

1.
准备文本文件
从文件创建RDD lines=sc.textFile()
筛选出含某个单词的行 lines.filter()
lambda 参数:条件表达式
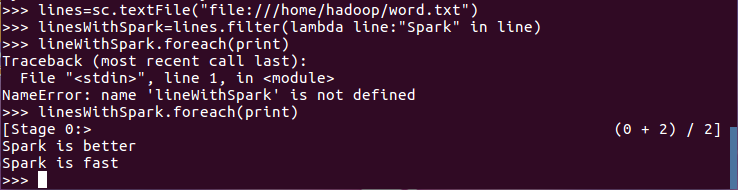
lines=sc.textFile("file:///home/hadoop/word.txt")
linesWithSpark=lines.filter(lambda line:"Spark" in line)
linesWithSpark.foreach(print)
2.
生成单词的列表
从列表创建RDD words=sc.parallelize()
筛选出长度大于2 的单词 words.filter()
wordsList='Spark is better'.split()
wordsRDD=sc.parallelize(wordsList)
wordsRDD.filter(lambda word:len(word)>2).collect()

3.
筛选出的单词RDD,映射为(单词,1)键值对。 words.map()
wordsRDD.map(lambda word:(word,1)).collect()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号