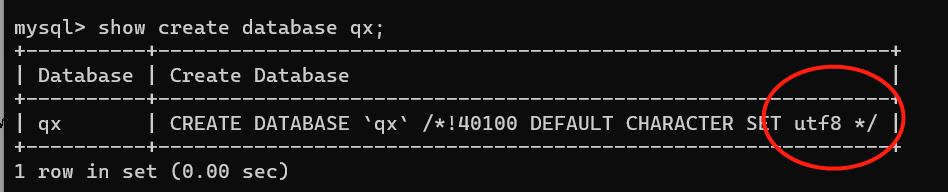
数据库
数据的演变史
1、数据存在了文件中
文件名:user.txt、userinfo.txt
数据格式:会用特殊符号分隔开,如lin|123
2、软件开发目录规范
db文件夹
专门用来存储数据文件,但是,当数据文件较多的时候,占用过多的资源,也会产生很多文件。
3、数据库阶段
解决了以上所有问题(采用统一储存格式)
数据的发展史
1、单机游戏阶段
数据会单独存在一台计算机上,不是实现数据的共享
2、联网游戏阶段
实现了数据的共享、把数据单独存放在一台计算机上(服务器)
数据的分类
1、关系型数据
MySQL(开源的)、Oracle(收费的)、SQLserver、DB2、sqllite、access、MariaDB等
2、非关系型数据
Redis(缓存数据库)——市面上使用最多的、memcache(缓存数据库)、mongoDB(爬虫)
Redis能做的,memcache不能做
memcache不能做的,Redis都能做
二者特点:
1、关系型数据库顾名思义是可以建立关系
拥有固定的表结构,表与表之间可以建立表关系
2、非关系型数据不能够建立表关系
以K:V键值对形式存在的
压根没有表的概念
数据库的本质
本质:其实是一款C/S架构的软件
C/S架构的软件必须是有客户端和服务端的,理论上说,我们自己也能开发出这样的数据库软件,但是没人使用。
SQL与MoSQL的由来
关系型数据库,为了兼容各个客户端,所以每个客户端都要使用MySQL语言,它就是我们说的SQL语句——》关系型数据库
非关系型数据库:Nosql语句
MySQL的介绍
生产环境尽量不要使用最新版本,新版本未经过大量测试,不稳定
生产环境:项目上线之后的环境
测试环境:本地自己使用
当之前安装过MySQL,但是卸载未卸载干净,就会安装不上,就可以下载一个杀毒软件,检测电脑上的残留垃圾文件,删除即可。
MySQL的下载与安装
1、官网下载
https://downloads.mysql.com/archives/community/
2、使用
解压即可
3、MySQL主要文件介绍
bin:存放MySQL的一些启动文件
MySQL.exe:MySQL自带的客户端
MySQLd.exe:MySQL自带的服务端
data:mysql数据的存储文件夹
my-default.ini:MySQL的配置文件
README:MySQL的说明文件
4、MySQL如何启动
由于MySQL是有客户端和服务端的,因此,我们要启动服务端和客户端来使用
1、先启动服务端:mysqld.exe
2、然后启动客户端去连接服务端
启动:
1、切换路径至bin目录下,先打开cmd——输入mysqld启动服务端——再打开一个cma窗口——输入mysql连接服务端
2、客户端连接上服务端之后,退出客户端:exit
服务端启动后,如何终止服务端:ctrl+c
localhost:代表本机
127.0.0.1:也代表本机
某些情况下,两个有区别
5、加入环境变量
把bin目录加入环境变量后,任何位置都可以找到服务端和客户端
6、系统服务制作(要用管理员权限)
1、先打开cmd窗口
mysqld -- install (第一次安装成功,需要手动重启)
如何找到服务:1、此电脑 ---- 管理 2、cmd ---- services.msc 3、
2、如何启动服务
1、鼠标点击启动按钮
2、net start mysql
3、如何关闭服务
1、鼠标点击启动按钮
2、net stop mysql
4、如何卸载MySQL服务
mysqld -- remove
7、卸载mysql
1、先卸载服务
2、在关闭服务端
3、直接删除MySQL文件夹
8、杀进程((只有在管理员cmd窗口下才能成功))
tasklist 查看端口
taskkill /pid 端口 -f
管理员修改密码及忘记密码
1、游客模式登录:mysql(功能少,权限低)
2、管理员登录:mysql -u root -p (回车就登录成功了)
3、连接别人电脑数据库,需要指定IP和port:
mysql -h 127.0.0.1 -P 3360 -u root -p 123
4、给管理员设置密码
mysqladmin -u root -p 旧密码 password 新密码
5、密码忘记
使用跳过授权表的形式
1、先把服务端关闭
2、使用跳过授权表的形式启动服务端
mysqld (不跳过授权表)
mysqld --skip-grant-table (跳过授权表:客户端在连接服务端的时候,不需要验证密码,直接登陆成功)
3、再次使用管理员账号来登录进去,就不需要密码了
进入mysql之后,需要修改密码:
update mysql.user set password=password('root') where Host='localhost' and User='root';
flush privileges; # 刷新权限(立刻将修改数据刷到硬盘)
退出客户端
退出服务端
4、改完之后,一定要终止服务端,重新不跳过授权表,启动服务端,再次使用管理员登录即可。
MySQL的配置文件
\s 输出MySQL的基本信息
mysql的默认配置文件:my-default.ini,文件复制一份命名为my.ini/。
配置文件的作用:修改字符编码
在my.ini中输入一下内容 [mysqld] character-set-server=utf8 collation-server=utf8_general_ci [client] default-character-set=utf8 [mysql] default-character-set=utf8
以后改变配置文件,一定要重启服务端,配置文件才能生效
值得注意的是,改配置之前建立的数据库,字符编码还会是之前的,但是改后就会变成之后的。
修改配置前建立的数据库

修改配置后建立的数据库
重要概念
库 》》》 文件夹
表 》》》文件夹中的文件
记录 》》》 文件夹中的文件的一行行数据
现有库,再有表,最后有记录
先创建数据库,再在库里创建数据表,最后在表里插入记录
数据库相关命名
1、查看所有数据库
show databases;
默认的数据库:
information_schema # 默认创建在内存中的数据库
mysql # MySQL默认创建的数据库,不要动
performance_schema #
test # 空数据
2、如何选择数据库
use 库名;
use mysql;
3、增加数据库
create database 数据库名
4、删除数据库
drop database 数据库名
5、修改数据库
一般情况下,我们只要创建了数据库,就不会修改,如果要修改,就直接删除,创建新的
alter database 数据库名 charset = ‘gbk’;
针对库的sql语句
show databases;
show create database db1;
create database db1;
alter database db1 charset = ‘gbk’;
drop database db1;
use mysql;
针对表的SQL语句
有表的前提是先有库
表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应标题,称为表的字段。
查看当前库所在位置:select database();
选择库:use db1;
查看表:show tables;
查看表结构:show create table t1;
格式化之后的表结构(表的详细信息):describe t1;desc t1(这两个一样)
创建表:create table t1(id int, name varchar(23),age int);
修改表:alter table t1 rename tt1;
删除表:drop table t1;
针对记录的sql语句
1、查看表中的数据:
select * from t1;
select id from t1;
select id,name from t1;
2、增加数据:
insert into t1 values(1,'lin',20);
insert into t1 values(2,'qx',18),(3,'yy',19);
insert into t1(id,name) values(1,'lin'); 逗号隔开增加多条。
3、修改数据:
update 表名 set 字段名 = ‘字段值’ where 条件;
字段名可多个修改,用逗号隔开,where 的条件用and连接
注意:where 后面一定要增加值,一定要检测更新条件,要有安全意识。
4、删除数据:
delete from t1 where id = 1;
delete from t1 where id = 1 and name = '要删除值的名字';(这个删除指定数据)
存储引擎(存储数据的方式)
存储引擎:存储数据的方式
cmd中查看MySQL中存储数据的方式:
show engines;
存储引擎一共九种,要掌握两种,了解一种。
MYISAM: 它是MySQL5.5及之前的版本默认存储引擎,它的存取速度更快,但是数据相对InnoDB不够安全。
InnoDB: 它是MySQL5.6及之前的版本默认的存储引擎,它的存取速度相对MYISAM更慢一点,但是数据相对它更安全。
MEMORY:它的数据是在内存中存着的,内存是基于电工作的,所以断电数据就会丢失,重启服务端也会丢失数据。
以上三者存储产生的文件:
create table t2(id int) engine=MyISAM;
create table t3(id int) engine=InnoDB;
create table t4(id int) engine=MEMORY;
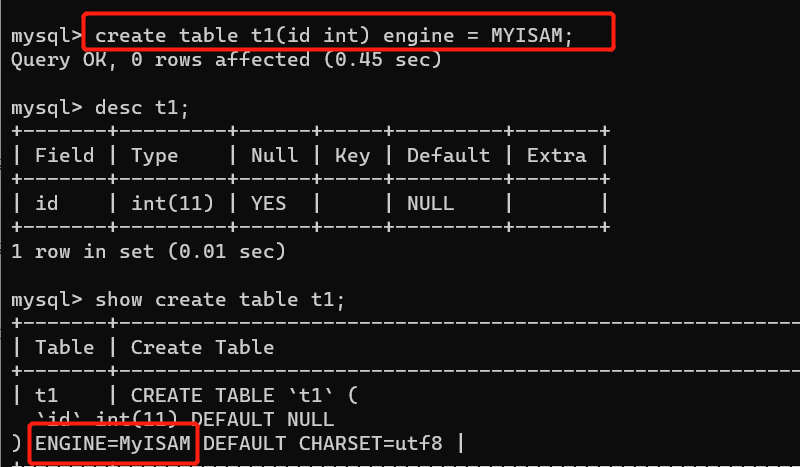
MYSIAM:
产生三个文件:
.frm : 这个文件存表结构
.MYD : 这个文件存数据 data
.MYI:这个文件存数据的索引 index (类似于书的目录,会加快查询速度)
InnoDB:
产生两个文件
.frm:这个文件存表结构
.ibd:这个文件存数据的索引和数据 index (同.MYI)
MEMORY:
产生两个文件
.frm:这个文件存表结构
数据类型(重要)
1、整型
tinyint smallint mediumint int bigint
不同的数据类型存储范围不同
存储范围比较:
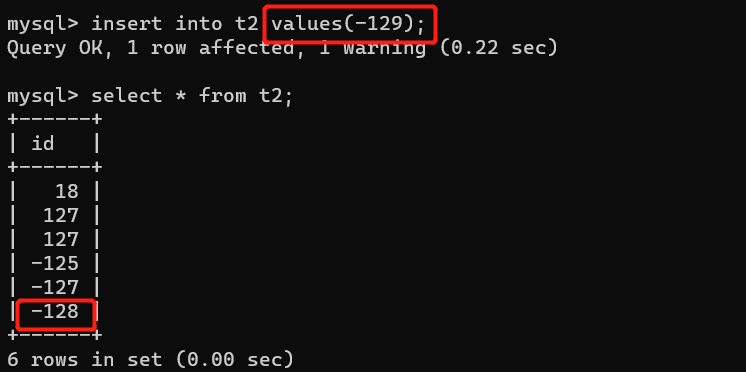
tinyint:1个字节 ------ 8位 ------- 2**8 ------- 256 ------ 0-255 ----- -128-127
smallint:2个字节 ----- 16位 ----- 2**16 ----- 65536 ---- 0-65535 ----- -32768-32767
int:4个字节 ---- 32位 ---- 2**32 ----- 21... ----
bigint :8个字节 --- 64位 ---- 2**64 ----- 很大
默认情况下整型带符号:
create table t5 (id tinyint);
create table t5 (id smallint);
create table t5 (id int);
create table t5 (id bigint);
得出结论:默认情况整型是带负号。
当存储的值超过能存储的最大值,只会写范围内的最大值
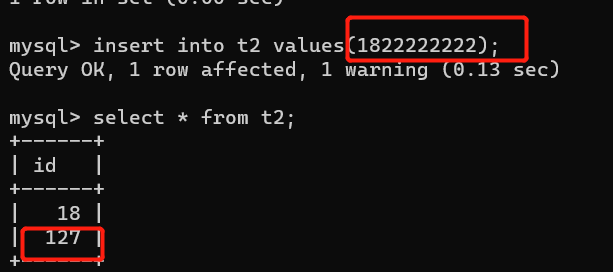
当存储的值超过能存储的最小值,只会写范围内的最小值。(可以带负号)
2、浮点型
小数
float double decimal
语法格式:
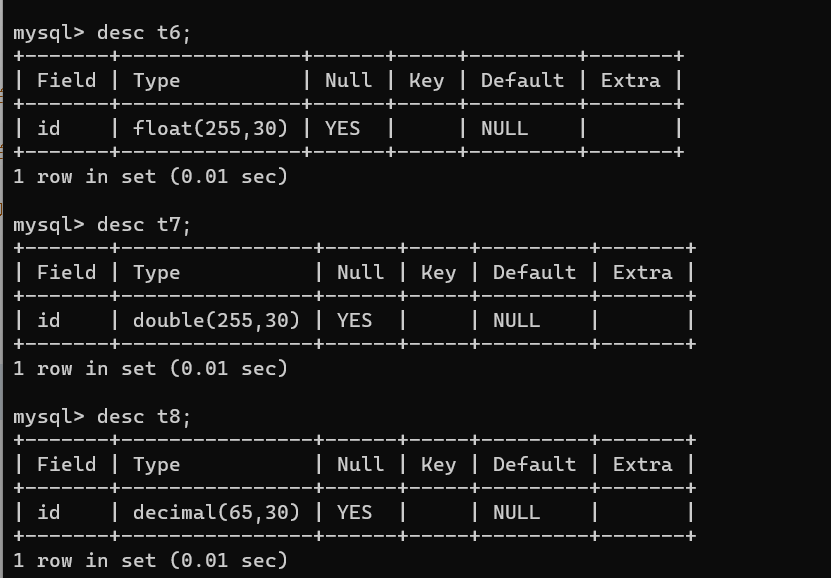
float(255,30); 255表示的是存储位数,30代表的是小数位数
double(255,30);255表示的是存储位数,30表示的是小数位数
decimal(65,30);65表示的是存储位数,30表示的是小数位数
decimal(8,2) 表示的是最大范围是 999999.99 (精确度最高,也是使用最多的)
创建表:
create table t6(id float(255, 30));
create table t7(id double(255, 30));
create table t8(id decimal(65, 30));
当插入数据:
insert into t6 values(1.111111111111111111111111);
insert into t7 values(1.111111111111111111111111);
insert into t8 values(1.111111111111111111111111);
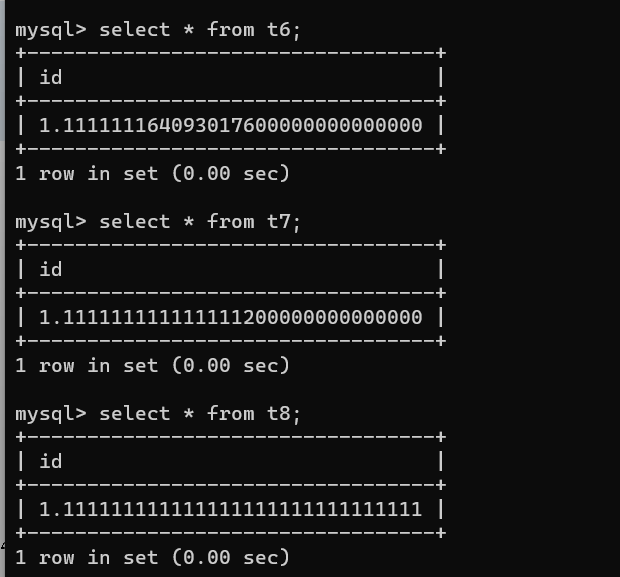
由上图可以看出,以上三个精确度不同
decimal 》》》》 double 》》》》》 float
3、字符串
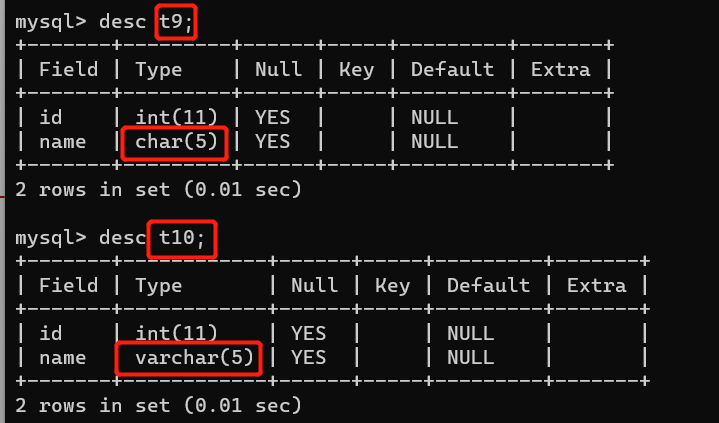
char() varchar() 有多少就存多少
都是用来存储字符串的
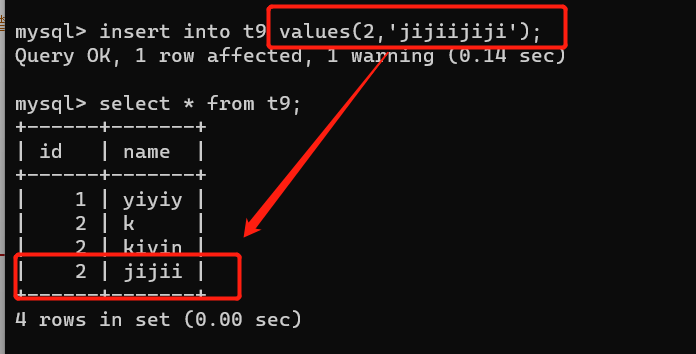
char(4):它是定长,就存4位,如果没有超过4位,空格填充到4位,超过4位,报错或者最大存4位。
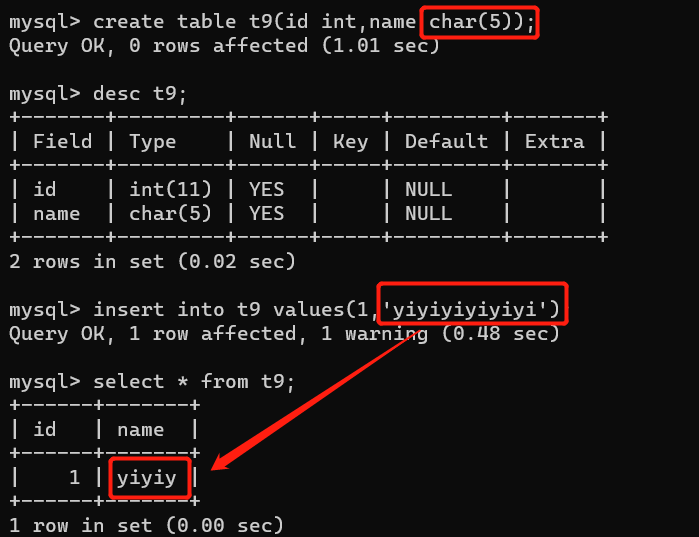
varchar(4):可变长,不超过4位,有几位存几位,超过四位,报错或者最大存4位。

以上只是有几位存几位,并没有报错,如果想要报错,需要修改配置文件(也就是变成严格模式)
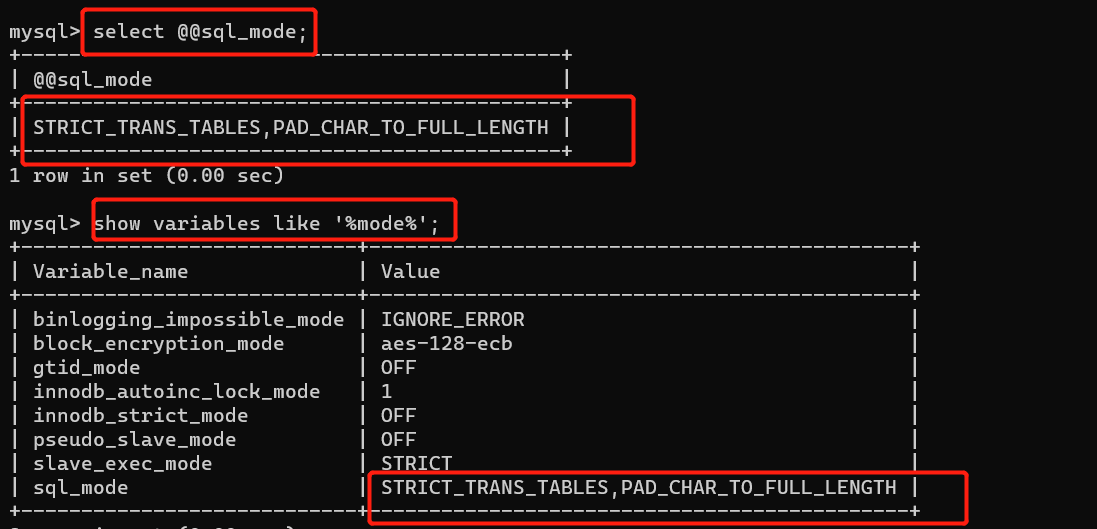
如何查看严格模式:
1、select @@sql_mode;
2、show variables like ‘%mode%’ 模糊查询,变量中带有mode的,引号里的值可以修改。
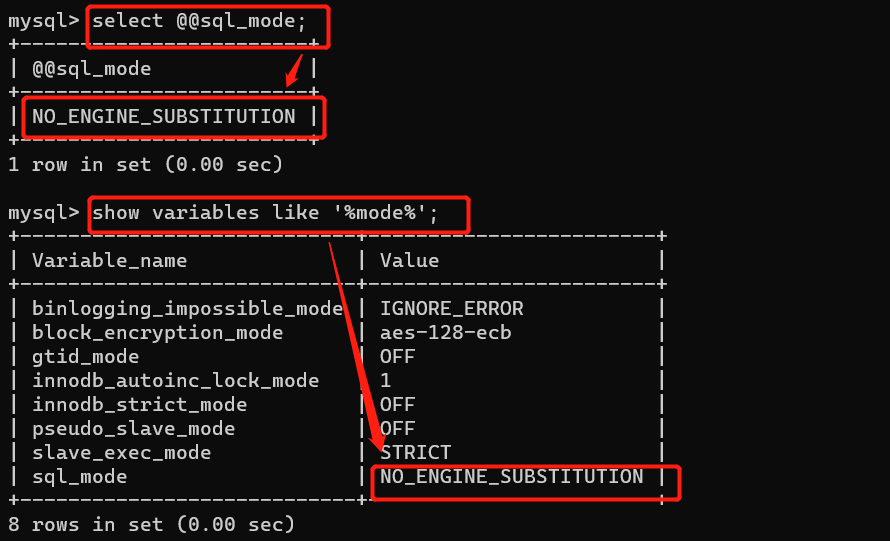
设置严格模式
1、永久修改:修改配置文件
2、临时修改:‘STRICT_TRAMS_TABLES’,PAD_CHAR_TO_FULL_LENGTH';(这里是增加了两个严格模式,可以只增加一个)
修改完成后,重新进入服务器即可
研究定长和可变长:
增加char()里的数据
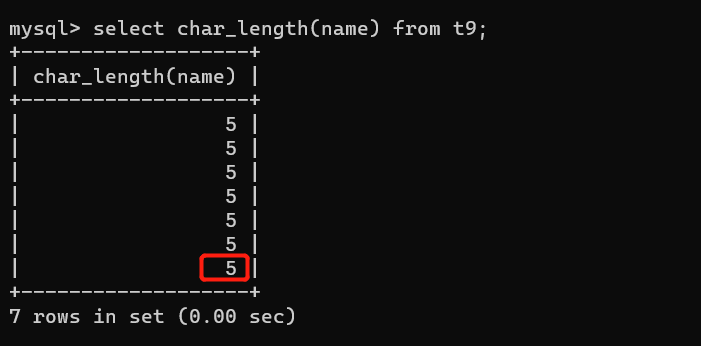
(这里插入为一位,但是因为严格模式所以自动补零)
增加varchar()里的数据
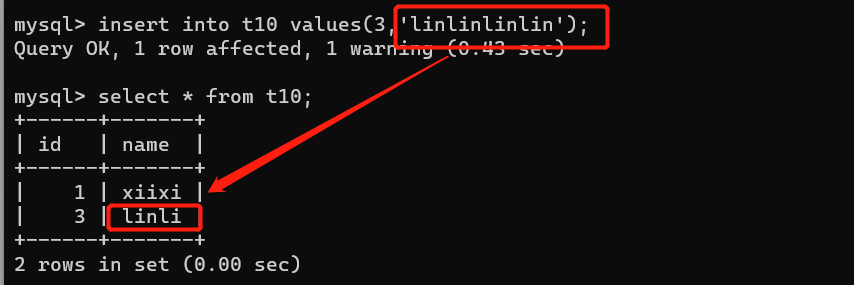
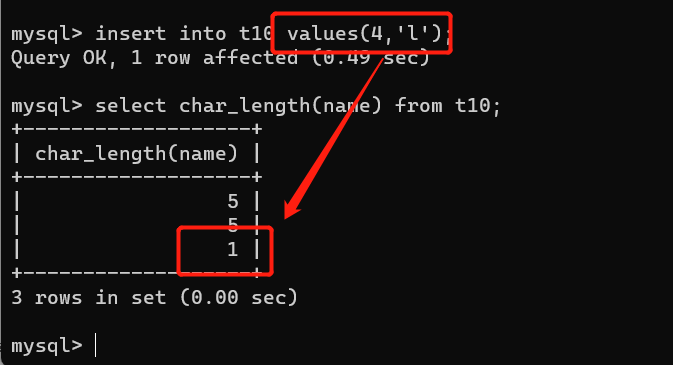
ps:大多数情况下使用的都是varchar,如果存储数据是固定的,就是char。
4、日期类型
datetime date time year
年月日 时分秒 年月日 时分秒 年份
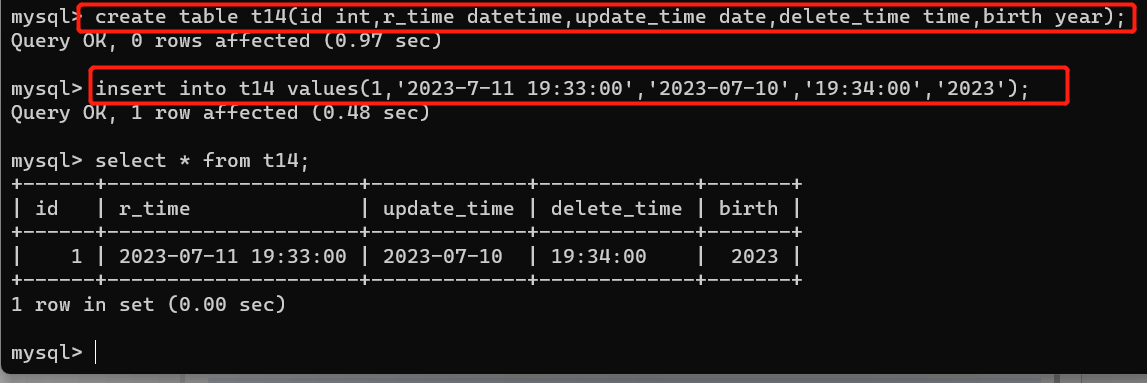
5、枚举类型
enum:多选一
必须填这里面的值,否则会报错。
create table t15(id int,name varchar(32),hobby enum('read','listen','play','sleep'));
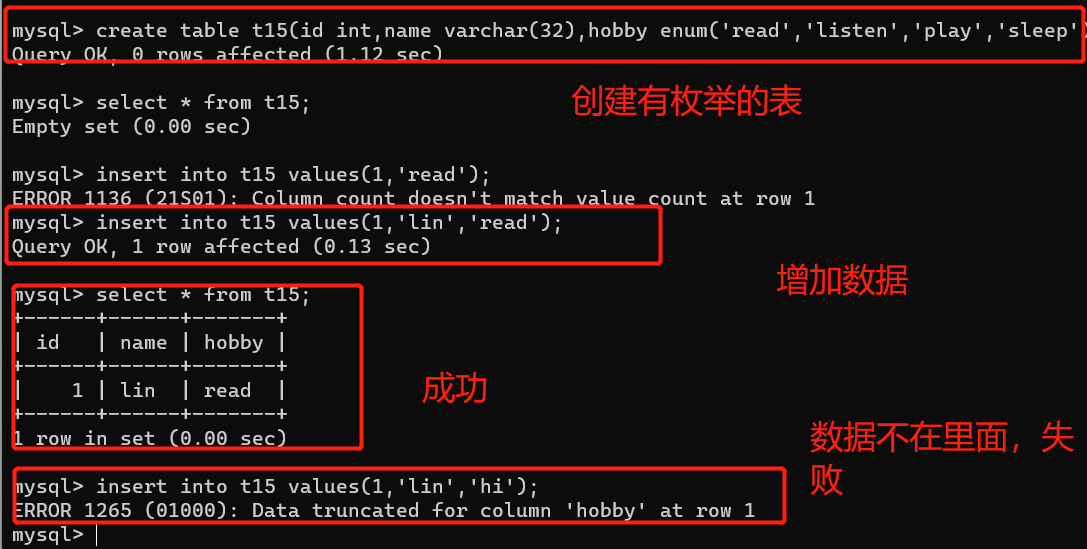
set: 多选多
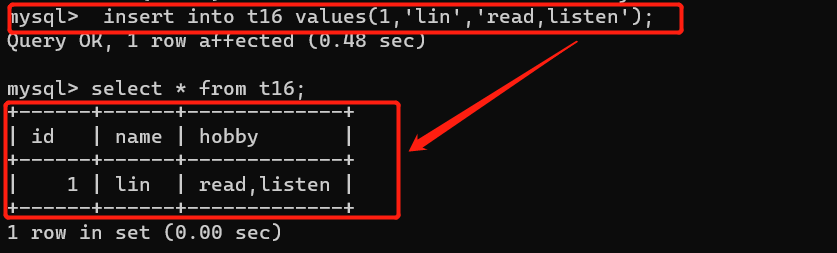
集合可以只写一个,但是不能写没有列举出来的。
整型中的数字代表
char(4) varchar(4) 括号里的数字代表的是存储长度。
int tinyint smallint 整型的存储范围完全是和关键字相关
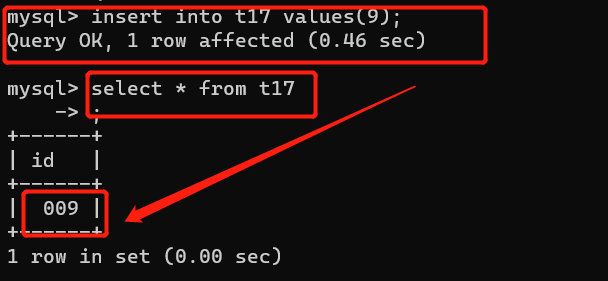
整型中括号里的数字代表的是数据展示位数:
create table t12 (id int(3) zerofill); 但是只有加了zerofill才会有0补位。
创建表的完整语法结构
create table 表名(
字段名1 数据类型 约束条件 约束条件 约束条件,
字段名2 数据类型 约束条件 约束条件 约束条件,
字段名3 数据类型 约束条件 约束条件 约束条件,
字段名4 数据类型 约束条件 约束条件 约束条件,
字段名5 数据类型 约束条件 约束条件 约束条件
);
注意:
1、字段名和数据类型是必须要写的
2、约束条件是可选的,有就写,没有就不写
3、最后一个字段的末尾不能加逗号
约束条件
约束条件的意思是在数据类型的基础上再添加限制条件
1、unsigned: 去除符号 输入负值会变成0,但是设置了严格模式,就会报错
2、zerofill :补零 例如当输入值的范围是到5,但是输入了一位,就会自动用0补成5位。
3、not null:非空 值得注意的是 ‘’ 和null不同。
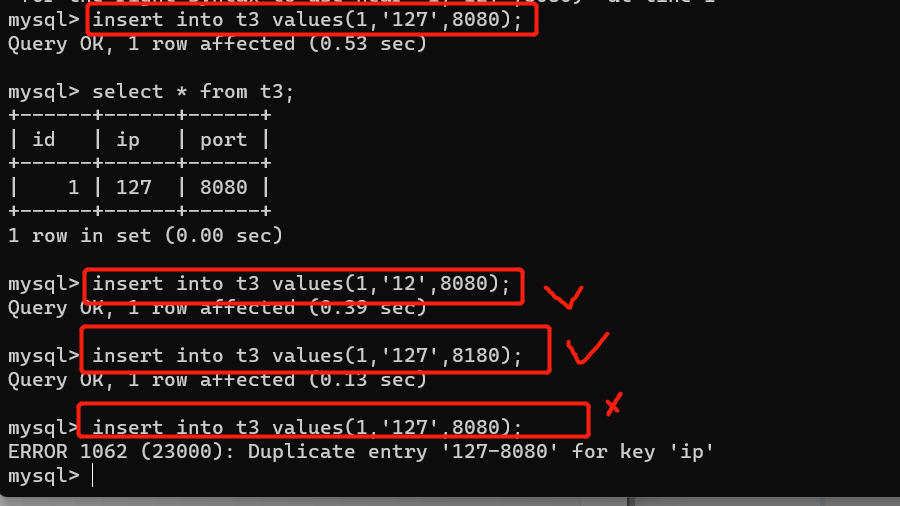
4、unique:唯一 唯一分为单列唯一和联合唯一。
单列唯一:不能加入重复值,加入重复值就会报错。
联合唯一:如下图所示,联合唯一就是如果绑定两个值在一起唯一,那么这两个值就不能在一个语法里重复。
语法结构: create table t3(id int,ip varchar(32),port int ,unique(ip,port));
5、default:默认值 默认值就是在部分字段加入时,如果没有加入该值,则不会默认为空,会默认为自己在创建表时定义的值。 语法结构: create table t2(id int,age int default 18);
6、primary key:主键,主键就相当于not null + unique,非空且唯一。
语法结构:create table t4(id int primary key ,name varchar(32));
InnoDB存储引擎要求每一张表都要有一个主键,但是之前创建的表都成功了,是因为InnoDB存储引擎内部隐藏的有一个主键字段,但是这个隐藏的字段我们看不到,这个主键的目的主要是用来帮助将表创建成功而已。
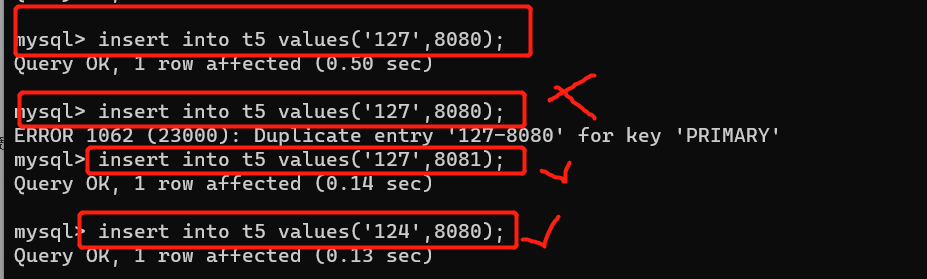
联合主键(多个字段联合起来作为表的主键 本质还是一个主键): create table t5(ip char(16),port int,primary key(ip,port));
7、auto_increment:自增 原来基础上每次加一,当不手动加入编号时,就会自动加一。语法结构:create table t6(id int primary key auto_increment,name varchar(32));
正常配合主键一起使用。
清空表的两种方式
1、delete from t1; 不会把主键id值重置。也就是说删除之后再添加数据的id值会从删除的地方开始。
2、truncate t1:
1、会把主键id的值重置为开始。
2、把数据也清空了。
3、遇到清空表的情况,推荐用truncate,因为删除后想恢复数据还有机会补救,在binlog日志里,记录数据库的变化过程。
补充其他SQL语句
1、修改表名:alter table 表名 rename 新表名;
例如:alter table t6 rename t66;
2、增加字段:alter table 表名 add 字段名 数据类型【完整约束条件】
例如:alter table t66 add height int not null;
2.1 增加字段在特定字段后:例如: alter table t66 add weight int after id;
2.2增加字段在第一位:例如:alter table t66 add beautiful enum('yes','no') first;
在增加字段的时候,一定要考虑这张表是否已经有数据了。
3、删除字段:alter table 表名 drop 字段名;
例如:alter table t66 drop name;
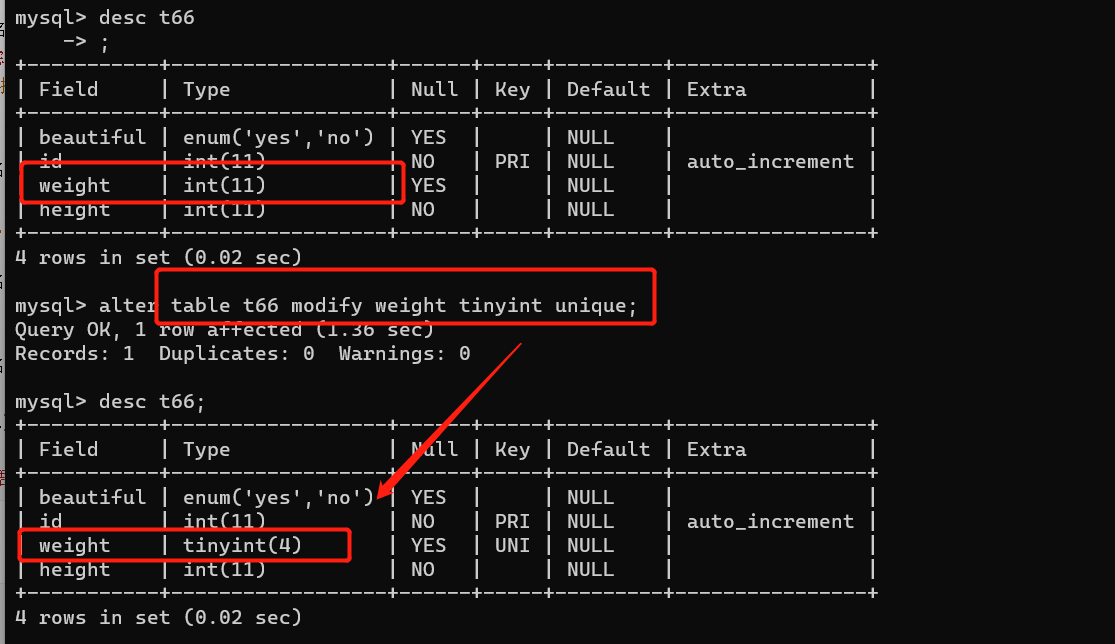
4、修改字段:modify只能修改字段数据类型完整约束,不能改字段名,但是change可以。
alter table 表名 modify 字段名 数据类型【完整性约束条件】
例如:alter table t66 modify weight tinyint unique;
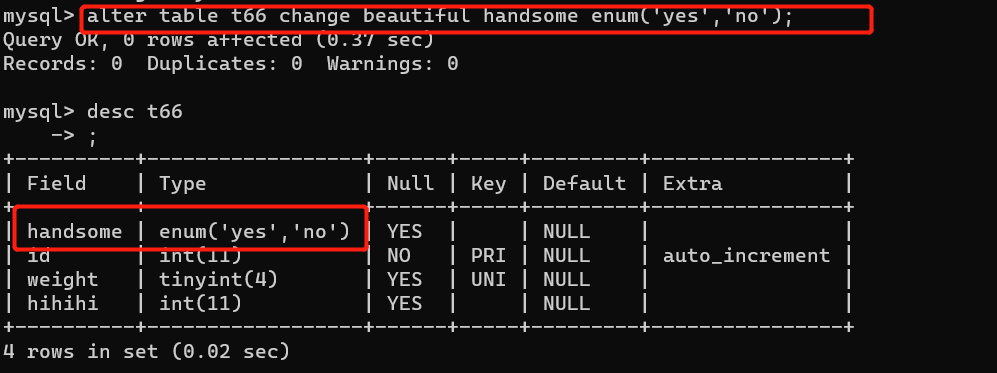
alter table 表名 change 旧字段名 新字段名 旧数据类型;
例如:alter table t66 change beautiful handsome enum('yes'.'no');
关于下列笔记的数据,仅用于举例。
# 数据准备 create table emp( id int primary key auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age smallint(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一个部门一个屋子 depart_id int ); """在mysql中,#代表的是注释符号""" insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values ('tom','male',78,'20150302','teacher',1000000.31,401,1),#以下是教学部 ('kevin','male',81,'20130305','teacher',8300,401,1), ('tony','male',73,'20140701','teacher',3500,401,1), ('owen','male',28,'20121101','teacher',2100,401,1), ('jack','female',18,'20110211','teacher',9000,401,1), ('jenny','male',18,'19000301','teacher',30000,401,1), ('sank','male',48,'20101111','teacher',10000,401,1), ('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('呵呵','female',38,'20101101','sale',2000.35,402,2), ('西西','female',18,'20110312','sale',1000.37,402,2), ('乐乐','female',18,'20160513','sale',3000.29,402,2), ('拉拉','female',28,'20170127','sale',4000.33,402,2), ('僧龙','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3);
查询关键词——where
where筛选功能
模糊查询:
没有明确的筛选条件
关键字:like
关键符号:
%:匹配任意个数任意字符
—:匹配当个个数任意字符
show variables like ‘%mode%’
1.查询id大于等于3小于等于6的数据
select * from emp where id>=3 and id <= 6;
select * from emp where id between 3 and 6;
2.查询薪资是20000或者18000或者17000的数据
select * from emp where salary = 20000 or salary = 18000 or salary = 17000;
select * from emp where salary in(20000,18000,17000);
3.查询员工姓名中包含o字母的员工姓名和薪资
select name,salary from emp where name like '%o%';
select name,salary from emp where name like '%o';
select name,salary from emp where name like 'o%';
4.查询员工姓名是由四个字符组成的员工姓名与其薪资
select name ,salary from emp where name like '____';
select name ,salary from emp where char_length(name)=4;
5.查询id小于3或者大于6的数据
select * from emp where id <3 or id >6;
select * from emp where id not between 3 and 6;
6.查询薪资不在20000,18000,17000范围的数据
select * from emp where salary not in (20000,18000,17000);
7.查询岗位描述为空的员工名与岗位名 针对null不能用等号,只能用is
select name,post from emp where post_comment is NULL;
select name,post from emp where post_comment is not NULL;
在sql中,null和‘’不一样,一般最好设置为‘’,方便归档数据。
查询关键字——group by
分组:把一个整体分成若干个个体。
关键字:group by
分组后,得到的是每一个分组中的第一条数据,分组之后只能得到一个分组依据。
分组之后默认只能够直接过去到分组的依据,其他数据都不能直接获取。
针对5.6需要自己设置sql_mode
set global sql_mode = 'only_full_group_by,STRICT_TRANS_TABLES,PAD_CHAR_TO_FULL_LENGTH';
聚合函数:
sum max min avg count
分组一般会配合聚合函数使用,当遇到每个,就是需要分组的,按照每字后面的那个字段分组。
1、每个部门的最低工资
select post,min(salary) from emp group by post;
2、每个部门的平均工资
select post,avg(salary) from emp group by post;
3、每个部门的工资总和
select post,sum(salary) from emp group by post;
4、每个部门的人数
select post,count(id) from emp group by post;
select post, count(id) from emp group by post;
select post, count(1) from emp group by post;
配合分组使用的其他函数,分组之后只能获取到分组的依据。
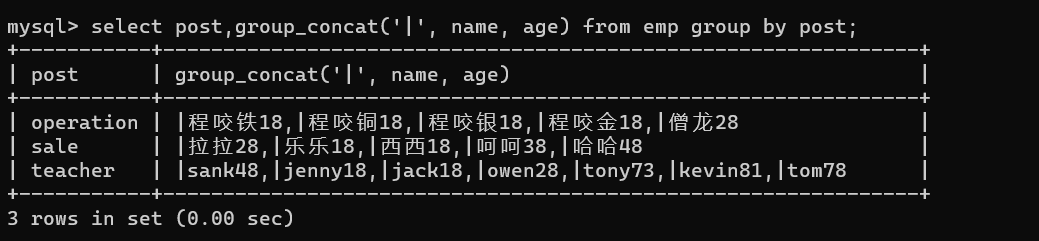
group_concat:用在分组之后
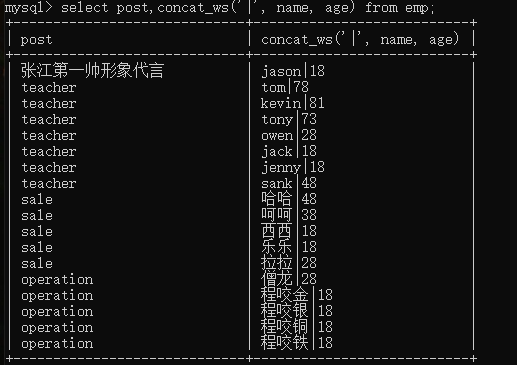
concat_ws :一般用于分组前,分组后使用的话,按照什么分组就只能拿到分组 其他字段不能直接获取
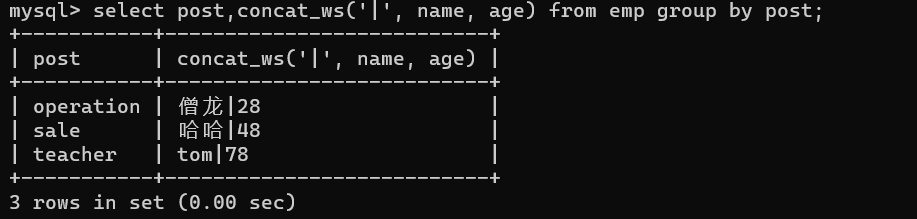
concat 分组之前,不分组使用:select concat(name,sex) from emp;(将名字和性别合并在了一起)
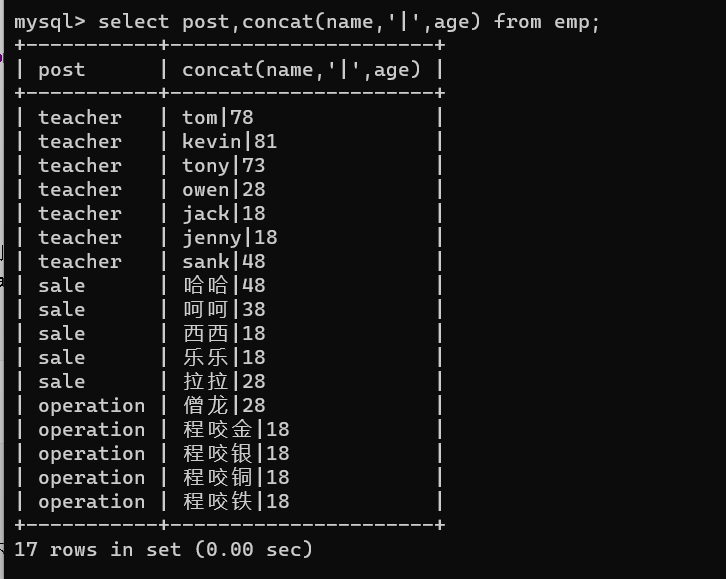
select concat(name,'|',sex) from emp; (用 | 分开)
还可以给字段起别名:
select post as '部门',max(salary) as '最高工资' from emp group by post;
as 可以省略,但是不推荐省略,因为寓意不明确
关键字having过滤
having也是用来过滤筛选数据的,功能上和where一样
where 用在分组前,先筛选一遍
having用在分组之后再筛选
1.统计各部门年龄在30岁以上的员工平均薪资,并且保留平均薪资大于10000的部门.
select post, avg(salary) from emp where age>30 group by post having avg(salary) >10000;
关键字distinct去重
把重复的去除
对有重复的展示数据进行去重操作,一定是重复的数据
select distinct age from emp;
关键字order by排序
order by如果不加或者加esc则是升序排序
加desc则是降序排序
1. 统计各部门年龄在10岁以上的员工平均工资,并且保留平均工资大于1000的部门,然后对平均工资进行排序
select name,avg(salary),post from emp where age >10 group by post having avg(salary) >1000 order by avg(salary) ;
限制展示条数
select * from emp limit 3;(展示前三条)
select * from emp limit 0,5; # 第一个参数表示起始位置,第二个参数表示的是条数,不是索引位置
select * from emp limit 5,5; # 第一个参数代表的是起始位置,第二个参数是限制 的条数
分页:
第一页:select *from emp limit 0, 10;
第二页:select *from emp limit 10, 10;
第三页:select *from emp limit 20, 10;
第四页:select *from emp limit 30, 10;
select * from emp where name regexp '^j.*(n|y)$';
练习题
1. 查询岗位名以及岗位包含的所有员工名字
select post,group_concat(name) from emp group by post;
2. 查询岗位名以及各岗位内包含的员工个数
select post,count(name) from emp group by post;
3. 查询公司内男员工和女员工的个数
select count(name),sex from emp group by sex;
4. 查询岗位名以及各岗位的平均薪资
select avg(salary),post from emp group by post;
5. 查询岗位名以及各岗位的最高薪资
select post,max(salary) from emp group by post;
6. 查询岗位名以及各岗位的最低薪资
select post,min(salary) from emp group by post;
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select sex,avg(salary) from emp group by sex;
表关系外键
使用外键原因:1、表不清晰。2、字段需要重复写,浪费资源。3、兼容性差,牵一发动全身。
外键 :通过字段可以查询到另一张表的数据。
表关系
一对多、一对一、多对多、没有关系
一对多
以图书表和出版表为例:
图书表角度,一本书只能有一个出版社出版。 ————n
出版社角度,一个出版社可以有多本书。——————1
1:n就是一对多。多表的创建
举例:
在cmd中先创建出版社,再创建图书表,因为出版社表中有图书表要绑定的外键。
create table book(
id int primary key auto_increment,
title varchar(128),
price decimal(8,2),
publish_id int,
foreign key(publish_id references publish(id))
);
create table publish(
id int primary key auto_increment,
title varchar(128)
);
往book表中录入数据
insert into book(title,price,publish_id) values ('第一本',1000,1);
insert into book(title,price,publish_id) values ('第二本',1000,2);
往出版社中录入数据,先录入,因为book表里有连publish的外键
insert into publish(title) values('北京出版社‘);
insert into publish(title) values('上海出版社‘);
外键约束
1、在创建表的时候,应该先创建被关联表(没有外键字段的表)
2、在录入数据的时候,应该先录入被关联表(没有外键字段的表)
3、在录入数据的时候,应该录入被关联表中已经存在的表。
4、如果对被关联表中的数据进行修改和删除的时候,需要把关联表中的数据也跟着修改或删除。(不现实)
级联删除和级联更新:
先创建图书表
create table book(
id int primary key auto_increment,
title varchar(128),
price decimal(8, 2),
publish_id int,
foreign key(publish_id) references publish(id) # 意思是:book表中的publish_id和publish表中的id是外键关系
on update cascade # 级联更新
on delete cascade #
);
出版表同上。
但是由于创建了外键关系和级联更新,级联删除,那么,两张表之间就有了强制约束关系,这样旧增加了表和表之间的强耦合度。
所以在以后的实际项目中,一般不建立这样的强耦合关系,我们使用的的hi建立逻辑意义上的关系。(假装外键存在,但其实并不建立)
多对多的表关系
还是以图书表和作者表为例
图书表的角度:一本书可以有多个作者写 ——————n
作者表的角度:一个作者可以写多本书 ——————n
n:n就是多对多的表关系
多对多的外键字段需要建立第三张表来存储
建立图书表:
create table book1(
id int primary key auto_increment,
title varchar(180)
);
建立作者表
create table auther(
id int primary key auto_increment,
name varchar(32)
);
建立作者对图书表
create table a_to_b(
id int primary key auto_increment,
book_id int,
auther_id int,
foreign key(book_id) references book(id)
on update cascade
on delete cascade,
foreign key(auther_id) references book(id)
on update cascade
on delete cascade
);
一对一表关系
以作者和作者详情表为例
站在作者角度:一个作者不能有多个作者详情 ——————1
站在作者详情上来说:一个作者详情只能是一个作者 ——————1
一对一的外键字段可以建立在任何一张表中,但是推荐建在查询频率较高的一张表中。
create table author(
id int primary key auto_increment,
name varchar(32),
author_detail_id int unique,
foreign key (author_detail_id) references author_detail(id)
);
create table author_detail(
id int primary key auto_increment,
addr varchar(32),
height decimal(5,2)
);
多表查询(重点)
数据准备
create table dep(
id int primary key auto_increment,
name varchar(20)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入数据
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营'),
(205,'保洁');
insert into emp(name,sex,age,dep_id) values
('jason','male',18,200),
('egon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
多表查询就是多张表连在一起
查询思路:
1、子查询
一条sql语句的执行结果被当成另外一条sql语句的执行条件,也就是分布操作
例如:
查看姓名为jason的部门名称
select name from dep where id = (select dep_id from emp where name = 'jason');
2、连表查询
把多张实际存在的表按照表的关系连成一张虚拟表(只是临时存在的表)
连表的语法
inner join :内连接,数据只取两张表中共有的数据
left join: 左连接,数据以左表为准,展示左表所有的数据,右表没有的数据用null填充
right join:右连接,数据以右表为准,展示右表所有数据,左表没有的数据用null填充
union:连接多条sql语句执行结果
例题:
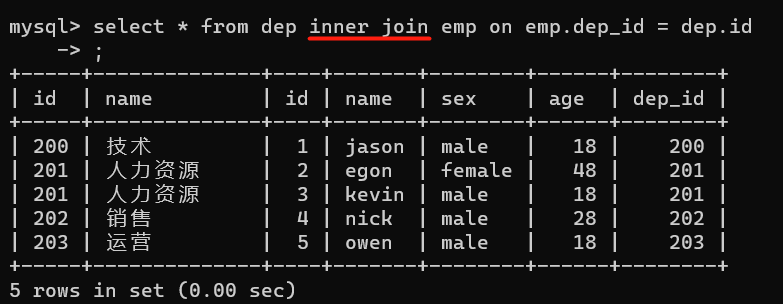
1、inner join
select * from dep inner join emp on emp.dep_id = dep.id;
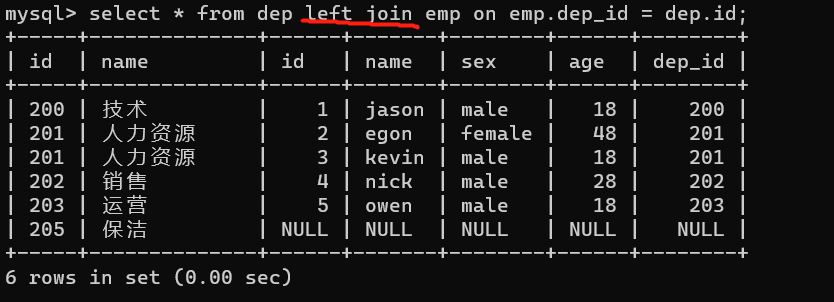
2、left join
select * from dep left join emp on emp.dep_id = dep.id;(dep是左表,emp是右表)
3、right join
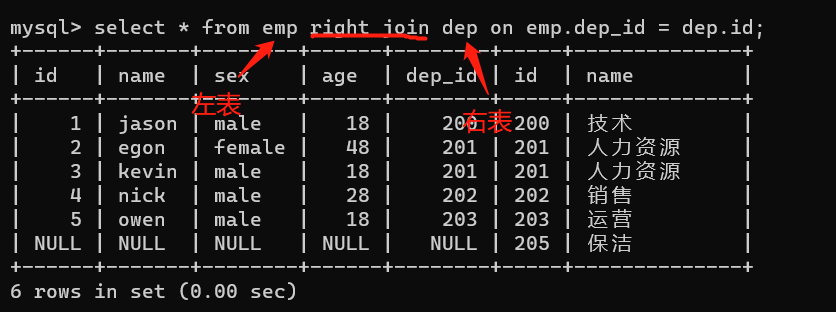
select * from dep right join emp on emp.dep_id = dep.id;
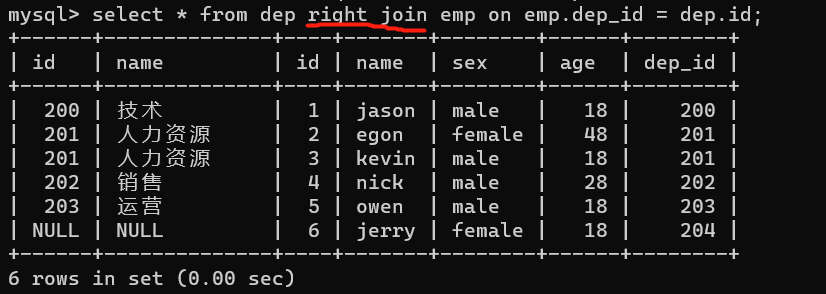
select * from emp right join dep on emp.dep_id = dep.id;
4、union(两条语句,用union连接起来,要保证上下语句表顺序一致)
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
总结:
多表查询就两种方式
先拼接表再查询
子查询 一步一步来
5、给表起别名(as 当表名过于长时可以起别名)
select * from emp as a inner join dep as d on a.dep_id = d.id;
Navicat格式化工具
https://www.cr173.com/soft/126934.html
优点:
"
navicat能够充当多个数据库的客户端
navicat图形化界面有时候反应速度较慢 你可以选择刷新或者关闭当前窗口再次打开即可
当你有一些需求该软件无法满足的时候 你就自己动手写sql
"
如何操作MySQL呢
需要借助于第三方模块
1. pymysql
2. mysqlclient----->非常好用,一般情况下很难安装成功
3. mysqldb
pip install pymysql;
import pymysql
# 1. 连接MySQL的服务端
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='root',
db='db8',
charset='utf8',
autocommit=True
)
# 2. 获取游标
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 3. 执行SQL语句了
# sql = 'select *from emp;'
sql = "insert into emp (name, sex, age, dep_id, gender) values('aa', 'male', 10, 1, 0)"
# 4. 开始执行
affect_rows = cursor.execute(sql) # 影响的行数
print(affect_rows) # 6行
'''增加,修改,删除的数据的时候,需要二次提交, 只有查询的时候不需要二次提交'''
# conn.commit()
# 5. 如何拿到具体的数据
# print(cursor.fetchall())
1、查询所有的课程的名称以及对应的任课老师姓名
select teacher.tname,course.cname from course INNER JOIN teacher on teacher.tid = course.teacher_id;
2、查询平均成绩大于八十分的同学的姓名和平均成绩
SELECT student.sname,avg(num) from student INNER JOIN score on student.sid = score.student_id GROUP BY student.sid having avg(num)>80;
3、查询没有报李平老师课的学生姓名
SELECT student.sname from student INNER JOIN score on student.sid = score.sid WHERE score.course_id not in (SELECT course.cid from course INNER JOIN teacher on course.teacher_id = teacher.tid where teacher.tname = '李平老师');
4、查询挂科超过两门(包括两门)的学生姓名和班级
select student.sname,class.caption from class INNER JOIN student on class.cid = student.class_id where student.sid in (SELECT student_id from score GROUP BY num <60 HAVING count(course_id) > 2);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号