机器学习中的过拟合和欠拟合及交叉验证
机器学习中的过拟合和欠拟合
1、机器学习算法对于整体的数据训练和拟合,以典型的多元线性回归的方式为例,通过设定拟合的最高次数,然后对比输出的曲线结果可以看出,随着拟合函数次数的增大,其拟合线性回归模型的R2的值在不断地增大,均方差也在不断地减小,看起来拟合的结果越来越准确,其实质只是对于所存在原始数据的拟合误差越来越小,而对于新的数据样本则并不一定适合,这就是说存在过拟合(overfitting)的现象;而如果设定的多项式次数太小,又会使得整体的R2值太小,均方误差太大,从而使得拟合结果不足,这又是欠拟合(under fitting)的情况。
其中过拟合和欠拟合的输出准确度一般可以用均方差来进行对比和衡量,将不同机器学习算法的学习曲线定义为函数输出如下所示:
#将不同的机器学习算法的学习曲线封装成为函数可以方便输出
def plot_learning_curve(algo,x_train,x_test,y_train,y_test):
train_score = []
test_score = []
for i in range(1, len(x_train)):
algo.fit(x_train[:i], y_train[:i])
y_train_pre = algo.predict(x_train[:i])
y_test_pre =algo.predict(x_test)
train_score.append(mean_squared_error(y_train[:i], y_train_pre))
test_score.append(mean_squared_error(y_test, y_test_pre))
plt.figure()
plt.plot([i for i in range(1, len(x_train))], np.sqrt(train_score), "g", label="train_error")
plt.plot([i for i in range(1, len(x_train))], np.sqrt(test_score), "r", label="test_error")
plt.legend()
plt.axis([0,len(x_train)+1,0,5])
plt.show()
plot_learning_curve(LinearRegression(),x_train,x_test,y_train,y_test)
plot_learning_curve(polynomialRegression(degree=1),x_train,x_test,y_train,y_test) #欠拟合的情况
plot_learning_curve(polynomialRegression(degree=2),x_train,x_test,y_train,y_test) #最佳拟合的情况
plot_learning_curve(polynomialRegression(degree=10),x_train,x_test,y_train,y_test) #过拟合的情况
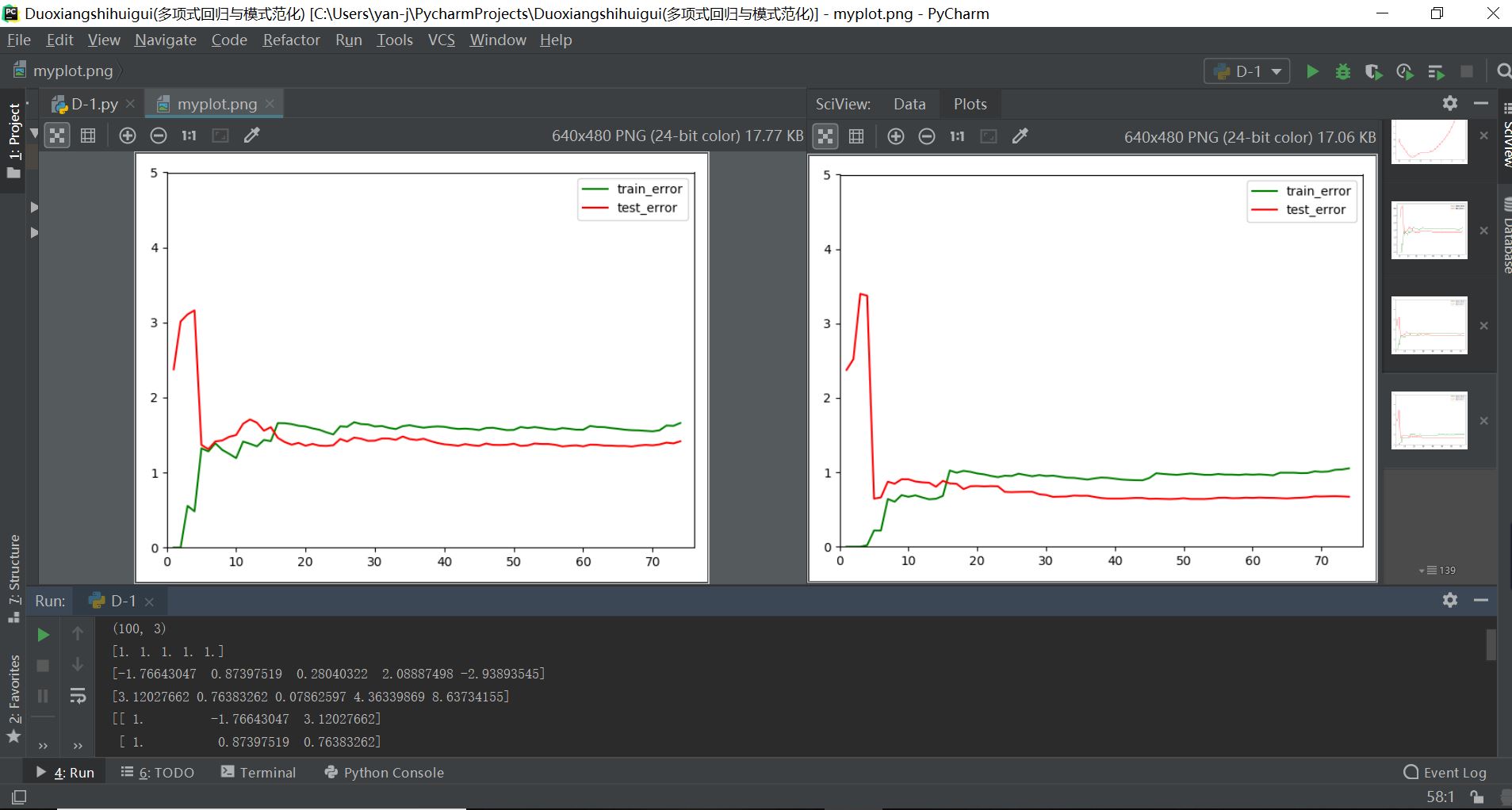
其中机器学习算法存在过拟合和欠拟合情况时的均方差输出如下图所示:
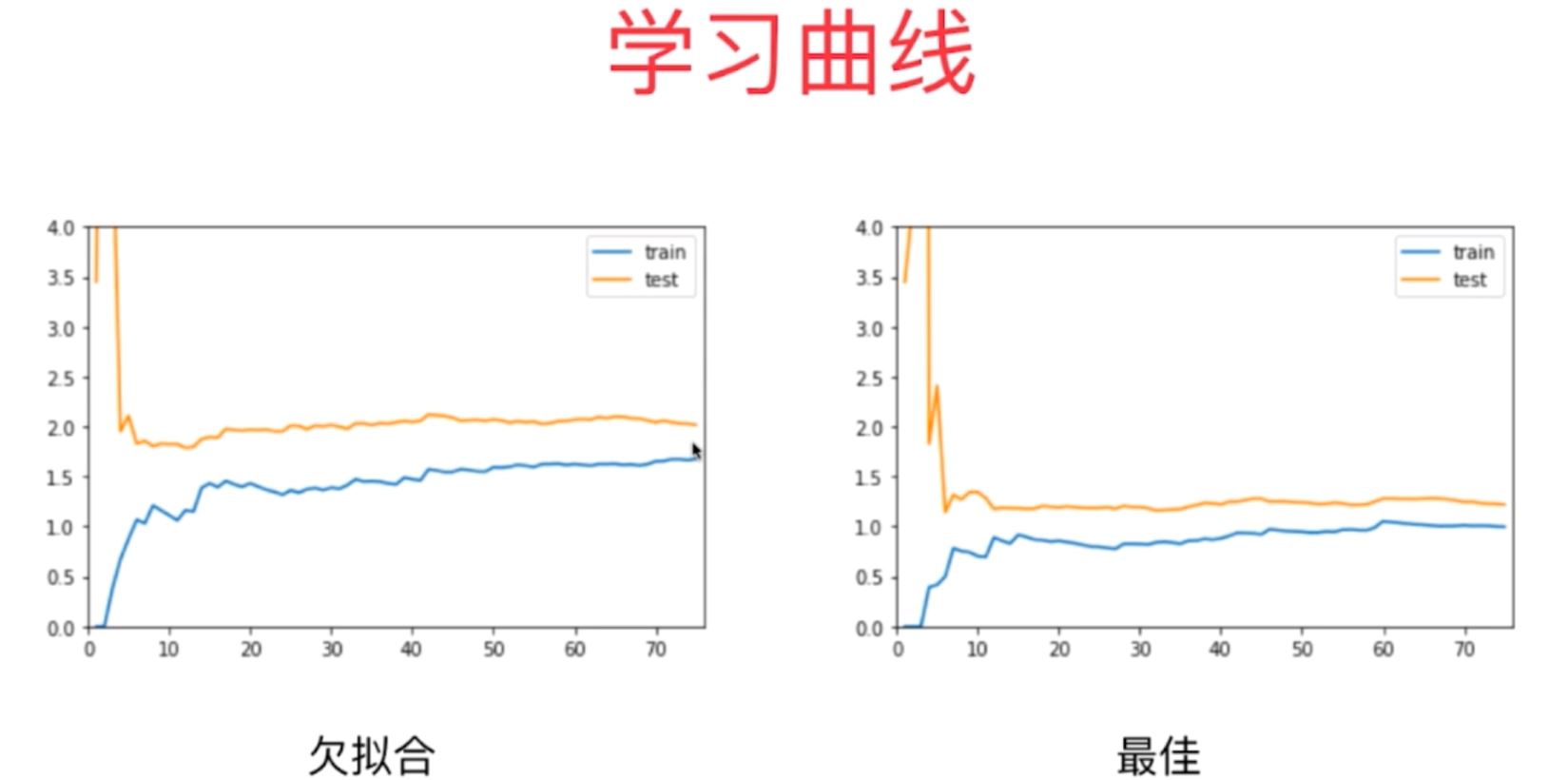
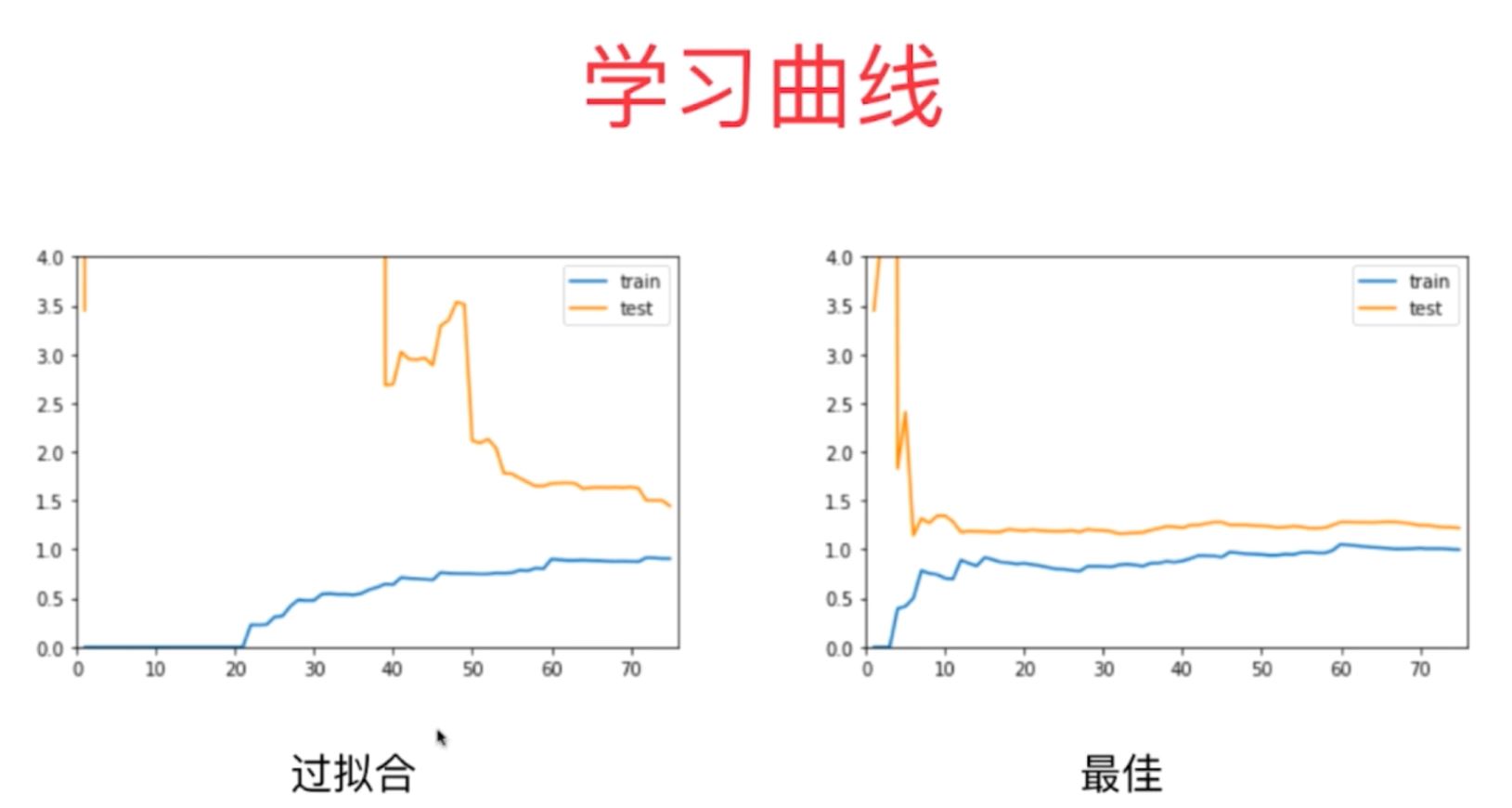
从上面两张图对比可以明显看出,机器学习算法过拟合和欠拟合时学习曲线的特点总结如下:
(1)欠拟合:学习曲线的训练均方差一直增大,而测试数据集的均方差一直减小,最终都趋于一定的定值不变,并且这两个定值也大致趋近,但是总体明显要大于1;
(2)最佳拟合:学习曲线的训练均方差一直增大,而测试数据集的均方差一直减小,最终都趋于一定的定值不变,并且这两个定值相近,都在1附近;
(3)过拟合:学习曲线的训练均方差刚开始几乎为0,后续随着数据集的增多一直增大,趋于定值;而测试数据集的均方差波动起伏,整体趋势一直减小,最终也趋于一定的定值不变,但是这两者定值之间存在一定的差距,并且过拟合的测试数据集均方差在开始和后续一些地方是趋于无穷的;
因此,对于机器学习算法的使用,在数据训练的过程中可能会出现训练的欠拟合和过拟合现象,这个必须尽量注意和避免!
2、机器学习算法对于数据的处理主要是解决过拟合的现象,对于过拟合的训练模型,其实质是指模型的泛化能力不足,而要解决数据训练模型的过拟合现象,比较有效的方法就是将其数据集分为训练数据集合测试数据集进行训练和相关测试,这就是机器学习算法中利用sklearn中的train_test_split函数的意义所在。
3、对于数据的拟合过程,其训练模型复杂度越高,其训练数据的准确率会越高,但是对于新的测试数据集的预测准确度呈现先增后降的变化趋势,主要是因为基础数据集存在数据噪音,随着模型复杂度的增高,其算法过多的表达了数据间噪音的关系,因此我们需要找到对于测试数据集预测率最高的那个数据训练模型,也就是所说的泛化能力最好的数据模型。
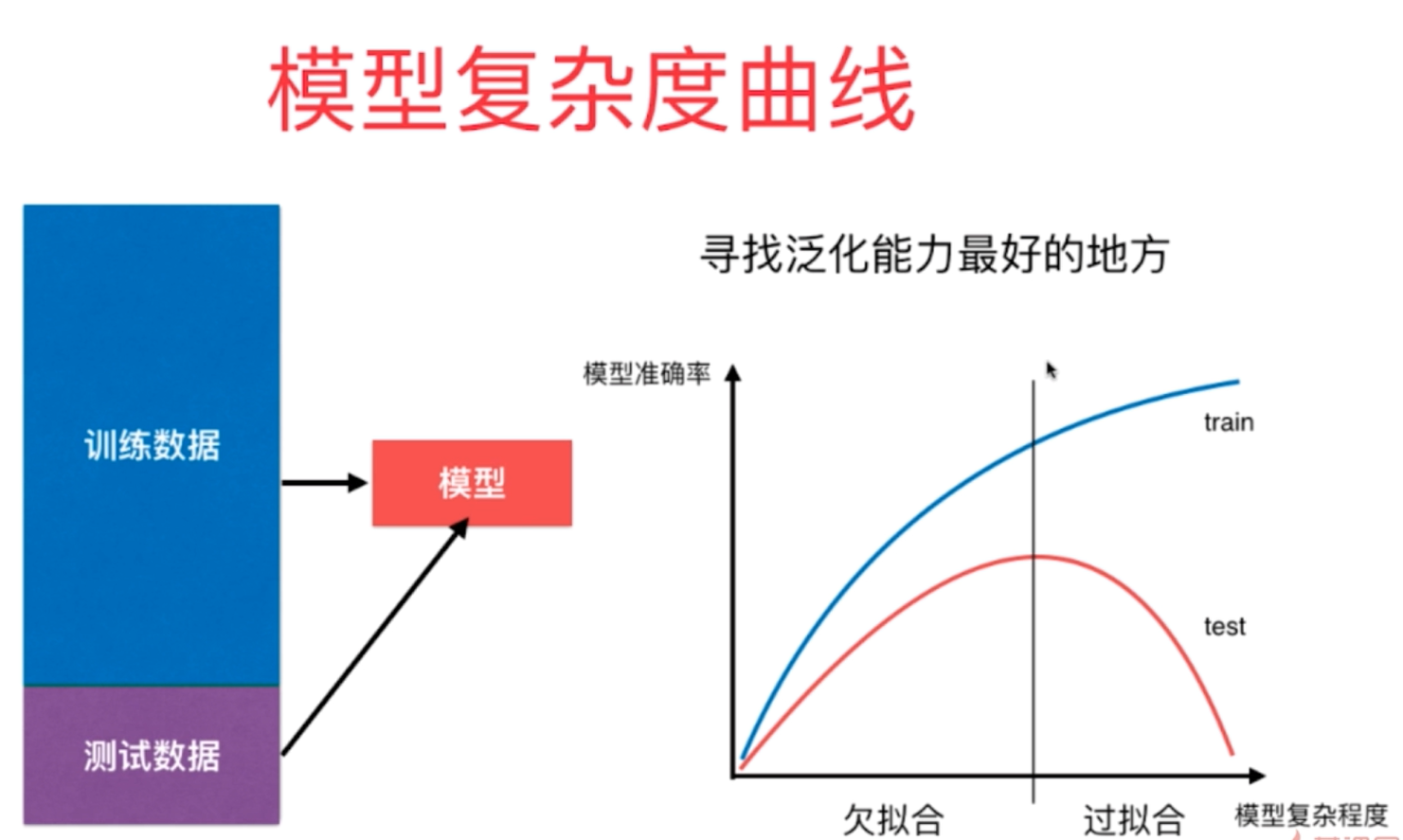
4、对于机器学习算法的过拟合现象,将数据分割成为训练集和测试集进行模型的训练是一种有效避免的方式,但是并不是最好的方式,因为这样的方式可能会使得训练数据集出现过拟合的现象。为了更好地去提高模型的准确度,避免训练过程中出现的过拟合和欠拟合现象,更加有效地方式是采用验证数据集进行交叉验证的方式,这样可以最大程度地避免训练过程中存在过拟合的现象,提高训练模型的准确度。

5、机器学习算法的交叉验证的方式可以使用sklearn库中的cross_var_score(knn1,x_train,y_train,cv)函数来进行,其中cv参数就是指交叉验证时将训练数据集划分的份数,它的本质其实和GridSearch网格搜索的验证方式是一致的,都是交叉验证,并且GridSearch网格搜索函数也含有一个自定义参数cv,它和cross_var_score的cv参数是一致的。
6、采用交叉验证的方式对于模型进行训练的结果是相对比较靠谱的一种训练方式,并且将训练数据集划分为k份进行交叉验证的方式一般可以称为k-fold cross validation,随着k的增大,其验证的结果是越来越可靠的。不过也有它的缺点:每次训练k个模型,相当于整体的性能慢了k倍。
7、留一法(LOO CV):Leaves-One-Out cross validation是指训练数据x_train集含有多少个数据样本(即数据的长度m),则将其划分为多少份进行交叉验证,其中m-1份数据用来训练,剩余一份用来数据的验证,它的最大优点在于这种方式将完全不受随机的影响,得到的性能指标最接近真正的性能指标,不过因为数据量的巨大,整体的计算量巨大,计算过程非常慢。一般很少用这种方法,不过在学术研究过程中为了结果的可靠和准确也会经常用到。
其中关于交叉验证的具体的代码如下所示:
#机器学习算法的交叉验证方式实现代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
digits=datasets.load_digits()
x=digits.data
y=digits.target
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.4,random_state=666)
#1-1普通的训练测试方式
from sklearn.neighbors import KNeighborsClassifier
best_score=0
best_p=0
best_k=0
for k in range(2,11):
for p in range(1,6):
knn1=KNeighborsClassifier(weights="distance",p=p,n_neighbors=k)
knn1.fit(x_train,y_train)
score=knn1.score(x_test,y_test)
if score>best_score:
best_p=p
best_k=k
best_score=score
print("best_score:",best_score)
print("best_k:",best_k)
print("best_p:",best_p)
#1-2交叉验证方式
from sklearn.model_selection import cross_val_score
best_p=0
best_k=0
best_score=0
for k in range(2,11):
for p in range(1,6):
knn2=KNeighborsClassifier(weights="distance",p=p,n_neighbors=k)
knn2.fit(x_train,y_train)
scores=cross_val_score(knn2,x_train,y_train,cv=5) #这里的cv参数就是指将训练数据集分为几份进行交叉验证,默认为3
score=np.mean(scores)
if score>best_score:
best_p=p
best_k=k
best_score=score
print("best_score:",best_score)
print("best_k:",best_k)
print("best_p:",best_p)
knn11=KNeighborsClassifier(weights="distance",p=2,n_neighbors=2)
knn11.fit(x_train,y_train)
print(knn11.score(x_test,y_test))
#1-3利用网格搜索的方式寻找最优的超参数组合就是对于训练数据集进行交叉验证寻找最优
from sklearn.model_selection import GridSearchCV
knn3=KNeighborsClassifier()
param=[
{
"weights":["distance"],
"n_neighbors":[i for i in range(2,11)],
"p":[k for k in range(1,6)]
}
]
grid1=GridSearchCV(knn3,param,verbose=1,cv=5) #这里的cv参数就是指将训练数据集分为几份进行交叉验证,默认为3
grid1.fit(x_train,y_train)
print(grid1.best_score_)
print(grid1.best_params_)
kn2=grid1.best_estimator_
print(kn2.score(x_test,y_test))
其具体的结果如下所示:
(1)过拟合和最佳拟合学习曲线实际输出
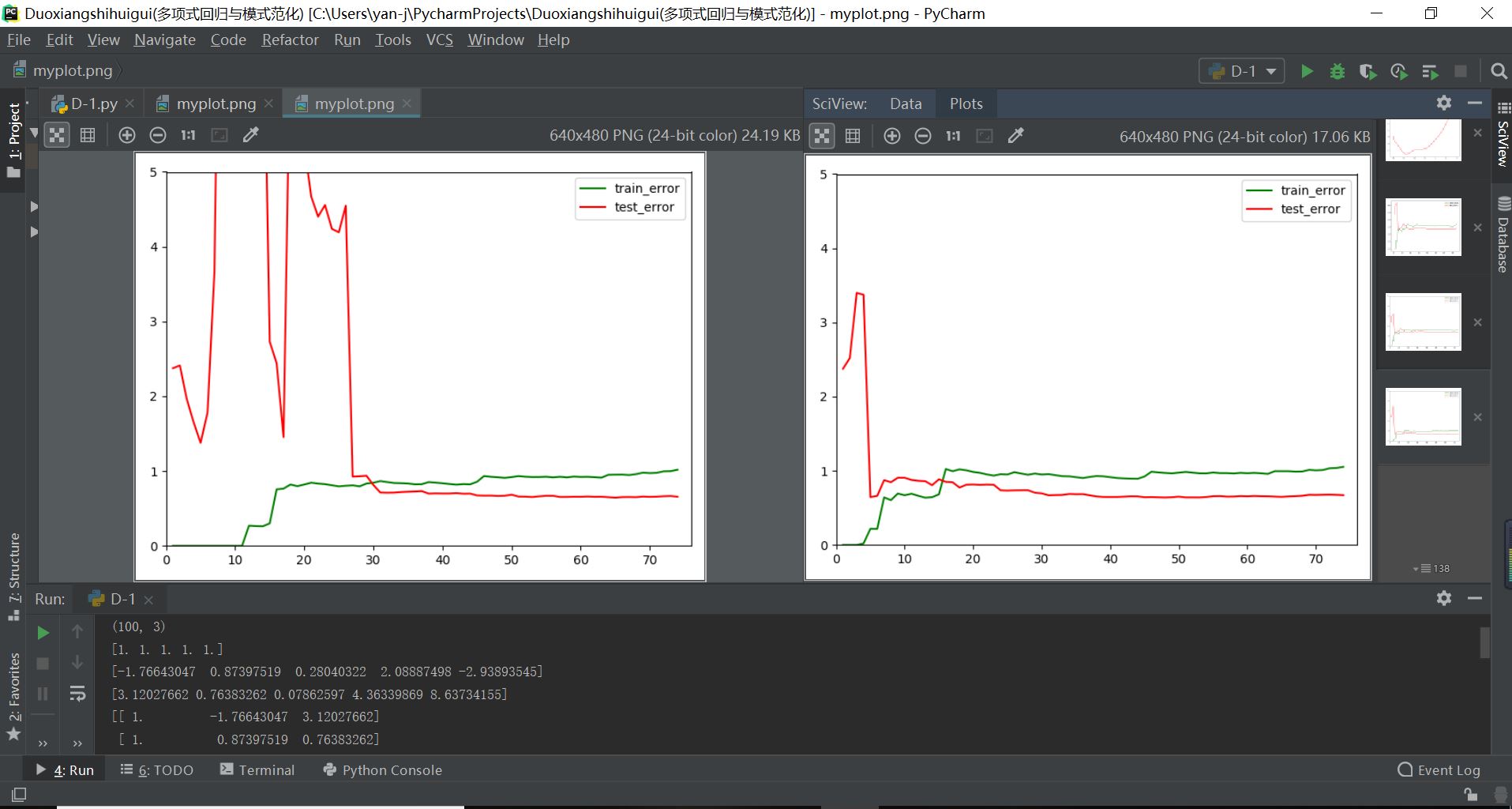
(2)欠拟合和最佳拟合学习曲线实际输出