

论文查重
论文查重
| 这个作业属于哪个课程 | 首页 - 软件工程2024 - 广东工业大学 - 班级博客 - 博客园 (cnblogs.com) |
|---|---|
| 这个作业要求在哪里 | 个人项目 - 作业 - 软件工程2024 - 班级博客 - 博客园 (cnblogs.com) |
| 这个作业的目标 | 编写能实现文章查重的程序,用git管理代码,体验程序开发的整个流程 |
一、Github链接
Leunglx/PlagiarismChecker (github.com)
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 20 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | 1010 | 1120 |
| · Analysis | · 需求分析 (包括学习新技术) | 420 | 450 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 60 | 50 |
| · Coding | · 具体编码 | 360 | 420 |
| · Code Review | · 代码复审 | 60 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 120 | 80 |
| · Test Repor | · 测试报告 | 60 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1150 | 1210 |
三、接口的设计与实现
设计流程
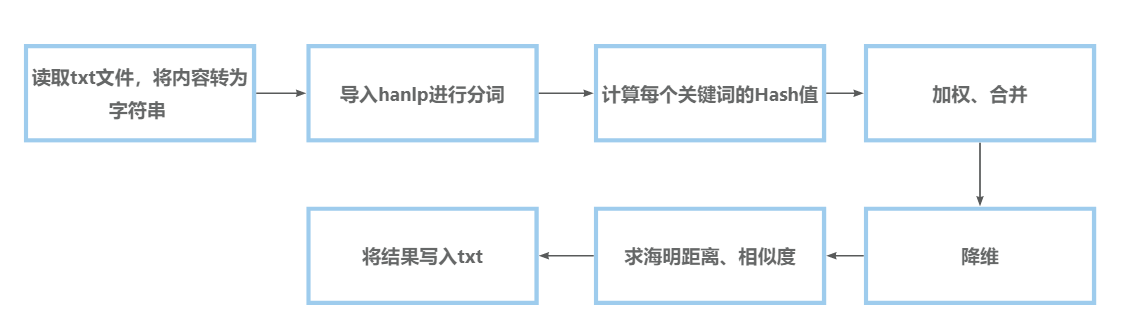
SimHash算法原理:https://www.likecs.com/show-204424165.html
核心函数
TxtUtils类
readTxt:读取txt文件,将内容转为字符串并返回。writeTxt:传入相似度,格式化为2位小数,将相似度写入指定路径对应的txt。
SimHashUtils类
-
getMD5Hash:传入字符串,用MD5获取hash值并返回。 -
getSimHash:传入字符串,使用hanlp包提取出关键词,然后调用getMD5Hash方法计算出hash值,再算出每个关键词的权重向量,把所有词的权重向量相累加,得到一个新的权重向量;最后进行降维,对于合并后得到的权重向量,遍历每一位,如果该位大于0则记为1,小于等于0则记为0,就得到了该文本的SimHash值。(注:由于本人Java刚学,水平有限,未能综合考虑关键词在文中出现的次数、关键词在文中的重要性等因素后再给每个词赋予合适的权重,目前暂时把权重统一设为1,导致文本相似度的计算结果的准确度降低)。
HammingAndSimilarity类
SimilarityResult:传入2个SimHash,计算海明距离(海明距离越小,文本越相似),最后算出文本相似度。
main主模块
- 流程:读取输入的路径名对应的txt文件,将内容转为字符串,再分别计算出2个字符串对应的SimHash值,然后计算相似度,最后将结果写入文件中。
四、性能分析

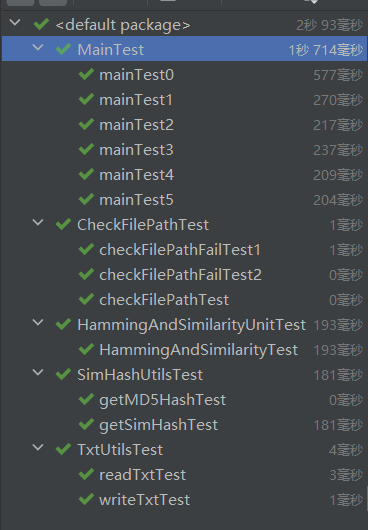
五、单元测试
部分单元测试代码
package utils;
import org.junit.Test;
public class SimHashUtilsTest {
@Test
public void getMD5HashTest() {
String[] words = {"世界", "时时刻刻", "人文精神", "夏天", "的"};
for(String word: words) {
System.out.println(SimHashUtils.getMD5Hash(word));
}
}
@Test
public void getSimHashTest(){
String str1 = TxtUtils.readTxt("D:/testTxt/orig.txt");
String str2 = TxtUtils.readTxt("D:/testTxt/orig_0.8_del.txt");
System.out.println(SimHashUtils.getSimHash(str1));
System.out.println(SimHashUtils.getSimHash(str2));
}
}
getMD5HashTest模拟了传入分出来的关键词给getMD5Hash方法,计算出关键词对应的hash值的情况
getSimHashTest模拟了传入文件路径给getSimHash方法,计算出txt内容转为字符串后对应的SimHash值的情况。
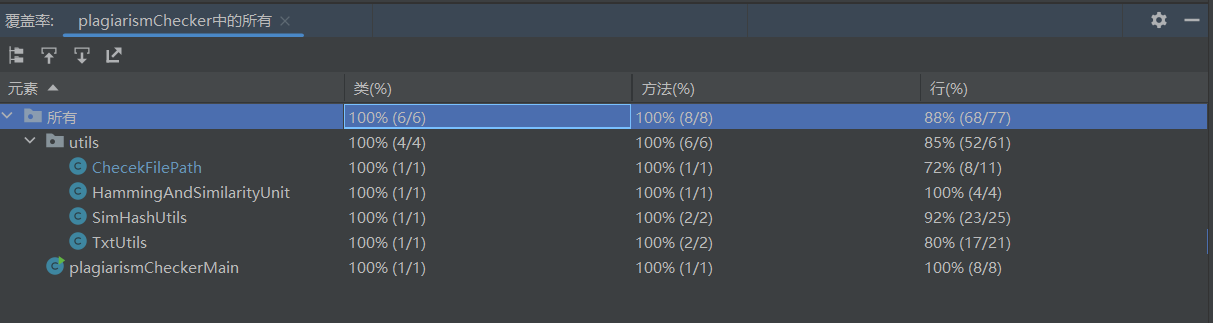
测试覆盖率
六、异常处理
CheckFilePath类
pathChecker:传入String类型数组,长度为3,数组元素为2个要对比的txt文件路径以及用于保存结果的txt。用于检测数组的元素个数是否为3个、路径对应的文件是否存在、路径对应的文件是否是txt格式
单元测试样例



