
SilhoNet:一种用于3D对象位姿估计和抓取规划的RGB方法
作者:康斯坦奇来源:公众号@3D视觉工坊
论文题目:SilhoNet:An RGB Method for 3D Object Pose Estimation and Grasp Planning
论文地址:公众号「3D视觉工坊」后台回复「silhonet」,即可获得论文原文。
摘要:自主机器人操纵通常涉及估计待操纵物体的位姿和选择可行的抓取点。使用RGB-D数据的方法在解决这些问题方面取得了巨大成功。但是,在某些情况下,成本限制或工作环境可能会限制RGB-D传感器的使用。当仅限于单目相机数据时,对象位姿估计和抓取点选择的问题都是非常具有挑战性的。过去,研究的重点是分别解决这些问题。在这项工作中,本文引入了一种名为SilhoNet的新方法,它弥合了这两项任务之间的差距。本文使用卷积神经网络(CNN)架构,该架构接收感兴趣区域(ROI)的提议,以此来同时预测具有相关遮挡掩模的对象的中间轮廓表示。然后从预测的轮廓回归3D位姿。在预先计算的数据库中抓取点通过将它们反投影到遮挡掩模上来过滤,以找出在场景中可见的点。本文表明,本文的方法在YCB视频数据集上比用于3D位姿估计的最先进的PoseCNN网络实现了更好的整体性能。
一、位姿估计简介
使用中间轮廓表示来促进在合成数据上学习模型以预测真实数据上的3D对象位姿,有效地桥接SIM到实际域移位;
在本文中,本文提出以下贡献:
1)SilhoNet,一种新的基于RGB的深度学习方法,用于估计覆盖场景遮挡的位姿估计;
2)使用中间轮廓表示来促进学习合成数据模型以预测在实际数据上的3D对象位姿,有效地弥合了SIM到实际的域转移;
3)在新场景中使用推断轮廓的投影选择未被遮挡的抓取点的方法;
4)对视觉上具有挑战性的YCB-Video数据集进行评估,其中提出的方法优于最先进的RGB方法。
二、SilhoNet方法
本文介绍了一种新颖的方法,该方法对单目彩色图像进行操作,以估计相对于相机中心的3D物体旋转位姿,并预测视觉上未被遮挡的抓取点。该方法在两个阶段中操作,首先预测对象的中间轮廓表示和遮挡掩模,然后从预测的轮廓回归3D方向四元数。基于RGB视点中检测到的对象的估计遮挡和对象模型的先验知识,从预先计算的抓取数据库确定可行抓取点。以下部分详细介绍了本文的方法。
A.网络架构叙述
图1显示了本文的网络架构。网络的输入是RGB图像,其具有用于检测到的对象和相关联的类标签的边界框ROI提议。第一阶段使用VGG16主干,最后使用反卷积层,从RGB输入图像生成特征图。该特征提取网络与PoseCNN中使用的相同。来自输入图像的提取特征与来自一组渲染对象视点的特征连接,然后通过具有相同结构的两个网络分支来预测完整的未被遮挡的轮廓和遮挡掩模。网络的第二阶段通过ResNet-18架构传递预测的轮廓,在末端具有两个全连接层,以输出表示3D位姿的L2正则化四元数。
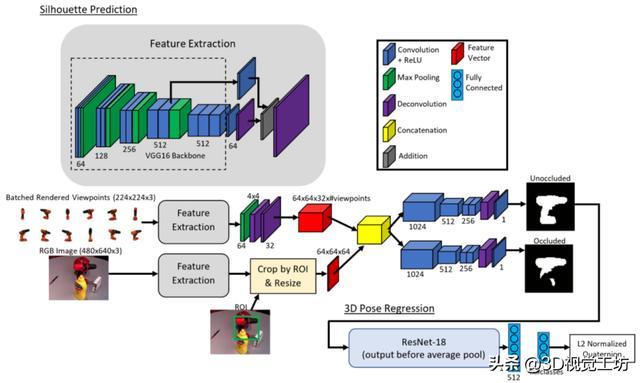
图1 用于轮廓预测和3D位姿回归的SilhoNet网络概述
1)预测的ROIs:本文在YCB-video数据集上训练了来自Tensorpack的现成的Faster RCNN模型,以预测ROI建议框。该网络在两个Titan-VGPU上进行了训练,在训练图像集上使用默认参数进行了3,180,000次迭代,并且没有任何合成数据增强。ROI提议在特征提取阶段之后作为网络的输入提供,其中它们用于从输入图像特征图中裁剪出相应的区域。然后通过缩小特征图或使用双线性插值将其缩放,将裁剪的特征图调整宽度和高度为64x64。
2)渲染模型视点:文中通过生成一组与检测到的对象类相关联的合成预渲染视点作为网络第一阶段的附加输入来提高轮廓预测性能。对于每个类,文中从对象模型渲染了一组12个视点,每个视点的维度为224x224。这些视点是使用Phong着色在0°到300°的方位角间隔生成的,仰角为-30°和30°。由于中间目标是轮廓预测,尽管模拟物体的视觉外观存在典型的区域变化,但是这些合成渲染在捕捉不同方向的真实物体的形状和轮廓方面表现出色。
检测到的对象类的所有视点都通过特征提取阶段,然后通过将它们传递到宽度为4和步幅为4的最大池化层,然后再增加两个反卷层,将其调整为64x64,通道尺寸为32。文中为每个对象检测提取了渲染的视图的特征映射。但是,为了增加网络性能时间,可以预先计算并存储这些提取的特征映射。这些渲染的视点特征映射通过将它们堆叠在通道维度上然后与裁剪和调整大小的输入图像特征图连接而提供给网络(图1)。
3)轮廓预测:网络的第一阶段将对象的中间轮廓表示预测为64×64维二元掩模。此轮廓表示对象的完整未被遮挡的视觉外形,就好像它使用相同的3D方向渲染但在框架中居中。框架中轮廓的大小对于图像中对象的比例是不变的。为每个对象选择该距离,使得轮廓仅在框架内用于任何3D方向。网络的这个阶段还具有并行分支,其输出类似的轮廓,仅对象的未被遮挡的部分可见。本文将此被遮挡的输出称为“遮挡掩模”。
网络的第一部分是VGG16特征提取器,它以1/2,1/4,1/8和1/16比例生成特征图。1/8和1/16比例特征图都具有512的输出通道尺寸。使用两个卷积层将两者的通道尺寸减小到64,之后使用因子2将1/16比例尺放大到2倍。解卷积,然后用1/8比例映射求和。使用第二次反卷积将求和的地图放大8倍,以获得与输入图像具有相同尺寸的最终特征图,其特征通道宽度为64(图1)。
在输入图像通过特征提取器之后,用于检测到的对象的输入ROI提议用于裁剪出所得特征映射的相应区域并将其大小调整为64x64。此特征贴图与渲染的视点特征贴图连接在一起,从而生成大小为64x64x448的单个特征向量矩阵。
特征向量矩阵被馈送到两个相同的网络分支中,其中一个输出轮廓预测而另一个输出遮挡掩模。每个分支由4个卷积层组成,每个卷层具有滤波器宽度,通道尺寸和步幅(2,1024,1),(2,512,2),(3,256,1)和(3,256),1)分别是具有滤波器宽度,通道尺寸和(2,256,2)步幅的去卷积层。反卷积层的输出被馈送到降维卷积滤波器,其单通道输出形状为64×64。在输出处应用S形激活函数以产生概率图。
4)3D位姿回归:本文对3D位姿使用四元数表示,其可以将连续空间中的任意3D旋转表示为长度为4的单位向量。四元数表示特别有吸引力,因为它不像欧拉角表示那样受到万向节锁定的影响。
网络的第二阶段接收预测的轮廓概率图,将某些值阈值化为二进制掩模,并输出对象位姿的四元数预测。网络的这个阶段由ResNet-18骨干网组成,其中来自平均池和下面的层被两个完全连接的层替换。最后一个完全连接的层具有输出维度4x(#class),其中每个类具有单独的输出向量。从输出中提取检测到的对象的类的预测矢量,并使用L2范数进行归一化以获得最终的四元数预测(图1)。
因为对象的轮廓表示是无特征的,所以该方法将对象形状中的对称性视为3D位姿空间中的等效对称。在许多机器人操作场景中,这是一个有效的假设。例如,在RGB特征空间中可能不对称的诸如螺丝刀之类的工具在形状上是对称的并且在抓取空间中等效地对称。然而,这项工作的未来目标是将3D位姿估计扩展到特征空间中的非对称性。可以在形状上对称但不在特征空间中的对象的示例是具有特征丰富标签的汤罐。在某些操作任务中,可能需要以特定方式定向标签,在这种情况下,需要特征空间中的独特位姿。
通过从中间轮廓表示回归3D位姿,本文能够仅使用合成渲染的轮廓数据来训练网络的这个阶段。在本文的结果中,本文表明网络很好地预测了真实数据上的位姿,表明这种中间表示是桥接真实数据和合成数据之间域转换的有效方法。
B.抓取点检测
本文方法的最后一步是检测视觉上可行的抓取点。给定对象的估计3D位姿和预先计算的抓取点的数据库,本文将每个抓取点从对象框架投影到相机框架中的遮挡掩模上。位于掩模的未被遮挡部分上的点被认为是有效的,并且可以从有效集中选择最高得分抓取。本文使用自定义生成的对象抓取点数据库演示了图4中的方法。有许多库可用于促进抓取点数据库的自动计算,例如DexNetAPI。
C.数据集
本文在YCB视频数据集上评估了本文的方法,该数据集由92个视频序列组成,包括133,827个帧,共包含21个对象,以不同的排列方式出现,具有不同的遮挡水平。从训练集中保留了12个视频序列以进行验证和测试。在轮廓空间中,该数据集中的对象由五种不同类型的对称性表征:非对称,关于平面对称,关于两个垂直平面对称,关于轴对称,关于轴和平面对称。本文对所有呈现任何形式对称的对象的坐标系应用了旋转校正,以使每个轴或对称平面与坐标轴对齐。从标记的对象位姿生成地面实况四元数,使得只有一个唯一的四元数与产生相同视觉外壳的每个视点相关联。对于所有匹配的轮廓视点具有一致的四元数标签使得位姿预测网络能够有效地训练所有类型使用非常简单的距离损失函数的对象对称性。
补充YCB-视频数据集中的真实图像数据是80,000个合成渲染图像,所有21个对象以透明背景的各种组合和随机位姿出现。本文通过从COCO2017数据集中随机抽样图像并在训练时将它们作为这些合成图像的背景应用来补充训练数据。
D.训练网络
所有网络都使用TitanV或TitanXGPU上的Adam优化器进行训练。使用ImageNet预训练的权重初始化VGG16骨干,并且使用批量大小为6的325,000次迭代的交叉熵损失来训练轮廓预测网络。本文使用地面实况ROI对网络进行了训练,并针对地面实况ROI和来自在YCB视频数据集上训练的Faster-RCNN网络的预测ROI进行了测试。
使用预测和地面实况四元数之间的以下对数距离函数来训练3D位姿回归网络:
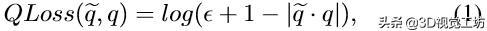
其中q是基本事实四元数,eq是预测的四元数,并且是稳定性的一个小值,在本文的例子中e鈭鈭位姿预测网络经过380,000次迭代训练,批量大小为16,仅使用完美的地面实况轮廓为了训练。测试是根据铿乺st阶段网络的预测轮廓进行的。
为了减少在轮廓预测网络的训练期间的过度配置,在特征提取网络的最后一个去卷积层之前以及在每个轮廓预测分支的第四卷积层上以0.5的速率应用丢失。在训练3D位姿回归网络期间,在第一完全连接层之前以0.8的速率应用丢失。作为减少过度训练和扩展训练数据的进一步策略,训练图像的色调,饱和度和曝光随机缩放了1.5倍。
三、结果
以下部分介绍了在YCB视频数据集上测试的SilhoNet的性能。A部分表示轮廓预测阶段的准确性。B部分比较了SilhoNet的3D位姿估计性能与PoseCNN的性能。并且C部分讨论了使用预测的遮挡掩模和3D位姿进行抓取点检测的方法。
A.掩码预测
本文使用来自YCB数据集的真值标定ROI输入和来自FasterRCNN网络的预测ROI输入测试了SilhoNet的轮廓预测阶段的性能。图2示出了测试集中的一个图像的轮廓预测的示例。表I显示了被遮挡和未被遮挡的轮廓预测的准确度,测量为预测轮廓与地面实况轮廓的平均交叉(IoU)。总体而言,当预测的ROI作为输入而不是基础事实提供时,性能会降低几个百分点,但在大多数类别中,预测对ROI输入是稳健的。当使用预测的ROI时,性能的最大降级是针对“037剪刀”和“011香蕉”类别,其具有薄且低纹理的特征。
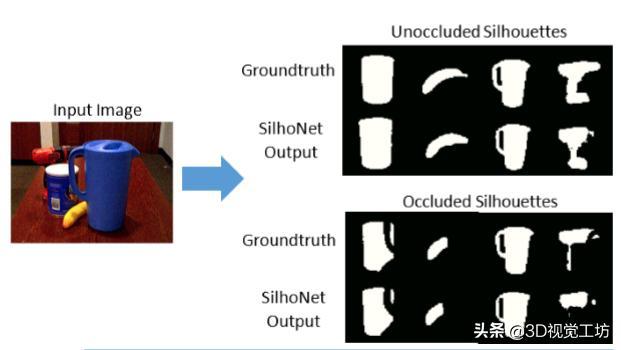
图2 示例预测来自测试图像的被遮挡和未被遮挡的轮廓
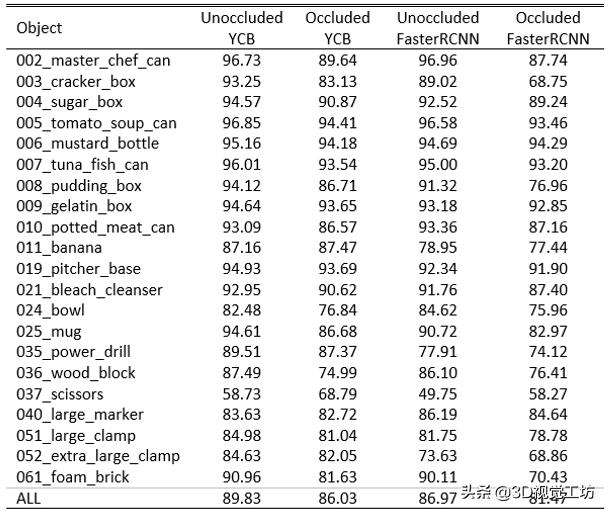
表1 在YCB-VIDEO测试装置上预测的SILHOUETTES的平均精度
B.3D位姿回归
本文比较了SilhoNet的3D位姿预测与PoseCNN的公布结果的性能,无论是否有迭代最近点(ICP)改进。图3显示了PoseCNN和SilhoNet两种方法的准确度曲线,其中YCB地面实况ROI输入和FasterRCNN预测ROI输入。SilhoNet的整体性能与基本事实和预测的投资回报率相当,总体而言,SilhoNet在有或没有ICP改进的情况下显着优于PoseCNN。表II列出了PoseCNN和SilhoNet方法中每个类别的平均准确度误差。SilhoNet相对于PoseCNN的预测精度最差的类别是“021漂白清洁剂”。SilhoNet将此对象视为轮廓空间中的非对称,但形状几乎是平面对称的,因此轮廓中的位姿预测可能很容易混淆。对于几个质地较差的物体,SilhoNet的表现优于PoseCNN。最好的例子是“011banana”类,它在特征和轮廓空间都是非对称的。
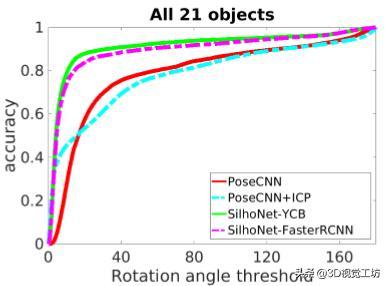
图3. YCB视频数据集中所有对象的3D位姿精度曲线
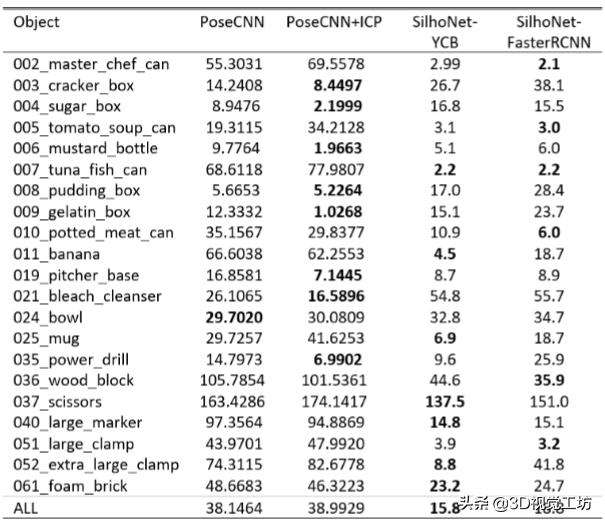
表2 YCB-VIDEO测试装置中的平均三维位置旋转误差
C.抓取点检测
该方法的目标是融合单眼图像中的对象的3D位姿估计与未被遮挡的抓取点检测,以便在杂乱的场景中进行抓取规划。本文通过在对象框架中获取预先计算的抓取点并将它们投影到预测的对象遮挡掩模上来实现此目的。那些不在遮挡掩模上的点被认为是无效的。图4显示了将预测的遮挡掩模和3D位姿估计与预先计算的抓取数据库组合以过滤可见抓取点的过程的示意图。图中的最终图像显示了投射回场景的抓取点,并通过哪些点可见并因此有效而着色。了解哪个抓取点被遮挡可以使机器人能够确定物体是否足够清晰以便抓取或者是否必须采取一些其他步骤以实现对物体的无阻碍抓取。
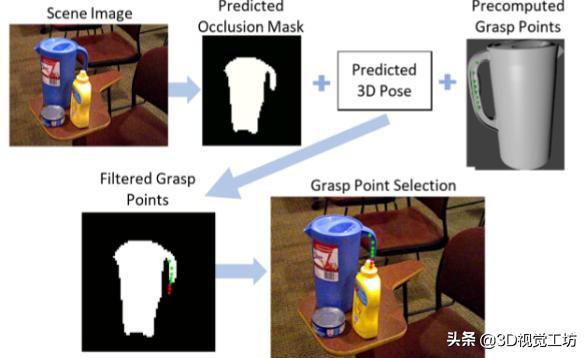
图4.未被遮挡的抓取点以绿色显示,而遮挡的点以红色显示
四、结论
本文表明该方法优于最先进的PoseCNN网络,用于3D位姿估计。YCB视频数据集中的大多数对象类。此外,通过对检测到的对象使用中间轮廓表示,本文示出了可以在图像中检测到视觉上未被遮挡的抓取点并且用于从预先计算的抓取数据库中通知抓取规划。目前,该方法预测了轮廓空间中对称性所特有的3D位姿。未来的工作将集中在扩展此方法以构建在特征空间中也是唯一的预测,尽管对象形状是对称的。
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
个人微信公众号:3D视觉工坊

 浙公网安备 33010602011771号
浙公网安备 33010602011771号