日志收集系列:消息队列(七)
7. 消息队列
7.1 部署Zookeeper
Zookeeper下载:https://zookeeper.apache.org/releases.html ,同时需要有JDK环境。
在es01、es02、es03上安装Zookeeper
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz --no-check-certificate
解压Zookeeper安装包,并创建数据和日志目录
mkdir -p /app/tools
tar xf apache-zookeeper-3.7.1-bin.tar.gz -C /app/tools/
mv /app/tools/apache-zookeeper-3.7.1-bin/ /app/tools/zookeeper
mkdir -p /app/tools/zookeeper/{data,logs}
修改配置文件
#cat /app/tools/zookeeper/conf/zoo.cfg
# 服务器之间或客户端与服务器之间维持心跳的时间间隔
# tickTime以毫秒为单位。
tickTime=2000
# 集群中的follower服务器(F)与leader服务器(L)之间的初始连接心跳数
initLimit=10
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数
syncLimit=5
# 数据保存目录
dataDir=../data
#dataDir=/app/tools/zookeeper/data/
# 日志保存目录
dataLogDir=../logs
#/app/tools/zookeeper/logs/
# 客户端连接端口
clientPort=2181
# 客户端最大连接数。# 根据自己实际情况设置,默认为60个
maxClientCnxns=60
# 三个节点配置,格式为: server.服务编号=服务地址、LF通信端口、选举端口
server.1=10.0.0.90:2888:3888
#data/myid文件 存放 数字1
server.2=10.0.0.91:2888:3888
server.3=10.0.0.92:2888:3888
修改id号
#es01
echo "1" >/app/tools/zookeeper/data/myid
#es02
echo "2" >/app/tools/zookeeper/data/myid
#es03
echo "3" >/app/tools/zookeeper/data/myid
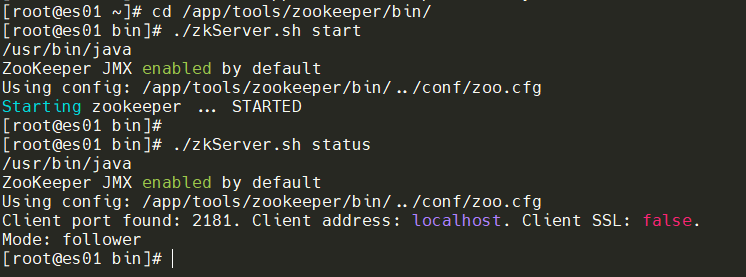
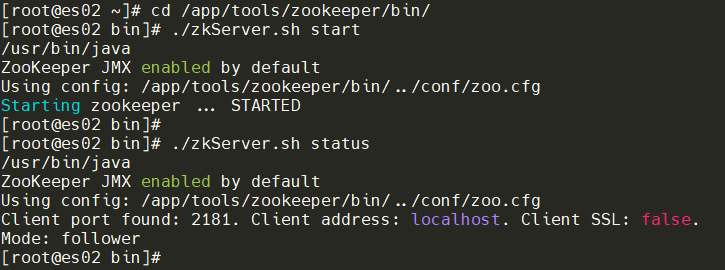
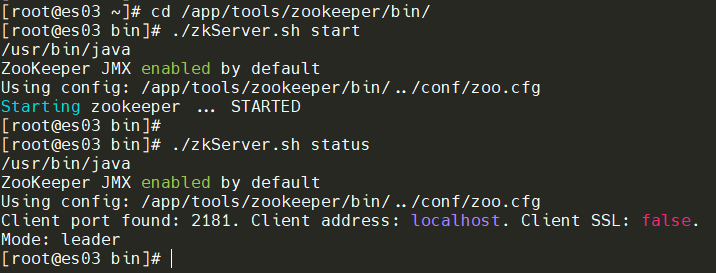
启动每个节点的Zookeeper
cd /app/tools/zookeeper/bin/
./zkServer.sh start
7.2 部署Kafka
Kafka下载:http://archive.apache.org/dist/kafka/,同时需要有JDK环境。
wget http://archive.apache.org/dist/kafka/2.8.2/kafka_2.12-2.8.2.tgz
解压Kafka软件包
tar xf kafka_2.12-2.8.2.tgz -C /app/tools/
mv /app/tools/kafka_2.12-2.8.2/ /app/tools/kafka
es01、es02、es03主机上修改配置,broker.id的值记得修改。
# cat /app/tools/kafka/config/server.properties
############################# Server Basics #############################
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=
############################# Socket ServerSettings #############################
# kafka默认监听的端口为9092 (默认与主机名进行连接)
listeners=PLAINTEXT://:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
############################# Log Basics #############################
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition数量
num.partitions=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
############################# Log Flush Policy #############################
# 消息刷新到磁盘中的消息条数阈值
#log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s
#log.flush.interval.ms=1000
############################# Log RetentionPolicy #############################
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=10.0.0.90:2181,10.0.0.91:2181,10.0.0.92:2181
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=6000
启动Kafka
#主机资源不足可以限制资源
export KAFKA_HEAP_OPTS="-Xmx256M -Xms256M
#前台启动
cd /app/tools/kafka/bin/
./kafka-server-start.sh ../config/server.properties
#后台运行
cd /app/tools/kafka/bin/
./kafka-server-start.sh -daemon ../config/server.properties
查看日志
tail /app/tools/kafka/logs/kafkaServer.out
7.3 Kafka测试
创建topic测试
cd /app/tools/kafka/bin/
./kafka-topics.sh \
--create \
--zookeeper 10.0.0.90:2181,10.0.0.91:2181,10.0.0.92:2181 \
--partitions 3 \
--replication-factor 1 \
--topic yinjay-kafka
查看topic详情
./kafka-topics.sh --bootstrap-server localhost:9092 --describe yinjay-kafka

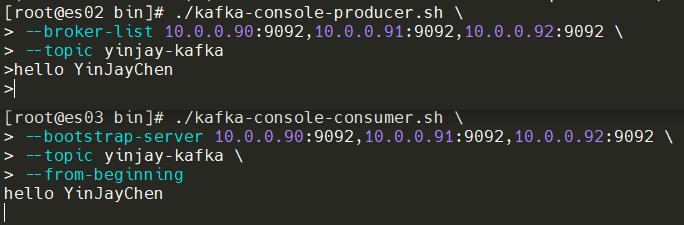
es02主机生产消息
./kafka-console-producer.sh \
--broker-list 10.0.0.90:9092,10.0.0.91:9092,10.0.0.92:9092 \
--topic yinjay-kafka
es03主机订阅、消费消息
./kafka-console-consumer.sh \
--bootstrap-server 10.0.0.90:9092,10.0.0.91:9092,10.0.0.92:9092 \
--topic yinjay-kafka \
--from-beginning
测试完成,没问题!
7.4 接入日志收集集群
web01、web02节点配置Filebeat输出数据到Kafka中
# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
tags: "nginx-access"
- type: log
enabled: true
paths:
- /var/log/nginx/error.log
tags: "nginx-error"
output.kafka:
hosts: #kafka集群地址
- "10.0.0.90:9092"
- "10.0.0.91:9092"
- "10.0.0.92:9092"
topics:
- topic: "kafka-nginx-access #topic名称
when.contains:
tags: "access"
- topic: "kafka-nginx-error"
when.contains:
tags: "error"
Tips:当标签中包含"access"时,日志将发送到名为"kafka-nginx-access"的topics。对于nginx错误日志,当标签中包含"error"时,日志将发送到名为"kafka-nginx-error"的topics。
重启Filebeat
systemctl restart filebeat.service
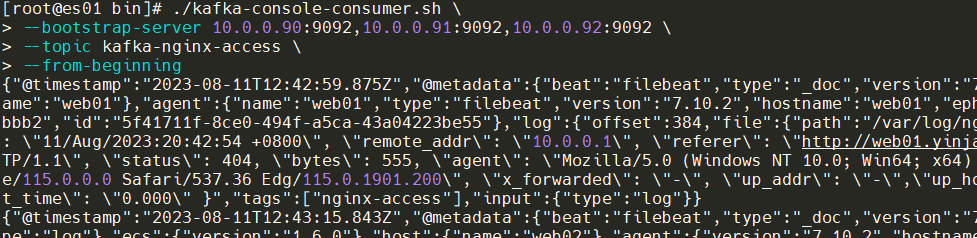
Kafka节点上进行查看消息队列,此时web01、web02任意节点进行访问一下,能有数据就OK。
./kafka-console-consumer.sh \
--bootstrap-server 10.0.0.90:9092,10.0.0.91:9092,10.0.0.92:9092 \
--topic kafka-nginx-access \
--from-beginning
7.5 配置Logstash订阅Topics
Logstash主机上进修改配置文件,从消息队列取出数据经过filter阶段的处理和转换等,最后输出到ES集群。
[root@es01 bin]# cat /etc/logstash/conf.d/nginx-logstash.conf
input {
kafka {
bootstrap_servers => "10.0.0.90:9092,10.0.0.91:9092,10.0.0.92:9092"
topics => ["kafka-nginx-access"]
group_id => "logstash"
consumer_threads => 3
codec => "json"
}
kafka {
bootstrap_servers => "10.0.0.90:9092,10.0.0.91:9092,10.0.0.92:9092"
topics => ["kafka-nginx-error"]
group_id => "logstash"
consumer_threads => 3
codec => "json"
}
}
filter {
if "nginx-access" in [tags][0] {
grok {
patterns_dir => ["/etc/logstash/grok/patterns/"]
match => {
message => "%{CLIENT_IP:client_ip}.*?%{RQ:request}.*?%{STATUS:status}"
}
}
mutate {
remove_field => ["message"]
add_field => { "target_index" => "logstash-kafka-nginx-access-%{+YYYY.MM}" }
}
}
else if "nginx-error" in [tags][0] {
grok {
patterns_dir => ["/etc/logstash/grok/patterns/"]
match => {
message => "%{CLIENT_IP:client_ip}.*?%{RQ:request}.*?%{STATUS:status}"
}
}
mutate {
remove_field => ["message"]
add_field => { "target_index" => "logstash-kafka-nginx-error-%{+YYYY.MM}" }
}
}
}
output {
elasticsearch {
hosts => ["es01.yinjay.com:9200","es02.yinjay.com:9200","es03.yinjay.com:9200"]
index => "%{[target_index]}"
template_overwrite => true
}
}
重启Logstash
systemctl restart logstash.service
访问一下web01、web02站点,查看ES,已经有了数据,再查看kibana。
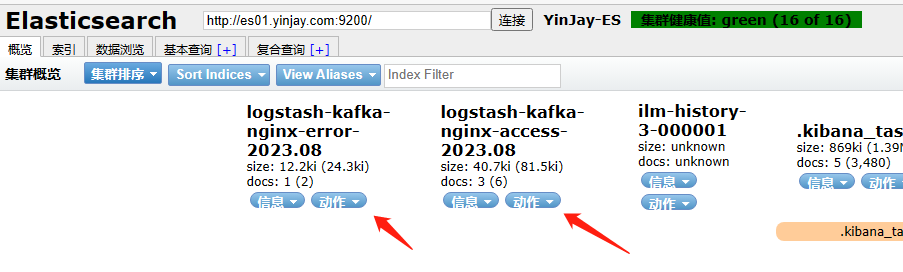
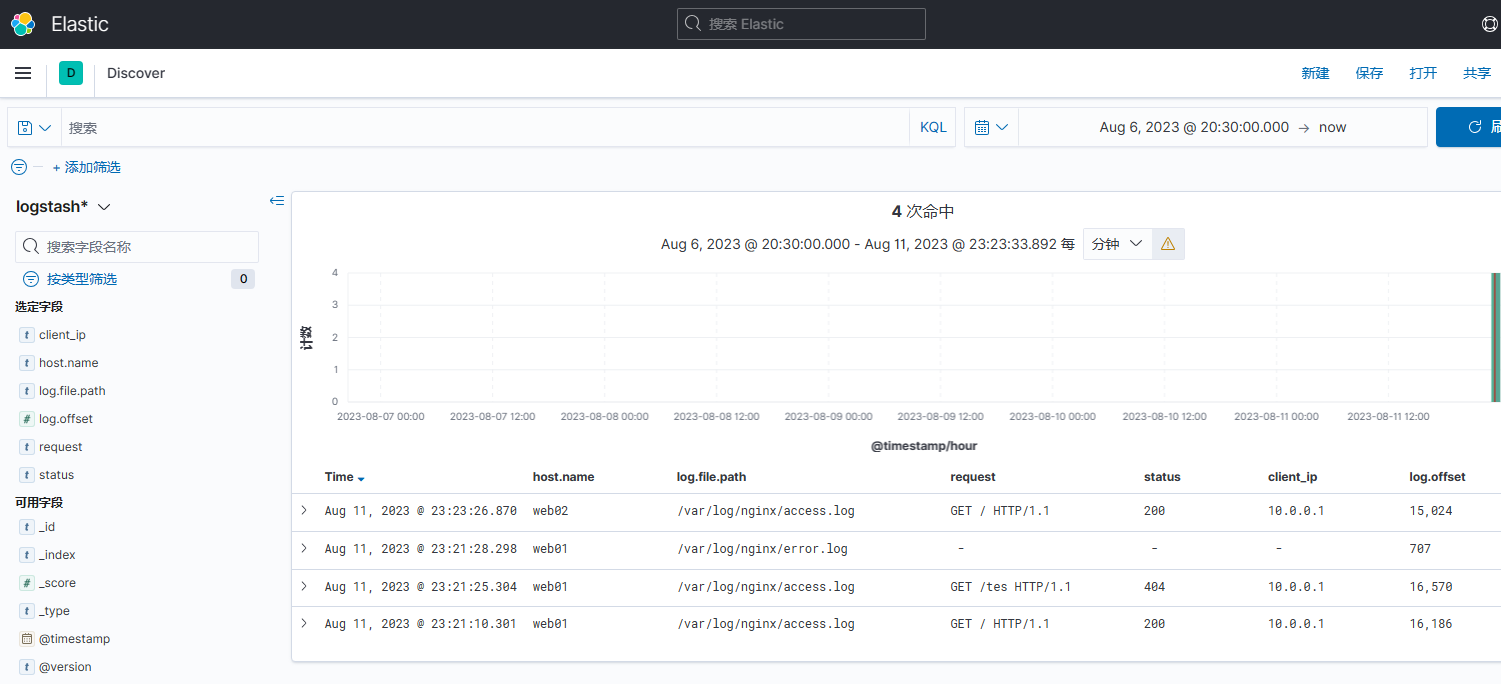
数据流:Filebeat进行收集日志 -> kafka消息队列集群(Kafka 充当缓冲层) -> Logstash可以进行过滤转换等操作 -> 数据传给ES集群 -> Kibana进行展示
作者:YinJay
Email:szgetshell@163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号