【数据采集与融合技术】 第三次大作业
作业①:
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
-
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图。
1.思路及代码
码云链接:
1.1 网站选择
在中国天气网浏览了一遍,最终选取了中国天气网的图片频道——天气现场 来爬取图片。
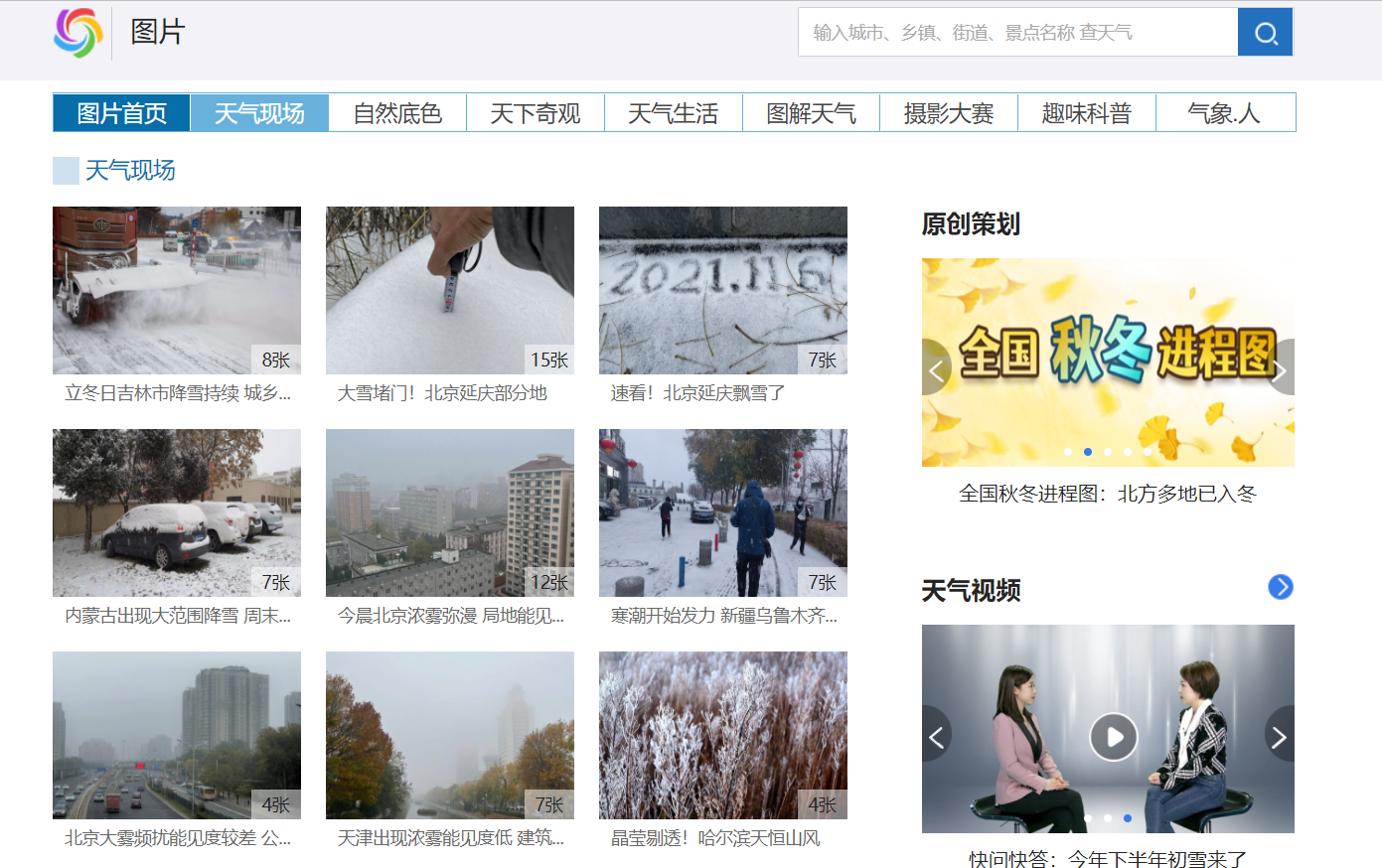
1.2 网页分析
经过分析,发现每个要爬取的网页链接可以用以下CSS语句表示:div[class="oi"] div[class="bt"] a,获得了这个元素之后,只需要取出href属性值就是我们要的网页链接。
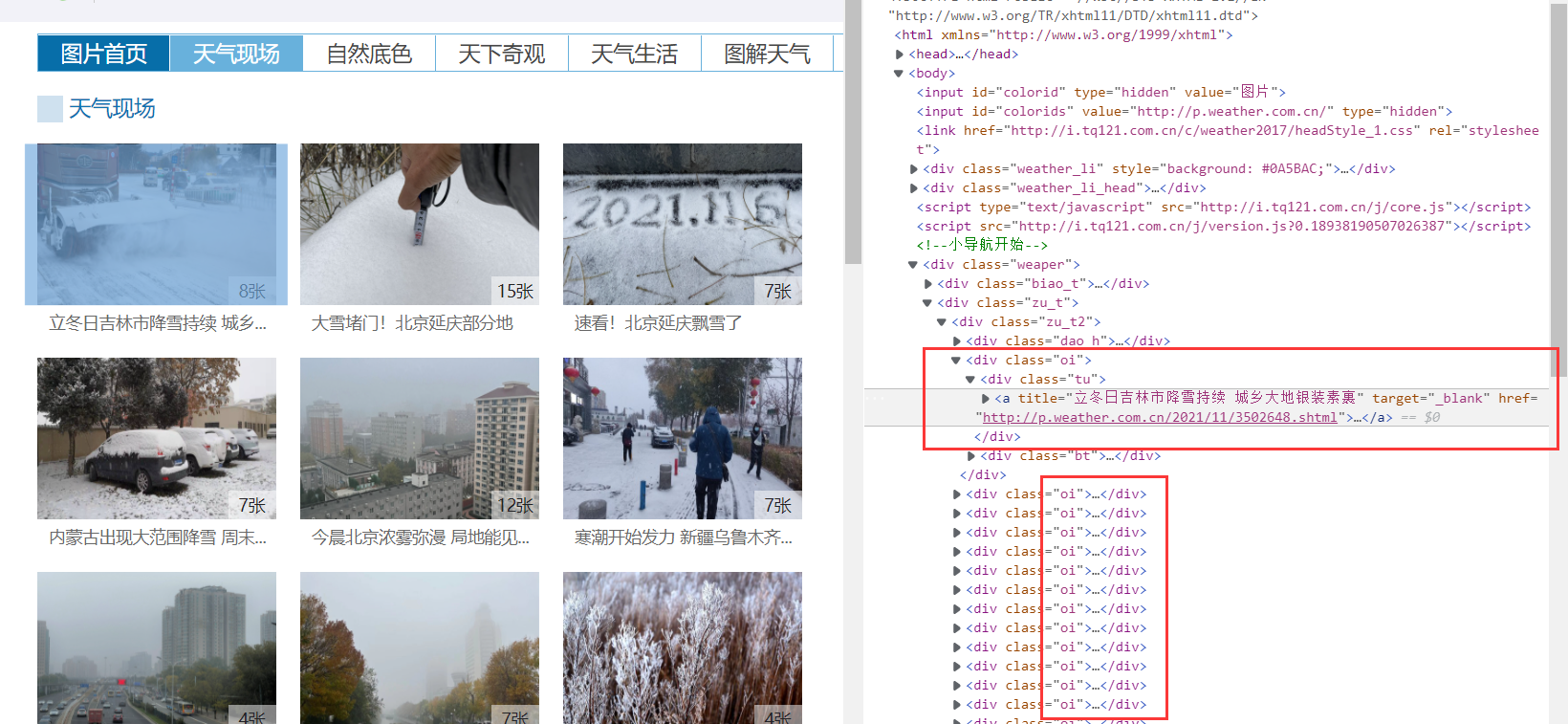
核心代码如下:
soup = BeautifulSoup(data, 'html.parser')
pageUrl = soup.select('div[class="oi"] div[class="bt"] a')
pageUrl = [x['href'] for x in pageUrl]
进入其中一个网页,继续分析我们最终要爬取的目标,可以发现都在我们要的图片是在一排并列的span下面的,所以可以通过CSS语句提取:div[class="buttons"] span img,然后获得其src属性值即可得到图片链接。

1.3 图片下载
定义下载函数
def downloadPic(pic_url, cnt_t):
"""
:param pic_url: 图片url
:param cnt_t: 计数器,用于文件命名
"""
if not os.path.exists('pic'):
os.mkdir('pic')
res = requests.get(pic_url)
with open("pic/{}.jpg".format(cnt_t), "wb") as f:
f.write(res.content)
print("{} {}".format(cnt_t, pic_url))
单线程下载:
我为了代码简洁,将单线程下载与多线程下载合并在一起,由逻辑变量doThread控制。将doThread设置为False,就是单线程下载。
首先将img标签提取出来,然后获取src属性值就是我们要的图片url链接,然后执行downloadPic函数即可下载,当图片下载数量大于学号位数127时,停止下载。
pics = soup.select('div[class="buttons"] span img')
for p in pics:
if doThread:
T = threading.Thread(target=downloadPic, args=(p['src'], cnt))
T.setDaemon(False)
T.start()
threads.append(T)
time.sleep(random.uniform(0.02, 0.05))
else:
downloadPic(p['src'], cnt)
cnt += 1
if cnt > 127:
return
多线程下载:
与单线程大同小异,调用threading库的方法进行添加线程,并且将其设置为前台线程,为了防止速度过快出错,启动线程的间隔设置为20~50ms。
T = threading.Thread(target=downloadPic, args=(p['src'], cnt))
T.setDaemon(False) # 设置为前台线程
T.start() # 启动线程
threads.append(T)
time.sleep(random.uniform(0.02, 0.05)) # 随机休眠20~50ms
还要在主函数里利用线程的join方法进行线程同步,即主线程任务结束之后,进入阻塞状态,一直等待其他的子线程执行结束之后,主线程再终止。
if doThread:
for t in threads:
t.join()
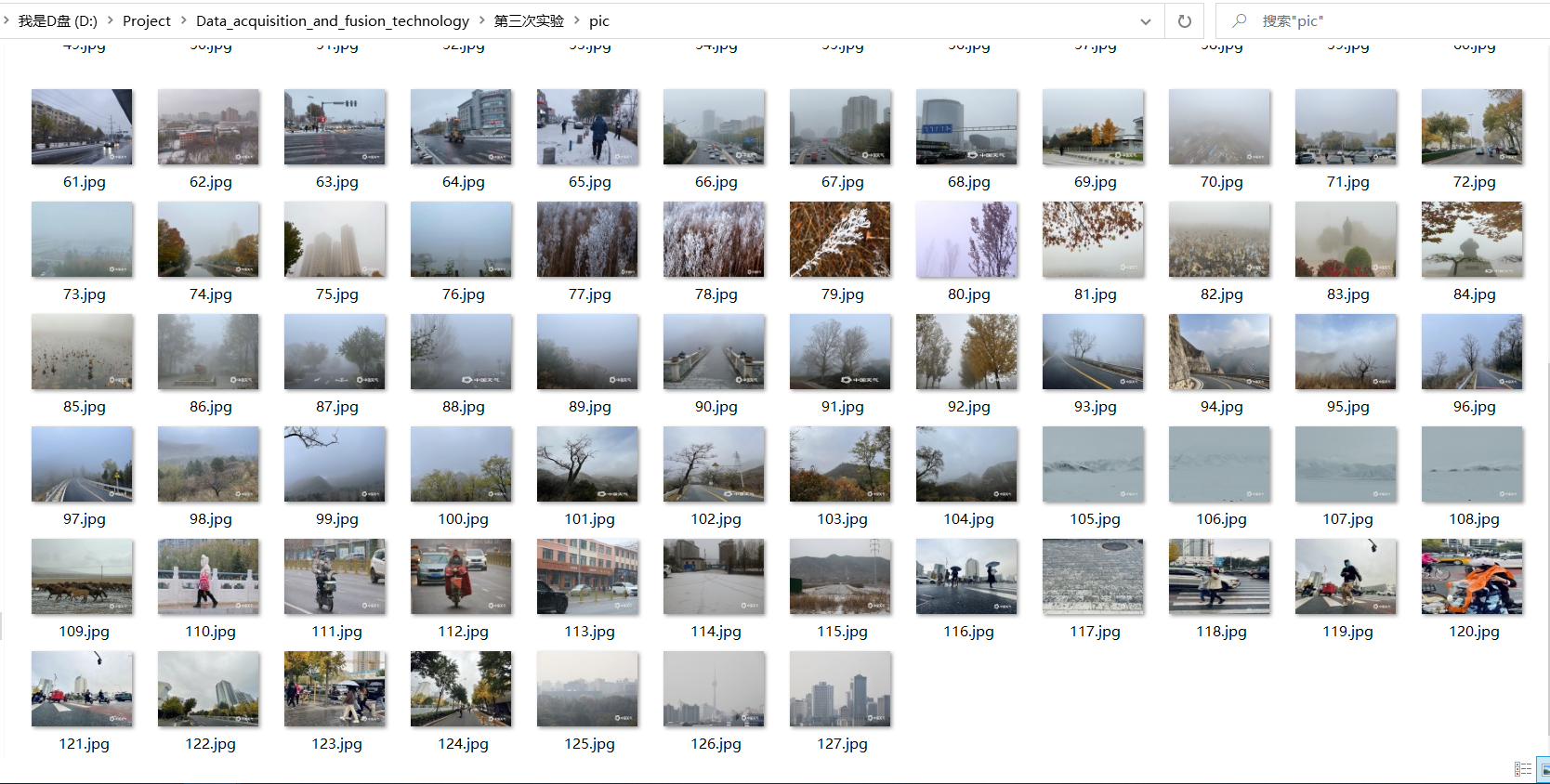
1.4 结果
单线程:

多线程:

2.心得体会
1. 在进行多线程爬取的时候,要控制速度,防止出错,也减少对网站的负担。
2. 相对于单线程,多线程的顺序具有不确定性,在编程的时候要注意这一点,否则可能会出现意想不到的错误。
作业②:
-
要求:使用scrapy框架复现作业①。
-
输出信息:
同作业①
1.思路及代码
码云链接:
1.1 总体思路
爬取的流程与作业1大同小异。
第一步是解析网页,获得链接,这一步对应的是scrapy的爬虫类。
第二步是然后是根据链接下载图片,对于scrapy框架的数据管道类。
在第一步与第二步之间起承上启下作用的是item数据项目类。
1.2 编写数据项目类
数据项目类里包括图片的序号no和图片的链接url两个属性,no用来图片命名,url用来下载图片
class PicItem(scrapy.Item):
no = scrapy.Field()
url = scrapy.Field()
1.3 编写爬虫类
由于进行的是多网页的图片爬虫,所以我定义了两个parse方法,分别对应多网页的链接获取和网页内图片下载。
首先是发起请求,回调函数使用parse方法来实现多网页的链接获取。然后parse再次调用parsePage的方法,实现网页内图片下载。
def start_requests(self):
source_url = 'http://p.weather.com.cn/tqxc/index.shtml'
yield scrapy.Request(url=source_url, callback=self.parse)
# 多网页的链接获取
def parse(self, response, **kwargs):
data = response.body.decode(response.encoding)
selector = scrapy.Selector(text=data)
pageUrl = selector.xpath('//div[@class="oi"]/div[@class="bt"]/a/@href').extract()
for u in pageUrl:
if self.count <= 127:
yield scrapy.Request(url=u, callback=self.parsePage)
# 网页内图片爬取
def parsePage(self, response, **kwargs):
data = response.body.decode(response.encoding)
selector = scrapy.Selector(text=data)
pics_url = selector.xpath('//div[@class="buttons"]/span/img/@src').extract()
for p in pics_url:
item = PicItem()
item['url'] = p
item['no'] = self.count
if self.count <= 127:
print(self.count, p)
self.count += 1
yield item
1.4 编写数据管道类
与之前的数据管道类不同,由于scrapy有专门的用于图片下载的数据管道类ImagesPipeline,所以可以继承这个类,并重写其几个方法,来实现高效率的图片下载。
其中,get_media_requests方法用来下载图片;item_completed来判断下载是否成功;file_path实现对文件的重命名。
class Hw2Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 下载图片,如果传过来的是集合需要循环下载
# meta里面的数据是从spider获取,然后通过meta传递给下面方法:file_path
yield Request(url=item['url'], meta={'name': item['no']})
def item_completed(self, results, item, info):
# 是一个元组,第一个元素是布尔值表示是否成功
if not results[0][0]:
raise DropItem('下载失败')
return item
# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
def file_path(self, request, response=None, info=None, *, item=None):
# 接收上面meta传递过来的图片名称
name = request.meta['name']
return str(name)+'.jpg'
1.5 setting的设置
首先将是否遵守robots协议设置为False。日志等级设置为Error级别,使输出简洁。此外,由于继承了ImagesPipeline,需要设置图片的存储位置。最后,设置启用ITEM_PIPELINES。
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR' # 日志等级设置为Error级别,使输出简洁
IMAGES_STORE = './pics'
ITEM_PIPELINES = {
'hw_2.pipelines.Hw2Pipeline': 300,
}
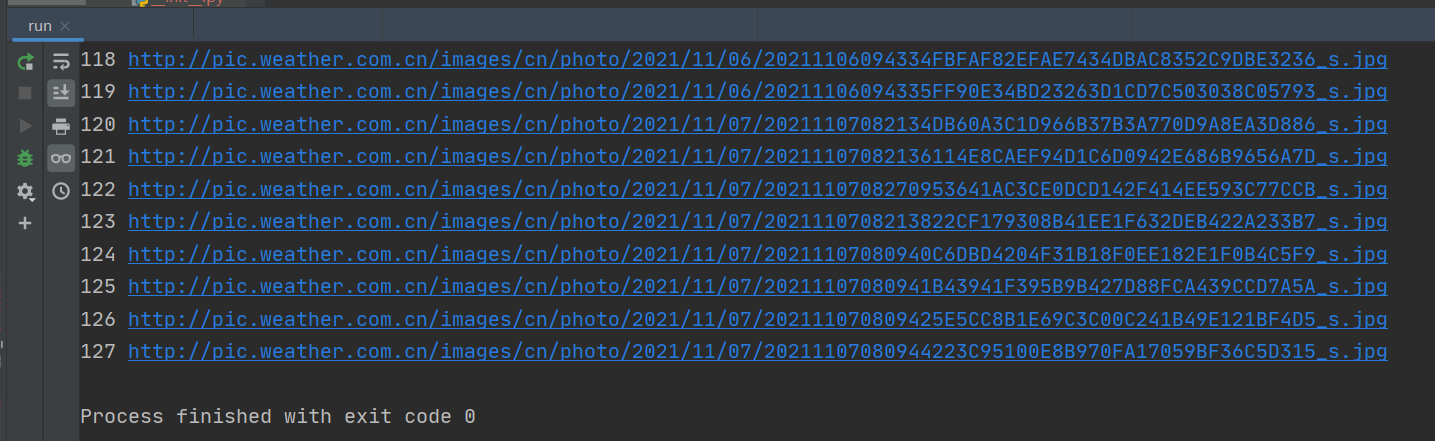
1.6 结果
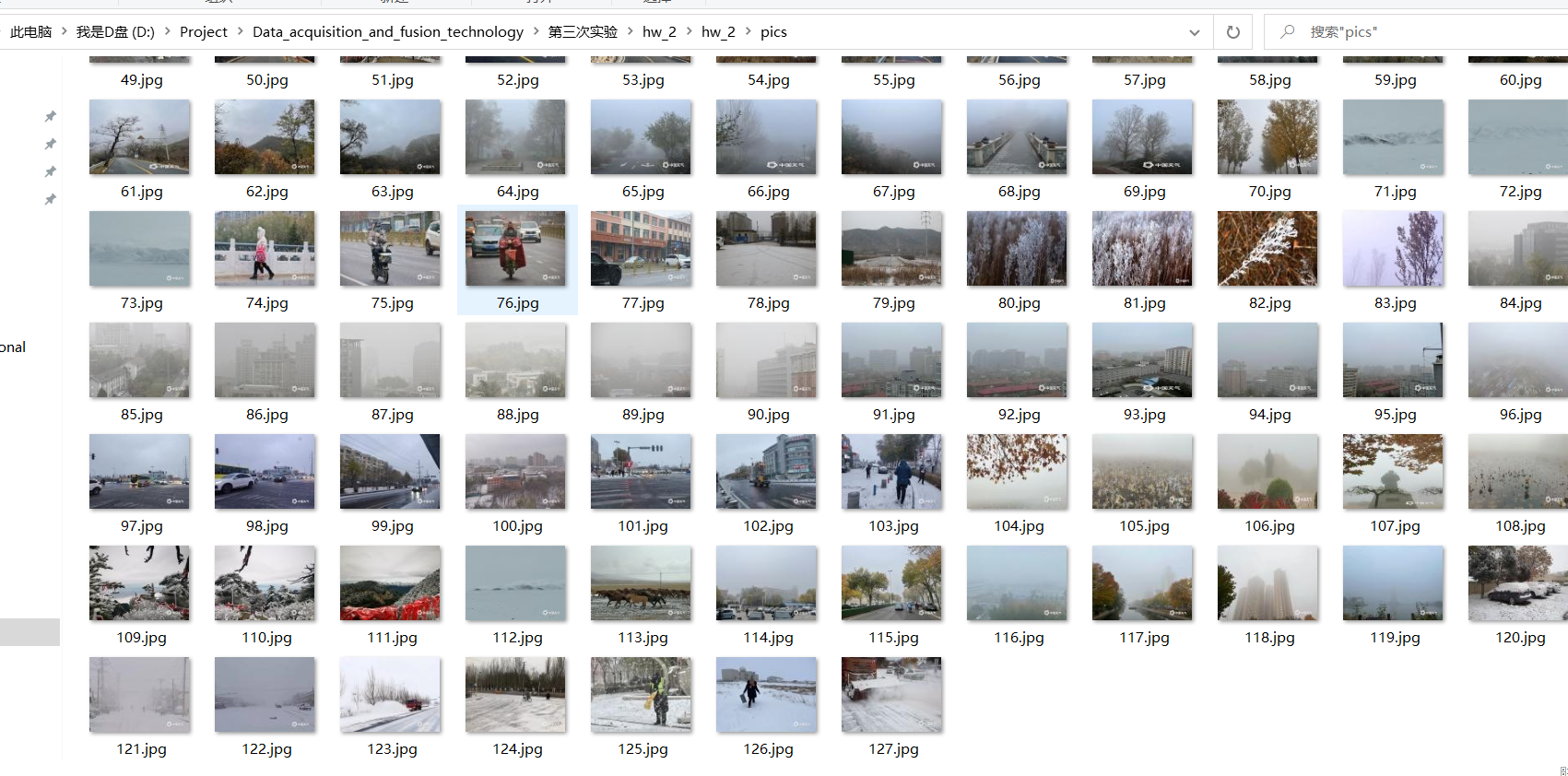
2.心得体会
1. 在编写数据管道类时,一定要记得继承`ImagesPipeline`,由于我在编写数据管道类时忘了继承这个类,导致一直没有下载图片,耗费了很多时间。
2. 对seething的配置很重要,在编写完代码后,要记得对setting做相应的配置。
作业③:
-
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
-
输出信息:
序号 电影名称 导演 演员 简介 电影评分 电影封面 1 肖申克的救赎 弗兰克·德拉邦特 蒂姆·罗宾斯 希望让人自由 9.7 ./imgs/xsk.jpg 2....
1.思路及代码
码云链接:
1.1 网页分析
元素分析
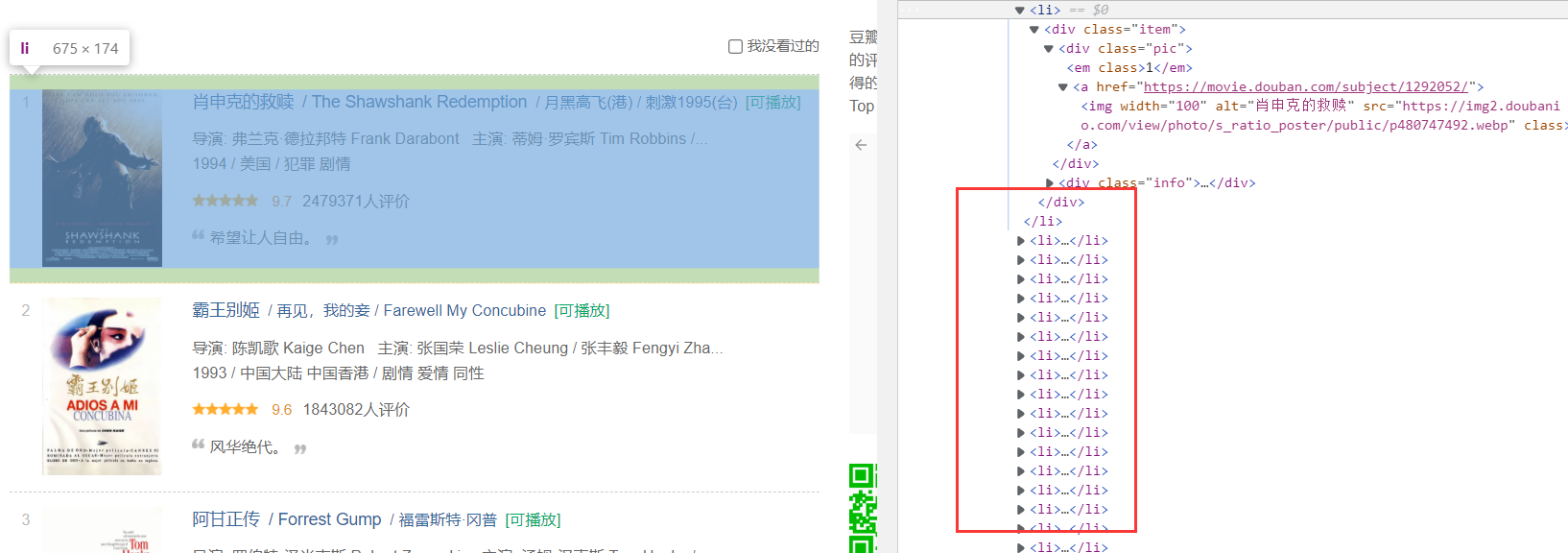
通过分析可以发现,每个电影都在li标签里,而且其各个字段均可以用xpth准确定位。
其中,各个字段的xpath如下:
排名://div[@class='item']/div[@class='pic']/em/text()
电影名称://div[@class='item']/div[@class='info']//span[@class='title'][1]/text()
导演及演员://div[@class='item']/div[@class='info']//p[1]/text()[1]
简介://div[@class='item']/div[@class='info']//p[2]/span/text()
评分://div[@class='item']/div[@class='info']//span[@class='rating_num']/text()
封面图片url://div[@class='item']/div[@class='pic']//img/@src
翻页处理
可以发现,翻页可以用url的start参数来处理:https://movie.douban.com/top250?start=100中的start=100表示的是第101个电影开始的25个电影。所以可以用以下代码实现翻页处理:
url = 'https://movie.douban.com/top250?start='
urls = []
for i in range(0, 250, 25):
urls.append("{}{}".format(url, i))
1.2 初步思路
我初步的设想是根据每个字段的xpath定位形成的元素列表,然后将每个字段的列表一一定位形成每一条记录。
item['ranks'] = selector.xpath("//div[@class='item']/div[@class='pic']/em/text()").extract()
item['titles'] = selector.xpath("//div[@class='item']/div[@class='info']//span[@class='title'][1]/text()").extract()
item['members'] = selector.xpath("//div[@class='item']/div[@class='info']//p[1]/text()[1]").extract()
item['introductions'] = selector.xpath("//div[@class='item']/div[@class='info']//p[2]/span/text()").extract()
item['scores'] = selector.xpath(
"//div[@class='item']/div[@class='info']//span[@class='rating_num']/text()").extract()
item['imgUrls'] = selector.xpath("//div[@class='item']/div[@class='pic']//img/@src").extract()
存在的问题
当我按照这个思路编写完代码的时候,发现此路不通,因为有一些电影“介绍”字段是空的,导致无法一一对应。

1.4 最终思路
由于存在某些电影“介绍”字段是空的,所以只能改变思路。
首先,先爬取每个电影对应的li标签下div标签形成列表,然后再接着在每个div标签里提取数据,这样子就能保住每条记录都一一对应。
1.5 核心代码
根据scrpy框架的设计思路,爬虫类主要用于爬取网页。数据管道类用于数据处理。所以爬虫类只需要获得我们需要的原始数据,其余的数据处理操作均由数据管道类来完成。
请求头:
需要设置请求头,否则无法爬取。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40'}
数据项目类:
仅有一个字段data用来存储每个div标签的数据
class MoviePageItem(scrapy.Item):
data = scrapy.Field() # 存储每个div标签的数据
pass
爬虫类:
def parse(self, response, **kwargs):
data = response.body.decode(response.encoding)
selector = scrapy.Selector(text=data)
item = MoviePageItem()
item['data'] = selector.xpath("//div[@class='item']").extract()
yield item
数据管道类:
由于本题目要求不仅是图片的下载,还要将各个字段存入数据库,所以需要有两个数据管道类和一个数据库类。
数据库类:用来进行数据库的连接、创建、插入操作
class douBanDB:
def openDB(self):
self.con = sqlite3.connect("DouBan.db")
self.cursor = self.con.cursor()
try:
# 数据库不存在则创建
self.cursor.execute(
"create table IF NOT EXISTS douban("
"rank TINYINT primary key,"
"name varchar(32),"
"director varchar(32),"
"actor varchar(32),"
"introduction varchar(128),"
"score FLOAT(3,1),"
"path varchar(32))")
except Exception as e:
print(e)
# 关闭数据库的方法
def closeDB(self):
self.con.commit()
self.con.close()
# 插入数据的方法
def insert(self, data):
try:
self.cursor.execute("insert into douban (rank, name, director, actor, introduction, score, path ) "
"values (?,?,?,?,?,?,?)", data)
except Exception as err:
print(err)
图片下载管道类:
class downloadImg(ImagesPipeline):
def get_media_requests(self, item, info):
data = item['data']
for d in data:
selector = scrapy.Selector(text=d)
imgUrl = selector.xpath("//div[@class='pic']//img/@src").extract_first()
title = selector.xpath("//div[@class='info']//span[@class='title'][1]/text()").extract_first()
print("下载封面\t{}".format(title))
yield Request(url=imgUrl, meta={'name': title})
def item_completed(self, results, item, info):
# 是一个元组,第一个元素是布尔值表示是否成功
if not results[0][0]:
raise DropItem('下载失败')
return item
# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
def file_path(self, request, response=None, info=None, *, item=None):
# 接收上面meta传递过来的图片名称
name = request.meta['name']
return str(name) + '.jpg'
数据处理类核心代码:
主要包括对各个字段的解析定位。
由于导演和演员是连在一起的,所以需要将其分开:
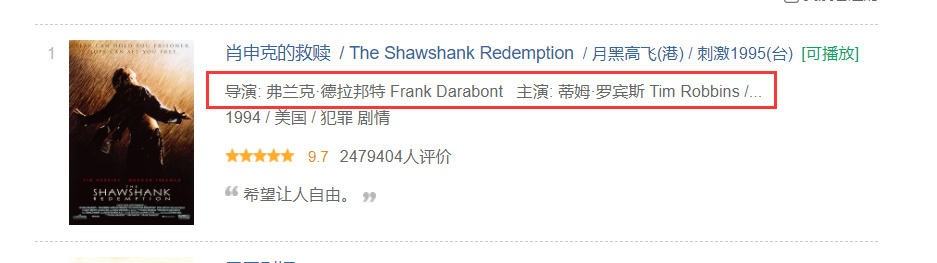
代码如下:
members = selector.xpath("//div[@class='info']//p[1]/text()[1]").extract_first().strip() # 获得导演和演员
director = members[3:members.find("主")].strip() # 获取导演
actor = members[members.find("主演:") + 3:].strip() # 演员
if actor == '':
actor = None
setting的设置:
需要配置以下内容:
需要注意的是:
1. ROBOTS协议要设置为False,否则无法下载图片。
2. 由于有两个数据管道类,所以需要在配置文件里相应的配置两个管道。
BOT_NAME = 'hw_3'
SPIDER_MODULES = ['hw_3.spiders']
NEWSPIDER_MODULE = 'hw_3.spiders'
LOG_LEVEL = 'WARNING'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.2
IMAGES_STORE = './imgs'
ITEM_PIPELINES = {
'hw_3.pipelines.Hw3Pipeline': 300,
'hw_3.pipelines.downloadImg': 400,
}
1.6 结果展示
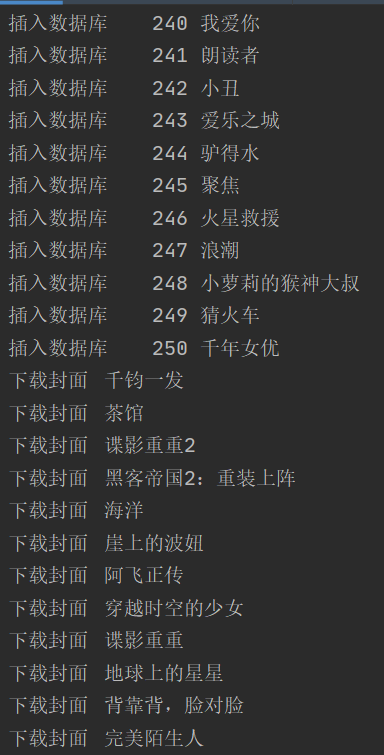


2.心得体会
1. 需要设置请求头,否则无法爬取。
2. 我再次认识到setting的设置很重要,ROBOTS协议要设置为False,否则无法下载图片。而由于有两个数据管道类,所以需要在配置文件里相应的配置两个管道。
3. 爬取完后要检查结果是否对应,若不对应,可以采取其他思路进行爬取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号