【YashanDB知识库】Flink CDC实时同步Oracle数据到崖山
本文内容来自YashanDB官网,原文内容请见 https://www.yashandb.com/newsinfo/7396983.html?templateId=1718516
概述
本文主要介绍通过flink cdc实现oracle数据实时同步到崖山,支持全量和增量,DML支持新增、修改和删除。
环境
JDK版本:11
Flink版本:1.18.1
flink-sql-connector-oracle-cdc版本:3.1.1
flink-connector-yashandb版本:1.18.1.1
Streampark版本:2.1.4
YMP版本:23.2.1.5
源Oracle版本:11.2.0.2.0
目标YashanDB版本:23.2.2.100
操作步骤
Oracle启用日志归档
Step1:以DBA权限登录Oracle数据库
sqlplus /nolog CONNECT sys/system AS SYSDBA |
Step2:启用日志归档
-- 确认归档日志是否已开启,未开启则需开启 archive log list; -- 查看db_recovery_file_dest参数 show parameter db_recovery_file_dest; -- 设置数据库恢复文件目标大小为10G alter system set db_recovery_file_dest_size = 10G; -- 设置数据库恢复文件目标路径 alter system set db_recovery_file_dest = '/u01/app/oracle/fast_recovery_area' scope=spfile; -- 立即关闭数据库 shutdown immediate; -- 以mount模式启动数据库 startup mount; -- 启用数据库归档日志模式 alter database archivelog; -- 打开数据库,允许用户访问 alter database open; -- 再次确认归档日志是否已开启 archive log list; |
用户赋权
Step1:创建表空间
-- 创建一个名为"logminer_tbs"的表空间 CREATE TABLESPACE logminer_tbs DATAFILE '/u01/app/oracle/oradata/XE/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED; |
Step2:创建用户并赋予权限
-- 创建一个名为"flinkuser"的用户,密码为"flinkpw",将其默认表空间设置为"LOGMINER_TBS",并在该表空间上设置无限配额。 CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS;
-- 允许"flinkuser"用户创建会话,即允许该用户连接到数据库。 GRANT CREATE SESSION TO flinkuser;
-- (不支持Oracle 11g)允许"flinkuser"用户在多租户数据库(CDB)中设置容器。 -- GRANT SET CONTAINER TO flinkuser;
-- 允许"flinkuser"用户查询V_$DATABASE视图,该视图包含有关数据库实例的信息。 GRANT SELECT ON V_$DATABASE TO flinkuser;
-- 允许"flinkuser"用户执行任何表的闪回操作。 GRANT FLASHBACK ANY TABLE TO flinkuser;
-- 允许"flinkuser"用户查询任何表的数据。 GRANT SELECT ANY TABLE TO flinkuser;
-- 允许"flinkuser"用户拥有SELECT_CATALOG_ROLE角色,该角色允许查询数据字典和元数据。 GRANT SELECT_CATALOG_ROLE TO flinkuser;
-- 允许"flinkuser"用户拥有EXECUTE_CATALOG_ROLE角色,该角色允许执行一些数据字典中的过程和函数。 GRANT EXECUTE_CATALOG_ROLE TO flinkuser;
-- 允许"flinkuser"用户查询任何事务。 GRANT SELECT ANY TRANSACTION TO flinkuser;
-- (不支持Oracle 11g)允许"flinkuser"用户进行数据变更追踪(LogMiner)。 -- GRANT LOGMINING TO flinkuser;
-- 允许"flinkuser"用户创建表。 GRANT CREATE TABLE TO flinkuser;
-- 允许"flinkuser"用户锁定任何表。 GRANT LOCK ANY TABLE TO flinkuser;
-- 允许"flinkuser"用户修改任何表。 GRANT ALTER ANY TABLE TO flinkuser;
-- 允许"flinkuser"用户创建序列。 GRANT CREATE SEQUENCE TO flinkuser;
-- 允许"flinkuser"用户执行DBMS_LOGMNR包中的过程。 GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser;
-- 允许"flinkuser"用户执行DBMS_LOGMNR_D包中的过程。 GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOG视图,该视图包含有关数据库日志文件的信息。 GRANT SELECT ON V_$LOG TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOG_HISTORY视图,该视图包含有关数据库历史日志文件的信息。 GRANT SELECT ON V_$LOG_HISTORY TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOGMNR_LOGS视图,该视图包含有关LogMiner日志文件的信息。 GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOGMNR_CONTENTS视图,该视图包含LogMiner日志文件的内容。 GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOGMNR_PARAMETERS视图,该视图包含有关LogMiner的参数信息。 GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOGFILE视图,该视图包含有关数据库日志文件的信息。 GRANT SELECT ON V_$LOGFILE TO flinkuser;
-- 允许"flinkuser"用户查询V_$ARCHIVED_LOG视图,该视图包含已归档的数据库日志文件的信息。 GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser;
-- 允许"flinkuser"用户查询V_$ARCHIVE_DEST_STATUS视图,该视图包含有关归档目标状态的信息。 GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser; |
启用增量日志记录
-- 为数据库启用增强日志记录: ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; |
迁移oracle元数据到YashanDB
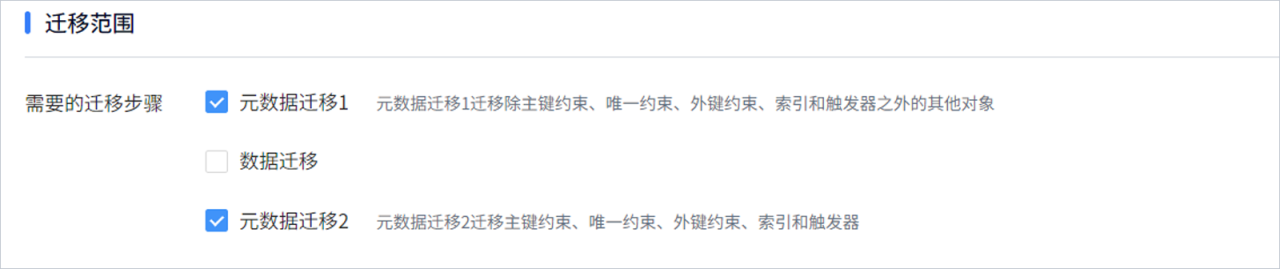
可通过崖山迁移平台YMP进行迁移,迁移范围只需选择“元数据迁移1 ”和“元数据迁移2”即可,“数据迁移”不用选。
安装flink
Step1:创建flink安装用户
adduser -d /home/flink -m flink
passwd flink
flink
Step2:授权
chown -R flink:flink /data/flink
Step3:设置免密
cd ~
ssh-keygen # 一直按回车,按默认设置创建密钥对
ssh-copy-id flink@192.168.133.18
Step4:解压flink安装包
cd /data/flink
tar -zxvf flink-1.18.1-bin-scala_2.12.tgz
Step5:修改flink-conf.yaml配置:
cd /data/flink/flink-1.8.1/conf
vi flink-conf.yaml
- xxx.bind-host和xxx.bind-address都设置成0.0.0.0
2)taskmanager.numberOfTaskSlots修改为和CPU核数一致:
taskmanager.numberOfTaskSlots: 8
- 去掉注释并修改checkpoint和savepoints路径配置:
state.checkpoints.dir: file:///data/flink/flink-checkpoints
state.savepoints.dir: file:///data/flink/flink-savepoints
- 去掉注释并修改classloader.resolve-order配置:
classloader.resolve-order: parent-first
Step6:安装flink-oracle-cdc和flink-connector-yashandb相关的jar包到flink
cp /tmp/flink/flink-sql-connector-oracle-cdc-3.1.1.jar /data/flink/flink-1.18.1/lib
cp /tmp/flink/ojdbc8-19.3.0.0.jar /data/flink/flink-1.18.1/lib
cp /tmp/flink/xdb-19.3.0.0.jar.jar /data/flink/flink-1.18.1/lib
cp /tmp/flink/flink-connector-yashandb-1.18.1.1.jar /data/flink/flink-1.18.1/lib
cp /tmp/flink/yashandb-jdbc-1.7.1.jar /data/flink/flink-1.18.1/lib
Step7:设置环境变量
vi ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.19.0.7-1.el7_9.x86_64
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tool.jar
export FLINK_HOME=/data/flink/flink-1.18.1
export PATH=$JAVA_HOME/bin:$FLINK_HOME/bin:$PATH
source ~/.bashrc
Step8:启动flink
cd /data/flink/flink-1.8.1/bin
./start-cluster.sh
生成flinksql文件
Step1:解压flinksql生成工具gen-flinksql-1.0-bin.zip
unzip gen-flinksql-1.0-bin.zip
Step2:修改gen-flinksql/conf/jdbc.properties配置文件
source.oracle.url = jdbc:oracle:thin:@//192.168.133.18:1521/xe
source.oracle.user = flinkuser
source.oracle.password = flinkpw
source.oracle.schema = SEARCHUSER #此处为需要同步的源库名
sink.yashandb.url = jdbc:yasdb://192.168.133.18:1688/yashandb
sink.yashandb.user = SEARCHUSER
sink.yashandb.password = yasdb_123
sink.yashandb.schema = SEARCHUSER #此处为需要同步的目标库名
Step3:执行生成flinksql文件命令:
cd gen-flinksql/bin
./gen-flinksql.sh oracle2yashandb /data/flink
执行完成后,会在/data/flink目录生成以schema命名的flink sql文件:SEARCHUSER.sql
安装streampark
Step1:解压streampark安装包
cd /data/flink
tar -zxvf apache-streampark_2.12-2.1.4-incubating-bin.tar.gz
Step2:启动streampark
cd /data/flink/apache-streampark_2.12-2.1.4-incubating-bin/bin
./startup.sh
访问地址:http://192.168.133.18/10000
admin/streampark
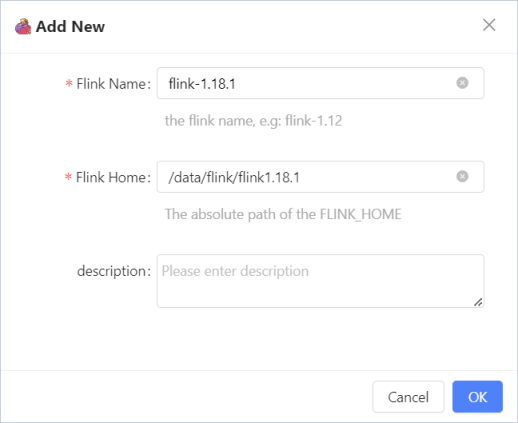
Step3:配置Flink Home
进入菜单setting - > Flink Home,点击Add New按钮:
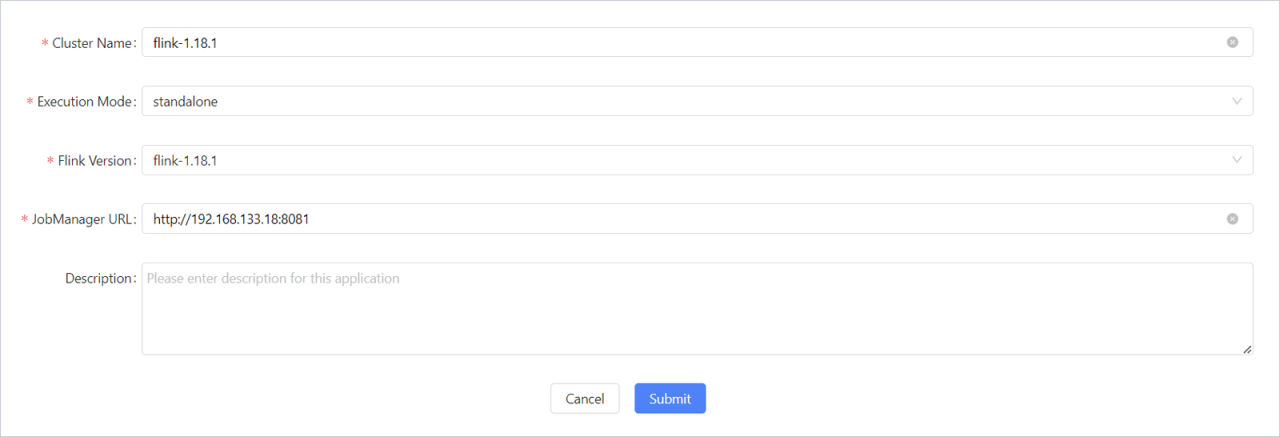
Step4:配置Flink Cluster
进入菜单setting - > Flink Cluster,点击Add New按钮:
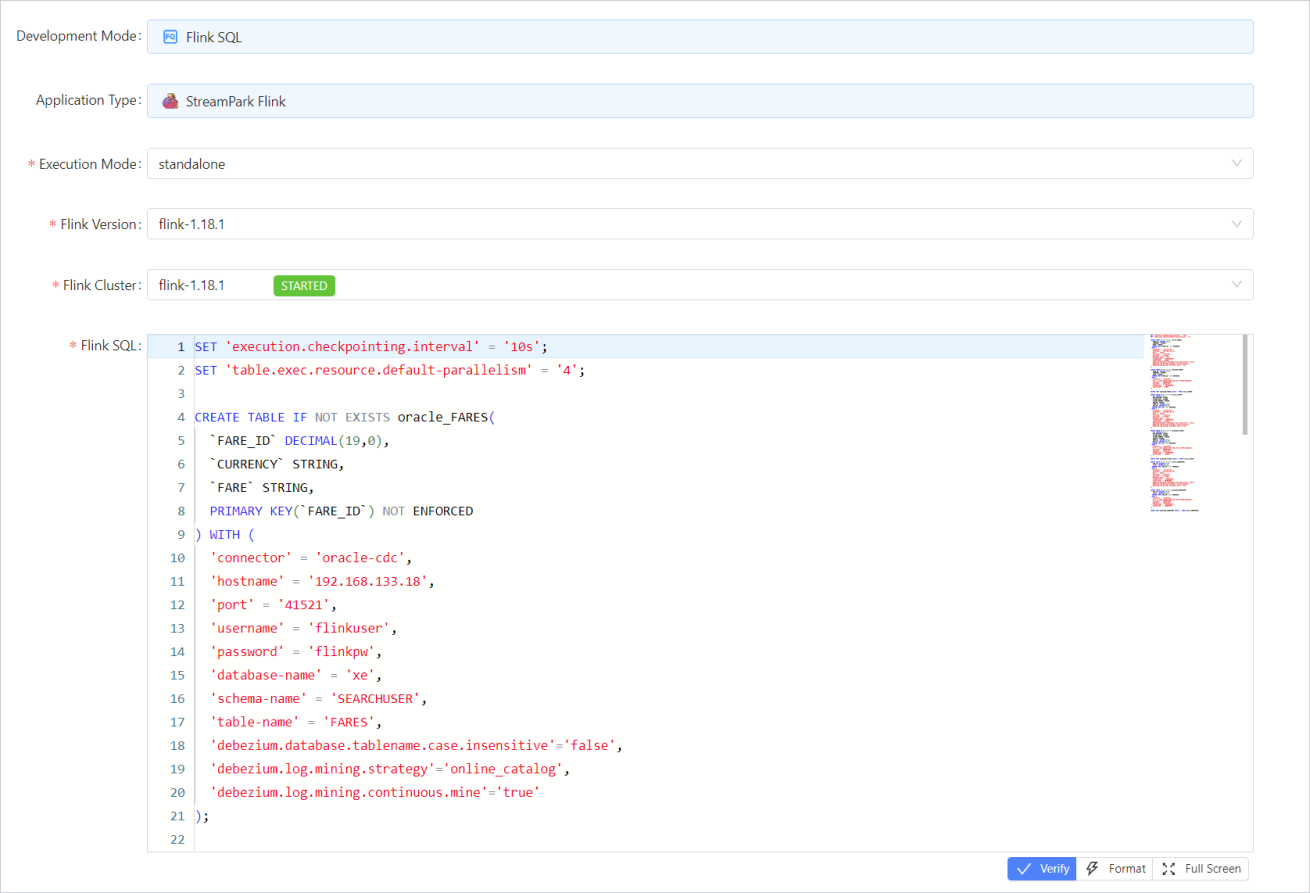
创建实时同步任务
Step1:进入菜单Apache Flink -> Application,Add New一个任务,Excution Mode选standalone,然后再选择对应的Flink Version和Flink Cluster,FlinkSQL输入gen-flinksql工具生成的sql内容,最后输入Job Name点submit按钮进行保存;
Step2:在任务列表界面Release Job进行job发布,再点Start Job按钮启动同步任务;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号