[MQ]再谈延时队列
小记
最近项目里有需求,在接口调用完毕后将一些消息通过MQ通知给另一个服务,并且因为业务的原因,需要停留一分钟再投递到MQ,另一个团队来消费,我本来想用RabbitMQ(以下简称RMQ)来实现,但经过和同事讨论决定不用RMQ来实现延时,RMQ只充当消息通知,延时在本地进行实现。本地采用一个单机的延时队列,是我另一个同事写的简单组件,拿过来直接用就行了,把功能做完,顺利上线,但是之后问题还是暴露了出来,MQ消费者那边的团队反馈消息有时候没收到,于是我开始排查问题所在,确认了我业务代码是没问题的,但是看服务端的日志显示的确没发出去,但是因为是本地的一个延时队列,消息放在内存里,我也没法查队列里的具体消息情况,也不敢下结论是本地延时队列的问题,因为开发环境和测试环境都没出现问题。只能先跟踪一下,第二天把前面三天的日志都拉下来看发现问题所在,许多实例都出现了消息在第二天要么就当天的很晚的时候才发出去的情况,排除了可能是因为虚拟机没有同步宿主机的时间的原因之后(因为延时队列里面是获取的当前时间和消息创建时间的差来判断时间间隔),我这下基本确定这个是我同事写的延时队列的问题。
问题来源
其实这个延时队列逻辑很简单,数据结构就是一个数组,入队列就是把消息放在可用位置上,到了数量满足一定条件的时候就扩容,出队列的时候全数组扫描,当碰到到期的消息的时候,将消息取出。其实现在看来这个延时队列其实设计得不是很优雅,如果取元素,需要经过很多次扫描大数组,并且扩容的时候对内存的消耗也大,这里代码就不帖了,这个故事告诉我们,一个组件要给别人用,必须要经过多方面专业的测试才行,这次的问题后来我和同事讨论其实还是因为有些case没有测试到导致的。另外就是,选用组件的时候最好还是选用已知的稳定的,因为经过检验的才是出故障可能性比较小的。
扯一扯延时队列
延时队列在业务中经常会用到,比如网上买个东西,订单生成了但是多少时间内没支付就关闭订单,定时逻辑等等。之前我在学RabbitMQ的时候也实现过类似的功能。具体可以看RabbitMQ延时队列,今天来整理一下去设计一个延时队列需要些什么并且有哪些方案。
- 设计延时队列(单机/分布式)需要考虑哪些
- 及时性 消费者端能否及时收到
- 可靠性 消息不能像我那里的问题一样,没有被及时消费
- 可恢复 万一出现问题,之前的数据需要能够恢复
- 可撤回 还没有到延时时间的消息可以撤回
- 高可用 在一个实例失效的情况下其他实例还能继续工作
- 任务丢失补偿 任务丢失了之后咋办
- .....
单机延时队列
- Java自带的DelayQueue
来粗略看一下里面带的结构有啥
public class DelayQueue<E extends Delayed> extends AbstractQueue<E>
implements BlockingQueue<E> {
private final transient ReentrantLock lock = new ReentrantLock();
private final PriorityQueue<E> q = new PriorityQueue<E>();
.....
可以看到实际上这里面的结构是一个PriorityQueue,我们知道实际上这个队列可以用来做最大堆或者最小堆,取出的元素是通过比较器的规则比较出来的最大值或者最小值。再来看泛型里的参数,是都需要实现一个Delayed的接口的,再来看看接口
public interface Delayed extends Comparable<Delayed> {
/**
* Returns the remaining delay associated with this object, in the
* given time unit.
*
* @param unit the time unit
* @return the remaining delay; zero or negative values indicate
* that the delay has already elapsed
*/
long getDelay(TimeUnit unit);
}
从注释中,可以得知这里面的方法是用来获取剩余的时间的。并且这接口还是实现了比较器的接口的,所以不难推出,这里其实就是通过堆排序,来找到最早过期的元素。也就是最先应该出队列的元素。
简单做个demo,是实现以下Delayed的接口
public class DelayTask implements Delayed {
/**
* 消息编号
* */
private int index;
/**
* 延时时长+入队时间的值
* */
private long dealAt;
public DelayTask(long time,int index){
this.dealAt = time;
this.index = index;
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(
dealAt-System.currentTimeMillis(),
TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
if(getDelay(TimeUnit.MILLISECONDS)>o.getDelay(TimeUnit.MILLISECONDS)) {
return 1;
}else {
return -1;
}
}
//getter setter
}
做个简单的测试
public class DelayQueueTest {
public static void main(String[] args) throws InterruptedException{
DelayQueue<DelayTask> queue = new DelayQueue<>();
long currentTime = System.currentTimeMillis();
long[] delayTimes = {10000L,5000L,15000L};
for (int i = 0;i < delayTimes.length;i++) {
DelayTask t = new DelayTask(delayTimes[i]+currentTime,i);
queue.add(t);
}
while(!queue.isEmpty()) {
DelayTask t = queue.take();
if (t != null) {
queue.poll();
System.out.println("当前执行的任务编号为:" + t.getIndex());
long timeSpan = System.currentTimeMillis()-currentTime;
System.out.println("时间间隔为:"+timeSpan);
}
Thread.sleep(1000);
}
}
}
运行结果
当前执行的任务编号为:1
时间间隔为:5001
当前执行的任务编号为:0
时间间隔为:10000
当前执行的任务编号为:2
时间间隔为:15000
那么上面的方法有啥利弊呢,首先优点肯定是简单,缺点也显而易见,可靠性差,并且内存占用的问题也很明显。
- 时间轮算法
像我前面提到我公司的同事的做法中,循环去遍历整个数组去检测消息是否达到延时时间的方法其实只能适用于小服务并且调用量不大的情况,一旦像调用量大了起来,实际上轮询整个数组去检测消息是否达到延时时间是很低效的。那么在这基础上,可以采用时间轮的办法,一个时间轮代表一个周期,一个周期里分为几个时间间隔,每一个时间间隔里包含在这一分钟内所有的定时任务,时间轮在结构上是一个双向链表。
如图所示
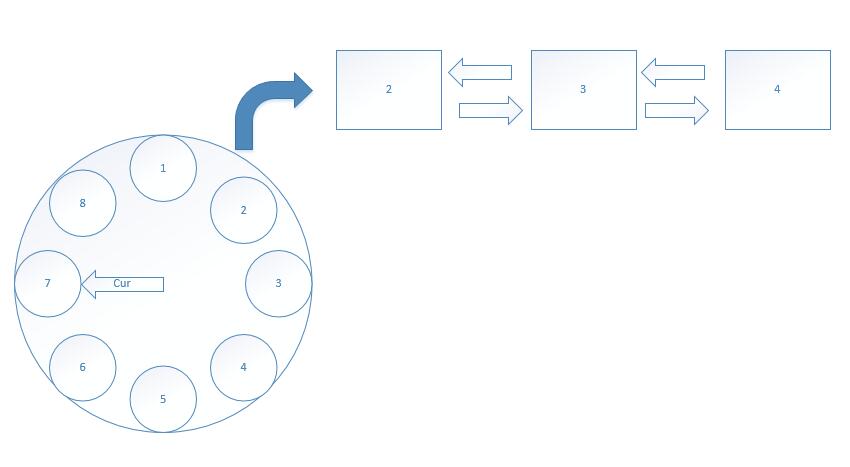
假设这里一个时间节点代表一分钟,这里一个时间轮也就是周期为八分钟,当当前时间到达时间节点2的时候,这说明1中的任务已经全部过期且处理完成,时间节点2对应的定时任务就开始处理。这样做的优点是可以通过一个线程监控多个定时任务,但是缺点也很明显,就是时间颗粒度由节点的间隔决定,并且这些任务的时间间隔还需要用同样的时间颗粒度。并且需要考虑,不在时间周期里的任务如何处理。然后延时队列的其他特性都还需要通过自己实现来补上。
代码这里先挖个坑,之后我补上。
分布式中的延时队列
- Redis实现
Zset的排序功能,直接提供了很方便的解决办法,只要我们把Score设置为定时任务预计执行时间的时间戳,也就是当前时间+延时的时间,这样排序后首先拿到的就是最早过期的,命令也很简单,就是
ZRANGEBYSCORE key min max
就可以获取到max对应时间戳之前的所有任务。这种做法的优点是,许多功能redis都实现了,比如持久化,高可用性这些。但是缺点也有,那就是消息的延时和我们轮询读redis的速度有关,获取当前时间之前的定时任务,可能有任务离当前时间比较远,并且消息过多的情况下,redis本身会受一定影响
- RabbitMQ实现
这个我在前面有写过类似的文章。
- RocketMQ实现
阿里的开源消息队列,但我目前还没做太多了解,在我补齐这个中间件的技能点的时候一块儿补上。

