
数据库索引
概念:
数据库索引首先是一个排序的数据结构,通常以B+树索引或Hash索引实现。
理解B+树得先明白B树
- 阶数:一个节点最多有多少个孩子节点。(一般用字母m表示)
- 关键字:节点上的数值就是关键字
- 度:一个节点拥有的子节点的数量。
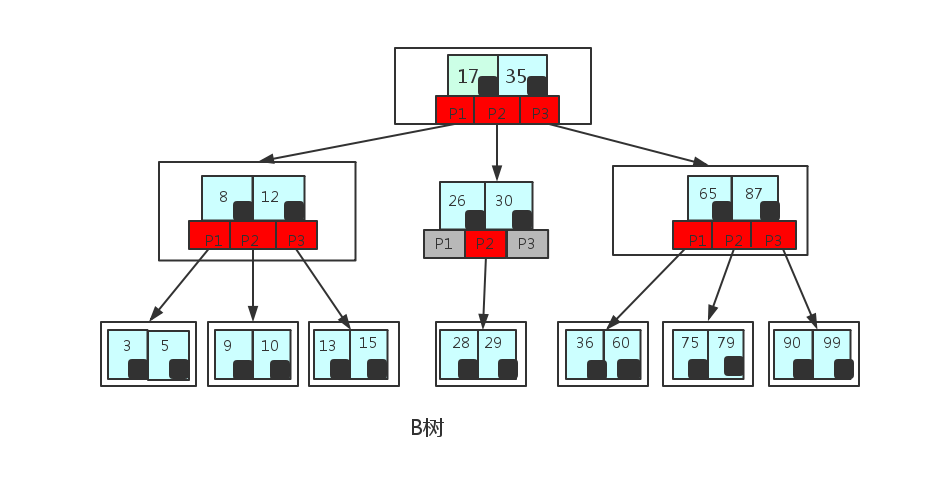
B树:一个M阶的树
- 根结点至少有两个子女;
- 每个非根节点所包含的关键字个数 j 满足:⌈m/2⌉ - 1 <= j <= m - 1.(⌈⌉表示向上取整)
- 有k个关键字(关键字按递增次序排列)的非叶结点恰好有k+1个孩子。
- 所有的叶子结点都位于同一层。
B+树:一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针相互链接。
应文件系统所需而产生的一种B树的变形树(文件的目录一级一级索引,只有最底层的叶子节点(文件)保存数据.),非叶子节点只保存索引,不保存实际的数据,数据都保存在叶子节点中
- 每个结点至多有m个子女;
- 非根节点关键值个数范围:⌈m/2⌉ - 1 <= k <= m-1
- 相邻叶子节点是通过指针连起来的,并且是关键字大小排序的。
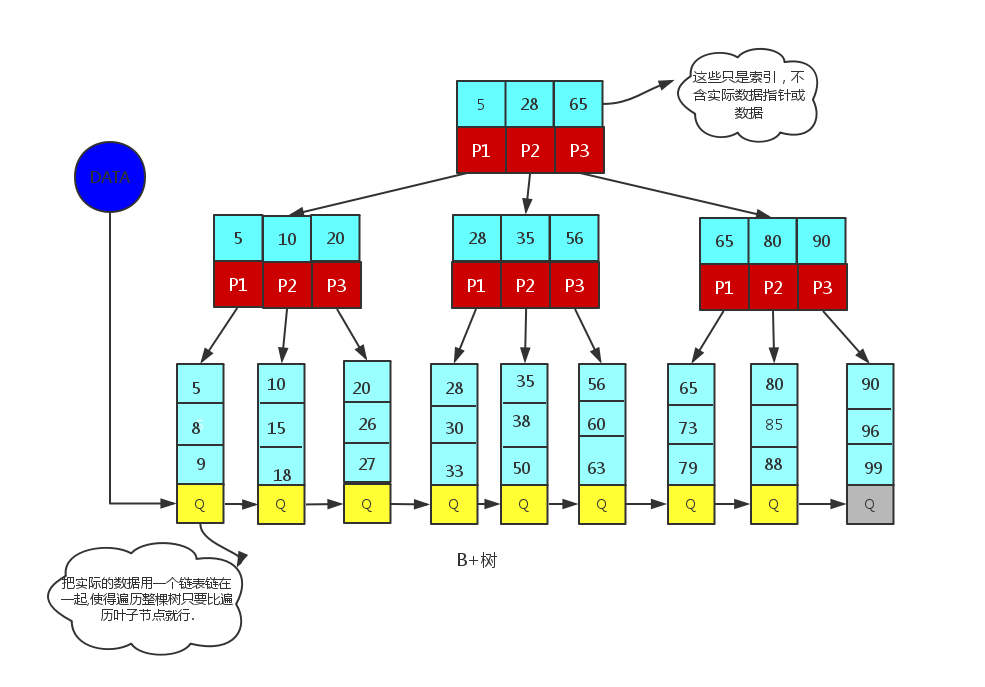
B+树和B-树的主要区别如下:
- B-树内部节点是保存数据的;而B+树内部节点是不保存数据的,只作索引作用,它的叶子节点才保存数据。
- B+树相邻的叶子节点之间是通过链表指针连起来的,B-树却不是。
- 查找过程中,B-树在找到具体的数值以后就结束,而B+树则需要通过索引找到叶子结点中的数据才结束
- B-树中任何一个关键字出现且只出现在一个结点中,而B+树可以出现多次。
Hash索引:简单地说,哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
哈希索引示意图:
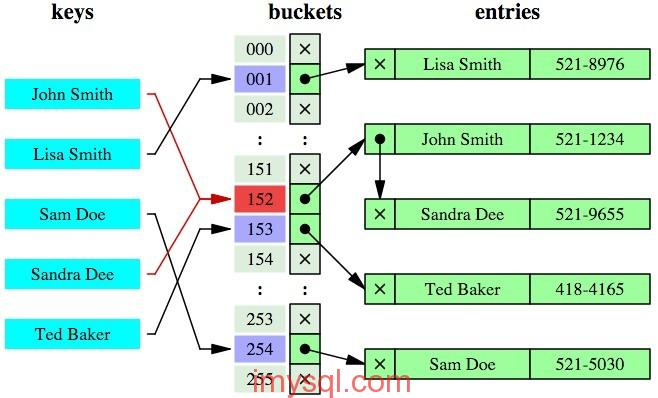
两种结构区别:
- 从示意图中也能看到,如果是范围查询检索,这时候哈希索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
- 同理,哈希索引也没办法利用索引完成排序,以及like ‘xxx%’ 这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);
- 哈希索引也不支持多列联合索引的最左匹配规则;
索引主要种类:唯一索引,主键索引,聚集索引
- 唯一索引:任意两行数据库不能相同,比如姓名。
- 主键索引:唯一索引的特殊例子,一般为表的主键
- 聚集索引:一个表只能有一个聚集索引
优点:
- 通过索引,可提高系统性能
- 建立唯一索引还可以保证数据的唯一性
- 在分组与排序语句中优化查询时间
缺点:
- 首先他是占据物理空间的,如果要建立聚簇索引,空间需求会更大
- 其次创建的索引是需要维护的,会随数据量的增加而增大
- 最后对数据增删改是需要更多是时间,索引也要动态维护
建议创建索引的地方:
- 经常需要搜索的:比如登录的账号密码
- 设置为主键的,一般主键也是唯一索引
- 范围搜索的
- 经常需要排序的
不建议创建的:
- 不经常用的列,按实际业务分析设计
- 数据值很少的,比如年龄,性别
- 数据量特别大的,text,image
- 经常增加,删除,修改的
索引失效:
条件中用or
对于多列(复合、联合)索引,不是使用的第一部分,则不会使用索引
like的模糊查询以%开头,索引失效
如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不会使用索引


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App