
C++中一些散碎的知识点_int **指针与二维数组问题_memset()和memcpy()_C++中vector的介绍_C++读txt中数据到一个vector中_C++ split分割字符串函数_随机函数初始化函数srand_关于getline()_istringstream的用法_迭代器_正则表达式_Qt中的foreach()_strlen()和sizeof的区别
目录
4、C++读txt中数据到一个vector中 *****
7、关于getline()函数:分在<istream>中的getline()和在<string>中的getline()
(5)regex_replace()函数 涉及到交换字符串中两个正则表达式代表的内容
15、printf中只有%d没有后面的参数会怎么样 附上了printf()中参数的执行过程
18、algorithm头文件中的sort()排序函数使用方法
20、C++中的to_string()---将int、long、double、float等转换成string
1、int **指针与二维数组问题
01)定义二维数组方法:
int matrix[ROWS][COLUMNS]; //定义一个二维数组,其中ROWS和COLUMNS为常数
02)加入有如下声明的子函数:
void printMatrix(int ** numbers,int rows,int columns);
03)如果直接使用如下方法调用,是错误的;
printMatrix(matrix,ROWS,COLUMNS); //直接这样调用时错误的
原因在于matrix是 int (*)[COLUMNS]类型的,但是函数printMatrix需要的是int **类型的,这两者明显不匹配。
int **从类型上讲是一个指向整型指针的指针,那么如果想要用它来表示一个矩阵需要怎么做呢?因为它的元素是一个指针,如果如果它的每一个元素都表示矩阵的一行,那么它就可以用来表示一个矩阵了。实现代码如下:


1 //生成矩阵 2 int ** generateMatrix(int rows,int columns) 3 { 4 int **numbers=new int*[rows]; 5 for(int i=0;i<rows;i++){ 6 numbers[i]=new int[columns]; 7 for(int j=0;j<columns;j++) 8 numbers[i][j]=i*columns+j; 9 } 10 return numbers; 11 }
把int*当做一个整体。它表示创建了一个大小为rows的数组,这个数组的每一个元素代表一个指针。内存布局如下:
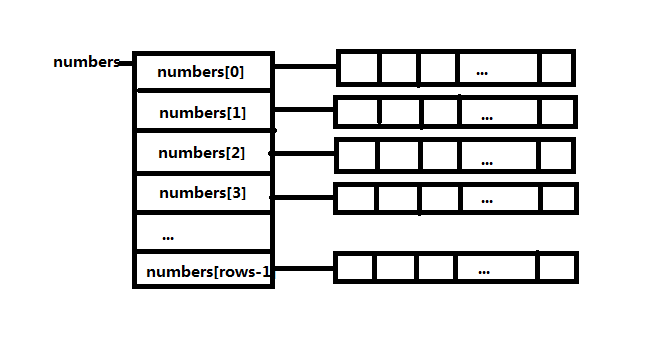
这里numbers是一个指向指针的指针,能够用numbers用来表示矩阵的关键就在于使用new关键字分配的内存是连续的,这样number[i]的地址就可以根据numbers的地址计算出来,因为指针变量占据4个字节的内存区域(32位机器)。如果不使用上面的方式分配内存,numbers就真的只是一个指向指针的指针了
04)正确使用printMatrix(matrix,ROWS,COLUMNS)的测试代码:
1 #include <stdlib.h> 2 #include <stdio.h> 3 #include <iostream> 4 //打印矩阵 5 void printMatrix(int ** numbers,int rows,int columns){ 6 for(int i=0;i<rows;i++) 7 { 8 for(int j=0;j<columns;j++) 9 std::cout<<numbers[i][j]<<" "; 10 std::cout<<std::endl; 11 } 12 } 13 14 //生成矩阵 15 int ** generateMatrix(int rows,int columns) 16 { 17 int **numbers=new int*[rows]; 18 for(int i=0;i<rows;i++){ 19 numbers[i]=new int[columns]; 20 for(int j=0;j<columns;j++) 21 numbers[i][j]=i*columns+j; 22 } 23 return numbers; 24 } 25 int main(){ 26 int **numbers=generateMatrix(4,5); 27 printMatrix(numbers,4,5); 28 //释放内存 29 for(int i=0;i<4;i++) 30 delete [] numbers[i]; 31 delete numbers; 32 return 0;
参考博客:
https://www.cnblogs.com/lpxblog/tag/C%2B%2B%E9%9D%A2%E8%AF%95%E9%A2%98/
2、memset()和memcpy()
一、memset()用法
void *memset(void *s,int c,size_t n)
作用:将已开辟内存空间 s 的首 n 个字节的值设为值 c(给空间初始化)
C语言需要包含头文件string.h;C++需要包含cstring 或 string.h
1 #include <string.h> 2 3 #include <stdio.h> 4 5 #include <memory.h> 6 7 int main(void) 8 9 { 10 11 char buffer[] = "Hello world\n"; 12 13 printf("Buffer before memset: %s\n", buffer); 14 15 memset(buffer, '*', strlen(buffer) ); 16 17 printf("Buffer after memset: %s\n", buffer); 18 19 return 0; 20 21 }
输出结果:
Buffer before memset: Hello world
Buffer after memset: ***********
memset() 函数常用于内存空间初始化。如:
char str[100];
memset(str,0,100);
memset()错误用法:
1 int main(void) 2 3 { 4 5 char *buffer = "Hello world\n"; 6 7 printf("Buffer before memset: %s\n", buffer); 8 9 memset(buffer, '*', strlen(buffer) ); 10 11 printf("Buffer after memset: %s\n", buffer); 12 13 return 0; 14 15 }
报错原因:char * buffer = "Hello world\n"; 字符串"Hello world\n"存在于只读存储区,其内容不能被随意更改!!!!
二、memcpy()函数用法
void *memcpy(void *dest, const void *src, size_t n);
C语言需要包含头文件string.h;C++需要包含cstring 或 string.h。
用法:用来将src地址处的内容拷贝n个字节的数据至目标地址dest指向的内存中去。函数返回指向dest的指针。
示例1:
作用:将s中的字符串复制到字符数组d中
1 #include <stdio.h> 2 #include <string.h> 3 int main() 4 { 5 char *s="Golden Global View"; 6 char d[20]; 7 clrscr(); 8 memcpy(d,s,( strlen(s)+1) ); 9 printf("%s",d); 10 getchar(); 11 return 0; 12 } 13 输出结果:Golden Global View
示例2:
作用:将s中第14个字符开始的4个连续字符复制到d中。(从0开始)
1 #include <string.h> 2 int main( 3 { 4 char *s="Golden Global View"; 5 char d[20]; 6 memcpy(d,s+14,4); //从第14个字符(V)开始复制,连续复制4个字符(View) //memcpy(d,s+14*sizeof(char),4*sizeof(char));也可 7 d[4]='\0'; 8 printf("%s",d); 9 getchar(); 10 return 0; 11 } 12 输出结果: View
示例3:
作用:复制后覆盖原有部分数据;
1 #include <stdio.h> 2 #include <string.h> 3 int main(void) 4 { 5 char src[] = "******************************"; 6 char dest[] = "abcdefghijlkmnopqrstuvwxyz0123as6"; 7 printf("destination before memcpy: %s\n", dest); 8 memcpy(dest, src, strlen(src)); 9 printf("destination after memcpy: %s\n", dest); 10 return 0; 11 } 12 输出结果: 13 destination before memcpy:abcdefghijlkmnopqrstuvwxyz0123as6 14 destination after memcpy: ******************************as6
三、注意事项:
memcpy用来做内存拷贝,你可以拿它拷贝任何数据类型的对象,可以指定拷贝的数据长度;例:char a[100],b[50]; memcpy(b, a, sizeof(b));注意如用sizeof(a),会造成b的内存溢出。
另外:strcpy只能拷贝字符串,它遇到'\0'就结束拷贝;例:char a[100],b[50];strcpy(a,b);如用strcpy(b,a),要注意a中的字符串长度(第一个‘\0’之前)是否超过50位,如超过,则会造成b的内存溢出。会造成缓冲区溢出,轻者程序崩溃,重者系统会出现问题!!
3、C++中vector的介绍
1)相关头文件和命名域
在使用它时, 需要包含头文件 vector, 即: #include<vector>
vector属于std命名域的,因此需要通过命名限定,如下完成你的代码:using std::vector;
2)、vector向量声明和初始化
1 vector<int> a ; //声明一个int型向量a 2 vector<int> a(10) ; //声明一个初始大小为10的向量 3 vector<int> a(10, 1) ; //声明一个初始大小为10且初始值都为1的向量 4 vector<int> b(a) ; //声明并用向量a初始化向量b 5 vector<int> b(a.begin(), a.begin()+3) ; //将a向量中从第0个到第2个(共3个)作为向量b的初始值
除此之外, 还可以直接使用数组来初始化向量:
1 int n[] = {1, 2, 3, 4, 5} ; 2 vector<int> a(n, n+5) ; //将数组n的前5个元素作为向量a的初值 3 vector<int> a(&n[1], &n[4]) ; //将n[1] - n[4]范围内的元素作为向量a的初值
3)、元素输入和输出
1 #include<iostream> 2 #include<vector> 3 4 using namespace std ; 5 6 int main() 7 { 8 vector<int> a(10, 0) ; //大小为10初值为0的向量a 9 10 //对其中部分元素进行输入 11 cin >>a[2] ; 12 cin >>a[5] ; 13 cin >>a[6] ; 14 15 //全部输出 16 int i ; 17 for(i=0; i<a.size(); i++) 18 cout<<a[i]<<" " ; 19 20 return 0 ; 21 }
向量元素的位置便成为遍历器, 同时, 向量元素的位置也是一种数据类型, 在向量中遍历器的类型为: vector<int>::iterator。 遍历器不但表示元素位置, 还可以再容器中前后移动。
1 //使用迭代器全部输出 2 vector<int>::iterator t ; 3 for(t=a.begin(); t!=a.end(); t++) //a.begin()表示容器中的第一个元素位置,a.end()表示容器a中最后一个元素位置 4 cout<<*t<<" " ; // *t 为指针的间接访问形式, 意思是访问t所指向的元素值。
4)、向量的基本操作
1 1>. a.size() //获取向量中的元素个数 2 2>. a.empty() //判断向量是否为空 3 3>. a.clear() //清空向量中的元素 4 4>. 复制 a = b ; //将b向量复制到a向量中 5 5>. 比较 6 保持 ==、!=、>、>=、<、<= 的惯有含义 ; 7 如: a == b ; //a向量与b向量比较, 相等则返回1 8 6>. 插入 - insert 9 ①、 a.insert(a.begin(), 1000); //将1000插入到向量a的起始位置前 10 11 ②、 a.insert(a.begin(), 3, 1000) ; //将1000分别插入到向量元素位置的0-2处(共3个元素) 12 13 ③、 vector<int> a(5, 1) ; 14 vector<int> b(10) ; 15 b.insert(b.begin(), a.begin(), a.end()) ; //将a.begin(), a.end()之间的全部元素插入到b.begin()前 16 7>. 删除 - erase 17 ①、 b.erase(b.begin()) ; //将起始位置的元素删除 18 ②、 b.erase(b.begin(), b.begin()+3) ; //将(b.begin(), b.begin()+3)之间的元素删除 19 8>. 交换 - swap 20 b.swap(a) ; //a向量与b向量进行交换
1 c.max_size() // 返回容器中最大数据的数量。 2 c.pop_back() // 删除最后一个数据。 3 c.push_back(elem) // 在尾部加入一个数据。 4 c.rbegin() // 传回一个逆向队列的第一个数据。 5 c.rend() // 传回一个逆向队列的最后一个数据的下一个位置。 6 c.resize(num) // 重新指定队列的长度。 7 c.reserve() // 保留适当的容量。 8 c.size() // 返回容器中实际数据的个数。 9 c1.swap(c2) 10 swap(c1,c2) // 将c1和c2元素互换。同上操作。
加:插入元素: vec.insert(vec.begin()+i,a);在第i+1个元素前面插入a;
删除元素: vec.erase(vec.begin()+2);删除第3个元素
vec.erase(vec.begin()+i,vec.end()+j);删除区间[i,j-1];区间从0开始
向量大小:vec.size();
清空:vec.clear();
5)、和vector相关的算法(以下均需要包含头文件:#include <algorithm>)
1 reverse(vec.begin(),vec.end());将元素翻转,即逆序排列!sort(vec.begin(),vec.end());(默认是按升序排列,即从小到大). 2 /*输出Vector的中的元素 */ 3 /*方法一:*/ 4 vector<float> vecClass; 5 int nSize = vecClass.size(); 6 for(int i=0;i<nSize;i++) 7 { 8 cout<<vecClass[i]<<" "; 9 } 10 cout<<endl; 11 /*方法二:*/ 12 vector<float> vecClass; 13 int nSize = vecClass.size(); 14 for(int i=0;i<nSize;i++) 15 { 16 cout<<vecClass.at(i)<<" "; 17 } 18 cout<<endl; 19 /*方法三:*/ 20 for(vector<float>::iterator it = vecClass.begin();it!=vecClass.end();it++) 21 { 22 cout<<*it<<" "; 23 } 24 cout<<endl;
6)、注意事项
1)、如果你要表示的向量长度较长(需要为向量内部保存很多数),容易导致内存泄漏,而且效率会很低;
2)、Vector作为函数的参数或者返回值时,需要注意它的写法:
double Distance(vector<int>&a, vector<int>&b) 其中的“&”绝对不能少!!!
7)、其他
vector默认构造函数会将容器内的值设置为0
例:
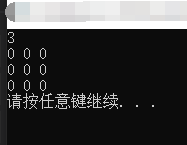
1 #include <iostream> 2 #include <vector> 3 4 using namespace std; 5 6 int mian() 7 { 8 vector<vector<int>> tempResult(L); 9 for (int i = 0; i < tempResult.size(); i++) 10 tempResult[i].resize(L); //resize()函数设置数组大小,会分配内存;reserve()不会分配内存,只是设置容器大小 11 for (int i = 0; i < L; i++) 12 { 13 for (int j = 0; j < L; j++) 14 { 15 cout << tempResult[i][j] << " "; 16 } 17 cout << endl; 18 } 19 20 system("pause"); 21 return 0; 22 }
运行结果:
参考博客:
https://blog.csdn.net/duan19920101/article/details/50617190
https://www.cnblogs.com/aminxu/p/4686332.html
4、C++读txt中数据到一个vector中
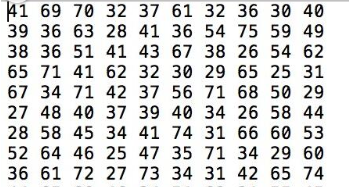
1 #include <iostream> 2 using namespace std; 3 #include <cmath> 4 #include <vector> 5 #include <fstream> 6 7 //将文本文件中得数据读入vector中,并返回一个vector。 8 vector<int> *InputData_To_Vector() 9 { 10 vector<int> *p = new vector<int>; 11 ifstream infile("/Users/……/inputdata.txt"); 12 int number; 13 while(! infile.eof()) 14 { 15 infile >> number; 16 p->push_back(number); 17 } 18 p->pop_back(); //此处要将最后一个数字弹出,是因为上述循环将最后一个数字读取了两次 19 return p; 20 } 21 22 inline int Num_Square(int n) 23 { 24 return n*n; 25 } 26 27 int Sum_Of_Num_Square(vector<int> *p) 28 { 29 int Sum2 = 0; 30 vector<int>::iterator it; 31 for(it=p->begin(); it!=p->end(); it++) 32 { 33 Sum2 += Num_Square(*it); 34 } 35 return Sum2; 36 } 37 38 //调用传入的vector 39 int main(int argc, const char * argv[]) { 40 // insert code here... 41 vector<int> *file_to_vector = InputData_To_Vector(); 42 cout<<"sum2="<<Sum_Of_Num_Square(file_to_vector)<<endl; 43 return 0; 44 } 45
带注释版本:
1 #include <iostream> 2 #include <cmath> 3 #include <vector> 4 #include <fstream> 5 #include <string> 6 7 using namespace std; 8 9 //将文本文件中得数据读入vector中,并返回一个vector。 10 vector<int> *InputData_To_Vector() 11 { 12 vector<int> *p = new vector<int>; 13 ifstream infile("inputdata.txt"); 14 if (infile.peek() == EOF) //若txt为空则peek()返回EOF 15 { 16 cout << "file is empty!" << endl; 17 system("pause"); 18 return 0; 19 } 20 int number; 21 string str; 22 while (!infile.eof()) //若读到文件尾,eof()返回true 23 { 24 //infile >> number; //以空格作为数字和数字之间的分隔符 25 //p->push_back(number); 26 getline(infile, str, '\n'); //若是逗号作为分隔符,则使用getline()输入方法,之后再分割数字 27 cout << str << endl; 28 } 29 //p->pop_back(); //此处要将最后一个数字弹出,是因为上述循环将最后一个数字读取了两次 30 infile.close(); //关闭文件 31 return nullptr; 32 } 33 34 inline int Num_Square(int n) 35 { 36 return n * n; 37 } 38 39 int Sum_Of_Num_Square(vector<int> *p) 40 { 41 int Sum2 = 0; 42 vector<int>::iterator it; 43 for (it = p->begin(); it != p->end(); it++) 44 { 45 Sum2 += Num_Square(*it); 46 } 47 return Sum2; 48 } 49 50 //调用传入的vector 51 int main(int argc, const char * argv[]) { 52 // insert code here... 53 vector<int> *file_to_vector = InputData_To_Vector(); 54 /*for (int i = 0; i < file_to_vector->size(); i++) 55 cout << file_to_vector->at(i) << " "; 56 cout << endl;*/ 57 //cout << "sum2=" << Sum_Of_Num_Square(file_to_vector) << endl; 58 system("pause"); 59 return 0; 60 }
运行结果:
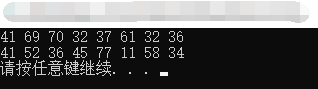
注:在该vs工程目录下有一个inputdata.txt文件内容即为上图中的数字
5、C++ split分割字符串函数
将字符串绑定到输入流istringstream,然后使用getline的第三个参数,自定义使用什么符号进行分割就可以了。
1 #include <iostream> 2 #include <sstream> 3 #include <string> 4 #include <vector> 5 using namespace std; 6 void split(const string& s,vector<int>& sv,const char flag = ' ') { 7 sv.clear(); 8 istringstream iss(s); 9 string temp; 10 11 while (getline(iss, temp, flag)) { 12 sv.push_back(stoi(temp)); 13 } 14 return; 15 } 16 17 int main() { 18 string s("123:456:7"); 19 vector<int> sv; 20 split(s, sv, ':'); 21 for (const auto& s : sv) { 22 cout << s << endl; 23 } 24 system("pause"); 25 return 0; 26 }
注:C++中是没有split()函数的。但是在Qt中是有的
带注释版本:
1 #include <iostream> //for istringstream 2 #include <sstream> 3 #include <string> 4 #include <vector> 5 using namespace std; 6 void split(const string& s, vector<int>& sv, const char flag = ' ') 7 { 8 sv.clear(); 9 istringstream iss(s); //将字符串s中的字符输入到输入流中去,并构造字符串输入流对象iss 10 string temp; 11 12 while (getline(iss, temp, flag)) //将iss中的字符输入到temp中去,以字符串变量flag为分隔符,遇到换行符则结束while循环 13 { 14 sv.push_back(stoi(temp)); //int stoi(const string* str) stoi将数字字符串str转换成十进制并返回 15 } //int atoi(const char* str) atoi将数字字符串str转换成十进制并返回 16 return; //c_str()将string类型的字符串转换成char型的,c_str()是string类下的一个方法 17 } 18 19 int main() 20 { 21 string s("123:456:7"); 22 vector<int> sv; 23 split(s, sv, ':'); 24 for (const auto& str : sv) //str为一个引用变量,即修改str的值也会修改sv中的值 25 { 26 cout << str << endl; //等价于不断输出sv[0]、sv[1]... 27 } 28 system("pause"); 29 return 0; 30 }
参考博客:https://www.cnblogs.com/dingxiaoqiang/p/8228390.html
6、随机函数初始化函数srand
srand函数是随机数发生器的初始化函数,
计算机并不能产生真正的随机数,而是已经编写好的一些无规则排列的数字存储在电脑里,把这些数字划分为若干相等的N份,并为每份加上一个编号用srand()函数获取这个编号,然后rand()就按顺序获取这些数字,当srand()的参数值固定的时候,rand()获得的数也是固定的,所以一般srand的参数用time(NULL),因为系统的时间一直在变,所以rand()获得的数,也就一直在变,相当于是随机数了。
如果想在一个程序中生成随机数序列,需要至多在生成随机数之前设置一次随机种子。 即:只需在主程序开始处调用srand((unsigned)time(NULL)); 后面直接用rand就可以了。不要在for等循环放置srand((unsigned)time(NULL));
参考博客:https://blog.csdn.net/jx232515/article/details/51510336
7、关于getline()函数:分在<istream>中的getline()和在<string>中的getline()
此部分在第五部分中构造split()函数有使用到
(1)在<istream>中的getline()
在<istream>中的getline()函数有两种重载形式:(自己的理解)
1 getline(char* s,streamsize n,char str) 2 getline(char* s,streamsize n)
都是从输入流中读取至多n的字符保存在s中,即使没有读够n个字符,遇到了str,则读取也会终止,str不会保存在s中.
在<istream>中的getline()函数有两种重载形式:(别人的理解)
1 istream& getline (char* s, streamsize n ); 2 istream& getline (char* s, streamsize n, char delim );
从istream中读取至多n个字符(包含结束标记符)保存在s对应的数组中。即使还没读够n个字符,
如果遇到delim或 字数达到限制,则读取终止,delim都不会被保存进s对应的数组中。
(2)在<string>中的getline()
在<string>中的getline函数有四种重载形式:
1 istream& getline (istream& is, string& str, char delim); 2 istream& getline (istream&& is, string& str, char delim); 3 istream& getline (istream& is, string& str); //默认delim = '\n' 4 istream& getline (istream&& is, string& str); //默认delim = '\n'
用法和<istream>中的getlien()类似,但是读取的istream是作为参数is传进函数的。读取的字符串保存在string类型的str中。
函数的变量:
is :表示一个输入流,例如cin。
str :string类型的引用,用来存储输入流中的流信息。
delim :char类型的变量,所设置的截断字符;在不自定义设置的情况下,遇到’\n’,则终止输入。
参考博客:https://blog.csdn.net/qfc8930858/article/details/80957329
8、istringstream的用法
istringstream在第5部分中split()函数的构造中有使用到
istringstream 类用于执行C++风格的串流的输入操作
istringstream用空格作为字符串分隔符
istringstream的构造函数原形如下:
istringstream::istringstream(string str);
它的作用是从string对象str中读取字符。
测试代码:
1 #include<iostream> 2 #include<sstream> //istringstream 必须包含这个头文件 3 #include<string> 4 using namespace std; 5 int main() 6 { 7 string str = "I am a boy"; 8 istringstream is(str); //从str读取字符串到输入流中 9 string s; 10 while (is >> s) //以空格为分隔符,遇到换行符'\n'结束 11 { 12 cout << s << endl; 13 } 14 system("pause"); 15 return 0; 16 }
运行结果:
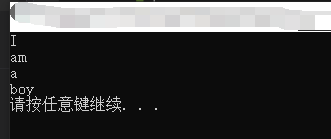
参考博客:https://blog.csdn.net/longzaitianya1989/article/details/52909786
9、迭代器
对于以下代码:
1 vector<string> &strs; 2 for (const auto &s : strs) 3 { 4 //do nothing; 5 }
可以替换为:
1 vector<string> strs; 2 const vector<string>::iterator end_it = strs.end(); 3 4 for (vector<string>::iterator it = strs.begin(); it != end_it; ++it) 5 { 6 const string& s = *it; 7 // Some code here... 8 }
迭代器的几种输出方式:
1 #include<vector> 2 #include<string> 3 #include<iostream> 4 using namespace std; 5 int main() 6 { 7 vector<string> text; 8 string word; 9 while (getline(cin, word)) 10 { //循环读入字符串至vector<string>中,以trl+z回车结束 11 text.push_back(word); 12 } 13 //下标迭代方式输出 14 cout << "下标迭代方式输出" << endl; 15 for (vector<string>::size_type ix = 0; ix != text.size(); ++ix) 16 cout << text[ix] << endl; 17 18 //迭代器方式输出 19 cout << "迭代器方式输出" << endl; 20 for (vector<string>::iterator it = text.begin(); it != text.end(); it++) 21 { 22 cout << *it << endl; 23 } 24 //int result = uniqueMorseRepresentations(text); 25 26 //精简迭代方式输出 27 cout << "精简迭代方式输出" << endl; 28 for (const string& words : text) 29 { 30 cout << words << endl; 31 } 32 getchar(); 33 return 1; 34 }
10、正则表达式
(1)字符表达式常见的字符
\d{1,} 就可以匹配1个或多个数字,等价于\d+,实际上写的时候要写成\\d+,其中第一个\表示转义;
\d{2,3} 可以匹配2~3位的数字
\d{1} 就是刚好1位数字
1 ^[-]?(\\d){1,}\\.(\\d){3}[,]\\s[-]?(\\d){1,}\\.(\\d){4}[e][-](\\d){2}$ 2 3 ^匹配字符串开头 $匹配结尾 -?表示减号可选 (\\d){1,}匹配一个或多个数字,第一个反斜杠表示转义 4 \\.(\\d){3}[,]表示匹配小数点后三个数字再加一个逗号 5 \\s[-]?匹配空格且减号可选,第一个反斜杠还是表示转义:\s表示空格,\表转义 6 7 所以该正则表达式匹配如下所示的数字 8 1.90, -1.3345e-3
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 后向引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 ‘\\' 匹配 "\" 而 "\(" 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n' 或 ‘\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n' 或 ‘\r' 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。 * 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 ‘o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 ‘o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 ‘o+'。'o{0,}' 则等价于 ‘o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。刘, "o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 ‘o?'。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 ‘o+' 将匹配所有 ‘o'。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 ‘\n' 在内的任何字符,请使用象 ‘[.\n]‘ 的模式。 |
| (pattern) | 匹配pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 ‘‘或‘‘或‘'。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, ‘industr(?:y|ies) 就是一个比 ‘industry|industries' 更简略的表达式。 |
| (?=pattern) | 正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如, ‘Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 负向预查,在任何不匹配Negative lookahead matches the search string at any point where a string not matching pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如'Windows (?!95|98|NT|2000)' 能匹配 "Windows 3.1" 中的 "Windows",但不能匹配 "Windows 2000" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
| x|y | 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]‘ 可以匹配 "plain" 中的 ‘a'。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]‘ 可以匹配 "plain" 中的'p'。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,'[a-z]‘ 可以匹配 ‘a' 到 ‘z' 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]‘ 可以匹配任何不在 ‘a' 到 ‘z' 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b' 可以匹配"never" 中的 ‘er',但不能匹配 "verb" 中的 ‘er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 ‘er',但不能匹配 "never" 中的 ‘er'。 |
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。 x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c' 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]‘。 |
| \W | 匹配任何非单词字符。等价于 ‘[^A-Za-z0-9_]‘。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如, ‘\x41′ 匹配 "A"。'\x041′ 则等价于 ‘\x04′ & "1"。正则表达式中可以使用 ASCII 编码。. |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1′ 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个后向引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为后向引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个后向引用。如果 \nm 之前至少有is preceded by at least nm 个获取得子表达式,则 nm 为后向引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的后向引用。如果前面的条件都不满足,若 n 和 m均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
(2)转义字符
如果对正则表达式不清楚可以看这个链接: 参考链接(2)
1 //\d不加转义字符'\' 2 cout << regex_match("123", regex("\d+")) << endl; //结果为0,需要转义字符'\' 3 //\d加转义字符'\' 4 cout << regex_match("123", regex("\\d+")) << endl; //结果为1,完全匹配 如果全部匹配,regex_match()函数返回值为1,否则返回0
- \d:匹配一个数字字符;
- + :匹配一次或多次;
C++中必须要对表达式中的’'进行转义,为什么?
(3)regex_match()函数
match是全文匹配,即要求整个字符串符合匹配规则,如果整个字符串符合匹配规则,regex_match()返回true,否则返回false
regex_match(string a, regex b) 第一个参数为要匹配的字符串,第二个参数为正则表达式(匹配规则)
1 cout << regex_match("123", regex("\\d")) << endl; //结果为0 \\d表示只匹配一个数字 2 cout << regex_match("123", regex("\\d+")) << endl; //结果为1 \\d+表示可以匹配多个数字
更多的时候我们希望能够获得匹配结果(字符串),对结果进行操作。这时就需要对匹配结果进行存储,共有两种存储方式。
1 match_results<string::const_iterator> result; 2 smatch result; //推荐
示例:
1 string str = "Hello_2018"; 2 smatch result; 3 regex pattern("(.{5})_(\\d{4})"); //匹配5个任意单字符 + 下划线 + 4个数字 .匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 4 5 if (regex_match(str, result, pattern)) 6 { 7 cout << result[0] << endl; //完整匹配结果,Hello_2018 8 cout << result[1] << endl; //第一组匹配的数据,Hello 9 cout << result[2] << endl; //第二组匹配的数据,2018 10 cout<<"结果显示形式2"<<endl; 11 cout<< result.str() << endl; //完整结果,Hello_2018 12 cout<< result.str(1) << endl; //第一组匹配的数据,Hello 13 cout << result.str(2) << endl; //第二组匹配的数据,2018 14 } 15 16 //遍历结果 17 for (int i = 0; i < result.size(); ++i) 18 { 19 cout << result[i] << endl; 20 }
result[]与result.str()这两种方式能够获得相同的值,我更喜欢用数组形式的。
在匹配规则中,以括号()的方式来划分组别,实例中的规则共有两个括号,所以共有两组数据。
(4)regex_search()函数
search是搜索匹配,即搜索字符串中存在符合规则的子字符串。
search_match(string a, regex b) 第一个参数为要匹配的字符串,第二个参数为正则表达式(匹配规则)。匹配则返回true,否则返回false
match与search一比较便知:
1 cout << regex_match("123", regex("\\d")) << endl; //结果为0 只匹配一个数字,match必须是全部符合匹配规则才可以 2 cout << regex_search("123", regex("\\d")) << endl; //结果为1 只匹配一个数字,search有可以匹配的则返回true
示例:
1 string str = "Hello 2018, Bye 2017"; 2 smatch result; 3 regex pattern("\\d{4}"); //匹配四个数字,匹配结果只有一个,因为只有一个括号,即只可以写result[0] 4 5 //迭代器声明 6 string::const_iterator iterStart = str.begin(); 7 string::const_iterator iterEnd = str.end(); 8 string temp; 9 while (regex_search(iterStart, iterEnd, result, pattern)) 10 { 11 temp = result[0]; 12 cout << temp << " "; 13 iterStart = result[0].second; //更新搜索起始位置,搜索剩下的字符串 14 } 15 16 输出结果:2018 2017
(5)regex_replace()函数
replace是替换匹配,即可以将符合匹配规则的子字符串替换为其他字符串。
1 string str = "Hello_2018!"; 2 regex pattern("Hello"); 3 cout << regex_replace(str, pattern, "") << endl; //输出:_2018,将Hello替换为"" 4 cout << regex_replace(str, pattern, "Hi") << endl; //输出:Hi_2018,将Hello替换为Hi
除了直接替换以外,还有可以用来调整字符串内容(缩短、顺序等)。
1 string str = "Hello_2018!"; 2 regex pattern2("(.{3})(.{2})_(\\d{4})"); //匹配3个任意字符+2个任意字符+下划线+4个数字 3 cout << regex_replace(str, pattern2, "$1$3") << endl; //输出:Hel2018,将字符串替换为第一个和第三个表达式匹配的内容 ***** 4 cout << regex_replace(str, pattern2, "$1$3$2") << endl; //输出:Hel2018lo,交换位置顺序 *****
(6)匹配忽略大小写
有时我们希望能够匹配的时候忽略大小写,这时候就要用到Regex的语法选项了。
1 cout << regex_match("aaaAAA", regex("a*", regex::icase)) << endl; //结果为1 2 cout << regex_match("aaaAAA", regex("a*")) << endl; //结果为0
注意:*匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。
(7)帮助网站
附上两个写正则表达式常用到的网站
以上参考博客链接
11、Qt中的foreach()
1 QStringList listTemp; 2 listTemp.append("aaa"); 3 listTemp.append("bbb"); 4 listTemp.append("ccc"); 5 6 QString strTemp1; 7 QString strTemp2; 8 9 foreach(strTemp1,listTemp) 10 { 11 strTemp2= strTemp1; 12 }
以上代码中,listTemp会把自己的每个项,依次赋值给strTemp1。本例中,strTemp共有三项,foreach会循环三次,strTemp1在这三次循环中,依次被赋值“aaa”,“bbb”,“ccc”。
总结:foreach用来遍历list,可以在遍历中基于 list 的相应项做相应操作。
12、C++中的关键字static
(1)静态局部变量:有时希望函数中的局部变量的值在函数调用结束后不消失而保留原值,即其占用的存储单元不释放,在下一次该函数调用时,该变量保留上一次函数调用结束时的值。这时就应该指定该局部变量为静态局部变量(static local variable)。
(2)static 修饰全局变量的时候,这个全局变量只能在本文件中访问,不能在其它文件中访问,即便是 extern 外部声明也不可以。
(3)static 修饰一个函数,则这个函数的只能在本文件中调用,不能被其他文件调用。
(4)考虑到数据安全性(当程序想要使用全局变量的时候应该先考虑使用 static).
(5)在类中静态数据成员可以实现多个对象之间的数据共享,静态成员函数和静态数据成员一样,它们都属于类的静态成员,他们都不属于对象成员,因此对静态成员的引用不需要使用对象名。
1 //#include<iostream> 2 //#include<string> 3 //#include <algorithm> 4 // 5 //using namespace std; 6 // 7 //class Solution { 8 //public: 9 // string ReverseSentence(string str) { 10 // int len = str.size(); 11 // int start = 0; 12 // for (int i = 0; i < len; i++) 13 // { 14 // if (str[i] == ' ') 15 // { 16 // reverse(str.begin() + start, str.begin() + i); //遇到第一个空格时,start=0,i=8,反转区间[0,8)区间内的字符,将student.反转为.tneduts a am I 17 // start = i + 1; //遇到第二个空格时,start=9,i=10,反转区间[9,10)区间内的字符,将a反转为a,此时str变为.tneduts a am I 18 // } //遇到第三个空格时,start=11,i=13,反转区间[11,13)区间内的字符,将a反转为a,此时str变为.tneduts a ma I 19 // if (i == len - 1) //后start=14,i=14,进入下一个if循环 20 // { 21 // reverse(str.begin() + start, str.end()); //反转最后一个空格后的其余字符,此时str变为.tneduts a ma I 22 // } 23 // } 24 // reverse(str.begin(), str.end()); //此时str变为I am a students. 25 // return str; 26 // } 27 //}; 28 //int main() 29 //{ 30 // 31 // Solution so; 32 // string str = "student. a am I"; 33 // 34 // string s = so.ReverseSentence(str); 35 // cout << s << endl; 36 // 37 // cout << endl; 38 // system("pause"); 39 // return 0; 40 //} 41 42 #include <iostream> 43 using namespace std; 44 int f(int a) //定义f函数,a为形参 45 { 46 auto b = 0; //定义b为自动变量 47 static int c = 3; //定义c为静态局部变量,只初始化一次,下次调用该函数的时候会保存c上一次的调用值 48 b = b + 1; 49 c = c + 1; 50 return a + b + c; 51 } 52 53 int main() 54 { 55 int a = 2, i; 56 for (i = 0; i < 3; i++) 57 cout << f(a) << " "; //第一次调用f函数,a=2,b=1,c=4,所以a=a+b+c=7 58 cout << endl; //第二次调用f函数,a=2,b=1,c=5,所以a=a+b+c=8 59 system("pause"); //第三次调用f函数,a=2,b=1,c=6,所以a=a+b+c=9 60 return 0; 61 }

13、自增运算符
++i(在使用i之前,先使i的值加1,如果i的原值为3,则执行j=++i后,j的值为4)
--i (在使用i之前,先使i的值减1,如果i的原值为3,则执行j=--i后,j的值为2)
i++ (在使用i之后,使i的值加1,如果i的原值为3,则执行j=i++后,j的值为3,然后i变为4)
i--(在使用i之后,使i的值减1,如果i的原值为3,则执行j=i--后,j的值为3,然后i变为2)
++i是先执行i=i+1后,再使用i的值;而i++是先使用i的值后,再执行i=i+1。
++和--的结合方向是“自左至右”
1 #include <iostream> 2 #include <string> 3 4 using namespace std; 5 6 int main() 7 { 8 string str = "HelloWorld"; 9 int i = 0; 10 cout << str[i++] << endl; //i++先使用i的值再自增 11 cout << i << endl; 12 13 system("pause"); 14 return 0; 15 }

1 #include <iostream> 2 #include <string> 3 4 using namespace std; 5 6 int main() 7 { 8 string str = "HelloWorld"; 9 int i = 0; 10 cout << str[++i] << endl; //i++先自增再使用i的值 11 cout << i << endl; 12 13 system("pause"); 14 return 0; 15 }
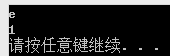
14、使用cin输入以空格为间隔的字符串的问题
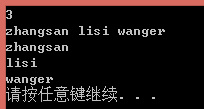
用cin>> 读取数据时遇到空白字符(包括空格 tab键和回车)作为终止字符
1 //直接使用库里提供的[]运算符重载。通过键值找节点,直接给给实值+1. 2 #include <iostream> 3 #include <map> 4 #include <string> 5 #include <vector> 6 7 using namespace std; 8 9 int main() 10 { 11 int N = 0; 12 vector<string> vecStr; 13 string temp; 14 cin >> N; 15 getchar(); //接收上一句最后输入的换行符 16 for (int i = 0; i < N; i++) 17 { 18 cin >> temp; 19 getchar(); 20 vecStr.push_back(temp); 21 } 22 23 for (int i = 0; i < N; i++) 24 cout << vecStr[i] << endl; 25 26 system("pause"); 27 return 0; 28 }
以下cin输入以空格为间隔的字符串将不会正常结束
1 int main() 2 { 3 stack<string> sta; 4 string temp; 5 while (cin >> temp) //只输入一个换行符或者输入非string变量的时候才会跳出while循环,输入字符串+空格+字符串+换行符不会跳出循环 6 { 7 getchar(); 8 sta.push(temp); 9 temp.clear(); 10 } 11 12 system("pause"); 13 return 0; 14 }
15、printf中只有%d没有后面的参数会怎么样
1 printf("\n %d,%d\n",a);
windows下(vc6.0):输出10和0;
Linux下:(会有警告)输出10和一个不确定的数。
附上printf()函数内参数的执行过程
1 int a = 10, b = 20, c = 30; 2 printf("\n %d..%d..%d \n", a+b+c, (b = b*2), (c = c*2));
printf函数在处理参数的时候是从右向左处理的,即先处理(c = c*2),再处理(b = b*2),再处理a+b+c,最后处理"\n %d..%d..%d \n"。其中,printf最后三个参数从右向左依次压入栈中,存放在栈中从高到低的地址里面,然后再格式化输出,输出时从低地址到高地址输出。即整个操作可以看做两部分:数据的处理(压栈)和格式化的输出(出栈)。
17、strlen()和sizeof的区别
1、strlen是一个函数,原型为:
1 int strlen(const char *str) 2 { 3 int len = 0; 4 assert(str != NULL); 5 while(*str++) 6 { 7 len++; 8 } 9 return len; 10 }
由函数原型可以知道:
strlen所作的仅仅是一个计数器的工作,它从内存的某个位置(可以是字符串开头,中间某个位置,甚至是某个不确定的内存区域)开始扫描,直到碰到第一个字符串结束符'\0'为止,然后返回计数器值。
而sizeof是一个运算符,不是函数,sizeof是C/C++中的一个操作符或关键字(operator),简单的说其作用就是返回一个对象或者类型所占的内存字节数。
2、strlen(char*)函数求的是字符串的实际长度,它求得方法是从开始到遇到第一个'\0',如果你只定义没有给它赋初值,这个结果是不定的,它会从aa首地址一直找下去,直到遇到'\0'停止。
而sizeof()返回的是变量声明后所占的内存数,不是实际长度,此外sizeof不是函数,仅仅是一个操作符,strlen是函数。,如:
1 char aa[10];cout<<strlen(aa)<<endl; //结果是不定的 2 char aa[10]={'\0'}; cout<<strlen(aa)<<endl; //结果为0 3 char aa[10]="jun"; cout<<strlen(aa)<<endl; //结果为3 4 5 char aa[10];cout<<sizeof(aa)<<endl; //打印10 6 char aa[10]={'\0'}; cout<<sizeof(aa)<<endl; //打印10 7 char aa[10]="jun"; cout<<sizeof(aa)<<endl; //打印10 8 9 int a[10]; cout<< sizeof(a)<<endl; //打印40,一个int型变量在32位系统下占4个字节
1 char str[20]="0123456789"; 2 int a=strlen(str); //a=10; 3 int b=sizeof(str); //而b=20;
上面是对静态数组处理的结果,如果是对指针,结果就不一样了
1 char* ss = "0123456789"; 2 sizeof(ss); //结果 4 ===》ss是指向字符串常量的字符指针,sizeof 获得的是一个指针的之所占的空间,应该是长整型的,所以是4 3 sizeof(*ss) ; //结果 1 ===》*ss是第一个字符 其实就是获得了字符串的第一位'0' 所占的内存空间,是char类型的,占了 1 位 4 strlen(ss); // j结果10 如果要获得这个字符串的长度,则一定要使用 strlen
再如:
1 int ss[100] = "0123456789"; 2 sizeof(ss); //结果为400,ss表示在内存中的大小,100*4 3 strlen(ss); //错误,strlen的参数只能是char *,且必须是以\0结尾。
18、algorithm头文件中的sort()排序函数使用方法
头文件及函数原型
1 #include<algorithm> 2 //默认函数原型,默认从小到大排序 3 template <class RandomAccessIterator> 4 void sort (RandomAccessIterator first, RandomAccessIterator last); 5 //template <class RandomAccessIterator, class Compare> 6 void sort (RandomAccessIterator first, RandomAccessIterator last, Compare comp);
其中first和last可以是迭代器也可以是数组地址
下面介绍Compare类函数
(1)普通函数实现方法
1 //实现从大到小排序 2 bool com(int a,int b){ 3 if(a > b) 4 return true; 5 else 6 return false; 7 }
(2)在类中定义方法:使用对"()"的重载
同时可以使用sort()实现对string进行排序
方法如下:
1 string str = "Hello world"; 2 sort(str.begin(),str.end());
对数组排序
1 int a[] = {9,5,2,7,6,1,3}; 2 sort(a,a+7); //从小到大排序
19、状态压缩dp算法中常用的位运算及biset()
按位运算相关
1 //lowbit()返回a的二进制中从右向左出现的第一个1,01101011返回的是1;01100100返回的是100;10011000返回的是1000 2 inline int lowbit(int a){ 3 return (a & (-a)); 4 } 5 intline int highbit(int a){ 6 int p = lowbit(a); 7 while(p!=a){ 8 a -= p; 9 p=lowbit(a); 10 } 11 return p; 12 } 13 14 //判断a是否是2的幂次方 15 bool powerOf2(int a){ 16 return 17 } 18 19 int main(){ 20 int A,B; //A B为二进制集合,但是转化为了十进制数 21 long long C; 22 int c; //一个数字 23 A |= 1<<c; //将c插入到A中;1<<c等价于2的c次方,也相当于将A中的第c位设置为1 24 A &= ~(1<<c); //erase c,将A中的第c位设置为0,也相当于将A中的c删除掉 25 A ^= (1<<c); //erase c,此时是已知在A中的第c位一定为1(在A中一定有c),将A中的第c位设置为0 26 A = 0; //将集合A置0 27 A|B; //集合A和B取并集 28 A&B; //集合A和B取交集 29 30 int si=15; 31 int All=(1<<15)-1; //1<<15一共有16位,即1后面有15个0,再减1就一共有15位了,且这15位全是1;或者说是取All的全集 32 All^A; //求全集All中A的补集 33 (A&B)==B; //判断B是否为A的子集 34 35 //枚举所有全集All的所有子集 36 for(int i=0;i<All;++i){ 37 38 } 39 40 //枚举某一个集合的子集 41 int subset=A; 42 do{ 43 //do something 44 subset=(subset-1)&A; 45 }while(subset != A) 46 47 //计算集合A的元素的个数方法一 48 int cnt=0; 49 for(int i=0;i<si;++i){ 50 if(A & (1<<i)) 51 cnt++; 52 } 53 54 //计算集合A的元素的个数方法二 55 for(int i=A;i;i>>=1) 56 cnt+=i&1; 57 58 }
bitset()
需要包含的头文件,即构造函数bitset()的使用方法
1 #include <bitset> 2 bitset<4> bitset1; //无参构造,长度为4,默认每一位为0 3 4 bitset<8> bitset2(12); //长度为8,二进制保存,前面用0补充 5 6 string s = "100101"; 7 bitset<10> bitset3(s); //长度为10,前面用0补充 8 9 char s2[] = "10101"; 10 bitset<13> bitset4(s2); //长度为13,前面用0补充 11 12 cout << bitset1 << endl; //0000 13 cout << bitset2 << endl; //00001100 14 cout << bitset3 << endl; //0000100101 15 cout << bitset4 << endl; //0000000010101
注意:
用字符串构造时,字符串只能包含 '0' 或 '1' ,否则会抛出异常。
构造时,需在<>中表明bitset 的大小(即size)。
在进行有参构造时,若参数的二进制表示比bitset的size小,则在前面用0补充(如上面的栗子);若比bitsize大,参数为整数时取后面部分,参数为字符串时取前面部分(如下面栗子):
1 bitset<2> bitset1(12); //12的二进制为1100(长度为4),但bitset1的size=2,只取后面部分,即00 2 3 string s = "100101"; 4 bitset<4> bitset2(s); //s的size=6,而bitset的size=4,只取前面部分,即1001 5 6 char s2[] = "11101"; 7 bitset<4> bitset3(s2); //与bitset2同理,只取前面部分,即1110 8 9 cout << bitset1 << endl; //00 10 cout << bitset2 << endl; //1001 11 cout << bitset3 << endl; //1110
bitset类对象之间的与或非及异或操作
1 bitset<4> foo (string("1001")); 2 bitset<4> bar (string("0011")); 3 4 cout << (foo^=bar) << endl; // 1010 (foo对bar按位异或后赋值给foo) 5 cout << (foo&=bar) << endl; // 0010 (按位与后赋值给foo) 6 cout << (foo|=bar) << endl; // 0011 (按位或后赋值给foo) 7 8 cout << (foo<<=2) << endl; // 1100 (左移2位,低位补0,有自身赋值) 9 cout << (foo>>=1) << endl; // 0110 (右移1位,高位补0,有自身赋值) 10 11 cout << (~bar) << endl; // 1100 (按位取反) 12 cout << (bar<<1) << endl; // 0110 (左移,不赋值) 13 cout << (bar>>1) << endl; // 0001 (右移,不赋值) 14 15 cout << (foo==bar) << endl; // false (0110==0011为false) 16 cout << (foo!=bar) << endl; // true (0110!=0011为true) 17 18 cout << (foo&bar) << endl; // 0010 (按位与,不赋值) 19 cout << (foo|bar) << endl; // 0111 (按位或,不赋值) 20 cout << (foo^bar) << endl; // 0101 (按位异或,不赋值)
可以通过[]运算符来访问类对象中的元素,如:
1 bitset<4> foo ("1011"); 2 3 cout << foo[0] << endl; //1 4 cout << foo[1] << endl; //1 5 cout << foo[2] << endl; //0
bitset类下的方法
1 bitset<8> foo ("10011011"); 2 3 cout << foo.count() << endl; //5 (count函数用来求bitset中1的位数,foo中共有5个1 4 cout << foo.size() << endl; //8 (size函数用来求bitset的大小,一共有8位 5 6 cout << foo.test(0) << endl; //true (test函数用来查下标处的元素是0还是1,并返回false或true,此处foo[0]为1,返回true 7 cout << foo.test(2) << endl; //false (同理,foo[2]为0,返回false 8 9 cout << foo.any() << endl; //true (any函数检查bitset中是否有1 10 cout << foo.none() << endl; //false (none函数检查bitset中是否没有1 11 cout << foo.all() << endl; //false (all函数检查bitset中是全部为1
补充说明一下:test函数会对下标越界作出检查,而通过 [ ] 访问元素却不会经过下标检查,所以,在两种方式通用的情况下,选择test函数更安全一些
另外,含有一些函数:
1 bitset<8> foo ("10011011"); 2 3 cout << foo.flip(2) << endl; //10011111 (flip函数传参数时,用于将参数位取反,本行代码将foo下标2处"反转",即0变1,1变0 4 cout << foo.flip() << endl; //01100000 (flip函数不指定参数时,将bitset每一位全部取反 5 6 cout << foo.set() << endl; //11111111 (set函数不指定参数时,将bitset的每一位全部置为1 7 cout << foo.set(3,0) << endl; //11110111 (set函数指定两位参数时,将第一参数位的元素置为第二参数的值,本行对foo的操作相当于foo[3]=0 8 cout << foo.set(3) << endl; //11111111 (set函数只有一个参数时,将参数下标处置为1 9 10 cout << foo.reset(4) << endl; //11101111 (reset函数传一个参数时将参数下标处置为0 11 cout << foo.reset() << endl; //00000000 (reset函数不传参数时将bitset的每一位全部置为0
同样,它们也都会检查下标是否越界,如果越界就会抛出异常
最后,还有一些类型转换的函数,如下:
1 bitset<8> foo ("10011011"); 2 3 string s = foo.to_string(); //将bitset转换成string类型 4 unsigned long a = foo.to_ulong(); //将bitset转换成unsigned long类型 5 unsigned long long b = foo.to_ullong(); //将bitset转换成unsigned long long类型 6 7 cout << s << endl; //10011011 8 cout << a << endl; //155 9 cout << b << endl; //155
20、C++中的to_string()---将int、long、double、float等转换成string
需要包含的头文件:
1 #include <string> 2 std::to_string; //在名称空间std中
函数原型:
1 string to_string (int val); 2 string to_string (long val); 3 string to_string (long long val); 4 string to_string (unsigned val); 5 string to_string (unsigned long val); 6 string to_string (unsigned long long val); 7 string to_string (float val); 8 string to_string (double val); 9 string to_string (long double val)
举例:
1 // to_string example 2 #include <iostream> // std::cout 3 #include <string> // std::string, std::to_string 4 5 int main () 6 { 7 std::string pi = "pi is " + std::to_string(3.1415926); 8 std::string perfect = std::to_string(1+2+4+7+14) + " is a perfect number"; 9 std::cout << pi << '\n'; 10 std::cout << perfect << '\n'; 11 return 0; 12 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号