
mongodb4.4特定类型的查询
1.null
null 的行为有一些特别。它可以与自身匹配,所以如果有一个包含如下文档的集合:
db.c.insertMany([{"y" : null },{"y" : 1 },{"y" : 2 }])

那么可以按照预期的方式查询 "y" 键为 null 的文档:
db.c.find({"y" : null})

不过,null 同样会匹配“不存在”这个条件。因此,对一个键进行 null 值的请求还会返回缺少这个键的所有文档:
db.c.find({"z" : null})

如果仅想匹配键值为 null 的文档,则需要检查该键的值是否为 null,并且通过 "$exists"条件确认该键已存在。
db.c.find({"z" : {"$eq" : null, "$exists" : true}})

2.正则表达式
"$regex" 可以在查询中为字符串的模式匹配提供正则表达式功能。正则表达式对于灵活的字符串匹配非常有用。
(1).如果要查找所有用户名为 joE 或 joe 的用户,那么可以使用正则表达式进行不区分大小写的匹配
db.users.find( {"name" : {"$regex" : /joE/i } })

(2).还希望匹配如“joey”这样的键,那么可以改进一下刚刚的正则表
db.users.find({"name" : /joey?/i})
3.数组查询
查询数组元素的方式与查询标量值相同。假设有一个数组是水果列表,如下所示:
db.food.insertOne({"fruit" : ["apple", "banana", "peach"]})
则下面的查询可以成功匹配到该文档
db.food.find({"fruit" : "banana"})

(1). "$all"
如果需要通过多个元素来匹配数组,那么可以使用 "$all"。这允许你匹配一个元素列表。假设我们创建了一个包含 3 个元素的集合:
db.food.drop() db.food.insertOne({"_id" : 1, "fruit" : ["apple", "banana", "peach"]}) db.food.insertOne({"_id" : 2, "fruit" : ["apple", "kumquat", "orange"]}) db.food.insertOne({"_id" : 3, "fruit" : ["cherry", "banana", "apple"]})
可以使用 "$all" 查询来找到同时包含元素 "apple" 和 "banana" 的文档:
db.food.find({fruit : {$all : ["apple", "banana"]}})

这里的顺序无关紧要。注意,上面第二个结果中的 "banana" 在 "apple" 之前。如果在 "$all" 中使用只有一个元素的数组,那么这个效果和不使用 "$all" 是一样的。
例如, {fruit : {$all : ['apple']} 和 {fruit : 'apple'} 会匹配相同的文档。也可以使用整个数组进行精确匹配。不过,精确匹配无法匹配上元素丢失或多余的文档。
例如,下面这样可以匹配之前的第一个文档:
db.food.find({"fruit" : ["apple", "banana", "peach"]})

但是下面这样就不行:
db.food.find({"fruit" : ["apple", "banana"]})
这样也无法匹配:
db.food.find({"fruit" : ["banana", "apple", "peach"]})
如果想在数组中查询特定位置的元素,可以使用 key.index 语法来指定下标:
db.food.find({"fruit.2" : "peach"})

数组下标都是从 0 开始的,因此这个语句会用数组的第 3 个元素与字符串 "peach" 进行匹配。
(2). "$size"
"$size" 条件运算符对于查询数组来说非常有用,可以用它查询特定长度的数组,如下所示:
db.food.find({"fruit" : {"$size" : 3}})

一种常见的查询是指定一个长度范围。 "$size" 并不能与另一个 $ 条件运算符(如 "$gt" )组合使用,但这种查询可以通过在文档中添加一个 "size" 键的方式来实现。之后每次向指定数组添加元素时,同时增加 "size" 的值。
db.food.update(criteria,{"$push" : {"fruit" : "strawberry"}, "$inc" : {"size" : 1}})
自增操作的速度非常快,因此任何性能损失都可以忽略不计。这样存储文档后就可以执行如下查询:
db.food.find({"size" : {"$gt" : 3}})
(3). "$slice"
正如本章前面提到的,find 的第二个参数是可选的,可以指定需要返回的键。这个特别的 "$slice" 运算符可以返回一个数组键中元素的子集。
db.blog.posts.insertOne( { "title" : "A blog post", "content" : "test111", "comments" : [ { "name" : "bob", "email" : "bob@example.com", "content" : "good post." }, { "name" : "joe", "email" : "joe@example.com", "content" : "nice post." }, { "name" : "tom", "email" : "tom@example.com", "content" : "test1." }, { "name" : "jk", "email" : "jk@example.com", "content" : "test2." } ] } )
假设现在有一个关于博客文章的文档,我们希望返回前 3 条评论:
db.blog.posts.findOne({}, {"comments" : {"$slice" : 3}})
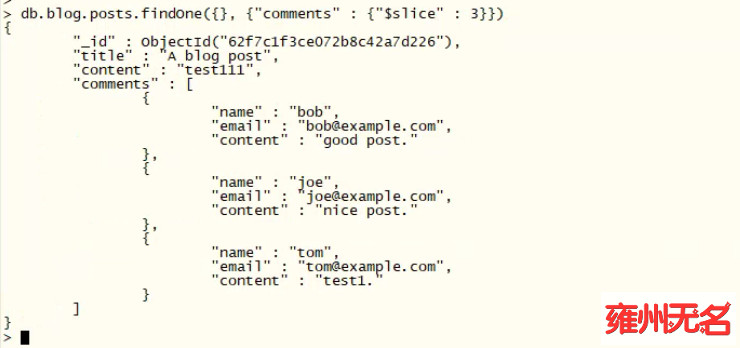
同样,如果想返回后 2 条评论,则可以使用 -2:
db.blog.posts.findOne({}, {"comments" : {"$slice" : -2}})
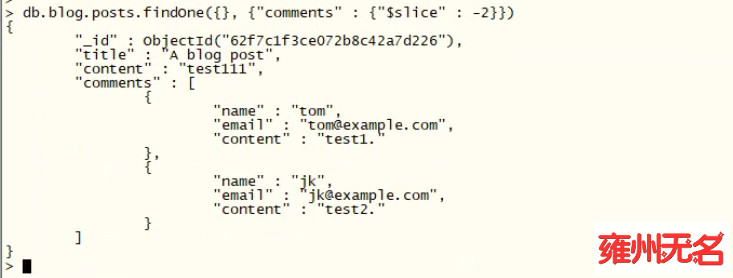
"$slice" 也可以指定偏移量和返回的元素数量来获取数组中间的结果:
db.blog.posts.findOne({}, {"comments" : {"$slice" : [1, 2]}})
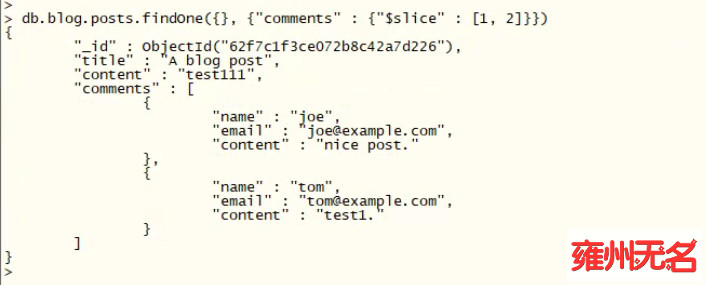
这个操作会略过前 1 个元素,返回第 2 ~ 3 个元素。如果数组中的元素少于 3 个,则会返回尽可能多的元素。
可以使用 "$slice" 来获取最后一条评论,如下所示:
db.blog.posts.findOne({}, {"comments" : {"$slice" : -1}})
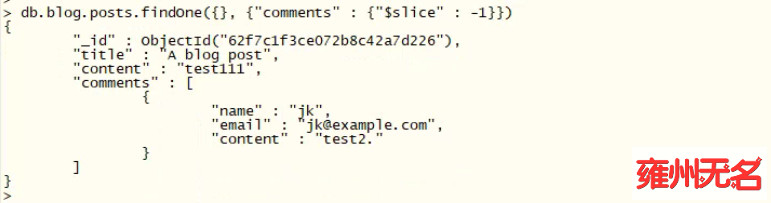
(4).返回一个匹配的数组元素
如果知道数组元素的下标,那么 "$slice" 非常有用。但有时我们希望返回与查询条件匹配的任意数组元素。这时可以使用 $ 运算符来返回匹配的元素。
对于前面的博客文章示例,可以这样获得 Bob 的评论:
db.blog.posts.find({"comments.name" : "bob"}, {"comments.$" : 1})

db.test1.insertOne({"x" : 5})
db.test1.insertOne({"x" : 15})
db.test1.insertOne({"x" : 25})
db.test1.insertOne({"x" : [5, 25]})

如果想找出 "x" 的值在 10 和 20 之间的所有文档,那么你可能会本能地构建这样的查询,即 db.test1.find({"x" : {"$gt" : 10, "$lt" : 20}}) ,然后期望它会返回一个文档:{"x" : 15}。然而,当实际运行时,我们得到了两个文档,如下所示:

5 和 25 都不在 10 和 20 之间,但由于 25 与查询条件中的第一个子句("x" 的值大于 10)相匹配,5 与查询条件中的第二个子句("x" 的值小于 20)相匹配,因此这个文档会被返回。
这样就使得针对数组的范围查询基本上失去了作用:一个范围会匹配任何多元素数组。有几种方法可以获得预期的行为。
可以使用 "$elemMatch" 强制 MongoDB 将这两个子句与单个数组元素进行比较。不过,这里有一个问题, "$elemMatch" 不会匹配非数组元素:

文档 {"x" : 15} 不再与查询条件匹配了,因为它的 "x" 字段不是一个数组。也就是说,你应该有充分的理由在一个字段中混合数组和标量值,而这在很多场景中并不需要。对于这样的情况, "$elemMatch" 为数组元素的范围查询提供了一个很好的解决方案。
如果在要查询的字段上有索引,那么可以使用 min 和 max 将查询条件遍历的索引范围限制为 "$gt" 和 "$lt" 的值:
db.test1.createIndex({x:1})
db.test1.find({"x" : {"$gt" : 10, "$lt" : 20}}).hint({x:1}).min({"x" : 10}).max({"x" : 20})

现在,这条查询语句只会遍历值在 10 和 20 之间的索引,不会与值为 5 和 25 的这两个条目进行比较。但是,只有在要查询的字段上存在索引时,才能使用 min 和 max,并且必须将索引的所有字段传递给 min 和 max。在查询可能包含数组的文档的范围时,使用 min 和 max 通常是一个好主意。在整个索引范围内对数组使用 "$gt"/"$lt" 进行查询是非常低效的。它基本上接受任何值,因此会搜索每个索引项,而不仅仅是索引范围内的值。
特别注意:如果上面查询中不使用hint的话,会报错 planner returned error :: caused by :: When using min()/max() a hint of which index to use must be provided

4.查询内嵌文档
查询内嵌文档的方法有两种:查询整个文档或针对其单个键 – 值对进行查询。查询整个内嵌文档的工作方式与普通查询相同。假设有这样一个文档:
db.people.insertOne({"name":{"first" : "Joe","last" : "Schmoe"},"age" : 45})
可以像下面这样查询姓名为 Joe Schmoe 的人:
db.people.find({"name" : {"first" : "Joe", "last" : "Schmoe"}})

然而,如果要查询一个完整的子文档,这个子文档就必须精确匹配。如果 Joe 决定添加一个代表中间名的字段,这个查询就无法工作了,因为查询条件不再与整个内嵌文档相匹配。而且这种查询还是与顺序相关的:{"last" : "Schmoe", "first" : "Joe"} 就无法匹配。

如果可能,最好只针对内嵌文档的特定键进行查询。这样,即使数据模式变了,也不会导致所有查询因为需要精确匹配而无法使用。可以使用点表示法对内嵌文档的键进行查询:
db.people.find({"name.first" : "Joe", "name.last" : "Schmoe"})

这时,如果 Joe 增加了更多的键,那么这个查询仍然可以匹配他的姓和名。
这种点表示法是查询文档和其他文档类型的主要区别。查询文档可以包含点,表示“进入内嵌文档内部”的意思。点表示法也是待插入文档不能包含 . 字符的原因。当人们试图将URL 保存为键时,常常会遇到这种限制。解决这个问题的一种方法是在插入前或者提取后始终执行全局替换,用点字符替换 URL 中不合法的字符。
随着文档结构变得越来越复杂,内嵌文档的匹配可能会变得有点儿棘手。假设我们正在存储博客文章,要找到 Joe 发表的 5 分以上的评论。可以按照以下方式对文章进行建模:
db.blog.insertOne( { "content" : "test1", "comments" : [ { "author" : "joe", "score" : 3, "comment" : "nice post" }, { "author" : "mary", "score" : 6, "comment" : "terrible post" } ] } )
这时,不能直接使用以下语句进行查询:

内嵌文档的匹配必须匹配整个文档,而这个查询不会匹配 "comment" 键。
使用以下查询也不行,因为符合作者条件的评论与符合分数条件的评论可能不是同一条。也就是说,这会返回上面显示的那个文档:因为它匹配了第一条评论中的 "author" : "joe" 和第二条评论中的 "score" : 6。
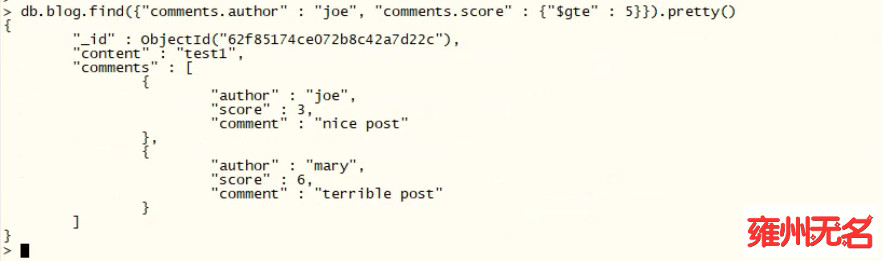
要正确指定一组条件而无须指定每个键,请使用 "$elemMatch" 。这种模糊的命名条件允许你在查询条件中部分指定匹配数组中的单个内嵌文档。正确的查询如下所示:
db.blog.find({comments:{"$elemMatch":{author:"joe",score:{"$gte":5}}}}).pretty()

"$elemMatch" 允许你将限定条件进行“分组”。仅当需要对一个内嵌文档的多个键进行操作时才会用到它。

