

Python pytagcloud 中文分词 生成标签云 系列(一)
转载地址:https://zhuanlan.zhihu.com/p/20432734
工具
Python 2.7 (前几天试了试 Scrapy 所以用的 py2 。血泪的教训告诉我们能用 py3 千万别用 py2 ,编码问题累死人)
jieba 结巴分词 fxsjy/jieba · GitHub
pytagcloud 词云生成 atizo/PyTagCloud · GitHub
安装过程应该没什么坑,不像 Scrapy 光安装都能写一篇出来。自行补充依赖就好。
Step 1 爬虫抓取文本
这个阶段比较简单。虽然我欠了半年的爬虫系列一直没有写,但是抓个贴子标题都不涉及模拟登陆,对入门的人应该问题不大。随便改了一下以前的代码就跑出来了。
# -*- coding: utf-8 -*-
import requests
import re
import os
import codecs
def get_title(url):
s = requests.session()
h = s.get(url)
html = h.content.decode('utf-8')
#print html
qurl = r'<a href="forum.*? class="s xst">(.*?)</a>'
qurllist = re.findall(qurl,html)
#print qurllist
for each in qurllist:
f = codecs.open("result.txt", 'a', 'utf-8')
f.write(each+'\n')
print each
#f.flush()
f.close()
for i in range(1,1000):
url = 'http://rs.xidian.edu.cn/forum.php?mod=forumdisplay&fid=72&page='+str(i)
get_title(url)
值得注意的还是编码问题,用 py3 的可以忽略。
Step 2 中文分词,提取关键词
jieba 的分词效果还是比较理想的。不过我在统计词频的时候一时没想起什么太好的解决办法,加上编码问题把我烦的够呛。于是偷懒地选择了 jieba 自带的提取关键词并给出权重的功能。
详见 jieba/extract_tags.py at master · fxsjy/jieba · GitHub
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags_with_weight.py [file name] -k [top k] -w [with weight=1 or 0]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
parser.add_option("-w", dest="withWeight")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
if opt.withWeight is None:
withWeight = False
else:
if int(opt.withWeight) is 1:
withWeight = True
else:
withWeight = False
content = open(file_name, 'rb').read()
tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=withWeight)
if withWeight is True:
for tag in tags:
print("tag: %s\t\t weight: %f" % (tag[0],tag[1]))
else:
print(",".join(tags))
需要命令行运行。
先 cd 到目录,然后使用命令
python extract_tags_with_weight.py [file name] -k [top k] -w [with weight=1 or 0]
其中 -k 后输入关键词个数 -w 选择是否显示权重。如图:(具体的文本和结果我后面打包发一下,就不贴了)
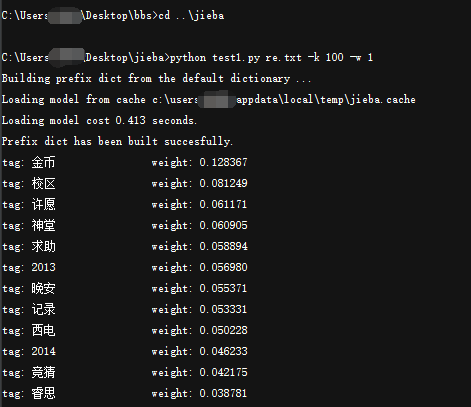 说明:
说明:
其实标准的过程应该是分词以后统计词频,生成 k-v 的 Python 字典然后交由 pytagcloud 生成词云。由于我也是刚接触分词这块,不太熟悉,统计词频时力不从心,所以直接用了现成的关键词提取。
另外由于生成词云时需要的格式为 Python 字典(k-v),我自己在中间用 Notepad++ 和 Excel 做了一些文本上的预处理,这方面就八仙过海各显神通了。
还有,我使用了默认词典,没有自定义内容(jieba 是可以自定义词典的),所以一些词在提取时出现偏差,比如"新校区"、"老校区"就全部提成了"校区",X号楼只保留下来了"号楼"。另外我没有做词性筛选,导致许多无意义副词出现在结果里,后面生成词云时自己手动去掉了。
Step 3 生成词云
关于 pytagcloud ,搜到的唯一一篇比较有价值的文章就是Python中文标签云之pytagcloud 更多的还是要参考官方示例 atizo/PyTagCloud · GitHub 。我也没把功能全试完,大家可以自己向深处挖掘。
# -*- coding: utf-8 -*-
import codecs
import random
from pytagcloud import create_tag_image, create_html_data, make_tags, \
LAYOUT_HORIZONTAL, LAYOUTS
from pytagcloud.colors import COLOR_SCHEMES
from pytagcloud.lang.counter import get_tag_counts
wd = {}
fp=codecs.open("rsa.txt", "r",'utf-8');
alllines=fp.readlines();
fp.close();
for eachline in alllines:
line = eachline.split(' ')
#print eachline,
wd[line[0]] = int(line[1])
print wd
from operator import itemgetter
swd = sorted(wd.iteritems(), key=itemgetter(1), reverse=True)
tags = make_tags(swd,minsize = 50, maxsize = 240,colors=random.choice(COLOR_SCHEMES.values()))
create_tag_image(tags, 'keyword_tag_cloud4.png', background=(0, 0, 0, 255),
size=(2400, 1000),layout=LAYOUT_HORIZONTAL,
fontname="SimHei")
输出结果如图。
补充:使用 pytagcloud 一定要记得添加中文字体并修改其配置文件,具体方法:
准备一个 ttf 中文字体,如 simhei.ttf ,将其移动到 C:\Users\~\AppData\Roaming\Python\Python27\site-packages\pytagcloud\fonts
并修改该文件夹下的 fonts.json 文件,添加相应的字体记录,如
{
"name": "SimHei",
"ttf": "simhei.ttf",
"web": "none"
},
输出结果还是比较有趣的,不过校外的人可能不熟悉。当然这本身也只是个很入门的东西,算作娱乐吧。
代码部分原创的不多…很多是网上拼拼凑凑找的。但是 pytagcloud 相关的内容搜出来比较少,对中文支持也需要自己修改,有人要自己做的话最好用谷歌搜索,然后参考前几篇文章和官方示例自己尝试。
在此顺便吐槽百度一发,实在难用,百度搜来搜去的结果,远不如谷歌直击要害。当然英语好就更棒了,能直接读文档和看 stackoverflow 。
想要自己尝试的可以用我这次的文档,或者自己抓感兴趣的资料。
http://pan.baidu.com/s/1mhn4mN2
拓展的话,感兴趣的可以多尝试几款分词比较一下。具体的就不推荐了我也不了解,搜一下会有很多,功能很丰富,语义分析,情感倾向,都有,可玩性比较高吧。
另外有另一款 Python 下的词云生成器 amueller/word_cloud · GitHub 留作以后研究吧。另外过程中看文章时发现好多词频统计和标签云是用 R 做的,有机会可以学习一下。
噢对了, pytagcloud 支持直接生成 HTML 网页的标签云,官方 demo 里有,我这边没做,就不展示了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号