


1. 逻辑查询处理步骤序号
(8)SELECT (9)DISTINCT (11)<TOP_specification> <select_list>
(1)FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4)WHERE <where_condition>
(5)GROUP BY <group_by_list>
(6)WITH {CUBE | ROLLUP}
(7)HAVING <having_condition>
(10)ORDER BY <order_by_list>
每个步骤产生一个虚拟表,该虚拟表被用作下一个步骤的输入。只有最后一步生成的表返回给调用者。如果没有某一子句,则跳过相应的步骤。
1. FROM:对FROM子句中的前两个表执行笛卡尔积,生成虚拟表VT1。
2. ON:对VT1应用ON筛选器。只有那些使<join_condition>为真的行才被插入VT2。
3. OUTER(JOIN):如果指定了OUTER JOIN,保留表中未找到匹配的行将作为外部行添加到VT2,生成VT3。如果FROM子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1到步骤3,直到处理完所有的表为止。
4. 对VT3应用WHERE筛选器。只有使<where_condition>为TRUE的行才被插入VT4。
5. GROUP BY:按GROUP BY 子句中的列列表对VT4中的行分组,生成VT5。
6. CUBE|ROLLUP:把超组插入VT5,生成VT6。
7. HAVING:对VT6应用HAVING筛选器。只有使<having_condition>为TRUE的组才会被插入VT7。
8. SELECT:处理SELECT列表,产生VT8。
9. DISTINCT:将重复的行从VT8中移除,产生VT9。
10. ORDER BY:将VT9中的行按ORDER BY子句中的列列表排序,生成一个有表(VC10)。
11. TOP:从VC10的开始处选择指定数量或比例的行,生成表VT11,并返回给调用者。
2. 准备数据
SET NOCOUNT ON;
USE tempdb;
GO
IF OBJECT_ID('dbo.Orders') IS NOT NULL
DROP TABLE dbo.Orders;
GO
IF OBJECT_ID('dbo.Customers') IS NOT NULL
DROP TABLE dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
customerid CHAR(5) NOT NULL PRIMARY KEY,
city VARCHAR(10) NOT NULL
);
INSERT INTO dbo.Customers(customerid,city) VALUES('FISSA', 'Madrid');
INSERT INTO dbo.Customers(customerid,city) VALUES('FRNDO', 'Madrid');
INSERT INTO dbo.Customers(customerid,city) VALUES('KRLOS', 'Madrid');
INSERT INTO dbo.Customers(customerid,city) VALUES('MRPHS', 'Zion');
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL PRIMARY KEY,
customerid CHAR(5) NULL REFERENCES Customers(customerid)
);
INSERT INTO dbo.Orders(orderid, customerid) VALUES(1,'FRNDO');
INSERT INTO dbo.Orders(orderid, customerid) VALUES(2,'FRNDO');
INSERT INTO dbo.Orders(orderid, customerid) VALUES(3,'KRLOS');
INSERT INTO dbo.Orders(orderid, customerid) VALUES(4,'KRLOS');
INSERT INTO dbo.Orders(orderid, customerid) VALUES(5,'KRLOS');
INSERT INTO dbo.Orders(orderid, customerid) VALUES(6,'MRPHS');
INSERT INTO dbo.Orders(orderid, customerid) VALUES(7, NULL);
执行结果:

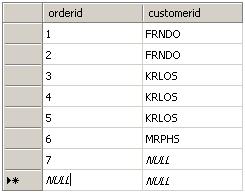
3. 查询语句
USE tempdb;
GO
SELECT C.customerid, COUNT(O.orderid) AS numorders
FROM dbo.Customers AS C
LEFT OUTER JOIN dbo.Orders AS O
ON C.customerid = O.customerid
WHERE C.city = 'Madrid'
GROUP BY C.customerid
HAVING COUNT(O.orderid) < 3
ORDER BY numorders;
执行结果:
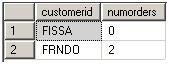
4. 逻辑查询处理步骤详解
1. 执行笛卡尔乘积,形成VT1。如果左表包含n行,右表包含m行,VT1将包含n×m行。
执行结果VT1:
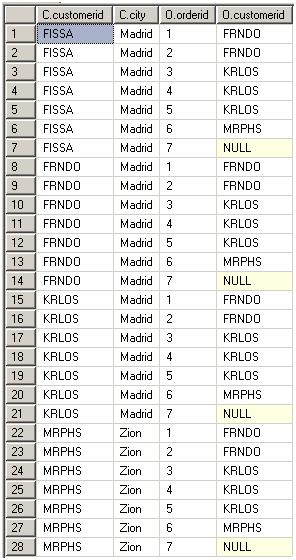
2. 应用ON 筛选器,只有<join_condition>为TRUE的那些行才会包含在VT2中。
ON C.customerid = O.customerid
三值逻辑:
TRUE、FALSE、UNKNOWN为SQL中逻辑表达式的可能值。
UNKNOWN值通常出现在含NULL值的逻辑表达式中,如NULL > 42; NULL = NULL; X + NULL > Y。
NOT TRUE 等于 FALSE
NOT FALSE 等于TRUE
NOT UNKNOWN 等于 UNKNOWN
所有的查询筛选器,如ON、WHERE、HAVING把UNKNOWN看作为FALSE处理。
CHECK约束中的UNKNOWN值被当作TRUE对待。如果表中含有一个CHECK约束,要求salary列的值必须大于0,则插入salary为NULL的行时可以被接受。
UNIQUE约束、排序操作、分组操作认为两个NULL值是相等的。如,表中有一列定义了UNIQUE约束,则无法向表中插入该列值为NULL的两行。GROUP BY子句把所有NULL值分在一组。ORDERB BY子句把所有NULL值排列在一起。
对VT1增加ON筛选器的结果VT2:

3. 添加外部行,通过指定LEFT、RIGHT、FULL中的一种OUTER JOIN,可以把左表、右表、所有表标记为保留表。把一个表设为保留表表示返回该表的所有行,即使<join_condition>已经执行过筛选。保留表中的这些行被称为外部行,外部行中非保留表的属性被赋予NULL,最后生成VT3:
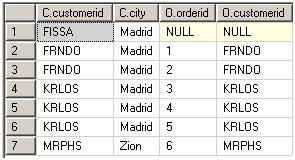
4. 应用WHERE筛选器,只有符合<where_condition>的行才会成为VT4的一部分。因为数据还没有被分组,所以不能使用聚合筛选器,例如WHERE orderdate = MAX(orderdate)。也不能饮用SELECT列表中的别名,因为SELECT列表这时还没有被处理,例如SELECT YEAR(orderdate) AS orderyear WHERE orderyear > 2000。
对于包含OUTER JOIN子句的查询,如何判断到底是在ON筛选器还是在WHERE筛选器中指定逻辑表达式:ON在添加外部行前被应用,WHERE在外部行添加之后被应用。ON筛选器对保留表中部分行的一处不是最终的,因为还要执行添加外部行的步骤,而WHERE筛选器对这些行的移除是最终的。
只有在使用外部联接时,ON和WHERE子句才会存在这种逻辑限制,当使用内部联接时,在那里指定逻辑表达式都无所谓,因为没有上面的步骤3。
WHERE C.city = 'Madrid'
生成虚拟表VT4:
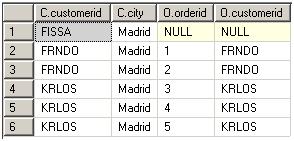
5. 分组。GROUP BY子句中列列表的每个唯一的值组合成为一组,生成VT5:
| Groups | Raw |
| C.customerid |
|
| FISSA | |
| FRNDO | |
| KRLOS |
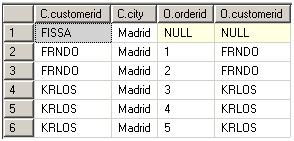
VT5由两部分组成:Group Section和Raw Section。
如果在查询中指定了GROUP BY子句,则后面的所有步骤(如:HAVING、SELECT)只能指定可以为成组得到的标量值的表达式。也就是说,表达式的结果是GROUP BY列表中的列/表达式(如:C.customer)或聚合函数(如:COUNT(O.orderid))。该限制是因为最终的结果集中最多只为每一个组包含一行。
这一阶段认为两个NULL是相等的。所有的NULL值会被分配到一组。
如果指定GROUP BY ALL,则在WHERE筛选中被移除的组将被添加到VT5中,且原始部分为空集合。在后面的步骤中,对该组应用COUNT聚合函数的结果将为0,应用其他聚合函数的结果为NULL。最好不要使用GROUP BY ALL。
6. 使用CUBE或ROLLUP选项,将创建超组并把它添加到上一步返回的虚拟表中,生成VT6。
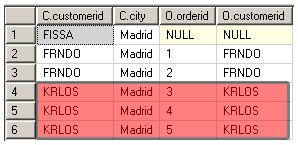
7. 应用HAVING 筛选器 ,只有符合<having_condition>的组才会成为VT7的一部分。HAVING是唯一的应用到已分组数据的筛选器。
HAVING COUNT(O.orderid) < 3
在这里使用了COUNT(O.orderid),而不是COUNT(*),所以外部行因为O.orderid为NULL,于是不计入COUNT中。如FISSA这组的COUNT(O.orderid)为0.
红色部分为被HAVING筛选掉的分组。
| Groups | Raw |
| C.customerid |
|
| FISSA | |
| FRNDO | |
|
|
8. 处理SELECT列表,为不是基列的表达式应用别名,使其在结果表中有一个名称。在SELECT列表中创建的别名不能再前面的步骤中使用,甚至不能再SELECT列表中使用,只能在ORDER BY中使用。
SELECT C.customerid, COUNT(O.orderid) AS numorders
生成VT8:
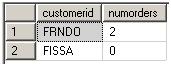
逻辑上,应当假设所有操作同时发生。
9. 应用DISTINCT子句,如果查询中指定了DISTINCT子句,将从上一步返回的虚拟表中移除重复行,并生成虚拟表VT9。使用GROUP BY,再使用DISTINCT是多余的。
10. 应用ORDER BY子句,按照ORDER BY子句中的列列表排序上一步返回的行,返回游标VC10。只有这一步可以使用SELECT别名。如果指定了DISTINCT,ORDER BY子句中的表达式只能访问上一步返回的虚拟表,只能按已经SELECT的列排序。
ANSI SQL 1999中增强了ORDER BY的支持,允许访问SELECT阶段的输入虚拟表和输出虚拟表。就是说如果未指定DISTINCT,可以在ORDER BY子句中指定任何可以在SELECT子句中使用的表达式,可以按最后结果集中不存在的表达式排序。
ORDER BY numorders;
也可以在ORDER BY子句中指定SELECT列表中结果列的序号:
ORDER BY 2, 1;
但是尽量不要这样去做,因为可能改变了SELECT列表却忘记了修改ORDER BY列表,而且当SELECT列表很长时,查序号不是一个好方法。
因为这一步不是返回表,而是返回游标,使用了ORDER BY子句的查询不能用作表表达式。表表达式包括:视图、内联表值函数、子查询、派生表和共用表表达式(CTE)。
不要为表中的行假定顺序,除非确实需要有序行,否则不要指定ORDER BY子句。排序是需要成本的,SQL Server需要执行有序索引扫描或使用排序运算符。
ORDER BY这一步认为两个NULL是相等的,所有的NULL会被排列在一起,ANSI并没有规定NULL比已知值高还是低,而是把这个问题留给了具体实现,在T-SQL中NULL排位比已知值低。
ORDER BY numorders
返回的游标VC10:
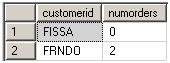
11. 应用TOP选项,从游标的最前面选择指定的行数,生成表VT11并返回给调用者。在SQLServer 2000中,TOP的输入必须为常量,而在2005中可以是任何独立的表达式。
如果没有ORDER BY子句或WITH TIES选项,返回的行正好是物理上最先访问的行,可能会产生不同的结果。
只有指定了TOP选项,才可以在表表达式中使用带有ORDER BY子句的查询:
SELECT *
FROM (SELECT TOP 100 PERCENT orderid, customerid
FROM dbo.Orders
ORDER BY orderid) AS D;

