日志收集系列:ElasticSearch(一)
1. ElasticSearch
1.1 ES数据库功能与特点
ES主要致力于结构化和非结构化数据的分布式实时全文搜索及分析,使用场景:
- 日志管理与分析(ELK)
- 系统指标分析
- 安全分析
- 企业搜索(OA、CRM、ERP)
- 网站搜索(电商、招聘、门户)
- 应用搜索
- 应用性能管理APM
1.2 ES主要功能
- 分布式实时文件存储,处理的结构化和非结构数据
- 实时分析的分布式搜索引擎,为用户提供关键字查询的全文检索功能
- 是实现企业级PB级海量数据处理分析的大数据解决方案(ELK)
1.3 ES主要特点
- ES默认把数据分成多个片,多个片可以组成一个完整的数据,这些片可以分布在集群中的各个机器节点中。
- 随着后期数据的越来越大,ES集群可以增加多个分片,把多个分片分散到更多的主机节点上,负责负载均衡,横向扩展。
- 而每个查询任务提交到某一个节点,该节点必须负责将数据进行整理汇聚,再返回给客户端。
1.4 自动索引
- ES所有数据默认都是索引的
- ES只有不加索引才需要额外处理
1.5 搜索是近实时的
- 你往 es 里写的数据,实际上都写到磁盘文件里去了
- 查询的时候,操作系统会将磁盘文件里的数据自动缓存到 filesystem cache 里面去。
- es 的搜索引擎严重依赖于底层的 filesystem cache,你如果给 filesystem cache 更多的内存
- 尽量让内存可以容纳所有的
idx segment file索引数据文件,那么你搜索的时候就基本都是走内存的,性能会非常高。
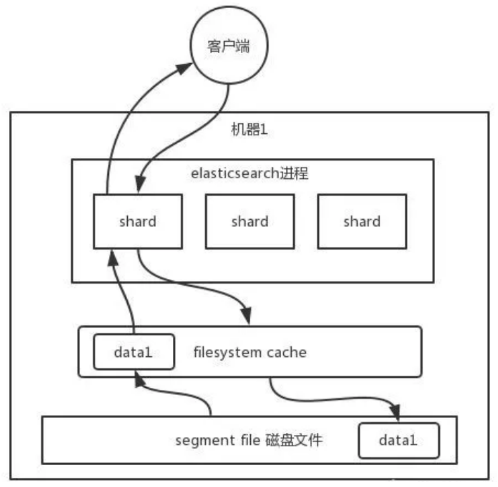
- 性能差距究竟可以有多大?经过很多的测试和压测:
- 如果走磁盘一般肯定上秒,搜索性能绝对是秒级别的,1秒、5秒、10秒。
- 但如果是走 filesystem cache,是走纯内存的,那么一般来说性能比走磁盘要高一个数量级,基本上就是毫秒级的,从几毫秒到几百毫秒不等。
1.6 ES集群介绍
1.6.1 ES分布式集群架构特性
- 在一个ES集群中,通过多个ES实例组成,其中有一个为主节点(master)
- ES是去中心化的,所以主节点是动态选举出来的,不是单点故障
- 你与任何一个节点通信和与整个ES集群通信结果是一样的
- 节点通信
- 在同一个子网中,只需要在每个节点上设置相同的集群名,ES就自动把这些几圈名相同的节点组成一个集群
- 节点与节点间通信以及节点之间的数据分配和平衡完全由ES自动管理
- 一个ES集群建议数量不要超过100个节点
1.6.2 ES主、备节点说明
- 每个运行ES实例称为一个节点,每一个ES运行实例(服务器进程)既可以在同一个机器上,也可以在不同机器上
- 在测试环境中,可以在一台服务器上运行多个服务器进程
- 在生产环境中,建议每一台服务器运行一个服务器进程
- ES主节点作用(Master)
- 主节点主要负责集群中的轻量级操作,负责创建索引,删除索引,分配分配,追踪集群中的节点状态等工作
- 集群中如果某一个主节点挂掉,从节点会重新选择主节点
- 数据节点作用(Slave)
- 数据节点存储了所有的分配,文档,索引数据
- 主要处理数据相关的操作,CRUD、搜索和聚合
- 数据节点需要大量的空间来存储数据,索引和搜索等数据操作对CPU、内存、IO密集型的消耗非常大
- 需要大量的磁盘空间来存储数据
1.6.3 ES分布式集群特性
1.6.3.1 分片(shards)
- ES会把一个索引分解成多个小索引,每个小的索引就叫做分片
- 再把各个分片分配到不同的节点中去
- 过多的分片数量会照成较大的管理压力,ES7.x 默认分片为1
1.6.3.2 副本(replicas)
- ES的每一个分片都可以有0~N个副本,而每个副本也都是分片的完整拷贝
- 作用:故障转移/集群恢复,通过副本进行负载均衡
- ES的某一个节点数据损坏或者服务器不可用的时候,那么这个时候就可以用其他节点来替换坏掉的节点,已到达高可用的目的
- 当主分片异常时,副本可以提供数据的查询等操作
- 对文档的新建、索引和删除请求都是写操作,必须在主分片上完成之后才能被复制到相关的副本分片
1.6.4 ES分布式集群路由机制
1.6.4.1 集群是如何组成的
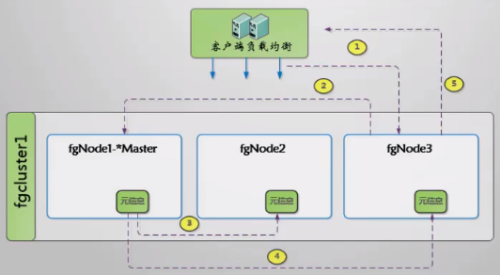
- A. 首先启动第一个节点fgNode1
- 第一个节点的一定是主节点,主节点存储的是集群的元数据信息
- B. 然后启动第二个节点fgNode2
- 启动之前会配置集群的名称Cluster-name:fgescluster1
- 然后配置可以作为主节点的IP地址信息
- 配置自己的ip地址和相关信息
- C. fgNode2启动的过程
- fgNode2启动的过程中会去找到主节点fgNode1,告诉fgNode1我要加入到集群
- 主节点fgNode1接受到请求后看看fgNode2是否满足加入集群的条件
- 如果满足就把fgNode2的ip地址加入的元信息里面,然后广播给集群中的其他节点
- 主节点会把最新的元信息发送给其他的节点中更新
1.6.4.2 集群中的索引是如何创建的
- 客户端请求到fgNode3节点创建索引
- fgNode3节点把请求转发给master主节点
- master主节点选择一个合适节点来存储分片和副本,并记录元信息
- 然后master主节点通知集群中存放索引分片和副本的相应节点,进行创建分片和副本
- 创建节点会向master主节点反馈结果
- master主节点向fgNode3反馈结果
- fgNode3节点响应客户端请求
- master主节点将元信息广播给所有从节点
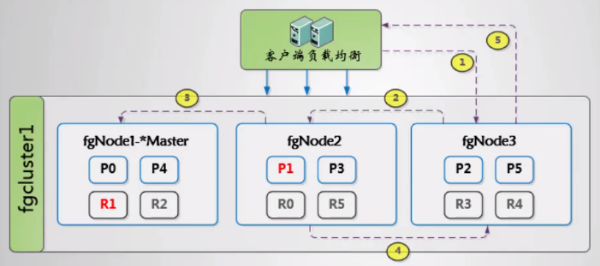
1.6.4.3 集群中如何存放文档
- 客户端请求fgNode3,fgNode3计算文档路由值并得到文档存放的分片(如:分片P1)
- fgNode3将文档转发给分片1(P1)的主分片节点fgNode2
- fgNode2索引文档,同步给副本(R1)节点fgNode1索引文档
- fgNode2向fgNode3反馈结果
- fgNode3做出响应
1.6.4.4 集群中如何搜索文档
- 客户端搜索索引 fgindex,并请求 fgNode3
- fgNode3将查询发给索引 fgindex 的 分片/副本节点(P0P5,R0R5)
- 各个节点执行查询,将结果给 fgNode3
- fgNode3合并结果,响应客户端
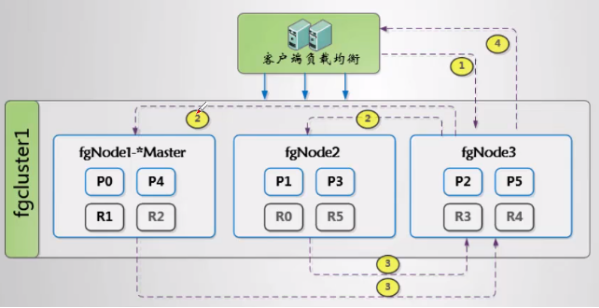
举例:
- 所以 fgindex 中有6个分片,每个分片有1个副本,共12个分片
- 一次搜索请求会由6个分片来完成,他们可能是主分片也可能是副本分片【如:P0,P1,P2,R3,R4,R5】
- 所以一次搜索请求智慧命中所有分片副本中的一个(分片/副本),所以增加副本数不会因并行查询而变快
- 但是在某些场景下多个副本,可能会选择出一个当前集群状态写能快速响应的副本,从而加快速度
1.7 安装ElasticSearch
安装要求:jdk环境(oracle jdk,ES 7.0之后已经内置JDK环境)
es软件包下载:https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/yum/
| 主机名 | 配置 | IP | 角色 |
|---|---|---|---|
| es01 | 2c4g | 10.0.0.90、172.16.1.90 | ElasticSearch |
rpm安装并启动ES服务
#安装
rpm -ivh https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/yum/7.10.2/elasticsearch-7.10.2-x86_64.rpm
#设置开机自启并启动
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl start elasticsearch.service
访问测试
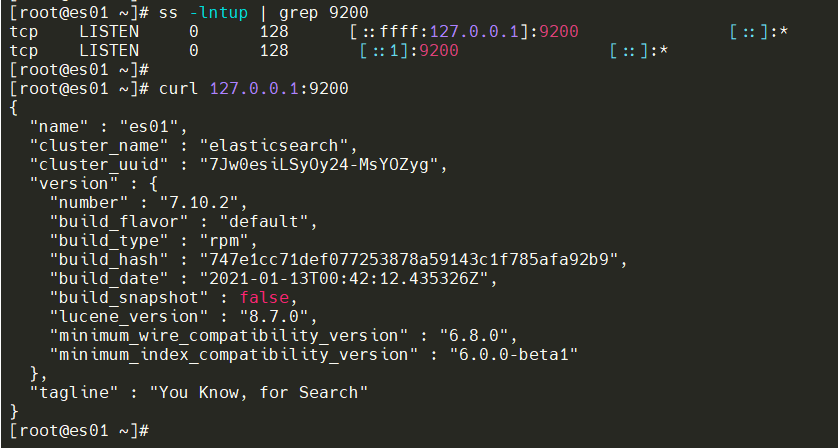
1.7 配置详解与修改
| 目录和配置文件 | |
|---|---|
| /etc/elasticsearch | 配置目录 |
| elasticsearch.yml | 配置文件,主要修改的对象。 |
| jvm.options | 配置java jvm选项 |
| /usr/share/elasticsearch/modules | 依赖的jar包目录 |
| /var/lib/elasticsearch | 数据目录 |
| /var/log/elasticsearch | 日志目录 |
elasticsearch.yml配置说明并修改
#备份配置文件
cp /etc/elasticsearch/elasticsearch.yml{,.bak}
#配置说明
node.name: es01.yinjay.com #节点名称
path.data: /var/lib/elasticsearch #数据目录
path.logs: /var/log/elasticsearch #日志目录
bootstrap.memory_lock: true #锁定内存,防止别人占用属于ES的内存。
network.host: 10.0.0.90,127.0.0.1 #监听IP地址
http.port: 9200 #ES端口(api接口端口)
discovery.seed_hosts: ["10.0.0.90"] ##发现节点,这里可以使用域名
cluster.initial_master_nodes: ["10.0.0.90"] ##集群初始化节点,这里可以使用域名
#修改配置
cat >/etc/elasticsearch/elasticsearch.yml<<EOF
node.name: es01.yinjay.com
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 10.0.0.90,127.0.0.1
http.port: 9200
discovery.seed_hosts: ["10.0.0.90"]
cluster.initial_master_nodes: ["10.0.0.90"]
EOF
重启会导致内存锁定失败,需要先修改Systemd
#找到elasticsearch.service,在[Service]下添加 LimitMEMLOCK=infinity 即可。
vim /usr/lib/systemd/system/elasticsearch.service
#重新加载服务并重启
systemctl daemon-reload
systemctl restart elasticsearch.service
访问测试
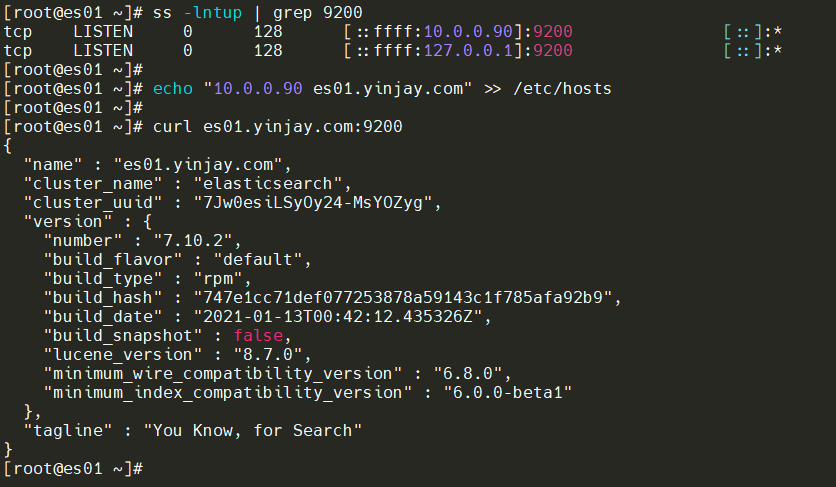
宿主机添加hosts解析并访问
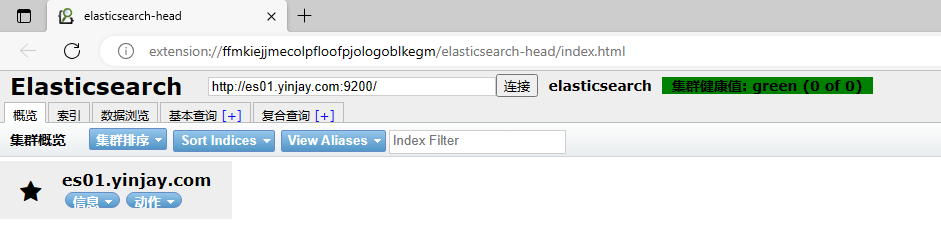
1.8 部署es-head插件
功能介绍
elasticsearch-head是一款用来管理Elasticsearch集群的第三方插件工具。es通过程序代码调用es各种api接口,
es-head查看与显示es状态信息,数据量,具体数据。
elasticsearch-Head插件在5.0版本之前可以直接以插件的形式直接安装,但是5.0以后安装方式发生了改变,需要nodejs环境支持,或者直接使用别人封装好的docker镜像,更推荐的是谷歌浏览器的插件。
通过浏览器的插件进行连接ES
1.9 ES数据增删改查
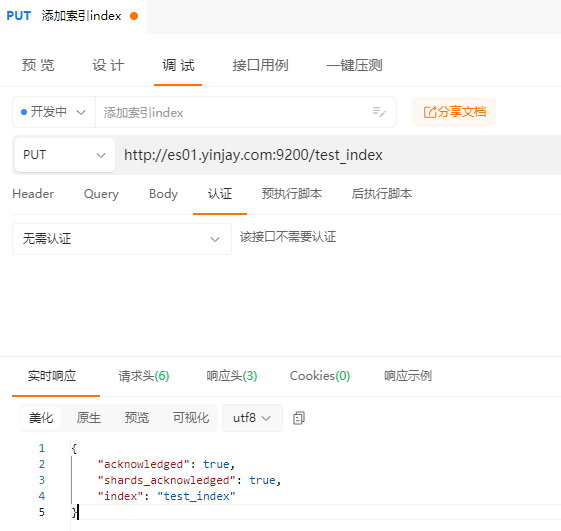
1.9.1 添加索引index
添加索引index类似于数据库
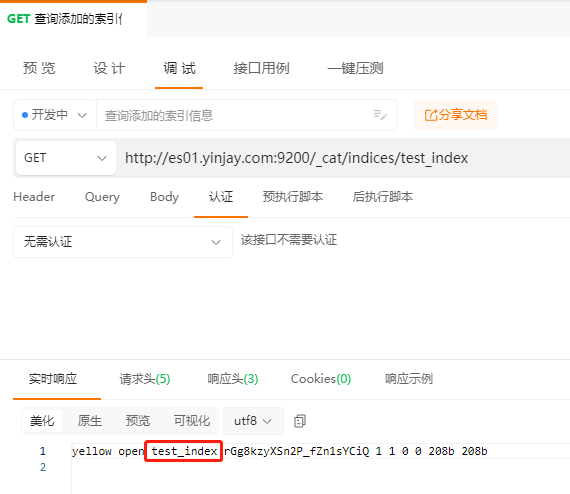
查询添加的索引信息
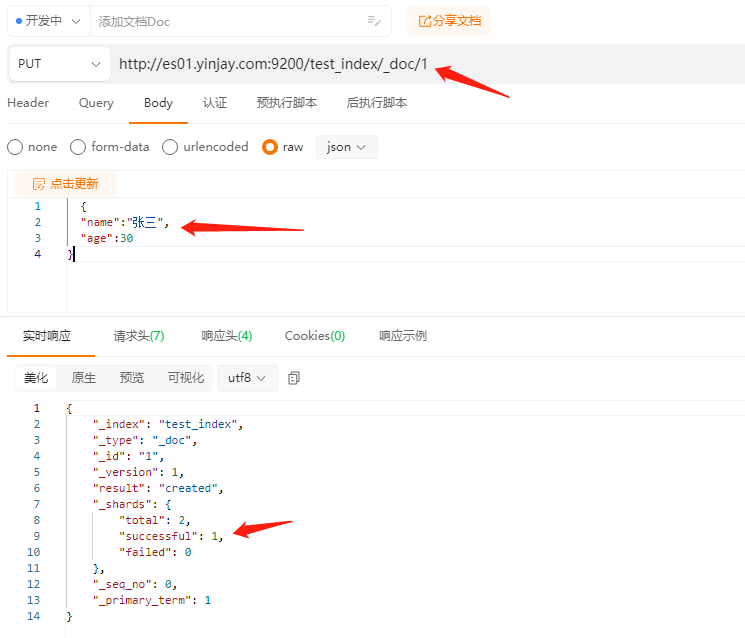
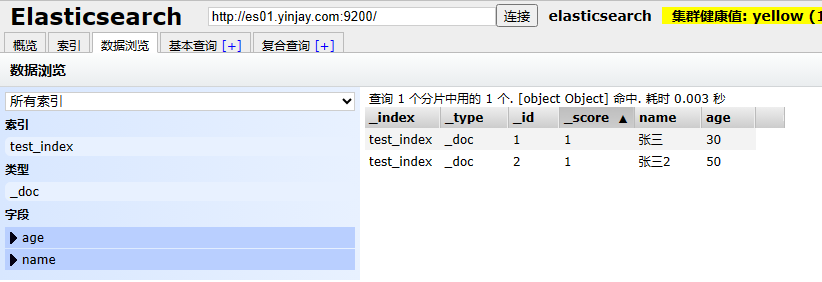
1.9.2 添加文档doc
添加文档(相当于表中的每行数据)
//1是文档的id
PUT /test_index/_doc/1
{
"name":"张三",
"age":30
}
//再添加一行
PUT /test_index/_doc/2
{
"name":"李四",
"age":35
}
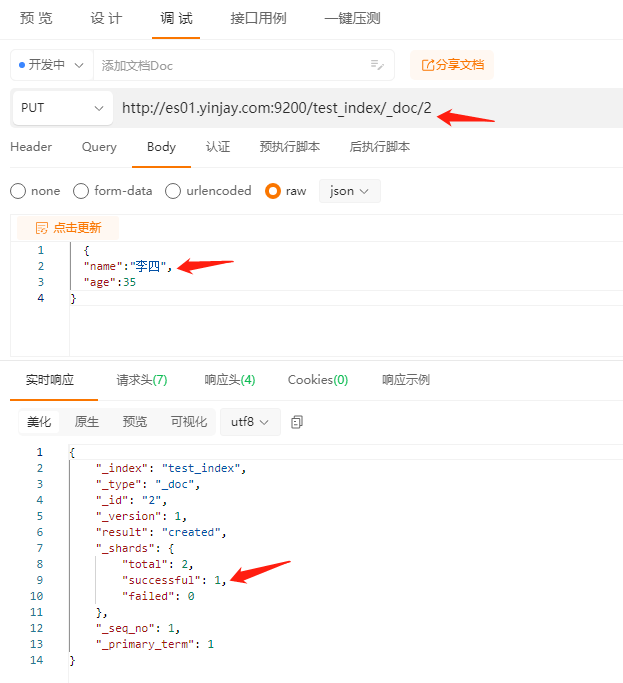
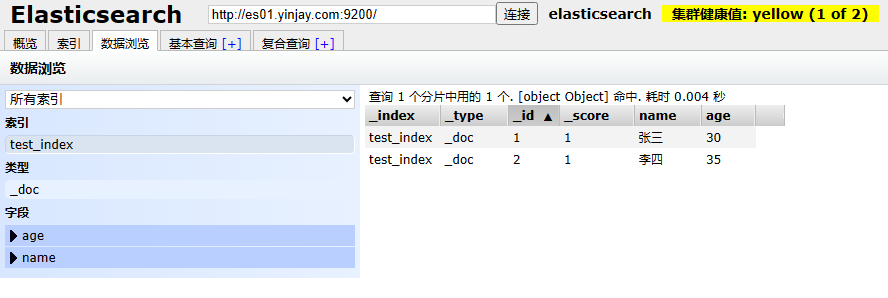
1.9.3 修改文档doc
PUT 更新,相当于覆盖重新添加
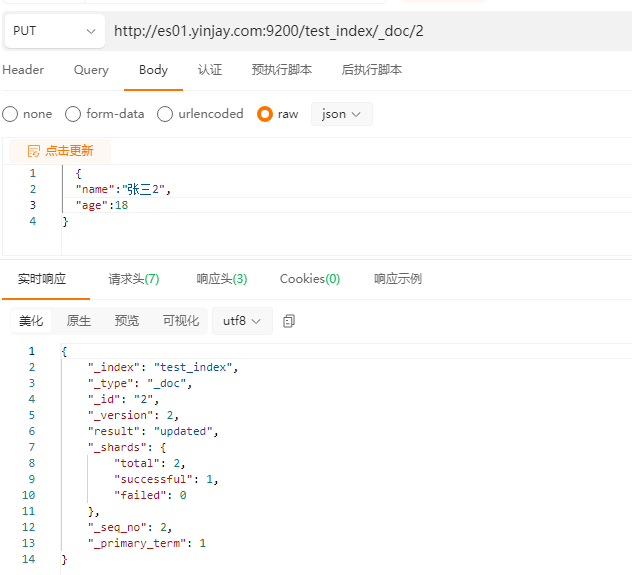
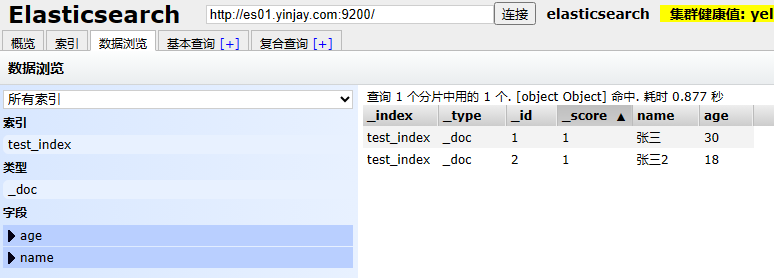
POST更新,针对某个字段更新。
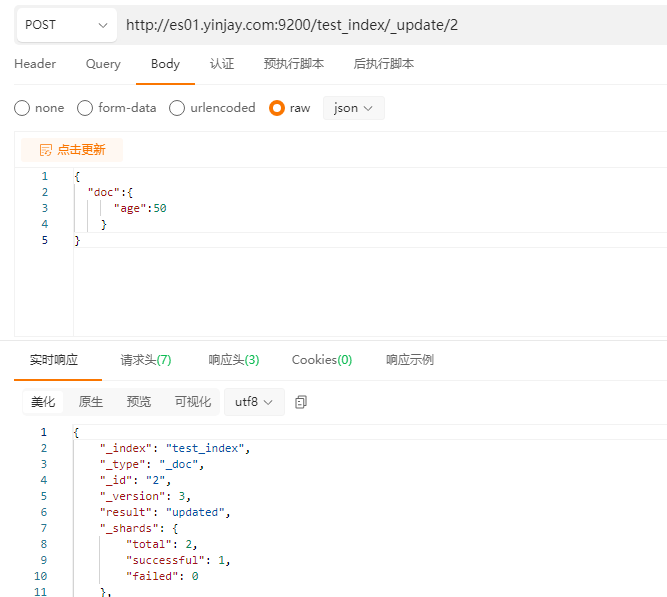
1.9.4 查询
查询索引
#查询全部索引
GET _cat/indices
#查询指定索引
GET _cat/indices/test_index
查询索引中的数据
#查询全部
GET /test_index/_search
//或者
GET /test_index/_search
{
"query": {"match_all": {}}
}
1.9.5 删除
#删除索引
DELETE /test_index
#删除文档
DELETE /test_index/_doc/1
1.10 部署ElasticSearch集群
1.10.1 安装ES
安装要求:jdk环境(oracle jdk,ES 7.0之后已经内置JDK环境)
es软件包下载:https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/yum/
| 主机名 | 配置 | IP | 角色 |
|---|---|---|---|
| es01 | 2c4g | 10.0.0.90、172.16.1.90 | ElasticSearch(主) |
| es02 | 2c4g | 10.0.0.91、172.16.1.91 | ElasticSearch(备) |
| es03 | 2c4g | 10.0.0.92、172.16.1.92 | ElasticSearch(备) |
rpm安装并启动ES服务
#所有主机安装
mkdir -p /soft ; cd /soft
wget https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/yum/7.10.2/elasticsearch-7.10.2-x86_64.rpm --no-check-certificate
rpm -ivh elasticsearch-7.10.2-x86_64.rpm
#修改Systemd文件,找到elasticsearch.service,在[Service]下添加 LimitMEMLOCK=infinity 即可。
vim /usr/lib/systemd/system/elasticsearch.service
#所有主机设置开机自启并启动
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl start elasticsearch.service
三台都进行访问测试,都出现以下结果即可。
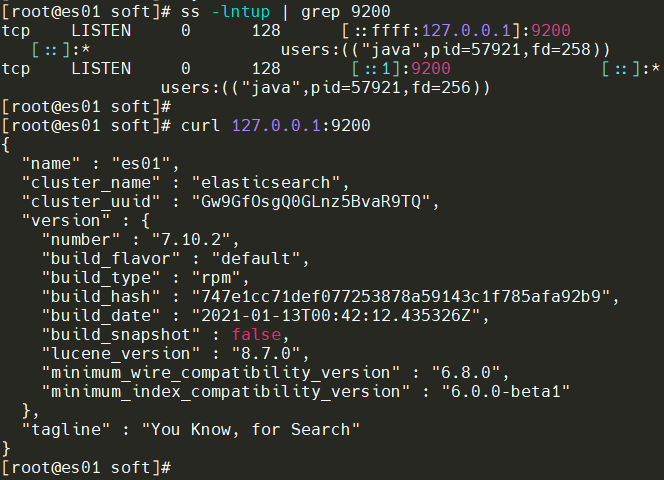
1.10.2 配置集群
配置hosts解析
echo "10.0.0.90 es01.yinjay.com" >> /etc/hosts
echo "10.0.0.91 es02.yinjay.com" >> /etc/hosts
echo "10.0.0.92 es03.yinjay.com" >> /etc/hosts
配置说明
#/etc/elasticsearch/elasticsearch.yml配置说明
cluster.name: YinJay-ES #集群名称(所有节点一致)
node.name: es0X.yinjay.com #节点名称(各主机不一样)
path.data: /var/lib/elasticsearch #数据目录
path.logs: /var/log/elasticsearch #日志目录
bootstrap.memory_lock: true #锁定内存,防止别人占用属于ES的内存。
network.host: 10.0.0.XX,127.0.0.1 #监听IP地址
http.port: 9200 #ES端口(api接口端口)
discovery.seed_hosts: ["主域名","从域名","从域名"] ##发现节点,这里可以使用域名
cluster.initial_master_nodes: ["主域名"] ##集群初始化节点,这里可以使用域名
修改配置文件(es01)
#备份配置文件
cp /etc/elasticsearch/elasticsearch.yml{,.bak}
#修改配置
cat >/etc/elasticsearch/elasticsearch.yml<<EOF
cluster.name: YinJay-ES
node.name: es01.yinjay.com
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 10.0.0.90,127.0.0.1
http.port: 9200
discovery.seed_hosts: ["es01.yinjay.com","es02.yinjay.com","es03.yinjay.com"]
cluster.initial_master_nodes: ["es01.yinjay.com"]
EOF
修改配置文件(es02)
#备份配置文件
cp /etc/elasticsearch/elasticsearch.yml{,.bak}
#修改配置
cat >/etc/elasticsearch/elasticsearch.yml<<EOF
cluster.name: YinJay-ES
node.name: es02.yinjay.com
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 10.0.0.91,127.0.0.1
http.port: 9200
discovery.seed_hosts: ["es01.yinjay.com","es02.yinjay.com","es03.yinjay.com"]
cluster.initial_master_nodes: ["es01.yinjay.com"]
EOF
修改配置文件(es03)
#备份配置文件
cp /etc/elasticsearch/elasticsearch.yml{,.bak}
#修改配置
cat >/etc/elasticsearch/elasticsearch.yml<<EOF
cluster.name: YinJay-ES
node.name: es03.yinjay.com
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 10.0.0.92,127.0.0.1
http.port: 9200
discovery.seed_hosts: ["es01.yinjay.com","es02.yinjay.com","es03.yinjay.com"]
cluster.initial_master_nodes: ["es01.yinjay.com"]
EOF
三节点重启服务
systemctl restart elasticsearch.service
1.10.3 查看集群状态
绿色:所有数据都完整,且副本数满足
黄色:所有数据都完整,但是副本数不满足
红色: 一个或多个索引数据不完整
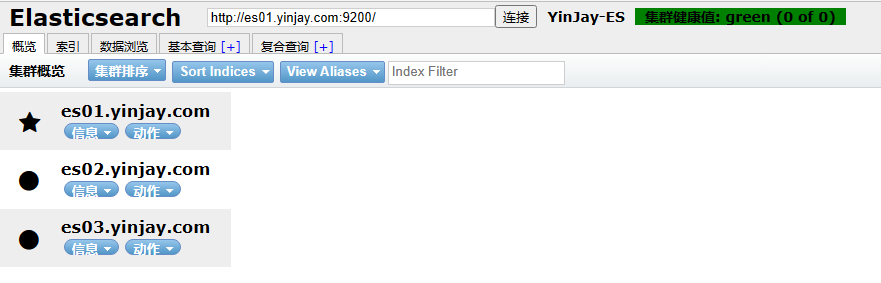
Tips:星星是Master节点、圆圈是Slave节点!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号