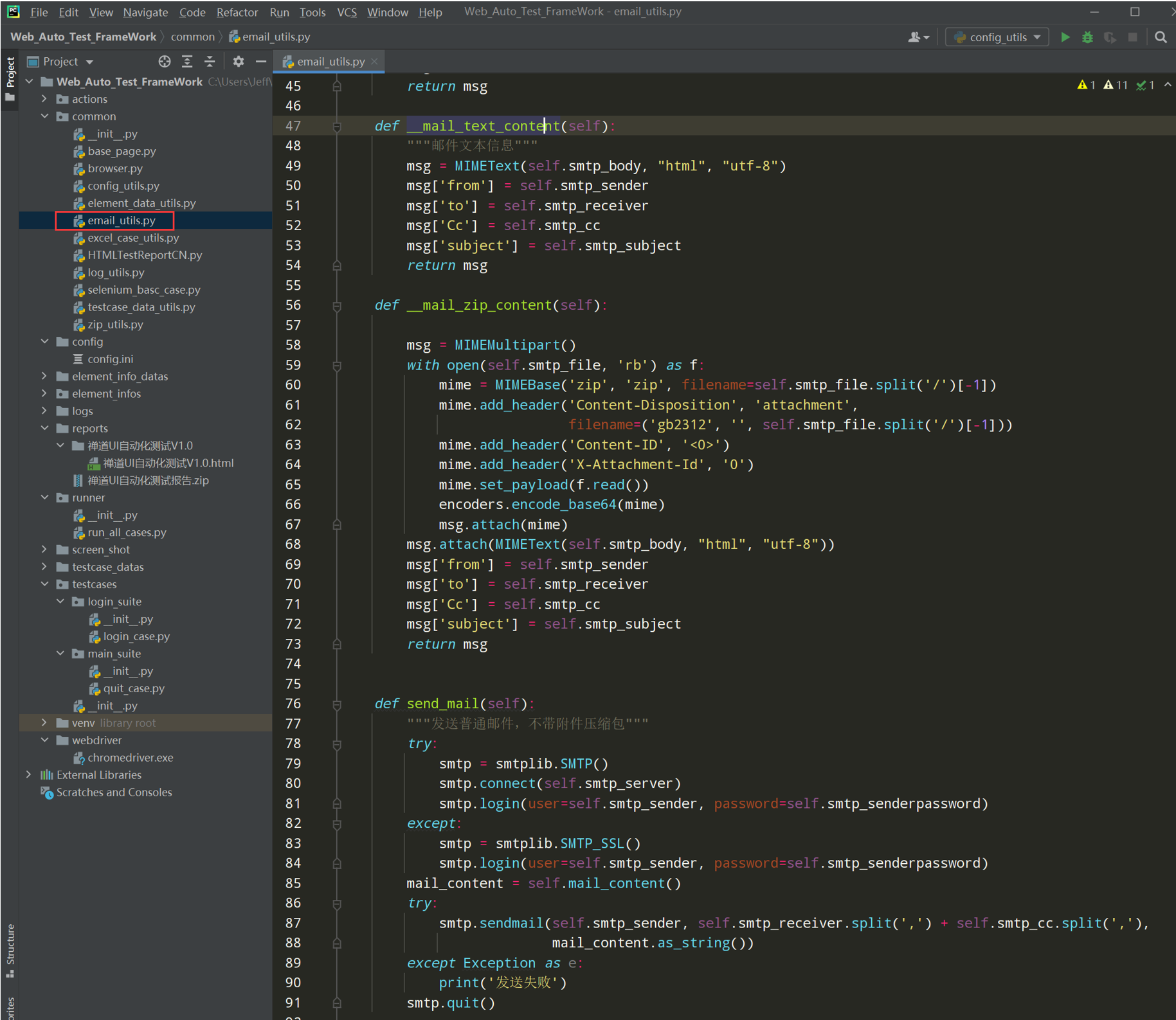
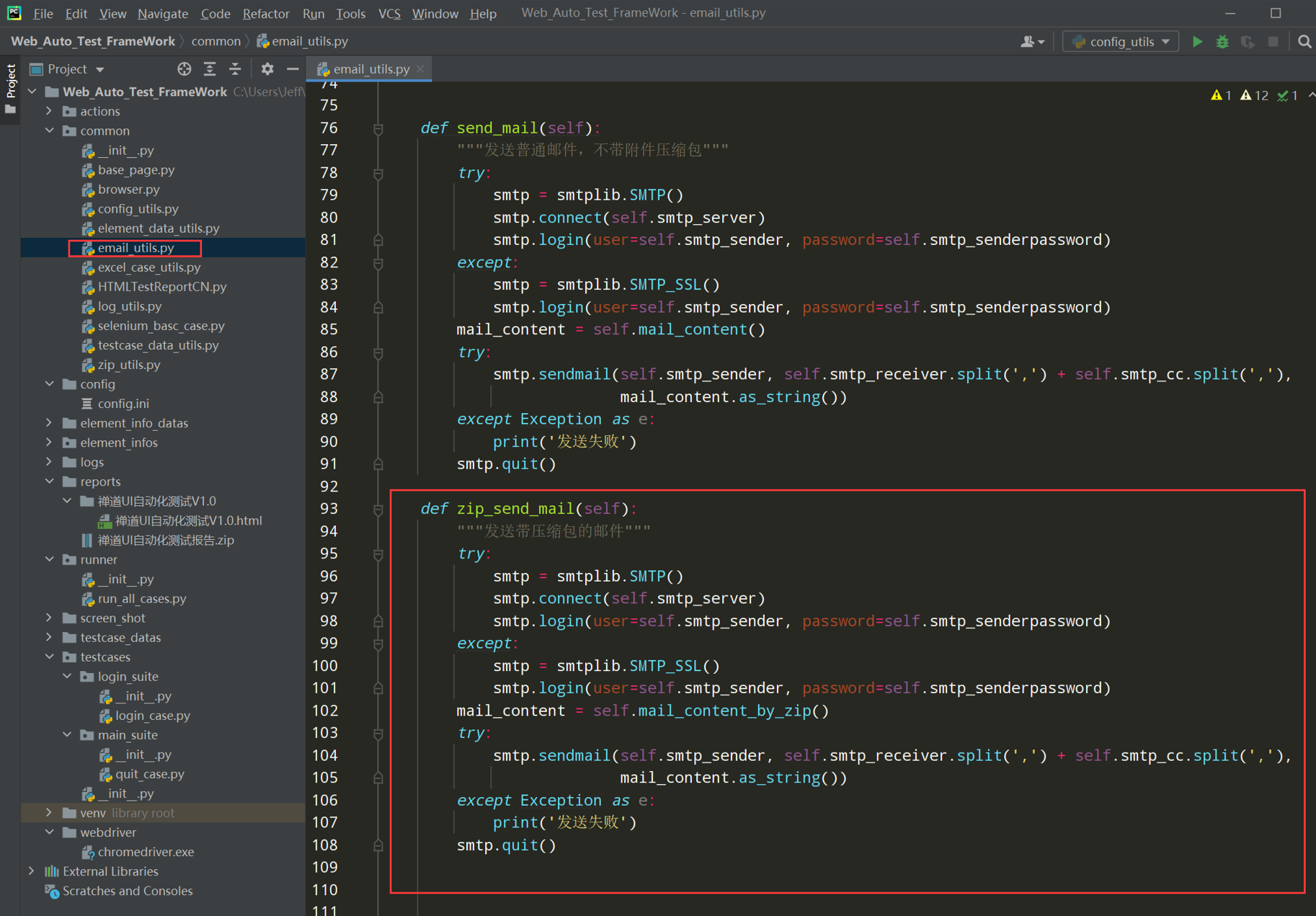
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: email_utils.py # @time: 2022/7/22 23:24 # @desc: 邮件封装 import os import smtplib from email import encoders from email.mime.base import MIMEBase from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText from common.config_utils import local_config from common import zip_utils class EmailUtils: def __init__(self, smtp_body, smtp_file_path=None): self.smtp_server = local_config.get_smtp_server self.smtp_sender = local_config.get_smtp_sender self.smtp_senderpassword = local_config.get_smtp_senderpassword self.smtp_receiver = local_config.get_smtp_receiver self.smtp_cc = local_config.get_smtp_cc self.smtp_subject = local_config.get_smtp_subject self.smtp_body = smtp_body self.smtp_file = smtp_file_path def mail_content(self): """ 邮件内容 :return: """ if self.smtp_file != None: if self.smtp_file.split('.')[-1].__eq__('zip'): return self.__mail_zip_content() # elif 扩展 else: return self.__mail_text_content() def mail_content_by_zip(self): """对文件进行压缩""" report_zip_path = self.smtp_file + '/../禅道UI自动化测试报告.zip' zip_utils.zip_dir(self.smtp_file, report_zip_path) self.smtp_file = report_zip_path # 压缩后修改为压缩路径 msg = self.mail_content() return msg def __mail_text_content(self): """邮件文本信息""" msg = MIMEText(self.smtp_body, "html", "utf-8") msg['from'] = self.smtp_sender msg['to'] = self.smtp_receiver msg['Cc'] = self.smtp_cc msg['subject'] = self.smtp_subject return msg def __mail_zip_content(self): msg = MIMEMultipart() with open(self.smtp_file, 'rb') as f: mime = MIMEBase('zip', 'zip', filename=self.smtp_file.split('/')[-1]) mime.add_header('Content-Disposition', 'attachment', filename=('gb2312', '', self.smtp_file.split('/')[-1])) mime.add_header('Content-ID', '<0>') mime.add_header('X-Attachment-Id', '0') mime.set_payload(f.read()) encoders.encode_base64(mime) msg.attach(mime) msg.attach(MIMEText(self.smtp_body, "html", "utf-8")) msg['from'] = self.smtp_sender msg['to'] = self.smtp_receiver msg['Cc'] = self.smtp_cc msg['subject'] = self.smtp_subject return msg def send_mail(self): """发送普通邮件,不带附件压缩包""" try: smtp = smtplib.SMTP() smtp.connect(self.smtp_server) smtp.login(user=self.smtp_sender, password=self.smtp_senderpassword) except: smtp = smtplib.SMTP_SSL() smtp.login(user=self.smtp_sender, password=self.smtp_senderpassword) mail_content = self.mail_content() try: smtp.sendmail(self.smtp_sender, self.smtp_receiver.split(',') + self.smtp_cc.split(','), mail_content.as_string()) except Exception as e: print('发送失败') smtp.quit() def zip_send_mail(self): """发送带压缩包的邮件""" try: smtp = smtplib.SMTP() smtp.connect(self.smtp_server) smtp.login(user=self.smtp_sender, password=self.smtp_senderpassword) except: smtp = smtplib.SMTP_SSL() smtp.login(user=self.smtp_sender, password=self.smtp_senderpassword) mail_content = self.mail_content_by_zip() try: smtp.sendmail(self.smtp_sender, self.smtp_receiver.split(',') + self.smtp_cc.split(','), mail_content.as_string()) except Exception as e: print('发送失败') smtp.quit()
步骤6:把压缩文件代码和发送邮件代码整合到run_all_cases.py框架中
导包:
from common.zip_utils import zip_dir
from common.email_utils import EmailUtils
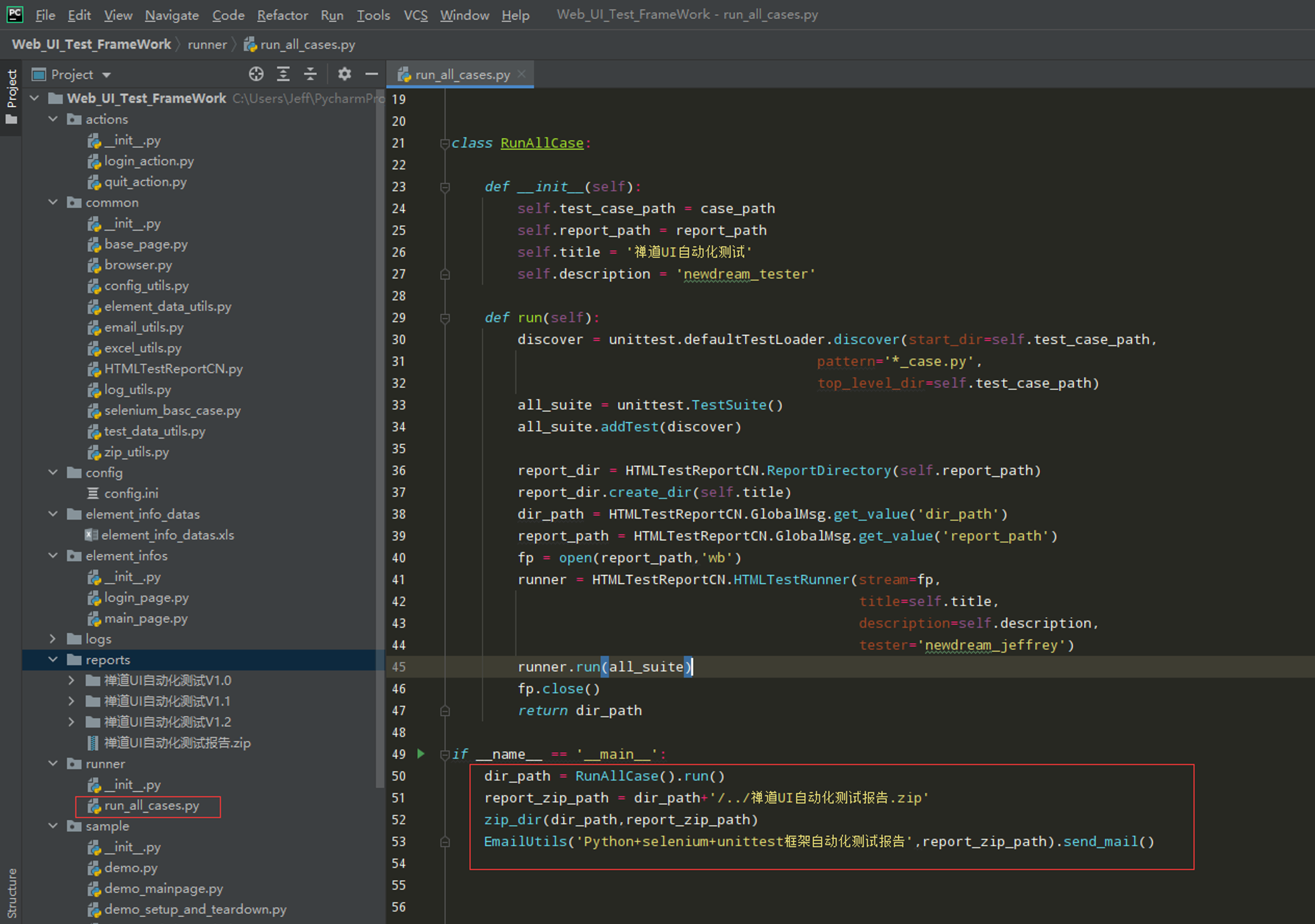
代码示例:
import os import unittest from common import HTMLTestReportCN from common.config_utils import local_config from common.zip_utils import zip_dir from common.email_utils import EmailUtils current_path = os.path.dirname(__file__) case_path = os.path.join(current_path,'..',local_config.get_case_path) report_path = os.path.join(current_path,'..',local_config.get_report_path) class RunAllCase: def __init__(self): self.test_case_path = case_path self.report_path = report_path self.title = '禅道UI自动化测试' self.description = 'newdream_tester' def run(self): discover = unittest.defaultTestLoader.discover(start_dir=self.test_case_path, pattern='*_case.py', top_level_dir=self.test_case_path) all_suite = unittest.TestSuite() all_suite.addTest(discover) report_dir = HTMLTestReportCN.ReportDirectory(self.report_path) report_dir.create_dir(self.title) dir_path = HTMLTestReportCN.GlobalMsg.get_value('dir_path') report_path = HTMLTestReportCN.GlobalMsg.get_value('report_path') fp = open(report_path,'wb') runner = HTMLTestReportCN.HTMLTestRunner(stream=fp, title=self.title, description=self.description, tester='newdream_jeffrey') runner.run(all_suite) fp.close() return dir_path if __name__ == '__main__': dir_path = RunAllCase().run() report_zip_path = dir_path+'/../禅道UI自动化测试报告.zip' zip_dir(dir_path,report_zip_path) EmailUtils('Python+selenium+unittest框架自动化测试报告',report_zip_path).send_mail()
执行run_all_cases.py查看执行结果:
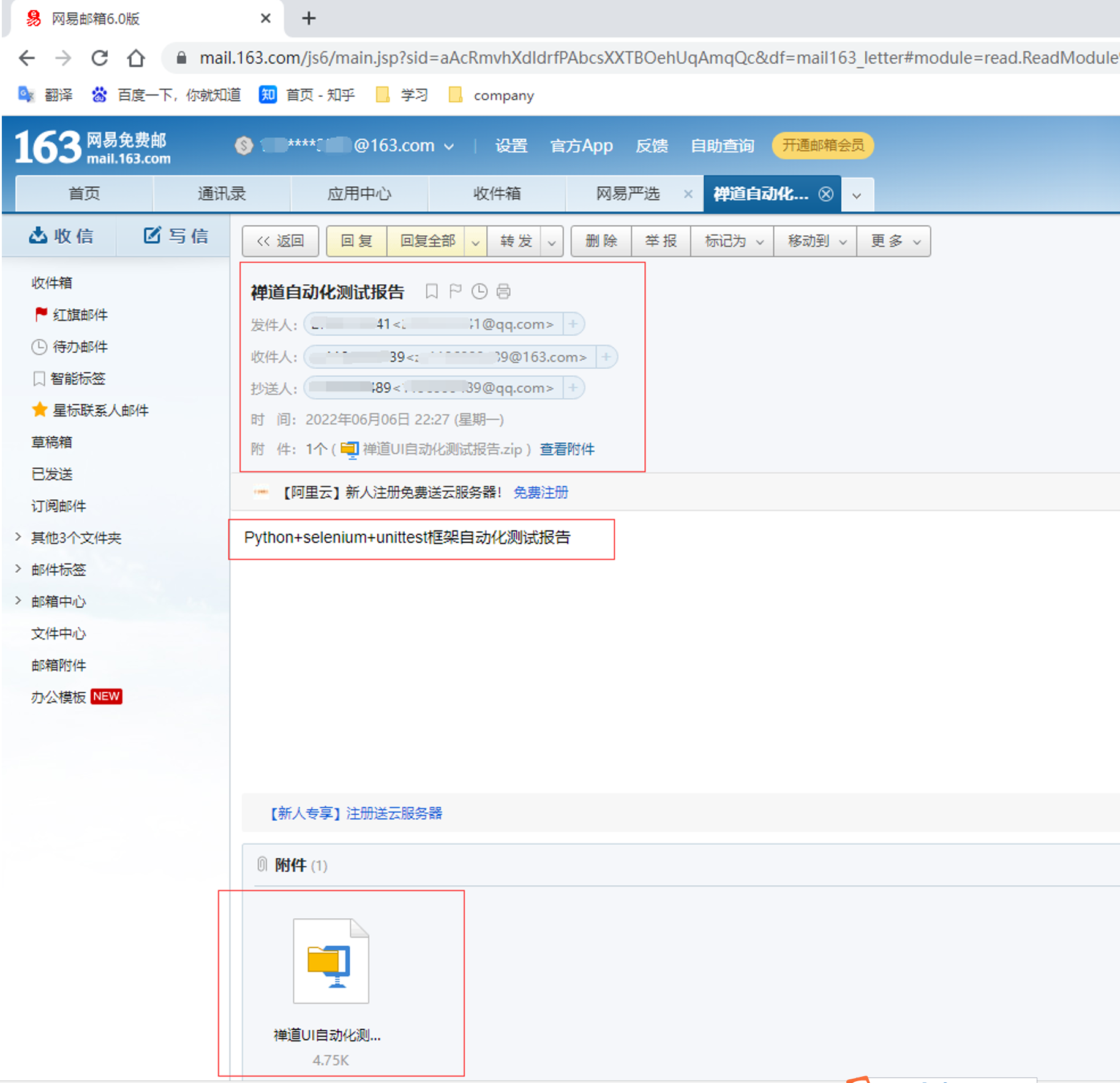
步骤7:把压缩文件打包功能封装到发送邮件中(详细代码见步骤5)
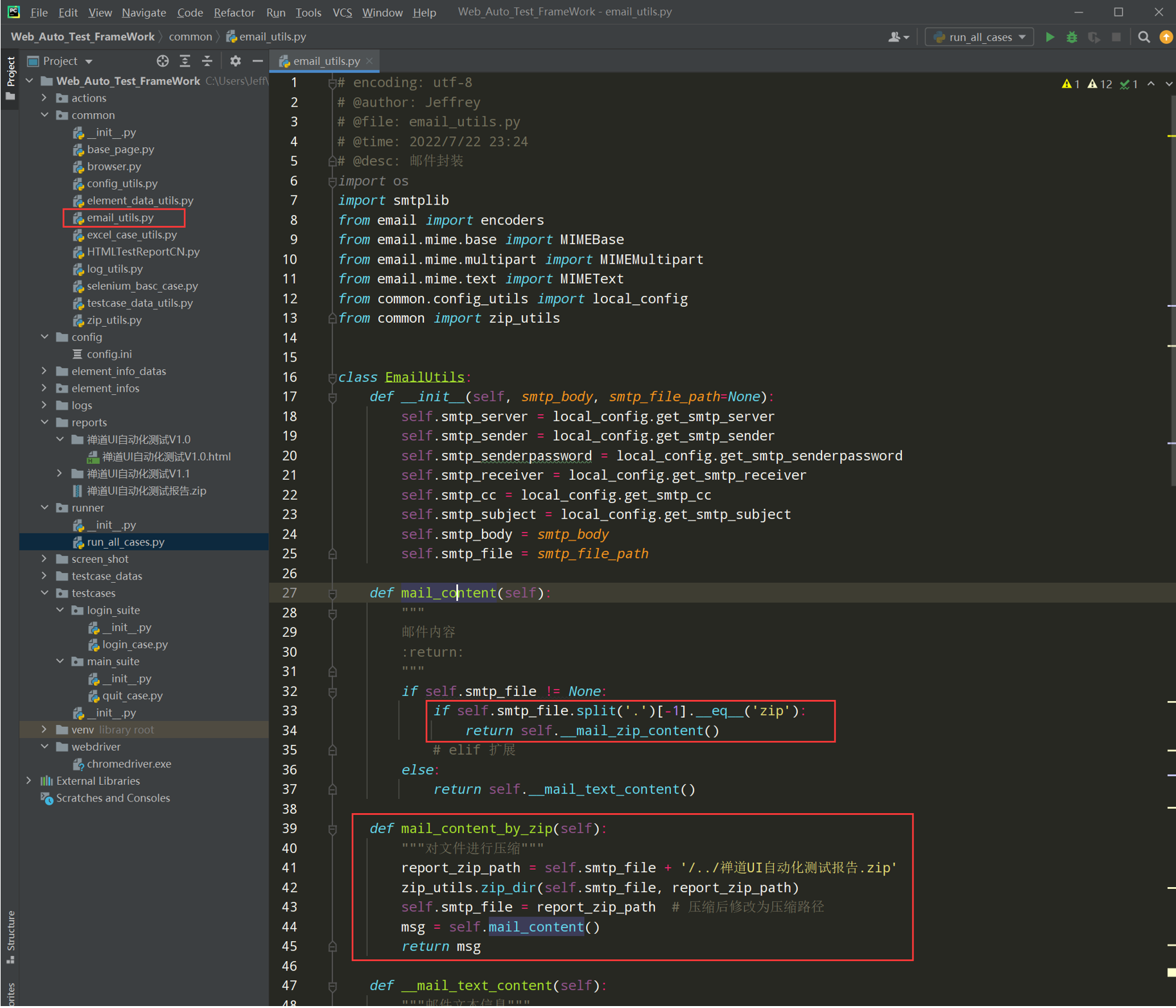
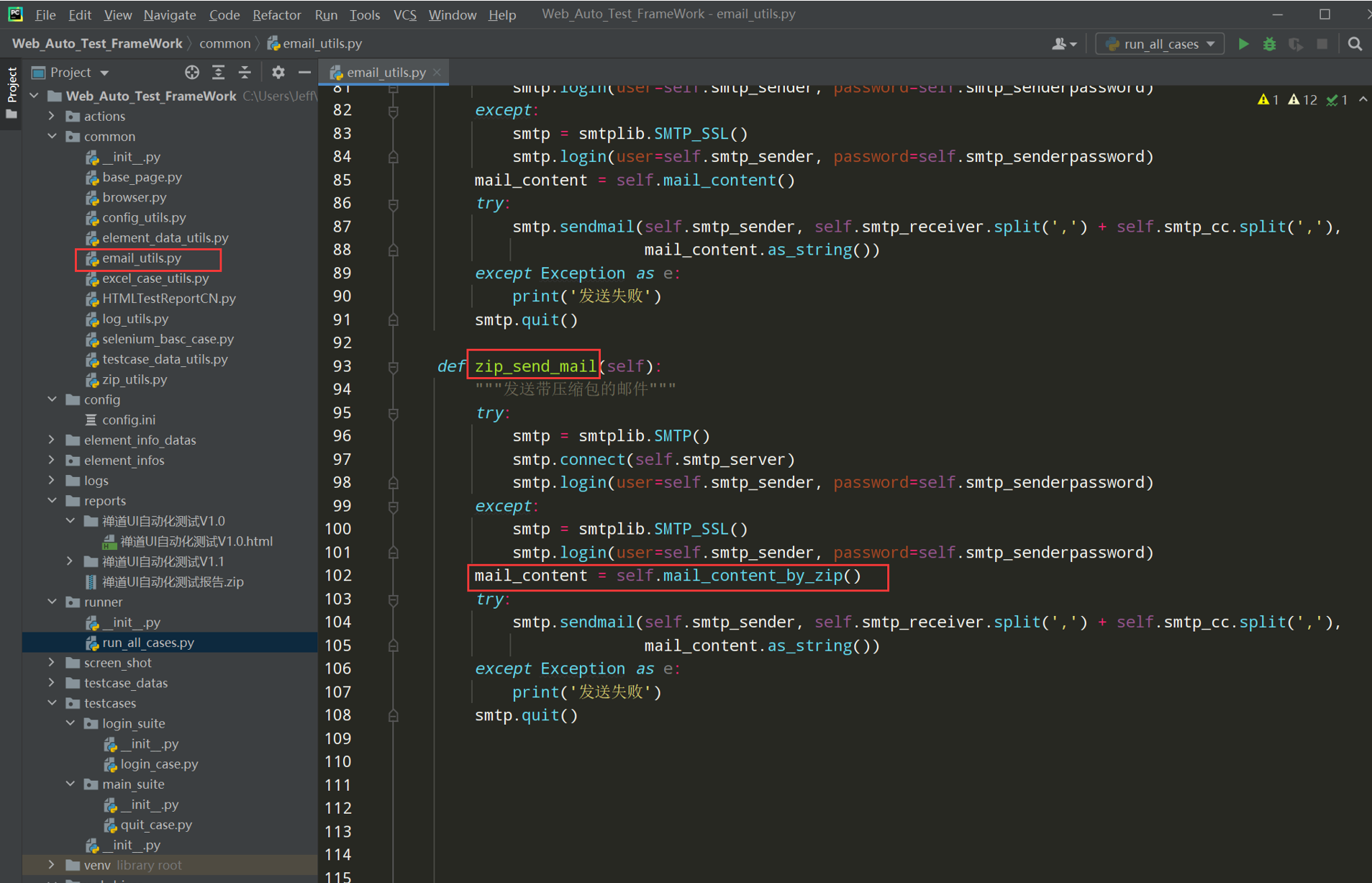
步骤8:执行,检查是否可以收到邮件,附件为测试结果打包的文件夹
执行run_all_cases.py,查收邮件
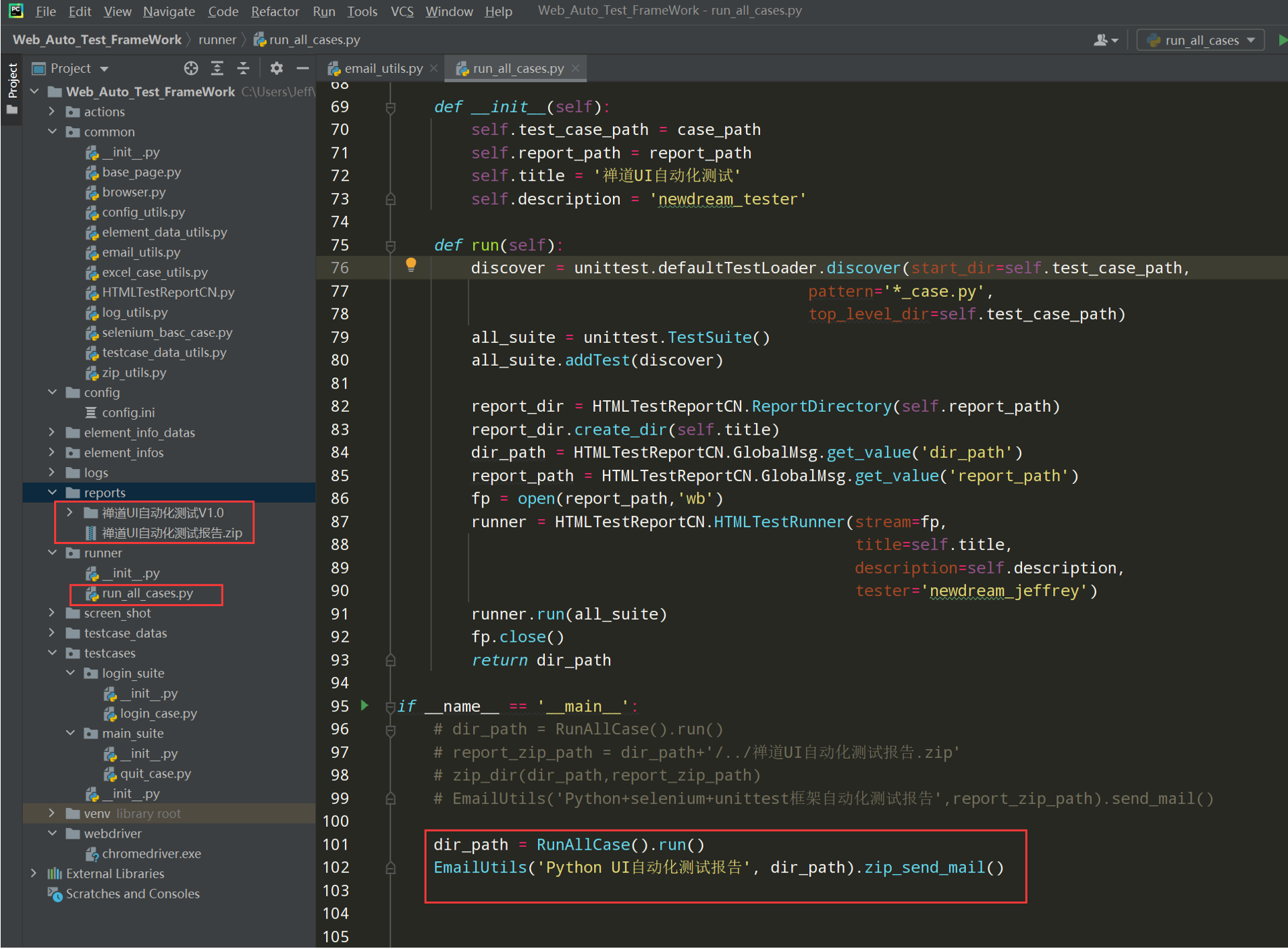
查看执行结果:
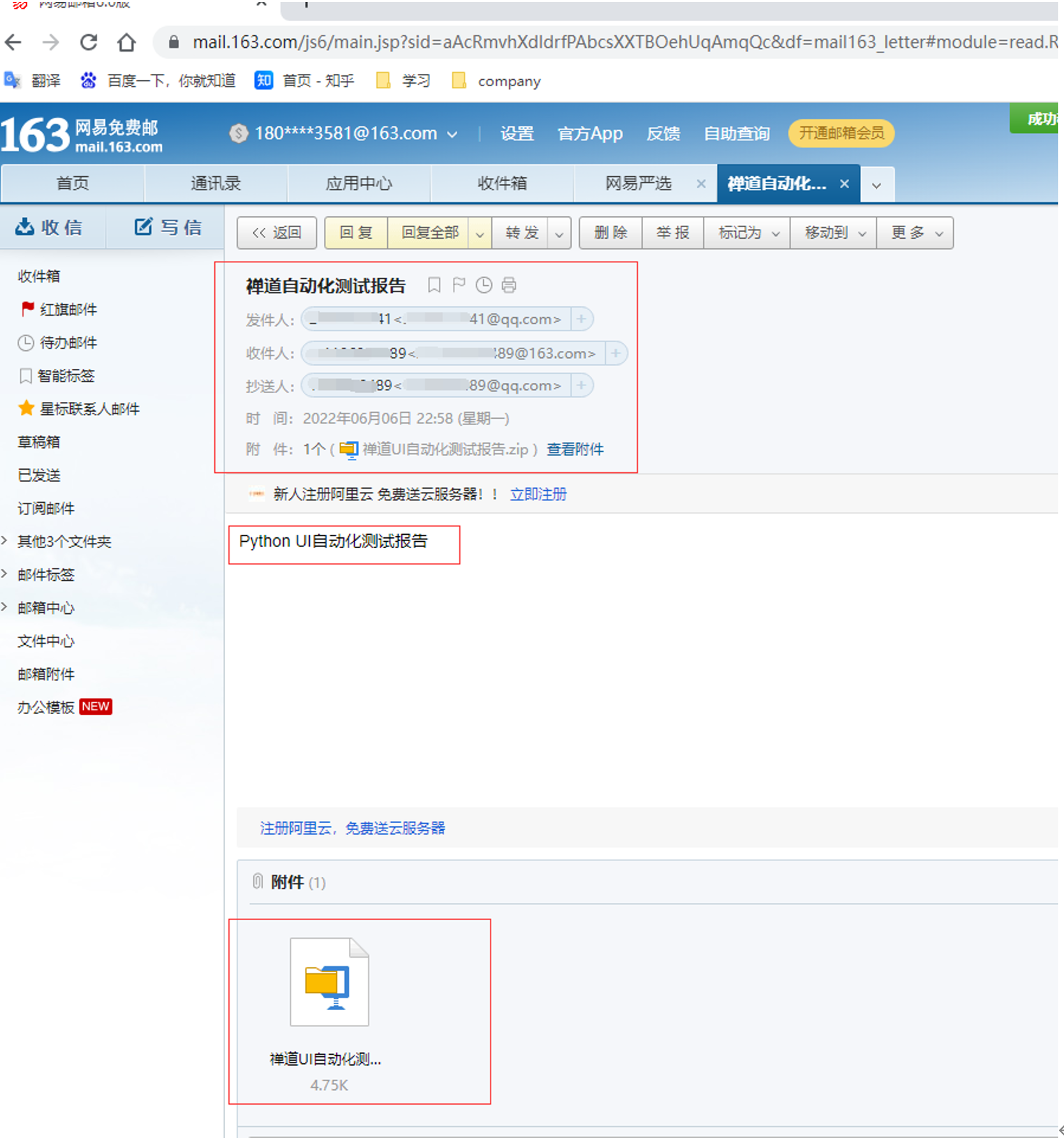
框架17-元素识别数据的优化

多人协助办公
痛苦点1:多人同时编写测试用例的时候,同一时间点,只能有一个人去测试数据文件
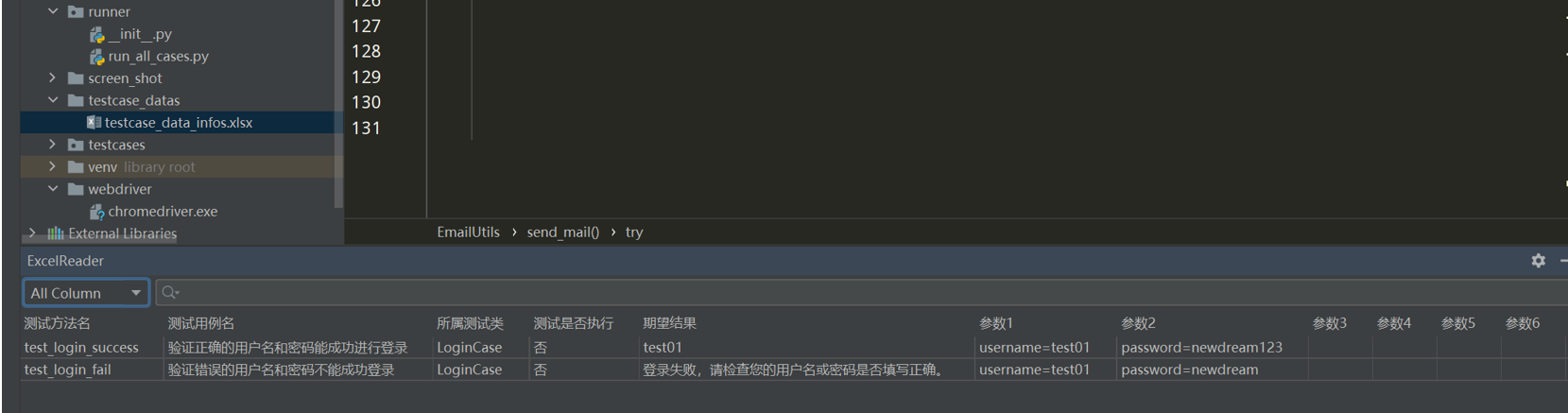
痛苦点2:分离页面的时候,只能一个人去改元素识别信息Excel
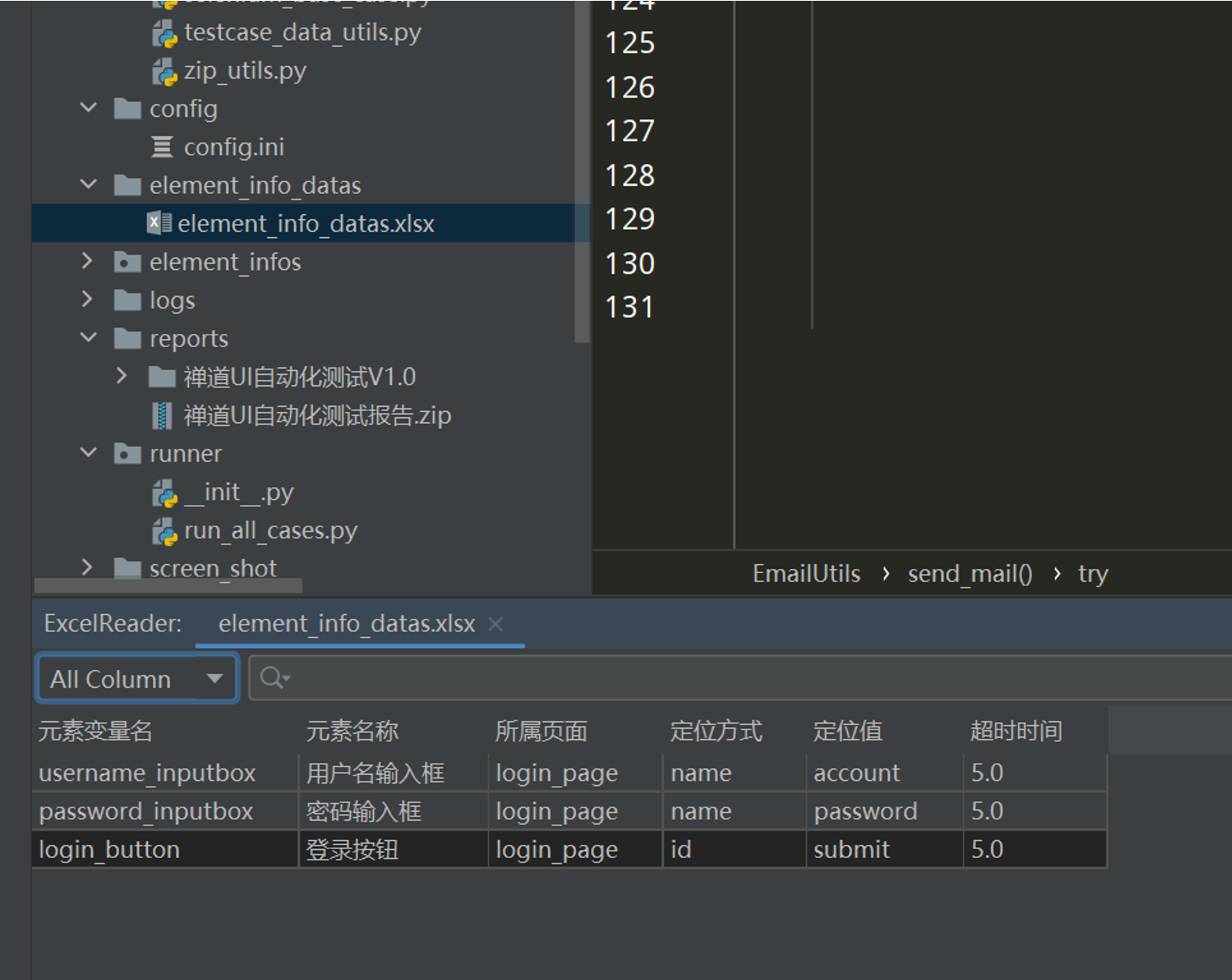
处理方法:改上面说的两个Excel文件拆开
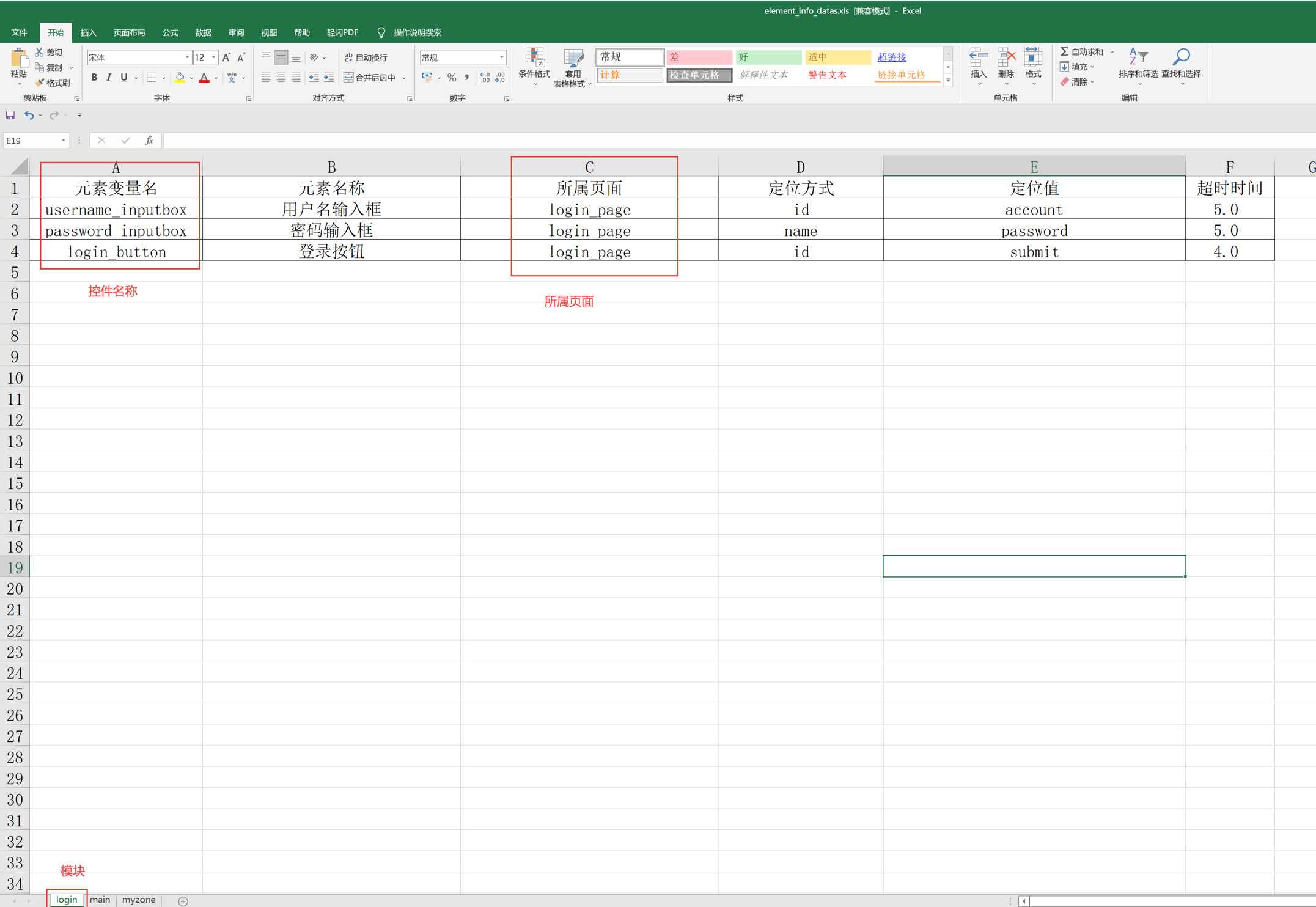
重新设计数据:
步骤1:把元素识别数据改成 模块-->页面
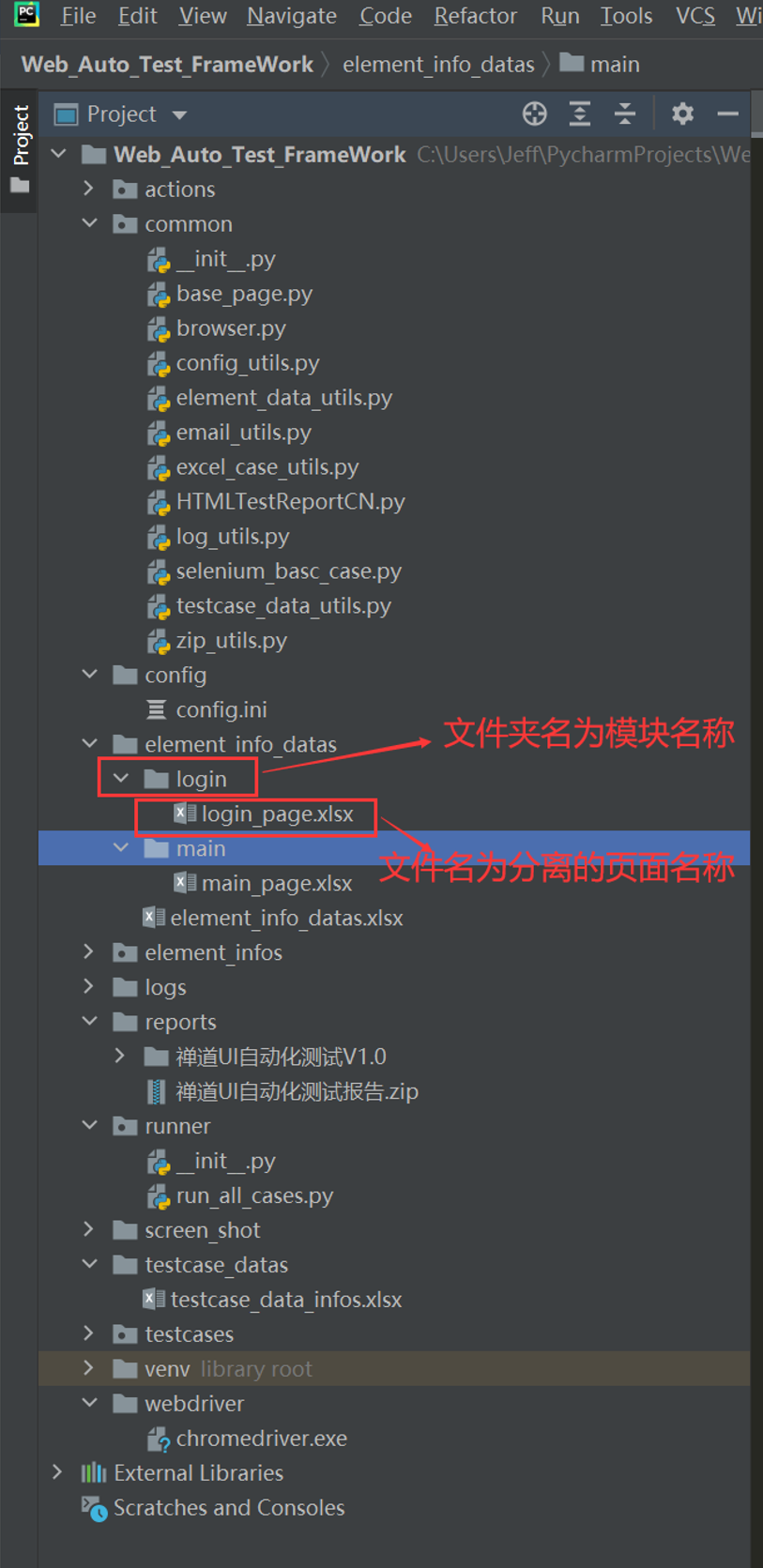
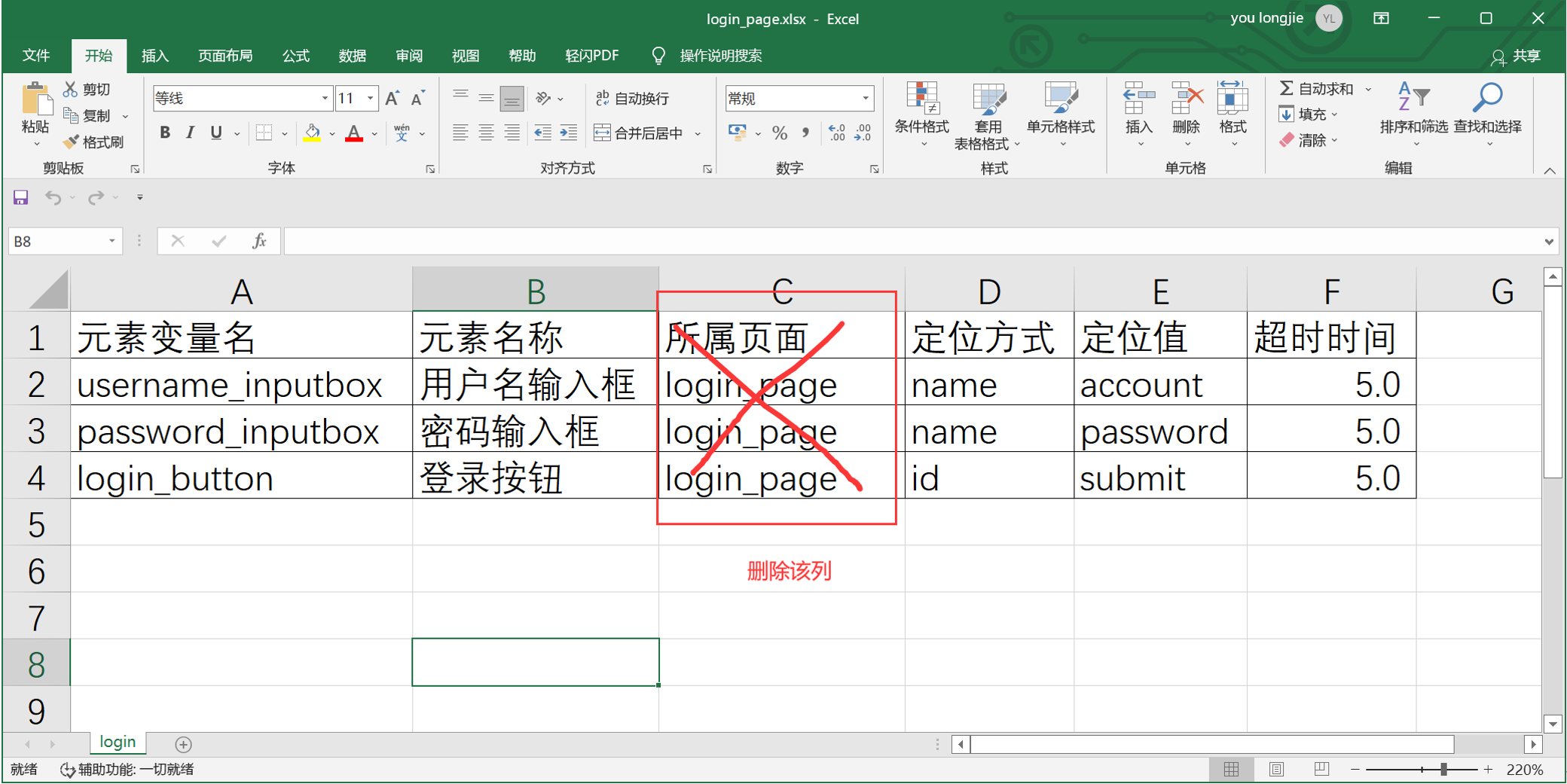
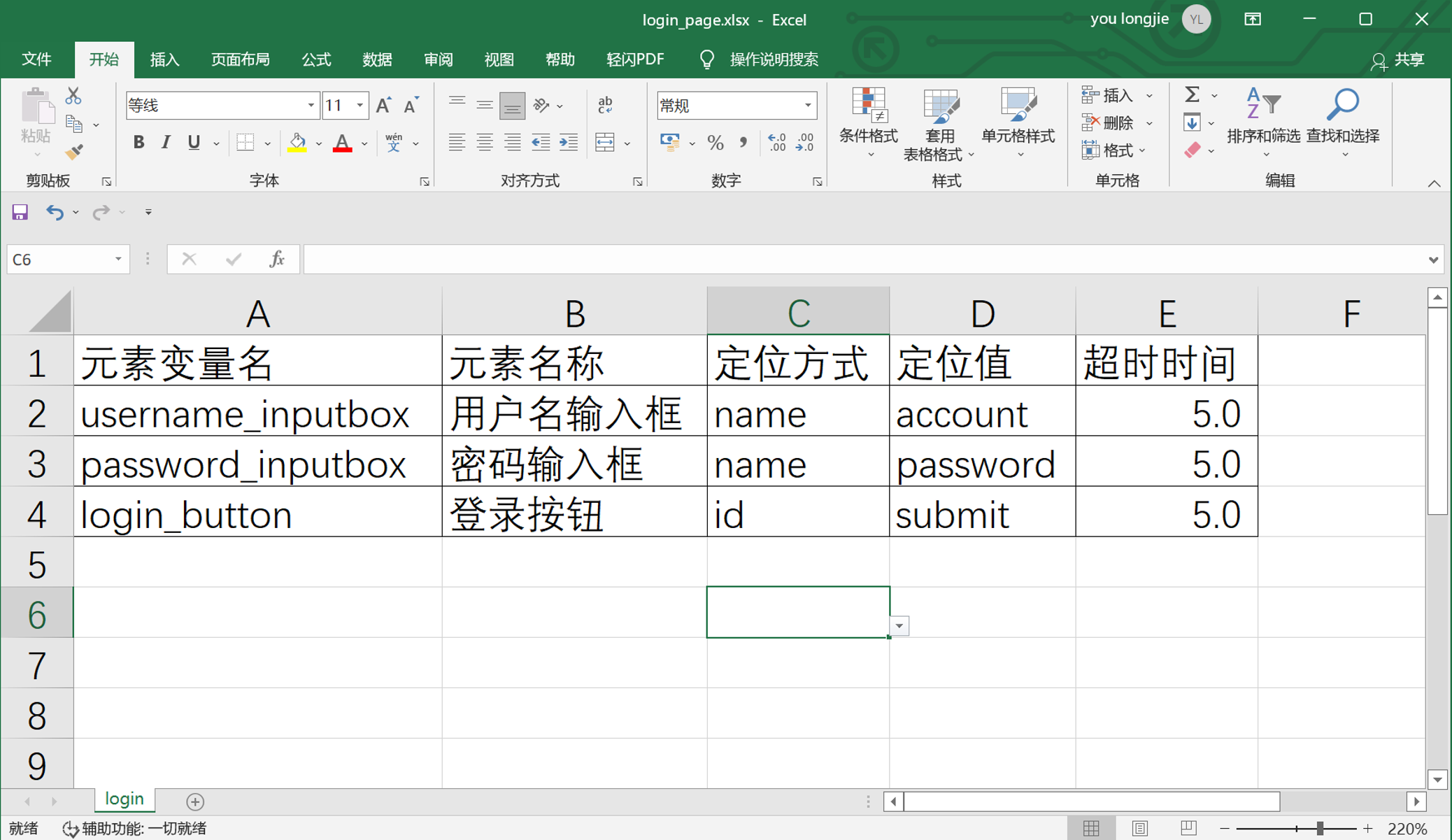
步骤2: 把页面层改成 模块-->页面
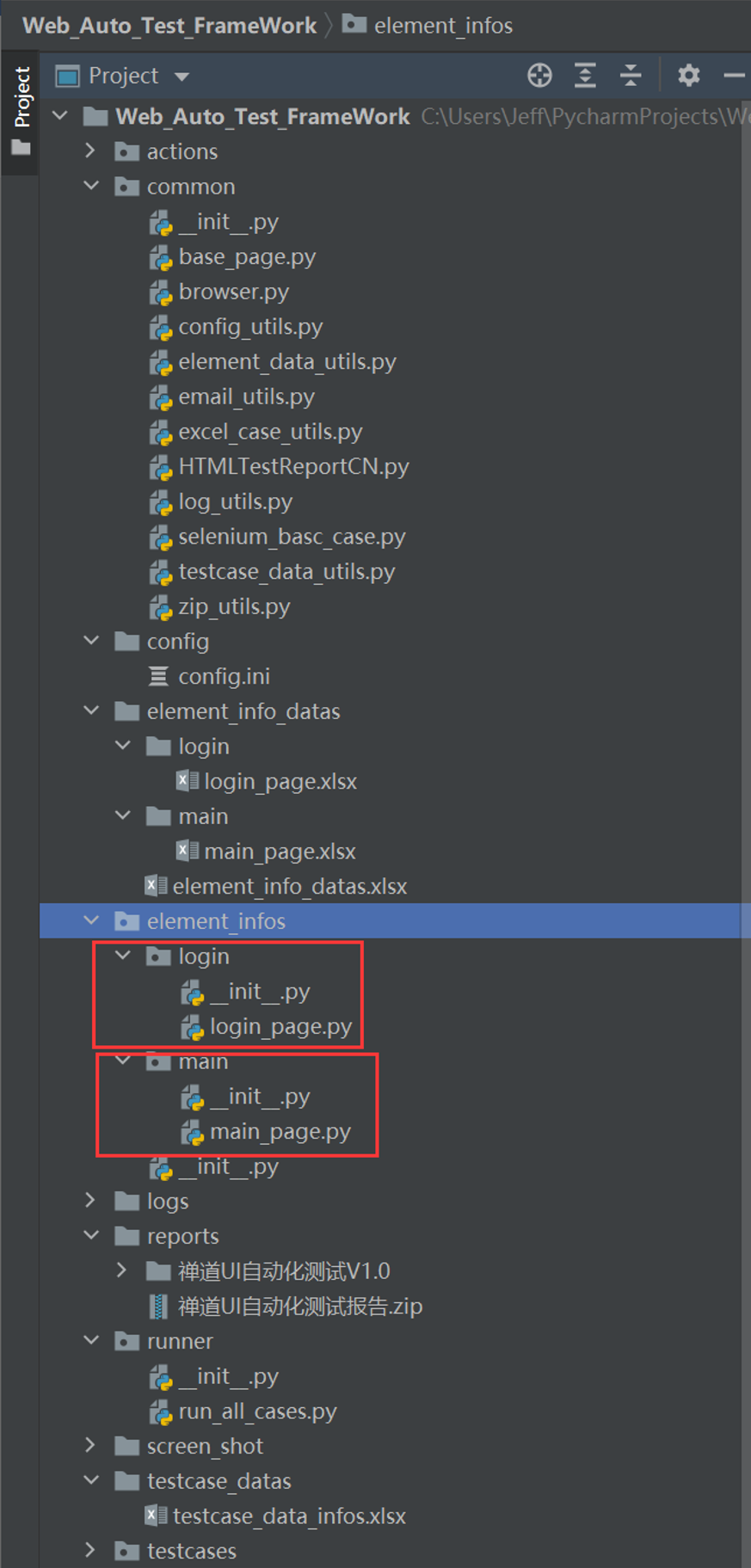
步骤3:在ini文件中配置元素识别信息的路径;如下图
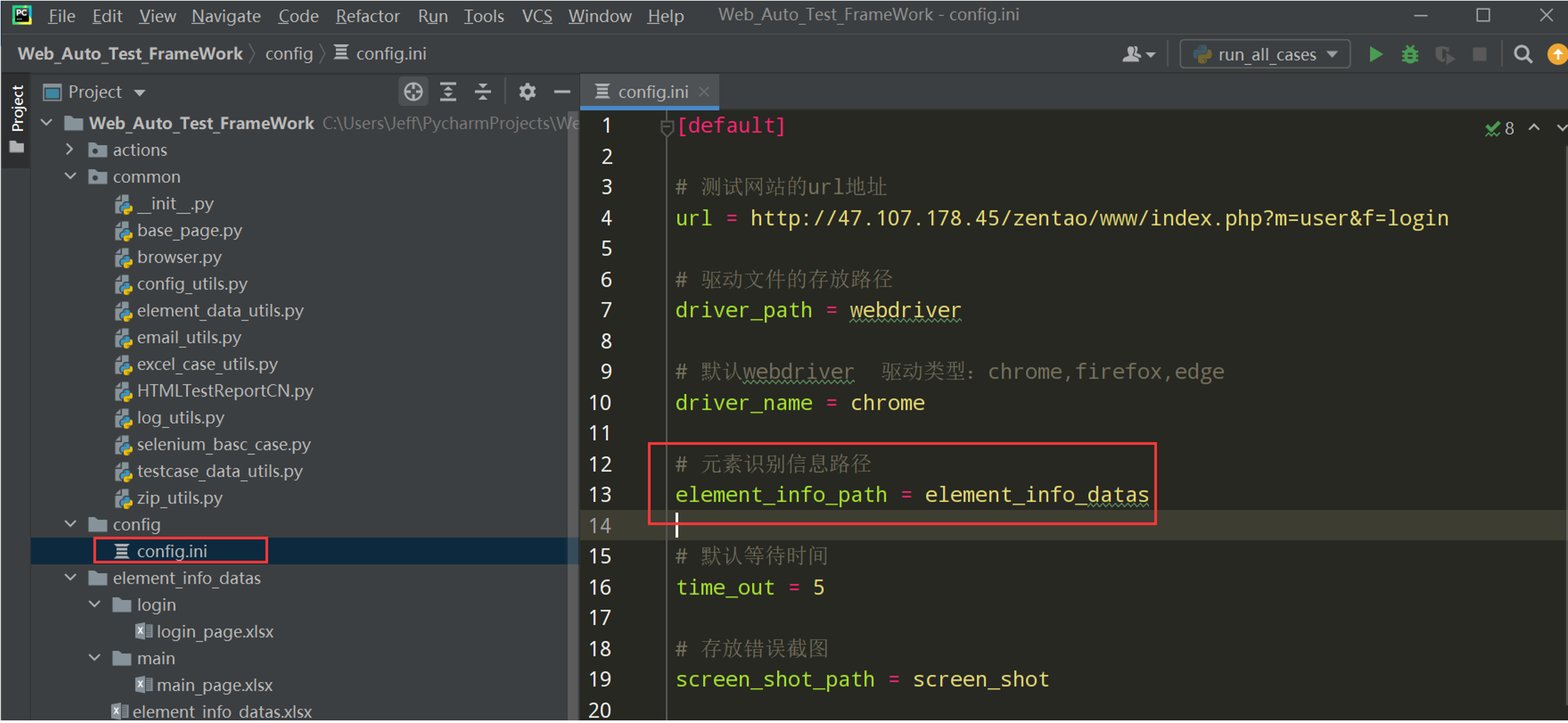
在config_utils.py中封装读取元素识别信息的路径
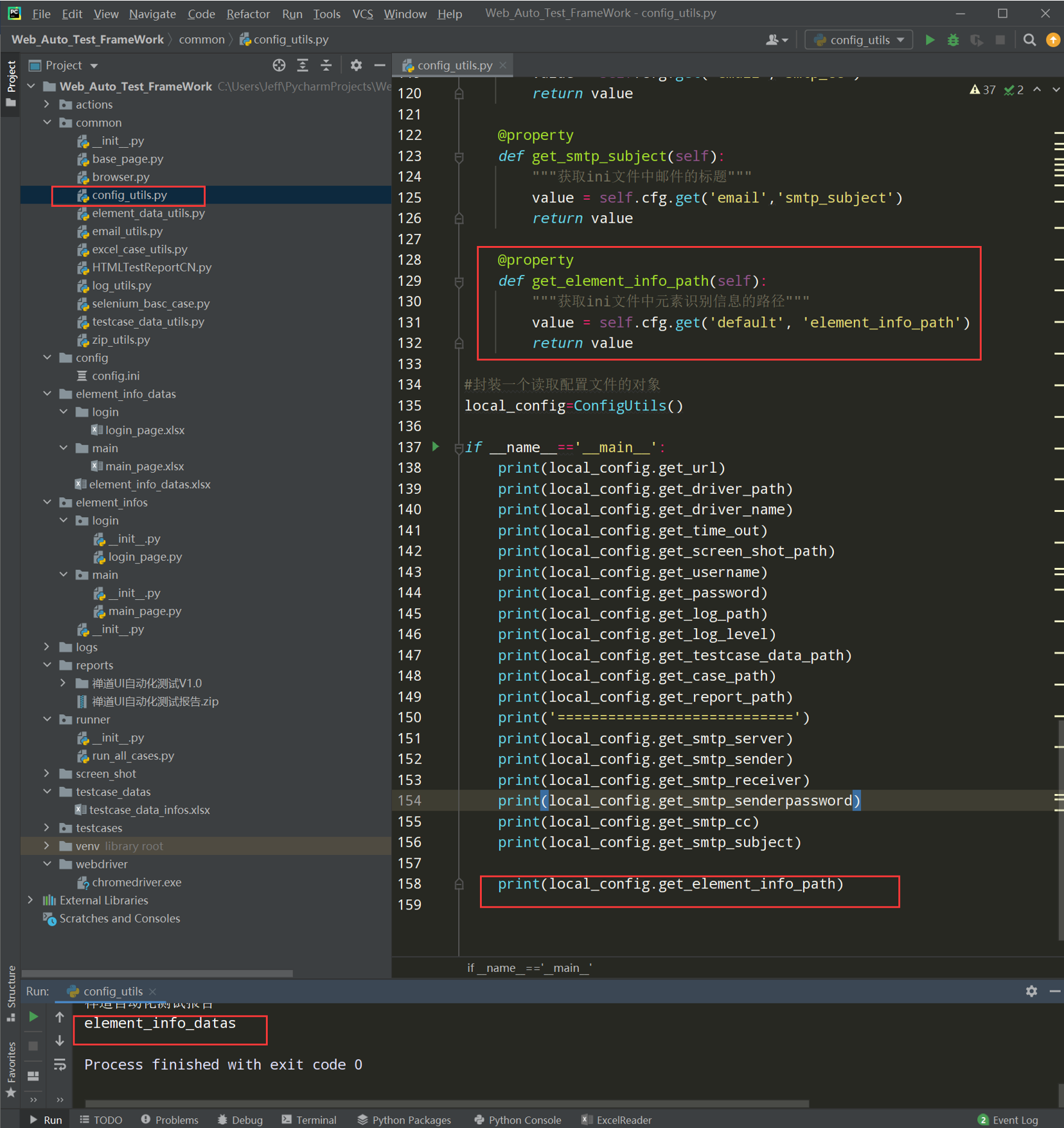
步骤4:调整element_data_utils.py文件中的代码;如下图
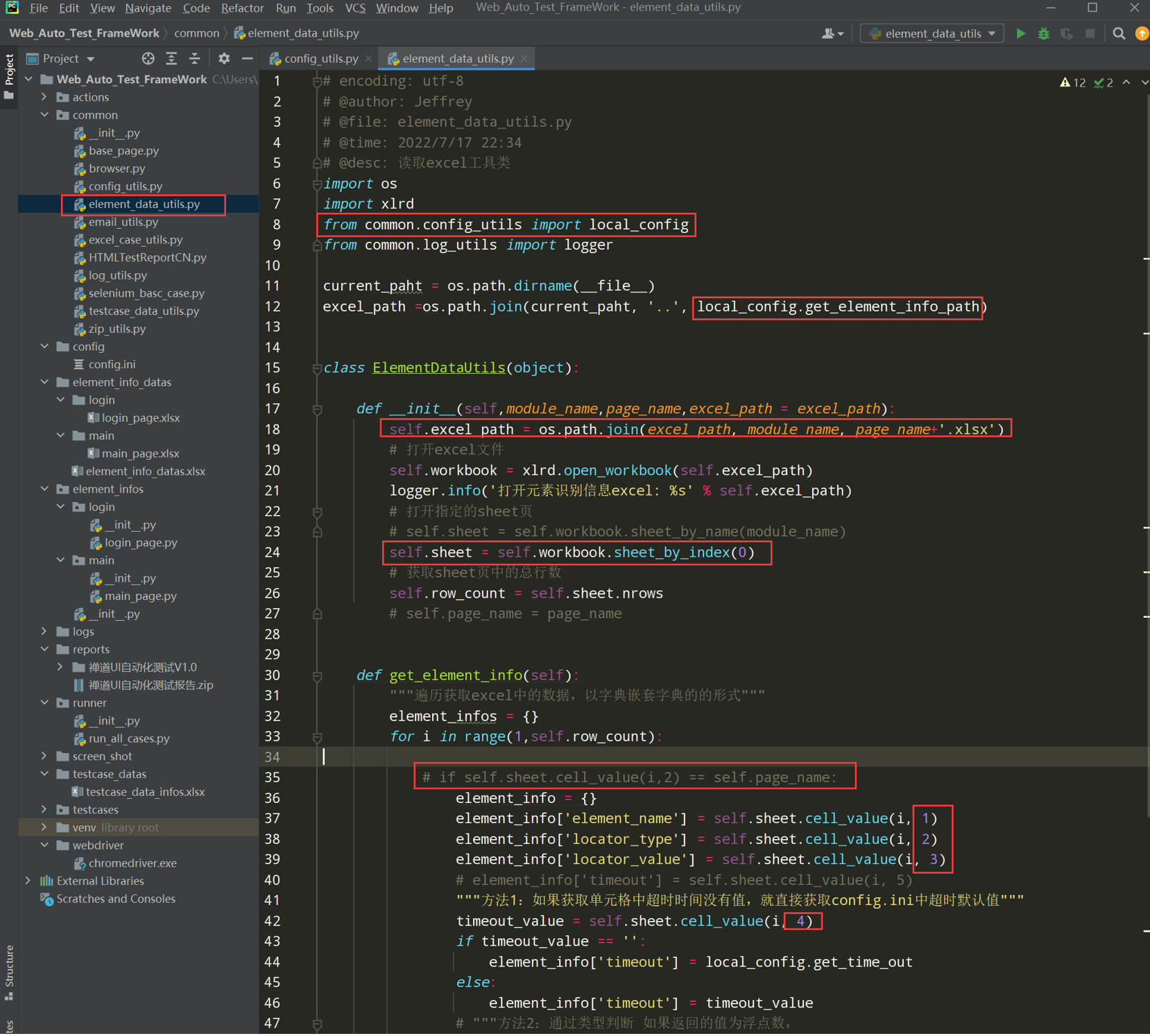
查看执行结果:
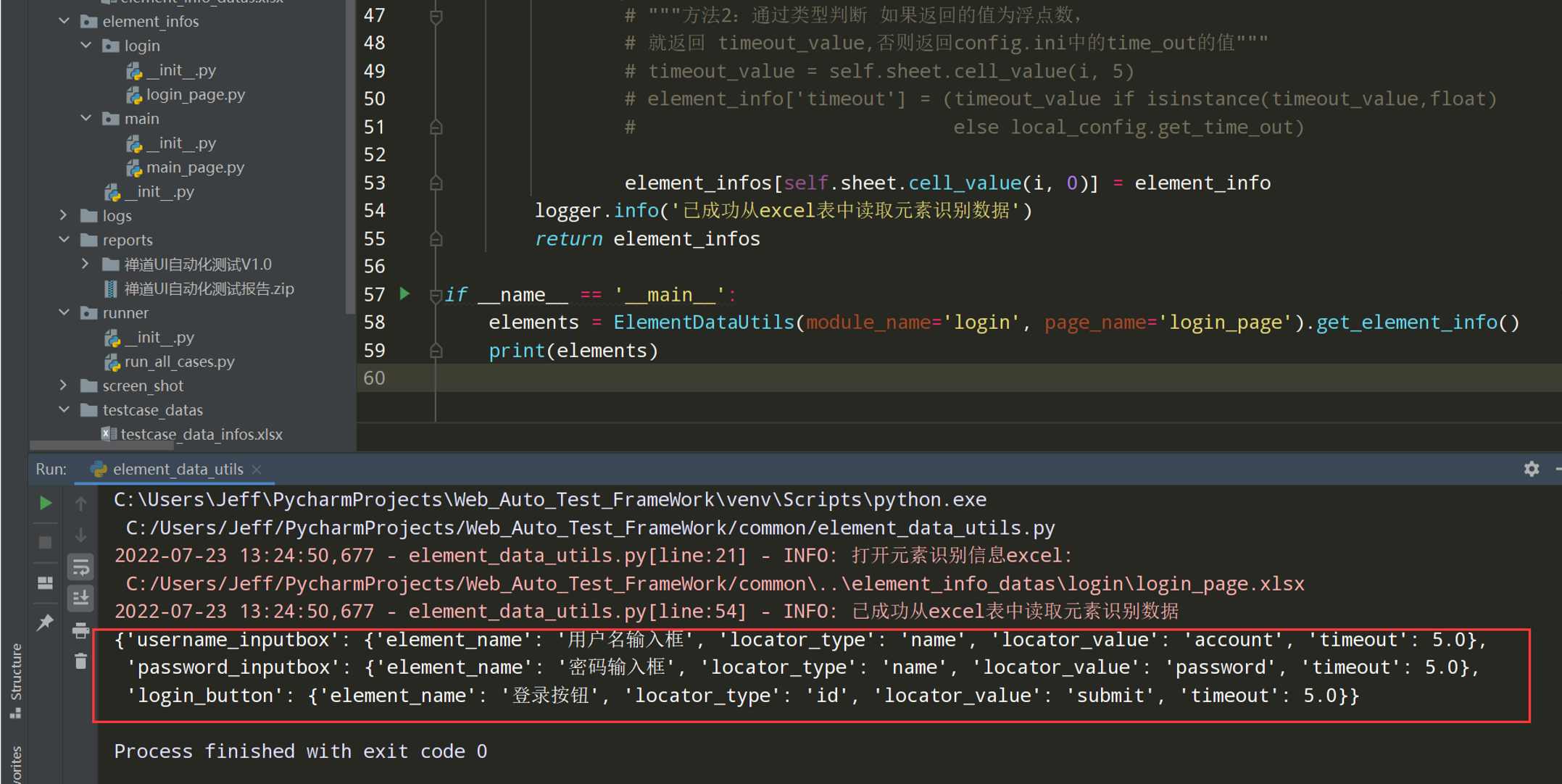
代码示例:
# encoding: utf-8 # @author: Jeffrey # @file: element_data_utils.py # @time: 2022/7/17 22:34 # @desc: 读取excel工具类 import os import xlrd from common.config_utils import local_config from common.log_utils import logger current_paht = os.path.dirname(__file__) excel_path =os.path.join(current_paht, '..', local_config.get_element_info_path) class ElementDataUtils(object): def __init__(self,module_name,page_name,excel_path = excel_path): self.excel_path = os.path.join(excel_path, module_name, page_name+'.xlsx') # 打开excel文件 self.workbook = xlrd.open_workbook(self.excel_path) logger.info('打开元素识别信息excel: %s' % self.excel_path) # 打开指定的sheet页 # self.sheet = self.workbook.sheet_by_name(module_name) self.sheet = self.workbook.sheet_by_index(0) # 获取sheet页中的总行数 self.row_count = self.sheet.nrows # self.page_name = page_name def get_element_info(self): """遍历获取excel中的数据,以字典嵌套字典的的形式""" element_infos = {} for i in range(1,self.row_count): # if self.sheet.cell_value(i,2) == self.page_name: element_info = {} element_info['element_name'] = self.sheet.cell_value(i, 1) element_info['locator_type'] = self.sheet.cell_value(i, 2) element_info['locator_value'] = self.sheet.cell_value(i, 3) # element_info['timeout'] = self.sheet.cell_value(i, 5) """方法1:如果获取单元格中超时时间没有值,就直接获取config.ini中超时默认值""" timeout_value = self.sheet.cell_value(i, 4) if timeout_value == '': element_info['timeout'] = local_config.get_time_out else: element_info['timeout'] = timeout_value # """方法2:通过类型判断 如果返回的值为浮点数, # 就返回 timeout_value,否则返回config.ini中的time_out的值""" # timeout_value = self.sheet.cell_value(i, 5) # element_info['timeout'] = (timeout_value if isinstance(timeout_value,float) # else local_config.get_time_out) element_infos[self.sheet.cell_value(i, 0)] = element_info logger.info('已成功从excel表中读取元素识别数据') return element_infos if __name__ == '__main__': elements = ElementDataUtils(module_name='login', page_name='login_page').get_element_info() print(elements)
把login_page.py文件中调用ElementDataUtils类的方法修改一下;如下图
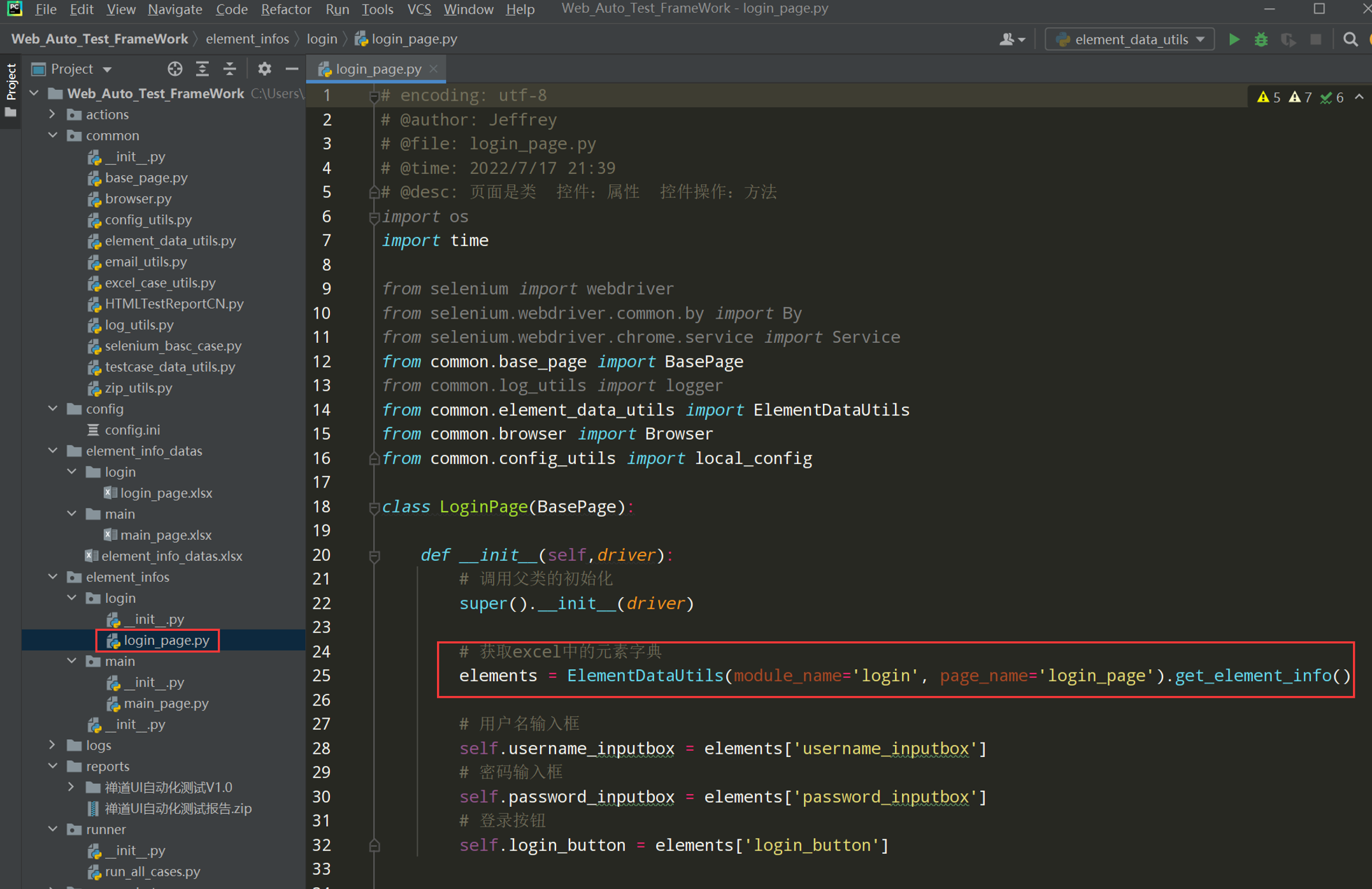
执行run_all_cases.py文件;查看是否能执行成功
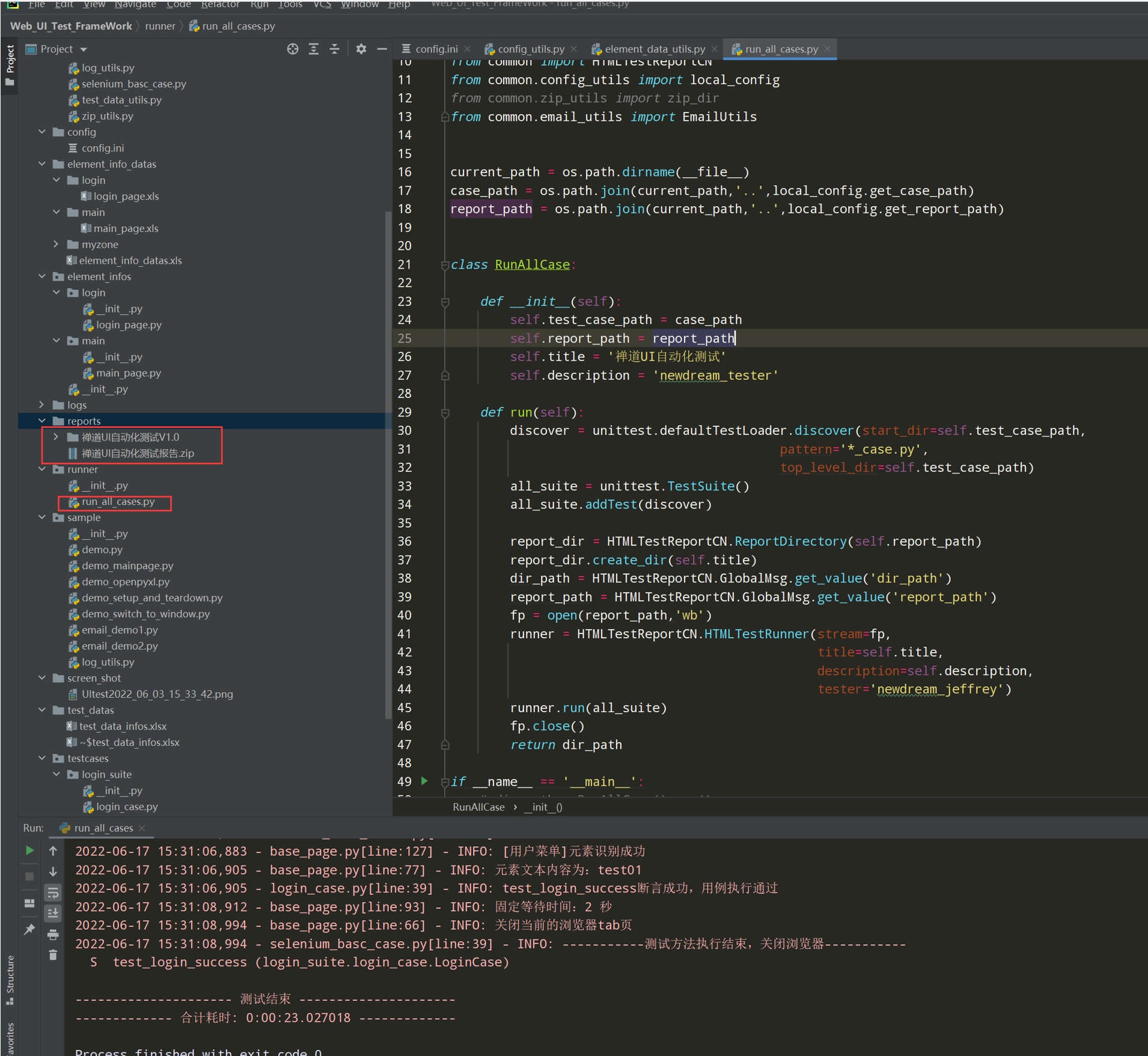
注:Main的excel文件按照上方的方法自己修改
框架18--测试用例数据的优化
步骤1:拆分测试用例数据

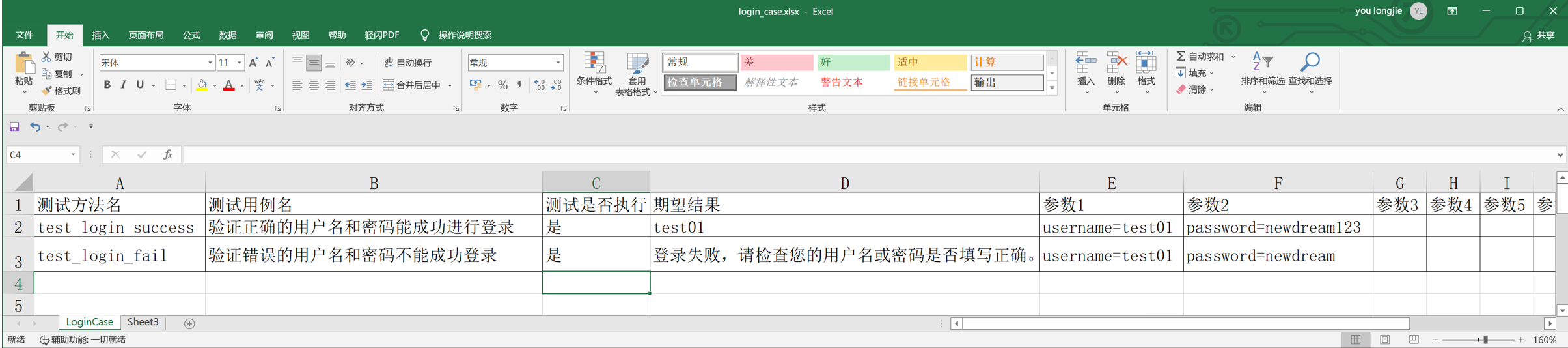
步骤2:改配置文件
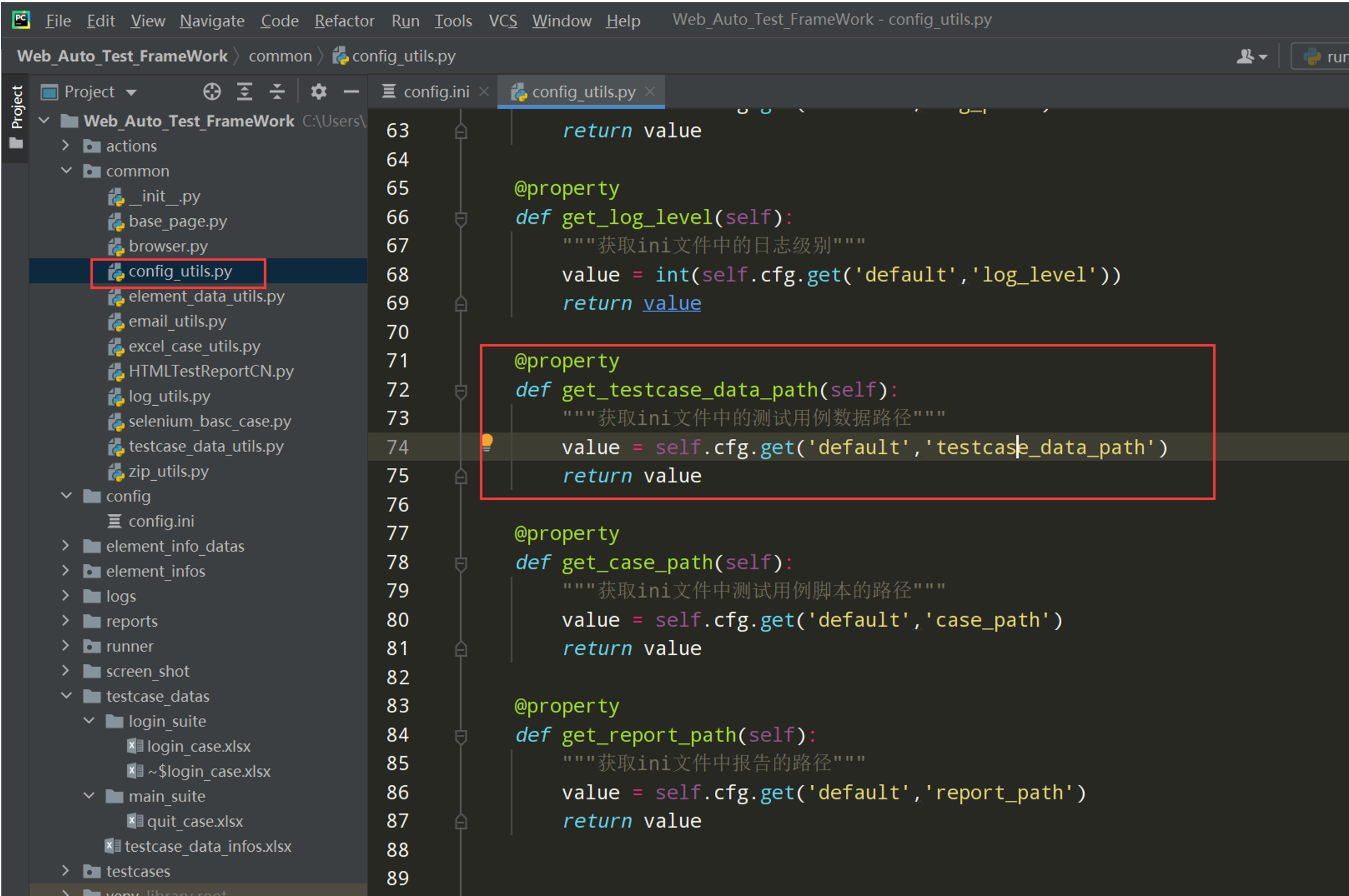
步骤3:改common->testcase_data_utils.py
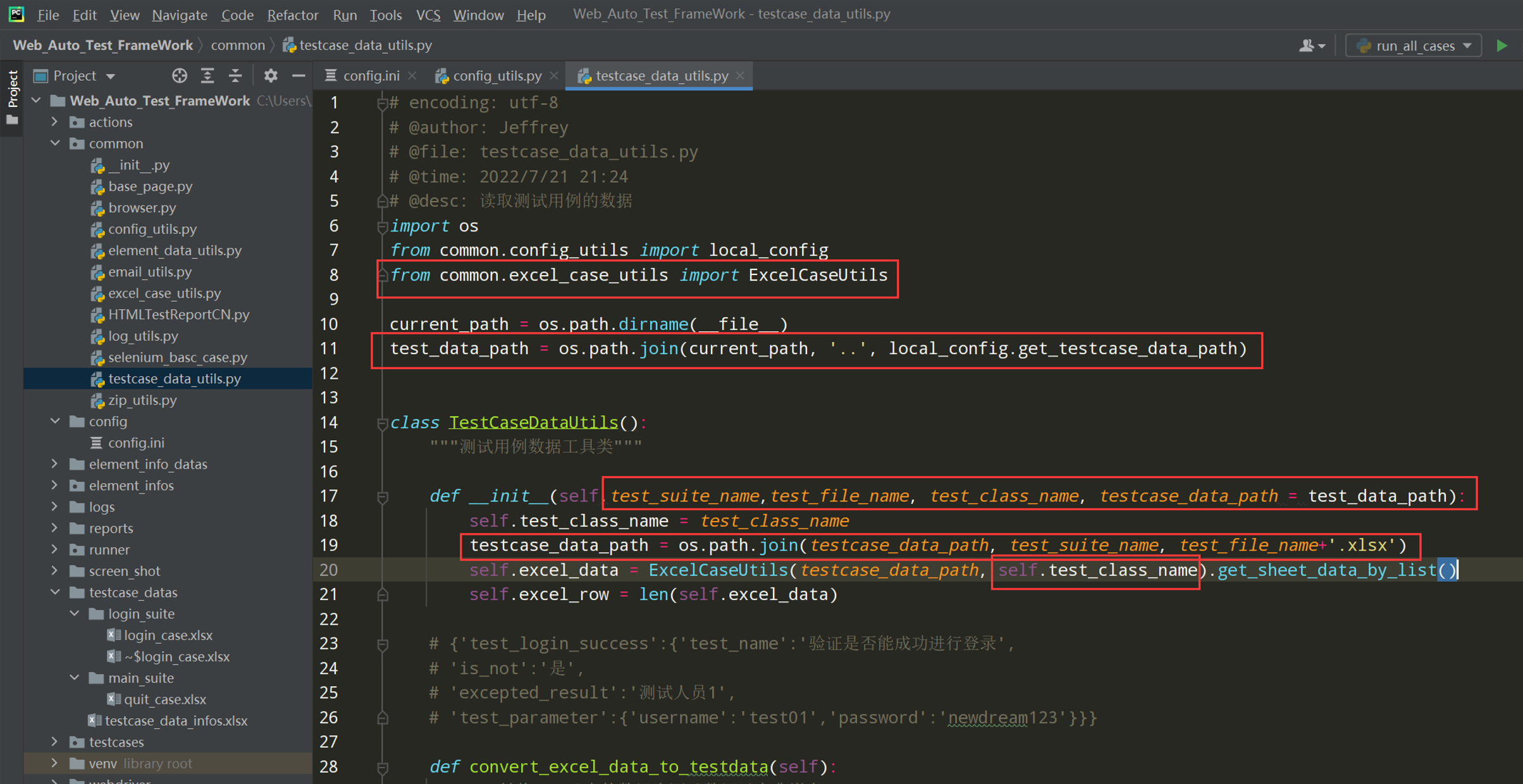
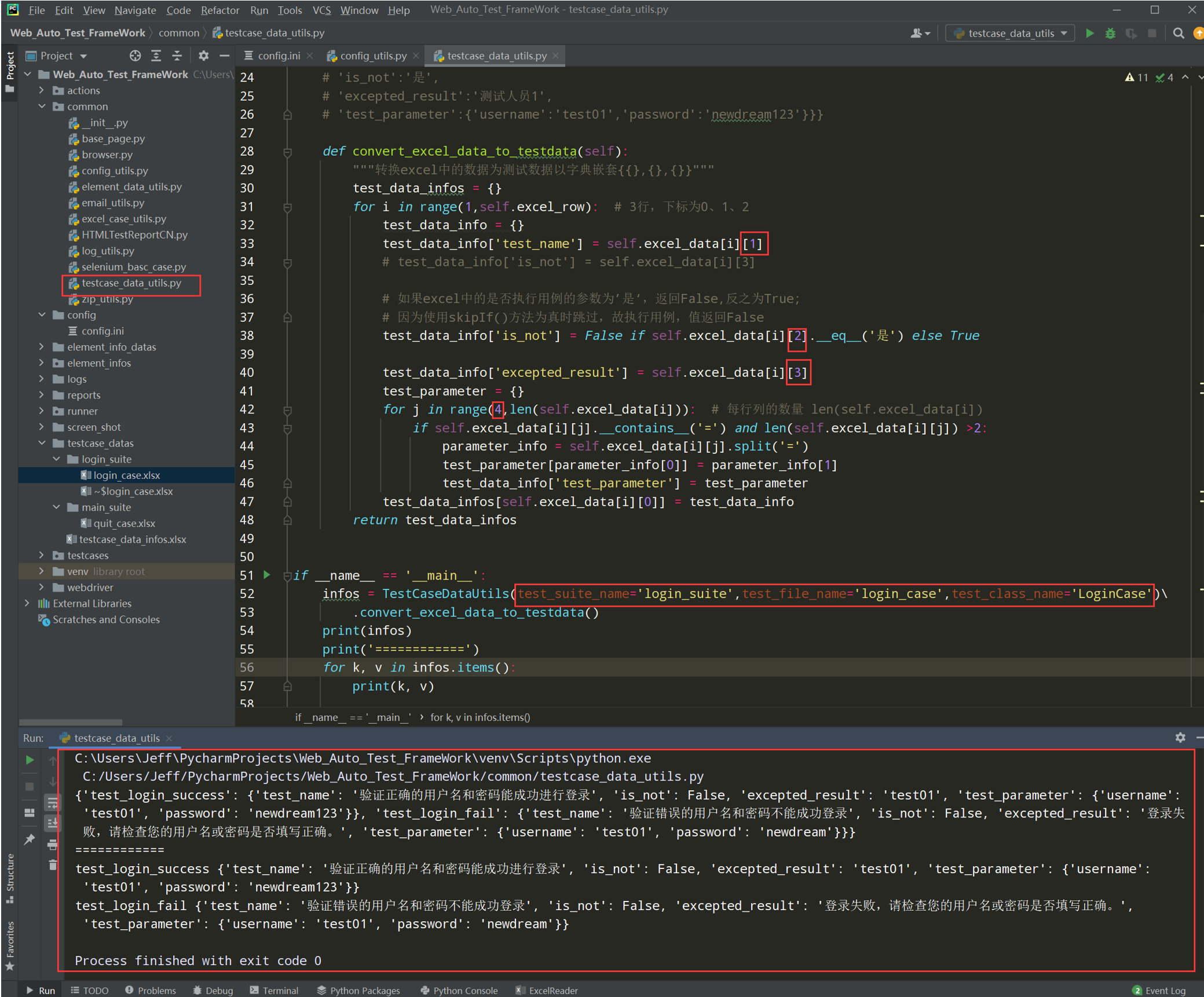
查看执行结果:

注:自己修改quit_case.xlsx中的数据
步骤4:改测试用例层里面的测试用例
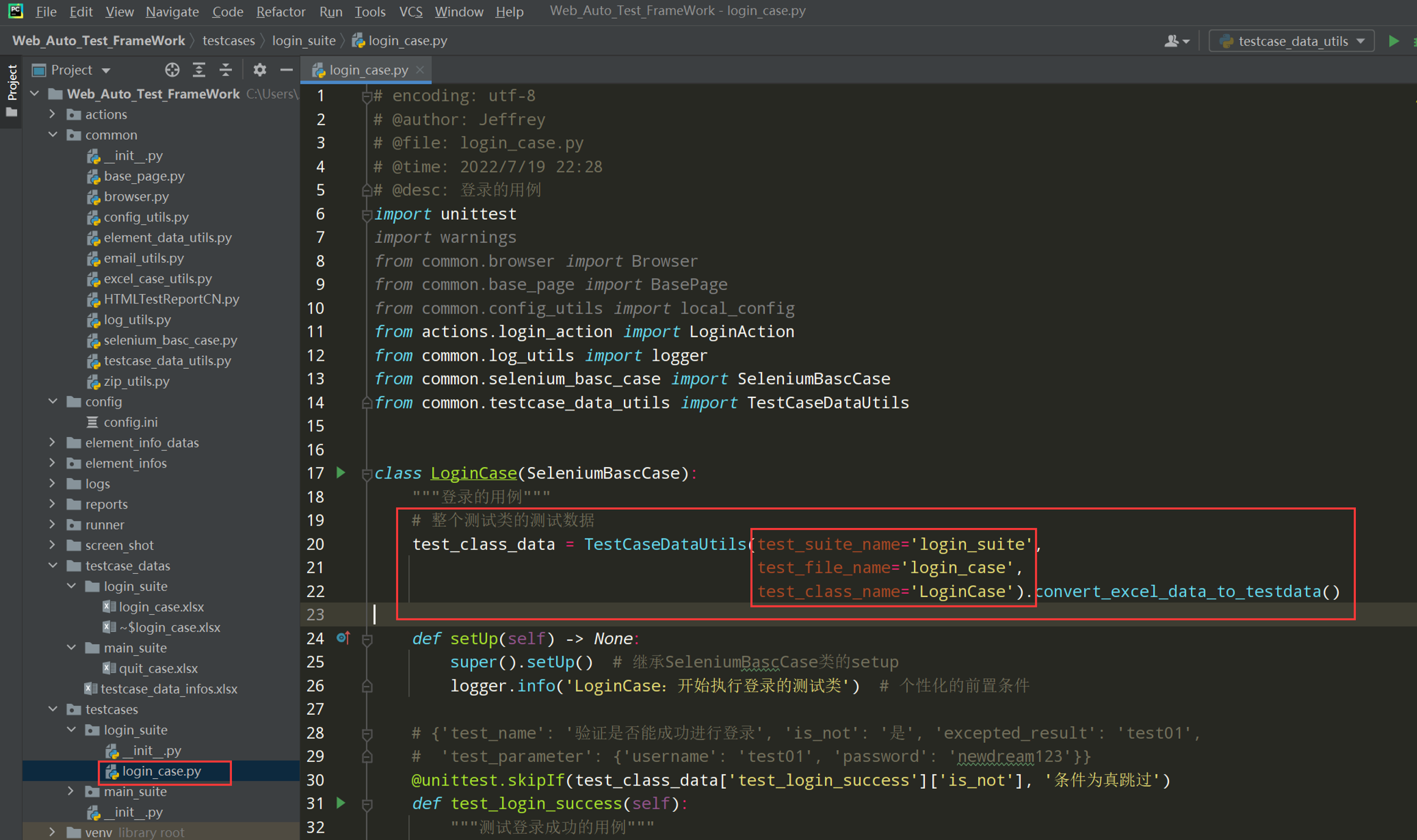
注:自己修改quit_case.py文件中的数据;按照上方的修改方式
步骤5:启动执行层 runner-->run_all_cases.py,检查是否正确读取测试数据
查看报告
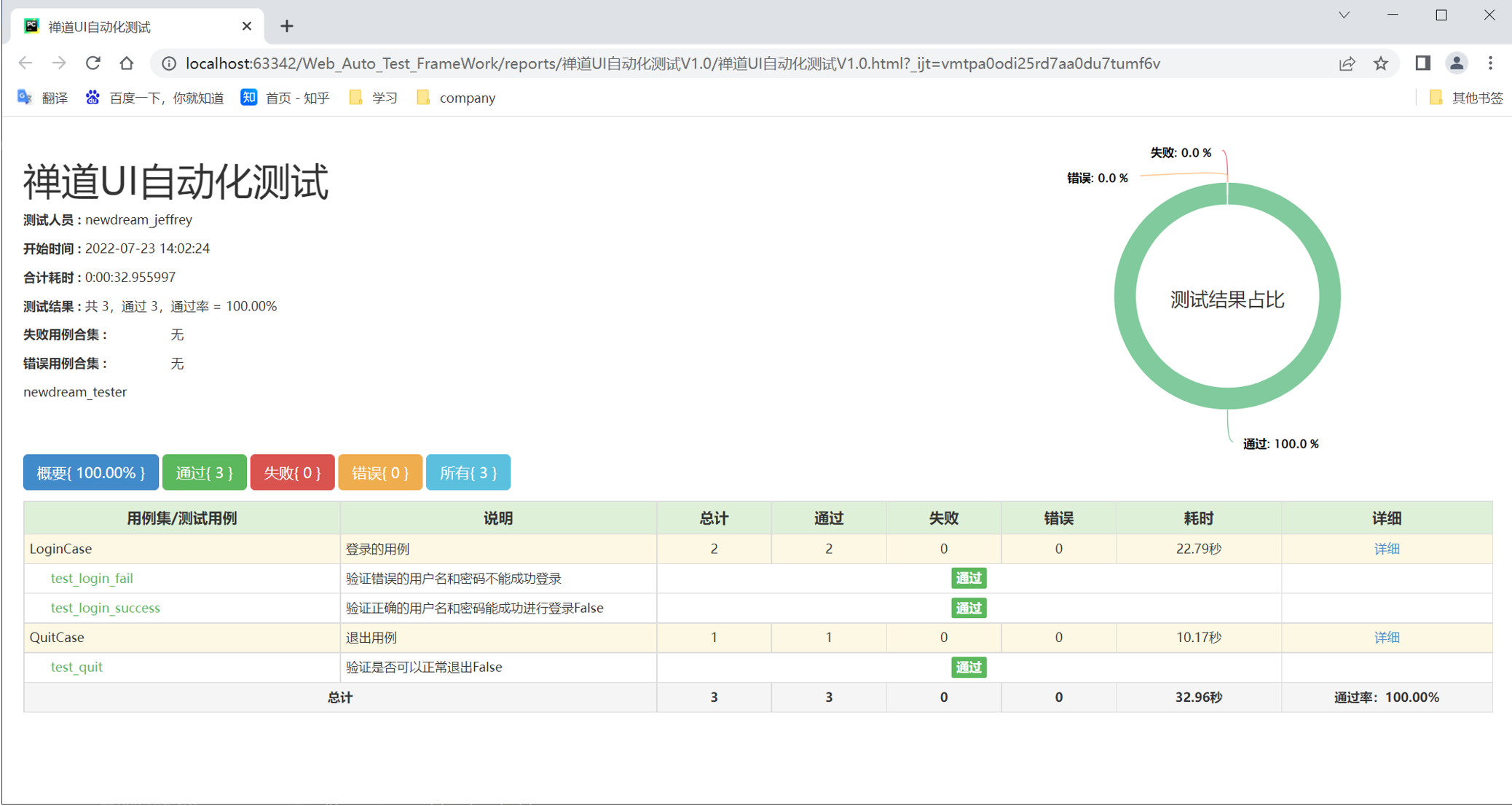

 浙公网安备 33010602011771号
浙公网安备 33010602011771号