传统神经网络所存在的问题
目前为止,CNNs (卷积神经网络)仍是最先进的图像分类识别方法。
简单来讲,CNNs 通过逐层累加调整实现分类。它首先检测到边缘,然后是形状,然后是实际的识别对象。CNN 的实现方式极具创新,然而在这一过程中却有一项重要的信息丢失了——特征之间的空间关系。下面是一个 CNN 工作原理的简化描述:
如果有两只眼睛,一只鼻子,一张嘴,那么这就是一张脸。
乍一看完全没问题啊,完美!那我们拿卡戴珊大姐的照片来试一下,看看会怎么样:
(前方高能……
请帮忙计算一下这位大姐的心理阴影面积……但话说回来,这也确实是两只眼睛,一个鼻子和一个嘴巴呀!我们很容易就能发现,这些特征的空间位置明显是错误的,不符合“脸”的特征,然而 CNN 在处理这一概念上却十分笨拙。
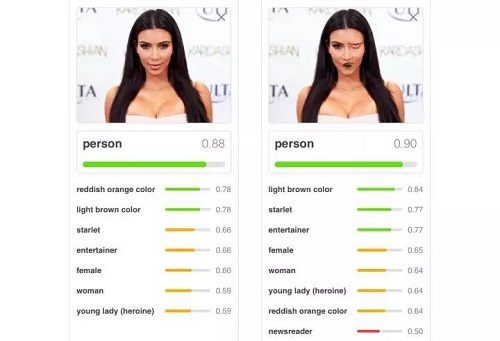
除了被图像的错误位置所迷惑,CNN 在查看不同方向的图像时也很容易混淆。解决这个问题的方法之一,就是对所有可能的角度进行大量训练,但是这需要花费很多时间,而且似乎有些违反常理。
我们只要把 Kim 的照片颠倒一下,就能发现其性能的大幅下降:
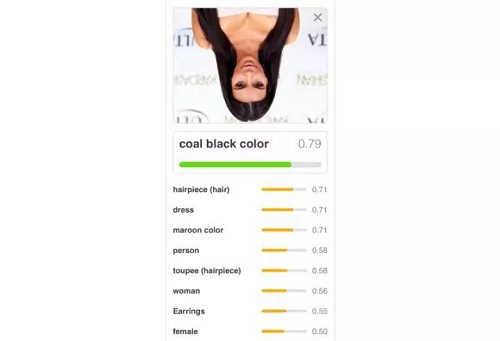
颠倒的 Kardashian 被识别成了“炭黑色”
最后,卷积神经网络可能很容易受到白盒对抗攻击(攻击者知晓机器学习所用的算法和相关参数,并据此在对抗性攻击过程中与系统交互)。这种攻击在对象上嵌入了一个秘密的图案,由此使这张图片被错误识别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号