
从1写TCPIP协议栈8:网页结构与设计简介
概述
在完成传输层的开发后,我们进入应用层HTTP超文本传输协议的开发,这部分对于使用者来说就是网页浏览器。网页浏览器实际上是对HTML内容解析的结果。
Web开发引述
Web简介
一个Web的实现包括通信协议栈+样式表+资源文件,一般来说HTTP协议是借助TCP/IP协议传输,或者是TLS加密的TCP协议,目前Golgal也开发了基于UDP传输得HTTP协议QUIC。
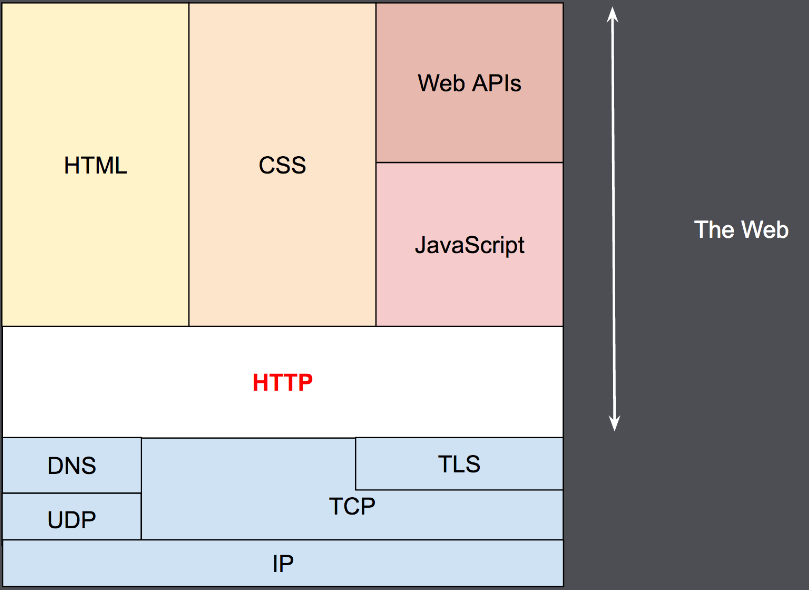
Web的核心实际是HTML语言,而HTML语言描述了文本与文本之间的关系。您可以随机打开一个网页按下Ctrk+U就能查看Web网页的HTML源码。例如:
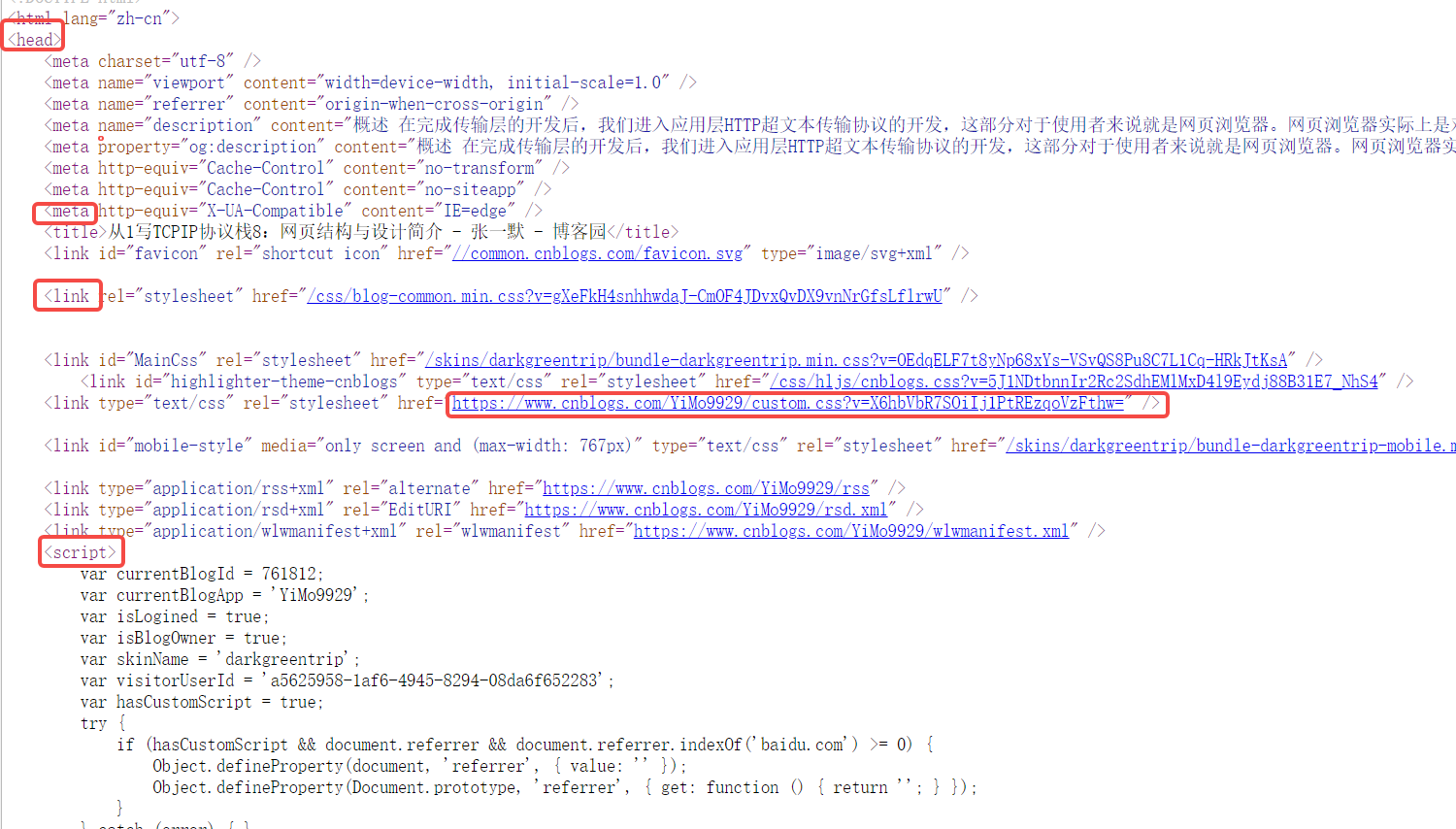
如上图所战术,我们可以看到HTML源码中最多描述便是各种标签(标签手册),比如Body、scri pt和一些URL资源定位符。本质上HTML语言的结构类似于XML语言,表现为:
- <标签名 属性1='值' 属性2='值' > 内容 </标签名>
- 内容可以为文本或者子元素
HTML语言介绍
在一个web网页中,HTML只是提供了基本的文本关系,至于文本的动态展示样式组需要我们用JS脚本去控制。一个入门的用法就是首先创建文件HTMLPage1.html:
<html> <head> <title>张一默的个人网站</title> <link type="text/css" rel="stylesheet" href="StyleSheet1.css"/> //css文件关联 <script type="text/javascript" src="Script1.js"></script> //js文件关联 </head> <body> <p class="red">恭喜你的练习进入了尾声~</p> <a href="page1.html">尝试进入您的空间</a> <button id="button1" type="button" onclick="button_click()"> "点我统计次数"</button> //按钮关联 <p id="count_label">次数</p> </body> </html>
然后针对指向超链接标签<a>我们还需要创建一个文件page1.html:
<html> <head> <title>张一默的私密空间</title> </head> <body> <p>车门给我焊丝~</p> </body> </html>
最后我们跟着教程照猫画虎,编写CSS与JS文件:
//Css code .red { color:red; }
// JavaScript source code var i = 0; function button_click() { i = i + 1; document.getElementById("count_label").innerHTML = i +""; }
此时我们的文件一共有:

我们直接在文件夹中打开文件HTMLPage1.html即可看到:
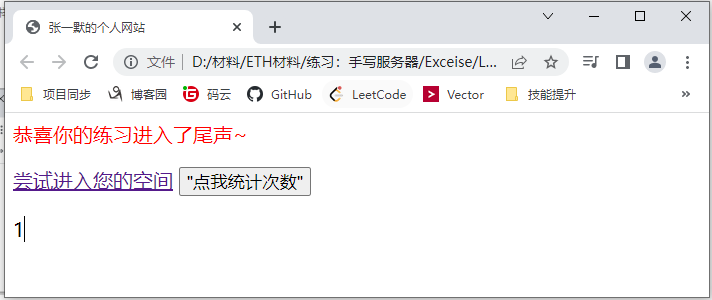
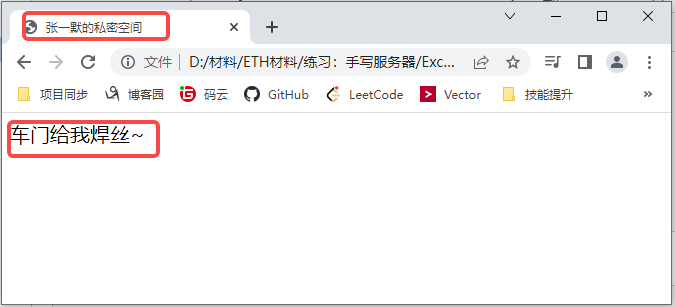
总之,一个完整的Web页面有HTML(控制网页内容结构)、CSS(控制显示样式)、Javascript(控制内容行为)三个共同组成,三者之间通过href/src等各种标签将不同的资源链接起来。而每一个资源(图片、声音等)都是一个TCP链接。针对于这些TCP Sokcet我们需要建立一个FIFO队列来进行缓存。
HTTP协议简介
HTTP概述
HTTP超文本协议本质是查询资源,通常由Web浏览器发起请求。一个完整资源是由多种格式的文件组成,比如图片、音视频、文本等。HTTP的端口为80,HTTPS(HTTP+TLS)的端口号为443。
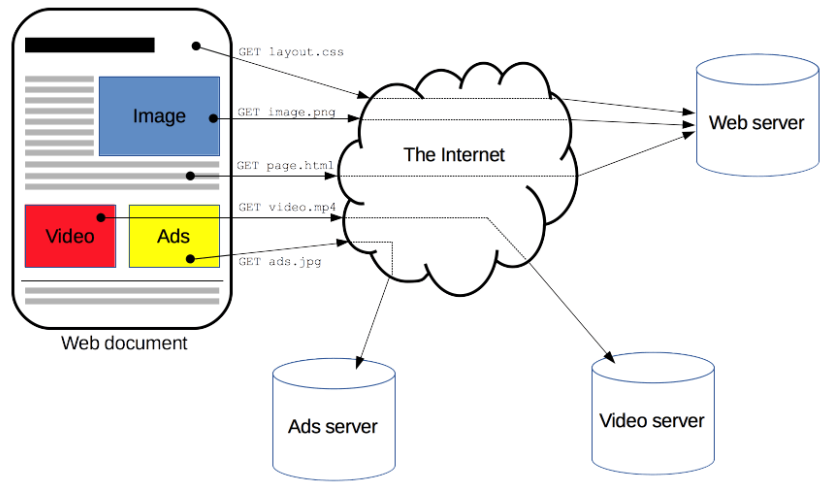
HTTP请求
HTTP请求报文格式
HTTP报文由请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
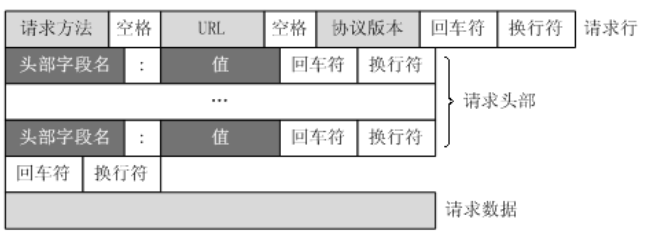
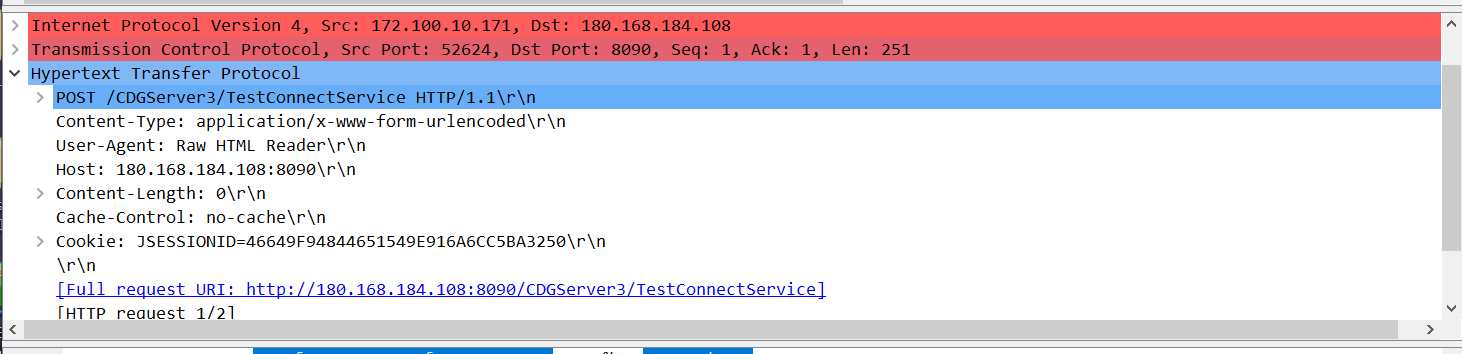
阅读时第一行是请求行,然后从请求行到空行中间的所有部分都是请求头部。空行后的则为请求数据。
HTTP请求类型
HTTP1.1 协议中共定义了八种方法来指定的资源的不同操作方式:
- OPTIONS:返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送'*'的请求来测试服务器的功能性。
- HEAD:向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。
- GET:向特定的资源发出请求。
- POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。
- PUT:向指定资源位置上传其最新内容。
- DELETE:请求服务器删除 Request-URI 所标识的资源。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
- CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
虽然 HTTP 的请求方式有 8 种,但是我们在实际应用中常用的也就是 get 和 post,其他请求方式也都可以通过这两种方式间接的来实现。
POST与GET的区别
- 方法的作用途径不同:
get只是用来获取和请求资源,post则会修改资源,从用途来说post是相对不安全的。 - 限制的长度不同:
get命令协议本身虽然没有被限制长度,但是因为url本身必须作为一个完整的字符串解读或者浏览器自己的规定,比如IE浏览器限制在2048字节,Chorme限制为2M,而post则不会。 - 格式不同:
get中保存url,post中保存表单。 - 缓存不同:
get可以被浏览器缓存,post则不行。 - 同性:
get体育post中的数据本身都是明文,双方都谈不上安全,只有HTTPS才可以保证安全。
HTTP响应
HTTP响应报文格式
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
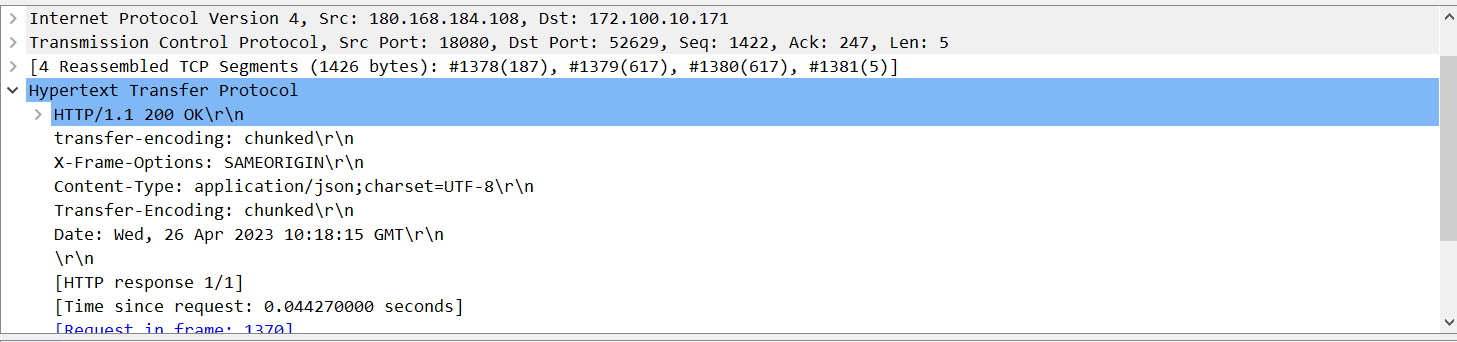
HTTP响应状态码
HTTP响应的状态行中包含了状态码,状态码用来表示此报文状态,最常用的为:
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
程序员最想看到的:200-OK。
程序员不想看到的:500-Internal-Server-Error。
用户不想看到的:401-Unauthorized、403-Forbidden、408-Request-Time-out、404-not-found。
TCP-FIFO缓冲队列实现
FIFO原理

static xhttp_fifo_init(_xttp_fifo* fifo) { fifo->count = 0; fifo->front = fifo->tail = 0; }
FIFO写入
static _type_drv_err xhttp_fifo_in(_xttp_fifo* fifo , _tcp_packet* tcp) { if (fifo->count >= XTCP_FIFO_SIZE) return DRIVE_ERR_IO; fifo->buffer[fifo->front++] = tcp; if (fifo->front >= XTCP_FIFO_SIZE) fifo->front = 0; fifo->count++; return DRIVE_ERR_OK; }
FIFO读取
static _tcp_packet* xhttp_fifo_out(_xttp_fifo* fifo) { _tcp_packet* tcp; if (fifo->count == 0) return (_tcp_packet*)0; tcp = fifo->buffer[fifo->tail++]; if (fifo->tail >= XTCP_FIFO_SIZE) fifo->tail = 0; fifo->tail--; return tcp; }
HTTP组包
换电脑了~后补~20230503
本文来自博客园,作者:{张一默},转载请注明原文链接:https://www.cnblogs.com/YiMo9929/p/17327530.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)