sql 分组(group by)
分组(group by)
group_by的意思是根据by对数据按照对应字段进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
select 查询字段 from 表名 group by 分组字段
解析:简单点来说就是以 “分组字段” 为依据进行聚合操作,比如:很多门课和很多个学生,你如果想取得每个学生上了多少门客,那么我就以每个学生分组 ,来求课程数
示例:课程表Course
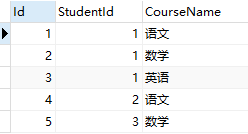
select StudentId,Count(*)CourseNumber from Course GROUP BY StudentId
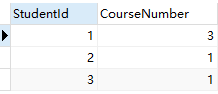
解析:首先我以学生ID 进行的分组,那么所有学生ID相同的数据都是一个组,然后我在组内进行取行数【count(*)】,然后的给个别名CourseNumber
这里要注意使用使用了group by 就不能用*,只能使用group by的字段,因为select的语句执行的先后顺序是先group by 再select ,这个时候其实数据已经分组了,所以你的“查询字段”里面只能出现【分组字段】和【分组聚合函数】
select 字段 from 表名 where 过滤条件 group by 字段 having 过滤条件
解析:having是分组之后再进行条件筛选的关键词,和where不同的是 where条件在分组之前执行和having条件在分组之后执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号