
python中groupby函数详解(非常容易懂)
一、groupby 能做什么?
python中groupby函数主要的作用是进行数据的分组以及分组后地组内运算!
对于数据的分组和分组运算主要是指groupby函数的应用,具体函数的规则如下:
df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式——函数名称)
举例如下:
print(df["评分"].groupby([df["地区"],df["类型"]]).mean())
#上面语句的功能是输出表格所有数据中不同地区不同类型的评分数据平均值
二、单类分组
A.groupby("性别")
首先,我们有一个变量A,数据类型是DataFrame
想要按照【性别】进行分组
得到的结果是一个Groupby对象,还没有进行任何的运算。
describe()
描述组内数据的基本统计量
A.groupby("性别").describe().unstack()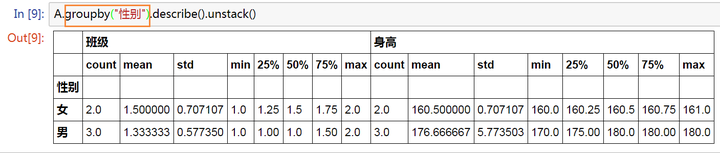
* 只有数字类型的列数据才会计算统计
* 示例里面数字类型的数据有两列 【班级】和【身高】
但是,我们并不需要统计班级的均值等信息,只需要【身高】,所以做一下小的改动:
A.groupby("性别")["身高"].describe().unstack()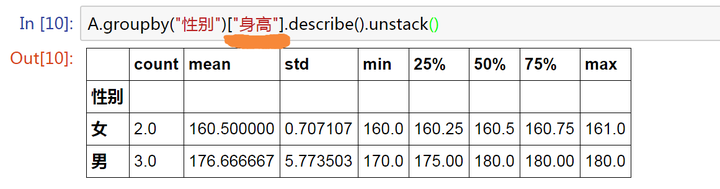
unstack()
索引重排
上面的例子里面用到了一个小的技巧,让运算结果更便于对比查看,感兴趣的同学可以自行去除unstack,比较一下显示的效果
三、多类分组
A.groupby( ["班级","性别"])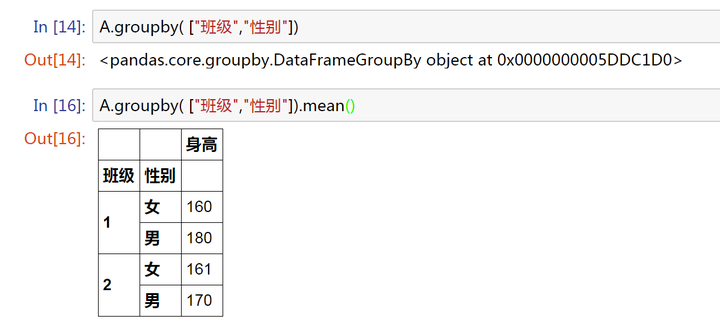
单独用groupby,我们得到的还是一个 Groupby 对象。
mean()
组内均值计算
DataFrame的很多函数可以直接运用到Groupby对象上。
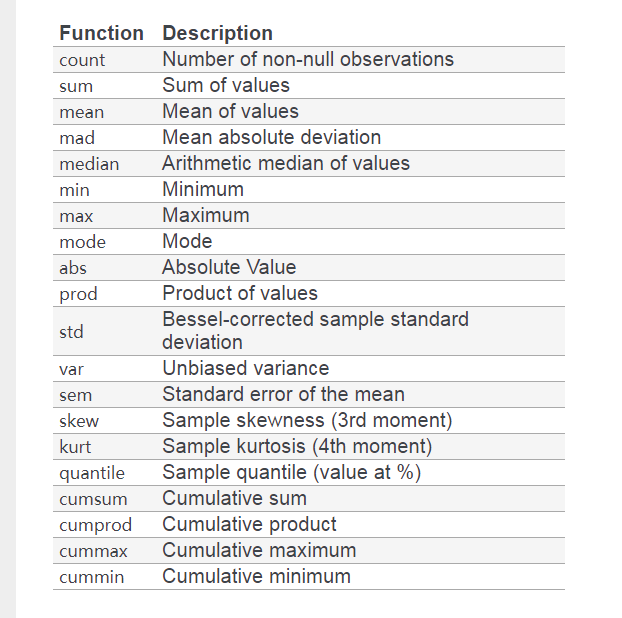
上图截自 pandas 官网 document,这里就不一一细说。
我们还可以一次运用多个函数计算
A.groupby( ["班级","性别"]).agg([np.sum, np.mean, np.std]) # 一次计算了三个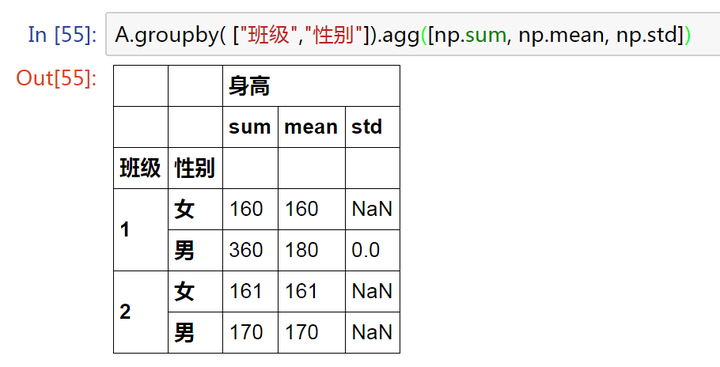
agg()
分组多个运算
四、时间分组
时间序列可以直接作为index,或者有一列是时间序列,差别不是很大。
这里仅仅演示,某一列为时间序列。
为A 新增一列【生日】,由于分隔符 “/” 的问题,我们查看列属性,【生日】的属性并不是日期类型
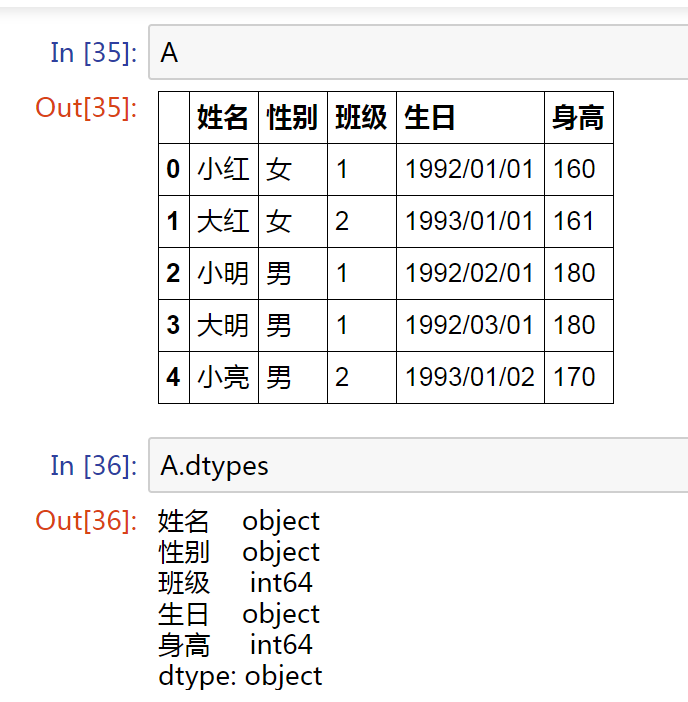
我们想做的是:
1、按照【生日】的【年份】进行分组,看看有多少人是同龄?
A["生日"] = pd.to_datetime(A["生日"],format ="%Y/%m/%d") # 转化为时间格式
A.groupby(A["生日"].apply(lambda x:x.year)).count() # 按照【生日】的【年份】分组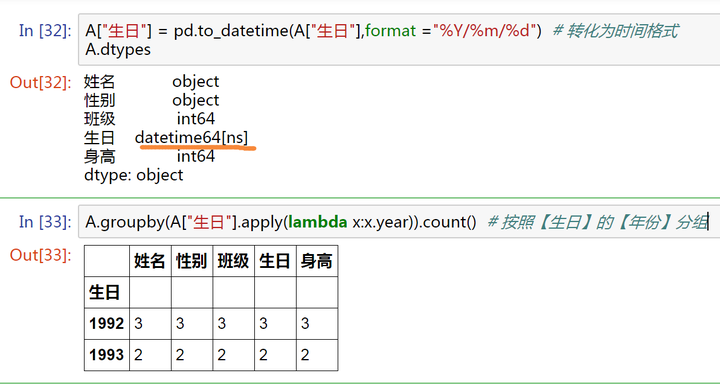
进一步,我们想选拔:
2、同一年作为一个小组,小组内生日靠前的那一位作为小队长:
A.sort_values("生日", inplace=True) # 按时间排序
A.groupby(A["生日"].apply(lambda x:x.year),as_index=False).first() 
as_index=False
保持原来的数据索引结果不变
first()
保留第一个数据
Tail(n=1)
保留最后n个数据
再进一步:
3、想要找到哪个月只有一个人过生日
A.groupby(A["生日"].apply(lambda x:x.month),as_index=False) # 到这里是按月分组
A.groupby(A["生日"].apply(lambda x:x.month),as_index=False).filter(lambda x: len(x)==1)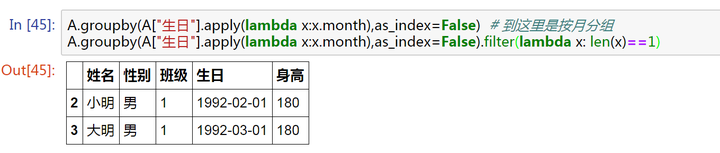
filter()
对分组进行过滤,保留满足()条件的分组
以上就是 groupby 最经常用到的功能了。
用 first(),tail()截取每组前后几个数据
用 apply()对每组进行(自定义)函数运算
用 filter()选取满足特定条件的分组

 浙公网安备 33010602011771号
浙公网安备 33010602011771号