译:Google的大规模集群管理工具Borg(二)------ Borg架构
3、Borg 架构
一个Borg的cell由一系列的机器组成,通常在cell运行着一个逻辑的中央控制器叫做Borgmaster,在cell中的每台机器上则运行着一个叫Borglet的代理进程。而Borg的所有组件都是用C++编写的。
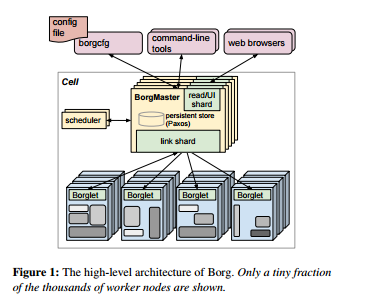
3.1、Borgmaster
每个cell的Borgmaster主要由两个进程组成:一个主Borgmaster进程以及一个分离的调度器。主Borgmaster进程用于处理各种客户的RPC请求,这些请求无非包括状态变更(用于创建job)或者对数据的只读访问(用于查询的job)。它还用于管理系统中各个对象(机器,task,alloc等)的状态机,和Borglets之间的交互以及提供一个web的UI作为Sigma的备份。
从逻辑上来说,Borgmaster是一个单一的进程,但事实上它有五个重复单元。每个重复单元都维护了一个cell在内存中的大部分状态,并且这些状态同时用高可用的,分布式的,基于Paxos算法的手法记录在重复单元的本地磁盘上。每一个当选的master都同时作为Paxos leader以及状态变更者,用于处理所有改变cell状态的操作,例如提交一个job或者终止一台机器上的一个task。当一个cell刚刚启动或者当选的master故障的时候,我们需要利用Paxos算法选举出新的master,在这个过程中我们需要获取一个Chubby锁,从而能让其他系统发现它。选举一个master节点通常需要10s钟的时间,但是对于一些比较大的cell,这可能需要花上一分钟,因为许多在内存中的状态信息需要进行重构。当一个重复单元从故障中恢复过来的时候,它需要动态地与其他的重复单元进行同步,从而更新到最新的状态。
Borgmaster在一个给定时间点的状态叫做checkpoint,通常它们以定期快照加上更改日志的形式存放在Paxos store中。Checkpoint有很多的用处,包括将Borgmaster的状态恢复到之前任意的一个时间点(比如回到接收触发Borg缺陷的请求之前的状态,因此我们就能据此进行调试);在极端情况下进行手动修复;构建一个持久性的事件日志用于以后的查询;以及用于离线的模拟。
有一个高保真的Borgmaster模拟器叫做Fauxmaster可以用来读取checkpoints文件,存放完整的Borgmaster代码拷贝,以及废弃的Borglets接口。它能够接收RPC用于状态机的转换并且执行一些操作,例如,“调度所有挂起的task”,我们还可以用它来调试错误,通过与它交互,仿佛它是一个真的Borgmaster一样,然后再通过模拟的Borglet从而重现checkpoint中所有的真实交互。这样用户就能一步一步地分析观察在过去真实发生的系统的变化。Fauxmaster同样对于容量计划非常有用(比如对于“这种类型创建多少新的job比较合适”这样的问题),而且还能在对一个cell的配置进行更改前进行完整性检查(比如“这样的更改会不会对一些重要的job产生影响”)。
3.2、调度
当一个job被提交的时候,Borgmaster会将它持续性地记录在Paxos中,并且将该job中的task都加入挂起队列中。这些都是由调度器异步扫描完成的,它会在有足够资源并且符合job的限制条件的时候将task部署到机器上。(调度器主要操作的是task,而不是job)。扫描根据优先级从高到底进行,在同一优先级内按照轮转法进行调节从而确保各用户间的公平性并且避免大型job的头端阻塞。调度算法主要由两部分组成:feasibility checking,用于发现task可以运行的机器,和scoring,选取其中一个可行的机器。
在feasibility checking中,调度器会找到一系列的机器,这些机器符合task限制条件并且拥有足够的可用的资源(包括那些被分配给低优先级task的资源)。在scoring中,调度器会再对那些满足基本要求的机器进行打分评判。打分会考虑不同用户的偏好,但主要还是由一些内置的标准决定的:例如最小化被抢占进程的数目和优先级,选取那些已经有该task包的机器,在电源和失败域内传播task,以及打包质量包括将高优先级和低优先级的task混合放在一台机器中从而让那些高优先级的task能扩展它们的负载峰值。
Borg原生使用的是一种E-PVM的变体用于scoring。它能够用来对各种各样的资源产生一个单一的成本价值并且最小化部署一个task带来的改变成本。事实上,E-PVM在所有机器上分布负载,而是将留下的余量用于负载峰值,这是以增加碎片为代价的,特别是对于那些需要占用机器大部分资源的大型task来说,我们通常叫这种做法为“worst fit"。
“worst fit”的对立面自然是"best fit":它试图将机器塞得越满越好。这通常会给用户job留下不少空的机器(当然这些机器上面依然运行着存储服务器),因此对于大型task的部署就非常容易了,但是这种紧密的打包方式会使任何用户或者Borg对于资源请求的错误估计都带来不利的影响。这会对有着突发负载的应用造成伤害,对于批处理job是尤其不利的,因为它们会指定很低的CPU需求从而使它们能被轻松调度,在一些资源不被使用的时候趁机运行:通常20%的non-prod job都只需要不到0.1的CPU核。
我们现在使用的scoring模型是一种混合体。它试着减少标准资源的数量-----它们不能被使用,因为该机器上的另外一种资源已经全部被分配了。它能够提供比“best fit”好大概3%-5%的打包效率。
如果通过scoring被选中的机器没有足够的可用资源去运行新的task。Borg就会抢占(甚至杀死)低优先级的task,按照优先级从低到高的顺序,直到满足条件为止。我们将被抢占的task放到调度器的挂起队列中,而不是迁移或者让它们休眠。
task的启动延迟(从job提交到task运行的时间)是一个持续受到重视的领域。它的变化会比较大,平均值大概在25s左右。包的安装大概占到了总时间的80%左右:一个已知的瓶颈是用于写入包的本地磁盘的争夺。为了减少task的启动时间,调度器往往更愿意将task部署在已经安装了相应包(包括程序和数据)的机器;大多数包都是一成不变的,因此能够被共享和缓存(这是Borg调度器唯一支持的数据局部性的形式)。另外,Borg通过tree and torrent-like 协议将包并行地分发到机器上。
最后,调度器使用另外一些技术使它能扩展到那些有着成千上万台机器的cell上。
3.3、Borglet
Borglet是一个本地的Borg代理,它会出现在cell中的每一台机器上。它启动,停止task;在task失败的时候重启它们,通过控制操作系统内核设置来管理本地资源以及向Borgmaster和其他监视系统报告机器状态。
Borgmaster每过几分钟就轮询每个Borglet获取机器的当前状态,同时向它们发送外部的请求。这能够让Borgmaster控制交互的速率,避免了显示的流量控制和恢复风暴。
被选中的master用于准备发送给Borglet的信息以及利用Borglet的反馈更新cell的状态。为了性能的扩展性,每个Borgmaster重复单元都运行了一个link shard,用来处理和一些Borglet的交互;通常在Borgmaster的选举到来的时候,分区会被重新计算。为了弹性,Borglet通常会汇报它的全部状态,但是link shard会汇聚并且压缩这些信息,只汇报各个状态机的改变,从而降低选中的master的更新负载。
如果一个Borglet接连没有回复好几条轮询信息,那么相应的机器就被标志为down,并且它上面运行的任何task都将被重新调度到其他机器上。假如交互又恢复了,那么Borgmaster就会告诉对应的Borglet杀死那些已经被重新调度的task,从而避免重复。当Borglet失去了与Borgmaster的联系的时候,它依旧继续执行正常的操作,所以即使在所有的Borgmaster重复单元都挂掉之后,正在运行状态的task和服务依旧保持正常运行。
3.4、可扩展性
我们并不确定最终的扩展性限制会来自Borg中心化结构的什么地方;至今为止,每次我们感到到达了一个极限的时候,我们总能够最终消除它。一个单一的Borgmaster可以管理一个cell中许许多多的机器,而一些cell每分钟要接收超过1000个的task。一个忙碌的Borgmaster会使用10-14个CPU核心以及搞到50G的RAM。我们使用了多项技术来实现这样的扩展性。
早期的Borgmaster只有一个单一的,同步的循环用于接收请求,调度task以及和Borglet进行通信。为了应付大型的cell,我们将调度器分配到一个独立进程中,从而使它能够和其他用于异常处理的Borgmaster函数并行工作。一个调度器的重复单元通常在一个缓存的cell状态拷贝上进行操作。它循环执行以下操作:从当选的master中获取状态改变(包括已经被部署以及挂起的工作);更新它的本地缓存;向已经部署的task做一轮调度;并且将这些部署操作通知当前当选的master。master会接收并且应用这些部署,除非它们是不恰当的(比如它们基于的是已经过时的状态),这样它们在下一轮调度中被重新考虑。这和Omega中的乐观并发控制是非常类似的。事实上,现在我们已经能让Borg针对不同的负载类型使用不同的调度器了。
为了提高响应时间,我们添加了额外的线程用于和Borglet的交互以及响应只读的RPC。为了提高性能,我们在五个Borgmaster重复单元间共享(部分地)这些功能。上述这些改进让99%的UI相应时间降低到1s以下,而让95%的Borglet轮询间隔降低到10s以下。而以下的几项技术让Borg的调度器更具扩展性:
Score caching:评估一台机器的可用性并为它评分是非常昂贵的,因此Borg会缓存它们直到机器或者task的特性发生改变,例如,机器上的一个task终止,属性的改变或者task的请求改变。忽略小的资源请求数量的改变有利于降低缓存的失效。
Equivalence classes:一个Borg job里的task通常拥有相同的要求和限制条件。因此Borg并不会对每个挂起的task,对每台机器做可行性分析,并且为每台可行的机器打分。Borg只会对每个Equivalence classes里的一个task做可行性分析以及打分操作,而Equivalence classes其实就是一组具有相同请求的task。
Relaxed randomization:对一个大的cell中的每台机器都进行可行性计算和打分是非常浪费的,因此调度器会对机器进行随机的测试直到找到足够多可行的机器用于打分,然后再在其中挑选出最好的。这样做就降低了在task进入以及离开系统时,带来的打分以及缓存失效的数目,并且加速了task到机器上的部署。Relaxed randomization有点类似于Sparrow中的批量采样,同时它还能处理优先级,抢占,异质性以及包安装带来的开销。
在我们的实验中,从零开始调度一个cell的全部负载需要花费数百秒的时间,但是如果禁用上面这些技术,那么用三天的时间也完成不了。然而,一般来说,对于挂起队列的一次调度循环往往能在不到半秒的时间内完成。
注:翻译中部分内容可能比较晦涩或者并非十分流畅,欢迎指正
原文地址:http://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/43438.pdf


 浙公网安备 33010602011771号
浙公网安备 33010602011771号