【第1篇】Python爬虫实战-王者荣耀高清壁纸下载
目录
1、页面分析
通过F12打开浏览器控制台,刷新一下页面,通过依次查看,可以找到页面请求请求地址
 由于返回的数据不是标准的JSON格式我们需要对url进行简化处理,最终得到url地址为:
由于返回的数据不是标准的JSON格式我们需要对url进行简化处理,最终得到url地址为:
请求这个url地址就可以得到一个标准的JSON数据格式,其中page表示当前页码,iListNum表示每页展示多少条数据。
我们再来分析这个JSON,通过页面源码可以找到这段代码
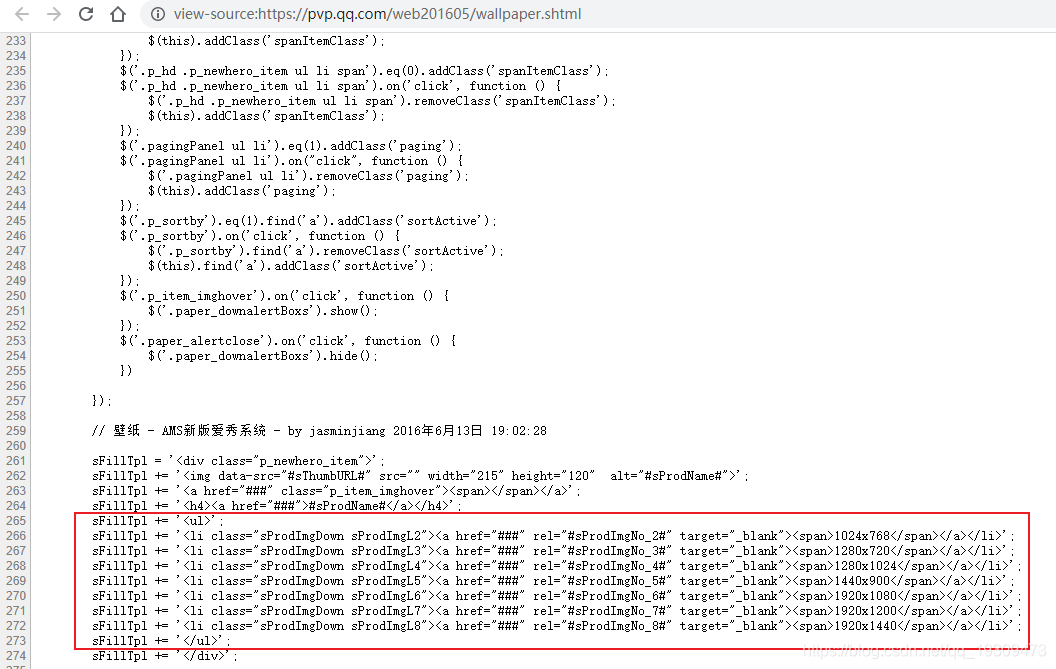
说明:
sProdImgNo_2对应的图片分辨率:1024x768
sProdImgNo_3对应的图片分辨率:1280x720
下面依次类推……
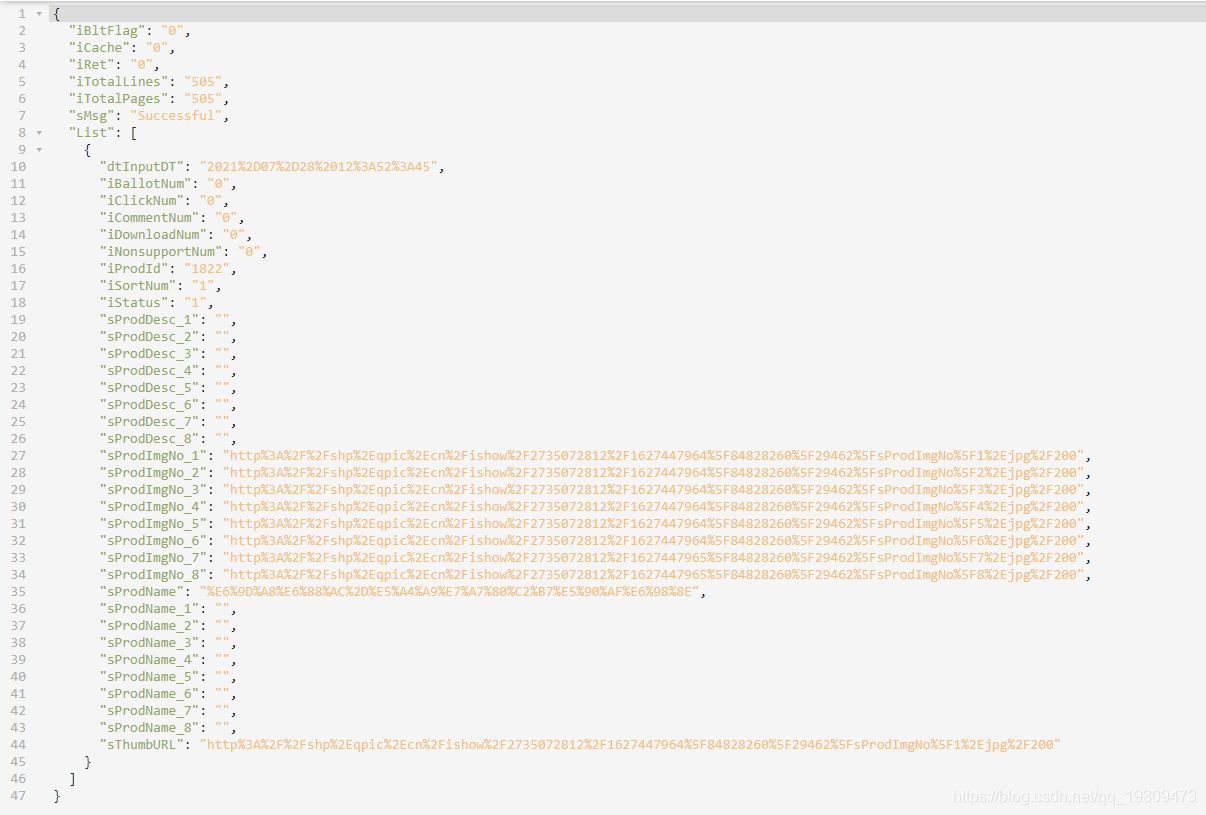
我们以sProdImgNo_2的值举例:
http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735072812%2F1627447964%5F84828260%5F29462%5FsProdImgNo%5F2%2Ejpg%2F200
我们对该地址进行url解码之后,发现
http://shp.qpic.cn/ishow/2735080511/1628133281_84828260_9817_sProdImgNo_2.jpg/200
这个地址是压缩图片地址
http://shp.qpic.cn/ishow/2735080511/1628133281_84828260_9817_sProdImgNo_2.jpg/0
这个是真实的图片地址
如何找到真实地址,简单就是把url地址末尾的200改为0即可。
至此页面请求分析完成。
2、程序源码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author: YangPC
@QQ:327844761
@微信公众号:ewbang
"""
import requests
from urllib import parse
import os
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
def func(page=1):
url = f'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?iTypeId=2&sDataType=JSON&iListNum=20&page={page}&iActId=2735'
response = requests.get(url=url, headers=headers).json()
# 总页数
iTotalPages = int(response['iTotalPages'])
# 列表数据
img_list = response['List']
print(f"正在爬取第{page}页的数据".center(100, '*'))
for img_info in img_list:
# 图片名称
img_name = parse.unquote(img_info['sProdName']).strip()
# 图片地址
sProdImgNo_2 = img_info['sProdImgNo_2']
save(img_name, sProdImgNo_2, "1024x786")
sProdImgNo_3 = img_info['sProdImgNo_3']
save(img_name, sProdImgNo_3, "1280x720")
sProdImgNo_4 = img_info['sProdImgNo_4']
save(img_name, sProdImgNo_4, "1280x1024")
sProdImgNo_5 = img_info['sProdImgNo_5']
save(img_name, sProdImgNo_5, "1440x900")
sProdImgNo_6 = img_info['sProdImgNo_6']
save(img_name, sProdImgNo_6, "1920x1080")
sProdImgNo_7 = img_info['sProdImgNo_7']
save(img_name, sProdImgNo_7, "1920x1200")
sProdImgNo_8 = img_info['sProdImgNo_8']
save(img_name, sProdImgNo_8, "1920x1440")
# 下一页
if page < iTotalPages:
func(page + 1)
# 保存图片到目录
def save(img_name, url, size):
# 找到真实的文件路径
url = parse.unquote(url).replace("/200", "/0")
# 文件保存路径
path = os.getcwd() + f'\\{img_name}\\'
# 如果目录不存在就创建目录
if not os.path.exists(path):
os.makedirs(path)
try:
with open(f"{path}{img_name}_{size}.jpg", 'wb') as f:
f.write(requests.get(url).content)
print(f"{img_name}_{size}.jpg,下载成功。")
except Exception as e:
print(f"{img_name}_{size}.jpg,下载失败。")
pass
if __name__ == '__main__':
func()
3、结果展示


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}