


C专家编程_读书笔记
不允许嵌套定义函数(函数内部包含另一个函数的定义)。
两个操作数都是指向有限定符或无限定符的相容类型的指针,左边指针所指向的类型必须具有右边指针所指向类型的全部限定符。
char *cp; const char *ccp ccp = cp;
1.左操作数是一个指向有const限定符的char的指针。
2.右操作数是一个指向没有const限定符的char的指针。
3.char类型与char类型是相容的,左操作数所指向的类型具有右操作数所指向类型的限定符(无),再加上自身的限定符(const)。
注意:反过来就不能进行赋值。
cp = ccp /*结果产生编译警告*/
const放在*的左侧任意位置,限定了指针指向的数据不能更改;const放在*的右侧,限定了指针不能更改(const 指针)。
const float *类型并不是一个有限定符的类型---它的类型是“指向一个具有const限定符的float类型的指针”,也就是说const限定符是修饰指针指向的类型而不是指针本身。
类似地,const char **也是一个没有限定符的指针类型。它的类型是“指向有const限定符的char类型的指针的指针”。
由于char **和const char ** 都是没有限定符的指针类型,但它们所指向的类型不一样(前者指向char * ,后者指向const char *),因此它们不相容。因此,类型char **的实参与类型const char **的形参是不相容的,编译器必然会产生一条诊断信息。
一个'L'的NULL用于结束一个ASCII字符串,ASCII字符中零的位模式被称为'NUL';两个'LL'的NULL用于表示什么也不指向(空指针)。
结构体定义的通常形式:
struct 结构标签(可选){
类型1 标识符1;
类型2 标识符2;
……
类型N 标识符N;
}变量定义(可选);
结构内部有一个指向结构自身的指针
struct node { int data; struct node *next; }; struct node a, b; a.next = &b; a.next->next = NULL;
在联合中,所有成员都从偏移地址零开始存储。这样,每个成员的位置都重叠在一起:在某一时刻,只有一个成员真正存储于该地址。联合的定义的一般形式:
union 可选标签{
类型1 标识符1;
类型2 标识符2;
……
类型N 标识符N;
}变量定义(可选的);
联合一般被用来节省空间,因为有些数据项是不可能同时出现的,如果同时存储它们内存颇为浪费。
枚举通过一种简单的途径,把一串名字与一串整型值联系在一起。
enum 可选标签{ 内容…… }变量定义(可选);
在缺省情况下,整型值从零开始。如果对列表中的某个标识符进行了赋值,那么紧接着其后的那个标识符的值就比所赋的值大1,然后类推。
理解C语言声明的优先级规则
A 声明从它的名字开始读取,然后按照优先级依次读取。
B 优先级从高到低依次是:
1.声明中被括号括起来的那部分
2. 后缀操作符:括号()表示这是一个函数,而方括号 [ ] 表示这是一个数组。
3.前缀操作符:星号 * 表示“指向……的指针”。
C 如果const或volatile关键字的后面紧跟类型说明符(如int,long等),那么它作用于类型说明符。在其它情况下,const或volatile关键字作用于它左边紧邻的指针星号。
用优先级规则分析C语言声明一例:char * const *(*next)( );
首先,看变量名“next”,并注意到它直接被括号所括住。所以先把括号里的东西作为一个整体,得出“next是一个指向……的指针”然后考虑括号外面的东西,在星号前缀和括号后缀之间作出选择。规则告诉我们优先级较高的是右边的函数括号,所以得出“next是一个函数指针,指向一个返回……的函数”。然后,处理前缀 * 得出指针所指的内容。最后,把"char * const"解释为指向字符的常量指针。上述分析结果加以概括,这个声明,这个声明表示“next是一个指针,它指向一个函数,该函数返回另一个指针,该指针指向一个类型为char的常量指针。
用优先级规则分析C语言声明一例:char * (* c[10])(int **p); //函数指针数组
c是一个数组,它的元素类型是函数指针,其所指向的函数的返回值是一个指向char的指针。
typedef与define的区别:
不要在一个typedef中放入几个声明器,如下所示:
typedef int *ptr, (*funptr)( ), arr[6];
ptr是"指向int的指针"类型,funptr是"定义一个返回值为int不带参数的函数指针"类型,arr是"长度为6的int型数组"类型。
就是说funptr 是 int (*)()型的指针
funptr arr[10];(函数指针数组)定义一个数组,这个数组是funptr类型的。就是说这个数组内的内容是一个指针,这个指针指向一个返回值为int,不带参数的函数。
#define peach int
unsigned peach i; //没问题
typedef int babana;
unsigned babana i; //错误!非法
其次,在连续几个变量的声明中,用typedef定义的类型能够保证声明中所有的变量均为同一种类型,而用#define定义的类型则无法保证。
#define int_ptr int *
int_ptr chalk,cheese;
经过宏扩展,第二行变为:int * chalk,cheese;
这使得chalk和cheese成为不同的类型,chalk是一个指向int的指针,而cheese则是一个int。相反,下面的代码中:
typedef char * char_ptr; typedef为数据类型创建别名,而不是创建新的数据类型。
char_ptr Bentley,Royce;
Bentley和Royce的类型依然相同,都是指向char的指针。
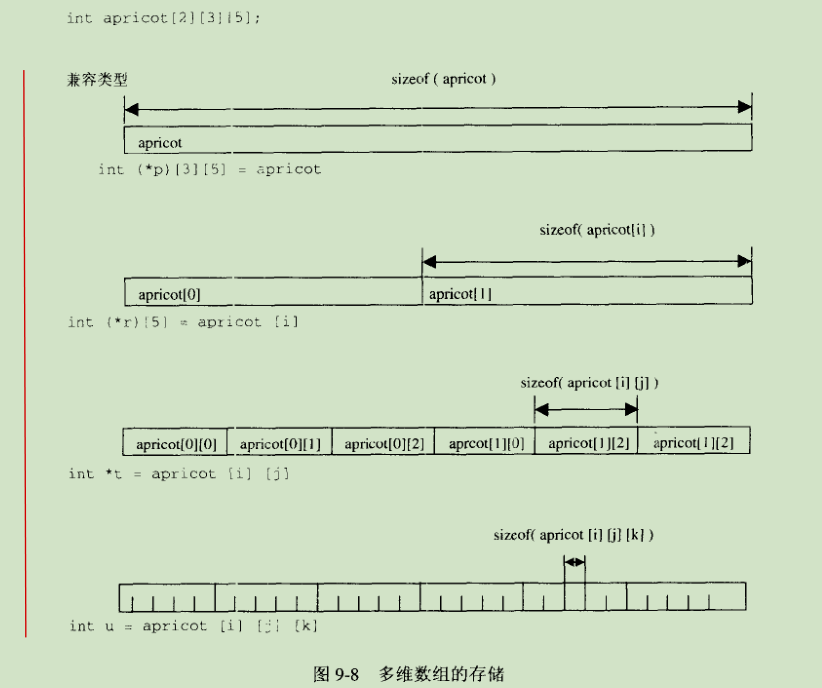
C语言中的对象必须有且只有一个定义,但它可以有多个extern声明。extern 对象声明告诉编译器对象的类型和名字,对象的内存分配在别处进行。由于并未在声明中为数组分配内存,所以并不需要提供关于数组长度的信息。对于多维数组,需要提供除最左边一维之外其它维度的长度--这就给编译器足够的信息产生相应的代码。
地址(左值)和地址的内容(右值)之间的区别:
X = Y 符号X的含义是X所代表的地址。这称为左值。左值在编译时可知,左值便是存储结果的地方。
符号Y的含义是Y所代表的地址的内容。这称为右值。右值直到运行时才知。如无特别说明,右值表示"Y的内容"。
C语言也引用了“可修改的左值”这个术语。它表示左值允许出现在赋值语句的左边。这个奇怪的术语是为与数组名区分,数组名也用于确定对象在内存中的位置,也是左值,但它不能作为赋值的对象。因此,数组名是个左值但不是可修改的左值。标准规定赋值符必须用可修改的左值作为它左边一侧的操作数。用通俗的话说,只能给可以修改的东西赋值。
定义指针时,编译器并不为指针所指向的对象分配空间,它只是分配指针本身的空间,除非在定义时同时赋给指针一个字符串常量进行初始化。例如,下面的定义创建了一个字符串常量(为其分配了内存):
char *p = "beautiful";
注意只有对字符串常量才是如此。不能指望为浮点数之类的常量分配空间,如:float *pi = 3.141;//错误!无法通过编译
“表达式中的数组名”就是指针
对数组下标的引用总是可以写成“一个指向数组的起始地址的指针加上偏移量”。例如,假如我们声明:
int a[10], *p, i = 2; 就可以通过以下任何一种方法来访问a[i]:
1. p = a; p[i]; 2. p = a; *(p + i); 3. p = a + i; *p;
对数组的引用如a[i]在编译时总是被编译器改写成 *(a + i)的形式。
“作为函数参数的数组名”等同于指针
形参 它是一个变量,在函数定义或函数声明的原型中定义。又称为“形式参数”。
实参 在实际调用一个函数时所传递给函数的值。又称“实际参数”。
数组和指针参数是如何被编译器修改的
“数组名被改写成一个指针参数”规则并不是递归定义的。数组的数组会被改写为“数组的指针”而不是“指针的指针”

C标准规定%s说明符的参数必须是一个指向字符数组的指针。
从逻辑上删除一段C代码,更好的办法是使用#if指令。只要像下面这样使用:
#if 0
Statements;
#endif
在#if和#endif之间的程序段就可以有效地从程序中去除,即使这段代码之间原先存在注释也无妨,所以这是一种更安全的方法。
预处理指令
#include<stdio.h>
#define MAX_INPUT 1000
这两行称为预处理指令,因为它们是由预处理器解释的。预处理器读入源代码根据预处理指令对其进行修改然后把修改过的源代码递交给编译器。比如在这个例子中,预处理器用名叫stdio.h的库函数头文件的内容替换第一条#include指令语句,其结果就仿佛是stdio.h的内容被逐字写到源文件的那个位置。
另一种预处理指令是#define ,它把名字MAX_INPUT定义为1000。当这个名字以后出现在源文件的其它地方时它就会被替换为定义的值。由于它们被定义为字面值常量,所以这些名字不能出现于有些普通变量可以出现的场合(比如赋值符的左边)。这些名字一般都大写,用于提醒它们并非普通的变量。
gets函数从标准输入读取一行文本(直到遇见回车、换行符或EOF时停止)并把它存储于作为参数传递给它的数组中。gets函数丢弃换行符并在该行的末尾存储一个NUL字节(一个NUL字节是指字节模式为全0的字节,类似' \0' 这样的字符常量。然后,gets函数返回一个非NULL值,表示该行已被成功读取。当gets函数被调用但事实上不存在输入行时,它就返回NULL值,表示它到达了输入的末尾(文件尾)。
2011年12月,ANSI 采纳了 ISO/IEC 9899:2011 标准,标准中删除了 gets( )函数,使用一个新的更安全的函数gets_s( )替代
字符串常量就是源程序中被双引号括起来的一串字符。例如,字符串常量:"Hello"
在内存中占据6个字节空间按顺序分别是H、e、l、l、o和NUL。
NUL是ASCII字符集中'\0 '字符的名字,它的字节模式为全0。NULL指一个其值为0的指针。另一方面,并不存在预定义符号NUL ,所以如果你想使用它而不是字符常量’\0’,你必须自行定义。之所以选择NUL作为字符串的终止符,因为它是一个不可打印的字符。
puts(const char *str)函数是gets函数的输出版本,它把指定的字符串写到标准输出并在末尾添上一个换行符。str可以是字符指针变量名、字符数组名,或者直接是一个字符串常量。输出时只有遇到 '\0' 也就是字符串结束标志符才会停止。
getchar函数从标准输入读取一个无符号字符(包括空格 回车Tab )并返回它的值。如果输入中不再存在任何字符(到达文件的末尾),函数就会返回常量EOF(键盘输入EOF : ctrl + z),用于提示文件的结尾或遇到换行符'\n'结束读取。当程序调用getchar时,程序就等着用户按键。用户输入的字符被存放在键盘缓冲区中。直到用户按回车(回车符也会被读入stdin流中)为止。当用户键入回车之后,getchar才开始从stdin流中每次读入一个字符。getchar函数的返回值是用户输入的字符的ASCII码,若文件结尾则返回-1(EOF),且将用户输入的字符回显到屏幕。如用户在按回车之前输入了不止一个字符,其他字符会保留在键盘缓存区中,等待后续getchar调用读取。也就是说,后续的getchar调用不会等待用户按键,而直接读取缓冲区中的字符,直到缓冲区中的字符读完后,才等待用户按键。
char ch; while ((ch = getchar() != '\n')) putchar(ch);
getchar()会从输入缓冲区去读取内容,也就是说我们把所有的内容都输入完成并且按下了Enter键后,我们的输入才被送进去了输入缓冲区,这个时候,while循环才开始工作,每一次getchar()从输入缓冲区读取一个字符,然后如果不是换行符就输出该字符。
缓冲区会在以下三种情况下被刷新:
1、缓冲区满
2、执行flush刷新缓冲区的语句
3、程序正常结束。
首先,用getchar()函数进行字符的输入,并不是直接从键盘这个硬件中读取输入的字符,而是从“输入缓冲区”中得到的字符。输入缓冲区是一个字符的队列,其中存储了所有你尚未读取的字符。每次调用getchar函数,它就会从输入缓冲区中读出第一个字符,并把这个字符从输入缓冲区中清除。然而,这个输入缓冲区的设计,是把所有从键盘上输入的东西都放进去的,包括你每次按的回车符‘\n’,而getchar函数只读走了你在回车前输入的那个字符,而将回车符保留在了输入缓冲区中。于是,第二次调用getchar时,函数就从输入缓冲区中读出了'\n'。
要解决这个问题,有两种可行的途径。
一是多加一个getchar(),过滤掉回车,但是这种方法有不足,就是如果你在调用第一个getchar时输入了多个字符,那么,加入一个getchar并不能把所有未读取的字符过滤。如果你的本意是重新从“键盘”读取的话,最好是加一个fflush(stdin);清除输入缓冲区所有注释都会被预处理器拿掉,取而代之的是一个空格。
函数如果不显示地声明返回值的类型,它就会默认返回整型。
int const *pci; 是一个指向整型常量的指针。可以修改指针的值,但不能修改它所指向的值。
int *const cpi; 是一个指向整型的常量指针。此时指针是常量,必须在定义时初始化,它的值无法修改,但可以修改它所指向的整型的值。

