【YashanDB知识库】Hive 命令工具insert崖山数据库报错
本文内容来自YashanDB官网,原文内容请见 https://www.yashandb.com/newsinfo/7919217.html?templateId=1718516
【问题分类】功能兼容
【关键字】spark 30041、不兼容
【问题描述】
本项目的架构是hadoop+hive+yashandb
使用崖山数据库,初始化所有的原数据表和数据
新建表之后,插入数据时候报错,hadoop code 30041 sparktask

【问题原因分析】
综合分析如下可能性,逐一排查
关于Hadoop中出现的错误代码30041,特别是在使用Spark作为Hive的执行引擎时,这个错误通常指的是`org.apache.hadoop.hive.ql.exec.spark.SparkTask`执行失败。以下是一些可能的原因和解决方案:
1、Spark未启动:确保Spark集群已经启动。如果Spark服务未启动,需要在Spark的安装路径下执行`./sbin/start-all.sh`来启动Spark服务。
2、版本不兼容:检查Spark和Hive的版本是否兼容。例如,Hive 3.1.2 默认不支持Spark 3.0.0,需要重新编译Hive以支持特定的Spark版本。
3、内存资源不足:如果因为内存资源不足导致Hive连接Spark客户端超时,可以在配置文件中增加executor内存或减少每个executor的线程数。
4、配置文件调整:在`hive-site.xml`中增加或调整以下配置,以延长Hive和Spark连接的超时时间:
```xml
```
这可以有效避免超时报错。
5、网络问题:排查集群内的网络连接,确保通信畅通无阻,因为Spark作业依赖于良好的网络环境来完成节点间的通信。
6、YARN配置:检查YARN配置,如`spark.executor.memory`和`yarn.scheduler.maximum-allocation-mb`,确保YARN配置的最大内存不小于Spark配置的内存。
7、环境变量和类路径:确认`SPARK_HOME`环境变量设置正确,并且`spark-env.sh`文件中包含了正确的类路径设置,例如:
```sh
export SPARK_DIST_CLASSPATH=$(hadoop classpath);
```
这有助于确保Spark能够找到Hadoop的类路径。
8、报错分析:查看SparkSubmit日志,找到导致任务失败的详细原因,这些信息通常能提供更具体的错误线索。
【解决/规避方法】
将上述可能性一一排除,发现spark环境还没配置成功,下载对应版本的spark进行配置调通之后,该问题就解决了
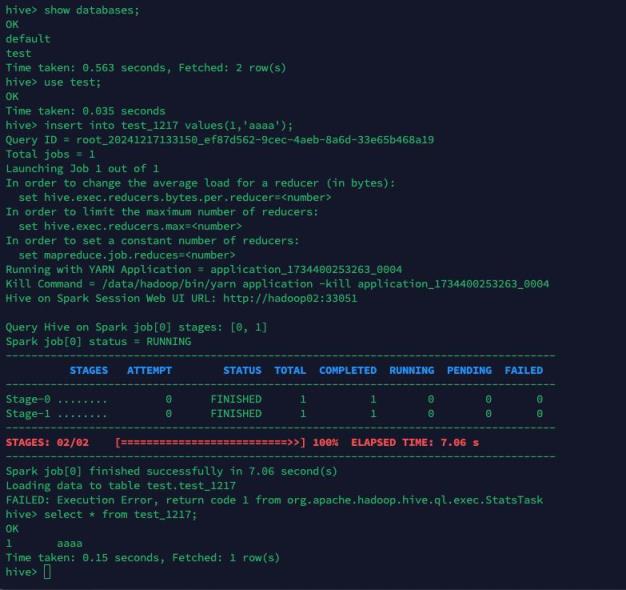
【影响范围】
【修复版本】-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号