3.Spark设计与运行原理,基本操作
1.用图文阐述Spark生态系统的组成及各组件的功能。
随着spark的日趋完善,Spark以其优异的性能正逐渐成为下一个业界和学术界的开源大数据处理平台。随着Spark1.1.0的发布和Spark生态圈的不断扩大,可以预见在今后的一段时间内,Spark将越来越火热。
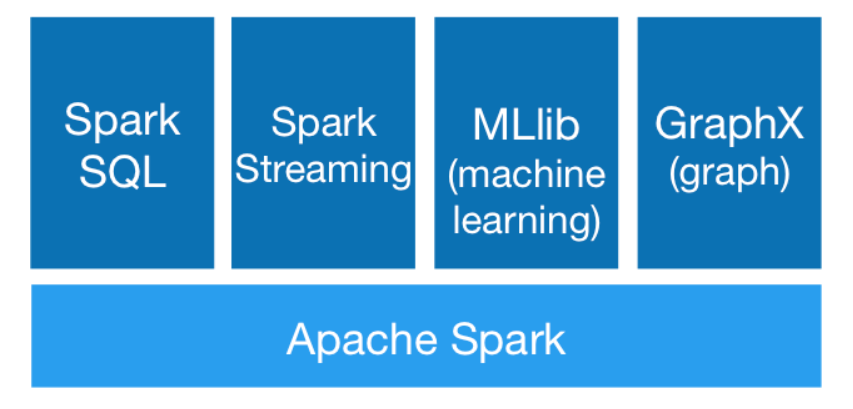
Spark生态圈以Spark为核心引擎,以HDFS、S3、Techyon为持久层读写原生数据,以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成spark应用程序的计算;而这些spark应用程序可以来源于不同的组件,如Spark的批处理应用、SparkStreaming的实时处理应用、Spark SQL的即席查询、BlinkDB的权衡查询、MLlib或MLbase的机器学习、GraphX的图处理等等。
图源来自:Spark开发指南
Spark
Spark是一个快速的通用大规模数据处理系统,和Hadoop MapRedeuce相比:
更好的容错性和内存计算 高速,在内存中运算100倍速度于MapReduce 易用,相同的应用程序代码量要比MapReduce少2-5倍 提供了丰富的API 支持互动和迭代程序
Spark大数据平台之所以能日渐红火,得益于Spark内核架构的优秀:
- 支持DAG图的分布式并行计算框架,减少IO开销
- 支持多次迭代计算(Cache机制),减少IO开销
- RDD fail掉了也能通过父RDD重建,提高了容错性
- RDD就近读取分布式文件系统中的数据块到各个节点内存中进行计算
- 多线程池模型来减少task启动开销
- shuffle过程中避免不必要的sort操作
- 用容错的、高可伸缩性的akka作为通讯框架
而Spark主要有以下几个组件:
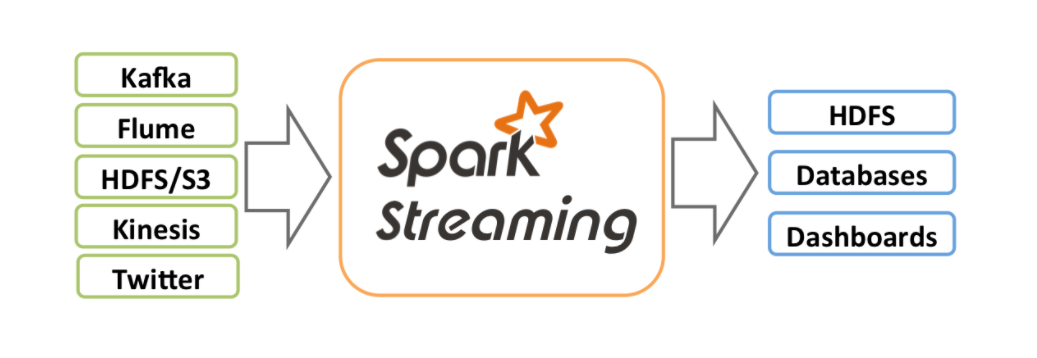
SparkStreaming
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以进行类似map、reduce、join、window等复杂操作在不同种类的数据流上,并将结果保存到外部文件系统、数据库等
并且在SparkStreaming中有以下特点:
- 流式计算会被分解成一系列相对较小的批处理作业
- 将执行较慢以及执行失败的任务放在其它节点上并行执行
- 较强的容错能力(BDD)
- 语义与BDD相似
图源来自:Spark编程指南
Spark SQL
Spark SQL是一个查询系统,可以通过SQL、Hive或者Scala DSL在Spark上执行查询。
Spark SQL的特点:
- 引入了新的RDD类型SchemaRDD,可以象传统数据库定义表一样来定义SchemaRDD,SchemaRDD由定义了列数据类型的行对象构成。
- 可以使用HiveQL从Hive中获取SchemaRDD,也可以从RDD转换过来,还可以从Parquet文件读入
- 可以混合使用不同来源的数据
- 用户查询语句进行自动优化(catalyst)

图片来源:Spark SQL介绍
MLlib
MLlib是Spark实现一些常见的机器学习算法和实用程序,包括分类,回归,聚类,协同过滤,降维,以及底层
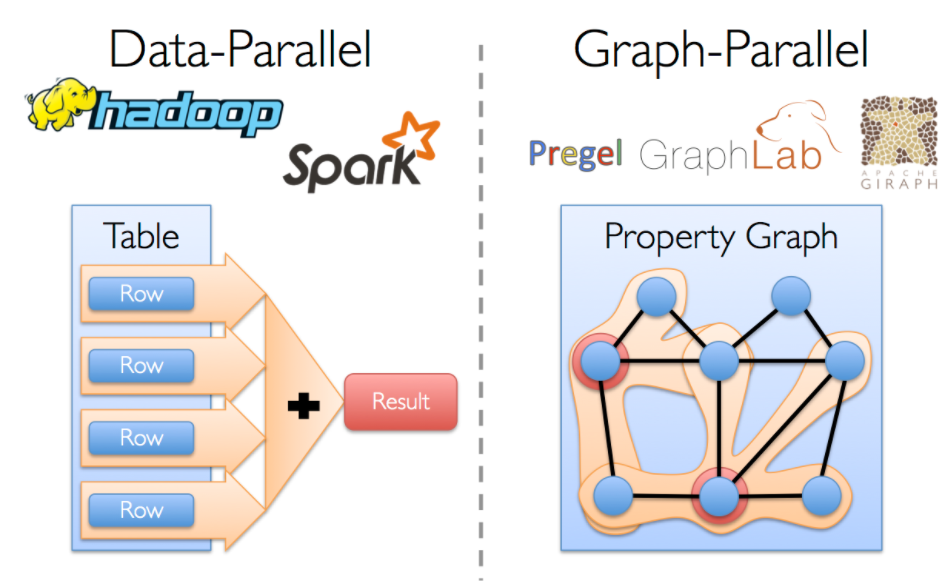
GraphX
GraphX是基于Spark的图处理和图并行计算的API。其定义了一个新的概念:弹性分布式属性图,一个每个顶点和边都带有属性的定向多重图;并引入了三种核心RDD:Vertices、Edges、Triplets;并且在不断的扩展图形算法和图形构建工具来简化图分析工作。
图源来自:Spark编程指南
2.请详细阐述Spark的几个主要概念及相互关系:
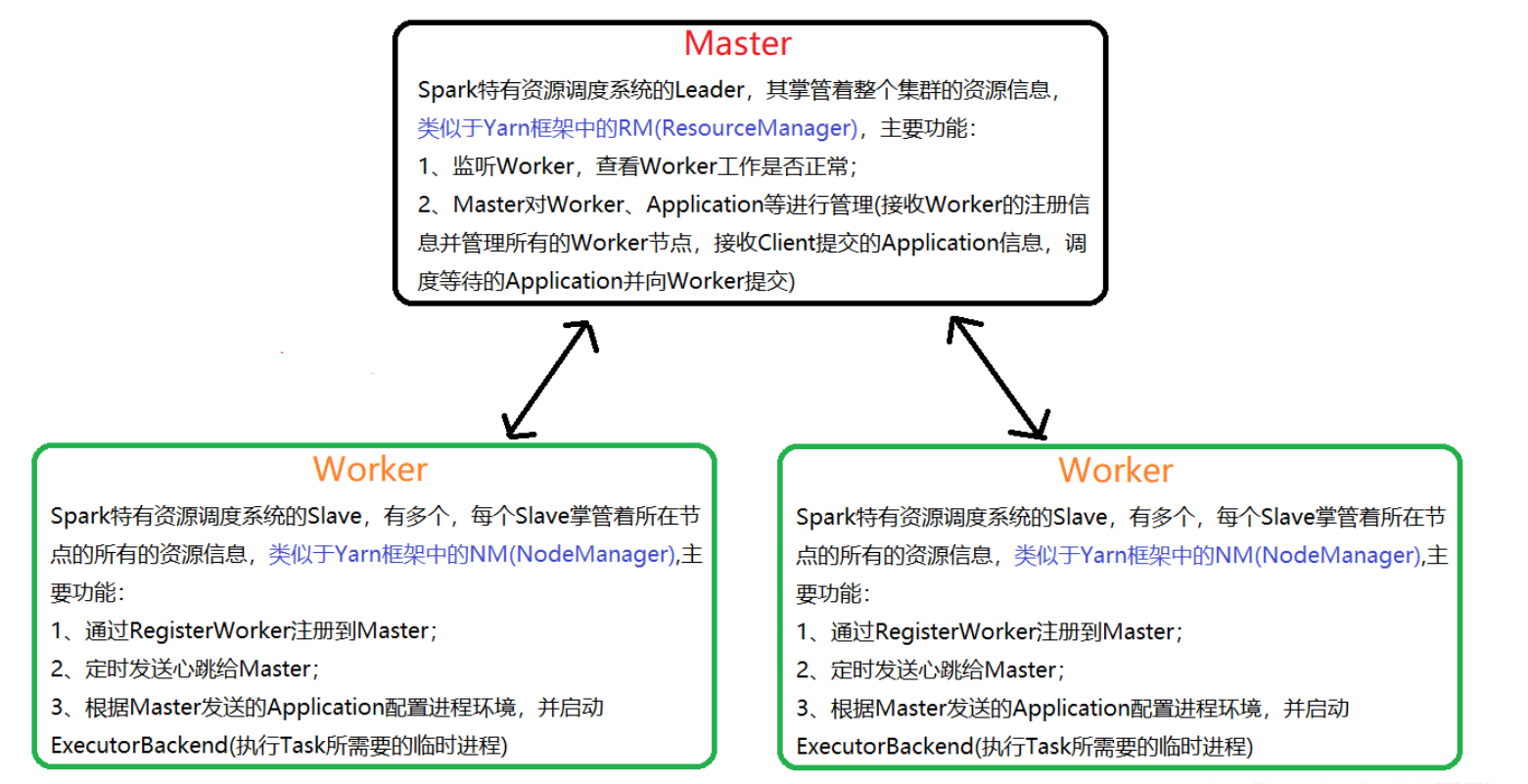
Master, Worker
Master和Worker是Spark的守护进程,即Spark在特定模式下正常运行所必须的进程。
-
Master是spark中资源调度系统主功能,就类似于领导的身份,管理整个集群中的资源信息,相当于YARN中的RM(ResourceManager)
-
Worker是spark中资源调度系统的子节点(slave),管理所在结点的资源信息,相当于YARN中的NodeManager
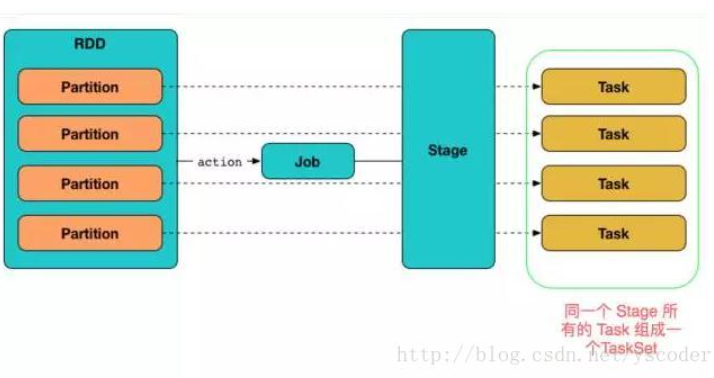
RDD,DAG
-
RDD它是spark中一种基本的数据抽象,有容错机制并可以被并行操作的元素集合,具有只读、分区、容错、高效、无需物化、可以缓存、RDD依赖等特征。
-
RDD算子构建了RDD之间的关系,整个计算过程形成了一个由RDD和关系构成的DAG。
算子是spark中对一些数据处理的常用操作的抽象,spark算子分为两类:transform和action
transform算子是一种延迟性操作,也就是把一个RDD转换成另外一个RDD而不是马上执行,不会提交job
action算子会对RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如 HDFS)中。每有一个action便会提交一个job
DAG对比hadoop来说,不用每执行一个map或reduce都要开启一个新的进程,而是在spark中通过划分RDD的依赖关系,让多个窄依赖在一个线程中以流水线执行,快速且节省资源。
DAG将一个job根据宽依赖划分多个stage,一个stage的父stage都执行完才能开始执行,通过这样有逻辑地执行任务可以避免冗余操作,合理安排执行顺序,大大节约了时间。
Application, job,stage,task
-
Application其实就是用spark-submit提交的程序。例如spark examples中的计算pi的SparkPi。
-
Spark中的Job和MR中Job不一样。MR中Job主要是Map或者Reduce Job。而Spark中一个action算子就算一个Job
-
Stage概念是spark中独有的。一般而言一个Job会切换成一定数量的stage。各个stage之间按照顺序执行。
-
Task是Spark中的执行单元。RDD一般是带有partitions的,每个partition的在一个executor上的执行可以任务就是一个Task。
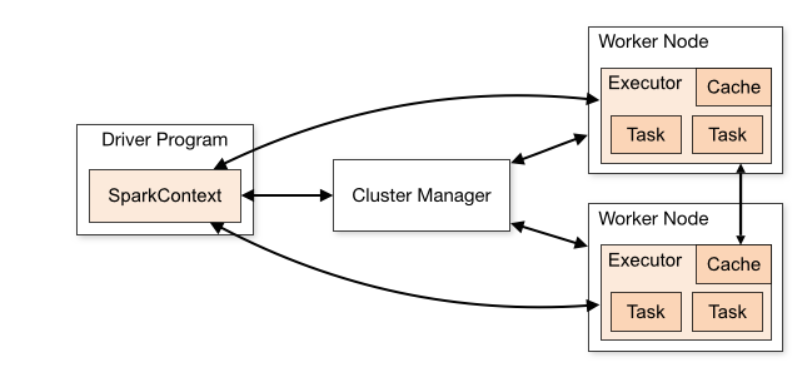
driver,executor,Cluster Manager
-
driver就是我们编写的spark应用程序,用来创建sparkcontext或者sparksession,driver会和cluster mananer通信,并分配task到executor上执行
-
Executors是一个独立JVM进程,主要用来执行task,一个executor内,可以同时并行的执行多个task。
-
Cluster Manager是Spark的集群管理器,主要负责资源的分配与管理。集群管理器分配的资源属于一级分配,它将各个Worker上的内存、CPU等资源分配给应用程序,但是并不分配Executor的资源。
SparkContext
SparkContext是编写Spark程序用到的第一个类,SparkContext的重要性非常之高。SparkContext作为Spark的主要入口点,相当于应用程序的main函数。如把Spark集群当作服务端那Spark Driver就是客户端,SparkContext则是客户端的核心,它可以用来连接Spark集群、创建RDD、累加器、广播变量等。在一个JVM进程中可以创建多个SparkContext,但是只能有一个active级别的。
DAGScheduler
DAGScheduler是任务调度中的其中一个环节,是任务调度的第一步。DAGScheduler是Spark的较高层次的调度器,它实现了面向Stage的调度。DAGScheduler为每个作业计算出一个描述stages的DAG,跟踪哪些RDD和stage输出实现,并找到运行作业的最小计划。然后,它将stages封装为TaskSets提交给在集群上运行它们的底层TaskScheduler实现。
Stages:Stage是一组任务(TaskSet),用于计算作业中的中间结果,其中每个任务在同一个RDD的分区上计算相同的函数。Stage在shuffle边界处分离,这会引入一个屏障(我们必须等待上一阶段完成获取输出)。有两种阶段的Stage:ResultStage和ShuffleMapStage。前者主要是对于执行操作的最后阶段,后者则是主要是为shuffle写入映射输出文件。
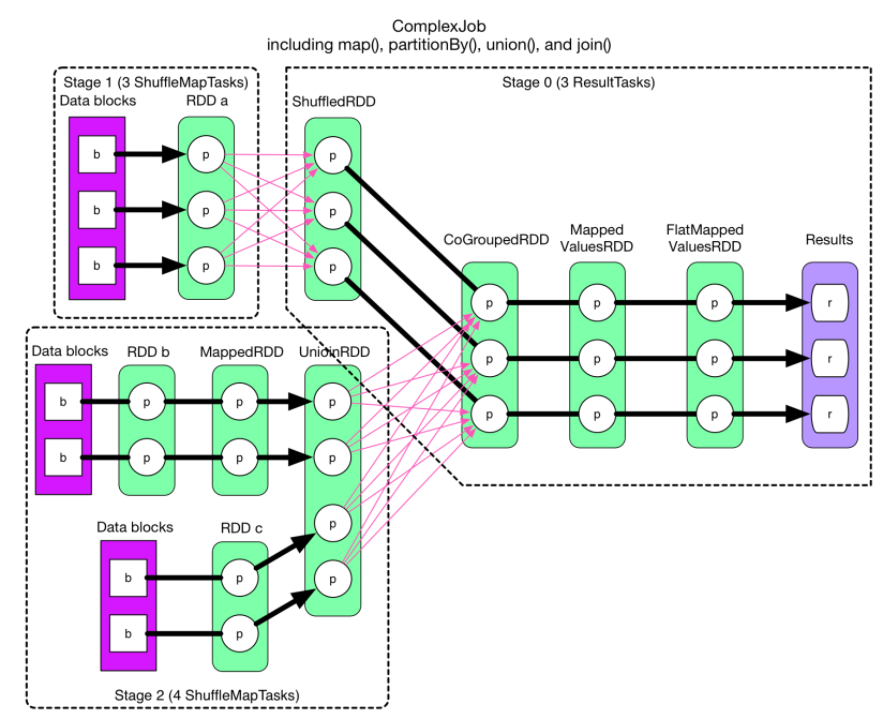
TaskScheduler
当DAGScheduler完成Task的创建后,就会把Task按Task集(Task Set)的方式交给TaskScheduler,接下来就由TaskScheduler来接管后续的过程。
TaskScheduler的核心任务是提交TaskSet到集群运算并汇报结果。它能够为TaskSet创建和维护一个TaskSetManager,同时追踪任务的本地性以及错误信息。在遇到Straggle任务时,会放到其他节点进行重试。然后向DAGScheduler汇报执行情况,包括在Shuffle输出丢失的时候报告fetch failed错误等信息。
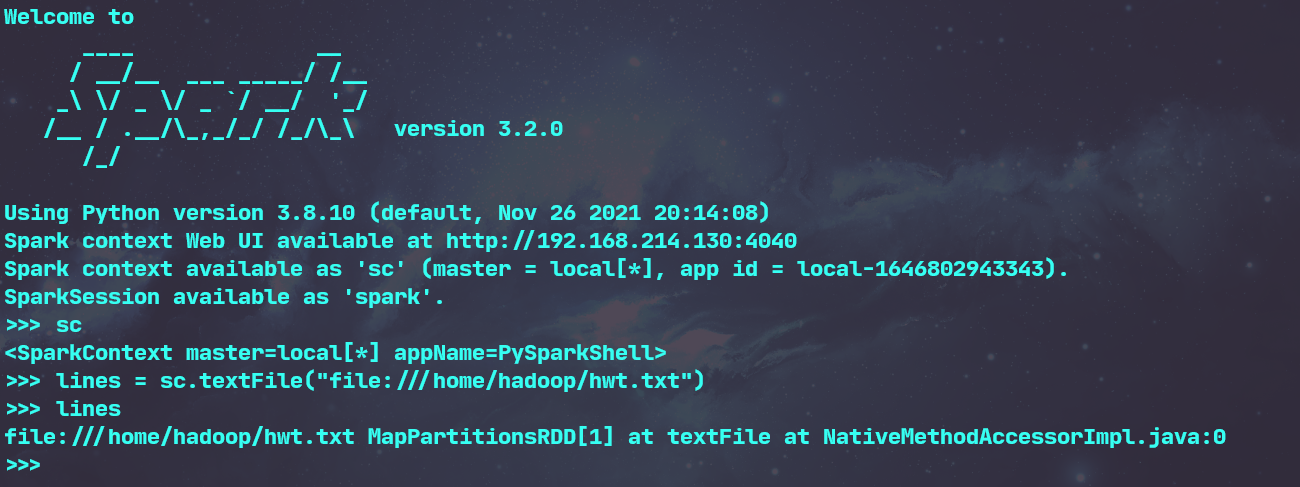
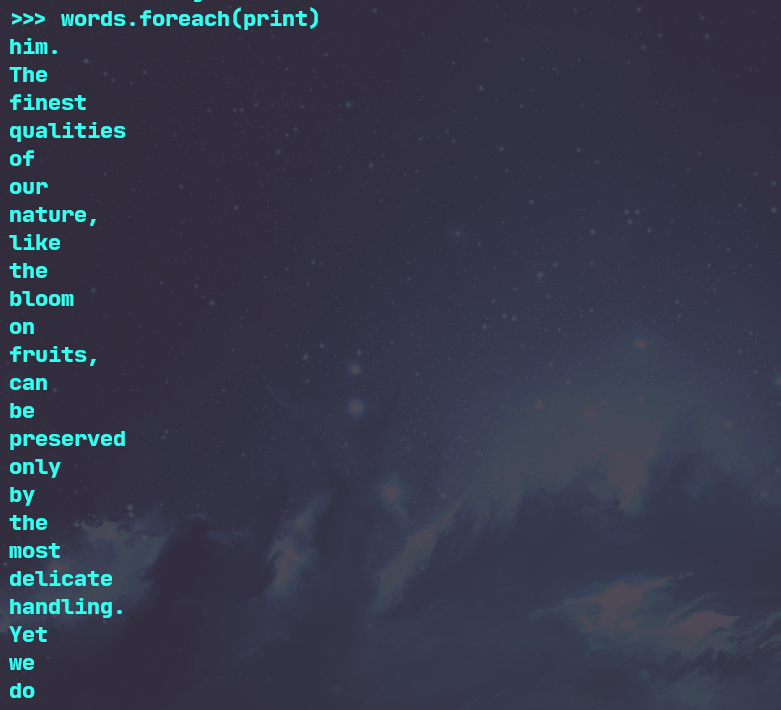
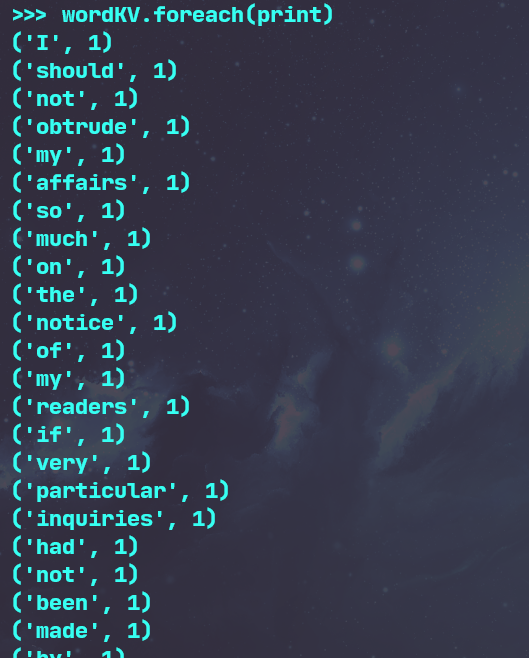
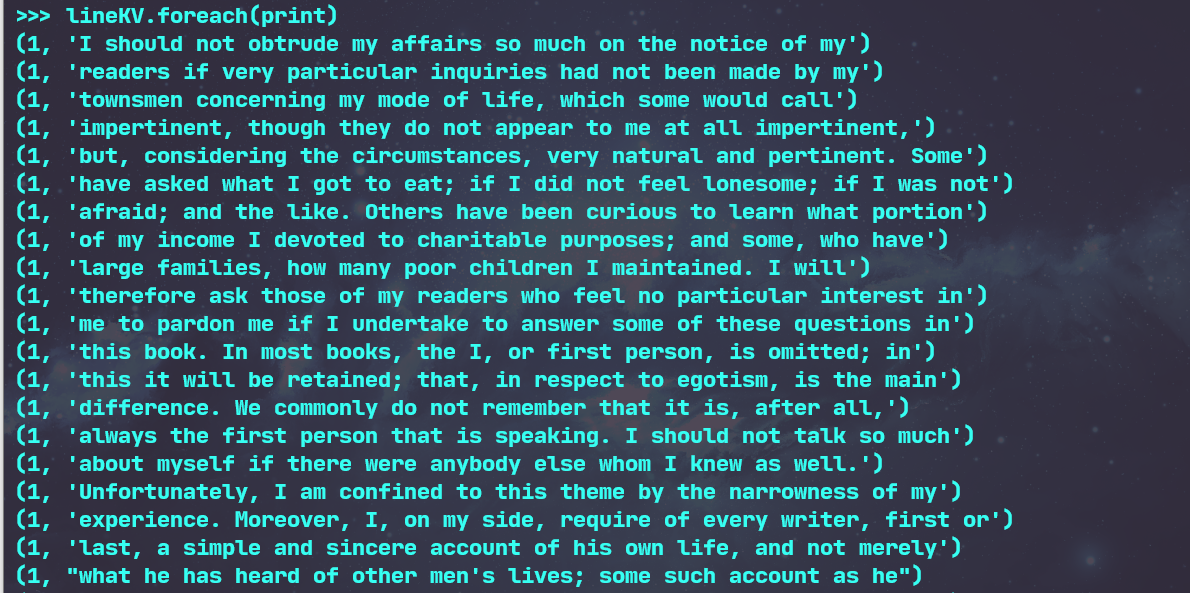
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号