
点云学习在自动驾驶中的研究概述
作者:蒋天园Date:2020-04-17
自动驾驶公司的发展
有关自动驾驶的研究最早可以追述到2004年的DARPA Grand Challenge和2007年的DARPA Urban Challenge,目的是研究如何在各种情形下提高自动驾驶的能力;2009年,谷歌开创了waymo公司目的是促使之前成熟的技术进一步商业化;2013到2014年深度学习的出现使得该领域的感知算法飞速发展;15年Uber Advanced Technologies Group以自动驾驶可完全加入驾驶服务为目的开展研究;到目前为止,已有很多公司开展了自动驾驶方面的研究工作:Apple, Aptiv, Argo AI, Aurora, Baidu, GM Cruise,Didi, Lyft, Pony.ai,Tesla, Zoox都是比较出名的自动驾驶公司。
自动驾驶系统的重要模块
1.传感器模块
在自动驾驶中,会用到多传感器融合感知环境,激光雷达因为可以直接提供一个3D精确的场景而备受自动驾驶研究者的关注。尽管以前已经有很多采用三维重建或者从二维图像中采用深度估计的方法提升算法对环境的感知能力,但是算法估计还是不能达到传感器的精确和可信,同时光照条件等对图像的质量影响很大。作为对比,3D点云具有周围环境的几何结构和深度信息,这使得目前基于点云的方法在3D感知方面成为主流,并取得了SoTA的感知效果。
2.HD 地图模块
地图构建模块一般主要包括两层:一个是point-cloud map用于展示周围的几何环境信息;第二个是traffic-rule-related semantic feature map,记录道路边界,交通线,信号灯等。这两层地图会被配准在一起形成HDmap用于提供导航精细的信息。其中前者主要是为了提供定位信息,后者主要是决策信息。
3.定位模块
该模块则是从上述的HD map中精确定位无人车的位置和朝向等信息,这个模块的核心技术之一是3D点云配准技术,通过配准前后两帧点云定位,在后续的文章中会讲到。
4.感知模块
第三个模块是感知模块,也是目前研究比较多的模块,主要的研究是在3D场景中检测,追踪和判别物体,之前一直被认作是自动驾驶的瓶颈,最近由于大规模的自动驾驶数据集的公布和新的研究方法将该模块的感知能力大大提升。也会在后续介绍到。
5.预测模块
该模块是为了预测3D场景中物体未来的运动轨迹。无人处附近的物体下一步的运动轨迹对规划也是很重要的。
6.路线规划模块
该模块是控制无人车从起始点到目的点的高级路径设置,该模块的输出是一个运动规划模块的high level指导信息
7.运动规划模块
根据环境信息和hig-level的指导,做出对当前环境下的运动规划。
8.运动控制模块
这是motion-planning module的底层控制模块,负责油门,刹车,方向盘的控制工作。
3D点云的处理和学习概述
如下图所示,在自动驾驶无人车中,两种点云被时常使用:实时扫描的lidar sweep和point-cloud map(也就是上文中的HD map的前者);在下图中,point-cloud map显示了点云的初级环境信息:该map的作用是(1)定位模块在点云配准中以该Map为参考得到自身的定位信息(2)感知模块通过pointcloud map分割前景和背景;lidar sweep信息则是在定位模块中与point cloud配准的点云信息和为感知模块用于检测周围的object。
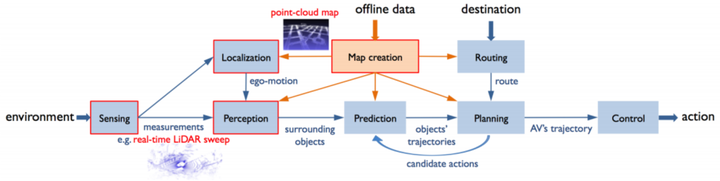
上文提到了lidar sweep和point-cloud map,下文着重介绍一这两种点云:
Real-time LiDAR sweeps
根据lidar扫描的机制,我们可以得到每一个点对应的激光束和对应的时间戳,因此也可以将点云按照x轴(时间戳)和y轴(激光束)将点云定义为二维image,如果这样,我们可以把每一个sweep当做是一个有规律的点云。例如,对于64线的点云中的每一束激光会发射数千次在1秒内,因此我们可以得到一系列和64个方位角相关的3D点。但是对于点云而言,上下两束位置的激光是不同步的,同时会受到距离远近的问题。因此LiDAR sweeps包含的特性有:
-
Pseudo 3D:Real-time LiDARsweeps在二维晶格上布置点,但是因为不同步,所以不是完美的规整的。和一般的从多个角度得到的点云不同的是,该点云仅仅只包含一个特殊的角度。
-
Occlusion:前面的物体会遮挡后面点的点云
-
Sparse point clouds:不能提供很细节的形状信息对于比较远的物体而言这也就是KITTI目标检测中的3D数据类型,通常包含了点的反射强度信息。
Point-cloud maps
这是上文提到的第二类点云,实际上是从多个无人车上同时得到的Real-time LiDAR sweeps的集合,总结一下具有如下特性:
-
Full 3D:由多个sweep整合得到的,因此可以得到比较细节的3D形状
-
Irregularity:无序性
-
No occlusion:多视角融合,可以使得物体遮挡问题消失
-
Dense point clouds
-
Semantic meanings:更多的细节信息和更完整的几何结构会得到更准确的语义信息,一般的Point-cloud maps不含有点的强度信息,但是具有点云的法向量信息。
如下面视频展示的内容,上层蓝色的点表示实时扫描的Lidar sweep,下层白色点云则是通过缝合得到的point-cloud.
HD map构建
概述
前文提到HD map 的构建有两层地图,分别是pointcloud map和traffic map;构建HD map主要的原因是实时的理解交通规则在当前是很具有挑战性的,尤其是对交叉路口的分叉路或者是道路交汇的正确道路选择。但是这些交通规则信息可以比较容易的在HD map中进行编码得到,而HD map的构建是在人为监督和质量保证下完成的。HD map提供了强大和不可缺少的先验,从根本上简化了自主系统中多个模块的设计,包括定位、感知、预测和运动规划。
1.定位的先验信息
在自动驾驶场景中,构建HD map可以采用路标或者线杆等作为先验定位信息。这些信息用于和liadr sweep配准定位当前姿态和位置。
2.感知的先验信息
感知模块使用HD MAP作为先验信息,有了这些先验,就可以将场景分割为前景和背景,接着可以去除掉背景点,仅仅将前景点用于后续模块处理,该方法可以显著降低目标检测的计算量,提高目标检测的精度。
3.Priors for prediction
本模块用于预测未来信息,3D道路中的交通线和路标几何信息可以作为该模块的重要先验
4.Priors for motion planning
在HD map中,traffic map可以作为先验用于后续运动决策。上述中的先验知识中可看出,HDmap占据了很重要的位置,因此创建的HD map必须是高精度和最新的。如下图所示,一个标准的map creation主要包含两步分内容:点云缝合和语义信息提取。其中点云缝合的目的是得到高精度的point-cloud map,语义信息特取为了得到能指导决策的语义信息
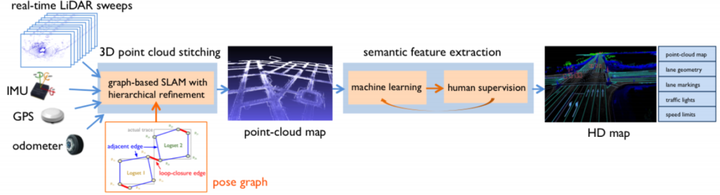
一张完整的HD map构建完成,如下视频显示的内容; 不仅仅包括了完成的point-cloud map,同时也包含有更高级的语义信息。
定位模块
概述
该模块前文所述是在HDmap中找到自身相对位置,该模块联系是联系HD map和和自动驾驶系统中的其他模块,需要多传感器信息融合,如下图所示。
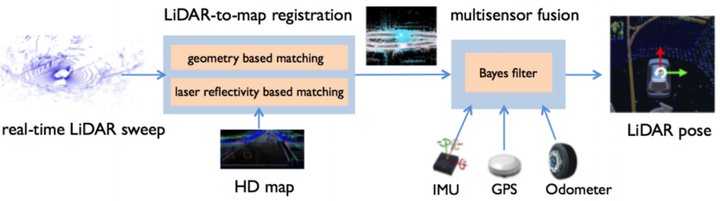
在自动驾驶场景中,高精度的要求表明平移误差应在厘米级,旋转角度误差应在微弧度级,这在这其中是很重要的;同时要具有很好的鲁棒性,保证在不同的自动驾驶场景都能使用。
如同上图展示的内容,标准的定位模块包括了两个核心组件:点云-地图配准和多传感器融合技术。其中点云-地图配准则是通过实时点云sweep和HD map配准得到初始的pose,后续采用多传感器融合的方式进一步提高pose的置信度和鲁棒性。多传感器融合组件是通过对多个传感器的测量,包括IMU、GPS、里程计、相机,以及上一个liar to map中得到的初始pose。
多传感器融合的标准方法是采用贝叶斯滤波形式,如卡尔曼滤波、扩展卡尔曼滤波或粒子滤波。贝叶斯滤波器考虑了一种基于车辆运动动力学和多传感器读数的迭代方法来预测和修正激光雷达的姿态和其他状态。在自主驾驶中,Bayes滤波器跟踪和估计的状态通常包括姿态、速度、加速度等与运动相关的状态,以及IMU偏差等与传感器相关的状态。 Bayes过滤器工作在两个迭代的步骤:预测和校正。在预测步骤中,在传感器读数之间的间隙,Bayes滤波器根据车辆运动动力学和假设的传感器模型预测状态;在校正步骤中,当接收到传感器读数或位姿测量时,贝叶斯滤波器根据相应的观测模型对状态进行校正。
如下视频展示的定位内容,定位模块首先根据实时点云sweep和point-cloud 地图进行配准得到初始pose,再根据贝叶斯滤波进行多传感器信息融合得到更加鲁棒和精确的Pose.
感知模块
该模块前文介绍到时为了感知到自动驾驶的周围环境信息,采用之前的HD map和定位信息以及实时的lidarsweep作为输入,输入的是3D目标检测的Bbox。如下图(a)中展示的是展示了一个基于后融合的感知模块的标准框架,是多个检测结果的融合结果。相比之下,图6 (b)显示了一个先融合的感知模块,它使用一个早期融合探测器来获取所有传感模式的输出,并生成所有的3D边界框,然后,它使用关联和跟踪组件来关联跨帧的3D包围框,并为每个对象分配标识。 基于后融合的方法更加成熟,而基于早融合的方法被认为具有更大潜力。几十年来,业界一直采用基于延迟融合的方法,因为这种方法将任务模块化,使每个传感器管道易于实现、调试和管理。基于先融合的方法具有端到端学习的有点,能够在高维特征空间中相互促进多种感知模式。
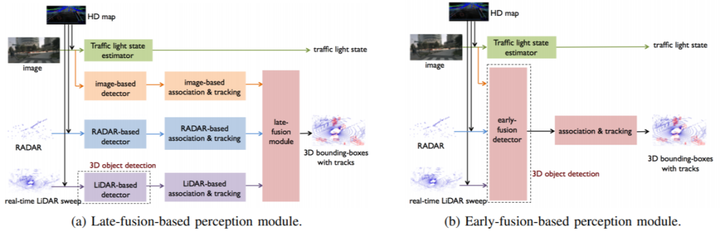
3D检测
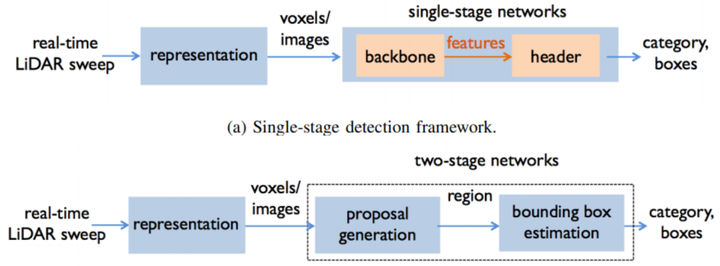
上图中的内容中,仅仅采用real-time lidar sweep的方法目前是学术研究的热点,主要可以分为point-based和voxel-based的方法;后续博主继续会写一些比较细节的综述文章介绍这两个系列的研究文章。目前更多的是按照二维的方式分为一阶段和两阶段的方式,如下图:
这里展示了19年CVPR文章pointpillars的实验效果如下,也是采用的上文提到的lidar sweep作为输入。

后续笔者会就3D感知方面的最新研究做一定的细致的记录。
参考文献
[1] Lasernet: An efficientprobabilistic 3d object detector for autonomous driving
[2] Go-icp: A globally optimal solution to 3d ICP point-set registration
[3] 3D Point Cloud Processing and Learning for Autonomous Driving
[4] Second: Sparsely embedded convolutional detection
[5] Pointpillars: Fast encoders for object detection from point clouds [6] Feature pDyramid networks for object detection
个人微信公众号:3D视觉工坊

 浙公网安备 33010602011771号
浙公网安备 33010602011771号