
sklearn中实现随机梯度下降法(多元线性回归)
sklearn中实现随机梯度下降法
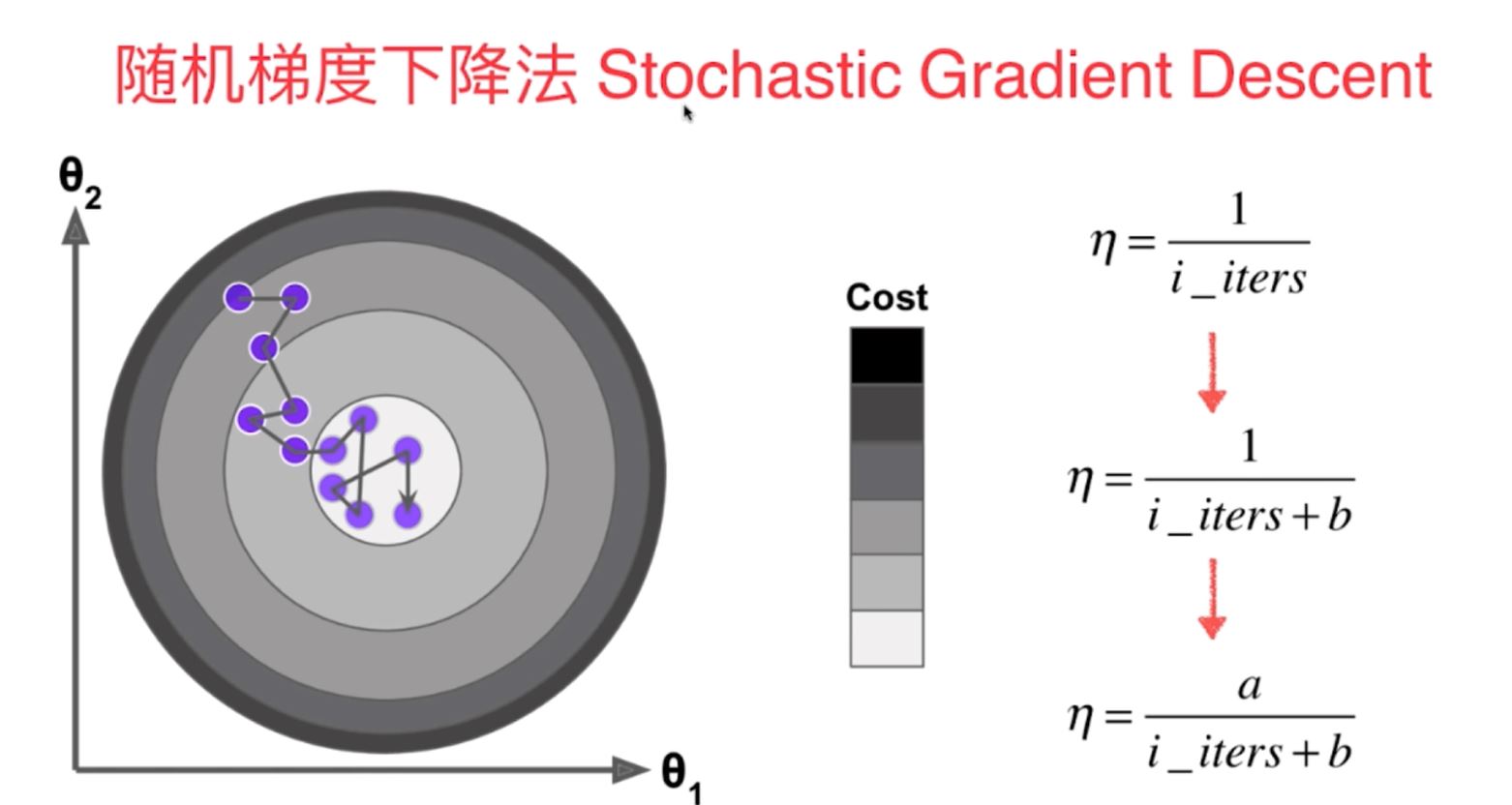
随机梯度下降法是一种根据模拟退火的原理对损失函数进行最小化的一种计算方式,在sklearn中主要用于多元线性回归算法中,是一种比较高效的最优化方法,其中的梯度下降系数(即学习率eta)随着遍历过程的进行在不断地减小。另外,在运用随机梯度下降法之前需要利用sklearn的StandardScaler将数据进行标准化。

#sklearn中实现随机梯度下降多元线性回归
#1-1导入相应的数据模块
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
#1-2导入相应的基础训练数据集
x=np.random.random(size=1000)
y=x*3.0+4+np.random.normal(size=1000)
x=x.reshape(-1,1)
from sklearn import datasets
d=datasets.load_boston()
x=d.data[d.target<50]
y=d.target[d.target<50]
from sklearn.model_selection import train_test_split
x_train1,x_test1,y_train1,y_test1=train_test_split(x,y,random_state=1)
#1-3进行数据的标准化
from sklearn.preprocessing import StandardScaler
stand1=StandardScaler()
stand1.fit(x_train1)
x_train_standard=stand1.transform(x_train1)
x_test_standard=stand1.transform(x_test1)
#1-4导入随机梯度下降法的多元线性回归算法进行数据的训练和预测
from sklearn.linear_model import SGDRegressor
sgd1=SGDRegressor()
sgd1.fit(x_train_standard,y_train1)
print(sgd1.coef_)
print(sgd1.intercept_)
print(sgd1.score(x_test_standard,y_test1))
sgd2=SGDRegressor()
sgd2.fit(x_train1,y_train1)
print(sgd2.coef_)
print(sgd2.intercept_)
print(sgd2.score(x_test1,y_test1))
注解:对于多元回归的随机梯度下降法需要对数据进行向量化和标准化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号