
ECCV20| 3D目标检测时序融合网络
点击上方“3D视觉工坊”,选择“星标”

0 前言
1 背景知识
1.1 什么是点云中的时序融合
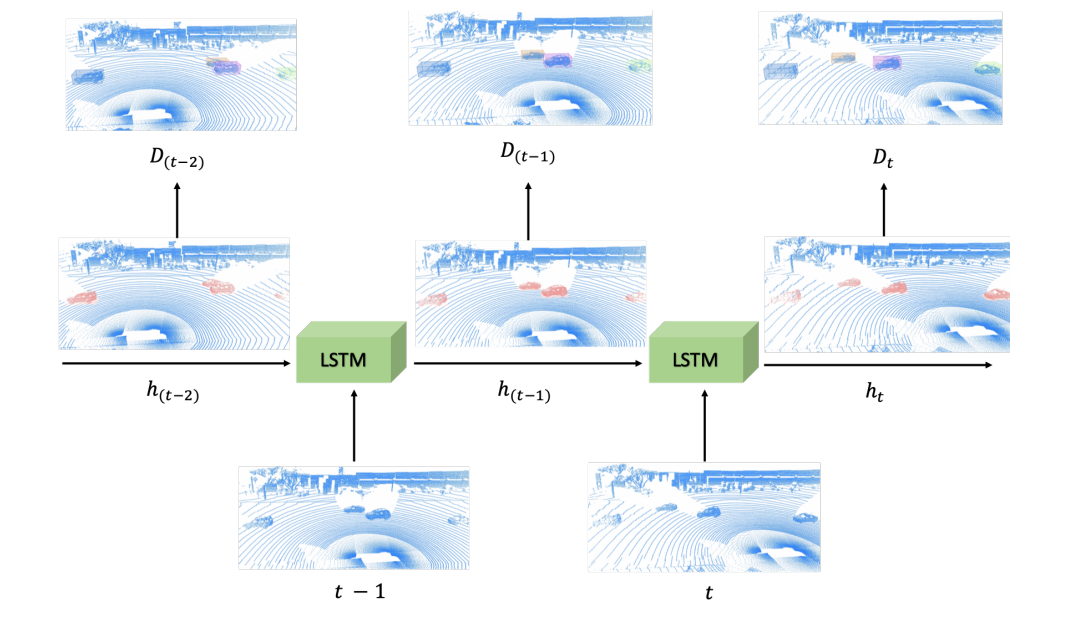
如下图所示,展示了再waymo中连续三帧的场景展示。

1.2 LSTM
1.3 点云时序融合现状
2 本文的工作
1. 主要贡献点
(1)设计了一个LSTM-based的多帧时序同和点云目标检测网络
(2)该3D-Sparse-Conv-LSTM网络采用稀疏U-Net代替全连接层,更高效和更小显存占用。
2. 主要思路
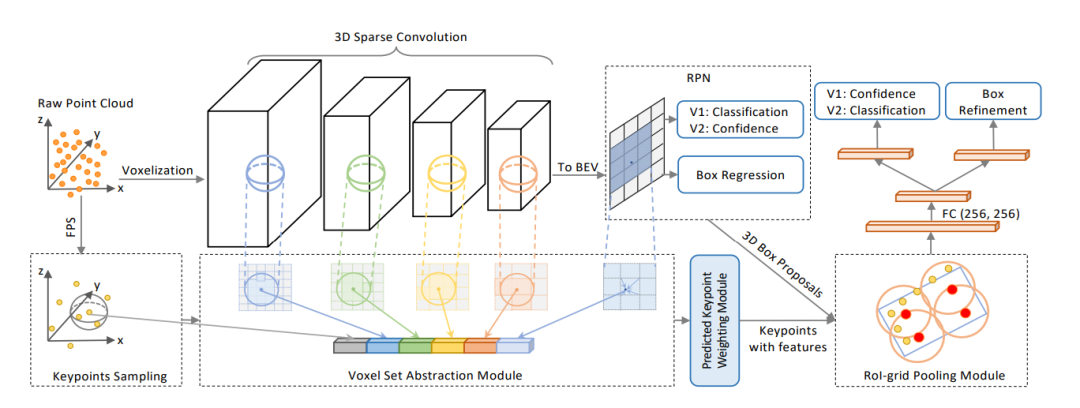
3. 网络结构设计

3.1 3D稀疏U-Net
3.2 3D稀疏LSTM
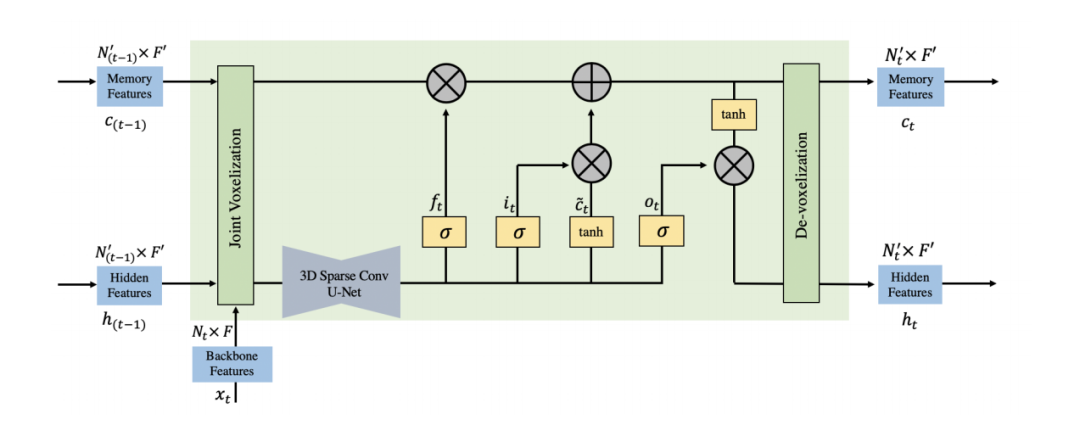
上图中的LSTM结构即是Vanilla LSTM的衍生,对于一般的LSTM有如下图的计算公式,这里的 表示当前特征, 表示隐含层的特征。这里的几个LSTM中的gate都是从根据这二者的特征融合,这里的 表示memroy中的特征。类比3D稀疏backbone而言,本文的的表示的是当前帧的点云特征,memory中和隐含层的特征则是上一帧的特征,
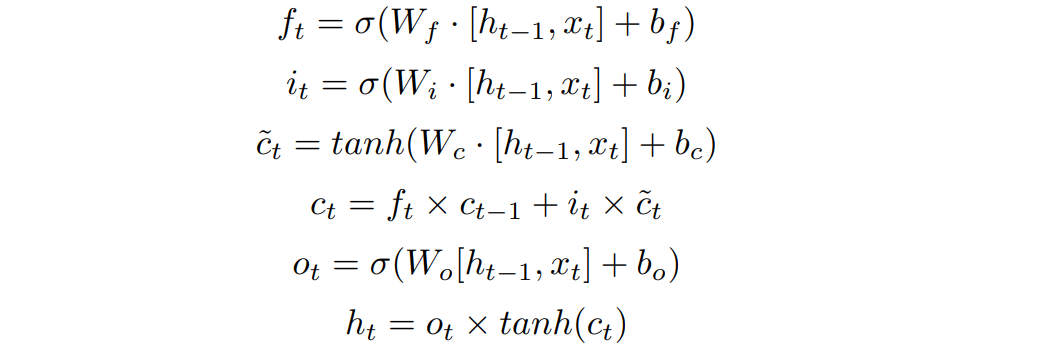
3.3 训练方法
4 实验
waymo数据集
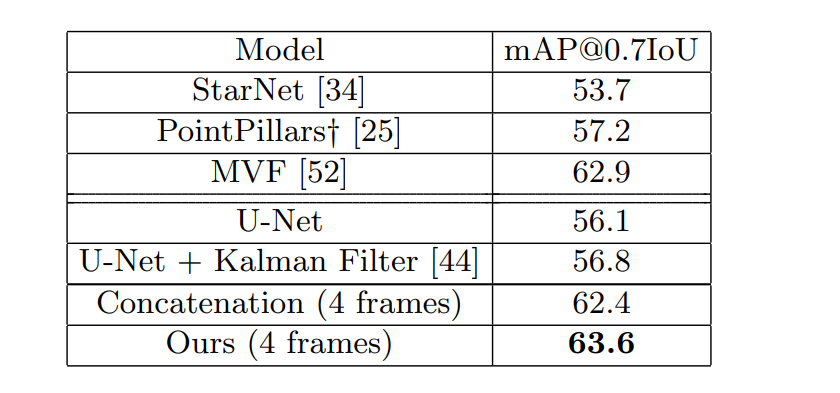
5讨论
额外分享
文章: PV-RCNN: The Top-Performing LiDAR-only Solutions for 3D Detection / 3D Tracking / Domain Adaptation of Waymo Open Dataset Challenges
论文链接:https://arxiv.org/pdf/2008.12599.pdf
代码链接 :https://github.com/open-mmlab/OpenPCDet
1. PV-RCNN 时序信息合并
2. 追踪任务
参考文献
[2]nuscenes: A multimodal dataset for autonomous driving : https://arxiv.org/abs/1903.11027
[3]Scalability in perception for autonomous driving: Waymo open dataset https://waymo.com/open/
[4]Dops: Learning to detect 3d objects and predict their 3d shapes. :https://arxiv.org/pdf/2004.01170
[5] Long short-term memory. Neural computation.
[6] A baseline for 3d multiobject tracking. arXiv preprint arXiv:1907.03961, 2019.
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。
![]()
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款 ![]()
圈里有高质量教程资料、可答疑解惑、助你高效解决问题 觉得有用,麻烦给个赞和在看~
个人微信公众号:3D视觉工坊

 浙公网安备 33010602011771号
浙公网安备 33010602011771号