sqltext的参数化处理
说到sql的参数化处理,我也是醉了,因为sql引擎真的是一个无比强大的系统,我们平时做系统的时候都会加上缓存,我想如果没有缓存,就不会有什么
大网站能跑的起来,而且大公司一般会在一个东西上做的比较用心,比较细,sqlserver同样也使用了缓存,其中就包括Data cache 和Plan cache两个大头。
现在我们也知道了Plan cache包括上一篇生成的xml结构和sql text,更有趣的是,sql text 还可以做到参数化。。。也就是模板化了。。
一:Sql参数化
<1> 先来做一个Person表,插入1000条数据,然后清空下缓存,再select出一个数据,如图:

1 DROP TABLE dbo.Person 2 CREATE TABLE Person(ID INT IDENTITY,NAME CHAR(5) DEFAULT 'aaaaa') 3 INSERT INTO dbo.Person DEFAULT VALUES 4 go 1000 5 6 DBCC freeproccache 7 SELECT * FROM dbo.Person WHERE ID=100
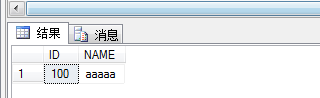
<2> 数据已经查询出来了,下面我们看下dm_exec_sql_text中的sql会是怎样?
1 SELECT usecounts,objtype,cacheobjtype, plan_handle,query_plan,text FROM sys.dm_exec_cached_plans 2 CROSS APPLY sys.dm_exec_query_plan(plan_handle) 3 CROSS APPLY sys.dm_exec_sql_text(plan_handle) 4 WHERE text LIKE '%Person%'

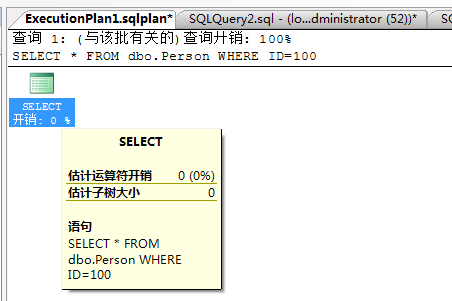
从上面的图中可以看到,当我select一下后,出现了两个sql text,第一个叫Adhoc(即时查询),一个叫Prepared(参数化),然后我点击第二个记录
的query_plan,会出现图形化的执行计划,如下图:
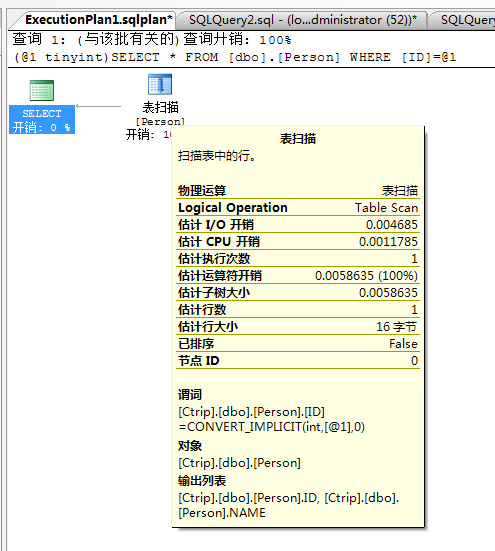
跟着好奇心,我继续点击第三个记录的query_plan会是怎样???
通过这两个sql text的执行计划,不知道你观察出来下面四点了没有:
(1) 我的sql是执行表扫描的,这个没有问题,问题在于我的两个sql text中,第一个plan居然没有完整的执行计划,而仅仅是一个图形化的select,
第二个参数化sql,它的plan是一个完整的执行计划。。。那这说明什么呢???既然Prepared是完整的执行计划,那干嘛还要把adhoc这个
sql缓存起来呢???其实这个我也不清楚。。。我猜测肯定是让引擎快速的找到prepared这个完整的执行计划吧。。。
(2) 就是想为什么sqltext要做参数化,仔细想想应该明白参数化的目的就是为了重用执行计划,因为这时候的xml已经生成好了,不然的话,你
每次执行的sql中只要参数不同都要生成一次query_plan的xml,是不是会拉查询速度的后腿呢???
(3) 你有没有关注到参数化的类型是tinyint,看到这个tinyint我马上就想破它了,我们知道tinyint就是byte类型,表示的范围也就到256...也许
引擎看我where 100才觉得我好欺负。。。那我现在想法就是where 500,看看会是什么效果???
1 SELECT * FROM dbo.Person WHERE ID=500 2 3 SELECT usecounts,objtype,cacheobjtype, plan_handle,query_plan,text FROM sys.dm_exec_cached_plans 4 CROSS APPLY sys.dm_exec_query_plan(plan_handle) 5 CROSS APPLY sys.dm_exec_sql_text(plan_handle) 6 WHERE text LIKE '%Person%'
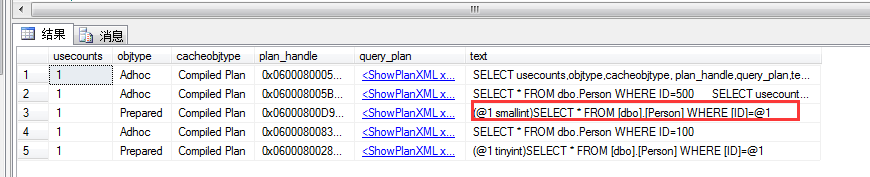
从图中可以看到,当我where 500的时候,引擎会再次生成一个prepared的sqltext,这样就有两个prepared了,那我在想,为什么不直接
给一个(@1 int)呢???像目前这样sql引擎的处理方式,会有几条prepared记录的xml和sqltext的,是不是有点浪费内存呢?
(4) 仔细想想你会知道,sql引擎还是挺色胆包天的,因为prepared的记录已生成,执行计划也就生成了。。。。那说明什么呢???说明这时候
的xml已经是死的了,也就说明执行计划也是定死的了,难道@1参数的不同不会导致执行计划有变更么???如果有变更难道还让我执行原来
这个表扫描执行计划么???有点奇葩,好了,我准备在下面仔细说说。
二:参数的变化对prepared的影响
如果你看过之前的博文,你应该明白有一个叫做书签查找的玩意。。。它的原理是在非聚集索引上通过B树查找,当查找到目标键的时候拿到这
个键的聚集索引key,然后通过key来取数据的记录,如果你的非聚集索引的键值的唯一性比较高,这时候sql引擎会走书签查找,但是如果你的键值
唯一性比较低或者在数据量比较小的情况,sql引擎就不会走书签查找,而转向聚集索引扫描。。。那这说明什么呢?说明执行计划在有些时候会跟
(@1 int)这个值有关系。。。那这样的话貌似就不能重用执行计划了,对吧。。。。为了验证sql引擎怎么处理的,我们来做一个测试。
1.先清空缓存,再在Name列上建索引,然后我们select下,如下图:
1 DBCC freeproccache 2 CREATE INDEX idx_Name ON dbo.Person(NAME) 3 SELECT * FROM dbo.Person WHERE NAME='aaaaa'
2. 然后还是继续看看xml和sqltext
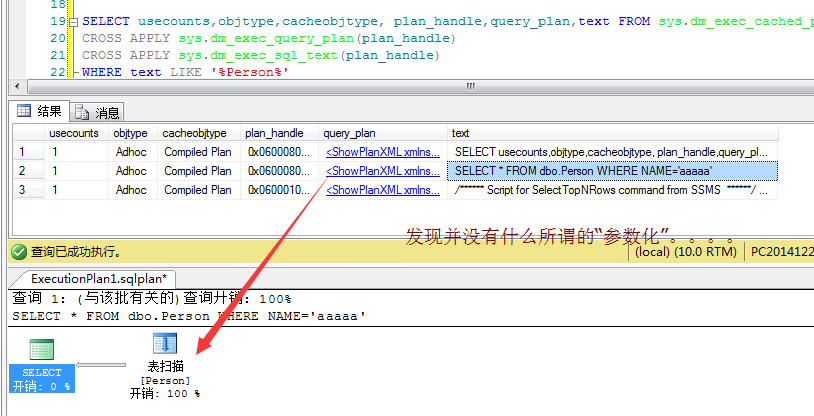
你有什么发现吗?在记录中并没有发现什么prepared记录,这说明什么。。。说明sqlserver很聪明,它知道Name可能会有 “表扫描”到
“书签扫描”的来回切换,为了验证问题,我继续向Person表插入1w条数据,然后再插入一个唯一性数据。如下图:
1 INSERT INTO dbo.Person DEFAULT VALUES
2 go 10000
3 INSERT INTO dbo.Person(NAME ) VALUES ('ccccc')
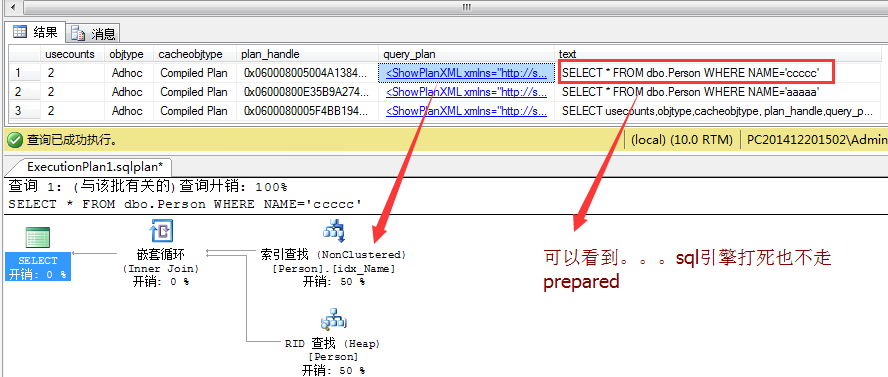
确实,如我猜想的一样,sqlserver很聪明的。。。如果它觉得这个Name不靠谱的话,它是绝对不敢给这条sqltext生成prepared的。。。转过
头来再想想第一条为什么会有sqltext,那是因为a列不管取值多少,都改变不了走表扫描的现实,所以sql引擎才敢这么大胆。。。突然觉得人生
不就是这样嘛????很多人都是不把稳的事情是绝对不敢做的。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号