selenium+phantomjs爬取bilibili
selenium+phantomjs爬取bilibili
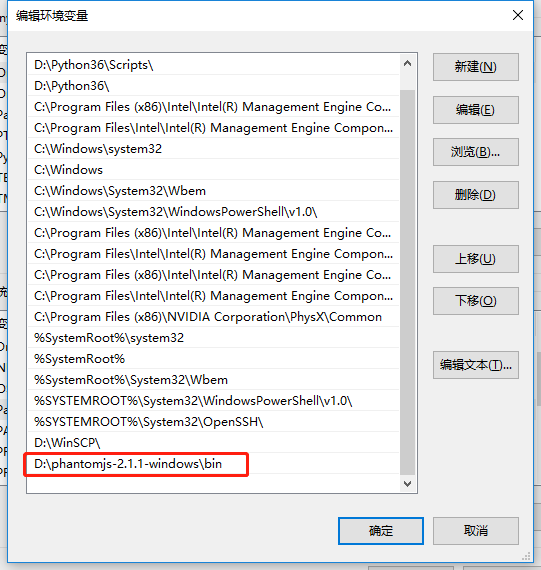
首先我们要下载phantomjs 你可以到 http://phantomjs.org/download.html 这里去下载 下载完之后解压到你想要放的位置 你需要配置一下环境变量哦
如下图:
首先,我们怎么让浏览器模拟操作,也就是我们自己先分析好整个操作过程,哪个地方有什么问题,把这些问题都提前测试好,没问题了再进行写代码。
打开bilibili网站 https://www.bilibili.com/ 发现下图登陆弹窗
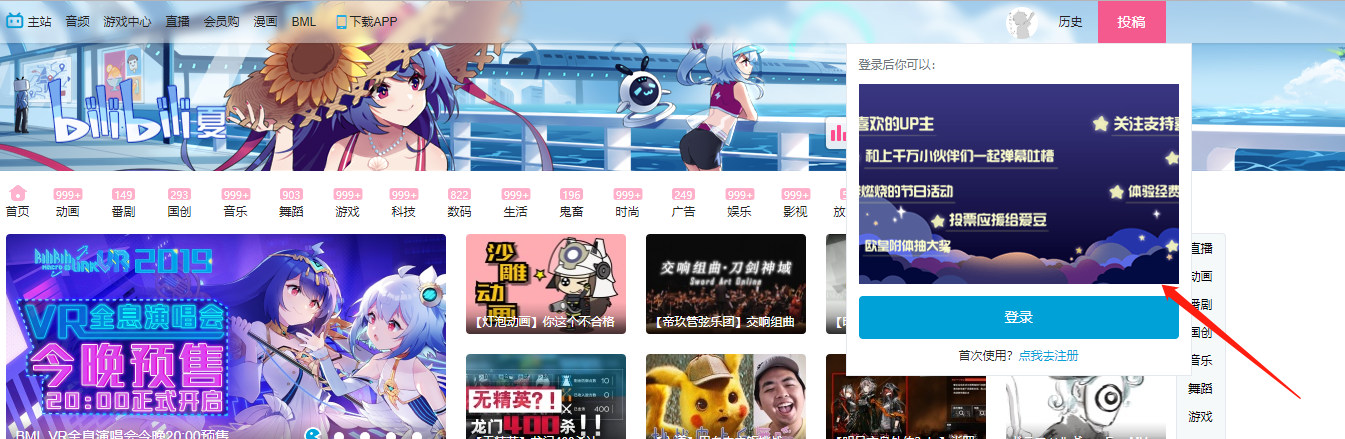
那么这里我们就得先把这个弹窗去除,怎么去呢?你刷新一下或者点一下 首页 就不会出现了,所以这里我们可以模拟再刷新一次或者点击首页。
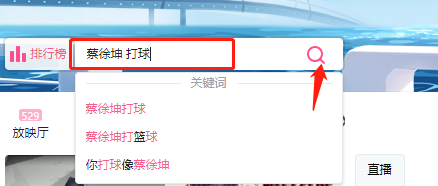
接下来搜索关键词 蔡徐坤 打球 这时就涉及到搜索输入框和搜索按钮
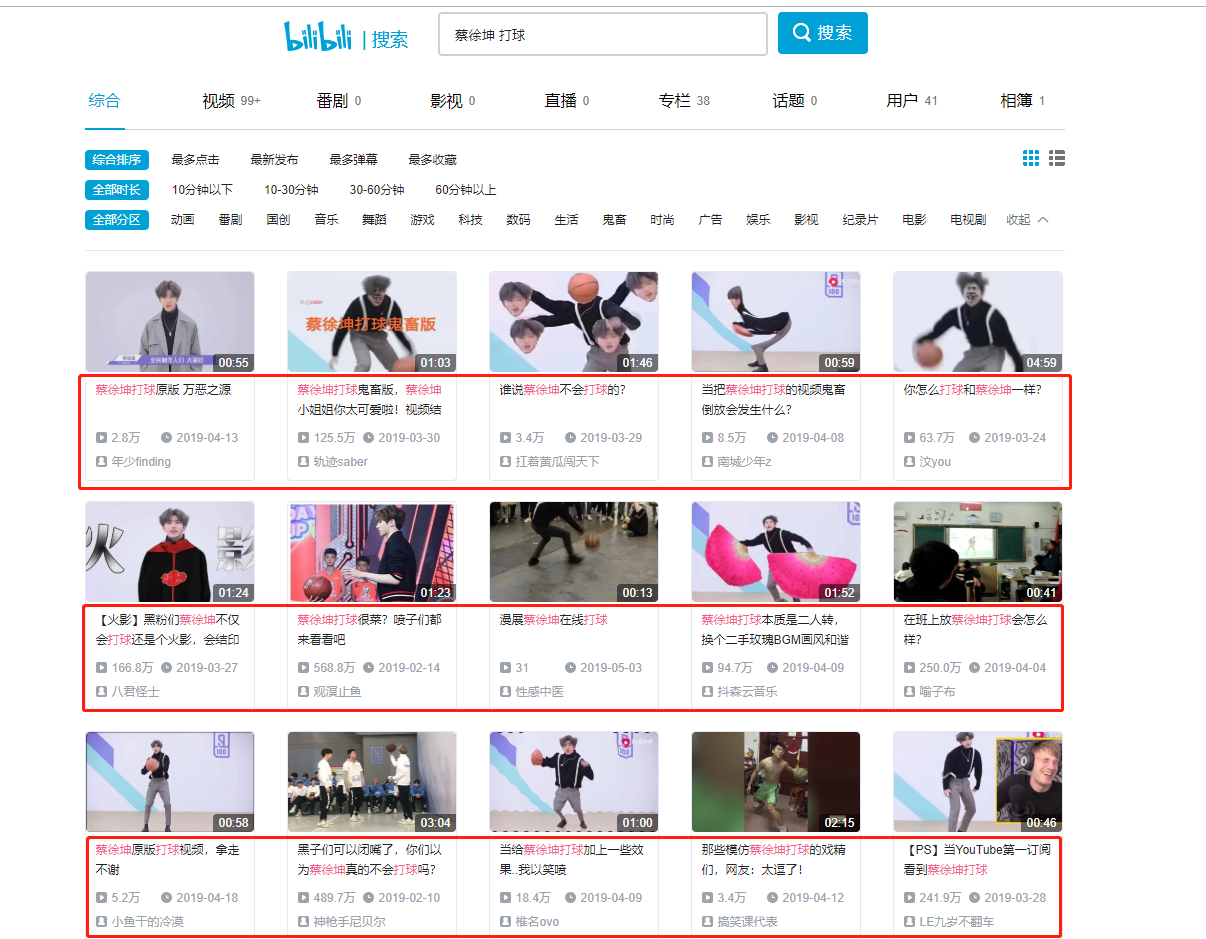
点击搜索后我们看到了下列内容,其中圈起来的就是要爬的信息啦 这时就涉及到页面源码获取,数据元素定位
那么上面这个过程走完了的话 我们也可以选择写入xls格式,同时这里还少了一个事,那就是我现在才爬了一页,那难道不写个自动化爬取全部吗?

那此时就得解决循环获取和写入xls 更重要的事怎么去操作页数和下一页按钮
大致的思路就是这样子了!!!
先导入这些模块
from selenium import webdriver
from selenium.common.exceptions import TimeoutException #一条命令在足够的时间内没有完成则会抛出异常
from selenium.webdriver.common.by import By #支持的定位器分类
from selenium.webdriver.support.ui import WebDriverWait #等待页面加载完成,找到某个条件发生后再继续执行后续代码,如果超过设置时间检测不到则抛出异常
from selenium.webdriver.support import expected_conditions as EC #判断元素是否加载
from bs4 import BeautifulSoup
import xlwt
定义一个浏览器对象并设置其他功能
browser = webdriver.Chrome() #初始化浏览器对象
WAIT = WebDriverWait(browser,10) #显式等待,等待的时间是固定的,这里为10秒 元素在指定时间内不可见就引发异常TimeoutException
browser.set_window_size(1400,900) #设置浏览器窗口大小
创建excel文件,再创建一张工作表,名为 蔡徐坤篮球,并且设置支持覆盖原数据!
book=xlwt.Workbook(encoding='utf-8',style_compression=0) #创建excel文件,设置utf-8编码,这样就可以在excel中输出中文了
sheet=book.add_sheet('蔡徐坤篮球',cell_overwrite_ok=True) #添加一张工作表 cell_overwrite_ok=True 时可以覆盖原单元格中数据。
sheet.write(0,0,'名称')
sheet.write(0,1,'地址')
sheet.write(0,2,'描述')
sheet.write(0,3,'观看次数')
sheet.write(0,4,'弹幕数')
sheet.write(0,5,'发布时间')
打开网站
browser.get('https://www.bilibili.com/')
寻找 “首页” 元素
index = WAIT.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#primary_menu > ul > li.home > a')))
# 配合WebDriverWait类的until()方法进行灵活判断 进行下一步操作
# 通过EC进行判断某个元素中是否可见并且是enable的 这样的话叫clickable(可点击)
# 使用CSS选择器选中页面中的 首页 进行点击 目的为了第一次有个登录弹窗 刷新就没有 那就点击下首页来实现刷新
index.click() #点击!
先判断是否加载 输入框 再判断搜索按钮是否能点击 达到条件后输入内容进行搜索
input = WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#banner_link > div > div > form > input'))) #判断某个元素是否被加到DOM树里,并不代表该元素一定可见(元素可以是隐藏的)
submit = WAIT.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="banner_link"]/div/div/form/button'))) #判断搜索按钮是否能点击,这里使用Xpath来寻找元素
input.send_keys('蔡徐坤 篮球') #用send_keys()方法进行搜索输入框中输入内容
submit.click() #点击搜索!
这时搜索完 是弹出新的窗口 这时就得获取窗口句柄 实现标签页跳转
all_h = browser.window_handles #获取所有窗口句柄
browser.switch_to.window(all_h[1]) #switch_to.window 标签页跳转
接下来就是获取页面源码了(此处非全部源码)
WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#server-search-app > div.contain > div.body-contain > div > div.result-wrap.clearfix'))) #坚持是否加载完所有搜索结果
html = browser.page_source #page_source方法可以获取到页面源码
然后搜索元素并提取内容进行保存
#遍历所有搜索信息 并保存
list = soup.find(class_='all-contain').find_all(class_='info')
for item in list:
item_title = item.find('a').get('title')
item_link = item.find('a').get('href')
item_dec = item.find(class_='des hide').text
item_view = item.find(class_='so-icon watch-num').text
item_biubiu = item.find(class_='so-icon hide').text
item_date = item.find(class_='so-icon time').text
print('爬取:' + item_title)
再最后就是循环获取每一页提取数据最后写入xls文件!!!
下面就直接贴出代码了
from selenium import webdriver
from selenium.common.exceptions import TimeoutException #一条命令在足够的时间内没有完成则会抛出异常
from selenium.webdriver.common.by import By #支持的定位器分类
from selenium.webdriver.support.ui import WebDriverWait #等待页面加载完成,找到某个条件发生后再继续执行后续代码,如果超过设置时间检测不到则抛出异常
from selenium.webdriver.support import expected_conditions as EC #判断元素是否加载
from bs4 import BeautifulSoup
import xlwt
browser = webdriver.Chrome() #初始化浏览器对象
WAIT = WebDriverWait(browser,10) #显式等待,等待的时间是固定的,这里为10秒 元素在指定时间内不可见就引发异常TimeoutException
browser.set_window_size(1400,900) #设置浏览器窗口大小
book=xlwt.Workbook(encoding='utf-8',style_compression=0) #创建excel文件,设置utf-8编码,这样就可以在excel中输出中文了
sheet=book.add_sheet('蔡徐坤篮球',cell_overwrite_ok=True) #添加一张工作表 cell_overwrite_ok=True 时可以覆盖原单元格中数据。
sheet.write(0,0,'名称')
sheet.write(0,1,'地址')
sheet.write(0,2,'描述')
sheet.write(0,3,'观看次数')
sheet.write(0,4,'弹幕数')
sheet.write(0,5,'发布时间')
n = 1
def seach():
try:
print('开始访问b站....')
browser.get('https://www.bilibili.com/')
index = WAIT.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#primary_menu > ul > li.home > a')))
# 配合WebDriverWait类的until()方法进行灵活判断 进行下一步操作
# 通过EC进行判断某个元素中是否可见并且是enable的 这样的话叫clickable(可点击)
# 使用CSS选择器选中页面中的 首页 进行点击 目的为了第一次有个登录弹窗 刷新就没有 那就点击下首页来实现刷新
index.click() #点击!
input = WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#banner_link > div > div > form > input'))) #判断某个元素是否被加到DOM树里,并不代表该元素一定可见(元素可以是隐藏的)
submit = WAIT.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="banner_link"]/div/div/form/button'))) #判断搜索按钮是否能点击,这里使用Xpath来寻找元素
input.send_keys('蔡徐坤 篮球') #用send_keys()方法进行搜索输入框中输入内容
submit.click() #点击搜索!
print('跳转到新窗口')
all_h = browser.window_handles #获取所有窗口句柄
browser.switch_to.window(all_h[1]) #switch_to.window 标签页跳转
get_source()
total = WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#server-search-app > div.contain > div.body-contain > div > div.page-wrap > div > ul > li.page-item.last > button"))) #等待加载后获取所有页数按钮
return int(total.text) #返回页码数量
except TimeoutException:
return seach()
def get_source():
WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#server-search-app > div.contain > div.body-contain > div > div.result-wrap.clearfix'))) #坚持是否加载完所有搜索结果
html = browser.page_source #page_source方法可以获取到页面源码
soup = BeautifulSoup(html,'lxml')
save_to_excel(soup)
def save_to_excel(soup):
#遍历所有搜索信息 并保存
list = soup.find(class_='all-contain').find_all(class_='info')
for item in list:
item_title = item.find('a').get('title')
item_link = item.find('a').get('href')
item_dec = item.find(class_='des hide').text
item_view = item.find(class_='so-icon watch-num').text
item_biubiu = item.find(class_='so-icon hide').text
item_date = item.find(class_='so-icon time').text
print('爬取:' + item_title)
global n
sheet.write(n, 0, item_title)
sheet.write(n, 1, item_link)
sheet.write(n, 2, item_dec)
sheet.write(n, 3, item_view)
sheet.write(n, 4, item_biubiu)
sheet.write(n, 5, item_date)
n = n + 1
def next_page(page_num):
try:
print('获取下一页数据')
next_btn = WAIT.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#server-search-app > div.contain > div.body-contain > div > div.page-wrap > div > ul > li.page-item.next > button')))
#等待加载 下一页 按钮
next_btn.click() #点击下一页!
WAIT.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#server-search-app > div.contain > div.body-contain > div > div.page-wrap > div > ul > li.page-item.active > button'),str(page_num)))
#判断某个元素中的text是否包含了预期的字符串
get_source()
except TimeoutException:
browser.refresh() #刷新页面
return next_page(page_num)
def main():
try:
total = seach()
for i in range(2,int(total+1)):
next_page(i)
finally:
browser.close()
browser.quit()
if __name__ == '__main__':
main()
book.save(u'蔡徐坤篮球.xls') #在字符串前加r,声明为raw字符串,这样就不会处理其中的转义了。否则,可能会报错
作者:YinJay
Email:szgetshell@163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号