
机器学习No.1
一.AI&ML&DL
1.机器学习
机器学习是解决人工智能问题的最核心的技术。机器学习的核心是,从数据中自动学出规律。
2.深度学习
深度学习是一个框架,“深”即为把多个简单的模型叠加在一起。
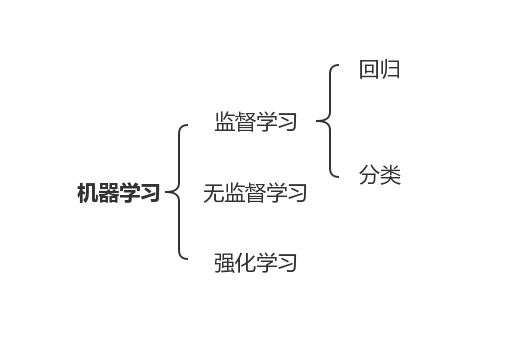
3.数据的特征,样本,标签
(1)标签
标签是我们要预测的事物,即简单线性回归中的 y 变量。标签可以是小麦未来的价格、图片中显示的动物品种、音频剪辑的含义或任何事物。
(2)特征
特征是输入变量,即简单线性回归中的 x 变量。简单的机器学习项目可能会使用单个特征,而比较复杂的机器学习项目可能会使用数百万个特征。
(3)样本
样本是指数据的特定实例:x,分为有标签样本和无标签样本。
4.编写第一个AI程序
(1)
首先,这道题是根据身高预测体重,身高即为特征,体重为预测变量。
(2)数据可视化
这道题的特征只有体重,所以可以将数据在二维空间进行可视化,绘制散点图,通过散点图可以看出身高与体重之间的线性关系,随着身高的增加,体重也呈线性增加,所以本题的数据可以采用线性模型。
(3)训练
根据数据来拟合线性模型,通过得到的模型去预测给出的身高体重。
1)实例化模型
2)使用fit函数训练模型,x为特征,y为标签。
在data[:,0]中添加了一个reshape的函数,主要的原因是在之后调用fit函数的时候对特征矩阵x是要求是矩阵的形式。
reshape()函数可以改变数组的形状,并且原始数据不发生变化:
import numpy as np a = np.array([1,2,3,4,5,6,7,8]) b = a.reshape((2,4)) print(b) c = a.reshape((2,2,2)) print(c)
结果为:
[[1 2 3 4] [5 6 7 8]] [[[1 2] [3 4]] [[5 6] [7 8]]]
3)针对x计算模型的预测值,然后进行可视化。

二.学习KNN
1.算法思想
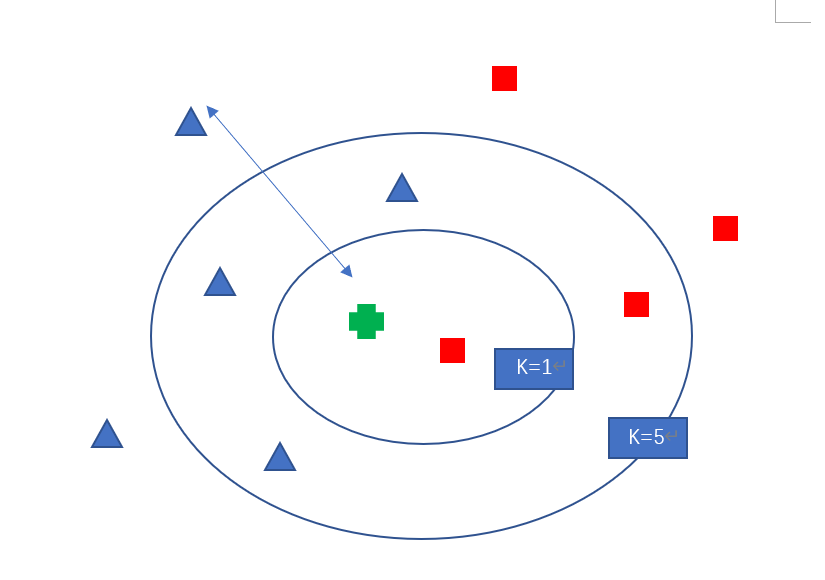
当K=5时,蓝色三角形占3/5,红色方块占2/5,所以绿色加号属于蓝色三角形这一类。
KNN即K-最近邻算法,它是一种消极学习方法,不需要事先对训练数据建立分类模型,而是当需要分类未知样本时才使用具体的训练样本进行预测。
优点:算法简单,易于实现。
缺点:训练样本数量很大时,算法的时间开销很大。
2.距离
一般选欧几里得距离作为距离度量,但是这是只适用于连续变量。对于文档的分类,数据维度非常高,不能用欧几里得距离,通常使用余弦相似度。
3.K值选择
K值太小,容易受到训练数据中噪声的影响,K值太大,在计算得到的测试样本的最近邻样本列表中可能包含远离近邻的数据点。可以根据测试样本到每个最近邻的距离不同对其加权,使远离测试样本的训练数据对分类的影响要比靠近测试样本的训练数据弱一些。
4.使用使用sklearn自带的工具实现KNN
(1)导入要用到的包
from sklearn import datasets from sklearn.neighbors import KNeighborsClassifier from sklearn.modelselection import train_test_split
这几个包之前都没有详细接触过。第一个import是用来导入一个样本数据。sklearn库本身已经提供了不少可以用来测试模型的样本数据,所以通过这个模块的导入就可以直接使用这些数据了。 第二个import是用来做数据集的分割,把数据分成训练集和测试集,这样做的目的是为了评估模型。第三个是导入了KNN的模块,是sklearn提供的现成的算法。
(2)导入数据集
导入数据集iris,将特征值数据存储在iris.data中,标签在iris.target中。
5.一些感想
数据挖掘中学到过KNN,算法思想都是类似的。
python还是要进一步熟悉。
感觉如果拿到题目直接让自己完整的实现还是有些吃力,代码能力还是不够,要继续强化。

