决策树简述
决策树是机器学习中一类非常常见的算法,它是一种分类与回归算法,但以分类为主。它的决策思维非常符合人类正常的决策方式。举一个简单的例子, 比如我们要挑选一个书包,我们就需要做出以下决策:我需要一个男包还是女包?女包。我需要一个双肩背包还是斜挎包?双肩包。我需要一个大包还是小包?小包。我需要一个白色的包还是黑色的包?白色。以上几个选择做完,我就可以将具有{女包、双肩包、小包、白色}这一属性组的包做一个“可以买”的标记。如果我认为包可以不是白色的,也可以是蓝色的,那么{女包、双肩包、小包、蓝色}这样一个属性组也可以标记为“可以买”。其实,针对{性别、包型、大小、颜色}这样一组特征来说,会有很多个不同组合的属性组合。我们可以一一考虑,并分布给每一个分支一个标记,“可以买”或“不会买”。这就是一个简单的决策树决策过程。
在实际问题中,由上面的例子可以看到,在决策过程中,对于特征的选择还是比较重要的。比如一个包,其实不仅仅只有上面几个特征,可能还有千千万万的特征,如{长带还是短带,材质,价位,品牌}等等。那么,对于一个具有多个特征的决策问题,我们应该从哪个特征开始进行分类尼?随机选择显然是不好的,因此,我们定义了信息增益和信息增益比两个指标来指导特征选择。
首先给出信息熵的定义。假设样本集合是D,其中,第k类样本所占的比例为,则D的信息熵为
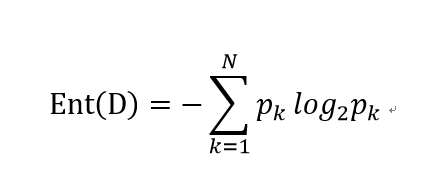
信息熵表示了样本纯度,信息熵越小,样本纯度越高。其中,N代表了样本类的个数。
基于信息熵,我们可以对某个属性a定义“信息增益”
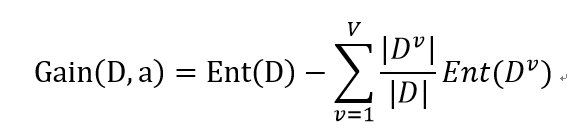
其中,a属性有V个可能取值,而D中在属性a上取值为的样本记为。
再进一步,基于信息增益我们还可以定义信息增益率
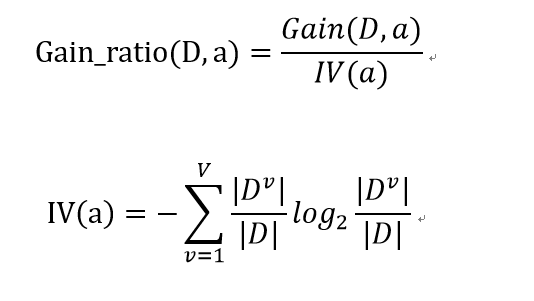
下面我们介绍决策树算法发展过程中出现的几个非常重要的算法。
首先是ID3算法。它的应用到了信息增益来选择特征
ID3算法:
输入:训练数据集D,特征集A,阈值;
输出:决策树T。
算法流程:
1、 若D中所有实例属于同一类C,则T为单节点树,并将C作为该结点的类标记,返回T;
2、 若A=空集,则T为单节点树,并将D中实例数最多的类C作为该结点的类标记,返回T;
3、 否则,计算A中各特征对D的信息增益,选择信息增益最大的特征A1;
4、 对A1的每一个取值,将D相应地分割成若干非空子集
5、 以每一个子集重新作为根节点,重复上述过程,并依次递归进行
这样最终将会形成一个决策树。
接下来介绍著名的C4.5算法。
C4.5算法与上边的ID3算法非常相似,唯一的不同是,ID3算法是用信息增益来选择特征,而C4.5算法使用信息增益率来选择特征。在使用信息增益作为训练数据集特征时会偏向于取值较多的特征,而用信息增益率则避免了这一问题。
其实,想形成一个决策树的过程并不复杂,但是,如果只“生成树”而不进行“剪枝”的话很容易产生过拟合的问题。过拟合问题是机器学习建模中一个比较令人头疼的问题。什么是过拟合尼?就是训练出来的模型“太好了”,很好地适应了训练集数据,但是却根本无法用于其他数据,因为它把训练集中一些本不该考虑的问题也考虑了进来。比如我们在训练一个“什么是水杯”的问题时,我们可以说,可以盛水的是水杯,但我们不能说,有盖子的是水杯,因为可能只是训练集取样不当的原因会使我们得出“有盖子的是水杯”这一结论,但事实上并不是这样的。这就是“过拟合”。为了避免过拟合问题,决策树还应该进行“剪枝处理”。
决策树的剪枝主要有两种策略,分别是“预剪枝”和“后剪枝”。其中,预剪枝是指在决策树生成过程中,对每个结点事先估计,若不能提升泛化性能,则停止划分当前结点。预剪枝降低了过拟合的风险,也减少了决策树的训练时间,但是它是一种“贪心算法”很有可能会造成欠拟合。后剪枝是先从训练集生成一颗完整决策树,然后自底向上进行考察并逐渐剪枝。后剪枝欠拟合风险很小,也可以有效避免过拟合,但是时间开销相对较大。
以上介绍的决策树都用于分类环境,那么,决策树是否可以进行回归?答案是可以。决策树中有极其著名的CART算法,全名是分类和回归树。它使用基尼系数进行属性划分。
CART生成算法
CART生成算法与C4.5算法相类似,它与C4.5算法的主要区别是使用基尼系数进行属性选择。
CART剪枝算法
输入:CART算法生成的决策树Tq;
输出:剪枝后的最优决策树Ta.
1、 k=0,T=Tq
2、a等于正无穷
3、 自下而上地对各内部结点t计算C(T),有
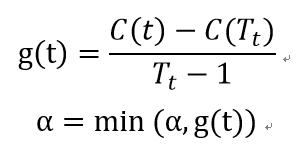
这里是以t为根节点的子树,C()表示了预测误差,如基尼系数等。
4、 自上而下访问内部结点t,如果有g(t)=a,进行剪枝,并对叶节点t以多数表决法决定其类,得到树T
5、 设k=k+1,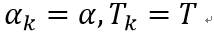
6、 如果T不是由根节点单独构成的树,回到步骤4
7、 采用交叉验证法在子树序列中选取最优子树
参考资料来自:《统计学习方法》 李航 《机器学习》 周志华

 浙公网安备 33010602011771号
浙公网安备 33010602011771号