
数据比赛项目数据可视化模块代码大全
import numpy as np #导入数据结构nmupy模块
import matplotlib.pyplot as plt #导入matplotlib图像输出模块
plt.rcParams["font.sans-serif"]=["SimHei"] #输出图像的标题可以为中文正常输出
plt.rcParams["axes.unicode_minus"]=False #可以正常输出图线里的负号
import pandas as pd
from pandas.plotting import scatter_matrix
import seaborn as sns
#1-1连续变量之间散点图输出
data=pd.read_excel("数据清洗完的最终有效数据1.xlsx")
x=data["点赞数"]
y=data["评论数"]
#data=data[["点赞数","评论数","得分1","得分2","得分3","得分4"]]
#data=data[["点赞数","评论数"]]
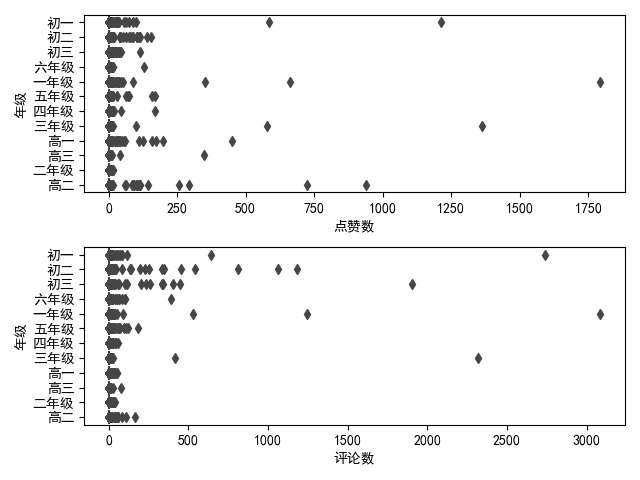
#离散特征与连续变量之间的箱式图分布
plt.figure()
x1=["点赞数","评论数"]
for i in range(len(x1)):
plt.subplot(2,1,i+1)
sns.boxplot(data[x1[i]],data["年级"],orient="h")
#plt.title("话题与{}箱式图分布".format(x1[i]))
plt.show()
'''
corr=data.corr()
corr=abs(corr)
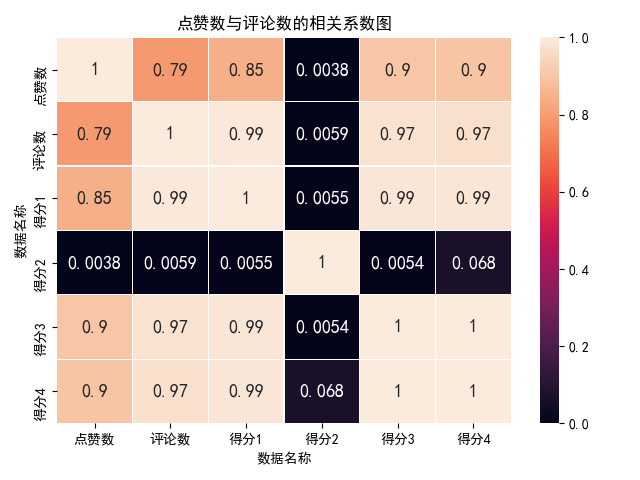
ax=sns.heatmap(corr,vmax=1,vmin=0,annot=True,annot_kws={"size":13,"weight":"bold"},linewidth=0.05)
#plt.xticks(fontsize=15)
#plt.yticks(fontsize=15)
plt.xlabel("数据名称")
plt.ylabel("数据名称")
plt.title("点赞数与评论数的相关系数图")
plt.show()
#离散特征与连续变量之间的箱式图分布
plt.figure()
x1=["得分1","得分2","得分3","得分4"]
for i in range(len(x1)):
plt.subplot(2,2,i+1)
sns.boxplot(data[x1[i]],data["年级"],orient="h",color="black")
#plt.title("话题与{}箱式图分布".format(x1[i]))
plt.show()
plt.subplot(2,2,2)
plt.scatter(data["评论数"],data["得分2"]) #画散点图的函数scatter(其中XY表示数值的大小,s表示散点的尺寸大小,c表示颜色,alpha表示透明度)
plt.xlabel("评论数")
plt.ylabel("得分2")
plt.subplot(2,2,3)
plt.scatter(data["评论数"],data["得分3"]) #画散点图的函数scatter(其中XY表示数值的大小,s表示散点的尺寸大小,c表示颜色,alpha表示透明度)
plt.xlabel("评论数")
plt.ylabel("得分3")
plt.subplot(2,2,4)
plt.scatter(data["评论数"],data["得分4"]) #画散点图的函数scatter(其中XY表示数值的大小,s表示散点的尺寸大小,c表示颜色,alpha表示透明度)
plt.xlabel("评论数")
plt.ylabel("得分4")
#plt.title("评论数与各个目标得分之间的分布散点图")
plt.show()
corr=data.corr()
corr=abs(corr)
ax=sns.heatmap(corr,vmax=1,vmin=0,annot=True,annot_kws={"size":13,"weight":"bold"},linewidth=0.05)
#plt.xticks(fontsize=15)
#plt.yticks(fontsize=15)
plt.xlabel("数据名称")
plt.ylabel("数据名称")
plt.title("点赞数评论数与四大目标评分的相关系数图")
plt.show()
corr=data.corr()
corr=abs(corr)
ax=sns.heatmap(corr,vmax=1,vmin=0,annot=True,annot_kws={"size":13,"weight":"bold"},linewidth=0.05)
#plt.xticks(fontsize=15)
#plt.yticks(fontsize=15)
plt.xlabel("数据名称")
plt.ylabel("数据名称")
plt.title("点赞数评论数与四大目标评分的相关系数图")
plt.show()
scatter_matrix(data)
#plt.title("各数据之间散布矩阵")
plt.show()
#plt.axes([0.025,0.025,0.95,0.95]) #指定显示范围
plt.scatter(x,y) #画散点图的函数scatter(其中XY表示数值的大小,s表示散点的尺寸大小,c表示颜色,alpha表示透明度)
#plt.xlim(-1.5,1.5),plt.xticks([]) #x和y坐标轴的范围
#plt.ylim(-1.5,1.5),plt.yticks([]) #x和y坐标轴的范围
plt.axis() #显示所有图像范围
plt.title("点赞数与评论数散点图输出")
plt.xlabel("点赞数")
plt.ylabel("评论数")
plt.show()
fig,ax=plt.subplots(figsize=(12,10))
sns.regplot("点赞数","评论数",data=data,ax=ax)
ax.set_xlabel("点赞数")
ax.set_ylabel("评论数")
fig.tight_layout()
#不同连续变量之间的可视化展示
cov = np.corrcoef(data.T)
img = plt.matshow(cov,cmap=plt.cm.winter)
plt.colorbar(img, ticks=[-1,0,1])
plt.xticks(np.arange(len(data.keys())), data.keys())
plt.yticks(np.arange(len(data.keys())), data.keys())
#plt.title("各数据之间相关系数分布图")
plt.show()
#第一种箱式图
data[["点赞数","话题"]].boxplot(by="话题")
plt.xlabel("话题种类")
plt.ylabel("点赞数大小")
#plt.title("话题-点赞数箱式图")
plt.show()
#第二种seaborn绘制箱线图
import warnings
warnings.filterwarnings("ignore")#不显示warning
#plt.style.use("ggplot")#美化图片
#plt.figure(figsize=(15,8))
for i in ["话题","省","学段","年级"]:
sns.boxplot(data["点赞数"],data[i],orient="h")
plt.title("{}与点赞数箱式图分布".format(i))
plt.show()
sns.boxplot(data["评论数"],data[i],orient="h")
plt.title("{}与评论数箱式图分布".format(i))
plt.show()
'''
#value_counts的函数输出展示
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
price =data["年级"].value_counts().values
x=len(data["年级"].value_counts())
"""
绘制水平条形图方法barh
参数一:y轴
参数二:x轴
"""
plt.barh(range(x), price, height=0.8, color='steelblue', alpha=0.9) # 从下往上画
plt.yticks(range(x),data["年级"].value_counts().index )
plt.ylabel("不同年级")
plt.xlabel("人数分布")
plt.title("不同区间分布数量")
for x, y in enumerate(price):
plt.text(y+100, x+0.1, '%s' % y)
plt.show()
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"]#输出图像的标题可以为中文正常输出
plt.rcParams["axes.unicode_minus"]=False #可以正常输出图线里的负号
name_list = ["评分1","评分2'","评分3", "评分4"]
num_list = [0.912,0.914,0.957,0.851]
num_list1 = [0.976, 0.914,0.916,0.734]
x = list(range(len(num_list)))
total_width, n = 0.6, 3
width = total_width / n
plt.bar(x, num_list, width=width, label="LogisticRegression", fc = "b")
plt.text(x[0],num_list[0],"91.2%",ha='center',va='bottom',fontsize=10)
plt.text(x[1],num_list[1],"91.4%",ha='center',va='bottom',fontsize=10)
plt.text(x[2],num_list[2],"96.7%",ha='center',va='bottom',fontsize=10)
plt.text(x[3],num_list[3],"85.1%",ha='center',va='bottom',fontsize=10)
for i in range(len(x)):
x[i] = x[i] + width
plt.bar(x, num_list1, width=width, label="RandomForest", tick_label = name_list, fc ="r")
plt.xlabel("不同评分目标类型",fontsize=12)
plt.ylabel("不同模型的准确率大小",fontsize=12)
plt.title("不同评分结果的机器学习算法模型精度表现",fontsize=15)
plt.text(x[0],num_list1[0],"97.6%",ha='center',va='bottom',fontsize=10)
plt.text(x[1],num_list1[1],"91.4%",ha='center',va='bottom',fontsize=10)
plt.text(x[2],num_list1[2],"91.6%",ha='center',va='bottom',fontsize=10)
plt.text(x[3],num_list1[3],"73.4%",ha='center',va='bottom',fontsize=10)
plt.legend(fontsize=9)
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号