
机器学习No.4
任务七——深挖K近邻
一.缺失值的处理
1.也就是数据清洗的一步,最简单的方法是删除法:删除列、删除行。
2.另一种是填补法:
对于数值型变量:平均值填补、中位数填补等。
其他的方法:
(1)填补上下值
(2)插值法拟合出缺失的数据进行填补
for f in features: # 插值法填充 train_data[f] = train_data[f].interpolate() train_data.dropna(inplace=True)
二.特征编码技术
主要是解决将字符串转换成数值类型(向量或矩阵)
1.类别型变量
(1)标签编码
直接用0、1、2 等去标,不能直接输到模型里。
(2)独热编码
使用向量,除了一个位置是1,其他位置均为0, 1的位置对应的是相应类别出现的位置。
2.数值型变量
连续性特征的离散化操作可以增加模型的非线性型,同时也可以有效地处理数据分布的不均匀的特点。
主要知识我就不罗列了,直接放链接吧:https://www.cnblogs.com/zongfa/p/9434418.html
3.顺序变量
看做数值型变量来处理。
三.KNN解决回归
1.使用read_csv读取数据, 并显示数据内容
import pandas as pd df = pd.read_csv('D:/car price.csv') print(df)
读取结果:

2.特征处理
把类别型特征转换成独热编码:
df_colors = df['Color'].str.get_dummies().add_prefix('Color:') df_type = df['Type'].apply(str).str.get_dummies().add_prefix('Type:') df = pd.concat([df,df_colors,df_type],axis = 1) df = df.drop(['Brand','Type','Color'],axis = 1) print(df)
读取结果:

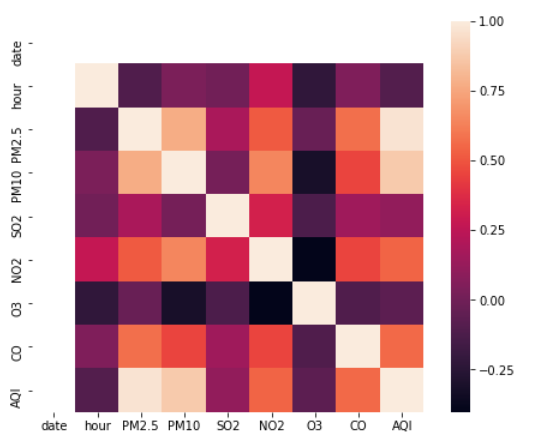
3.特征相关性
corr()函数:pandas的一个函数,可以计算两列值的相关系数,默认用的是pearson相关系数。取值范围是[-1, 1],越接近 1 表示正相关性越强,越接近-1 表示负相关性越强。 想看两列数据的相关性,可以用seaborn的热力图来可视化。
我觉得这个还挺好玩的,就用我们树蛙大作业的数据,截了50条来试了一下(指标是污染物和AQI)。
4.特征归一化
把原始特征转换成均值为0方差为1的高斯分布。
5.训练模型然后进预测。
四.KD树
使用KD树来加速搜索速度,一般只适合用在低维的空间。
把KD树看作是一种数据结构,而且这种数据结构把样本按照区域重新做了组织,这样的好处是一个区域里的样本互相离得比较近。假如之后来了一个新的预测样本,这时候我们首先来判定这个预测样本所在的区域,而且离它最近的样本很有可能就在这个区域里面。KD树的经典应用场景:在地图上的搜索。如搜索离当前点最近的加油站、餐馆,等等。

