2.安装Spark与Python练习
一、安装Spark
(1)检查基础环境hadoop,jdk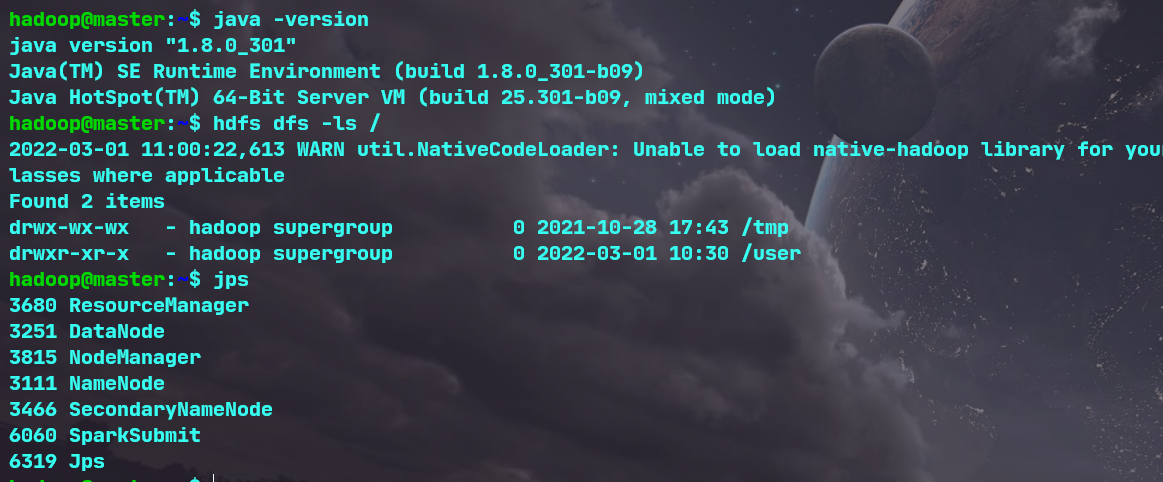
(2)配置文件
vim /usr/local/spark/conf/spark-env.sh

(3)环境变量
vim ~/.bashrc

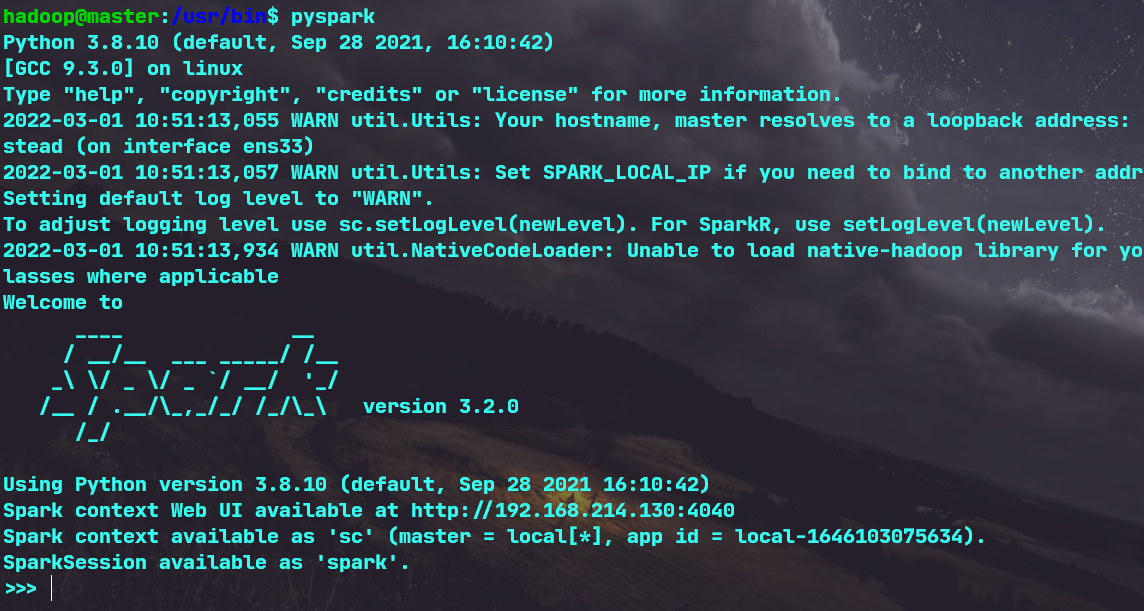
(4)试运行Python代码
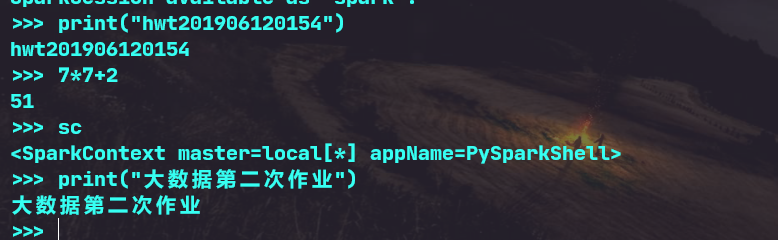
二、Python编程练习:英文文本的词频统计
(1)准备文本文件(txt)
(2)读文件
open(r'D:\桌面\countWord\waerdenghu.txt','rb')
input_text.read()
(3)预处理
去除标点符号并转换成小写:word.strip(string.punctuation).lower()
去重:words_index = set(words)
(4)分词
text.read().split()
(5)储存单词以及单词出现的次数:
count_dict = {index:words.count(index) for index in words_index}
(6)按词频大小排序
字典中的值为排序的参数:
for word in sorted(counts_dict,key=lambda x: counts_dict[x],reverse=True)
(7)结果写文件
output_text.writelines('{}--{} times'.format(word,count_dict[word]) + '\n')
(8)运行结果


点击查看源代码
import string
from os import path
with open(r'D:\桌面\countWord\waerdenghu.txt','rb') as input_text:
words = [word.strip(string.punctuation).lower() for word in str(input_text.read()).split()]
words_index = set(words)
count_dict = {index:words.count(index) for index in words_index}
with open(r'D:\桌面\countWord\hwtcount.txt','a+') as output_text:
output_text.writelines('词频统计的结果为:' + '\n')
for word in sorted(count_dict,key=lambda x:count_dict[x],reverse=True):
output_text.writelines('{}--{} times'.format(word,count_dict[word]) + '\n')
input_text.close()
output_text.close()
三、根据自己的编程习惯搭建编程环境
使用PyCharm



 浙公网安备 33010602011771号
浙公网安备 33010602011771号