

用R语言对NIPS会议文档进行聚类分析
一、用R语言建立文档矩阵
(这里我选用的是R x64 3.2.2)
(这里我取的是04年NIPS共计207篇文档做分析,其中文档内容已将开头的作者名和最后的参考文献进行过滤处理)
##1.Data Import 导入自己下的3084篇NIPStxt文档
library("tm")#加载tm包
stopwords<- unlist(read.table("E:\\AllCode\\R\\stopwords.txt",stringsAsFactors=F))
dir<-"E:\\newtext(No including Authors and References)\\2004" #NIPS文本文档的路径
nips<-Corpus(DirSource(dir),readerControl=list(language="en"))
##2.Transformations
nips <- tm_map(nips, stripWhitespace)#去多余空白
nips <- tm_map(nips, content_transformer(tolower))#转换为小写
nips <- tm_map(nips, removeWords, stopwords)#去停用词
library("SnowballC")
nips <-tm_map(nips, stemDocument)#采用Porter‘s stemming 算法提取词干
##3.Creating Term-Document Matrices
#将处理后的语料库进行断字处理,生成词频权重矩阵(稀疏矩阵)也叫词汇文档矩阵
dtm <- DocumentTermMatrix(nips)
##4.Reducing dimensions
#因为生成的矩阵是一个稀疏矩阵,再进行降维处理,之后转为标准数据框格式
#我们可以去掉某些出现频次太低的词。
dtm1<- removeSparseTerms(dtm, sparse=0.6))#除了词频统计中低于40%的稀疏条目项
data <- as.data.frame(inspect(dtm1))
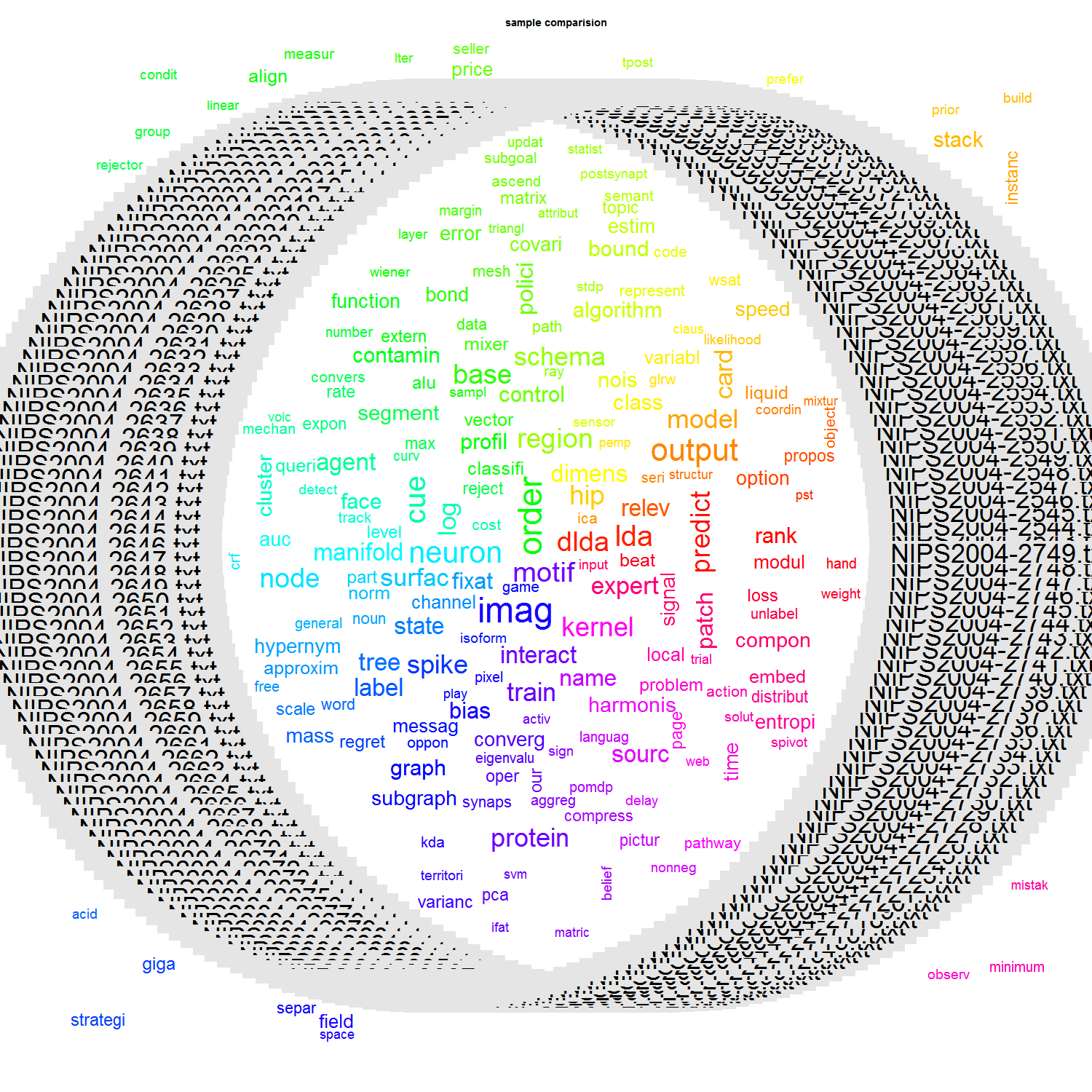
二、WordCloud
library(wordcloud);
tdm<-TermDocumentMatrix(nips)
tdm_matrix<-as.matrix(tdm)
v <- sort(rowSums(tdm_matrix),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
wordcloud(d$word,d$freq,c(8,.3),2)

png(paste("d://wb//sample_comparison",".png", sep = ""), width = 1500, height = 1500 );
comparison.cloud(tdm_matrix,colors=rainbow(ncol(tdm_matrix)));####由于颜色问题,稍作修改
title(main = "sample comparision");
dev.off();
三、文档矩阵进行聚类分析
层次聚类的结果图如下:(看不清)
##5.Clustering
#再之后就可以利用R语言中任何工具加以研究了,下面用层次聚类试试看
#先进行标准化处理,再生成距离矩阵,再用层次聚类
data.scale <- scale(data)
d <- dist(data.scale, method = "euclidean")
fit <- hclust(d, method="ward.D")
plot(fit,main ="文件聚类分析")

当然也可以用Kmeans聚类:
##5.Clustering
#下面用kmeans聚类分析
km<-kmeans(dtm1,centers=3)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号