

前端接受后端文件流并下载的几种方法
方法一
使用场景
针对后端的get请求
具体实现
-
<a href="后端文件下载接口地址" >下载文件</a>
-
复制代码
直接用个<a>标签来接受后端的文件流
方法二
使用场景
针对后端的post请求 利用原生的XMLHttpRequest方法实现
具体实现
-
function request () {
-
const req = new XMLHttpRequest();
-
req.open('POST', '<接口地址>', true);
-
req.responseType = 'blob';
-
req.setRequestHeader('Content-Type', 'application/json');
-
req.onload = function() {
-
const data = req.response;
-
const blob = new Blob([data]);
-
const blobUrl = window.URL.createObjectURL(blob);
-
download(blobUrl) ;
-
};
-
req.send('<请求参数:json字符串>');
-
};
-
-
function download(blobUrl) {
-
const a = document.createElement('a');
-
a.download = '<文件名>';
-
a.href = blobUrl;
-
a.click();
-
}
-
-
request();
-
复制代码
方法三
使用场景
针对后端的post请求 利用原生的fetch方法实现
具体实现
-
function request() {
-
fetch('<接口地址>', {
-
method: 'POST',
-
headers: {
-
'Content-Type': 'application/json',
-
},
-
body: '<请求参数:json字符串>',
-
})
-
.then(res => res.blob())
-
.then(data => {
-
let blobUrl = window.URL.createObjectURL(data);
-
download(blobUrl);
-
});
-
}
-
-
function download(blobUrl) {
-
const a = document.createElement('a');
-
a.download = '<文件名>';
-
a.href = blobUrl;
-
a.click();
-
}
-
-
request();
-
复制代码
总结
- 如果后端提供的下载接口是
get类型,可以直接使用方法一,简单又便捷;当然如果想使用方法二、三也是可以的,不过感觉有点舍近求远了。 - 如果后端提供的下载接口是
post类型,就必须要用方法二或者方法三了。
方法二和方法三怎么取舍?
- 当你的项目里的接口请求全是基于
XMLHttpRequest实现的,这时方法二就更加适合,只要基于你原来项目中的接口请求工具类加以扩展就行了。 - 当你的项目里的接口请求全是基于
fetch实现的,这时方法三就更加适合,比如我现在的做的一个项目就是基于ant design pro的后台管理系统,它里面的请求类就是基于fetch的,所以我就直接用的方法三,只要在它的request.js文件中稍作修改就行。 - 我这里讨论的是两种原生的请求方式,如果你项目中引用了第三方请求包来发送请求,比如axios之类的,那就要另当别论了。
以下是个人项目中 利用上述方法二改成针对后端的get请求下载
效果图

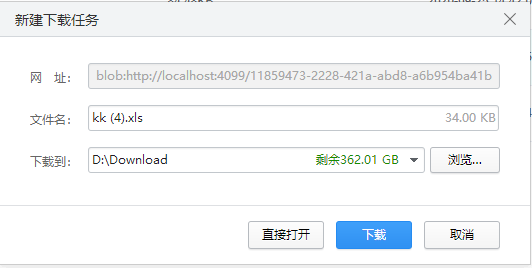
前端:
html:
js:
/// <summary>
/// DownloadBigFile用于下载大文件,循环读取大文件的内容到服务器内存,然后发送给客户端浏览器
/// </summary>
[HttpGet("buckets/file/download")]
public IActionResult DownloadBigFile([Required] string bucketName, [Required] string fileName)
{
var s3Client = GetAS3Client;
try
{
GetObjectRequest request = new GetObjectRequest
{
BucketName = bucketName,
Key = fileName
};
int bufferSize = 10240000;//这就是ASP.NET Core循环读取下载文件的缓存大小,这里我们设置为了1024字节,也就是说ASP.NET Core每次会从下载文件中读取1024字节的内容到服务器内存中,然后发送到客户端浏览器,这样避免了一次将整个下载文件都加载到服务器内存中,导致服务器崩溃
var contentDisposition = "attachment;" + "filename=" + HttpUtility.UrlEncode(fileName);//在Response的Header中设置下载文件的文件名,这样客户端浏览器才能正确显示下载的文件名,注意这里要用HttpUtility.UrlEncode编码文件名,否则有些浏览器可能会显示乱码文件名
Response.Headers.Add("Content-Disposition", new string[] { contentDisposition });
//使用FileStream开始循环读取要下载文件的内容
using (GetObjectResponse response = s3Client.GetObjectAsync(request).Result)
using (Stream fs = response.ResponseStream)
{
Response.ContentType = response.Headers["Content-Type"];
using (Response.Body)//调用Response.Body.Dispose()并不会关闭客户端浏览器到ASP.NET Core服务器的连接,之后还可以继续往Response.Body中写入数据
{
long contentLength = fs.Length;//获取下载文件的大小
Response.ContentLength = contentLength;//在Response的Header中设置下载文件的大小,这样客户端浏览器才能正确显示下载的进度
byte[] buffer;
long hasRead = 0;//变量hasRead用于记录已经发送了多少字节的数据到客户端浏览器
//如果hasRead小于contentLength,说明下载文件还没读取完毕,继续循环读取下载文件的内容,并发送到客户端浏览器
while (hasRead < contentLength)
{
//HttpContext.RequestAborted.IsCancellationRequested可用于检测客户端浏览器和ASP.NET Core服务器之间的连接状态,如果HttpContext.RequestAborted.IsCancellationRequested返回true,说明客户端浏览器中断了连接
if (HttpContext.RequestAborted.IsCancellationRequested)
{
//如果客户端浏览器中断了到ASP.NET Core服务器的连接,这里应该立刻break,取消下载文件的读取和发送,避免服务器耗费资源
break;
}
buffer = new byte[bufferSize];
int currentRead = fs.ReadAsync(buffer, 0, bufferSize).Result;//从下载文件中读取bufferSize(1024字节)大小的内容到服务器内存中
Response.Body.Write(buffer, 0, currentRead);//发送读取的内容数据到客户端浏览器
Response.Body.Flush();//注意每次Write后,要及时调用Flush方法,及时释放服务器内存空间
hasRead += currentRead;//更新已经发送到客户端浏览器的字节数
}
}
}
}
catch (AmazonS3Exception e)
{
// If bucket or object does not exist
Console.WriteLine("Error encountered ***. Message:'{0}' when reading object", e.Message);
}
catch (Exception e)
{
Console.WriteLine("Unknown encountered on server. Message:'{0}' when reading object", e.Message);
}
return new EmptyResult();
}
