
从1写TCPIP协议栈3:以太网包的收发实现
协议传输机制
WEB服务器和客户计算机得交互过程简述如下:
1、应用层协议栈软件将文件数据进行提取封装,并添加HTTP协议报头向传输层进行传输
2、传输层协议栈软件在上层传递下来得数据包基础上继续添加TCP报头向链路层进行传输
3、链路层协议栈软件在上层传递下来得数据包基础上继续添加IP头/IP地址然后通过以太网接口将逻辑信号转为物理链路得物理信号
4、客户计算机提取物理链路上得物理型号并进行逻辑信号转换,然后依次剔除各层报头,一直往客户计算机应用层传递
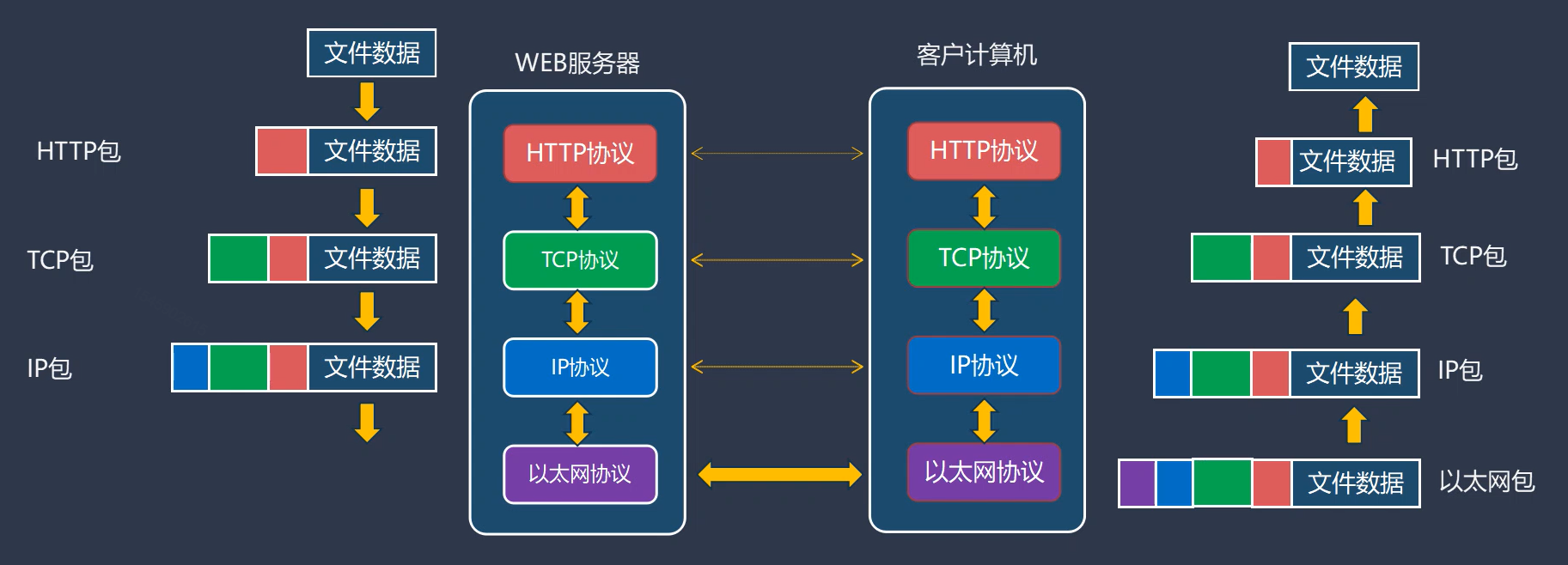
包的结构
从上面的交互流程来看,主机和服务器交互时最重要的不是文件文本的数据,而是各层协议的包头,那定义包头需要考虑的核心问题就是:需要各层协议栈软件支持对应包头和不通数据长度包处理。
那可以简单定义为下面的数据包结构:包的有效长度+指向添加包头的指针+文件数据,那可以定义为一个结构体:
/*定义包的成员及相关参数*/ #define PACKET_SIZE 1516 //以太网链路的最大就是1514,考虑CRC则是1516 typedef struct _eth_packet { uint16_t size;//包大小 uint8_t* dataptr;//指向包头的指针 uint8_t payload[PACKET_SIZE];//用于存放文本数据和各协议栈包头:链路层以太网包,网络层IP协议包,传输层TCP,应用层HTTP }_eth_packet; _eth_packet tx_packet; _eth_packet rx_packet;
操作包
在定义好基本的数据包格式后,我们需要定义数据包的发送、接收、包头增加、包头移除四个最基本的函数,至于包中实际数据的操作,我们在说到各协议时再提:
数据包发送与接收
/* brief:处理tx的数据 return:返回处理好的数据地址指针 */ _eth_packet* tx_eth_packet(uint16_t rsize) { //分配文件的缓冲空间 tx_packet.dataptr = tx_packet.payload + PACKET_SIZE;//将指针指向数组的末尾,因为变化的只是包头,而不是包尾 tx_packet.size = rsize; return &tx_packet; } /* brief:处理rx的数据 return:返回处理好的数据地址指针 */ _eth_packet* rx_eth_packet( uint16_t rsize) { //分配文件的缓冲空间 rx_packet.dataptr = rx_packet.payload;//直接指向数据包的地址 rx_packet.size = rsize; return &rx_packet; }
需要注意几个点,首先我们不可以将struct eth_packet按值传递,如果想要按值传递,请将你得数据包声明为static,例如:
static _eth_packet tx_packet; static _eth_packet rx_packet;
其次就是指针的移动方向需要设置为<<,这是因为以太网的数据包总是增删包头,因此将包尾视为指针基地址比较合理,此操作在包头的增删函数中会有体现。
包头的增删
/* brief:添加包头 return:返回处理好的数据地址指针 */ _eth_packet* add_header(_eth_packet* eth_packet, uint16_t rsize/*包头大小*/) { eth_packet->dataptr -= rsize;//包中首个数据的地址 eth_packet->size += rsize;//数据长度=原本数据长度+包头大小 return eth_packet; } /* brief:去除包头 return:返回处理好的数据地址指针 */ _eth_packet* del_header(_eth_packet* eth_packet, uint16_t rsize) { eth_packet->dataptr += rsize; eth_packet->size -= rsize; return eth_packet; }
可以看出在add_header()中的eth_packet->dataptr -= rsize;正是基于包指针地址为结尾的思想去实现的。
包的截取
在操作eth_packet.payload[]数据前我们首先需要检查包的数据长度是否合理,过长则需要截取然后立即转发,这一思想和Autosar-PDUR中的gatingway-on-fly类似,本次练习我们只截取,不做分批发送:
_eth_packet* truncate_header(_eth_packet* eth_packet, uint16_t rsize) { eth_packet->size = ((eth_packet->size)>(rsize)) ? rsize : eth_packet->size;//取最小值 return eth_packet; }
以太网驱动封装
因为驱动层是我们1的基础,不是本次学习的协议范围,这里我就直接按照博主的代码copy了:
static pcap_t* pcap; const char MY_MAC_ADDR[] = {0x11,0x22,0x33,0x44,0x55,0x66,0x77,0x88}; const char* Host_IP = "192.168.254.1"; typedef enum _eth_err_type { DRIVE_ERR_OK = 0, DRIVE_ERR_IO = -1}_eth_err_type; _eth_err_type _eth_driver_open(uint8_t*mac_addr) { pcap_t* ret = 0; ret = 0; memcpy(mac_addr,MY_MAC_ADDR,sizeof(MY_MAC_ADDR));//拷贝数据包 ret = pcap_device_open(Host_IP,MY_MAC_ADDR,1);//pacp查询数据包 if (ret == (pcap_t*)0) { printf("pcap查询失败!"); exit(0); } return DRIVE_ERR_OK; } _eth_err_type _eth_drive_send(_eth_packet* packet) { return pcap_device_send(pcap,packet->dataptr,packet->size); } _eth_err_type _eth_drive_read(_eth_packet* packet) { uint16_t size = 0; //把全局rx包的地址存放到get_packet,后续继续处理 _eth_packet* get_packet = rx_eth_packet(PACKET_SIZE); //驱动读取数据并返回数据大小,将原本的get_packet(rx_packet)覆盖为新的数据 size = pcap_device_read(pcap, get_packet->dataptr, PACKET_SIZE); if (size)//>0 则成功读取数据包,将拿到的数据r_packet赋值给传入的参数packet { //新的数据get_packet.size参数修正 get_packet->size = size; //新的参数get_packet传给输入的参数 packet = get_packet; return DRIVE_ERR_OK; } return DRIVE_ERR_IO; }
记得要在"xnet_tiny.h"文件中声明驱动相关函数~
以太网的输入输出处理
做好了基本的数据结构和驱动封装,接下来就是针对链路层-以太网包格式的具体定义了。因为在TCP/IP协议栈中,以太网的封装格式由RFC894定义,这里我们可以将包的结构体进一步细化为以下几个部分:
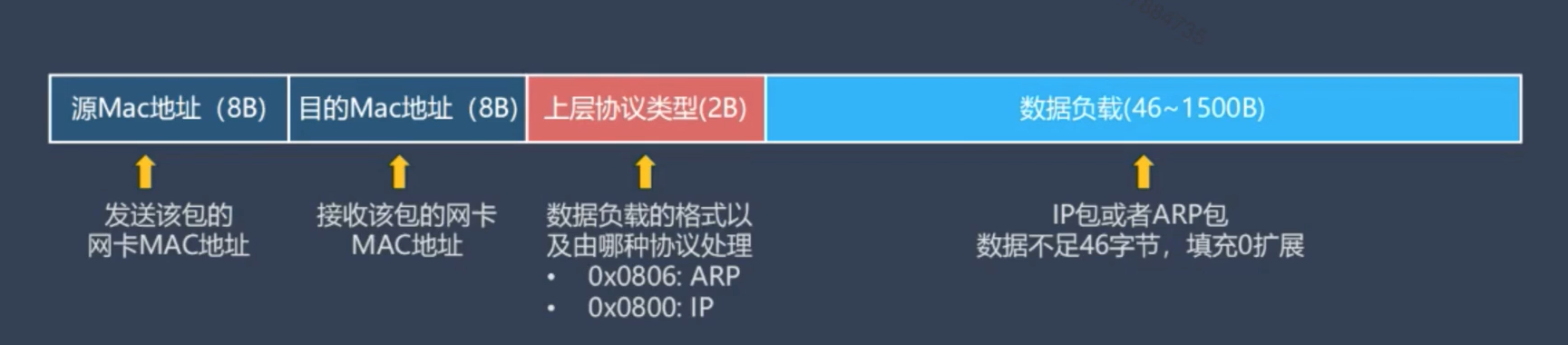
不清楚的也可以在Wireshark抓的包中查看以太网包的具体格式。本次定义不考虑前导码,CRC,也不考虑和RFC1042混合包,毕竟RFC1042是配角。具体代码如下:
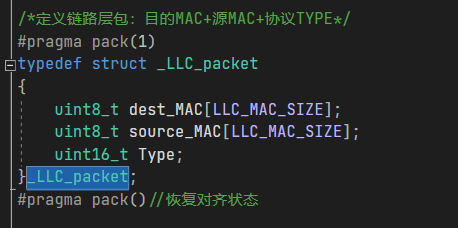
#define LLC_MAC_SIZE 6 //链路层包中MAC地址的大小-byte /*定义链路层包:目的MAC+源MAC+协议TYPE*/ #pragma pack(1)//字节对齐 typedef struct _LLC_packet { uint8_t dest_MAC[LLC_MAC_SIZE];//6个单字节 uint8_t dest_MAC[LLC_MAC_SIZE]; uint16_t Type;//两字节 }_LLC_packet; #pragma pack()
需要说明一个问题,就是字节填充与对齐,RFC894中明确指出如有必要,应填充数据字段(八位字符为零),以满足以太网最小帧大小并且合理的进行数据对其也会提高储存和访问效率。进行#pragma pack(1)将默认的uint16_t2字节对齐修改为1字节对齐,这样数据包在内存中所有的有效值数据都是依次连续的~如果不这莫做,比如uint16_t Type只存放了一个字节的数据,那空的字节编译器就会自己填充,不同编译器的填充规则和对齐方式可能不一样,因此指定对齐方式避免不通编译环境产生的数据对齐问题是开发协议栈必须要做的事情!
接下来就是以太网的输入输出:
static _eth_err_type _ethernet_send(_eth_protocol_type protocol_type/*协议类型*/, const* mac_addr/*目标mac地址*/, _eth_packet* packet/*发送的包*/) { _LLC_packet* eth_header=NULL;//mac地址是llc层的包中数据 //将mac地址添加近packet中 add_header(packet, sizeof(eth_header)); eth_header = (_LLC_packet*)packet->dataptr; memcpy(eth_header->dest_MAC,mac_addr, LLC_MAC_SIZE);//目标主机的mac地址 memcpy(eth_header->source_MAC, netif_mac, LLC_MAC_SIZE);//源网卡的mac地址 eth_header->Type = protocol_type; return _eth_drive_send(packet);//通过驱动发送包 } static _eth_err_type _ethernet_input(_eth_packet* packet/*发送的包*/) { _LLC_packet* eth_header = NULL;//用于解析mac地址 if (packet->size <= sizeof(_LLC_packet)) { return; } eth_header = packet->dataptr;//直接给,因为packet中最开始的数据就是dest mac和source mac,这也体现了数据对齐的重要性 switch (eth_header->Type) { case ARP_PROTOCOL: break; case TCPIP_PROTOCOL:break; } }
这里的_eth_err_type实际是枚举类型,不用纠结,就认为他是返回0/-1用于判断执行结果就好啦。到这里我们已经实现了一个基础的抓包发包框架,剩下就是针对ARP\TCP协议进行专门的接口编写。
流程小结
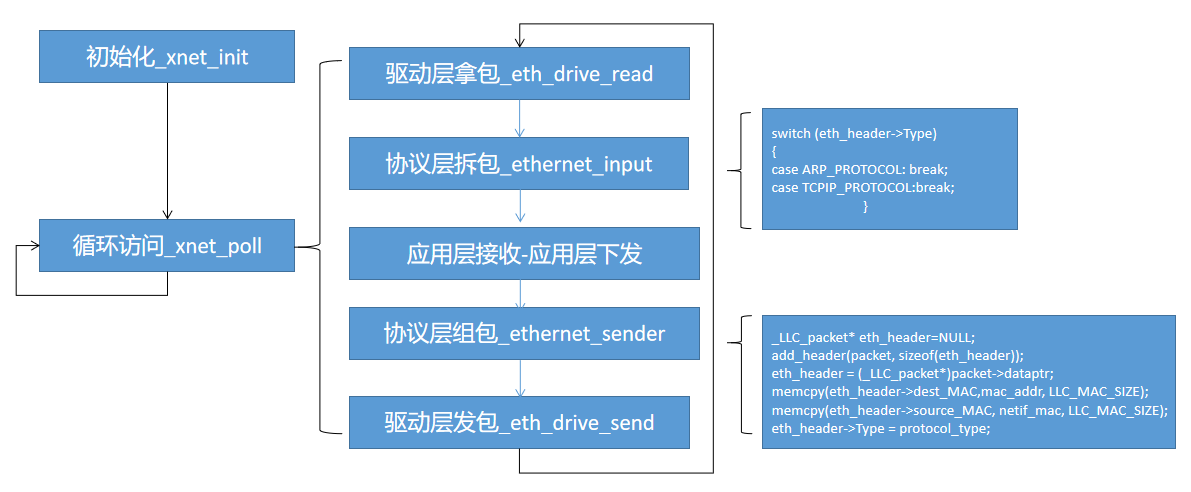
结果检验
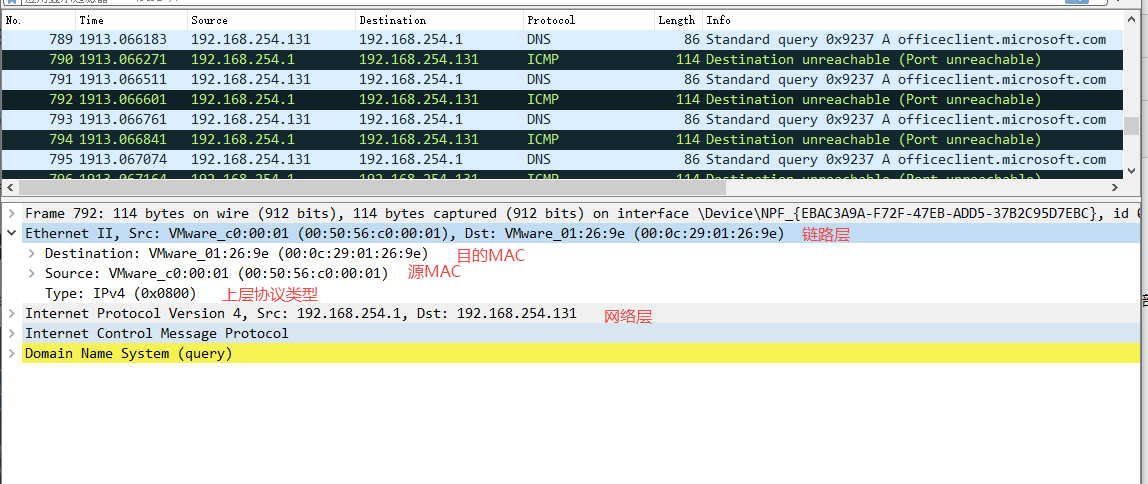
利用现有的简本,我们可以做一个简单的校验,在程序中打上断点,尝试ping工程的地址192.168.254.2:
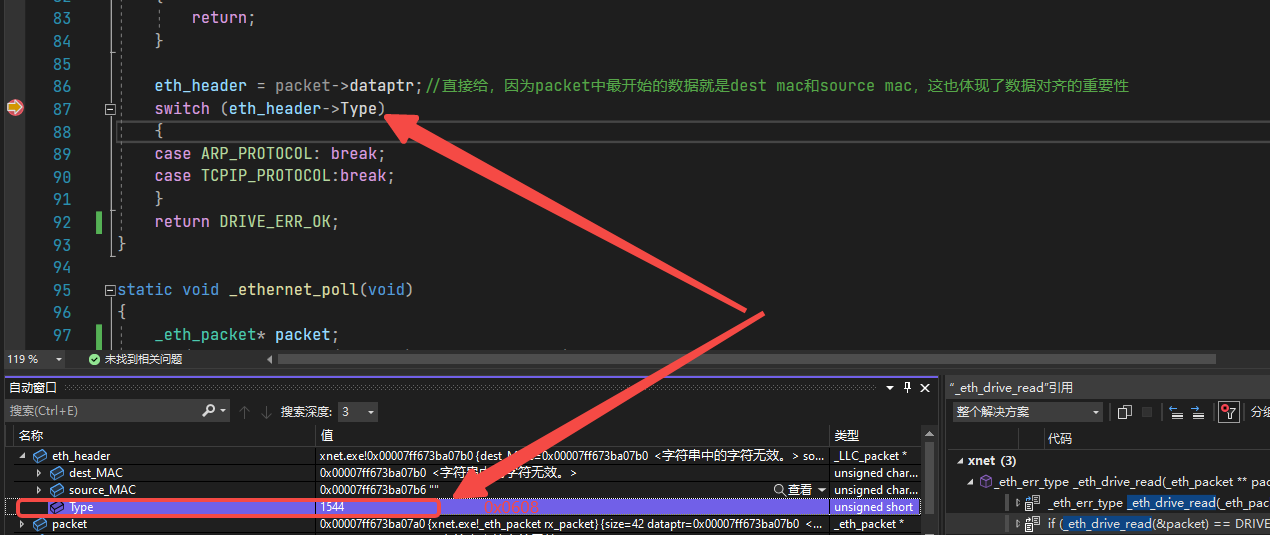
wireshark抓包如下:
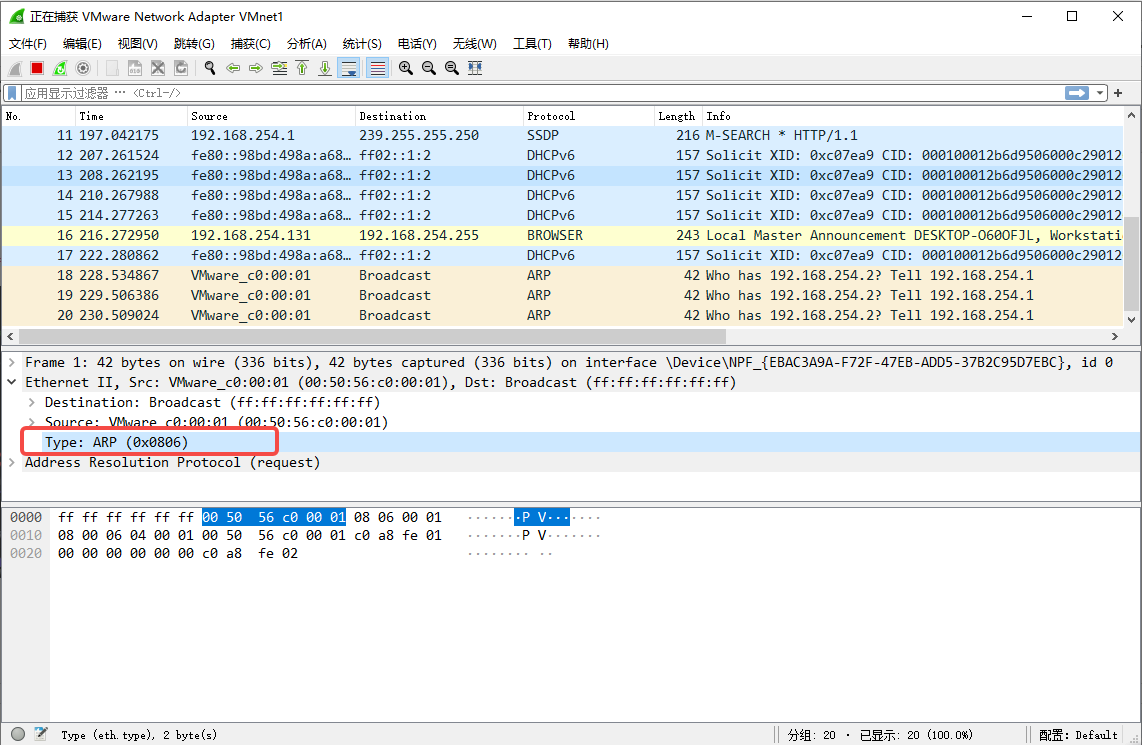
可以看出程序中抓的包和上位机抓到的LLC以太网包中协议类型是颠倒的,这就说明了协议栈开发时还要考虑字节序的问题,一般机器上是小端在前,取出来后表现在网络传输就是大端在前(高位高地址,低位低地址),那ARP协议就是大端在前的形式。我们顺便再看细看一看ARP地址解析协议映射到链路层的42字节数据:
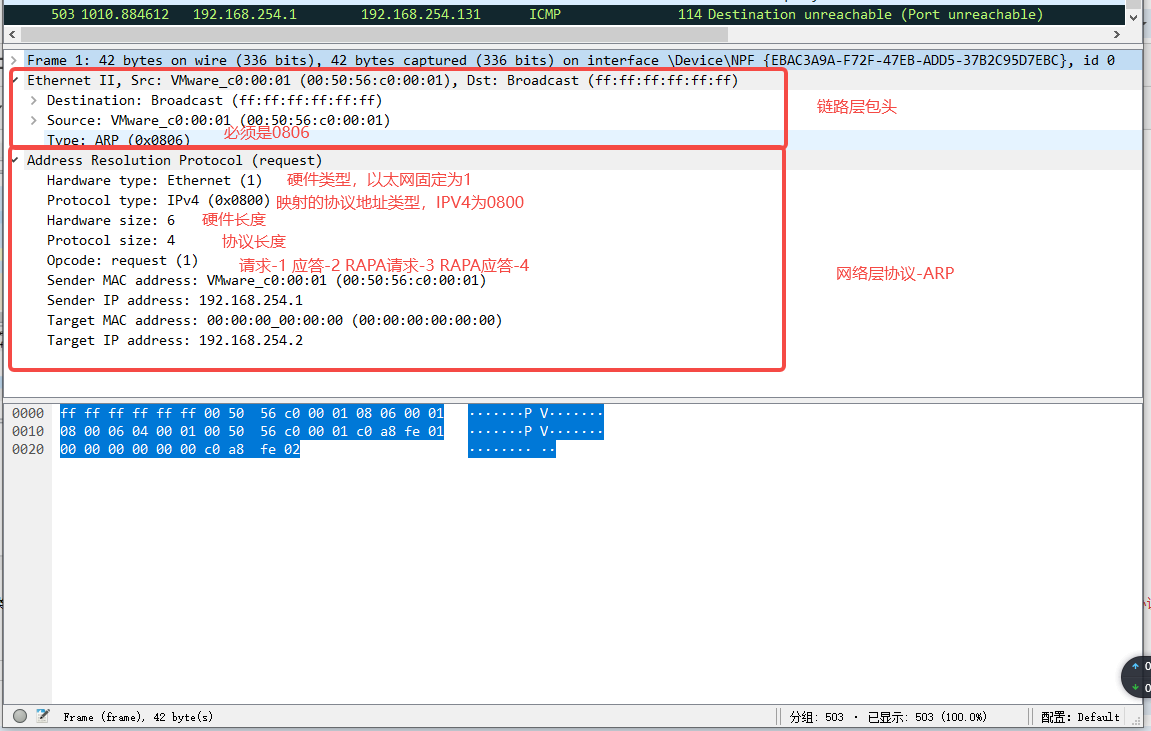
ARP的前8字节是统一且固定的格式,表示了ARP报文:硬件类型/大小+协议类型/大小+报文类型,书中提到IPV4映射到48位MAC地址使用的ARP格式,指的是将48位的MAC地址和ARP地址组包,说是映射有点牵强~
本文来自博客园,作者:{张一默},转载请注明原文链接:https://www.cnblogs.com/YiMo9929/p/17092244.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)