
如何降低神经网络模型的过拟合和欠拟合?
1、根据神经网络建立模型的复杂度和数据模型真正复杂度之间的相对大小,其主要存在三种情况:
(1)欠拟合:underfitting

(2)相对准确
(3)过拟合:overfitting


图
2、一般情况下在不知数据模型复杂度的情况下,很容易出现建立模型过拟合的情况,这是因为原始数据中本身存在一些噪声数据,而这些噪声数据会使得所建立模型对于loss函数进行过度寻优,从而极易出现过拟合的情况。
3、对于模型的过拟合,主要有两个方面:
(1)如何检测?
(2)如何减少和改善?

4、对于过拟合的检测,可以使用交叉验证的方式,将其数据集分为三部分:训练数据集,验证数据集和测试数据集,从而达到较好的检测和确定
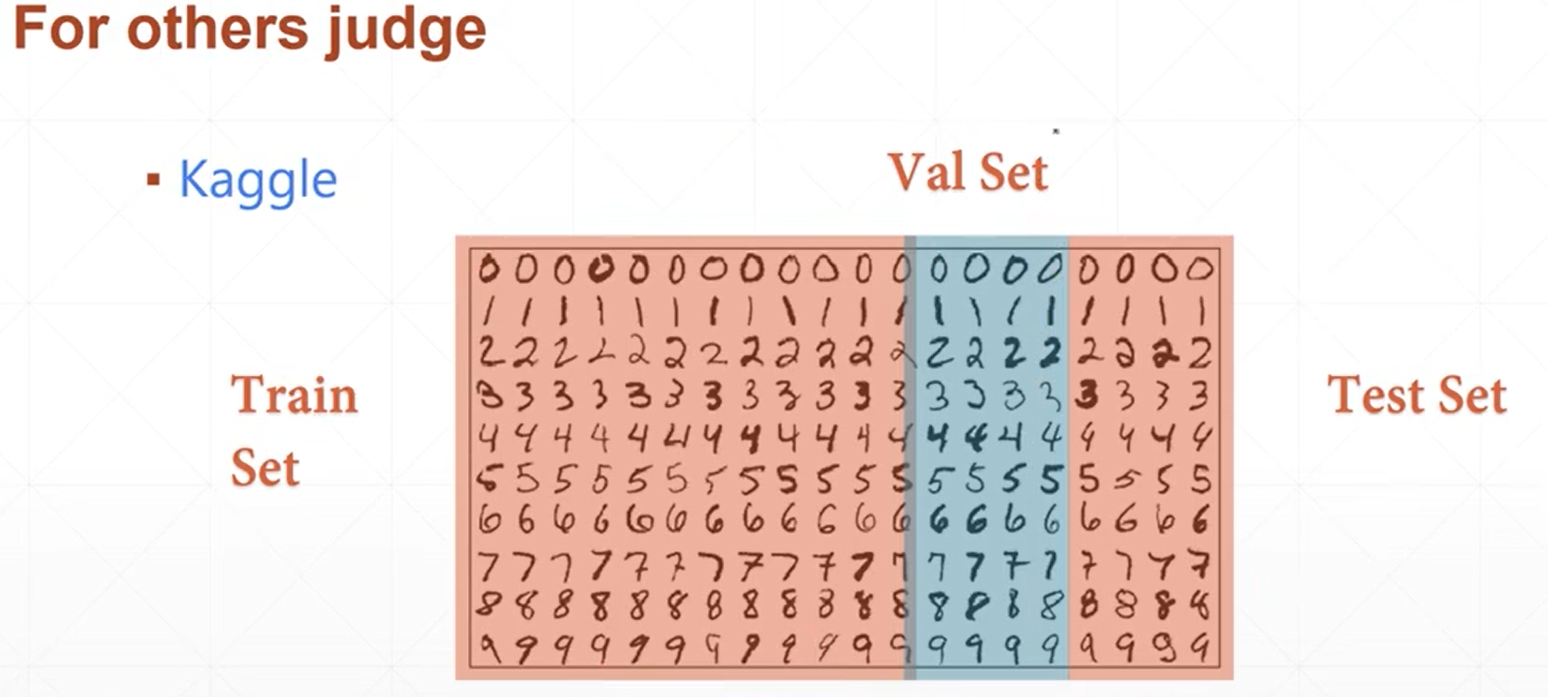
5、对于防止过拟合情况的出现和过拟合现象的改善和减少方法主要有以下方法:



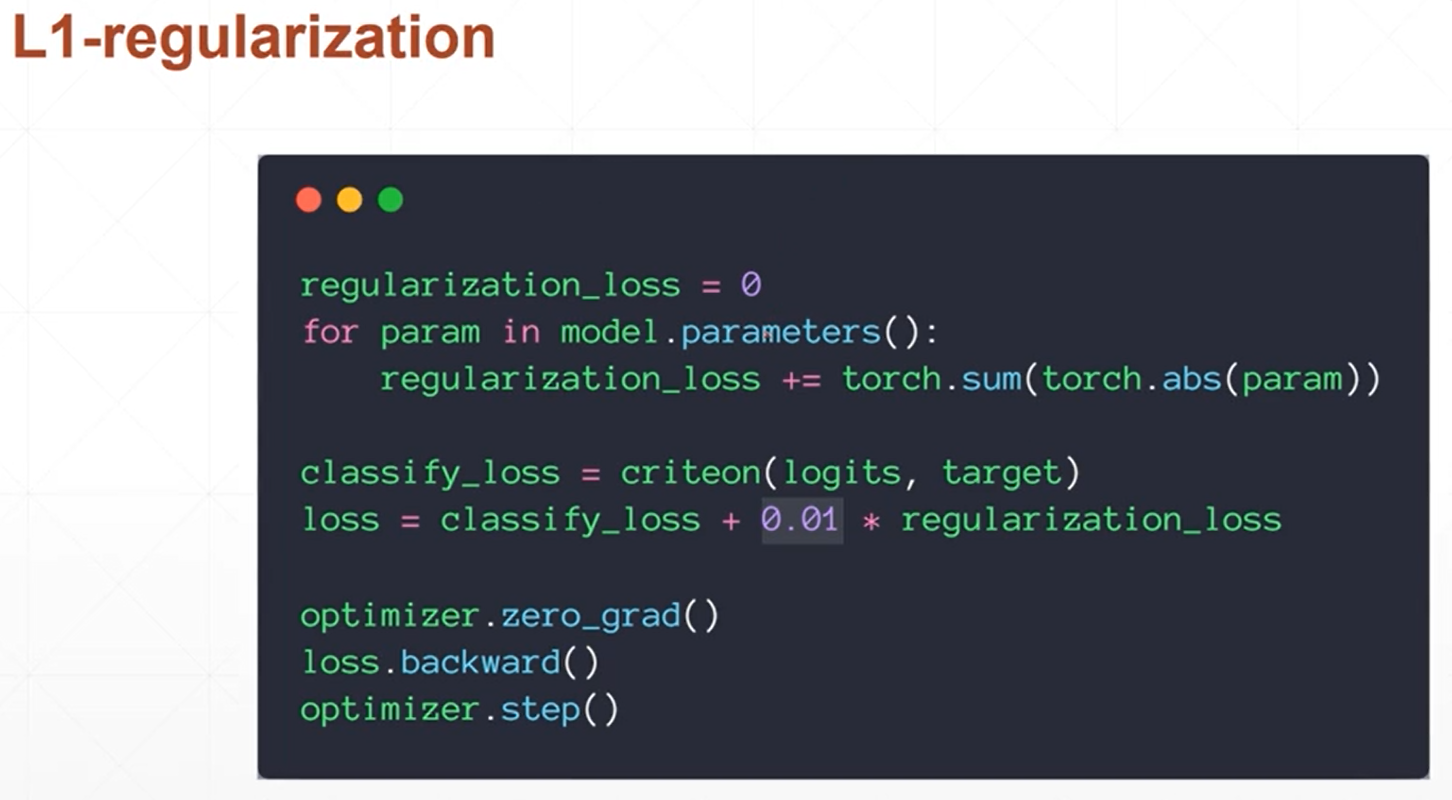
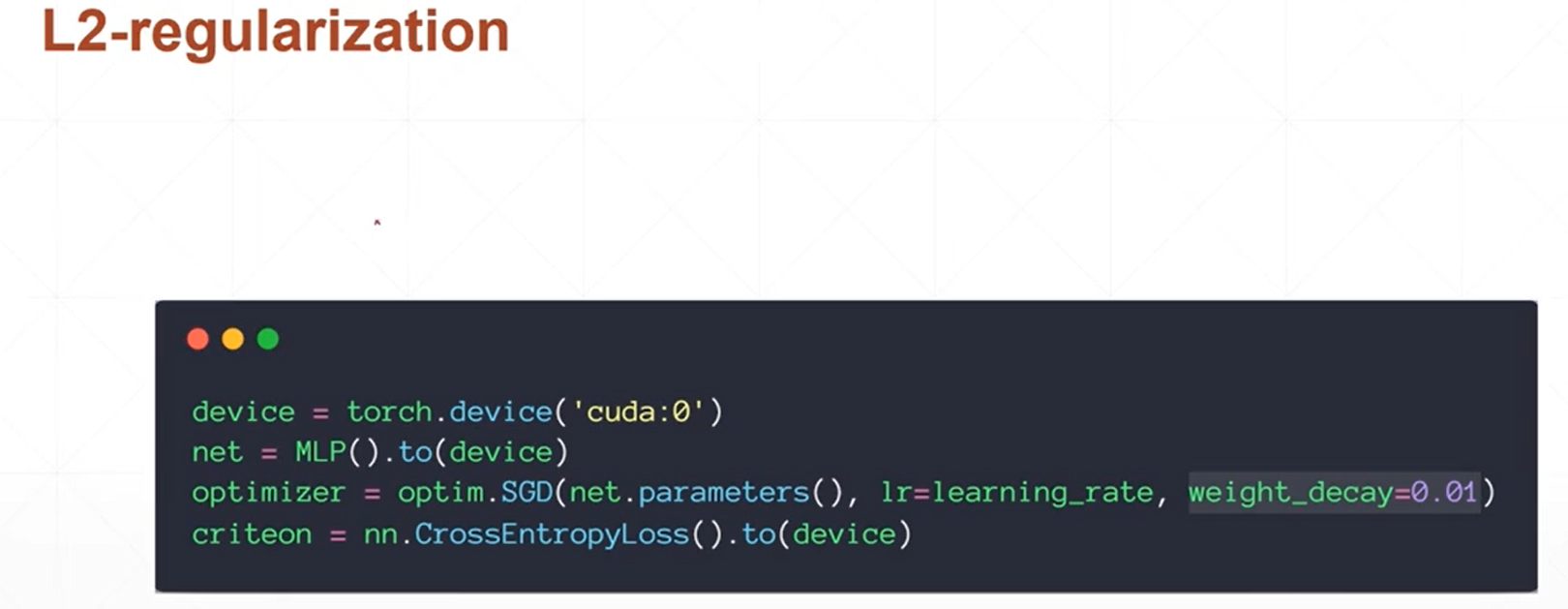
(1)regularization方式(L1/L2)

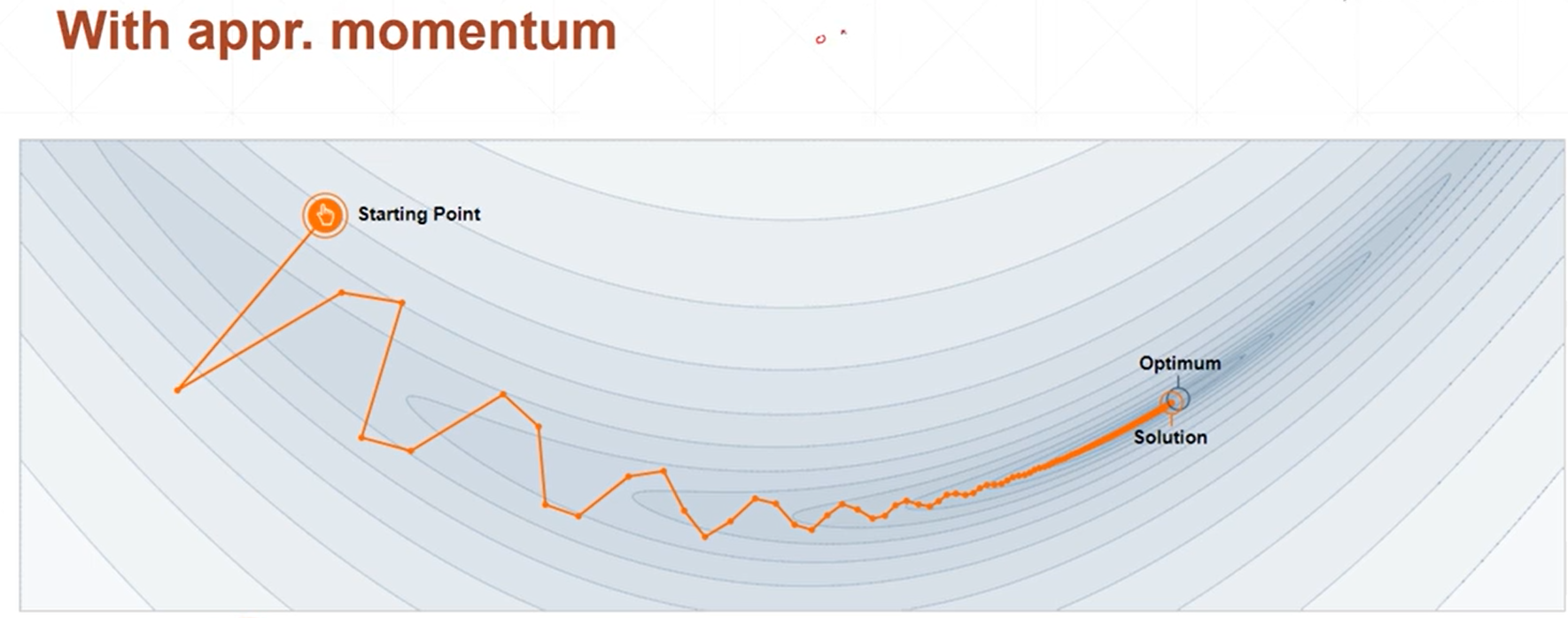
(2)momentium:添加动量(主要是指梯度)


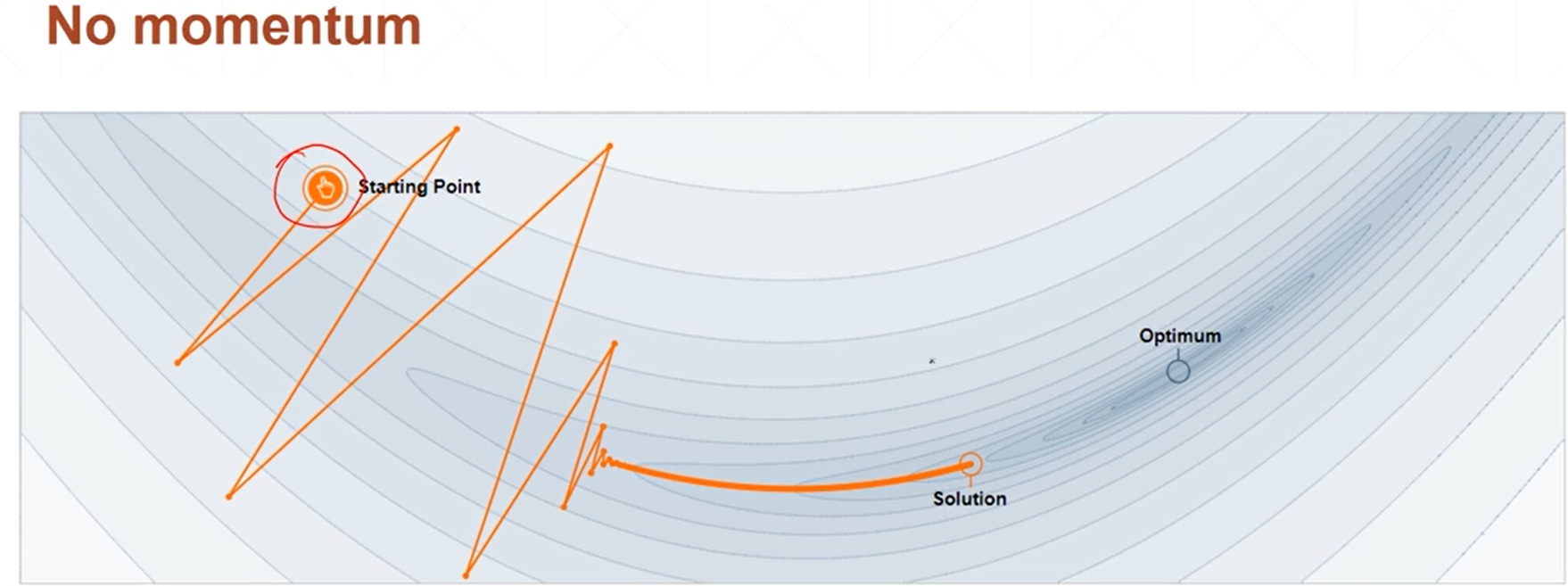
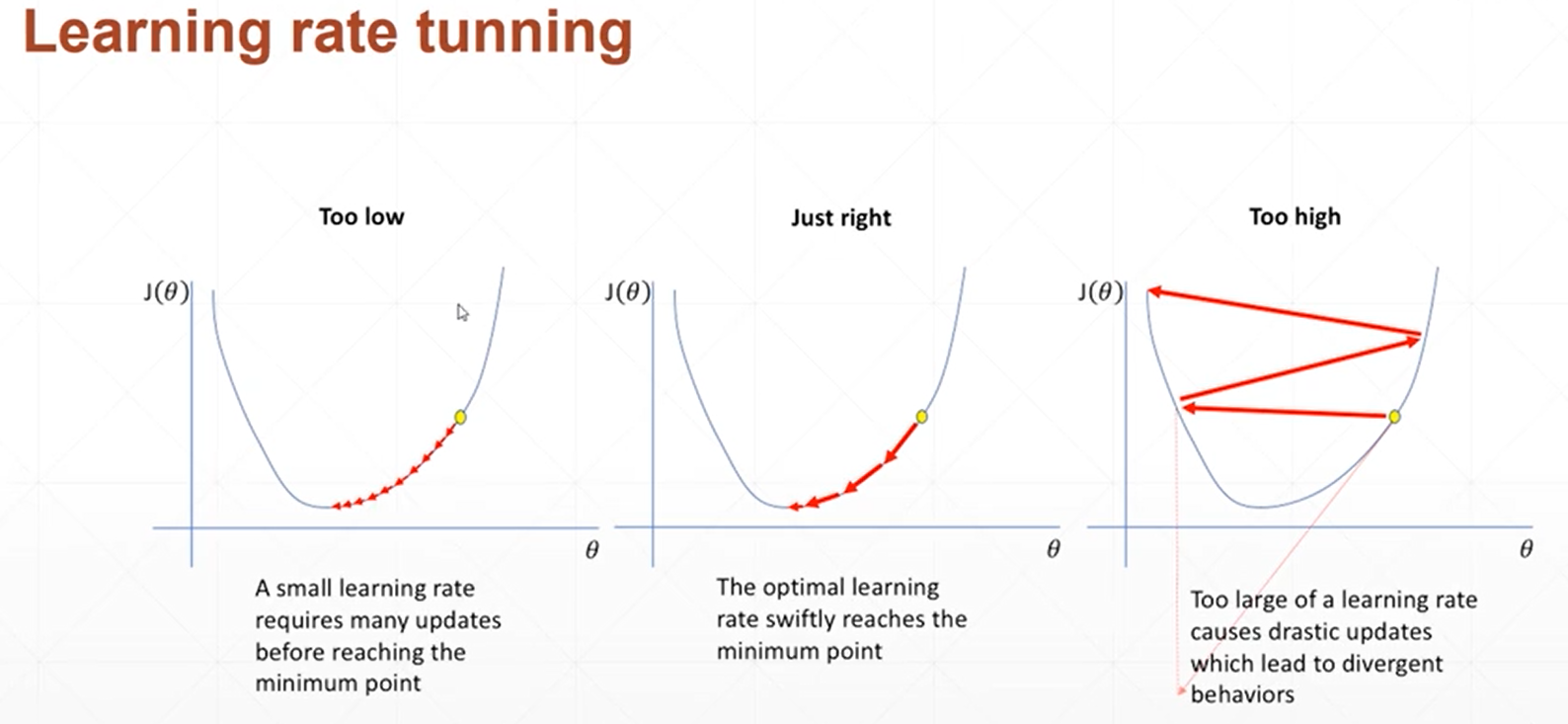
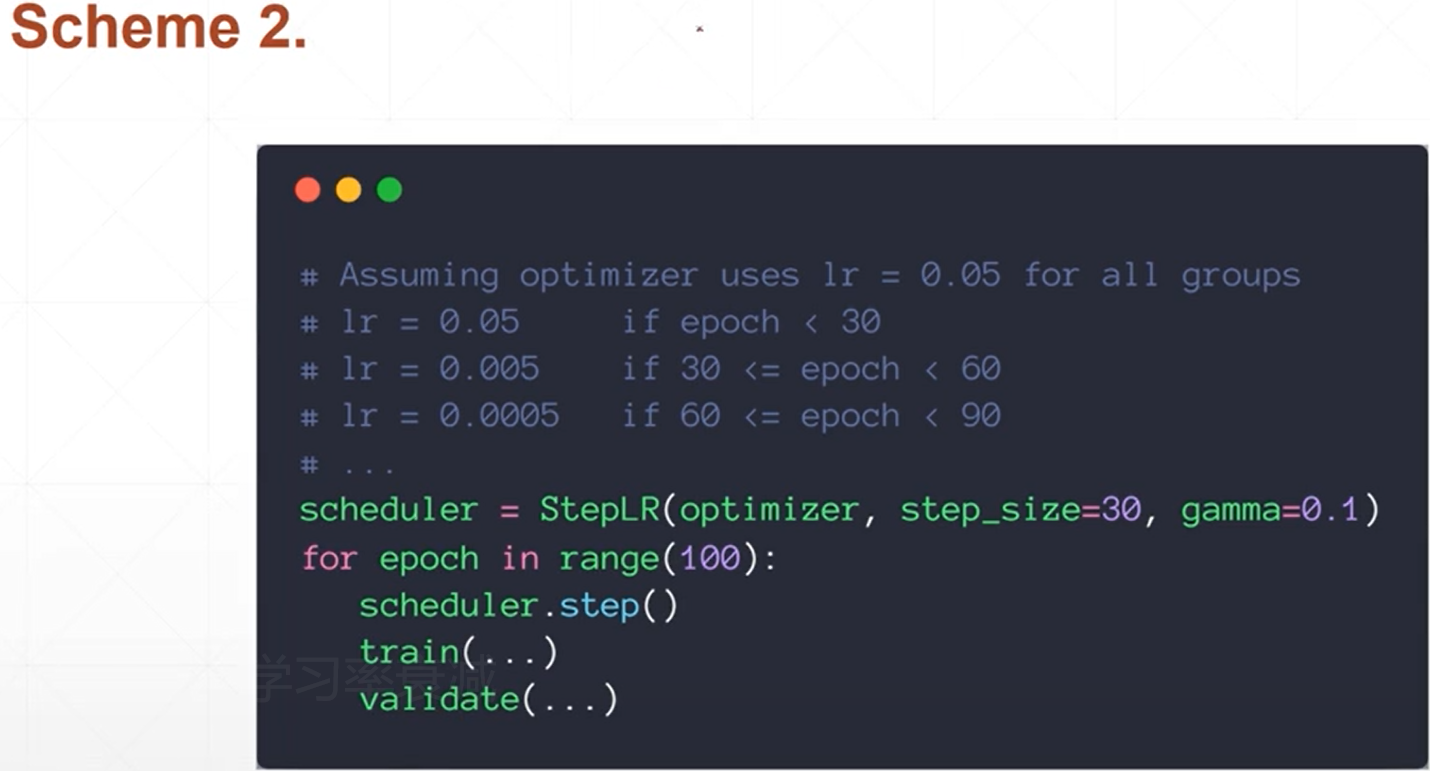
(3)learning rate decay(学习率衰减方式1/2)

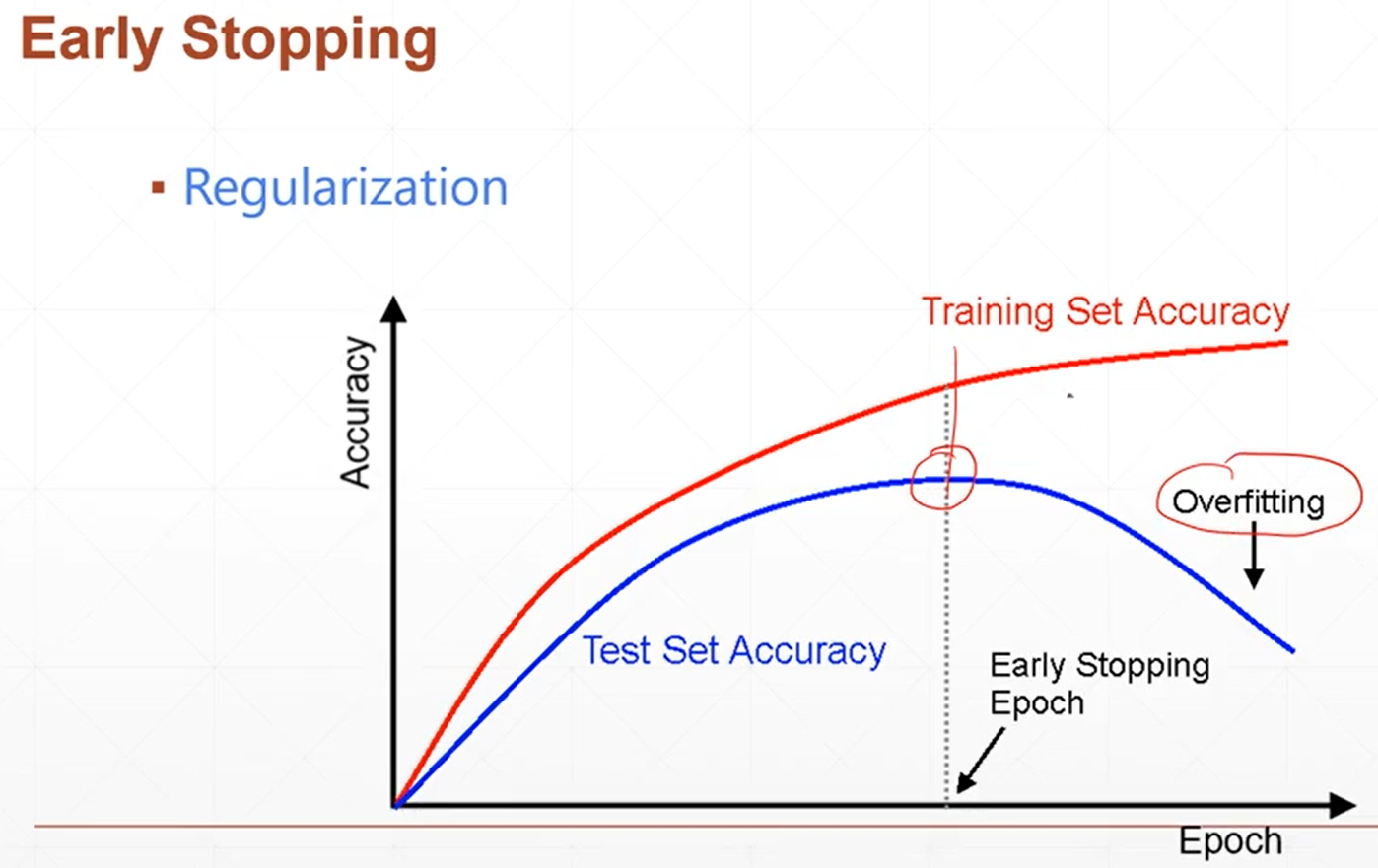
(4)earlystopping

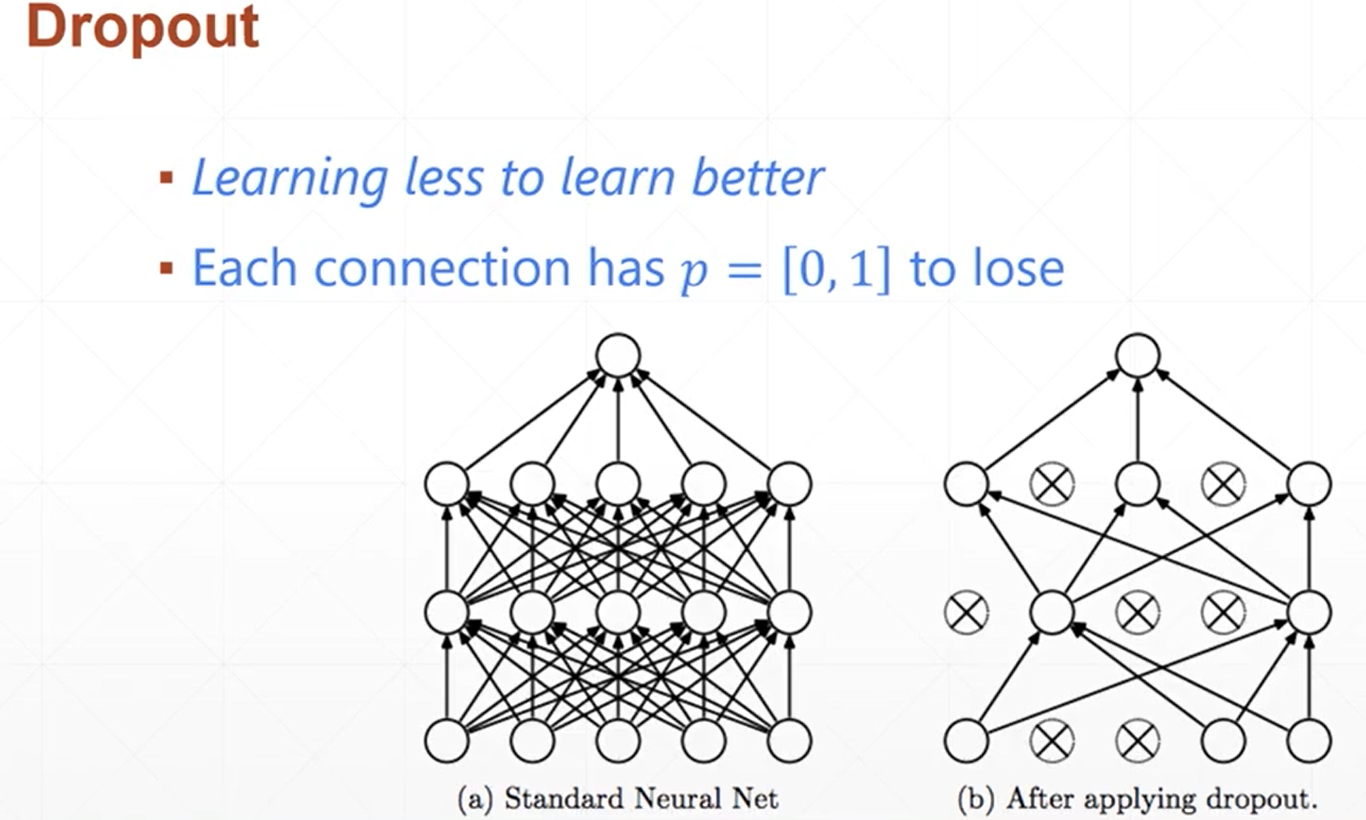
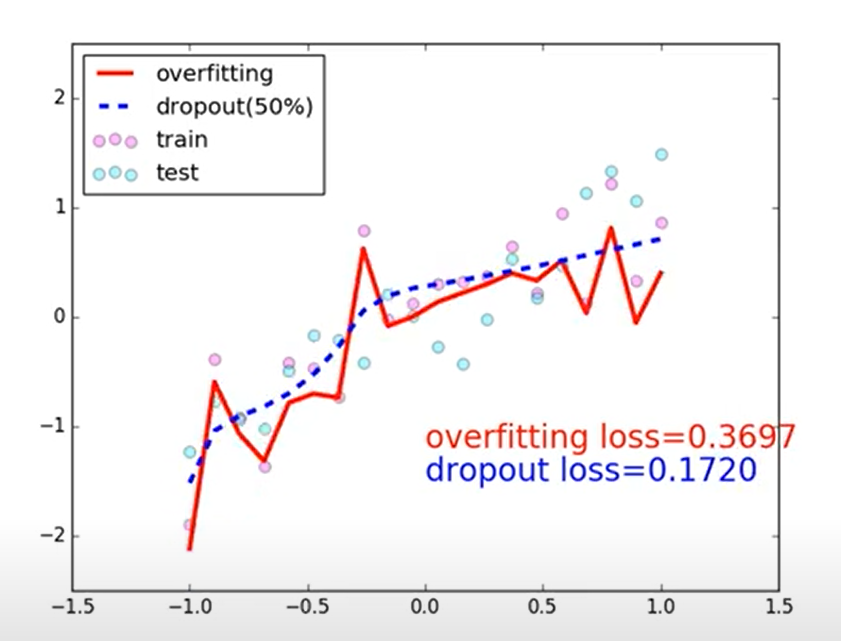
(5)dropout

(6)SGD:随机梯度下降法




 浙公网安备 33010602011771号
浙公网安备 33010602011771号