


人人贷网的数据爬取
之前看到过网上有一篇有关爬取P2P网站上散标投资数据和借贷人的信息数据的博文,后应他人请求,帮忙实现。发现存在不少问题,先整合前人资料(http://sanwen8.cn/p/156w57U.html),说一下爬取中遇到的问题:
(一)首先分析"散标投资"这一个模块,共有51个页面
- 进入首页,调用360浏览器的F12(界面如下)选择Network->XHR
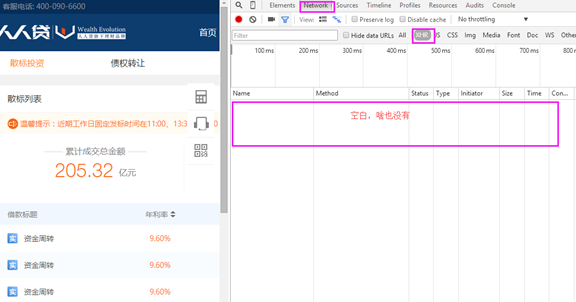
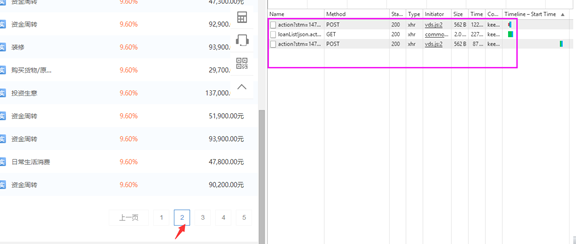
- 后在上图中左侧点击到第2个页面,右侧那一栏会弹出3个事件(对其中Method为GET的那一个事件进行分析)
- 点击Header,对General->Requesl URL, 和Request Headers->User-Agent 进行分析(后文中会用到)
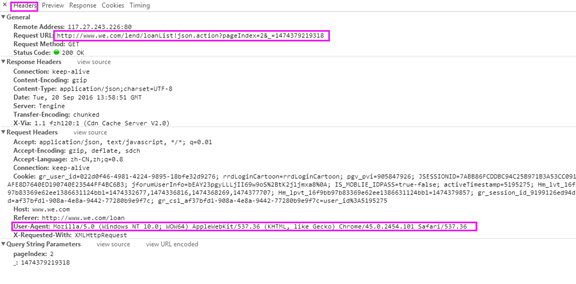
仔细观察Request URL:http://www.we.com/lend/loanList!json.action?pageIndex=2&_=1474379219318,你会发现数据是Json格式,查看下一页,发现也是如此,不同页面的数据格式是相同的。对此,我们的抓取思路就是:获取网页源代码,从源代码中提取数据。
数据来自于类似这样的地址:http://www.we.com/lend/loanList!json.action?pageIndex=2&_=1457395836611,删除&_=1457395836611后的链接依然有效,打开链接发现是json格式的数据,而且数据就是当前页面的数据。至此,我们就找到了真正的数据来源
- 以下就是爬取"散标列表"数据的代码(Python 3.5.2 |Anaconda 4.0.0 (64-bit),低版本好像不能解析utf-8)
要想配置高版本见http://www.cnblogs.com/Yiutto/p/5631930.html
import pandas as pd import numpy as np import requests headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'} #headers得根据自己的浏览器F12下自行修改调整,具体可见步骤c #自定义了一个解析网页的函数 def parse_html(i): url = "http://www.we.com/lend/loanList!json.action?pageIndex=%s&" % i #数据的真正来源(Request URL) resp=requests.get(url,headers=headers) #获取页面 html=resp.json() #页面文字 data=pd.DataFrame(html['data']['loans']) data.to_csv('loans%s.csv' % i) #将整理后的数据写入csv格式文档 print("%s successsed" % i)
- 进入首页,调用360浏览器的F12(界面如下)选择Network->XHR
(页面总共51个,可自己写个循环语句,但循环过程中可能出错,我自己就是一个个页面爬取的,然后再把51个页面的数据loan整合)
总的来说,第一步为得是给第二步做铺垫,因为第二步需要用到第一步中loans.csv中的loanId,可自行将其单独整理为一个csv文档
(二)如何获取借贷人信息
a.点击其中一栏即可进入借贷人信息
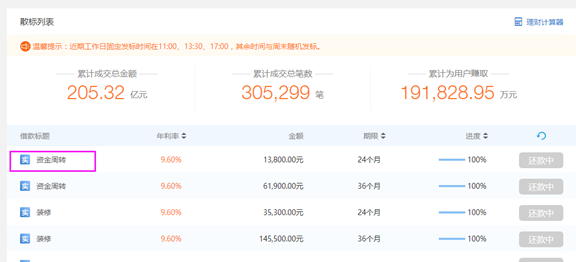
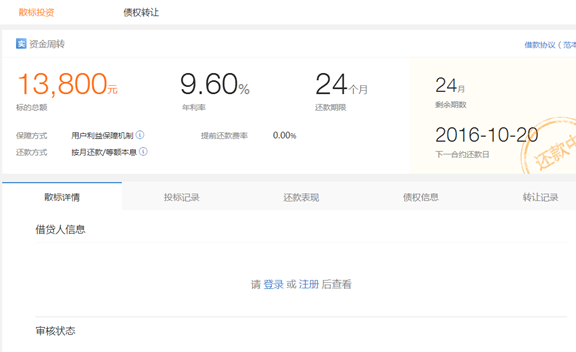
为什么看不到借贷人信息呢,首先你的搞到一个帐号登录即可见(自己随便注册一个啦)
b.帐号登录后,按F12,刚开始又是空白,如下图
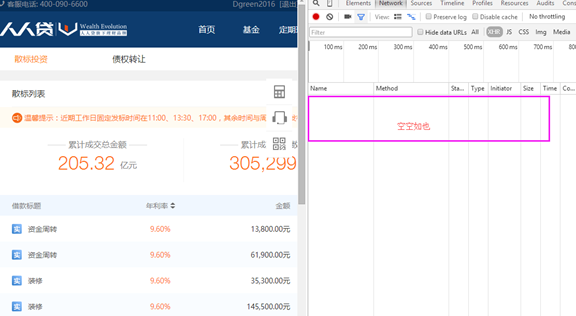
这时只要刷新一下页面,然后找到Method为Get的事件,点击打开
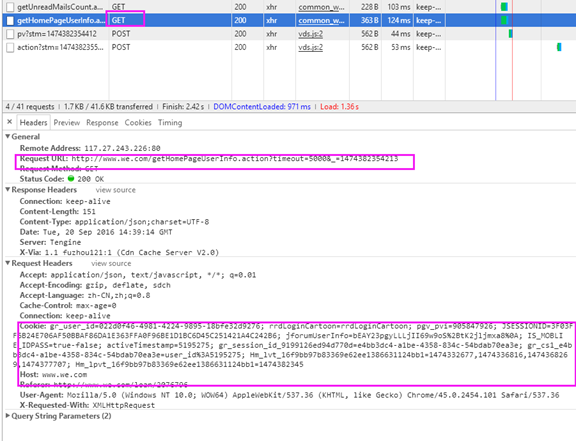
记住Request Headers->Cookie, 后面代码需要用到它
c.爬取借贷人信息的源代码
import pandas as pd
import re
import numpy as np
import requests
import time
import random
from bs4 import BeautifulSoup
s=requests.session()
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
#根据浏览器下自行修改
headers['Cookie'] = 'gr_user_id=022d0f46-4981-4224-9895-18bfe32d9276; rrdLoginCartoon=rrdLoginCartoon; pgv_pvi=905847926; Hm_lvt_16f9bb97b83369e62ee1386631124bb1=1474288518,1474332677,1474336816,1474368269; Hm_lpvt_16f9bb97b83369e62ee1386631124bb1=1474372985; JSESSIONID=7EB90C9967D8C42B08DFB18EB9A9F74ED2ACC468B7D56B9372E2A20684713847; jforumUserInfo=bEAY23pgyLLLjII69w9oS%2BtK2jljmxa8%0A; IS_MOBLIE_IDPASS=true-false; activeTimestamp=5195275; gr_session_id_9199126ed94d770d=70bbe285-4ac6-42c9-a49b-9255d0eb9c46; gr_cs1_70bbe285-4ac6-42c9-a49b-9255d0eb9c46=user_id%3A5195275'
#根据浏览器F12下的Request Headers->Cookie自行复制上去即可
def parse_userinfo(loanid):#自定义解析借贷人信息的函数
timestamp=str(int(time.time())) + '%03d' % random.randint(0,999)
urll="http://www.we.com/lend/detailPage.action?loanId=%.0f×tamp=" % loanid+timestamp
#这个urll我也不知道怎么来的,貌似可以用urll="http://www.we.com/loan/%f" % loanid+timestamp
#(就是页面本身,我也没试过)
result = s.get(urll,headers=headers)
html = BeautifulSoup(result.text,'lxml')
info = html.find_all('table',class_="ui-table-basic-list")
info1= info[0]
info2 = info1.find_all('div',class_="basic-filed")
userinfo = {}
for item in info2:
vartag = item.find('span')
var = vartag.string
if var == '信用评级':
var = '信用评分'
pf1 = repr(item.find('em'))
value = re.findall(r'\d+',pf1)
else:
valuetag = item.find('em')
value = valuetag.string
userinfo[var]=value
data = pd.DataFrame(userinfo)
return data
rrd=pd.read_csv('loanId.csv') #loanId是之前散标数据中的loanId,将其单独整理为一个csv文档
loanId=rrd.ix[:,'loanId']
user_info = ['昵称', '信用评分',
'年龄', '学历', '婚姻',
'申请借款', '信用额度', '逾期金额', '成功借款', '借款总额', '逾期次数','还清笔数', '待还本息', '严重逾期',
'收入', '房产', '房贷', '车产', '车贷',
'公司行业', '公司规模', '岗位职位', '工作城市', '工作时间']
table = pd.DataFrame(np.array(user_info).reshape(1, 24), columns=user_info)
i = 1
for loanid in loanId:
table = pd.concat([table, parse_userinfo(loanid)])
print(i)
i += 1 #看一下循环多少次
table.to_csv('userinfo.csv',header=False)
整理出来的数据可能会有点乱,但总的来说还是不错的。(相信大家还是能清理的)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号