Jmeter压力测试笔记(6)性能调测-压力并发-模拟生产环境数据
问题原因找到了,那就好办了。
找到阿里云技术人员,让他们强行给我们上架了一个共享代理模式的RDS。 并重新进行压力测试。
哦豁~ 开心,压力测试顺利,异常率大大降低实际为:

数据库DBA反馈,数据库收到很多请求处理,数据库开始正常工作。(之前都是,数据库连接满,但活跃连接只有1到5个)。 数据库连接数在50到100之间波动,且基本都是活跃连接。
NGINX和php那边都工作正常,服务器cpu压力下降。各项功能都平稳。
然后开始真真正正进行模拟生产用户数据压力测试:
生产环境数据如下:
高峰时期: 总并发连接数12w 活跃连接数10万;新建连接数1300/s;吞吐量:6200/S。
如何通过调整jmeter脚本的线程数,吞吐量来实现该场景,就得多次尝试了。
jmeter运行环境如下: centos7 java1.8.161; jmeter 5.2.1 4C8G。 阿里云机器。
1,实现并发连接数和活跃连接数。
并发连接数=活跃连接数+非活跃连接数
活跃连接数=jmeter线程数*执行机器数量
非活跃连接数=tcp连接中断数: 实际执行过程中发现:如果设置的吞吐量过高,会造成大量的非活跃连接数。与真实请求场景不一致。 后面细说。
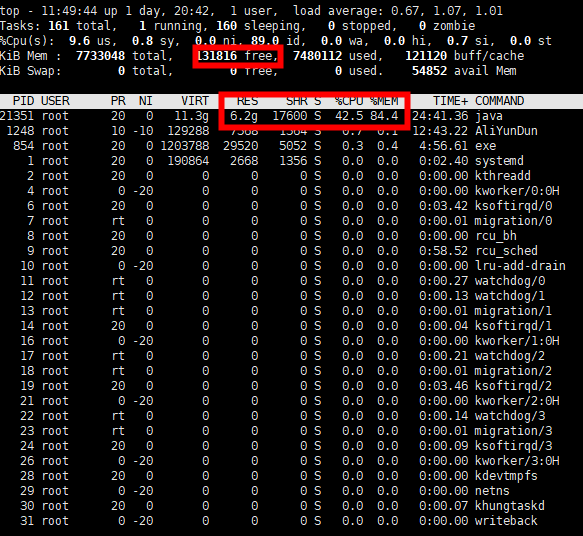
如何提升活跃连接数:------加机器+内存。没其它办法。现在的机器一般cpu都是够用的。 实际设置1800线程运行时,机器只有20%的cpu使用率。
通过测试的经验计算,大概一个线程需要消耗3M内存。所有如果想跑2000线程,那么你得设置虚拟机6000m,否则,会爆出内存溢出错误。
通过命令启动执行机:
JVM_ARGS="-Xms1024m -Xmx6000m" ./jmeter-server & ####注意,不要超过自己机器实际能使用的内存!!!!留点空闲给机器本身用,否则会很卡,很慢。异常高。
我喜欢这种方式,方便调整内存。哈哈。
顺便写几个清理内存和杀进程的命令:
查看执行机运行日志: tail -f apache-jmeter-5.2.1/bin/jmeter-server.log 查看1099端口: netstat -an|grep 1099 查看java进程: ps -ef|grep java 批量杀进程操作:我特别喜欢哈哈 ps -ef|grep java|awk '{print $2}'|xargs kill -9 统计查询tcp 80端口数量: netstat -nat|grep -i 80|wc -l 统计查询tcp time_wait 端口数量: netstat -an | awk '/^tcp/ {++s[$NF]} END {for(a in s) print a,s[a]}'
查看内存使用量:
free -m
同步缓存:
sync
清理内存:建议在杀java进程后使用,先使用sync同步。
echo 3 > /proc/sys/vm/drop_caches
实际运行效果,机器正常跑2000线程正常,不卡,不慢,非常happy~
然后计算10万用户=10万除以2000===50个机器~~~ 汗~~有点难申请。还要加5个调度机、、一共是55个机器~ 1个调度机带10个执行机。
和大佬凶猛的沟通了一阵子~ 同意了。直接在阿里云上复制已经调试好jmeter的执行机。刷刷刷刷~~~机器到手了。 反正阿里云按量收费,用一天也没多少钱。
如何降低非活跃连接数呢?
由于我设置的tcp连接超时周期为30秒,当我未对吞吐量进行限制时:发现非活跃连接数非常多。 这与生产环境不一致。(该测试结果图片基于 1带13执行机,用户线程1500.当时的吞吐量为12000/s,大大超过实际的需求)

生产环境数据:
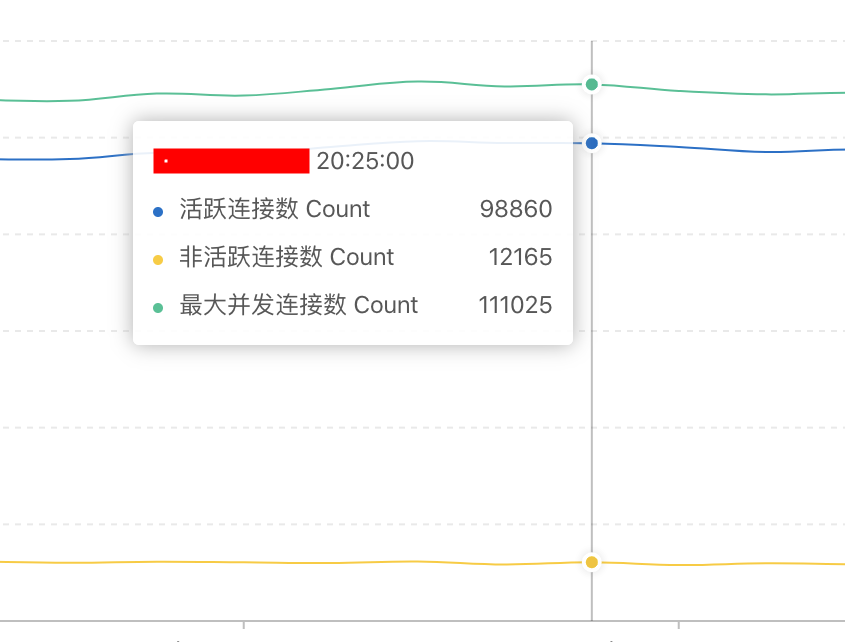
仔细琢磨计算了一下。生产10万活跃用户,才6200吞吐量,那么。 2万活跃用户的吞吐量应该是===1300:
这里发现一个关键指标: 新建并发连接数:生产环境高峰期也就1300,而我 6000+;所以,会出现大量的非活跃连接请求就很正常了。
解决办法:使用jmeter定时器》》精准吞吐量计时器来对吞吐量进行限制。降低新建连接数,降低吞吐量。
通过计算:20000活跃用户吞吐量1300,那么jmeter脚本2000线程对于吞吐量是130/s。额好低。不忍直视。习惯了几千几千上万的,吞吐量。最后发现只要设置130。
所以:这里有一个结论,真真的性能大神测试时,都不是像我这样的搞茫茫多机器去跑,一般也就设置100到200线程,进行服务器性能测试。通过性能调优来优化服务器。通过对测试结果日志的分析,来找到服务器问题的。
而不是像我这样,去想着把服务器搞挂,来复现问题…………
好了,设置好jmeter吞吐量,再进行一波测试。
非活跃连接数大大降低~~达到理想要求。 但还是比较多~ 新建请求连接数1690~ 超过高峰1300. 还需要慢慢优化~
脚本环境都调试完毕,以后,就开始加机器,测试吧~~~
待补充: 等测完了再来补充
过去了一个月,终于有时间来补欠下的债了。。
与运维沟通配置3套压测机环境,都是1带14.共组成42个执行机。
单机脚本配置2200用户。
测试接口共配置51个业务接口,共组成7个业务流程。
测试计划为:
|
业务量类型 |
80% |
100% |
150% |
目的 |
|
并发数 |
9600 |
12000 |
18000 |
分析性能变化趋势 分析性能问题 帮助定容定量 |
|
TPS |
4960 |
6200 |
9300 |
|
|
新建连接数 |
1680 |
2100 |
3250 |
80% 场景结果:

根据图表数据可以看到;业务系统服务器内存使用40%,cpu使用52%,服务器各个指标稳定。Jmeter请求响应平均响应时间100ms,请求异常数量为0;RDS各项指标也很稳定,主库从库连接数,TPS都很正常。请求连接没有积压。
100%请求场景:
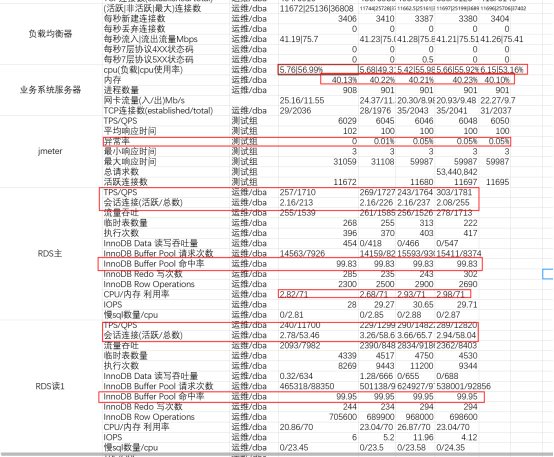
根据测试结果数据可以看到,业务系统服务器CPU,内存稳定,负载均衡器也很稳定。RDS主库和从库都很稳定。
Jmeter 请求有0.05%的异常概率,经过分析,为压测机器tcp端口耗尽超时导致。不影响服务器性能。
150%性能场景:

当进行150%负载时,服务器cpu达到90%以上,并出现排队现象。
TPS/QPS稳定在9000左右。 数据RDS连接数增加到100%时的几倍。请求响应平均时间为400ms。服务器已经满负荷运行。
使用手机进行打开APP进行体验:打开页面缓慢,打开链接页面在3秒左右,但都能正常操作。服务器能正常处理数据,未出现卡死,奔溃。
稳定性测试结果: 持续运行3小时。
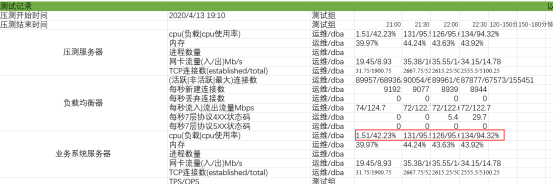
测试结果:实际活跃连接数为90000左右,总连接数为155500左右。服务器cpu性能跑满。RDS压力不大。持续运行3小时后,系统能正常提供服务,但比较慢。
测试结果总结:
|
参数 |
测试数据 |
||
|
性能指标 |
80% |
100% |
150% |
|
ART(ms) |
90 |
100 |
400 |
|
TPS |
4900 |
6050 |
9000 |
|
CPU |
40.1% |
40.2% |
90% |
|
MEM |
40 |
40 |
44 |
|
RDS主QPS/TPS |
1811/257 |
1781/303 |
2624/412 |
|
RDS读QPS/TPS |
13195/279 |
12820/289 |
19443/411 |
测试数据已经完成,剩下的就是分析调优了,这个后续再开新章节。
遇到一个新的错误: 机器内存耗尽了。自动杀死进程。--调整jvm的内存,减少线程数。保证可用内存大于200M。