

关于《Detection of Adversarial Training Examples in Poisoning Attacks through Anomaly Detection》的阅读分享
1. 背景
机器学习在我们的生活中有许多应用,包括计算机视觉,网络入侵检测等。但是 通过这些模型容易受到攻击。攻击者可以在训练数据中投放恶意样本来破坏学习过程。最近研究表明,通过最优攻击策略可以破坏机器学习的性能。
本文提出一中基于离群点检测的防御机制来减轻这些最优投毒攻击的影响。之前提出的提出的防御策略依赖于测量每个样本对算法性能的影响。尽管检测到一些投毒攻击是有效的,但是在训练数据集中测试每个样本的影响通常是非常复杂的,因为它需要对集合中的每个样本重新训练和评估算法的性能。本文方法:提出了一种不同的投毒攻击对抗实例检测方法
本文主要贡献如下:
- 提出了一种基于数据预滤波和离群点检测的线性分类器投毒攻击的有效算法。这种防御策略是不可知的具体参数的实际学习算法,为增强实际机器学习系统的安全性以抵御投毒攻击提供了一种有用的方法。
- 在真实数据集上进行的实验评估,显示了我们提出的防御方法的有效性,包括特征数与训练点数相比较高的示例。实验结果表明,我们的对策大大减轻了论文[16]-[18]所述“最佳”投毒策略的影响。
- 我们的实验表明,更简单的约束攻击,如标签翻转,更难检测。我们也提供了一个经验比较的效果,这是第一次系统地研究离群点检测的好处,以减轻数据中毒对机器学习算法的影响。
2. 最佳投毒攻击
在投毒攻击中,根据攻击者定义的目标,在学习者的训练数据集中注入对抗实例来影响学习算法。典型的对抗性例子是为了最大化学习算法的误差而设计的,这里只考虑二元线性分类问题。
2.1 问题描述
假设分类器是由w参数化的,可以将攻击者的目标表示为如下的双层优化问题:
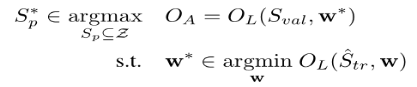
可以利用梯度上升策略得到优化问题的一个局部最大值,只要损失函数和学习算法是连续可微的,就可以将上述问题的内部优化问题替换为对应的一阶最优性条件:
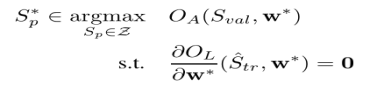
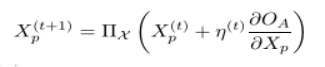
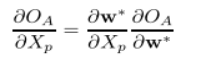
2.1线性回归分类:套索投毒
学习此分类器参数最简单的方法是最小化训练集上的均方误差(MSE)。学习算法的损失函数可以表示为:
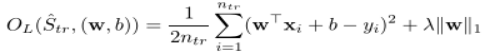


3.防御方法
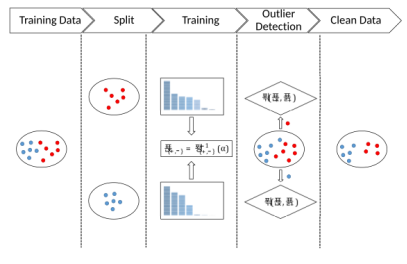
由于许多应用程序收集了大量的数据,因此训练数据的保存并不总是可能的,中毒攻击是一种严重的威胁。然而,一小部分数据的精确处理是可以实现的。在这些背景下,我们建议使用基于距离的异常检测来检测对抗训练的例子,使用一小部分可信数据点。在这些背景下,我们建议使用基于距离的异常检测来检测对抗训练的例子,使用一小部分可信数据点。
4.实验结果
在实验部分我们采用了mnist数据集和Spambse数据集,这两个数据集都是网上公开的数据集,具有普遍性,能更能证明我们的防御方法。
4.1Mnist数据集
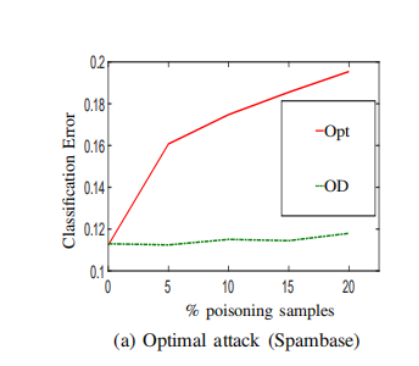
在这种情况下,我们选择正则化参数λ通过一个5倍交叉验证程序。 当λ被选择与数据相关的过程,作为交叉验证,它的值也受到中毒点的增加的影响。在这种情况下,由于训练集相对较小,与特征数量相比,中毒攻击更加有效。 误差从干净数据集中的0.037提高到0.391 增加20%的中毒点,即。 误差增加10倍以上。 在这种情况下,当不进行辩护时,误差的标准偏差相当大。

参考文献:
[1]Detection of Adversarial Training Examples in Poisoning Attacks through Anomaly Detection

