
Deep Learning of Graph Matching 阅读笔记
CVPR2018的一篇文章,主要提出了一种利用深度神经网络实现端到端图匹配(Graph Matching)的方法. 该篇文章理论性较强,较难读懂。。。
介绍这篇文章之前,需要先了解一下什么是图匹配,图匹配是干嘛的。
图匹配
图匹配简单来说就是将已有的两个图中对应的顶点关联起来实现能量函数最大。以多目标跟踪任务来说,每帧图像中的观测都可以构成一个拓扑图,希望将两帧图像中的拓扑图匹配起来以实现同一条轨迹中的观测成功匹配。
Formulation

这里需要说明的是,一般而言两个图之间节点的匹配,直接根据关联矩阵就可以了,比如 中分别有个节点,那么关联矩阵就决定了节点的匹配结果,但是这样只考虑了两个点之间的相似度而没有考虑更高阶信息。高阶信息,说起来挺玄的,其实就是更全局的信息。比如这里两个点之间是否匹配不仅仅取决这两个点之间的相似度还要考虑这两个点匹配的话对其他匹配的影响,从而选取一种匹配使得总体的能量最大。
举个简单的例子,现在有两个男孩 和两个女孩, 有一个挣钱的工作必须男女搭档完成(一股铜臭味,谁让我掉钱眼里了呢。。。),已知搭档性价比如下:
| 挣钱(元) | A | B |
|---|---|---|
| a | 1000 | 900 |
| b | 800 | 600 |
现在让你分组你怎么分?
那么这里是怎么刻画高阶信息的呢?其实是二阶信息。
还以这个例子来说,构建如下的矩阵
| Aa | Ab | Ba | Bb | |
|---|---|---|---|---|
| Aa | 1000 | 0 | 0 | 1600 |
| Ab | 0 | 800 | 1700 | 0 |
| Ba | 0 | 1700 | 900 | 0 |
| Bb | 1600 | 0 | 0 | 600 |
对角线表示两个点匹配的能量,称为边的unary energy, 非对角线表示对应的两个匹配同时成立的能量,比如(Aa, Bb)=1600表示Aa和Bb同时成立,(Aa,Ab)=0是因为A不可能同时分给两个人。
这里公式(1)其实约束有点问题 . 如果那么约束不可能同时成立。
在使用深度学习框架学习的时候牵涉到大量的矩阵求导操作,所以论文首先给出了矩阵求导需要使用的公式:

这段话想说啥?无非就是矩阵的复合求导过程。
Deep Network Optimization for Graph Matching 框架
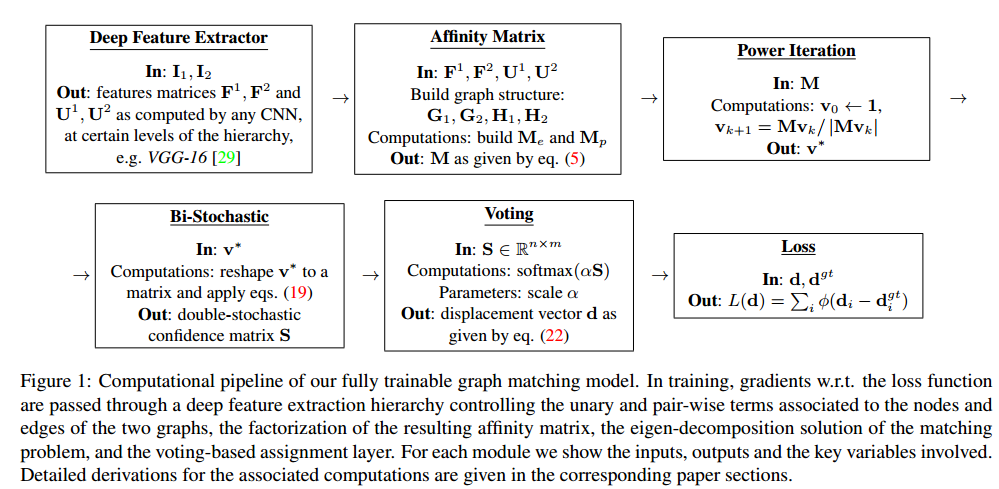
这里我们先来看看框架流程,先别管具体推导过程。首先利用深度学习框架生成每一个顶点的深度特征(Deep Feature Extractor), 然后将这些特征送到Affinity Matrix Layer生成Affinity Matrix, 接着采用幂迭代(Power Iteration)的方法对Affinity Matrix进行分解,再然后通过Bi-Stochastic layer添加 one-to-one约束,最后两层是用于计算网络损失的。
可以参考链接1,看看之前Affinity Matrix是怎么用Power Iteration分解的

可以发现矩阵分解部分就是直接将传统的操作放到了网络里面,所以本文实现的Deep Learning的重点其实是如何用深度网络构建Affinity Matrix。
Deep Network Optimation
OK, 不管愿不愿意,还是介绍到了公式的部分。。。
首当其中的就是Affinity Matrix Layer,直观上我们将顶点组合成edge,再由edge组成pairs然后放到网络里自然可以学到对应的能量,但是这样会导致计算规模太大,而且Affinity Matrix还有对称非负(元素非负)约束等。 而正是由于这些特性,可以将Affinity Matrix 分解成了两个较小部分再进行运算。
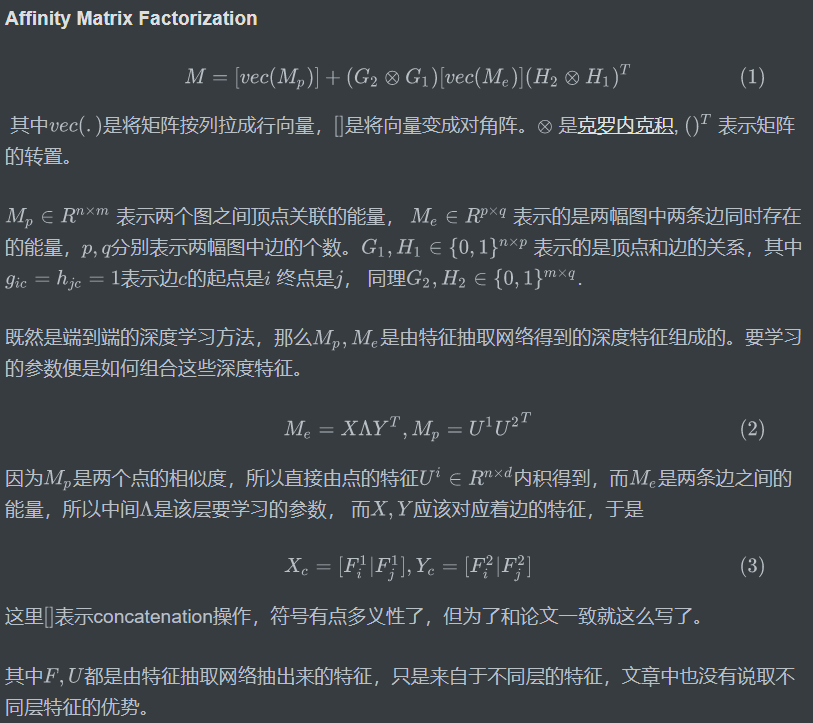
那么Affinity Matrix Layer的前向计算过程如下:


Power Iteration Layer

Bi-Stochastic Layer

Loss Layer

Experiments
实验数据集我也不了解,具体就不介绍了,只看一下定性结果吧

Conclusion
We have presented an end-to-end learning framework for graph matching with general applicability to models containing deep feature extraction hierarchies and combinatorial optimization layers. We formulate the problem as a quadratic assignment under unary and pair-wise node relations represented using deep parametric feature hierarchies. All model parameters are trainable and the graph matching optimization is included within the learning formulation. As such, the main challenges are the calculation of backpropagated derivatives through complex matrix layers and the implementation of the entire framework (factorization of the affinity matrix, bi-stochastic layers) in a computationally efficient manner. Our experiments and ablation studies on diverse datasets like PASCAL VOC keypoints, Sintel and CUB show that fully learned graph matching models surpass nearest neighbor counterparts, or approaches that use deep feature hierarchies that were not refined jointly with (and constrained by) the quadratic assignment problem.
网络的计算还是相当耗时的,论文中也给出了一些加速的建议,不过这些加速会影响性能。
参考文献

