基于python的OCR中文识别教程
目录
一、下载最新的识别库
下载地址:https://download.csdn.net/download/qq_19309473/85576080
二、安装下载的识别库
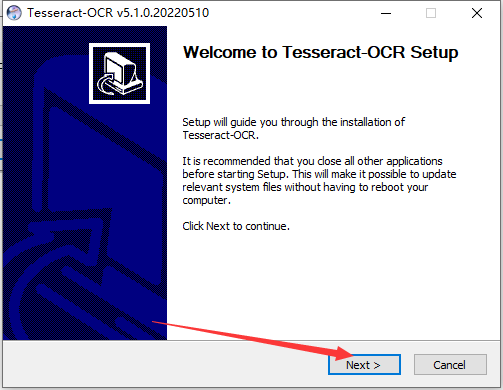
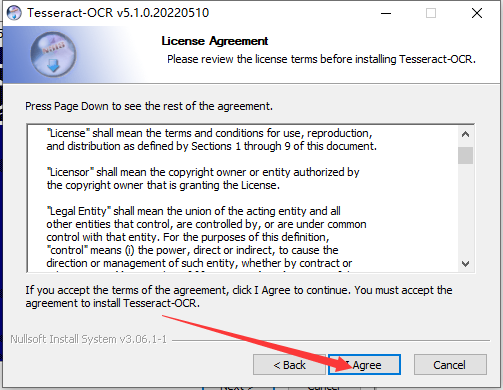
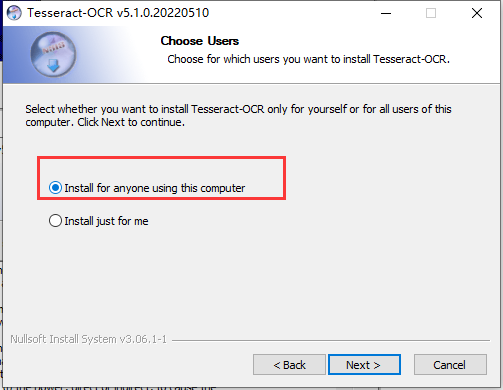
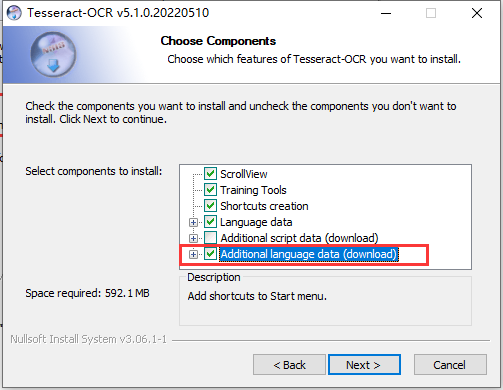
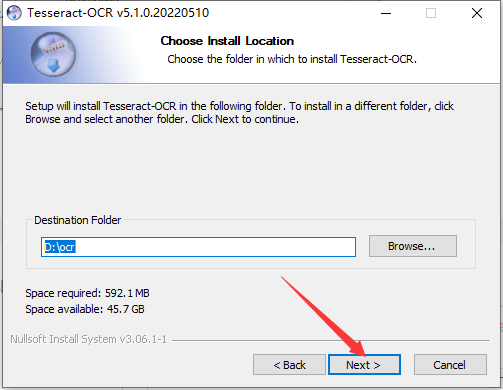
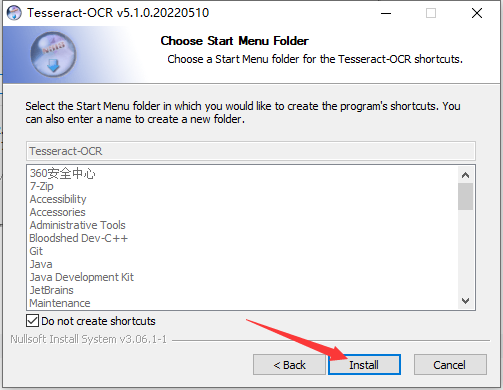
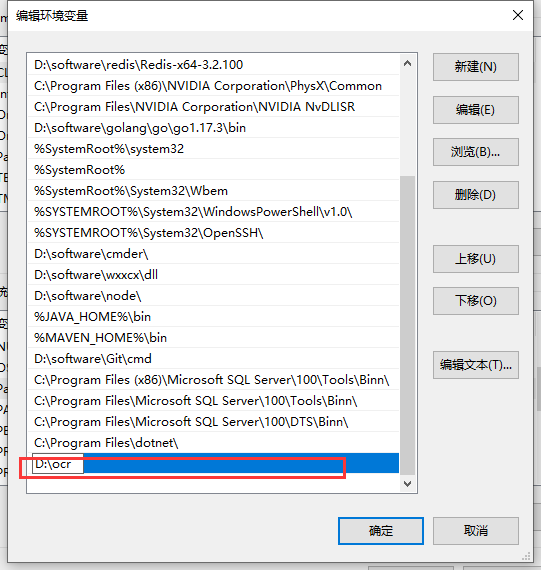
三、配置ocr环境变量
(1) 检查环境变量是否配置成功
Tesseract -v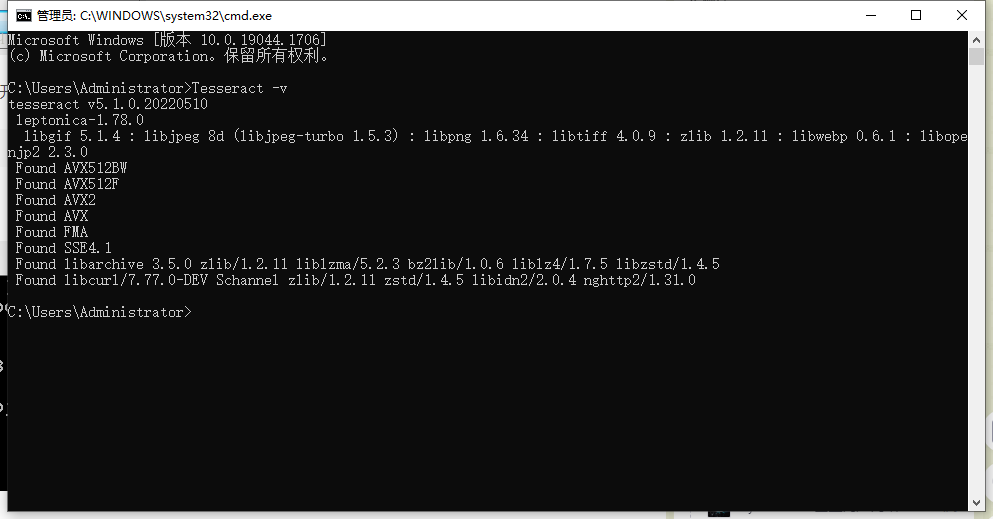
(2)安装python依赖
pip install Pillow
pip install pytesseract(3)编辑pytesseract.py文件
D:\software\python3\Lib\site-packages\pytesseract\pytesseract.py
注意:你的python安装路径可能和我的不一样,在你的python安装目录中可以找到。
将
tesseract_cmd = 'tesseract'
改为:
tesseract_cmd = 'D:\\ocr\\tesseract'
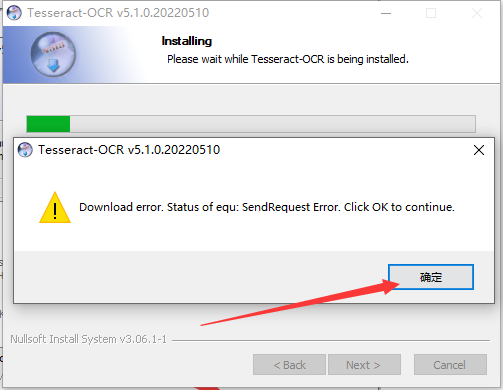
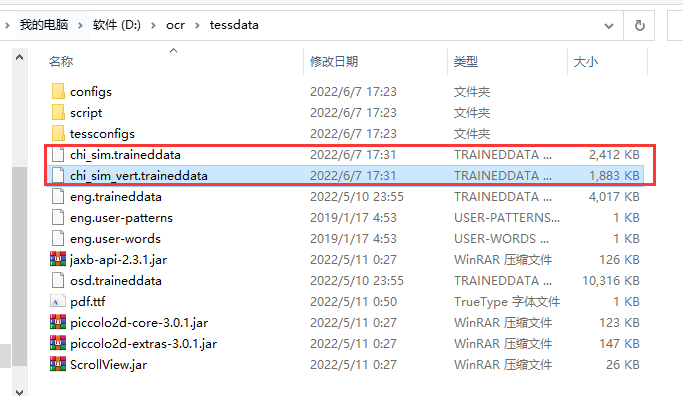
(4)如果中文识别库下载失败
如果中文识别库下载失败,需要手动将中文识别库文件,放在D:\ocr\tessdata目录中。
这两个文件,在上面的下载资源包里面有。
四、编写python代码
测试图片:

#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pytesseract
from PIL import Image
# open image
image = Image.open('test.png')
result = pytesseract.image_to_string(image, lang='chi_sim')
print("识别结果:", result)
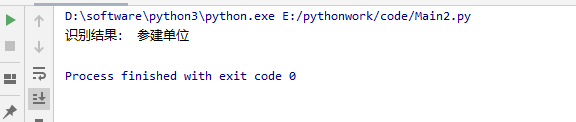
五、程序识别结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号