python初识
python基础
Python的变量及数据类型
数据类型
一个程序要运行,就要先描述其算法。描述一个算法应先说明算法中要用的数据,数据以变量或常量的形式来描述。每个变量或常量都有数据类型。Python的基本数据类型有5种: 整型(int), 浮点型(float), 字符型(string), 布尔型(bool),空值(None).
整数
Python可处理任意大小的整数,在程序中的表示方法和数学上的写法完全一样。
浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差。
字符串
字符串是以''或""括起来的任意文本,比如'abc',"xyz"等等。请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符。如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"包含的字符是I,',m,空格,O,K这6个字符。
如果字符串内部既包含'又包含"怎么办?可以用转义字符\来标识,比如:
'I\'m \"OK\"!' 表示的字符串内容是:
I'm "OK"! 转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\,可以在Python的交互式命令行用print打印字符串看看:
>>> print 'I\'m ok.' I'm ok. >>> print 'I\'m learning\nPython.' I'm learning Python. >>> print '\\\n\\' \ \ 如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r''表示''内部的字符串默认不转义,可以自己试试:
>>> print '\\\t\\' \ \ >>> print r'\\\t\\' \\\t\\ 如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容,可以自己试试:
>>> print '''line1 ... line2 ... line3''' line1 line2 line3 上面是在交互式命令行内输入,如果写成程序,就是:
print '''line1 line2 line3''' 多行字符串'''...'''还可以在前面加上r使用,请自行测试。
布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来:
>>> True True >>> False False >>> 3 > 2 True >>> 3 > 5 False 布尔值可以用and、or和not运算。
and运算是与运算,只有所有都为True,and运算结果才是True:
>>> True and True True >>> True and False False >>> False and False False or运算是或运算,只要其中有一个为True,or运算结果就是True:
>>> True or True True >>> True or False True >>> False or False False not运算是非运算,它是一个单目运算符,把True变成False,False变成True:
>>> not True False >>> not False True 布尔值经常用在条件判断中,比如:
if age >= 18: print 'adult' else: print 'teenager' 空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
此外,Python还提供了列表、字典等多种数据类型,还允许创建自定义数据类型。
变量和常量
在计算机中,变量就是用来在程序运行期间存储各种需要临时保存可以不断改变的数据的标识符,一个变量应该有一个名字,并且在内存中占据一定的存储单元,在该存储单元中存放变量的值。请注意区分变量名和变量值这两个不同的概念。
变量命名规则
先介绍标识符的概念。和其他高级语言一样,用来标识变量、符号常量、函数、数组、类型等实体名字的有效字符序列称为标识符(identifier)。简单地说,标识符就是一个名字。变量名是标识符的一种,变量的名字必须遵循标识符的命名规则。
Python语言和java,c++等很多语言一样,规定标识符只能由字母、数字和下划线3种字符组成,且第一个字符必须为字母或下划线。下面列出的是合法的标识符,也是合法的变量名:
sum, average, total, day, month, Student_name, tan, BASIC, li_ling
下面是不合法的标识符和变量名:
M.D.John, $442, #4, 3G64, Alex Li, C++, Zhang-ling,姓名, U.S.A.
注意:在Python中,大写字母和小写字母被认为是两个不同的字符。因此,sum和SUM是两个不同的变量名。一般地,变量名用小写字母表示,与人们日常习惯一致,以增加可读性。应注意变量名不能与Python的关键字、系统函数名和类名相同。
变量名命名习惯
当你的代码越写越多的时候,你会发现你定义的变量也会越来越多,为了增加代码的易读性和方便调试,给变量起名时一定要遵循一定的命名习惯,你起的变量名称最好能让人一眼就大概知道这个变量是干什么用的,比如,getUserName一看就知道,这个变量应该是要获取用户的姓名,check_current_conn_count代表是要检查现在的连接数,只有这样,别人才能在看你的代码时知道你的这些变量的作用,而如果你把变量名全起成了var1,var2,var3…..varN,那别人再看你的代码时会骂死你的。
变量名的定义在能表达清楚它的作用的前提下最越简洁越好,能用一个单词表述清楚的尽量就不要用两个。变量起名时一般有这么几种写法,你觉得哪种最简洁,你就选哪种吧。
CheckCurrentConnCount
check_current_conn_count
checkCurrentConnCount
不好的起名:
CHECKCURRENTCONNCOUNT
Var1 var2 var3 varN
Checkcurrentconncount
定义变量
了解了变量的概念和用途后,我们一起来定义几个简单的变量看一下
name = ‘Alex Li’ #name 是字符串,字符串要加上引号噢
age = 29 #age 是整数,整数不要加引号,加了引号后就变成字符串了
has_girlfriend = False #是布尔值,一般用这个做逻辑判断,如if has_girlfriend:print ‘good for you !’
age = age + 1 #这个结果应该是30,运算流程是先将=号后面的age +1结果算出,然后再把这个结果重赋值给age, 由于age之前的值是29,重新赋值后,age值变为30.
最后,理解变量在计算机内存中的表示也非常重要。当我们写:
name = 'Alex'
时,Python解释器干了两件事情:
- 在内存中创建一个”Alex”的字符串;
- 在内存中创建了一个名为name的变量,并把它指向”Alex”的内存地址。
也可以变量name赋值给另一个变量name2,这个操作实际上是把变量name2指向的数据
但是不是已经把name2 等于name变量了吗?name 值改了以后,name2不跟着改吗?没错,当name 的值由”Alex”改成”Jack”后,name2还是指向原来的”Alex”,我们来一步步分析一下:
1. 定义name=”Alex”,解释器创建了字符串”Alex”和变量name,并把name指向了”Alex”
2. 执行name2=name,解释器创建了name2变量,并把name2指向了name变量所指向的字符串
3. 这时通过id内置函数来查看一下这两个变量分别指向的内存地址,结果都是指向了同一地址。
4. 执行name=”Jack”,解释器创建一个新的变量”Jack”,并把name的指向改成了”Jack”
5. 此时再查看两个变量的内存地址指向就会发现,name的指向已经变成了一个新的地址,也就是”Jack”所在内存地址,但是name2依然还是指向原来的”Alex”。
Now, 你明白了吗? 再总结一下,当你把一个变量name赋值给另一个变量name2时,解释器只是把name变量所指向的内存地址赋值给了name2,因此name 和 name2并未发生直接的关联,只不过是他们都同时指向了同一个内存地址而已,这也就是为什么你把name再指向一个新地址后,而name2的值还保持不变的原因。
常量
刚才说到了变量,还有一概念就是常量,所谓常量就是不能变的变量,比如常用的数学常数π就是一个常量。在Python中,通常用全部大写的变量名表示常量:
PI = 3.14159265359
但事实上PI仍然是一个变量,Python根本没有任何机制保证PI不会被改变,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。
数据运算符
和其它语言一样,python也支持进行各种各样的数学和逻辑运算,我们一起来看一些。
python语言支持以下几种运算
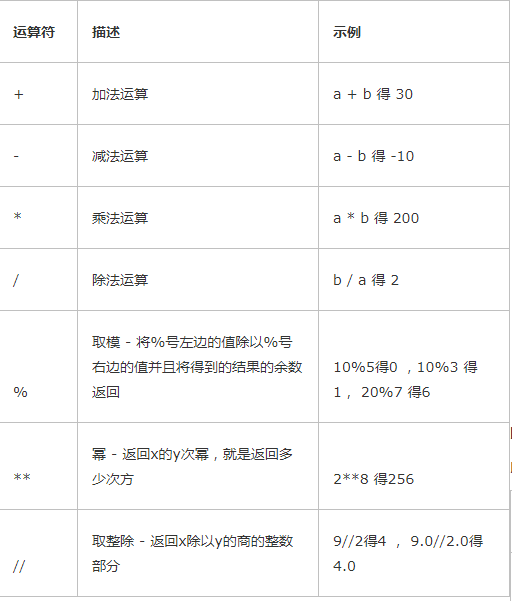
算术运算
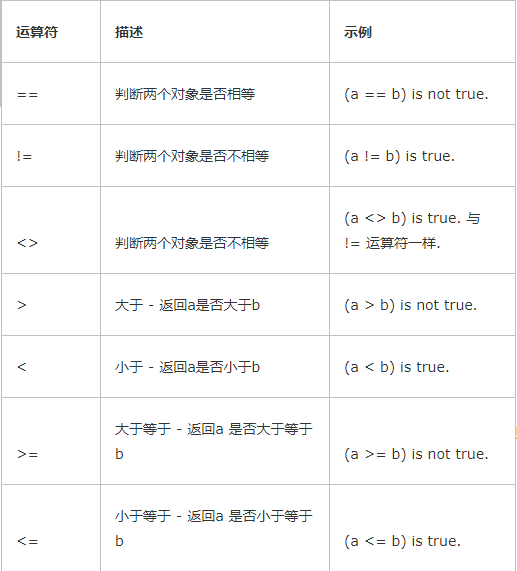
比较运算
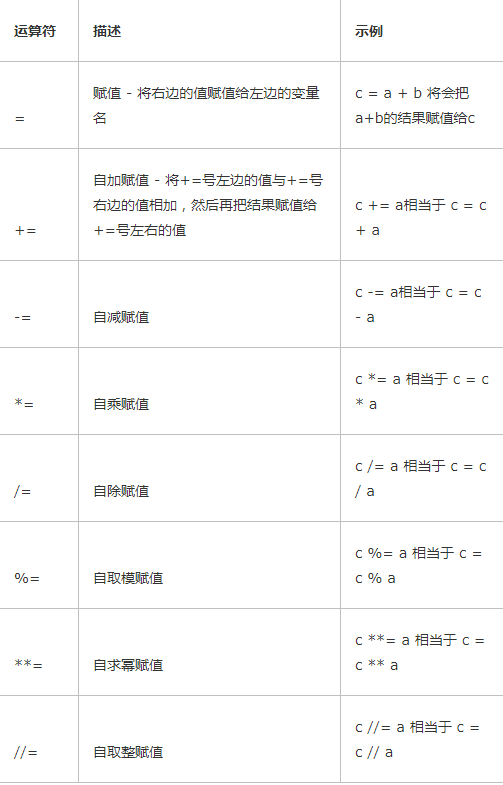
Assignment Operators
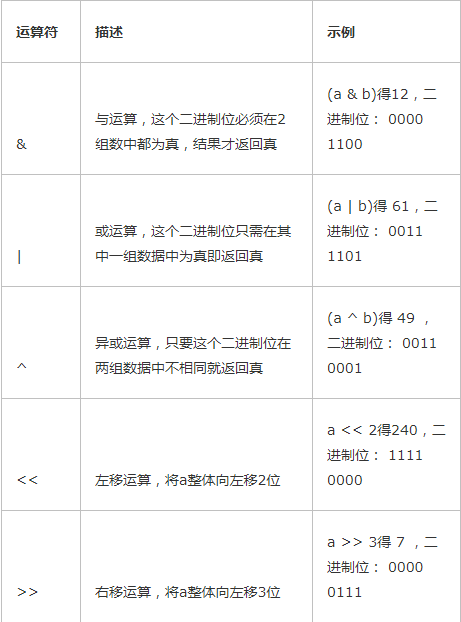
二进制运算
关系运算
验证运算
算术运算
以下例子a = 10 , b= 20
按位运算(二进制运算)
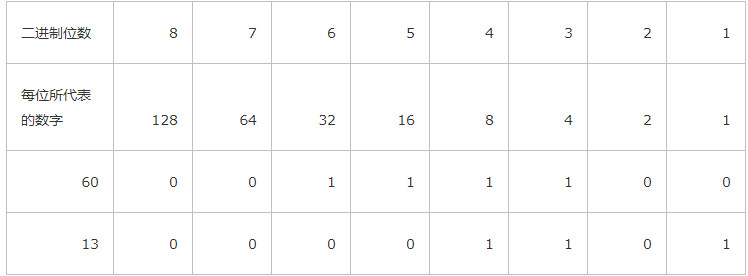
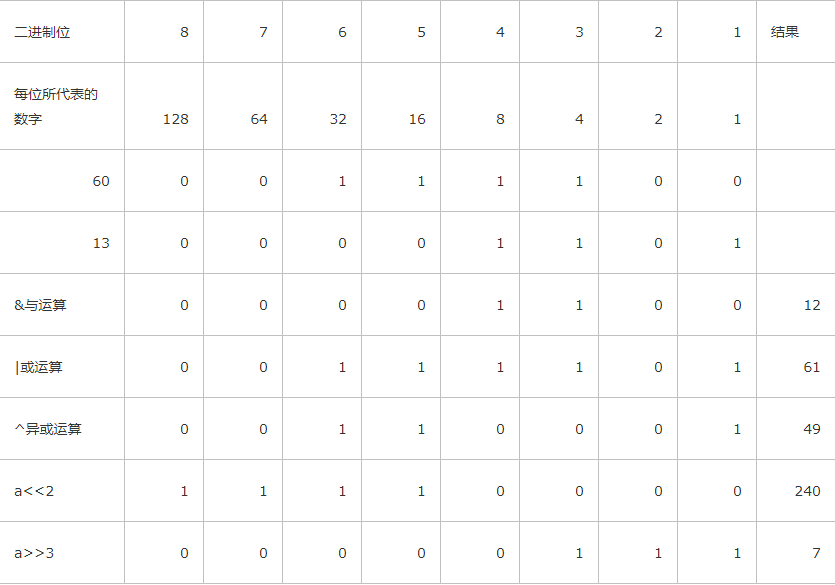
我们都知道,计算机处理数据的时候都会把数据最终变成0和1的二进制来进行运算,也就是说,计算机其实只认识0和1, 那按位运算其实就是把数字转换成二进制的形式后再进行位运算的,唉呀,说的好迷糊,直接看例子,我们设定a=60; b=13; 要进行位运算,就得把他们先转成2进制格式,那0和1是如何表示60和13的呢?学过计算机基础的人都知道,计算机最小的存储单位是字节,也就是说一个数字、一个字母最少需要用一个字节来存储,然后呢,一个字节又由8个2进制位来表示,也就是8bit,所以呢,一个计算机中最小的数据也需要用一个字节来存储噢。那为是什么8位而不是9位、10位、20位呢?这个问题上学的时候应该都讲过,不明白的自己网上查下吧再。8个二进制如何表示60这个数字呢?聪明的计算机先人们想到了用占位的方式来轻松的实现了,怎么占位呢?如下表所示,我们把8个二进制位依次排列,每个二进制位代表一个固定的数字,这个数字是由2的8次方得来的,即每个二进制位代表的值就是2的第几次方的值,8个二进制位能表示的最大数是2**8=256, 那把60分解成二进制其实就是以此在这8位上做个比对,只要把其中的几位相加,如果结果正好等于60,那这个位就找对了,首先看60 肯定占不了128和64那两位,不占位就设为0,后面的32+16+8+4=60,所以这几位要设置为1,其它的全设置为0,13的二进制算法也是一样的。
好,知道了10进制如何转2进制了之后,我们接着来看,如果进行2个10进制数字的位运算
看下面的运算过程:
后面还有
逻辑运算符 and 、or 、not
关系运算符 in 、not in
验证运算符 is 、 is not
因为我们现在还没有学流程控制相关的,现在说这些反而会让你迷惑,先忘掉这几个吧,以后我们用到的时候你自然就会明白了哈。
字符编码 <引用3>
字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
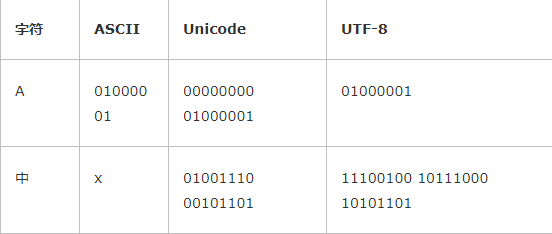
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Python的字符串
搞清楚了令人头疼的字符编码问题后,我们再来研究Python对Unicode的支持。
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串'ABC'在Python内部都是ASCII编码的。Python提供了ord()和chr()函数,可以把字母和对应的数字相互转换:
>>> ord('A') 65 >>> chr(65) 'A' Python在后来添加了对Unicode的支持,以Unicode表示的字符串用u'...'表示,比如:
>>> print u'中文' 中文 >>> u'中' u'\u4e2d' 写u'中'和u'\u4e2d'是一样的,\u后面是十六进制的Unicode码。因此,u'A'和u'\u0041'也是一样的。
两种字符串如何相互转换?字符串'xxx'虽然是ASCII编码,但也可以看成是UTF-8编码,而u'xxx'则只能是Unicode编码。
把u'xxx'转换为UTF-8编码的'xxx'用encode('utf-8')方法:
>>> u'ABC'.encode('utf-8') 'ABC' >>> u'中文'.encode('utf-8') '\xe4\xb8\xad\xe6\x96\x87' 英文字符转换后表示的UTF-8的值和Unicode值相等(但占用的存储空间不同),而中文字符转换后1个Unicode字符将变为3个UTF-8字符,你看到的\xe4就是其中一个字节,因为它的值是228,没有对应的字母可以显示,所以以十六进制显示字节的数值。len()函数可以返回字符串的长度:
>>> len(u'ABC') 3 >>> len('ABC') 3 >>> len(u'中文') 2 >>> len('\xe4\xb8\xad\xe6\x96\x87') 6 反过来,把UTF-8编码表示的字符串'xxx'转换为Unicode字符串u'xxx'用decode('utf-8')方法:
>>> 'abc'.decode('utf-8') u'abc' >>> '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') u'\u4e2d\u6587' >>> print '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') 中文 由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python # -*- coding: utf-8 -*- 第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
格式化
最后一个常见的问题是如何输出格式化的字符串。我们经常会输出类似'亲爱的xxx你好!你xx月的话费是xx,余额是xx'之类的字符串,而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hello, %s' % 'world' 'Hello, world' >>> 'Hi, %s, you have $%d.' % ('Michael', 1000000) 'Hi, Michael, you have $1000000.' 你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
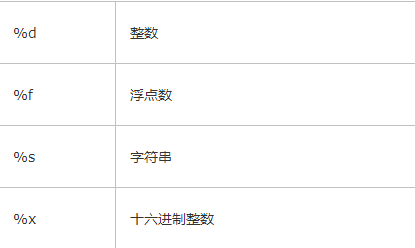
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
>>> '%2d-%02d' % (3, 1) ' 3-01' >>> '%.2f' % 3.1415926 '3.14' 如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True) 'Age: 25. Gender: True' 对于Unicode字符串,用法完全一样,但最好确保替换的字符串也是Unicode字符串:
>>> u'Hi, %s' % u'Michael' u'Hi, Michael' 有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7 'growth rate: 7 %'
小结
由于历史遗留问题,Python 2.x版本虽然支持Unicode,但在语法上需要'xxx'和u'xxx'两种字符串表示方式。
Python当然也支持其他编码方式,比如把Unicode编码成GB2312:
>>> u'中文'.encode('gb2312') '\xd6\xd0\xce\xc4' Try
但这种方式纯属自找麻烦,如果没有特殊业务要求,请牢记仅使用Unicode和UTF-8这两种编码方式。
在Python 3.x版本中,把'xxx'和u'xxx'统一成Unicode编码,即写不写前缀u都是一样的,而以字节形式表示的字符串则必须加上b前缀:b'xxx'。
格式化字符串的时候,可以用Python的交互式命令行测试,方便快捷。
1:第一句python
-后缀名可以任意
-导入模块时,如果不是.py文件报错 ->文件后缀是.py
print('hello world')
C:\Users\uxsino_wh_001>python D:\python_test\1.txt hello world C:\Users\uxsino_wh_001>
2:两种执行方式
python解释器py文件路径
python进入解释器:
实时输入并获取执行结果
3:解释器路径
#!/usr/bin/env python
4:编码
# -*- coding=utf8 -*- (python2 每个文件中出现中文,头部必须加;python3无需关注)
#!/usr/bin/env python# -*- coding=UTF-8 -*- print('hello world')
5:执行一个操作
提醒用户输入密码:用户名与密码
获取用户名与密码,检测:用户名与密码
正确:登录成功
错误:登录失败
a:input的用法,永远等待,直到用户输出了值,就会将这个值赋值给下一个
#!/usr/bin/env python# -*- coding=UTF-8 -*- print('hello world') name=input('请输入用户名:') pw=input('请输入密码:') print(name) print(pw)
6:变量名:
-字母
-数字
-下划线
PS:数字不能开头;不能是关键字;最好不要跟python的内置变量重复
7:条件语句
1:基础
2:嵌套
3:if ->elif else ...
8:while循环
1:while循环:
...
print('...')
补充:while else
count = 0 while count < 10: print(count) count = count + 1 else: print('else') print('.....')
2:continue 调回下一次循环,终止当前循环
while count < 10: if count == 7 count = count + 1 continue print(count) count = count + 1
3:break。终止全部循环
count = 0 while count < 10: count = count + 1 print(count) break print('1111111') print("end")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号