


多目标跟踪方法 NOMT 学习与总结
多目标跟踪方法 NOMT 学习与总结
读 ‘W. Choi, Near-Online Multi-target Tracking with Aggregated Local Flow Descriptor, ICCV,2015’笔记
NOMT这个方法在MOTChallenge2015,MOTChallenge2016库上的结果都算比较好的了,虽然方法比较老了。另外一个显著的特点就是该方法的各种tricks实在是太多,虽没有找到源码,但对作者还真是佩服。
概述
这篇文章涉及到了多目标跟踪中的两个关键方面: 相似性的度量和目标块之间的匹配。
相似性度量方面,提出了一种Aggregate Local Flow Descriptor (ALFD)的描述子用于描述patch块之间的相对运动信息。
目标匹配的过程中利用了ALFD信息,表观相似度,运动特征和轨迹的平滑性等
该方法属于tracking by detection的一种,在KITTI和MOT库上的结果都比较好
先避开细节不谈,看看NOMT的总的流程

为什么称为Near-Online方法?对于第t帧,之前t-1帧中的detections都已经串成不同的轨迹了,但是在t-1帧中只有
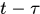 之前的轨迹串才保持不变,称为'Clean Targets',
之前的轨迹串才保持不变,称为'Clean Targets',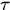 是时间窗,那么在t时刻需要处理的不仅仅是第t帧的detections还包括
是时间窗,那么在t时刻需要处理的不仅仅是第t帧的detections还包括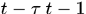 帧间的所有detections,即时间窗内的匹配结果是可以改变的,所以称为Near-Online方法,如上图中(a),
帧间的所有detections,即时间窗内的匹配结果是可以改变的,所以称为Near-Online方法,如上图中(a),  之前的是固定不变的跟踪结果,后面的则可能会随着第t帧处理结果发生改变
之前的是固定不变的跟踪结果,后面的则可能会随着第t帧处理结果发生改变整个跟踪过程采用的是‘hypothesis generation and selection scheme’。意味着每一个时刻现在时间窗内生成许多hypothesis,然后为每一个轨迹选择一个hypothesis。但是时间窗内完备的假设集往往是相当庞大的,比如时间窗为5,每帧有5个detections,那么长度为5的tracklet假设就有
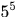 种,再考虑轨迹起点、终点或者遮挡产生的假设,那就会爆炸。所以NOMT在Hypotheses Generation中通过距离约束首先产生了一些可能的tracklets,然后再将这些tracklets分配到不同的子集中,每个子集对应着可能匹配的一个已有轨迹。不同的子集中可能存在交集,这种交集包括 存在相同的tracklets(比如图b中
种,再考虑轨迹起点、终点或者遮挡产生的假设,那就会爆炸。所以NOMT在Hypotheses Generation中通过距离约束首先产生了一些可能的tracklets,然后再将这些tracklets分配到不同的子集中,每个子集对应着可能匹配的一个已有轨迹。不同的子集中可能存在交集,这种交集包括 存在相同的tracklets(比如图b中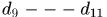 )或者 tracklets之间存在交集(比如图b中蓝色子集中
)或者 tracklets之间存在交集(比如图b中蓝色子集中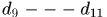 与黄色子集中
与黄色子集中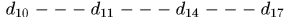 )
)正是由于2中不同子集之间存在这相互关系,所以假设与轨迹之间的匹配采用了Conditional Random Field完成
将匹配假设中的tracklet加到对应的轨迹中,处理下一帧
无论是tracklets的生成还是hypothses的分配都需要刻画相似度,而NOMT使用了多种相似度的融合。先来看一看文中提出的ALFD描述子
Aggregated Local Flow Descriptor (ALFD)
这个方法的根本思想是利用关键点(interest points)的光流来刻画boxes之间的相对运动信息,从而判断两个boxes的相似度。比如在box1中的一个关键点是鼻尖,然后该关键点依据该点的光流可以推测在下一帧的位置,如果预测位置刚好在下一帧某个box2中的鼻尖处,那么box1与box2之间的匹配置信度显然要提高一点,那么统计所有的关键点就可以统计boxes之间的相似度。
但是呢,人体是非刚体,同一部位的关键点不同boxes中的位置很可能不同,而且光流本身就存在误差,所以使用直方图的统计特征比逐点匹配更加靠谱
那么是如何使用直方图统计该特征的呢?我们借下图分析下

对于box1和box2,分别计算box1中关键点在box2中的投影点分布,和box2中关键点在box1中投影点分布,然后将两个分布结合起来就组成了整体的alfd特征。以box1投影到box2为例
首先将box1划分成n*n的网格,示例中n=2,实验中n=4,然后将box2以box2为基础划分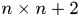 个bins,具体而言就是将box2分成
个bins,具体而言就是将box2分成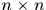 个网格,然后box2周围
个网格,然后box2周围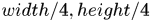 之内的区域归为一个bin,之外的 区域归为一个bin。那么对于box1中的某一个关键点的相对运动信息就应该这么刻画:该点属于box1的哪个网格中,投影点落到box2的哪个bin中,于是直方图的长度为
之内的区域归为一个bin,之外的 区域归为一个bin。那么对于box1中的某一个关键点的相对运动信息就应该这么刻画:该点属于box1的哪个网格中,投影点落到box2的哪个bin中,于是直方图的长度为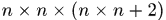 ,示例中为288维
,示例中为288维
将box1投影到box2的相对运动信息表示为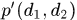 ,那么两个boxes之间总的alfd特征为
,那么两个boxes之间总的alfd特征为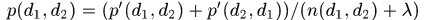 ,其中
,其中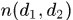 是两个boxes中总的关键点的个数,
是两个boxes中总的关键点的个数,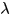 是一个正则项,用来约束关键点个数的影响:如果两个boxes中的关键点很少,那么他俩的匹配对整个跟踪过程中匹配的影响就很小。文中
是一个正则项,用来约束关键点个数的影响:如果两个boxes中的关键点很少,那么他俩的匹配对整个跟踪过程中匹配的影响就很小。文中
论文方法使用FAST 方法提取interest points,且任意两个points之间距离要 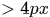 , 光流法使用的时Farneback光流法,当光流的大小
, 光流法使用的时Farneback光流法,当光流的大小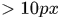 时该轨迹终止
时该轨迹终止
如何将描述子向量转化为相似性度量?
显然alfd直方图的每个bin对相似性的贡献是不一样的,比如上面的Fig3中,包含红色矩形框的bins值越大,两个patch的匹配程度就越高,而如果最外面两个bins的值越大那么相似度就越小,所以文中将描述子向量的每个元素进行加权求和作为相似性的度量
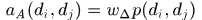
而对于权重向量是在训练集中统计出来的,这里我更偏向于使用统计而不是训练。
首先对训练集中的detections进行筛选(存在gt与之IoU>0.5的认为是positive detections)
在positive detections中计算任意两个时间间隔在
 内的pair的margin
内的pair的margin
如果两个detection是同一个目标 ,否则
,否则 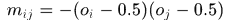
然后权重向量就可以如下获得:
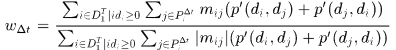
其中 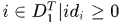 是表示所有detections中与真实gt的最大IoU大于0.5的detections,
是表示所有detections中与真实gt的最大IoU大于0.5的detections,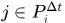 是指与detection i时间差在
是指与detection i时间差在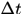 之内的detection。 详细的符号意义参见论文
之内的detection。 详细的符号意义参见论文
其实这个权重计算式相当于强化了那些对分类(相似与不相似)起重要作用的特征,最终可以通过判断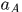 的符号判断相不相似,想起来线性分类器
的符号判断相不相似,想起来线性分类器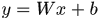
然后我们来看看论文中另一个主要贡献点NOMT
NOMT
首先声明一些变量
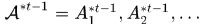 表示clean targets at frame t,啥意思呢?就是t时刻已经跟踪到的轨迹
表示clean targets at frame t,啥意思呢?就是t时刻已经跟踪到的轨迹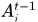 的
的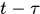 之前的轨迹部分,这部分被认为是准确无误的,不在更改,所以称为clean targets。
之前的轨迹部分,这部分被认为是准确无误的,不在更改,所以称为clean targets。
Hypotheses 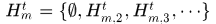 表示的是可能分配给轨迹
表示的是可能分配给轨迹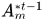 的假设集,
的假设集,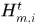 表示tracklet,空集表示轨迹结束,另外注意空集也可能对应一个假设集,表示新产生的轨迹。
表示tracklet,空集表示轨迹结束,另外注意空集也可能对应一个假设集,表示新产生的轨迹。
Model Representation
模型可以形式化表示为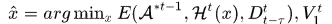 ,x是一个对应着
,x是一个对应着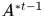 的指示向量,整型数据,表示对应的轨迹匹配的Hypothesis标号,
的指示向量,整型数据,表示对应的轨迹匹配的Hypothesis标号,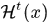 表示x选中的Hypotheses,
表示x选中的Hypotheses,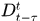 表示时间窗内的detections,
表示时间窗内的detections, 表示帧图像。
表示帧图像。
能量函数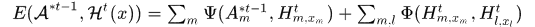
显然第一项表示将假设分配给轨迹的代价,第二项表示分配的假设之间的相互关系
Single Targt Consistency
也就是上面的第一项,它由三部分组成,Hypothesis中的detections与轨迹的相似度、Hypothesis本身的一致性(可以理解为hypothesis本身的可靠程度)、将假设分配给该轨迹后的整体运动平滑性以及表观一致性,注意目标函数是最小化,有些式子里面包含的负号
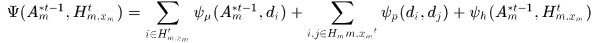
其中第一项称为Unary potential,融合了alfd相似度和使用运动估计得到的相似度。这里为什么使用到运动估计,是因为alfd对于遮挡或者光流估计误差较大的情况匹配精度不好,这时候可以将运动估计作为补充
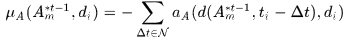
其中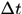 表示时间窗,
表示时间窗,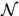 表示预定义的近邻帧,文中取{1,2,5,10,20},
表示预定义的近邻帧,文中取{1,2,5,10,20},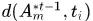 表示轨迹在
表示轨迹在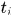 帧对应的关联detection,但是对于有可能不存在关联detection的帧怎么处理文中没说,我觉得就是直接跳过,求和项不加那一项
帧对应的关联detection,但是对于有可能不存在关联detection的帧怎么处理文中没说,我觉得就是直接跳过,求和项不加那一项

其中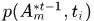 表示对轨迹使用最小二乘估计拟合曲线在时刻
表示对轨迹使用最小二乘估计拟合曲线在时刻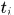 的位置和大小,拟合的曲线阶数在不同数据集上不同,MOT数据集上采用的是一阶,即直线,KITTI上采用的是二阶。
的位置和大小,拟合的曲线阶数在不同数据集上不同,MOT数据集上采用的是一阶,即直线,KITTI上采用的是二阶。 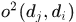 表示两个detections的IoU,
表示两个detections的IoU, 是衰退因子(0.98),表示相同IoU条件下,随着帧间间隔增大相似度降低。
是衰退因子(0.98),表示相同IoU条件下,随着帧间间隔增大相似度降低。

 表示detection的置信度,显然上式表示alfd和运动估计特征,谁可靠取谁,如果
表示detection的置信度,显然上式表示alfd和运动估计特征,谁可靠取谁,如果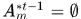 ,表示可能是一个新轨迹起点,那么就看detection的置信度
,表示可能是一个新轨迹起点,那么就看detection的置信度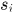 了
了
针对于第二项刻画Hypothesis本身的一致性,就使用了alfd相似度
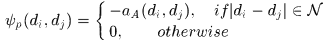
第三项刻画了加入hypothesis之后整条轨迹的平滑性,使用了运动估计特征和表观特征。
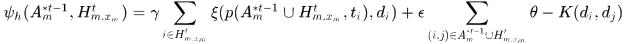
其中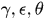 均为标量参数,实验中取(20,0.4,0.8),
均为标量参数,实验中取(20,0.4,0.8),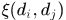 表示两个detections之间的(x,y,height)的距离的平方,那么式子的前一项就是预测的detection与检测到的detection之间的差异(有点类似于Kalman滤波思想),注意这里的height是经过归一化,
表示两个detections之间的(x,y,height)的距离的平方,那么式子的前一项就是预测的detection与检测到的detection之间的差异(有点类似于Kalman滤波思想),注意这里的height是经过归一化,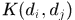 刻画了两个detection的表观相似度,使用颜色直方图表示patch块,具体而言就是每个patch块在LAB空间内将AB通道分别划分4个bins,然后每个采用金字塔形式统计直方图分布,金字塔的第一层1个,第2层分解成
刻画了两个detection的表观相似度,使用颜色直方图表示patch块,具体而言就是每个patch块在LAB空间内将AB通道分别划分4个bins,然后每个采用金字塔形式统计直方图分布,金字塔的第一层1个,第2层分解成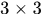 的网格,总体的bins就是
的网格,总体的bins就是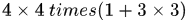 ,然后计算两个直方图的intersection得到K
,然后计算两个直方图的intersection得到K
上面仅考虑单独的轨迹怎么分配hypothsis,其实不同的轨迹分配不同的hypotheses,相互之间往往是相互影响的,也就是总能量表达式的第二项
Mutual Exclusion

其中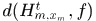 表示假设
表示假设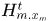 在时刻f的detections,前一项表示两个假设存在重叠的程度,
在时刻f的detections,前一项表示两个假设存在重叠的程度,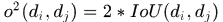 ,
,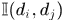 表示
表示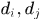 是同一个目标,
是同一个目标,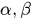 分别表示惩罚系数,论文中
分别表示惩罚系数,论文中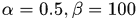 ,显然对分配假设中存在相同detection的情形零容忍。
,显然对分配假设中存在相同detection的情形零容忍。
上面讲NOMT的模型总是提到Hypotheses集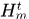 ,那么假设是怎么生成的呢?
,那么假设是怎么生成的呢?
Hypothesis Generation
在生成假设的过程中,NOMT就是在时间窗内生成一些tracklets作为假设,而tracklets包括两种形式,一种就是由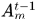 在时间窗内的部分生成,另一部分则是使用alfd度量相似度生成的,有点类似于聚类。
在时间窗内的部分生成,另一部分则是使用alfd度量相似度生成的,有点类似于聚类。
Starting from a detection 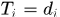 然后在剩下不在该tracklet中的detections中选取最相似的放进去,直到tracklet中个数等于窗口长度或者tracklet内部detections与外部detections之间最好的相似度都小于0.4时终止。
然后在剩下不在该tracklet中的detections中选取最相似的放进去,直到tracklet中个数等于窗口长度或者tracklet内部detections与外部detections之间最好的相似度都小于0.4时终止。
这样生成的tracklets依然有许多是没有用的,所以采用了门限策略进一步筛选这些hypotheses。具体而言利用最小均方误差估计轨迹模型,通过判断预测box与tracklet中box的IoU值来筛选tracklets,实验中门限阈值设为0.1,这么小的原因是为了产生较多的tracklets。另外对于一段时间内没有匹配到detections的轨迹认为已经终止,论文中这个时间阈值为1s
关于新轨迹的产生,对于没有匹配的tracklets,采用non-maximum suppression的方式规避重复的目标。
目标函数现在已经给出来了,那么如何求解呢?
Inference with Dynamic Graphical Model
如图2所示,首先将每个轨迹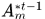 可能分配的假设集
可能分配的假设集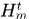 分出来,表示一个节点,而里面具体的假设表示状态,就构成了一个undirected graphical model。对于这个图模型划分不同的独立的子图,不同结构的子图采用不同的方式进行求解
分出来,表示一个节点,而里面具体的假设表示状态,就构成了一个undirected graphical model。对于这个图模型划分不同的独立的子图,不同结构的子图采用不同的方式进行求解
如果子图中包含多个node,那么采用CRF模型进行处理,如果仅含有1个节点,就选择集合中最好的假设分配给节点,这个时候就不用考虑Mutual Exclusion哪项势函数了。
关于CRF模型,待补充
实验
论文中验证了ALFD的表征能力,并分别在KITTI的部分子集和MOT2015数据集上做了实验验证了NOMT相对于当时已有方法的优势,这个优势还是相当明显的。具体数值结果见论文和相关网站
总结
该文章提出了一种基于光流的特征描述子ALFD,描述了patch块之间的相对运动关系,其实仔细想想这个描述子不仅包含了运动信息,还包含了纹理信息,比如关键点的选取,因为是相对关系,所以和patch之间的距离,即空间关系也有关,所以该描述子有效还是很好解释的
NOMT方法采用的是一种滑动时间窗的更新方式,这种方式允许前若干时刻的分配结果随着新detections的到来而发生更改,这样跟踪效果显然会好一些,毕竟利用了前后帧的关系
方法中用到了好多tricks,比如使用最小平方误差算法构建轨迹预测器,使用运动特征去处理遮挡问题,使用运动特征和表观特征正则化假设集的分配,等等,且方法中给定了许多参数
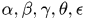 等
等在使用ALFD计算相似度时,使用的时统计得来的权重向量,起始可以由训练得到。
这个假设分配的过程或许并非一定要通过CRF这么计算`

