
机器学习No.3
任务四——KNN的决策边界+交叉验证+特征规范化
一.KNN的决策边界以及K的影响
这一部分主要是围绕着如何选择合适的K。
首先,决策边界分为:线性决策和非线性决策。随着K的增加,决策边界会变得更加平滑,模型也就越稳定。
二.交叉验证
“调参”
常用的交叉验证技术就是K折交叉验证。我们先把训练数据分成训练集和测试集,之后使用训练集来训练模型,然后在测试集上评估模型的准确率。
三.特征规范化
KNN是很依赖距离的一个算法,所以这种依赖于距离的算法,特征规范化就非常重要,除了老师文件里面的之外,这学期的树蛙课还学了几种,下面说一下其他的这几种吧。
小数定标规范化: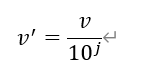 (j是使Max(|v’|)<1的最小整数)
(j是使Max(|v’|)<1的最小整数)
z-score规范化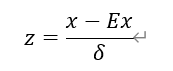 (Ex是均值,分母是标准差)
(Ex是均值,分母是标准差)
任务五——图像识别学习
一.图像的读取及表示
图像可以通过python自带的库来读取。
示例图片:
import matplotlib.pyplot as plt img = plt.imread('d:\Lena.jpg') print(img.shape) plt.imshow(img)
读取结果:
(512L, 512L, 3L)
二.图像的特征
这里提到的方法是做图像上的特征工程,因为KNN不会考虑图像被遮挡、旋转、亮度等。
颜色特征:
(1) SIFT特征是一种局部特征,其具有尺度不变性,即使改变旋转角度,图像亮度或拍摄视角,仍然能够得到好的检测效果,是一种非常稳定的局部特征。
(2) HOG是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性。
三.图片特征的降维
这一部分我主要去了解了一下PCA,也就是主成分分析。(我说感觉好像很熟悉PCA,数图大作业的时候查资料好像查到过这个,但是我们当时大作业是用的SVD奇异值分解去降维的,然后这一部分其实到现在也还是比较懵的...需要复习一下概率论的数学知识,有些公式忘了---)
关于主成分分析,到网上查资料查到了这样一段解释:

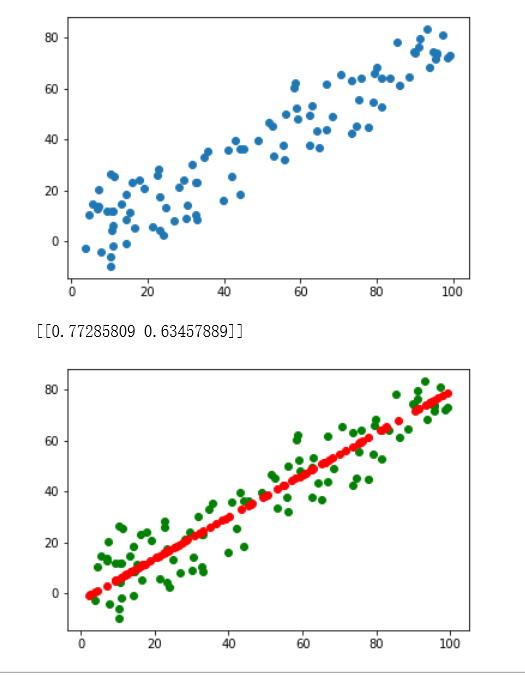
说白了他就是把高维的向量映射到低维中。试着用sklearn去调用了一下:
import numpy as np import matplotlib.pyplot as plt x=np.empty((100,2)) x[:,0]=np.random.uniform(0.0,100.0,size=100) x[:,1]=0.75*x[:,0]+3.0*np.random.normal(0,3,size=100) plt.figure() plt.scatter(x[:,0],x[:,1]) plt.show() from sklearn.decomposition import PCA #在sklearn中调用PCA机器学习算法 pca=PCA(n_components=1) #定义所需要分析主成分的个数n pca.fit(x) #对基础数据集进行相关的计算,求取相应的主成分 print(pca.components_) #输出相应的n个主成分的单位向量方向 x_reduction=pca.transform(x) #进行数据的降维 x_restore=pca.inverse_transform(x_reduction) #对降维数据进行相关的恢复工作 plt.figure() plt.scatter(x[:,0],x[:,1],color="g") plt.scatter(x_restore[:,0],x_restore[:,1],color="r") plt.show()
任务六——利用KNN 进行图像识别
一.文件的读取、可视化、采样
图片展示:
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] num_classes = len(classes) # 样本种类的个数 samples_per_class = 5 # 每一个类随机选择5个样本 # TODO 图片展示部分的代码需要在这里完成。 hint: plt.subplot函数以及 plt.imshow函数用来展示图片 plt.figure(figsize=(10,10)) #图片的尺寸 import random for i in range(num_classes): indexs = np.where(y_train==i)[0] random.shuffle(indexs) for j in range(samples_per_class): ax = plt.subplot(7,10,10*j+i+1) if j==0: ax.set_title(classes[i]) plt.axis('off') plt.imshow(X_train[indexs[j]]/255)
(图片尺寸5×5我有点看不清就改成了10×10)
先获取每一类图片在训练集里面的下标值,打乱下标,随机获取前j个。ax = plt.subplot(7,10,10*j+i+1)的间距确实比ax = plt.subplot(5,10,10*j+i+1)看起来舒服。
--------我是分割线---------
--------我是分割线---------
下一步,emm如果不跟着老师的例子走的话我肯定想不起来统计每一个类别图片出现的次数,分析样本是否平衡还是不平衡。
# 统计并展示每一个类别出现的次数 for i in range(num_classes): print("%s:%d"%(classes[i],len(np.where(y_train==i)[0])))
得到结果:
plane:5000 car:5000 bird:5000 cat:5000 deer:5000 dog:5000 frog:5000 horse:5000 ship:5000 truck:5000
随机采样这里要注意random函数不要用python的numpy矩阵,要用shuffle numpy的矩阵和numpy.random!
numpy.random,shuffle(x)是进行原地洗牌,直接改变x的值,而无返回值。对于多维度的array来说,只对第一维进行洗牌,比如一个 3×3 的array,只对行之间进行洗牌,而行内内容保持不变。
我在跑的时候试了一下直接用了Python的numpy和random,果然是出问题了。
二.使用KNN算法识别图片
我用的是:
params_k = [1,3,5] # 可以选择的K值 params_p = [1,2] # 可以选择的P值
不过还是没跑出来。。。
然后去了解了一下GridSearchCV,是一种调参手段,防止参数选择不当出现过度拟合或者欠拟合的情况。经GridSearchCV计算返回的对象既可以fit(),也可以返回最佳参数。
三.抽取图片特征,用KNN识别图片
这个准确率也没跑出来。。。
最后
关于numpy的使用,还是不太熟练吧,用的时候还是要查文档查资料多一下。

