
数据结构与算法分析_二阶指针做为形参_链表头插入法工作流程及测试_链表尾插入法工作流程及测试_双向链表_优先队列(堆)测试_优先队列上滤插入和下滤删除_C语言实现最小堆和堆排序_队列(循环队列方法实现)_栈_快速排序_冒泡排序_生成n位格雷码
目录
3.1调试deleteElementByIndex()函数发现,主函数中的linkPtr经过showlinkList()函数之后已经成为了NULL空指针
5.1++i和i++运算符的测试 m41
(1)自己实现
(2)使用C++库函数stack
(3)使用两个站实现一个队列:参考笔试练习:m12
8、快速排序 时间复杂度O(nlogn)
9、冒泡排序 时间复杂度O(n^2)
2、非递归方法实现三种遍历
(1)非递归方式前序遍历---使用栈数组
(2)非递归方式中序遍历---使用栈数组
(3)非递归方式后序遍历---使用栈数组
3、二叉树中的平衡的概念(顺便引出平衡二叉树的概念) 判断二叉树是否为平衡二叉树链接
12、C++中的四个智能指针:auto_ptr,shared_ptr,weak_ptr,unique_ptr,其中auto_ptr已经被C++11抛弃
1、auto_ptr(C++98中的放案,C++11已经抛弃)
3、shared_ptr 自己手写的shared_ptr的C++实现
15、堆排序(重新学习) 时间复杂度O(nlogn),这里的堆实现方法为实现一颗完全二叉树
2、实例:求f(x) = x ^ 3 - x - 1在[1,1.5]内的一个实根,使误差不超过0.005。
1)自己先写的(有缺陷,在二分法子函数那里)
2)看来答案之后的修改版本
3)二分法总结
17、使用stringstream类将string类型转换为int、float、double等类型
18、归并排序原理和C++实现 时间复杂度O(nlogn),适用于元素较多的时候排序
19、插入排序 时间复杂度为O(n^2) 希尔排序(shell排序)
21、以前写的博客---无缺陷的String类实现方法----关于复制构造函数和赋值构造函数
1、二阶指针作为形参的目的
1)普通变量做为形参,不能改变主函数中实参的值
例子:


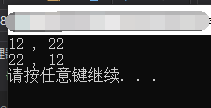
1 //01)形参改变,实参并没有改变的例子 2 #include <iostream> 3 4 using std::cout; 5 using std::endl; 6 7 /*交换a和b的值子函数*/ 8 void changeParameters(int a, int b) 9 { 10 int temp; 11 temp = a; 12 a = b; 13 b = temp; 14 } 15 16 int main() 17 { 18 int num1 = 12; 19 int num2 = 22; 20 cout << num1 << " , " << num2 << endl; 21 changeParameters(num1, num2); //此时num1和num2知识形参交换,实际参数并没有交换 22 cout << num1 << " , " << num2 << endl; 23 24 system("pause"); 25 return 0; 26 }
运行结果:

2)一阶指针作为形参,变量地址作为实参可以改变主函数中实参的值
例子:
1 //02)实参发生改变的例子 2 #include <iostream> 3 4 using std::cout; 5 using std::endl; 6 7 /*交换a和b的值子函数*/ 8 void changeParameters(int* a, int* b) 9 { 10 int temp; //此处改成int* temp交换地址,然后把*a和*b去掉也是可以的 11 temp = *a; 12 *a = *b; 13 *b = temp; 14 } 15 16 int main() 17 { 18 int num1 = 12; 19 int num2 = 22; 20 cout << num1 << " , " << num2 << endl; 21 changeParameters(&num1, &num2); //此时是对存储空间这的两个数进行交换,所以num1和num2的值会发生交换 22 cout << num1 << " , " << num2 << endl; 23 24 system("pause"); 25 return 0; 26 }
运行结果:
3)二阶指针做为形参,对指针用取地址运算符取地址后作为实参,可以改变实参的值
例子:
1 #include <iostream> 2 3 using std::cout; 4 using std::endl; 5 6 /*交换a和b的值子函数(相关解释见下)*/ 7 void changeParameters(int** a, int** b) 8 { 9 int* temp; 10 temp = *a; //保存*a指向的地址 11 *a = *b; //将*b指向的地址赋给*a指向的地址 12 *b = temp; 13 } 14 15 int main() 16 { 17 int a = 12; 18 int b = 22; 19 int* num1 = &a; 20 int* num2 = &b; 21 cout << *num1 << " , " << *num2 << endl; 22 changeParameters(&num1, &num2); //对指针取地址,即只想指针的指针,或者是地址的地址 23 cout << *num1 << " , " << *num2 << endl; 24 25 system("pause"); 26 return 0; 27 } 28 29 /* 30 int a = 12; //假设存储a变量的地址是00424A30 31 int* pc = &a; //则pc指向地址00424A30,假设存储pc的地址是00424A38 32 int** ppc = &pc; //ppc指向pc的地址(00424A38) 33 34 cout << "a的地址是: " << &a << endl; //打印 a的地址是: 00424A30 35 cout << "pc的值是: " << pc << endl; //打印 pc的值是: 00424A30 pc的值就是a的地址 36 cout << "*pc的值是: " << pc << endl; //打印 *pc的值是: 12 37 cout << "pc的地址是: " << &pc << endl; //打印 *pc的值是: 00424A38 38 cout << "ppc的值是: " << ppc << endl; //打印 ppc的值是: 00424A38 (ppc的值就是pc的地址) 39 cout << "*ppc的值是: " << ppc << endl; //打印 ppc的值是: 00424A38 (ppc的值就是pc的地址) 40 cout << "*(*ppc)的值是: " << *(*ppc) << endl; //打印 ppc的值是: 2 41 */
运行结果:

在例子中的一个解析:
1 int a = 12; //假设存储a变量的地址是00424A30 2 int* pc = &a; //则pc指向地址00424A30,假设存储pc的地址是00424A38 3 int** ppc = &pc; //ppc指向pc的地址(00424A38) 4 5 cout << "a的地址是: " << &a << endl; //打印 a的地址是: 00424A30 6 cout << "pc的值是: " << pc << endl; //打印 pc的值是: 00424A30 pc的值就是a的地址 7 cout << "*pc的值是: " << pc << endl; //打印 *pc的值是: 12 8 9 cout << "pc的地址是: " << &pc << endl; //打印 *pc的值是: 00424A38 10 cout << "ppc的值是: " << ppc << endl; //打印 ppc的值是: 00424A38 (ppc的值就是pc的地址) 11 12 cout << "*ppc的值是: " << ppc << endl; //打印 ppc的值是: 00424A38 (ppc的值就是pc的地址) 13 cout << "*(*ppc)的值是: " << *(*ppc) << endl; //打印 ppc的值是: 2
参考博客:https://blog.csdn.net/qq_34991245/article/details/81868212
04)二阶指针作为形参,一阶指针的地址作为实参,将形参赋给子函数中的一个变量,后改变该变量的值不会影响实参的值
例子:
1 #include <iostream> 2 3 using std::cout; 4 using std::endl; 5 6 /*交换a和b的值子函数(相关解释见下)*/ 7 void changeParameters(int** a, int** b) 8 { 9 int* temp = *a; 10 int p = 33; 11 temp = &p; //验证一下实参a的值会不会改变,此句不会改变实参a的值 12 *temp = p; //此句不会改变实参a的值 13 } 14 15 int main() 16 { 17 int a = 12; 18 int b = 22; 19 int* num1 = &a; 20 int* num2 = &b; 21 cout << *num1 << " , " << *num2 << endl; 22 changeParameters(&num1, &num2); //对指针取地址,即只想指针的指针,或者是地址的地址 23 cout << *num1 << " , " << *num2 << endl; 24 25 system("pause"); 26 return 0; 27 }
运行结果:

05)二阶指针作为形参,一阶指针的地址作为实参,改变子涵数(形参)实参的值会影响实参的值
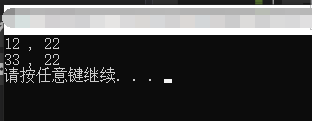
1 #include <iostream> 2 3 using std::cout; 4 using std::endl; 5 6 /*交换a和b的值子函数(相关解释见下)*/ 7 void changeParameters(int** a, int** b) 8 { 9 int p = 33; 10 *a = &p; //直接对形参(实参)赋值这样是会改变实参的值的 11 } 12 13 int main() 14 { 15 int a = 12; 16 int b = 22; 17 int* num1 = &a; 18 int* num2 = &b; 19 cout << *num1 << " , " << *num2 << endl; 20 changeParameters(&num1, &num2); //对指针取地址,即只想指针的指针,或者是地址的地址 21 cout << *num1 << " , " << *num2 << endl; 22 23 system("pause"); 24 return 0; 25 }
运行结果:
06)一阶指针做为实参和形参
(1)一阶指针做为实参和形参以下实现方法不会改变实参的值
这是由于指针传参也会给指针复制一份,并将这个复制的指针传递给子涵数,然后将这个复制得到的指针重新指向了一个新的地址,但是原指针还是指向原来的地址
1 void func(int* p) { 2 int m_value = 1; 3 p = &m_value; 4 }
如下:
1 #include <iostream> 2 3 using std::cout; 4 using std::endl; 5 6 7 void func(int* p) { 8 int m_value = 1; 9 p = &m_value; 10 //*p = m_value; 11 } 12 13 int main() 14 { 15 int num1 = 12; 16 int num2 = 22; 17 18 int *pn = &num1; 19 cout << "*pn=" << *pn << endl; 20 func(pn); 21 //func(&num1); //也是一样的 22 cout << "*pn=" << *pn << endl; 23 24 system("pause"); 25 return 0; 26 }
执行结果:

结果没有发生改变的原因:
假如主函数中pn指向的内存块标记为a,那么当调用func(pn)的时候,形参p和实参pn都指向了内存块a,而上面的子函数func()只是把形参p的指向改变了,主函数中的pn的指向还是不变的。
(2)下面的方法将会改变实参的值
1 void func(int* p) { 2 int m_value = 1; 3 *p = m_value; 4 }
如下:
1 #include <iostream> 2 3 using std::cout; 4 using std::endl; 5 6 7 void func(int* p) { 8 int m_value = 1; 9 *p = m_value; 10 } 11 12 int main() 13 { 14 int num1 = 12; 15 int num2 = 22; 16 17 int *pn = &num1; 18 cout << "*pn=" << *pn << endl; 19 func(pn); 20 //func(&num1); //也是一样的 21 cout << "*pn=" << *pn << endl; 22 23 system("pause"); 24 return 0; 25 }
执行结果:

此时可以改变主函数中pn指向的内存的值,这是由于形参p和实参pn都指向了一块内存,而上面的子函数通过形参p将这块内存中的值改变了,所以主函数中实参pn指向的值也会发生了改变。
2、链表头插入法工作流程及测试
01)头插法工作流程:

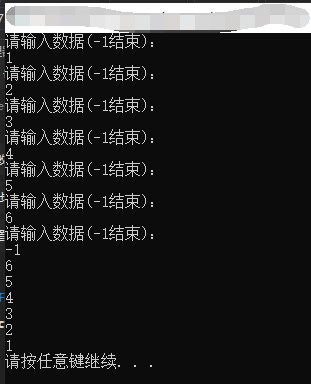
1 /*链表*/ 2 3 #include <iostream> 4 5 using std::cin; 6 using std::cout; 7 using std::endl; 8 9 typedef int ElementType; 10 11 /*定义一个结构*/ 12 struct linkList 13 { 14 ElementType Element; //定义结构中的一个数据(数据域) 15 linkList* next; //定义指向下一个结构的指针(指针域) 16 }; 17 18 typedef struct linkList *PtrtoNode; //PtrtoNode是一个类型,可以定义变量,且PtrtoNode是一个指针,指向结构体Node 19 typedef PtrtoNode List; //为PtrtoNode起别名为List 20 typedef PtrtoNode Position; //为PtrtoNode起别名为Position 21 22 void initlinkList(linkList** head); 23 void destroylinkListByHead(linkList** head); 24 void destroylinkListByTail(linkList** head); 25 void insertDatabyHead(linkList** head); 26 void insertDatabyTail(linkList* head); 27 void showlinkList(linkList** head); 28 linkList* indexof(linkList* head, int index); 29 int deleteElementByIndex(linkList* head, int index);
1 #include "stacktp1.h" 2 3 /* 4 01)链表的初始化(给头节点申请空间),所以在使用改函数的时候,只传入已创建结构的next指针即可; 5 02)使用指向指针的指针作为形参的原因在于要传入的参数是一个指针(要传入的参数是结构中的next指针), 6 如果形参定义为一层指针,那么就会发生形参改变而实参并没有发生任何改变的情况。 7 */ 8 void initlinkList(linkList** head) 9 { 10 if ((*head) == NULL) //如果结构这的next指针为空,那么表明已经初始化完成;刚刚这里写成了 != 导致在插入数据的时候head->next访问不了 11 return; 12 *head = (linkList*)malloc(sizeof(linkList)); //给结构分配足够的内存空间 13 (*head)->Element = 0; 14 (*head)->next = NULL; //head此时即是头节点也是尾节点,因为此时head指向了NULL 15 } 16 17 /* 18 01)链表的销毁 19 02)链表所有节点包括头结点都是动态申请的堆空间,使用完毕后必须手动释放,这里的销毁要把所有的节点空间全部释放; 20 03)方法一:从链表头开始遍历,也就是从前向后逐个释放每一个节点的空间 21 */ 22 void destroylinkListByHead(linkList** head) 23 { 24 linkList* header = *head; 25 linkList* p; 26 while ( header != NULL) //原来这里的条件是(*head)!=NULL,导致p->next指向了空指针;或者是循环了无数次 27 { 28 p = header; //讲当前数据节点保存下来 29 header = p->next; //将下一个数据节点保存下来 30 free(p); //讲当前节点空间释放 31 } 32 free(header); //释放头节点 33 head = NULL; //空间释放完的指针指向空指针 34 } 35 36 /* 37 01)方法二:从链表尾部向头部开始销毁,就不用临时保存 38 02)用递归遍历到最后一个结点,逐层向上返回,销毁每一个节点,顺序就是从头尾向头结点的顺序销毁。 39 */ 40 void destroylinkListByTail(linkList** head) 41 { 42 if ((*head) == NULL) 43 return; 44 destroylinkListByTail(&((*head)->next)); //递归调用 45 free(*head); 46 head = NULL; 47 } 48 49 /* 50 01)向链表这插入数据 51 02)头插法:每次在头结点H的后面插入一个输入的数据,链表中的数据顺序和实际输入顺序相反 52 03)插入的过程主要是:先申请一个新的结点,链表不像数组一次性分配指定长度的空间, 53 链表是需要增长一个就再申请一份,然后链接起来。申请完了之后给节点赋值,让新申请的节 54 点指向头结点的next,也就是node->next = h->next,再让头结点指向这个新节点, 55 H->next = node就完成插入操作。 56 04)传入的参数可以是头结点(头节点指向的是NULL) 57 05)传入的参数也可以是一个linkList结构的地址 58 06)以为此时是要向一个链表中插入数据,所以在使用malloc之后并没有释放内存 59 */ 60 void insertDatabyHead(linkList** head) 61 { 62 linkList* node; //新建一个需要插入的节点 63 int x; 64 cout << "请输入数据(-1结束):" << endl; 65 cin >> x; 66 while (x != -1) 67 { 68 node = (linkList*) malloc(sizeof(linkList)); //为需要插入的节点分配空间 69 node->Element = x; 70 //如果头节点指向的是NULL,所以下面这一句node->next换成NULL也可以 71 node->next = (*head)->next; //使node成为head指向的一个节点之后的节点 72 (*head)->next = node; //使 73 cout << "请输入数据(-1结束):" << endl; //接着输入数据 74 cin >> x; 75 } 76 } 77 78 /* 79 01)向链表这插入数据 80 02)尾插法:每次插入新的数据在链表的尾部插入就行,链表中的数据顺序和实际输入顺序相同 81 03)先找到链表的尾节点H->next == NULL,就是最后一个节点,同样插入就行。相比头插法, 82 尾插法插入数据的时候如果链表不是一条空链表,得遍历先找到尾节点。 83 04)传入的参数的头结点(头节点指向的是NULL) 84 05)输入的参数是一个linkList结构的地址 85 */ 86 87 void insertDatabyTail(linkList* head) 88 { 89 linkList* node; 90 linkList* remove; 91 int x; 92 while (head->next != NULL) //如果head不是尾节点,那么找到尾节点,并使head成为尾节点;尾节点指向NULL 93 head = head->next; 94 remove = head; //将head(尾节点)赋给remove,是remove也成为尾节点 95 cout << "请输入要插入的数据(-1结束): " << endl; 96 cin >> x; 97 while (x != -1) 98 { 99 node = (linkList*)malloc(sizeof(linkList)); 100 node->Element = x; 101 node->next = remove->next; //此处也可以使用head->next,但使用remove是为了循环大计 102 remove->next = node; //此处也可以使用head->next,但是链表就是断的了 103 remove = node; //为下一次循环做准备 104 cout << "请输入要插入的数据(-1结束): " << endl; 105 cin >> x; 106 } 107 } 108 109 /* 110 01)打印链表 111 02)输入为当前节点,或者是一个结构的地址 112 */ 113 114 void showlinkList(linkList** head) 115 { 116 if ((*head)->next == NULL ) //如果当前节点是头节点,则指向下一个节点;以为头节点是没有数据的 117 (*head) = (*head)->next; 118 (*head) = (*head)->next; //不显示头结点中的元素;上面那个if肯定不会被执行的,因为传入的参数是头结点,头结点的下一个节点肯定不是空(只要有数据) 119 while ((*head) != NULL ) 120 { 121 cout << (*head)->Element << endl; 122 (*head) = (*head)->next; 123 } 124 } 125 126 /* 127 01)删除第index个节点 128 */ 129 /*返回第index个节点*/ 130 linkList* indexof(linkList* head, int index) 131 { 132 linkList* p; 133 if (head->next == NULL) 134 { 135 cout << "输入的当前节点为头节点" << endl; 136 return NULL; 137 } 138 int j; 139 for (j = 1, p = head->next; p != NULL && j < index; j++) //如果index等于1,则该for循环会忽略p=NULL的情况 140 p = p->next; 141 return j == index ? p : NULL; 142 } 143 /*删除第index个节点*/ 144 int deleteElementByIndex(linkList* head, int index) 145 { 146 linkList* p; 147 linkList* temp; 148 p = indexof(head, index); //找到第index个节点 149 if (p == NULL) 150 { 151 cout << "要删除的为头节点" << endl; 152 return false; 153 } 154 temp = index == 1 ? NULL : indexof(head, index - 1); //找到要删除节点的前一个节点(前驱节点) 155 temp->next = p->next; //让要删除节点的前驱节点指向要删除节点的下一个节点 156 free(p); //释放要删除节点的内存 157 return true; 158 }
1 #include "stacktp1.h" 2 3 int main() 4 { 5 linkList* linkPtr; 6 initlinkList(&linkPtr); 7 insertDatabyHead(&linkPtr); 8 showlinkList(&linkPtr); 9 destroylinkListByHead(&linkPtr); 10 11 system("pause"); 12 return 0; 13 }
运行结果:
3、链表尾插入法工作流程及测试

3.1调试deleteElementByIndex()函数的发现,使用二阶指针是要谨慎的
调试deleteElementByIndex()函数发现,主函数中的linkPtr经过showlinkList()函数之后已经成为了NULL空指针,原因在于所有的函数都使用二阶指针,一旦子函数中对实参进行了赋值的操作,
那么主函数中的实参也是会发生变化的,如:05)二阶指针作为形参,一阶指针的地址作为实参,改变子涵数(形参)实参的值会影响实参的值,所以使用二阶指针需谨慎~

改进的方法:
01)将实参传递给子涵数中的一个一阶指针,然后改变该一阶指针,这样就不会改变实参,如 04)二阶指针作为形参,一阶指针的地址作为实参,将形参赋给子函数中的一个变量,改变该便利的值不会影响实参的值
02)将部分函数中的二阶形参该为一阶形参
下面附上全部子函数使用二阶指针的例子,该例子中的showlinkList()函数会使linPtr成为NULL空指针,导致接下来继续调用linkPtr出错
1 #include "stacktp1.h" 2 3 int main() 4 { 5 linkList* linkPtr; //创建链表的头结点 6 initlinkList(&linkPtr); 7 insertDatabyTail(&linkPtr); 8 //showlinkList(&linkPtr); //此句已经使linkPt成为了尾节点,所以执行下一句会报错 9 deleteElementByIndex(&linkPtr,5); //删除头结点为linkPtr,链表中第二个数 10 showlinkList(&linkPtr); //此句已经使linkPt成为了尾节点,所以不会执行下一个函数中的while循环,即不会删除链表 11 destroylinkListByHead(&linkPtr); 12 13 system("pause"); 14 return 0; 15 }
1 #include "stacktp1.h" 2 3 /* 4 01)链表的初始化(给头节点申请空间),所以在使用改函数的时候,只传入已创建结构的next指针即可; 5 02)使用指向指针的指针作为形参的原因在于要传入的参数是一个指针(要传入的参数是结构中的next指针), 6 如果形参定义为一层指针,那么就会发生形参改变而实参并没有发生任何改变的情况。 7 */ 8 void initlinkList(linkList** head) 9 { 10 if ((*head) == NULL) //如果结构这的next指针为空,那么表明已经初始化完成;刚刚这里写成了 != 导致在插入数据的时候head->next访问不了 11 return; 12 *head = (linkList*)malloc(sizeof(linkList)); //给结构分配足够的内存空间 13 (*head)->Element = 0; 14 (*head)->next = NULL; //head此时即是头节点也是尾节点,因为此时head指向了NULL 15 } 16 17 /* 18 01)链表的销毁 19 02)链表所有节点包括头结点都是动态申请的堆空间,使用完毕后必须手动释放,这里的销毁要把所有的节点空间全部释放; 20 03)方法一:从链表头开始遍历,也就是从前向后逐个释放每一个节点的空间 21 */ 22 void destroylinkListByHead(linkList** head) 23 { 24 linkList* header = *head; 25 linkList* p; 26 while ( header != NULL) //原来这里的条件是(*head)!=NULL,导致p->next指向了空指针;或者是循环了无数次 27 { 28 p = header; //讲当前数据节点保存下来 29 header = p->next; //将下一个数据节点保存下来 30 free(p); //讲当前节点空间释放 31 cout << "删除数据: " <<p->Element << endl; 32 } 33 free(header); //释放头节点 34 head = NULL; //空间释放完的指针指向空指针 35 cout << "链表已被删除完毕" << endl; 36 } 37 38 /* 39 01)方法二:从链表尾部向头部开始销毁,就不用临时保存 40 02)用递归遍历到最后一个结点,逐层向上返回,销毁每一个节点,顺序就是从头尾向头结点的顺序销毁。 41 */ 42 void destroylinkListByTail(linkList** head) 43 { 44 if ((*head) == NULL) 45 return; 46 destroylinkListByTail(&((*head)->next)); //递归调用 47 free(*head); 48 head = NULL; 49 cout << "链表已被删除完毕" << endl; 50 } 51 52 /* 53 01)向链表这插入数据 54 02)头插法:每次在头结点H的后面插入一个输入的数据,链表中的数据顺序和实际输入顺序相反 55 03)插入的过程主要是:先申请一个新的结点,链表不像数组一次性分配指定长度的空间, 56 链表是需要增长一个就再申请一份,然后链接起来。申请完了之后给节点赋值,让新申请的节 57 点指向头结点的next,也就是node->next = h->next,再让头结点指向这个新节点, 58 H->next = node就完成插入操作。 59 04)传入的参数可以是头结点(头节点指向的是NULL) 60 05)传入的参数也可以是一个linkList结构的地址 61 06)以为此时是要向一个链表中插入数据,所以在使用malloc之后并没有释放内存 62 */ 63 void insertDatabyHead(linkList** head) 64 { 65 linkList* node; //新建一个需要插入的节点 66 int x; 67 cout << "请输入数据(-1结束):" << endl; 68 cin >> x; 69 while (x != -1) 70 { 71 node = (linkList*) malloc(sizeof(linkList)); //为需要插入的节点分配空间 72 node->Element = x; 73 //如果头节点指向的是NULL,所以下面这一句node->next换成NULL也可以 74 node->next = (*head)->next; //使node成为head指向的一个节点之后的节点 75 (*head)->next = node; //使 76 cout << "请输入数据(-1结束):" << endl; //接着输入数据 77 cin >> x; 78 } 79 } 80 81 /* 82 01)向链表这插入数据 83 02)尾插法:每次插入新的数据在链表的尾部插入就行,链表中的数据顺序和实际输入顺序相同 84 03)先找到链表的尾节点H->next == NULL,就是最后一个节点,同样插入就行。相比头插法, 85 尾插法插入数据的时候如果链表不是一条空链表,得遍历先找到尾节点。 86 04)传入的参数的头结点(头节点指向的是NULL) 87 05)输入的参数是一个linkList结构的地址 88 */ 89 90 void insertDatabyTail(linkList** head) 91 { 92 linkList* node; 93 linkList* remove; 94 int x; 95 while ((*head)->next != NULL) //如果head不是尾节点,那么找到尾节点,并使head成为尾节点;尾节点指向NULL 96 (*head) = (*head)->next; 97 remove = (*head); //将head(尾节点)赋给remove,是remove也成为尾节点 98 cout << "请输入要插入的数据(-1结束): " << endl; 99 cin >> x; 100 while (x != -1) 101 { 102 node = (linkList*)malloc(sizeof(linkList)); 103 node->Element = x; 104 node->next = remove->next; //此处也可以使用head->next,但使用remove是为了循环大计 105 remove->next = node; //此处也可以使用head->next,但是链表就是断的了 106 remove = node; //为下一次循环做准备 107 cout << "请输入要插入的数据(-1结束): " << endl; 108 cin >> x; 109 } 110 } 111 112 /* 113 01)打印链表 114 02)输入为当前节点,或者是一个结构的地址 115 */ 116 117 void showlinkList(linkList** head) 118 { 119 if ((*head)->next == NULL ) //如果当前节点是头节点,则指向下一个节点;以为头节点是没有数据的 120 (*head) = (*head)->next; 121 (*head) = (*head)->next; //不显示头结点中的元素;上面那个if肯定不会被执行的,因为传入的参数是头结点,头结点的下一个节点肯定不是空(只要有数据) 122 while ((*head) != NULL ) 123 { 124 cout << (*head)->Element << endl; 125 (*head) = (*head)->next; //注意!!这里已经将传入的头结点变成了NULL!!!!!且实参是头结点的地址,所以会改变实参的值 126 } 127 } 128 129 /* 130 01)删除第index个节点 131 */ 132 /*返回第index个节点*/ 133 linkList* indexof(linkList* head, int index) 134 { 135 linkList* p = head; 136 if (head->next == NULL) //(*head)->next == NULL 137 { 138 cout << "输入的链表只有一个节点,且该节点为尾节点" << endl; 139 return NULL; 140 } 141 int j; 142 for (j = 0; p != NULL && j < index; j++) //如果index等于1,则该for循环会忽略p=NULL的情况 143 p = p->next; 144 return j == index ? p : NULL; 145 } 146 /*删除第index个节点*/ 147 int deleteElementByIndex(linkList** head, int index) 148 { 149 linkList* p; 150 linkList* temp; 151 p = indexof(*head, index); //找到第index个节点 152 if (p == NULL) 153 { 154 cout << "要删除的为头节点" << endl; 155 return false; 156 } 157 temp = index == 1 ? NULL : indexof(*head, index - 1); //找到要删除节点的前一个节点(前驱节点) 158 temp->next = p->next; //让要删除节点的前驱节点指向要删除节点的下一个节点 159 free(p); //释放要删除节点的内存 160 return true; 161 }
1 /*链表*/ 2 #include <iostream> 3 4 using std::cin; 5 using std::cout; 6 using std::endl; 7 8 typedef int ElementType; 9 10 /*定义一个结构*/ 11 struct linkList 12 { 13 ElementType Element; //定义结构中的一个数据(数据域) 14 linkList* next; //定义指向下一个结构的指针(指针域) 15 }; 16 17 typedef struct linkList *PtrtoNode; //PtrtoNode是一个类型,可以定义变量,且PtrtoNode是一个指针,指向结构体Node 18 typedef PtrtoNode List; //为PtrtoNode起别名为List 19 typedef PtrtoNode Position; //为PtrtoNode起别名为Position 20 21 void initlinkList(linkList** head); 22 void destroylinkListByHead(linkList** head); 23 void destroylinkListByTail(linkList** head); 24 void insertDatabyHead(linkList** head); 25 void insertDatabyTail(linkList** head); 26 void showlinkList(linkList** head); 27 linkList* indexof(linkList** head, int index); 28 int deleteElementByIndex(linkList** head, int index);
运行结果:

3.2 改进(将showlinkList()中定义一个变量a,将形参赋值给变量a,改变变量a,而不改变实参即可)
如下图所示:

另外在destroylinkListByHead()函数中的while循环中加入了一个cout用于显示删除的数据

1 #include "stacktp1.h" 2 3 int main() 4 { 5 linkList* linkPtr; //创建链表的头结点 6 initlinkList(&linkPtr); 7 insertDatabyTail(&linkPtr); 8 showlinkList(&linkPtr); //此句已经使linkPt成为了尾节点,所以执行下一句会报错 9 deleteElementByIndex(&linkPtr,5); //删除头结点为linkPtr,链表中第二个数 10 showlinkList(&linkPtr); //此句已经使linkPt成为了尾节点,所以不会执行下一个函数中的while循环,即不会删除链表 11 destroylinkListByHead(&linkPtr); 12 13 system("pause"); 14 return 0; 15 }
1 #include "stacktp1.h" 2 3 /* 4 01)链表的初始化(给头节点申请空间),所以在使用改函数的时候,只传入已创建结构的next指针即可; 5 02)使用指向指针的指针作为形参的原因在于要传入的参数是一个指针(要传入的参数是结构中的next指针), 6 如果形参定义为一层指针,那么就会发生形参改变而实参并没有发生任何改变的情况。 7 */ 8 void initlinkList(linkList** head) 9 { 10 if ((*head) == NULL) //如果结构这的next指针为空,那么表明已经初始化完成;刚刚这里写成了 != 导致在插入数据的时候head->next访问不了 11 return; 12 *head = (linkList*)malloc(sizeof(linkList)); //给结构分配足够的内存空间 13 (*head)->Element = 0; 14 (*head)->next = NULL; //head此时即是头节点也是尾节点,因为此时head指向了NULL 15 } 16 17 /* 18 01)链表的销毁 19 02)链表所有节点包括头结点都是动态申请的堆空间,使用完毕后必须手动释放,这里的销毁要把所有的节点空间全部释放; 20 03)方法一:从链表头开始遍历,也就是从前向后逐个释放每一个节点的空间 21 */ 22 void destroylinkListByHead(linkList** head) 23 { 24 linkList* header = (*head)->next; //由于传入的是头结点,所以越过头结点,保留头结点 25 linkList* p; 26 cout << "开始删除链表" << endl; 27 while ( header != NULL) //原来这里的条件是(*head)!=NULL,导致p->next指向了空指针;或者是循环了无数次 28 { 29 p = header; //讲当前数据节点保存下来 30 cout << "删除数据: " << p->Element << endl; 31 header = p->next; //将下一个数据节点保存下来 32 free(p); //讲当前节点空间释放 33 } 34 free(header); //释放头节点 35 head = NULL; //空间释放完的指针指向空指针 36 cout << "链表已被删除完毕" << endl; 37 } 38 39 /* 40 01)方法二:从链表尾部向头部开始销毁,就不用临时保存 41 02)用递归遍历到最后一个结点,逐层向上返回,销毁每一个节点,顺序就是从头尾向头结点的顺序销毁。 42 */ 43 void destroylinkListByTail(linkList** head) 44 { 45 if ((*head) == NULL) 46 return; 47 destroylinkListByTail(&((*head)->next)); //递归调用 48 free(*head); 49 head = NULL; 50 cout << "链表已被删除完毕" << endl; 51 } 52 53 /* 54 01)向链表这插入数据 55 02)头插法:每次在头结点H的后面插入一个输入的数据,链表中的数据顺序和实际输入顺序相反 56 03)插入的过程主要是:先申请一个新的结点,链表不像数组一次性分配指定长度的空间, 57 链表是需要增长一个就再申请一份,然后链接起来。申请完了之后给节点赋值,让新申请的节 58 点指向头结点的next,也就是node->next = h->next,再让头结点指向这个新节点, 59 H->next = node就完成插入操作。 60 04)传入的参数可以是头结点(头节点指向的是NULL) 61 05)传入的参数也可以是一个linkList结构的地址 62 06)以为此时是要向一个链表中插入数据,所以在使用malloc之后并没有释放内存 63 */ 64 void insertDatabyHead(linkList** head) 65 { 66 linkList* node; //新建一个需要插入的节点 67 int x; 68 cout << "请输入数据(-1结束):" << endl; 69 cin >> x; 70 while (x != -1) 71 { 72 node = (linkList*) malloc(sizeof(linkList)); //为需要插入的节点分配空间 73 node->Element = x; 74 //如果头节点指向的是NULL,所以下面这一句node->next换成NULL也可以 75 node->next = (*head)->next; //使node成为head指向的一个节点之后的节点 76 (*head)->next = node; //使 77 cout << "请输入数据(-1结束):" << endl; //接着输入数据 78 cin >> x; 79 } 80 } 81 82 /* 83 01)向链表这插入数据 84 02)尾插法:每次插入新的数据在链表的尾部插入就行,链表中的数据顺序和实际输入顺序相同 85 03)先找到链表的尾节点H->next == NULL,就是最后一个节点,同样插入就行。相比头插法, 86 尾插法插入数据的时候如果链表不是一条空链表,得遍历先找到尾节点。 87 04)传入的参数的头结点(头节点指向的是NULL) 88 05)输入的参数是一个linkList结构的地址 89 */ 90 91 void insertDatabyTail(linkList** head) 92 { 93 linkList* node; 94 linkList* remove; 95 int x; 96 while ((*head)->next != NULL) //如果head不是尾节点,那么找到尾节点,并使head成为尾节点;尾节点指向NULL 97 (*head) = (*head)->next; 98 remove = (*head); //将head(尾节点)赋给remove,是remove也成为尾节点 99 cout << "请输入要插入的数据(-1结束): " << endl; 100 cin >> x; 101 while (x != -1) 102 { 103 node = (linkList*)malloc(sizeof(linkList)); 104 node->Element = x; 105 node->next = remove->next; //此处也可以使用head->next,但使用remove是为了循环大计 106 remove->next = node; //此处也可以使用head->next,但是链表就是断的了 107 remove = node; //为下一次循环做准备 108 cout << "请输入要插入的数据(-1结束): " << endl; 109 cin >> x; 110 } 111 } 112 113 /* 114 01)打印链表 115 02)输入为当前节点,或者是一个结构的地址 116 */ 117 118 void showlinkList(linkList** head) 119 { 120 linkList* header = *head; 121 if (header->next == NULL ) //如果当前节点是头节点,则指向下一个节点;以为头节点是没有数据的 122 header = header->next; 123 header = header->next; //不显示头结点中的元素;上面那个if肯定不会被执行的,因为传入的参数是头结点,头结点的下一个节点肯定不是空(只要有数据) 124 while (header != NULL ) 125 { 126 cout << header->Element << endl; 127 header = header->next; //注意!!这里已经将传入的头结点变成了NULL!!!!!且实参是头结点的地址,所以会改变实参的值 128 } 129 } 130 131 /* 132 01)删除第index个节点 133 */ 134 /*返回第index个节点*/ 135 linkList* indexof(linkList* head, int index) 136 { 137 linkList* p = head; 138 if (head->next == NULL) //(*head)->next == NULL 139 { 140 cout << "输入的链表只有一个节点,且该节点为尾节点" << endl; 141 return NULL; 142 } 143 int j; 144 for (j = 0; p != NULL && j < index; j++) //如果index等于1,则该for循环会忽略p=NULL的情况 145 p = p->next; 146 return j == index ? p : NULL; 147 } 148 /*删除第index个节点*/ 149 int deleteElementByIndex(linkList** head, int index) 150 { 151 linkList* p; 152 linkList* temp; 153 p = indexof(*head, index); //找到第index个节点 154 if (p == NULL) 155 { 156 cout << "要删除的为头节点" << endl; 157 return false; 158 } 159 temp = index == 1 ? NULL : indexof(*head, index - 1); //找到要删除节点的前一个节点(前驱节点) 160 temp->next = p->next; //让要删除节点的前驱节点指向要删除节点的下一个节点 161 cout << "开始删除第" << index << "个节点" << endl; 162 free(p); //释放要删除节点的内存 163 return true; 164 }
1 /*链表*/ 2 #include <iostream> 3 4 using std::cin; 5 using std::cout; 6 using std::endl; 7 8 typedef int ElementType; 9 10 /*定义一个结构*/ 11 struct linkList 12 { 13 ElementType Element; //定义结构中的一个数据(数据域) 14 linkList* next; //定义指向下一个结构的指针(指针域) 15 }; 16 17 typedef struct linkList *PtrtoNode; //PtrtoNode是一个类型,可以定义变量,且PtrtoNode是一个指针,指向结构体Node 18 typedef PtrtoNode List; //为PtrtoNode起别名为List 19 typedef PtrtoNode Position; //为PtrtoNode起别名为Position 20 21 void initlinkList(linkList** head); 22 void destroylinkListByHead(linkList** head); 23 void destroylinkListByTail(linkList** head); 24 void insertDatabyHead(linkList** head); 25 void insertDatabyTail(linkList** head); 26 void showlinkList(linkList** head); 27 linkList* indexof(linkList* head, int index); 28 int deleteElementByIndex(linkList** head, int index);
执行结果:

3.3链表翻转(20200321)
指针反转原理及代码:
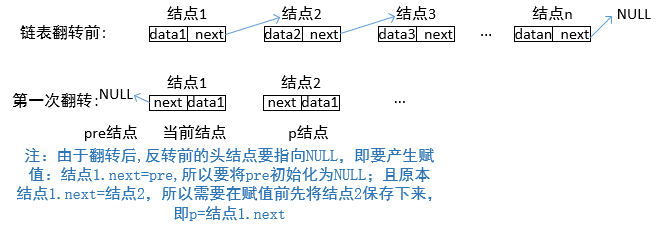

1 题目描述 2 输入一个链表,反转链表后,输出新链表的表头。 3 4 /* 5 struct ListNode { 6 int val; 7 struct ListNode *next; 8 ListNode(int x) : 9 val(x), next(NULL) { 10 } 11 };*/ 12 class Solution { 13 public: 14 ListNode* ReverseList(ListNode* pHead) 15 { 16 ListNode* pre=NULL; //初始化当前结点的前一个结点为NULL,反转后,头结点的next指针指向NULL 17 ListNode* p; //由于要操作pHead->next,所以需要保存当前节点的下一个节点 18 19 while(pHead!=NULL) 20 { 21 p=pHead->next; //保存当前节点的下一个节点 22 pHead->next=pre; //当前节点指向当前节点的前一个节点 23 pre=pHead; //更新当前节点的前一个节点为当前节点 24 pHead=p; //更新当前节点为当前节点的下一个节点 25 } 26 return pre; 27 } 28 };
3.4合并两个有序的链表
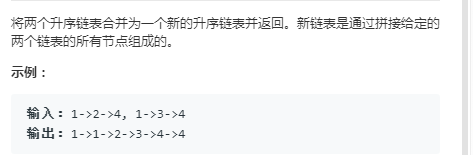
1 /** 2 * Definition for singly-linked list. 3 * struct ListNode { 4 * int val; 5 * ListNode *next; 6 * ListNode(int x) : val(x), next(NULL) {} 7 * }; 8 */ 9 class Solution { 10 public: 11 ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) { 12 if(l1==NULL) 13 return l2; 14 if(l2==NULL) 15 return l1; 16 ListNode* head=new ListNode(sizeof(ListNode)); 17 ListNode* t=head; //要将l1和l2和并后的头结点保存下来,而且head->next才是l1和l2中的数据,即返回值必须为head->next 18 while(l1!=NULL && l2!=NULL){ 19 if(l1->val < l2->val){ 20 t->next=l1; 21 l1=l1->next; 22 } 23 else{ 24 t->next=l2; 25 l2=l2->next; 26 } 27 t=t->next; //在这里如果是head=head->next,那么头节点就保存不下来了,所以找一个中间变量 28 }//执行完while循环之后l1和l2总有一个为空的 29 if(l1!=NULL) 30 t->next=l1; 31 else if(l2!=NULL) 32 t->next=l2; 33 return head->next; 34 } 35 };
3.5k个为一组反转链表
题目:
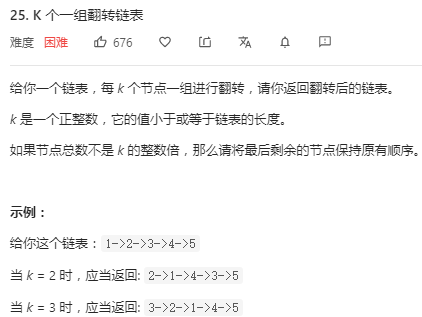
1 /** 2 * Definition for singly-linked list. 3 * struct ListNode { 4 * int val; 5 * ListNode *next; 6 * ListNode(int x) : val(x), next(NULL) {} 7 * }; 8 */ 9 class Solution { 10 public: 11 ListNode* reverseKGroup(ListNode* head, int k) { 12 ListNode* dummy=new ListNode(0); 13 dummy->next=head; //相当于创建一个虚头节点(在头节点的前面) 14 ListNode* pPre=dummy; 15 ListNode* KNodeNext=head; 16 while(pPre!=nullptr){ 17 //找到第k的节点的下一个节点 18 for(int i=0;i<k;++i){ 19 if(KNode==nullptr) 20 return dummy->next; 21 KNodeNext=KNodeNext->next; 22 } 23 //pTmp为k个为一组的头节点 24 ListNode* pTmp=pPre->next; 25 /*反转pTmp节点和KNode节点之间的节点,第一次返回值返回给了dummy->next 26 * 虽然传入的是KNodeNext,但是在子函数中最后head=KNodeNext的时候不会执行 27 * 所以反转的是[head,KNode]之间的节点 28 * 举例传入a->b->c->d返回节点顺序为null<-a<-b<-c,且返回值为c节点 29 */ 30 pPre->next=reverse(pTmp,KNodeNext); 31 /*反转后pTmp为[pTmp结点,KNode节点]的尾节点,将该节点和KNode的下一个节点连接上 32 *假如完整的链表顺序为a->b->c->d->e 且k=3 33 *则首先将a->b->c反转成c->b->a,此时pTmp还是指向a节点的,KNodeNext指向d结点 34 *那么将pTmp->next=KNodeNext即可完成连接 35 */ 36 pTmp->next=KNodeNext; 37 //更新pPre和KNode指向下一组的头节点 38 pPre=pTmp; 39 } 40 return dummy->next; 41 } 42 43 //将head节点和tail节点之间的节点反转(a->b->c->d->NULL)变成(NULL<-a<-b<-c<-d) 44 ListNode* reverse(ListNode* head,ListNode* tail){ 45 if(head==nullptr){ 46 return head; 47 } 48 ListNode* pre=nullptr; 49 ListNode* pNext; 50 while(head!=tail){ 51 pNext=head->next; 52 head->next=pre; //改变头节点的指向 53 pre=head; 54 head=pNext; 55 } 56 return pre; //返回d节点 57 } 58 };
二刷:
1 /** 2 * Definition for singly-linked list. 3 * struct ListNode { 4 * int val; 5 * ListNode *next; 6 * ListNode(int x) : val(x), next(NULL) {} 7 * }; 8 */ 9 class Solution { 10 public: 11 ListNode* reverseKGroup(ListNode* head, int k) { 12 ListNode* dummy=new ListNode(sizeof(ListNode)); 13 dummy->next=head; 14 ListNode* pre=dummy; //pre和dummy相当于头节点的前一个节点,所以要用pre->next;第二遍刷的时候也没有意识到pre节点相当于是一个头结点或者是k个为一组的头节点的前一个节点 15 ListNode* KNodeNext=head; 16 while(pre!=nullptr){ 17 for(int i=0;i<k;++i){ 18 if(KNodeNext==nullptr) 19 return dummy->next; 20 //找到第K个节点的下一个节点;第二遍刷的时候没有意识到这里找到的是第K个节点的下一个节点 21 KNodeNext=KNodeNext->next; 22 } 23 ListNode* KGrooupHead=pre->next; 24 pre->next=reverse(KGrooupHead,KNodeNext); 25 KGrooupHead->next=KNodeNext; //连接 26 pre=KGrooupHead; 27 } 28 return dummy->next; 29 } 30 31 //翻转 32 ListNode* reverse(ListNode* head,ListNode* tail){ 33 if(head==nullptr) 34 return nullptr; 35 ListNode* pre=nullptr; 36 ListNode* pNext; 37 while(head!=tail){ 38 pNext=head->next; //保存头节点的下一个节点 39 head->next=pre; 40 pre=head; 41 head=pNext; 42 } 43 return pre; 44 } 45 };
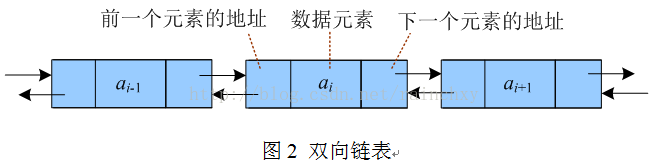
4、双向链表 m44
给每个元素附加两个指针域,一个存储前一个元素的地址,一个存储下一个元素的地址。这种链表称为双向链表,如下图所示:
(1) 链表初始化和创建 m441
初始化和创建双向链表的代码:
1 #pragma once 2 3 typedef int Type; 4 5 6 struct doubleLinklist 7 { 8 Type data; //存储数据 9 doubleLinklist* prior; //前向指针 10 doubleLinklist* next; //后继指针 11 }; 12 13 typedef struct doubleLinklist* PtrNode; 14 15 void initdoubleLinklist(doubleLinklist** head); 16 void creeatdoubleLinklist(doubleLinklist** head); //和单向链表的insert是一样的,连续的插入并不只是插入一个数据
1 #include <iostream> 2 #include "doubleLinkList.h" 3 4 using std::cin; 5 using std::cout; 6 using std::endl; 7 8 void initdoubleLinklist(doubleLinklist** head) 9 { 10 if ((*head) == NULL) 11 return; 12 (*head) = new doubleLinklist; 13 (*head)->data = 0; 14 (*head)->prior = NULL; 15 (*head)->next = NULL; 16 } 17 void creeatdoubleLinklist(doubleLinklist** head) 18 { 19 doubleLinklist* node; 20 cout << "请输入一个Type类型的数据(-1结束): " << endl; 21 Type x; 22 cin >> x; 23 while (x != -1) 24 { 25 node = new doubleLinklist; 26 node->data = x; 27 if ((*head)->next != NULL) 28 (*head)->next->prior = node; 29 node->next = (*head)->next; 30 node->prior = (*head); 31 (*head)->next = node; 32 cout << "请输入一个Type类型的数据(-1结束): " << endl; 33 cin >> x; 34 } 35 }
1 /*双向链表测试*/ 2 #include <iostream> //for system() 3 #include "doubleLinkList.h" 4 5 void showAll(doubleLinklist** head) 6 { 7 doubleLinklist* header = (*head)->next; //越过头节点 8 while (header != NULL) 9 { 10 cout << header->data << endl; 11 header = header->next; 12 } 13 } 14 15 int main() 16 { 17 doubleLinklist* PtrLinklist; 18 initdoubleLinklist(&PtrLinklist); 19 creeatdoubleLinklist(&PtrLinklist); 20 showAll(&PtrLinklist); 21 22 system("pause"); 23 return 0; 24 }
运行结果:
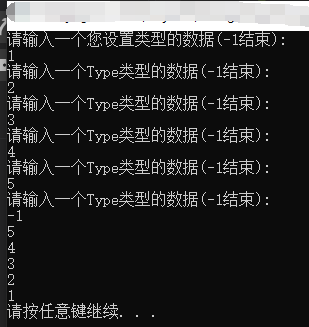
(2) 在链表的第i个位置插入数据data
“在链表的第i个位置插入数据data”的插入过程其实和创建链表插入第2个数据步骤是一样的,具体参考图
1 #pragma once 2 3 typedef int Type; 4 5 6 struct doubleLinklist 7 { 8 Type data; //存储数据 9 doubleLinklist* prior; //前向指针 10 doubleLinklist* next; //后继指针 11 }; 12 13 typedef struct doubleLinklist* PtrNode; 14 15 void initDULinklist(doubleLinklist** head); 16 void creeatDULinklistByHead(doubleLinklist** head); //和单向链表的insert是一样的,连续的插入并不只是插入一个数据 17 void insertToDULinkList(doubleLinklist** head, int i, int data); 18 19 void showAllByNext(doubleLinklist** head);
1 #include <iostream> 2 #include "doubleLinkList.h" 3 4 using std::cin; 5 using std::cout; 6 using std::endl; 7 8 /*双向链表初始化*/ 9 void initDULinklist(doubleLinklist** head) 10 { 11 if ((*head) == NULL) 12 return; 13 (*head) = new doubleLinklist; 14 (*head)->data = 0; 15 (*head)->prior = NULL; 16 (*head)->next = NULL; 17 } 18 19 /*头插入创造双向链表*/ 20 void creeatDULinklistByHead(doubleLinklist** head) 21 { 22 doubleLinklist* node; 23 cout << "请输入一个您设置类型的数据(-1结束): " << endl; 24 Type x; 25 cin >> x; 26 while (x != -1) 27 { 28 node = new doubleLinklist; 29 node->data = x; 30 if ((*head)->next != NULL) 31 (*head)->next->prior = node; 32 node->next = (*head)->next; 33 node->prior = (*head); 34 (*head)->next = node; 35 cout << "请输入一个Type类型的数据(-1结束): " << endl; 36 cin >> x; 37 } 38 } 39 40 /*在链表的第i个位置插入数据data*/ 41 void insertToDULinkList(doubleLinklist** head, int i, int data) 42 { 43 doubleLinklist* header = (*head)->next; //越过头节点 44 doubleLinklist* node; //创建新插入的节点 45 int j=1; 46 while (header != NULL && j < i) //找到第i个节点 47 { 48 header = header->next; 49 j++; 50 } 51 node = new doubleLinklist; //为新创建的节点分配空间 52 node->data = data; 53 header->next->prior = node; 54 node->next = header->next; 55 node->prior = header; 56 header->next = node; 57 } 58 59 void showAllByNext(doubleLinklist** head) 60 { 61 doubleLinklist* header = (*head)->next; //越过头节点 62 while (header != NULL) 63 { 64 cout << header->data << endl; 65 header = header->next; 66 } 67 }
1 //#include "stacktp1.h" 2 // 3 //int main() 4 //{ 5 // linkList* linkPtr; //创建链表的头结点 6 // initlinkList(&linkPtr); 7 // insertDatabyTail(&linkPtr); 8 // showlinkList(&linkPtr); //此句已经使linkPt成为了尾节点,所以执行下一句会报错 9 // deleteElementByIndex(&linkPtr,5); //删除头结点为linkPtr,链表中第二个数 10 // showlinkList(&linkPtr); //此句已经使linkPt成为了尾节点,所以不会执行下一个函数中的while循环,即不会删除链表 11 // destroylinkListByTail(&linkPtr); 12 // 13 // system("pause"); 14 // return 0; 15 //} 16 // 17 18 /*最大堆测试*/ 19 //#include "PriorityQueue.h" 20 // 21 //int main() 22 //{ 23 // { 24 // int arr[] = { 37,26,14,52,69,78,98,48,69,70 }; 25 // int n = sizeof(arr) / sizeof(arr[0]); //获取数组元素个数的新方法 26 // Heap<int>* heap = new Heap<int>(20); //新建指向类模板的指针,不新建指针也是可以的如Heap<int> heap(20); 27 // for (int i = 0; i < n; i++) 28 // { 29 // heap->insert(arr[i]); 30 // } 31 // heap->showHeap(); 32 // cout << endl; 33 // 34 // cout << "添加元素100" << endl; 35 // heap->insert(100); 36 // heap->showHeap(); 37 // cout << endl; 38 // 39 // cout << "删除元素78" << endl; 40 // heap->remove(78); 41 // heap->showHeap(); 42 // } 43 // 44 // system("pause"); 45 // return 0; 46 //} 47 48 //#include <iostream> 49 //#include <cstdio> 50 //#include <queue> 51 // 52 //using namespace std; 53 // 54 //int main() 55 //{ 56 // priority_queue<int> q; 57 // int arr[] = { 37,26,14,52,69,78,98,48,69,70 }; 58 // int n = sizeof(arr) / sizeof(arr[0]); //获取数组元素个数的新方法 59 // for (int i = 0; i < n; i++) 60 // { 61 // q.push(arr[i]); 62 // } 63 // while (!q.empty()) 64 // { 65 // cout << q.top() << " " << endl; 66 // q.pop(); 67 // } 68 // 69 // system("pause"); 70 // return 0; 71 //} 72 73 //#include <iostream> 74 // 75 //using std::cout; 76 //using std::endl; 77 // 78 //int main() 79 //{ 80 // int i = 8; 81 // int arr[] = { 1,2,3,4,5,6,7,8,9 }; 82 // 83 // //cout << arr[i--] << endl; //打印9 先使用后修改 84 // //cout << arr[i--] << endl; //打印8 85 // 86 // //cout << arr[--i] << endl; //打印8 先修改后使用 87 // //cout << arr[--i] << endl; //打印7 88 // //cout << endl; 89 // //cout << i; //此时i=6 90 // 91 // int c[] = { 2,3,4,5 }; 92 // int j, *p = c, *q = c; 93 // for (j = 0; j < 4; j++) 94 // { 95 // printf(" %d", *c); 96 // ++q; 97 // } 98 // for (j = 0; j < 4; j++) 99 // { 100 // printf(" %d", *p); 101 // ++p; 102 // } 103 // 104 // system("pause"); 105 // return 0; 106 //} 107 108 //#include "queue.h" 109 // 110 //int main() 111 //{ 112 // int x; 113 // int temp; 114 // int size = 6; 115 // Queue<int>* queue = new Queue<int>(size); 116 // cout << "请输入一个整数,按字母q结束:"; 117 // cin >> x; 118 // while (x != 0) 119 // { 120 // queue->enqueue(x); 121 // cout << "请输入一个整数,按字母q结束:"; 122 // cin >> x; 123 // } 124 // cout << "队中元素个数为:" << queue->queueLength() << endl; 125 // int n = queue->queueLength(); 126 // for (int i = 0; i <= n; i++) 127 // { 128 // queue->dequeue(temp); 129 // cout << "出队的元素是:" << temp << endl; 130 // } 131 // /*queue->dequeue(temp); 132 // cout << "出队的元素是:" << temp << endl; 133 // queue->dequeue(temp); 134 // cout << "出队的元素是:" << temp << endl; 135 // queue->dequeue(temp); 136 // cout << "出队的元素是:" << temp << endl; 137 // queue->dequeue(temp); 138 // cout << "出队的元素是:" << temp << endl; 139 // queue->dequeue(temp); 140 // cout << "出队的元素是:" << temp << endl; 141 // queue->dequeue(temp); 142 // cout << "出队的元素是:" << temp << endl; 143 // 144 // queue->dequeue(temp); 145 // cout << "出队的元素是:" << temp << endl;*/ 146 // 147 // system("pause"); 148 // return 0; 149 //} 150 151 //#include "queue.h" 152 // 153 //int main() 154 //{ 155 // int x; 156 // int temp; 157 // int size = 6; 158 // Queue<int>* queue = new Queue<int>(size); 159 // cout << "请输入一个整数,按字母q结束:"; 160 // cin >> x; 161 // queue->enqueue(x); 162 // cout << "请输入一个整数,按字母q结束:"; 163 // cin >> x; 164 // queue->enqueue(x); 165 // queue->dequeue(temp); 166 // cout << "出队的元素是:" << temp << endl; 167 // queue->dequeue(temp); 168 // cout << "出队的元素是:" << temp << endl; 169 // 170 // system("pause"); 171 // return 0; 172 //} 173 174 /*双向链表测试*/ 175 #include <iostream> //for system() 176 #include "doubleLinkList.h" 177 178 using std::cout; 179 using std::endl; 180 181 int main() 182 { 183 doubleLinklist* PtrLinklist; 184 initDULinklist(&PtrLinklist); 185 creeatDULinklistByHead(&PtrLinklist); 186 showAllByNext(&PtrLinklist); 187 cout << "开始插入数据" << endl; 188 insertToDULinkList(&PtrLinklist, 2, 45); 189 showAllByNext(&PtrLinklist); 190 191 system("pause"); 192 return 0; 193 }
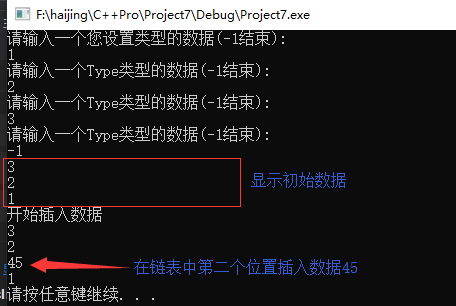
运行结果(该方法是先的是在第二个节点之后插入新数据,把3所在的节点当做是第一个节点):
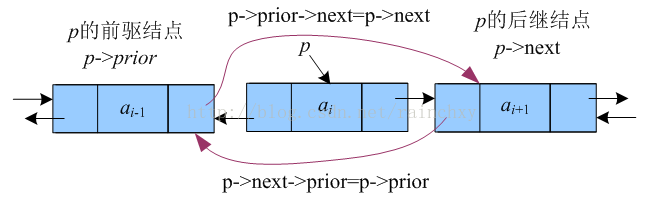
(3) 删除链表中的第i个节点
删除一个结点,实际上是把这个结点跳过去。要想跳过第i个结点,可以先找到第i个结点。然后修改指针,如图:
1 #pragma once 2 3 typedef int Type; 4 5 6 struct doubleLinklist 7 { 8 Type data; //存储数据 9 doubleLinklist* prior; //前向指针 10 doubleLinklist* next; //后继指针 11 }; 12 13 typedef struct doubleLinklist* PtrNode; 14 15 void initDULinklist(doubleLinklist** head); 16 void creeatDULinklistByHead(doubleLinklist** head); //和单向链表的insert是一样的,连续的插入并不只是插入一个数据 17 void insertToDULinkList(doubleLinklist** head, int i, int data); 18 void deleteOneNode(doubleLinklist** head, int i); //删除第i个节点 19 20 void showAllByNext(doubleLinklist** head);
1 #include <iostream> 2 #include "doubleLinkList.h" 3 4 using std::cin; 5 using std::cout; 6 using std::endl; 7 8 /*双向链表初始化*/ 9 void initDULinklist(doubleLinklist** head) 10 { 11 if ((*head) == NULL) 12 return; 13 (*head) = new doubleLinklist; 14 (*head)->data = 0; 15 (*head)->prior = NULL; 16 (*head)->next = NULL; 17 } 18 19 /*头插入创造双向链表*/ 20 void creeatDULinklistByHead(doubleLinklist** head) 21 { 22 doubleLinklist* node; 23 cout << "请输入一个您设置类型的数据(-1结束): "; 24 Type x; 25 cin >> x; 26 while (x != -1) 27 { 28 node = new doubleLinklist; 29 node->data = x; 30 if ((*head)->next != NULL) 31 (*head)->next->prior = node; 32 node->next = (*head)->next; 33 node->prior = (*head); 34 (*head)->next = node; 35 cout << "请输入一个您设置类型的数据(-1结束): "; 36 cin >> x; 37 } 38 } 39 40 /*在链表的第i个位置插入数据data*/ 41 void insertToDULinkList(doubleLinklist** head, int i, int data) 42 { 43 doubleLinklist* header = (*head)->next; //越过头节点 此时header是第一个节点,所以j=1 44 doubleLinklist* node; //创建新插入的节点 45 int j=1; 46 while (header != NULL && j < i) //找到第i个节点 47 { 48 header = header->next; 49 j++; 50 } 51 node = new doubleLinklist; //为新创建的节点分配空间 52 node->data = data; 53 header->next->prior = node; 54 node->next = header->next; 55 node->prior = header; 56 header->next = node; 57 } 58 59 /*删除第i个节点*/ 60 void deleteOneNode(doubleLinklist** head, int i) 61 { 62 doubleLinklist* header = (*head)->next; //越过头节点(第0个节点) 63 int j = 1; // 64 while (header != NULL && j < i) //找到第i个节点 65 { 66 header = header->next; 67 j++; 68 } 69 header->next->prior = header->prior; 70 header->prior->next = header->next; 71 delete header; //删除第i个节点 72 } 73 74 void showAllByNext(doubleLinklist** head) 75 { 76 doubleLinklist* header = (*head)->next; //越过头节点 77 while (header != NULL) 78 { 79 cout << header->data << endl; 80 header = header->next; 81 } 82 }
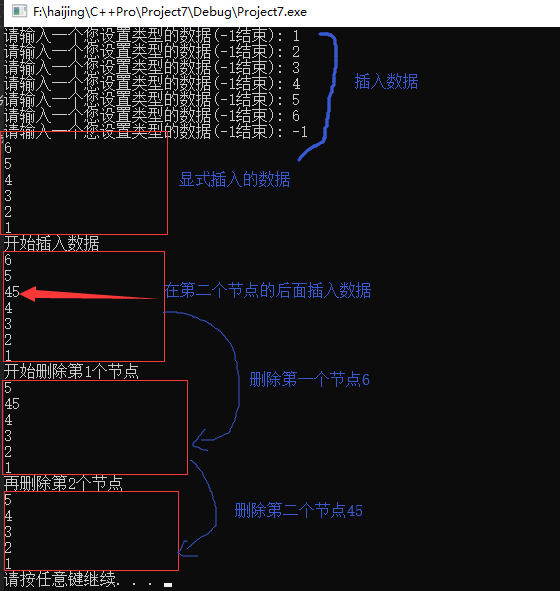
1 //#include "stacktp1.h" 2 // 3 //int main() 4 //{ 5 // linkList* linkPtr; //创建链表的头结点 6 // initlinkList(&linkPtr); 7 // insertDatabyTail(&linkPtr); 8 // showlinkList(&linkPtr); //此句已经使linkPt成为了尾节点,所以执行下一句会报错 9 // deleteElementByIndex(&linkPtr,5); //删除头结点为linkPtr,链表中第二个数 10 // showlinkList(&linkPtr); //此句已经使linkPt成为了尾节点,所以不会执行下一个函数中的while循环,即不会删除链表 11 // destroylinkListByTail(&linkPtr); 12 // 13 // system("pause"); 14 // return 0; 15 //} 16 // 17 18 /*最大堆测试*/ 19 //#include "PriorityQueue.h" 20 // 21 //int main() 22 //{ 23 // { 24 // int arr[] = { 37,26,14,52,69,78,98,48,69,70 }; 25 // int n = sizeof(arr) / sizeof(arr[0]); //获取数组元素个数的新方法 26 // Heap<int>* heap = new Heap<int>(20); //新建指向类模板的指针,不新建指针也是可以的如Heap<int> heap(20); 27 // for (int i = 0; i < n; i++) 28 // { 29 // heap->insert(arr[i]); 30 // } 31 // heap->showHeap(); 32 // cout << endl; 33 // 34 // cout << "添加元素100" << endl; 35 // heap->insert(100); 36 // heap->showHeap(); 37 // cout << endl; 38 // 39 // cout << "删除元素78" << endl; 40 // heap->remove(78); 41 // heap->showHeap(); 42 // } 43 // 44 // system("pause"); 45 // return 0; 46 //} 47 48 //#include <iostream> 49 //#include <cstdio> 50 //#include <queue> 51 // 52 //using namespace std; 53 // 54 //int main() 55 //{ 56 // priority_queue<int> q; 57 // int arr[] = { 37,26,14,52,69,78,98,48,69,70 }; 58 // int n = sizeof(arr) / sizeof(arr[0]); //获取数组元素个数的新方法 59 // for (int i = 0; i < n; i++) 60 // { 61 // q.push(arr[i]); 62 // } 63 // while (!q.empty()) 64 // { 65 // cout << q.top() << " " << endl; 66 // q.pop(); 67 // } 68 // 69 // system("pause"); 70 // return 0; 71 //} 72 73 //#include <iostream> 74 // 75 //using std::cout; 76 //using std::endl; 77 // 78 //int main() 79 //{ 80 // int i = 8; 81 // int arr[] = { 1,2,3,4,5,6,7,8,9 }; 82 // 83 // //cout << arr[i--] << endl; //打印9 先使用后修改 84 // //cout << arr[i--] << endl; //打印8 85 // 86 // //cout << arr[--i] << endl; //打印8 先修改后使用 87 // //cout << arr[--i] << endl; //打印7 88 // //cout << endl; 89 // //cout << i; //此时i=6 90 // 91 // int c[] = { 2,3,4,5 }; 92 // int j, *p = c, *q = c; 93 // for (j = 0; j < 4; j++) 94 // { 95 // printf(" %d", *c); 96 // ++q; 97 // } 98 // for (j = 0; j < 4; j++) 99 // { 100 // printf(" %d", *p); 101 // ++p; 102 // } 103 // 104 // system("pause"); 105 // return 0; 106 //} 107 108 //#include "queue.h" 109 // 110 //int main() 111 //{ 112 // int x; 113 // int temp; 114 // int size = 6; 115 // Queue<int>* queue = new Queue<int>(size); 116 // cout << "请输入一个整数,按字母q结束:"; 117 // cin >> x; 118 // while (x != 0) 119 // { 120 // queue->enqueue(x); 121 // cout << "请输入一个整数,按字母q结束:"; 122 // cin >> x; 123 // } 124 // cout << "队中元素个数为:" << queue->queueLength() << endl; 125 // int n = queue->queueLength(); 126 // for (int i = 0; i <= n; i++) 127 // { 128 // queue->dequeue(temp); 129 // cout << "出队的元素是:" << temp << endl; 130 // } 131 // /*queue->dequeue(temp); 132 // cout << "出队的元素是:" << temp << endl; 133 // queue->dequeue(temp); 134 // cout << "出队的元素是:" << temp << endl; 135 // queue->dequeue(temp); 136 // cout << "出队的元素是:" << temp << endl; 137 // queue->dequeue(temp); 138 // cout << "出队的元素是:" << temp << endl; 139 // queue->dequeue(temp); 140 // cout << "出队的元素是:" << temp << endl; 141 // queue->dequeue(temp); 142 // cout << "出队的元素是:" << temp << endl; 143 // 144 // queue->dequeue(temp); 145 // cout << "出队的元素是:" << temp << endl;*/ 146 // 147 // system("pause"); 148 // return 0; 149 //} 150 151 //#include "queue.h" 152 // 153 //int main() 154 //{ 155 // int x; 156 // int temp; 157 // int size = 6; 158 // Queue<int>* queue = new Queue<int>(size); 159 // cout << "请输入一个整数,按字母q结束:"; 160 // cin >> x; 161 // queue->enqueue(x); 162 // cout << "请输入一个整数,按字母q结束:"; 163 // cin >> x; 164 // queue->enqueue(x); 165 // queue->dequeue(temp); 166 // cout << "出队的元素是:" << temp << endl; 167 // queue->dequeue(temp); 168 // cout << "出队的元素是:" << temp << endl; 169 // 170 // system("pause"); 171 // return 0; 172 //} 173 174 /*双向链表测试*/ 175 #include <iostream> //for system() 176 #include "doubleLinkList.h" 177 178 using std::cout; 179 using std::endl; 180 181 int main() 182 { 183 doubleLinklist* PtrLinklist; 184 initDULinklist(&PtrLinklist); 185 creeatDULinklistByHead(&PtrLinklist); 186 showAllByNext(&PtrLinklist); 187 188 cout << "开始插入数据" << endl; 189 insertToDULinkList(&PtrLinklist, 2, 45); 190 showAllByNext(&PtrLinklist); 191 192 cout << "开始删除第1个节点" << endl; 193 deleteOneNode(&PtrLinklist, 1); 194 showAllByNext(&PtrLinklist); 195 196 cout << "再删除第2个节点" << endl; 197 deleteOneNode(&PtrLinklist, 2); 198 showAllByNext(&PtrLinklist); 199 200 201 system("pause"); 202 return 0; 203 }
运行结果:
(4) 删除所有元素
删除元素借鉴了单向链表删除所有元素的方法
1 #pragma once 2 3 typedef int Type; 4 5 6 struct doubleLinklist 7 { 8 Type data; //存储数据 9 doubleLinklist* prior; //前向指针 10 doubleLinklist* next; //后继指针 11 }; 12 13 typedef struct doubleLinklist* PtrNode; 14 15 void initDULinklist(doubleLinklist** head); 16 void creeatDULinklistByHead(doubleLinklist** head); //和单向链表的insert是一样的,连续的插入并不只是插入一个数据 17 void insertToDULinkList(doubleLinklist** head, int i, int data); 18 void deleteOneNode(doubleLinklist** head, int i); //删除第i个节点 19 void deleteAll(doubleLinklist** head); //删除所有节点 20 21 void showAllByNext(doubleLinklist** head);
1 #include <iostream> 2 #include "doubleLinkList.h" 3 4 using std::cin; 5 using std::cout; 6 using std::endl; 7 8 /*双向链表初始化*/ 9 void initDULinklist(doubleLinklist** head) 10 { 11 if ((*head) == NULL) 12 return; 13 (*head) = new doubleLinklist; 14 (*head)->data = 0; 15 (*head)->prior = NULL; 16 (*head)->next = NULL; 17 } 18 19 /*头插入创造双向链表*/ 20 void creeatDULinklistByHead(doubleLinklist** head) 21 { 22 doubleLinklist* node; 23 cout << "请输入一个您设置类型的数据(-1结束): "; 24 Type x; 25 cin >> x; 26 while (x != -1) 27 { 28 node = new doubleLinklist; 29 node->data = x; 30 if ((*head)->next != NULL) 31 (*head)->next->prior = node; 32 node->next = (*head)->next; 33 node->prior = (*head); 34 (*head)->next = node; 35 cout << "请输入一个您设置类型的数据(-1结束): "; 36 cin >> x; 37 } 38 } 39 40 /*在链表的第i个位置插入数据data*/ 41 void insertToDULinkList(doubleLinklist** head, int i, int data) 42 { 43 doubleLinklist* header = (*head)->next; //越过头节点 此时header是第一个节点,所以j=1 44 doubleLinklist* node; //创建新插入的节点 45 int j=1; 46 while (header != NULL && j < i) //找到第i个节点 47 { 48 header = header->next; 49 j++; 50 } 51 node = new doubleLinklist; //为新创建的节点分配空间 52 node->data = data; 53 header->next->prior = node; 54 node->next = header->next; 55 node->prior = header; 56 header->next = node; 57 } 58 59 /*删除第i个节点*/ 60 void deleteOneNode(doubleLinklist** head, int i) 61 { 62 doubleLinklist* header = (*head)->next; //越过头节点(第0个节点) 63 int j = 1; // 64 while (header != NULL && j < i) //找到第i个节点 65 { 66 header = header->next; 67 j++; 68 } 69 header->next->prior = header->prior; 70 header->prior->next = header->next; 71 delete header; //删除第i个节点 72 } 73 74 /*删除所有节点*/ 75 void deleteAll(doubleLinklist** head) 76 { 77 doubleLinklist* header = (*head)->next; 78 doubleLinklist* p; 79 while (header != NULL) 80 { 81 p = header; //必须找一个中间变量,否则会发生访问权限错误 82 cout << "删除元素: " << p->data <<endl; 83 header = p->next; 84 delete(p); 85 } 86 delete(header); //删除头结点 87 cout << "所有节点删除完毕" << endl; 88 } 89 90 void showAllByNext(doubleLinklist** head) 91 { 92 doubleLinklist* header = (*head)->next; //越过头节点 93 while (header != NULL) 94 { 95 cout << header->data << endl; 96 header = header->next; 97 } 98 }
1 /*双向链表测试*/ 2 #include <iostream> //for system() 3 #include "doubleLinkList.h" 4 5 using std::cout; 6 using std::endl; 7 8 int main() 9 { 10 doubleLinklist* PtrLinklist; 11 initDULinklist(&PtrLinklist); 12 creeatDULinklistByHead(&PtrLinklist); 13 showAllByNext(&PtrLinklist); 14 15 cout << "开始插入数据" << endl; 16 insertToDULinkList(&PtrLinklist, 2, 45); 17 showAllByNext(&PtrLinklist); 18 19 cout << "开始删除第1个节点" << endl; 20 deleteOneNode(&PtrLinklist, 1); 21 showAllByNext(&PtrLinklist); 22 23 cout << "再删除第2个节点" << endl; 24 deleteOneNode(&PtrLinklist, 2); 25 showAllByNext(&PtrLinklist); 26 27 deleteAll(&PtrLinklist); 28 29 30 system("pause"); 31 return 0; 32 }
运行结果:

(5) 最后的修改
1 #include <iostream> 2 #include "doubleLinkList.h" 3 4 using std::cin; 5 using std::cout; 6 using std::endl; 7 8 /*双向链表初始化*/ 9 void initDULinklist(doubleLinklist** head) 10 { 11 if ((*head) == NULL) 12 return; 13 (*head) = new doubleLinklist; 14 (*head)->data = 0; 15 (*head)->prior = NULL; 16 (*head)->next = NULL; 17 } 18 19 /*头插入创造双向链表*/ 20 void creeatDULinklistByHead(doubleLinklist** head) 21 { 22 doubleLinklist* node; 23 cout << "请输入一个您设置类型的数据(-1结束): "; 24 Type x; 25 cin >> x; 26 while (x != -1) 27 { 28 node = new doubleLinklist; 29 node->data = x; 30 if ((*head)->next != NULL) 31 (*head)->next->prior = node; 32 node->next = (*head)->next; 33 node->prior = (*head); 34 (*head)->next = node; 35 cout << "请输入一个您设置类型的数据(-1结束): "; 36 cin >> x; 37 } 38 } 39 40 /*在链表的第i个位置插入数据data*/ 41 void insertToDULinkList(doubleLinklist** head, int i, int data) 42 { 43 doubleLinklist* header = (*head)->next; //越过头节点 此时header是第一个节点,所以j=1 44 doubleLinklist* node; //创建新插入的节点 45 int j=1; 46 while (header != NULL && j < i) //找到第i个节点 47 { 48 header = header->next; 49 j++; 50 } 51 node = new doubleLinklist; //为新创建的节点分配空间 52 node->data = data; 53 header->next->prior = node; 54 node->next = header->next; 55 node->prior = header; 56 header->next = node; 57 } 58 59 /*删除第i个节点*/ 60 void deleteOneNode(doubleLinklist** head, int i) 61 { 62 doubleLinklist* header = (*head)->next; //越过头节点(第0个节点) 63 int j = 1; // 64 while (header != NULL && j < i) //找到第i个节点 65 { 66 header = header->next; 67 j++; 68 } 69 if (header->next == NULL) 70 { 71 cout << "deleteOneNode()子程序中出现了header->next=NULL的情况!" << endl; 72 return; //退出程序 73 } 74 header->next->prior = header->prior; 75 header->prior->next = header->next; 76 delete header; //删除第i个节点 77 } 78 79 /*删除所有节点*/ 80 void deleteAll(doubleLinklist** head) 81 { 82 doubleLinklist* header = (*head)->next; 83 doubleLinklist* p; 84 while (header != NULL) 85 { 86 p = header; //必须找一个中间变量,否则会发生访问权限错误 87 cout << "删除元素: " << p->data <<endl; 88 header = p->next; 89 delete(p); 90 } 91 delete(header); //删除头结点 92 cout << "所有节点删除完毕" << endl; 93 } 94 95 void showAllByNext(doubleLinklist** head) 96 { 97 doubleLinklist* header = (*head)->next; //越过头节点 98 while (header != NULL) 99 { 100 cout << header->data << ", "; 101 header = header->next; 102 } 103 cout << endl; 104 } 105 106 void showAllByPrior(doubleLinklist** head) 107 { 108 doubleLinklist* header = *head; 109 while (header->next != NULL) //找到尾节点(使header成为尾结点) 110 header = header->next; 111 while (header->prior != NULL) //不显示头结点的数据 112 { 113 cout << header->data <<", "; 114 header = header->prior; 115 } 116 cout << endl; 117 }
1 #pragma once 2 3 typedef int Type; 4 5 6 struct doubleLinklist 7 { 8 Type data; //存储数据 9 doubleLinklist* prior; //前向指针 10 doubleLinklist* next; //后继指针 11 }; 12 13 typedef struct doubleLinklist* PtrNode; 14 15 void initDULinklist(doubleLinklist** head); 16 void creeatDULinklistByHead(doubleLinklist** head); //和单向链表的insert是一样的,连续的插入并不只是插入一个数据 17 void insertToDULinkList(doubleLinklist** head, int i, int data); 18 void deleteOneNode(doubleLinklist** head, int i); //删除第i个节点 19 void deleteAll(doubleLinklist** head); //删除所有节点 20 21 void showAllByNext(doubleLinklist** head); 22 void showAllByPrior(doubleLinklist** head);
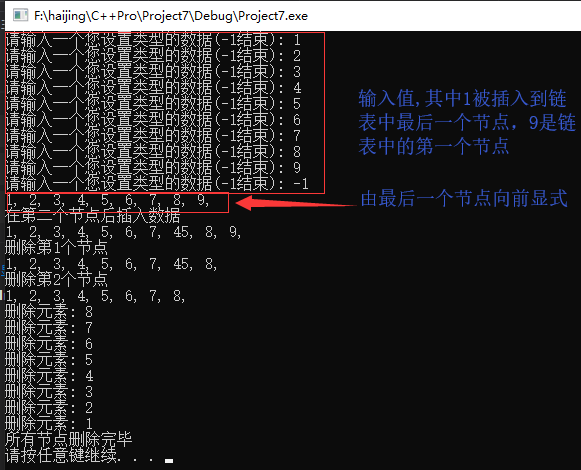
1 /*双向链表测试*/ 2 #include <iostream> //for system() 3 #include "doubleLinkList.h" 4 5 using std::cout; 6 using std::endl; 7 8 int main() 9 { 10 doubleLinklist* PtrLinklist; 11 initDULinklist(&PtrLinklist); 12 creeatDULinklistByHead(&PtrLinklist); 13 showAllByPrior(&PtrLinklist); 14 15 cout << "在第二个节点后插入数据" << endl; 16 insertToDULinkList(&PtrLinklist, 2, 45); 17 showAllByPrior(&PtrLinklist); 18 19 cout << "删除第1个节点" << endl; 20 deleteOneNode(&PtrLinklist, 1); 21 showAllByPrior(&PtrLinklist); 22 23 cout << "删除第2个节点" << endl; 24 deleteOneNode(&PtrLinklist, 2); 25 showAllByPrior(&PtrLinklist); 26 27 deleteAll(&PtrLinklist); 28 29 30 system("pause"); 31 return 0; 32 }
测试结果:
5、优先队列(堆)测试
5.1++i和i++运算符的测试
1 #include <iostream> 2 3 using std::cout; 4 using std::endl; 5 6 int main() 7 { 8 int i = 8; 9 int arr[] = { 1,2,3,4,5,6,7,8,9 }; 10 11 //cout << arr[i--] << endl; //打印9 先使用后修改 12 //cout << arr[i--] << endl; //打印8 13 14 cout << arr[--i] << endl; //打印8 先修改后使用 15 cout << arr[--i] << endl; //打印7 16 cout << endl; 17 cout << i; //此时i=6 18 19 system("pause"); 20 return 0; 21 }
5.2优先队列上滤插入和下滤删除
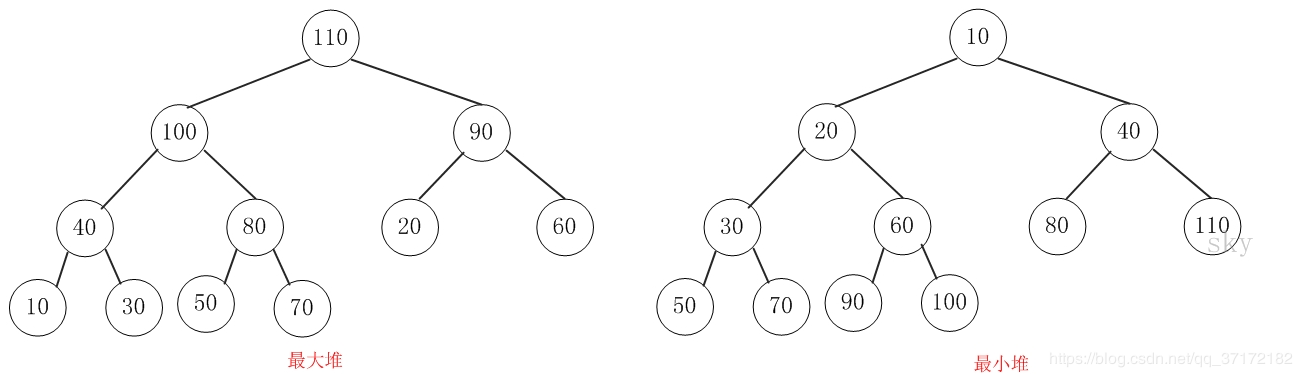
最大堆:父结点的键值总是大于或等于任何一个子节点的键值;
最小堆:父结点的键值总是小于或等于任何一个子节点的键值;
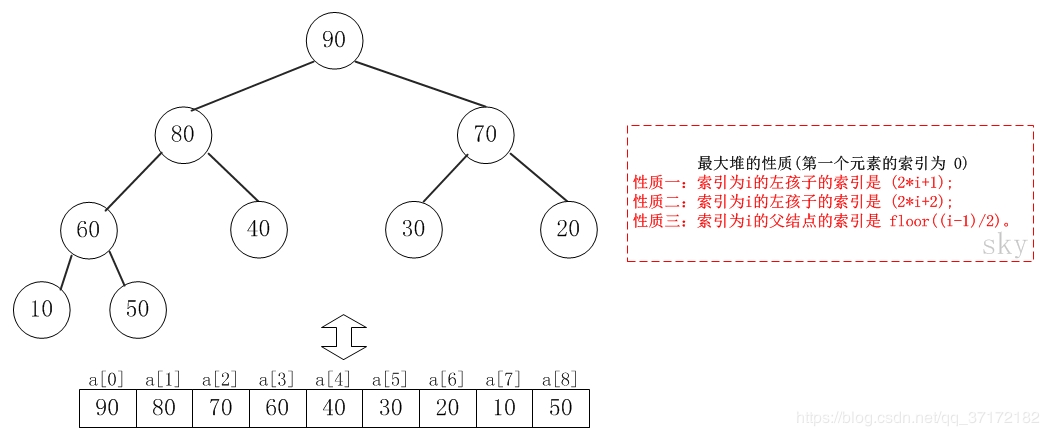
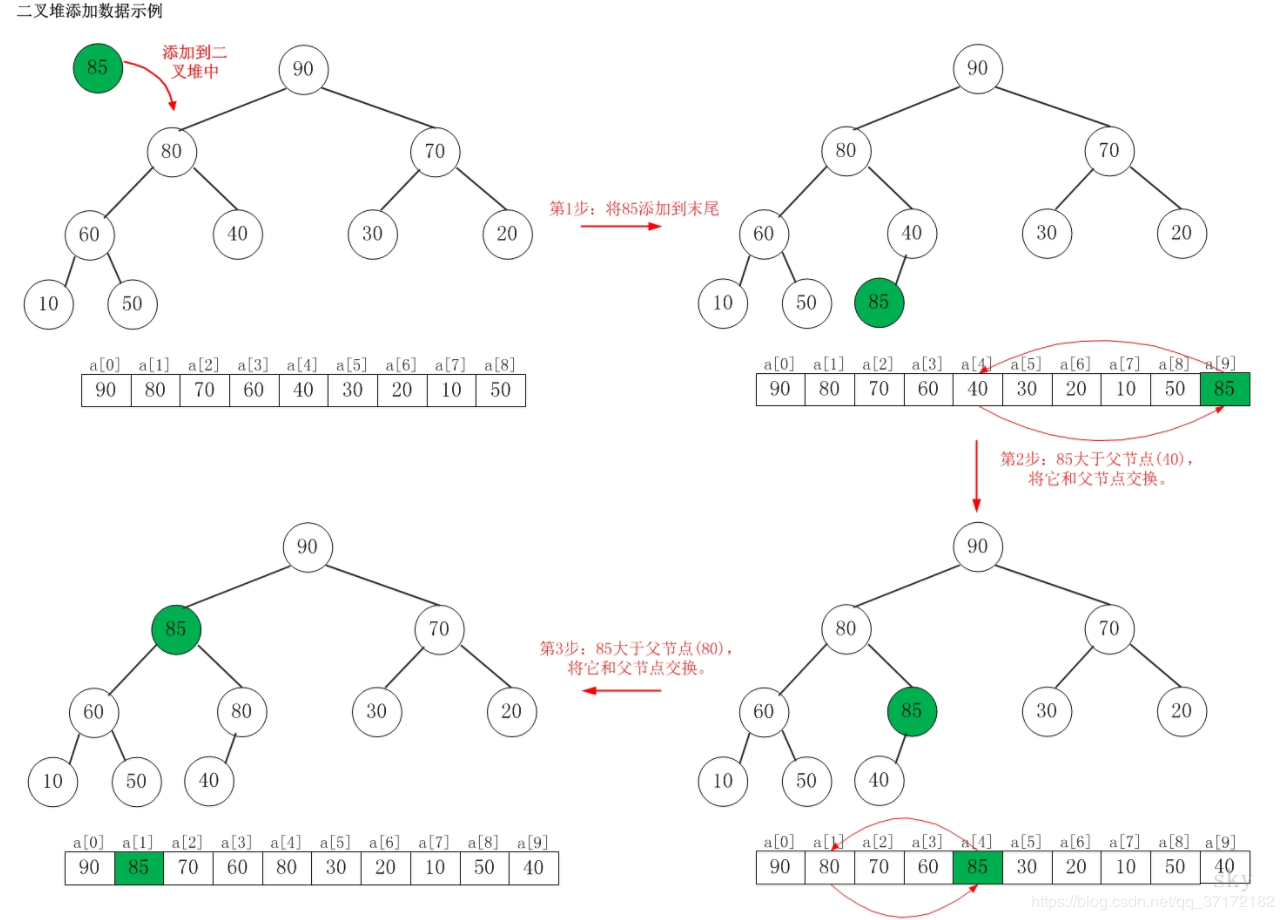

1 /*最大堆的实现*/ 2 #pragma once 3 #include <iostream> 4 5 using std::cout; 6 using std::endl; 7 8 template<class Type> 9 class Heap 10 { 11 private: 12 Type* array; //存放数据的堆矩阵 13 int totalsize; //可以存放的总的数据个数 14 int currentsize; //目前数据个数的索引 15 void filterDown(int start, int end); //删除数据使用下滤方法 16 void filterUp(int start); //插入数据使用上滤方法 17 public: 18 Heap(int size = 30); //默认堆大小为30 19 ~Heap(); 20 int getIndex(Type data); //获取data在堆内的索引 21 int insert(Type data); 22 int remove(Type data); 23 void showHeap(); 24 }; 25 26 template<class Type> 27 Heap<Type>::Heap(int size) 28 { 29 array = new Type[totalsize]; //为堆(数组分配空间) 30 totalsize = size; 31 currentsize = 0; 32 } 33 34 template<class Type> 35 Heap<Type>::~Heap() 36 { 37 totalsize = 0; 38 currentsize = 0; 39 delete[] array; 40 } 41 42 template <class Type> 43 int Heap<Type>::getIndex(Type data) 44 { 45 for (int i = 0; i < currentsize; i++) 46 { 47 if (array[i] == data) 48 return i; 49 } 50 return -1; //没有在堆array中找到data则返回-1 51 } 52 53 template <class Type> 54 int Heap<Type>::insert(Type data) //data即为要插入的数据 55 { 56 if (currentsize == totalsize) //判断堆是否已满 57 return -1; 58 array[currentsize] = data; //将新插入的数据data先存入array数组的最后,注crrentsize是从0开始 59 filterUp(currentsize); 60 currentsize++; 61 return 0; 62 } 63 64 template <class Type> 65 void Heap<Type>::filterUp(int start) 66 { 67 int i = start; //将传入的当前索引值传递给i 68 int p = (i - 1) / 2; //获取索引为i节点的父节点(根节点的索引从0开始) 69 Type temp = array[i]; //将要插入的元素值赋给temp 70 while (i > 0) 71 { 72 if (array[p] >= temp) //由于实现的是最大堆,节点比左右字树值都是要大的 73 break; 74 else 75 { 76 array[i] = array[p]; //将父节点的值向下移动,移到当前新插入的元素的位置 77 i = p; //再沿着新插入节点的父节点为基础向上查找 78 p = (i - 1) / 2; //找到索引为i的节点的父节点 79 } 80 } 81 array[i] = temp; //执行完while循环之后找到的i就是我们要把元素插入的地方(索引) 82 } 83 84 template <class Type> 85 int Heap<Type>::remove(Type data) 86 { 87 if (currentsize == 0) 88 return -1; 89 int index = getIndex(data); //获取要删除元素的索引 90 if (index == -1) //如果没有在队列中找到data则getIndex()函数返回-1 91 return -1; 92 array[index] = array[--currentsize]; //将要删除的位置用最后一个元素替换(因为在插入函数里面插入元素后currentsize自加1,所以这里要加1) 93 filterDown(index, currentsize - 1); //将队列中倒数第二个元素的索引传入 94 return 0; 95 } 96 97 template <class Type> 98 void Heap<Type>::filterDown(int start, int end) 99 { 100 int i = start; 101 int leftNode = 2 * i + 1; //索引为i对应的左节点,右节点索引为2*i+2 102 int temp = array[i]; //将最后一个元素(现在索引为要删除元素的索引)赋给一个临时变量 103 while (leftNode <= end) 104 { 105 if (leftNode < end && array[leftNode] < array[leftNode + 1]) //leftNode+1则为右节点了 106 leftNode = leftNode + 1; //如果左节点的值小于右节点的值,则让左节点变成右节点 107 if (temp >= array[leftNode]) //如果最后一个元素(此时索引为要删除的元素的索引)大于左右节点中最大的一个节点,则退出循环 108 break; 109 else 110 { 111 array[i] = array[leftNode]; //将要删除的元素下的左右节点中最大的一个节点替换掉最后一个元素 112 i = leftNode; //再以leftNode为主节点,向下比较 113 leftNode = 2 * leftNode + 1; 114 } 115 } 116 array[i] = temp; //将队列中最后一个值赋给经过第112行变换后、索引为i的地方 117 } 118 119 template <class Type> 120 void Heap<Type>::showHeap() 121 { 122 for (int i = 0; i < currentsize; i++) 123 cout << array[i] << " " << endl; 124 }
1 /*最大堆测试*/ 2 #include "PriorityQueue.h" 3 4 int main() 5 { 6 { 7 int arr[] = { 37,26,14,52,69,78,98,48,69,70 }; 8 int n = sizeof(arr) / sizeof(arr[0]); //获取数组元素个数的新方法 9 Heap<int>* heap = new Heap<int>(20); //新建指向类模板的指针,不新建指针也是可以的如Heap<int> heap(20); 10 for (int i = 0; i < n; i++) 11 { 12 heap->insert(arr[i]); 13 } 14 heap->showHeap(); 15 cout << endl; 16 17 cout << "添加元素100" << endl; 18 heap->insert(100); 19 heap->showHeap(); 20 cout << endl; 21 22 cout << "删除元素78" << endl; 23 heap->remove(78); 24 heap->showHeap(); 25 } 26 27 system("pause"); 28 return 0; 29 }
运行结果:

参考博客:https://blog.csdn.net/qq_37172182/article/details/88978808
5.3 C语言实现最小堆和堆排序
插入优先队列(堆)中的流程图:
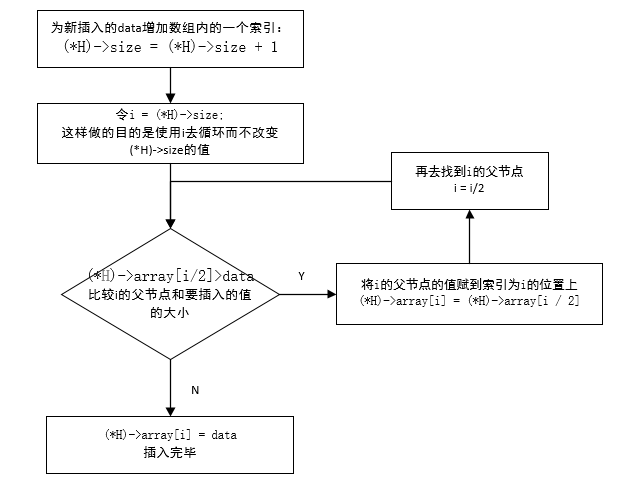
删除写了注释,就没有画流程图。。。脑补原因吧~~哈哈
1 #pragma once 2 /*c语言实现优先队列(堆)*/ 3 #include <iostream> 4 using std::cout; 5 using std::endl; 6 7 typedef int Type; 8 #define Mindata (-32767) 9 10 struct PriorQueue 11 { 12 int size; //堆当前元素数目 13 int capacity; //堆可容纳最大元素数 14 Type* array; 15 }; 16 17 PriorQueue* initQueue(int maxElements); //优先队列(堆)初始化,返回值为一个指向结构的指针 18 bool isFull(PriorQueue* H); 19 bool isEmpty(PriorQueue* H); 20 void insert(PriorQueue** H, Type data); 21 Type deleteMinC(PriorQueue** H); 22 Type findMin(PriorQueue* H); 23 void destroy(PriorQueue** H); 24 void makeEmpty(PriorQueue** H);
1 /*C语言实现最小堆*/ 2 3 #include "PriorityQueueC.h" 4 5 /*C语言实现有限队列初始化*/ 6 PriorQueue* initQueue(int maxElements) 7 { 8 PriorQueue* H = new PriorQueue; //为结构分配空间 9 H->array = new Type[maxElements + 1]; //为结构中的优先队列(实际上是一个数组)分配空间,由于数组索引从0开始,而最开始的索引0是不用的,故要加1才够maxElements数目 10 H->size = 0; 11 H->capacity = maxElements; 12 H->array[0] = Mindata; //初始化优先队列中第一个元素为-32767 13 return H; 14 } 15 16 bool isFull(PriorQueue* H) 17 { 18 if (H->size == H->capacity) 19 return true; 20 else 21 return false; 22 } 23 bool isEmpty(PriorQueue* H) 24 { 25 if (H->size == 0) 26 return true; 27 else 28 return false; 29 } 30 31 /* 32 01)优先队列(堆插入元素) 33 02)要向队列中插入data,要首先将其插入到数组的新开辟的位置上,数组新开辟的位置索引是(H->size)+1 34 03)由于根节点在数组内的索引是1,即第一个元素的索引为1;(索引为0的位置在初始化的时候已被占用) 35 所以索引为i的父节点索引为i/2,左子节点索引为2*i,右子节点索引为2*i+1 36 04)首先为新插入的数分配一个数组索引i,然后比较i的父节点和索引为i的值的大小;若小于父节点则上去,否则不上去 37 */ 38 void insert(PriorQueue** H, Type data) 39 { 40 if (isFull(*H)) 41 { 42 cout << "优先队列(堆)已满!" << endl; 43 return; 44 } 45 (*H)->size = (*H)->size + 1; //为要插入的数字新开辟一个空间(数组内索引加1) (*H)->size就类似于一个int型变量 46 int i; 47 for (i = (*H)->size; (*H)->array[i / 2] > data; i = i / 2) 48 (*H)->array[i] = (*H)->array[i / 2]; //如果父节点的值大于要插入的值,则将父节点的值插入到最后一个节点处(第一次循环) 49 (*H)->array[i] = data; //为data找到一个合适的节点i 50 } 51 52 /* 53 01)删除元素(堆排序) 54 02)不断的去找一个节点i来存放堆内最后一个值,该节点i的特征是:堆内最后一个值比i的左右节点处的值都小; 55 所以要先找出来节点i的左右节点中较小的那一个,然后再和堆内最后一个值比较; 56 03)要判断堆中元素数目为奇数还是偶数,因为如果堆内元素数为偶数,则有一个节点不存在右节点; 57 判断方法为:if (child != (*H)->size && (*H)->array[child] > (*H)->array[child + 1]) 58 (01)如果(*H)->size为奇数,则child != (*H)->size恒成立(因为child=2*i);此时任何一个节点都存在左右节点; 59 (02)如果(*H)->size为偶数,则当child=(*H)->size的时候,不再执行后面的判断,因此不会报错。 60 */ 61 Type deleteMinC(PriorQueue** H) 62 { 63 if (isEmpty(*H)) 64 { 65 cout << "优先队列(堆)已空!" << endl; 66 return (*H)->array[0]; //不能只写一个return,是会报错的;返回默认的元素就好了 67 } 68 int i, child; 69 Type lastData = (*H)->array[(*H)->size]; 70 Type minData = (*H)->array[1]; //先将最小的值保存起来,以免后面被破坏 71 (*H)->size = (*H)->size - 1; //由于是要删除根节点的元素,所以堆内元素数是要减1的 72 for (i = 1; i * 2 <= (*H)->size; i = child) //从根节点开始,比较节点i的左右节点的大小,将较小的放入i的位置处 73 { 74 child = 2 * i; //节点i的左子节点 75 if (child != (*H)->size && (*H)->array[child] > (*H)->array[child + 1]) 76 child++; //如果左子节点的值大于右子节点的值,则让child变成右子节点 77 if ((*H)->array[child] < lastData) 78 (*H)->array[i] = (*H)->array[child]; //如果节点i左右节点中较小的那一个比最后一个还要小,则让节点i处放左右节点中较小的那一个值 79 else 80 break; //否则,结束循环,即找到了存放lastData的节点i 81 } 82 (*H)->array[i] = lastData; 83 return minData; 84 } 85 86 Type findMin(PriorQueue* H) 87 { 88 if (isEmpty(H)) 89 { 90 cout << "优先队列(堆)已空!" << endl; 91 return 0; 92 } 93 else 94 return H->array[1]; 95 } 96 97 void makeEmpty(PriorQueue** H) 98 { 99 (*H)->size = 0; 100 } 101 102 void destroy(PriorQueue** H) 103 { 104 delete[](*H)->array; 105 delete (*H); 106 cout << "释放空间完毕" << endl; 107 }
1 /*C语言实现最小堆测试*/ 2 #include "PriorityQueueC.h" 3 4 int main() 5 { 6 PriorQueue* Queue; 7 Queue = initQueue(10); 8 int ar[] = { 32, 21, 16, 24, 31, 19, 68, 65, 26, 13 }; 9 cout << "输入的元素为:" << endl; 10 for(int i = 0; i < 10; i++) 11 cout << ar[i] << ", "; 12 cout << endl; 13 14 cout << "将数组内元素插入到优先队列(堆)中:" << endl; 15 for (int i = 0; i < 10; i++) 16 insert(&Queue, ar[i]); 17 for(int i=1;i<11;i++) 18 cout << Queue->array[i] << ", "; 19 cout << endl; 20 21 cout << "将优先队列(堆)中的元素进行堆排序:" << endl; 22 for (int i = 0; i < 10; i++) 23 cout << deleteMinC(&Queue) << ", "; 24 cout << endl; 25 26 destroy(&Queue); //释放空间 27 28 system("pause"); 29 return 0; 30 }
运行结果:
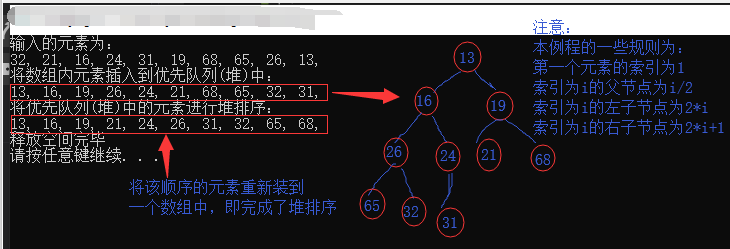
2019.10.04 下午
于 杭电 二教
6、队列
队列也是一种线性表,只不过它是操作受限的线性表,只能在两端操作,先进先出(First In First Out,FIFO)。进的一端称为队尾(rear),出的一端称为队头(front)。队列可以用顺序存储,也可以用链式存储。
(1) 队列结构体定义;

(2) 循环队列出队入队图解
1)开始时为空队,Q.front=Q.rear,如图所示:

2)元素a1进队,放入尾指针Q.rear(整型下标)的位置,Q.rear后移一位,如图所示:
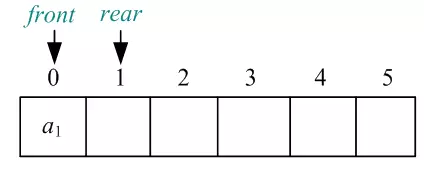
03)元素a2进队,放入尾指针Q.rear(整型下标)的位置,Q.rear后移一位,如图所示:

04)元素a3,a4,a5分别按顺序进队,尾指针Q.rear依次后移,如图所示:
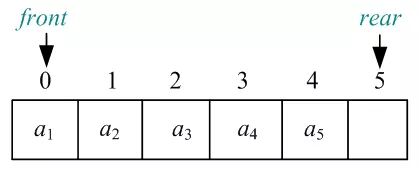
05)元素a1出队,头指针Q.front(整型下标)后移一位,如图所示:
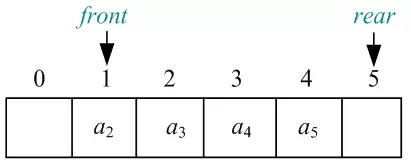
06)元素a2出队,头指针Q.front(整型下标)后移一位,如图所示:
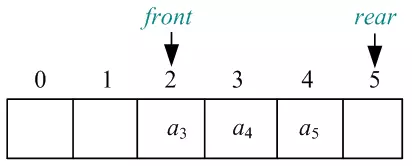
07)元素a6进队,放入尾指针rear(整型下标)的位置,rear后移一位,如图所示:
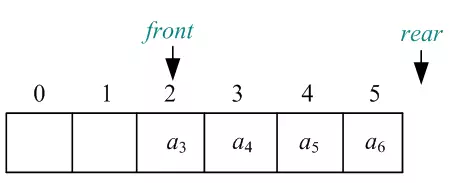
素a6进队之后,尾指针Q.rear要后移一个位置,此时已经超过了数组的下标,即Q.rear+1=Maxsize(最大空间数6),那么如果前面有空闲,Q.rear可以转向前面0的位置,如图所示:

08)元素a7进队,放入尾指针Q.rear(整型下标)的位置,Q.rear后移一位,如图所示:

09)元素a8进队,放入尾指针Q.rear(整型下标)的位置,Q.rear后移一位,如图所示:

10)这时候虽然队列空间存满了,但是出现了一个大问题,队满时Q.front=Q.rear,这和队空的条件一模一样,无法区分队空还是队满,如何解决呢?有两种办法:一是设置一个标志,标记队空和队满;另一种办法是浪费一个空间,当尾指针Q.rear的下一个位置Q.front是时,就认为是队满。如图所示:

此时认为队列已满(浪费了一个空间)
(3) 临界状态下,front和rear的取值方式
循环队列无论入队还是出队,出队或入队之后,队尾、队头加1后都要取模运算,例如入队后队尾后移一位:Q.rear =(Q.rear+1)%Maxsize。
为什么要使用Maxsize对(rear+1)取余呢?
主要是为了处理临界状态,即Q.rear向后移动一个位置Q.rear+1后,很有可能超出了数组的下标,这时它的下一个位置其实是0,如果将一维数组画成环形图,如图所示:
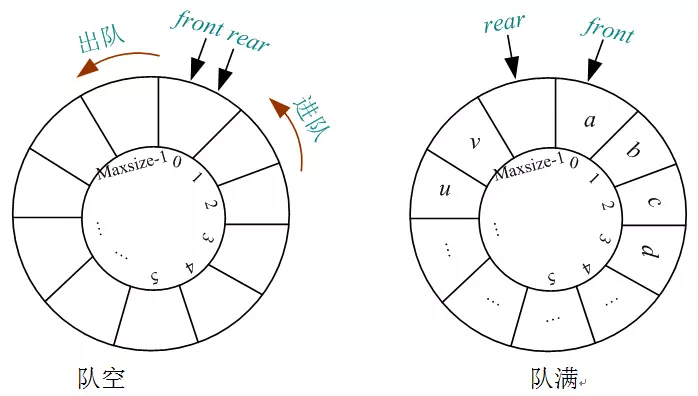
因此无论是front还是rear向后移动一个位置时,都要加1与最大空间Maxsize取模运算,处理临界问题。
(4) 总结
队空:Q.front=Q.rear; // Q.rear和Q.front指向同一个位置
队满: (Q.rear+1) %Maxsize=Q.front; // Q.rear向后移一位正好是Q.front
入队:
Q.base[Q.rear]=x; //将元素放入Q.rear所指空间,
Q.rear =( Q.rear+1) %Maxsize; // Q.rear向后移一位
出队:
e= Q.base[Q.front]; //用变量记录Q.front所指元素,
Q.front=(Q.front+1) %Maxsize // Q. front向后移一位
(5) 循环队列中存储的元素个数计算方式
因为队列是循环的,所以存在两种情况:
1) Q.rear>= Q.front,如下图所示:
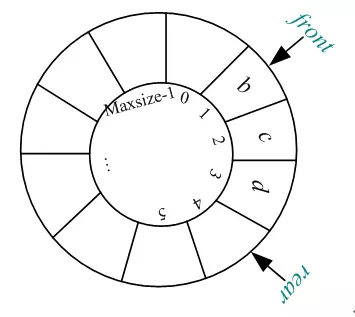
这种情况队列中元素个数为:Q.rear-Q.front=4-1=3。
2) Q.rear< Q.front,如下图所示:
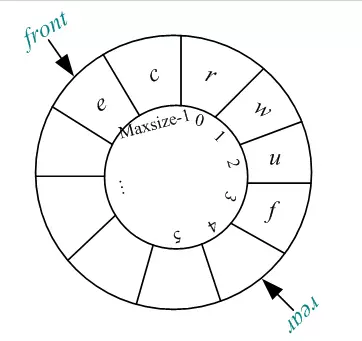
此时,Q.rear=4,Q.front=Maxsize-2,Q.rear-Q.front=6-Maxsize。但是我们可以看到循环队列中的元素实际上为6个,那怎么办呢?当两者之差为负数时,可以将差值+Maxsize计算元素个数,即:Q.rear-Q.front+Maxsize=6-Maxsize+Maxsize =6,元素个数为6。
那么在计算元素个数时,可以分两种情况判断:
Q.rear>= Q.front:元素个数为Q.rear-Q.front;
Q.rear<Q.front:元素个数为Q.rear-Q.front+ Maxsize;
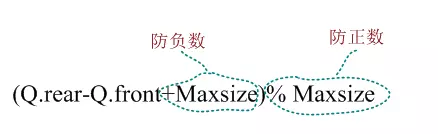
也可以采用取模的方法把两种情况统一为一个语句:
队列中元素个数:(Q.rear-Q.front+Maxsize)% Maxsize
当Q.rear-Q.front为负数时,加上Maxsize再取余正好是元素个数,如(-2+6)%6=4;当Q.rear-Q.front为正数时,加上Maxsize超过了最大空间数,取余后正好是元素个数,如(3+6)%6=3。
(6)、调试
1 #pragma once 2 3 #include <iostream> 4 5 using std::cout; 6 using std::endl; 7 using std::cin; 8 9 template <class Type> 10 class Queue 11 { 12 private: 13 Type* queue; 14 int rear; 15 int front; 16 int size; 17 public: 18 explicit Queue(int totalsize = 30); //队列大小默认为30 19 ~Queue(); 20 bool isEmpty(); 21 bool isFull(); 22 void enqueue(Type data); 23 void dequeue(Type & data); //data对应于主函数中的实参,用于显示出队的元素 24 Type getFront(); //取队首元素 25 int queueLength(); //队列中元素个数 26 /*void show();*/ 27 }; 28 29 /*队列初始化*/ 30 template <class Type> 31 Queue<Type>::Queue(int totalsize) 32 { 33 queue = new Type[totalsize]; 34 size = totalsize; 35 front = 0; 36 rear = 0; 37 } 38 39 /*析构函数*/ 40 template <class Type> 41 Queue<Type>::~Queue() 42 { 43 delete[] queue; 44 size = rear = front = 0; 45 } 46 47 /*判断队列是否为空*/ 48 template <class Type> 49 bool Queue<Type>::isEmpty() 50 { 51 if (front == rear) 52 return true; //如果为空,则返回true 53 else 54 return false; 55 } 56 57 /*判断队列是否已满*/ 58 template <class Type> 59 bool Queue<Type>::isFull() 60 { 61 if (front == (rear+1)%size) 62 return true; //如果已满,则返回true 63 else 64 return false; 65 } 66 67 /*入队*/ 68 template <class Type> 69 void Queue<Type>::enqueue(Type data) 70 { 71 if (isFull()) 72 { 73 cout << "The queue is full!" << endl; 74 return; 75 } 76 queue[rear] = data; //元素入队 77 rear = (rear + 1) % size; //队为加1,为防止溢出.rear加1后对size取余 78 } 79 80 /* 81 01)出队 82 02)有缺陷:队列中最后一个元素不会出队 83 */ 84 template <class Type> 85 void Queue<Type>::dequeue(Type & data) 86 { 87 if (isEmpty()) 88 { 89 cout << "The queue is empty!" << endl; 90 return; 91 } 92 data = queue[front]; //由于形参是引用,所以形参的改变也会影响到实参,这里是要引用的目的是便于显示 93 front = (front + 1) % size; //将front加1,为防止溢出.front加1后对size取余 94 } 95 96 /*取队首元素*/ 97 template <class Type> 98 Type Queue<Type>::getFront() 99 { 100 if (isEmpty()) 101 return 0; 102 else 103 return queue[front]; //返回队首元素 104 } 105 106 /*返回队列中元素个数*/ 107 template <class Type> 108 int Queue<Type>::queueLength() 109 { 110 return (((rear - front) + size) % size); 111 } 112 113 //template <class Type> 114 //void Queue<Type>::show() 115 //{ 116 // int n = queueLength(); 117 // for (int i = 0; i < n; i++) 118 // { 119 // cout << queue[i]; 120 // } 121 //}
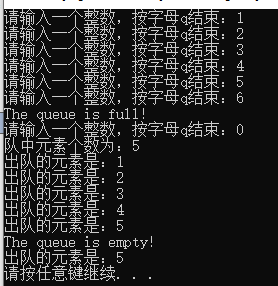
1 #include "queue.h" 2 3 int main() 4 { 5 int x; 6 int temp; 7 int size = 6; 8 Queue<int>* queue = new Queue<int>(size); 9 cout << "请输入一个整数,按字母q结束:"; 10 cin >> x; 11 while (x != 0) 12 { 13 queue->enqueue(x); 14 cout << "请输入一个整数,按字母q结束:"; 15 cin >> x; 16 } 17 cout << "队中元素个数为:" << queue->queueLength() << endl; 18 for (int i = 0; i <= queue->queueLength(); i++) 19 { 20 queue->dequeue(temp); 21 cout << "出队的元素是:" << temp << endl; 22 } 23 24 system("pause"); 25 return 0; 26 }
运行结果:


是for循环出了问题,不能使用函数queue->queueLength()写在for循环里边
1 #include "queue.h" 2 3 int main() 4 { 5 int x; 6 int temp; 7 int size = 6; 8 Queue<int>* queue = new Queue<int>(size); 9 cout << "请输入一个整数,按字母q结束:"; 10 cin >> x; 11 while (x != 0) 12 { 13 queue->enqueue(x); 14 cout << "请输入一个整数,按字母q结束:"; 15 cin >> x; 16 } 17 cout << "队中元素个数为:" << queue->queueLength() << endl; 18 int n = queue->queueLength(); 19 for (int i = 0; i <= n; i++) 20 { 21 queue->dequeue(temp); 22 cout << "出队的元素是:" << temp << endl; 23 } 24 /*queue->dequeue(temp); 25 cout << "出队的元素是:" << temp << endl; 26 queue->dequeue(temp); 27 cout << "出队的元素是:" << temp << endl; 28 queue->dequeue(temp); 29 cout << "出队的元素是:" << temp << endl; 30 queue->dequeue(temp); 31 cout << "出队的元素是:" << temp << endl; 32 queue->dequeue(temp); 33 cout << "出队的元素是:" << temp << endl; 34 queue->dequeue(temp); 35 cout << "出队的元素是:" << temp << endl; 36 37 queue->dequeue(temp); 38 cout << "出队的元素是:" << temp << endl;*/ 39 40 system("pause"); 41 return 0; 42 }
(7)C++中的queue类
用法:
1 queue<int> Q; //定义一个int型队列 2 Q.empty(); //返回队列是否为空 3 Q.size(); //返回当前队列长度 4 Q.front(); //返回当前队列的第一个元素 5 Q.back(); //返回当前队列的最后一个元素 6 Q.push(); //在队列后面插入一个元素, 比如插入数字5: Q.push(5) 7 Q.pop(); //从当前队列里,移出第一个元素
1 #include <iostream> 2 #include <queue> 3 4 using namespace std; 5 int main() 6 { 7 queue<int> Q; 8 cout<<"queue empty? "<<Q.empty()<<endl; 9 10 for(int i=0;i<5;i++) 11 { 12 Q.push(i); //进队列 13 } 14 15 cout<<"queue empty? "<<Q.empty()<<endl; 16 cout<<"queue size: "<<Q.size()<<endl; 17 cout<<endl; 18 19 for(int i=0;i<5;i++) 20 { 21 cout<<"queue front: "<<Q.front()<<endl; 22 Q.pop(); //出队列 23 } 24 25 return 0; 26 }
参考博客:https://www.cnblogs.com/lifexy/p/8884048.html
7、栈
(1)自己的方法实现
栈的最基本操作是后进先出,其实前边已经实现了这种功能,只是函数名字不是push()和pop(),比如链表的初始化和创建

1 #pragma once 2 /*栈的列表实现*/ 3 #include <iostream> 4 5 using std::cout; 6 using std::endl; 7 8 typedef int Type; 9 struct Stack 10 { 11 Type data; 12 Stack* next; 13 }; 14 15 16 void initStack(Stack** head); 17 bool isEmpty(Stack** head); 18 void push(Stack** head, Type data); //该data是传入到栈的数据,不可以省略 19 void pop(Stack** head, Type & data); //该data是传入到主函数用于显示,可以省略 20
1 #include "stack.h" 2 3 void initStack(Stack** head) 4 { 5 if ((*head) == NULL) 6 return; 7 (*head) = new Stack; 8 (*head)->next = NULL; 9 (*head)->data = 0; 10 } 11 12 bool isEmpty(Stack** head) 13 { 14 return (*head)->next == NULL ? true : false; 15 } 16 17 /*利用链表的头插法实现入栈操作*/ 18 void push(Stack** head, Type data) 19 { 20 Stack* node; 21 node = new Stack; 22 node->next = (*head)->next; 23 node->data = data; 24 (*head)->next = node; 25 } 26 27 /*传入的是头结点*/ 28 void pop(Stack** head, Type & data) 29 { 30 Stack* node; 31 if (isEmpty(&(*head))) 32 { 33 cout << "栈已空!" << endl; 34 return; 35 } 36 node = (*head)->next; //node为头结点的下一个节点,即要输出的数据的节点 37 data = node->data; 38 (*head)->next = node->next; 39 delete node; 40 }
1 /*栈测试代码*/ 2 #include "stack.h" 3 4 Type data; 5 6 int main() 7 { 8 Stack* stack; 9 initStack(&stack); 10 cout << "入栈的数据为:" << 1 << endl; 11 push(&stack, 1); 12 cout << "入栈的数据为:" << 2 << endl; 13 push(&stack, 2); 14 cout << "入栈的数据为:" << 3 << endl; 15 push(&stack, 3); 16 17 cout << endl; 18 19 pop(&stack, data); 20 cout << "出栈的数据为:" << data << endl; 21 pop(&stack, data); 22 cout << "出栈的数据为:" << data << endl; 23 pop(&stack, data); 24 cout << "出栈的数据为:" << data << endl; 25 26 pop(&stack, data); 27 28 system("pause"); 29 return 0; 30 }
运行结果:
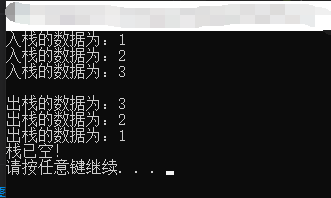
2019.10.02 晚
于杭电二教南336
(2)使用C++库函数stack实现
C++中的stack为程序员实现了堆栈的全部功能,也就是说实现了一个先进后出(FILO)的数据结构。
1 #include <iostream> 2 #include <stack> 3 4 using namespace std; 5 6 int main() 7 { 8 stack<int> s; 9 s.push(1); //入栈 10 s.push(2); 11 s.push(3); 12 s.push(4); 13 s.push(5); 14 15 cout << "栈中元素个数为:" << s.size() << endl; 16 17 while (!s.empty()) //如果栈中元素为空,empty()则返回0 18 { 19 cout << s.top() << " "; //top()返回栈顶元素 20 s.pop(); //将当前栈顶元素出栈 21 } 22 cout << endl; 23 system("pause"); 24 return 0; 25 }
运行结果:

8、快速排序
快速排序算法是一种基于交换的高效的排序算法,它采用了分治法的思想:
1、从数列中取出一个数作为基准数(枢轴,pivot)。
2、将数组进行划分(partition),将比基准数大的元素都移至枢轴右边,将小于等于基准数的元素都移至枢轴左边。
3、再对左右的子区间重复第二步的划分操作,直至每个子区间只有一个元素。
快排最重要的一步就是划分了。划分的过程用通俗的语言讲就是“挖坑”和“填坑”。
算法流程如下所示:
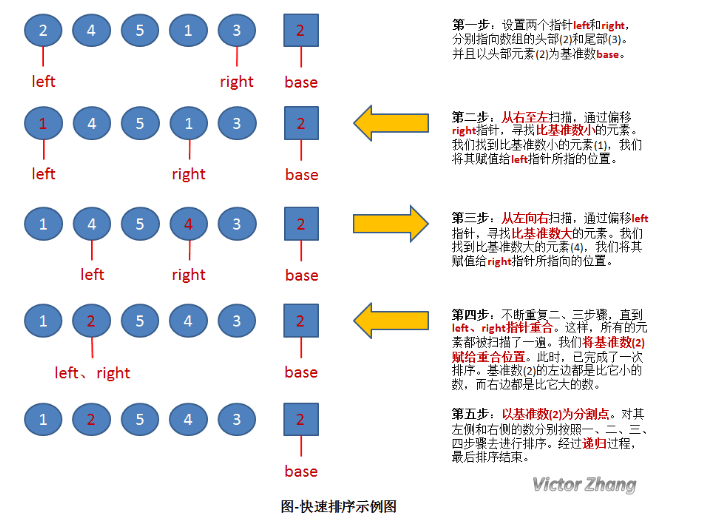
参考博客:https://www.cnblogs.com/miracleswgm/p/9199124.html
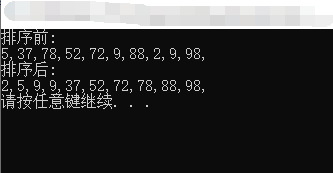
1 /*快速排序*/ 2 #define _CRT_SECURE_NO_WARNINGS 3 #include <iostream> 4 #include <string> 5 #include <vector> 6 #include <algorithm> 7 #include <time.h> 8 9 using namespace std; 10 11 void QuickSort(int array[], int start, int last) 12 { 13 int i = start; 14 int j = last; 15 int temp = array[i]; 16 /*下面的循环直到i=j结束,即找到中心,再以i为中心,分别对左右分别进行快速排序*/ 17 if (i < j) 18 { 19 while (i < j) 20 { 21 // 22 while (i < j && array[j] >= temp) //从右向左扫描,找到比temp小的值,并退出循环 23 j--; //通过自减j,找到第一个比temp小的值的位置j 24 if (i < j) 25 { 26 array[i] = array[j]; //将第一个比temp小的值赋在数组中i的位置上 27 i++; //赋值后将左边指针自加1 28 } 29 30 while (i < j && temp > array[i]) //从左向右扫描,找到比temp大的值,并退出循环 31 i++; //通过自增i,找到第一个比temp大的值的位置i 32 if (i < j) 33 { 34 array[j] = array[i]; //将第一个比temp大的值赋在数组中j的位置 35 j--; //赋值后将右边指针自减1 36 } 37 38 } 39 //把基准数放到中间i位置 40 array[i] = temp; 41 //递归方法,以i为中心,分左右进行快速排序 42 QuickSort(array, start, i - 1); //对从start到i-1的数字进行快速排序 43 QuickSort(array, i + 1, last); //对从i+1到last的数字进行快速排序 44 } 45 } 46 47 void PrintArray(int array[], int len) 48 { 49 for (int i = 0; i < len; i++) 50 { 51 cout << array[i] << " "; 52 } 53 cout << endl; 54 } 55 56 int main(void) 57 { 58 const int NUM = 10; 59 int array[NUM] = { 0 }; 60 srand((unsigned int)time(nullptr)); 61 for (int i = 0; i < NUM; i++) 62 { 63 array[i] = rand() % 100 + 1; 64 } 65 cout << "排序前:" << endl; 66 PrintArray(array, NUM); 67 cout << "排序后:" << endl; 68 QuickSort(array, 0, NUM - 1); 69 PrintArray(array, NUM); 70 71 system("pause"); 72 return 0; 73 } 74 75 /*递归*/ 76 /* 77 void recurs(argumentlist) 78 { 79 statment1; 80 if (test) 81 recurs(arguments); 82 statment2; 83 } 84 01)通常是将递归调用放在if语句中,例如上述递归调用recurs(arguments);放在了if语句中 85 02)当test为true时,每个recurs()都将执行statment1,然后再调用recurs(),而不会执行statment2; 86 03)当test为false时,当前调用执行statment2,程序将控制权返回给调用它的recurs(),而该recurs()将执行它的statment2部分,然后结束 87 并将控制权返回给前一个调用,以此类推; 88 04)因此,如果recurs()执行了5次递归调用,则statment1将按照函数调用顺序执行5次,statment2将按照与函数调用相反的顺序执行5次 89 */
执行结果:
假如要对6 1 2 7 9 3 4 5 10 8 这十个数字进行从小到大排序:
(1)选第一个数字6为基准数,分别从左边探测第一个比6大的数,从右边探测第一个比6小的数,如果找到了,则交换二者,注意如果选左边第一个数作为基准数,则此时要先 从右边开始扫描;若选右边第一个数作为基准数,则先从左边开始扫描;为方便,令i指向第一个位置,j指向最后一个位置,刚开始的时候让i指向序列的最左边(即i=1),指向数字6。让j指向序列的最右边(即j=10),指向数字8;
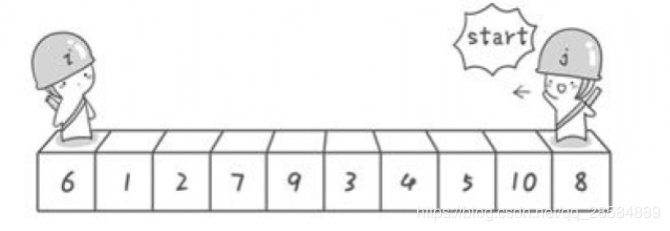
(2)先让j向左移动,即j--,直到找到第一个比6小的位置,即5停下来;然后让i向右移动,即i++,直到找到第一个比6大的位置,即7停下来;交换i和j位置处的值,即交换5和7;

(3)接下来开始j继续向左挪动(再友情提醒,每次必须是哨兵j先出发),直到在4的位置停下来,i也继续向右挪动的,他发现了9(比基准数6要大,满足要求)之后停了下来。交换i和j位置处的值,即交换9和4;
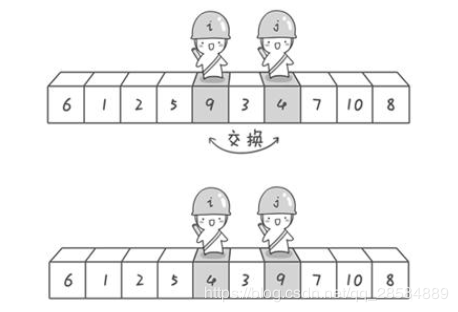
(4)j继续先向右移动(j--),在3的位置停下来,假如i遇到比6大的值,一定是会停下来的,如果没有遇到,则i和j相遇,此时是要交换首位置和此时j所处的位置的值,满足了6的左边全是比6小的值 和 6的右边全是比6大的值的特点;这也许是必须先从右边移动的原因了吧,关键是在于相遇时的值的确定的问题,即假如先从右边开始移动的话,那么相遇处的值一定是会比基准值小的,在相遇时,要交换相遇位置的值和首位值的值,如下所示:
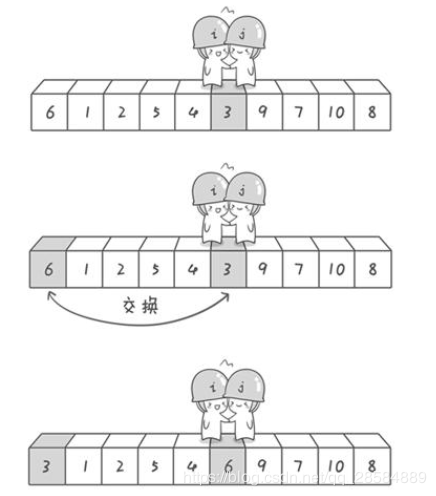
到此第一轮“探测”真正结束。此时以基准数6为分界点,6左边的数都小于等于6,6右边的数都大于等于6。回顾一下刚才的过程,其实哨兵j的使命就是要找小于基准数的数,而哨兵i的使命就是要找大于基准数的数,直到i和j碰头为止。
此时我们已经将原来的序列,以6为分界点拆分成了两个序列,左边的序列是“3 1 2 5 4”,右边的序列是“9 7 10 8”。接下来还需要分别处理这两个序列,使用递归即可。
霸气的图描述算法全过程:

参考博客:https://blog.csdn.net/qq_28584889/article/details/88136498
实现代码:
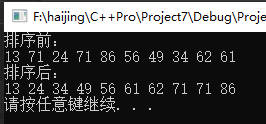
1 /*方法二实现快速排序*/ 2 void QuickSort(int arr[], int left, int right) 3 { 4 int i = left; 5 int j = right; 6 int base = arr[i]; //以最左边的值为基准值 7 if (i > j) 8 return; 9 while (i < j) 10 { 11 while (base <= arr[j] && i<j) //找到比temp小的值(此时为从小到大排序,如果是要从大到小排序,则此处找比temp大的值) 12 j--; 13 while (base >= arr[i] && i<j) //找到比temp大的值(此时为从小到大排序,如果是要从大到小排序,则此处找比temp小的值) 14 i++; 15 if (i < j) 16 { 17 int temp = arr[i]; //交换位置i个位置j处的值 18 arr[i] = arr[j]; 19 arr[j] = temp; 20 } 21 } 22 arr[left] = arr[i]; //将i和j相遇处的值放在首位置,因为是从右边开始探索比基准值小的值,所以i和j相遇处的值一定比6小 23 arr[i] = base; //将基准值放在"中间位置",该"中间位置"的左边全是比base小的值,右边全是比base大的值 24 QuickSort(arr, left, i - 1); 25 QuickSort(arr, i + 1, right); 26 } 27 28 void PrintArray(int array[], int len) 29 { 30 for (int i = 0; i < len; i++) 31 { 32 cout << array[i] << " "; 33 } 34 cout << endl; 35 } 36 37 int main(void) 38 { 39 const int NUM = 10; 40 int array[NUM] = { 0 }; 41 srand((unsigned int)time(nullptr)); 42 for (int i = 0; i < NUM; i++) 43 { 44 array[i] = rand() % 100 + 1; 45 } 46 cout << "排序前:" << endl; 47 PrintArray(array, NUM); 48 cout << "排序后:" << endl; 49 QuickSort(array, 0, NUM - 1); 50 PrintArray(array, NUM); 51 52 system("pause"); 53 return 0; 54 } 55 56 /*递归*/ 57 /* 58 void recurs(argumentlist) 59 { 60 statment1; 61 if (test) 62 recurs(arguments); 63 statment2; 64 } 65 01)通常是将递归调用放在if语句中,例如上述递归调用recurs(arguments);放在了if语句中 66 02)当test为true时,每个recurs()都将执行statment1,然后再调用recurs(),而不会执行statment2; 67 03)当test为false时,当前调用执行statment2,程序将控制权返回给调用它的recurs(),而该recurs()将执行它的statment2部分,然后结束 68 并将控制权返回给前一个调用,以此类推; 69 04)因此,如果recurs()执行了5次递归调用,则statment1将按照函数调用顺序执行5次,statment2将按照与函数调用相反的顺序执行5次 70 */
运行结果:
(3)使用快速排序算法找到数组中第k大的值(笔试题)
1 int QuickSort(vector<int> arr,int left,int right,int k) 2 { 3 int i=left; 4 int j=right; 5 int base=arr[i]; 6 while(i<j) 7 { 8 while(base>=arr[j] && i<j) 9 j--; 10 while(base<=arr[i] && i<j) 11 i++; 12 if(i<j) 13 { 14 int temp=arr[i]; 15 arr[i]=arr[j]; 16 arr[j]=temp; 17 } 18 } 19 arr[left]=arr[i]; 20 arr[i]=base; 21 if(k == i+1) //数组元素从0开始 22 return arr[i]; 23 else if(k<i+1) //说明第k大的元素在数组前半段 24 return QuickSort(arr,left,i-1,k); 25 else //说明第k大元素在数组后半段 26 return QuickSort(arr,i+1,right,k); 27 }
牛客网原题位置:https://www.nowcoder.com/practice/e016ad9b7f0b45048c58a9f27ba618bf
(4)快速排序是一种不稳定的排序方法的原因

9、冒泡排序
原理:
(1)两两比较相邻元素A(I)和A(I+1)(I=1,2,…N-1),如果A(I)>A(I+1),则交换A(I)和A(I+1)的位置;
(2)对剩下的N-1个元素,再两两进行比较,按同样规则交换它们的位置,经过N-2次比较,将次最大值交换到A(N-1)的位置;
(3)如法炮制,经过N-1趟的“冒泡处理”,每趟进行N-i次的比较,全部数列有序。
该图片地址:https://img-blog.csdnimg.cn/20190326182928474.gif (注:有的浏览器可能播放不了该图片中的动画)
代码(使用srand()和rand()自动生成数组):
1 #include <iostream> 2 #include <time.h> //for time() 3 4 using namespace std; 5 6 7 /*冒泡排序*/ 8 void BubbleSort(int arr[], int n) 9 { 10 for (int i = 0; i < n - 1; i++) 11 { 12 for (int j = 0; j < n - i - 1; j++) 13 { 14 if (arr[j] > arr[j + 1]) //如果前一个数比后一个数大,则交换二者的顺序;总的来说就是将大的数字后移 15 { 16 int temp = arr[j]; 17 arr[j] = arr[j + 1]; 18 arr[j + 1] = temp; 19 } 20 } 21 } 22 } 23 24 /*打印数组*/ 25 void PrintArray(int arr[], int n) 26 { 27 for (int i = 0; i < n; i++) 28 cout << arr[i] << ","; 29 cout << endl; 30 } 31 32 int main() 33 { 34 const int NUM = 10; //NUM如果作为数组大小,必须为常量 35 int array[NUM]; 36 srand((unsigned int)time(nullptr)); //初始化随机生成函数 37 for (int i = 0; i < NUM; i++) 38 { 39 array[i] = rand() % 100 + 1; //随机生成1-100以内的数字 40 } 41 cout << "排序前: " << endl; 42 PrintArray(array, NUM); 43 cout << "排序后: " << endl; 44 BubbleSort(array, NUM); 45 PrintArray(array, NUM); 46 47 system("pause"); 48 return 0; 49 }
(1)i=0即可完成将数组中最大值放到数组最后的位置,第一次循环n-1-0次
(2)i=1即可完成将数组中第二大值放到数组倒数第二的位置 ,第二次循环n-1-1次,由于在数组中n-2到n-1位置已经排序完成,故下一次循环n-1-2次即可
(3)i=1即可完成将数组中第三大值放到数组倒数第三的位置 ,第三次循环n-1-2次,由于在数组中n-3到n-1位置已经排序完成,故下一次循环n-1-3次即可
即第二次层循环中j结束条件为j< n - i -1
运行结果:
10、生成n位格雷码
在一组数的编码中,若任意两个相邻的代码只有一位二进制数不同, 则称这种编码为格雷码(Gray Code)
例如:
1 1位格雷码为:0 1 2 2位格雷码为:00 01 11 10 3 3位格雷码为:000 001 011 010 110 111 101 100
格雷码有如下规律:
- 除了1之外,其他所有位数的格雷码的个数都是2的n次方
n=3的gray码其实就是对n=2的gray码首位添加0或1生成的,添加0后变成(000,001,011,010),添加1后需要顺序反向就变成(110,111,101,100),组合在一起就是(000,001,011,010,110,111,101,100)
1 #include <iostream> 2 #include <vector> 3 #include <string> 4 5 using std::endl; 6 using std::cout; 7 using std::cin; 8 using std::string; 9 using std::vector; 10 11 vector<string> getGray(int n) 12 { 13 vector<string> gray; 14 vector<string> lastGray; 15 if (n == 1) 16 { 17 gray.push_back("0"); 18 gray.push_back("1"); 19 return gray; 20 } 21 lastGray = getGray(n - 1); 22 /*在n-1位格雷码的前面加(顺序)0*/ 23 for (int i = 0; i < lastGray.size(); i++) 24 gray.push_back("0" + lastGray[i]); 25 /*在n-1为格雷码的前面(反序)加1*/ 26 for (int i = lastGray.size() - 1; i >= 0; i--) 27 gray.push_back("1" + lastGray[i]); 28 return gray; 29 } 30 31 int main() 32 { 33 vector<string> gray; 34 int n = 3; 35 gray = getGray(n); 36 cout << n << "位格雷码为:" << endl; 37 for (int i = 0; i < gray.size(); i++) 38 cout << gray[i] << " "; 39 cout << endl; 40 41 system("pause"); 42 return 0; 43 }
运行结果:

11、二叉树
1、基本概念以及初级实现和遍历方法
对于二叉树,有深度遍历和广度遍历,深度遍历有前序、中序以及后序三种遍历方法;广度遍历即我们寻常所说的层次遍历。
以图片的方式呈现吧

1 #include <iostream> 2 3 using namespace std; 4 5 struct treeNode 6 { 7 char data; 8 treeNode* LChild; 9 treeNode* RChild; 10 }; 11 12 //typedef struct treeNode* LPTREE; 13 #define LPTREE treeNode* 14 15 //指针一般用LP开头 16 LPTREE createNode(const char data) //此处的LPTREE就是一个指针,如果传入的数据为'A',那么'A'就是const类型的,data如果不是const就会报错 17 { 18 LPTREE newNode = (LPTREE)malloc(sizeof(treeNode)); 19 //LPTREE newNode = new treeNode; 20 newNode->data = data; 21 newNode->LChild = NULL; 22 newNode->RChild = NULL; 23 return newNode; 24 } 25 26 //插入数据 27 void insertNode(LPTREE parentNode, LPTREE LChild, LPTREE RChild) 28 { 29 parentNode->LChild = LChild; 30 parentNode->RChild = RChild; 31 } 32 33 //打印当前结点数据 34 void printCurNodeData(LPTREE curData) 35 { 36 cout << curData->data << "\t"; 37 } 38 39 //递归法遍历 40 //先序遍历:根左右 41 void preOrder(treeNode* root) //传入要打印的树的根节点 42 { 43 if (root != NULL) 44 { 45 printCurNodeData(root); //前序遍历先打印根节点 根 46 preOrder(root->LChild); //再打印根节点的左节点 左 47 preOrder(root->RChild); //再打印根节点的右节点 右 48 } 49 } 50 51 //中序遍历:左根右 52 void midOrder(LPTREE root) //传入要打印的树的根节点 53 { 54 if (root != NULL) 55 { 56 midOrder(root->LChild); //左 57 printCurNodeData(root); //根 58 midOrder(root->RChild); //右 59 } 60 } 61 62 //后序遍历:左右根 63 void lastOrder(LPTREE root) //传入要打印的树的根节点 64 { 65 if (root != NULL) 66 { 67 lastOrder(root->LChild); //左 68 lastOrder(root->RChild); //右 69 printCurNodeData(root); //根 70 } 71 } 72 73 int main() 74 { 75 LPTREE A = createNode('A'); 76 LPTREE B = createNode('B'); 77 LPTREE C = createNode('C'); 78 LPTREE D = createNode('D'); 79 LPTREE E = createNode('E'); 80 LPTREE F = createNode('F'); 81 LPTREE G = createNode('G'); 82 83 //很死板的创建二叉树方法 84 insertNode(A, B, C); 85 insertNode(B, D, NULL); 86 insertNode(D, NULL, G); 87 insertNode(C, E, F); 88 89 cout << "先序遍历" << endl; 90 preOrder(A); 91 92 cout << "\n\n中序遍历\n"; 93 midOrder(A); 94 95 cout << "\n\n后序遍历\n"; 96 lastOrder(A); 97 98 system("pause"); 99 return 0; 100 }
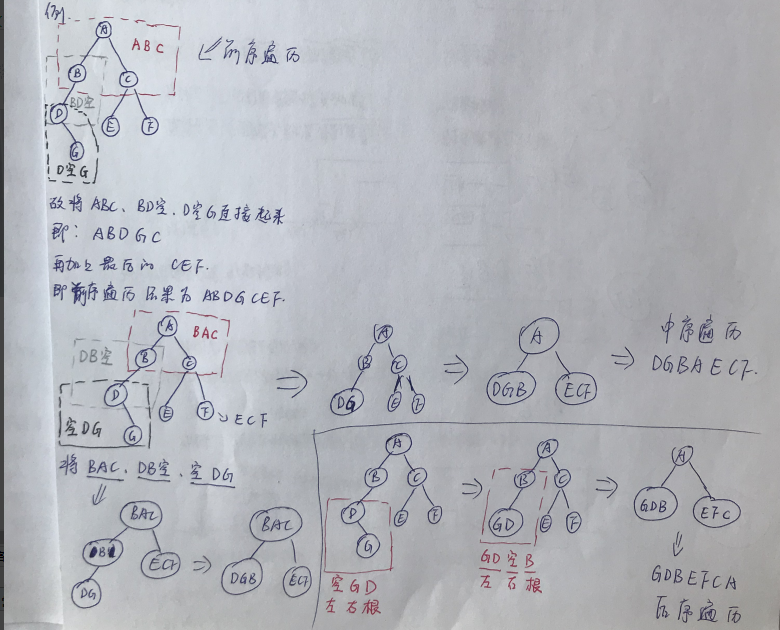
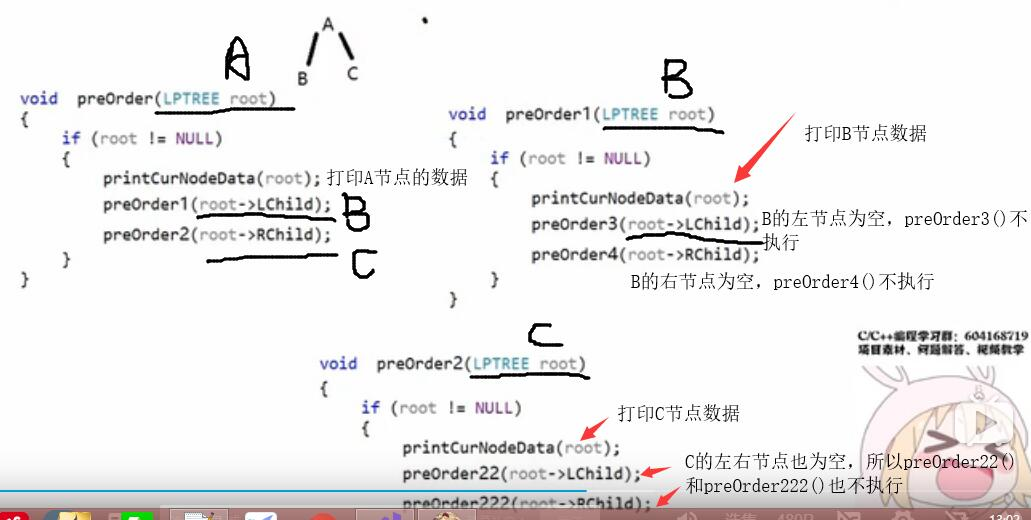
原理:以三个结点为例
执行结果:

2、非递归方法实现三种遍历


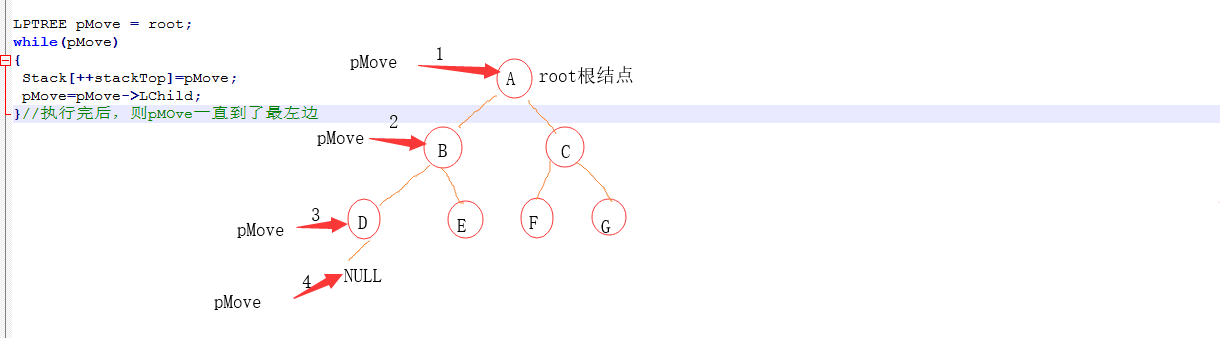
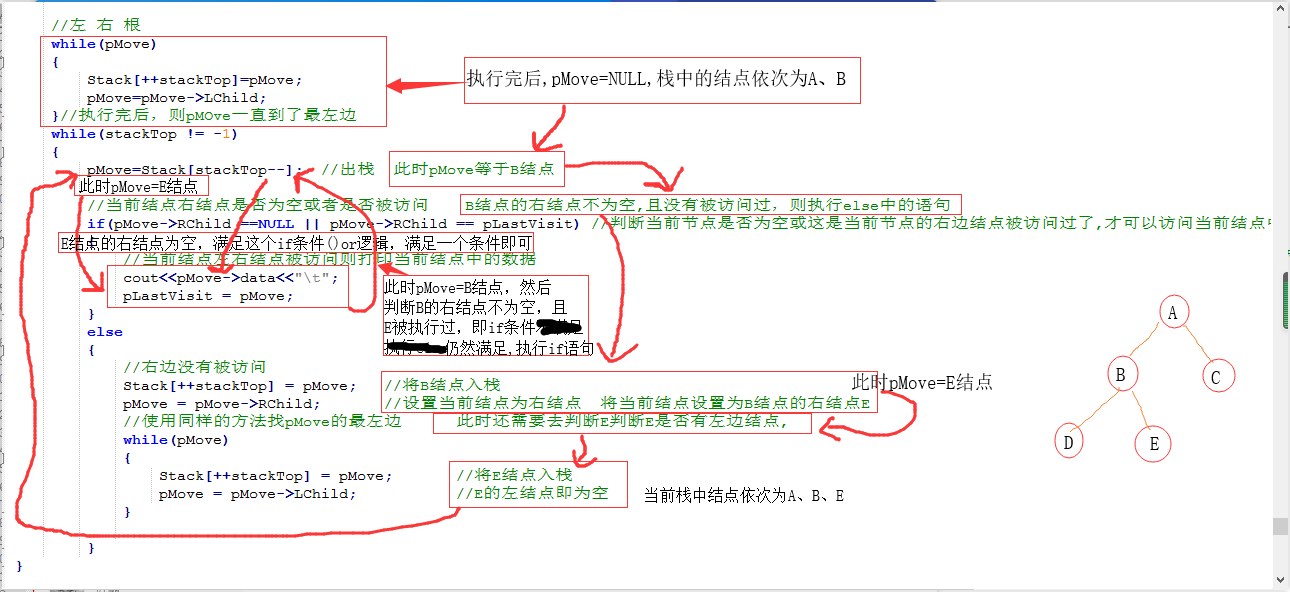
非递归遍历代码实现:
1 #include <iostream> 2 3 using namespace std; 4 5 struct treeNode 6 { 7 char data; 8 treeNode* LChild; 9 treeNode* RChild; 10 }; 11 12 //typedef struct treeNode* LPTREE; 13 #define LPTREE treeNode* 14 15 //指针一般用LP开头 16 LPTREE createNode(const char data) //此处的LPTREE就是一个指针,如果传入的数据为'A',那么'A'就是const类型的,data如果不是const就会报错 17 { 18 LPTREE newNode = (LPTREE)malloc(sizeof(treeNode)); 19 //LPTREE newNode = new treeNode; 20 newNode->data = data; 21 newNode->LChild = NULL; 22 newNode->RChild = NULL; 23 return newNode; 24 } 25 26 //插入数据 27 void insertNode(LPTREE parentNode, LPTREE LChild, LPTREE RChild) 28 { 29 parentNode->LChild = LChild; 30 parentNode->RChild = RChild; 31 } 32 33 //打印当前结点数据 34 void printCurNodeData(LPTREE curData) 35 { 36 cout << curData->data << "\t"; 37 } 38 39 //递归法遍历 40 //先序遍历:根左右 41 void preOrder(treeNode* root) //传入要打印的树的根节点 42 { 43 if (root != NULL) 44 { 45 printCurNodeData(root); //前序遍历先打印根节点 根 46 preOrder(root->LChild); //再打印根节点的左节点 左 47 preOrder(root->RChild); //再打印根节点的右节点 右 48 } 49 } 50 51 //中序遍历:左根右 52 void midOrder(LPTREE root) //传入要打印的树的根节点 53 { 54 if (root != NULL) 55 { 56 midOrder(root->LChild); //左 57 printCurNodeData(root); //根 58 midOrder(root->RChild); //右 59 } 60 } 61 62 //后序遍历:左右根 63 void lastOrder(LPTREE root) //传入要打印的树的根节点 64 { 65 if (root != NULL) 66 { 67 lastOrder(root->LChild); //左 68 lastOrder(root->RChild); //右 69 printCurNodeData(root); //根 70 } 71 } 72 73 //非递归方式前序遍历---使用栈数组 74 void preOderByStack(LPTREE root) 75 { 76 if (root == NULL) 77 return; 78 //住准备栈 79 LPTREE Stack[10]; //一般使用数组栈,很少再写一个栈实现 80 int stackTop = -1; //栈顶标记 81 LPTREE pMove = root; //从根节点开始打印 82 83 //当栈里面还有路径可以退或者是当前结点pMOve不为空 84 while (stackTop != -1 || pMove) 85 { 86 //根左右 87 //下面的这个循环即可找到最左边的节点 88 while (pMove) 89 { 90 //把走过的路径入栈+打印走过的结点 91 cout << pMove->data << "\t"; //打印 92 Stack[++stackTop] = pMove; //入栈,一定是++stackTop,因为stackTop初始化为-1 93 /* 94 如果stackTop初始化为50,则入栈的时候写成stack[++stackTop-50] = pMove;即可 95 */ 96 pMove = pMove->LChild; //将当前pMove的左节点赋给pMove 97 } 98 //找到最左边的节点后便无路可走,那么此时出栈 99 if (stackTop != -1) 100 { 101 pMove = Stack[stackTop]; //获取栈顶元素 102 stackTop--; //伪出栈 103 pMove = pMove->RChild; //将当前结点的右结点赋给pMove 104 } 105 } 106 } 107 108 //非递归方式中序遍历---使用栈数组 109 /* 110 01)定义一个指针移动到最左边,把走过的地方入栈 111 02)无路的时候,出栈,打印当前结点中的元素 112 03)出栈后,打印当前结点元素,判断当前结点是否存z右边结点,如果存在就去右边 113 */ 114 void midOrderByStack(LPTREE root) 115 { 116 if (root == NULL) 117 return; 118 LPTREE Stack[10]; 119 int stackTop = -1; 120 121 //定义移动指针,初始化指向根结点root 122 LPTREE pMove = root; 123 //当栈里面还有路径可以退或者是当前结点pMOve不为空 124 while (stackTop != -1 || pMove) 125 { 126 //走到最左边,把走做的路径入栈 127 while (pMove) 128 { 129 Stack[++stackTop] = pMove; //将当前结点入栈(走过的结点入栈) 130 pMove = pMove->LChild; //将当前结点的右结点赋给当前结点 131 } 132 //当当前节点的左结点为空,即无路可走时执行下面代码 133 if (stackTop != -1) 134 { 135 pMove = Stack[stackTop--]; //先将栈中最上面元素赋给pMove:pMove = Stack[stackTop];然后stackTop-- 136 cout << pMove->data << "\t"; //打印当前结点根结点中的元素 137 pMove = pMove->RChild; 138 } 139 } 140 } 141 142 //非递归方式后序遍历---使用栈数组 143 void lastOrderByStack(LPTREE root) 144 { 145 if (root == NULL) 146 return; 147 LPTREE Stack[10]; 148 int stackTop = -1; 149 150 //定义移动指针,初始化指向根结点root 151 LPTREE pMove = root; 152 153 LPTREE pLastVisit = NULL; //最后一次访问的标记 154 155 //左 右 根 156 while (pMove) 157 { 158 Stack[++stackTop] = pMove; 159 pMove = pMove->LChild; 160 }//执行完后,则pMOve一直到了最左边 161 while (stackTop != -1) 162 { 163 pMove = Stack[stackTop--]; //出栈 此时pMove等于B结点 164 165 //当前结点右结点是否为空或者是否被访问 B结点的右结点不为空,且没有被访问过,则执行else中的语句 166 if (pMove->RChild == NULL || pMove->RChild == pLastVisit) //判断当前节点是否为空或这是当前节点的右边结点被访问过了,才可以访问当前结点中的数据 167 { 168 //当前结点左右结点被访问则打印当前结点中的数据 169 cout << pMove->data << "\t"; 170 pLastVisit = pMove; 171 } 172 else 173 { 174 //右边没有被访问 175 Stack[++stackTop] = pMove; //将B结点入栈 176 pMove = pMove->RChild; //设置当前结点为右结点 将当前结点设置为B结点的右结点E 177 //使用同样的方法找pMove的最左边 此时还需要去判断E判断E是否有左边结点, 178 while (pMove) 179 { 180 Stack[++stackTop] = pMove; //将E结点入栈 181 pMove = pMove->LChild; //E的左结点即为空 182 } 183 184 } 185 } 186 } 187 188 189 int main() 190 { 191 LPTREE A = createNode('A'); 192 LPTREE B = createNode('B'); 193 LPTREE C = createNode('C'); 194 LPTREE D = createNode('D'); 195 LPTREE E = createNode('E'); 196 LPTREE F = createNode('F'); 197 LPTREE G = createNode('G'); 198 199 //很死板的创建二叉树方法 200 insertNode(A, B, C); 201 insertNode(B, D, NULL); 202 insertNode(D, NULL, G); 203 insertNode(C, E, F); 204 205 cout << "先序遍历" << endl; 206 preOrder(A); 207 208 cout << "\n\n非递归方式先序遍历\n" << endl; 209 preOderByStack(A); 210 211 cout << "\n\n中序遍历\n"; 212 midOrder(A); 213 214 cout << "\n\n非递归方式中序遍历\n"; 215 midOrderByStack(A); 216 217 cout << "\n\n后序遍历\n"; 218 lastOrder(A); 219 220 cout << "\n\n非递归后序遍历\n"; 221 lastOrderByStack(A); 222 223 system("pause"); 224 return 0; 225 }
执行结果:

(4)层序遍历---使用队列
原理:
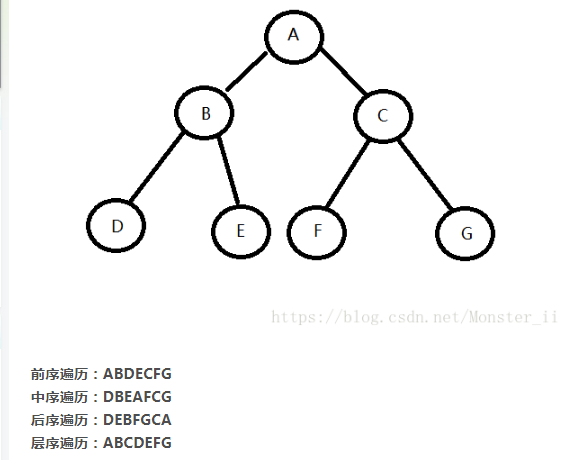
代码实现:
1 #include <iostream> 2 #include <queue> 3 4 using namespace std; 5 6 struct treeNode 7 { 8 char data; 9 treeNode* LChild; 10 treeNode* RChild; 11 }; 12 13 //typedef struct treeNode* LPTREE; 14 #define LPTREE treeNode* 15 16 //指针一般用LP开头 17 LPTREE createNode(const char data) //此处的LPTREE就是一个指针,如果传入的数据为'A',那么'A'就是const类型的,data如果不是const就会报错 18 { 19 LPTREE newNode = (LPTREE)malloc(sizeof(treeNode)); 20 //LPTREE newNode = new treeNode; 21 newNode->data = data; 22 newNode->LChild = NULL; 23 newNode->RChild = NULL; 24 return newNode; 25 } 26 27 //插入数据 28 void insertNode(LPTREE parentNode, LPTREE LChild, LPTREE RChild) 29 { 30 parentNode->LChild = LChild; 31 parentNode->RChild = RChild; 32 } 33 34 //打印当前结点数据 35 void printCurNodeData(LPTREE curData) 36 { 37 cout << curData->data << "\t"; 38 } 39 40 //递归法遍历 41 //先序遍历:根左右 42 void preOrder(treeNode* root) //传入要打印的树的根节点 43 { 44 if (root != NULL) 45 { 46 printCurNodeData(root); //前序遍历先打印根节点 根 47 preOrder(root->LChild); //再打印根节点的左节点 左 48 preOrder(root->RChild); //再打印根节点的右节点 右 49 } 50 } 51 52 //中序遍历:左根右 53 void midOrder(LPTREE root) //传入要打印的树的根节点 54 { 55 if (root != NULL) 56 { 57 midOrder(root->LChild); //左 58 printCurNodeData(root); //根 59 midOrder(root->RChild); //右 60 } 61 } 62 63 //后序遍历:左右根 64 void lastOrder(LPTREE root) //传入要打印的树的根节点 65 { 66 if (root != NULL) 67 { 68 lastOrder(root->LChild); //左 69 lastOrder(root->RChild); //右 70 printCurNodeData(root); //根 71 } 72 } 73 74 //非递归方式前序遍历---使用栈数组 75 void preOderByStack(LPTREE root) 76 { 77 if (root == NULL) 78 return; 79 //住准备栈 80 LPTREE Stack[10]; //一般使用数组栈,很少再写一个栈实现 81 int stackTop = -1; //栈顶标记 82 LPTREE pMove = root; //从根节点开始打印 83 84 //当栈里面还有路径可以退或者是当前结点pMOve不为空 85 while (stackTop != -1 || pMove) 86 { 87 //根左右 88 //下面的这个循环即可找到最左边的节点 89 while (pMove) 90 { 91 //把走过的路径入栈+打印走过的结点 92 cout << pMove->data << "\t"; //打印 93 Stack[++stackTop] = pMove; //入栈,一定是++stackTop,因为stackTop初始化为-1 94 /* 95 如果stackTop初始化为50,则入栈的时候写成stack[++stackTop-50] = pMove;即可 96 */ 97 pMove = pMove->LChild; //将当前pMove的左节点赋给pMove 98 } 99 //找到最左边的节点后便无路可走,那么此时出栈 100 if (stackTop != -1) 101 { 102 pMove = Stack[stackTop]; //获取栈顶元素 103 stackTop--; //伪出栈 104 pMove = pMove->RChild; //将当前结点的右结点赋给pMove 105 } 106 } 107 } 108 109 //非递归方式中序遍历---使用栈数组 110 /* 111 01)定义一个指针移动到最左边,把走过的地方入栈 112 02)无路的时候,出栈,打印当前结点中的元素 113 03)出栈后,打印当前结点元素,判断当前结点是否存z右边结点,如果存在就去右边 114 */ 115 void midOrderByStack(LPTREE root) 116 { 117 if (root == NULL) 118 return; 119 LPTREE Stack[10]; 120 int stackTop = -1; 121 122 //定义移动指针,初始化指向根结点root 123 LPTREE pMove = root; 124 //当栈里面还有路径可以退或者是当前结点pMOve不为空 125 while (stackTop != -1 || pMove) 126 { 127 //走到最左边,把走做的路径入栈 128 while (pMove) 129 { 130 Stack[++stackTop] = pMove; //将当前结点入栈(走过的结点入栈) 131 pMove = pMove->LChild; //将当前结点的右结点赋给当前结点 132 } 133 //当当前节点的左结点为空,即无路可走时执行下面代码 134 if (stackTop != -1) 135 { 136 pMove = Stack[stackTop--]; //先将栈中最上面元素赋给pMove:pMove = Stack[stackTop];然后stackTop-- 137 cout << pMove->data << "\t"; //打印当前结点根结点中的元素 138 pMove = pMove->RChild; 139 } 140 } 141 } 142 143 //非递归方式后序遍历---使用栈数组 144 void lastOrderByStack(LPTREE root) 145 { 146 if (root == NULL) 147 return; 148 LPTREE Stack[10]; 149 int stackTop = -1; 150 151 //定义移动指针,初始化指向根结点root 152 LPTREE pMove = root; 153 154 LPTREE pLastVisit = NULL; //最后一次访问的标记 155 156 //左 右 根 157 while (pMove) 158 { 159 Stack[++stackTop] = pMove; 160 pMove = pMove->LChild; 161 }//执行完后,则pMOve一直到了最左边 162 while (stackTop != -1) 163 { 164 pMove = Stack[stackTop--]; //出栈 此时pMove等于B结点 165 166 //当前结点右结点是否为空或者是否被访问 B结点的右结点不为空,且没有被访问过,则执行else中的语句 167 if (pMove->RChild == NULL || pMove->RChild == pLastVisit) //判断当前节点是否为空或这是当前节点的右边结点被访问过了,才可以访问当前结点中的数据 168 { 169 //当前结点左右结点被访问则打印当前结点中的数据 170 cout << pMove->data << "\t"; 171 pLastVisit = pMove; 172 } 173 else 174 { 175 //右边没有被访问 176 Stack[++stackTop] = pMove; //将B结点入栈 177 pMove = pMove->RChild; //设置当前结点为右结点 将当前结点设置为B结点的右结点E 178 //使用同样的方法找pMove的最左边 此时还需要去判断E判断E是否有左边结点, 179 while (pMove) 180 { 181 Stack[++stackTop] = pMove; //将E结点入栈 182 pMove = pMove->LChild; //E的左结点即为空 183 } 184 185 } 186 } 187 } 188 189 //层序遍历---使用队列 190 void levelOrderByQueue(LPTREE root) 191 { 192 if (root == NULL) 193 return; 194 queue<LPTREE> qu; //创建队列 195 qu.push(root); //先将根结点入队 196 LPTREE pMove; 197 while (qu.size() != 0) 198 { 199 pMove = qu.front(); //取出队首元素,此时pMove=root 200 qu.pop(); //将队首元素丢弃 201 cout << pMove->data << "\t"; 202 if (pMove->LChild) //如果pMove的左结点不为空,则将pMOve的左结点先入队,注必须是左结点先入队 203 qu.push(pMove->LChild); 204 if (pMove->RChild) //如果pMove的左结点不为空,则将pMOve的左结点先入队 205 qu.push(pMove->RChild); 206 } 207 } 208 209 210 211 int main() 212 { 213 LPTREE A = createNode('A'); 214 LPTREE B = createNode('B'); 215 LPTREE C = createNode('C'); 216 LPTREE D = createNode('D'); 217 LPTREE E = createNode('E'); 218 LPTREE F = createNode('F'); 219 LPTREE G = createNode('G'); 220 221 //很死板的创建二叉树方法 222 insertNode(A, B, C); 223 insertNode(B, D, NULL); 224 insertNode(D, NULL, G); 225 insertNode(C, E, F); 226 227 cout << "先序遍历" << endl; 228 preOrder(A); 229 230 cout << "\n\n非递归方式先序遍历\n" << endl; 231 preOderByStack(A); 232 233 cout << "\n\n中序遍历\n"; 234 midOrder(A); 235 236 cout << "\n\n非递归方式中序遍历\n"; 237 midOrderByStack(A); 238 239 cout << "\n\n后序遍历\n"; 240 lastOrder(A); 241 242 cout << "\n\n非递归后序遍历\n"; 243 lastOrderByStack(A); 244 245 cout << "\n\n层序遍历\n"; 246 levelOrderByQueue(A); 247 248 system("pause"); 249 return 0; 250 }
测试结果:

3、二叉树中的平衡的概念(顺便引出平衡二叉树的概念)
平衡:当结点固定时,左右子树的高度越接近,这棵二叉树就越平衡
平衡二叉树:根结点的左右子高度差为1
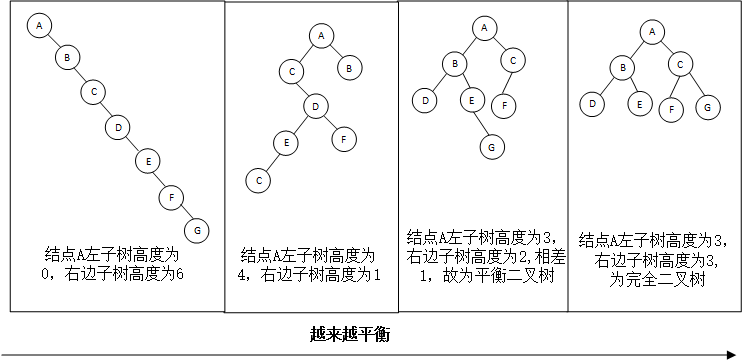
12、C++中的四个智能指针:auto_ptr,shared_ptr,weak_ptr,unique_ptr,其中auto_ptr已经被C++11抛弃
1、auto_ptr(C++98中的放案,C++11已经抛弃)
1 //auto_ptr 2 #include <iostream> 3 #include <memory> //for auto_ptr、shared_ptr... 4 #include <string> 5 6 using namespace std; 7 8 class Test 9 { 10 private: 11 string str; 12 public: 13 Test(string s):str(s) //使用成员初始化列表为类私有数据赋值 14 { 15 cout << "Tets类对象已创建: " << str << "\n"; 16 } 17 ~Test() 18 { 19 cout << "Test类对象已删除:" << str << endl; 20 } 21 string & getStr() 22 { 23 return str; //返回私有数据 24 } 25 void setStr(string s) 26 { 27 str = s; 28 } 29 void print() 30 { 31 cout << str << endl; //访问Test类对象指针p的数据 32 } 33 }; 34 35 int main() 36 { 37 //为了更好的观察到类对象指针pTest被释放的过程,此处加一个大括号 38 { 39 auto_ptr<Test> pTest(new Test("123")); //使用auto_ptr创建指向Test类对象的指针pTest,当pTest过期时候自动释放内存 40 pTest->setStr("HelloWorld"); //修改pTest指向的Test类对象中数据的内容 41 pTest->print(); //打印pTest指向的Test类对象中数据的内容 42 43 44 /* 45 auto_ptr类成员函数reset()的使用 46 01)使用auto_ptr类成员函数对pTest指向的对象重新绑定,此时auto_ptr会释放掉pTest原指向的内存,相当于原类对象不存在了,故会调用Test析构函数; 47 创建pTest新指向的类对象,故会调用pTest构造函数 48 03)故下面这句会调用Test类析构函数和构造函数,而auto_ptr释放掉原pTest指向的类对象内存是默默执行的 49 04)当我们想要在中途释放资源,而不是等到智能指针被析构时才释放,我们可以使用ptest.reset(); 语句 50 */ 51 pTest.reset(new Test("123")); 52 pTest->print(); 53 54 55 /* 56 auto_ptr类成员函数release()的使用 57 */ 58 pTest.release(); //只是将pTest赋值为空,但是它原来指向的内存并没有被释放(没有执行Test的析构函数),相当于它只是释放了对资源的所有权 59 } 60 61 system("pause"); 62 return 0; 63 } 64 65 66 67 /* 68 使用成员初始化列表的原因: 69 在创建继承类对象时候。需要首先对基类中的私有数据进行赋值,再对继承类中的私有数据进行赋值, 70 这个时候要是用成员初始化列表 71 */
运行结果:
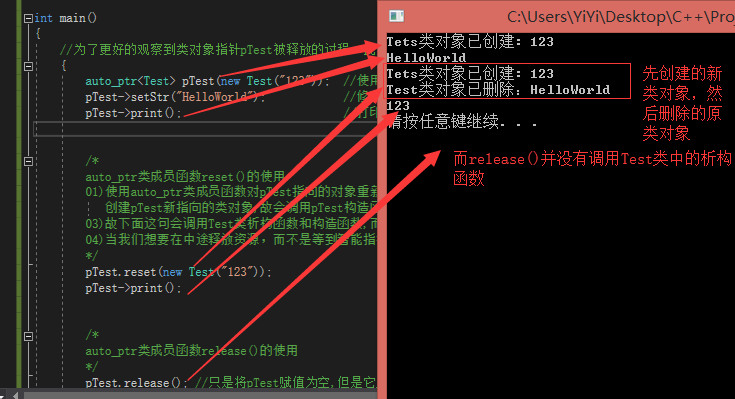
2、auto_ptr存在的问题:
但是下面的语句将有潜在的问题
1 auto_ptr<string> pStr1(new string("Hello")); 2 auto_ptr<string> pStr2; 3 pStr2 = pStr1;
此时理论上第三行不会报,错实际上在VS2017下已报错,pStr2剥夺了pStr1的所有权,pStr1变成了空指针,当程序运行时访问pStr1将会报,如果pStr2原来不是空指针,那么auto_ptr会释放掉pStr2原来指向的内存,基于这个原因,应该避免把auto_ptr放到容器中,因为算法对容器操作时,很难避免STL内部对容器实现了赋值传递操作,这样会使容器中很多元素被置为NULL。判断一个智能指针是否为空不能使用if(ptest == NULL),应该使用if(ptest.get() == NULL)。
所以auto_ptr的缺点是:存在潜在的内存崩溃问题!
2、unique_ptr
unique_ptr 是一个独享所有权的智能指针,它提供了严格意义上的所有权,包括:
1)、拥有它指向的对象
2)、无法进行复制构造,无法进行复制赋值操作。即无法使两个unique_ptr指向同一个对象。但是可以进行移动构造和移动赋值操作(使用move()函数)
方法如下:
1 unique_ptr<Test> ptest(new Test("123"));//调用构造函数,输出Test creat 2 unique_ptr<Test> ptest2(new Test("456"));//调用构造函数,输出Test creat 3 ptest->print();//输出123 4 ptest2 = std::move(ptest);//不能直接ptest2 = ptest,调用了move后ptest2原本的对象会被释放,ptest2对象指向原本ptest对象的内存,最后ptest变为空指针,输出Test delete 456 5 if (ptest == NULL) 6 cout << "ptest = NULL\n";//因为两个unique_ptr不能指向同一内存地址,所以经过前面move后ptest会被赋值NULL,输出ptest=NUL
3)、保存指向某个对象的指针,当它本身被删除释放的时候,会使用给定的删除器释放它指向的对象
具体使用方法:
1 //#include <iostream> 2 // 3 //using namespace std; 4 // 5 //struct treeNode 6 //{ 7 // char data; 8 // treeNode* LChild; 9 // treeNode* RChild; 10 //}; 11 // 12 ////typedef struct treeNode* LPTREE; 13 //#define LPTREE treeNode* 14 // 15 ////指针一般用LP开头 16 //LPTREE createNode(const char data) //此处的LPTREE就是一个指针,如果传入的数据为'A',那么'A'就是const类型的,data如果不是const就会报错 17 //{ 18 // LPTREE newNode = (LPTREE)malloc(sizeof(treeNode)); 19 // //LPTREE newNode = new treeNode; 20 // newNode->data = data; 21 // newNode->LChild = NULL; 22 // newNode->RChild = NULL; 23 // return newNode; 24 //} 25 // 26 ////插入数据 27 //void insertNode(LPTREE parentNode, LPTREE LChild, LPTREE RChild) 28 //{ 29 // parentNode->LChild = LChild; 30 // parentNode->RChild = RChild; 31 //} 32 // 33 ////打印当前结点数据 34 //void printCurNodeData(LPTREE curData) 35 //{ 36 // cout << curData->data << "\t"; 37 //} 38 // 39 ////递归法遍历 40 ////先序遍历:根左右 41 //void preOrder(treeNode* root) //传入要打印的树的根节点 42 //{ 43 // if (root != NULL) 44 // { 45 // printCurNodeData(root); //前序遍历先打印根节点 根 46 // preOrder(root->LChild); //再打印根节点的左节点 左 47 // preOrder(root->RChild); //再打印根节点的右节点 右 48 // } 49 //} 50 // 51 ////中序遍历:左根右 52 //void midOrder(LPTREE root) //传入要打印的树的根节点 53 //{ 54 // if (root != NULL) 55 // { 56 // midOrder(root->LChild); //左 57 // printCurNodeData(root); //根 58 // midOrder(root->RChild); //右 59 // } 60 //} 61 // 62 ////后序遍历:左右根 63 //void lastOrder(LPTREE root) //传入要打印的树的根节点 64 //{ 65 // if (root != NULL) 66 // { 67 // lastOrder(root->LChild); //左 68 // lastOrder(root->RChild); //右 69 // printCurNodeData(root); //根 70 // } 71 //} 72 // 73 ////非递归方式前序遍历---使用栈数组 74 //void preOderByStack(LPTREE root) 75 //{ 76 // if (root == NULL) 77 // return; 78 // //住准备栈 79 // LPTREE Stack[10]; //一般使用数组栈,很少再写一个栈实现 80 // int stackTop = -1; //栈顶标记 81 // LPTREE pMove = root; //从根节点开始打印 82 // 83 // //当栈里面还有路径可以退或者是当前结点pMOve不为空 84 // while (stackTop != -1 || pMove) 85 // { 86 // //根左右 87 // //下面的这个循环即可找到最左边的节点 88 // while (pMove) 89 // { 90 // //把走过的路径入栈+打印走过的结点 91 // cout << pMove->data << "\t"; //打印 92 // Stack[++stackTop] = pMove; //入栈,一定是++stackTop,因为stackTop初始化为-1 93 // /* 94 // 如果stackTop初始化为50,则入栈的时候写成stack[++stackTop-50] = pMove;即可 95 // */ 96 // pMove = pMove->LChild; //将当前pMove的左节点赋给pMove 97 // } 98 // //找到最左边的节点后便无路可走,那么此时出栈 99 // if (stackTop != -1) 100 // { 101 // pMove = Stack[stackTop]; //获取栈顶元素 102 // stackTop--; //伪出栈 103 // pMove = pMove->RChild; //将当前结点的右结点赋给pMove 104 // } 105 // } 106 //} 107 // 108 ////非递归方式中序遍历---使用栈数组 109 ///* 110 //01)定义一个指针移动到最左边,把走过的地方入栈 111 //02)无路的时候,出栈,打印当前结点中的元素 112 //03)出栈后,打印当前结点元素,判断当前结点是否存z右边结点,如果存在就去右边 113 //*/ 114 //void midOrderByStack(LPTREE root) 115 //{ 116 // if (root == NULL) 117 // return; 118 // LPTREE Stack[10]; 119 // int stackTop = -1; 120 // 121 // //定义移动指针,初始化指向根结点root 122 // LPTREE pMove = root; 123 // //当栈里面还有路径可以退或者是当前结点pMOve不为空 124 // while (stackTop != -1 || pMove) 125 // { 126 // //走到最左边,把走做的路径入栈 127 // while (pMove) 128 // { 129 // Stack[++stackTop] = pMove; //将当前结点入栈(走过的结点入栈) 130 // pMove = pMove->LChild; //将当前结点的右结点赋给当前结点 131 // } 132 // //当当前节点的左结点为空,即无路可走时执行下面代码 133 // if (stackTop != -1) 134 // { 135 // pMove = Stack[stackTop--]; //先将栈中最上面元素赋给pMove:pMove = Stack[stackTop];然后stackTop-- 136 // cout << pMove->data << "\t"; //打印当前结点根结点中的元素 137 // pMove = pMove->RChild; 138 // } 139 // } 140 //} 141 // 142 ////非递归方式后序遍历---使用栈数组 143 //void lastOrderByStack(LPTREE root) 144 //{ 145 // if (root == NULL) 146 // return; 147 // LPTREE Stack[10]; 148 // int stackTop = -1; 149 // 150 // //定义移动指针,初始化指向根结点root 151 // LPTREE pMove = root; 152 // 153 // LPTREE pLastVisit = NULL; //最后一次访问的标记 154 // 155 // //左 右 根 156 // while (pMove) 157 // { 158 // Stack[++stackTop] = pMove; 159 // pMove = pMove->LChild; 160 // }//执行完后,则pMOve一直到了最左边 161 // while (stackTop != -1) 162 // { 163 // pMove = Stack[stackTop--]; //出栈 此时pMove等于B结点 164 // 165 // //当前结点右结点是否为空或者是否被访问 B结点的右结点不为空,且没有被访问过,则执行else中的语句 166 // if (pMove->RChild == NULL || pMove->RChild == pLastVisit) //判断当前节点是否为空或这是当前节点的右边结点被访问过了,才可以访问当前结点中的数据 167 // { 168 // //当前结点左右结点被访问则打印当前结点中的数据 169 // cout << pMove->data << "\t"; 170 // pLastVisit = pMove; 171 // } 172 // else 173 // { 174 // //右边没有被访问 175 // Stack[++stackTop] = pMove; //将B结点入栈 176 // pMove = pMove->RChild; //设置当前结点为右结点 将当前结点设置为B结点的右结点E 177 // //使用同样的方法找pMove的最左边 此时还需要去判断E判断E是否有左边结点, 178 // while (pMove) 179 // { 180 // Stack[++stackTop] = pMove; //将E结点入栈 181 // pMove = pMove->LChild; //E的左结点即为空 182 // } 183 // 184 // } 185 // } 186 //} 187 // 188 // 189 //int main() 190 //{ 191 // LPTREE A = createNode('A'); 192 // LPTREE B = createNode('B'); 193 // LPTREE C = createNode('C'); 194 // LPTREE D = createNode('D'); 195 // LPTREE E = createNode('E'); 196 // LPTREE F = createNode('F'); 197 // LPTREE G = createNode('G'); 198 // 199 // //很死板的创建二叉树方法 200 // insertNode(A, B, C); 201 // insertNode(B, D, NULL); 202 // insertNode(D, NULL, G); 203 // insertNode(C, E, F); 204 // 205 // cout << "先序遍历" << endl; 206 // preOrder(A); 207 // 208 // cout << "\n\n非递归方式先序遍历\n" << endl; 209 // preOderByStack(A); 210 // 211 // cout << "\n\n中序遍历\n"; 212 // midOrder(A); 213 // 214 // cout << "\n\n非递归方式中序遍历\n"; 215 // midOrderByStack(A); 216 // 217 // cout << "\n\n后序遍历\n"; 218 // lastOrder(A); 219 // 220 // cout << "\n\n非递归后序遍历\n"; 221 // lastOrderByStack(A); 222 // 223 // system("pause"); 224 // return 0; 225 //} 226 227 //auto_ptr 228 #include <iostream> 229 #include <memory> //for auto_ptr、shared_ptr... 230 #include <string> 231 232 using namespace std; 233 234 class Test 235 { 236 private: 237 string str; 238 public: 239 Test(string s):str(s) //使用成员初始化列表为类私有数据赋值 240 { 241 cout << "Tets类对象已创建: " << str << "\n"; 242 } 243 ~Test() 244 { 245 cout << "Test类对象已删除:" << str << endl; 246 } 247 string & getStr() 248 { 249 return str; //返回私有数据 250 } 251 void setStr(string s) 252 { 253 str = s; 254 } 255 void print() 256 { 257 cout << str << endl; //访问Test类对象指针p的数据 258 } 259 }; 260 261 int main() 262 { 263 //为了更好的观察到类对象指针pTest被释放的过程,此处加一个大括号 264 { 265 unique_ptr<Test> pTest(new Test("123")); //使用auto_ptr创建指向Test类对象的指针pTest,当pTest过期时候自动释放内存 266 pTest->setStr("HelloWorld"); //修改pTest指向的Test类对象中数据的内容 267 pTest->print(); //打印pTest指向的Test类对象中数据的内容 268 269 270 /* 271 auto_ptr类成员函数reset()的使用 272 01)使用auto_ptr类成员函数对pTest指向的对象重新绑定,此时auto_ptr会释放掉pTest原指向的内存,相当于原类对象不存在了,故会调用Test析构函数; 273 创建pTest新指向的类对象,故会调用pTest构造函数 274 03)故下面这句会调用Test类析构函数和构造函数,而auto_ptr释放掉原pTest指向的类对象内存是默默执行的 275 04)当我们想要在中途释放资源,而不是等到智能指针被析构时才释放,我们可以使用ptest.reset(); 语句 276 */ 277 pTest.reset(new Test("123")); 278 pTest->print(); 279 280 281 /* 282 auto_ptr类成员函数release()的使用 283 */ 284 pTest.release(); //只是将pTest赋值为空,但是它原来指向的内存并没有被释放(没有执行Test的析构函数),相当于它只是释放了对资源的所有权 285 } 286 287 system("pause"); 288 return 0; 289 } 290 291 292 293 /* 294 使用成员初始化列表的原因: 295 在创建继承类对象时候。需要首先对基类中的私有数据进行赋值,再对继承类中的私有数据进行赋值, 296 这个时候要是用成员初始化列表 297 */
另外unique_ptr还有更聪明的地方:当程序试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这么做;如果源 unique_ptr 将存在一段时间,编译器将禁止这么做,比如:
1 unique_ptr<string> pu1(new string ("hello world")); 2 unique_ptr<string> pu2; 3 pu2 = pu1; // #1 不允许 4 unique_ptr<string> pu3; 5 pu3 = unique_ptr<string>(new string ("You")); // #2 允许
其中#1留下悬挂的unique_ptr(pu1),这可能导致危害。而#2不会留下悬挂的unique_ptr,因为它调用 unique_ptr 的构造函数,该构造函数创建的临时对象在其所有权让给 pu3 后就会被销毁。这种随情况而已的行为表明,unique_ptr 优于允许两种赋值的auto_ptr 。
注:如果确实想执行类似与#1的操作,要安全的重用这种指针,可给它赋新值。C++有一个标准库函数std::move(),让你能够将一个unique_ptr赋给另一个。尽管转移所有权后 还是有可能出现原有指针调用(调用就崩溃)的情况。但是这个语法能强调你是在转移所有权,让你清晰的知道自己在做什么,从而不乱调用原有指针。
3、shared_ptr
多个shared_ptr指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。
它使用计数机制来表明资源被几个指针共享。可以通过成员函数use_count()来查看资源的所有者个数。除
了可以通过new来构造,还可以通过传入auto_ptr, unique_ptr,weak_ptr来构造。当我们调用release()时,
当前指针会释放资源所有权,计数减一。当计数等于0时,资源会被释放。
shared_ptr类中新建了Counter类对象s,当进行shared_ptr类指针赋值或复制时候,将调用shared_ptr类中的赋值构造函数和复制构造函数,此时将Counter类对象s中的一个int型变量进行自加一即可。
1 string *pStr = new string("123"); 2 shared_ptr<string> p1(pStr); //将p1指向pStr指向的内存区域,在shared_ptr构造函数中Counter类对象中的int型变量赋值为1 3 shared_ptr<string> p2; 4 p2=p1; //将调用shared_ptr类中的赋值构造函数,在该函数中将Counter类对象中的int型变量自加一 5 int a = p1.use_count(); //a=2 6 int b = p2.use_count(); //b=2
复习何时调用赋值构造函数和复制构造函数:
1 //假设Test是一个类 2 Test dog("Hello"); 3 Test cat = dog; //cat类对象初始化,将调用Test类中的复制构造函数Test(cosnt Test & t) 4 Test bird; 5 bird = dog; //将调用赋值构造函数(对等号的重载) Test & operator=(const Test & t)
shared_ptr的具体使用方
1 //shared_ptr 2 #include <iostream> 3 #include <memory> //for auto_ptr、shared_ptr... 4 #include <string> 5 6 using namespace std; 7 8 class Test 9 { 10 private: 11 string str; 12 public: 13 Test(string s):str(s) //使用成员初始化列表为类私有数据赋值 14 { 15 cout << "Tets类对象已创建: " << str << "\n"; 16 } 17 ~Test() 18 { 19 cout << "Test类对象已删除:" << str << endl; 20 } 21 string & getStr() 22 { 23 return str; //返回私有数据 24 } 25 void setStr(string s) 26 { 27 str = s; 28 } 29 void print() 30 { 31 cout << str << endl; //访问Test类对象指针p的数据 32 } 33 }; 34 35 int main() 36 { 37 //为了更好的观察到类对象指针pTest被释放的过程,此处加一个大括号 38 { 39 shared_ptr<Test> pTest1(new Test("123")); //调用shred_ptr类中的构造函数,并将Counter类对象中int型变量赋值为1 40 pTest1->setStr("HelloWorld"); //修改pTest1指向的Test类对象中数据的内容 41 pTest1->print(); //打印pTest1指向的类对象中的内容 42 43 shared_ptr<Test> pTest2; 44 pTest2 = pTest1; //调用shared_ptr类中的赋值构造函数,并将Counter类对象中int型变量自加1 45 cout << "pTest1.use_count=" << pTest1.use_count() << endl; //查看pTest1对象下Counter类对象中int型变量的值 46 cout << "pTest2.use_count=" << pTest2.use_count() << endl; //查看pTest2对象下Counter类对象中int型变量的值 一样的,由于use_count()是shared_ptr类函数,故使用.来访问use_count() 47 48 /*Test* pTest3 = new Test("456"); 49 shared_ptr<Test> pTest4(pTest3);*/ //这样创建的shred_ptr指针不可以使用swap() 50 51 shared_ptr<Test> pTest4(new Test("pTest4")); 52 cout << "pTest1= " << (pTest1.get()) << endl; //查看pTest1指向的对象的地址 53 cout << "pTest2= " << (pTest2.get()) << endl; //查看pTest2指向的对象的地址 54 cout << "pTest4= " << (pTest4.get()) << endl; //查看pTest3指向的对象的地址 55 cout << "pTest1.use_count=" << pTest1.use_count() << endl; 56 cout << "pTest4.use_count=" << pTest4.use_count() << endl; 57 cout << "执行swap(pTest1,pTest4)\n"; 58 swap(pTest1, pTest4); //原来pTest2和pTest1指向相同的类对象,交换之后pTest2还是指向原来的类对象,pTest1指向的类对象变了 59 cout << "pTest1= " << (pTest1.get()) << endl; //查看pTest1指向的对象的地址 60 cout << "pTest2= " << (pTest2.get()) << endl; //查看pTest2指向的对象的地址 61 cout << "pTest4= " << (pTest4.get()) << endl; //查看pTest3指向的对象的地址 62 cout << "pTest1.use_count=" << pTest1.use_count() << endl; 63 cout << "pTest4.use_count=" << pTest4.use_count() << endl; 64 65 66 cout << "执行pTest2.reset(new Test(789))\n"; 67 pTest2.reset(new Test("789")); //更改pTest2指向的对象中的内容,会引起pTest对象中Counter类对象中int型变量减1 68 pTest2->print(); //pTest作为指向Test类对象的指针访问Test类中的方法 69 cout << "pTest1.use_count=" << pTest1.use_count() << endl; //查看pTest1对象下Counter类对象中int型变量的值 70 cout << "pTest2.use_count=" << pTest2.use_count() << endl; //查看pTest2对象下Counter类对象中int型变量的值 71 cout << "pTest4.use_count=" << pTest4.use_count() << endl; 72 //pTest2.release(); //shared_ptr中没有release() 73 } 74 75 system("pause"); 76 return 0; 77 }
执行结果:
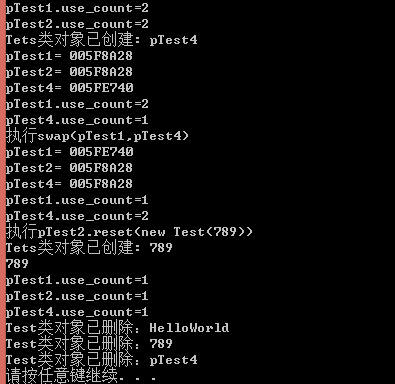
4、weak_ptr
weak_ptr是用来解决shared_ptr相互引用时的死锁问题, 如果说两个shared_ptr相互引用, 那么这两个指针的引用计数永远不可能下降为0, 资源永远不会释放。如下将会出现shared_ptr互锁的现象
详细的shraed_ptr出现互锁的例子:
1 #include <iostream> 2 using namespace std; 3 4 #include <memory> 5 #include "SharedPtr.h" 6 7 struct Node 8 { 9 Node(int va) 10 :value(va) 11 12 { 13 cout<<"Node()"<<endl; 14 } 15 16 17 ~Node() 18 { 19 cout<<"~Node()"<<endl; 20 } 21 shared_ptr<Node> _pre; 22 shared_ptr<Node> _next; 23 int value; 24 }; 25 26 void funtest() 27 { 28 shared_ptr<Node> sp1(new Node(1)); 29 shared_ptr<Node> sp2(new Node(2)); 30 31 sp1->_next=sp2; 32 sp2->_pre=sp1; 33 } 34 int main() 35 { 36 funtest(); 37 return 0; 38 }
1 shared_ptr<B> pb(new B()); 2 shared_ptr<A> pa(new A()); 3 pb->pa_ = pa; 4 pa->pb_ = pb;
waek_ptr的赋值构造函数形式为:WeakPtr<T> &operator=(SharePtr<T> &s);可以看出weak_prt的赋值构造函数形参为shared_ptr
于是可以将shared_ptr指针赋值给weak_ptr指针,但是在该赋值构造函数下,引用计数并没有自加1,从而不会引起函数执行完后引用计数不为0的情况
以下将会解决问题:
1 shared_ptr<B> pb(new B()); 2 weak_ptr<A> pa(new A()); 3 pb->pa_ = pa; 4 pa->pb_ = p
5、总结
1 总结: 2 由于在使用new创建指针时候,可能存在忘记加delete从而导致出现内存泄漏的情况,于是引入了智能指针 3 首先是auto_ptr它可以在类构造函数中为指针分配内存空间,在析构函数中释放内存,当指针结束生命周期时候就会自动调用析构函
数 4 以释放内存空间。但是auto_ptr指针之间不可以相互赋值,编译器会报错 5 再者就是unique_ptr,它弥补了auto_ptr的缺点,两个指针之间可以赋值,通过类方法move()实现,假如p1=p2,那么p2就会成为空指针,可能以后还会使用p2 6 故也存在风险 7 还有就是shared_ptr,它引入了一个引用计数的概念,在构造函数中将该引用计数赋值为1,在和赋值、复制构造函数中都将该引用计数自加1。 8 在需要将shred_ptr指针销毁的时候,会将该引用计数自减1,等到该引用计数为0时候就会调用析构函数释放内存。 9 最后就是weak_ptr引入主要是为了解决shred_ptr自锁的问题,解决方法是在类构造函数、赋值构造函数中将shared_ptr类对象作为形参,但是在构造函数和赋值构造函数 10 、复制构造函数中没有引入引用计数 11 注:引用计数可以是一个类对象中的一个int型变量
6、测试两个普通指针是否可以指向同一块内存区域
1 //测试两个普通指针是否可以指向同一块内存区域 2 #include <iostream> 3 using namespace std; 4 class A 5 { 6 private: 7 int aa; 8 public: 9 A(int temp) :aa(temp) {} 10 void dis() 11 { 12 cout << aa << endl; 13 } 14 }; 15 int main() 16 { 17 A a(112); //创建一个指向A类对象的指针p_a 18 A* p_b; 19 A* p_c; 20 p_b = &a; 21 p_c = p_b; 22 p_b->dis(); 23 p_c->dis(); //即允许两个普通指针同时指向一块内存区域,但是指针指针auto_ptr和unique_ptr是不允许的 24 25 system("pause"); 26 return 0; 27 } 28 29 不允许将一个auto_ptr指针赋值给另外一个auto_ptr指针的原因是: 30 假如有两个auto_ptr指针p1和p2,如果将p2赋给p1,那么p2指向的内存会被释放掉,此时p2指针为空指针,再使用p2指针的时候会出错
结果是两个普通指针可以指向同一块内存区域
7、VS2017环境下内存泄漏检测
VS中自带了内存泄露检测工具,若要启用内存泄露检测,则在程序中包括以下语句:
1 #define _CRTDBG_MAP_ALLOC 2 #include <crtdbg.h>
它们的先后顺序不能改变。通过包括 crtdbg.h,将malloc和free函数映射到其”Debug”版本_malloc_dbg和_free_dbg,这些函数将跟踪内存分配和释放。此映射只在调试版本(在其中定义了_DEBUG)中发生。#define语句将CRT堆函数的基版本映射到对应的”Debug”版本。
测试代码如下
1 //以下两条语句顺序不可改变 2 #define _CRTDBG_MAP_ALLOC //将 CRT 堆函数的基版本映射到对应的“Debug”版本。 并非绝对需要该语句;但如果没有该语句,内存泄漏转储包含的有用信息将较少。 3 #include <crtdbg.h> 4 5 #include <iostream> 6 using namespace std; 7 8 void getMemory(char* p, int num) 9 { 10 //p = new char[num]; //new分配的内存不可以定位到内存泄漏的行数 11 p = (char*)malloc(sizeof(char)*num); //maloc分配的内存可以定位到内存泄漏的行数 12 } 13 14 int main() 15 { 16 char* str = NULL; 17 getMemory(str, 100); 18 cout << "Memory leak test!" << endl; 19 _CrtDumpMemoryLeaks(); //将在输出窗口输出内存泄漏信息 20 21 system("pause"); 22 return 0; 23 }
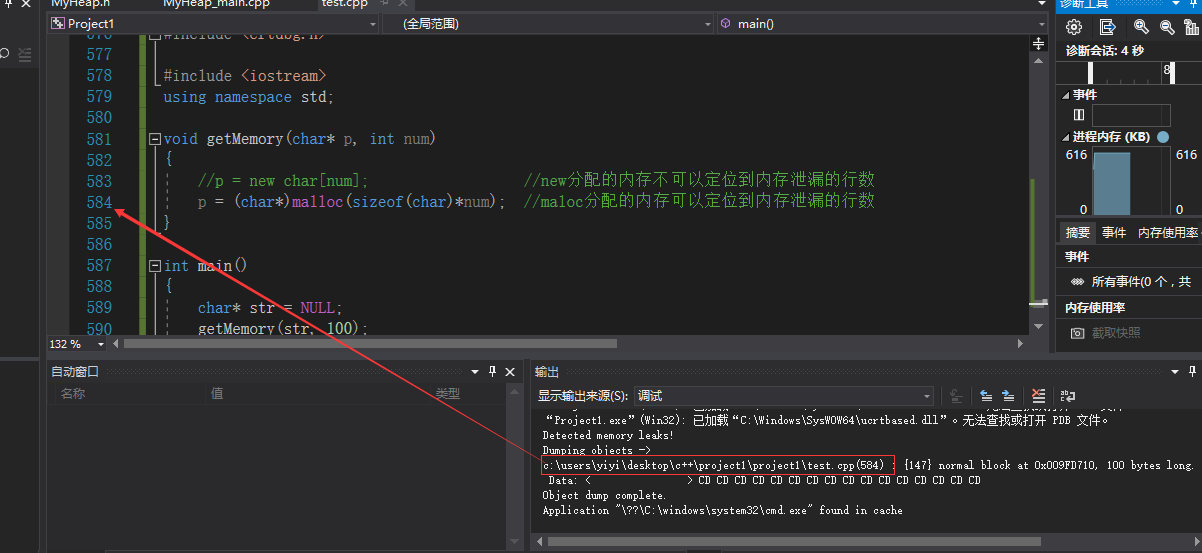
内存泄露检测之使用CRT的Debug技术
基本原理
内存泄露主要指的是我们分配的堆内存没有被释放,随着程序的运行,可能会积少成多,导致系统可用内存降低,甚至造成系统瘫痪。一般分配堆内存的C++方式有:
malloc
new
当然,如果说更深一层,new最终调用的是malloc,而malloc调用的则是Windows API堆分配函数(如:HeapAlloc)来进行分配堆内存的。但平常我们并不直接调用很底层的函数。
Debug版本的 CRT定义了一套调试版本的内存分配函数(如_malloc_dbg)。当你包含了CRTDBG.h后,如果当前是Debug工程,十有八九会有_DEBUG宏,这时,malloc函数会被被映射为_malloc_dbg。
当如果是Release版本,它什么都不做。这样以来,如果是Debug版本,我们调用的malloc或者new,其实最终调用的都是_malloc_dbg。而_malloc_dbg会分配多于我们指定的内存大小,用来存储调试信息,用来跟踪内存分配和释放是否对应。
现在,我们可以暂时想象CRT是如何跟踪内存泄露的:调用_malloc_dbg,它将分配一个内存地址,将地址存储到一个列表中,当调用free的时候,肯定还是传入该地址,然后从列表中移除。当程序结束的时候,如果没有内存泄露,这个列表就应该为空,如果不为空,那么就出现了内存泄露,CRT库就将这些地址打印到调试窗口中,编译程序员进行排查。当然这个过程要比我说的复杂很多,但原理都差不多。
当然,这一切的前提,都是你得直接或者间接的调用malloc,不然一切都是空谈。
以上所有的技术针对的都是针对于malloc,我也说了new最终调用的也是malloc,那new应该也会有效。的确,new的确起了作用,但你会发现,你基本上无法定位你是在哪里调用的new,因为没有源码行号显示,原因是new可能经过了几层调用,才调用到了malloc,而且是在CRT库中调用的malloc,打印的地址,也是CRT的地址,显然这是不对的。CRT虽然是C Rumtime library,但他照顾了C++一些特性,例如new。Debug CRT重载了new,实现了Debug版本的new。所以,我们要多做一些工作,让其正确工作:
1 //for new显示内存泄漏的行号 2 #ifdef _DEBUG 3 #ifndef DBG_NEW 4 #define DBG_NEW new ( _NORMAL_BLOCK , __FILE__ , __LINE__ ) 5 #define new DBG_NEW 6 #endif 7 #endif // _DEBUG
1 //for new显示内存泄漏的行号 2 #ifdef _DEBUG 3 #ifndef DBG_NEW 4 #define DBG_NEW new ( _NORMAL_BLOCK , __FILE__ , __LINE__ ) 5 #define new DBG_NEW 6 #endif 7 #endif // _DEBUG 8 9 //以下两条语句顺序不可改变 10 #define _CRTDBG_MAP_ALLOC //将 CRT 堆函数的基版本映射到对应的“Debug”版本。 并非绝对需要该语句;但如果没有该语句,内存泄漏转储包含的有用信息将较少。 11 #include <crtdbg.h> 12 13 #include <iostream> 14 using namespace std; 15 16 void getMemory(char** p, int num) //这里必须设置成二级指针,否则实参的值是不会变的 17 { 18 *p = new char[num]; //new分配的内存不可以定位到内存泄漏的行数 19 //*p = (char*)malloc(sizeof(char)*num); //maloc分配的内存可以定位到内存泄漏的行数 20 cout << "子函数中p指向的内存地址为:"<< (void*)(*p) << endl; 21 } 22 23 int main() 24 { 25 char* str = NULL; 26 getMemory(&str, 100); 27 cout << "主函数中str指向的内存地址:" << (void*)str << endl; 28 cout << sizeof(str) << endl; 29 cout << "Memory leak test!" << endl; 30 _CrtDumpMemoryLeaks(); //将在输出窗口输出内存泄漏信息 31 32 delete [] str; 33 34 system("pause"); 35 return 0; 36 }
运行结果:

由于主函数中的str和p指向同一块内存,故只在主函数中使用了delete [] str; 没有在子函数中使用delete [] p
故此时出现了报错:
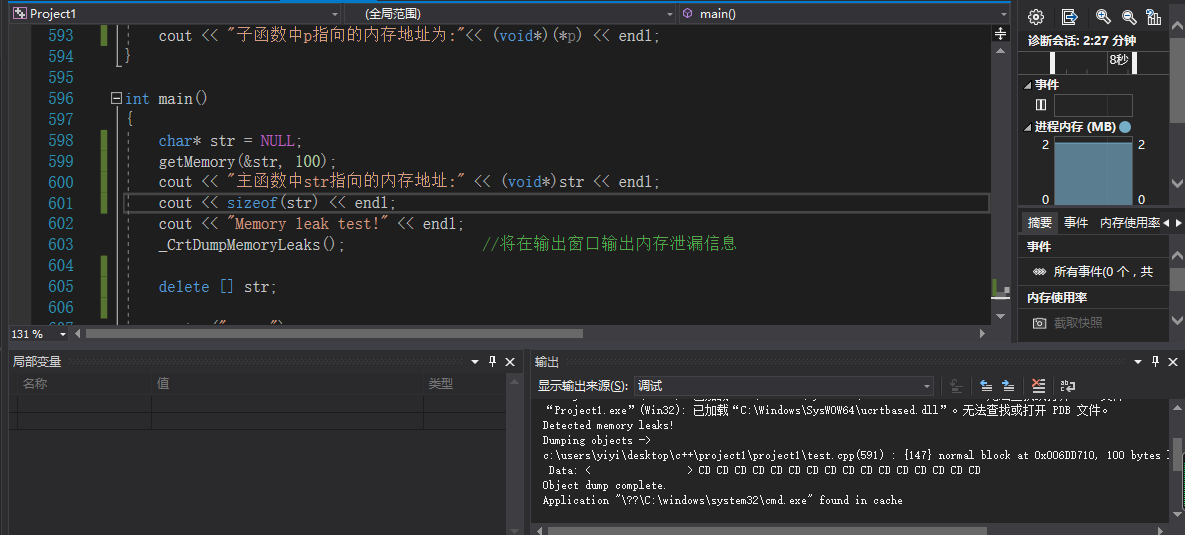
但是,如果程序可能会在多个地方退出该怎么办呢?在每一个可能的出口处调用 _CrtDumpMemoryLeaks 肯定是不可取的,那么这时可以在程序开始处包含下面的调用:_CrtSetDbgFlag ( _CRTDBG_ALLOC_MEM_DF | _CRTDBG_LEAK_CHECK_DF );这条语句无论程序在什么地方退出都会自动调用 _CrtDumpMemoryLeaks。注意:这里必须同时设置两个位域标志:_CRTDBG_ALLOC_MEM_DF 和 _CRTDBG_LEAK_CHECK_DF。
参考博客:
https://blog.csdn.net/song_lipeng/article/details/102931987
8、make_shared m128
1 #include <iostream> 2 #include <memory> //for shared_ptr 3 #include <vector> 4 #include <string> 5 6 using namespace std; 7 8 int main() 9 { 10 shared_ptr<string> p1 = make_shared<string>("Hello"); //p1指向字符串Hello 11 shared_ptr<string> p2 = make_shared<string>(10, 'H'); //p2指向十个H,即"HHHH...." 12 shared_ptr<string> p3 = make_shared<string>(); //p3指向NULL 13 14 cout << p1 << endl; //打印p1指向的地址 15 cout << p2 << endl; 16 17 cout << *p1 << endl; //打印Helllo 18 cout << *p2 << endl; 19 20 system("pause"); 21 return 0; 22 23 }
运行结果:
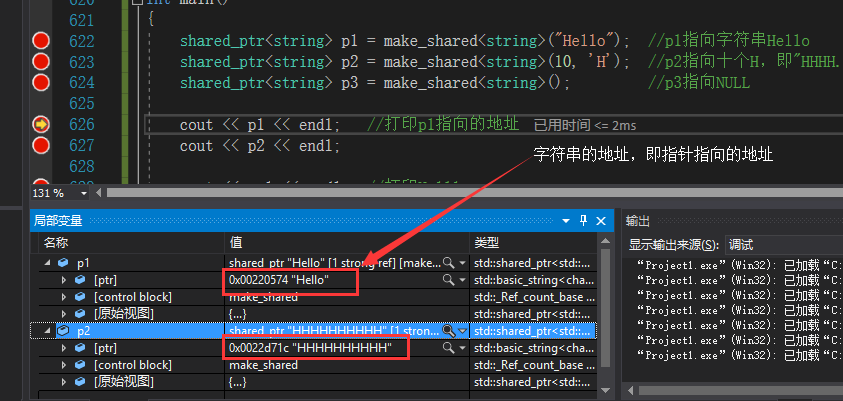
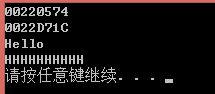
make_shared和new的区别
make_shared函数的主要功能是在动态内存中分配一个对象并初始化它,返回指向此对象的shared_ptr
new先在堆上分配一块内存用来使用,然后再给智能控制块分配一块内存,但是这两个内存区域是不连续的
make_shared在堆上分配一个足够大的内存,其中包含两部分,上部分是内存(用来使用),下面是智能指针控制块
因此make_shared分配的内存是连续的,访问速度较快
13、友元函数复习
1、以前学习的友元类传送门
2、复习
1 #include <iostream> 2 3 using namespace std; 4 5 class A 6 { 7 private: 8 int dog; 9 friend class B; //使类B成为类A的友元类,以便于在类B中的方法实现里访问类A中的私有数据 10 public: 11 A(int t) :dog(t) {}; 12 13 }; 14 class B 15 { 16 private: 17 A a; //只不过在创建B的类对象时候,需要传入一个A的类对象 18 19 public: 20 B(A test) :a(test) {}; 21 void dis() 22 { 23 cout << "类B中的方法,但是访问的是类A中的数据" << a.dog << endl; 24 } 25 26 }; 27 int main() 28 { 29 A a(112); //创建A的类对象 30 B b(a); 31 b.dis(); 32 33 system("pause"); 34 return 0; 35 36 }
假如将类A中的friend class B;去掉,那么会报错如下:

恢复后正常执行如下:

14、虚函数复习
C++的虚函数主要作用是“运行时多态”,父类中提供虚函数的实现,为子类提供默认的函数实现。
子类可以重写父类的虚函数实现子类的特殊化。
1、虚函数和普通函数的区别
假如有两个基类指针,分别指向了一个基类对象和一个继承类对象,然后该基类指针调用了基类和继承类下的一个方法
假如该方法是虚函数,那么要根据基类指针指向的对象去判断执行基类方法还是继承类方法
加入该方法是普通函数,那么两个基类指针调用的都是基类中的方法
原理:
虚函数主要是通过虚函数表和虚函数指针来实现。
虚函数表存放类中函数的地址,加入继承类重写了基类中的虚函数,在继承类的虚函数表中会将基类对应的函数地址覆盖掉;
虚函数指针存放在类对象中(会放在类对象地址开始处),并且它执行该类对象所在的虚函数表。
普通函数不存在虚函数表,它只有一个函数地址,不存在继承类函数地址覆盖掉基类函数地址的情况,一般是基类强制子类使用
某个函数
2、纯虚函数
C++中包含纯虚函数的类,被称为是“抽象类”。抽象类不能使用new出对象,只有实现了这个纯虚函数的子类才能new出对象。
C++中的纯虚函数更像是“只提供申明,没有实现”,是对子类的约束,是“接口继承”。
C++中的纯虚函数也是一种“运行时多态”。
4、函数指针定义方法
/*函数指针实现方法一*/
//形式1:返回类型(*函数名)(参数表)
1 /*函数指针实现方法一*/ 2 //形式1:返回类型(*函数名)(参数表) 3 #include <iostream> 4 5 using namespace std; 6 7 char fun(int a) 8 { 9 cout << a << endl; 10 return 0; 11 } 12 13 int main() 14 { 15 char(*pFun)(int); //定义一个函数指针,它可以指向一个返回值为char型变量、形参为int型变量的函数 16 17 pFun = fun; 18 (*pFun)(112); //执行fun()函数,和fun(112);效果是一样的 19 20 system("pause"); 21 return 0; 22 }
/*函数指针实现方法二*/
//形式2:typedef 返回类型(*新类型)(参数表)
1 /*函数指针实现方法二*/ 2 //形式2:typedef 返回类型(*新类型)(参数表) 3 #include <iostream> 4 5 using namespace std; 6 7 char fun(int a) 8 { 9 cout << a << endl; 10 return 0; 11 } 12 13 int main() 14 { 15 typedef char(*PTRFUN)(int); //定义一个函数指针,它可以指向一个返回值为char型变量、形参为int型变量的函数 16 PTRFUN pFun; //像int、char等类型一样使用PTRFUN 17 18 pFun = fun; 19 (*pFun)(112); //执行fun()函数,和fun(112);效果是一样的 20 21 system("pause"); 22 return 0; 23 }
注typedef最常用:
1 int i;//定义一个整型变量i 2 typedef myInt int; 3 myInt j;//定义一个整型变量
5、虚函数表的进一步解释


15、堆排序(重新学习)
1、一个一个的插入实现方法
c malloc 堆内存
C++ new 堆内存
二叉树:一个结点最多只能有两个结点
满二叉树:一个结点要么有结点,要么没有结点,且叶结点全在同一层
满二叉树结点数:(2n次方)-1,其中n为层数
完全二叉树:满二叉树从下往上、从右向左删除结点后的数位完全二叉树
struct nodeList //链表
{
int data;
nodeList *nextNode;
};
struct node //二叉树
{
int data;
node* pLChild;
node* pRChild;
};
针对完全二叉树可以使用数组来盛放每个结点(完全二叉树的优势)
假设根结点下标为0开始
已知父结点下标为n,则左子结点的下标为2n+1
已知父结点下标为n,则右子结点的下标为2n+2
已知左子结点下标为m,则父结点的下标为(m-1)/2
已知右子结点下标为m,则父结点的下标为(m-2)/2
如果m=1,则其父结点下标为(1-1)/2=0
如果m=2,则其父结点下标为(2-1)/2=0
即在计算机中(m-1)/2=(m-2)/2
int型变量相除只看个位
堆:有序的完全二叉树,但是这个有序只是限定父子之间有序
01)最大堆(大顶堆):父结点中存的数大于子结点中存的数
02)最下堆(小顶堆):父结点中存的数小于子结点中存的数
所以堆即是完全二叉树也是一个数组,因为完全二叉树可以使用数组表示方便
堆排序原理:

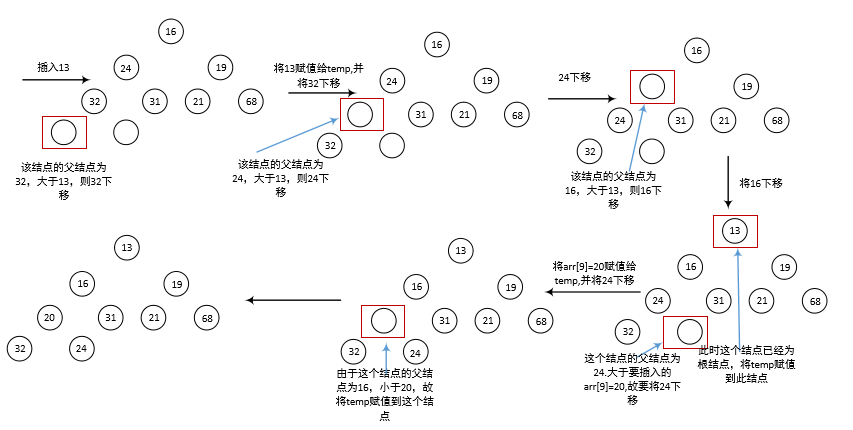
以下是使用类模板方法实现堆,因此在该h文件中对函数做了实现
1 #pragma once 2 3 #include <iostream> 4 5 using namespace std; 6 7 template <class T> 8 class MyHeap 9 { 10 T* pBuff; //数组首地址 11 size_t size; //堆元素个数 12 size_t maxSize; //堆容量 13 public: 14 MyHeap() 15 { 16 pBuff = NULL; 17 size = 0; 18 maxSize = 0; 19 } 20 ~MyHeap() 21 { 22 if (pBuff) 23 delete pBuff; 24 size = maxSize = 0; 25 } 26 //1、一个一个元素插入到堆中 27 void insertDataToHeap(const T & data); 28 //2、删除堆顶元素 29 //3、用数组来初始化堆 30 //4、打印数组中的元素 31 void _travel(); 32 private: 33 34 }; 35 36 //1、一个一个元素插入到堆中(实现小顶堆) 37 template <class T> 38 void MyHeap<T>::insertDataToHeap(const T & data) 39 { 40 //1.1使用完全二叉树的方式插入,即数组挨个赋值 41 if (maxSize <= size) //如果当前数组中元素个数大于数组容量 42 { 43 //新开内存是原内存的1.5倍或者是原内存加1 44 //maxSize >> 1等价于maxSize=maxSize*1.5 45 maxSize = maxSize + (((maxSize >> 1) > 1) ? (maxSize >> 1) : 1); 46 47 T* pTemp = new T[maxSize]; //开内存 48 if (pBuff != NULL) //如果原来有内存,将原来内存数据拷贝到新内存中 49 { 50 memcpy(pTemp, pBuff, sizeof(T)*size); //将原pBuff中的数据拷贝到pTemp中,拷贝sizeof(T)*size个字节 51 delete[] pBuff; //释放pBuff 52 } 53 pBuff = pTemp; //将pBuff重新指向pTemp指向的内存,pBuff指向的内存消失,但是pBuff指针还是存在的 54 } 55 pBuff[size++] = data; //将数字插入数组 56 57 //1.2检查父是否小于子 这一步在第四步中有对应的代码 58 59 //1.3临时存储插入数据 60 T temp = data; 61 int currendIndex = size - 1; //加入当前有五个元素,那么最后的元素下标为4 62 int parentIndex; //当前父结点下标 63 //1.4循环比较当前位置a和其父结点b位置是否满足父小于子 64 //如果满足或b没有父了则循环结束,否则让结点b位置的数字替代a结点中的数字 65 //注:a结点是位置放的是要插入的数字 66 //当前下标为0则循环结束 67 while (currendIndex) 68 { 69 parentIndex = (currendIndex - 1) / 2; //在计算机中(currendIndex-1)/2=(currendIndex-2)/2,所以不用分currendIndex是左结点下标还是右结点下标 70 if (pBuff[parentIndex] > temp) //如果当前结点的父节点大于要插入的数,则冲突 71 { 72 pBuff[currendIndex] = pBuff[parentIndex]; //用当前节结点的父结点替代当前结点中的数 73 } 74 else 75 { 76 break; //如果不冲突跳出循环 77 78 } 79 currendIndex = parentIndex; //下标向上移动 80 } 81 //1.5临时存储的新插入数据覆盖当前位置 82 pBuff[currendIndex] = temp; 83 //_travel(); //打印数据 84 } 85 86 //4、打印数组中的元素 87 template <class T> 88 void MyHeap<T>::_travel() 89 { 90 cout << "heap:"; 91 for (int i = 0; i < size; i++) 92 cout << pBuff[i] << " "; 93 cout << endl; 94 }
测试用代码:
1 #include <iostream> 2 #include "MyHeap.h" 3 4 using namespace std; 5 6 int main() 7 { 8 MyHeap<int> heap; 9 int arr[] = { 32,21,16,24,31,19,68,13,20 }; 10 for(int i=0;i<sizeof(arr)/sizeof(arr[0]);i++) 11 heap.insertDataToHeap(arr[i]); 12 heap._travel(); 13 14 system("pause"); 15 return 0; 16 }
测试结果:
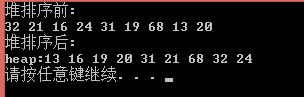
2、删除堆顶元素,即删除堆中最小元素
删除堆顶元素后,需要补一个元素进来,那么就首先考虑堆数组中的最后一个元素lastData,但是也不知直接将堆数组中最后一个元素直接赋值
到堆顶,而是先将lastData存起来。然后进行如下的判断:如果lastData大于堆顶元素左结点和右结点中较小的一个结点值,说明当前堆顶不可以放
lastData,可以将(堆顶元素左结点和右结点中较小的一个结点值)放在堆顶,然后继续判断(堆顶元素左结点和右结点中较小的一个结点)的左右结点和lastData
的大小关系,直到找到lastData小于(当前结点i的左右结点较小的一个值),那么结点i就是lastData要存放的地址。
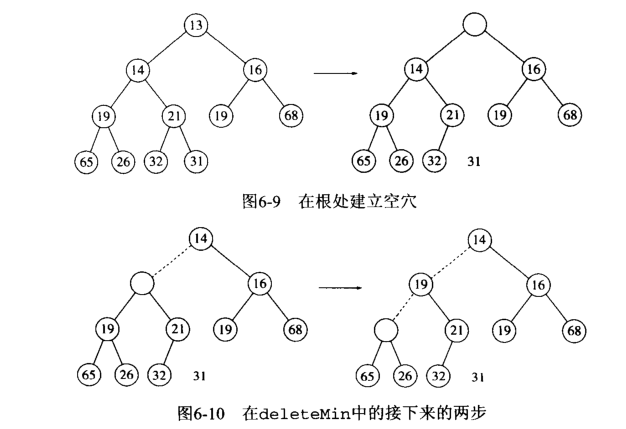

实现及测试代码:
1 #pragma once 2 3 #include <iostream> 4 5 using namespace std; 6 7 template <class T> 8 class MyHeap 9 { 10 T* pBuff; //数组首地址 11 size_t size; //堆元素个数 12 size_t maxSize; //堆容量 13 public: 14 MyHeap() 15 { 16 pBuff = NULL; 17 size = 0; 18 maxSize = 0; 19 } 20 ~MyHeap() 21 { 22 if (pBuff) 23 delete pBuff; 24 size = maxSize = 0; 25 } 26 //1、一个一个元素插入到堆中 27 void insertDataToHeap(const T & data); 28 //2、删除堆顶元素 29 T deleteMinData(); 30 //3、用数组来初始化堆 31 //4、打印数组中的元素 32 void _travel(); 33 private: 34 35 }; 36 37 //1、一个一个元素插入到堆中(实现小顶堆) 38 template <class T> 39 void MyHeap<T>::insertDataToHeap(const T & data) 40 { 41 //1.1使用完全二叉树的方式插入,即数组挨个赋值 42 if (maxSize <= size) //如果当前数组中元素个数大于数组容量 43 { 44 //新开内存是原内存的1.5倍或者是原内存加1 45 //maxSize >> 1等价于maxSize=maxSize*1.5 46 maxSize = maxSize + (((maxSize >> 1) > 1) ? (maxSize >> 1) : 1); 47 48 T* pTemp = new T[maxSize]; //开内存 49 if (pBuff != NULL) //如果原来有内存,将原来内存数据拷贝到新内存中 50 { 51 memcpy(pTemp, pBuff, sizeof(T)*size); //将原pBuff中的数据拷贝到pTemp中,拷贝sizeof(T)*size个字节 52 delete[] pBuff; //释放pBuff 53 } 54 pBuff = pTemp; //将pBuff重新指向pTemp指向的内存,pBuff指向的内存消失,但是pBuff指针还是存在的 55 } 56 pBuff[size++] = data; //将数字插入数组 57 58 //1.2检查父是否小于子 这一步在第四步中有对应的代码 59 60 //1.3临时存储插入数据 61 T temp = data; 62 int currendIndex = size - 1; //加入当前有五个元素,那么最后的元素下标为4 63 int parentIndex; //当前父结点下标 64 //1.4循环比较当前位置a和其父结点b位置是否满足父小于子 65 //如果满足或b没有父了则循环结束,否则让结点b位置的数字替代a结点中的数字 66 //注:a结点是位置放的是要插入的数字 67 //当前下标为0则循环结束 68 while (currendIndex) 69 { 70 parentIndex = (currendIndex - 1) / 2; //在计算机中(currendIndex-1)/2=(currendIndex-2)/2,所以不用分currendIndex是左结点下标还是右结点下标 71 if (pBuff[parentIndex] > temp) //如果当前结点的父节点大于要插入的数,则冲突 72 { 73 pBuff[currendIndex] = pBuff[parentIndex]; //用当前节结点的父结点替代当前结点中的数 74 } 75 else 76 { 77 break; //如果不冲突跳出循环 78 } 79 currendIndex = parentIndex; //下标向上移动 80 } 81 //1.5临时存储的新插入数据覆盖当前位置 82 pBuff[currendIndex] = temp; 83 //_travel(); //打印数据 84 } 85 86 template <class T> 87 T MyHeap<T>::deleteMinData() 88 { 89 if (size == 0) 90 return 0; 91 T minData = pBuff[0]; //保存栈顶即最小元素 92 //T lastData = pBuff[size--]; //刚才这一句写成这个样子导致lastData没有值,这是因为数组中一共有size个数,最后一个数的下标是size-1 93 T lastData = pBuff[--size]; //将堆中最后一个元素赋值给lastData后,size自减1,这是由于删除堆顶元素后,堆数组内元素减少1 94 int currnetIndex = 0; //当前元素(栈顶元素)的下标,即0 95 int i, child; //child为结点i的左结点或右结点 96 for (i = currnetIndex; 2 * i + 1 < size; i = child) 97 { 98 child = 2 * i + 1; //设置child为结点i的左结点 99 if (child != size && pBuff[child] > pBuff[child + 1]) 100 child++; //如果当前结点的右结点小于左结点,那么让child成为右结点 101 if (pBuff[child] < lastData) 102 pBuff[i] = pBuff[child]; //如果堆数组中最后一个元素大于当前节点i左结点或者是右结点中较小的一个数字,那么说明需要将左结点或者是右结点中较小的一个数字填充在当前节点i上 103 else 104 break; //否则说明数组中最后一个元素比当前节点i左结点或者是右结点中较小的一个数字还要小,那么当前结点的索引i就是要存放lastData的地方 105 } //执行完for循环后,就找到了一个结点i来存放lastData 106 pBuff[i] = lastData; 107 108 return minData; 109 } 110 111 //4、打印数组中的元素 112 template <class T> 113 void MyHeap<T>::_travel() 114 { 115 cout << "heap:"; 116 for (int i = 0; i < size; i++) 117 cout << pBuff[i] << " "; 118 cout << endl; 119 } 120 121 //删除堆顶元素,即删除堆中最小元素 122 //删除堆顶元素后,需要补一个元素进来,那么就首先考虑堆数组中的最后一个元素lastData,但是也不知直接将堆数组中最后一个元素直接赋值 123 //到堆顶,而是先将lastData存起来。然后进行如下的判断:如果lastData大于堆顶元素左结点和右结点中较小的一个结点值,说明当前堆顶不可以放 124 //lastData,可以将(堆顶元素左结点和右结点中较小的一个结点值)放在堆顶,然后继续判断(堆顶元素左结点和右结点中较小的一个结点)的左右结点和lastData 125 //的大小关系,直到找到lastData小于(当前结点i的左右结点较小的一个值),那么结点i就是lastData要存放的地址。
1 #include <iostream> 2 #include "MyHeap.h" 3 4 using namespace std; 5 6 int main() 7 { 8 MyHeap<int> heap; 9 int arr[] = { 32,21,16,24,31,19,68,13,20 }; 10 cout << "堆排序前: \n"; 11 for (int i = 0; i < 9;i++) 12 cout << arr[i] << " "; 13 cout << "\n堆排序后:\n"; 14 for(int i=0;i<sizeof(arr)/sizeof(arr[0]);i++) 15 heap.insertDataToHeap(arr[i]); 16 heap._travel(); 17 int temp = heap.deleteMinData(); //删除堆顶元素 18 cout << "删除堆顶元素后:\n"; 19 heap._travel(); 20 21 system("pause"); 22 return 0; 23 }
测试结果:
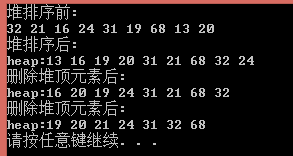
3、总结
/* 总结(堆数组的插入和删除,以小顶堆为例) 01)堆数组插入一个元素(实际上执行的是堆中新开辟的一个结点执行上滤的操作) 堆数组插入一个元素是将要堆中新开辟的一个结点执行上滤操作。假如要插入的数据为data,首先将该数据放在一个临时存储区temp,然后 然后找到堆中最后一个结点的父结点(结点1),加入结点1的数据大于temp,那么将结点1移动到堆中最后一个结点;然后比较结点1的 父结点(结点2)和temp的大小,假如结点2中的数据大于temp,则将结点2赋值到结点1,以此类推,直到找到一个结点i,结点i的父 结点小于temp,将temp赋值到结点i; 02)堆数组删一个元素(实际上执行的是堆顶结点执行下滤的操作) 堆顶元素被删除,那么我们可以选择堆数组中最后一个元素来弥补这个空缺的位置,但并不是直接将堆数组最后一个元素插入到堆顶就完了。 假如堆中最后一个元素比堆顶结点的左右结点中较小的一个数还要小,那么就将堆中最后一个元素放在堆顶; 假如堆中最后一个元素比堆顶结点的左右结点中较小的一个数还要大,那么将顶结点的左右结点中较小的一个数插入到堆顶,假如是左结点较小 那么再比较该左结点的左右结点和temp的大小,直到找到一个结点i,最后一个元素比结点i的左右结点中较小的一个数还要小,那么我们就将堆 中最后一个元素放在结点i。 */
16、二分法
1、二分法查找简答实现
1 //二分法查找简答实现 2 #include <iostream> 3 #include <vector> 4 #include <algorithm> 5 6 using namespace std; 7 8 int main() 9 { 10 vector<int> value = { 24,56,72,49,15,37,28,57,83,12,32,20,18 }; 11 int target = 56; 12 sort(value.begin(), value.end()); //将数组value进行从小到大排序 13 for (int i = 0; i < value.size(); i++) 14 cout << value[i] << " "; 15 cout << endl; 16 int i = 0; 17 int j = value.size() - 1; 18 while (i <= j) 19 { 20 int mid = (i + j) / 2; //找出中间的Index 21 if (value[mid] < target) 22 i = mid + 1; 23 else if (value[mid] > target) 24 j = mid - 1; 25 else if (value[mid] == target) 26 { 27 cout << mid << endl; 28 system("pause"); 29 return value[mid]; 30 } 31 } 32 33 system("pause"); 34 return 0; 35 }
执行结果:

2、实例:求f(x) = x ^ 3 - x - 1在[1,1.5]内的一个实根,使误差不超过0.005。
1 //实例: 2 //求f(x) = x ^ 3 - x - 1在[1,1.5]内的一个实根,使误差不超过0.005。 3 #include <iostream> 4 #include <math.h> 5 6 using namespace std; 7 8 float getValue(float & x) 9 { 10 return x * x*x - x - 1; 11 } 12 13 int main() 14 { 15 float error = 0.0005f; //加f是为了防止"“初始化”: 从“double”到“float”截断"警告 16 float low = 1.0f; 17 float high = 1.5f; 18 float middle=0.0f; //小数点后9个数字 19 double test = 1.8; //小数点后16个数字 20 21 while (fabs((high-low))>=error) //区间缩小在error内,则解一定是在这个区间内了 22 { 23 middle = (low + high) / 2; 24 if ((getValue(middle)*getValue(low)) < 0) //说明在区间[low,middle]内有解,则缩小区间让high=middle 25 high = middle; 26 else 27 low = middle; 28 } 29 cout << "该方程的解是:" << middle << endl; 30 31 system("pause"); 32 return 0; 33 }
运行结果:

3、远亲不如紧邻笔试题---使用二分法实现
1 class Solution { 2 public: 3 /** 4 * 远亲不如近邻 5 * @param n int整型 居民个数 6 * @param m int整型 方案个数 7 * @param a int整型vector 居民的位置 8 * @param x int整型vector 方案对应的位置 9 * @return int整型vector 10 */ 11 //其中n为居民个数(邻居个数),数组a为邻居的位置,target为居住方案对应的位置之一 12 int TwoDivid(int n,vector<int>& a,int target) 13 { 14 int low=0; 15 int high=n-1; 16 int middle; 17 sort(a.begin(),a.end()); 18 while(low<high) 19 { 20 middle=(low+high)/2; 21 if(a[middle]<target) 22 low=middle+1; 23 if(a[middle]>target) 24 high=middle-1; 25 } 26 return a[middle]; 27 } 28 vector<int> solve(int n, int m, vector<int>& a, vector<int>& x) 29 { 30 vector<int> disShortest(m); //刚刚由于没有给disShortest初始化数据的个数,导致在使用disShortest[j++]报错数组越界 31 int j=0; 32 for(int i=0;i<m;i++) 33 { 34 int value=TwoDivid(n,a,x[i]); 35 disShortest[j++]=abs((x[i]-value)); 36 } 37 return disShortest; 38 } 39 };
1 class Solution { 2 public: 3 /** 4 * 远亲不如近邻 5 * @param n int整型 居民个数 6 * @param m int整型 方案个数 7 * @param a int整型vector 居民的位置 8 * @param x int整型vector 方案对应的位置 9 * @return int整型vector 10 */ 11 //其中n为居民个数(邻居个数),数组a为邻居的位置,target为居住方案对应的位置之一 12 int TwoDivid(int n,vector<int>& a,int target) 13 { 14 int low=0; 15 int high=n-1; 16 int middle; 17 int temp=2e9; //加入一个很大的数字,以便于在第一次取最小值的时候不取该值 18 sort(a.begin(),a.end()); 19 /* 20 01)查找a中最小的大于等于target的位置 21 02)由于是找最小的大于等于target的位置,那么只需要在[low,middle]区间内招一个位置和target最接近即可 22 */ 23 if(a[0]>target) //此时a数组是从小到大已经排序好了的,如果a数组中第一个数都比target大,那么就不需要二分查找了 24 temp=a[0]-target; 25 else 26 { 27 while(low<high) 28 { 29 //middle=(low+high)/2; 30 middle=(low+high)>>1; 31 if(a[middle]<=target) 32 { 33 temp=min(temp,target-a[middle]); //由于是找最小的大于等于target的位置,那么只需要在[low,middle]区间内招一个位置和target最接近即可 34 low=middle+1; 35 } 36 //if(a[middle]>target) 37 else 38 high=middle-1; //由于是找最小的大于等于target的位置,那么在[middle,high]区间内没必要再去取最小值 39 } 40 } 41 42 /*查找a中最大的小于等于target的位置*/ 43 if(a[n-1]<target) //此时a数组是从小到大已经排序好了的,如果a数组中最后一个数都比target小,那么就不需要二分查找了 44 temp=min(temp,target-a[n-1]);//min()中的temp是上面的temp结果 45 else 46 { 47 low=0; 48 high=n-1; 49 while(low<high) 50 { 51 //middle=(low+high)/2; 52 middle=(low+high)>>1; 53 if(a[middle]<target) 54 low=middle+1; 55 //if(a[middle]>=target) 56 else 57 { 58 temp=min(temp,a[middle]-target); 59 high=middle-1; 60 } 61 } 62 } 63 return temp; 64 } 65 vector<int> solve(int n, int m, vector<int>& a, vector<int>& x) 66 { 67 vector<int> disShortest(m); //刚刚由于没有给disShortest初始化数据的个数,导致在使用disShortest[j++]报错数组越界 68 int j=0; 69 for(int i=0;i<m;i++) 70 { 71 int value=TwoDivid(n,a,x[i]); 72 disShortest[j++]=value; 73 } 74 return disShortest; 75 } 76 };
这个通过率为75%,运行时间超时,但是这个和标准答案差不了哪儿了
对于二分法,首先要有一个数组,这个数组的大小是已知的,即区间范围[a,b]是已知的,那么令low=a,high=b,并对a数组进行排序 一般使用vector数组,那么排序的方法为sort(a.begin(),a.end()) 在循环里面令middle=(low+high)/2;判断target和a[middle]的大小: 01)如果target>a[middle],则说明target在[middle,high]之间,令low=middle+1; 02)如果target<a[middle],则说明target在[low,middle]之间,令high=middle-1; 循环结束的条件为low>high,则进入循环体的条件为low>=high。在不断地循环的同时,也可以找到target和a[middle]的最小值,即 "远亲不如近邻"这道题。
4、移位与乘除法的关系
a=a*4; 可以替换为:a=a<<2;
b=b/4; 可以替换为:b=b>>2;
说明:
除2 = 右移1位 乘2 = 左移1位
除4 = 右移2位 乘4 = 左移2位
除8 = 右移3位 乘8 = 左移3位
a=a*9
分析a*9可以拆分成a*(8+1)即a*8+a*1, 因此可以改为: a=(a<<3)+a
a=a*7
分析a*7可以拆分成a*(8-1)即a*8-a*1, 因此可以改为: a=(a<<3)-a
2、有符号数据类型的移位操作
对于char、short、int、long这些有符号的数据类型:
对负数进行左移:符号位始终为1,其他位左移
对正数进行左移:所有位左移,即 <<,可能会变成负数
对负数进行右移:取绝对值,然后右移,再取相反数
对正数进行右移:所有位右移,即 >>
3、无符号数据类型的移位操作
对于unsigned char、unsigned short、unsigned int、unsigned long这些无符号数据类型:
参考博客:https://blog.csdn.net/newbird105/article/details/45332621
17、使用stringstream类将string类型转换为int、float、double等类型
1 //使用stringstream类将string类型转换为int、float、double等类型 2 #include <iostream> 3 #include <string> 4 #include <sstream> 5 #include <vector> 6 7 using namespace std; 8 9 string value = "12.2354"; 10 string value2 = "154.122"; 11 vector<string> value3 = { "32.11","68.234","123.32","09.56" }; 12 13 14 int main() 15 { 16 double v1 = atof("23.1"); //atof(char*)即atof()参数只能是char类型的,这个是c语言中的函数 17 cout << v1 << endl; 18 19 stringstream ss(value); 20 float v2; 21 ss >> v2; 22 cout << v2 << endl; 23 24 stringstream ss2(value2); 25 int v3; 26 ss2 >> v3; 27 cout << v3 << endl; 28 29 vector<float> v4(value3.size()); //必须制定v4的大小,否则在使用v4[j++]的时候会报错数组越界 30 int j = 0; 31 cout << "string类型: "; 32 for (int i = 0; i < value3.size(); i++) 33 { 34 stringstream ss3(value3[i]); 35 ss3 >> v4[j++]; 36 cout << value3[i] << ","; 37 } 38 cout << endl; 39 cout << "float类型(对string类型加1): "; 40 for (int i = 0; i < v4.size(); i++) 41 cout << v4[i]+1 << ","; 42 cout << endl; 43 44 45 system("pause"); 46 return 0; 47 }
运行结果:
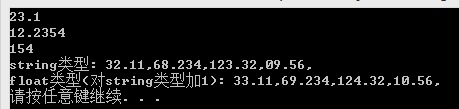
18、归并排序原理和C++实现
实现原理:采用分治的思想

具体治(合并)的方法为:这里以最长的合并为例
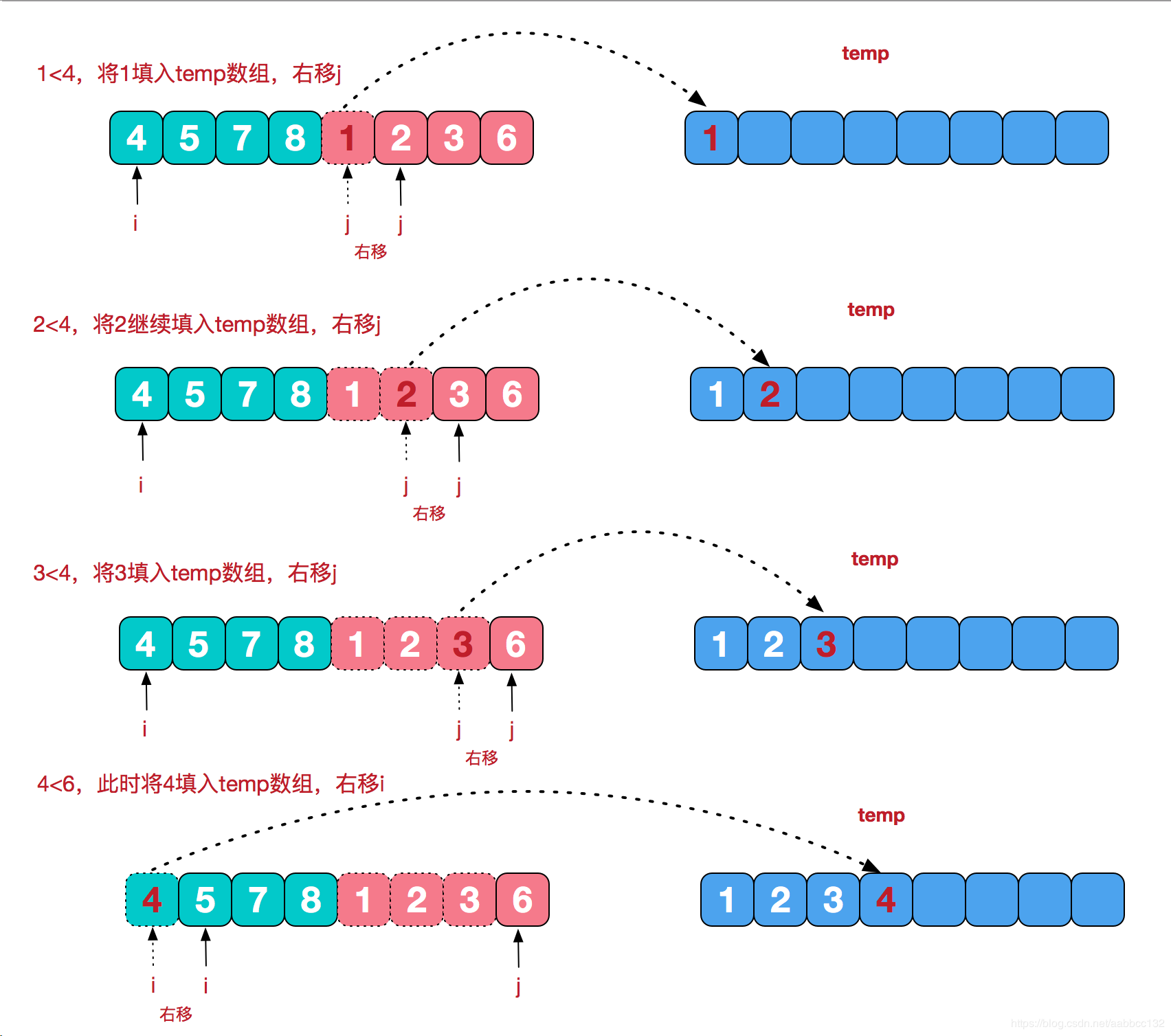
C++实现:
1 //归并排序 2 #include <iostream> 3 4 using namespace std; 5 6 const int maxn = 9; 7 int a[maxn] = { 0,8,4,5,7,1,3,6,2 }; 8 int temp[maxn]; 9 10 void merge(int l, int r, int mid) 11 { 12 int i, j, p; 13 i = l; 14 j = mid; 15 p = l; //p为temp数组的下标 16 17 while (i < mid && j <= r) //i<mid表示数组1还有数字,j<=r表示数组2还有数字 18 { 19 if (a[i] < a[j]) 20 temp[p++] = a[i++]; //把较小的元素放到temp中去 21 else 22 temp[p++] = a[j++]; //否则将 23 } 24 //还有可能i<mid && j<=r只满足一个 25 //i<mid表示数组1还有数字,数组2已经没有数字 26 while (i < mid) 27 temp[p++] = a[i++]; 28 //j<=r表示数组2还有数字,数组1已经没有数字 29 while (j <= r) 30 temp[p++] = a[j++]; 31 p = l; i = l; 32 while (p <= r) 33 a[i++] = temp[p++]; //将temp数组中的数据copy到a数组中 34 } 35 36 void merge_sort(int l, int r) 37 { 38 if (l < r) 39 { 40 int mid = (l + r) / 2; 41 merge_sort(l, mid); 42 merge_sort(mid + 1, r); 43 44 merge(l, r, mid + 1); //合并,mid+1表示后边那个矩阵的第一个下标 45 } 46 } 47 48 49 int main() 50 { 51 merge_sort(0, 8); 52 for (int i = 0; i < maxn; i++) 53 cout << a[i] << " "; 54 cout << endl; 55 56 system("pause"); 57 return 0; 58 }
19、插入排序
原理即将p指向的元素,向前移动,直到找到一个合适的位置
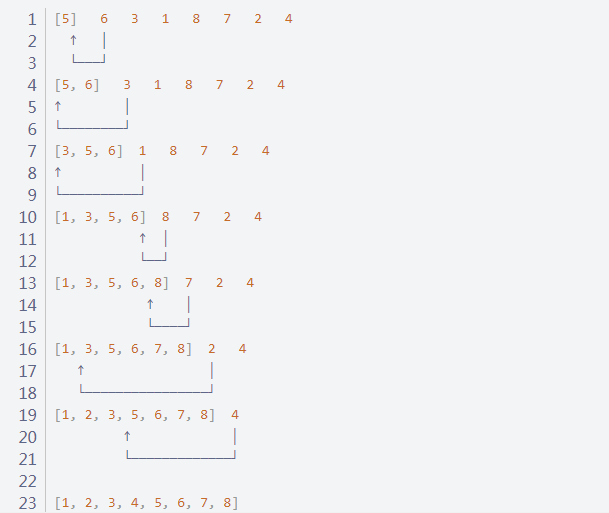
1 //插入排序 2 #include <iostream> 3 4 using namespace std; 5 6 void swap(int & a, int & b) 7 { 8 int temp = a; 9 a = b; 10 b = temp; 11 } 12 13 //arr为待排序数组,N为数组内元素个数 14 void insertSort(int* arr, int N) 15 { 16 for (int i = 1; i < N; i++) 17 { 18 for (int j = i - 1; j >= 0 && arr[j] > arr[j + 1]; j--)//如果数组arr中前一个元素arr[i]比后一个元素arr[j+1]大,则交换二者的位置 19 { 20 swap(arr[j], arr[j + 1]);//相当于将小的值不断的移动到靠前的位置 21 } 22 } 23 } 24 25 int main() 26 { 27 const int N = 10; 28 int arr[N] = { 2,1,4,5,3,8,7,9,0,6 }; 29 30 insertSort(arr, N); 31 32 for (int i = 0; i < N; i++) 33 cout << arr[i] << " "; 34 cout << endl; 35 36 system("pause"); 37 return 0; 38 }

插入排序原理,其中N为要排序的数组内元素的个数:
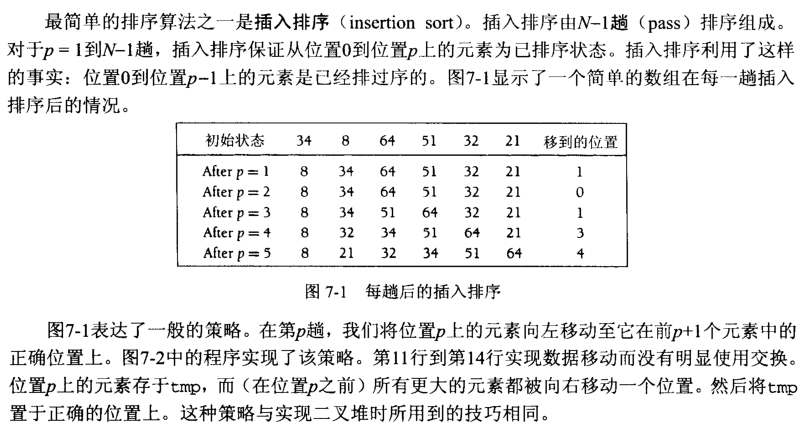
按照上图的思路重新整理的插入排序算法实现:
1 void insertsort(vector<int>& vec) { 2 for (int i = 1; i < vec.size(); ++i) { 3 for (int p = i; p > 0 && vec[p] < vec[p - 1]; --p) { 4 swap(vec[p], vec[p - 1]); 5 } 6 } 7 }
希尔排序(shell排序)m19000
shell排序在不相邻的元素之间比较和交换。利用了插入排序的最佳时间代价特性,它试图将待排序序列变成基本有序的,然后再用插入排序来完成排序工作。
在执行每一次循环时,Shell排序把序列分为互不相连的子序列,并使各个子序列中的元素在整个数组中的间距相同,每个子序列用插入排序进行排序。
举例说明:
以一个整数序列为例来说明{12,45,90,1,34,87,-3,822,23,-222,32},该组序列包含N=11个数。不少已有的说明中通常举例10个数,这里说明一下,排序算法与序列元素个数无关!
首先声明一个参数:增量gap。gap初始值设置为N/2。缩小方式一般为gap=gap/2.
第一步,gap=N/2=5,每间隔5个元素取一个数,组成一组,一共得到5组: 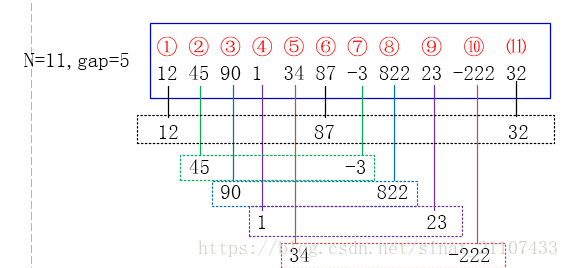
对每组使用插入排序算法,得到每组的有序数列:
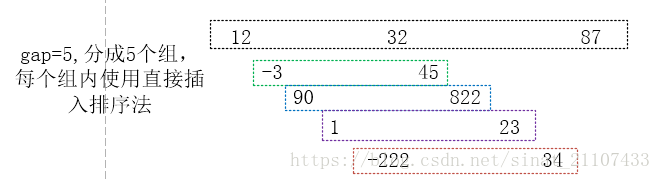
至此,数列已变为:
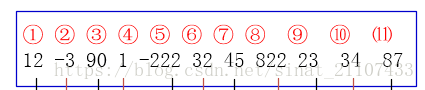
第二步,缩小gap,gap=gap/2=2,每间隔2取一个数,组成一组,共两组:
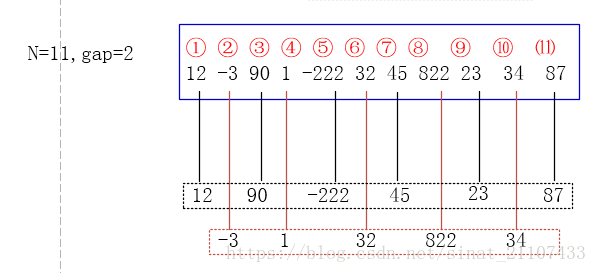
同理,分别使用插入排序法,得到每组的有序数列:
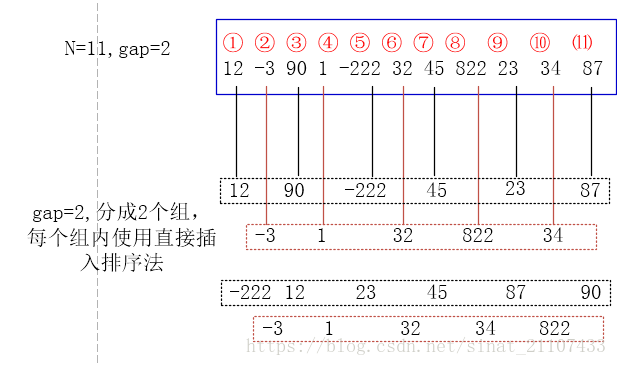
至此,数列已变为:
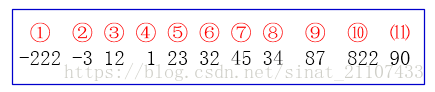
第三步,进一步缩小gap,gap=gap/2=1,此时只有一组,直接使用插入排序法,玩完成排序,图略。
即shell排序先让一组内的数据有序(也是使用插入排序),然后再使用插入排序对整组的数据排序
图片描述:下面的图中一共10个数据,故gap=5
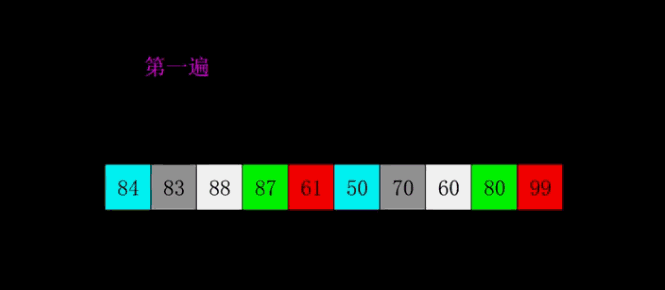
1 #include <iostream> 2 #include <vector> 3 using namespace std; 4 5 void shellsort(vector<int> & vec) { 6 int gap = vec.size() / 2; 7 while (gap >= 1) { 8 for (int i = gap; i < vec.size(); ++i) { 9 int tmp = vec[i]; 10 int j; 11 for (j = i; j >= gap && tmp < vec[j - gap]; j -= gap) 12 vec[j] = vec[j - gap]; 13 vec[j] = tmp; 14 } 15 gap /= 2; 16 } 17 } 18 19 void insertsort(vector<int>& vec) { 20 for (int i = 1; i < vec.size(); ++i) { 21 for (int p = i; p > 0 && vec[p] < vec[p - 1]; --p) { 22 swap(vec[p], vec[p - 1]); 23 } 24 } 25 } 26 27 int main() { 28 vector<int> vec = { 9,10,5,6,4,7,8,22,0,1,33 }; 29 shellsort(vec); 30 for (int i = 0; i < vec.size(); ++i) 31 cout << vec[i] << " "; 32 cout << endl; 33 34 system("pause"); 35 return 0; 36 }
执行结果:
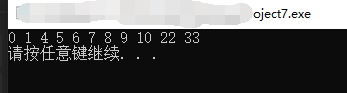
根据自己的理解写的插入排序和shell排序
1 #include <iostream> 2 #include <vector> 3 using namespace std; 4 5 void insertSort(vector<int> & vec) { 6 for (int i = 1; i < vec.size(); ++i) { 7 for (int j = i; j >0 && vec[j]<vec[j-1]; --j) { 8 swap(vec[j], vec[j - 1]); 9 } 10 } 11 } 12 13 void shellSort(vector<int> & vec) { 14 int gap = vec.size() / 2; 15 while (gap >= 1) { 16 for (int i = gap; i < vec.size(); ++i) { 17 for (int j = i; j >= gap && vec[j] < vec[j - gap]; j -= gap) { 18 swap(vec[j], vec[j - gap]); 19 } 20 } 21 gap /= 2; 22 } 23 } 24 25 int main() { 26 27 vector<int> vec = { 23,11,4,46,34,18,90 }; 28 shellSort(vec); 29 for (int i = 0; i < vec.size(); ++i) 30 cout << vec[i] << " "; 31 cout << endl; 32 33 system("pause"); 34 return 0; 35 }
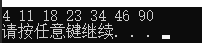
20、单调栈
从名字上就听的出来,单调栈中存放的数据应该是有序的,所以单调栈也分为单调递增栈和单调递减栈
- 单调递增栈:数据出栈的序列为单调递增序列
- 单调递减栈:数据出栈的序列为单调递减序列
ps:这里一定要注意所说的递增递减指的是出栈的顺序,而不是在栈中数据的顺序
现在有一组数10,3,7,4,12。从左到右依次入栈,则如果栈为空或入栈元素值小于栈顶元素值,则入栈;否则,如果入栈则会破坏栈的单调性,则需要把比入栈元素小的元素全部出栈。单调递减的栈反之。
- 10入栈时,栈为空,直接入栈,栈内元素为10。
- 3入栈时,栈顶元素10比3大,则入栈,栈内元素为10,3。
- 7入栈时,栈顶元素3比7小,则栈顶元素出栈,此时栈顶元素为10,比7大,则7入栈,栈内元素为10,7。
- 4入栈时,栈顶元素7比4大,则入栈,栈内元素为10,7,4。
- 12入栈时,栈顶元素4比12小,4出栈,此时栈顶元素为7,仍比12小,栈顶元素7继续出栈,此时栈顶元素为10,仍比12小,10出栈,此时栈为空,12入栈,栈内元素为12。
单调栈的伪代码:
1 stack<int> st; 2 //此处一般需要给数组最后添加结束标志符,具体下面例题会有详细讲解 3 for (遍历这个数组) 4 { 5 while (栈不为空 && 栈顶元素小于当前元素) 6 { 7 栈顶元素出栈; 8 更新结果; 9 } 10 当前数据入栈; 11 }
(1)单调栈的应用---逛街
输入描述:
示例输入:
6 5 3 8 3 2 5
示例输出:
3 3 5 4 4 4
说明:
当小Q处于位置3时,他可以向前看到位置2,1处的楼,向后看到位置4,6处的楼,加上第3栋楼,共可看到5栋楼。当小Q处于位置4时,他可以向前看到位置3处的楼,向后看到位置5,6处的楼,加上第4栋楼,共可看到4栋楼
1 #include <iostream> 2 #include <stack> 3 #include <vector> 4 using namespace std; 5 6 int main() { 7 int n; 8 cin >> n; 9 int arr[100001]; 10 stack<int> sta; 11 vector<int> left(n); //保存向左可以看到的楼的个数 12 vector<int> right(n); //保存向右可以看到的楼的个数 13 for (int i = 0; i < n; ++i) 14 cin >> arr[i]; 15 //向左看(构建单调递增栈,但实际上在栈中存储的顺序是单调递减的) 16 for (int i = 0; i < n; ++i) { 17 //left.push_back(sta.size()); 18 left[i] = sta.size(); //left从0到n-1开始填充数据 19 while (!sta.empty() && sta.top() <= arr[i]) { //如果栈不为空,且当前元素大于栈顶元素 20 sta.pop(); //将栈顶元素出栈 21 } 22 sta.push(arr[i]); 23 } 24 //清空栈 25 while (!sta.empty()) 26 sta.pop(); 27 //向右看 28 for (int i = n - 1; i >= 0; --i) { 29 right[i]=sta.size(); 30 while (!sta.empty() && sta.top() <= arr[i]) { 31 sta.pop(); 32 } 33 sta.push(arr[i]); 34 } 35 //输出结果 36 for (int i = 0; i < n; ++i) 37 cout << left[i] + right[i] + 1 << " "; 38 system("pause"); 39 return 0; 40 }

