日志收集系列:Logstash(五)
5. Logstash
5.1 什么是Logstash
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的“存储”。(当然,我们最喜欢的是Elasticsearch)
输入:采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
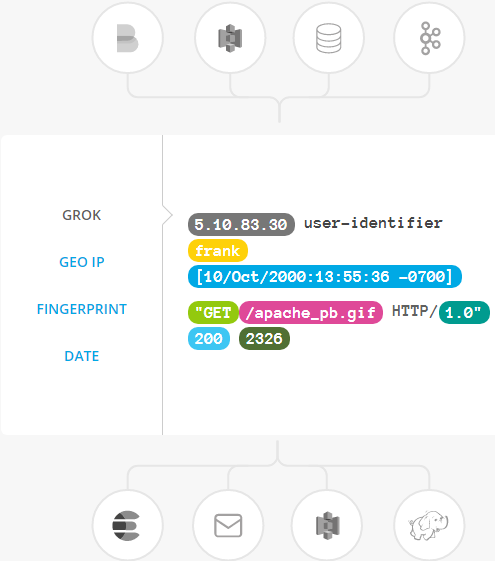
过滤器:实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 整体处理不受数据源、格式或架构的影响
输出:选择你的存储,导出你的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
5.2 Logstash工作原理
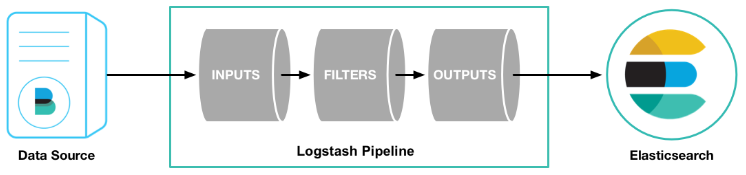
输入(INPUTS),以下是常见得输入内容:
- file:从文件系统上的文件读取,与UNIX命令非常相似 tail -0F
- syslog:在已知端口上侦听syslog消息进行解析
- redis:使用redis通道和redis列表从redis服务器读取。Redis通常用作集中式Logstash安装中的“代理”,该安装将Logstash事件从远程Logstash“托运人”排队。
- beats:处理 Beats发送的事件,beats包括filebeat、packetbeat、winlogbeat。
过滤(FILTERS),以下是常见的过滤器:
- grok:解析并构造任意文本。Grok是目前Logstash中将非结构化日志数据解析为结构化和可查询内容的最佳方式。(Logstash内置了120种模式)
- mutate:对事件字段执行常规转换。您可以重命名,删除,替换和修改事件中的字段。
- drop:完全删除事件,例如调试事件。
- clone:制作事件的副本,可能添加或删除字段。
- geoip:添加有关IP地址的地理位置的信息(也在Kibana中显示惊人的图表!)
输出(OUTPUTS),以下是常见得输出内容:
- elasticsearch:将事件数据发送给Elasticsearch。如果您计划以高效,方便且易于查询的格式保存数据。
- file:将事件数据写入磁盘上的文件。
- graphite:将事件数据发送到graphite,这是一种用于存储和绘制指标的流行开源工具。http://graphite.readthedocs.io/en/latest/
- statsd:将事件数据发送到statsd,这是一种“侦听统计信息,如计数器和定时器,通过UDP发送并将聚合发送到一个或多个可插入后端服务”的服务。
5.3 目录结构
| 目录结构 | 说明 |
|---|---|
| /etc/logstash/logstash.yml | 服务的配置文件。日志,数据目录等。 |
| /etc/logstash/logstash-sample.conf | 书写的logstash的配置文件 |
| /etc/logstash/conf.d/ | 书写的logstash的配置目录 |
| /etc/logstash/jvm.options | logstash,jvm配置这里可以设置为512m |
5.4 安装并使用Logstash
在es01主机上进行安装Logstash
rpm -ivh --nosignature https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/yum/7.10.2/logstash-7.10.2-x86_64.rpm
下载地址:https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/yum/
5.5 从标准输入读取内容
修改logstash配置文件
[root@es01 ~]# cat /etc/logstash/conf.d/stdin-logstash.conf
input {
stdin {
type => "stdin"
tags => "stdin_tags"
}
}
output {
elasticsearch {
hosts => ["http://es01.yinjay.com:9200","http://es02.yinjay.com:9200","http://es02.yinjay.com:9200"]
index => "logstash-test-%{+YYYY.MM.dd}"
#ES有配置账号密码就开启下列参数
#user => "elastic"
#password => "changeme"
}
}
启动logstash
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/stdin-logstash.conf
Tips:Systemd默认启动的配置文件是固定的,可查看Systemd的管理配置。另外使用自定义配置可以用 & 来后台运行该进程!
跑起Sucessfully,输入一些数据。
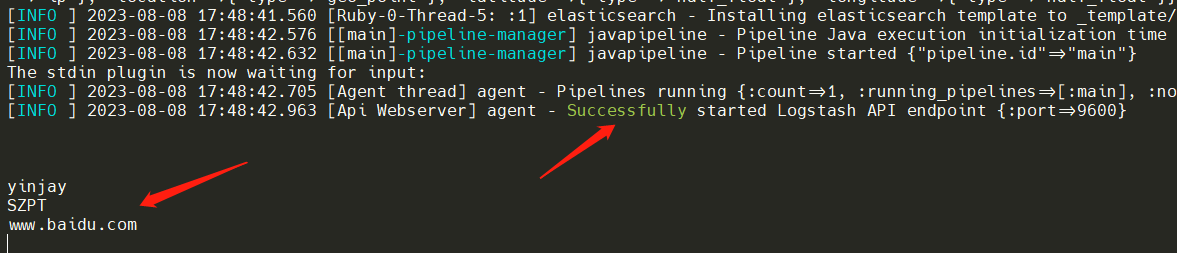
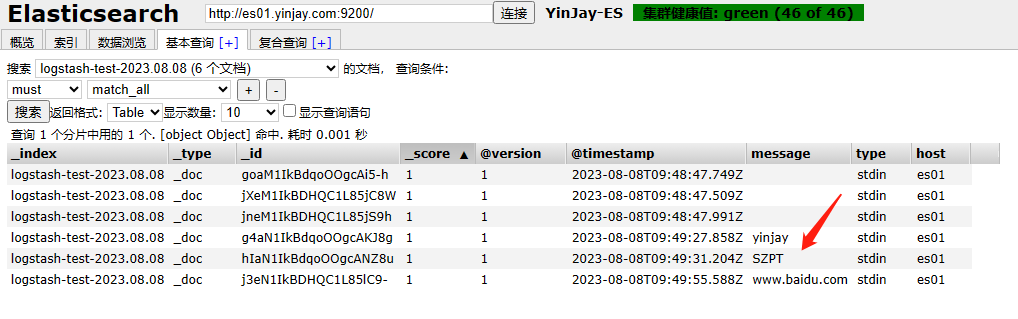
通过ES进行查看数据
其余的INPUT插件
| INPUT插件 | 说明 |
|---|---|
| file | 从文件读取内容 |
| stdin | 从标准输入读取内容 |
| beats | 通过beats插件读取,一般是filebeat,常用。 |
| kafka | 通过kafka读取数据,常用。 |
5.4 Grok插件
GROK是一种采用组合多个预定义的正则表达式,用来匹配分割文本并映射到关键字的工具。通常用来对日志数据进行处理。
在Grok中进行正则匹配,一种是使用logstash中先前定义好的grok-patterns进行正则匹配;另一种是自己定义正则表达式,同时可以借助已有的grok-patterns,进行组合,构造适用的正则表达式。
GROK模式说明以及内置的常用语法: https://help.aliyun.com/zh/sls/user-guide/grok-patterns
下面通过自定义规则来过滤nginx日志,下面内容是日志demo。
{"@timestamp": "07/Aug/2023:14:37:50 +0800", "remote_addr": "10.0.0.1", "referer": "-", "request": "GET / HTTP/1.1", "status": 200, "bytes": 1/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188", "x_forwarded": "up_host": "-","up_resp_time": "-","request_time": "0.000" }
首先在测试平台测试,是否能够匹配对应内容。(其余内容略,只演示匹配一个)
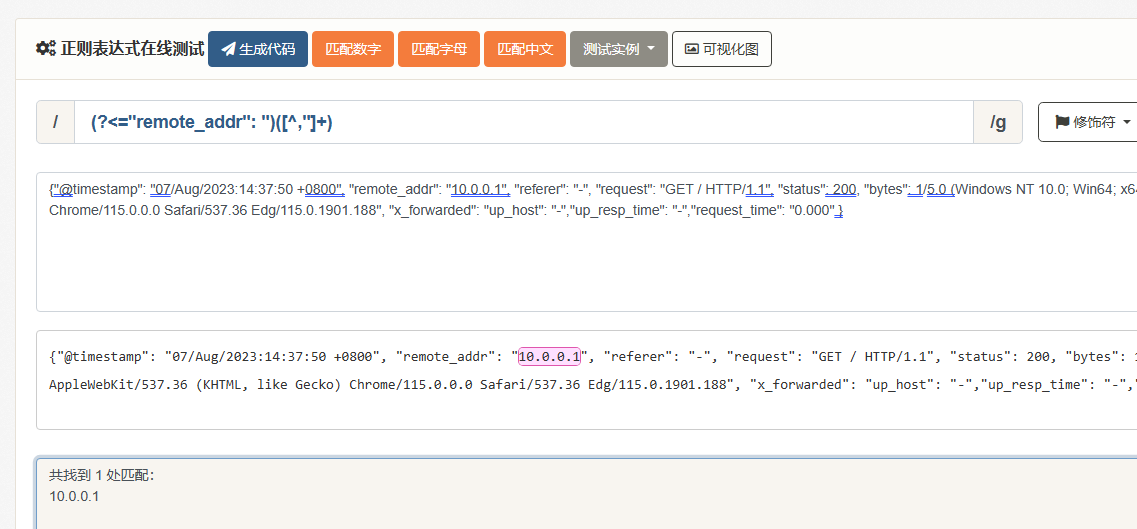
Tips:正则表达式在线测试
在kibana的开发者工具中进行测试是否获取到想要的内容
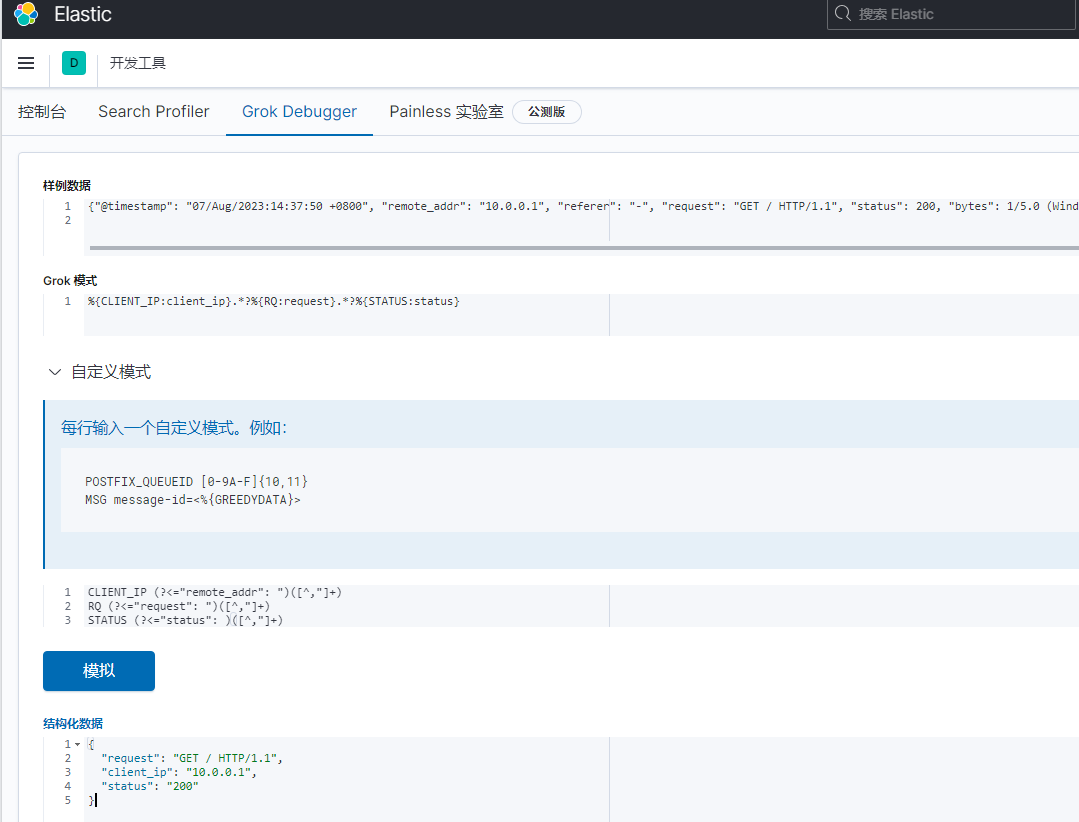
书写自定规则
[root@es01 ~]# cat /etc/logstash/grok/patterns/nginx-grok
CLIENT_IP (?<="remote_addr": ")([^,"]+)
RQ (?<="request": ")([^,"]+)
STATUS (?<="status": )([^,"]+)
书写logstash配置文件,本示例只是从标准输入进行获取内容进行匹配,然后标准输出内容。
[root@es01 conf.d]# cat /etc/logstash/conf.d/nginx-logstash.conf
input {
stdin {
}
}
filter {
grok {
patterns_dir => ["/etc/logstash/grok/patterns/"]
match => {
message => "%{CLIENT_IP:client_ip}.*?%{RQ:request}.*?%{STATUS:status}"
}
}
}
output {
stdout {
codec => rubydebug
}
}
启动logstash,然后粘贴日志内容进行处理。
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/nginx-logstash.conf
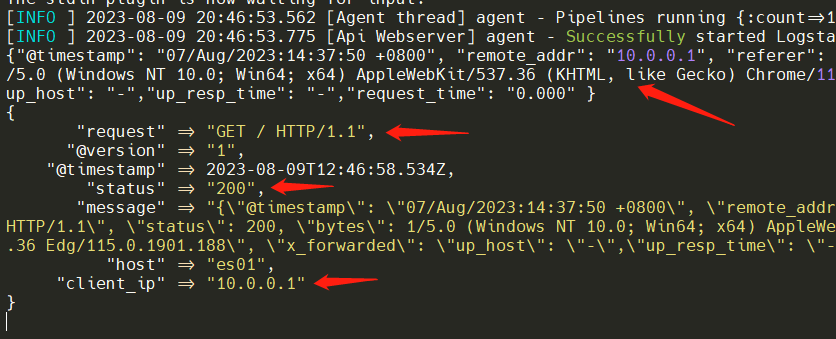
Tips:Logstash还有很多优秀的插件,比如时间格式转换、IP地址归属地、客户端信息等等。还支持判断、增删字段等高级用法筛选数据!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号